第6章相关分析回归分析和聚类分析
第六章 相关分析与回归分析

b<0,y 有随 x 的增加而减少的趋势
●●●回归直线一定通过由观测值的平均值(x,y )所组成的点:
∵ yˆ a bx
a y bx
∴ yˆ y bx bx y b(x x)
当 xx 时, yˆ y,即回归直线通过点(x,y )
●直线回归方程配置的实例
实例:对表 6-1 的北碚大红番茄果实横径与果重进行回归分析
| r |愈接近于 1,相关愈密切 | r |愈接近于 0,相关愈不密切 0<r<1 时,为正相关 -1<r<0 时,为负相关 ●相关系数计算的实例: 实例:表 6-1 为番茄果实横径与果实重的观测值,求其相关性。
表 6-1 北碚大红番茄果实横径与果实重
果实横径(cm)
果重(g)
x
y
10.0
140
其中: r
n
[ x2 ( x)2 ][ y 2 ( y)2 ]
n
n
x、y——为两个变数的成对观测值 n——为观测值的对数(样本容量)
●●相关系数的性质:
●●●r 的符号取决于 x、y 离均差的乘积和(lxy 或 SP);符号的
性质表示两个变数之间的相关性质,即
r>0,表示正相关
r<0,表示负相关
∑y2=133071.0
n=10
a=-23.834
b=16.425
r=0.9931
结论:北碚大红番茄果实横径与果实重量的回归方程为:
yˆ 23.834 16.425 x
●回归关系的显著性测定——有 3 种方法。 ●●直线回归方程的方差分析
●●●y 的总变异的分解
SS y lyy ( y y)2 [( y yˆ) ( yˆ y)]2 ( y yˆ)2 ( yˆ y)2 2 ( y yˆ)(yˆ y) ( y yˆ)2 ( yˆ y)2 其中: 2 ( y yˆ )( yˆ y) =0
第六章相关与回归分析

第六章相关与回归分析第六章相关与回归分析(一)教学目的相关与回归分析是一种常用的统计分析方法。
通过本章的学习使学生对相关的概念、类型有一定的认识,掌握相关程度的测定方法、判定相关的类别以及回归分析的基本方法。
(二)基本要求要求了解相关的概念、类型,掌握相关程度的测定方法,学会线性回归分析的方法及检验。
(三)教学要点1、相关关系的概念、种类和特点;2、回归分析的概念、种类和特点;3、线性相关下相关程度的测定及判断;4、最小二乘估计的原理。
(四)教学时数6课时(五)教学内容本章共分两节:第一节相关分析一、函数关系与相关关系(一)确定性的函数关系1. 是一一对应的确定关系设有两个变量 x 和 y ,变量 y 随变量 x 一起变化,并完全依赖于x ,当变量 x 取某个数值时, y 依确定的关系取相应的值,则称 y 是 x 的函数,记为 y = f (x),其中 x 称为自变量,y 称为因变量。
各观测点落在一条线上。
2. 当一个或几个相互联系的变量取一定数值时,与之相对应的另一变量的值虽然不确定,但它仍按某种规律在一定的范围内变化,变量间的这种相互关系,称为具有不确定性的相关关系(二)相关关系1. 变量间关系不能用函数关系精确表达2.一个变量的取值不能由另一个变量唯一确定3. 当变量 x 取某个值时,变量 y 的取值可能有几个4. 各观测点分布在直线周围二、相关关系的种类(一)按相关程度划分可分为完全相关、不完全相关、和不相关1.不相关。
如果变量间彼此的数量变化互相独立,则其关系为不相关。
自变量x变动时,因变量y的数值不随之相应变动。
2.完全相关。
如果一个变量的变化是由其他变量的数量变化所唯一确定,此时变量间的关系称为完全相关。
即因变量y的数值完全随自变量x的变动而变动,它在相关图上表现为所有的观察点都落在同一条直线上,这种情况下,相关关系实际上是函数关系。
所以,函数关系是相关关系的一种特殊情况。
3.不完全相关。
第6章 大数据分析与挖掘习题答案

