模式识别报告 bayes分类
模式识别第二章

p(x)~N(μ,Σ)
第二章 贝叶斯决策理论
37
等概率密度轨迹为超椭球面
正态分布 Bayes决策
p ( x ) c ( x μ ) T 1 ( x μ ) 2
i
第二章 贝叶斯决策理论
9
分类器设计
判别 函数
分类器是某种由硬件或软件组成的“机器”:
➢计算c个判别函数gi(x)
➢最大值选择
x1
g1
x2
g2
ARGMAX
a(x)
.
.
.
.
.
.
xn
gc
多类识别问题的Bayes最大后验概率决策:gi(x) = P (ωi |x)
第二章 贝叶斯决策理论
10
2.3 Bayes最小错误率决策
根据已有知识和经验,两类的先验概率为:
➢正常(ω1): P(ω1)=0.9 ➢异常(ω2): P(ω2)=0.1 ➢对某一样本观察值x,通过计算或查表得到:
p(x|ω1)=0.2, p(x|ω2)=0.4
如何对细胞x进行分类?
第二章 贝叶斯决策理论
15
Bayes最小错误率决策例解(2)
最小错误 率决策
利用贝叶斯公式计算两类的后验概率:
P ( 1|x ) 2 P P ( ( 1)jp )( p x (x | | 1 )j)0 .9 0 0 ..9 2 0 0 ..2 1 0 .40 .8 1 8
j 1
P ( 2|x ) 2 P P ( ( 2)jp )( p x (x | | 2)j)0 .2 0 0 ..9 4 0 0 ..1 4 0 .1 0 .1 8 2
模式识别(3-1)

§3.2 最大似然估计
最大似然估计量: -使似然函数达到最大值的参数向量。 -最符合已有的观测样本集的那一个参数向量。 ∵学习样本从总体样本集中独立抽取的
N ) p( X | ) p( X k | i ) k 1 N个学习样本出现概率的乘积
i
i
∴
p( X | i . i
i
§3.2 Bayes学习
假定: ①待估参数θ是随机的未知量 ②按类别把样本分成M类X1,X2,X3,… XM 其中第i类的样本共N个 Xi = {X1,X2,… XN} 并且是从总体中独立抽取的 ③ 类条件概率密度具有某种确定的函数形式,但其 参数向量未知。 ④ Xi 中的样本不包含待估计参数θj(i≠j)的信息,不 同类别的参数在函数上是独立的,所以可以对每一 类样本独立进行处理。
有时上式是多解的, 上图有5个解,只有一个解最大即 (对所有的可能解进行检查或计算二阶导数)
§3.2 最大似然估计
例:假设随机变量x服从均匀分布,但参数1, 2未知, 1 1 x 2 p ( x | ) 2 1 , 0 其他 求1, 2的最大似然估计量。 解:设从总体中独立抽取N个样本x1 , x2 , , xN , 则其似然函数为: 1 p ( x1 , x2 , , xN | 1, 2 ) ( 2 1 ) N l ( ) p ( X | ) 0
§3.2 Bayes学习
p ~ N 0 , 0
2
其中 0和 0 是已知的
2
已知的信息还包括一组抽取出来的样本X i x1 , x2 ,, xN ,从而 可以得到关于 的后验概率密度:
模式识别上机实验报告

实验一、二维随机数的产生1、实验目的(1) 学习采用Matlab 程序产生正态分布的二维随机数 (2) 掌握估计类均值向量和协方差矩阵的方法(3) 掌握类间离散度矩阵、类内离散度矩阵的计算方法(4) 熟悉matlab 中运用mvnrnd 函数产生二维随机数等matlab 语言2、实验原理多元正态分布概率密度函数:11()()2/21/21()(2)||T X X d p X eμμπ---∑-=∑其中:μ是d 维均值向量:Td E X μμμμ=={}[,,...,]12Σ是d ×d 维协方差矩阵:TE X X μμ∑=--[()()](1)估计类均值向量和协方差矩阵的估计 各类均值向量1ii X im X N ω∈=∑ 各类协方差矩阵1()()iTi iiX iX X N ωμμ∈∑=--∑(2)类间离散度矩阵、类内离散度矩阵的计算类内离散度矩阵:()()iTi iiX S X m X m ω∈=--∑, i=1,2总的类内离散度矩阵:12W S S S =+类间离散度矩阵:1212()()Tb S m m m m =--3、实验内容及要求产生两类均值向量、协方差矩阵如下的样本数据,每类样本各50个。
1[2,2]μ=--,11001⎡⎤∑=⎢⎥⎣⎦,2[2,2]μ=,21004⎡⎤∑=⎢⎥⎣⎦ (1)画出样本的分布图;(2) 编写程序,估计类均值向量和协方差矩阵;(3) 编写程序,计算类间离散度矩阵、类内离散度矩阵; (4)每类样本数增加到500个,重复(1)-(3)4、实验结果(1)、样本的分布图(2)、类均值向量、类协方差矩阵根据matlab 程序得出的类均值向量为:N=50 : m1=[-1.7160 -2.0374] m2=[2.1485 1.7678] N=500: m1=[-2.0379 -2.0352] m2=[2.0428 2.1270] 根据matlab 程序得出的类协方差矩阵为:N=50: ]0628.11354.01354.06428.1[1=∑ ∑--2]5687.40624.00624.08800.0[N=500:∑--1]0344.10162.00162.09187.0[∑2]9038.30211.00211.09939.0[(3)、类间离散度矩阵、类内离散度矩阵根据matlab 程序得出的类间离散度矩阵为:N=50: ]4828.147068.147068.149343.14[=bS N=500: ]3233.179843.169843.166519.16[b =S根据matlab 程序得出的类内离散度矩阵为:N=50:]0703.533088.73088.71052.78[1=S ]7397.2253966.13966.18975.42[2--=S ]8100.2789123.59123.50026.121[=W SN=500: ]5964.5167490.87490.86203.458[1--=S ]8.19438420.78420.70178.496[2=S ]4.24609071.09071.06381.954[--=W S5、结论由mvnrnd 函数产生的结果是一个N*D 的一个矩阵,在本实验中D 是2,N 是50和500.根据实验数据可以看出,当样本容量变多的时候,两个变量的总体误差变小,观测变量各个取值之间的差异程度减小。
[数学]模式识别方法总结
![[数学]模式识别方法总结](https://img.taocdn.com/s3/m/9bfe35a6a0116c175f0e484a.png)
假定有m个类别ω1, ω2, …, ωm的模式识别问题,
每类有Ni(i=1, 2, …, m)个样本, 规定类ωi的判别函数
为
gi (x) min x xik
i
k 1, 2,
, Ni
其中, xki表示第i类的第k个元素。 判决准则: gi (x) ,则x∈ω 若 g j (x) i min j 1,2, , m
定义Fisher线性判决函数为
( 1 2 )2 J F (w ) S1 S2
分子反映了映射后两类中心的距离平方,
该值越大, 类间可
分性越好;
分母反映了两类的类内离散度,
从总体上来讲,
其值越小越好;
JF(w)的值越大越好。 使JF(w)达到最大值的w即为最
在这种可分性评价标准下,
如果P(ω1|x)<P(ω2|x), 则判决x属于ω2;
如果P(ω1|x)=P(ω2|x), 则判决x属于ω1或属于ω2。
这种决策称为最大后验概率判决准则, 也称为贝叶斯 (Bayes)判决准则。 假设已知P(ωi)和p(x|ωi)(i=1, 2, …, m), 最大后验概率判 决准则就是把样本x归入后验概率最大的类别中, 也就是,
0
Sigmoid (a) 取值在(0, 1)内; (b) 取值在(-1, 1)内
神经网络结构 神经网络是由大量的人工神经元广泛互连而成 的网络。 根据网络的拓扑结构不同, 神经网络可分
R( j | x) ( j , i ) P(i | x)
i 1 m
最小风险贝叶斯判决准则: 如果
R( k | x) min R( j | x)
j 1, 2 ,, m
《模式识别》实验报告-贝叶斯分类

