国际金融研究-变系数模型
【国家社会科学基金】_变系数模型_基金支持热词逐年推荐_【万方软件创新助手】_20140805
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
科研热词 推荐指数 变系数模型 2 高技术产品 1 面板数据模型 1 面板单位根检验 1 面板协整检验 1 非房地产投资 1 门槛效应 1 金砖国家 1 经济增长 1 空间计量 1 碳排放 1 知识生产函数 1 生物产业 1 物价波动 1 校企联盟 1 时变系数 1 房地产投资 1 异质性 1 工资增长机制 1 城镇居民消费行为 1 城市化 1 固定效应模型 1 区域创新 1 动态面板数据 1 创新单元 1 分位数回归 1 出口竞争力 1 panel 1 data 1 bric countries high-tech products 1 export competit
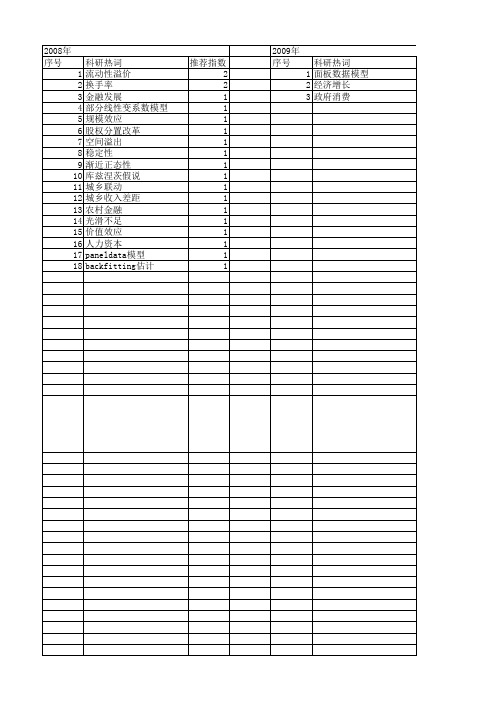
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
科研热词 流动性溢价 换手率 金融发展 部分线性变系数模型 规模效应 股权分置改革 空间溢出 稳定性 渐近正态性 库兹涅茨假说 城乡联动 城乡收入差距 农村金融 光滑不足 价值效应 人力资本 paneldata模型 backfitting估计
推荐指数 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2009年 序号
科研热词 1 面板数据模型 2 经济增长 3 政府消费
推荐指数 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
科研热词 高技术产业 面板数据模型 面板数据 金融发展 部分线性变系数模型 进出口贸易 行业标准化 能源需求 缺失数据 系数模型 渐近正态 时变回归分析 截据模型 弹性系数 居民消费 变量含误差 变系数面板模型 人口迁移 人口流动 r&d投入 r&d产出 profile最小二乘 mcmc
我国商业银行盈利能力影响因素的实证分析

内资产和表 内负债 , 而形成非利息收入的业务。 7非 利息 费用 支 出( P 。 . T)
力的主要因素, 银行卡业务和收费业务与商业银行 的 8国内生产 总值 ( D ) . G P 。指每个年度我 国所生 盈利能力负相关( 白积洋 ,OO 。商业银行的盈利能 产 出的全部最终产品和劳务的价值。本文对其取了 2L) 力与净息差正相关 , 与成本收入 比、 收益留存率 、 不良 贷款率和贷存 比成负相关( 郭小群 ,00 。 2 1)
行、民生银行和兴业银行。数据是从 19 年—20 99 08
2 . 总资产( A 。指商业银行拥有的或能控制的 T)
收稿 日期 :0 10 — 2 21-70 作者简介 : ̄0 1 8 -, 3 , 林( 1 ) J 9 新疆财经大学金融学院硕士研究生 。主要研究方向 : 国际金融 。
.
1 5.
3变系数 模 型 .
YF + + i b iu i l … N, l … T = , t , = () 3
率和宏观环境的改善 , 会增强银行的赢利性 ; 而贷款 规模和预留现金的增加 ,会降低商业银行的赢利性 ; 资产规模越大 , 其赢利性越低( 黄金秋 , 0 ) 商业银 2 6。 0 行 的产权 性质是 影响商业 银行盈 利能力 的重要 因素 ,
存款 的增加 也会降低商业银行 的赢 利性 ( 窦育民 , 20 )扩大市场份额可以提高商业银行的盈利能力 , 07 。 而提高市 场集 中度 则会得 到相反 的结果 ( 忠 , 徐 20 ) 09 。商业银行的内在因素是影响商业银行盈利能
二 、 证分 析 实
自然对 数 。
9消 费者 价格 指数 ( P ) . C I。是衡 量所 选定 的一篮 子 消费 品购 买价格 的指数 。
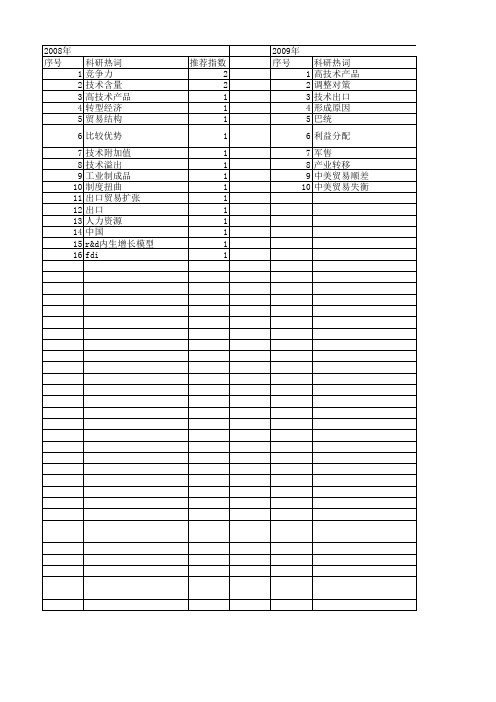
【国家社会科学基金】_高技术产品出口_基金支持热词逐年推荐_【万方软件创新助手】_20140806
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
科研热词 高技术产品 面板数据 实证分析 出口 高新技术产品 金融发展 贸易争端 结构优化 经济增长 竞争力 科技评价 科学发展观 渠道关联 指标数值变化 投资动机 技术寻求 技术外溢 技术出口限制 影响 对外贸易 对外直接投资 实证研究 完全信息动态博弈 垂直专业化 囚徒困境 升级 区域金融 出口相似指数 出口技术复杂度 出口商品结构之谜 出口信用保险 优化指数 价值链体系 产品密度 产品内垂直分工 产业内贸易 中-欧 专利 var
2009年 序号 1 2 3 4 5 6 7 8 9 10
科研热词 高技术产品 调整对策 技术出口 形成原因 巴统 利益分配 军售 产业转移 中美贸易顺差 中美贸易失衡
推荐指数 2 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
2011年 科研热词 高技术产品 出口竞争力 出口相似度 转移份额分析 技术结构 高技术产业 面板数据分析 金融发展 逆向选择 进口机械设备 贸易失衡 自主创新 技术含量 工业制成品 国际竞争力 国际技术溢出 出口贸易 出口管制 出口技术复杂度 信息不对称 体现式技术溢出效应 中美贸易 推荐指数 3 3 3 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
金融市场评价模型研究

金融市场评价模型研究随着金融市场的迅猛发展和全球化程度的加深,金融市场评价模型的研究变得更加重要。
这些模型帮助投资者和决策者更准确地评估市场风险和回报,以提高投资决策的准确性和可靠性。
