经验分布函数与直方图
经验分布函数

(1)均匀分布U(a,b) 1)unifrnd (a,b)产生一个[a,b] 均匀分布的随机数
2)unifrnd (a,b,m, n)产生m行n列的均匀分布随机数矩阵 当只知道一个随机变量取值在(a,b)内,但不 知道(也没理由假设)它在何处取值的概率大,在 何处取值的概率小,就只好用U(a,b)来模拟它。
f分布的逆累积分布函数 伽玛分布的逆累积分布函数 几何分布的逆累积分布函数 超几何分布的逆累积分布函数 正态分布的逆累积分布函数 泊松分布的逆累积分布函数
X=tinv(p,v) X=Unidnv(p,N) X=unifinv(p,A,B)
学生氏t分布的逆累积分布函数 离散均匀分布的逆累积分布函数 连续均匀分布的逆累积分布函数
(2)方差未知(检验法)
方差未知时,采用检验法,MATLAB函数为 h=ttest(x,m ,alpha,tail) 各参数意义同上,同样ttest函数也有几个常见 用法: [h,p]=ttest(参数) [h,p,ci]=ttest(参数)
(3)泊松分布 参数估计命令为 [lambdahat,lambdaci]=poissfit(x,alpha) 返回参数的估计值和置信区间. (4)均匀分布(已知,未知) 参数估计命令为 [ahat,bhat,aci,bci]=unifit(x,alpha) 返回值分别为参数的估计值和置信区间. (5)指数分布 参数估计命令为 [lambdahat, lambdaci]=expfit(x,alpha)
解:输入a1=a';b=a1(:); %将矩阵变成数列 [p1,p2,p1ci,p2ci]= normfit (b) 或者: a1=a';b=a1(:); 均值、标准差的极 [p,pci]=mle('norm',b) 输出:[p1,p2,p1ci,p2ci]= normfit (b) 大似然估计分别 为:600和195.6436 p1 =600 p2 =196.6292 均值95%的置信区 p1ci = 560.9845 间为:(561.6536, 639.0155 638.3464); p2ci =172.6418 标准差95%的置信 228.4192 区间为:(170.6834, 或phat =600.0000 195.6436 220.6038); pic = 561.6536 170.6834 638.3464 220.6038
1.3 顺序统计量

PX (1) u, X ( n ) v Pu X 1 v,, u X n v Pu X 1 v Pu X n v [ F ( v ) F ( u)]n , 若u v, 0 , 若u v ; F ( u, v ) PX (1 ) u, X ( n ) v PX ( n ) v PX (1 ) u, X ( n ) v [ F (v )]n [ F (v ) F ( u )]n , 若u v, n , 若 u v. [ F (v )]
1.3 顺序统计量
§1.3
顺序统计量、经验分布函数和直方图
一、顺序统计量 另一类常见的统计量是顺序统计量. 定义 1 设 X 1 , X 2 ,, X n 是取自总体 X 的样本, X ( i ) 称为 该样本的第 i 个顺序统计量,它的取值是将样本观测值由小 到大排列后得到的第 i 个观测值。x(1) x( 2 ) x( n ) ,X ( i ) 的值是 x ( i ) 。其中 X (1) minX 1 , X 2 ,, X n 称为该样本的最小顺 序统计量,称 X ( n ) maxX 1 , X 2 ,, X n 为该样本的最大顺序统 计量。 我们知道, 在一个样本中, X 1 , X 2 ,, X n 是独立同分布的, 而次序统计量 X (1) , X ( 2) ,, X ( n) 则既不独立,分布也不相同, 看下例。
假设总体 X 在区间[0,2]上服从均匀分布; Fn ( x )
是总体 X 的经验分布函数, 基于来自 X 的容量为 n 的简单随 机样本,求 Fn ( x ) 的概率分布,数学期望和方差. 解 总体 X 的分布函数为
应用数理统计课件(配庄楚强版教材)第二章

(ξ1,ξ2,..,ξn), 则(ξ1,ξ2,…,ξn)的联合分布函
数为: F ( x1 , x2 ,L , xn )
= P { ξ1 < x1 , ξ 2 < x2 , ..., ξ n < xn }
= P { ξ1 < x1}P{ ξ 2 < x2 } ⋅ ... ⋅ P{ ξ n < xn }
(2)χ2 分布(Chi-square distribution)
χ 2 ~χ 2 (n)
{ } p分位点:χ p2 (n ) 满足P
χ
2
<
χ
2 p
(n)
=p
p53(9 347)表 4
χ
2 0.95
(9
)
=
16.91(9
p540)
表p 4 χ2 分布分位数表
n
p
8
9
0 .90 13.362 14.684
又如:α = 0.1,uα = u0.1 = ? (表中没有)
u0.1 = −u1−0.1 = −u0.9 = −1.282
对称性(symmetricy):
0.1
uα = −u1−α
α = 0.1
u0.1
u1− 0.1
习题或附表中α通常是指分位点之外的概率(面积)
单侧分位点:α放在分位点u1−α的一侧 双侧分位点: α分割放在正负对称的
2 +L +
)
m
1
9
二. t 分布 (t distribution)
Definition: 若ξ~N(0,1), η~χ2(n)且相互独立,
则有
t=
ξ η
~ t (n )
描述性统计分析与探索性统计分析