《模式识别》实验报告---最小错误率贝叶斯决策分类一、实验原理对于具有多个特征参数的样本(如本实验的iris 数据样本有4d =个参数),其正态分布的概率密度函数可定义为112211()exp ()()2(2)T d p π-⎧⎫=--∑-⎨⎬⎩⎭∑x x μx μ 式中,12,,,d x x x ⎡⎤⎣⎦=x 是d 维行向量,12,,,d μμμ⎡⎤⎣⎦=μ是d 维行向量,∑是d d ⨯维协方差矩阵,1-∑是∑的逆矩阵,∑是∑的行列式。
本实验我们采用最小错误率的贝叶斯决策,使用如下的函数作为判别函数()(|)(),1,2,3i i i g p P i ωω==x x (3个类别)其中()i P ω为类别i ω发生的先验概率,(|)i p ωx 为类别i ω的类条件概率密度函数。
由其判决规则,如果使()()i j g g >x x 对一切j i ≠成立,则将x 归为i ω类。
我们根据假设:类别i ω,i=1,2,……,N 的类条件概率密度函数(|)i p ωx ,i=1,2,……,N 服从正态分布,即有(|)i p ωx ~(,)i i N ∑μ,那么上式就可以写为1122()1()exp ()(),1,2,32(2)T i i dP g i ωπ-⎧⎫=-∑=⎨⎬⎩⎭∑x x -μx -μ对上式右端取对数,可得111()()()ln ()ln ln(2)222T i i i i dg P ωπ-=-∑+-∑-i i x x -μx -μ上式中的第二项与样本所属类别无关,将其从判别函数中消去,不会改变分类结果。
则判别函数()i g x 可简化为以下形式111()()()ln ()ln 22T i i i i g P ω-=-∑+-∑i i x x -μx -μ二、实验步骤(1)从Iris.txt 文件中读取估计参数用的样本,每一类样本抽出前40个,分别求其均值,公式如下11,2,3ii iii N ωωω∈==∑x μxclear% 原始数据导入iris = load('C:\MATLAB7\work\模式识别\iris.txt'); N=40;%每组取N=40个样本%求第一类样本均值 for i = 1:N for j = 1:4w1(i,j) = iris(i,j+1); end endsumx1 = sum(w1,1); for i=1:4meanx1(1,i)=sumx1(1,i)/N; end%求第二类样本均值 for i = 1:N for j = 1:4 w2(i,j) = iris(i+50,j+1);end endsumx2 = sum(w2,1); for i=1:4meanx2(1,i)=sumx2(1,i)/N; end%求第三类样本均值 for i = 1:N for j = 1:4w3(i,j) = iris(i+100,j+1); end endsumx3 = sum(w3,1); for i=1:4meanx3(1,i)=sumx3(1,i)/N; end(2)求每一类样本的协方差矩阵、逆矩阵1i -∑以及协方差矩阵的行列式i ∑, 协方差矩阵计算公式如下11()(),1,2,3,41i ii N i jklj j lk k l i x x j k N ωωσμμ==--=-∑其中lj x 代表i ω类的第l 个样本,第j 个特征值;ij ωμ代表i ω类的i N 个样品第j 个特征的平均值lk x 代表i ω类的第l 个样品,第k 个特征值;iw k μ代表i ω类的i N 个样品第k 个特征的平均值。
Bayes分类器算法

