排队论(Lingo方法)
高级运筹学-排队论

3、守序性:设在[t, t+t)内到达多于一个顾客的概率为
极小o(t)。 lim o(t) 0 t0 t
Pn (t,t t) o(t)
n2
实际情况是否符合三条性质
到达工厂机修车间的要维修的机器情况分析: 因为每台机器在各个时刻处的状态大致一样,所以在相
等时间区间内各台机器损坏的概率大致相同,即要求维 修的机器的流具有平稳性 由于一台机器的故障不会引起另一台机器的故障,而对 同一台机器,这段时间内损坏的次数不影响到以后损坏 次数多少,这表明具有无后效性 由于每台机器损坏概率很小,在足够小的时间区间内发 生两台及以上机器损坏的概率几乎为0,这就符合普通性。 因此对到达机修车间的要维修的机器数可以认为是最简 单流,即poisson流。
如何减少排队?
减少等候时间的解决方案 :
开设更多的服务点; 提供自助服务解决方案; 雇用更多员工。
排队管理系统的应用
近两年,许多公共服务场所出现了排队机 (ticket dispenser unit) ,窗口秩序为之一变, 一种令人耳目一新的排队方式:
进得大门,在排队机的触摸屏上点一下所要 办理的项目,排队机就会“吐”出一张像名 片大小的号票,拿着这张号票安安静静地坐 在休息区舒适的椅子上等候,轮到自己时, 大屏幕和语音系统会提醒你到相应的窗口办 理,井然有序。
顾客 汽车 卡车 轮船 飞机 人员 装货工人 卸货工人 跑道 飞机 出租车 电梯 消防车 停车空间 急救车
4.1.2 排队系统的组成
排队系统的三个基本组成部分: •输入过程 (顾客按照怎样的规律到达); •排队规则 (顾客按照一定规则排队等待服务); •服务机构 (服务机构的设置,服务台的数量,服务 的方式,服务时间分布等)
LINGO的使用方法说明大全

