对应分析,典型相关分析,定性数据分析,张
科研常用的实验数据分析与处理方法

科研常用的实验数据分析与处理方法对于每个科研工作者而言,对实验数据进行处理是在开始论文写作之前十分常见的工作之一。
但是,常见的数据分析方法有哪些呢?常用的数据分析方法有:聚类分析、因子分析、相关分析、对应分析、回归分析、方差分析。
1、聚类分析(Cluster Analysis)聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。
聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。
聚类分析所使用方法的不同,常常会得到不同的结论。
不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。
2、因子分析(Factor Analysis)因子分析是指研究从变量群中提取共性因子的统计技术。
因子分析就是从大量的数据中寻找内在的联系,减少决策的困难。
因子分析的方法约有10多种,如重心法、影像分析法,最大似然解、最小平方法、阿尔发抽因法、拉奥典型抽因法等等。
这些方法本质上大都属近似方法,是以相关系数矩阵为基础的,所不同的是相关系数矩阵对角线上的值,采用不同的共同性□2估值。
在社会学研究中,因子分析常采用以主成分分析为基础的反覆法。
3、相关分析(Correlation Analysis)相关分析(correlation analysis),相关分析是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度。
相关关系是一种非确定性的关系,例如,以X和Y 分别记一个人的身高和体重,或分别记每公顷施肥量与每公顷小麦产量,则X与Y显然有关系,而又没有确切到可由其中的一个去精确地决定另一个的程度,这就是相关关系。
4、对应分析(Correspondence Analysis)对应分析(Correspondence analysis)也称关联分析、R-Q 型因子分析,通过分析由定性变量构成的交互汇总表来揭示变量间的联系。
数学建模各种分析方法

现代统计学1.因子分析(Factor Analysis)因子分析的基本目的就是用少数几个因子去描述许多指标或因素之间的联系,即将相关比较密切的几个变量归在同一类中,每一类变量就成为一个因子(之所以称其为因子,是因为它是不可观测的,即不是具体的变量),以较少的几个因子反映原资料的大部分信息.运用这种研究技术,我们可以方便地找出影响消费者购买、消费以及满意度的主要因素是哪些,以及它们的影响力(权重)运用这种研究技术,我们还可以为市场细分做前期分析。
2.主成分分析主成分分析主要是作为一种探索性的技术,在分析者进行多元数据分析之前,用主成分分析来分析数据,让自己对数据有一个大致的了解是非常重要的.主成分分析一般很少单独使用:a,了解数据。
(screening the data),b,和cluster analysis一起使用,c,和判别分析一起使用,比如当变量很多,个案数不多,直接使用判别分析可能无解,这时候可以使用主成份发对变量简化。
(reduce dimensionality)d,在多元回归中,主成分分析可以帮助判断是否存在共线性(条件指数),还可以用来处理共线性。
主成分分析和因子分析的区别1、因子分析中是把变量表示成各因子的线性组合,而主成分分析中则是把主成分表示成个变量的线性组合。
2、主成分分析的重点在于解释个变量的总方差,而因子分析则把重点放在解释各变量之间的协方差。
3、主成分分析中不需要有假设(assumptions),因子分析则需要一些假设。
因子分析的假设包括:各个共同因子之间不相关,特殊因子(specific fact or)之间也不相关,共同因子和特殊因子之间也不相关.4、主成分分析中,当给定的协方差矩阵或者相关矩阵的特征值是唯一的时候,的主成分一般是独特的;而因子分析中因子不是独特的,可以旋转得到不同的因子。
5、在因子分析中,因子个数需要分析者指定(spss根据一定的条件自动设定,只要是特征值大于1的因子进入分析),而指定的因子数量不同而结果不同。
常用数据处理方法

