阿尔法狗-课件·PPT
人工智能AlphaGo

——给ATM研究的一些启示
I.
AlphaGo的成长之路
II. AlphaGo中的核心AI技术 III. AI在ATM中的应用实例及启示
I.
AlphaGo的成长之路
I.
AlphaGo的成长之路
这是什么狗?
I.
AlphaGo的成长之路
阿尔法围棋(AlphaGo)是第一个击败人类职业围 棋选手、第一个战胜围棋世界冠军的人工智能程序,由 谷歌(Google)旗下DeepMind公司戴密斯·哈萨比斯 领衔的团队开发。其主要工作原理是“深度学习”。
III.
AI在ATM中的应用实例及启示
III.
AI在ATM中的应用实例及启示
可以考虑使用AI技术的问的特点: 战术性的、决策性的、规则相对明确的、信息完全的、经典算法难以解决的 使用AI技术解决此类问题的难点:
模型简化程度和模型贴合实际程度间的权衡问题、静态问题到动态问题的延伸、
单一个体到多个体的延伸 如:实时改航策略,离场时隙分配,实时地面等待策略…… 注:该处对AI技术的启示仅从AlphaGo引申而出,AI技术在大数据等领域 亦有重大潜力
II.
AlphaGo中的核心AI技术
III.
AI在ATM中的应用实例及启示
III.
AI在ATM中的应用实例及启示
III.
AI在ATM中的应用实例及启示
Module of flow balancing Module of monitoring and scenario forecast Module for evaluation and decision support
2017年5月,以3:0战胜排名世界第一的世界围棋冠军柯洁。
阿尔法狗的工作原理及核心技术

阿尔法狗的工作原理及核心技术阿尔法围棋(AlphaGo)是第一个击败人类职业围棋选手、第一个战胜围棋世界冠军的人工智能程序,由谷歌(Google)旗下DeepMind公司戴密斯哈萨比斯领衔的团队开发。
那么阿尔法狗的工作原理是什么?相关技术又有哪些呢?下面让我们一起来看看。
阿尔法狗工作原理阿尔法围棋(AlphaGo)为了应对围棋的复杂性,结合了监督学习和强化学习的优势。
它通过训练形成一个策略网络(policynetwork),将棋盘上的局势作为输入信息,并对所有可行的落子位置生成一个概率分布。
然后,训练出一个价值网络(valuenetwork)对自我对弈进行预测,以-1(对手的绝对胜利)到1(AlphaGo的绝对胜利)的标准,预测所有可行落子位置的结果。
这两个网络自身都十分强大,而阿尔法围棋将这两种网络整合进基于概率的蒙特卡罗树搜索(MCTS)中,实现了它真正的优势。
新版的阿尔法围棋产生大量自我对弈棋局,为下一代版本提供了训练数据,此过程循环往复。
在获取棋局信息后,阿尔法围棋会根据策略网络(policynetwork)探索哪个位置同时具备高潜在价值和高可能性,进而决定最佳落子位置。
在分配的搜索时间结束时,模拟过程中被系统最频繁考察的位置将成为阿尔法围棋的最终选择。
在经过先期的全盘探索和过程中对最佳落子的不断揣摩后,阿尔法围棋的搜索算法就能在其计算能力之上加入近似人类的直觉判断。
围棋棋盘是19x19路,所以一共是361个交叉点,每个交叉点有三种状态,可以用1表示黑子,-1表示白字,0表示无子,考虑到每个位置还可能有落子的时间、这个位置的气等其他信息,我们可以用一个361*n维的向量来表示一个棋盘的状态。
我们把一个棋盘状态向量记为s。
当状态s下,我们暂时不考虑无法落子的地方,可供下一步落子的空间也是361个。
我们把下一步的落子的行动也用361维的向量来表示,记为a。