LINGO 程序框架LINGO 可以求解线性规划、二次规划、非线性规划、整数规划、图论及网络最优化问题和最大最小求解问题,以及排队论模型中最优化等问题.一个LINGO 程序一般会包括以下几个部分:(1)集合段:集部分是LINGO 模型的一个可选部分.在 LINGO 模型中使用集之前,必须在集部分事先定义.集部分以关键字“ sets: ”开始,以“ endsets ”结束.一个模型可以没有集部分,或有一个简单的 集部分,或有多个集部分.一个集部分可以放置于模型的任何地方,但是一个集及其属性在模型约束中被 引用之前必须先定义.(2)数据段:在处理模型的数据时,需要为集部分定义的某些元素在值.数据部分以关键字"data: ”开始,以关键字"enddata "结束.LING O 的使用简介 LINGO 软件是美国的LINGO 系统公司开发的一套专门用于求解最优化问题的软件包. LINGO 除了能够 用于求解线性规划和二次规划外,还可以用于非线性规划求解、以及一些线性和非线性方程 (组)的求解 等.LINGO 软件的最大特色在于它允许优化模型中的决策变量为整数,即可以求解整数规划,而且执行速 度快.LINGO 是用来求解线性和非线性优化问题的简易工具. LING O 内置了一种建立最优化模型的语言,可 以简便地表达大规模问题,利用 LINGO 高效的求解器可快速求解并分析结果.在这里仅简单介绍 LINGO 的 使用方法. LINGO(Linear INteractive and General Op timizer ) 的基本含义是交互式的线性和通过优化求解 器.它是美国芝加哥大学的 Linus Schrage 教授于1980年开发了一套用于求解最优化问题的工具包,后来 经过完善成何扩充,并成立了 LINDO 系统公司.这套软件主要产品有: LINDO, LINGO, 口NDOAPI 和What ' sBest .它们在求解最优化问题上,与同类软件相比有着绝对的优势.软件有演示版和正式版.正式版包括: 求解包(solver suite) 、高级版(super)、超级版(hyper)、工业版(industrial) 、扩展版(extended).不 同版本的LINGO 对求解问题的规模有限制,如附表3 -1所示. 附表3 -1 不同版本LINGO 对求解规模的限制版本类型总变量数整数变量数非线性变量数 约束数演示版300 30 30 150 求解包 500 50 50 250 高级版 2000 200 200 1000 超级版8000 800 800 4000工业版 320003200 32000 16000扩展版 无限无限 无限无限LINGO 求解模型之前为其指定(3)目标和约束段:这部分用来定义目标函数和约束条件等•该部分没有开始和结束的标记•主要是要用到LINGO的内部函数,尤其是与集合有关的求和与循环函数等.(4)初始段:这个部分要以关键字“INIT ::开始,以关键字“ ENDINIT”结束,它的作用是对集合的属性定义一个初值•在一般的迭代算法中,如果可以给一个接近最优解的初始值,会大大减少程序运行的时间.(5)数据预处理段:这一部分是以关键字“ CALC”开始,以关键字“ ENDCAL”结束.它的作用是把原始数据处理成程序模型需要的数据,它的处理是在数据段输入完以后、开始正式求解模型之前进行的, 程序语句是按顺序执行的.LINGO中集合的概念在对实际问题建模的时候,总会遇至L群或多群相联系的对象,比如工厂、消费者群体、交通工具和雇工等等.LINGO允许把这些相联系的对象聚合成集(sets ). 一旦把对象聚合成集,就可以利用集来最大限度地发挥LING0建模语言的优势•现在将深入介绍如何创建集,并用数据初始化集的属性.集的构成集是LING0建模语言的基础,是程序设计最强有力的基本构件•借助于集能够用一个单一的、简明的复合公式表示一系列相似的约束,从而可以快速方便地表达规模较大的模型.集是一群相联系的对象,这些对象也称为集的元素•一个集可能是一系列产品、卡车或雇员•每个集的元素可能有一个或多个与之有关联的特征,把这些特征称为属性•属性值可以预先给定,也可以是未知的,有待于LING0求解的.LINGO有两种类型的集:原始集(P rimitiveset)和派生集(derived set)一个原始集是由一些最基本的对象组成的.一个派生集是用一个或多个其它集来定义的,也就是说,它的元素来自于其它已存在的集.模型的集部分集部分在程序中又称为集合段,它是LINGO模型的一个可选部分.在LINGO模型中使用集之前,必须在集部分事先定义.集部分以关键字“sets: ”开始,以“ endsets ”结束.一个模型可以没有集部分,或有一个简单的集部分,或有多个集部分•一个集部分可以放置于模型的任何地方,但是一个集及其属性在模型约束中被引用之前必须先定义.(1)原始集的定义为了定义一个原始集,必须详细说明集的名字,而集的元素和相应的属性是可选的.定义一个原始集,用下面的语法:setname[/member_list/][:attnbute_list];注意:用“ [] ”表示该部分内容是可选的(下同)Setname是用来标记集的名字,最好具有较强的可读性.集名字必须严格符合标准命名规则:以拉丁字母或下划线为首字符,其后由拉丁字母、下划线、阿拉伯数字组成的总长度不超过32个字符的字符串,且不区分大小写.注意:该命名规则同样适用于集元素名和属性名等的命名.Member_list 是集元素的列表.如果集元素放在集定义中,那么对它们可采取显式和隐式罗列两种方式.如果集元素不放在集定义中,那么可以在随后的数据部分定义.① 当显式罗列元素时,必须为每个元素输入一个不同的名字,中间用空格或逗号隔开,允许混合使用.例定义一个名为friends 的原始集,它具有元素John,Jill ,Rose和Mike,其属性有sex和age:sets:friends/John Jill, Rose Mike/: sex, age;endsets② 当隐式罗列元素时,不必罗列出每个集元素.可采用如下语法:setname/member1..member N/[: attribute_list];这里的member是集的第一个元素名,membe N是集的最后一个元素名.LINGO将自动产生中间的所有元素名.LINGO也接受一些特定的首元素名和末元素名,用于创建一些特殊的集.③ 集元素不放在集定义中,而在随后的数据部分来定义.! 集部分;sets:friends:sex,age;endsets! 数据部分;data:friends,sex,age=John,1,16 Jill,0,14 Rose,0,17 Mike,1,13;enddata注意:开头用感叹号(!),末尾用分号(; )表示注释,可跨多行.在集部分只定义了一个集friends ,并未指定元素.在数据部分罗列了集元素John,Jill ,Rose 和Mike,并对属性sex和age分别给出了值.集元素无论用何种字符标记, 它的索引都是从1开始连续计数.在attribute_ list 可以指定一个或多个集元素的属性,属性之间必须用逗号隔开.LINGO内置的建模语言是一种描述性语言,用它可以描述现实世界中的一些问题, 然后再借助于LINGO 求解器求解.因此,集属性的值一旦在模型中被确定,就不可能再更改.只有在初始部分中给出的集属性值在以后的求解中可更改.这与前面并不矛盾,初始部分是 的.(2)定义派生集为了定义一个派生集,必须详细说明集的名字和父集的名字,而集元素和属性是可选的.可用下面的 语法定义一个派生集:setname(parent_set_list)[/member_list/][:attribute_list];setname 是集的名字. parent_set_list 是已定义的集的列表,多个时要用逗号隔开.如果没有指定成员列表,那么LINGO 会自动创建父集元素的所有组合作为派生集的元素. 也可以是其它的派生集.sets:product/A,B/; machine/M,N/; week/1..2/;allowed(product,machine,week):x; endsets编号(A,M,1) (A,M,2) (A,N,1) (A,N,2) (B,M,1) (B,M,2) (B,N,1) (B,N,2)元素列表被忽略时,派生集成员由父集成员所有的组合构成,这样的派生集成为稠密集.如果限制派 生集的成员,使它成为父集成员所有组合构成的集合的一个子集,这样的派生集成为稀疏集.同原始集一 样,派生集元素的说明也可以放在数据部分.一个派生集的元素列表有两种方式生成:①显式罗列;②设 置元素选择的过滤器.当采用方式①时,必须显式罗列出所有要包含在派生集中的元素,并且罗列的每个 元素要属于稠密集.使用前面的例子,显式罗列派生集的元素,如:allowed(product,machine,week)/A M 1,A N 2,B N 1/;如果需要生成一个大的、稀疏的集,那么显式罗列就十分麻烦.但是许多稀疏集的元素都满足一些条 件,可以把这些逻辑条件看作过滤器,在 LINGO 生成派生集的元素时把使逻辑条件为假的元素从稠密集中过滤掉.sets:!学生集:性别属性sex , 1表示男性,0表示女性;年龄属性 age; students/John,Jill,Rose,Mike/:sex,age; !男学生和女学生的联系集:友好程度属性friend ! [0,1]之间的数;linkmf(students,students)|sex(&1)#eq#1#and#sex(&2)#eq#0: friend; !男学生和女学生的友好程度大于的集 linkmf2(linkmf) | friend(&1, &2) #ge# : x; endsets data:LINGO 求解器的需要,并不是描述问题所必须派生集的父集既可以是原始集,LINGO 生成了三个父集的所有组合共八组作为allowed 集的元素,列表如下:元素sex,age =1 16,0 14,0 17,0 13; friend =,,; enddata用竖线(I )来标记一个元素过滤器的开始. #eq#是逻辑运算符,用来判断是否“相等” .&1可看作派生集的第1个原始父集的索引,它取遍该原始父集的所有元素;&2可看作派生集的第2个原始父集的索引, 它取遍该原始父集的所有元素; &3, &4,…,依此类推.注意如果派生集B 的父集是另外的派生集 A 那么上面所说的原始父集是集A 向前回溯到最终的原始集,其顺序保持不变,并且派生集集B 仍然有效.因此,派生集的索引个数是最终原始父集的个数,索引的取值是从原始父集到当前派生集 所作限制的总和.LINGO 数据部分和初始部分在处理模型的数据时,需要为集指定一些元素并且在 LINGO 求解模型之前为集的某些属性指定数值.为此,LINGO 为用户提供了两个可选部分:输入集元素数值的数据部分( 初始值的初始部分(Init Section ).数据部分(1)数据部分入门数据部分以关键字“ data: ”开始,“enddata ”结束.在这里,可以指定集元素和集的属性.其语法 如下:object_list = value_list;对象列(object_list )包含要指定值的属性名、要设置集元素的集名,用逗号或空格隔开.一个对 象列中只能有一个集名,而属性名可以有任意多个.如果对象列中有多个属性名,那么它们的类型必须一 致.数值列(value_list )包含要分配给对象列中对象的值,用逗号或空格隔开.注意属性值的个数必须 等于集元素的个数.sets:SET0/A,B,C/: X,Y; endsets data: X=1,2,3; Y=4,5,6; enddata在集SET 冲定义了两个属性 X 和Y . X 的三个值是1, 2, 3, Y 的三个值是4, 5, 6.也可采用如下例 子中的复合数据说明( data statement )实现同样的功能.sets:SET0/A,B,C/: X,Y; endsetsA 的过滤器对派生Data Section )和为决策变量设置X,Y=1 4 2,5 3 6;enddata如果对象列中有n个对象,LINGO在为对象指定值时,首先在n个对象的第1个索引处依次分配数值列中的前n个对象,然后在n个对象的第2个索引处依次分配数值列中紧接着的n个对象,…,依此类推.(2)参数输入在数据部分也可以指定一些标量变量( scalar variables ).当一个标量变量在数据部分确定时,称之为参数.例如,假设模型中用利率9%作为一个参数,就可以输入一个利率作为参数.data:interest_rate = .09;enddata实际中也可以同时指定多个参数.如:data:interest_rate,inflation_rate = .09, .025;enddata(3)实时数据处理在某些情况下,模型中的某些数据并不是定值.譬如模型中有一个参数在求解模型,观察模型2%至6%范围内,对不同的值的结果对参数依赖的程度,那么把这种情况称为实时数据处理.处理方法是在该语句的数值后面输入一个问号()interest_rate,inflation_rate = .09 ;enddata在每一次求解模型时,LINGO都会提示为参数inflation_rate 输入一个值.在WINDOW操作系统下,将会看到一个如下面的对话框:直接输入一个值再点击0K按钮,LINGO就会把输入的值指定赋给inflation_rate ,然后继续求解模型.除了参数之外,也可以实时输入集的属性值,但不允许实时输入集元素名.(4)指定属性为一个值可以在数据定义的右边输入一个值来把所有的元素的该属性指定为一个值.如下面的例子.sets:days /MO,TU,WE,TH,FR,SA,SU/:needs;endsetsdata:needs = 40;enddataLINGO将用40指定days集的所有元素的needs属性.对于多个属性的情形如下:sets:days /MO,TU,WE,TH,FR,SA,SU/:needs,cost;endsetsdata:needs cost = 40 90;enddata(5)数据部分的未知数值表示法有时候只需为一个集的部分元素的某个属性指定数值,而让其余元素的该属性是未知的,以便让LINGO 去求出它们的最优值.在数据定义中输入两个相连的逗号表示该位置对应元素的属性值未知,两个逗号间可以有空格.sets:years/1..6/: capacity;endsetsdata:capacity = ,24,40,,,;属性capacity的第2个和第3个值分别为24和40,其余的未知.初始部分初始部分是LINGO提供的另一个可选内容•在初始部分中,与数据部分中的数据定义相同,可以输入初始定义(initialization statement ).在对实际问题的建模时,初始部分并不起到描述模型的作用,初始部分输入的值仅被LING 0求解器当作初始值来使用,并且仅仅对非线性模型有用•这与数据部分指定变量的值不同,LINGO求解器可以自由改变初始部分初始化变量的数值.一个初始部分以关键字“init: ”开始,以关键字“ endinit ”结束.初始部分的初始定义规则和数据部分的数据定义规则相同•也就是说,可以在定义的左边同时初始化多个集属性,即可以把集属性初始化为一个数值,也可以用问号定义为实时数据,还可以用逗号指定为未知数值.init:X,Y = 1,0;endinitY=@log(X);XA2+YA2<=I;LINGO函数运算符及其优先级LINGO中的运算符可以分为三类:算数运算符、逻辑运算符和关系运算符.(1) 算数运算符算数运算符分为5种:(加法),(减法),(乘法),(除法),(求幂).逻辑运算符逻辑运算符分为两类:#AND#(与),#OR#(或),#NOT#非):这3个运算符是参与逻辑值之间的运算,其结果还是逻辑值.运算符#EQ#等于),#NE#(不等于),#GT#(大于),#GE#(大于等于),#LT#(小于),#LE#(小于等于)是用于“数与数之间”的比较,其结果是实逻辑值.关系运算符LINGO中有3种关系运算符:<(小于等于),>(大于等于),=(等于).注意LINGO中优化模型的约束一般没有严格大于、严格小于,要和逻辑运算符区分开.运算符的优先等级如附表3-2所示.附表3-2运算符的优先级优先级运算符#N0# ,-(负号)*,/高级#EQ#,#NE#,# GT#,# GE## LT#,#LE#,#AN#,#OR最低LINGO数学函数(1)基本数学函数LINGO中有相当丰富的数学函数,这些函数的用法简单.下面列表对各个函数的用法做简单的介绍,具体情况如附表3-3所示.(2)集合循环函数集合循环是指对集合上的元素(下标)进行循环操作的函数,它的一般用法如下:@function(setname[(set_index_list)[|condition]]:ex pression_list)其中function 是集合函数名,是FOR,MAX,MIN,PROD,SU五种之一.setname 是集合名;set_index_list是集合索引列表(可以省略);condition 是实用逻辑表达式描述的过滤条件(通常含有索引,可以省略); expression_list 是一个表达式(对@FO可以是一组表达式).下面对具体的集合函数作如下解释:@FOR集合元素的循环函数):对集合setname的每个元素独立生成表达式,表达式由expression_list 描述.@MAX|合属性的最大值):返回集合setname上的表达式的最大值.@MIN集合属性的最小值):返回集合setname上的表达式的最小值.@PROD|合元素的乘积函数):返回集合setname上的表达式的积.@SUM|合元素的求和函数):返回集合setname上的表达式的和.表附3-3(3)集合操作函数集合操作函数是对集合进行操作的函数,主要有4种,下面分别介绍它们的一般用法.1)@INDEX([set_name,]primitive_set_element)这个函数给出元素primitive_set_element 在集合set_name中的索引值(即按定义集合时元素出现顺序的位置编号).如果省略编号set_name, LINGO按模型中定义的集合顺序找到第一个含有元素primitive_set_element 的集合,并返回索引值.通过下面例子解释函数的使用方法.例如,假设定义一个女孩的姓名集合和一个男孩的姓名集合:SETS:GIRLS/DEBBLE,SUE,ALICE/;BOYS/BOB,JOE,SUE,FRED/;ENDSETS注意到女孩集和男孩集中都有一个为SUE的元素,如果要调用此函数@INDEX(SUE)则得到返回索引值是2.因为集合GIRLS在集合BOYS>前,则索引函数只对集合GIRLS检索.如果想查找男孩集中的SUE则应该使用@INDEX(BOYS,SU,)则此时得到的索引值是 3.2)@IN(set_name,primitive_index_1[,pnmitive_index_2这个函数用于判断一个集合中是否含有某个索引值.它的返回值是“假”).例全集为I , B是I的一个子集,C是B的补集.sets:l/x1..x4/; …])1(逻辑值“真”),或是0(逻辑值B(I)/x2/;C(I)|#not#@in(B,&1):;endsets3)@wrap(index,limit)该函数返回j=index-k*limit ,其中k 是一个整数,取适当值保证j 落在区间[1 ,limit] 内.该函数相当于index 模limit 再加1.该函数在循环、多阶段计划编制中特别有用.4)@size(set_name)该函数返回集set_name的元素个数.在LINGO模型中,如果没有明确给出集的大小,则使用该函数能够使模型中的数据变化和集的大小改变更加方便.(4)变量定界函数变量界定函数能够实现对变量取值范围的附加限制,共4种:1) @bin(x) 表示限制就是x 为0或1;2) @bnd(L,x,U) 表示限制变量x 满足;3) @free(x) 表示取消对变量x 的默认下界为0的限制,x 可以取任意实数;4) @gin(x) 表示限制变量x 为整数.在默认情况下,LINGO规定变量是非负的,即下界值为0,上界为+S. @free取消了默认的下界为0的限制,使变量也可以取负值.@bnd用于设定一个变量的上下界, 它也可以取消默认下界为0的约束.(5)概率论中相关函数1)@pbn(p,n,x)二项分布的分布函数,当n和(或)x不是整数时, 用线性插值法进行计算.2)@pcx(n,x)自由度为n的X 2分布的分布函数在x点的取值.3)@peb(load,x)当到达负荷(平均服务强度)为load ,服务系统有x 个服务台,且系统容量无限时的Erlang 繁忙概率,多用于解决排队问题.4)@pel(load,x)当到达负荷(平均服务强度)为load ,服务系统有x 个服务台,系统容量为有限时的Erlang 繁忙概率,多用于解决排队问题.5)@pfd(n,d,x)自由度为n 和 d 的 F 分布的分布函数在x 点的取值.6)@pfs(load,x,c)当负荷上限为load,顾客数为C,平行服务台数量为x 时,顾客源有限的Poisson 服务系统的等待或有返回顾客数的期望值. load 是顾客数乘以平均服务时间,再除以平均返回时间.当 C 和(或) x 不是整数时,采用线性插值进行计算.7)@phg(pop,g,n,x)超几何( Hypergeometric )分布的分布函数. pop 表示产品总数,g 是正品数.从所有产品中任意取出n (nw pop)件.pop, g, n和x都可以是非整数,这时采用线性插值进行计算.8)@ppl(a,x)Poisson 分布的线性损失函数, 即返回max(0,z-x) 的期望值,其中随机变量z 服从均值为 a 的Poisson分布.9)@pps(a,x)均值为a的Poisson分布的分布函数在x点的取值.当x不是整数时,采用线性插值进行计算.10)@psl(x)单位正态线性损失函数,即返回max(0,z-x) 的期望值,其中随机变量z 服从标准正态分布.11)@psn(x)标准正态分布的分布函数在x 点的取值.12)@ptd(n,x)自由度为n的t分布的分布函数在x点的取值.13)@qrand(seed)产生(0,1)区间的拟随机数.@qrand只允许在模型的数据部分使用,它将用拟随机数填满集属性•通常定义一个mx n的二维表,m表示运行实验的次数,n表示每次实验所需的随机数的个数•在行内,随机数是独立分布的;在行间,随机数是非均匀的.这些随机数是用“分层取样”的方法产生的.(6)金融函数目前LING0提供了两个金融函数.1)@fpa(I,n)返回如下情形的净现值:单位时段利率为I ,连续n 个时段支付,每个时段支付单位费用.若每个时段支付x单位的费用,则净现值可用x乘以@fpa(I,n)得到.@fpa的计算公式为净现值就是在一定时期内为了获得一定收益,在该时期初所支付的实际费用.2)@fpl(I,n)返回如下情形的净现值:单位时段利率为I ,第n 个时段支付单位费用. @fpl(I,n) 的计算公式为这两个函数间的关系:7)输入和输出函数输入和输出函数可以把模型与外部数据(如文本文件、数据库和电子表格等)连接起来.1) @file 函数该函数用于从外部数据文件中输入数据,它可以放在模型中任何地方.该函数的语法格式为@file( ' filename ') .这里filename 是文件名,可以采用相对路径和绝对路径两种表示方式.记录结束标记( ~)之间的数据文件部分称为记录.如果数据文件中没有记录结束标记,那么整个文件被看作单个记录.除了记录结束标记外,从模型外部调用的文本和数据同在模型里是一样的.下面介绍一下在数据文件中的记录结束标记连同模型中@file 函数调用是如何工作的.当在模型中第一次调用@file函数时,LINGO打开数据文件,然后读取第一个记录;第二次调用@file 函数时,LINGO读取第二个记录等等.文件的最后一条记录可以没有记录结束标记,当遇到文件结束标记时,LINGO会读取最后一条记录,然后关闭文件.如果最后一条记录也有记录结束标记,那么直到LINGO 求解完成模型后关闭该文件.注意,如果有多个文件同时保持打开状态,可能就会导致一些问题,LINGO允许同时打开文件的上限数是16.在LING0中不允许嵌套调用@file函数.2)@text 函数该函数被用在数据部分,用来把求解结果输出至文本文件中.它可以输出集元素和集属性值.其语法@text([ ' filename '])这里filename 是文件名,可以采用相对路径和绝对路径两种表示方式.如果忽略filename ,那么数据就被输出到标准输出设备(大多数情形都是屏幕) . @text 函数仅能出现在模型数据部分的一条语句的左边,右边是集名(用来输出该集的所有元素名)或集属性名(用来输出该集属性的值)用接口函数产生输出的数据定义称为输出操作.输出操作仅当求解器求解完模型后才执行,执行次序取决于其在模型中出现的先后.3) @ole函数@0L是从EXCE冲引入或输出数据的接口函数,它是基于传输的OLE技术.OLE传输直接在内存中传输数据,并不借助于中间文件•当使用@OL时,LINGO先装载EXCEL再通知EXCEI装载指定的电子数据表,最后从电子数据表中获得Ranges.为了使用@ OLE函数,必须有EXCEL及其以上版本.@ OLE函数可在数据部分和初始部分引入数据.@OL可以同时读集元素和集属性, 集元素最好使用文本格式,集属性最好使用数值格式. 原始集每个集元素需要一个单元(cell),而对于n 元的派生集每个集元素需要n 个单元,这里第一行的n 个单元对应派生集的第一个集元素,第二行的n 个单元对应派生集的第二个集元素,依此类推.4) @ranged(variable_or_row_name)为了保持最优基不变,变量的费用系数或约束行的右端项允许减少的量.5)@rangeu(variable_or_row_name)为了保持最优基不变,变量的费用系数或约束行的右端项允许增加的量.6)@status()返回LINGO求解模型后的结束状态:0 --- Global Optimum (全局最优) ;1 --- Infeasible 不可行);2 --- Unbounded (无界);3 --- Undetermined (不确定);4 --- Feasible (可行);5 ——Infeasible or Unbounded (通常需要关闭“预处理”选项后重新求解模型,以确定模型究竟是不可行还是无界)6 --- Local Optimum (局部最优);7 --- Locally Infeasible (局部不可行,尽管可行解可能存在,但是LINGO并没有找到一个);8 --- Cutoff (目标函数的截断值被达到)9 --- Numeric Error (求解器因在某约束中遇到无定义的算术运算而停止)通常,如果返回值不是0, 4或6时,那么解将不可信,几乎不能用.该函数仅被用在模型的数据部分来输出数据.7)@dual(vanable_or_row_name)返回变量的判别数(检验数)或约束行的对偶(影子)价格(dual Prices ).(8)辅助函数1) @if(logical_condition,true_result,false_result)@if函数将评价一个逻辑表达式logical_condition 是否为真,如果为真,返回true_ result,否则返回false result2) @warn(' text ' ,logical_condition)如果逻辑条件logical_condition 为真,则产生一个内容为’text '的信息框.3)@user(user_determined_arguments)该函数允许用户自己编写函数,可以用c语言等编写,返回值为用户函数计算的结果.3. 5 LINGO程序出错信息。
排队论——精选推荐

