(优选)第十四讲直接存储器访问
DMA(直接内存访问)技术说明文档

DEVICE_DESCRIPTION dd;RtlZeroMemory(&dd, sizeof(dd));dd.Version = DEVICE_DESCRIPTION_VERSION;dd.Master = TRUE;dd.InterfaceType = InterfaceTypeUndefined;dd.MaximumLength = MAXTRANSFER;dd.Dma32BitAddresses = TRUE;pdx->AdapterObject = IoGetDmaAdapter(pdx->Pdo, &dd,&pdx->nMapRegisters);DEVICE_DESCRIPTION结构如下页:VOID StopDevice(...){if (pdx->AdapterObject)(*pdx->AdapterObject->DmaOperations->PutDmaAdapter) (pdx->AdapterObject);pdx->AdapterObject = NULL;}Field Name Description Relevant to DeviceVersion Version number of structure—initialize to DEVICE_DESCRIPTION_VERSIONAllMaster Bus-master device—set based on your knowledge of deviceAllScatterGather Device supports scatter/gather list—set based on your knowledge of deviceAllDemandMode Use system DMA controller’s demandmode—set based on your knowledge of deviceSlaveAutoInitialize Use system DMA controller’s autoinitialize mode—set based on your knowledge of deviceSlaveDma32BitAddresses Can use 32-bit physical addresses AllIgnoreCount Controller doesn’t maintain an accurate transfer count—set based on your knowledgeof deviceSlaveReserved1 Reserved—must be FALSEDma64BitAddresses Can use 64-bit physical addresses All DoNotUse2 Reserved—must be 0DmaChannel DMA channel number—initialize from Channel attribute of resource descriptorSlaveInterfaceType Bus type—initialize to InterfaceType-UndefinedAllDmaWidth Width of transfers—set based on your knowledge of device to Width8Bits,Width16Bits, or Width32BitsSlaveDmaSpeed Speed of transfers—set based on your knowledge of device to Compatible, TypeA, TypeB, TypeC, or TypeFSlaveMaximumLength Maximum length of a single transfer—set based on your knowledge of device (and roundup to a multiple of PAGE_SIZE)AllDmaPort Microchannel-type bus port number—-initialize from Port attribute of resource descriptorSlavetypedef struct _DEVICE_EXTENSION {PADAPTER_OBJECT AdapterObject; // device's adapter objectULONG nMapRegisters; // max # map registersULONG nMapRegistersAllocated; // # allocated for this xferULONG numxfer; // # bytes transferred so farULONG xfer; // # bytes to transfer during this stage ULONG nbytes; // # bytes remaining to transferPVOID vaddr; // virtual address for current stagePVOID regbase; // map register base for this