常用数据分析方法:聚类分析、因子分析、相关分析、对应分析、回归分析、方差分析;问卷调查常用数据分析方法:描述性统计分析、探索性因素分析、Cronbach’a信度系数分析、结构方程模型分析(structural equations modeling) 。
数据分析常用的图表方法:柏拉图(排列图)、直方图(Histogram)、散点图(scatter diagram)、鱼骨图(Ishikawa)、FMEA、点图、柱状图、雷达图、趋势图。
数据分析统计工具:SPSS、minitab、JMP。
常用数据分析方法:1、聚类分析(Cluster Analysis)聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。
聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。
聚类分析所使用方法的不同,常常会得到不同的结论。
不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。
2、因子分析(Factor Analysis)因子分析是指研究从变量群中提取共性因子的统计技术。
因子分析就是从大量的数据中寻找内在的联系,减少决策的困难。
因子分析的方法约有10多种,如重心法、影像分析法,最大似然解、最小平方法、阿尔发抽因法、拉奥典型抽因法等等。
这些方法本质上大都属近似方法,是以相关系数矩阵为基础的,所不同的是相关系数矩阵对角线上的值,采用不同的共同性□2估值。
在社会学研究中,因子分析常采用以主成分分析为基础的反覆法。
3、相关分析(Correlation Analysis)相关分析(correlation analysis),相关分析是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度。
相关关系是一种非确定性的关系,例如,以X和Y分别记一个人的身高和体重,或分别记每公顷施肥量与每公顷小麦产量,则X与Y显然有关系,而又没有确切到可由其中的一个去精确地决定另一个的程度,这就是相关关系。
对应分析与典型相关分析

17
对应分析基本思想
v λ ... v λ 1m m 11 1 O M = ( λ1 v1 ,..., λm vm ), AR = M v λ L v p1 1 pm λm
u11 λ1 ... u1m λm AQ = M O M = ( λ1 u1,..., λm um ), un1 λ1 L unm λm
由于SR和 具有相同的非零特征值 具有相同的非零特征值, 由于 和SQ具有相同的非零特征值,而这些特征值又正好是各个 公共因子的方差,因此可以用相同的因子轴 相同的因子轴同时表示变量点和样品 公共因子的方差,因此可以用相同的因子轴同时表示变量点和样品 即把变量点和样品点同时反映在具有相同坐标轴的因子平面上, 点,即把变量点和样品点同时反映在具有相同坐标轴的因子平面上, 以便对变量点和样品点一起考虑进行分类。 以便对变量点和样品点一起考虑进行分类。
如果SR的特征值 如果 的特征值 λ i 对应的标准化特征向量为 vi , 则SQ的特征值 λi 对应的标准化特征向量: 的特征值 对应的标准化特征向量: 1 ui = Zv i
λi
由此可以方便地由R型因子分析而得到 型因子分析的结果 由此可以方便地由 型因子分析而得到Q型因子分析的结果。由SR的特征值和 型因子分析而得到 型因子分析的结果。 的特征值和 特征向量即可以写出R型因子分析的因子载荷矩阵 记为AR) 型因子分析的因子载荷矩阵( 特征向量即可以写出 型因子分析的因子载荷矩阵(记为 )和Q型因子分析的 型因子分析的 因子载荷矩阵(记为AQ): 因子载荷矩阵(记为 ):
3
引例1. 引例1.
下表为2006年年底我国 个省市按照行业(这里仅列出12 年年底我国31个省市按照行业 这里仅列出12 下表为 年年底我国 个省市按照行业( 个行业)城镇单位就业人数, 个行业)城镇单位就业人数,在一定程度上可以反映该地 区的经济结构。 区的经济结构。 我国地域辽阔,东西南北发展不平衡,是否按照地域划分 我国地域辽阔,东西南北发展不平衡,是否按照地域划分 就合理了呢? 就合理了呢? 自然地理位置对经济结构的影响固然重要,但是数据分析 自然地理位置对经济结构的影响固然重要,但是数据分析 显然更有说服力。 显然更有说服力。
对应分析

可见 λk 也是ZZ’的特征根,相应的特征向量是 Zu k
因此将原始数据矩阵X变换成矩阵Z,则变量和 样品的协差阵分别可表示为 A = Z ′Z 和B=ZZ′ ,A和 B具有相同的非零特征值,相应的特征向量有很密 切的关系。 这样就可以用相同的因子轴去同时表示变量 和样品,把变量和样品同时反映在具有相同坐标 轴的因子平面上。
= ∑ z ak z aj
a =1
n
pak − pa. p.k xak − xa. x.k = z ak = pa. p.k xa. x.k
令Z为zij所组成的矩阵,则 A = Z′Z
p1 j 称 p. j
p2 j p. j
L
pnj x1 j = p. j x. j
L
第i个行变量的期望:
E( pij p. j )=∑
j =1 p
pij p. j
. p. j = pi.
因为原始变量的数量等级可能不同,所以为了尽量 减少各变量尺度差异,将列形象中的各行元素均除以 其期望的平方根。得矩阵D(Q)
p11 p.1 p1. p21 D (Q ) = p.1 p2. M p n1 p.1 pn. p12 p.2 p1. p22 p.2 p2. M pn 2 p.2 pn.
X ⋅ X*
*
′
x11 − x1 x21 − x1 L xn1 − x1 x11 − x1 x12 − x2 L x1p − xp x12 − x2 x22 − x2 L xn2 − x2 x21 − x1 x22 − x2 L x2 p − xp = × M M M M M M x − x x − x L x − x x −x x − x L x − x np p n1 1 n2 2 np p 1p p 2 p p
对应分析