(1)请阐述什么是大数据分析。
大数据分析的主要任务主要有:第一类是预测任务,目标是根据某些属性的值,预测另外一些特定属性的值。
被预测的属性一般称为目标变量或因变量,被用来做预测的属性称为解释变量和自变量;第二类是描述任务,目标是导出概括数据中潜在联系的模式,包括相关、趋势、聚类、轨迹和异常等。
描述性任务通常是探查性的,常常需要后处理技术来验证和解释结果。
具体可分为分类、回归、关联分析、聚类分析、推荐系统、异常检测、链接分析等几种。
(2)大数据分析的类型有哪些?大数据分析主要有描述性统计分析、探索性数据分析以及验证性数据分析等。
(3)举例两种数据挖掘的应用场景?(1)电子邮件系统中垃圾邮件的判断电子邮件系统判断一封Email是否属于垃圾邮件。
这应该属于文本挖掘的范畴,通常会采用朴素贝叶斯的方法进行判别。
它的主要原理就是,根据电子邮件中的词汇,是否经常出现在垃圾邮件中进行判断。
例如,如果一份电子邮件的正文中包含“推广”、“广告”、“促销”等词汇时,该邮件被判定为垃圾邮件的概率将会比较大。
(2)金融领域中金融产品的推广营销针对商业银行中的零售客户进行细分,基于零售客户的特征变量(人口特征、资产特征、负债特征、结算特征),计算客户之间的距离。
然后,按照距离的远近,把相似的客户聚集为一类,从而有效地细分客户。
将全体客户划分为诸如:理财偏好者、基金偏好者、活期偏好者、国债偏好者等。
其目的在于识别不同的客户群体,然后针对不同的客户群体,精准地进行产品设计和推送,从而节约营销成本,提高营销效率。
(4)简述数据挖掘的分类算法及应用。
K-Means算法也叫作k均值聚类算法,它是最著名的划分聚类算法,由于简洁和效率使得它成为所有聚类算法中最广泛使用的。
决策树算法是一种能解决分类或回归问题的机器学习算法,它是一种典型的分类方法,最早产生于上世纪60年代。
决策树算法首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析,因此在本质上决策树是通过一系列规则对数据进行分类的过程。
回归分析与相关分析

回归分析与相关分析回归分析是通过建立一个数学模型来研究自变量对因变量的影响程度。
回归分析的基本思想是假设自变量和因变量之间存在一种函数关系,通过拟合数据来确定函数的参数。
回归分析可以分为线性回归和非线性回归两种。
线性回归是指自变量和因变量之间存在线性关系,非线性回归是指自变量和因变量之间存在非线性关系。
回归分析可用于预测、解释和控制因变量。
回归分析的应用非常广泛。
例如,在经济学中,回归分析可以用于研究收入与消费之间的关系;在医学研究中,回归分析可以用于研究生活方式与健康之间的关系。
回归分析的步骤包括确定自变量和因变量、选择合适的回归模型、拟合数据、检验模型的显著性和解释模型。
相关分析是一种用来衡量变量之间相关性的方法。
相关分析通过计算相关系数来度量变量之间的关系的强度和方向。
常用的相关系数有Pearson相关系数、Spearman相关系数和判定系数。
Pearson相关系数适用于连续变量,Spearman相关系数适用于顺序变量,判定系数用于解释变量之间的关系。
相关分析通常用于确定两个变量之间是否相关,以及它们之间的相关性强度和方向。
相关分析的应用也非常广泛。
例如,在市场研究中,相关分析可以用于研究产品价格与销量之间的关系;在心理学研究中,相关分析可以用于研究学习成绩与学习时间之间的关系。
相关分析的步骤包括确定变量、计算相关系数、检验相关系数的显著性和解释相关系数。
回归分析与相关分析的主要区别在于它们研究的对象不同。
回归分析研究自变量与因变量之间的关系,关注的是因变量的预测和解释;相关分析研究变量之间的关系,关注的是变量之间的相关性。
此外,回归分析通常是为了解释因变量的变化,而相关分析通常是为了量化变量之间的相关性。
综上所述,回归分析和相关分析是统计学中常用的两种数据分析方法。
回归分析用于确定自变量与因变量之间的关系,相关分析用于测量变量之间的相关性。
回归分析和相关分析在实践中有广泛的应用,并且它们的步骤和原理较为相似。
回归分析与聚类分析

