R语言单因素方差分析
全网最全R语言中的方差分析汇总

全网最全R语言中的方差分析汇总一文展示R语言中的方差分析常用模型 #2021.9.11 方差分析是一个全新的思路,它采用的是变异分解的思路,将组内组件分开,查看显著性。
变异分解,和数量遗传学的创立也密不可分,比如表型 = 基因+ 环境更进一步:表型 = 加性效应 + 非加性效应 + 环境更更进一步:表型 = 加性效应 + 显性效应 + 上位性效应 + 环境育种值是加性效应的部分杂种优势是显性和上位性效应的部分基因与环境互作是:环境*基因的效应另外还有重复力效应(个体永久环境效应)、母体效应、窝别效应等等,都是使用表型数据剖分的形式进行计算和评估。
很多人分析数据,想看一下显著性与否,显著的话就说明有差异,具体差异是多少,需要进行多重比较。
所以,先要有方差分析,才有显著性,只有显著了,才可以进行多重比较。
先后顺序不能错。
方差分析,还有一定的前提假定。
需要进行检验。
方差分析后,多重比较也有很多方法。
好在,现在的R语言足够友好,各种功能都已经打包好了,直接拿来用就行了。
下面看我的总结:1. 方差分析的假定上面这个思维导图,也可以看出,方差分析有三大假定:正态,独立和齐次,如果不满足,可以使用广义线性模型或者混合线性模型,或者广义线性混合模型去分析。
「本次我们的主题有:」2. 数据来源这里,我们使用的数据来源于R包agridat,它是讲农业相关的论文,书籍中相关的数据收集在了一起,更加符合我们的背景。
包的下载地址:/web/packages/agridat/index.html「包的介绍」「包的安装方式:」install.packages("agridat")3. 单因素方差分析「数据描述:」data(lasrosas.corn)dat <- lasrosas.cornstr(dat)「数据结构:」> str(dat)'data.frame': 3443 obs. of 9 variables:$ year : int 1999 1999 1999 1999 1999 1999 1999 1999 199 9 1999 ...$ lat : num -33.1 -33.1 -33.1 -33.1 -33.1 ...$ long : num -63.8 -63.8 -63.8 -63.8 -63.8 ...$ yield: num 72.1 73.8 77.2 76.3 75.5 ...$ nitro: num 132 132 132 132 132 ...$ topo : Factor w/ 4 levels "E","HT","LO",..: 4 4 4 4 4 4 4 4 4 4 ...$ bv : num 163 170 168 177 171 ...$ rep : Factor w/ 3 levels "R1","R2","R3": 1 1 1 1 1 1 1 1 1 1 . ..$ nf : Factor w/ 6 levels "N0","N1","N2",..: 6 6 6 6 6 6 6 6 6 6 ...这里数据有很多列,但是我们要演示单因素方差分析,这里的因素为nf,自变量(Y变量)是yield,想要看一下nf的不同水平是否达到显著性差异。
R语言学习笔记(七):方差分析

R语言学习笔记(七):方差分析单因素方程分析install.packages("multcomp")library(multcomp)attach(cholesterol)table(trt)aggregate(response, by=list(trt),FUN=mean)aggregate(response, by=list(trt),FUN=sd)fit<-aov(response~trt)summary(fit) Df Sum Sq Mean Sq F value Pr(>F)trt 4 1351.4 337.8 32.43 9.82e-13 ***Residuals 45 468.8 10.4---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1install.packages("gplots")library(gplots)plotmeans(response~trt,xlab="Treatment",ylab="Response", main="Mean Plot\nwith 95% CI")detach(cholesterol)#多重比较TukeyHSD(fit)par(las=2)par(mar=c(5,8,4,2))plot(TukeyHSD(fit))library(multcomp)par(mar=c(5,4,6,2))tuk<-glht(fit,linfct=mcp(trt="Tukey"))plot(cld(tuk,level=.05),col="lightgrey")#离群点检测 -#评估检验的假设条件library(car)qqPlot(lm(response~trt,data=cholesterol),simulate=TRUE,main="Q-Q Plot",labels=FALSE)#Bartlett检验bartlett.test(response~trt,data=cholesterol)Bartlett test of homogeneity of variancesdata: response by trtBartlett's K-squared = 0.57975, df = 4, p-value = 0.9653outlierTest(fit) #离群点检测No Studentized residuals with Bonferonni p < 0.05 没发现离群点Largest |rstudent|:rstudent unadjusted p-value Bonferonni p19 2.251149 0.029422 NA单因素协方差分析data(litter,package="multcomp")attach(litter)table(dose)weight<-weight[c(1:60)]gesttime<-gesttime[c(1:60)]aggregate(weight,by=list(dose),FUN=mean)fit<-aov(weight~gesttime+dose)summary(fit)Df Sum Sq Mean Sq F value Pr(>F)gesttime 1 107.0 107.04 7.099 0.0101 *dose 2 45.9 22.97 1.523 0.2269Residuals 56 844.3 15.08---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1library(effects)effect("dose",fit)dose effectdose0.5 1 230.44530 31.68956 29.46164#多重比较library(multcomp)contrast<-rbind("no drug vs. drug"=c(3,-1,-1,-1))summary(glht(fit,linfct=mcp(dose=contrast)))#评估验证的假设条件library(multcomp)fit2<-aov(weight~gesttime*dose,data=litter)fit2<-aov(weight~gesttime*dose,data=litter)summary(fit2)#结果可视化install.packages("HH")library(HH)ancova(weight~gesttime+dose,data=litter)双因素分析attach(ToothGrowth)table(supp,dose)aggregate(len,by=list(supp,dose),FUN=mean)aggregate(len,by=list(supp,dose),FUN=sd)dose<-factor(dose)fit<-aov(len~supp*dose)summary(fit)Df Sum Sq Mean Sq F value Pr(>F)supp 1 205.4 205.4 15.572 0.000231 ***dose 2 2426.4 1213.2 92.000 < 2e-16 ***supp:dose 2 108.3 54.2 4.107 0.021860 *Residuals 54 712.1 13.2---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1interaction.plot(dose,supp,len,type="b",col=c("red","blue"),pch=c(16,18),main="Interaction