对应分析法一、简介对应分析(Correspondence analysis)也称关联分析、R-Q型因子分析,是近年新发展起来的一种多元相依变量统计分析技术,是一种多元统计分析技术,主要分析定性数据的方法,也是强有力的数据图示化技术。
对应分析是一种数据分析技术,它能够帮助我们研究由定性变量构成的交互汇总表来揭示变量间的联系。
交互表的信息以图形的方式展示。
主要适用于有多个类别的定类变量,可以揭示同一个变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系,适用于两个或多个定类变量。
对应分析是由法国人Benzenci于1970年提出的,起初在法国和日本最为流行,然后引入到美国。
对应分析法是在R型和Q型因子分析的基础上发展起来的一种多元统计分析方法,因此对应分析又称为R-Q型因子分析。
在因子分析中,如果研究的对象是样品,则需采用Q型因子分析;如果研究的对象是变量,则需采用R型因子分析。
但是,这两种分析方法往往是相互对立的,必须分别对样品和变量进行处理。
因此,因子分析对于分析样品的属性和样品之间的内在联系,就比较困难,因为样品的属性是变值,而样品却是固定的。
于是就产生了对应分析法。
对应分析就克服了上述缺点,它综合了R型和Q型因子分析的优点,并将它们统一起来使得由R型的分析结果很容易得到Q型的分析结果,这就克服了Q 型分析计算量大的困难;更重要的是可以把变量和样品的载荷反映在相同的公因子轴上,这样就把变量和样品联系起来便于解释和推断。
对应分析数据的典型格式是列联表或交叉频数表。
常表示不同背景的消费者对若干产品或产品的属性的选择频率。
背景变量或属性变量可以并列使用或单独使用。
两个变量间——简单对应分析;多个变量间——多元对应分析。
对应分析的基本思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。
它最大特点是能把众多的样品和众多的变量同时作到同一张图解上,将样品的大类及其属性在图上直观而又明了地表示出来,具有直观性。
数学建模各种分析方法

现代统计学1.因子分析(Factor Analysis)因子分析的基本目的就是用少数几个因子去描述许多指标或因素之间的联系,即将相关比较密切的几个变量归在同一类中,每一类变量就成为一个因子(之所以称其为因子,是因为它是不可观测的,即不是具体的变量),以较少的几个因子反映原资料的大部分信息。
运用这种研究技术,我们可以方便地找出影响消费者购买、消费以及满意度的主要因素是哪些,以及它们的影响力(权重)运用这种研究技术,我们还可以为市场细分做前期分析。
2.主成分分析主成分分析主要是作为一种探索性的技术,在分析者进行多元数据分析之前,用主成分分析来分析数据,让自己对数据有一个大致的了解是非常重要的。
主成分分析一般很少单独使用:a,了解数据。
(screening the data),b,和cluster analysis一起使用,c,和判别分析一起使用,比如当变量很多,个案数不多,直接使用判别分析可能无解,这时候可以使用主成份发对变量简化。
(reduce dimensionality)d,在多元回归中,主成分分析可以帮助判断是否存在共线性(条件指数),还可以用来处理共线性。
主成分分析和因子分析的区别1、因子分析中是把变量表示成各因子的线性组合,而主成分分析中则是把主成分表示成个变量的线性组合。
2、主成分分析的重点在于解释个变量的总方差,而因子分析则把重点放在解释各变量之间的协方差。
3、主成分分析中不需要有假设(assumptions),因子分析则需要一些假设。
因子分析的假设包括:各个共同因子之间不相关,特殊因子(specific factor)之间也不相关,共同因子和特殊因子之间也不相关。
4、主成分分析中,当给定的协方差矩阵或者相关矩阵的特征值是唯一的时候,的主成分一般是独特的;而因子分析中因子不是独特的,可以旋转得到不同的因子。
5、在因子分析中,因子个数需要分析者指定(spss根据一定的条件自动设定,只要是特征值大于1的因子进入分析),而指定的因子数量不同而结果不同。
对应分析 课件讲解