这样,设计一个围棋人工智能的程序,就转换成为了,任意给定一个s状态,寻找最好的应对策略a,让你的程序按照这个策略走,最后获得棋盘上最大的地盘。
AlphaGo介绍(思维导图)
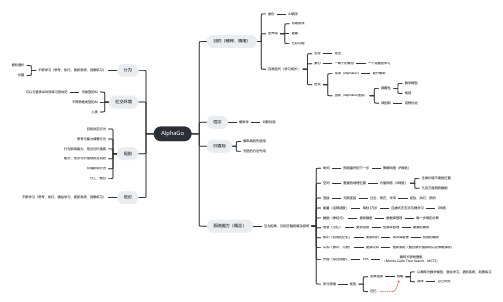
AlphaGo目的(精神、情绪)身份AI棋手世界观有限游戏输赢无穷可能自我迭代(学习成长)生存胜出繁衍一辈子的概念一个完整的学习进化传承(AlphaGo)提升概率创新(AlphaGo团队)颠覆性数学模型规则微创新流程优化信念概率学判断标准价值观概率高的先使用先进的方法先用系统能力(概念)互为因果、互相交融的复杂系统时间预测最好的下一步策略网络(P网络)空间重要的地理位置价值网络(V网络)去掉价值不高的位置几百万盘棋的数据连接无限连接过去、现在、未来经验、执行、预判能量(运算速度)每秒1万步自虐式左右手互搏学习S网络数据(神经元)更新数据数据库管理每一步棋的计算信息(记忆)更新信息信息库管理输赢的案例知识(有用的记忆)更新知识知识库管理有用的案例认知(意识、习惯)更新认知更新系统(整合新价值系统以及策略系统)价值(综合技能)PVS蒙特卡罗树搜索(Monte Carlo Tree Search,MCTS)多元思维优势运算速度战略以概率为数学模型,强化学习。
更新系统、刻意练习战术自己对弈记忆行为不断学习(思考、执行。
更新系统、刻意练习)复利增长长期社交环境同类型的AI 可以与更多AI对弈练习的地方不同思维类型的AI人类规则目的决定行为思考与能力调整行为行为影响能力、信念与价值观能力、信念与价值观改变目的环境影响行为分工、整合结论不断学习(思考、执行。
精益学习、更新系统、刻意练习)。
AlphaGo的基本原理

AlphaGo的基本原理全世界只有3.14 % 的人关注了数据与算法之美继 AlphaGo于2015年8月以5-0战胜三届欧洲冠军樊麾、2016年3月以4-1击败世界顶级棋手李世石后,今年1月,AlphGo的升级版本Master横扫各路高手,取得60比0的惊人战绩。
20 年前IBM 深蓝(Deep Blue)计算机击败国际象棋冠军卡斯帕罗夫的情景还历历在目,短短2年时间,人工智能在围棋领域又创造了人机对抗历史上的新里程碑。
根据谷歌DeepMind团队发表的论文,我们可以窥探到AlphaGo 的基本设计思路。
任何完全信息博弈都无非是一种搜索。
搜索的复杂度取决于搜索空间的宽度(每步的选择多寡)和深度(博弈的步数)。
对于围棋,宽度约为250,深度约为150。
AlphaGo用价值网络(value network)消减深度,用策略网络(policy network)消减宽度,从而极大地缩小了搜索范围。
所谓价值网络,是用一个“价值”数来评估当前的棋局。
如果我们把棋局上所有棋子的位置总和称为一个“状态”,每个状态可能允许若干不同的后续状态。
所有可能状态的前后次序关系就构成了所谓的搜索树。
一个暴力的搜索算法会遍历这个搜索树的每一个子树。
但是,其实有些状态是较容易判断输赢的,也就是评估其“价值”。
我们把这些状态用价值表示,就可以据此省略了对它所有后续状态的探索,即利用价值网络削减搜索深度。
所谓策略,是指在给定棋局,评估每一种应对可能的胜率,从而根据当前盘面状态来选择走棋策略。
在数学上,就是估计一个在各个合法位置上下子获胜的可能的概率分布。
因为有些下法的获胜概率很低,可忽略,所以用策略评估就可以消减搜索树的宽度。
更通俗地说,所谓“价值”就是能看懂棋局,一眼就能判断某给定棋局是不是能赢,这是个偏宏观的评估。