适用于多个自变量与一个因变量之间存在关系的 情况。
03 聚类分析
K-means聚类分析
定义
K-means聚类是一种无监督学习方法,通过 迭代过程将数据集划分为K个聚类,使得每 个数据点与其所在聚类的中心点之间的距离 之和最小。
优点
缺点
对初始聚类中心敏感,容易陷入局部 最优解;无法处理非凸形状的聚类; 对异常值敏感。
回归分析与聚类分析
目 录
• 引言 • 回归分析 • 聚类分析 • 回归分析与聚类分析的应用场景 • 回归分析与聚类分析的优缺点比较 • 回归分析与聚类分析的未来发展趋势
01 引言
主题简介
• 回归分析是一种统计学方法,用于研究自变量和因变量之间的 关系。通过回归分析,可以确定自变量对因变量的影响程度, 并预测因变量的未来值。聚类分析则是一种无监督学习方法, 用于将相似的对象分组,使得同一组内的对象尽可能相似,不 同组的对象尽可能不同。
金融预测
股票价格预测
通过分析历史股票价格、成交量 、财务数据等,建立回归模型预 测未来股票价格走势,帮助投资 者做出投资决策。
信用风险评估
基于借款人的财务状况、征信记 录等数据,建立回归模型预测借 款人的违约风险,用于信贷审批 和风险控制。
市场细分
消费者行为分析
通过聚类分析将消费者群体细分,了 解不同群体的消费习惯、偏好和需求 ,为产品定位、市场策略制定提供依 据。
简单易行,计算效率高,适合处理大 规模数据集。
层次聚类分析
定义
层次聚类是一种自底向上的聚类 方法,通过不断将相近的数据点 合并为新的聚类,直到满足终止
条件。
优点
能够处理任意形状的聚类;能够识 别不同规模的聚类;能够处理异常 值。
【毕业论文】相关分析和回归分析
相关分析和回归分析客观事物之间的关系分为函数关系和统计关系,函数关系也就是我们通常所说的一一对应的关系,而统计关系是指两事物之间的一种非一一对应的关系,即当一个变量x取一定值时,另一变量y无法依确定的函数取唯一确定的值。
事物之间的统计关系是普遍存在,且有的关系强,有的关系弱。
相关分析和回归分析都是以不同方式测度事物之间统计关系的有效工具。
实际应用中。
这两种分析方法经常互相结合渗透。
一、相关分析相关分析通过图形和数值两种方式,能够有效的揭示事物之间统计关系的强弱程度。
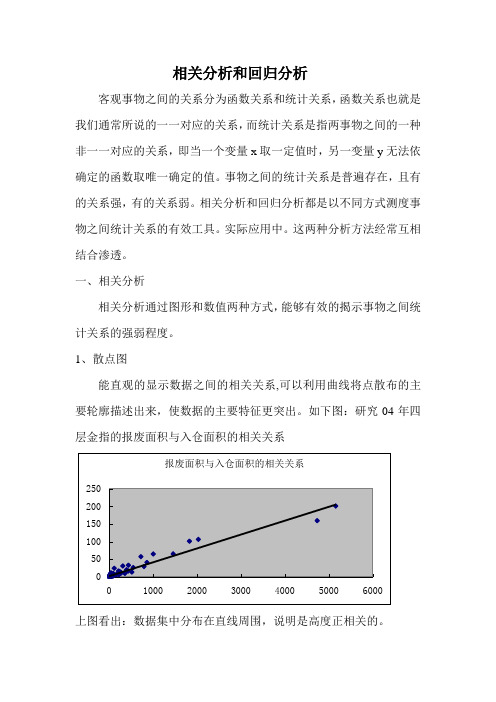
1、散点图能直观的显示数据之间的相关关系,可以利用曲线将点散布的主要轮廓描述出来,使数据的主要特征更突出。
如下图:研究04年四层金指的报废面积与入仓面积的相关关系上图看出:数据集中分布在直线周围,说明是高度正相关的。
2、相关系数散点图能直观的展现变量之间的统计关系,但并不精确。
相关系数以数值的方式精确的反映了两个变量间线形相关的强弱程度。
➢ R=yyxx xy L L L ,其中xx L =∑=--ni ix x12)(,∑=----=ni i i xy y y x x L 1))((,∑=--=ni i yy y y L 12)(.➢ 相关系数R 的取值在-1~+1之间。
➢ R>0表示两变量之间存在正的线性相关关系;R<0表示两变量之间存在负的线性相关关系。
➢ R=1表示两变量存在完全正相关;R=-1表示两变量存在完全负相关;R=0表示两变量不存在线性相关关系。
➢ |R|>0.8表示两变量之间具有较强的线性关系;|R|<0.3表示两变量之间的线性相关关系较弱。
上例中,R=0.974,说明报废面积与入仓面积之间是强正相关的。
二、一元线性回归在实际应用中,我们常常需要考虑某一现象与影响它的最主要因素的关系,回归分析不仅可以揭示变量x 对变量y 的影响大小,还可以由回归方程进行预测和控制。
一元线性回归是最简单的回归模型。
第6章相关分析与回归分析