第一章 描述性统计我们把对某一个问题的研究对象的全体称为总体,总体就是一个具有确定分布的随机变量.我们统计分析的目的是通过从总体中抽得的样本,对总体分布进行推断,要想较准确的推断出总体的分布,首先要对样本的分布状况有一个基本的了解,这一章就是介绍用以描述样本分布状况的一些常用统计分析方法,这些方法既直观又简单,而且也很实用.1.1频数分析与图形表示一、总体X 为只取少数个值的离散型随机变量 例1.1.1考察一枚骰子是否均匀,设计实验如下: 独立地掷这枚骰子42次,所得点数纪录如下:3 24 15 1 5 3 4 3 56 4 2 5 3 1 3 4 1 4 3 1 6 3 3 1 2 4 2 6 3 4 6 6 1 6 2 4 5 2 6 X 为掷一枚均匀的骰子一次所得的点数二、当总体X 取较多离散值或X 为连续取值时设x x x n ,,21是总体X 的一组样本观测值,具体做法如下:1求出x )1(和x n )(,取a 略小于x )1(,b 略大于x n )(;2将区间[a ,b]分成m 个小区间(m <n ),小区间长度可以不等,分点分别为a =t t t m <<< 10=b注意:使每个小区间中都要有一定量的观测值,且观测值不在分点上。
划分区间个数的确定:区间过少:分布信息混杂,丢失信息. 区间过多:出现很多空区间.区间划分个数m 依赖于样本总数n ,理论上有如下两个公式可参考: Moore(1986) : m ≈C n 5/2,C = 1~3; Sturges(1928) : m ≈1+3.322(lg n );3用n j 表示落在小区间(t j 1-,t j ]中观测值的个数(频数)并计算频率f j =nn j (j=1,2,…,m );4在直角坐标系x-o-y 的x 轴上标出t t t m ,,,10 ,分别以(t j 1-,t j ]为底边,以n j 为高作矩形,即得频数条形图。
概率统计习题 5.2