所谓的“策略”,是指在每一步博弈时,各种选择的取舍,这是个偏微观的评估。
AlphaGo利用模拟棋手、强化自我的方法,在宏观(价值评估)和微观(策略评估)两个方面提高了探索的效率。
中小学人工智能科普PPT课件

人工智能的应用-工 业 制 造
如品 质 监 控 是 生 产 过 程 中 最 重 要的环节,传统生产线上都安 排大量的检测工人用肉眼进行 质量检测。这种方式不仅容易 漏检和误判,更会给工人造成 疲劳飭害。因此很多任务业产 品公司开发使用人工智能的视 觉工具,帮助工厂自动检测出 形态各异的缺陷·
工业制造系统必须变得 更加“聪明",而人工智 能则是提升工业制造系 统的最强动
70 年 代 中 期 , 人 工 智 能 还 是 难 以 满 足 社 会 对 这 个领 域 不切实际的期待,因此进入了第一个冬天。
1963 年 , 美 国 高 等 研 究 计 划 局 投 入 两 百 万 美 元 给 麻 省 理工学院,培养了早期的计算机科学和人工智能人 才。
人工智能的出现及发展
人 工 智 能 的 第 = 次 浪 潮 (1980 -- 1987)
人工智能的出现及发展
人 工 智 能 的 第 一 次 浪 潮 ( 1956 -- 1974 )
1964 -- 1966 年 , 约 瑟 夫 · 维 森 鲍 姆 ( JosephWeizenbaum ) 教 授 建 立 了 世 界 上 第 一 个 宣 然 语 言 对 话 程 序 ELIZA 可 以 通 过 简 单 的 模 式 匹 配 和 对 话 规则与人聊夭。
有些新技术还能通过 多张医疗影像建出人 体官的三维模型,确 保医生手术更加精 准·
人工智能的应用-智 能 客 服
随着互联网和屯子商务的发展,咙们 和商家的交流变得越来越多元,为了 因应这种挑战,很多企业开始引入人 工智能技术打造智能客服系统。
智能客服可以像人一样和客户交流 沟通,进行准确得体且个性化的回 应,提升客户的体验。
“智能+”未来
【阿尔法狗】AlphaGo原理

【阿尔法狗】AlphaGo原理最近我仔细看了下AlphaGo在《自然》杂志上发表的文章,写一些分析给大家分享。
AlphaGo这个系统主要由几个部分组成:1. 走棋网络(Policy Network),给定当前局面,预测/采样下一步的走棋。
2. 快速走子(Fast rollout),目标和1一样,但在适当牺牲走棋质量的条件下,速度要比1快1000倍。
3. 估值网络(Value Network),给定当前局面,估计是白胜还是黑胜。
4. 蒙特卡罗树搜索(Monte Carlo Tree Search,MCTS),把以上这三个部分连起来,形成一个完整的系统。
我们的DarkForest和AlphaGo同样是用4搭建的系统。
DarkForest 较AlphaGo而言,在训练时加强了1,而少了2和3,然后以开源软件Pachi的缺省策略(default policy)部分替代了2的功能。
以下介绍下各部分。
1.走棋网络:走棋网络把当前局面作为输入,预测/采样下一步的走棋。
它的预测不只给出最强的一手,而是对棋盘上所有可能的下一着给一个分数。
棋盘上有361个点,它就给出361个数,好招的分数比坏招要高。
DarkForest在这部分有创新,通过在训练时预测三步而非一步,提高了策略输出的质量,和他们在使用增强学习进行自我对局后得到的走棋网络(RL network)的效果相当。
当然,他们并没有在最后的系统中使用增强学习后的网络,而是用了直接通过训练学习到的网络(SLnetwork),理由是RLnetwork输出的走棋缺乏变化,对搜索不利。