(二)散点图(相关图)
用直角坐标系的横轴代表变量x ,纵轴代表变量y ,将两
个变量间相对应的变量值用坐标点的形式描绘出来,用 以表明相关点分布状况的图形。
70
根据上 65
例资料 60
绘制的
55
相关图
50
Y
2020/7/24
45 200
400
600
800
X
1000
1200
x与y关系散点图的主要类型
函数关系往往通过相关关系表现出来。把影响因变量变 动的因素全部纳入方程,这时的相关关系就有可能转化 为函数关系。 相关关系经常可以用一定的函数形式去近似地描述。
2020/7/24
(二)相关关系与因果关系
因果关系∈相关关系; 现象之间是因果关系同时是相关关系,但是相关关系不 一定是因果关系。 统计只能说明现象间有无数量上的关系,不能说明谁因 谁果。 例:有数据显示世界各国平均每人拥有电视机数x及居民 预期寿命y之间有很强的正相关,可否认为电视机很多的 国家,居民预期寿命比较长?
▪ 收入水平(y)与受教育程度(x)之间的关系
2020/7/24
相关关系的特点:yx(1)变量间关系不能用函数关系 精确表达;
(2)一个变量的取值不能由另一 个变量唯一确定;
(3)当变量 x 取某个值时,变量 y 的取值可能有几个;
(4)各观测点分布在直线附近。
2020/7/24
函数关系与相关关系的联系
线性形式,即当一个变量变动一个单位时,另一 个变量也按一个大致固定的增(减)量变动,就 称为线性相关。
非线性相关:当变量间的关系不按固定比例变
化时,就称之为非线性相关。
2020/7/24
4. 按研究变量的多少 单相关:两个变量之间的相关,称为单相关。 复相关:一个变量与两个或两个以上其他变量
科研常用的实验数据分析与处理方法.doc

科研常用的实验数据分析与处理方法对于每个科研工作者而言,对实验数据进行处理是在开始论文写作之前十分常见的工作之一。
但是,常见的数据分析方法有哪些呢?常用的数据分析方法有:聚类分析、因子分析、相关分析、对应分析、回归分析、方差分析。
1、聚类分析(Cluster Analysis)聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。
聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。
聚类分析所使用方法的不同,常常会得到不同的结论。
不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。
2、因子分析(Factor Analysis)因子分析是指研究从变量群中提取共性因子的统计技术。
因子分析就是从大量的数据中寻找内在的联系,减少决策的困难。
因子分析的方法约有10多种,如重心法、影像分析法,最大似然解、最小平方法、阿尔发抽因法、拉奥典型抽因法等等。
这些方法本质上大都属近似方法,是以相关系数矩阵为基础的,所不同的是相关系数矩阵对角线上的值,采用不同的共同性□2估值。
在社会学研究中,因子分析常采用以主成分分析为基础的反覆法。
3、相关分析(Correlation Analysis)相关分析(correlation analysis),相关分析是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度。
相关关系是一种非确定性的关系,例如,以X和Y 分别记一个人的身高和体重,或分别记每公顷施肥量与每公顷小麦产量,则X与Y显然有关系,而又没有确切到可由其中的一个去精确地决定另一个的程度,这就是相关关系。
4、对应分析(Correspondence Analysis)对应分析(Correspondence analysis)也称关联分析、R-Q 型因子分析,通过分析由定性变量构成的交互汇总表来揭示变量间的联系。
相关分析及回归分析

相关分析与回归分析
相关分析 回归分析 应用相关与回归分析应注意问题
2010-7-13
1
8.1
相关分析
8.1.1相关关系(correlation)的概念 8.1.1相关关系(correlation) 相关关系 现象间的非确定性的数量上的依存关系 现象间的非确定性的数量上的依存关系 非确定性 两个特点 ⑴确实存在数量上的依存关系 ⑵数量依存关系的值不确定
2010-7-13 9
8.1.2相关关系的种类 8.1.2相关关系的种类 1.按相关程度不同 完全相关 不完全相关 不相关
完全相关
2010-7-13
不完全相关
不相关
10
正相关 2.按相关方向不同 2.按相关方向不同 负相关
正相关
2010-7-13
负相关
11
线性相关 3.按相关的表现形式不同 3.按相关的表现形式不同 非线性相关
x
2010-7-13
5
变量间的关系
函数关系的例子
(函数关系)
某种商品的销售额(y)与销售量 之间的关 某种商品的销售额 与销售量(x)之间的关 与销售量 为单价) 系可表示为 y = p x (p 为单价 圆的面积(S)与半径之间的关系可表示为S 圆的面积(S)与半径之间的关系可表示为S = 与半径之间的关系可表示为 π r2 企业的原材料消耗额(y)与产量 企业的原材料消耗额 与产量(x1) ,单位产 与产量 量消耗(x 原材料价格(x 之间的关系可 量消耗 2) , 原材料价格 3)之间的关系可 表示为y 表示为 = x1 x2 x3
a和b称为回归方程中的两个待定参数 需要根据相关表中的x与y的实际资料求解 需要根据相关表中的x a和b一旦确定, 一旦确定, 直线就被唯一确定 哪一个?? 哪一个??
回归及相关分析PPT课件

