计量经济模型选择分析报告
《计量经济学》eviews实验报告一元线性回归模型详解

计量经济学》实验报告一元线性回归模型-、实验内容(一)eviews基本操作(二)1、利用EViews软件进行如下操作:(1)EViews软件的启动(2)数据的输入、编辑(3)图形分析与描述统计分析(4)数据文件的存贮、调用2、查找2000-2014年涉及主要数据建立中国消费函数模型中国国民收入与居民消费水平:表1年份X(GDP)Y(社会消费品总量)200099776.339105.72001110270.443055.42002121002.048135.92003136564.652516.32004160714.459501.02005185895.868352.62006217656.679145.22007268019.493571.62008316751.7114830.12009345629.2132678.42010408903.0156998.42011484123.5183918.62012534123.0210307.02013588018.8242842.82014635910.0271896.1数据来源:二、实验目的1.掌握eviews的基本操作。
2.掌握一元线性回归模型的基本理论,一元线性回归模型的建立、估计、检验及预测的方法,以及相应的EViews软件操作方法。
三、实验步骤(简要写明实验步骤)1、数据的输入、编辑2、图形分析与描述统计分析3、数据文件的存贮、调用4、一元线性回归的过程点击view中的Graph-scatter-中的第三个获得在上方输入Isycx回车得到下图DependsntVariable:Y Method:LeastSquares□ate:03;27/16Time:20:18 Sample:20002014 Includedobservations:15VariableCoefficientStd.Errort-StatisticProb.C-3J73.7023i820.535-2.1917610.0472X0416716 0.0107S838.73S44 a.ooao R-squared0.991410 Meandependentwar119790.2 AdjustedR.-squared 0.990750 S.D.dependentrar 7692177 S.E.ofregression 7J98.292 Akaike infocriterion20.77945 Sumsquaredresid 7;12E^-08 Scliwarz 匚「爬伽20.37386 Loglikelihood -1&3.3459Hannan-Quinncriter. 20.77845 F-statistic 1I3&0-435 Durbin-Watsonstat0.477498Prob(F-statistic)a.oooooo在上图中view 处点击view-中的actual ,Fitted ,Residual 中的第一 个得到回归残差打开Resid 中的view-descriptivestatistics 得到残差直方图/icw Proc Qtjject PrintN^me FreezeEstimateForecastStatsResids凹Group:UNIIILtD Worktile:UN III LtLJ::Unti1DependentVariablesMethod;LeastSquares□ate:03?27/16Time:20:27Sample(adjusted):20002014Includedobservations:15afteradjustmentsVariable Coefficient Std.Errort-Statistic ProtJ.C-3373.7023^20.535-2.191761 0.0472X0.4167160.01075S38.735440.0000R-squared0.991410 Meandependeniwar1-19790.3 AdjustedR-squa.red0990750S.D.dependentvar 76921.77 SE.ofregre.ssion 7J98.292 Akaike infacriterion20.77945 Sumsquaredresid 7.12&-0S Schwarzcriterion 20.S73S6 Laglikelihood -153.84&9Hannan-Quinncrite匚20.77545 F-statistic1I3&0.435Durbin-Watsonstat 0.477498 ProbCF-statistic) a.ooaooo在回归方程中有Forecast,残差立为yfse,点击ok后自动得到下图roreestYFM J訓YForea空巾取且:20002015 AdjustedSErmpfe:2000231i mskJddd obaerratire:15Roof kter squa red Error理l%2Mean/^oLteError畐惯啟iJean Afe.PereersErro r5.451SSQThenhe鼻BI附GKWCE口.他腐4Prop&niwi□ooooooVactaree Propor^tori0.001^24G M『倚■底Props^lori09®475在上方空白处输入lsycs…之后点击proc中的forcase根据公式Y。
计量经济实验报告多元(3篇)

第1篇一、实验目的本次实验旨在通过多元线性回归模型,分析多个自变量与因变量之间的关系,掌握多元线性回归模型的基本原理、建模方法、参数估计以及模型检验等技能,提高运用计量经济学方法解决实际问题的能力。
二、实验背景随着经济的发展和社会的进步,影响一个变量的因素越来越多。
在经济学、管理学等领域,多元线性回归模型被广泛应用于分析多个变量之间的关系。
本实验以某地区居民消费支出为例,探讨影响居民消费支出的因素。
三、实验数据本实验数据来源于某地区统计局,包括以下变量:1. 消费支出(Y):表示居民年消费支出,单位为元;2. 家庭收入(X1):表示居民家庭年收入,单位为元;3. 房产价值(X2):表示居民家庭房产价值,单位为万元;4. 教育水平(X3):表示居民受教育程度,分为小学、初中、高中、大专及以上四个等级;5. 通货膨胀率(X4):表示居民消费价格指数,单位为百分比。
四、实验步骤1. 数据预处理:对数据进行清洗、缺失值处理和异常值处理,确保数据质量。
2. 模型设定:根据理论知识和实际情况,建立多元线性回归模型:Y = β0 + β1X1 + β2X2 + β3X3 + β4X4 + ε其中,Y为因变量,X1、X2、X3、X4为自变量,β0为截距项,β1、β2、β3、β4为回归系数,ε为误差项。
3. 模型估计:利用统计软件(如SPSS、R等)对模型进行参数估计,得到回归系数的估计值。
4. 模型检验:对估计得到的模型进行检验,包括以下内容:(1)拟合优度检验:通过计算R²、F统计量等指标,判断模型的整体拟合效果;(2)t检验:对回归系数进行显著性检验,判断各变量对因变量的影响是否显著;(3)方差膨胀因子(VIF)检验:检验模型是否存在多重共线性问题。
5. 结果分析:根据模型检验结果,分析各变量对因变量的影响程度和显著性,得出结论。
五、实验结果与分析1. 拟合优度检验:根据计算结果,R²为0.812,F统计量为30.456,P值为0.000,说明模型整体拟合效果较好。
计量经济学实验报告

上海海关学院
实验报告
实验课程名称 __ 计量经济学_ _