有意思的是在AlphaGo为了速度上的考虑,只用了宽度为192的网络,而并没有使用最好的宽度为384的网络(见图2(a)),所以要是GPU更快一点(或者更多一点),AlphaGo肯定是会变得更强的。
所谓的0.1秒走一步,就是纯粹用这样的网络,下出有最高置信度的合法着法。
这种做法一点也没有做搜索,但是大局观非常强,不会陷入局部战斗中,说它建模了“棋感”一点也没有错。
【推荐】关于阿尔法狗的知识-范文模板 (3页)

本文部分内容来自网络整理,本司不为其真实性负责,如有异议或侵权请及时联系,本司将立即删除!== 本文为word格式,下载后可方便编辑和修改! ==关于阿尔法狗的知识朋友圈一度被阿尔法狗(AlphaGo)大战中国最强棋手柯洁刷屏,那么关于阿尔法狗的知识你知道多少?下面小编为大家整理了相关关于阿尔法狗的知识,希望大家喜欢。
“阿尔法狗”们离我们还有多远宇宙,137亿可观测光年,10^80量级微观粒子总数。
国际象棋,8x8路,64个落子点,10^46种变化,1997年,DeepBlue(深蓝)击败了人类最伟大的国际象棋大师卡斯帕罗夫。
围棋,19X19路,361个落子点,所有可能的变化数量约10^176,远远超过了已知宇宙中微观粒子总和。
“阿尔法狗”(AlphaGo)是一款围棋人工智能程序。
通过两个不同“神经网络大脑”(棋局评估器、落子选择器)合作来改进下棋。
201X年,AlphaGO(阿尔法狗)击败曾经世界第一,目前世界排名第五的李世石。
一时间,关于人工智能或悲观或乐观的各种声音在网络上炸开了锅。
撇开这些对机器人展开的各种讨论不说,其实,高度的人工智能已经在慢慢渗透进无人机行业。
随着人工智能的飞速发展,神经元网络的进步,以及对人脑运作方式的逐步了解,发展出具有自主意识,超越人类智慧的AI已经越来越成为现实。
再加上无人机不用考虑过载、缺氧、疲劳等人类自身的缺陷,未来的无人机很有可能会代替人类进行作业。
亚马逊、谷歌等公司都在自主研发无人机产品,用于快速的货物、食物及药物等交递。
但是,目前无人机缺乏感知规避能力,无人机飞行范围必须在人类操作员的视觉范围内。
鉴于计算芯片过于耗电,目前无人机只能依靠短程传感器避免碰撞。
因此,实现无人机人工智能化的关键在于动物大脑仿生学。
由此,爱达荷州的博伊西科技利用忆阻器和记忆电阻器,建立感知规避系统,营造仿生脉冲,模拟生物大脑突触。
该科技或将用于学习系统,制造人工智能芯片。
此外,系统还可以识别云、鸟、建筑物等,估算物体距离,预计将于今年后半年用于无人机智能化,进行首次试飞。
《机器人技术概论》教学课件 模块7 机器人应用领域

五、 其他非工业应用
阿尔法狗(AlphaGo)围棋机器人是第一个击败人类职业围棋选手、第一个战胜围棋世界冠军的人工智能机 器人,它由谷歌旗下DeepMind公司戴密斯·哈萨比斯领衔的团队开发。
阿尔法狗围棋机器人用到了很多新技术,如神经网络、深度学习、 蒙特卡洛树搜索法等,使其实力有了实质性飞跃。美国脸书公司 “黑暗森林”围棋软件的开发者田渊栋在网上发表分析文章说,阿 尔法狗围棋机器人系统主要由几个部分组成: ① 策略网络(Policy Network):给定当前局面,预测并采样下一 步的走棋;
单元2
机器人在工业领域的应用
一、 搬运码垛应用
搬运码垛应用
搬运码垛应用
工业机器人发明到现在已经有五六十年了,历史上第一台工业机器人是用于通用汽车的 材料处理工作。“吃苦耐劳”“不要工资”的工业机器人在各个行业开花结果、广泛应 用。 搬运作业就是将工件从一个加工位置移到另一个加工位置,许多自动化生产线都需要使 用搬运机器人进行上下料、搬运以及码垛等操作,如图7-7所示。最早的搬运机器人出 现在1960年的美国,首次用于搬运作业的两种机器人分别为Versatran和Unimate。