⇒ x ∈ωi
2、具体步骤如下 A).算出各类别特征值的均值 B).求出特征值的协方差矩阵 C).将第二步所得矩阵代入判别函数 g1(x)、g2(x) D).将待测试样本集数据依次代入 g1(x)- g2(x),若 g1(x)- g2(x)>0,则判断其为第一类,反
之为第二类。 3、流程图
确定特征及先验概率
体重: clear all; load FEMALE.txt; load MALE.txt; fid=fopen('test2.txt','r'); test1=fscanf(fid,'%f %f %c',[3,inf]); test=test1';
fclose(fid); Fmean = mean(FEMALE); Mmean = mean(MALE); Fvar = std(FEMALE); Mvar = std(MALE); preM = 0.9; preF = 0.1; error=0; Nerror=0; figure; for i=1:300
Nerror = Nerror +1; end; else plot(test(i,1),test(i,2),'k*'); if (test(i,3)=='F')
Nerror = Nerror +1; end end hold on; end; title('身高体重不相关最小风险的 Bayes 决策'); ylabel('身高(cm)'),zlabel('体重(kg)'); error = Nerror/300*100; sprintf('%s %d %s %0.2f%s','分类错误个数:',Nerror,'分类错误率为:',error,'%')
贝叶斯决策理论

g(x)
判别计算
阈值单元
决策
贝叶斯决策理论
2.3 正态分布时的统计决策
重点分析正态分布情况下统计决策的原因是: ①正态分布在物理上是合理的、广泛的 ②正态分布 数学表达上简捷,如一维情况下只
有均值和方差两个参数,因而易于分析
贝叶斯决策理论
贝叶斯决策理论
目标:所采取的一系列决策行动应该使期 望风险达到最小
手段:如果在采取每一个决策时,都使其 条件风险最小,则对所有的 x 作决策时, 其期望风险也必然达到最小
决策:最小风险Bayes决策
贝叶斯决策理论
最小风险Bayes决策规则:
其中
采取决策
贝叶斯决策理论
最小风险Bayes决策的步骤
2.2.6 分类器设计
要点: • 判别函数 • 决策面(分类面) • 分类器设计
贝叶斯决策理论
决策面(分类面)
对于 c 类分类问题,按照决策规则可以把 d 维特 征空间分成 c 个决策域,我们将划分决策域的 边界面称为决策面(分类面)
贝叶斯决策理论
判别函数
用于表达决策规则的某些函数,则称为判别 函数
E{ xi xj } = E{ xi } E{ xj }
贝叶斯决策理论
相互独立
成立
成立?? 多元正态分布的任
不相关
意两个分量成立!
贝叶斯决策理论
说明:正态分布中不相关意味着协方差矩阵
是对角矩阵
并且有
贝叶斯决策理论
④边缘分布(对变量进行积分)和条件分布(固定变 量)的正态性
⑤线性变换的正态性
y=Ax A为线性变换的非奇异矩阵。若 x 为正态分布,
第3章 Bayes决策理论

第3章 Bayes决策理论
“概率论”有关概念复习
Bayes公式:设实验E的样本空间为S,A为E的事件,
第3章 Bayes决策理论
B1,B2,…,Bn为S的一个划分,且P(A)>0,P(Bi)>0,
(i=1,2,…,n),则:
P( Bi | A) P( A | Bi ) P( Bi )
n
P( A | B
返回本章首页
第3章 Bayes决策理论
平均错误概率
P(e)
P (e x ) p ( x ) d x
从式可知,如果对每次观察到的特征值 x , P(e x) 是 尽可能小的话,则上式的积分必定是尽可能小的。这就 证实了最小错误率的Bayes决策法则。下面从理论上给 予证明。以两类模式为例。
解法1:
利用Bayes公式
第3章 Bayes决策理论
p ( x 10 | 1 ) P(1 ) P(1 | x 10) p ( x 10) p ( x 10 | 1 ) P(1 ) p ( x 10 | 1 ) P(1 ) p( x 10 | 2 ) P(2 ) 0.05 1/ 3 0.048 0.05 1/ 3 0.50 2 / 3
解法2:
写成似然比形式
第3章 Bayes决策理论
p ( x 10 | 1 ) 0.05 l12 (x 10) 0.1 p ( x 10 | 2 ) 0.50 P (2 ) 2 / 3 判决阀值12 2 P (1 ) 1/ 3 l12 (x 10) 12 , x 2 , 即是鲑鱼。
若 P(i x) P( j x) , j i ,则判
若 P(i x) 若 若
基于贝叶斯决策理论的分类器

dx是d维特征空间的体积元,积分在整个特征空间。 • 期望风险R反映对整个特征空间上所有x的取值都采 取相应的决策a(x)所带来的平均风险;而条件风险 R(ai|x)只反映观察到某一x的条件下采取决策ai 所 带来的风险。 • 如果采取每个决策行动ai使条件风险R(ai|x)最小, 则对所有的x作出决策时,其期望风险R也必然最 小。这就是最小风险Bayes决策。
如果 (l21 l11 ) P (w1 | x ) (l12 l22 ) P (w2 | x ), 则决策w1;否则w2 p( x w1 ) l12 l22 P (w2 ) 如果 l ( x ) , p( x w2 ) l21 l11 P (w1 ) 则决策w1;否则w2
§2 Bayes 决策理论 1. Bayes公式,也称Bayes法则
已知:先验概率 (wi ), 类条件概率密度函数 p( x | wi ) P p( x | wi ) P (wi ) 则 后验概率为 P (wi | x ) p( x ) 其中,全概率密度 p( x ) p( x | wi )P (wi )
求:
exp(( x 1) 2 )
①若先验概率 P(w1) = P(w2) = 1/2,计算最小错误 率情况下的阈值 x0。 ②如果损失矩阵为
0 0.5 l 计算最小风险情况下的阈值 x0。 1 0
例2:条件同例1,利用决策表, 按最小风险Bayes决策分类。 已知:P(w1 ) 0.9, P(w2 ) 0.1 p( x | w1 ) 0.2, p( x | w2 ) 0.4 l11 0 l12 6 l21 1 l22 0 例 1 得到后验概率: (w1 | x) 0.818, P(w2 | x) 0.182 P
模式识别第五讲-二次、线性分类