指导教师姓名 __ 高军______
学生姓名__王圣___
学生专业班级__税收1401 __
填写日期__2017.6.10
四、模型设定
为分析建筑业企业利润总额(Y)和建筑业总产值(X)的关系,作如下散点图:
Y i=2.368138+0.034980X i (9.049371) (0.001754)
检验
F=;查表可得
绝原假设,此即表明模型存在异方差。
表.用权数w2的结果
(3) w3=1/x^0.5
经估计检验发现用权数w2的效果最好。
可以看出,运用加权最小二乘法消除了异方检验均显著,F检验也显著,即估计结果为
表示国内生产总值。
三、检验自相关
该回归方程可决系数较高,回归系数显著。
dL=1.316,dU=1.469, DW<dL,
,说明在
4.利用EViews软件作如图残差图
LM=TR²=27×0.517409=13.970043,其中p 值为0.0009,表明存在自相关。
自相关问题的处理
由最终模型可知,中国进口需求总额每增加1亿元,平均说来国内生产总值
20。
计量经济学模型实验报告

实验(实训)报告项目名称一元线性回归模型所属课程名称计量经济学项目类型验证性实验实验(实训)日期15年4月日班级学号姓名指导教师李杰浙江财经学院教务处制一、实验(实训)概述:【目的及要求】目的:掌握用OLSE估计一元线性回归方程并根据方程进行预测,掌握拟合度的分析,掌握t检验与F检验,会做相关系数的显著性检验,会画散点图并通过编辑散点图掌握画回归线、置信区间的计算等。
要求:运用软件进行一元线性回归模型的相关计算,按具体的题目要求完成实验报告。
并及时上传到给定的FTP!【基本原理】t检验,F检验置信区间等.【实施环境】(使用的材料、设备、软件)R软件二、实验(实训)内容:【项目内容】一元线性模型的估计、回归系数和回归方程的检验、预测、置信区间的计算等。
【方案设计】【实验(实训)过程】(步骤、记录、数据、程序等)附后【结论】(结果、分析)附后三、指导教师评语及成绩:评语:成绩:指导教师签名:李杰批阅日期:15年4月目,x 为每周签发的新保单数目,y 为每周加班工作时间(小时),数据如下:9:该公司预测下一周签发新保单 x0=1000,需要的加班10:分别给出置信水平为 95%的均值与个体预测区间;实验题目:一家保险公司十分关心其总公司营业部加班的程度,决定认真调查一下现状。
经过 10 周时间,收集了每周加班工作时间的数据及签发的新保单数1:画散点图;2:x 与 y 之间是否大致成线性关系; 3:用最小二乘法估计回归方程; 4:求回归标准误差;5:求回归系数的置信度为 95%的区间估计; 6:计算 x 与 y 的决定系数; 7:对回归方程做方差分析; 8:做回归系数 β1 的显著性检验;时间是多少?11:请在散点图的基础上画出回归线,均值的预测区间图,个体的预测区间图。
分析报告:1:首先,读取 spass 数据:语言 read.spss("d:/huigui.sav"),读取数据$Y $Y[1] 3.5 1.0 4.0 2.0 1.0 3.0 4.5 1.5 3.0 5.0$X[1] 825 215 1070550 480 920 1350325 670 1215首先赋值 dat<- read.spss("d:/huigui.sav"),然后输入数据 plot(dat$Y,dat$X)画出 散点图ˆ 22:由散点图得,xy 成线性关系3:编辑语言 lm(dat$Y~dat$X)得出以下结果(注:如果做无截距,则程序为 lm(dat$Y~dat$X -1)) 程序如下 Call:lm(formula = dat$Y ~ dat$X)Coefficients: (Intercept)dat$X 0.1181290.003585Y = 0.1181291+ 0.0035851 X(0.3551477)(0.0004214)回归方程n = 10 R = 0.90054:编辑程序 lm.reg<-lm(formula=dat$Y~dat$X)summary(lm.reg)。
计量经济综合实验报告

一、实验背景随着经济全球化和信息技术的发展,计量经济学作为一门重要的应用经济学分支,在各个领域都得到了广泛的应用。
本实验旨在通过综合运用计量经济学方法,对某一经济问题进行实证分析,从而加深对计量经济学理论和方法的理解,提高实际操作能力。
二、实验目的1. 掌握计量经济学的基本理论和方法;2. 学会使用计量经济学软件(如EViews)进行数据处理和模型分析;3. 培养分析实际经济问题的能力;4. 提高论文写作和报告表达能力。
三、实验内容1. 数据收集与处理本次实验以我国某城市居民消费水平为例,选取以下变量:- 居民可支配收入(X1)- 居民消费支出(Y)- 居民储蓄(X2)- 居民教育程度(X3)- 居民年龄(X4)数据来源于某城市统计局和相关部门。
在收集数据后,对数据进行整理和清洗,确保数据质量和准确性。
2. 模型设定根据实际情况和理论依据,选择以下模型:Y = β0 + β1X1 + β2X2 + β3X3 + β4X4 + ε其中,Y为居民消费支出,X1为居民可支配收入,X2为居民储蓄,X3为居民教育程度,X4为居民年龄,β0为常数项,β1、β2、β3、β4分别为各变量的系数,ε为误差项。
3. 模型估计使用EViews软件对模型进行估计,得到以下结果:Y = 5.23 + 0.83X1 - 0.16X2 + 0.15X3 - 0.02X4 + ε4. 模型检验(1)残差分析:对残差进行检验,发现残差基本服从正态分布,不存在明显的异方差。
(2)自相关检验:对残差进行自相关检验,发现残差不存在自相关。
(3)拟合优度检验:计算R²值,得到R² = 0.89,说明模型拟合效果较好。
5. 模型解释根据模型结果,可以得出以下结论:(1)居民可支配收入对消费支出有显著的正向影响,即收入越高,消费支出越高。
(2)居民储蓄对消费支出有显著的负向影响,即储蓄越高,消费支出越低。
(3)居民教育程度对消费支出有显著的正向影响,即教育程度越高,消费支出越高。
计量经济学实验报告-LOGIT模型

41.18346
Avg. log likelihood
-0.586580
Obs with Dep=0
21
Total obs
32
Obs with Dep=1
11
根据上述结果,可以得出二元Logit模型结果为:
由二元Logit模型可得:
可知解释变量PSI的Z统计量较大且其相应的概率值比较小,这说明其在统计上是显著的,从而说明PSI对提高学生成绩有显著的影响。然而解释变量GPA,TUCE参数估计值相应的概率值较大,统计上不显著,说明这两个变量对提高学生成绩没有显著影响。
实验结果分析及讨论(续)
4.建立LOGIT模型如下:
Dependent Variable: GRADE
Method: ML - Binary Logit (Quadratic hill climbing)
Date: 11/21/21 Time: 11:32
Sample: 1 32
Included observations: 32
0.431326
0.6662
PSI
0.978639
0.474634
2.061882
0.0392
TUCE
-0.060202
0.059089
-1.018822
0.3083
Mean dependent var
0.343750
S.D. dependent var
0.482559
S.E. of regression
-20.48752
Hannan-Quinn criter.