stage} DEVICE_EXTENSION, *PDEVICE_EXTENSION;VOID StartIo(PDEVICE_OBJECT fdo, PIRP Irp){PDEVICE_EXTENSION pdx =(PDEVICE_EXTENSION) fdo->DeviceExtension;PMDL mdl = Irp->MdlAddress;pdx->numxfer = 0;pdx->xfer = pdx->nbytes = MmGetMdlByteCount(mdl);pdx->vaddr = MmGetMdlVirtualAddress(mdl);ULONG nregs = ADDRESS_AND_SIZE_TO_SPAN_PAGES(pdx->vaddr,pdx->nbytes);if (nregs > pdx->nMapRegisters){nregs = pdx->nMapRegisters;pdx->xfer = nregs * PAGE_SIZE - MmGetMdlByteOffset(mdl);}pdx->nMapRegistersAllocated = nregs;NTSTATUS status = (*pdx->AdapterObject->DmaOperations->AllocateAdapterChannel)(pdx->AdapterObject, fdo, nregs, (PDRIVER_CONTROL) AdapterControl, pdx);if (!NT_SUCCESS(status)){CompleteRequest(Irp, status, 0);StartNextPacket(&pdx->dqReadWrite, fdo);}}IO_ALLOCATION_ACTION AdapterControl(PDEVICE_OBJECT fdo,PIRP junk, PVOID regbase, PDEVICE_EXTENSION pdx){PIRP Irp = GetCurrentIrp(&pdx->dqReadWrite);//这里如何取得IRP要看排队机制PMDL mdl = Irp->MdlAddress;PIO_STACK_LOCATION stack = IoGetCurrentIrpStackLocation(Irp);BOOLEAN isread = stack->MajorFunction == IRP_MJ_READ;pdx->regbase = regbase;KeFlushIoBuffers(mdl, isread, TRUE);PHYSICAL_ADDRESS address =(*pdx->AdapterObject->DmaOperations->MapTransfer)(pdx->AdapterObject, mdl, regbase, pdx->vaddr, pdx->xfer,!isread);……return DeallocateObjectKeepRegisters;}VOID DpcForIsr(PKDPC Dpc, PDEVICE_OBJECT fdo,PIRP junk, PDEVICE_EXTENSION pdx){PIRP Irp = GetCurrentIrp(&pdx->dqReadWrite);PMDL mdl = Irp->MdlAddress;BOOLEAN isread = IoGetCurrentIrpStackLocation(Irp)->MajorFunction == IRP_MJ_READ;(*pdx->AdapterObject->DmaOperations->FlushAdapterBuffers) (pdx->AdapterObject, mdl, pdx->regbase, pdx->vaddr,pdx->xfer, !isread);pdx->nbytes -= pdx->xfer;pdx->numxfer += pdx->xfer;NTSTATUS status = STATUS_SUCCESS;……判断是否读写正确的完成了if (pdx->nbytes && NT_SUCCESS(status)){pdx->vaddr = (PVOID) ((PUCHAR) pdx->vaddr + pdx->xfer); pdx->xfer = pdx->nbytes;ULONG nregs = ADDRESS_AND_SIZE_TO_SPAN_PAGES(pdx->vaddr, pdx->nbytes);if (nregs > pdx->nMapRegistersAllocated){nregs = pdx->nMapRegistersAllocated;pdx->xfer = nregs * PAGE_SIZE;}PHYSICAL_ADDRESS address =(*pdx->AdapterObject->DmaOperations->MapTransfer)(pdx->AdapterObject, mdl, pdx->regbase, pdx->vaddr,pdx->xfer, !isread);//这里是硬件特有的开始DMA传输的操作……}//如果出错了或者传输完成了else{ULONG numxfer = pdx->numxfer;(*pdx->AdapterObject->DmaOperations->FreeMapRegisters)(pdx->AdapterObject, pdx->regbase,pdx->nMapRegistersAllocated);StartNextPacket(&pdx->dqReadWrite, fdo);//开始下一次传输,这于依赖于排队机制CompleteRequest(Irp, status, numxfer);}}//两个数据结构typedef struct _SCATTER_GATHER_ELEMENT {PHYSICAL_ADDRESS Address;ULONG Length;ULONG_PTR Reserved;} SCATTER_GATHER_ELEMENT, *PSCATTER_GATHER_ELEMENT;typedef struct _SCATTER_GATHER_LIST {ULONG NumberOfElements;ULONG_PTR Reserved;SCATTER_GATHER_ELEMENT Elements[];} SCATTER_GATHER_LIST, *PSCATTER_GATHER_LIST;//AddDevice中申请资源pdx->sglist = (PSCATTER_GATHER_LIST)ExAllocatePool(NonPagedPool, sizeof(SCATTER_GATHER_LIST) + MAXSG * sizeof(SCATTER_GATHER_ELEMENT));//adapterControl中如下;IO_ALLOCATION_ACTION AdapterControl(PDEVICE_OBJECT fdo,PIRP junk, PVOID regbase, PDEVICE_EXTENSION pdx){PIRP Irp = GetCurrentIrp(&pdx->dqReadWrite);PMDL mdl = Irp->MdlAddress;BOOLEAN isread = IoGetCurrentIrpStackLocation(Irp)->MajorFunction == IRP_MJ_READ;pdx->regbase = regbase;KeFlushIoBuffers(mdl, isread, TRUE);PSCATTER_GATHER_LIST sglist = pdx->sglist;ULONG xfer = pdx->xfer;PVOID vaddr = pdx->vaddr;pdx->xfer = 0;ULONG isg = 0;//主要的不同在这里while (xfer && isg < MAXSG){ULONG elen = xfer;sglist->Elements[isg].Address =(*pdx->AdapterObject->DmaOperations->MapTransfer)(pdx->AdapterObject, mdl, regbase, pdx->vaddr,&elen, !isread);sglist->Elements[isg].Length = elen;xfer -= elen;pdx->xfer += elen;vaddr = (PVOID) ((PUCHAR) vaddr + elen);++isg;}sglist->NumberOfElements = isg;//这里开始设置特定的硬件,进行传输return DeallocateObjectKeepRegisters;}VOID StartIo(PDEVICE_OBJECT fdo, PIRP Irp){PDEVICE_EXTENSION pdx =(PDEVICE_EXTENSION) fdo->DeviceExtension;PIO_STACK_LOCATION stack = IoGetCurrentIrpStackLocation(Irp);NTSTATUS status;PMDL mdl = Irp->MdlAddress;ULONG nbytes = MmGetMdlByteCount(mdl);PVOID vaddr = MmGetMdlVirtualAddress(mdl);BOOLEAN isread = stack->MajorFunction == IRP_MJ_READ;pdx->numxfer = 0;pdx->nbytes = nbytes;status =(*pdx->AdapterObject->DmaOperations->GetScatterGatherList)(pdx->AdapterObject, fdo, mdl, vaddr, nbytes,(PDRIVER_LIST_CONTROL) DmaExecutionRoutine, pdx, !isread);if (!NT_SUCCESS(status)){CompleteRequest(Irp, status, 0);StartNextPacket(&pdx->dqReadWrite, fdo);}}//当条件满足时,调用这个例程VOID DmaExecutionRoutine(PDEVICE_OBJECT fdo, PIRP junk,PSCATTER_GATHER_LIST sglist, PDEVICE_EXTENSION pdx){PIRP Irp = GetCurrentIrp(&pdx->dqReadWrite);//保存以便这个地址被PutScatterGatherList用于释放列表。