g k (x) x mk K k x mk ln K k 2ln Prωk
T 1
x mk
2
• 后两项对所有类是共同的,可以省略。分母 中的 2也可以去掉,因而有等价的判别函数:
2
2nln 2ln Prωk
g k x x mk
0 m1 0
0 m2 2
求 h x T 0 的分类边界,并画出其曲线。
©北京工业大学计算机学院® 10
• 解: T 1 T 1 hx x m1 K1 x m1 x m2 K 2 x m2 ln
• 任何具有(※※)式的分类器都叫作二次分 类器。只有A、b、c是由高斯密度函数确定 时,才叫高斯分类器。
©北京工业大学计算机学院® 9
• 例1:两维时的二次分类器的决策边界 假定两类模式都是高斯分布的,参数为:
1 0 K1 1 0 4 1 0 K2 4 0 1
• 上式中,由于第一项和第四项对所有的类都 是相同的,所以等价的一组判别函数为:
g k x 2mk k
T 1
x mk k 1 mk 2lnPrωk ,k 1, 2, ,N c
T
(※※)
• 上式是 x 的线性函数。
©北京工业大学计算机学院® 22
• 例2:最小距离分类器。假定各类的先验概 2 K I,k 1, 2, ,N c。 率相等,而且各类 k 即x的各个分量不相关,且各类等方差。 解:这时的判别函数化为:
©北京工业大学计算机学院® 1
• 即使我们得到了密度函数,有时用似然比检 验的方法也很难计算分界面。
模式识别实验指导书2014版

cpmean(i,:)=mean(meas(strmatch(char(sta(i,1)),species,'exact'),:));
4 5
⎟⎟⎠⎞,
⎜⎜⎝⎛
− −
5 6
⎟⎟⎠⎞, ⎜⎜⎝⎛
− −
6 5
⎟⎟⎠⎞,
⎜⎜⎝⎛
5 5
⎟⎟⎠⎞,
⎜⎜⎝⎛
5 4
⎟⎟⎠⎞,
⎜⎜⎝⎛
4 5
⎟⎟⎠⎞,
⎜⎜⎝⎛
5 6
⎟⎟⎠⎞,
⎜⎜⎝⎛
6 5
⎟⎟⎠⎞⎭⎬⎫
,计算样本协方
差矩阵,求解数据第一主成分,并重建原始数据。
(2)使用 Matlab 中进行主成分分析的相关函数,实现上述要求。
有 c 个不同的水平,表示 c 个不同的类。
表 1-1 fit 方法支持的参数名与参数值列表
参数名
参数值
说明
'normal'
正态分布(默认)
核密度估计(通过‘KSWidth’参数设置核密度估计的窗宽
'kernel'
(默认情况下自动选取窗宽;通过‘KSSupport’参数设置
‘Distribution’ 'mvmn'
信息与电气工程学院专业实验中心 二〇一四年八月
《模式识别》实验一 贝叶斯分类器设计
一、实验意义及目的
掌握贝叶斯判别原理,能够利用 Matlab 编制程序实现贝叶斯分类器设计,熟悉基于 Matlab 的 算法处理函数,并能够利用算法解决简单问题。
模式识别大作业-许萌-1306020
第一题对数据进行聚类分析1.题目要求用FAMALE.TXT、MALE.TXT和/或test2.txt的数据作为本次实验使用的样本集,利用C 均值聚类法和层次聚类法对样本集进行聚类分析,对结果进行分析,从而加深对所学内容的理解和感性认识。
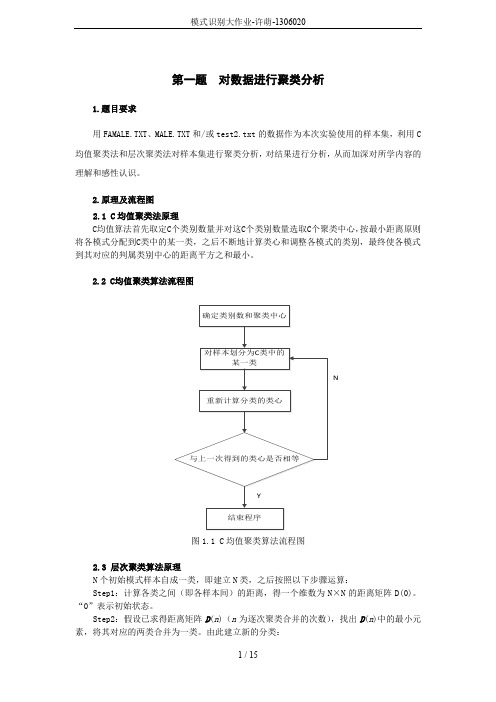
2.原理及流程图2.1 C均值聚类法原理C均值算法首先取定C个类别数量并对这C个类别数量选取C个聚类中心,按最小距离原则将各模式分配到C类中的某一类,之后不断地计算类心和调整各模式的类别,最终使各模式到其对应的判属类别中心的距离平方之和最小。
2.2 C均值聚类算法流程图N图1.1 C均值聚类算法流程图2.3 层次聚类算法原理N个初始模式样本自成一类,即建立N类,之后按照以下步骤运算:Step1:计算各类之间(即各样本间)的距离,得一个维数为N×N的距离矩阵D(0)。
“0”表示初始状态。
Step2:假设已求得距离矩阵D(n)(n为逐次聚类合并的次数),找出D(n)中的最小元素,将其对应的两类合并为一类。
由此建立新的分类:Step3:计算合并后所得到的新类别之间的距离,得D (n +1)。
Step4:跳至第2步,重复计算及合并。
直到满足下列条件时即可停止计算:①取距离阈值T ,当D (n )的最小分量超过给定值 T 时,算法停止。
所得即为聚类结果。
②或不设阈值T ,一直到将全部样本聚成一类为止,输出聚类的分级树。
2.4层次聚类算法流程图N图1.2层次聚类算法流程图3 验结果分析对数据文件FAMALE.TXT 、MALE.TXT 进行C 均值聚类的聚类结果如下图所示:图1.3 C 均值聚类结果的二维平面显示将两种样本即进行聚类后的样本中心进行比较,如下表:从下表可以纵向比较可以看出,C 越大,即聚类数目越多,聚类之间差别越小,他们的聚类中心也越接近。
横向比较用FEMALE,MALE 中数据作为样本和用FEMALE,MALE ,test2中),1(),1(21++n G n G数据作为样本时,由于引入了新的样本,可以发现后者的聚类中心比前者都稍大。
iris数据集的贝叶斯分类