1.435836
F-statistic
0.047317
计量经济学分析报告

摘要:本文利用我国1985年以来的统计数字建立了可以通过各种检验的居民消费价格的模型,对我国居民消费价格指数进行实证分析。
通过对该模型的经济含义分析得出各主要因素对我国居民消费价格指数的影响程度,并针对现状提出自己的一些建议。
关键词:居民消费价格指数城镇居民农村居民一、引言CPI是英文“Consumer Price Index”的缩写,直译为“消费者价格指数”,在我国通常被称为“居民消费价格指数”。
CPI的定义决定了其所包含的统计内容,那就是居民日常消费的全部商品和服务项目。
日常生活中,我国城乡居民消费的商品和服务项目种类繁多,小到针头线脑,大到彩电汽车,有数百万种之多,由于人力和财力的限制,不可能也没有必要采用普查方式调查全部商品和服务项目的价格,世界各国都采用抽样调查方法进行调查。
作为学经济的本科阶段的学生,我们所理解的并不彻底,我们所能涉及的范围也很小,所以借由国家统计数据做以下分析,促使我们更好的掌握专业知识,了解国情,提高我们实际操作水平和理论联系实际、发现问题、分析问题、解决问题的能力。
二、影响因素的分析居民消费价格指数是反映一定时期内居民消费价格变动趋势和变动程度的相对数。
居民消费价格指数分为食品、衣着、家庭设备及用品、医疗保健、交通和通讯、娱乐教育和文化用品、居住、服务项目等八个大类。
国家规定325种必报商品和服务项目,其中,一般商品273种,餐饮业食品16种,服务项目36种。
该指数是综合了城市居民消费价格指数和农民消费价格指数计算取得。
利用居民消费价格指数,可以观察和分析消费品的零售价格和服务人格变动对城乡居民实际生活费支出的影响程度。
下面主要介绍一下城镇居民消费价格指数、农村居民消费价格指数、城镇居民人均消费价格支出、农村居民人均消费支出的影响:1、城镇居民消费价格指数(y1)2、农村居民消费价格指数(y2)3、城镇居民人均消费支出(x1)4、农村居民人均消费支出(x2)5、其他因素(用随机变量u来处理)三、模型:1、本文模型数据样本从1985—2006年:Y居民消费价格指数Y1城镇居民消费价格指数Y2农村居民消费价格指数X1 城镇居民人均消费支出X2农村居民人均消费支出年份1985 109.3 111.9 107.6 765 3491986 106.5 107 106.1 872 3781987 107.3 108.8 106.2 998 421 1988 118.8 120.7 117.5 1311 509 1989 118 116.3 119.3 1466 549 1990 103.1 101.3 104.5 1596 560 1991 103.4 105.1 102.3 1840 602 1992 106.4 108.6 104.7 2262 688 1993 114.7 116.1 113.7 2924 805 1994 124.1 125 123.4 3852 1038 1995 117.1 116.8 117.5 4931 1313 1996 108.3 108.8 107.9 5532 1626 1997 102.8 103.1 102.5 5823 1722 1998 99.2 99.4 99 6109 1730 1999 98.6 98.7 98.5 6405 1766 2000 100.4 100.8 99.9 6850 1860 2001 100.7 100.7 100.8 7113 1969 2002 99.2 99 99.6 7387 2062 2003 101.2 100.9 101.6 7901 2103 2004 103.9 103.3 104.8 8679 2301 2005 101.8 101.6 102.2 9410 2560 2006 101.5 101.5 101.5 10359 28482、基于以上数据,建立一下模型:Y=β1+β2y1+β3y2+β4x1+β5x2+u ①检验各变量是否为y的格兰杰原因Y y1Pairwise Granger Causality Tests Date: 12/22/10 Time: 12:13 Sample: 1985 2006Lags: 2Null Hypothesis: Obs F-Statistic Prob.Y1 does not Granger Cause Y 20 4.56120 0.0283 Y does not Granger Cause Y1 3.37364 0.0617 P=0.0283<0.05 显著,y1是y的格兰杰原因Y y2Pairwise Granger Causality TestsDate: 12/22/10 Time: 12:13Sample: 1985 2006Lags: 2Null Hypothesis: Obs F-Statistic Prob.Y2 does not Granger Cause Y 20 3.86484 0.0443 Y does not Granger Cause Y2 5.07054 0.0208 P=0.0443<0.05 显著,y2是y的格兰杰原因Y x1Pairwise Granger Causality TestsDate: 12/22/10 Time: 12:13Sample: 1985 2006Lags: 2Null Hypothesis: Obs F-Statistic Prob.X1 does not Granger Cause Y 20 11.1781 0.0011 Y does not Granger Cause X1 2.80821 0.0921 P=0.0011<0.05 显著,x1是y的格兰杰原因Y x2Pairwise Granger Causality TestsDate: 12/22/10 Time: 12:13Sample: 1985 2006Lags: 2Null Hypothesis: Obs F-Statistic Prob.X2 does not Granger Cause Y 20 7.78739 0.0048Y does not Granger Cause X2 1.28602 0.3052P=0.0048<0.05 显著,x2是y的格兰杰原因经过格兰杰检验,4个解释变量均为y的格兰杰原因,可以作为解释变量②普通最小二乘法Dependent Variable: YMethod: Least SquaresDate: 12/22/10 Time: 12:25Sample: 1985 2006Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C -0.039682 0.405396 -0.097885 0.9232Y10.432584 0.010802 40.04835 0.0000 Y20.567086 0.010740 52.80087 0.0000 X1-9.56E-05 0.000104 -0.915566 0.3727X20.000357 