行记分(row score) xi和列记分yj的加权均值成 比例, 而列记分yj和行记分xi的加权均值成比 例. 数值r为行列记分的相关(在典型相关的意 义上).
记R=diag(ai.), C=diag(a.i), R1/2= diag(a.i1/2), 则上面式子为
rx=R-1Ay; ry=C-1A’x 或
例子(数据ChMath.txt )
该数据关于汉字读写能力的变量有三个水 平:
“纯汉字”意味着可以完全自由使用纯汉 字读写,
“半汉字”意味着读写中只有部分汉字 (比如日文),
而“纯英文”意味着只能够读写英文而不 会汉字。而数学成绩有4个水平(A、B、C、 D)。
人们可以对这个列联表进行前面所说的c2检验来考 察行变量和列变量是否独立。结果在下面表中 (通过Analyze-Descriptive Statistics-Crosstabs)
类似地,点击Continue之后,把“数学成绩” 选入Column (列),并以同样方式定义其范围 为1到4。
由于其他选项可以用默认值,就可以直接点击 OK来运行了。这样就得到上述表格和点图。
附录 对应分析的数学
因子分析对变量和对样品要分别对待. 对应分 析把变量和样本同时反映到相同坐标轴(因子 轴)的一张图形上. 数学上, 令A=[aij]为n×p矩阵, x=[xi] 为n-(列) 向量, y=[yj] 为p-(列)向量. 那么(r,x,y)称为对 应分析问题C0(A)的解, 如果
Z’Z的特征根为l1≥l2≥…≥lp; Z’Z相应的特征 向量为u1,u2…,up. ZZ’相应的特征向量为 v1,v2…,vn.对最大的m个特征值得因子载荷阵
u11
l1
F
对应分析,典型相关分析,定性数据分析,

2014-5-20
2 cxt
7.1 交叉列联表
描述属性变量(定类或定序尺度变量)的各种状态 或是相关关系。
例:研讨患肺癌与吸烟是否有关?
是否吸烟 是否 患肺癌 患肺癌 未患肺癌 合计
2014-5-20
吸烟 60 32 92
3 cxt
不吸烟 3 11 14
合计 63 43 106
当属性变量A和B的状态较多时,很难透过列联表作出 判断。 怎样简化列联表的结构? 利用降维的思想。如因子分析和主成分分析。但因子分 析的缺陷是在于无法同时进行R型因子分析和Q型因子 分析。 怎么办?
2014-5-20 5 cxt
3、对应分析的一大特点: 可以在一张二维图上同时表示出两类属性变量的各种 状态,以直观描述原始数据结构。
对应分析的关键问题是:
如何将多个类别点表示在低维空间中,以便于直接观察 如何确定各类别点的坐标,以易于鉴别类别间联系的强弱
2014-5-20
6 cxt
现实中: 如鸡蛋、猪肉的价格(作为第一组变量)和 相应产品的销量(第二组变量)有相关关系。如投资 性变量(劳力投入、财力投入、固定资产投资等)与 国民收入(工农业收入、建筑业收入、等)具有相关 关系。 如何研究两组变量之间的相关关系? 设两组变量用X1,X2….,XP以及Y1,Y2…YP表示。 (1)分别研究Xi和Yj之间的相关关系,列出相关系数表。 其缺陷:当两组变量较多时,处理较烦琐,不易抓住 问题的实质。(2)采用主成分分析的方法,每组变量 分别提取主成分,再通过主成分之间的关系反映两组 变量之间的关系。
2014-5-20
4 cxt
***7.2
对应分析的基本理论
1、什么是对应分析?
对应分析数据