习题与解答5.21. 以下是某工厂通过抽样调查得到的10名工人一周内生产的产品数 149 156 160 138 149 153 153 169 156 156 试由这批数据构造经验分布函数并作图. 解 此样本容量为10,经排序可得有序样本:(1)(2)(3)(4)(5)(6)(7)(8)(9)(10)138,149,153,156,160,169x x x x x x x x x x ==========其经验分布函数及其图形分别如下()01380.11490.31530.51560.81600.91691n x F <⎧⎪≤<⎪⎪≤<⎪=≤<⎨⎪≤<⎪≤<⎪⎪≥⎩,x ,, 138x ,, 149x ,, 153x ,, 156x ,, 160x ,, x 169.2. 下表是经过整理后得到的分组样本:试写出此分组样本的经验分布函数. 解 样本的经验分布函数为()037.50.1547.50.3557.50.7567.50.977.51n x x F <⎧⎪≤<⎪⎪≤<=⎨≤<⎪⎪≤<⎪≥⎩,,, 37.5x ,, 47.5x ,, 57.5x ,, 67.5x ,, x 77.5.3.假若某地区30名2000年某专业毕业生实习满后的月薪数据如下: 909 1086 1120 999 1320 1091 1071 1081 1130 1336 967 1572 825 914 992 1232 950 775 1203 1025 1096 808 1224 1044 871 1164 971 950 866 738 (1)构造该批数据的频率分布表(分6组); (2)画出直方图.解 此处数据最大观测值为1572,最小观测值为738,故组距近似为1572736140,6d -== 确定每组区间端点为 ,此处可取 ,于是分组区间为(](](](](](]735.875875101510151155115512951295143514351575.,,,,,,,,,, 其频数频率分布表如下:其直方图如图5.2.4.某公司对其250名职工上班所需时间进行了调查,下面是其不完整的频率分布表:(1)试将频率分布表补充完整;(2)该公司上班所需时间在半小时以内有多少人?解(1)由于频率和为1,故空缺的频率为1-0.1-0.24-0.18-0.14=0.34. (2)该公司上班所需的时间在半小时以内的人所占频率为0.1+0.24+0.34=0.68,该公司有职工250人,故该公司上班所需时间在半⨯=人.小时以内的人有2500.681705. 40种刊物的月发行量如下(单位:百册):(1)建立该批数据的频数分布表,取组距为1700百册;5954 5022 14667 6582 6870 1840 2662 45081208 3852 618 3008 1268 1978 7963 20483077 993 353 14263 1714 11127 6926 2047 714 5923 6006 14267 1697 13876 4001 2280 1223 12579 13588 7315 4538 13304 1615 8612 (2)画出直方图.解 此处数据最大观测值为14667,最小观测值为353,由于组距为1700,故组数为146673538.421700K -≥=,所以分9组.接下来确定每组区间端点,要求03539170014667aa <+⨯>,此处可取0300a =,于是可列出其频数频率分布表.其直方图为6.对下列数据构造茎叶图452 425 447 377 341 369 412 399400 382 366 425 399 398 423 384418 392 372 418 374 385 439 408409 428 430 413 405 381 403 469381 443 441 433 399 379 386 387解取百位数与十位数组成茎,个位数为叶,这组数据的茎叶图如下:34 13536 6 937 2 4 7 938 1 1 2 4 5 6 739 2 8 9 9 940 0 3 5 8 941 2 3 8 842 3 5 5 843 0 3 944 1 3 745 246 97. 根据调查,某集团公司的中层管理人员的年薪数据如下(单位:千元):40.6 39.6 37.8 36.2 38.838.6 39.6 40.0 34.7 41.7 38.9 37.9 37.0 35.1 36.7 37.1 37.7 39.2 36.9 39.3 试画出茎叶图.解 取整数部分为茎,小数部分为叶,这组数据的茎叶图如下: 34 7 35 1 36 2 7 9 37 0 1 7 8 9 38 3 6 8 9 39 2 6 6 40 0 6 41 78. 设总体X 的分布函数为()F x ,经验分布函数为()n F x ,试证()()()()()11.n n E x F x Var x F x F x nF F ⎡⎤⎡⎤==-⎡⎤⎣⎦⎣⎦⎣⎦, 证 设1,...,n x x 是取自总体分布函数为()F x 的样本,则经验分布函数为()()()110/12,..., 1.1.k nn x x x k n x x x k n x F +⎧<⎪⎪=≤<=-⎨⎪>=⎪⎩()(k ),当,当,,,当x 若令{}12,...,i x x i i n y I ≤==,,,则1,...,n y y 是独立同分布的随机变量,且 ()()()()()21111()E y P x x F x E y P x x F x =≤==≤=,, 于是()()()()2()[[1].]i Var F x F x F x Fx y =-=-又()n x F 可写为()n x F =11ni i n y =∑,故有()()()()()()1111,()1.n n E x EF x Var x Var F x F x nn y y F F ⎡⎤⎡⎤====-⎡⎤⎣⎦⎣⎦⎣⎦。
概率统计建模讲义(重要分布举例卡方检验)

数理统计例举王晓谦wxqmath@南京师范大学主要内容随机变量及其分布经验分布函数和频率直方图参数估计假设检验相关分析与回归分析简介MATLAB例题例1能量供应问题(二项分布)例2 放射性(泊松)例3正态分布例4指数分布例5 多元随机变量例6经验分布函数例7超市问题(指数分布)例8区间估计例9 拟合检验1例10拟合检验2 例11概率纸检验法例12道德(独立性检验)例13肠癌例14J 效应随机变量及其分布例1、能量供应问题(二项分布)假定有10n =个工人间歇性地使用电力,估计所需要的总负荷。
首先我们要知道,或者是假定,每个工人彼此独立工作,而每一时刻每个工人都以相同的概率p 需要一个单位的电力。
那么,同时使用电力的人数就是一个随机变量,它服从所谓的二项分布。
用X 表示这个随机变量,记做(,)X B n p ,且有()(1),k k n k n P X k C p p -==-0,1,,k n =这是非常重要的一类概率分布。
其中E(X)=np , D(X)=np(1-p)。
其次,要根据经验来估计出,p 值是多少?例如,一个工人在一个小时里有12分钟在使用电力,那么应该有120.260p ==。
最后,利用公式我们求出随机变量X 的概率分布表如下:为直观计,我们给出如下概率分布图:目录 Back Next可以看出,{6}1{6}0.000864P X P X >=-≤=,也就是说,如果供应6个单位的电力,则超负荷工作的概率只有0.000864,即每11147200.000864≈≈分钟小时中,才可能有一分钟电力不够用。
还可以算出,八个或八个以上工人同时使用电力的概率就更小了,比上面概率的111还要小。
问题:二项分布是一个重要的用来计数的分布。
什么样的随机变量会服从二项分布?进行n次独立观测,在每次观测中所关心的事件出现的概率都是p,那么在这n次观测中事件A出现的总次数是一个服从二项分布B(n,p)。
数据的分布.ppt