between Dose and Supplement Type")detach(ToothGrowth)library(gplots)plotmeans(len~interaction(supp,dose,sep=" "),connect = list(c(1,3,5),c(2,4,6)),col=c("red","darkgreen"),main="Interaction Plot with 95% CIs",xlab="Treatment and Dose Combination") library(HH)interaction2wt(len~supp*dose)重复测量方差分析CO2$conc<-factor(CO2$conc)w1b1<-subset(CO2,Treatment=='chilled')fit<-aov(uptake~conc*Type+Error(Plant/(conc)),w1b1)summary(fit)Error: PlantDf Sum Sq Mean Sq F value Pr(>F)Type 1 2667.2 2667.2 60.41 0.00148 **Residuals 4 176.6 44.1---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Error: Plant:concDf Sum Sq Mean Sq F value Pr(>F)conc 6 1472.4 245.40 52.52 1.26e-12 ***conc:Type 6 428.8 71.47 15.30 3.75e-07 ***Residuals 24 112.1 4.67---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1par(las=2)par(mar=c(10,4,4,2))with(w1b1,interaction.plot(conc,Type,uptake,type="b",col=c("red","blue"),pch=c(16,18),main="Interaction Plot for Plant Type and Concentration"))boxplot(uptake~Type*conc, data=w1b1,col=(c("gold","green")),main="Chilled Quebec and Mississippi Plants",ylab="Carbon dioxide uptake rate (umol/m^2 sec)")多元方差分析library(MASS)attach(UScereal)shelf<-factor(shelf)y<-cbind(calories,fat,sugars)aggregate(y,by=list(shelf),FUN=mean)cov(y)calories fat sugarscalories 3895.24210 60.674383 180.380317fat 60.67438 2.713399 3.995474sugars 180.38032 3.995474 34.050018fit<-manova(y~shelf)summary(fit)Df Pillai approx F num Df den Df Pr(>F)shelf 2 0.4021 5.1167 6 122 0.0001015 ***Residuals 62---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1summary.aov(fit)Response calories :Df Sum Sq Mean Sq F value Pr(>F)shelf 2 50435 25217.6 7.8623 0.0009054 ***Residuals 62 198860 3207.4---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Response fat :Df Sum Sq Mean Sq F value Pr(>F)shelf 2 18.44 9.2199 3.6828 0.03081 *Residuals 62 155.22 2.5035---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Response sugars :Df Sum Sq Mean Sq F value Pr(>F)shelf 2 381.33 190.667 6.5752 0.002572 **Residuals 62 1797.87 28.998---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1评估假设检验center<-colMeans(y)n<-nrow(y)p<-ncol(y)cov<-cov(y)d<-mahalanobis(y,center,cov)coord<-qqplot(qchisq(ppoints(n),df=p),d,main="Q-Q Plot Assessing Multivariate Normality",ylab="Mahalanobis D2") abline(a=0,b=1)identify(coord$x,coord$y,labels=s(UScereal))用回归来做ANOVAlibrary(multcomp)levels(cholesterol$trt)[1] "1time" "2times" "4times" "drugD" "drugE"fit.aov<-aov(response~trt,data=cholesterol)summary(fit.aov)Df Sum Sq Mean Sq F value Pr(>F)trt 4 1351.4 337.8 32.43 9.82e-13 ***Residuals 45 468.8 10.4---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1fit.lm<-lm(response~trt,data=cholesterol)summary(fit.lm)Call:lm(formula = response ~ trt, data = cholesterol)Residuals:Min 1Q Median 3Q Max-6.5418 -1.9672 -0.0016 1.8901 6.6008Coefficients:Estimate Std. Error t value Pr(>|t|)(Intercept) 5.782 1.021 5.665 9.78e-07 ***trt2times 3.443 1.443 2.385 0.0213 *trt4times 6.593 1.443 4.568 3.82e-05 ***trtdrugD 9.579 1.443 6.637 3.53e-08 ***trtdrugE 15.166 1.443 10.507 1.08e-13 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 3.227 on 45 degrees of freedomMultiple R-squared: 0.7425, Adjusted R-squared: 0.7196F-statistic: 32.43 on 4 and 45 DF, p-value: 9.819e-13contrasts(cholesterol$trt)2times 4times drugD drugE1time 0 0 0 02times 1 0 0 04times 0 1 0 0drugD 0 0 1 0drugE 0 0 0 1fit.lm<-lm(response~trt,data=cholesterol,contrasts="contr.helmert")summary(fit.lm)Call:lm(formula = response ~ trt, data = cholesterol, contrasts = "contr.helmert")Residuals:Min 1Q Median 3Q Max-6.5418 -1.9672 -0.0016 1.8901 6.6008Coefficients:Estimate Std. Error t value Pr(>|t|)(Intercept) 5.782 1.021 5.665 9.78e-07 ***trt2times 3.443 1.443 2.385 0.0213 *trt4times 6.593 1.443 4.568 3.82e-05 ***trtdrugD 9.579 1.443 6.637 3.53e-08 ***。