iris数据集的贝叶斯分类IRIS 数据集的Bayes 分类实验⼀、实验原理 1) 概述模式识别中的分类问题是根据对象特征的观察值将对象分到某个类别中去。
统计决策理论是处理模式分类问题的基本理论之⼀,它对模式分析和分类器的设计有着实际的指导意义。
贝叶斯(Bayes )决策理论⽅法是统计模式识别的⼀个基本⽅法,⽤这个⽅法进⾏分类时需要具备以下条件:各类别总体的分布情况是已知的。
要决策分类的类别数是⼀定的。
其基本思想是:以Bayes 公式为基础,利⽤测量到的对象特征配合必要的先验信息,求出各种可能决策情况(分类情况)的后验概率,选取后验概率最⼤的,或者决策风险最⼩的决策⽅式(分类⽅式)作为决策(分类)的结果。
也就是说选取最有可能使得对象具有现在所测得特性的那种假设,作为判别的结果。
常⽤的Bayes 判别决策准则有最⼤后验概率准则(MAP ),极⼤似然⽐准则(ML ),最⼩风险Bayes 准则,Neyman-Pearson 准则(N-P )等。
2) 分类器的设计对于⼀个⼀般的c 类分类问题,其分类空间:{}c w w w ,,,21 =Ω表特性的向量为:()T d x x x x ,,,21 =其判别函数有以下⼏种等价形式:a) ()()i j i w w i j c j w w x w P x w P ∈→≠=∈→>,且,,,2,11, b) ()()()()i j j i w w i j c j w P w x p w P w x p ∈→≠=>,且,,,2,1ic) ()()()()()i i j ji w w i j c j w P w P w x p w x p x l ∈→≠=>=,且,,,2,1d)()()()()ij j i i w w i j c j w P w x np w P w x p ∈→≠=+>+,且,,,2,1ln ln ln3) IRIS 数据分类实验的设计IRIS 数据集:⼀共具有三组数据,每⼀组都是⼀个单独的类别,每组有50个数据,每个数据都是⼀个四维向量。
贝叶斯分类原理

贝叶斯分类原理贝叶斯分类原理是一种基于贝叶斯定理的分类方法。
在机器学习中,分类是指将一个实例分配到一组预定义的类别中的任务。
在这种情况下,“贝叶斯分类”指的是将数据集分为一个或多个类别的算法。
随着互联网和人工智能的发展,贝叶斯分类原理在信息检索、垃圾邮件过滤、舆情分析和医疗诊断等领域中得到了广泛应用。
贝叶斯理论最早由英国统计学家托马斯·贝叶斯在18世纪提出。
贝叶斯分类原理是基于贝叶斯定理的。
贝叶斯定理的官方表述是:P(A|B) = P(B|A) × P(A) / P(B)P(A)和P(B)是事件A和事件B的先验概率分布;P(B|A)是在事件A下B的条件概率;P(A|B)是在已知事件B的情况下A的后验概率分布。
在贝叶斯分类中,我们将每个分类视为事件A并计算每个分类的先验概率P(A)。
然后考虑训练数据集中与该分类相关的每个特征,计算在每个类别中某一特征的条件概率P(B|A)。
使用贝叶斯公式来计算每个分类的后验概率P(A|B)。
将后验概率最高的分类作为预测结果。
贝叶斯分类的核心思想是通过先前的知识和后验概率的推断,来预测事物的未来发展。
在贝叶斯分类原理中,我们将每个分类视为一个“类别”,然后通过计算每个类别与每个特征的条件概率来进行分类。
具体过程如下:1.准备训练数据集。
2.计算训练数据集中每个类别的先验概率。
3.计算在每个类别下各特征的条件概率。
4.输入待分类的实例,计算在每个类别下该实例的后验概率。
5.选择后验概率最高的类别作为预测结果。
下面用一个简单的例子来说明贝叶斯分类原理。
假设我们需要对电子邮件进行自动分类,将它们分为“垃圾邮件” 和“正常邮件” 两类。
我们可以将邮件的主题、发件人信息、时间戳等各种特征作为分类依据。
现在我们已经有了一个训练集,并将训练集按照类别分别标记为“垃圾邮件” 和“正常邮件”。
在训练数据集中,假设类别“垃圾邮件” 的总数为1000封,其中主题包含“online casino” 的邮件有800封,主题不包含“online casino” 的邮件有200封;假设类别“正常邮件” 的总数为2000封,其中主题包含“online casino” 的邮件有100封,主题不包含“online casino” 的邮件有1900封。
模式识别论文——手写数字识别的GMM与最近邻分类器系统比较