第一节引言一、排队系统的特征及排队论排队论(queueing theory)是研究排队系统(又称为随机服务系统)的数学理论和方法,是运筹学的一个重要分支。
在日常生活中,人们会遇到各种各样的排队问题。
如进餐馆就餐,到图书馆借书,在车站等车,去医院看病,去售票处购票,上工具房领物品等等。
在这些问题中,餐馆的服务员与顾客、公共汽车与乘客、图书馆的出纳员与借阅者、医生与病人、售票员与买票人、管理员与工人等,均分别构成一个排队系统或服务系统(见表10-1)。
排队问题的表现形式往往是拥挤现象,随着生产与服务的日益社会化,由排队引起的拥挤现象会愈来愈普遍。
表 10-1排队除了是有形的队列外,还可以是无形的队列。
如几个顾客打电话到出租汽车站要求派车,如果出租汽车站无足够车辆,则部分顾客只得在各自的要车处等待,他们分散在不同地方,却形成了一个无形队列在等待派车。
排队的可以是人,也可以是物。
如生产线上的原材料或半成品在等待加工;因故障而停止运转的机器在等待修理;码头上的船只等待装货或卸货;要降落的飞机因跑道被占用而在空中盘旋等等。
当然,提供服务的也可以是人,也可以是跑道、自动售货机、公共汽车等。
为了一致起见,下面将要求得到服务的对象统称为“顾客”,将提供服务的服务者称为“服务员”或“服务机构”。
因此,顾客与服务机构(服务员)的含义完全是广义的,可根据具体问题而不同。
实际的排队系统可以千差万别,但都可以一般地描述如下:顾客为了得到某种服务而到达系统,若不能立即获得服务而又允许排队等待,则加入等待队伍,待获得服务后离开系统,见图10-1至图10-4。
类似地还可画出许多其他形式的排队系统,如串并混联的系统,网络排队系统等。
尽管各种排队系统的具体形式不同,但都可由图10-5加以描述。
图10-1 单服务台排队系统图10-2 s 个服务台,一个队列的排队系统图10-3 s 个服务台,s 个队列的排队系统图10-4 多个服务台得串联排队系统顾客到达顾客到达图10-5 随机服务系统通常称由10-5表示的系统为一个随机聚散服务系统,任一排队系统都是一个随机聚散服务系统。
运筹学课件第十章排队论