R语言之方差分析

一、单因素方差分析单因素方差分析只有一个分组变量,因此数据看起来像一个多列的数据框,如 Grass Heath Arable1 3 6 192 4 7 33 3 8 84 5 8 85 6 9 96 12 11 117 21 12 128 4 11 119 5 NA 910 4 NA NA11 7 NA NA12 8 NA NA方差分析的基本命令是aoc(),并且需要使用公式语法,并且数据结构也要为预测变量+因子的形式,因此对于前面的数据,如果直接使用将出现错误,我们使用stack()命令将其转化,转化后的数据形式如下:values ind1 3 Grass2 4 Grass3 3 Grass4 5 Grass5 6 Grass6 12 Grass7 21 Grass8 4 Grass9 5 Grass10 4 Grass11 7 Grass12 8 Grass13 6 Heath14 7 Heath15 8 Heath16 8 Heath17 9 Heath18 11 Heath19 12 Heath20 11 Heath21 NA Heath22 NA Heath23 NA Heath24 NA Heath25 19 Arable26 3 Arable27 8 Arable28 8 Arable29 9 Arable30 11 Arable31 12 Arable32 11 Arable33 9 Arable34 NA Arable35 NA Arable36 NA Arable原数据中带有NA项,如果想将其移除,可使用na.omit()。
将数据转化成预测变量+因子的形式之后,我们使用aov()命令进行方差分析,如:> aov(count~site,data=bfs)Call:aov(formula = count ~ site, data = bfs)Terms:site ResidualsSum of Squares 55.3678 467.6667Deg. of Freedom 2 26Residual standard error: 4.24113Estimated effects may be unbalanced我们对结果使用summary()命令,将其呈现为经典的方差分析表格,结果如下:> summary(aov(count~site,data=bfs))Df Sum Sq Mean Sq F value Pr(>F)site 2 55.4 27.68 1.539 0.233Residuals 26 467.7 17.99可以看出,上面的结果包含了F值及显著性。
r语言 单因素重复测量方差

r语言单因素重复测量方差朋友们!今天咱们要来聊聊r语言里一个挺酷的东西——单因素重复测量方差分析。
你可以把它想象成是统计界的一台“时光机”,为啥这么说呢?听我慢慢给你道来。
首先啊,啥是单因素重复测量方差分析呢?简单来讲,就是当我们要研究一个因素对某个观测指标的影响,而且呢,对同一组研究对象在这个因素的不同水平下进行了多次测量。
比如说,我们想看看不同的教学方法对学生成绩的影响,然后呢,我们对同一批学生分别用了几种不同的教学方法,每次用一种方法后就测一次成绩,这就是重复测量啦。
在r语言里进行单因素重复测量方差分析,就像是给我们的研究装上了一个精确的导航仪。
我们先得把数据准备好,这数据就好比是我们旅行的“地图”。
假设我们有一组学生在不同时间段的考试成绩数据,把它整理成一个数据框,每一行代表一个学生,每一列呢,可能是不同时间点的成绩。
接下来,我们就要调用r语言里相应的函数啦,就好像是启动了我们的“时光机”。
常用的函数有`aov()`,不过对于重复测量方差分析,还得稍微复杂一点处理,因为要考虑到数据的重复测量结构。
这时候可能就得用到一些扩展包,比如`nlme`包里面的`lme()`函数。
比如说,我们的代码可能会像这样:library(nlme)假设我们的数据框叫data,有学生编号id,时间点time和成绩score这三列。
model <lme(score ~ time, random = ~ 1 | id, data = data)anova(model)这里面,`lme()`函数就是在构建我们的模型,告诉r语言,成绩(score)是我们要研究的因变量,时间(time)是自变量,然后`random = ~ 1 | id` 这部分是在说明我们的数据是有重复测量结构的,是以学生编号(id)来分组的。
最后用`anova()`函数来进行方差分析,看看时间这个因素对成绩有没有显著影响。
但是啊,这过程中也可能会遇到一些小“坑”。
R语言学习系列27-方差分析

R语言学习系列27-方差分析(总21页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--22. 方差分析一、方差分析原理1. 方差分析概述方差分析可用来研究多个分组的均值有无差异,其中分组是按影响因素的不同水平值组合进行划分的。
方差分析是对总变异进行分析。
看总变异是由哪些部分组成的,这些部分间的关系如何。
方差分析,是用来检验两个或两个以上均值间差别显著性(影响观察结果的因素:原因变量(列变量)的个数大于2,或分组变量(行变量)的个数大于1)。
一元时常用F检验(也称一元方差分析),多元时用多元方差分析(最常用Wilks’∧检验)。
方差分析可用于:(1)完全随机设计(单因素)、随机区组设计(双因素)、析因设计、拉丁方设计和正交设计等资料;(2)可对两因素间交互作用差异进行显著性检验;(3)进行方差齐性检验。
要比较几组均值时,理论上抽得的几个样本,都假定来自正态总体,且有一个相同的方差,仅仅均值可以不相同。
还需假定每一个观察值都由若干部分累加而成,也即总的效果可分成若干部分,而每一部分都有一个特定的含义,称之谓效应的可加性。
所谓的方差是离均差平方和除以自由度,在方差分析中常简称为均方(Mean Square)。
2. 基本思想基本思想是,将所有测量值上的总变异按照其变异的来源分解为多个部份,然后进行比较,评价由某种因素所引起的变异是否具有统计学意义。
根据效应的可加性,将总的离均差平方和分解成若干部分,每一部分都与某一种效应相对应,总自由度也被分成相应的各个部分,各部分的离均差平方除以各自的自由度得出各部分的均方,然后列出方差分析表算出F检验值,作出统计推断。
方差分析的关键是总离均差平方和的分解,分解越细致,各部分的含义就越明确,对各种效应的作用就越了解,统计推断就越准确。
效应项与试验设计或统计分析的目的有关,一般有:主效应(包括各种因素),交互影响项(因素间的多级交互影响),协变量(来自回归的变异项),等等。
R语言单因素方差分析

R语言单因素方差分析课程报告分析题目:1、录入数据chanliang<-scan()24 30 28 2627 24 21 2631 28 25 3032 33 33 2821 22 16 212、形成数据框,如图chuli<-rep(c('A1','A2','A3','A4','A5'),c(4,4,4,4,4))jieguo=data.frame(chanliang,chuli)jieguo图13、数据分析fit<-aov(chanliang~chuli,data=jieguo)summary(fit)因为结果差异是否显著需要看数据P或Pr,若P上有符号“*”,则说明差异显著,且*越多,差异越大。
由下图结果显示,Pr的数据中有三个*,说明差异非为有多个数据,因此要进行多种比较分析。
如下。
4、对分析结果作比较TukeyHSD(fit)P adj越小越显著,又例如diff中,A5-A4<0,则说明A4比较厉害,A4比较符合预期要求。
由图可知,多种比较分析中,A5-A4的P值最小,且A5-A4<0,A4比较符合预期要求。
图2 5、画图(置信区间)plot(TukeyHSD(fit))图形说明:若图3中Ai-Aj(i=2,3,4,5.j=1,2,3,4)经过了0的那条虚线,则说明差异不显著,可以对第四步的分析做检验。
由图可知,A5-A4,A5-A3,A5-A1,A4-A2差异显著,其中A5-A4差异最显著。
由此检验图2。
图3 6、正态检验/方差齐性检验bartlett.test(chanliang~chuli,data=jieguo)由2图与图3对比可检验分析出所需的结论,更加实在的证明了所得结论。
方差分析满足以下3个性质:独立性(抽出来的数据不受控制、独立的)、正态性(符合正态分布)、等方差性(方差相等)。
用R语言做单因素方差分析及多重比较

用R语言做单因素方差分析及多重比较SPSS方差分析的应用已经做得非常好了,绝大多数的方差分析问题均可通过SPSS“点菜单”的方式得以解决,R语言在统计和可视化方面有自己的特色,我们不妨来对比着学习。