4
(5)Weibull分布
f
(x)
1
x
c 1
exp
x
c
,
0,
x
x0
(1.17)
EX (1 1), DX 2 {( 2 1) (1 1)}2
c
c
c
背景:由瑞典物理学家Wallodi Weibull于1939年引
100
C 80
u
m
u
l
a t
60
i
v
e
P e 40 r c e n t
20
0
60
65
70
75
80
85
x
Normal Curve:
Mu=73.66, Sigma=3.9401
2020/1/12
图1.6 n=100 蛋白含量的经验分布函数Fn (x)及拟合 F(x)
11
(3)作正态分布QQ图
85
图
80
密度
f (x)
1
2
exp
(x )2 2 2
EX , DX 2
(2)对数正态分布
(1.13)
f
(x)
1
2 (x
)
. exp
(log(x ) 2 2
)2
,
0,
x
(1.14)
x0
背景:如一变量可看成许多独立因子之和,近似正 态分布.如股票投资长益可看成每天收益率的乘积.
s 3.94 61.5
D分布函数与概率密度函数的近似解

1) Fn x 是单调非减跳跃函数(阶梯函数) 2) Fn x 在点 x xk 处有间断, 在每个间断点的跃度 1 为 , k 1,2,,n n
*
Fn ( x ) 0, 3) 0 Fn ( x ) 1 xlim
x
lim Fn ( x ) 1
2) 数频数 观测值落在各组的频数分别为
m1 ,2 , ,ml
频率为
ml m1 m2 , , , n n n
3) 作图 以各组为底边,以相应组的频率除以组距为高, 建立个 l 小矩形,即得总体的直方图 如图6-2 直方图中每一矩形的面积等于相应组的频率
y
f x
o
m2 m1 n a0 n a a
0,
Fn x
* x x1
* x* x x k k 1 k 1, 2, ,n 1
k , n
1,
x x* n
称 Fn x 是总体 X 的经验分布函数 其图如6-1
y
1
k n 1 n
x x
* 1
* 2
o
x
* k
x
* k 1
x
* n
x
图 6-1
由图6-1容易看出
第六章 第二节 分布函数与概率密度函数的 近似解
一、分布函数的近似解—经验分布
二、概率密度函数的近似解—直方图
一、分布函数的近似解—经验分布
设 X 1, X 2, X n 是来自总体 X 的样本, x2, xn x1,
是样本的一个观测值, 设这n个数值按由小到大的
* * x2, x* ,定义: 顺序排列后为 x1 n ,对 x R
显然满足一般分布函数的三个性质 随着 n 的增大,Fn ( x ) 越来越接近 X 的分布函数 F( x )
python 幂律衰减系数-概述说明以及解释

python 幂律衰减系数-概述说明以及解释1.引言1.1 概述Python是一种功能强大且广泛应用于数据分析和科学计算的编程语言。
随着互联网的发展以及大数据时代的来临,越来越多的研究者和数据科学家开始关注幂律衰减现象,并将其应用于各个领域的研究和实践中。
幂律衰减系数作为衡量幂律衰减程度的重要指标,因其在描述和分析幂律现象中的重要性而备受关注。
概括来说,幂律衰减系数是一种用来描述随机变量的衰减方式的指标。
在幂律分布中,随机变量的频率与其取值成幂律关系,即随机变量的概率密度函数以及累积分布函数呈现出幂律形式。
而幂律衰减系数则用于衡量这种幂律分布方式的强度和程度。
幂律衰减系数的计算方法有多种,常用的方法包括最小二乘法、极大似然估计法等。
这些方法可以帮助研究者从数据中获取幂律衰减系数的估计值,并进一步分析和解释这一指标的意义和作用。
通过计算幂律衰减系数,我们可以更好地理解数据的分布特征,揭示其背后的规律和本质。
幂律衰减系数在实际应用中具有广泛的意义和作用。
例如,在社交网络分析中,研究者经常使用幂律衰减系数来描述用户在社交网络中的贡献度和影响力,从而推测用户在网络中的地位和关系。
在金融领域,幂律衰减系数可以用于分析投资组合的风险和收益的关系,帮助投资者制定合理的投资策略。
在城市规划和交通管理方面,幂律衰减系数可以用于预测和优化城市中的人流和交通流量,提高城市的运行效率。
总之,幂律衰减系数作为衡量幂律衰减程度的重要指标,具有广泛的应用前景和研究价值。
通过深入研究和应用幂律衰减系数,可以更好地理解和分析幂律现象,并在实际应用中发挥重要作用。
在本篇长文中,我们将详细介绍幂律衰减系数的概念、计算方法和应用案例,以期为读者提供全面的幂律衰减系数知识和实践指导。
1.2文章结构1.2 文章结构本文将分为三个主要部分来介绍Python的幂律衰减系数。
首先在引言部分,我们将概述本文的主题,并介绍文章的结构。
接着在正文部分,我们将从三个方面来探讨幂律衰减系数。
也能做精算actuar 包学习笔记一