本文将重点探讨几个常见的金融市场评价模型,并分享它们的应用和局限性。
首先介绍的是有效市场假说(Efficient Market Hypothesis,EMH)。
EMH认为金融市场反映了所有可获得的信息,并且投资者无法通过分析信息来获得超额回报。
根据EMH,金融市场是完全有效的,不存在可以利用的市场失效。
EMH的实质是市场上的价格已经反映了所有信息,因此无法利用信息上的优势取得超额回报。
EMH的假设基础之一是市场参与者有理性的预期和行为。
根据这个假设,投资者会根据可用的信息进行合理的决策,市场价格也会随着这些决策的反馈而变化。
然而,EMH也有一些局限性。
首先,它假设投资者的信息获取成本为零,而实际上,信息获取往往需要时间和金钱。
其次,EMH没有考虑到市场的非理性行为,如投机和情绪波动,这些因素会导致市场产生偏离基本价值的波动。
另一个常见的金融市场评价模型是资本资产定价模型(Capital Asset Pricing Model,CAPM)。
CAPM是通过衡量资产的系统风险和市场风险之间的关系来评估资产回报的模型。
根据CAPM,资产的回报应该与其和整个市场组合的系统风险成正比。
该模型通过计算资产的贝塔系数来确定资产回报的预期收益率。
CAPM的优点之一是它提供了一个简单而直观的方法来评估资产回报。
然而,它也存在一些局限性。
首先,CAPM假设市场是完全有效的,即所有信息已经准确地反映在价格中,这与实际市场中的情况并不完全符合。
其次,CAPM忽略了其他因素对资产回报的影响,如公司的经营业绩和市场情绪。
因此,使用CAPM进行投资决策时需要谨慎考虑这些局限性。
除了EMH和CAPM,还有一些其他的金融市场评价模型。
例如,随机波动模型(Random Walk Model)认为金融市场的价格随机变动,无法预测。
中国商业银行盈利能力影响因素研究

中国商业银行盈利能力影响因素研究Analysis of the Factors Affecting the Profitabilityof Commercial Banks in China朱子文统计与应用数学学院统计学专业2009(1)班 2009710053指导教师:李小胜副教授内容摘要:作为以营利为目的的金融机构,盈利能力是商业银行生存和发展的重要基础。
但是由于我国现代经济发展起步较晚的原因,我国商业银行业在过去很长一段时间往往只把扩充银行资本量、扩大银行规模作为首要任务而忽略了对盈利能力的发展与提高。
针对“我国商业银行盈利能力影响因素”这个问题,许多专家学者都进行了深入的研究,并得出了很多极具价值的研究成果。
本文以资产收益率(ROA)作为衡量银行盈利能力的指标,选取了国内10家具有代表性的商业银行2004年~2009年间的相关数据作为分析样本,对影响我国商业银行盈利能力的主要因素进行了分析。
得到结论为:商业银行盈利能力与其权益资产率及国内经济状况呈正相关关系,与银行规模、银行信贷率及资产费用率呈负相关关系。
最后根据分析结果对如何提高我国商业银行盈利能力提出相应的建议。
关键词:商业银行;盈利能力;面板数据Abstract: As to the financial institutions for the purpose of profit, profit ability is an important foundation for the survival and development of commercial banks. But due to a late start of modern economic development in China, China's commercial banks for a long time in the past often only to overcharge bank capital, expand the scale of banks as the primary task and ignore the development and improvement of profitability. According to the "factors" the profitability of China's commercial banks influence the problem, many experts and scholars have conducted in-depth research, and obtained many valuable research results.In this paper, return on assets (ROA) as a measure of bank profitability index, the paper selects 10 representative commercial banks in 2004 to 2009 years relevant data as sample for analysis on the main factors affecting the profitability of commercial banks in China are analyzed. The conclusion is: the correlation between the profitability of commercial banks and equity ratio and the domestic economic situation positively, negatively correlates with the size of the bank, the bank credit rate and asset cost rate. Finally, according to results of the analysis of how to improve the profitability of commercial banks in China and put forward the corresponding suggestion.Keywords: Commercial Bank;Profitability;Panel data目录1.