选用R语言自带案例数据集PlantGrowth,研究两个处理和一个对照组对植物产量的影响,每组10例共3记录,主要考察处理对提高植物产量有无影响。
数据构成:因变量weight,因子变量group,三个水平依次为ctrl、trt1、trt2。
01数据正态性检验用夏皮罗-威尔克检验3组数据是否服从正态分布,样本容量3~5000均可,这一点比SPSS说得更明确。
语法代码:data <- PlantGrowth[,1]shapiro.test(data[1:10])shapiro.test(data[11:20])s hapiro.test(data[21:30])ctrl、trt1、trt2三个分组的shapiro.test检验概率p依次为0.7475、0.4519、0.5643,均大于0.05,原假设成立(H0:假设数据服从正态分布),表明3组数据均来自正态分布总体。
02方差齐次检验用bartlett.test检验3个分组数据方差是否一致。
语法代码:bartlett.test(weight~group,data = PlantGrowth)直接看p-value = 0.2371>0.05,原假设成立(H0:假设3组数据方差相等),表明3组数据的方差齐次。
单因素方差分析,必须对数据正态性和方差齐次做出判断,如果不满足正态或方差齐次,则需要做出有关相应。
(在《SPSS从入门到实践提高》课程中有具体讲述)03图形可视化用箱图观察一下3组数据的分布情况。
04单因素方差分析用R语言aov函数完成方差分析。
语法代码:dfc <- aov(weight~group,data = PlantGrowth)summary(dfc)R语言是用文本来输出结果,这一点比SPSS逊色多了,读取结果不够直观方便。
R语言单因素方差分析

R语言单因素方差分析单因素方差分析是一种用于比较不同组之间平均数是否有显著差异的统计方法。
它可以用来分析一个自变量对一个连续型因变量的影响。
在R 语言中进行单因素方差分析,可以通过使用内置的函数或者额外的包来实现。
下面将介绍如何使用R进行单因素方差分析的步骤及示例代码。
步骤一:安装和加载R语言的额外包,比如"lmtest"和"car"包。
```install.packages("lmtest")install.packages("car")library(lmtest)library(car)```步骤二:准备数据。
这里我们以一个虚拟的示例数据为例,假设有一个实验研究了三种不同处理对一些指标的影响,每种处理都有10个观测值。
数据存储在一个数据框中,变量名为“处理”(treatment)和“指标”(score)。
```treatment <- c(rep("A", 10), rep("B", 10), rep("C", 10))score <- c(1.7, 2.9, 2.3, 1.8, 3.1, 2.4, 2.2, 2.5, 2.8, 1.9, 4.2, 3.9, 4.0, 3.7, 3.2, 3.5, 3.6, 4.3, 3.0, 3.8, 2.1, 2.6, 2.7, 2.0, 2.3, 2.1, 2.4, 2.7, 2.5, 2.8)data <- data.frame(treatment, score)```步骤三:进行方差分析。
使用`aov(`函数创建一个方差分析模型,并用`summary(`函数查看分析结果。
```model <- aov(score ~ treatment, data=data)summary(model)```分析结果将输出方差分析表,包括误差平方和(SS)、均方(MS)、F值和p值等信息。
赖江山老师讲授R语言课程个人笔记

一、非对称分析(回归)做回归分析的前提条件:方差齐次性、独立、数据满足正态分布如果数据不正态,导致的后果平均值95%置信区间,两边不对称如果方差不等,某一边的标准差、置信区间大,有重叠回归Y定性时,整个式子叫做“分类排序”;X定性又定量时,整个方程叫“协方差分析”二、单因素方差分析(1)验证数据的正态性,零假设:均值相等,一组一组地验证:tapply(df$yield,df$Treat,shapiro.test),正态分析函数(shapiro.test),当结果P>0.05,则是一种自然分布(2)合并检验正态性:shapiro.test(resid(lm(yield~Treat,df)))(3)方差齐性检验,零假设:方差相等:bartlett.test(yield~Treat,df)(4)方差分析:fit <- aov(yield ~ Treat, df) 【“~”表示回归,aov是单因素方差分析ANOVA函数】(5)小知识:范函数:[summary.] /[plot.](6)P=1-pf(value组间方差-即组间变异幅度,Df-treat, Df-Residuals)Treat-Meansq/Treat-Value=Residuals-MeansqDf Sum Sq Mean Sq F value Pr(>F)Treat 4 301.2 75.30 11.18 0.000209 ***Residuals 15 101.0 6.73---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘’ 1(7)多重比较:安装赖老师的写的包(NEwR2),library(NEwR2),LSD多重比较:Least Significance Difference;多个t检验Install.package(‘agricolae’)(8)(9)结果P值,犯“1类错误,拒接真的原假设”的概率,正常我们说的P=0.05,就是:我们可以接受犯这个错误的概率。
实验的方差分析(R语言)

实验的⽅差分析(R语⾔)实验设计与数据处理(⼤数据分析B中也⽤到F分布,故总结⼀下,加深印象)第3课⼩结——实验的⽅差分析(one-wayanalysis of variance)概述实验结果\(S\)受多个因素\(A_i\)影响,但影响的程度各不相同,如何通过实验数据来确定因素的影响程度呢?其函数关系为\[S=f(A_1,A_2,\cdots,A_n) \tag{1} \]⽅差标准差的平⽅,表征\(x_i\)与\(\bar{x}\)的偏离程度。
⽅差分析(ANalysis Of VAriance,简称ANOVA)利⽤实验数据与均值的偏离程度来判断各因素对实验结果影响显著性程度的⽅法。
⽅差分析实质上是研究⾃变量(因素)与因变量(实验结果)的相互关系指标(experimental index)衡量或考核实验效果的参数。
因素(experimental factor)影响实验指标的条件,可控因素⽔平因素的不同状态或内容单因素实验的⽅差分析单因素实验⽅差分析基本问题(1)⽬的:检验⼀个因素对实验结果的影响是否显著性单因素实验⽅差分析基本步骤1)计算平均值组内平均值(同⼀⽔平的平均值)\[\overline{x_i}=\frac{1}{n_i}\sum_{j=1}^{n_i}{x_{ij}} \tag{2} \]总平均值\[\overline {x_i}=\frac{1}{n}\sum_{i=1}^{r}\sum_{j=1}^{n_i}{x_{ij}} \tag{3} \]2)计算离差平⽅和总离差平⽅和\(SS_T\)(sum of squares for total)\[SS_T = \sum_{i=1}^{r}{\sum_{j=1}^{n_i}({x_{ij}-\overline{x}})^2} \tag{4} \]表⽰了各实验值与总平均值的偏差的平⽅和反映了实验结果之间存在的总差异组间离差平⽅和 \(SS_A\) (sum of square for factor A)\[SS_A = \sum_{i=1}^{r}{\sum_{j=1}^{n_i}({\overline{x_{i}}-\overline{x}})^2} =\sum_{i=1}^{r}n_i({\overline{x_{i}}-\overline{x}})^2 \tag{5} \]反映了各组内平均值之间的差异程度由于因素A不同⽔平的不同作⽤造成的组内离差平⽅和$ SS_e $(sum of square for error)\[SS_T = \sum_{i=1}^{r}{\sum_{j=1}^{n_i}({x_{ij}-\overline{x}_i})^2} \tag{6} \]反映了在各⽔平内,各实验值之间的差异程度由于随机误差的作⽤产⽣三种离差平⽅和之间关系:\[SS_T = SS_A + SS_e \tag{7} \]3)计算⾃由度(degree of freedom)总⾃由度(\(SS_T\)对应的⾃由度):\(df_T=n-1\)组间⾃由度(\(SS_A\)对应的⾃由度):\(df_A=r-1\)组内⾃由度(\(SS_e\)对就的⾃由度):\(df_e=n-r\)三者关系:\(df_T=df_A+df_e\)4)计算平均平⽅均⽅ = 离差平⽅和除以对应的⾃由度\[MS_A = SS_A/df_A \quad \quad MS_e = SS_e / df_e \]式中,\(MA_A\)——组间均⽅,\(MS_e\)——组内均⽅/误差的均⽅5)F检验\[F_A = \frac{组间均⽅}{组内均⽅}=\frac{MS_A}{MS_e} \tag{8} \]服从⾃由度为\((df_A,df_e)\)的F分布(F distribution)对于给定的显著性⽔平\(\alpha\),从F分布表查得临界值\(F_{\alpha}(df_A,df_e)\)如果\(F_A > F_{\alpha}(df_A,df_e)\),则认为因素A对实验结果有显著影响,否则认为因素A对实验结果没有显著影响。