单片机指令集的存储器访问方法与原理

单片机指令集的存储器访问方法与原理单片机是一种集成电路,它包含了运算器、控制器和存储器等多个功能模块。
其中,存储器模块是单片机重要的组成部分之一,负责存储指令集和数据。
本文将介绍单片机指令集的存储器访问方法与原理。
一、存储器的基本概念存储器是计算机硬件中的重要组件,用于存储指令和数据。
在单片机中,存储器的类型包括ROM(只读存储器)和RAM(随机存储器)两种。
ROM是只读存储器,其储存的数据在通电之后不会发生变化,常用于存储程序代码和固件等。
而RAM是随机存储器,其储存的数据在断电后会丢失,因此常用于存储临时数据。
二、指令集的存储机制指令集是单片机能够识别和执行的一系列指令的集合。
在单片机中,指令集的存储通过ROM来实现。
ROM存储器分为只读存储器和可擦写存储器两种类型。
只读存储器中的数据在出厂时就已经被写入,无法被修改。
而可擦写存储器则可以通过特定的方法进行擦除和写入操作,常用的可擦写存储器包括EEPROM和Flash。
指令在单片机中以二进制的形式存储。
当单片机执行程序时,需要从存储器中读取指令,然后解码并执行。
指令集存储器是单片机能够运行程序的基础。
三、存储器访问方法单片机存储器的访问方法包括直接寻址、间接寻址和寄存器间接寻址等。
1. 直接寻址直接寻址是指根据指令中的地址直接访问存储单元。
当指令中给出特定地址时,单片机可直接访问该地址对应的存储单元。
2. 间接寻址间接寻址是指通过寄存器间接寻址存储单元。
在执行指令时,指令中给出的地址是一个存储器单元的地址,而该地址存放的是所需数据的地址。
单片机先通过指令中的地址找到所需数据的地址,然后再通过该地址访问存储单元。
3. 寄存器间接寻址寄存器间接寻址是指通过寄存器存放的数据来寻址存储单元。
在执行指令时,指令中给出的地址是一个寄存器的编号,而所需数据存放在对应编号的寄存器中。
单片机通过寄存器的编号访问所需数据。
四、存储器访问原理单片机存储器的访问原理包括存储地址的形成、地址总线和数据总线的控制等。
一文详解DMA(直接存储器访问)
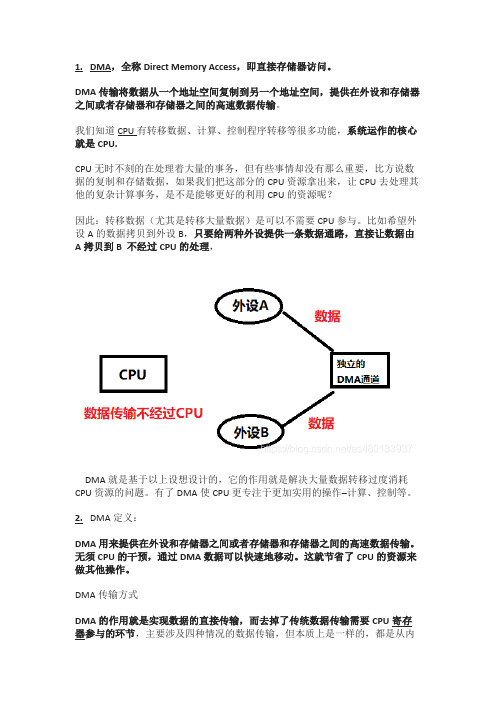
1.DMA,全称Direct Memory Access,即直接存储器访问。
DMA传输将数据从一个地址空间复制到另一个地址空间,提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。
我们知道CPU有转移数据、计算、控制程序转移等很多功能,系统运作的核心就是CPU.CPU无时不刻的在处理着大量的事务,但有些事情却没有那么重要,比方说数据的复制和存储数据,如果我们把这部分的CPU资源拿出来,让CPU去处理其他的复杂计算事务,是不是能够更好的利用CPU的资源呢?因此:转移数据(尤其是转移大量数据)是可以不需要CPU参与。
比如希望外设A的数据拷贝到外设B,只要给两种外设提供一条数据通路,直接让数据由A拷贝到B 不经过CPU的处理,DMA就是基于以上设想设计的,它的作用就是解决大量数据转移过度消耗CPU资源的问题。
有了DMA使CPU更专注于更加实用的操作–计算、控制等。
2.DMA定义:DMA用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。
无须CPU的干预,通过DMA数据可以快速地移动。
这就节省了CPU的资源来做其他操作。
DMA传输方式DMA的作用就是实现数据的直接传输,而去掉了传统数据传输需要CPU寄存器参与的环节,主要涉及四种情况的数据传输,但本质上是一样的,都是从内存的某一区域传输到内存的另一区域(外设的数据寄存器本质上就是内存的一个存储单元)。
四种情况的数据传输如下:外设到内存内存到外设内存到内存外设到外设3.DMA传输参数我们知道,数据传输,首先需要的是1 数据的源地址 2 数据传输位置的目标地址,3 传递数据多少的数据传输量,4 进行多少次传输的传输模式 DMA所需要的核心参数,便是这四个当用户将参数设置好,主要涉及源地址、目标地址、传输数据量这三个,DMA 控制器就会启动数据传输,当剩余传输数据量为0时达到传输终点,结束DMA传输,当然,DMA 还有循环传输模式当到达传输终点时会重新启动DMA传输。
直接存储器访问

地址线和数据线
地址线
用于指定要访问的内存地址。在直接存储器访问中,地 址线用于指定要访问的特定内存地址,以便从该地址读 取或写入数据。
数据线
用于传输数据。数据线在直接存储器访问中用于在内存 和设备之间传输数据。根据数据传输的方向,数据线可 以分为输入和输出数据线。
直接存储器访问的步骤
确定目标地址
直接存储器访问的优点和缺点
减轻CPU负担
通过使用DMA,CPU可以从繁重的内存访问任务 中解放出来,从而提高整体性能。
高速数据传输
DMA控制器通常使用专门硬件实现高速数据传输, 比CPU直接访问内存更快。
直接存储器访问的优点和缺点
• 灵活性:DMA控制器可以配置为从任何源地址到任何目标地址进行数据传输,提供了很大的 灵活性。
内存I/O是一种将外设寄存器映射到内存地址空间的技术。通过访
问这些内存地址,CPU可以直接与外设进行数据交换,无需进行常规的
I/O操作。
02