模式识别论⽂——⼿写数字识别的GMM与最近邻分类器系统⽐较2015 年秋季季学期研究⽣课程考核(读书报告、研究报告)考核科⽬:模式识别学⽣所在院(系):航天学院学⽣所在学科:控制科学与⼯程学⽣姓名:学号:15S004001学⽣类别:学术型考核结果阅卷⼈《模式识别》课程结业报告2015秋季学期姓名:学号:15S004001专业:控制科学与⼯程哈尔滨⼯业⼤学2015年12⽉两种⼿写数字识别系统的⽐较摘要:⼿写体数字识别是图像识别中⼀个较成熟的研究课题,是模式识别领域最成功的应⽤之⼀。
本论⽂旨在研究GMM分类器和最近邻分类器这两种基本算法在数字识别这⼀问题上的应⽤。
实验直接调⽤MNIST中数据集,集中每个⼿写数字存储为⼀个784维的归⼀化后的⼆值特征向量,因此可以省略数字的预处理过程,包括灰度化及⼆值化处理等。
直接进⾏特征提取即主成分分析,把重点放在不同样本总数下⼆种⽅法的识别正确率的⽐较,验证最近邻法的渐进错误率最优极限为贝叶斯错误率这⼀结论。
关键词:数字识别;特征提取;主成分分析;GMM分类器;最近邻分类器;渐进错误率1课题的背景⾃上世纪六⼗年代以来,计算机视觉与图像处理越来越受到⼈们的关注,并逐渐成为⼀门重要的学科领域。
⽽作为它们的研究对象的数字图像,也因为它含有研究⽬标的丰富信息⽽成为越来越重要的研究对象。
图像识别的⽬标是⽤计算机⾃动完成某些信息的处理,⽤来替代⼈⼯去处理图像分类及识别的任务。
⽽模式识别是六⼗年代初迅速发展起来的⼀门学科。
由于它研究的是如何⽤机器来实现⼈及某些动物对事物的学习、识别和判断能⼒,因⽽受到了很多科技领域研究⼈员的注意,成为⼈⼯智能研究的⼀个重要⽅⾯。
1.1⼿写数字识别的发展⼿写数字识别是图像识别学科下的⼀个分⽀,是图像处理和模式识别领域研究的课题之⼀,由于其具有很强的实⽤性⼀直是多年来的研究热点。
由于⼿写体数字的随意性很⼤,例如,笔画的粗细,字体的⼤⼩,倾斜等等都直接影响到字符的正确识别。
模式识别实验报告

实验一Bayes 分类器设计本实验旨在让同学对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识,理解二类分类器的设计原理。
1实验原理最小风险贝叶斯决策可按下列步骤进行:(1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑==cj iii i i P X P P X P X P 1)()()()()(ωωωωω j=1,…,x(2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险∑==cj j jii X P a X a R 1)(),()(ωωλ,i=1,2,…,a(3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策k a ,即则k a 就是最小风险贝叶斯决策。
2实验内容假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=0.9; 异常状态:P (2ω)=0.1。
现有一系列待观察的细胞,其观察值为x :-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 已知类条件概率密度曲线如下图:)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,0.25)(2,4)试对观察的结果进行分类。
3 实验要求1) 用matlab 完成分类器的设计,要求程序相应语句有说明文字。
2) 根据例子画出后验概率的分布曲线以及分类的结果示意图。
模式识别(四)

[(x
∫
∞
−∞
x i P ( x i ) dx
)T
− µ
)( x µ 1)
n
− µ
]
i
)
[( x 1
− µ
1
),..., ( x n
− µ
n
)] − µ
n
... ( x 1 − µ 1 )( x 1 − µ 1 ) ( x 1 − µ 1 ...... ( x n − µ n )( x 1 − µ 1 ) ( x n − µ ...
= max P( x ω j )P(ω j ) ⇒ x ∈ωi , (i = 1,2,...,M )
1≤ j ≤M
另一种形式:
gi(x) = ln P(x ωi) + ln P(ωi)
1≤ j ≤M
= max{ P(x ω j) + ln P(ωi)}⇒ x ∈ωi ln
3.决策面方程: 4.分类器设计:
1≤ w ≤ M
µ i , wi 0 = −
1
µ iT µ i + ln P (ωi )
{
}
对于二类情况 g ( x ) = g 2 ( x ) − g 1 ( x )
ω1 P (ω 1 ) = 2 ( µ 2 − µ1 ) x + ( µ 1 µ 1 − µ 2 µ 2 ) ln ⇒ x∈ 2 ω2 > P (ω 2 ) 2σ σ
2011-5-19 4
3、决策面方程:g(x)=0
x为一维时,决策面为一点,x为二维时决策面为曲线,x为 三维时,决策面为曲面,x大于三维时决策面为超曲面。 例:某地区细胞识别: P(ω1)=0.9, P(ω2)=0.1 未知细胞x,先 , 从类条件概率密度分布曲线上查到: P(x/ ω 1)=0.2, P(x/ ω 2)=0.4 解:该细胞属于正常细胞还是异常细胞,先计算后验概率:
温室黄瓜果实的模式识别与分割-利用Bayes分类判别模型

1 分类模型的提 出
一
个 物 体 是 一 个 物 理 单 位 ,在 图像 分 析 和 计 算
机 视 觉 中通 常 表 示 为 分 割 后 图像 中 的 一 个 区域 。物
体 识 别从 根 本 上 是 为物 体 标 明 类 别 ,而 用 来 进 行 物 体 识 别 的 工具 叫做 分 类 器 。分 类 器 并 不 是 根 据 物体 本 身 来 做 出 判 断 的 。而 是 根 据 物 体 被 感 知 到 的 某 些 性 质 。这些 被感 知 到 的 物 体 特 性 称 作 模 式 ,分 类 器 实 际 识 别 的 不 是 物 体 ,而 是 物 体 的模 式 。 因此 ,模 式 识 别 的分 类 问题 是 根据 识 别 对 象 特 征 的观 察 值 ,将 其 分 到 某 个 类 别 中 去 。 B y S 决 策 ae 规 则 ( 差 最 小 规 则 )是 统 计 模 式 识 别 中 的一 个 基 误 本 方 法 ,在 分 类 时 要 求 :一 是 各 类 别 总 体 的概 率 分
果实及其重心位置 。 中 图分 类 号 :T 3 14 P 9 .1
, 文 献 标 识 码 :A 文章 编 号 :1 0 — 1 8 (0 60 - 0 5 — 0 O 3 8 X 2 0 )7 1 0 4
关键 词 :计 算 机 应用 ;模 式 识 别 ;试 验 ;B y s决策 规则 ;黄 瓜 ;图 像 分 割 ;特 征 ae
维普资讯
20 06年 7月
农 机 化 研 究
第 7期
温 室 黄 瓜 果 实 的 模 式 识 别 与 分 割
一
利 用 B y s分 类 判 别模 型 ae
袁 国勇 ,张 铁 中
( 国 农 业 大 学 工 学 院 。北 京 10 8 ) 中 003 摘 要 :利用 黄 瓜 果 实 与 其 果 梗 叶 片 在 颜 色 深 度 上 的差 异 ,采 用 在 自然 背 景 下 的黄 瓜 图像 为训 练 样 本 ,分
模式识别-第四版Sergios Theodoridis

模式识别第四版Pattern Recognition Fourth EditionSergios Teodoridis / Konstantinos Koutroumbas第1章导论1.1 模式识别重要性1.2 特征、特征向量和分类器1.3 有监督、无监督和半监督学习1.4 MATLAB程序1.5 本书内容安排第2至10章有监督模式识别第2章估计未知概率密度函数的贝叶斯分类技术——重点关注:贝叶斯分类、最小距离、最近邻分类器、朴素贝叶斯分类器、贝叶斯网络。
第3章线性分类器的设计——均方理论的概率、偏差-方差、支持向量机(SVM Support Vector Machines)、线性可分性感知器算法均方和最小二乘法理论第4章非线性分类器的设计——反射传播算法基本原理、Cover定理、径向基函数(RBF Radial Basis Function)网络、非线性支持向量机、决策树、联合分类器第5章特征选择(介绍现有的知名技术)——t检验、发散、Bhattacharrya距离、散布矩阵、(重点)两类的Fisher线性判别方法(Fisher’s linear discriminant method LDA)第6章如何利用正交变换进行特征提取——KL变换、奇异值分解、DFT\DCT\DST\Hadamard\Haar变换、离散小波变换、第7章图像和声音分类中的特征提取一阶和二阶统计特征以及行程长度方法第8章模板匹配动态规划和Viterbi算法(应用于语音识别),相关匹配和可变形模板匹配的基本原理第9章上下文相关分类隐马尔可夫模型,并应用于通信和语音识别第10章系统评估和半监督学习第11章至第16章无监督模式识别第2章基于贝叶斯决策理论的分类器2.1 引言模式识别系统中的分类器设计共三章,这是其中的第1章以特征值的统计概率为基础。
设计分类器是将未知类型的样本分类到最可能的类别中。
现在的任务是定义什么是“最可能”首先要完成的任务是条件概率的计算,而贝叶斯规则条件概率是非常有用的2.2 贝叶斯决策理论BAYES DECISION THEORY概率中的贝叶斯规则P(x)是x的概率密度函数贝叶斯分类规则bayes classification rule结论等价表示为:若先验概率相等,上式可表示为:错误率Pe的计算公式最小化分类错误率Minimizing the Classification Error Probability:要证明贝叶斯分类器在最小化分类错误率上是最优的the Bayesian classifier is optimal with respect to minimizing the classification error probability.最小平均风险Minimizing the Average Risk用惩罚Penalty来衡量每一个错误it is more appropriate to assign a penalty term to weigh each error2.3 判别函数和决策面下面的主要讨论在高斯密度函数的情况下,与贝叶斯分类决策面有关的情况。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
西安交通大学《模式识别》实验一——IRIS正态分布假设下的贝叶斯分类吴娟梅硕20813112313030对于具有多个特征参数的样本(如本实验的iris 数据样本有4d =个参数),其正态分布的概率密度函数可定义为112211()exp ()()2(2)T dp π-⎧⎫=--∑-⎨⎬⎩⎭∑x x μx μ式中,12,,,d x x x ⎡⎤⎣⎦=x 是d 维行向量,12,,,d μμμ⎡⎤⎣⎦=μ 是d 维行向量,∑是d d ⨯维协方差矩阵,1-∑是∑的逆矩阵,∑是∑的行列式。
本实验我们采用最小错误率的贝叶斯决策,使用如下的函数作为判别函数()(|)(),1,2,3i i i g p P i ωω==x x (3个类别)其中()i P ω为类别i ω发生的先验概率,(|)i p ωx 为类别i ω的类条件概率密度函数。
由其判决规则,如果使()()i j g g >x x 对一切j i ≠成立,则将x 归为i ω类。
我们根据假设:类别i ω,i=1,2,……,N 的类条件概率密度函数(|)i p ωx ,i=1,2,……,N 服从正态分布,即有(|)i p ωx ~(,)i i N ∑μ,那么上式就可以写为1122()1()exp ()(),1,2,32(2)T i i dP g i ωπ-⎧⎫=-∑=⎨⎬⎩⎭∑x x -μx -μ对上式右端取对数,可得111()()()ln ()ln ln(2)222T i i i i dg P ωπ-=-∑+-∑-i i x x -μx -μ上式中的第二项与样本所属类别无关,将其从判别函数中消去,不会改变分类结果。
则判别函数()i g x 可简化为以下形式111()()()ln ()ln 22T i i i i g P ω-=-∑+-∑i i x x -μx -μ1.用部分数据来估计均值、协方差首先读入数据clear allclc% 原始数据导入,原数据以文本的形式存储,iris是一个L*12的矩阵,L为数据长度iris = load('C:\Documents andSettings\Administrator\IRIS_Data.txt');%求出数据长度Ldisplay('数据长度为') L=length(iris)%iris是一个L*12的矩阵,12列共分为三类数据,每类占4列%将数据分类存储于三个数组w1=iris(1:L,1:4);w2=iris(1:L,5:8);w3=iris(1:L,9:12);然后选取训练样本估计均值、协方差。
训练样本的选取有很多种方法,我们采用两种较为常见的方法进行选取。
方法一是顺序选取。
分别试取[1:10]、 [11:50]两组数据进行训练,用于对比训练数据多寡对于分类效果的影响。
%顺序选取,参数可调,待输入选取的训练样本的起始点和截止点display('请输入每类训练样本在顺序选取时的');N0 = input('数据起始点(大于0小于L的整数)N0=');Nj = input('数据截止点(大于N0小于L的整数)Nj=');display('则训练样本长度为')N=Nj-N0+1 %提取样本的统计特征值,均值和协方差display('用上述部分数据估计的三类样本均值、协方差依次为');mean1=mean(w1(N0:Nj,:))mean2=mean(w2(N0:Nj,:))mean3=mean(w3(N0:Nj,:))cov1=cov(w1(N0:Nj,:))cov2=cov(w2(N0:Nj,:))cov3=cov(w3(N0:Nj,:))方法二是随机选取N个数据。
试随机取N=10、N=40两组数据进行训练。
同样也是用于比对训练数据的多寡对分类器的性能有何影响。