引言 (1)1.1研究意义 (1)1.2我国商业银行现状 (1)2. 文献综述 (2)2.1我国学者对商业银行盈利能力的研究 (2)2.2本文的研究特点 (2)3. 指标的选取 (3)3.1指标的选取原则 (3)3.2指标的选取 (3)4. 数据来源及研究方法介绍 (4)4.1数据来源 (4)4.2研究方法介绍 (4)5. 面板模型介绍 (5)5.1面板数据模型解析 (5)5.2面板模型的分类 (5)6.实证分析 (5)6.1实证分析步骤 (5)6.2实证分析结果 (8)7.实证结论分析 (8)7.1银行规模对商业银行盈利能力的影响 (8)7.2银行信贷率对对商业银行盈利能力的影响 (9)7.3权益资产率对商业银行盈利能力的影响 (9)7.4资产费用率对商业银行盈利能力的影响 (9)7.5国内经济状况对商业银行盈利能力的影响 (9)8.建议 (10)9.附言 (10)参考文献 (11)1.引言商业银行作以营利为目的的金融机构,盈利能力是其在经营过程中应当考虑的首要指标,对其生存和发展起到了至关重要的作用。
财政金融投入的农业经济增长效应研究——基于变系数模型分析

之 间 关 系的实证 分 析提 供 了借鉴 和 帮助 , 也存 在 但 以下 不 足 : 用 面 板数 据模 型进 行 分 析 时 , 有 对 直 没
选 定 的面板 数据 模 型形 式进行 检 验 , 根据 经 验选 择 的模 型时样 本 的拟合 程 度有 限 , 接 影 响分 析 的结 直
准确性 ; 是从 财 政支农 和金 融信贷 资 金 两种 不 同 二 来 源 的资 金对农 业 经济 增 长支 持 的分 析 , 为选 择农 业 经济Байду номын сангаас增长 的资金 支持方式 提供 建议 ?
资金是农业生产主要的资金来源, 研究财政金融资金
对农业经济增长的效应就成为重要的研究 内容 : 财 政 金融 资 金 对农 业 经 济 增 长 的 研 究 主 要有 王 丹等 ( 0 )I 修正 误 差模 型对 安徽 省 金融 发展 2 6; 用 o  ̄ J 与农 业经 济增 长之 间 关系进 行 了验 证… 一左 晓 慧等
2 1年2 00 月 第 1 期
第2 3卷
总第 1 3期 3
财政金融投入的农业经济增长效应研究
— —
基 于 变 系数模 型分 析
徐 敏 i
( 西 北 农林 科 技 大 学经 济 管 理 学 院 ,陕 西 杨 凌 7 2 0 ;2 石 河 子大 学 商 学 院 ,新 疆 五 家 渠 8 1 0 ) 1 1 10 3 3 0
G Py , D ( ) 自变量选择 各 省 、 、 市 自治 区的财政 支农 金
基金项 目:弼家 自 然科学基金项 目一一“ 巾困政 府财政对农业投资的增长方式 与监督保障体系研究” 项 r编 号: 0 0 2 项 目负责人 : ( j 7 73 ; 0 罗 剑朝 ) 战果之 一 : 作者 简 介 :徐 敏 , 西北 农 林 科技 大学 博 士 研究 石河 子大 学 商学 院讲 师 ; 究方 向 : 村 金 融 : 乏, 研 农
金融市场波动的模型

金融市场波动的模型金融市场波动是指金融资产价格或市场指数的波动性,这种波动对经济体系、投资者和公司都有着深远的影响。
为了理解和预测这种波动,人们利用各种模型来解释和量化金融市场的波动性。
这些模型涵盖了不同的理论和方法,包括随机漫步、波动率模型、马尔可夫模型等。
1. 随机漫步模型随机漫步模型是描述金融市场波动的最简单模型之一。
它的基本假设是未来的价格变化是不可预测的,类似于随机过程中的随机步伐。
这种模型认为价格的变化是完全随机的,之前的价格变化不会对未来的变化产生影响。
尽管这个模型简单易懂,但它不能解释金融市场中复杂的波动特征,因为实际市场中价格的变化受多种因素影响。
2. 波动率模型波动率模型是用来描述价格波动率变化的模型。
这类模型试图捕捉市场波动率的变化规律,如 ARCH(自回归条件异方差)、GARCH (广义自回归条件异方差)等。
这些模型表明,市场的波动率并非恒定不变,而是会随着时间和事件的变化而变化,存在聚集性和波动聚集现象。
波动率模型帮助我们更好地理解金融市场中波动率的特征,并能提供对未来波动的一定预测。
3. 马尔可夫模型马尔可夫模型是一种基于状态转移的模型,它假设未来的状态仅与当前的状态相关。
在金融市场中,马尔可夫模型被用来分析价格走势。
马尔可夫链可以帮助理解价格的状态变化,但其局限性在于只考虑当前状态,而忽略了历史数据和其他影响因素,因此在某些情况下对复杂的市场波动性解释不足。
4. 随机波动模型随机波动模型是一类考虑了随机过程对价格走势影响的模型。
布朗运动和几何布朗运动是其中常见的模型。
这些模型假设价格走势受到随机因素的影响,但随机性程度不同。
几何布朗运动假设价格变化率是随机的,而布朗运动则是价格本身是随机的。
这些模型更符合实际市场的波动特性,但也有其复杂性和参数敏感性。
结论金融市场波动的模型多种多样,每种模型都有其局限性和适用范围。
综合运用不同的模型和方法能够更全面地理解和解释金融市场波动的本质。
Eviews之变系数回归模型

EVIEWS 之变系数回归模型1 变系数回归模型前面讨论的是变截距模型,并假定不同个体的解释变量的系数是相同的,然而在现实中变化的经济结构或者不同的经济背景等不可观测的反映个体差异的因素会导致经济结构的参数随着横截面个体的变化而变化,即解释变量对被解释变量的影响要随着截面的变化而变化。