05
相关分析
相关系数的计算
计算公式
相关系数r是通过两个变量之间的样本数据计算得出的,公式为r = (n Σxy - ΣxΣy) / (√(n Σx² - (Σx)²) * √(n Σy² - (Σy)²)),其中n是样本数量,Σx和Σy分别是x和y的样本总和,Σxy是x和y的样本乘积总和。
模型的评估与检验
模型的评估指标
模型的评估指标包括均方误差 (MSE)、均方根误差
(RMSE)、决定系数(R^2) 等,用于衡量模型的预测精度。
模型的检验方法
模型的检验方法包括残差分析、 正态性检验、异方差性检验等, 用于检查模型的假设是否成立。
模型的应用与推广
通过评估和检验模型,可以确定 模型在样本数据上的表现,并进 一步将其应用到更大范围的数据
回归及相关分析ppt课件
目 录
• 回归分析概述 • 一元线性回归分析 • 多元线性回归分析 • 非线性回归分析 • 相关分析
01
回归分析概述
回归分析的定义
01
回归分析是一种统计学方法,用 于研究自变量和因变量之间的相 关关系,并建立数学模型来预测 因变量的值。
02
它通过分析数据中的变量之间的 关系,找出影响因变量的重要因 素,并确定它们之间的数量关系 。
值。
模型的评估与检验
在估计多元线性回归模型的参 数后,需要对模型进行评估和 检验,以确保模型的有效性和 可靠性。
评估模型的方法包括计算模型 的拟合优度、比较模型的预测 值与实际值等。
检验模型的方法包括检验模型 的假设是否成立、检验模型的 残差是否符合正态分布等。
04
非线性回归分析
非线性回归模型
详细描述
第6章 相关分析回归分析和聚类分析

2 i
式中:Sxy是x,y的协方差
Sx是x的样本方差
Sy是y的样本方差
相关系数的假设检验
对简单相关系数的统计检验是计算t统计 量
r n2 t 2 1 r
T统计量服从n-2个自由度的t分布
例题1
某机构调查10个公司 的年龄和年销售额的 统计数据。
公司 1
基本思想
聚类分析就是采用定量数学方法,根据一批样 品的多个观测指标,具体找出一些能够度量样 品或指标之间相似程度的统计量,以这些统计 量为划分类型的依据。 把一些相似程度较大的样品(指标)聚合为一类 ,把另外一些彼此之间相似程度较大的样品又 聚合为另一类,关系密切的聚合到一个小的分 类单位,关系疏远的聚合到一个大的单位,直 到把所有的样品聚合完毕。
年龄X 3
销售额Y 25
2
3 4 5 6 7 8 9
10
5 6 12 15 9 2 9
60
25 35 60 65 60 20 55
10
7
50
步骤
在“Analyze”菜单“Correlate”中选择Bivariate 命令; 在Variable对话框中,选择”年龄”和”销售 额”两个变量; 在Correlation Coefficients框中选择相关系数的 类型,共有3中,本例选择Person 在Test of Significance框中选择Two-tailed检验 Flag significations correlations表示相关分析结 果将不显示统计检验的相伴概率,而是以*号 表示
乐购根据消费者的偏好识别了6个细分群 体;根据生活阶段分出了8个细分群体; 根据使用和购买周期划分了11个细分群 体;根据购买习惯和行为模式更是细分 5000个群体。
第二讲 相关分析与回归分析

第二讲相关分析与回归分析第一节相关分析1.1 变量的相关性1.变量的相关性分两种,一种是研究两个变量X与Y的相关性。
本节只研究前者,即两个变量之间的相关性;。
2.两个变量X与Y的相关性研究,是探讨这两个变量之间的关系密切到什么程度,能否给出一个定量的指标。
这个问题的难处在于“关系”二字,从数学角度看,两个变量X、Y之间的关系具有无限的可能性,一个比较现实的想法是:确立一种“样板”关系,然后把X、Y的实际关系与“样板”关系比较,看它们“像”到了什么程度,给出一个定量指标。
3.取什么关系做“样板”关系?线性关系。
这是一种单调递增或递减的关系,在现实生活中广为应用;另外,现实世界中大量的变量服从正态分布,对这些变量而言,可以用线性关系或准线性关系构建它们之间的联系。
1.2 相关性度量1.概率论中用相关系数(correlation coefficient)度量两个变量的相关程度。
为区别以下出现的样本相关系数,有时也把这里定义的相关系数称为总体相关系数。
可见相关系数是判断变量间线性关系的重要指标。
2.样本相关系数我们也只能根据这个容量为n的样本来判断变量X和Y的相关性达到怎样的程度。
这个估计称为样本相关系数,或Pearson 相关系数。
它能够根据样本观察值计算出两个变量相关系数的估计值。
和总体相关系数一样,如果0=XY ρ ,称X 和Y 不相关。
这时它们没有线性关系。
多数情况下,样本相关系数取区间(-1, 1)中的一个值。
相关系数的绝对值越大,表明X 和Y 之间存在的关系越接近线性关系。
1.3 相关性检验两个变量X 和Y 之间的相关性检验是对原假设H 0:Corr (X ,Y ) = 0的显著性进行检验。
检验类型为t 。
如果H 0显著,则X 和Y 之间没有线性关系。
1.4 计算样本相关系数Correlate\Bivariate例1 数据data02,计算变量当前薪金、起始薪金、受教育年限和工作经验之间的样本相关系数。
回归分析