二、 医疗应用
医用机器人是用于医院、诊所的医疗或辅助医疗的机器人。目前常见的医用机器人主要有运送物品的机器人、 移动病人的机器人、临床医疗用的机器人和为残疾人服务的机器人等。
“护士助手”机器人是自主式机器人,它不需要有线制导, 也不需要事先做计划,一旦编好程序,它随时可以完成以 下各项任务:运送医疗器材和设备,为病人送饭,送病历、 报表及信件,运送药品、运送试验样品及试验结果,在医 院内部送邮件及包裹。这种机器人由行走部分、行驶控制 器及大量的传感器组成。
二、 医疗应用
医用机器人是用于医院、诊所的医疗或辅助医疗的机器人。目前常见的医用机器人主要有运送物品的机器人、 移动病人的机器人、临床医疗用的机器人和为残疾人服务的机器人等。
阿尔法狗围棋十诀之一:没事点三三
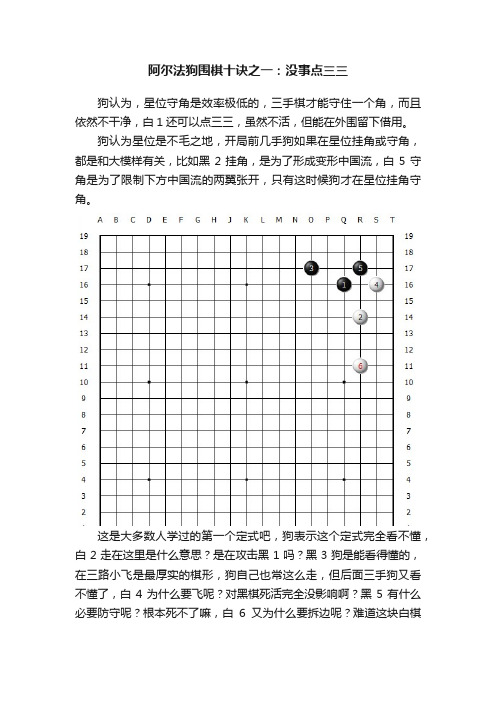
阿尔法狗围棋十诀之一:没事点三三狗认为,星位守角是效率极低的,三手棋才能守住一个角,而且依然不干净,白1还可以点三三,虽然不活,但能在外围留下借用。
狗认为星位是不毛之地,开局前几手狗如果在星位挂角或守角,都是和大模样有关,比如黑2挂角,是为了形成变形中国流,白5守角是为了限制下方中国流的两翼张开,只有这时候狗才在星位挂角守角。
这是大多数人学过的第一个定式吧,狗表示这个定式完全看不懂,白2走在这里是什么意思?是在攻击黑1吗?黑3狗是能看得懂的,在三路小飞是最厚实的棋形,狗自己也常这么走,但后面三手狗又看不懂了,白4为什么要飞呢?对黑棋死活完全没影响啊?黑5有什么必要防守呢?根本死不了嘛,白6又为什么要拆边呢?难道这块白棋的安全有问题吗?看狗疑惑不解,旁边有人类棋手过来对狗解释说:这几步棋不是什么死活问题,都是价值很大的棋,狗听了目瞪口呆:价值很大?白棋不过来挂角,让黑棋自己围,黑连花几手能围几目棋?白棋挂角的时候,黑棋小飞防守一下,后面都脱先,让白棋可着劲的在角上飞,尖三三,白连花几手能围几目棋?你告诉我这里价值很大?人类棋手说:那你说,当前四手占完四个空角之后,第五手走在哪儿价值最大?狗说:构筑大模样或者小目守角挂角,价值都很大,难分伯仲。
人类棋手说:嗯,我赞同,接下来什么价值最大?狗说:接下来是点三三。
狗咬狗50盘棋第三盘的实战图人类棋手:啊?为什么?狗说:因为布局走到这里,棋盘上没有可以攻杀的孤棋,也没有哪里可以马上能成大模样,此时最大的官子难道不是点三三吗?人类棋手:官子……好吧,单纯从目数上说,点三三确实是此时目数最大的,这个我确实无法反驳,可是…狗:那不就行了?围棋是比谁占的空更多,当然是哪里目数最大就下在哪里。
人类棋手:可是,点三三让对方成了一道外势,不怕影响全局吗?狗:缩在一个角上的外势能有什么全局影响?人类棋手:至少可以拆边成空啊。
狗:拆多大?拆小了是不是围空效率很低?拆大了我打入进去,你这道外势是不是自身不干净,没法攻击我?人类棋手:怎么没法攻击你?来,咱俩摆一盘试试。
【公务员考试】阿尔法狗的秘密

【公务员考试】阿尔法狗的秘密一、阿尔法狗简介绍阿尔法围棋(AlphaGo)是第一个击败人类职业围棋选手、第一个战胜围棋世界冠军的人工智能程序,其主要工作原理是“深度学习”。
阿尔法围棋是一款围棋人工智能程序,由谷歌旗下DeepMind公司的戴维·西尔弗、艾佳·黄和戴密斯·哈萨比斯与他们的团队开发,这个程序利用“价值网络”去计算局面,用“策略网络”去选择下子。