这时要考虑系数随着横截面个体的变化而变化的变系数模型。
1.变系数回归模型原理变系数模型一般形式如下:,1,2,,,1,2,,it i it i it y x u i N t T αβ=++==(1) 其中:it y 为因变量,it x 为1k ⨯维解释变量向量,N 为截面成员个数,T 为每个截面成员的观测时期总数。
参数i α表示模型的常数项,i β为对应于解释变量的系数向量。
随机误差项it u 相互独立,且满足零均值、等方差的假设。
在式子(1)中所表示的变系数模型中,常数项和系数向量都是随着截面个体变化而变化,因此将该模型改写为:it it i it y x u λ=+ (2)其中:1(1)(1,)it it k x x ⨯+=,'(,)ii i λαβ= 模型的矩阵形式为:u X Y +∆= (3)其中:11N NT y Y y ⨯⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦;121i i i iT T y y y y ⨯⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦;⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=N X X X X 00000021;112111222212i i ki i i ki i iTiT kiT T k x x x x x x x x x x ⨯⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦,12(1)1N N k λλλ+⨯⎡⎤⎢⎥⎢⎥∆=⎢⎥⎢⎥⎣⎦,11N NT u u u ⨯⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦,121i i i iT T u u u u ⨯⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦类似于变截距模型,根据系数变化的不同形式,变系数模型中系数的变化,即解释变量对被解释变量的影响也分固定影响和随机影响两类,相应的变系数模型也分为固定影响变系数模型和随机影响变系数模型两类,前者也被称为似不相关回归模型,后者包括Swamy 随机系数模型和Hsiao 模型等,本章只介绍Swamy 随机系数模型。
广东财经大学-广东商学院-国际金融研究-DSGE模型

Qt Kt 1 I t rt Kt
其中:
(12)
Kt 1 (1 ) Kt (
It ( It ) Kt Kt
It ) Kt Kt
(13)
I I (.) 0, (.) 0, (0) 0, ( ) K K
(14)
rt 为资本品生产者从中间品生产者租赁资本的价格, 为资本折旧率, 为递增的
1 P 1 t Rn ,t 1 t Ct Pt 1 Ct 1
期内最优消费与劳动力供给:
( 3)
1 Wt e L, t H t Ct Pt
2.中间品生产者 中间品生产者的生产者函数为: Yt ( At Lt ) K t
1
(4)
,对应的利润函数为: (5)
Yt Wt Pt Lt Pw,t Pt
(6)
Pw,t Yt P (1 ) K (1 )Qt t 资本品需求: t Qt 1
( 7)
每期期末,中间品生产者购买下一期的资本,使用的资金来源于净资产 N t (自有资金) 和银行贷款 Bt ,满足如下融资预算式:
Bernanke, Gertler 和 Gilchrist(1999)思想。净资产 N t 1 的演化路径为:
N t 1 [ Rk ,t Qt 1 K t Et 1 Rk ,t (Qt 1 K t N t )]
变系数模型的估计

Zhang (2007)[2] proposed varying-coefficient model with different smooth-
ing variables:
p qp
Y=
aαα (Xα)Zα(α ) + σ(X, Z) ,
(2)
α=1 α =1
where (Y, XT , ZT ) is random vector, Y ∈ R, X = (X1, · · · , Xp)T ∈ Rp, Z =
pБайду номын сангаас
Y = αi(U )Xi + σ(U, X) ,
(1)
i=1
where (Y, U, X1, X2, ..., Xp)T is the random vector, X = (X1, · · · , Xp)T ,
is a random error with E( |U, X) = 0, V ar( |U, X) = 1. The varying co-
太原理工大学硕士研究生学位论文
其 中Y 为 响 应 变 量,X = (X1, · · · , Xp)T 为 随 机 变 量, 为 随 机 误 差,q为 远 远 小 于p的 整 数.但是,模型(1.1)仍然存在局限性,当q较大时仍然存在“维数祸根”.事实上, 当样本 容量不太大且q ≥ 2时,模型(1.1)并不是非常实用的.另一种克服“维数祸根”的方法 称为函数近似, 即放宽对传统参数模型的条件,探索新的结构,如可加模型(additive model)[15,16]、低维交互模型(low-dimensional interaction model)[17,18,19]、部分线 性模型(partially linear model)[20,21]、变系数模型(varying coefficient model)[1,22,23,24]、 混合模型[25,26,27,28].在以上的半参数回归模型中,变系数模型获得了广泛的采用, 成功 地应用于多维非参数回归,广义线性模型,非线性时间序列模型,纵向数据,函数数据,生存 数据,金融数据和经济数据的分析中.