准差
r剩
S剩 (n r 1)
r 为进入回归模型的变量个数。上述公式表示对于任一给定 的自变量(x1, x2, xm),所对应因变量的实际值 y 以95%的概率落 在区间 ( yˆ 2r剩,yˆ 2r剩),即预测值 yˆ 与实际值 y之差有95%的概
率,使得 y yˆ 2r剩, 所以r剩 越小其预测精度越高。
此外,在检验得知方程是显著之后,还需检验方程中哪些变量 x1, x2 , xm
是影响 y 的重要变量,哪些是不重要变量,进而剔除不重要的变量,简化
方程,得到优化回归方程,这就是所谓的对每个变量要进行显著性检验 (t检验)
n
总离差平方和 S总 ( yi y)2 ,自由度为 n 1,如果观测值给定,S总 i 1
i 1
化对 y 的波动,其自由度为 m 。
n
记 S剩 ( yi yˆi )2 称为剩余平方和(或残差平方和),它是由实验 i1
误差以及其他因素引起的。它反映了实验误差以及其他因素对实验结果的
影响程度,其自由度为n m1。
于是
S总 S回 S剩
当 S总确定时, S剩 越小, S回 越大,则 S回 就越接近 S总,于是用 S回 是否接
一组回归系数 b1 ,b2 , bm 值。 设 b1 ,b2 , bm 分别为 0, 1, , m 的最小二乘估计值,于是
有
yˆ b0 b1x1 b2x2 bmxm
其中 yˆ 是 y 的一个最小二乘估计。
下用最小二乘法求b1 ,b2 , bm
令
1 x11 x12 x1m
4、回归分析预测法的步骤
(1).根据预测目标,确定自变量和因变量 明确预测的具体目标,也就确定了因变量。如预测具体
第六章spss相关分析和回归分析

第六章SPSS相关分析和回归分析第六章SPSS相关分析与回归分析6.1相关分析和回归分析概述客观事物之间的关系大致可归纳为两大类,即,函数关系:指两事物之间的一种一一对应的关系,如商品的销售额和销售量之间的关系。
,相关关系(统计关系):指两事物之间的一种非一一对应的关系,例如家庭收入和支出、子女身高和父母身高之间的关系等。
相关关系乂分为线性相关和非线性相关。
相关分析和回归分析都是分析客观事物之间相关关系的数量分析方法。
6. 2相关分析相关分析通过图形和数值两种方式,有效地揭示事物之间相关关系的强弱程度和形式。
6.2. 1散点图它将数据以点的的形式画在直角坐标系上,通过观察散点图能够直观的发现变量间的相关关系及他们的强弱程度和方向。
6.2.2相关系数利用相关系数进行变量间线性关系的分析通常需要完成以下两个步骤:第一,计算样本相关系数r;,+1之间,相关系数r的取值在-1,R>0表示两变量存在正的线性相关关系;r〈0表示两变量存在负的线性相关关系,R,1表示两变量存在完全正相关;r, -1表示两变量存在完全负相关;r, 0表示两变量不相关,|r|>0.8表示两变量有较强的线性关系;r <0.3表示两变量之间的线性关系较弱第二,对样本来自的两总体是否存在显著的线性关系进行推断。
对不同类型的变量应采用不同的相关系数来度量,常用的相关系数主要有Pearson 简单,相关系数、Spearman等级相关系数和Kendall相关系数等。
6. 2. 2. 1 Pearson简单相关系数(适用于两个变量都是数值型的数据)(,)(,)yy, ixxi,r 22(,), (,) yy,, ixxiPearson简单相关系数的检验统计量为:rn, 22t,6. 2. 2. 2 Spearman等级相关系数Spearman等级相关系数用来度量定序变量间的线性相关关系,设计思想与Pearson 简1, r(,)xyii单相关系数相同,只是数据为非定距的,故计算时并不直接采用原始数据,而是利(,)xy(,)UViiii用数据的秩,用两变量的秩代替代入Pearson简单相关系数计算公式中,于是xyii其中的和的取值范禺被限制在1和n之间,且可被简化为:2nn6D, i22,,,,,其中rDUV1 (),, iii,, 2, nn(l)iillnn22DUV,, (),, iii,, llii,如果两变量的正相关性较强,它们秩的变化具有同步性,于是的值较小,r趋向于1;nn22DUV,, (),, iii,, Uii,如果两变量的正相关性较弱,它们秩的变化不具有同步性,于是的值较大,r趋向于0;,在小样本下,在零假设成立时,Spearman等级相关系数服从Spearman分布; 在大样本下,Spearman等级相关系数的检验统计量为Z统计•量,定义为:Zrn,, 1Z统计量近似服从标准正态分布。
聚类分析以及相关系数PPT优质课件