工作原理
当CPU需要与外设通信时,它只需访问相应的内存地址,即可读写外设
的寄存器。这使得数据传输更加高效,减少了CPU与外设之间的数据传
编程接口
程序员可以使用PCIe总线的驱动程序来与外设进行通信。这 些驱动程序通常由硬件厂商提供,并提供了丰富的API供程 序员使用。通过这些API,程序员可以控制外设的寄存器、 配置外设的工作模式等。
05
直接存储器访问的发展趋势
高速直接存储器访问
01 高速直接存储器访问技术通过提高数据传输速率, 满足高性能计算和大数据处理对存储性能的需求。
直接存储器访问的优点和缺点
01 硬件开销
需要额外的硬件支持,如DMA控制器,增加了系 统的复杂性。
Cortex-M3开发技术及实践 第8章 直接存储器访问DMA PPT

个地址加上增量值。
➢“指针增量模式”的增量值取决于所选的数据宽度,其值可以 为1、2或4,即数据宽度是8位、16位还是32位。
- 13 -
DMA编程实例 --DMA配置步骤
通道2
通道3
通道4
SPI1_RX
SPI1_TX
USART3_T USART3_R
X
X
TIM1_CH1 TIM1_CH2
TIM2_UP
SPI/I2S2_RX
USART1_TX
I2C2_TX TIM1_TX4 TIM1_TRIG TIM1_COM
TIM3_CH3 TIM3_CH4 TIM3_UP
TIM4_CH2
SP2I/I2S
IWDG
1
WWDG
2
RTC
2
TIM7
1
TIM6
5
TIM5
4
TIM4
3
TIM3
2
TIM2
DMA 请求
DMA 请求
Ethernet MAC 以太网模块
USB OTG FS USB 模块
-4-
DMA功能描述--DMA结构及特性
➢ DMA控制器还有如下特性:
➢ 每个通道都直接连接专用的硬件DMA请求,每个通道都支持软件触发。 ➢ 在同一个DMA模块上,多个请求间的优先权可以通过软件编程设置 ➢ 数据源和目标数据区可选字节、半字、全字三种传输宽度。 ➢ 源地址和目标地址必须按数据传输宽度对齐。 ➢ 循环的缓冲器,以便用于数据长度固定并且周期操作的场合。 ➢ 每个通道都有3个事件标志(DMA半传输、DMA传输完成和DMA传输出错) ➢ 三种传输方式:存储器和存储器、外设和存储器以及存储器和外设之间。 ➢ 闪存、SRAM 、外设的SRAM 、APB1、APB2和AHB外设均可作为访问源或访问
直接存储器访问DMA

图形处理中的DMA
图形处理中的DMA用于高效地处理图形数据。
在图形处理中,DMA被用于在图形硬件和主存之间传输大量的图形数据。由于图形处理通常需要大量 的数据传输,因此DMA的使用可以大大提高图形处理的效率,使得GPU能够更快地渲染出高质量的 图像。
DMA控制器是一个独立的硬件组件,它拥有自 己的内存地址、数据宽度和传输控制逻辑,可 以独立完成数据传输任务。
在DMA传输过程中,CPU将控制权交给DMA 控制器,由DMA控制器负责数据的传输,CPU 可以继续执行其他任务。
功能
数据传输
DMA最基本的功能是在内存和外部设备之间传输数据。 它可以快速地、大批量地传输数据,而不需要CPU的干预 。
更小的延迟
总结词
为了满足实时性要求高的应用,DMA技术也在不断优化,以减小传输延迟。
详细描述
在许多应用中,如音频处理、视频处理等,对数据的实时性要求非常高。因此,DMA技术也在不断优 化,以减小传输延迟。例如,通过并行处理、流水线等技术,现代的DMA控制与CPU的比较
效率
DMA可以同时进行数据传输和 计算,提高了系统的整体效率。 而CPU在执行数据传输任务时, 必须等待数据传输完成才能继续
执行其他任务。
资源占用
使用DMA可以减少CPU的资源 占用,因为DMA控制器独立地 完成了数据传输任务。CPU可以 将更多的资源用于其他计算任务。
灵活性
DMA控制器具有更强的灵活性, 可以适用于各种不同的数据传输 场景。而CPU的数据传输能力则 受到指令集和硬件结构的限制。
《存储器访问指令》ppt课件

3.2 ARM指令系统
• ARM存储器访问指令——单存放器加载/存储
•LDR和STR——①字和无符号字节加载/存储指令编码
B为1表示字节访问, 为0表示字访问
P表示前/后变址 指令执行的条件码
L用于区别加载〔L为1〕 或存储〔L为0〕
I为0时,偏移量为12 位立即数,为1时, 偏移量为存放器移 位
U表示加/减
为指令的寻址方式 Rd为源/目的存放器 Rn为基址存放器 W表示回写
3.2 ARM指令系统
• ARM存储器访问指令——单存放器加载/存储
•LDR和STR——①字和无符号字节加载/存储指令
;符号扩展
错例:
半字或者有符号字节operands不能使用存放器移位方式
LDRSB
R1 , [R6], R3,LSL #4 ;这种格式只对字和无符号字节 ;传送有效
3.2 ARM指令系统
• ARM存储器访问指令——单存放器加载/存储
•LDR和STR指令应用例如:
1.加载/存储字和无符号字节指令
LDR STR LDRB
❖ ARM指令集——存储器访问指令
ARM 处 理 器 是 Load〔 从 内 存 加 载 到 CPU〕 /Store〔从CPU存储到内存〕型的,即它对数据的 操作是通过将数据从存储器〔内存〕加载到〔CPU〕 片内存放器中进展处理,处理完成后的结果经过存放 器存回到存储器中,以加快对片外存储器进展数据处 理的执行速度.