变系数统计模型研究进展

变系数统计模型研究进展变系数统计模型是一种统计模型,用于研究随机变量的不稳定性和变异性。
它是传统的平均数和方差模型的推广和拓展,能够更加准确地描述数据的变化特征。
在过去的几十年里,变系数统计模型得到了广泛的关注和研究。
本文将对变系数统计模型的研究进展进行探讨。
首先,变系数统计模型的理论基础得到了深入的研究。
早期的变系数模型是建立在平均值不变的假设下,而现在的研究则更加注重平均值和变异性之间的关系。
经过一系列的拓展和修改,变系数模型的理论框架得到了进一步的完善。
其次,变系数统计模型的应用领域不断拓展。
最初,变系数模型主要应用于金融和经济领域,用于研究股票价格和经济指标的波动性。
随着研究的深入,变系数模型的应用领域逐渐扩大到其他领域,如气象学、地质学和医学等。
这些应用研究不仅拓展了变系数统计模型的应用范围,同时也促进了该模型的发展和改进。
此外,变系数统计模型的推断方法也得到了改进。
传统的变系数模型通常采用极大似然估计方法进行参数估计,但该方法在实际中存在一些问题,如对模型的假设要求较高、计算复杂等。
因此,研究者们提出了一些新的推断方法,如贝叶斯估计、非参数估计等。
这些方法的应用使得变系数模型的推断更加准确和可靠。
最后,变系数统计模型的拓展形式也得到了关注。
最早的变系数模型是基于正态分布假设的,但现实中的数据往往不满足该假设。
为了更好地适应实际数据的特点,研究者们提出了更多的拓展形式,如广义变系数模型、混合变系数模型等。
这些拓展形式的提出使得变系数模型能够更好地适用于实际问题的研究。
综上所述,变系数统计模型是一种重要的统计工具,在过去的几十年里得到了广泛的研究和应用。
研究者们对该模型的理论基础、应用领域、推断方法和拓展形式等方面进行了深入的探讨,取得了一系列的研究成果。
然而,变系数统计模型仍然存在一些问题和挑战,如模型的建立和选择、参数估计和模型比较等。
未来的研究应该进一步加强对这些问题的研究,提高变系数模型的理论深度和应用价值。
5.2 变系数和动态Panel模型

α i = y i γy i , 1
i = 1,L, n
在包含外生解释变量的情况下,类似地,首先采用 在包含外生解释变量的情况下,类似地, 工具变量方法估计差分方程模型,得到γ和 的估计 工具变量方法估计差分方程模型,得到 和β的估计 然后求得α 的估计量。 量,然后求得 i的估计量。
2.随机影响模型 2.随机影响模型
Data计量经济学模型 计量经济学模型( §5.2Panel Data计量经济学模型(二) —变系数模型和动态模型 变系数模型和动态模型 变系数
一、变系数模型 二、动态模型 关于Panel Data模型的总结 三、关于 模型的总结
一、变系数模型
要点
变系数模型的表达式 固定影响模型 固定影响模型——随机干扰项在不同横截面个体 随机干扰项在不同横截面个体 之间不相关——OLS估计 之间不相关 估计 固定影响模型——随机干扰项在不同横截面个体 随机干扰项在不同横截面个体 固定影响模型 之间相关——GLS估计 之间相关 估计 随机影响模型的复合误差项 随机影响模型的 随机影响模型的GLS估计 估计
显然,如果随机干扰项在不同横截面个体之间不 显然, 相关,上述模型的参数估计极为简单, 相关,上述模型的参数估计极为简单,即以每个 截面个体的时间序列数据为样本, 截面个体的时间序列数据为样本,采用经典单方 程模型的估计方法分别估计其参数。 程模型的估计方法分别估计其参数。即使采用 GLS估计同时得到的 估计同时得到的GLS估计量,也是与在每个 估计量, 估计同时得到的 估计量 横截面个体上的经典单方程估计一样。 横截面个体上的经典单方程估计一样。 条件: 条件:
Eu it = 0
2 σ u Eu it u js = 0
i = j且t = s 否则
5.3 变系数Panel Data模型

n n ˆ Wi i X i i1 yi i 1 i 1
i2 I T i X i X i
n
复合随机项的协方差矩 阵的第i个对角分块
2 1 1 Wi [ i ( X i X i ) ] [ i2 ( X i X i ) 1 ]1 i 1
一、变系数Panel Data模型表达及含义
1、实际经济分析中的变系数问题
• 线性模型中,系数表示边际倾向(对于直接线性 模型)或者弹性(对于对数线性模型),而它们 相对于不同的截面个体经常是不同的。例如:
–不同地区收入的边际消费倾向不同。
–不同地区FDI的边际效益不同。
–不同家庭的边际储蓄倾向不同。
1
ˆ ( X X ) 1 X y i i i i i
说明GLS估计是每一个横截面个体 上最小二乘估计的矩阵加权平均。 权与它们的协方差成比例。
GLS 估计的协方差矩阵为:
ˆ ) X 1 X Var ( GLS i i i i 1
E(μiμj ) 0
i j
E(μi μ ) i2I i
• 这里可以将模型看成一个由n个方程组成的联立 方程模型,由于方程之间不存在相关性,分别估 计每个方程并没有信息损失。
• 即使采用系统估计方法同时估计所有方程的参数 ,与单方程估计是等价的,因为没有增加任何信 息。
• 附带回答一个问题:建立Panel Data模型时需要 多长的时间序列样本?