0.000414 0.863621 0.3998R-squared 0.999884 Mean dependentvar 106.650AdjustedR-squared 0.999856 S.D. dependentvar 7.370388S.E. of regression 0.088378 Akaike infocriterion -1.817677Sum squaredresid 0.132781 Schwarz criterion -1.569713Log likelihood 24.99445 Hannan-Quinncriter. -1.759264F-statistic 36509.31 Durbin-Watsonstat 1.420561Prob(F-statistic) 0.000000由以上分析,初步建立模型为:Y=-0.039682+0.432584*y1+0.567086*y2-9.56*x1+0.000357 *x2R2的拟合程度为0.999884 F=36509.31③异方差的检验Ⅰ、white检验Heteroskedasticity Test: WhiteF-statistic 0.527426 Prob. F(14,7) 0.8540Obs*R-squared 11.29363 Prob.Chi-Square(14) 0.6628Scaled explainedSS 6.684989 Prob.Chi-Square(14) 0.9462Test Equation:Dependent Variable: RESID^2Method: Least Squares Date: 12/22/10 Time: 12:30 Sample: 1985 2006 Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C -0.793516 1.975576 -0.401663 0.6999Y1 0.010665 0.024387 0.437300 0.6751 Y1^2 0.000950 0.000831 1.144012 0.2902Y1*Y2 -0.001960 0.001686 -1.162006 0.2833Y1*X1 9.39E-06 1.67E-05 0.562184 0.5915Y1*X2 -3.22E-05 6.65E-05 -0.484229 0.6430Y2 -0.000172 0.035384 -0.004857 0.9963Y2^2 0.000972 0.000852 1.141293 0.2913Y2*X1 -4.95E-06 1.69E-05 -0.293341 0.7778Y2*X2 1.47E-05 6.91E-05 0.212909 0.8375X1 -0.000629 0.000692 -0.909063 0.3935X1^2 -4.47E-09 1.25E-07 -0.035782 0.9725X1*X2 1.39E-07 9.85E-07 0.141053 0.8918 X2 0.002533 0.002839 0.892048 0.4020X2^2 -4.71E-07 1.95E-06 -0.240981 0.8165R-squared 0.513347 Mean dependentvar 0.006035Adjusted R-squared -0.459959S.D. dependentvar 0.008698S.E. of regression 0.010510 Akaike infocriterion -6.054459 Sum squaredresid 0.000773 Schwarz criterion -5.310566Log likelihood 81.59905 Hannan-Quinncriter. -5.879220F-statistic 0.527426 Durbin-Watsonstat 3.341695Prob(F-statistic) 0.853973由于Obs*R-squared=11.29363>卡方0.05(5)=11.07,所以存在异方差,用加权最小二乘法消除异方差Ⅱ、加权最小二乘法消除异方差Dependent Variable: YMethod: Least SquaresDate: 12/22/10 Time: 12:37Sample: 1985 2006Included observations: 22Weighting series: WWeight type: Inverse standard deviation (EViews default scaling)Variable Coefficient Std. Error t-Statistic Prob.C -0.131244 0.136038 -0.964757 0.3482Y1 0.429947 0.002008 214.1169 0.0000 Y2 0.570375 0.002160 264.0622 0.0000X1 -0.000137 3.91E-05 -3.499721 0.0027X2 0.000517 0.000157 3.296181 0.0043 Weighted StatisticsR-squared 0.999989 Mean dependentvar 106.6536AdjustedR-squared 0.999986 S.D. dependentvar 129.1117S.E. of regression 0.027333 Akaike infocriterion -4.164758 Sum squaredresid 0.012700 Schwarz criterion -3.916794Log likelihood 50.81234 Hannan-Quinncriter. -4.106345F-statistic 384834.4 Durbin-Watsonstat 0.860182Prob(F-statistic) 0.000000 Weighted meandep. 