(2)选定 则将 G K 和
D 0 中的最小元素,设为 G
G L合并成一个新类,记为
, KGLM,
即 G MG K ,G L。
(3)计算新类 G M 与任一类 G J 之间距离的
递推公式
D M i J G m M ,j G Jd iij n m i G m K i,j n G Jd i i,jin G m L ,j G Jd i ijn
可以定义第 i个样品与第 j个样品间的兰氏
距离为
dij
p
L
k1
xikxjk xikxjk
6.1.2
3.马氏(Mahalanobis)距离
第 i个样品与第 j个样品之间的马氏距离为
dM x xSx x T 1
为 个类 i j,类 的样品数和重心i
j
ij
6 .1 .3
其中 x x , x , , x , x x , x , , x , S 这里
这两名学员的第二个变量都取值“英”,称 为
配合的,第一个变量一个取值为“男”,另
一
Lance和Williams与1967年将这些递推公式
理或迭代比较稳定为止。
m (2) 中最小元素是
,于是将
个取值为“女”,称为1 不配合的。一般的, 2)式求得,其余行列上的距离值不变,这样就得到新的距离矩阵,记为 。
6.1.6
它是 R n 中变量 x i的观察向量 x1i,x2i,xniT
与变量x j 的观察向量
x1j,x2j, ,xn
T j
之间的
夹角 ij 的余弦函数,即 cij1coisj 。
2.相关系数
变量x i 与 x j的相关系数为
n
xk ixi xk jxj
回归分析和聚类分析