Y = Xβ + Xα + μ
α1 α2 α α n nK1
( Xα + μ)的协方差矩阵是对角分块阵,其第i个对角分块为:
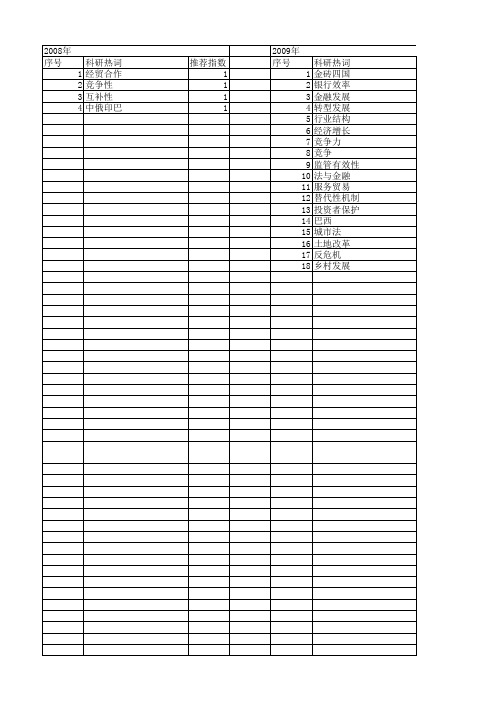
【国家社会科学基金】_金砖_基金支持热词逐年推荐_【万方软件创新助手】_20140806
推荐指数 6 3 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
2011年 科研热词 比较研究 创新模式 "金砖四国" 金砖四国 金砖赶超 行业结构 美国 经济增长 竞争力 独联体 服务贸易 服务出口 改革 投入-产出分析 对策 大国崛起 国际金融危机 国际金融体系 危机时期 卢布 医疗卫生 区域货币合作 公平与效率 俄罗斯 2009年 推荐指数 3 3 3 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
推荐指数 10 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
推荐指数 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 118 19 20
科研热词 金砖四国 服务业 异质性 金鳌新话 路径选择 股票市场 美国 社会福利函数 独创性 溢出效应 战略选择 幽魂世界 幽魂 大国崛起 增长方式转变 国际竞争 剪灯新话 公共选择 假说 一致同意
推荐指数 9 3 3 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
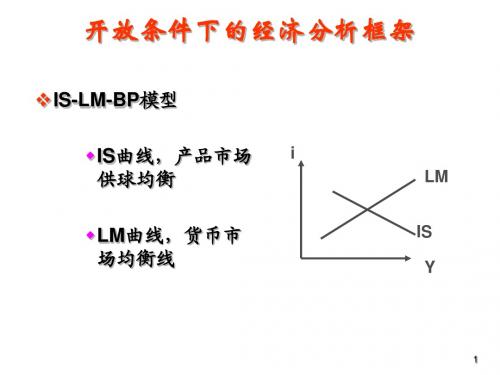
广东财经大学-广东商学院-国际金融研究-IS-LM模型分析框架
1 Y T m
在汇率既定时,贸易余额与国民收入和边际进 口倾向有关。
贸 易 差 额 与 利 率 无 关
16
CA曲线
贸易收支差额与利率无关,CA曲线由收入变动决 定。 CA曲线是一条垂直线
CA曲线左边的 点,经常账户 为顺差。
实际汇率q改变时,CA线的位置也会改变。 q值增大时,出口增加,自主性贸易余额改善,从而需要收入增加 以提高进口来维持经常账户收支平衡,CA曲线右移。
3
二、LM曲线
LM曲线为货币市场均衡线,即所有能够使货币市 场上货币供给(M)等于货币需求(L)的市场利 息率和国民收入的组合。
4
在简单模型中,货币供给是由中央银行决定的外生 变量或常数。货币需求则是市场利息率和国民收入 的函数,并与市场利息率负相关(货币的投机需 求),与国民收入正相关(货币的交易和谨慎性需 求)。曲线由左下方向右上方倾斜,因为在均衡条 件下,如果市场利息率水平上升而其它不变,则货 币的投机需求下降,要再度实现均衡,由于货币供 给是常数,则必须有国民收入水平的上升,从而使 货币的交易和谨慎性需求相应上升。货币供应量增 加,其它条件不变将使LM曲线向右移动。另外, 货币需求的下降,其它不变也将使LM曲线向右移 动。
18
(3)资本不完全流动时,Bp 线
资本不可完全流动时,资本与金融账户和经常账 户对国际收支都有影响, BP曲线是一条斜率为正的曲线
BP
在BP曲线右边的各点,表 明经济处于国际收支赤字状态, 在BP曲线左边的各点,则 反映经济处于国际收支盈余状 态。
资金流动性越大,这一曲 线就越平缓,因为比较小的 利率增加就能吸引更多的资 金流人。
CA曲线右边的点, 经常账户为逆差;
按混合模型、变截距模型和变系数模型区分

3. 手工输入/剪切和粘贴 可以通过手工输入数据,也可以使用剪切和粘贴工具输 入: (1) 通过确定工作文件样本来指定堆积数据表中要包含哪 些时间序列观测值。 (2) 打开Pool,选择View/Spreadsheet(stacked data), EViews会要求输入序列名列表,可以输入普通序列名或Pool 序列名。如果是已有序列,EViews会显示序列数据;如果这 个序列不存在,EViews会使用已说明的Pool序列的截面成员 识别名称建立新序列或序列组。
7
对截面成员的识别名称没有特别要求,但必须能使用这 些识别名称建立合法的EViews序列名称。此处推荐在每个识 别名中使用“_”字符,它不是必须的,但把它作为序列名的 一部分,可以很容易找到识别名称。
8
2. Pool序列命名 在Pool中使用序列的关键是序列命名:使用基本名和 截面识别名称组合命名。截面识别名称可以放在序列名中 的任意位置,只要保持一致即可。 例如,现有一个Pool对象含有识别名 _JPN, _USA, _UK,想建立每个截面成员的GDP的时间序列,我们就使 用“GDP”作为序列的基本名。 可以把识别名称放在基本名的后面,此时序列名为 GDP_JPN,GDP_USA,GDP_UK;或者把识别名称放 在基本名的前面,此时序列名为JPN_GDP,USA_GDP, UK_GDP。 把识别名称放在序列名的前面,中间或后面并没什么 关系,只要易于识别就行了。但是必须注意要保持一致, 不能这样命名序列:JPNGDP,GDPUSA,UKGDP1,因 为EViews无法在Pool对象中识别这些序列。
2
面板数据含有横截面、时间和指标三维信息,利用 面板数据模型可以构造和检验比以往单独使用横截面数 据或时间序列数据更为真实的行为方程,可以进行更加 深入的分析。正是基于实际经济分析的需要,作为非经 典计量经济学问题,同时利用横截面和时间序列数据的 模型已经成为近年来计量经济学理论方法的重要发展之 一。
函数型数据的变系数模型

函数型数据的变系数模型
函数型数据的变系数模型是一种针对函数型数据的建模方法。
在传统的统计模型中,通常假设数据服从某种固定的分布,但对于函数型数据来说,一个函数在不同的位置上可能具有不同的特征,因此无法简单地用一个固定的分布来描述。