用R也能做精算—actuar包学习笔记(一)李皞(中国人民大学统计学院风险管理与精算)本文是对R中精算学专用包actuar使用的一个简单教程。
actuar项目开始于2005年,在2006年2月首次提供公开下载,其目的就是将一些常用的精算功能引入R系统。
actuar是一个集成化的精算函数系统,虽然其他R包中的很多函数可以供精算师使用,但是为了达到某个目的而寻找某个包的某个函数是一个费时费力的过程,因此,actuar将精算建模中常用的函数汇集到一个包中,方便了人们的使用。
目前,该包提供的函数主要涉及风险理论,损失分布和信度理论,特别是为非寿险研究提供了很多方便的工具。
如题所示,本文是我在学习actuar包过程中的学习笔记,主要涉及这个包中一些函数的使用方法和细节,对一些方法的结论也有稍许探讨,因此能简略的地方简略,而讨论的地方可能讲的会比较详细。
文章主要是针对R语言的初学者,因此每种函数或数据的结构进行了尽可能直白的描述,以便于理解,如有描述不清或者错漏之处,敬请各位指正。
闲话少提,下面就正式开始咯!1 数据描述本节介绍描述数据的基本方法,数据类型主要分为分组数据和非分组数据。
对于非分组数据的描述方法大家会比较熟悉,无论是数量上,还是图形上的,比如均值、方差、直方图、柱形图还有核密度估计等。
因此下文的某些部分只介绍如何处理分组数据。
1.1 构造分组数据对象分组数据是精算研究中经常见到的数据类型,虽然原始的损失数据比分组数据包含有更多的信息,但是某些情况下受条件所限,只能获得某个损失所在的范围。
与此同时,将数据分组也是处理原始数据的基本方法,通过将数据分到不同的组中,我们可以看到各组中数据的相对频数,有助于对数据形成直观的印象(比如我们对连续变量绘制直方图);而且在生存函数的估计中,数据量经常成千上万,一种处理方法是选定合适的时间或损失额度间隔,对数据进行分组,然后再使用分组数据进行生存函数的估计,这样可以有效减小计算量。
直方图

直方图与经验分布函数
由 伯 努 利 大 数 定 理 知 Fn(x) 依 概 率 收 敛 于 F(x) .实际上, Fn(x) 还一致地收敛于 F(x) ,所谓 的格里文科定理指出了这一更深刻的结论,即
P{lim sup Fn ( x ) F ( x ) 0} 1
n x
实验步骤:
(1) 确定分组个数:因为 60 7.75,取分组个数为 8.数据的最小值为51,最大值为95,为分组方便 起见,考虑范围从 50 到 100 ,分为 8 个组,组距取 50 / 8 = 6.25 ,分点分别为: 50 , 56.25 , 62.5 , 68.75 , 75 , 81.25 , 87.5 , 93.75 , 100 。整理学生 成绩数据,在“组上限”栏中填入各组的上限值, 如图5-2左所示.
Fn(x)只在x = x(k),(k = 1,2,…,n)处有跃度为 1/n 的间断点,若有 l 个观测值相同,则 Fn(x) 在此观 测值处的跃度为 l/n .对于固定的 x , Fn(x) 即表示事
k F ( x ) 件{X x}在n次试验中出现的频率,即 n ,其 n
中k为落在(-,x)中xi的个数.
5.2.3 直方图
直方图与经验分布函数
如前所述,数理统计所研究的实际问题(总体) 的分布一般来说是未知的,需要通过样本来推 断.但如果对总体一无所知,那么,做出推断的 可信度一般也极为有限.在很多情况下,我们往 往可以通过具体的应用背景或以往的经验,再通 过观察样本观测值的分布情况,对总体的分布形 式有个大致了解.观察样本观测值的分布规律, 了解总体 X 的概率密度和分布函数,常用直方图 和经验分布函数.
或频率/组距,所得直方图分
别称为频数直方图、频率直
总体与样本直方图、条形图及经验分布函数

【质量控制问题】
某食盐厂用包装机包装的食盐,每袋重量500g, 通常在包装机正常的情况下,袋装食盐的重量X服 从正态分布,均值为500g,标准差为25g.为进行 生产质量控制,他们每天从当天的产品中随机抽 出30袋进行严格称重,以检验包装机工作是否正 常.某日,该厂随机抽取30袋盐的重量分别为:
475 500 485 454 504 439 492 501 463 461
464 494 512 451 434 511 513 490 521 514
449 467 499 484 508 478 479 499 529 480
从这些数据看,包装机的工作正常吗?
第6章 数理统计基础
6.1 总体和样本
6.1.1 总体与个体
总体或母体指我们研究对象的全体构成的集合, 个体指总体中包含的每个成员.
6.1.2 样本与抽样
设X1,X2,...,Xn是从总体X中抽出的简单随机样 本,由定义可知,X1,X2,...,Xn有下面两个特性:
(1) 代表性:X1,X2,...,Xn均与X同往分往布是,未知即或若不完
X F(x),则对每一个Xi都有 Xi F(xi),i = 1,2,…,n
全知道的,是需要 通过样本来进行研 究和推断的.
(2) 独立性:X1,X2,...,Xn相互独立.
数理统计基本概念