对应分析数据一、背景介绍在现代社会中,数据分析已经成为各行各业中不可或缺的重要工作。
对应分析数据是指根据已有的数据进行分析,以找出数据之间的对应关系,从而得出有价值的结论和预测。
本文将详细介绍对应分析数据的步骤、方法和应用场景。
二、对应分析数据的步骤1. 数据收集:首先需要收集与分析目标相关的数据。
可以通过调查问卷、实验数据、市场调研等方式来获取数据。
2. 数据清洗:对收集到的数据进行清洗,包括去除重复数据、处理缺失值、处理异常值等。
确保数据的准确性和完整性。
3. 数据整理:将清洗后的数据进行整理,使其符合对应分析的要求。
可以使用Excel等工具进行数据整理和处理。
4. 对应分析方法选择:根据具体的分析目标,选择合适的对应分析方法。
常用的对应分析方法包括相关分析、回归分析、因子分析等。
5. 数据分析:根据选择的对应分析方法,对数据进行分析。
可以使用统计软件如SPSS、Python等进行数据分析,得出相应的结果。
6. 结果解释:根据对应分析的结果,进行结果解释和结论提取。
需要将分析结果与实际情况相结合,进行合理的解释和推断。
三、对应分析数据的方法1. 相关分析:用于研究两个或多个变量之间的相关性。
通过计算相关系数,判断变量之间的线性关系强度和方向。
2. 回归分析:用于研究因变量与自变量之间的关系。
通过建立回归模型,预测因变量的值,并分析自变量对因变量的影响程度。
3. 因子分析:用于研究多个变量之间的共同因素。
通过提取共同因素,减少变量的数量,简化数据分析过程。
4. 聚类分析:用于将数据分为不同的群组或类别。
通过计算样本之间的相似性,将相似的样本归为一类。
5. 时间序列分析:用于研究时间序列数据的变化趋势和规律。
通过分析时间序列的趋势、周期、季节性等,进行预测和决策。
四、对应分析数据的应用场景1. 市场调研:对应分析数据可以用于了解消费者的购买行为和偏好,从而指导市场推广和产品设计。
2. 金融分析:对应分析数据可以用于分析股票、汇率、利率等金融数据的相关性,进行投资决策和风险管理。
应用统计学对应分析等
重庆交通大学管理学院
22:22:28
1、什么是典型相关分析? 典型相关分析是研究两组变量之间相关关系 的多元统计分析方法.它借用主成分分析降维的 思想,分别对两组变量提取主成分,且使两组变 量提取的主成分之间的相关程度达到最大,而从 同一组内部提取的各主成分之间互不相关,用从 两组之间分别提取的主成分的相关性来描述两组 变量整体的线性相关关系.
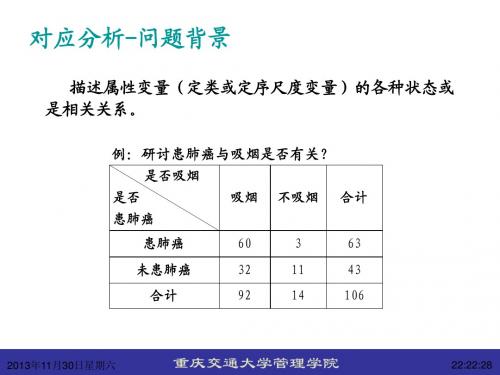
对应分析-问题背景
描述属性变量(定类或定序尺度变量)的各种状态或 是相关关系。
例:研讨患肺癌与吸烟是否有关?
是否吸烟 是否 患肺癌 患肺癌 未患肺癌 合计 60 32 92 3 11 14 63 日星期六
重庆交通大学管理学院
22:22:28
当属性变量A和B的状态较多时,很难透过列联表作 出判断。 怎样简化列联表的结构? 利用降维的思想。如因子分析和主成分分析。但因 子分析的缺陷是在于无法同时进行R型因子分析和Q 型因子分析。 怎么办?
2013年11月30日星期六
重庆交通大学管理学院
22:22:28
其优点是可以把方差分析和线性模型方法相结合,估 计模型中各个参数,而这些参数值使各个变量的效应和变 量间的交互作用效应得以数量化。
(2)Logistic 模型 是将概率比取对数后,再进行参数化而获得。设因变 量y为二值定性变量,用0和1表示两个不同状态,y=1的概 率p=P(y=1)是研究对象。若有多个因素影响y的取值,这 些因素就是自变量,记为:x1,x2…xk(既可以是定性变量 也可以是定量变量)。 Logistic 线性回归模型:
信度分类
内在信度:调查表中的一组问题(或整个调查表)是否测 量的是同一个概念,也就是这些问题之间的内在一致性 如何。 • 最常用的内在信度系数为克朗巴哈α系数和折半信度。 外在信度:在不同时间进行测量时调查表结果的一致性程 度。最常用的外在信度指标是重测信度,即用同一问卷 在不同时间对同一对象进行重复测量,然后计算一致程 度。
对应分析

STATA中对应分析应用
Syntax for predict:
predict [type] newvar [if] [in] [, statistic ] statistic description fit fitted values; the default rowscore(#) row score for dimension # colscore(#) column score for dimension #
STATA中对应分析应用
二元对应分析之后的统计量和作图
command description cabiplot biplot of row and column points caprojection CA dimension projection plot estat coordinates display row and column coordinates estat distances display chi-squared distances between row and column profiles estat inertia display inertia contributions of the individual cells estat loadings display correlations of profiles and axes("loadings") estat profiles display row and column profiles + estat summarize estimation sample summary(not available after camat.) estat table display fitted correspondence table screeplot plot singular values + predict fitted values, row coordinates, or column
(完整版)多元统计分析课后练习答案

第1章 多元正态分布1、在数据处理时,为什么通常要进行标准化处理?数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。
在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
其中最典型的就是0-1标准化和Z 标准化。
2、欧氏距离与马氏距离的优缺点是什么?欧氏距离也称欧几里得度量、欧几里得度量,是一个通常采用的距离定义,它是在m 维空间中两个点之间的真实距离。
在二维和三维空间中的欧氏距离的就是两点之间的距离。
缺点:就大部分统计问题而言,欧氏距离是不能令人满意的。
每个坐标对欧氏距离的贡献是同等的。
当坐标表示测量值时,它们往往带有大小不等的随机波动,在这种情况下,合理的方法是对坐标加权,使变化较大的坐标比变化较小的坐标有较小的权系数,这就产生了各种距离。
当各个分量为不同性质的量时,“距离”的大小与指标的单位有关。
它将样品的不同属性之间的差别等同看待,这一点有时不能满足实际要求。
没有考虑到总体变异对距离远近的影响。
马氏距离表示数据的协方差距离。
为两个服从同一分布并且其协方差矩阵为Σ的随机变量与的差异程度:如果协方差矩阵为单位矩阵,那么马氏距离就简化为欧氏距离,如果协方差矩阵为对角阵,则其也可称为正规化的欧氏距离。
优点:它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关。
由标准化数据和中心化数据计算出的二点之间的马氏距离相同。
马氏距离还可以排除变量之间的相关性的干扰。
缺点:夸大了变化微小的变量的作用。
受协方差矩阵不稳定的影响,马氏距离并不总是能顺利计算出。
3、当变量X1和X2方向上的变差相等,且与互相独立时,采用欧氏距离与统计距离是否一致?统计距离区别于欧式距离,此距离要依赖样本的方差和协方差,能够体现各变量在变差大小上的不同,以及优势存在的相关性,还要求距离与各变量所用的单位无关。
如果各变量之间相互独立,即观测变量的协方差矩阵是对角矩阵, 则马氏距离就退化为用各个观测指标的标准差的倒数作为权数的加权欧氏距离。
对应分析

对应分析(Correspondence Analysis)在进行数据分析时,经常要研究两个定性变量(品质变量)之间的相关关系。
我们曾经介绍过使用列联表和卡方检验来检验两个品质变量之间相关性的方法,但是该方法存在一定的局限性。
卡方检验只能对两个变量之间是否存在相关性进行检验,而无法衡量两个品质型变量各水平之间的内在联系。
例如,汽车按产品类型可以分豪华型、商务型、节能型、耐用型,按销售区域可分为华北区、华南区、华中区、华东区、西南区、西北区、东北区。
利用卡方检验,只能检验销售地区与对型的偏好之间是否相关,但无法知道不同地区的消费者到底比较偏好哪种车型。
对应分析方法(Correspondence Analysis)又称相应分析、关联分析,是一种多元相依变量统计分析技术,是对两个定性变量(因素)的多种水平之间的对应性进行研究,通过分析由定性变量构成的交互汇总数据来解释变量之间的内在联系。
同时,使用这种分析技术还可以揭示同一变量的各个类别之间的差异以及不同变量各个类别之间的对应关系。
特别是当分类变量的层级数比较大时,对应分析可以将列联表中众多的行和列的关系在低维的空间中表示出来。
而且,变量划分的类别越多,这种方法的优势就越明显。
对应分析以两变量的交叉列联表为研究对象,利用“降维”的方法,通过图形的方式,直观揭示变量不同类别之间的联系,特别适合于多分类定性变量的研究。
对应分析的基本思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。
它最大特点是能把众多的样品和众多的变量同时作到同一张图上,将样品的大类及其属性在图上直观而又明了地表示出来,具有直观性。
另外,它还省去了因子选择和因子轴旋转等复杂的数学运算及中间过程,可以从因子载荷图上对样品进行直观的分类,而且能够指示分类的主要参数(主因子)以及分类的依据,是一种直观、简单、方便的多元统计方法。
该统计研究技术在市场细分、产品定位、品牌形象以及满意度研究等领域得到了广泛的运用。
数据分析的几种方法