第一节 引言
一、排队系统的特征及排队论 排队论研究排队系统的数学理论和方法, 是运筹学的一个重要分支。 排队问题表现:
到达的顾客 1、不能运转机器 2、病人 3、打电话 4、等待降落飞机 5、河水进入水库
要求的服务 修理 就诊 通话 降落 放水,调整水 位
服务机构 修理工人 医生 交换台 跑道指挥机构 水闸管理员
四、排队系统的主要数量指标和记号 描述一个排队系统运行状况的主要指标: 1、队长、排队长 队长:系统中的顾客数量(排队顾客+接受服务顾客)。
排队长:系统中的正在排队等待服务的顾客数量。
2、等待时间和逗留时间 等待时间:从顾客到达时刻起到他开始接受服务止这段时间 为等待时间。 逗留时间:从顾客到达时刻起到他接受服务完成这段时间为 逗留时间。
(i)队长有限:系统等待空间有限。 有限系统的空间为K, 顾客到达时的队长为L。若 L<K,则顾客进入队列等待服务,若L=K,则 顾客离去。 (ii) 等待时间有限: 顾客对等待时间具有不耐烦 性的系统。设最长等待时间是T0,某个顾客从 进入队列后的等待时间为 T。若T<T0,顾客继 续等待;若T=T0,则顾客脱离队列而离去。 (iii)逗留时间有限:等待时间与服务时间之和。
排队可以是人,也可以是物。 为了一致:将要求得到服务的对象统称为“顾客”,将提 供服务的服务者称为“服务员”或“服务机构”。
排队系统的一般描述; 顾客为了得到服务而到达系统,如果不能 立刻得到服务而又允许排队等待,则加入 等待队伍,待获得服务后离开系统。
顾客到达 队列 服务台 单服务台服务系统 服务完后离开
n 0
n ,n C 1 , 2 , 3 ,...... n u n p p , n 1 , 2 , 3 ,...... n 0
[管理学]排队论方法
![[管理学]排队论方法](https://img.taocdn.com/s3/m/4ada1ac75ef7ba0d4a733b74.png)
♂
Probability
16 18 20 22 24 NUMBER IN SYSTEM
26
28
30
32
34
36
38
40
郑州轻工业学院数学系
M/M/c/ቤተ መጻሕፍቲ ባይዱ/∞ (系统容量有限的服务系统)
郑州轻工业学院数学系
(Kleinrock) "We study the phenomena of standing, waiting, and serving, and we call this study Queueing Theory." "Any system in which arrivals place demands upon a finite capacity resource may be termed a queueing system."
郑州轻工业学院数学系
2.排队系统的三个基本要素 二、排队规则 损失制- 顾客到达系统时,如果系统中所有 服务窗均被占用,则到达的顾客随即离去 等待制- 顾客到达系统时,如果所有服务窗 均被占用,则系统能够提供足够的排队空间让 顾客排队等待 混合制- 是损失制与等待制混合组成的排队 系统,此系统仅允许有限个顾客等候排队,其 余顾客被拒绝
(1 ) n , 1, n 0,1,2,.., N N 1 1 Pn 1 , 1, n 0,1,2,...,N N 1
( N 1) N 1 L , 1 N 1 1 1
Lq L (1 P0 ) L W (1 P0 ) Wq W 1
算法大全第06章_排队论