1 1 n1 n2
~ t ( n1 n2 2)
定理 5 (两总体样本方差比的分布)
且X与Y独立, 设X ~ N ( 1, ), Y ~ N ( 2 , ), X1, X2,…, X n1是取自X的样本, Y1,Y2,…, Yn2 是
样本是联系二者的桥梁 总体分布决定了样本取值的概率规律, 也就是样本取到样本值的规律,因而可以由 样本值去推断总体.
二、统计量和抽样分布 1. 统计量 由样本值去推断总体情况,需要对样本 值进行“加工”,这就要构造一些样本的 函数,它把样本中所含的(某一方面)的 信息集中起来.
这种不含任何未知参数的样本的函数 称为统计量. 它是完全由样本决定的量.
2. 独立性: X1,X2,…,Xn是相互独立的随机 变量.
由简单随机抽样得到的样本称为简单 随机样本,它可以用与总体独立同分布的 n个相互独立的随机变量X1,X2,…,Xn表示.
若总体的分布函数为F(x),则其简单随机 样本的联合分布函数为 F(x1) F(x2) … F(xn) 简单随机样本是应用中最常见的情 形,今后,当说到“X1,X2,…,Xn是取自某 总体的样本”时,若不特别说明,就指简 单随机样本.
数理统计的基本概 念
一、总体和样本
1.总体
一个统计问题总有它明确的研究对象.
研究对象的全体称为总体(母体), 总体中每个成员称为个体.
总体
…
研究某批灯泡的质量
然而在统计研究中,人们关心总体仅仅 是关心其每个个体的一项(或几项)数量指标 和该数量指标在总体中的分布情况. 这时, 每个个体具有的数量指标的全体就是总体.
统计中,总体这个概念 的要旨是:总体就是一个 概率分布.
D6-2_分布函数与概率密度函数的近似解-PPT文档资料

0 ,
Fn x
k , n
x x
* 1
* * x x x k 1 , 2 , , n 1 k k 1
1 ,
x x *n
称 F n x 是总体 X 的经验分布函数 其图如6-1
y
1
k n 1 n
x
* 1
x
* 2
o
x
* k
x
* k 1
x
* n
x
图 6-1
a
2
图62
a l1 a
l
x
注: 设总体的密度函数为 f x 则:总体 X 落在第k组
ak1 ,ak 的概率为
ak a k 1
f ( x )dx
由Bernoulli大数定理
当n很大时,样本观察值
落在该区间的频率趋近于此概率,即在 a k 1,a k 上 矩形的面积接近于 f ( x ) 在此区间上曲边梯形的面积 当n无限增大时,分组组距越来越小,直方图就越接近 总体 X 的密度函数 f x 的图象.
由图6-1容易看出
1) F n x 是单调非减跳跃函数(阶梯函数) 2) F n x 在点 x x 处有间断, 在每个间断点的跃度
* k
1 为 , n
, , k12
,n
x
0 , 1 limF(x) 3) 0F(x) n n x
limF(x) 1 n
2) 数频数 观测值落在各组的频数分别为
m,m, ,m 1 2 l
频率为
m1 m2 , , n n ml , n
3)作图 以各组为底边,以相应组的频率除以组距为高, 建立个 l 小矩形,即得总体的直方图 如图6-2 直方图中每一矩形的面积等于相应组的频率
经验分布函数与直方图

为总体 X 的经验分布函数。
例 某厂生产听装饮料,现从生产线上随机抽取5听饮 料,称其净重量(单位:g) 如下,求经验分布函数。
351,347,355 ,344,351
0, 0.2, F5 ( x) 0.4, 0.8, 1,
若 x 344 若344 x 347 若347 x 351 若351 x 355
Step4 统计样本值落入各区间的频数, 并求出频率。
三、样本数据的图形显示
1. 频率直方图(frequency histogram)
以“变量”为横轴, 以“频率”为纵轴画柱形图, 即得 频率直方图.
0.5 0.4 0.3 0.2 0.1
0 2700
体重频率)
设 x1,x2, ,xn是 总 体 分 布 函 数 为 F(x)的 样 本 , Fn(x)为 其 经 验 分 布 函 数 ,当 n时 ,有
P{lni m sux p|Fn(x)F(x)|0}1.
注:定理表明:只要 n 充分大, 经验分布数 Fn(x) 是总体分布函数 F(x) 的良好近似。这是用样本来 推断总体的理论依据。
3000
3300
3600
3900
经验分布函数与直方图经验分布函数matlab经验分布函数经验累积分布函数经验分布函数图概率密度与分布函数分布函数累积分布函数概率分布函数高斯分布函数
第二节 经验分布函数与直方图
1、经验分布函数 2、直方图
1 经验分布函数
2. 经验分布函数
问题引入的背景:设 X1 , X2,……, Xn 是取自某总体 X 的样本,X 的分布完全未知, 如何利用 X1 , X2,……, Xn 的信息,来推断总体 X 的 分布函数 F(x) 的形式!
概率论和数理统计数理统计的基本知识