数据分析的几种方法数据分析是当今社会中非常重要的一个领域,它可以帮助我们从海量的数据中提取有用的信息,为决策提供支持。
在进行数据分析时,我们可以采用多种方法来处理数据,下面就让我们来了解一下数据分析的几种方法。
首先,最常见的数据分析方法之一是描述性统计分析。
描述性统计分析是通过对数据进行总结和描述,来了解数据的基本特征。
它可以帮助我们了解数据的分布情况、中心趋势和离散程度,从而对数据有一个整体的认识。
描述性统计分析通常包括了均值、中位数、众数、标准差、方差等指标,通过这些指标我们可以对数据进行初步的了解和分析。
其次,另一个常见的数据分析方法是相关性分析。
相关性分析用来研究两个或多个变量之间的关系,它可以帮助我们了解变量之间的相关程度和相关方向。
在相关性分析中,我们通常会使用相关系数来衡量变量之间的相关性,常见的相关系数包括皮尔逊相关系数、斯皮尔曼相关系数等。
通过相关性分析,我们可以找出变量之间的相关关系,从而为后续的分析提供依据。
此外,还有一种重要的数据分析方法是回归分析。
回归分析是用来研究自变量和因变量之间的关系的方法,它可以帮助我们了解自变量对因变量的影响程度和方向。
在回归分析中,我们通常会使用线性回归、逻辑回归等方法来建立模型,通过模型来预测因变量的取值。
回归分析在实际应用中非常常见,它可以帮助我们进行预测和决策,对于商业分析和市场预测非常有用。
最后,还有一种重要的数据分析方法是聚类分析。
聚类分析是用来将数据集中的个体划分为若干个类别的方法,它可以帮助我们发现数据中的内在结构和规律。
在聚类分析中,我们通常会使用K均值聚类、层次聚类等方法来对数据进行分组,通过聚类分析,我们可以找出数据中的相似性和差异性,从而对数据进行更深入的理解。
综上所述,数据分析的几种方法包括描述性统计分析、相关性分析、回归分析和聚类分析。
每种方法都有其独特的作用和应用领域,我们可以根据具体的数据特点和分析目的来选择合适的方法进行分析,以期得到更准确、更有用的分析结果。
工业互联网平台 设备健康管理规范-最新国标

工业互联网平台设备健康管理规范1范围本文件针对工业互联网平台应用背景下设备健康状态监测、健康状况评估、健康问题诊断、维修维护复等典型设备健康管理活动,给出了设备健康管理的步骤、方法与要求,提供了设备健康管理的参考指南。
本文件适用于企业基于工业互联网平台开展设备健康管理活动,也适用于设备服务商提供设备健康管理服务。
2规范性引用文件下列文件中的内容通过文中的规范性引用而构成本文件必不可少的条款。
其中,注日期的引用文件,仅该日期对应的版本适用于本文件;不注日期的引用文件,其最新版本(包括所有的修改单)适用于本文件。
GB/T7826-2012系统可靠性分析技术失效模式和影响分析程序GB/T23021-2022信息化和工业化融合管理体系生产设备管理能力成熟度评价3术语、定义和缩略语3.1术语和定义GB/T23021-2022界定的术语和定义适用于本文件。
3.2缩略语下列缩略语适用于本文件。
RFID:射频识别(Radio Frequency Identification)ERP:企业资源计划(Enterprise Resource Planning)MES:制造执行系统(Manufacturing Execution System)FMECA:失效模式、影响及危害性分析(Failure Modes,Effects and Criticality Analysis)4设备健康管理的主要活动基于工业互联网平台的设备健康管理的主要活动包括但不限于健康状态监测、健康状况评估、健康问题诊断和维修维护:a)健康状态监测:以设备运行和生产的数据为基础,通过大数据监控分析,及时掌握设备的运行工况,预防非正常停机,为日常及定期维护提供决策支撑;b)健康状况评估:通过对设备运行实时数据的监测分析,建立设备健康状态评估模型,量化设备当前的性能和故障状态,指导设备运行优化;c)健康问题诊断:根据设备当前运行状态信息,以评估模型为判定手段,预测及检出设备的风险状态;d)维修维护:整合设备健康状态评估、管理制度、业务流程,以日常维修、定期维护为手段,对设备及其部件健康状态及其影响因素进行全面管理和控制。
多元统计分析及R语言建模考试试卷