约与区间长 Δt 成正比,即
∑ P (t, t + Δt ) = o( Δt )
n n=2
∞
(2)
-120-
在上述条件下,我们研究顾客到达数 n 的概率分布。 o 由条件 2 ,我们总可以取时间由 0 算起,并简记 Pn (0, t ) = Pn (t ) 。 由条件 1 和 2 ,有
o o
P0 (t + Δt ) = P0 (t ) P0 ( Δt )
P1 (t , t + Δt ) = λΔt + o( Δt ) (1) 其中 o( Δt ) ,当 Δt → 0 时,是关于 Δt 的高阶无穷小。 λ > 0 是常数,它表示单位时间
有一个顾客到达的概率,称为概率强度。 o 3 对于充分小的 Δt ,在时间区间 [t , t + Δt ) 内有两个或两个以上顾客到达的概率 极小,以致可以忽略,即
Pn (t + Δt ) = ∑ Pn − k (t ) Pk ( Δt ), n = 1,2,L
k =0 n
由条件 2 和 3 得
o
o
P0 ( Δt ) = 1 − λΔt + o( Δt )
因而有
P0 (t + Δt ) − P0 (t ) o( Δt ) = −λP0 (t ) + , Δt Δt Pn (t + Δt ) − Pn (t ) o ( Δt ) . = − λPn (t ) + λPn −1 (t ) + Δt Δt 在以上两式中,取 Δt 趋于零的极限,当假设所涉及的函数可导时,得到以下微分方程
服务台(但顾客是一队)的模型。 1.4 排队系统的运行指标 为了研究排队系统运行的效率,估计其服务质量,确定系统的最优参数,评价系统 的结构是否合理并研究其改进的措施,必须确定用以判断系统运行优劣的基本数量指
排队论(Lingo方法)

线性规划
01
Lingo方法是线性规划的一种求解算法,可以用于求解排队论中
的优化问题。
迭代法
02
对于一些复杂的问题,可以使用迭代法结合Lingo方法进行求解,
以逐步逼近最优解。
启发式算法
03
对于一些大规模问题,可以使用启发式算法结合Lingo方法进行
求解,以提高求解效率。
04
Lingo方法在排队论中的 案例分析
Lingo方法在排队论中的优化问题
最小化等待时间
通过Lingo方法,可以优化等待时间,以最小化顾 客或任务的等待时间。
最小化队列长度
通过Lingo方法,可以优化队列长度,以最小化等 待空间的使用。
最大化服务台效率
通过Lingo方法,可以优化服务台效率,以提高服 务台的工作效率。
Lingo方法在排队论中的求解算法
等问题。
计算机科学
排队论用于研究计算机 网络的性能分析、负载 均衡和分布式系统等问
题。
排队论的发展历程
1903年,费尔南多·柯尔莫哥洛夫提出概率论的公理化 体系,为排队论奠定了理论基础。
1950年代,肯德尔提出了肯德尔模型,为多服务台排 队模型奠定了基础。
1930年代,厄兰格和朱伯夫提出了厄兰格模型,为单 服务台排队模型奠定了基础。
Lingo方法的适用范围
Lingo方法适用于各种线性规划问题,包括生产计划、资源分 配、运输问题等。
尤其适用于具有大量约束条件和决策变量的复杂问题,能够 有效地解决这些问题的最优解。
Lingo方法的优势和局限性
Lingo方法的优势在于它能够处理大规模的线性规划问题,并且具有较高的计算效率和精度。此外,Lingo方法还具有灵活性 和通用性,可以应用于各种不同的领域和问题。
排队论方法讲解

方 法
dPn(t) dt
Pn(t)Pn1(t)
Pn(0)0,(n1)
讲
特别的,当n=0时,有
解
dP0 (t) dt
P0 (t)
P0 (0) 1
排
解上述两个方程组,可得
队
P0 ( t ) e t , P1 ( t ) te t ,
论
P2 (t )
( t ) 2 2!
e t ,
解
排队主体是物:生产线-产品,维修工
-待修机器,卫星-信息,跑道-飞机
排 1. 基本概念
队
1.排队过程的一般模型
进入排队系统(输等入候)服务
论
接受服 务离开系统(输出
方
顾客服务过程分为四个步骤:
法
输入过程
讲
排队系统
排队规则
服务机构
解
输出过程
顾客接受服务后立即离开系统,因此输出
过程可以不用考虑
概率为
方
P n ( t t) P { N ( t t) N ( 0 ) n }
n
法
P { N (t t) N (t) k } P { N (t) N (0 ) n k } k 0
n
讲
Pk(t,tt)Pnk(t) k0
P0(t,tt)Pn(t)P1(t,tt)Pn1(t)
解
n
Pk(t,tt)Pnk(t)
讲
Ws
Wq
1
,Ls
Lq
解
排 2.1.2 系统容量有限 M/M/1/N/∞
(1)系统状态概率
队
P0
1 1 N1
,
1
论
Pn
1 1 N1
n ,1
排队论

1.基 本 概 念
3.服务台情况。服务台可以从以下3方面 来描述: (1) 服务台数量及构成形式。从数量上说, 服务台有单服务台和多服务台之分。从构成形 式上看,服务台有: ①单队——单服务台式; ②单队——多服务台并联式; ③多队——多服务台并联式; ④单队——多服务台串联式; ⑤单队——多服务台并串联混合式,以及 多队——多服务台并串联混合式等等。 见前面图1至图5所示。
Q——任一顾客在稳态系统中的等待
时间。
1.基 本 概 念
N,U,Q都是随机变量。
对于损失制和混合制的排队系统,顾客 在到达服务系统时,若系统容量已满, 则自行消失。这就是说,到达的顾客不 一定全部进入系统,为此引入:
1.基 本 概 念
e ——有效平均到达率,即每单位时间
内进入系统的平均顾客数(期望值); 这时就是期望每单位时间内来到系统 (包括未进入系统)的平均顾客数(期 望值) 对于等待制的排队系统,有e = 。
排队问题
前 言
排队论(Queuing Theory), 又 称 随 机 服 务 系 统 理 论 (Random Service System Theory),是一门 研究拥挤现象(排队、等待)的科 学。具体地说,它是在研究各种 排队系统概率规律性的基础上, 解决相应排队系统的最优设计和 最优控制问题。
1.基 本 概 念
(三)排队系统的描述符号与分类
为了区别各种排队系统,根据输入 过程、排队规则和服务机制的变化对排 队模型进行描述或分类,可给出很多排 队模型。为了方便对众多模型的描述, 20世纪50年代肯道尔(D.G.Kendall) 提出了一种目前在排队论中被广泛采用 的“Kendall记号”,完整的表达方式 通常用到6个符号并取如下固定格式: A/B/C/D/E/F 各符号的意义为:
运筹08(第10章排队论)精品PPT课件