R语言-方差分析

R语⾔-⽅差分析⽅差分析指的是不同变量之间互相影响从⽽导致结果的变化1.单因素⽅差分析: 案例:50名患者接受降低胆固醇治疗的药物,其中三种治疗条件使⽤药物相同(20mg⼀天⼀次,10mg⼀天两次,5mg⼀天四次),剩下的两种⽅式是(drugE和drugD),代表候选药物 哪种药物治疗降低胆固醇的最多?1 library(multcomp)2 attach(cholesterol)3# 1.各组样本⼤⼩4 table(trt)5# 2.各组均值6 aggregate(response,by=list(trt),FUN=mean)7# 3.各组标准差8 aggregate(response,by=list(trt),FUN=sd)9# 4.检验组间差异10 fit <- aov(response ~ trt)11 summary(fit)12 library(gplots)13# 5.绘制各组均值和置信区间14 plotmeans(response ~ trt,xlab = 'Treatment',ylab = 'Response',main='MeanPlot\nwith 95% CI')15 detach(cholesterol) 结论: 1.均值显⽰drugE降低胆固醇最多,1time降低胆固醇最少. 2.说明不同疗法之间的差异很⼤ 多重⽐较药品和服药次数1 library(multcomp)2 par(mar=c(5,4,6,2))3 tuk <- glht(fit,linfct=mcp(trt='Tukey'))4 plot(cld(tuk,level=.05),col='lightgrey') 结论:每天复⽤4次和使⽤drugE的时候治疗胆固醇效果最好 评估检验的假设条件1 library(car)2 qqPlot(lm(response ~ trt,data=cholesterol),simulate=T,main='Q-Q Plot',labels=F)3 bartlett.test(response ~ trt,data=cholesterol)4# 检测离群点5 outlierTest(fit) 结论:数据落在95%置信区间的范围内,说明数据点满⾜正态性假设 2.单因素协⽅差分析 案例:怀孕的⼩⿏被分为4各⼩组,每个⼩组接受不同剂量的药物剂量(0.5,50,500)产下⼩⿏体重为因变量,怀孕时间为协变量1 data(litter,package = 'multcomp')2 attach(litter)3 table(dose)4 aggregate(weight,by=list(dose),FUN=mean)5 fit2 <- aov(weight ~ gesttime + dose)6 summary(fit2)7 library(effects)8# 取出协变量计算调整的均值9 effect('dose',fit2)10 contrast <- rbind('no drug vs drug' = c(3,-1,-1,-1))11 summary(glht(fit2,linfct=mcp(dose=contrast)))12 library(HH)13 ancovaplot(weight ~ gesttime + dose,data=litter) 结论:0剂量产仔20个,500剂量产仔17个 0剂量的体重在32左右,500剂量在30左右 怀孕时间和体重相关 ⽤药剂量和体重相关 结论:⼩⿏的体重和怀孕时间成正⽐和剂量成反⽐3.双因素⽅差分析 案例:随机分配60只豚⿏,分别采⽤两种喂⾷⽅法(橙汁或者维C),各种喂⾷⽅法中含有抗坏⾎酸3钟含量(0.5,1,2) 每种处理组合都分配10只豚⿏,⽛齿长度为因变量1 attach(ToothGrowth)2 table(supp,dose)3 aggregate(len,by=list(supp,dose),FUN=mean)4 aggregate(len,by=list(supp,dose),FUN=sd)5# 将dose转换为因⼦变量,这样就不是⼀个协变量6 dose <- factor(dose)7 fit3 <- aov(len ~ supp*dose)8 summary(fit3)9 detach(ToothGrowth) 结论:主效应的对豚⿏⽛齿影响很⼤ 结论:在0.5~1mg的区间中维C的豚⿏的⽛齿长度超过使⽤橙汁的⼩⿏,在1~2的区间内同理,当超过2mg时,两者对豚⿏⽛齿的影响相同4.重复测量⽅差 案例:在⼀定浓度的CO2的环境中⽐较寒带植物和⾮寒带植物的光合作⽤率进⾏⽐较1 CO2$conc <- factor(CO2$conc)2 w1b1 <- subset(CO2,Treatment == 'chilled')3 fit4 <- aov(uptake ~ conc*Type + Error(Plant/(conc)),w1b1)4 summary(fit4)5 par(las=2)6 par(mar=c(10,4,4,2))7 with(w1b1,interaction.plot(conc,Type,uptake,type='b',col=c('red','blue'),pch=c(16,18),8 main='Interaction plot for plant type and concentration'))9 boxplot(uptake~Type*conc,data=w1b1,col=c('gold','green'),10 main = 'Chilled Quebec and Mississippi Plants',11 ylab="Carbon dioxide uptake rate (umol/m^2 sec)") 结论:魁北克的植物⽐密西西⽐州的⼆氧化碳的吸收率⾼,随着CO2的浓度体⾼,效果越明显5.多元⽅差分析 案例:研究美国⾷物中的卡路⾥,脂肪,糖分是否会因货架的不同⽽不同1 library(MASS)2 attach(UScereal)3 shelf <- factor(shelf)4 y <- cbind(calories,fat,sugars)5 aggregate(y,by=list(shelf),FUN=mean)6 cov(y)7 fit5 <- manova(y ~ shelf)8 summary(fit5)9 summary.aov(fit5) 找出离群点1 center <- colMeans(y)2 n <- nrow(y)3 p <- ncol(y)4 cov <- cov(y)5 d <- mahalanobis(y,center,cov)6 coord <- qqplot(qchisq(ppoints(n),df=p),d,7 main="QQ Plot Assessing Multivariate Normality",8 ylab="Mahalanobis D2")9 abline(a=0,b=1)10 identify(coord$x,coord$y,labels = s(UScereal)) 结论:在不同的货架上的⾕物营养成分不同,有两个产品不符合多元正态分布1 library(rrcov)2# 稳健多元⽅差分析3 Wilks.test(y,shelf,method='mcd') 结论:稳健检测对离群点和违反MANOVA不敏感,证明了在不同货架的⾕物营养成分不同的结论。
r语言方差

r语言方差
一、完全随机设计资料的方差分析(单因素方差分析)
在R中aov(函数进行方差分析,结合summary(函数来查看结果。
函数用法如下
Usage
aov(formula, data = NULL, projections = FALSE, qr = TRUE, contrasts = NULL, ...)