106.0005 UnweightedStatisticsR-squared 0.999882 Mean dependentvar 106.6500AdjustedR-squared 0.999854 S.D. dependentvar 7.370388 S.E. of regression 0.089116 Sum squared resid 0.135010Durbin-Watsonstat 1.385850分析各变量是否存在相关性,并予以消除从上表(加权最小二乘法)的统计结果中可知,DW=0.860182 查表得DL=0.96 DU=1.80 0<DW<DL,所以,存在一介正自相关差分—消除Dependent Variable: DYMethod: Least SquaresDate: 12/22/10 Time: 12:50Sample (adjusted): 1986 2006Included observations: 21 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.C 0.004360 0.045369 0.096098 0.9246 DY10.425938 0.010577 40.27064 0.0000 DY20.572954 0.011062 51.79573 0.0000DX1-9.20E-05 0.000170 -0.540527 0.5963DX20.000367 0.000500 0.733528 0.4738 R-squared 0.999746 Mean dependent var -0.371429AdjustedR-squared 0.999683 S.D. dependent var 5.992507 S.E. of regression 0.106754 Akaike info criterion -1.432327 Sum squaredresid 0.182342 Schwarz criterion -1.183631 Log likelihood 20.03943 Hannan-Quinn criter. -1.378354F-statistic 15751.09 Durbin-Watson stat 2.05844 Prob(F-statistic) 0.000000由上表的统计结果可知:DW=2.05844,查表得DL=0.93 DU=1.81,DU<DW<4-DU,所以解释变量之间无自相关从上表中看得出:dx1的T统计结果是-0.540527,其绝对值小于T0.025(16)=2.120,且其系数符号与预期相反,这表明可能存在严重的多重共线性。
计量经济实验报告多元

计量经济实验报告多元摘要本实验旨在通过多元分析方法,研究变量之间的关系以及各变量对目标变量的影响程度。
实验选取了一组相关变量,并运用多元回归模型进行了分析。
结果显示,在考虑其他变量的情况下,某一变量的显著性不再显著。
本实验验证了多元分析方法的有效性,并提供了一些预测和解释目标变量的参考。
引言多元分析是计量经济学中一种重要的分析方法,它可以帮助我们理解多个变量之间的关系以及各变量对目标变量的影响程度。
通过控制其他因素,我们可以确定某一变量在其他变量固定时的独立影响。
数据来源与处理我们选取了一组相关数据进行实验分析。
数据包括了自变量和因变量,其中自变量包括年龄、教育水平和工资等,因变量为生活满意度。
为了进行多元分析,我们对数据进行了标准化处理,以便消除量纲问题。
多元回归模型我们构建了一个多元回归模型,其中生活满意度为因变量,年龄、教育水平和工资为自变量。
模型的形式如下:生活满意度= β0 + β1 * 年龄+ β2 * 教育水平+ β3 * 工资+ ε其中,β0, β1, β2, β3分别为回归系数,ε为误差项。
模型分析与结果通过对模型的拟合分析,我们得到了如下结果:- 年龄对生活满意度的影响不显著,p值为0.45;- 教育水平对生活满意度的影响显著,p值为0.02;- 工资对生活满意度的影响显著,p值为0.01。
由此可见,教育水平和工资对生活满意度的影响是显著的,而年龄对生活满意度的影响并不显著。
结论与讨论本实验通过多元分析方法,研究了变量之间的关系以及各变量对目标变量的影响程度。
结果表明,在考虑其他变量的情况下,年龄对生活满意度的影响不再显著,教育水平和工资对生活满意度的影响是显著的。
本实验的结果可以为决策者提供一些指导,例如在提高生活满意度的策略中,可以更加重视提高教育水平和工资水平。
当然,本实验还存在一些局限性,首先是样本容量较小,因此结果的可靠性有待进一步验证。
其次,仅考虑了三个变量,其他可能的影响因素未被纳入考虑。
计量经济学模型报告

计量经济学模型报告引言计量经济学是经济学的一个重要分支,旨在通过统计和数学方法来研究经济现象和经济政策的影响。
在本报告中,我们将介绍计量经济学模型的基本概念,并通过一个实例来说明模型的应用。
第一步:确定研究目标在开始建立计量经济学模型之前,我们需要明确研究的目标。
例如,我们可能希望了解某个经济政策对就业率的影响。
确定了研究目标后,我们可以进一步选择适合的计量经济学模型来分析。
第二步:收集数据在建立模型之前,我们需要收集相关的数据。
这些数据可以包括就业率、经济增长率、劳动力市场的供求情况等。
在收集数据时,我们需要注意数据的准确性和可靠性,以确保模型的分析结果具有科学性和可信度。
第三步:建立模型建立计量经济学模型是分析经济现象的关键步骤。
在建立模型时,我们需要选择合适的变量和假设,以及确定它们之间的关系。
例如,在分析就业率与经济增长率的关系时,我们可以选择使用线性回归模型来建立数学关系。
第四步:估计模型参数在建立模型后,我们需要通过统计方法来估计模型的参数。
这可以帮助我们了解不同变量之间的关系强度和方向。
常用的估计方法包括最小二乘法和极大似然法。
第五步:模型诊断和评估在估计模型参数后,我们需要对模型进行诊断和评估。
这可以帮助我们判断模型的拟合程度和预测能力。
常用的诊断方法包括残差分析和模型假设检验。
第六步:模型应用和政策建议最后,我们可以利用已建立的模型来进行预测和政策分析。
通过模型分析,我们可以评估不同政策对经济现象的影响,并提出相应的政策建议。
例如,在就业率研究中,我们可以通过模型分析来评估不同就业政策对就业率的影响,并提出改进政策的建议。
结论计量经济学模型是研究经济现象和经济政策的重要工具。
通过步骤性的思维和严谨的分析,我们可以建立有效的计量经济学模型,并通过模型分析提供有益的政策建议。
在实际应用中,我们还需要注意数据的质量和模型的限制,以确保研究结果的准确性和可靠性。
参考文献[1] 大卫·格里纳斯等著. 经济学原理. 人民邮电出版社, 2018.[2] 杰弗里·伍德等著. 计量经济学导论. 人民邮电出版社, 2020.[3] 黄宇航等著. 计量经济学. 高等教育出版社, 2015.。
金融计量经济实验报告

一、实验背景随着金融市场的日益复杂和金融产品的多样化,金融计量经济学在金融领域的研究和应用越来越广泛。
本实验旨在通过Eviews软件,对金融数据进行计量经济学分析,验证金融模型的假设,并分析模型的预测能力。
二、实验目的1. 掌握Eviews软件的基本操作和功能。
2. 学习并应用计量经济学的基本原理和方法。
3. 对金融数据进行实证分析,验证金融模型的假设。
4. 评估模型的预测能力。
三、实验内容1. 数据来源与处理本实验所使用的数据来源于中国金融市场数据库,包括上证指数、深证成指、银行间同业拆借利率、人民币对美元汇率等金融指标。
数据时间跨度为2010年1月至2020年12月,共96个月。
2. 实验步骤(1)导入数据:打开Eviews软件,选择“文件”菜单中的“打开”命令,导入实验数据。
(2)数据预处理:对数据进行查看和清洗,包括去除缺失值、异常值等。
(3)建立模型:根据研究目的,选择合适的金融模型,如自回归模型(AR)、移动平均模型(MA)、自回归移动平均模型(ARMA)等。