2020/11/30
7
排队系统类型3:
服务完成后离开
服务台1
顾客到达
服务完成后离开
服务台2
服务完成后离开
服务台s
S个服务台, S个队列的排队系统
2020/11/30
8
排队系统类型4:
顾客到达
服务台1
离开
服务台s
多服务台串联排队系统
2020/11/30
9
排队系统的描述 实际中的排队系统各不相同,但概括 起来都由三个基本部分组成: 1、输入过程; 2、排队及排队规则; 3、服务机构
2020/11/30
21
➢ 定长分布(D):每个顾客接受的服 务时间是一个确定的常数。
➢ 负指数分布(M):每个顾客接受的
服务时间相互独立,具有相同的负指
数分布: e- t t0
f(t)=
0
t<0
其中>0为一常数。
2020/11/30
22
➢ K阶爱尔朗分布(Ek):
f(t)=
k(kt)k-1 · e- kt
2
无形排队现象:如几个旅客同时打电话 订车票;如果有一人正在通话,其他人只 得在各自的电话机前等待,他们分散在不 同的地方,形成一个无形的队列在等待通 电话。
排队的不一定是人,也可以是物。如生 产线上的原材料,半成品等待加工;因故 障而停止运行的机器设备在等待修理;码 头上的船只等待装货或卸货;要下降的飞 机因跑道不空而在空中盘旋等。
理;出价高的顾客应优先考虑。
2020/11/30
20
❖ 3、服务机制
包括:服务员的数量及其连接方式(串联还是并联) 顾客是单个还是成批接受服务; 服务时间的分布
记某服务台的服务时间为V,其分布函数 为B(t),密度函数为b(t),则常见的分布 有:定长分布(D)
运筹学 第8章 排队论

第八章 排队论排队是日常生活和经济管理经常遇到的问题,如医院等待看病的病人、加油站等待加油的汽车、工厂等待维修的机器、港口等待停泊的船只等。
在排队论中把服务系统中这些服务的客体称为顾客。
由于系统中顾客的到来以及顾客在系统中接受服务的时间等均是随机的,因此排队现象是不可避免的。
对于随机服务系统,若扩大系统设备,会提高服务质量,但会增加系统费用。
若减少系统设备,能节约系统费用,但可能使顾客在系统中等待的时间加长,从而降低了服务质量,甚至会失去顾客而增加机会成本。
因此,对于管理人员来说,解决排队系统中的问题是:在服务质量的提高和成本的降低之间取得平衡,找到最适当的解。
排队论是优化理论的重要分支。
排队论是1909年由丹麦工程师爱尔郎(A.K.Erlang )在研究电话系统时首先提出,之后被广泛应用于各种随机服务系统。
第一节 排队论的基本概念及所研究的问题一、基本概念(一)排队系统的组成一般的排队系统有三个基本组成部分:顾客的到达(输入过程)、排队规则和服务机构,如图8—1所示。
1.输入过程输入过程指顾客按什么样的规律到达。
包括如下三个方面的内容:(1)顾客总体(顾客源) 指可能到达服务机构的顾客总数。
顾客总体数可能是有限的,也可能是无限。
如工厂内出现故障而等待修理的机器数是有限的,而到达某储蓄所的顾客源相当多,可近似看成是无限的。
(2)顾客到达的类型 指顾客的到达是单个的还是成批的;(3)顾客相继到达的时间间隔分布 即该时间间隔分布是确定的(定期运行的班车、航班等)还是随机的,若是随机的,顾客相继到达的时间间隔服从什么分布(一般为负指数分布);2.排队规则排队规则指顾客接受服务的规则(先后次序),有以下几种情况。
(1)即时制(损失制) 当顾客来到时,服务台全被占用,顾客随即离去,不排队等候。
这种排队规则会损失许多顾客,因此又称为损失制。
(2)等待制 当顾客来到时,若服务台全被占用,则顾客排队等候服务。
在等待制中,又可按顾客顾客达到排队系统 图8—1服务的先后次序的规则分为:先到先服务(FCFS,如自由卖票窗口等待卖票的顾客)、先到后服务(FCLS,如仓库存放物品)、随机服务(SIRO,电话交换台服务对话务的接通处理)和优先权服务(PR,如加急信件的处理)。
排队LINGO第10

Ls Ws或Ws
Ls
,
Lq Wq或Wq
Lq
,
Ws Wq
1
,
Ls Lq ,
6. 与排队论模型有关的LINGO函数
(1) @ peb (load, S) 该函数的返回值是当到达负荷为load, 服务系统中有S个服务 器且允许排队时系统繁忙的概率,也就是顾客等待的概率。 (2) @ pel (load, S) 该函数的返回值是当到达负荷为load, 服务系统中有S个服务 器且不允许排队时系统损失概率, 也就是顾客得不到服务离 开的概率。 (3) @ pfs (load, S, K) 该函数的返回值是当到达负荷为load, 顾客数为K,平行服务 器数量为S时, 有限源的Poisson服务系统等待或返修顾客数 的期望值。
例10.5
解 (1) 实质上是两个独立的M/M/1/∞系统,其参数S=1, R=λ1=λ2=4, T=1/μ=1/5=0.2, 编写其LINGO程序,程序 名: exam1005a.lg4. 计算结果见运行. (2) 是两个并联系统, 其参数S=2,R=λ=8, T=1/μ=1/5=0.2, 编写其LINGO程序, 程序名: exam1005b.lg4. 计算结果见 运行. 两种系统的计算结果
10. 2 等待制排队模型
等待制排队模型中最常见的模型是
M / M / S / ,
即顾客到达系统的相继到达时间间隔独立,且 服从参数为λ的负指数分布(即输入过程为 Poisson过程),服务台的服务时间也独立同分 布,且服从参数为μ的负指数分布,而且系统 空间无限,允许永远排队。
1. 等待制排队模型的基本参数
2. 排队服务系统的基本概念
排队规则是指服务允许
上海交通大学管理科学-运筹学课件第六章排队论

第6章 排队论在日常生活和工作中,人们常常会为了得到某种服务而排队等候。
比如顾客到商店购买东西,病人到医院看病,汽车进加油站加油,轮船进港停靠码头等,都会因为拥挤而发生排队等候的现象。
这时,商店的售货员和顾客,医院的医生和病人,加油站的加油泵和待加油的汽车,码头的泊位和停泊的轮船等,形成了各自的排队服务系统,简称排队系统。
在一个排队系统中,通常包括一个或多个“服务设施”,服务设施可以指人,如售货员,医院大夫等。
也可以是物,如加油泵、码头泊位等。
同时还包括许多进入排队系统要求得到服务的“顾客”。
这里的顾客是指请求服务的人或物。
如到医院看病的病人,或等待加油的汽车等。
作为顾客总希望一到系统马上就能得到服务,但客观情况并非如此。
由于顾客的到达和服务机构对每个顾客的服务时间具有随机性,因此出现排队现象几乎是不可避免的。
当然,为了方便顾客减少排队时间,排队系统可以多开设服务设施。
但那将增加系统的投资和运营成本,还可能发生空闲浪费。
排队论(Queueing Theory )是为解决上述问题而发展起来的一门学科。
排队论起源于上世纪初,当时的美国贝尔(Bell )电话公司发明了自动电话后,满足了日益增长的电话通讯的需要。
但另一方面,也带来了新的问题,即如何合理配置电话线路的数量,以尽可能减少用户的呼叫次数。
如今,通讯系统仍然是排队论应用的主要领域。
同时在运输、港口泊位设计、机器维修、库存控制等领域也获得了广泛的应用。
6. 1 排队系统的基本概念6. 1. 1排队系统的一般表示一个排队系统可以抽象描述为:为了获得服务的顾客到达服务设施前排队,等候接受服务。
服务完毕后就自行离开。
其中把要求得到服务的对象称为顾客,而把服务者统称为服务设施或服务台。
在排队论中,把顾客的到达和离开称为排队系统的输入和输出。
而潜在的顾客总体又称为顾客源或输入源。
因此任何一个排队系统是一种输入-输出系统,其基本结构如图6-1所示。
排队系统图6-16. 1. 2排队系统的特征由排队系统的基本结构可知,任何一个排队系统的特征可以从以下三个方面加以描述。
排队论详解及案例