变系数模型则允许函数的性质在不同的位置上发生变化,从而更加准确地描述函数型数据。
变系数模型的基本思想是将函数拆分为一个基本函数和一个系
数函数的乘积形式。
基本函数通常是一些已知的函数,如多项式函数或三角函数等,而系数函数则是需要估计的部分。
系数函数的变化可以是连续的或分段的,可以用一些光滑的函数来描述。
在实际应用中,变系数模型可以用于分析各种类型的函数型数据,如时间序列数据、曲线拟合等。
总之,函数型数据的变系数模型提供了一种灵活的建模方法,可以更好地适应函数性质的变化。
它在许多领域中具有广泛的应用,如气象预测、股票价格预测、医学诊断等。
- 1 -。
金融数据变结构波动性模型的综述及研究进展

随着全球金融市场的迅猛发展, 金融市场呈现出来的波动性也史无前例 。为了描述波动性的时变性和 1982 年, Engle 尖峰厚尾的现象,
[1 ]
引入了自回归条件异方差( ARCH) , 作为描述金融资产价格波动持续性的
ARCH 给出了计算时间序列的条件方差的方法 。 传统方法,
{
εt = σt zt z t : IID, E( z t ) = 1 , Var( z t ) = 0
p 2 σ t = ω0 + 2 α i ε t -i Σ i =1
其中 ε t , σ t 分别为 t 时刻的回报及条件方差。可是, 当模型中的阶数 q 受到样本容量的限制时, 也会影响预 Bollerslev 测。1986 年,
[2 ]
— —广义的自回归条件异方差模型 ( GARCH ) , 又提出了推广的 ARCH 模型— 即在方
596
重庆工商大学学报( 自然科学版)
第 28 卷
3
马尔可夫与 ARCH 类模型的联合
Pagan 和 Schwert ( 1990 ) [16]以及 Timmermann ( 2000 ) [11]指 马尔可夫混合模型能产生条件异方差 , 然而, 2 出, 像式( 1 ) 这种基本模型中方差只能得出有限的动态性 。这是因为时变的波动性仅仅是由尺度参数 σ 的 而并非包含收益过程及不同状态内连续方差的自身信息 。收益的波动性实际上是由冲击反 离散转换得来, [17 ] ARCH ( MarkovSwitching 应新 信 息 得 到 新 的 方 差。 由 此 Hamilton 与 Susmel ( 1994 ) 首 先 提 出 了 MSARCH) 模型, 用 ARCH 过程的规模因子变化表示体制( 状态) 的娈化。如下: ~ t ε t = ε σ ' s t, ~ ε = ηt σt ~2 ~2 σ2 = α + α ε t 0 1 t - 1 + … + α q ε t -q Cai ( 1994 ) [18]参考了 Lamoureux 及 Lastrapes ( 1990 ) [19]的发现, ARCH 模型只是考虑了方差 提出的 MS重常数项的状态转换, 在每一期的似然函数只依赖于最近 q 期的体制( 状态) 历史。其模型为: εt = ηt σt
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2008 年后 , 美国次贷危机和欧洲主权债务危机爆发 , 中国贸易顺差增速才出现了下降 。
那么 , 中国的贸易受到汇率变动的影响如何 ? 这些影响是否随着时间的发展而所有变化 , 以及 这些影响的作用为何与理论预期和政策目标产生了一定的偏离 ? 这是理论研究者和政策制定者亟需 解决的问题 。
Marshall (1923) 最先提出 , 在均衡条件下 , 当各国总体需求弹性小于 1 时 , 汇率的贬值对贸 易收支不会有积极的影响 。 Lerner (1946) 在其研究中阐述了类似的观点 。 后来研究者们将这些学 者的理论进行总结 , Robinson (1937) 提出了汇率贬值能改善贸易收支状况的条件是 , 进口和出口 的相对价格弹性之和大于 1, 这就是著名的 Marshall-Lerner 条件 。 后续出现了许多关于 ML 条件的 研究 , 但他们得出的结论不尽相同 。 如在传统的 OLS 模型下 , Goldstein & Khan ( 1978)、 Marquez & Schindler (2007)、 戴祖祥 (1997)、 卢向前和戴国强 (2005) 认为 ML 条件是满足的 , 即贬值能 够改善贸易状况 。 而 Miles ( 1979)、 Lau et al. ( 2004)、 Eckaus ( 2004)、 Ahmed ( 2009) 等则认为 ML 条件不满足 , 即货币的贬值不能改善贸易余额 。 随着计量技术的发展 , 协整理论被运用到各类 型的研究中 。 但研究结论依然存在争议 , 如 Bahmani-Oskooee ( 1998)、 Baharumshah ( 2002) 等认 为 ML 条 件 满 足 , 即 汇 率 贬 值 可 以 在 长 期 内 提 高 贸 易 余 额 。 而 Aziz & Li ( 2008) 、 Thorbecke (2010)、 Thorbecke & Smith (2010)、 谢建国和陈漓高 (2002)、 黄基伟和于中鑫 (2011) 等则认为 ML 条件不满足 , 即汇率对贸易余额的影响并不是负向的 。
赞 = ST,0(τ) ST,1(τ) θ ST,1(τ) ST,2(τ)
对 0燮k燮3, 有 :
T
燮
T ≡S 燮燮 燮 T
-1 n,0(τ) n,1(τ) T
-1 T
( τ ) Tt ( τ )
(3 )
ST,k(τ) =T-1∑XtX′t(τt-τ)kKh(τt-τ)和 Tn,0(τ)=T-1∑Xt(τt-τ)kKh(τt-τ)Yt
44 国际金融研究 2014 · 2
Global Finance
环球金融