多元统计分析及R 语言建模考试试卷一、简答题(共5小题,每小题6分,共30分)1. 常用的多元统计分析方法有哪些?(1)多元正态分布检验(2)多元方差-协方差分析(3)聚类分析(4)判别分析(5)主成分分析(6)因子分析(7)对应分析(8)典型相关性分析( 9)定性数据建模分析(10)路径分析(又称多重回归、联立方程) (11)结构方程模型 (12)联合分析 (13)多变量图表示法(14)多维标度法 2. 简单相关分析、复相关分析和典型相关分析有何不同?并举例说明之。
简单相关分析:简单相关分析是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度,是研究随机变量之间的相关关系的一种统计方法。
例如,以X、Y分别记小学生的数学与语文成绩,感兴趣的是二者的关系如何,而不在于由X去预测Y。
复相关分析;研究一个变量 x0与另一组变量 (x1,x2,…,xn)之间的相关程度。
例如,职业声望同时受到一系列因素(收入、文化、权力……)的影响,那么这一系列因素的总和与职业声望之间的关系,就是复相关。
复相关系数R0.12…n的测定,可先求出 x0对一组变量x1,x2,…,xn的回归直线,再计算x0与用回归直线估计值悯之间的简单直线回归。
复相关系数为R0.12…n的取值范围为0≤R0.12…n≤1。
复相关系数值愈大,变量间的关系愈密切。
典型相关分析就是利用综合变量对之间的相关关系来反映两组指标之间的整体相关性的多元统计分析方法。
它的基本原理是:为了从总体上把握两组指标之间的相关关系,分别在两组变量中提取有代表性的两个综合变量U1和V1(分别为两个变量组中各变量的线性组合),利用这两个综合变量之间的相关关系来反映两组指标之间的整体相关性。
3. 试说明主成分分析和因子分析不同点和相同之处。
主成分分析和因子分析的相同之处1.都可以降维、分析多个变量的基本结构2.因子分析是主成分分析的进一步推广。
对应分析

(2) 从协方差矩阵 A 出发,计算协方差矩阵 A 的特 征根 1 2 k , 0 k min{r , c} 1 以及对应的特征向
量 1 , 2 ,, k 。 (3) 根据累计方差贡献率确定最终提取特征根的个 ,并计算出相应的因子载荷矩阵 F,即: 数 m (通常 m 取 2)
对应分析
(Correspondence Analysis)
在进行数据分析时,经常要研究两个定性变量(品质变量)之间 的相关关系。 我们曾经介绍过使用列联表和卡方检验来检验两个品质 变量之间相关性的方法, 但是该方法存在一定的局限性。 卡方检验只 能对两个变量之间是否存在相关性进行检验, 而无法衡量两个品质型 变量各水平之间的内在联系。例如,汽车按产品类型可以分豪华型、 商务型、节能型、耐用型,按销售区域可分为华北区、华南区、华中 区、华东区、西南区、西北区、东北区。利用卡方检验,只能检验销 售地区与类型的偏好之间是否相关, 但无法知道不同地区的消费者到 底比较偏好哪种车型。
对应分析以两变量的交叉列联表为研究对象,利用“降维 ”的方 法,通过图形的方式,直观揭示变量不同类别之间的联系,特别适合 于多分类定性变量的研究。
对应分析的基本思想是在一个两变量列联表的基础上提取信息, 将变量内部各水平之间的联系以及变量与变量之间的联系同时反映 在一张二维或三维的散点图上,并使关系紧密的类别点聚集在一起, 而关系疏远的类别点距离较远。 另外, 它还省去了因子选择和因子轴旋转等复杂的数学运算及中 间过程, 可以从因子载荷图上对样品进行直观的分类, 而且能够指示 分类的主要参数(主因子)以及分类的依据,是一种直观、简单、方 便的多元统计方法。
差异时选 Principal 项。 该对话框中的选项一般无须改动。