参数formula为方差分析的表达式,如X~A或X~A+B,
表达式中可以使用特殊符号,各符合的意义如下表
data为我们分析的数据。
我们使用R自带的数据集iris进行数据分析,看看不同品种的花瓣长度是否有差异。
代码:
mod1<-aov(Sepal.Length~Species,data=iris)
summary(mod1)
Df表示自由度;Sum Sq表示平方和;Mean Sq 表示均方;F value 表示F值;Pr(>F)表示P值;Residuals表示残差,即误差。
图中P值小于0.001表示三个品种花瓣的长度是不一样的,差异具有统计学意义。
我们还可以可视化三组的均数
library(gplots)
plotmeans(Sepal.Length~Species,xlab
="Species",y="Sepal.Length",main="均数及其95%CI",data=iris)。
R语言单因素方差分析实例

1 单因素方差分析实例1
4
1 单因素方差分析实例1
5
>X<c(1600,1610,1650,1680,1700,1700,1780,1500,1640,1400,1700,1750,1640,1550,1600 ,1620,1640,1600,1740,1800,1510,1520,1530,1570,1640,1600)
小结
8
通过学习,了解单因素方差分析应用。
> A<-factor(c(rep(1,7),rep(2,5),rep(3,8),rep(4,6))) > lamp<-data.frame(X,A) > lamp.aov<-aov(X~A,data=lamp) > summary(lamp.aov)
1 单因素方差分析实例1
6
1单因素方差分析实例1
R语言单因素方差分析实例1
学习目标
2
了解单因素方差分析及应用。
1单因素方差分析实例1 3
在R中,aov()函数提供了方差分析表的计算: 进行方差分析的步骤: a.用数据框的格式输入数据 如:lamp<-data.frame(X=c(),A=factor()) b.调用aov()函数计算方差分析 lamp.aov<-aov(X~A,data=lamp) c.用summary()提取方差分析的信息 summary(lamp.aov)(anova.tab(lamp.aov))
7
分析上述计算结果,Df表示自由度,Sum Sq 表示平方和,Mean Sq 表示 均方,F value 是F值,Pr(>F)是p值,A即为因子A,Residuals 是残差。
从P值(ቤተ መጻሕፍቲ ባይዱ.121>0.05)可以看出,没有充分理由拒绝零假设H0,也就是说, 4种材料生产出来的零件寿命没有显著差异。
R语言 实验9 方差分析 (2)

实验9 方差分析一、实验目的:1.掌握单因素方差分析的思想和方法;2.掌握多重均值检验方法;3.掌握多个总体的方差齐性检验;4.掌握Kruskal-Wallis秩和检验的思想和方法;5.掌握多重Wilcoxon秩和检验的思想和方法。
二、实验内容:练习:要求:①完成练习并粘贴运行截图到文档相应位置(截图方法见下),并将所有自己输入文字的字体颜色设为红色(包括后面的思考及小结),②回答思考题,③简要书写实验小结。
④修改本文档名为“本人完整学号姓名1”,其中1表示第1次实验,以后更改为2,3,...。
如文件名为“1305543109张立1”,表示学号为1305543109的张立同学的第1次实验,注意文件名中没有空格及任何其它字符。
最后连同数据文件、源程序文件等(如果有的话,本次实验没有),一起压缩打包发给课代表,压缩包的文件名同上。
截图方法:法1:调整需要截图的窗口至合适的大小,并使该窗口为当前激活窗口(即该窗口在屏幕最前方),按住键盘Alt键(空格键两侧各有一个)不放,再按键盘右上角的截图键(通常印有“印屏幕”或“Pr Scrn”等字符),即完成截图。
再粘贴到word文档的相应位置即可。
法2:利用QQ输入法的截屏工具。
点击QQ输入法工具条最右边的“扳手”图标,选择其中的“截屏”工具。
)1.自行完成教材的相关例题。
2.(习题7.1)进行一次试验,当缓慢旋转的布面轮子受到磨损时,比较3种布上涂料的磨损量。
对每种涂料类型试验10个涂料样品,记录每个样品直到出现可见磨损时的小时数,数据由下表给出(数据存放在paint.data文件中)。
试用单因素方差分析方法分析:这3种涂料直至磨损明显可见的平均时间是否存在显著差异?如果存在,请做多重T 检验,分析哪种涂料之间存在显著差异。
三种涂料的磨损数据涂料磨损小时数A 148 76 393 520 236 134 55 166 415 153B 513 264 433 94 535 327 214 135 280 304C 335 643 216 536 128 723 258 3110 594 465解:(1)这3种涂料直至磨损明显可见的平均时间是否存在显著差异?提出假设:H0:这3种涂料直至磨损明显可见的平均时间不存在显著差异H1:这3种涂料直至磨损明显可见的平均时间存在显著差异源代码及运行结果:(复制到此处,不需要截图)> x<-scan(file.choose())Read 30 items> A<-factor(rep(1:3,c(10,10,10)))> aov.sol<-aov(x~A)> summary(aov.sol)Df Sum Sq Mean Sq F value Pr(>F)A 2 198772 99386 3.482 0.0452 *Residuals 27 770671 28543---Signif. codes: 0 ‘***’0.001 ‘**’0.01 ‘*’0.05 ‘.’0.1 ‘’1>结论:从P(0.0452<0.05)得,拒绝H,也就是说,这3种涂料直至磨损明显可见的平均时间存在显著差异(2)如果存在,请做多重T检验,分析哪种涂料之间存在显著差异?提出假设:H0:ui=ujH1:ui!+uj,i,j=1,2,3,i!=j源代码及运行结果:(复制到此处,不需要截图)> tapply(x,A,mean)1 2 3229.6 309.9 427.8> pairwise.t.test(x,A)Pairwise comparisons using t tests with pooled SDdata: x and A1 22 0.297 -3 0.042 0.261P value adjustment method: holm>结论:由检验结果得出:这3种涂料直至磨损明显可见的平均时间互相存在显著差异。
R语言方差分析案例1

单因素方差分析,group为不同的处理方法,分别为模型组,阳性药组,I号药,II号药,area为创面面积。
group area模型 1.438阳性0.622I 1.248II0.899模型0.797阳性0.648I 1.245II0.948模型0.617阳性 1.331I 1.726II 1.29模型 1.074阳性 1.418I 1.579II0.47模型 1.67阳性 1.561I 2.236II 1.148模型 1.865阳性0.388I 1.816II 1.62模型 1.228阳性 1.714I 1.551II0.878模型 1.865阳性 2.315I 2.225II 1.688模型0.793阳性 1.836I 1.592II 1.1220.读取数据data<-read.table("clipboard",header=T)0.1 用str来查看一下数据结构str(data)'data.frame': 36 obs. of 2 variables:$ group: Factor w/ 4 levels "I","II","模型",..: 3 4 1 2 3 4 1 2 3 4 ...$ area : num 1.438 0.622 1.248 0.899 0.797 ...可以发现,group一列为因子因素数据2.数据描述2.1用aggregate统计均值与标准差> data.mean <- aggregate(data$area, by=list(data$group), FUN=mean)> data.meanGroup.1 x1 I 1.6908892 II 1.1181113 模型 1.2607784 阳性 1.314778> data.sd <- aggregate(data$area, by=list(data$group), FUN=sd)> data.sdGroup.1 x1 I 0.35988562 II 0.38107893 模型 0.47609814 阳性 0.64094553.数据的正态性检验3.1用shapiro.test()函数> shapiro.test(data$area)Shapiro-Wilk normality testdata: data$areaW = 0.975, p-value = 0.5756W越接近于1,则越接近正态,p大于0.05,此处的函数使用的是W检验法,这是1965年S.S.Shapiro与M.B.Wik提出用顺序统计量W来检验分布的正态性,本法常用于小样本资料的正态性检验。
R语言实战-topic7方差分析报告

Topic7 方差分析一、相关术语以焦虑症治疗为例,现有两种治疗方案:认知行为疗法(CBT)和眼动脱敏再加工法(EMDR)。
我们招募10位焦虑症患者作为志愿者,随机分配一半的人接受为期五周的CBT,另外一半接受为期五周的EMDR,设计方案如表9-1所示。
在治疗结束时,要求每位患者都填写状态特质焦虑问卷(STAI),也就是一份焦虑度测量的自我评测报告。
在这个实验设计中,治疗方案是两水平(CBT、 EMDR)的组间因子。
之所以称其为组间因子,是因为每位患者都仅被分配到一个组别中,没有患者同时接受CBT和EMDR。
表中字母s代表受试者(患者)。
STAI是因变量,治疗方案是自变量。
由于在每种治疗方案下观测数相等,因此这种设计也称为均衡设计(balanced design);若观测数不同,则称作非均衡设计(unbalanceddesign)。
因为仅有一个类别型变量,表9-1的统计设计又称为单因素方差分析(one-way ANOVA),或进一步称为单因素组间方差分析。
方差分析主要通过F检验来进行效果评测,若治疗方案的F检验显著,则说明五周后两种疗法的STAI得分均值不同。
假设你只对CBT的效果感兴趣,则需将10个患者都放在CBT组中,然后在治疗五周和六个月后分别评价疗效,设计方案如表9-2所示。
疗法(therapy)和时间(time)都作为因子时,我们既可分析疗法的影响(时间跨度上的平均)和时间的影响(疗法类型跨度上的平均),又可分析疗法和时间的交互影响。
前两个称作主效应,交互部分称作交互效应。
当设计包含两个甚至更多的因子时,便是多因素方差分析设计,比如两因子时称作双因素方差分析,三因子时称作三因素方差分析,以此类推。
若因子设计包括组内和组间因子,又称作混合模型方差分析,当前的例子就是典型的双因素混合模型方差分析。
本例中,你将做三次F检验:疗法因素一次,时间因素一次,两者交互因素一次。
若疗法结果显著,说明CBT和EMDR对焦虑症的治疗效果不同;若时间结果显著,说明焦虑度从五周到六个月发生了变化;若两者交互效应显著,说明两种疗法随着时间变化对焦虑症治疗影响不同(也就是说,焦虑度从五周到六个月的改变程度在两种疗法间是不同的)。
R语言单双因素方差分析案例
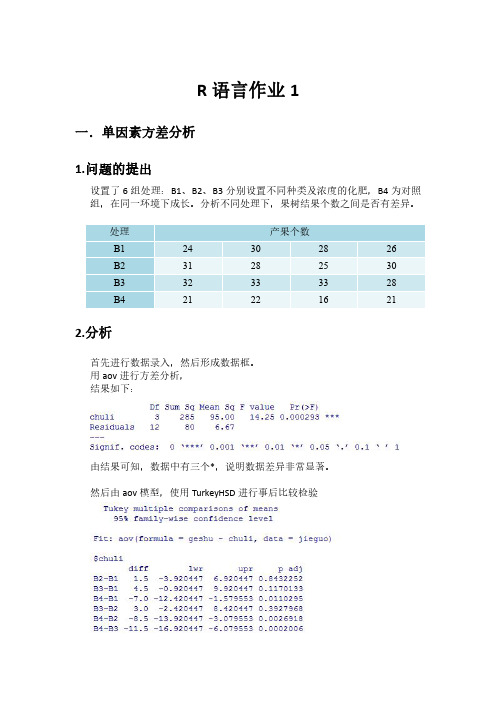
R语言作业1一.单因素方差分析1.问题的提出设置了6组处理:B1、B2、B3分别设置不同种类及浓度的化肥,B4为对照组,在同一环境下成长。
分析不同处理下,果树结果个数之间是否有差异。
2.分析首先进行数据录入,然后形成数据框。
用aov进行方差分析,结果如下:由结果可知,数据中有三个*,说明数据差异非常显著。
然后由aov模型,使用TurkeyHSD进行事后比较检验3.结果可视化由结果可知B4-B3的P值最小,且B4-B3<0,所以B3比较符合预期要求,可知B3处理方法可以使得果树产量最大化。
正态检验进一步证明了结论。
4.代码:>geshu<-scan()1:243028265:312825309:3233332813:2122162117:Read16items>chuli<-rep(c('B1','B2','B3','B4'),c(4,4,4,4))>jieguo=data.frame(geshu,chuli)>jieguogeshu chuli124B1230B1328B1426B1531B2628B2725B2830B2932B31033B31133B31228B31321B41422B41516B41621B4>fit<-aov(geshu~chuli,data=jieguo)>summary(fit)Df Sum Sq Mean Sq F value Pr(>F) chuli328595.0014.250.000293*** Residuals1280 6.67---Signif.codes:0‘***’0.001‘**’0.01‘*’0.05‘.’0.1‘’1>TukeyHSD(fit)Tukey multiple comparisons of means95%family-wise