第二章典型神经网络1——感知机
神经网络的发展历程与应用

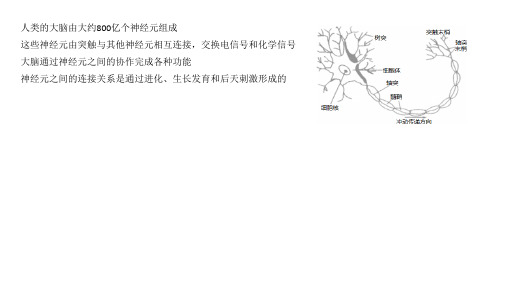
神经网络的发展历程与应用神经网络是一种仿生的人工智能技术,它模拟了人类大脑中神经元之间的连接和信息传递方式,具有自学习和适应性强的特点。
神经网络的发展历程可以追溯到上世纪50年代,经过了长期的理论研究和应用实践,如今已经成为了人工智能领域中的重要技术之一。
本文将从神经网络的发展历程、基本模型、优化算法以及应用领域等方面进行介绍。
一、神经网络的发展历程神经网络的发展历程可以分为三个阶段,分别是感知机、多层前馈神经网络和深度学习。
1. 感知机感知机是神经网络的起源,由美国心理学家罗森布拉特于1957年提出。
感知机是一种单层神经网络,由若干感知器(Perceptron)组成。
每个感知器接收输入信号并进行加权和,然后经过一个阈值函数得到输出。
该模型的最大缺点是只能处理线性可分问题,无法解决非线性问题。
2. 多层前馈神经网络为了克服感知机的局限性,科学家们开始尝试使用多层前馈神经网络来处理非线性问题。
多层前馈神经网络由输入层、隐藏层和输出层组成。
每个神经元都有一个激活函数,用于将输入信号转换为输出。
这种结构可以处理非线性问题,并且可以通过反向传播算法来训练网络参数。
多层前馈神经网络在图像识别、语音识别、自然语言处理等领域得到了广泛应用。
3. 深度学习深度学习是指使用多层神经网络来学习高层次特征表示的一种机器学习方法。
深度学习在计算机视觉、自然语言处理等领域有着广泛的应用。
其中最著名的就是卷积神经网络(CNN)和循环神经网络(RNN)。
卷积神经网络主要用于图像识别和分类问题,循环神经网络主要用于序列预测和语言建模。
二、神经网络的基本模型神经网络的基本模型可以分为三类,分别是前馈神经网络、反馈神经网络和自组织神经网络。
1. 前馈神经网络前馈神经网络是指信息只能从输入层到输出层流动的神经网络。
其中最常用的是多层前馈神经网络,它由多个隐藏层和一个输出层组成。
前馈神经网络的训练主要使用反向传播算法。
2. 反馈神经网络反馈神经网络是指信息可以从输出层到输入层循环反馈的神经网络。
感知机模型名词解释

感知机模型名词解释
感知机模型是一种简单的机器学习算法,属于监督学习的一种。
它由一层神经元组成,用于二元分类任务。
感知机模型主要用于将输入向量映射到某个特定的输出类别。
在训练过程中,模型根据输入特征向量和相应的标签进行调整,以便能够准确地对未知样本进行分类。
感知机模型的基本结构包括输入向量、权重向量和偏置项。
每个输入特征向量与相应的权重进行相乘,并将结果相加,再加上偏置项。
然后,将这个结果输入到激活函数中,激活函数一般采用阶跃函数或者sigmoid函数。
最后,根据激活函数的输出确定输入属于哪个类别。
感知机模型的训练过程利用了梯度下降算法。
首先,随机初始化权重向量和偏置项。
然后,遍历训练数据集,对于每个样本逐步更新权重和偏置项,直到达到停止条件。
更新的规则是通过计算预测输出与真实标签之间的误差,并将误差乘以学习率后加到权重和偏置项上。
然而,感知机模型存在一些限制。
它只能处理线性可分的数据集,对于非线性可分的数据集无法得到很好的结果。
为了解决这个问题,多层感知机模型(即神经网络)被提出。
它通过引入隐藏层和多个神经元来学习复杂的非线性关系。
总结而言,感知机模型通过简单的神经元结构和梯度下降算法,实现了对输入样本的分类任务。
虽然它的应用范围有限,但对于一些简单的分类问题仍然具有一定的实用性。
神经网络(NeuralNetwork)

神经⽹络(NeuralNetwork)⼀、激活函数激活函数也称为响应函数,⽤于处理神经元的输出,理想的激活函数如阶跃函数,Sigmoid函数也常常作为激活函数使⽤。
在阶跃函数中,1表⽰神经元处于兴奋状态,0表⽰神经元处于抑制状态。
⼆、感知机感知机是两层神经元组成的神经⽹络,感知机的权重调整⽅式如下所⽰:按照正常思路w i+△w i是正常y的取值,w i是y'的取值,所以两者做差,增减性应当同(y-y')x i⼀致。
参数η是⼀个取值区间在(0,1)的任意数,称为学习率。
如果预测正确,感知机不发⽣变化,否则会根据错误的程度进⾏调整。
不妨这样假设⼀下,预测值不准确,说明Δw有偏差,⽆理x正负与否,w的变化应当和(y-y')x i⼀致,分情况讨论⼀下即可,x为负数,当预测值增加的时候,权值应当也增加,⽤来降低预测值,当预测值减少的时候,权值应当也减少,⽤来提⾼预测值;x为正数,当预测值增加的时候,权值应当减少,⽤来降低预测值,反之亦然。
(y-y')是出现的误差,负数对应下调,正数对应上调,乘上基数就是调整情况,因为基数的正负不影响调整情况,毕竟负数上调需要减少w的值。
感知机只有输出层神经元进⾏激活函数处理,即只拥有⼀层功能的神经元,其学习能⼒可以说是⾮常有限了。
如果对于两参数据,他们是线性可分的,那么感知机的学习过程会逐步收敛,但是对于线性不可分的问题,学习过程将会产⽣震荡,不断地左右进⾏摇摆,⽽⽆法恒定在⼀个可靠地线性准则中。
三、多层⽹络使⽤多层感知机就能够解决线性不可分的问题,输出层和输⼊层之间的成为隐层/隐含层,它和输出层⼀样都是拥有激活函数的功能神经元。
神经元之间不存在同层连接,也不存在跨层连接,这种神经⽹络结构称为多层前馈神经⽹络。
换⾔之,神经⽹络的训练重点就是链接权值和阈值当中。
四、误差逆传播算法误差逆传播算法换⾔之BP(BackPropagation)算法,BP算法不仅可以⽤于多层前馈神经⽹络,还可以⽤于其他⽅⾯,但是单单提起BP算法,训练的⾃然是多层前馈神经⽹络。
神经网络学习笔记2-多层感知机,激活函数

神经⽹络学习笔记2-多层感知机,激活函数1多层感知机
定义:多层感知机是在单层神经⽹络上引⼊⼀个或多个隐藏层,即输⼊层,隐藏层,输出层
2多层感知机的激活函数:
如果没有激活函数,多层感知机会退化成单层
多层感知机的公式: 隐藏层 H=XW h+b h
输出层 O=HW0+b0=(XW h+b h)W0+b0=XW h W0+b0W0+b0
其中XW h W0相当于W,b0W0+b0相当于b,即WX+b的形式,与单层的同为⼀次函数,因此重新成为了单层
3激活函数的作⽤
(1)让多层感知机成为了真正的多层感知机,否则等于⼀层的感知机
(2)引⼊⾮线性,使⽹络逼近了任意的⾮线性函数,弥补了之前单层的缺陷
4激活函数的特质
(1) 连续可导(允许少数点不可导),便于数值优化的⽅法学习⽹络参数
(2)激活函数尽可能简单,提⾼计算效率
(3)激活函数的导函数的导函数的值域要在合适的区间,否则影响训练的稳定和效率
5 常见的激活函数
1 sigmod型
常见于早期的神经⽹络,RNN和⼆分类项⽬,值域处于0到1,可以⽤来输出⼆分类的概率
弊端:处于饱和区的函数⽆法再更新梯度,向前传播困难
2 tahn(双曲正切)
3 ReLu(修正线性单元)
最常⽤的神经⽹络激活函数,不存在饱和区,虽然再z=0上不可导,但不违背激活函数的特质(允许在少数点上不可导),⼴泛运⽤于卷积⽹络等。
《人工神经网络:模型、算法及应用》习题参考答案

习题2.1什么是感知机?感知机的基本结构是什么样的?解答:感知机是Frank Rosenblatt在1957年就职于Cornell航空实验室时发明的一种人工神经网络。
它可以被视为一种最简单形式的前馈人工神经网络,是一种二元线性分类器。
感知机结构:2.2单层感知机与多层感知机之间的差异是什么?请举例说明。
解答:单层感知机与多层感知机的区别:1. 单层感知机只有输入层和输出层,多层感知机在输入与输出层之间还有若干隐藏层;2. 单层感知机只能解决线性可分问题,多层感知机还可以解决非线性可分问题。
2.3证明定理:样本集线性可分的充分必要条件是正实例点集所构成的凸壳与负实例点集构成的凸壳互不相交.解答:首先给出凸壳与线性可分的定义凸壳定义1:设集合S⊂R n,是由R n中的k个点所组成的集合,即S={x1,x2,⋯,x k}。
定义S的凸壳为conv(S)为:conv(S)={x=∑λi x iki=1|∑λi=1,λi≥0,i=1,2,⋯,k ki=1}线性可分定义2:给定一个数据集T={(x1,y1),(x2,y2),⋯,(x n,y n)}其中x i∈X=R n , y i∈Y={+1,−1} , i=1,2,⋯,n ,如果存在在某个超平面S:w∙x+b=0能够将数据集的正实例点和负实例点完全正确地划分到超平面的两侧,即对所有的正例点即y i=+1的实例i,有w∙x+b>0,对所有负实例点即y i=−1的实例i,有w∙x+b<0,则称数据集T为线性可分数据集;否则,称数据集T线性不可分。
必要性:线性可分→凸壳不相交设数据集T中的正例点集为S+,S+的凸壳为conv(S+),负实例点集为S−,S−的凸壳为conv(S−),若T是线性可分的,则存在一个超平面:w ∙x +b =0能够将S +和S −完全分离。
假设对于所有的正例点x i ,有:w ∙x i +b =εi易知εi >0,i =1,2,⋯,|S +|。
python人工智能课程设计

python人工智能课程设计一、课程目标知识目标:1. 学生能理解人工智能的基本概念,掌握Python编程语言在人工智能中的应用。
2. 学生能掌握使用Python标准库和第三方库进行数据处理、图像处理和自然语言处理的基本方法。
3. 学生能了解常见的人工智能算法,如机器学习、深度学习等,并理解其基本原理。
技能目标:1. 学生能运用Python编程实现简单的人工智能应用,如聊天机器人、图像识别等。
2. 学生能通过实践操作,掌握数据预处理、模型训练和模型评估的基本步骤,具备初步的问题解决能力。
情感态度价值观目标:1. 学生培养对人工智能技术的兴趣,激发创新意识和探索精神。
2. 学生能够意识到人工智能在生活中的应用,认识到人工智能对社会发展的积极影响,树立正确的科技观。
3. 学生在团队合作中,学会沟通与协作,培养解决问题的能力和团队精神。
课程性质:本课程为选修课,旨在帮助学生了解人工智能的基本知识,提高编程实践能力。
学生特点:学生为高中生,具备一定的数学基础和编程能力,对新鲜事物充满好奇心。
教学要求:结合学生特点,注重理论与实践相结合,强调动手实践,提高学生的实际操作能力。
在教学过程中,关注学生的个体差异,因材施教,使学生在掌握基本知识的基础上,发挥自身潜能。
通过小组合作、讨论交流等形式,培养学生的团队协作能力和沟通能力。
最终实现课程目标,为学生后续学习打下坚实基础。
二、教学内容1. Python基础回顾:变量、数据类型、运算符、条件语句、循环语句、函数、列表、字典等。
2. 人工智能概述:人工智能发展历程、应用领域、未来发展趋势。
3. 数据处理与分析:- 数据预处理:数据清洗、数据整合、特征工程。
- 数据分析:使用Pandas、NumPy等库进行数据分析。
4. 机器学习基础:- 监督学习:线性回归、逻辑回归、决策树、随机森林。
- 无监督学习:聚类、降维。
5. 深度学习基础:- 神经网络:感知机、反向传播算法。
2012神经网络指导

第三部分 神经网络控制技术一 感知机1) 感知机概念感知机是最早被设计并被实现的人工神网络。
感知器是一种非常特殊的神经网络,它在人工神经网络的发展历史上有着非常重要的地位,尽管它的能力非常有限,主要用于线性分类。
图1 单神经元结构模型概念: (P125)x1…xn 为输入信号;w1...wn 表示连接权系数,即权值,连接权; y 为输出;θ为阈值(阀值); 模型可描述为:θ∑ω-==i n1j j ij i x net响应函数为:)net (f y i i =或f(•)也称为变换函数,活化函数(activation function),激发函数。
2)感知器的工作方式:学习阶段——修改权值(例:根据“已知的样本”对权值不断修改;――有导师学习) 工作阶段 ——计算单元变化,由响应函数给出新输入下的输出。
感知机的学习算法样本:X ={X1, X2…… Xp}Y ={y1, y2…… yp}3)响应函数(激活函数)响应函数(激活函数)的基本作用: (1).控制输入对输出的激活作用; (2).对输入、输出进行函数转换;(3).将可能无限域的输入变换成指定的有限范围内的输出。
1).阈值单元单层感知器:✓ 两个输入 x1 和 x2 。
✓ 一个阈值(阀值) θ✓ 两个待调整的权值W1和W2 ✓ 决策函数为()θ-+=ωωx x 2211X d ✓ 样本集分别属于2类。
4)工作阶段理解的例题x 1为考试成绩、x 2为平时成绩,将x 1、x 2作为两个输入,构建两输入、单输出的感知机实现练习2设一平面上有两类点,使用横坐标x 1和纵坐标x 2作为两个输入,构建两输入、单输出的感知器的建立:学习阶段——修改权值(例:根据“已知的样本”对权值不断修改;――有导师学习) 工作阶段 ——计算单元变化,由响应函数给出新输入下的输出。
01算法步骤:1)设输入变量为x1,x2…,xm;(j=1 ,2,…,m),设置权系数初值wj(wj一般取[-1,1]之间的随机小数);2)确定学习样本,即给定输入/输出样本对,输入:u={u1,u2……un},⎪⎪⎪⎪⎭⎫ ⎝⎛=xmi i 2x i 1x ui ,(i=1,2,…,n)输出:d={d1,d2……dn}, (i=1,2,…,n)3)分别计算感知机在ui 作用下的输出yi ;⎪⎪⎭⎫ ⎝⎛ω=⎪⎪⎭⎫ ⎝⎛θ-ω=∑∑==n 0i i i n 1i i i i u )t (f u )t (f )t (yt 指第t 次计算并调整权值。
《神经网络电子教案》课件

《神经网络电子教案》PPT课件第一章:神经网络简介1.1 神经网络的定义1.2 神经网络的发展历程1.3 神经网络的应用领域1.4 神经网络的基本组成第二章:人工神经元模型2.1 人工神经元的结构2.2 人工神经元的激活函数2.3 人工神经元的训练方法2.4 人工神经元的应用案例第三章:感知机3.1 感知机的原理3.2 感知机的训练算法3.3 感知机的局限性3.4 感知机的应用案例第四章:多层前馈神经网络4.1 多层前馈神经网络的结构4.2 反向传播算法4.3 多层前馈神经网络的训练过程4.4 多层前馈神经网络的应用案例第五章:卷积神经网络5.1 卷积神经网络的原理5.2 卷积神经网络的结构5.3 卷积神经网络的训练过程5.4 卷积神经网络的应用案例第六章:递归神经网络6.1 递归神经网络的原理6.2 递归神经网络的结构6.3 递归神经网络的训练过程6.4 递归神经网络的应用案例第七章:长短时记忆网络(LSTM)7.1 LSTM的原理7.2 LSTM的结构7.3 LSTM的训练过程7.4 LSTM的应用案例第八章:对抗网络(GAN)8.1 GAN的原理8.2 GAN的结构8.3 GAN的训练过程8.4 GAN的应用案例第九章:强化学习与神经网络9.1 强化学习的原理9.2 强化学习与神经网络的结合9.3 强化学习算法的训练过程9.4 强化学习与神经网络的应用案例第十章:神经网络的优化算法10.1 梯度下降算法10.2 动量梯度下降算法10.3 随机梯度下降算法10.4 批梯度下降算法10.5 其他优化算法简介第十一章:神经网络在自然语言处理中的应用11.1 词嵌入(Word Embedding)11.2 递归神经网络在文本分类中的应用11.3 长短时记忆网络(LSTM)在序列中的应用11.4 对抗网络(GAN)在自然语言中的应用第十二章:神经网络在计算机视觉中的应用12.1 卷积神经网络在图像分类中的应用12.2 递归神经网络在视频分析中的应用12.3 对抗网络(GAN)在图像合成中的应用12.4 强化学习在目标检测中的应用第十三章:神经网络在推荐系统中的应用13.1 基于内容的推荐系统13.2 协同过滤推荐系统13.3 基于神经网络的混合推荐系统13.4 对抗网络(GAN)在推荐系统中的应用第十四章:神经网络在语音识别中的应用14.1 自动语音识别的原理14.2 基于神经网络的语音识别模型14.3 深度学习在语音识别中的应用14.4 语音识别技术的应用案例第十五章:神经网络在生物医学信号处理中的应用15.1 生物医学信号的特点15.2 神经网络在医学影像分析中的应用15.3 神经网络在生理信号处理中的应用15.4 神经网络在其他生物医学信号处理中的应用重点和难点解析重点:1. 神经网络的基本概念、发展历程和应用领域。
感知机的基本原理和数学表达式

感知机的基本原理和数学表达式感知机是一种简单而有效的线性分类算法,其基本原理是通过学习一组权重参数,将输入数据划分为两个不同的类别。
感知机模型的数学表达式可以描述为以下形式:y = sign(wx + b)其中,y表示样本的预测输出,w表示权重向量,x表示输入向量,b表示偏置项,sign()函数表示符号函数,即当wx + b大于0时,输出为1;当wx + b小于等于0时,输出为-1。
感知机的基本原理是通过不断调整权重参数,使得感知机能够正确地对样本进行分类。
具体来说,感知机的学习过程可以分为以下几个步骤:1. 初始化权重参数w和偏置项b,可以随机选择一组初始值。
2. 对于训练数据集中的每一个样本x,根据当前的参数w和b计算预测输出y。
3. 如果预测输出y与样本的真实标签不一致,则更新权重参数w和偏置项b。
更新的方式可以使用梯度下降法,即根据损失函数对参数进行调整,使得损失函数的值逐渐减小。
4. 重复步骤2和步骤3,直到所有的样本都被正确分类,或者达到一定的迭代次数。
感知机的学习过程可以用数学表达式来描述。
假设训练数据集为{(x1, y1), (x2, y2), ..., (xn, yn)},其中xi为输入向量,yi 为样本的真实标签。
对于每一个样本(xi, yi),我们定义损失函数L(w, b)为:L(w, b) = -∑(yi(wx + b))其中,∑表示对所有样本求和。
损失函数的目标是最小化误分类样本的数量。
为了调整参数w和b,我们需要计算损失函数对参数的梯度。
对于权重向量w的梯度∂L/∂w和偏置项b的梯度∂L/∂b,可以按照以下方式计算:∂L/∂w = -∑(yi * xi)∂L/∂b = -∑(yi)根据梯度的方向,我们可以更新参数w和b的值:w = w + η∂L/∂wb = b + η∂L/∂b其中,η表示学习率,决定了每次更新参数的步长。
感知机算法的收敛性定理表明,如果训练数据集是线性可分的,即存在一组参数使得所有样本都能被正确分类,那么经过有限次的迭代,感知机算法能够收敛到一个使得所有样本都被正确分类的参数组合。
感知机名词解释

感知机名词解释1. 引言感知机(Perceptron)是一种最简单的人工神经网络模型,也是一种二元分类器。
由于其简洁性和效率,感知机在机器学习领域中具有重要地位。
本文将对感知机进行详细解释,并介绍其核心概念、原理、训练算法以及应用场景。
2. 感知机的核心概念2.1 神经元感知机的基本单元是神经元(Neuron),也称为感知机模型。
神经元接收多个输入信号,通过加权求和和激活函数的处理产生输出信号。
2.2 激活函数激活函数是神经元中非线性转换的关键部分。
常用的激活函数有阶跃函数、Sigmoid函数和ReLU函数等。
在感知机中,通常使用阶跃函数作为激活函数。
2.3 权重和偏置感知机中,每个输入信号都有一个对应的权重(Weight),用于调节该信号对输出结果的影响程度。
此外,还引入了一个偏置(Bias)项,用于调整神经元的易激活性。
2.4 分类决策感知机的输出结果是根据输入信号的加权和经过激活函数处理后得到的。
对于二分类问题,通过设置阈值,可以将输出结果划分为两类。
3. 感知机的原理感知机的原理可以简单描述为:给定一组输入向量和对应的标签,通过调整权重和偏置等参数,使得感知机能够正确地分类输入向量。
具体而言,感知机通过以下步骤实现:3.1 初始化参数初始化权重和偏置项为随机值或者0。
3.2 计算输出将输入向量与对应的权重进行加权求和,并加上偏置项。
然后使用激活函数处理得到神经元的输出。
3.3 更新参数根据实际输出与期望输出之间的误差,调整权重和偏置项。
常用的更新规则是使用梯度下降法进行参数优化。
3.4 迭代训练重复执行步骤3.2和步骤3.3,直到达到预设条件(如达到最大迭代次数或误差小于阈值)为止。
4. 感知机的训练算法感知机的训练算法主要有两种:原始形式(Original Form)和对偶形式(Dual Form)。
4.1 原始形式原始形式的感知机算法是最早提出的一种训练方法。
它通过迭代地调整权重和偏置项,使得分类误差最小化。
数据挖掘方法PPT课件

第二章 管理与决策支持的数据挖掘方法-神经网络
自组织(Kohonen)神经网络学习过程:
第二章 管理与决策支持的数据挖掘方法-神经网络
自组织(Kohonen)神经网络具体实现过程:
第二章 管理与决策支持的数据挖掘方法-神经网络
自组织(Kohonen)神经网络具体实现过程:
第二章 管理与决策支持的数据挖掘方法-神经网络
第二章 管理与决策支持的数据挖掘方法-神经网络
第二章 管理与决策支持的数据挖掘方法-神经网络
XOR问题的BP模型建立
第二章 管理与决策支持的数据挖掘方法-神经网络
XOR问题的BP模型建立
第二章 管理与决策支持的数据挖掘方法-神经网络
评价分四级: v—非常好, g—好, a— 一般, b—差
第二章 管理与决策支持的数据挖掘方法-神经网络
自组织(Kohonen)神经网络学习过程:
第二章 管理与决策支持的数据挖掘方法-神经网络
自组织(Kohonen)神经网络学习过程:
第二章 管理与决策支持的数据挖掘方法-神经网络
自组织(Kohonen)神经网络学习过程:
第二章 管理与决策支持的数据挖掘方法-神经网络
自组织(Kohonen)神经网络学习过程:
第二章 管理与决策支持的数据挖掘方法-神经网络
有关概念——神经元的定义
有关概念——常见几种映射函数
第二章 管理与决策支持的数据挖掘方法-神经网络
有关概念——常见几种映射函数:
第二章 管理与决策支持的数据挖掘方法-神经网络
第二章 管理与决策支持的数据挖掘方法-神经网络
第二章 管理与决策支持的数据挖掘方法-神经网络
第二章 管理与决策支持的数据挖掘方法-神经网络
神经网络基本知识

神经网络基本知识目录1. 内容概要 (2)1.1 神经网络的概念及发展 (2)1.2 神经网络的应用领域 (4)1.3 本文组织结构 (5)2. 神经网络的数学基础 (6)2.1 激活函数及其种类 (7)2.2 损失函数 (8)2.2.1 均方误差 (10)2.2.2 交叉熵 (10)2.2.3 其他损失函数 (11)2.3 反向传播算法 (13)2.4 梯度下降优化算法 (14)2.4.1 批量梯度下降 (14)2.4.2 随机梯度下降 (15)2.4.3 小批量梯度下降 (17)2.4.4 其他优化算法 (17)3. 神经网络的神经元结构 (18)3.1 特征节点和输出节点 (19)3.2 权重和偏置 (20)4. 常用神经网络架构 (21)4.1 多层感知机 (23)4.2 卷积神经网络 (24)4.2.1 卷积层 (26)4.2.2 池化层 (27)4.2.3 全连接层 (28)4.3 反馈神经网络 (29)4.4 其他神经网络架构 (31)1. 内容概要神经元模型:深入讲解神经网络的基本单元——神经元,包括其结构、激活函数以及学习机制。
网络架构:探讨常见神经网络架构,例如感知机、多层感知机、卷积神经网络以及循环神经网络,并介绍各自的特点和适用场景。
训练过程:分解神经网络训练的过程,包括数据预处理、模型优化、正则化技术以及评估指标等。
应用案例:展示神经网络在图像识别、自然语言处理、语音识别等实际应用中的成果。
未来发展:展望神经网络发展趋势,包括新的架构设计、算法改进以及硬件平台的优化。
本文档旨在为初学者提供一站式学习资源,帮助理解神经网络的基本原理,激发您对深度学习的兴趣和理解。
1.1 神经网络的概念及发展神经网络是一种受到生物神经元工作原理启发的人工智能技术。
这种模型由多个节点(即神经元)相互连接组成,它们能够处理和传递信息,这是一个由输入层、若干隐藏层和输出层构成的层次结构。
神经网络通过对输入数据学习,并按层次逐层传递信息,最终输出结果。
神经网络中的感知器与多层感知器

神经网络中的感知器与多层感知器神经网络是一种模仿人类神经系统的信息处理系统,能够通过学习和自我适应来完成任务。
神经网络在图像识别、语音识别、自然语言处理等领域有着广泛的应用。
其中,感知器和多层感知器是神经网络中最基本的结构,本文将分别介绍它们的原理、应用和局限性。
一、感知器(Perceptron)感知器是神经网络的最基本单元,它基于线性分类模型,能够将输入数据进行分类。
感知器的构成由输入层、权值、偏移量、激活函数和输出层组成。
1、输入层:输入层是感知器的数据源,同时也是神经元的接收器,输入层的节点数决定了输入数据的维度。
2、权值:输入信号与感知器之间的连接是用权值来表示的,权值决定了输入节点的重要程度。
权值的调整也是感知器训练的核心。
3、偏移量:偏移量是一个常数,它与权值结合起来作为阈值判断的依据。
4、激活函数:激活函数是连接多个神经元之间的唯一方式,也是用于处理输入数据的函数,它将输入的信号进行处理后输出到输出层。
5、输出层:输出层的节点数决定了对数据进行分类的结果。
可以是二分类或多分类。
感知器的训练过程就是通过上面的结构来不停地调整每个输入节点的权值,从而不停地改进分类结果。
感知器的应用:感知器广泛应用于二元分类的问题中,例如数字识别和人脸识别。
感知器的局限性:但是,感知器有很大的局限性,例如无法处理非线性分类问题,只能进行两类问题的分类。
因此,需要使用多层感知器来解决这些问题。
二、多层感知器(Multi-Layer Perceptron, MLP)多层感知器是感知器的扩展,通过添加多个隐藏层使其可以处理非线性分类问题。
隐藏层的加入使得神经网络学习到了更加复杂的特征,并且可以解决分类问题。
多层感知器的结构与感知器相似,只是中间加入了隐藏层,隐藏层将原数据进行转换和处理,以得到更好的输入数据。
隐层和输出之间的连接仍然可以使用任何激活函数,例如Sigmoid函数。
多层感知器的训练过程和感知器类似,也是不断地调整权重来训练,但多层感知器的训练相较于单层感知器显得更加复杂,因为它需要在每个隐藏层之间做权值传导和梯度求导。
机器学习十七:感知机

机器学习十七:感知机AI菌感知机可以说是最古老的分类方法之一了,今天看来它的分类模型在大多数时候泛化能力不强,但是它的原理却值得好好研究。
因为研究透了感知机模型,既可以发展成支持向量机(通过简单地修改一下损失函数)、又可以发展成神经网络(通过简单地堆叠),所以它也拥有一定的地位。
所以这里对感知机的原理做一个简介感知机模型感知机的思想很简单,比如我们在一个平台上有很多的男孩女孩,感知机的模型就是尝试找到一条直线,能够把所有的男孩和女孩隔离开。
下面这张动图或许能够给观众老爷们一些直观感受:放到三维空间或者更高维的空间,感知机的模型就是尝试找到一个超平面,能够把所有的二元类别隔离开。
当然你会问,如果我们找不到这么一条直线的话怎么办?找不到的话那就意味着类别线性不可分,也就意味着感知机模型不适合你的数据的分类。
使用感知机一个最大的前提,就是数据是线性可分的。
这严重限制了感知机的使用场景。
它的分类竞争对手在面对不可分的情况时,比如支持向量机可以通过核技巧来让数据在高维可分,神经网络可以通过激活函数和增加隐藏层来让数据可分。
用数学的语言来说,如果我们有m个样本,每个样本对应于n维特征和一个二元类别输出,如下:我们的目标是找到这样一个超平面,即:让其中一种类别的样本都满足让另一种类别的样本都满足从而得到线性可分。
如果数据线性可分,这样的超平面一般都不是唯一的,也就是说感知机模型可以有多个解。
为了简化这个超平面的写法,我们增加一个特征x0=1 ,这样超平面为进一步用向量来表示为:,其中θ为(n+1)x1的向量,x为(n+1)x1的向量, ∙.后面我们都用向量来表示超平面。
但除了θ 称为权值,还有 b 称为偏置,故超平面的完整表达为:θ*x+b=0而感知机的模型可以定义为y=sign(θ∙x+b) 其中:如果我们将sign称之为激活函数的话,感知机与logistic regression的差别就是感知机激活函数是sign,logistic regression 的激活函数是sigmoid。
感知机的数学表达式

感知机的数学表达式感知机是一种二分类的线性分类模型,其数学表达式为:$$f(x) = sign(\sum_{i=1}^{n} w_i x_i + b)$$其中,$x$ 是输入向量,$w$ 是权重向量,$b$ 是偏置。
$n$ 是输入向量的维度。
感知机的主要思想是将输入向量乘以权重向量并加上偏置,得到一个值,然后通过一个符号函数将这个值映射为类别标签。
如果这个值大于等于零,则将类别标签设置为正类(+1),否则设置为负类(-1)。
感知机的训练过程是通过不断调整权重向量和偏置来找到一个最优的超平面,使得训练样本能够被正确分类。
具体来说,感知机采用的是在线学习算法,即一次只处理一个样本,根据预测结果和真实标签的差异来调整参数。
训练过程如下:1. 初始化权重向量 $w$ 和偏置 $b$;2. 选择一个训练样本 $(x, y)$,其中 $x$ 是输入向量,$y$ 是真实标签;3. 计算预测输出 $output = \sum_{i=1}^{n} w_i x_i + b$;4. 如果预测输出 $output$ 与真实标签 $y$ 不一致,则更新参数: - $w_i = w_i + \eta \cdot y \cdot x_i$,其中 $\eta$ 是学习率; - $b = b + \eta \cdot y$;5. 重复步骤2-4,直到所有训练样本都被正确分类或达到停止条件。
感知机的收敛性定理表明,如果训练样本是线性可分的,并且学习率$\eta$ 足够小,那么感知机算法经过有限次迭代就能找到一个将训练样本完全正确分类的超平面。
然而,如果训练样本线性不可分,则感知机算法将无法收敛。
感知机作为最早的神经网络模型之一,具有简单高效的特点。
然而,它也存在一些局限性,比如只能处理线性可分问题,对噪声敏感,并且不能学习非线性关系。
为了克服这些问题,后续发展出了更复杂的神经网络模型,如多层感知机、支持向量机等。
总结起来,感知机是一种二分类的线性分类模型,通过计算输入向量与权重向量的线性组合并加上偏置,然后通过符号函数将结果映射为类别标签。
一、人工神经元模型与感知机

⼀、⼈⼯神经元模型与感知机AI最核⼼------->深度学习------->与神经⽹络联系紧密传统⼈⼯神经⽹络是深度学习的基础Hadoop分布式⽂件系统的架构Namenode存储着⽂件系统的索引和元数据Datanode存储着具体的数据⽂件【数量可多达⼏千台】⼤数据计算模型( Spark,Storm等)最简单的⼈⼯神经⽹络----------> ⼀个神经元构成组成要素⼈⼯神经元基本结构M-P模型 -----神经⽹络的基础相关解释:p是输⼊w是p到神经元的权值(连接的强度)b是神经元的偏置(偏置的权重)1是神经元的固定偏置输⼊【模拟⽣物神经元的内在化学性质】s是累加器【也叫输⼊函数,⼀般对p和偏置进⾏加权求和】s输出是wp+b*1,s的输出通常成为净输⼊net偏置1和b不是必须的f是传输函数 a =f(net),也就模拟了⽣物神经元的轴突信号w,b可以调整,f和s可以选择传输函数类型 -----> 直接决定了神经元的输出值感知机 ---------》处理简单的线性分类问题识别⽔果1. 确定感知机的输⼊p shape color apple11 banana-1-12. 确定传输函数过程:输⼊1,1 -------》 apple 输⼊-1,-1 -----》 banana记忆逻辑与 ---------> 基于上述判断边界和权值向量的关系学习算法让感知机⾃⼰学习到合理的权重和配置感知机的学习规则:e表⽰误差 e = 期望输出 - 实际输出; e = t - a同的算法进⾏处理,直到没有误差,或误差在可接受范围内。
机器学习与应用第02讲人工神经网络ppt课件
1
w(2) 21
y1
w222
y2
w223
y3
w224
y4
b22
神经网络每一层完成的变换
ul Wlxl1 bl
xl f ul
权重矩阵的每一行为本层神经元与上一层所有神经 元的连接权重
激活函数分别作用于每个神经元的输出值,即向量 的每个分量,且使用了相同的函数
内积 加偏置
激活函数
w11l
以下面的3层网络为例:
输入层
隐含层
输出层
激活函数选用sigmoid:
f
x
1
1 exp
x
隐含层完成的变换:
y1 1 exp
1
w(1) 11
x1
w112 x2
w113 x3
b11
1
y2 1 exp
w(1) 21
x1
w212 x2
w213 x3
b21
y3 1 exp
1
w(1) 31
分类问题-手写数字图像识别
28 28
输入层有784个神经元
隐含层的神经元数量根据需要设定
0 1 2 3 4 5 6 7 8 9
输出层有10个神经元
回归问题-预测人脸关键点 神经网络直接为输入图像预测出关键点的坐标(x, y)
反向传播算法简介 解决神经网络参数求导问题 源自微积分中多元函数求导的链式法则 与梯度下降法配合,完成网络的训练
y1
w122
y2
w132
y3
w142
y4
b12
z2 1 exp
1
w(2) 21
y1
w222
y2
w223
y3
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
27
a1=simup(p,w1,b1);%%%%%%仿真 a1 if all(a==t),disp(‘It works!’); e=t-a1; k=1:1:4; figure(3); plot(k,e)们可以看出感 知器的基本功能是将输入矢量转化成0或1 的输出。这一功能可以通过在输人矢量空 间里的作图来加以解释。
感知器权值参数的设计目的,就是根据学习法则设 计一条W*P+b=0的轨迹,使其对输入矢量能够达 到期望位置的划分。
29
以输入矢量r=2为例,对于选定的 权值w1、w2和b,可以在以p1和p2分别 作为横、纵坐标的输入平面内画出 W*P+b=w1 p1十w2 p2十b=0的轨迹, 它是一条直线,此直线上的及其线以上 部分的所有p1、p2值均使w1 p1十w2 p2 十b>0,这些点若通过由w1、w2和b构 成的感知器则使其输出为1;该直线以 下部分的点则使感知器的输出为0。
ji xi ,
i 0 n
i 1
x0 j , ji 1
y
j
f
S
j
j 为阀值, ji 为连接权,f(•)为变换 其中, 函数,也称激发函数(activation function)。
感知机的结构
4
1 特点: 1)多输入,单输出 2)激活函数/传递函数为二值,一般为阶跃函 数或符号函数 3)输出为二值:0/1或-1/1
(4-5)
上述用来修正感知器权值的学习算法在MATLAB神 经网络工具箱中已编成了子程序,成为一个名为 1earnp.m的函数。只要直接调用此函数,即可立即获 得权值的修正量。此函数所需要的输入变量为:输入、 输出矢量和目标矢量:P、A和T。调用命令为: [dW,dB]=learnp(P,A,T);
人工神经网络模型
——感知机
1
感知机是最早被设计并被实现的人工神经网络。感 知器是一种非常特殊的神经网络,它在人工神经网 络的发展历史上有着非常重要的地位,尽管它的能 力非常有限,主要用于线性分类。
x1 1
xn
n
θ
或
yj
yj
某个神经元 j 的输入—输出关系为 n
s j ji xi j
%直接利用mat 工具箱(initp trainp simup) clear all NNTWARN OFF p=[0 0 1 1 ; 0 1 0 1] t=[0 0 0 1] [w1,b1]=initp(p,t) %初始化 [w1,b1,epoches,errors]=trainp(w1,b1,p,t,[-1]);%训练 %%%%%%%%%%计算完毕 figure(2); ploterr(errors)
Y=[1 1 1 1], 即y1=y2=y3=y4=1;
20
调整权值和阈值 由
求 E(t ) ei (t ) 3 ,设
ei (t ) di yi (t )
e(t ) (1,1,1,0)
0.5
w1 (t 1) w1 (t ) ( d i yi (t ) x1 ) 0 0.5 (1,1,1,0) (0,0,1,1 ) 0.5 w2 (t 1) w2 (t ) ( d i yi (t ) x2 )
类似的,新的偏差bi为旧偏差bi加
上它的输入1;
12
如果第i个神经元的输出为1,但期望
输出为0,即有yi=1,而ti=0,此时 权值修正算法为:新的权值wij等于旧 的权值wij减去输入矢量pj;
类似的,新的偏差bi为旧偏差bi减去1。
13
感知器学习规则的实质为:
权值的变化量等于正负输入矢量。
η :训练步长,一般0<η<1 ,η大收敛快,易
振荡, η小,收敛慢,不易振荡
16
y
我们以单层感知器来说明: θ 2 1 两个输入 x1 和 x2 。 x2 x1 一个阀值 θ 两个待调整的权值W1和W2 d X 1 x d X 决策函数为 d X 1 x1 2 x2 d X 1 样本集分别属于2类。
w的解并不唯一,能把两类分开即可 由于网络是以w1x1+w2x2+……+θ=0为分界线的, 这可以看成一直线或一超平面。
所以,感知机具有线性分类能力,可用于两类模 式分类,得到的w1,w2,θ不唯一,但只限于线 性分类。
感知机只能对线性可分离的模式进行正确的分类。
与运算 为0, 为1
或运算 为1, 为0
14
算法步骤:
1)设置权系数初值wj(wj一般取[-1,1]之间的随机小数); 2)确定学习样本,即给定输入/输出样本对,
输入:p={p0,p1……pn}
输出:y= 1 -1
yi (t ) f
n
p i∈ A pi∈B
3)计算感知机在pi作用下的输出yi ;
i ( t ) pi f i 1
10
输入矢量P,输出矢量Y,目标矢量为 T的感知器网络,其学习规则为:
如果第i个神经元的输出是正确的,
即有:yi=ti,那么与第i个神经元 联接的权值wij和偏差值bi保持不变;
11
如果第i个神经元的输出是0,但期
望输出为1,即有yi=0,而ti=1, 此时权值修正算法为:新的权值wij 为旧的权值wij加上输入矢量pj;
34
当输入模式是线性不可分时,则无论怎样调节 突触的结合强度(连接权值)和阈值的大小也 不可能对输入进行正确的分类。
异或运算
为0, 为1
35
16个布尔代数表
x1 x2 y0 y 1 y2 y3 y4 y5 y6 y7 y8 y9
y10 y11 y12 y13 y14 y15
0 0 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1
24
%第二阶段工作期,验证网络 X1=X; NETi=Wij*X1;[M,N]=size(X1); for j=1:N for i=1:L if(NETi(i,j)>=b(i)) y(i,j)=1; else y(i,j)=0; end end end y
25
初始化:initp 训练:trainp 仿真: simup 初始化: initp 可自动产生[-1,1]区间中的随机初始权值 和阈值, 例: [w,b]=initp(2,8) 或 [w,b]=initp(p,t) 训练: trainp 感知器网络学习和仿真的过程 tp=[disp_freq max_epoch]; (显示频率和训练的最大步数) [w,b,te]=trainp[w,b,p,t,tp]; Train函数完成每一步训练后,返回新的网络权值和阈值,并显示 已完成的训练步数ep及误差te 注意:使用trainp函数并不能保证感知器网络在取训练所得到的 权值和阈值时就可以顺利达到要求,因此,训练完成后,最好要验证 一下: a=simup[p,w,b]; 26 if all(a==t),disp(‘It works!’),end
2
0 0.5 (1,1,1,0) (0,1,0,1 ) 0.5
(t 1) (t ) ( E(t )) 0 9 9
由此
w1 0.5, w2 0.5, 9
21
返回上步重新计算,直到E满足要求
%建立一个感知机网络,使其能够完成“与”的功能 %感知机神经网络学习阶段 %自编程,没用mat工具箱 err_goal=0.001;lr=0.9; max_expoch=10000; X=[0 0 1 1;0 1 0 1];T=[0 0 0 1]; [M,N]=size(X);[L,N]=size(T); Wij=rand(L,M);y=0;b=rand(L);
30
所以当采用感知器对不同的输入矢 量进行期望输出为0或1的分类时, 其问题可转化为:对于已知输入矢 量在输入空间形成的不同点的位置, 设计感知器的权值W和b,将由W*P+b =0的直线放置在适当的位置上使输入 矢量按期望输出值进行上下分类。
31
图4.4 输入矢量平面图
32
举例:用感知机实现“与”的功能
n 4) y f i x i i 1
n f i xi i 0
1 0 u>0 u≤ 0
5
f s
1 -1
u>0 u≤ 0
或
2 感知机的工作方式:
学习阶段——修改权值 (根据“已知的样本”对权值不断修改; ――有导师学习) 工作阶段 ——计算单元变化,由响应函 数给出新输入下的输出。
n i 0
i
i ( t ) pi i 0
n
t指第t次计算并调整权值。 s
p ,
i
设
p
0
1,
i
1 , s0 y p f (s) 1 , s 0
15
4)求e(t)=di-yi(t) 5)若e(t)=0,则t=t+1,取下一个样本重复3), 当 e(t)|t=1,2……n=0,则结束。 若e(t) ≠0,调整权值 w(t+1)=w(t)+η[di-yi(t)]ui,返回3)
时 y1=0, y2=0, y3=0, y4=1; 3)计算感知机在ui作用下的输出yi
18
由模型可描述为:
s x
i j1 j j
n
j=1,2 n=2 i=1,2,3,4, 用矩阵表示为
0 s1 (w1 , w2 ) u1 (0,0) 0 0 0 0 s2 (w1 , w2 ) u2 (0,0) 1 0 0
8