clear allclc% 原始数据导入,原数据以文本的形式存储,iris是一个L*12的矩阵,L为数据长度iris = load('C:\Documents andSettings\Administrator\IRIS_Data.txt');%求出数据长度Ldisplay('数据长度为')L=length(iris)%iris是一个L*12的矩阵,12列共分为三类数据,每类占4列%将数据分类存储于三个数组w1=iris(1:L,1:4);w2=iris(1:L,5:8);w3=iris(1:L,9:12);%随机选取,参数可调,待输入选取的训练样本的个数NN=input('请输入每类训练样本在随机选取时的样本长度为N=');%随机选取N个训练样本,即产生N个不大于数据长度L的不重复的整数作为其样本序号Numberranddata=randperm(L);Number1=randdata(1:N);Number=sort(Number1);%提取样本的统计特征值,均值和协方差display('用上述部分数据估计的三类样本均值、协方差依次为'); mean1=mean(w1(Number,:)) mean2=mean(w2(Number,:)) mean3=mean(w3(Number,:)) cov1=cov(w1(Number,:)) cov2=cov(w2(Number,:)) cov3=cov(w3(Number,:))2.用后验概率去判断数据的类型首先选取测试分类数据。
令先验概率可变,即选取不同的测试数据组数进行实验。
试取测试数据组数为10、10、10,正常取值,来考查前述训练样本数对分类结果的影响。
再试取数据组数为试取数据组数为4、40、50;45、4、3进行分类。
研究当先验概率很小时对分类效果的影响。
%选取w1[N10:N1j],w2[N20:N2j],w3[N30:N3j]用作每类测试的分类样本,可变先验概率%顺序选取,参数可调,待输入选取的测试分类样本的起始点和截止点%1类测试分类数据display('请输入1类测试分类样本在顺序选取时的');N10 = input('数据起始点(大于0小于L的整数)N10=');N1j = input('数据截止点(大于N0小于L的整数)N1j=');display('则1类测试分类样本长度为')N1=N1j-N10+1test1=w1(N10:N1j,:);%2类测试分类数据display('请输入第2类测试分类样本在顺序选取时的');N20 = input('数据起始点(大于0小于L的整数)N20=');N2j = input('数据截止点(大于N0小于L的整数)N2j=');display('则第2类测试分类样本长度为')N2=N2j-N20+1test2=w1(N20:N2j,:);%3类测试分类数据display('请输入第3类测试分类样本在顺序选取时的');N30 = input('数据起始点(大于0小于L的整数)N30=');N3j = input('数据截止点(大于N0小于L的整数)N3j=');display('则第3类测试分类样本长度为')N3=N3j-N30+1test3=w1(N30:N3j,:);%选取的测试分类数据存入一个数组test test=[test1;test2;test3];然后分别两两分组,第1&2类、第2&3类、第1&3类,计算判别函数,判别分类正确率。
%计算协方差阵的行列式和逆cov1_det=det(cov1);cov2_det=det(cov2); cov3_det=det(cov3); cov1_inv=inv(cov1); cov2_inv=inv(cov2);cov3_inv=inv(cov3);%进行第1次实验,即第1&2分组实验display('对一二分组时第一、二类测试数据的先验概率(%)依次为');pw11=N1/(N1+N2)pw12=1-pw11rate11=0.0;rate12=0.0;fori = 1:(N1+N2)g11=(-0.5)*(test(i,:)-mean1)*cov1_inv*(test(i,: )'-mean1')-0.5*log(abs(cov1_det))+log(pw11);g12=(-0.5)*(test(i,:)-mean2)*cov2_inv*(test(i,: )'-mean2')-0.5*log(abs(cov2_det))+log(pw12);if g11>g12ifi<(N1+1)rate11=rate11+1;endelseifi>N1rate12=rate12+1;endendenddisplay('对一二分组时第一、二类测试数据的分类正确率(%)依次为为');rate11=rate11/N1*100rate12=rate12/N2*100%进行第2次实验,即第2&3分组实验display('对二三分组时第二、三类测试数据的先验概率(%)依次为');pw22=N2/(N2+N3)pw23=1-pw22rate22=0.0;rate23=0.0;fori = (N1+1):(N1+N2+N3)g22=(-0.5)*(test(i,:)-mean2)*cov2_inv*(test(i,: )'-mean2')-0.5*log(abs(cov2_det))+log(pw22);g23=(-0.5)*(test(i,:)-mean3)*cov3_inv*(test(i,:)'-mean3')-0.5*log(abs(cov3_det))+log(pw23);if g22>g23ifi<(N1+N2+1)rate22=rate22+1;endelseifi>(N1+N2)rate23=rate23+1;endendenddisplay('对二三分组时第二、三类测试数据的分类正确率(%)依次为');rate22=rate22/N2*100rate23=rate23/N3*100%进行第3次实验,即第1&3分组实验display('对一三分组时第一、三类测试数据的先验概率(%)依次为');pw31=N1/(N1+N3)pw33=1-pw31rate31=0.0;rate33=0.0;fori = [1:N1,N1+N2+1:N1+N2+N3]g31=(-0.5)*(test(i,:)-mean1)*cov1_inv*(test(i,: )'-mean1')-0.5*log(abs(cov1_det))+log(pw31);g33=(-0.5)*(test(i,:)-mean3)*cov3_inv*(test(i,: )'-mean3')-0.5*log(abs(cov3_det))+log(pw33);if g31>g33ifi<(N1+1)rate31=rate31+1;endelseifi>(N1+N2)rate33=rate33+1;endendenddisplay('对一三分组时第一、三类测试数据的分类正确率(%)依次为');rate31=rate31/N1*100 rate33=rate33/N3*100结果分析与结论结果分析一:试取测试数据组数为10、10、10,正常取值,来考查前述训练样本数对分类结果的影响。