3.2 ARM指令系统
• ARM存储器访问指令——多存放器加载/存储
《直接存储器访问》课件

通过将数据传输任务交给DMA控制器, CPU可以专注于执行其他计算任务,提高 了系统的效率和响应速度。
支持并行处理
适用于多种应用场景
DMA使得CPU和外部设备可以同时工作, 支持并行处理和多任务处理,提高了系统 的并发性能。
DMA广泛应用于各种需要高速数据传输和 处理的应用场景,如音频和视频处理、网 络通信、游戏等。
大规模并行计算
云计算
云计算平台需要处理大量用户请求和数据,直接存储器访问能够提 供更快的计算和数据传输速度。
人工智能
人工智能应用需要进行大规模并行计算,直接存储器访问能够提高 算法的训练和推理速度。
高性能计算
在高性能计算领域,如超级计算机、数据中心等,需要处理大规模数 据集和进行复杂的计算,直接存储器访问能够提供更高的计算性能。
《直接存储器访问》 ppt课件
xx年xx月xx日
• 引言 • 直接存储器访问的工作原理 • 直接存储器访问的应用场景 • 直接存储器访问的优缺点 • 直接存储器访问的发展趋势
目录
01
引言
什么是直接存储器访问
直接存储器访问(DMA)是一 种允许外部硬件在不需要CPU干 预的情况下直接读写内存的技术
02
兼容性测试
为了确保不同厂商的直接存储器访问产品之间的兼容性,一些组织开展
了广泛的兼容性测试和认证。
03
安全标准
随着数据安全问题的日益突出,直接存储器访问的安全标准也受到了越
来越多的关注,相关组织正在制定和完善安全标准和规范。
02
直接存储器访问的工作原 理
硬件架构
总线架构
描述直接存储器访问控制器与处理器、内存以及其他I/O设备之间 的连接方式。
地址和数据总线
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
– 提供了16个通道 – 由事件触发相应通道的传输 – 通道优先级设置更加灵活 – 可以实现数据传输的链接 – 独特的快速DMA(QDMA)
EDMA —框图
EDMA —传输类型
• 数据单元(element)的传输 • 帧(frame)的传输 • 阵列(array)的传输 • 块(block)的传输 • 2-维(2-D)的传输 • 非2-维(non 2-D)的传输
EXT_INT4 EXT_INT5 EXT_INT6 EXT_INT7 DMA_INT0 DMA_INT1 DMA_INT2 DMA_INT3
XEVT0 REVT0 XEVT1 REVT1 DSPINT XEVT2 REVT2
保留
同步事件
没有同步事件
定时器 0 中断 定时器 1 中断 EMIF SDRAM 定时器中断
参数RAM(Parameter RAM,PaRAM)的容量为2K byte,其中存放EDMA的传输参数,以控制不同的传 输行为。另外,参数入口还可以被彼此链接起来, 以实现某些复杂数据流的处理
事件参数 事件 1 的参数(6 words) 事件 2 的参数(6 words) … … 事件 14 的参数(6 words) 事件 15 的参数(6 words) 重加载/连接参数 事件 N 重加载/连接参数 … … 事件 Z 的重加载参数 没用使用的区域 Scratch pad area (2 words)
传输—同步
事件号(二进制) 00000 00001 00010 00011 00100 00101 00110 00111 01000 01001 01010 01011 01100 01101 01110 01111 10000
10001[注] 10010[注]
其它
事件缩写 NONE TINT0 TINT1 SD_INT
• 32-bit 地址寄存器
• 地址的基本调整
– 递增/递减/Байду номын сангаас定不变
• 索引值调整
– 16-bit 索引值
– 帧索引和数据单元索引
31
0
SRC/DST ADDRESS
传输—几种用法