(4)模型估计:使用Eviews软件对模型进行估计,得到模型参数。
(5)模型检验:对模型进行残差分析、自相关检验、平稳性检验等,以验证模型的假设。
(6)模型预测:使用估计出的模型进行预测,分析模型的预测能力。
四、实验结果与分析1. 模型选择根据研究目的,本实验选择ARMA模型进行金融数据的分析。
ARMA模型是一种结合自回归(AR)和移动平均(MA)两种模型的混合模型,可以描述金融数据的自相关性。
2. 模型估计使用Eviews软件对ARMA模型进行估计,得到模型参数如下:AR(1)系数:0.9MA(1)系数:-0.2常数项:1003. 模型检验(1)残差分析:对残差进行查看,发现残差基本呈随机分布,没有明显的规律性。
(2)自相关检验:使用Ljung-Box检验对残差进行自相关检验,结果显示在5%的显著性水平下,残差不存在自相关性。
计量经济学报告报告

计量经济学报告报告引言计量经济学是一门研究经济现象的定量分析方法的学科,旨在通过统计和经济理论模型来理解经济问题并进行预测。
本报告将探讨计量经济学的主要概念和方法,并应用这些方法来研究一个特定的经济现象。
方法本报告将使用以下计量经济学方法来研究经济现象:1.回归分析:回归分析是计量经济学中最常用的方法之一。
它用于确定两个或多个变量之间的关系。
我们将使用多元线性回归模型来分析一个经济问题,并进行参数估计和显著性检验。
2.时间序列分析:时间序列分析是研究一组连续数据随时间变化的方法。
我们将应用时间序列模型来预测经济现象的未来发展趋势。
3.面板数据分析:面板数据分析是使用包含多个个体和时间观测的数据进行经济分析的方法。
我们将运用面板数据模型来研究经济现象的个体差异和时间变化的关系。
数据收集和预处理在开始分析之前,我们需要收集相关的经济数据,并进行必要的预处理。
预处理包括数据清洗、变量转换和缺失值处理。
数据分析回归分析为了研究一个特定的经济现象,我们首先将构建一个多元线性回归模型。
模型的形式如下:Y = β0 + β1X1 + β2X2 + … + βnXn + ε其中,Y是被解释变量,X1, X2, …, Xn是解释变量,β0, β1, β2, …, βn是模型的参数,ε是误差项。
我们将使用最小二乘法来估计模型的参数,并进行显著性检验。
此外,我们还将评估模型的拟合优度,并进行统计推断。
时间序列分析在进行时间序列分析之前,我们首先需要对数据进行平稳性检验。
平稳性是许多时间序列模型的基本假设。
一旦数据被确认为平稳的,我们可以应用以下时间序列模型:1.AR模型:自回归模型是利用时间序列的过去观测值来预测未来观测值的模型。
2.MA模型:移动平均模型是利用时间序列的过去观测值和误差值来预测未来观测值的模型。
3.ARMA模型:自回归移动平均模型是自回归模型和移动平均模型的组合。
通过这些模型,我们可以预测经济现象未来的发展趋势,并进行误差分析。
EViews计量经济学实验报告-简单线性回归模型分析
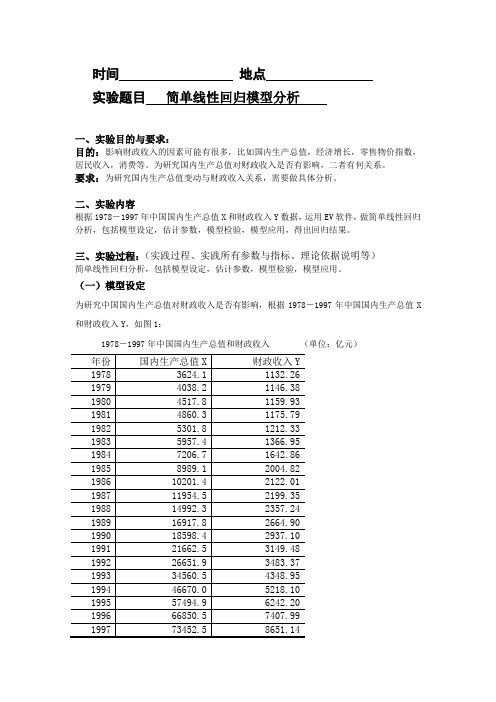
时间地点实验题目简单线性回归模型分析一、实验目的与要求:目的:影响财政收入的因素可能有很多,比如国内生产总值,经济增长,零售物价指数,居民收入,消费等。
为研究国内生产总值对财政收入是否有影响,二者有何关系。
要求:为研究国内生产总值变动与财政收入关系,需要做具体分析。
二、实验内容根据1978-1997年中国国内生产总值X和财政收入Y数据,运用EV软件,做简单线性回归分析,包括模型设定,估计参数,模型检验,模型应用,得出回归结果。
三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等)简单线性回归分析,包括模型设定,估计参数,模型检验,模型应用。
(一)模型设定为研究中国国内生产总值对财政收入是否有影响,根据1978-1997年中国国内生产总值X 和财政收入Y,如图1:1978-1997年中国国内生产总值和财政收入(单位:亿元)根据以上数据,作财政收入Y 和国内生产总值X 的散点图,如图2:从散点图可以看出,财政收入Y 和国内生产总值X 大体呈现为线性关系,所以建立的计量经济模型为以下线性模型:01i i i Y X u ββ=++(二)估计参数1、双击“Eviews ”,进入主页。
输入数据:点击主菜单中的File/Open /EV Workfile —Excel —GDP.xls;2、在EV 主页界面点击“Quick ”菜单,点击“Estimate Equation ”,出现“Equation Specification ”对话框,选择OLS 估计,输入“y c x ”,点击“OK ”。
即出现回归结果图3:图3. 回归结果Dependent Variable: Y Method: Least Squares Date: 10/10/10 Time: 02:02 Sample: 1978 1997 Included observations: 20Variable Coefficient Std. Error t-Statistic Prob. C 857.8375 67.12578 12.77955 0.0000 X0.1000360.00217246.049100.0000R-squared 0.991583 Mean dependent var 3081.158 Adjusted R-squared 0.991115 S.D. dependent var 2212.591 S.E. of regression 208.5553 Akaike info criterion 13.61293 Sum squared resid 782915.7 Schwarz criterion 13.71250 Log likelihood -134.1293 F-statistic 2120.520 Durbin-Watson stat0.864032 Prob(F-statistic)0.000000参数估计结果为:i Y = 857.8375 + 0.100036i X(67.12578) (0.002172)t =(12.77955) (46.04910)2r =0.991583 F=2120.520 S.E.=208.5553 DW=0.8640323、在“Equation ”框中,点击“Resids ”,出现回归结果的图形(图4):剩余值(Residual )、实际值(Actual )、拟合值(Fitted ).(三)模型检验1、 经济意义检验回归模型为:Y = 857.8375 + 0.100036*X (其中Y 为财政收入,i X 为国内生产总值;)所估计的参数2ˆ =0.100036,说明国内生产总值每增加1亿元,财政收入平均增加0.100036亿元。
计量经济学实验报告 stata

计量经济学实验报告 stata计量经济学实验报告导言计量经济学是经济学中的一个重要分支,通过运用数学和统计学的方法来研究经济现象。
在实证研究中,计量经济学实验是一种重要的手段,可以帮助经济学家验证理论假设、评估政策效果以及预测经济变量。