应用统计学作业学生:王灵波学号:******************专业:技术经济及管理三、回归分析:回归分析: 货运总量与工业总产值, 农业总产值, 居民非商品支出回归方程为货运总量 = - 348 + 3.75 工业总产值 + 7.10 农业总产值 + 12.4 居民非商品支出系数标自变量系数准误 T P常量 -348.3 176.5 -1.97 0.096工业总产值 3.754 1.933 1.94 0.100农业总产值 7.101 2.880 2.47 0.049居民非商品支出 12.45 10.57 1.18 0.284S = 23.4419 R-Sq = 80.6% R-Sq(调整) = 70.8%PRESS = 17731.2 R-Sq(预测) = 0.00%方差分析来源自由度 SS MS F P回归 3 13655.4 4551.8 8.28 0.015残差误差 6 3297.1 549.5合计 9 16952.5来源自由度 Seq SS工业总产值 1 5234.1农业总产值 1 7659.1居民非商品支出 1 762.2异常观测值工业总拟合值标准化观测值产值货运总量拟合值标准误残差残差6 68.0 220.00 245.20 20.19 -25.20 -2.12RR 表示此观测值含有大的标准化残差(1)相关: 货运总量, 工业总产值, 农业总产值, 居民非商品支出货运总量工业总产值农业总产值工业总产值 0.5560.095农业总产值 0.731 0.1130.016 0.756居民非商品支出 0.724 0.398 0.5470.018 0.254 0.101单元格内容: Pearson 相关系数P 值(2)货运总量 = - 348 + 3.75 工业总产值 + 7.10 农业总产值 + 12.4 居民非商品支出(3) R2值表明这些预测变量可以解释货运总量中R-Sq = 80.6%的方差。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Bij Bii B jj
结果与讨论
第二节 回归分析
回归分析是通过一定的数学表达式描述 变量之间的数量变化关系,并进行预测。 回归分析分为:一元线性回归分析、多 元线性回归分析、非线性回归分析、曲 线估计、时间序列的曲线估计等模型。
回归分析和相关分析都是研究变量间关 系的统计学课题。但两者有所侧重: 在回归分析中,变量Y成为因变量,自变 量x可以是随机变量;而在相关分析中, x,y都是随机变量; 回归分析通过一定的数学表达式描述变 量之间的数量变化关系,并进行预测。
相关系数r的取值范围
正相关:0<r≤1 负相关:-1≤r<0 完全相关:|r|=1 函数关系 完全不相关: |r|=0 高度相关: |r|≥0.8 中度相关: 0.5≤|r|≤0.8 不相关: |r|≤0.3
一、简单相关分析
总体相关系数
Cov( x, y ) xy Var( x )Var( y )
第6章 相关分析,回归分析和聚类分析
本章内容
第一节 相关分析 第二节 回归分析 第三节 聚类分析
第一节 相关分析
什么是相关分析?
相关分析是一种描述变量之间的相关程 度的分析方法。 在相关分析中,所有变量都是随机变量, 它们之间并不存在被解释变量和解释变 量之间的关系。 相关分析有简单相关和多元相关、线性 相关和非线性相关之间的关系、正相关 和负相关之分。
一、一元线性回归分析
是在排除其他影响因素或假定其他影响 因素确定的条件下,分析某一个因素(自 变量)是如何影响另一事务(因变量)的过 程。
在多元相关分析中,偏相关是指对两个变量在其 余变量保持不变的条件下的相关关系。 例如:Y=β1+β2xi2+β3xi3+ui 剔除x2的影响,求Y由其他变量所解释的成分 Yi=d1+d2xi3+li 剔除Y的影响,求x2由其他变量所解释的成分 xi2=g1+g2xi3+hi li,hi为残差。
求偏相关系数
i i i i 2 2 i i 2 i
2 i
式中:Sxy是x,y的协方差
Sx是x的样本方差
Sy是y的样本方差
相关系数的假设检验
对简单相关系数的统计检验是计算t统计 量
r n2 t 2 1 r
T统计量服从n-2个自由度的t分布
例题1
某机构调查10个公司 的年龄和年销售额的 统计数据。
公司 1
记Y与x3的偏相关系数为r12.3
r12.3
lh l h
i i 2 i
2 i
任意两个变量i,j的偏相关系数为:
rij.12...(i 1)( i 1)( j 1)( j 1)k
r 11 r B 21 rk 1 r 12 r22 rk 2 ... ... ... r 1k r2 k rkk
Cov(x,y)表示随机变量x与y的协方差 Var(x)表示随机变量x的方差 Var(y)表示随机变量y的方差
总体相关系数满足如下性质:
|ρxy|≤1 |ρxy|=1的充要条件是X和Y依概率线性相 关。
总体相关系数ρxy一般是得不到的,我们只 能根据样本观测值估计。
样本相关系数
rxy S xy Sx S y ( X X )(Y Y ) xy ( X X ) (Y Y ) x y
Yi 1 2 X 2 3 X 3 ....... k X ik ui
公司 1 2 3 4
销售额Y 25 60 25 35
年龄X2 3 10 5 6
人数x3 4 14 6 10
5
6 7 8 9
60
65 60 20 55
12
15 9 2 9
16
17 13 2 7
10
50
7
年龄X 3
销售额Y 25
2
3 4 5 6 7 8 9
10
5 6 12 15 9 2 9
60
25 35 60 65 60 20 55
10
7
50
步骤
在“Analyze”菜单“Correlate”中选择Bivariate 命令; 在Variable对话框中,选择”年龄”和”销售 额”两个变量; 在Correlation Coefficients框中选择相关系数的 类型,共有3中,本例选择Person 在Test of Significance框中选择Two-tailed检验 Flag significations correlations表示相关分析结 果将不显示统计检验的相伴概率,而是以*号 表示
6
多元相关系数
多元相关系数是度量一个变量与其他所 有变量相关程度的数量指标。记为R。 R定义为最小二乘估计值Ŷ与变量Y的观测 值的简单相关系数。
多元相关系数R
RY . x1x2 ...xk
式中:
SYˆY rYˆY 2 SYˆ S Y (Yi Y )
SY
SY ˆ
SYY
2 (Yi Y )
(Y
i
Y )
n 1 ˆ (Yi Y )(Yi Y )
2 ( Y Y ) i
n 1
n 1
式中: R表示变量Y与变量x2,x3,…,xk的相关程度 用多重相关系数
多重相关系数的显著性检验
构造零假设:H0: 对立假设:H1:
Y . X X
1
Y . X X ...X 0
1 2 k
2 ...X k
0
假设检验统计量为:
பைடு நூலகம்F
R
(1 R
2 Y . X 2 X 3 .. X K 2 Y . X 2 X 3 .. X K
(n k ) )( k 1)
~ F (k 1, n k )
偏相关系数
绘制散点图
在“Graphs”菜单中选择scatter命令 本例只想绘制年龄和销售额的散布情况, 因此选择”Simple” 打开“Difine”对话框,选择X 、Y轴 单击“OK”
结果与讨论
相关系数为0.923,通过99%的可信度检验
二、多元相关分析
相关分析的目的在于对若干变量之间的关联程 度进行估计。一般都进行多元线性相关分析, 而很少考虑非线性的相关关系。这是因为后者 可以进行变量的转换,最终将其归到线性关系。 多元线性回归模型: