基于规则的模型自动转换方法
机器翻译方法

机器翻译方法机器翻译(Machine Translation,MT)是指利用计算机技术实现自然语言之间的翻译。
随着人工智能技术的快速发展,机器翻译已经成为解决语言交流障碍的有效工具。
本文将介绍几种常见的机器翻译方法,并分析它们的优缺点。
一、基于规则的基于规则的机器翻译方法是早期机器翻译技术的主要方法之一。
它通过事先构建一系列的翻译规则,然后根据这些规则将源语言文本转换成目标语言文本。
这种方法需要大量的人工工作,主要包括:1. 构建词汇库:将源语言词汇与目标语言词汇一一对应。
2. 编写规则:根据语法规则和词汇库,编写一系列的翻译规则。
3. 设计规则匹配算法:将源语言文本与规则进行匹配,并生成目标语言文本。
优点:基于规则的机器翻译方法可以实现精确的翻译,尤其在语法规则复杂的语言对之间效果较好。
缺点:构建规则和词汇库需要耗费大量时间和人力,且对语言灵活性要求较高,无法处理多义词和歧义的情况。
二、基于统计的基于统计的机器翻译方法通过分析大规模的双语语料库,学习源语言与目标语言之间的统计规律,从而实现自动翻译。
主要步骤包括:1. 建立双语语料库:收集大规模的源语言和目标语言平行语料,如新闻报道、书籍等。
2. 分词与对齐:将源语言和目标语言文本进行分词,并进行句子级别的对齐。
3. 训练模型:利用统计算法,根据对齐的双语语料库,学习源语言和目标语言之间的翻译模型。
4. 解码翻译:根据学习到的翻译模型,将源语言文本翻译成目标语言文本。
优点:基于统计的机器翻译方法可以自动学习源语言和目标语言之间的翻译规律,无需人工构建规则和词汇库。
缺点:对于生僻词和长句等复杂情况,效果不如基于规则的机器翻译方法。
三、基于神经网络的近年来,随着深度学习的广泛应用,基于神经网络的机器翻译方法逐渐兴起。
该方法通过构建深层神经网络模型,直接将源语言文本映射到目标语言文本,实现端到端的翻译。
主要步骤包括:1. 构建编码器-解码器模型:编码器将源语言文本映射到一个语义空间,解码器将语义空间中的信息转换为目标语言文本。
基于规则库的工作流流程文件转换方法

先通 过建立 映射 规则库 来存储 不 同流程 定义语 言间相 互转 换 的规 则 ,然后 在转换 过程 中动态 查找规 则库 , 获取 -前 流程 定 - 3 义转换 所需要 的规则 , 最后 用获取 的规 则初 始化转换 引擎以 实现 流程 定 义文件 的转挟 。采用上述 方法建 立 了从 X D X P L( ml poesdf io nug)0 P Lb s es rcs eeui g aeJ P L到 X D rcs e t nl g ae E (ui s poes xct nl ug) k E i i a n B n o a n 3B P L之 间 的转 换规则库 , 运用该规 则库 完成 了实例 的相互转换 。 实验 结果表 明 了该转换 方 法的可行性 和有效性 。 关键 词: 流程定 义;转换 框 架; 规则库 ;元模 型;模 型 中图法分类号 : P 1. T 31 6 5 文献标识 码: A 文章编 号 :007 2 2 1) 918 .5 10 —04(00 0 —900
18 2 1, 9 90 00 1( 3 )
・人 工 智 能 。
计 算 机 工程 与 设计 C m u r ni e n ad ei o pt E g er g n D s n e n i g
基于规则库的工作流Байду номын сангаас程文件转换方法
周文 斌 , 兰雨晴
( 北京航 空航 天 大学 计 算机 学 院,北 京 109) 011
u e l sd r g t eta so mai n p o e s a d f al eta s o mai n e g n n t l e y t ea q i d r l st c iv e s f r e u n n f r to r c s , n i l t r f r t n i e i i i ai d b c ur e o a h e e t ul u i h r n yh n o s i z h e u h
自然语言处理算法

自然语言处理算法自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个重要研究方向,旨在让计算机能够理解、处理和生成人类语言。
为了实现这一目标,需要使用一系列的算法和技术来解决涉及语义、语法和语用等多个层面的问题。
下面将介绍几种常见的自然语言处理算法。
1. 词袋模型与TF-IDF词袋模型是一种简单而常用的文本表示方法,它将文本看作是由单词构成的袋子,忽略了单词顺序和语法结构。
每个文档可以表示为一个由各个单词频率构成的向量。
然而,单纯的词袋模型无法区分关键词和常用词,因此引入了TF-IDF (Term Frequency-Inverse Document Frequency)算法来提高特征的重要性。
TF-IDF通过计算一个词在文档中的频率与在整个语料库中的逆文档频率的乘积,从而得到一个更加准确的文本表示。
2. 基于规则的方法基于规则的方法是一种早期的自然语言处理算法,它通过预先定义的规则和模式来处理文本。
这种方法需要专家手动编写大量规则,对于不同的语言和任务来说并不通用。
然而,在特定领域或任务中,基于规则的方法可以取得较好的效果。
例如,在问答系统中,可以根据问题的结构和关键词,设计一系列规则来生成相应的回答。
3. 统计语言模型与n-gram模型统计语言模型通过统计文本数据中的频率和概率来建模一个语言的规律和特征。
常见的统计语言模型有n-gram模型,其中n表示模型中考虑的上下文的长度。
通过计算n-gram序列的频率,可以估计一个单词在给定上下文中出现的概率。
例如,二元(bigram)模型只考虑一个单词的上一个单词,三元(trigram)模型考虑两个上一个单词。
这些统计语言模型可以用于自动语音识别、机器翻译和文本生成等任务。
4. 词嵌入与深度学习词嵌入是一种将文本中的词汇映射到低维向量空间中的技术。
通过将词与其上下文的共现信息进行建模,可以得到具有语义关联性的词向量表示。
《2024年蒙汉语码转换研究》范文

《蒙汉语码转换研究》篇一一、引言随着全球化的推进和信息技术的飞速发展,语言交流的多样性变得越来越重要。
蒙汉语码转换作为一种特殊的语言交流方式,其重要性逐渐凸显。
蒙汉语码转换研究,不仅对于深入了解两种语言的特点及其背后的文化背景有着重要意义,还有助于推动语言技术的创新和语言服务的发展。
本文将针对蒙汉语码转换的相关问题进行研究分析,为进一步探讨蒙汉语码转换的应用与发展提供参考。
二、蒙汉语码转换概述蒙汉语码转换,是指在不同语言之间进行文字编码的转换,使蒙文和汉字在计算机系统中实现互通。
这种转换主要涉及字符编码的转换和语义信息的传递。
蒙文和汉字分别属于不同的文字体系,因此,进行蒙汉语码转换需要解决文字编码、语义对应等关键问题。
三、蒙汉语码转换的技术方法(一)基于规则的转换方法基于规则的转换方法是通过制定一定的转换规则来实现蒙汉语码的转换。
这种方法需要建立一套完整的规则体系,包括字符编码的对应关系、语法规则、语义对应等。
在应用中,该方法需结合具体场景和需求,灵活运用规则进行转换。
(二)基于统计的转换方法基于统计的转换方法则是通过分析大量语料库中的数据来寻找蒙汉两种语言之间的对应关系。
这种方法主要利用自然语言处理技术和机器学习算法,对语料库进行训练和优化,从而实现蒙汉语码的自动转换。
(三)混合方法混合方法则是结合了基于规则和基于统计两种方法的优点,既考虑了语言的规则性,又利用了统计数据来提高转换的准确率。
这种方法在处理复杂语言现象时具有较好的表现。
四、蒙汉语码转换的应用与发展(一)应用领域蒙汉语码转换在多语言环境下的信息处理、跨文化交流、教育、翻译等领域具有广泛的应用价值。
例如,在多语言环境下的信息处理中,蒙汉语码转换技术可以实现不同语言之间的互通,提高信息处理的效率;在跨文化交流中,该技术有助于促进不同民族之间的交流与理解;在教育领域,该技术可以辅助双语教学,帮助学生更好地掌握两种语言;在翻译领域,该技术可以辅助计算机辅助翻译,提高翻译的准确性和效率。
自然语言生成模型的原理与实现

自然语言生成模型的原理与实现自然语言生成(Natural Language Generation,简称NLG)是人工智能领域中的一个重要研究方向,旨在让计算机能够以自然语言的形式生成人类可理解的文本。
自然语言生成模型的原理与实现是实现该目标的关键。
一、自然语言生成模型的原理自然语言生成模型的原理可以分为两个主要部分:语言模型和生成算法。
1. 语言模型语言模型是自然语言生成模型的基础,它用于计算一个句子在语言中的概率。
常见的语言模型有n-gram模型和神经网络模型。
- n-gram模型:n-gram模型是一种基于统计的语言模型,它假设一个词的出现只与前面n-1个词有关。
通过统计语料库中的词频和词组频率,可以计算一个句子的概率。
然而,n-gram模型忽略了词之间的长距离依赖关系,因此在生成长句时效果不佳。
- 神经网络模型:神经网络模型利用深度学习的方法,通过训练大量的语料库来学习语言的规律。
其中,循环神经网络(Recurrent Neural Network,简称RNN)和变种模型如长短时记忆网络(Long Short-Term Memory,简称LSTM)是常用的模型。
这些模型可以捕捉到词之间的长距离依赖关系,从而提高了生成的质量。
2. 生成算法生成算法是自然语言生成模型的核心,它决定了如何根据语言模型生成合理的句子。
常见的生成算法有基于规则的方法和基于概率的方法。
- 基于规则的方法:基于规则的方法通过事先定义一系列语法规则和转换规则,根据这些规则逐步生成句子。
这种方法的优点是生成的句子结构准确,但缺点是需要手动定义大量的规则,且难以覆盖复杂的语言现象。
- 基于概率的方法:基于概率的方法利用语言模型计算句子的概率分布,并根据概率进行采样生成句子。
这种方法的优点是可以自动学习语言的规律,生成的句子更加自然。
常见的基于概率的生成算法有贪心搜索、束搜索和蒙特卡洛搜索。
二、自然语言生成模型的实现自然语言生成模型的实现需要考虑数据预处理、模型训练和生成过程。
基于规则的Open Street Map数据模型转换

基于规则的Open Street Map数据模型转换江瑜;周晓光;李志盛;赵肄江【期刊名称】《测绘与空间地理信息》【年(卷),期】2016(39)1【摘要】周边区域地理信息的获取是我国地缘环境研究中的一个难题,志愿者地理信息( volunteered geographic in-formation, VGI)的兴起为解决该难题提供了一个可行的方法。
在目前一系列的 VGI 项目中, OpenStreetMap( OSM)是比较领先的应用,但OSM数据模型不同于我国周边应用的专业矢量数据模型,因此,利用OSM数据时首先需要对其进行模型转换。
有鉴于此,本文提出了一种基于规则的OSM数据到专业应用矢量数据模型转换方法。
该方法首先利用OSM定义的几何类型与地物属性作为分类依据,建立了模型转换基本规则库;对于志愿者根据自己的理解自行标注未包含在基本规则库中的目标采用人机交互方式进行模型转换,并在此过程中不断完善规则库,利用越南与巴基斯坦数据进行实验,最终形成了包括2344条转换规则的模型转换规则库,为OSM数据模型到专业应用矢量数据模型的转换提供了一条可行途径。
%Spatial data acquisition is a bottleneck for borderland researching.In recent years, Volunteered Geographic Information (VGI) has been proven to be a very successful means of acquiring timely and detailed global spatial data.OpenStreetMap (OSM) has been known as the most successful VGI resource.But OSM data model is far different from the traditional geographic information mod-el.Thus the OSM data needs to be converted to the scientist customized data model at first.Therefore, a rule_based transformation method ispresented after analysing OSM data characteristics in this paper.In this method, a basic transformation rule base is estab-lished using geometry type and thematic attribute defined by OSM Features firstly.Then, the left unusual objects tagged by the volun-teers according to their understanding are converted by human-computer interaction and the responding transformation rules are re-membered into the rule base.A transformation rule base with 2344 rules was established in the experiment.OSM data of Vietnam, Pa-kistan is used to test and verify the the effectiveness of the method.Experiment proved that the method presented in this paper provide a solution for OSM data model converting to traditional authoritative data model.【总页数】4页(P31-34)【作者】江瑜;周晓光;李志盛;赵肄江【作者单位】中南大学地球科学与信息物理学院,湖南长沙410083;中南大学地球科学与信息物理学院,湖南长沙410083;中南大学地球科学与信息物理学院,湖南长沙410083;中南大学地球科学与信息物理学院,湖南长沙410083【正文语种】中文【中图分类】P208【相关文献】1.嗨,兄弟!没你不行 Maple street 33 [J],2.将关系数据模型转换为对象数据模型的研究 [J], 刘义英;郝忠孝3.基于Open Street Map数据的地理信息分析与提取技术 [J], 任常青;陈杰;查祝华;周晓光4.Open Street Map的数据转换方法研究 [J], 姜晶莉;郭黎;邓圣乾;赵家瑶5.ArcView Street Map系统 [J], 柴振荣因版权原因,仅展示原文概要,查看原文内容请购买。
人工智能机器翻译方法

人工智能机器翻译方法引言随着全球化的进展,跨国交流和合作日益频繁,语言之间的障碍成为了一个亟待解决的问题。
人工智能机器翻译作为一种快速自动翻译技术,已经取得了显著的进展。
本文将探讨人工智能机器翻译的几种常见方法及其优缺点。
一、基于规则的机器翻译方法基于规则的机器翻译(Rule-based Machine Translation,RBMT)方法是早期机器翻译技术的一种。
该方法通过人类专家创建的一系列规则进行翻译处理。
这些规则通常基于语法、词汇和句法等语言知识。
RBMT方法的优势在于可以精确控制翻译过程,但是缺点也很明显,例如对于复杂的语言现象和语义问题处理能力有限。
二、基于统计的机器翻译方法基于统计的机器翻译(Statistical Machine Translation,SMT)是近年来被广泛研究和应用的机器翻译技术。
该方法基于大规模的双语平行语料库,通过统计建模和机器学习算法进行翻译。
SMT方法的特点是可以自动学习翻译模型,因此适用于处理大量的语料。
然而,SMT 方法在处理语义和长句子时存在一定的困难,同时对于非平行数据的利用还有待改进。
三、基于神经网络的机器翻译方法随着深度学习技术的发展,基于神经网络的机器翻译(Neural Machine Translation,NMT)方法逐渐兴起。
NMT方法通过神经网络模型将源语言句子直接映射到目标语言句子。
与传统方法相比,NMT方法能够更好地处理上下文信息和语义关联,进一步提升翻译质量。
然而,NMT方法需要大量的训练数据和计算资源,且模型解释性较差。
四、混合模型机器翻译方法为了克服单一模型的局限性,近年来研究者提出了一种混合模型机器翻译(Hybrid Model Machine Translation)方法。
该方法结合了基于规则、统计和神经网络的机器翻译技术,利用它们各自的优势来提高翻译效果。
混合模型机器翻译方法的具体实施方式有很多种,例如基于规则和统计的混合方法、基于统计和神经网络的混合方法等。
自动驾驶场景生成方法分类

自动驾驶场景生成方法可以根据不同的分类标准进行分类,以下是一些常见的分类方式:
1. 基于规则的方法:这种方法通过定义一系列规则和约束条件来生成自动驾驶场景。
例如,规定道路布局、交通规则、车辆行为等,然后根据这些规则生成具体的场景。
2. 数据驱动的方法:利用实际采集或模拟的数据来训练模型,然后使用模型生成新的场景。
这种方法可以基于机器学习算法,如深度学习,对大量的场景数据进行学习和预测。
3. 混合方法:结合了基于规则和数据驱动的方法,以充分利用两者的优势。
例如,先使用规则定义基本场景结构,再通过数据驱动的方法进行细节调整和优化。
4. 随机生成方法:通过随机抽样或随机过程来生成场景,这种方法可以产生多样化的场景,但可能需要进一步的筛选和过滤来确保场景的合理性和安全性。
5. 基于模型的方法:使用数学模型或物理模型来描述场景中的元素和关系,然后通过仿真或计算生成具体的场景。
6. 交互性方法:允许用户与系统进行交互,例如通过指定场景参数、添加障碍物或改变环境条件,从而生成个性化的场景。
7. 实时生成方法:在运行时实时生成场景,例如根据传感器数据和当前环境信息动态地生成场景,以适应不断变化的驾驶环境。
这些分类方法并不是互斥的,实际应用中可能会采用多种方法的组合。
选择合适的场景生成方法取决于具体的应用需求、数据可用性、计算资源等因素。
不同的方法在效率、真实性、多样性等方面可能有不同的特点,需要根据具体情况进行选择和权衡。
chn的原理

chn的原理“chn”,全称为中文简繁转换,是一种用于将繁体中文转换为简体中文或将简体中文转换为繁体中文的技术。
在中文文字处理领域中,繁简转换是一个常见的需求,尤其是在跨境合作、文档编辑和信息传播等方面。
繁简转换技术不仅能够提高文字信息的传播效率,还可以减少人工翻译的工作量,帮助用户更好地理解和使用中文文字。
“chn”技术的原理主要包括字词对应、规则匹配和语义转换等过程。
在具体实现中,一般常用的方法有基于词典的转换、基于规则的转换和基于机器学习的转换等。
下面将详细介绍这几种常用的繁简转换方法,以及它们的原理和特点。
一、基于词典的转换基于词典的转换方法是将繁体字与简体字一一对应,构建一个繁简转换的词典,然后根据词典进行转换。
这种方法的优点是简单直观,易于实现和维护,对于常见的字词转换效果较好。
但是,由于中文文字的复杂性和多义性,单纯依靠词典匹配可能存在一些问题,如歧义字词的翻译、专有名词的处理等。
在基于词典的转换方法中,通常会使用开源的繁简转换词典或人工构建自定义词典。
通过对应关系建立繁简字典,并根据字典进行逐字匹配转换,将繁体字逐个替换为对应的简体字。
这种方法虽然简单,但是对于一些长词、短语和专有名词等难以处理,需要额外的规则和处理技巧来提高转换的准确性和效率。
二、基于规则的转换基于规则的转换方法是根据繁体字和简体字之间的规则和特征进行转换。
这种方法不依赖于完整的词典,而是通过规则匹配和推断来实现繁简转换。
在实践中,可以使用一些专门设计的规则集合,如繁体简体字对应规则、句子结构规则、词类转换规则等。
通过这些规则,可以识别并转换繁简字之间的对应关系,实现繁简转换的自动化处理。
基于规则的转换方法既能够处理单字转换,又能够处理词组和句子的翻译,具有较好的通用性和适应性。
同时,规则转换也能够灵活地处理一些特殊情况和复杂转换,提高转换的准确性和效率。
然而,规则转换的过程需要耗费大量的人力和时间进行规则设计和验证,且在面对中文文字的多义性和歧义性时仍有局限性。
《基于规则和统计的西里尔与传统蒙古文相互转换方法研究》范文

《基于规则和统计的西里尔与传统蒙古文相互转换方法研究》篇一一、引言随着信息技术的飞速发展,文本处理和语言转换技术在全球范围内得到了广泛的应用。
对于蒙古文这一特殊的语言体系,其书写形式多样,包括西里尔蒙古文和传统蒙古文等。
因此,基于规则和统计的西里尔与传统蒙古文相互转换方法的研究显得尤为重要。
本文旨在探讨这一领域的研究现状、方法及未来发展方向。
二、西里尔蒙古文与传统蒙古文概述西里尔蒙古文是一种以西里尔字母为基础的蒙古文书写系统,广泛应用于蒙古国等地区。
而传统蒙古文则以传统的蒙古文字母为基础,包括古回鹘蒙古文和蒙古族手写字体等。
两种书写系统在字符形状、发音及语法结构等方面存在差异,这为两者之间的相互转换带来了一定的挑战。
三、基于规则的转换方法基于规则的转换方法主要依赖于语言学知识和专家制定的规则。
该方法首先对两种书写系统的语法、词汇和发音等语言特征进行深入研究,然后制定相应的转换规则。
这些规则包括字符映射、词法分析和句法分析等。
通过这些规则,可以实现西里尔蒙古文与传统蒙古文之间的相互转换。
四、基于统计的转换方法基于统计的转换方法主要利用机器学习和自然语言处理技术。
该方法首先需要构建大规模的双语平行语料库,即西里尔蒙古文和传统蒙古文的对应文本。
然后,通过训练机器学习模型(如神经网络、决策树等),学习两种书写系统之间的映射关系。
在测试阶段,模型可以根据输入的文本自动进行转换。
五、研究现状与挑战目前,基于规则和统计的西里尔与传统蒙古文相互转换方法已经取得了一定的研究成果。
然而,仍存在一些挑战和问题。
首先,由于两种书写系统的差异较大,转换过程中可能存在语义丢失或歧义现象。
其次,大规模的双语平行语料库的构建仍然是一个难题,这限制了统计方法的性能。
此外,不同地区和方言的蒙古文书写形式也存在差异,这为转换方法的通用性带来了挑战。
六、未来发展方向针对于西里尔与传统蒙古文相互转换方法的研究,未来可以采取以下发展方向:首先,加强语言学研究,进一步深入探讨两种书写系统的语法、词汇和发音等语言特征,为制定更准确的转换规则提供支持。
自然语言识别和自然语言处理

自然语言识别和自然语言处理自然语言识别和自然语言处理是人工智能领域中的两个重要分支,它们都与自然语言相关,但是具体的任务和应用场景有所不同。
本文将从定义、任务、技术方法等多个方面进行详细阐述。
一、自然语言识别1.定义自然语言识别(Natural Language Understanding, NLU)是指让计算机理解人类所使用的自然语言,并将其转化为计算机可以处理的形式。
NLU通常包括文本分类、实体识别、关系抽取等任务。
2.任务(1)文本分类:将文本划分到不同的类别中,如新闻分类、情感分析等。
(2)实体识别:从文本中提取出具有特定意义的实体,如人名、地名、组织机构名等。
(3)关系抽取:从文本中提取出实体之间的关系,如“张三是李四的父亲”。
3.技术方法(1)基于规则的方法:通过设计一些规则来解决特定问题,如正则表达式、有限状态自动机等。
(2)基于统计模型的方法:通过学习大量数据来构建模型,并利用模型进行预测或分类,如朴素贝叶斯、支持向量机等。
(3)基于深度学习的方法:通过构建深层神经网络来学习特征表示,并利用模型进行预测或分类,如卷积神经网络、循环神经网络等。
二、自然语言处理1.定义自然语言处理(Natural Language Processing, NLP)是指让计算机对自然语言进行处理和分析,包括文本生成、机器翻译、问答系统等任务。
2.任务(1)文本生成:根据给定的信息和规则生成新的文本,如自动生成新闻报道、诗歌等。
(2)机器翻译:将一种语言翻译成另一种语言,如中英互译、日英互译等。
(3)问答系统:根据用户提出的问题,从知识库中找到最合适的答案并返回给用户。
3.技术方法(1)基于规则的方法:通过设计一些规则来解决特定问题,如句法分析、语义分析等。
(2)基于统计模型的方法:通过学习大量数据来构建模型,并利用模型进行预测或分类,如隐马尔可夫模型、条件随机场等。
(3)基于深度学习的方法:通过构建深层神经网络来学习特征表示,并利用模型进行预测或分类,如循环神经网络、注意力机制等。
知识图谱自动构建方法比较综述

知识图谱自动构建方法比较综述知识图谱自动构建是一项重要的研究领域,通过将各种数据和知识连接在一起,构建一个具有结构化、可查询和可推理的知识库。
在过去的几十年里,研究人员提出了许多不同的方法来实现知识图谱的自动构建。
本文将综述其中一些常用的方法,并比较它们的优缺点。
一、基于规则的方法基于规则的方法是最早被提出的知识图谱构建方法之一。
它通过手工定义一系列规则来从文本中抽取实体和关系,然后将其存储到知识图谱中。
这种方法的优点是可以根据具体任务需求设计相应的规则,具有较高的准确性。
然而,它的缺点是规则需要人工编写,且无法处理大规模的数据。
二、基于统计的方法基于统计的方法利用机器学习算法自动从文本中学习实体和关系的抽取模式,然后应用这些模式来构建知识图谱。
这种方法的优点是可以处理大规模数据,且效果较好。
然而,它需要大量的标注数据来训练模型,并且对于新领域或未知实体关系的抽取效果较差。
三、基于语义网的方法基于语义网的方法使用RDF(Resource Description Framework)作为知识表示和存储格式,将实体和关系以三元组的形式表示,并利用本体来进行语义推理。
这种方法的优点是可以充分利用本体的语义信息,实现更精确的知识抽取和推理。
然而,它需要事先定义好本体和推理规则,且对本体的设计和构建要求较高。
四、基于深度学习的方法近年来,基于深度学习的方法在知识图谱自动构建领域取得了重要进展。
这种方法利用神经网络模型自动学习特征和模式,并应用于实体和关系的抽取、分类和链接预测等任务。
这种方法的优点是可以自动学习复杂的特征表示,并且在大规模数据上表现出色。
然而,深度学习方法需要大量的计算资源和标注数据,且对模型的解释性较差。
综上所述,知识图谱自动构建方法具有各自的优势和局限性。
基于规则的方法适用于小规模任务,基于统计的方法适用于大规模任务,基于语义网的方法适用于充分利用本体的任务,基于深度学习的方法适用于大规模数据和复杂模式的任务。
基于规则的自动语义转换方法研究
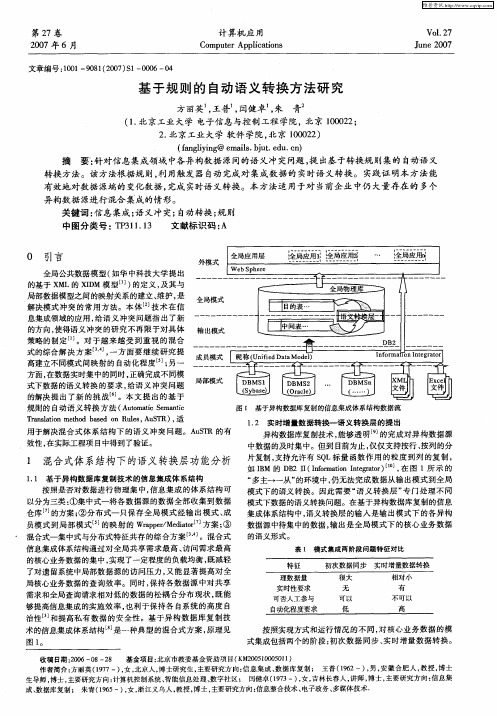
方面 , 在数据 实时集 中的同时 , 正确完成不同模 式下数据的语义转换 的要 求 , 给语义 冲突 问题 的解决 提出 了新 的挑 战 j 。本 文提 出的基 于
规则的 自动ቤተ መጻሕፍቲ ባይዱ语义 转换 方 法 ( u macSmat A t t e ni o i c
Tas t nm to ae nR ls A S R) 适 r l i e db sd o ue , uT , n ao h
生导师 , 士, 博 主要研究方 向: 计算机控制系统 、 能信息处理 、 智 数字社 区; 闰健卓 (9 3 , , 17 一) 女 吉林长春人 , 讲师 , 博士 , 主要研究方 向: 息集 信 成、 数据库复制 ; 朱青( 9 5 , , 16 一) 女 浙江义乌人 , 教授 , 士 , 博 主要研究方 向: 信息整合技术 、 电子政务 、 多媒体技术 .
收 稿 日期 :0 6— 8—2 基金项 目: 20 0 8 北京 市教委基 金资助项 目( M2 0 10 5 1 ) K 0 50 0 0 1 作者简介 : 方丽英 (9 7 , , 17 一) 女 北京人 , 士研究 生, 博 主要研究 方向 : 息集成 、 信 数据库复 制; 王普 ( 92一) 男 , 徽合肥人 , 1 6 , 安 教授 , 士 博
(a g y g e a sbu. d .n fnl i @ m i .jte u c ) in l
摘 要‘ : 针对 信 息集成领 域 中各异 构数 据 源 间的语 义冲 突 问题 , 出基 于转换 规 则集 的 自动 语 义 提 转换方 法 。该 方 法根 据规 则 , 用触发 器 自动 完成 对 集成 数 据 的 实时语 义 转换 。 实践证 明本 方 法 能 利 有效地 对数据 源端的 变化数 据 , 完成 实时语 义转 换 。本 方 法适 用于对 当前 企业 中仍 大 量存 在 的 多个 异 构数 据 源进 行 混合 集成 的情形 。
自然语言处理中的词法分析算法综述

自然语言处理中的词法分析算法综述引言随着计算机技术的发展,自然语言处理成为了人工智能领域的重要组成部分。
而在自然语言处理中,词法分析是一项基础性的工作,用于将句子分解为单个的词语,并确定每个词语的词性(part-of-speech,POS)标签。
本文将对自然语言处理中的词法分析算法进行综述。
一、基于规则的方法基于规则的方法是词法分析中最早被采用的方法之一。
这种方法主要基于事先定义好的规则,通过匹配和替换来识别和标记句子中的词语。
例如,通过匹配单词的后缀来识别和标记名词的复数形式。
虽然基于规则的方法在处理简单的规则和句子时效果不错,但对于复杂的语法规则和包含歧义的句子,这种方法的准确性和效率都较低。
二、基于统计的方法基于统计的方法是近年来在词法分析中得到广泛应用的方法之一。
这种方法通过训练大数据集,学习语言模型和词频分布,并利用统计模型对句子进行分析。
其中,最常用的统计模型是隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Fields,CRF)。
HMM模型通过观察序列和隐藏状态之间的转移概率来预测最可能的词汇和词性序列。
而CRF模型则通过定义特征函数和标签转移概率来进行词汇和词性标记。
基于统计的方法在一定程度上提高了词法分析的准确性。
然而,这种方法仍然存在一些问题,例如对未登录词的处理和对上下文的建模。
三、基于机器学习的方法基于机器学习的方法是目前自然语言处理中词法分析算法的主要研究方向之一。
这种方法通过使用机器学习算法和大规模训练样本集来提高词法分析的准确性和泛化性。
其中,最常用的机器学习算法包括支持向量机(Support Vector Machines,SVM)、最大熵模型(Maximum Entropy Models,MaxEnt)和神经网络等。
这些算法可以通过训练样本集来建立分类模型,用于对句子中的每个词语进行标记。
基于机器学习的方法在训练集足够大且标注正确的情况下,可以取得较好的词法分析效果。
文本生成的工作原理

文本生成的工作原理在当今信息时代,文本生成技术的发展日新月异。
文本生成是指通过计算机程序自动生成具有一定语言表达能力的文本。
它不仅在自然语言处理、人工智能等领域具有重要应用,还为我们提供了便捷高效的创作工具。
本文将深入探讨文本生成的工作原理及其在不同领域的应用。
一、统计语言模型文本生成的基础是统计语言模型。
统计语言模型是基于一定规则和数据集的语言建模方法,它通过分析文本中词语之间的关联关系,预测下一个可能出现的词语。
常见的统计语言模型包括n-gram模型和神经网络语言模型。
1. n-gram模型n-gram模型是一种简单且常用的语言模型。
它假设当前词语的出现只与前n-1个词语有关,通过统计语料库中的词语出现概率来计算下一个词语的可能性。
例如,在一个二元模型中,给定前一个词语的情况下,当前词语出现的概率可以通过简单的频率计算得出。
2. 神经网络语言模型神经网络语言模型是使用神经网络进行语言建模的方法。
它通过训练神经网络来学习词语之间的关联关系,预测下一个词语的出现概率。
神经网络语言模型可以处理更复杂的语言结构,具有较好的表达能力。
二、生成模型在了解了统计语言模型的基础上,我们再来探讨文本生成的具体工作原理。
文本生成模型主要分为基于规则的生成模型和基于神经网络的生成模型。
1. 基于规则的生成模型基于规则的生成模型是一种传统的文本生成方法,它基于规则和模板,通过替换关键字、填充内容等方式生成文本。
例如,在合同文本生成中,可以根据特定的规则和要求,将合同中的各项信息替换成相应的变量值,从而生成符合标准格式的合同文本。
这种方法需要事先定义好一套规则和模板,在特定领域的文本生成中效果较好。
2. 基于神经网络的生成模型基于神经网络的生成模型利用深度学习技术,通过大规模的训练数据来学习文本的生成规律。
其中,循环神经网络(RNN)和变种的长短期记忆网络(LSTM)是常用的生成模型。
这些模型可以捕捉到句子之间的上下文关系,生成更具连贯性和语义合理性的文本。
《基于规则和统计的西里尔与传统蒙古文相互转换方法研究》范文

《基于规则和统计的西里尔与传统蒙古文相互转换方法研究》篇一一、引言蒙古文是蒙古国以及中国内蒙古自治区等地所使用的官方语言,有着深厚的历史文化背景。
传统蒙古文和西里尔蒙古文是蒙古语的两种书写系统。
传统蒙古文以其独特的字母和书写规则,承载着丰富的历史和文化信息。
而西里尔蒙古文则是以西里尔字母为基础的书写系统,更便于国际交流和计算机处理。
因此,研究两种蒙古文之间的相互转换方法具有重要的实际意义。
本文将探讨基于规则和统计的西里尔与传统蒙古文相互转换方法。
二、传统蒙古文与西里尔蒙古文的概述1. 传统蒙古文:传统蒙古文是一种表意文字,由基本字母、元音符号和附加符号组成,具有独特的音节结构和书写规则。
2. 西里尔蒙古文:西里尔蒙古文是以西里尔字母为基础的书写系统,具有较好的国际通用性,便于计算机处理。
三、基于规则的转换方法基于规则的转换方法主要是通过制定一系列的转换规则来实现两种蒙古文之间的转换。
具体步骤如下:1. 制定转换规则:根据两种蒙古文的音节结构和书写规则,制定相应的转换规则。
这些规则包括音节对应关系、字母对应关系、元音和附加符号的转换等。
2. 人工校对与优化:由于语言的多义性和复杂性,仅靠自动转换难以完全准确。
因此,需要人工校对转换结果,并对转换规则进行优化。
3. 实际应用:将优化后的转换规则应用于实际转换中,实现传统蒙古文与西里尔蒙古文的相互转换。
四、基于统计的转换方法基于统计的转换方法主要是利用大量的双语平行语料进行训练,学习两种蒙古文之间的对应关系,从而实现相互转换。
具体步骤如下:1. 收集语料:收集大量的双语平行语料,包括传统蒙古文和西里尔蒙古文的文本数据。
2. 训练模型:利用统计方法训练转换模型,学习两种蒙古文之间的对应关系。
常用的统计方法包括隐马尔可夫模型、条件随机场等。
3. 转换实现:将训练好的模型应用于实际转换中,实现传统蒙古文与西里尔蒙古文的相互转换。
五、综合应用规则与统计的转换方法综合应用规则与统计的转换方法可以结合两者的优点,提高转换的准确性和效率。
相似问生成

相似问生成相似问生成(Paraphrase Generation)指的是将一个句子转换为一个与其含义相同但形式略有不同的句子。
在自然语言处理中,相似问生成是一个非常重要的任务,可以在问答系统、信息检索等领域中起到很好的作用。
本文将介绍相似问生成的基本原理、应用场景以及现有方法和技术,并探讨未来的发展趋势。
一、基本原理相似问生成的核心思想是通过语言模型和转换规则将源句子转换为目标句子。
语言模型可以用来对句子进行建模,找出句子中的语法规则和句法结构,特别是找出句子中的主谓宾、修饰词和动词等。
转换规则则可以根据语言模型中的模式,将源句子转换为目标句子。
常用的转换规则包括替换、删除、插入和重新排列等。
其中替换在相似问生成中应用最广,可以将句子中的词语、短语和句子结构替换为具有相同语义的其他词语、短语和句子结构。
例如,将“can you speak Chinese?”转换为“are you able to speak Chin ese?”这样的句子就是通过替换操作得到的。
二、应用场景相似问生成在问答系统、机器翻译、信息检索和文本摘要等领域中都有广泛的应用。
在问答系统中,相似问生成可以将一个问题转换为多个具有相同意义但不同形式的问题,提高系统的覆盖率和准确性。
例如,将“what's the capital of China?”转换为“what's the name of the capital of China?”就可以通过不同的问题形式获取相同的答案。
在机器翻译中,相似问生成可以将一种语言的句子转换为同义但不同形式的句子,提高翻译的质量和流畅度。
在信息检索和文本摘要中,相似问生成可以将原始文章中的句子转换为具有相同或相似含义但不同结构的句子,提高检索和摘要的准确性和可读性。
三、现有方法和技术目前,相似问生成的研究主要集中于基于模型的方法和基于规则的方法两类。
基于模型的方法使用了神经网络等深度学习技术,构建了一种可学习的模型,自动学习句子之间的相似性规律。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
i ue ec b ets d l dmapn l . nX l f bt c srne aeidr e . xmpeo iu lee c njbs es s sdt d sr et kmo e p igr e A MLfeo sr t e t c ei d Ane a l f r arsa ho t s o i h a n a u s i a a u i r f s v vt r o r
和A I U 元模型 ,采用基于对象约束语言 的规则表示方法定义 T 到 A I M U 的映射规则 ,使用可扩展标记语言(ML描述 T 和映射规则 , X ) M 得到 A I X U 的 ML文件 。通过一个虚拟工作压力调查实例验证该方法 的可行性和易用性 。 关奠词 :任 务模型 ;抽象 用户界面 ;模型转换 ;元模型 ;可扩展标记语言
第 3 卷 第 2 7 O期
、0 _7 ,l3
・
计
算
机
工
பைடு நூலகம்程
21 0 1年 l O月
O cob r 0l t e 2 1
No.0 2
Co mpu e gi e i trEn ne rng
软件 技 术 与数据 库 ・
文章编号:l 0-48010 06 3 文献标识码t 0 _32( 12 4—o 0 2 )—0 A
DoI 1.9 9jsn10 -4 8 0 1 00 6 : 03 6 /i .0 03 2 . 1 . .1 .s 2 2
1 概述
基于 并发任 务树(T ) C T 任务模 型【 自动生成 用户界面 的 J
一
般过程为 : 首先依据任务模型得到活动任务集(T ) 然后 E S,
2 C T任务模型的元模型 . 1 T 本文提 出的 T 元模型是依据 C T任务模型定义的 。 M T 任 务模型 的元模型( t 。 是对 任务模型结构 以及它所 涉及 的 Mea k )
Ru e b s d M o e t m a i n e so e h d l. a e d l Au o tc Co v r i n M t o
YANG . i o S u He b a . HI n Y_
(c o l f o ue ce c n eeo S h o mp tr i eadT lcmmu i t nE gn e n ,in s iesyZ ej g2 2 1, hn) oC S n nc i n ier g JaguUnv ri , h ni 10 3 C ia ao i t n a
中 田分类 P1 号t 31 T
基 于规 则 的模 型 自动转 换 方 法
杨鹤标 ,石 云
( 苏大学计 算机科 学与通信工程 学院,江苏 镇江 2 2 1) 江 10 3
擅
要 :为实现任务模型(M) T 到抽象 甩户界 面( U) AI 模型 的自动转换 ,提出一个基于规则的模型转换方法 。构建并发任务树的 T 元模型 M
[ sr c]nodroraieh uo t o v r o f akMo e(M)o s at e t fc ( )ti pp r rsns l—ae d l Abtat I re l e tmai cn es no T s d l t e zt a c i T t t c r ne aeAUI h s ae eet a uebsdmo e Ab r Us I r , p r a tma ccn es nmeh d T e M t d l f o c rakt eadA t dl r o s u tdT e ue e rsna o ae nObe t uo t o v ri to . h me mo e n u s e UI amo e aecnt ce . h lrpee tt nb sdo jc i o T a oc t r n me r r i
元素之间关系的抽象 描述 。
一
根据 E S生成相应的抽象用户界 面( s atUsrItr c, T Abt c e nef e r a
A ) UI 。 i
个任 务模 型( sMo e) t k d1包含许 多任 务( s) 任务 之 a t k和 a
当前研究主要集中在从任 务模 型中抽取 E SE beT s T (al ak S t ,很少有 人关注任务模型 到 A es J ) UI的映射 。任务模型 (akMo e, M) A I T s dl T 到 U 的转换是界面精化 的核心问题。但 是 , 目前缺乏对 A 的定义和相应的规则形式化表示 方法 , UI
i v n t e nsr t h e sbi t d a c s i l y o i eho s gi e o d mo t e t e f a i l y a c e sbi t ft s t d. a i n i h m
[ y od ]T s d l M)A s at s t f e U )m d l ov r o ; e o e e t s l Ma u ag a e ML Ke r s ak w Mo e T ; b t c U e I e a ( I o e c nes n m t m d l X e i e r p n u g( ( r rn r c A ; i a ; nb k L X )