含着系数变动是连续的假定 , 不用考虑变化点的确定问题 ; 另一方面 , 时变系数模型的估计系数可 以有各自的变化特点 , 并不需要与其他变量有着同样的变化时点 。 综合以上的考虑 , 本文试图采用 时变系数协整方法分析人民币对贸易出口 、 进口和净出口行为的时变影响 。 本文安排如下 : 第一部分是实证模型的设定及估计 ; 第二部分是数据选择与变量的设定 ; 第三 部是实证结果与分析 ; 第四部分是全文的结论 。
造的统计量如下 :
τn=
赞 b = 赞 (b) s
赞 b
(4 )
2
姨
赞 /∑(t- 軃 ω t)
2 M
赞 2 为u 赞 2=∑k 赞 2t 的长期方差的一致非参估计 , ω 其中 , ω
h=-M -1 2 t -1 2 j j
h · ) 为定义在 [-1 , 1] 的滞后窗 C (h ), k ( 燮 M 燮
t=1 t=1
Xiao (2009) 得出了关于估计系数的统计推断 , 并提出了对函数化系数模型的协整检验方法 。 赞 (zt)′xt 是否平稳来实现 。 当 ut 是平稳变量时 , 赞 t=yt-β 其主要思想是检验估计模型的残差回归残差为 u 那么其方差为常数 , 即 E ( u2t) =σ2u。 而当 ut 为不平稳变量时 , E ( u2t) 是随时间而增 大 的 , 即 E 赞 是否显著大于零 。 Xiao (2009) 构 赞 2t=a+bt+et。, 并检验系数 b 的估计b (u2t) =a+bt 。 因此 , 基于回归 u
cient ) 的半参数估计方法建立时变的回归方程 , 以考虑汇率变动对贸易影响的时变性 。 此前 , 国外已有作者对时变系数的模型进行了讨论 。 Robinson (1989, 1991) 在平稳变量的假定
下 , 将模型的估计系数设定为时间的函数以考虑系数的时变性 。 这种模型实质上是一种函数化系数 (Functional coefficient) 模型 。 Orbe et al. (2003, 2005) 在时变系数的设定下 , 考虑了季节效应的约 束。 他们的模型设定都在同质方差的假定下进行估计 。 Cai (2007) 考虑了异方差性提出局部线性估计 方法 (local linear estimation), 这种方法在内点值的估计与 Nadaraya-Watson 方法的渐近性质非常接 近 , 且 不 必 假 设 扰 动 项 的 分 布 。 与 此 同 时 , 非 参 研 究 中 的 非 平 稳 变 量 也 得 到 发 展 , 如 Sun et al. (2011)、 Pitarakis & Banerjee (2012)、 Gao & Phillips (2011)、 Cai et al. (2009) 和 Xiao (2009) 等 。 其中 , Cai et al. (2009) 和 Xiao (2009) 对非平稳数据下 , 函数化系数模型的估计问题 , 可以推广到 一般的时变模型 。 Cai et al. (2009) 在 Fan & Zhang (1999)、 Cai (2002a) 等的两步估计法基础上 , 解决了带非平稳和平稳变量下的函数化系数模型的估计问题 。 Xiao (2009) 则解决了函数化系数模型 的协整问题 。 时变系数模型不仅优于常系数模型 , 还优于带结构突变的模型 。 其原因主要有 : 一方面 , 其隐
Yt≈Z′tθ+ut, 其中 Zt=
那么 , 局部加权残差和为 :
T
X β (t ) θ 和 θ=θ (t ) = 燮 =燮 燮 燮 燮 燮 x (τ -τ) β′(t) θ
t 1 2 t t
∑
t=1
{Yt-Z′tθ} 2Kh (τt-τ)
(2 )
其中 , Kh (u) =K (u/h ), K ( · ) 是核函数 , 且 h=hn>0, 符合当 T→∞ 时 , 有 h→0 和 Th→∞ 。 局部多项式估计是要最小化公式 (2 ), 其解为 :
Global Finance
环球金融
人民币汇率变动对中国贸易收支 时变性影响的实证研究
—基于半参数函数化系数 本文采用函数化系数半参数估计模型 , 实证研究了人民币汇率变动对中国 贸易出口 、 进口以及净出口的时变性影响 。 实证结果表明 , 汇率变动对贸易收支的影响机 制在 2002 年中国加入世界贸易组织和 2005 年人民币汇率形成机制改革后有较为明显的变 化 。 2002 年前 , 汇率变动对出口的负向影响不断加强 , 而在 2002-2005 年期间 , 这种负向 影响达到最大 , 且相对稳定 。 在此期间 , 由于进口与出口的同向变动 , 汇率对贸易差额的 影响并不明显 。 2005 年后 , 由于汇率制度改革后出现人民币的单边升值 , 汇率对中国贸易 收支影响的内涵也有一定的变化 。 国际资本为了从人民币升值中获益 , 通过贸易渠道进入 中国 , 从而促进了出口的增加 。 由于汇率变动对进口影响强度变化不大 , 最终出现了货币 升值与贸易顺差增长共存的局面 。 关键词 : 人民币汇率 中图分类号 : F831 贸易收支 半参数函数化系数模型 文献标识码 : A
一、模型估计与实证步骤
本文考虑的时变参数模型设定如下 : (1 ) Yt=X′tβ (zt) +εt 式中 , Yt 和 Xt 分别为 1 维和 k 维为 I (1) 变量 , β (zt) 为 k×1 的系数向量 , 其值是 zt 的函数 , 其中 zt 是单变量 I (0) 过程 , 假设 zt=t/T 。 在实际估计中 , Yt 是中国的出口额或进口额 , Xtj 是包括 汇率 、 收入等在内的解释变量 。 对于模型 (1), 关键是通过 {(Yt, Xt)} Tt=1 来估计 {βj ( ·)} 。 本文采用局部多项式 (Local Polynomial ) 的方法进行估计 。 假设 βj (·) 是有连续的二阶导数 , 即 β′ j (·) 存在 , 那么将其线性展 开 : βj (τt) ≈aj+bj (τt-τ ), 0燮j燮d, 其中 aj=βj (τ) 和 bj=β′j (τ)。 那么 , (1) 可以近似写成 :