• 一帧传输个数<65536 • 多帧模式传输的数据最多可达
65536*65536*4=16GB • 利用帧索引代替重载地址
概述—控制寄存器
• DMA通道0/1/2/3:
– 源地址寄存器(32-bit) – 目的地址寄存器(32-bit) – 主控寄存器 – 副控寄存器 – 传输计数寄存器(16-bit/16-bit))
• DMA全局地址寄存器A/B/C/D
• DMA全局计数重装载寄存器A/B • DMA全局索引寄存器A/B • DMA辅助控制
外中断 4 外中断 5 外中断 6 外中断 7 DMA 通道 0 中断 DMA 通道 1 中断 DMA 通道 2 中断 DMA 通道 3 中断 串口 0 发送事件 串口 0 接收事件 串口 1 发送事件 串口 1 接收事件 主机向 DSP 发出的中断 串口 2 发送事件 串口 2 接收事件
传输—地址产生
– 例子:每帧从固定的外部地址移动10 bytes, 在目的处彼此相距一个字节排列
– 设置
• SRC DIR=00b(源固定) • DST DIR=11b(目的用索引调整) • ELEMENT INDEX=10b(以步幅2递增) • FRAME INDEX= -(9×2)= -18 =FFEEh
传输—几种用法
概述— C6000 DMA特点
• 后台操作,吞吐率高 • 四个通道,一个辅助通道 • 单通道分割(split-channel)操作 • 支持多帧(frame)传输方式 • 多种地址产生方式 • 32位地址范围,支持8-/16-/32-bit字长 • 传输支持自动初始化 • 可以设定同步事件控制传输过程
(优选)第十四讲直接存储器 访问
BIT / TI
第十四讲 DMA/EDMA
1
概述—直接存储器访问
From: 外部存储器 片内数据存储器
To: 片内数据存储器 片内程序存储器 外部存储器
传输的实现: •CPU •DMA
概述—直接存储器访问
为了建立任何一种方式的传输,我们需要:
概述— C6000 DMA
EDMA —结构
•16组通道传输参数 •69组重加载参数 •空闲区
EDMA —事件控制
• 16个通道,每个通道都有一个事件与之 关联,由这些事件触发相应通道的传输
• 由有关的控制寄存器完成对事件的不同 处理
– ER/EER/ECR/ESR/PQSR/CIPR/CIER/CCER
• 事件编码器
EDMA —参数RAM
传输—启动
•程序启动
–向主控制寄存器START域写入00b,停止当前通道 –设定源地址 –设定目的地址 –设定传输个数 –设置其他的有关模式,向START域写入01b,启动传输
•自动初始化方式启动
–多次传输,只需设置一次
传输—例子(参数)
C6201
A/D
DMA
我们需要知道 那些参数?
DATA MEMORY
EDMA —传输链
• 类似于DMA中的自动初始化
– 更灵活,参数可变 – 便于实现某些复杂的数据传输的应用要求
• 传输链
– 多种参数的EDMA传输过程相连接 – 链的长度没有限制
• 在传输链中,一次传输的结束会导致自 动从参数RAM中装载下一次事件应用的 传输参数
EDMA —传输链参数重加载
• 数据整序
传输—分裂通道&辅助通道
• 分裂通道模式
– 使得一个通道可以提供双向的数据流传输 – 收发利用同一个计数器 – 需要利用DMA global address register作为
分裂地址控制
• 辅助通道
– HPI主机口专用
后处理—状态与中断
EDMA—概述
• 扩展的直接存储器访问,是C6211/C6711的独 有特征
传输—例子(参数)
源地址: 目的地址: 传输计数值: 源地址的方向: 目的地址的方向: 中断CPU: 同步: 同步事件 利用:
A_D_SRC DMEM_DST 200h Inc/Dec/None Inc/Dec/None Yes/No Yes/No A/D(RDY) INT4/5/6/7
• 读同步 • 写同步 • 帧同步