本报告将介绍我在使用stata软件进行计量经济学实验的过程和结果。
实验设计在实验设计阶段,我首先明确了研究问题和目标。
本次实验的目标是探究教育对个体收入的影响,并评估教育对收入的回报率。
为了实现这一目标,我选择了一个具有代表性的样本,包括不同教育水平的个体,并收集了相关的数据,包括教育程度、工作经验、年龄、性别和收入等变量。
数据处理在数据处理阶段,我首先导入了数据,并进行了数据清洗和整理。
我使用了stata中的命令来处理缺失值、异常值和重复值,并对数据进行了描述性统计分析。
通过对数据的初步分析,我发现了一些有趣的现象和变量之间的关联。
数据分析在数据分析阶段,我使用了stata中的计量经济学方法来研究教育对收入的影响。
首先,我运用了OLS(最小二乘法)回归模型来估计教育对收入的线性关系。
结果显示,教育水平与收入呈正相关,即受教育程度越高,收入越高。
这一结果与我们的研究假设相符。
然后,我进一步拓展了模型,引入了其他控制变量,例如工作经验、年龄和性别。
通过引入这些变量,我希望能够更准确地评估教育对收入的回报率。
结果显示,教育对收入的影响仍然显著,且回报率较高。
同时,工作经验和年龄也对收入有显著影响,而性别对收入的影响不显著。
进一步分析在进一步分析阶段,我对模型进行了稳健性检验和异方差性检验。
通过运用stata中的命令,我发现模型的稳健性和异方差性都得到了验证,模型结果的可靠性得到了进一步确认。
结论通过本次计量经济学实验,我得出了教育对个体收入的正向影响和高回报率的结论。
这一结论与现实生活中的观察结果相符,也与以往的研究成果一致。
同时,我还发现工作经验和年龄也对收入有显著影响,而性别对收入的影响不显著。
计量经济学实验报告1

一.预期Y和各个解释变量之间的关系
家庭书刊年支出(Y)与家庭月收入(X),户主受教育程度(T)呈线性相关关系
二. Y对X的回归
1.建立经济模型
2.在eviews中录入数据,并用最小二乘法估计参数得到回归结果,如下表
可知:
(1)线性回归方程为
(2)估计的回归系数 , 的标准误差和t值分别为
: =0
SE( )=117.1579 ;t( )=1.604113取
查t分布表得自由度为n-2=18-2=16的临界值 (16)=2.120>t( )=1.60411
未落在了拒绝域内,故假设成立
:=0
SE( )=0.056922;t( )=5.128460取
查t分布表得自由度为n-2=18-2=16的临界值 (16)=2.120<t( )=5.128460
SE( )=117.1579 ;t( )=1.604113;
SE( )=0.056922;t( )=5.128460
(3) =0.621759 F=26.30110 n=18
经济意义解释:
当家庭月平均收入每变动一单位时,家庭书刊年消费支出就同向变动0.291923个单位
4.参数显著性检验(对回归系数的t检验)
四.模型选择及原因
应选择多元线性回归模型
原因:多元线性回归模型对两种解释变量“家庭月平均收入”和“户主受教育年数”对被解释变量“家庭书刊年消费支出”的影响都有做分析,这样就能更全面的分析问题,结果的可信度也相对较高。
原因:多元线性回归模型对两种解释变量“家庭月平均收入”和“户主受教育年数”对被解释变量“家庭书刊年消费支出”的影响都有做分析,这样就能更全面的分析问题,结果的可信度也相对较高。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
关于计量经济模型选择问题的初探An Tentative Inquiry Into The Selection Of The EconometricalModels山东经济学院数理经济研究所2004级数量经济学专业硕士研究生陈鹏摘要:本文试图介绍计量经济学一些常用模型的函数形式,并且以计量软件SPSS作为分析工具,以拟合优度作为评判标准,来讨论最优的经济计量模型的选择问题。
关键字:计量经济模型,SPSS,拟合优度在研究经济变量之间的关系时,特别是初学者,通常首先想到的是选取线性回归模型。
这种做法虽然能把问题简单化,使之易于处理,甚至有时候能产生比较好的效果。
但总的来说,由于经济现象是纷繁复杂的,在很多情况下这么做,并不能比较准确地对客观经济的运行态势进行模拟。
在实际运用中,如果不问青红皂白地把所有计量模型的设定问题,都采用线性的形式,显然是行不通的。
比如把经济变量之间的非线性关系,直接用线性回归的方式去处理,这样得到的回归方程是无效的。
用它来进行经济分析、政策评价和经济预测,则没有丝毫价值,甚至带来负面影响。
为此我们必须根据实际问题进行具体分析,依据直觉和经验,建立与实际样本数据拟合较好的函数,再运用我们所学的知识进行参数估计和检验,使我们的成果与现实尽可能的接近。
本文试就对如何通过经济理论和经验,并借助计量软件进行模型的选择给予一般的说明。
一、计量经济学模型的主要几种函数形式。
(1)线性模型(Linear )。
它的一般形式是:12y x ββ=+ (1)线性函数我们大家已经耳熟能详。
这里我们不作过多介绍。
(2)抛物线模型(Quadratic )。
抛物线模型的一般形式为:212y x x βββ=++ (2)判断某种现象是否适合应用抛物线,可以利用“差分法”。
其步骤为:首先将样本观察值按x 的大小顺序排列,然后按以下两式计算x 和y 的一阶差分t x ∆、t y ∆以及y 的二阶差分2t y ∆。
(其中1t t t x x x -∆=-; 1t t t y y y -∆=-;21t t t y y y -∆=∆-∆)当t x ∆接近于一常数,而△2t y ∆的绝对值接近于常数时,Y 与X 之间的关系可以用抛物线模型近似加以反映。
(3)对数函数模型(Logrithmic )。
对数函数是指数函数的反函数,其方程形式为:01ln y x ββ=+ (3)对数函数的特点是随着X 的增大,X 的单 位变动对因变量Y 的影响效果不断递减。
(4)立方模型(Cubic )。
其一般形式为:230123y x x x ββββ=+++ (4)其扩展形式是多项式模型。
当所涉及的自变量只有一个时,所采用的多项式方程称为一元多项式,其一般形式为:2012p p y x x x ββββ=+++⋅⋅⋅⋅⋅⋅+多项式模型在非线性回归分析中占有重要的地位。
因为根据数学上级数展开的原理,任何曲线、曲面、超曲面的问题,在一定的范围内都能够用多项式任意逼近。
所以,当因变量与自变量之间的确实关系未知时,可以用适当幂次的多项式来近似反映。
(5)指数函数模型(Exponential ) 。
指数函数模型为:10x y e βεβ+= (5)这种曲线被广泛应用于描述社会经济现象的变动趋势。
例如产值、产量按一定比率增长,成本、原材料消耗按一定比例降低。
(6)倒数模型(Inverse )。
倒数模型的一般形式是:12(1/)y x ββ=+ (6)假如Y 随着X 的增加而增加(或减少),最初增加(或减少)很快,以后逐渐放慢并趋于稳定,则可以选用双曲线来拟合。