3/11/2021
〖定义〗 设总体X的 n个独立观测值为x1,x2,…,xn, 将它们从小到大
排序后为x1*,x2 *,…,xn *, 令
0,
Fn
(
x)
k n
,
1,
x x1*
x
* k
x
x* k 1
xn* x
称Fn(x)为总体X 的经验分布函数. (也称为样本分布函数)
① 0 Fn( x) 1 ② 单调不减; ③ 处处右连续.
n
P( X xi )
i 1
8
3/11/2021
例1 已知总体X ~()分布,写出样本 (X1, X2,…, Xn)的分布律。
析:
X的分布律 P{ X k} k e ,
k!
可以写成 P{ X x} x e ,
x!
k 0,1,2, x 0,1,2,
样本 (X1, X2,…, Xn)的分布律
5
3/11/2021
❖3、样本
➢从总体X中随机抽取n个个体X1,X2,Xn所组成的一个个体 组(X1,X2,,Xn),称为总体X的一个样本,个体的数目n
称为样本容量。
➢ 通过试验对样本(X1,X2,,Xn)进行观测,得到的n个确定的 实验数据(x1,x2,,xn),称为样本(X1,X2,,Xn)的一个观察值,
(X1 ,X2,…Xn1), (Y1 ,Y2,…Yn2)分别为取自总体X,Y的样本,则
3/11/2021
1> 当12= 22时
(X Y ) ( 1 2)
S
11 n1 n2
~
t(n1 n2 2)
其中S 2
(n1
1)S12 (n2 1)S22 n1 n2 2
《概率论与数理统计B》实验教学指导书分析
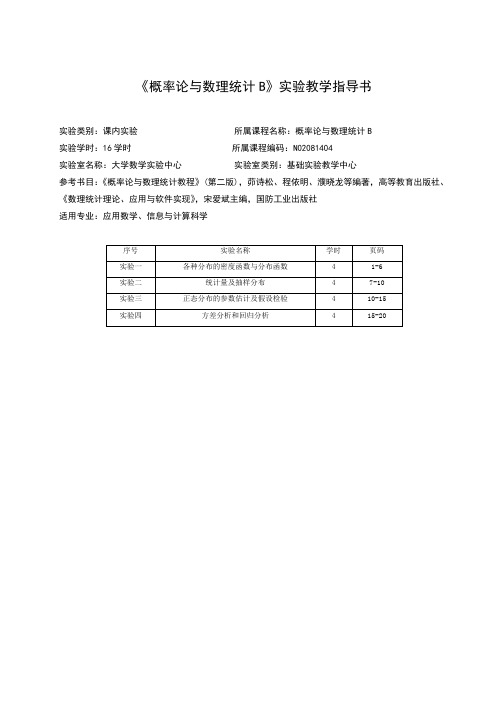
《概率论与数理统计B》实验教学指导书实验类别:课内实验所属课程名称:概率论与数理统计B实验学时:16学时所属课程编码:N02081404实验室名称:大学数学实验中心实验室类别:基础实验教学中心参考书目:《概率论与数理统计教程》(第二版),茆诗松、程依明、濮晓龙等编著,高等教育出版社、《数理统计理论、应用与软件实现》,宋爱斌主编,国防工业出版社适用专业:应用数学、信息与计算科学实验一 各种分布的密度函数与分布函数一、实验目的使学生了解MATLAB 系统,熟练掌握MATLAB 中基本语句以及分布律,概率密度函数和分布函数的相关命令并运用这些命令进行简单的相关概率运算。
二、实验内容及要求1、会利用 MATLAB 软件计算离散型随机变量的概率、连续型随机变量概率密度值, 以及产生离散型随机变量的概率分布(即分布律);2、会利用 MATLAB 软件计算分布函数值,即:计算形如事件{}X x 的概率;3、给出概率p 和分布函数,会求下侧p 分位数;4、会利用 MATLAB 软件画出各种常见分布图形。
三、实验的重点和难点实验的重点和难点是要求学生掌握基本的MATLAB 软件的编程语言,掌握基本的调用命令。
四、实验准备实验室电脑需要安装MATLAB 软件。
五、实验步骤1、通过MATLAB 函数计算概率分布律及密度函数值 函数:pdf 或者namepdf格式:Y=pdf(‘name',K,A,B)或者:namepdf (K,A,B)说明:(1)上述函数表示返回在X=K 处、参数为A 、B 、C 的概率值或密度值,对于不同的分布,参数个数是不同;name 为分布函数名,其取值如表1。
(2)第一个函数名加' ',第二个无需加。
表1-1 常见分布名称表注意以下几个分布的分布律和密度定义: ①几何分布:(),k P X k pq ==0,1,k =L ,(),qE X p=2()q Var X p =;②正态分布:第二个参数是σ;③指数分布:1,0()0,0xe x p x x θθ-⎧>⎪=⎨⎪≤⎩,参数是θ;例1.事件A 在每次试验中发生的概率是0.3,计算在10次试验中A 恰好发生6次的概率。
样本分布函数 直方图