训练这些深度神经网络的,是对人类专业棋局的监督学习以及让它和自己对弈的增强学习。
2016年9月Google 宣布即将把支持AlphaGo赢得围棋人机大战的深度神经网络应用于Google翻译中,让机器翻译更加通顺流畅,表意清晰,该系统仅应用于中文到英文的语言翻译。
2017年5月27日,中国围棋峰会人机大战,最终,柯洁九段执白209手中盘负围棋人工智能AlphaGo。
柯洁以0比3的总比分落败。
二、阿尔法狗工作原理阿尔法围棋(AlphaGo)是一款围棋人工智能程序。
其主要工作原理是“深度学习”。
“深度学习”是指多层的人工神经网络和训练它的方法。
一层神经网络会把大量矩阵数字作为输入,通过非线性激活方法取权重,再产生另一个数据集合作为输出。
这就像生物神经大脑的工作机理一样,通过合适的矩阵数量,多层组织链接一起,形成神经网络“大脑”进行精准复杂的处理,就像人们识别物体标注图片一样。
阿尔法围棋系统主要由几个部分组成:一、策略网络,给定当前局面,预测并采样下一步的走棋;二、快速走子,目标和策略网络一样,但在适当牺牲走棋质量的条件下,速度要比策略网络快1000倍;三、价值网络,给定当前局面,估计是白胜概率大还是黑胜概率大;四、蒙特卡洛树搜索,把以上这三个部分连起来,形成一个完整的系统。
(一)两个大脑阿尔法围棋(AlphaGo)是通过两个不同神经网络“大脑”合作来改进下棋。
这些“大脑”是多层神经网络,跟那些Google图片搜索引擎识别图片在结构上是相似的。
从阿尔法狗得到的启示

从阿尔法狗得到的启示近年来,人工智能技术的发展日新月异,其中最具代表性的就是Google旗下的阿尔法狗。
阿尔法狗是一个基于深度强化学习的计算机程序,在围棋领域展现了惊人的实力,战胜了多位世界级围棋大师。
从阿尔法狗的成功中,我们可以得到一些启示。
阿尔法狗的成功彰显了人工智能技术的巨大潜力。
阿尔法狗通过大量的数据学习和自我训练,不断改进自身的围棋水平。
这表明,通过大数据和机器学习,人工智能可以具备超越人类的智慧和能力。
这对我们来说是一个重要的启示,人工智能技术有着广阔的应用前景,可以帮助我们解决许多复杂的问题。
阿尔法狗的成功也告诉我们,团队合作是取得突破的重要因素。
阿尔法狗的开发团队由众多领域的专家组成,他们各自担当着不同的角色,共同努力。
正是这种合作精神,使得阿尔法狗能够在围棋领域取得突破性的成果。
这给我们提供了一个宝贵的经验教训,只有团结协作,才能充分发挥每个人的优势,实现更大的突破。
阿尔法狗的成功还揭示了深度强化学习的重要性。
深度强化学习是一种结合了深度学习和强化学习的方法,通过不断试错和优化,不断提高系统性能。
阿尔法狗正是通过深度强化学习,不断优化自身的围棋水平,最终取得了巨大的成功。
这对我们来说是一个重要的启示,我们可以借鉴深度强化学习的思想,通过不断试错和学习,提升自己的能力和技术水平。
阿尔法狗的胜利还告诉我们,坚持不懈是取得成功的关键。
阿尔法狗在与人类围棋大师的对决中,遇到了许多困难和挑战,但它始终没有放弃,坚持不懈地努力。
正是这种坚持不懈的精神,使得阿尔法狗最终战胜了强大的对手。
这给我们带来了一个重要的启示,无论面对什么样的困难和挑战,只要坚持不懈,就一定能够取得成功。
阿尔法狗的成功也引发了对人工智能对人类的影响和未来发展的思考。
尽管阿尔法狗在围棋领域取得了巨大的成就,但它仍然是一个计算机程序,不能具备人类的情感和创造力。
这意味着,人工智能技术的发展仍然需要人类的指导和控制,不能盲目追求技术的进步,而忽视了对人类的影响。