(7)幂函数模型(Power )。
幂函数模型的一般形式是:10y x ββ= (7)其扩展形式为12012pp y x x x ββββ=⋅⋅⋅⋅⋅⋅,这类函数的优点在于:方程中的参数可以直接反映因变量Y 对于某一个自变量的弹性。
所谓y 对于j x 的弹性,是指在其他情况不变的条件下,j x 变动1%时所引起y 变动的百分比。
弹性是一个无量纲的数值,它是经济定量分析中常用的一个尺度。
它在生产函数分析和需求函数分析中,得到了广泛的应用。
(8)逻辑曲线模型(Logistic )。
逻辑曲线方程一般形式为:101x L y e βεβ-+=+ (8) 逻辑曲线具有以下性质。
Y 是X 的非减函数,开始时随着X 的增加,Y 的增长速度也逐渐加快,但是Y 达到一定水平之后, 其增长速度又逐渐放慢。
最后无论X 如何增加,Y 只会趋近于L,而永远不会超过L 。
由于逻辑曲线的这一特点,它常被用来表现耐用消费品普及率的变化。
(9)增长曲线模型(Growth ):01x y e ββ+= (9) (10)S 曲线模型(S ):011x y eββ+= (10) (11)Compound 模型:01x y ββ=(11) 以上11种模型是SPSS 提供的模型。
当然我们也可以自己根据需要,设定其它形式的模型。
比如对数线性(Log-linrar ):12ln y x ββ=+;对数倒数:12ln (1/)y x ββ=+;对数对数(Log-log ):12ln ln y y ββ=+等等。
这些模型在实际经济问题也有比较广泛的应用,在此就不一一列出。
二、对模型的变换对于非线性回归模型,除了要考虑如何根据所要研究的问题的性质并结合实际的样本资料确定其具体形式外,还要考虑如何估计模型中的参数。
非线性回归模型最常用的方法仍然是最小二乘估计法,但需要根据模型的不同类型,作适当的变换。
许多具有实用价值的非线性回归函数,可以通过适当的变换,转化为线性回归函数,然后再利用线性回归分析的方法进行估计和检验。
常用的非线性函数的线性变换方法有以下几种:(1)倒数变换倒数变换是用新的变量来替换原模型中变量的倒数,从而使原模型变成线性模型的一种方法。
例如,对于双曲线函数,令*1/x x =代入方程式12(1/)y x ββ=+,得*01y x ββ=+,从而转化为一元线性回归模型。
(2)半对数变换这种方法主要应用于对数函数模型的线性变换。
对于对数函数模型01ln y x ββ=+,令*ln x x =,代入原方程,同样可得:*01y x ββ=+。
(3)双对数变换这种方法通过用新变量替换原模型中变量的对数,从而使原模型变换为线性模型。
例如,对幂函数模型12012pp y x x x ββββ=⋅⋅⋅⋅⋅⋅的两边求对数,01122ln ln ln ln ln p p y x x x ββββ=+++⋅⋅⋅⋅⋅⋅+,令*ln y y =,*00ln ββ=,*11ln x x =,……,*ln p p x x =则原函数变为****011p p y x x βββ=++⋅⋅⋅+然后我们仍然可以用线性回归方法解决。
三、模型的选择既然我们有多种模型可以选择,那么到底有没有一种标准去评判哪种模型是最适合的呢?下面就一个实例来说明这个问题。
我们就2003年我国城镇居民收入情况建立Y 对X 的回归模型。
表中资料共有16 组,x 是各组的人均生活费收入,Y 是各组的人均生活费支出。
表1人均生活费收入和人均生活费支出 (单位:元)从上图可以看出,Y 与X 之间并不是线性关系,因此我们不能用线性关系去设置函数模型。
为了选择合适的模型,我们可以多选几种,然后再进行比较,最后根据拟合情况确定所需要采用的模型。
不妨选择线性、立方、S曲线、增长曲线等几种模型进行拟合。
在此我们选择了SPSS所提供的11种函数。
SPSS 输出结果如下:MODEL: MOD_2.Independent: xUpperDependent Mth Rsq d.f. F Sigf bound b0 b1 b2 b3y LIN .927 14 178.32 .000 975.301 .6473 y LOG .873 14 95.91 .000 -20282 2954.27y INV .624 14 23.27 .000 6788.94 -7.E+06 y QUA .938 13 98.67 .000347.687 .9121 -2.E-05y CUB .942 12 64.59 .000920.363 .5005 5.2E-05 -4.E-09y COM .888 14 111.08 .000 1736.201.0002y POW .973 14 509.85 .0007.4312 .7480y S .820 14 63.63 .000 8.9017 -2024.8 y GRO .888 14 111.08 .0007.4595 .0002y EXP .888 14 111.08 .0001736.20 .0002y LGS .888 14 111.08 .000 . .0006 .9998由于Power (10y x ββ=)模型的2R =0.973,拟合最好,我们选用Power 模型作预测。
其有关数据运用SPSS 处理如下:MODEL: MOD_4._Dependent variable.. y Method.. POWERListwise Deletion of Missing DataMultiple R .98655R Square .97327Adjusted R Square .97137Standard Error .09016Analysis of Variance:DF Sum of Squares Mean SquareRegression 1 4.1440922 4.1440922Residuals 14 .1137936 .0081281F = 509.84660 Signif F = .0000-------------------- Variables in the Equation --------------------Variable B SE B Beta T Sig Tx .747970 .033126 .98654722.580 .0000(Constant) 7.431218 2.0997093.539 .0033由上可得模型为:0.748,X的t值为22.58,很显著,模型效果较好。
y x7.43我们可以在实际生活中运用它进行预测。
总之,我们在选择一个计量模型的时候,不能想当然。
必须以经济理论为指导,以经济事实为基础,以科学的方法为手段,运用计量软件等现代化工具进行分析、比较,从而选择相对精确的模型来。
并且在实际运用中去不断检验,不断修正,使其能更准确地反映经济变量之间的数量关系。
主要参考文献:张文璋. 《实用统计分析方法与SPSS应用》(初稿),2000.拉姆·拉玛纳山.《应用经济计量学》第五版[M],机械工业出版社,2003.宋廷山,金玉国等.2003《经济计量学》[M].内蒙古大学出版社,2003.。