各子区间的长度可以相等,也可以不等.若使各子区间的长度相等, 则有
ti
ba l
(i
1,2,,l)
子区间的个数 l 一般取为 8 至 15 个,太多则由于频率的随机摆
动而使分布显得杂
乱,太少则难于显示分布的特征.此外,为了方便起见,分点 ti 应
(3)把所有样本观测值逐个分到各子区间内,并计算样
最小值
x
* n
,分别记作
x1* min( x1, x2 ,, xn )
xn* max( x1, x2 ,, xn )
(2)适当选取略小于
x
* 1
的数
a
与略大于
x
* n
的数 b
,并用分点
a = t0 t1 t2 tl1 tl b
把区间 (a, b) 分为 l 个子区间
( a, t1 ) ,( t1 , t2 ) ,…,( tl1, b) 第 i 个子区间的长度为
样本分布函数 直方图
1.1样本分布函数
定义 5.3 设 x1, x2, , xn 是总体 X ~ F(x) 的一个容量 为 n 的样本值,先将 x1, x2, , xn 按自小到大的次序排列,并 重新编号.设为
则函数
x(1) x(2) x(n) ,
0,
Fn
(
x)
k n
,
1,
x x(1) , x(k) x x(k 1) , k 1, 2, x x(n)
本观测值落在各子区间内
的频数 ni 及率
fi
ni n
,( i
1,2,,l) .
(4)在 Ox 轴上截取各子区间,并以各子区间为底,以
中国大陆地区年最大平均风速的概率密度函数

文章编号 : 1004 24574 ( 2006 ) 05 20076 207中国大陆地区年最大平均风速的概率密度函数李 杰 ,陈建兵 ,张琳琳 ,韦 笠(同济大学 土木工程学院 ,上海 200092 )摘要 :根据中国大陆地区 1951 - 2002年的实测风速数据资料 ,采用密度演化方法进行了各站点年最 大平均风速的概率密度函数估计 ,给出了大陆地区年最大平均风速均值和标准差的等值线分布图 。
与常用的基于拟合优度检验的概率密度函数估计和统计量分析不同 ,所提方法不需要进行先验分布 ,可以通过直接计算给出与基本数据经验分布函数符合得较好的概率密度函数与概率分 布函数 。
对比研究表明 ,该方法给出的统计结果是可信的 ,具有工程实用参考价值 。
中图分类号 : T U312 + . 1 文献标识码 : AProba b il i ty den s i ty fun c t i on of yea r l y m a x i m um a vera g ew in d speed in m a in lan d of C h inaL I J i e, CH E N J i an 2b i ng, ZHAN G L i n 2li n, W E I L i( Schoo l of C ivil Enginee ring, Tongji U n i ve rsity, Shangha i 200092 , Ch ina )A b s tra c t :B a s ed on su r veyi ng da t a ob t a i ned i n the m a i n l and of Ch i na fr om 1951 th r ough 2002 , the p r obab i lity den 2sity func ti o n of the yea rl y m axi m um ave rage va l ue of the w i nd sp eed is e sti m a ted th r ough the p r obab ility den s i t y evo 2l u ti o n m e thod. I n con tra st t o wha t is done i n the w i de l y u sed te st 2of 2goodne ss 2of 2fit ba sed sta t isti ca l m e thod s, a p ri 2o ri p robab ility den sity func ti o n is no t needed i n the p re sen ted m e thod. The p r obab ility den sity func ti o n tha t i s d i 2rec tl y ob ta i ned by the p r obab ility den sity evo l u ti o n m e thod acco rd s we ll w ith the emp iri ca l d istri bu ti o n func ti o n. T he i nve sti ga ti o n s i nd i ca te tha t the p r obab ility den sity func ti o n s of the ba si c w i nd sp eed and the yea rl y m axi m u m w i n dsp e ed d i stri bu t i o n a r e re li ab l e and va l uab l e i n engi nee ri ng p rac t ice .Key word s : yea rl y m a xi m u m ave r age w i nd sp e ed; e mp iri ca l d i stri bu t i o n func t i on; p r obab i lity den s ity func t i o n;p r obab i lity den s ity evo l u t i o n m e t hod基本风速 (亦称标准风速 )是风的一个重要统计特征 ,对确定结构作用风力大小具有决定性的意义 。