confidence levelFit:aov(formula=geshu~chuli,data=jieguo)$chulidiff lwr upr p adjB2-B1 1.5-3.920447 6.9204470.8432252B3-B1 4.5-0.9204479.9204470.1170133B4-B1-7.0-12.420447-1.5795530.0110295B3-B2 3.0-2.4204478.4204470.3927968B4-B2-8.5-13.920447-3.0795530.0026918B4-B3-11.5-16.920447-6.0795530.0002006>plot(TukeyHSD(fit))>bartlett.test(geshu~chuli,data=jieguo)Bartlett test of homogeneity of variancesdata:geshu by chuliBartlett's K-squared=0.048517,df=3,p-value=0.9972二.双因素方差分析随机分配60只老鼠,分别采用两种喂食方法,各喂食方法中抗坏血酸含量有三种水平。
r语言 单因素方差 标记字母法

r语言单因素方差标记字母法本篇文章将介绍如何使用R语言进行单因素方差分析,并介绍标记字母法对方差分析结果进行多重比较的方法。
首先,我们需要导入包含数据的 CSV 文件,并用 `read.csv()` 函数读取该文件。
假设我们的数据文件名为 `data.csv`,则以下代码可以读取并显示该文件的前 5 行数据:```data <- read.csv('data.csv')head(data)```接下来,我们可以使用 `aov()` 函数对数据进行单因素方差分析。
该函数的参数包括一个公式和数据。
公式的格式为 `response ~ group`,其中 `response` 是因变量的名称,`group` 是自变量的名称。
例如,如果我们的因变量为 `y`,自变量为 `x`,则公式应为 `y ~ x`。
以下代码演示了如何使用 `aov()` 函数进行单因素方差分析: ```model <- aov(y ~ x, data = data)summary(model)```执行上述代码后,R 会输出包含 ANOVA 表格的摘要信息。
该表格列出了各项参数的 F 值、p 值和标准误等信息,用于评估因变量与自变量之间的关系。
在进行方差分析后,我们通常会使用多重比较方法来确定哪些组之间存在显著差异。
常用的多重比较方法之一是标记字母法。
标记字母法将每个组与其他组进行比较,并根据显著性水平使用字母进行标记。
相同字母表示两个组之间没有显著差异。
以下代码演示了如何在 R 中使用 `multcomp` 包进行标记字母法分析:```library(multcomp)mc <- glht(model, linfct = mcp(x = 'Tukey'))summary(mc)````glht()` 函数用于生成比较对象。
在上述代码中,我们使用`linfct = mcp(x = 'Tukey')` 指定了使用 Tukey 的多重比较方法进行分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
R语言单因素方差分析课程报告
分析题目:
1、录入数据
chanliang<-scan()
24 30 28 26
27 24 21 26
31 28 25 30
32 33 33 28
21 22 16 21
2、形成数据框,如图
chuli<-rep(c('A1','A2','A3','A4','A5'),
c(4,4,4,4,4))
jieguo=data.frame(chanliang,chuli)
jieguo
图1
3、数据分析
fit<-aov(chanliang~chuli,data=jieguo)
summary(fit)
因为结果差异是否显著需要看数据P或Pr,若P上有符号“*”,则说明差异显著,且*越多,差异越大。
由下图结果显示,Pr的数据中有三个*,说明差异非
为有多个数据,因此要进行多种
比较分析。
如下。
4、对分析结果作比较
TukeyHSD(fit)
P adj越小越显著,又例如diff
中,A5-A4<0,则说明A4比较厉
害,A4比较符合预期要求。
由
图可知,多种比较分析中,A5-A4
的P值最小,且A5-A4<0,A4
比较符合预期要求。
图2 5、画图(置信区间)
plot(TukeyHSD(fit))
图形说明:若图3中
Ai-Aj(i=2,3,4,5.j=1,2,3,4)经
过了0的那条虚线,则说明差异不
显著,可以对第四步的分析做检验。
由图可知,A5-A4,A5-A3,A5-A1,
A4-A2差异显著,其中A5-A4差异
最显著。
由此检验图2。
图3 6、正态检验/方差齐性检验
bartlett.test(chanliang~chuli,data=jieguo)
由2图与图3对比可检验分析出所需的结论,更加实在的证明了所得结论。
方差分析满足以下3个性质:独立性(抽出来的数据不受控制、独立的)、正态性(符合正态分布)、等方差性(方差相等)。
7、线性建模
result<-lm(chanliang~chuli,data=jieguo)
library(car)
qqPlot(result,main="aa",lab="FLAST")
散点图中的点在实线的
周围,且实线在对角线
上,即说明正态分布符
合。
由图4可知,实线
在对角线上且点基本在
实线周围,因此可知正
态分布合理。
图4
报告总结:由R语言的单因素方差分析可知,由3的数据分析知在不同施肥处理手段下,水稻稻谷产量存在非常显著的差异,即水稻产量的多少与施加不同的化肥有很大的关联。
其中,由4分析比较知,A5-A4存在的差异最显著,且A4最厉害,则说明用A4处理手法(施加尿素)可以使水稻产量最大化(对比其它几种施肥手法)。
A5-A3<0可知A3比A5厉害,即用A3(施加碳酸氢铵)处理水稻得到的产量次之。
其中,在4分析比较中,A5-A1和A4-A2的P知一样大小,说明A5与A1、A4与A2之间的差异是一样的,然而A5-A1<0,A4-A2>0,说明A1比较厉害。
又A2-A1<0,即A1比较厉害,说明A1的氨水对稻谷产量的影响比较大。
A5-A2<0,即A2也比A5厉害。
因此由5、6、7检验也可验证以上结论。
由于A5是对照处理的,所以施加
尿素、碳酸氢铵、不同工艺下的氨水对水稻稻谷的产量都有促进作用,促进作用:尿素>碳酸氢铵>A1处理下的氨水>A2处理下的氨水>自来水。