负指数分布具有下列性质:
cmLiu@shufe
Operations Research
9.2.3 负指数分布
负指数分布具有下列性质:
cmLiu@shufe
Operations Research
当 N (t满) 足下列三个条件时,我们说顾客的到达符合泊松分布 (1)平稳性:在时间区间 [t0,t0 + ∆t) 内到达的顾客数 N (t ) ,只与区间长度
有关而与时间起点 t0 无关。
(2)无后效性:在时间区间 [t0,t0 + ∆t) 内到达的顾客。 数 N (t ) ,与 t0 以前
到达的顾客数独立。 (3)普通性:在充分短的时间区间 ∆t 内,到达两个或两个以上顾客的概率
• 如略去后三项,即指X/Y/Z/∞/∞/FCFS的情形。
cmLiu@shufe
Operations Research
9.1.3 排队论研究的基本问题
(1)排队系统工作状况的衡量 一个排队系统运行状况的好坏不仅会影响顾客的利益,也会影响服务 机构的利益,甚至会影响到社会效果的好坏。通过研究运行系统在平 衡状态下的概率分布及其数字特征,了解排队系统运行的效率、服务 质量等等,进而可以判断系统运行状况的优劣。
cmLiu@shufe
Operations Research
第九章
排队论
9.1 基本概念 9.2 几个常用的概率分布 9.3 单服务台负指数分布的排队系统 9.4 多服务台负指数分布排队系统模型 9.5 一般服务时间M/G/1模型 9.6 排队系统的建模与优化 9.7 电子表格建模和求解 9.8 案例分析 办公室设施公司(OEI)服务能力分析
cmLiu@shufe
排队论公式
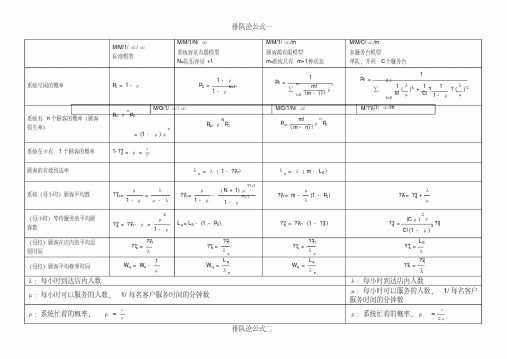
1/ 每名客户
λ
ρ:系统忙着的概率,ρ =
cμ
系统(每小时)顾客平均数
(每小时)等待服务的平均 顾客数 (每位)顾客在店内的平均 逗留时间 (每位)顾客平均修理时间
2
2
ρ + λ D(v)
????= ρ +
2(1 - ρ )
?q? = λ ??q = ????- ρ ????
???? ??s =
λ
e
Lq Wq =
λ
e
μ:每小时可以服务的人数, 1/ 每名客户服务时间的分钟数
λ
e
=
λ( m -
LS)
μ ????= m - (1 - P0 )
λ
??q = ????- (1 - ??0 )
???? ??s =
λ
e
Lq Wq =
λ
e
λ
ρ:系统忙着的概率, ρ = μ
排队论公式二
M/M/C/ ∞ /m 多服务台模型 单队,并列 C个服务台
P0 = ∑
1
C-1
k=0
1 k!
( λ )k μ
+
1 C!
?
1
1 -
ρ
?
λ () μ
C
M/????/1/ ∞ /m
λ ????= ??q +
μ
C
(Cρ ) ρ
??q =
2 ??0
C! (1 - ρ )
LS ??s =
λ
??q ??q =
λ
n
= (1 - ρ ) ρ
1- ??0 =
ρ
(完整版)排队论公式1

M/M/1/∞/∞标准模型M/M/1/N/∞
系统容量有限模型
N=队伍容量+1
M/M/1/∞/m
顾客源有限模型
m=系统只有m+1种状态
M/M/C/∞/m
多服务台模型
单队,并列C个服务台
系统空闲的概率
ρ
系统有n个顾客的概率(顾
客损失率)
系统至少有1个顾客的概率1-
顾客的有效到达率
系统(每小时)顾客平均数
(每小时)等待服务的平均
顾客数
=
(每位)顾客在店内的平均
逗留时间
(每位)顾客平均修理时间
λ:每小时到达店内人数λ:每小时到达店内人数
µ:每小时可以服务的人数,1/每名客户服务时间的分钟数µ:每小时可以服务的人数,1/每名客户服务时间的分钟数
排队论公式一
排队论公式二
ρ:系统忙着的概率,ρ:系统忙着的概率,
M/G/1/∞/∞M/D/1/N/∞M//1/∞/m 系统(每小时)顾客平均数
(每小时)等待服务的平均
顾客数
(每位)顾客在店内的平均
逗留时间
(每位)顾客平均修理时间
λ:每小时到达店内人数
µ:每小时可以服务的人数,1/每名客户服务时间的分钟数E(v):服务时间v的期望
D(v):方差
ρ:系统忙着的概率,λ:每小时到达店内人数
µ:每小时可以服务的人数,1/每名客户服务时间的分钟数
:服务时间v的期望
D(v):方差
ρ:系统忙着的概率,。
排队论

实用排队论排队论又称随机服务系统,它应用于一切服务系统,包括生产管理系统、通信系统、交通系统、计算机存储系统。
它通过建立一些数学模型,以对随机发生的需求提供服务的系统预测。
现实生活中如排队买票、病人排队就诊、轮船进港、高速路上汽车通过收费站、机器等待修理等等。
一、排队论的基本构成(1)输入过程输入过程是描述顾客是按照怎样的规律到达排队系统的。
包括①顾客总体:顾客的来源是有限的还是无限的。
②到达的类型:顾客到达是单个到达还是成批到达。
③相继顾客到达的时间间隔:通常假定是相互独立同分布,有的是等间隔到达,有的是服从负指数分布,有的是服从k 阶Erlang 分布。
(2)排队规则排队规则指顾客按怎样的规定的次序接受服务。
常见的有等待制,损失制,混合制,闭合制。
当一个顾客到达时所有服务台都不空闲,则此顾客排队等待直到得到服务后离开,称为等待制。
在等待制中,可以采用先到先服务,如排队买票;也有后到先服务,如天气预报;也有随机服务,如电话服务;也有有优先权的服务,如危重病人可优先看病。
当一个顾客到来时,所有服务台都不空闲,则该顾客立即离开不等待,称为损失制。
顾客排队等候的人数是有限长的,称为混合制度。
当顾客对象和服务对象相同且固定时是闭合制。
如几名维修工人固定维修某个工厂的机器就属于闭合制。
(3)服务机构服务机构主要包括:服务台的数量;服务时间服从的分布。
常见的有定长分布、负指数分布、几何分布等。
二、排队系统的数量指标(1)队长与等待队长队长(通常记为s L )是指系统中的平均顾客数(包括正在接受服务的顾客)。
等待队长(通常记为q L )指系统中处于等待的顾客的数量。
显然,队长等于等待队长加上正在服务的顾客数。
(2)等待时间等待时间包括顾客的平均逗留时间(通常记为s W )和平均等待时间(通常记为q W )。
顾客的平均逗留时间是指顾客进入系统到离开系统这段时间,包括等待时间和接受服务的时间。
顾客的平均等待时间是指顾客进入系统到接受服务这段时间。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
· Ws=RWs
Lq= λ· Wq=R Wq
等待制排队模型实例
1.S=1 (M/M/1/∞)
例1:某维修中心在周末现只安排一名员工为顾客提供服务, 新来维修的 顾客到达后,若已有顾客正在接受服务,则需要 排队等待,假设来维修的顾客到达过程为Poisson流,平均每 小时4人,维修时间服从负指数分布,平均需要6min,试求该 系统的主要数量指标。 2.S=3 (M/M/S/∞) 例2:设打印室有3名打字员,平均每个文件的打印时间为 10min,而文件到达率为每小时15件,试求该打印室的主要数 量指标。
量和潜在的顾客数都为K,顾客到达率为 λ,服务 台的平均服务率为μ ,这样的系统称为闭合式排队 模型,记为:M/M/S/K/K
闭合式排队模型的基本参数
1.平均队长:Ls=@pfs(load,S,K),load=K· λ/μ =KRT 即: 系统的负荷=系统的顾客数×顾客到达率×顾客的服务时间 2.单位时间平均进入系统的顾客数: λe= λ (K-Ls)=R(K-Ls)=Re
排队系统的最优化模型
2.系统服务台的确定 例:一个大型露天矿山, 正考虑修建矿石卸位的个 数,估计运矿石的车将按 Poisson流到达,平均每 小时15辆,卸矿石时间服 从负指数分布,平均3min 卸一辆,又知每辆运送矿 石的卡车售价是8万元,修 建一个卸位的投资是14万 元,问应建多少个矿石卸 位最gt;1(M/M/S/S) 例2:某单位电话交换台有一台200门内线的总 机,已知在上班8小时内,有20%的内线分机 平均每40min要一次外线电话,80%的分机 平均间隔120min要一次外线。又知外线打入 内线的电话平均每分钟1次。假设与外线通话 的时间为平均3min,并且上述时间均服从负 指数分布,如果要求电话的通话率为95%, 问该交换台应设置多少条外线?
3.顾客处于正常情况的概率:P=(K-Ls)/K
4.平均逗留时间、平均等待队长和平均排队等待时间 Ws=Ls/ λe=Ls/Re Wq=Ws-1/ μ=Ws-T 5.每个服务台的工作强度:Pwork= λe/(Sμ) Lq=Ls- λ e/ μ =Ls-Re· T
排队系统的最优化模型
1.系统服务时间的确定
L_q=R*W_q;
W_s=W_q+T;L_s=W_s*R; END
损失制排队模型
损失制排队模型通常记为
M/M/S/S,
当S个服务器被占用后,顾客自动离 去
损失制排队模型的基本参数
1.系统损失的概率:Plost=@pel(load,S) 2.单位时间内平均进入系统的顾客数: λ e=Re= λ(1-Plost)=R(1-Plost) 3.系统的相对通过能力(Q)与绝对通过能力(A) Q=1-Plost, A= λe· Q= λ(1-Plost)2 =Re· Q= R(1-Plost)2 4.系统在单位时间内占用服务台的均值:Ls= λe/μ=Re· T 注意:在损失制系统中,Lq=0,即等待队长为0 5.系统服务台的效率:η =Ls/S 6.顾客在系统内平均逗留时间:Ws=1/ μ=T 注意:在损失制系统中,Wq=0,即等待时间为0
排队论模型的符号表示
通常由3-5个英文字母组成, 其形式为 A/B/C/n, 其中 A表示输入过程, B表示服务时间, C表示服务台数目, n表示系统空间数
排队模型的表示: X/Y/Z/A/B/C X—顾客相继到达的间隔时 间的分布; Y—服务时间的分布; Z—服务台个数; A—系统容量限制(默认为 ∞); B—顾客源数目(默认为 ∞); C—服务规则 (默认为先到 先服务FCFS)。 M—负指数分布、D—确定 型、Ek —k阶爱尔朗分布。
2)顾客到达后排成一个队列,顾 客发现哪个窗口空闲时,他就接 受该窗口的服务,如下图 λ=8 到达 μ =5 μ =5 离去 离去
损失制排队模型实例
S=1(M/M/1/1)
例1:设某条电 话线,平均每 分钟有0.6次呼 唤,若每次通 话时间平均为 1.25min,求系 统相应的参数 指标。 model: S=1;R=0.6;T=1.25;load=R*T; Plost=@pel(load,S); Q=1-Plost;R_e=Q*R;A=Q*R_e; L_s=R_e*T,eta=L_s/S; end
其中S是服务台或服务员的个数,load= λ / μ =RT, 其中R= λ ,T= 1/μ ,R是顾客的平均到达率,T是平 均服务时间 2.顾客的平均等待时间:Wq= Pwait·T/(S-load),
其中T/(S-load)可以看成一个合理的长度间隔,
3.顾客的平均逗留时间、队长和等待队长(little公式)
混合制排队模型
混合制排队模型通常记为:M/M/S/K,即有S个服 务台或服务员,系统空间容量为K,当K个位置已 被顾客占用时,新到的顾客自动离去,当系统中 有空位置时,新到的顾客进入系统排队等待。
闭合式排队模型
设系统内有M个服务台,顾客到达系统的间隔时间
和服务台的服务时间均为负指数分布,而系统的容
=1-服务设施总的空闲时间/服务设施总的服务时间
与排队论模型有关的LINGO函数
1.@peb(load,S) 该函数返回值是当到达负荷为load,系统中有S个服务台且允 许排队时系统繁忙的概率,也就是顾客等待的概率
2.@pel(load,S)
该函数返回值是当到达负荷为load,系统中有S个服务台且不 允许排队时系统损失的概率,也就是顾客得不到服务离开的概 率 3.@pfs(load,S,K) 该函数的返回值是当到达负荷为load ,顾客数为K,平行服务台 数量为S时,有限源的Poisson服务系统等待或返修顾客数的 期望值
数学建模讲座
排队论模型
排队系统的描述
服务系统
顾客总体
输入
队伍
服务台
输出
排队服务系统的基本概念
输入过程:描述顾客来源是按怎样的规律抵达排队 系统。 1.顾客源总体:有限还是无限 2.到达类型:单个到达还是成批到达 3.相继顾客到达的时间间隔:相互独立、同分布的; 等时间间隔的;服从Poisson分布的; k阶Erlang分 布
例:某工人照管4台自动 机床,机床运转时间平均 为负指数分布,假定平均 每周有一台机床损坏需要 维修,机床运转单位时间 内平均收入100元,而每 增加一单位μ的维修费用 为75元,求使总利益达到 最大的μ*
分析:这是一个闭合式排队 系统M/M/1/K/K,且K=4,设 Ls是队长,则正常运转的机 器为K-Ls部,因此目标函 数为:f=100(K-Ls) -75 μ Model: S=1;K=4;R=1; L_s=@pfs(K*R/mu,S,K); Max=100*(K-L_s)-75*mu; end
等待制排队模型
等待制排队模型中最常见的模型是:
M/M/S/∞,
即顾客到达系统的相继到达时间间隔独立,且 服从参数为λ 的负指数分布(即输入过程为过 程),服务台的服务时间也独立同分布,且服 从参数为μ 的负指数分布,而且系统空间无限, 允许永远排队
等待制排队模型的基本参数
1.顾客等待的概率:Pwait=@peb(load,S),
Plost<=0.05;
Q=1-Plost; R_e=Q*R;A=Q*R_e; L_s=R_e*T;eta=L_s/S; Min=S;@gin(S); end
λ= λ1+ λ2=140+60=200
2)按题目要求,系统损失的概率不能超过 5%,即Plost≤0.05
3)外线是整数,在满足条件下,条数越 少越好
损失制排队模型实例
例2:分析:
1)电话交换台的服务分成两类,第一类内 线打外线,其强度为
λ1=(0.2×60/40+0.8×60/120) ×200=140
Model: R=200;T=3/60;load=R*T; Plost=@pel(load,S);
第二类是外线打内线,其强度为
λ2 =1×60=60 因此总的强度为
试着做一做
某售票点有两个售票窗 口,顾客按参数λ=8人 /min的Poisson流到达, 每个窗口的售票时间服 从参数μ =5人/min的负 指数分布,试比较以下 两种排队方案的运行指 标,并指出哪种售票方 式效率更高。
1)顾客到达后,以1/2的概率站 成两个队列,如下图
λ1=4 λ=8 到达 λ2=4 μ =5 μ =5 离去 离去
泊松分布适合于描述单位时间内随机事件发生的次数。如某一服务设施在 一定时间内到达的人数,电话交换机接到呼叫的次数,汽车站台的候客人 数,机器出现的故障数,自然灾害发生的次数等等。
排队服务系统的基本概念
排队规则:指服务系统是否允许排队,顾客是否愿意排队
1.损失制排队系统:顾客到达若所有服务台被占,服务 机构又不允许顾客等待,此时该顾客就自动离去。
2.等待制排队系统:顾客到达时若服务台均被占,他们 就排队等待。服务顺序有:先到先服务、后到先服务、 随机服务、有优先权的服务
3.混合制排队系统:损失制与等待制的混合。队长(容 量)有限的混合;等待时间有限的混合;逗留时间有 限的混合
排队服务系统的基本概念
服务机构:
1.服务台的数目
2.顾客所需的服务时间服从怎样的概率分布 (常见顾客的服务时间分布有:定长分布、负 指数分布、超指数分布、k阶Erlang分布、 几何分布、一般分布)
分析:用等待制排队系统 M/M/S/∞进行分析,其费用包括 建造卸位的费用和卡车处于排 队状态不能工作的费用,目标 函数为:F=14S+8Ls Model: R=15;T=3/60;load=R*T; Pwait=@peb(load,S); W_q=Pwait*T/(S-load); W_s=W_q+T;L_s=W_s*R; Min=8*L_s+14*S; @gin(S);@bnd(1,S,5); end