张伟豪AMOS培训视频4笔记
如何利用AMOS进行结构方程模型研究?亚洲AMOS一哥张伟豪视频三部

如何利用AMOS进行结构方程模型研究?亚洲AMOS一哥张伟豪视频三部现在无论是社会学、经济学、心理学、临床医学、护理学都越来越多的喜欢采用量表的方式开展研究,统称为量化研究。
比如临床上,基于患者报告结局的研究越来越多。
先前,我们从网上购买得到台湾著名的SPSS统计分析专家,号称Amos 亚洲一哥张伟豪带来的两部基于问卷和量表的统计分析视频。
但AMOS一哥看家本领,莫过于AMOS进行结构方程模型研究了!现在我们继续求购获得其AMOS结构方程模型视频教程,特贡献给诸位。
视频包括三部,分别是“初级教程”、“高级教程”和“论文写作教程”。
如何下载?我们老规矩: 如果需要下载,请关注公众号,发送关键词“结构方程”至公众号对话框,可获得下载百度盘地址。
内容包括视频、讲义、还有AMOS23的安装软件。
本公众号有更多的量表研究资源和方法:1.“我的研究是基于量表的调查,如何计算样本量?”2.【免费下载】SPSS经典教程:张文彤SPSS初级+高级操作视频3.【资源下载】量表的制作和分析(第一批)4.问卷和量表如何统计分析?Amos亚洲一哥张伟豪"量化研究SPSS视频"下载!欢迎关注本公众号,我们是资源的搬运工,所有科研资源全部免费下载:1. 医学统计学习全套视频,妙趣+高级+SPSS+测试题,让你从入门到精通!2. 重磅资源:100本“临床试验与统计学方法”英文书籍大放送!3.《中国统计年鉴》1978-2019,巨量呈现40年全国各行业指标(包括卫生、人口在内)!4. 最新!2019年卫生健康统计年鉴来了!2006-2019中国卫生统计年鉴合集下载5. 不做实验如何利用临床数据库发表论文?精选临床预测模型视频合集6. 全网最全的R语言资源下载:入门视频、临床预测模型视频、书籍、ppt7. 【软件下载】最新Win和MAC版统计软件SPSS 26.0、Stata16.0和Graphpad prism8.08.【免费下载】SPSS经典教程:张文彤SPSS初级+高级操作视频9.“临床研究设计与统计分析方法”(恒瑞医药讲座)精品10讲PPT来了,有兴趣可以下载10.精选的meta分析视频来了!。
张伟豪元分析培训视频笔记-L5-0114-多重结果在研究中的应用

比如上图要做一个TPP计划行为理论的研究,AAA代表一篇论文,里面会有三种关系,就是outcome栏里的,那么这个就需要做多重结果
后面就需要选择相关分析correlation,如上
然后建立上图档案,红框中选择auto就行了,前面相关系数一定要输入文章中的皮尔森相关系数,不能输入回归系数,切记!
分析结果后,如果要查看分开的结果,就需要选红框中select by
选择框中的选项,就是选三个其中一个,因此左边框中的出来的结果就是选中的分析结果
如果要把三个所有结果都做出来,就选择上图红框中的选项
结果就会三种都出现
如果要将三种结果作对比,就是ATTtoBI,PBCtoBI等,就要选择group by选项,如上,选择群组比较
结果如上,那么这个和次群体比较有什么区别呢?解释如下
如果要做如上分析,相当于在前面例子的基础上又加上了性别分组
整合之后就如上,这样的话就相当于将次群体和多重结果两项功能合并了,那么就可以在一篇论文中比较不同性别结果有什么不一样,不同性别间的不同变量比较有什么不一样等。
张伟豪元分析培训视频笔记-L5-0108-异质性检验Heterogeneity

如果组间方差够大,就是有异质性,一般组间方差占组内方差超过三分之一,就是够大了。
如果异质性值大于0.1(因为异质性统计值不够大,所以显著性不用0.05,而用0.1),那么就是没有异质性。
异质性检验主要的方法是卡方检验或者称为Q检验异质性检验是检验组间差异,主要检验指标就是上图中的统计检验的三个值,T2,Q检验,I2那么I2是怎么得来的?看上图中,分析数据出来后就是上图中的森林图上图中,森林图每条线段的中间点是点估计值,点的两边线段就是区间估计值。
1.00代表没有异质性(如果是OR或CR,就是1,如果是相关分析就是0)。
也就是区间包含0或1代表不显著,比如第一条线段包含1,显著性就是0.116,不显著,第二条线段不包含1,显著性就是0.000,显著。
森林图是视觉看有没有异质性,上图看着每条线段差距比较大,有左有右,认为是有异质性,就需要看下next table。
Df自由度是12代表有13篇论文,Q-value的显著性显著,代表有异质性。
上图中的T au Squared就是组间方差,I-Squared就是Tau(组间方差)除以组间加组内。
一般I-Squared值低于25%代表没有异质性,50%以上比较严重的异质性,上图中已经是92.645,代表有很高的异质性。
上图为森林图,黑框越大,代表样本数越大,权重越大。
黑框两边为置信区间,如果穿过Y 轴,代表置信区间包含0,也就是不显著。
Y轴有可能是0,有可能是1(上边解释过原因)。
菱形代表所有样本的集合,因为是所有样本,所以置信区间很小,小到看不到。
异质性检验不能在统计结果出来后再解释为什么有异质性,应该是作者在数据建档之后就要解释“论文可能存在异质性,原因可能是。
”,而不能在统计结果出来再解释。
异质性的来源有以上几种然后要找出异质性的原因,其实就是进行调节变量分析调节变量分析就两类,一类是类别变量,就是方差分析,一类是连续变量,就是回归分析如果做回归分析,要有5个尺度,也就是5个选项。
AMOS基础手把手教

AMOS基础手把手教∙第一部分: 介绍o关于文挡o访问AMOSo文挡o获得AMOS帮助∙第二部分: SEM 基础o SEM概述o SEM术语o为什么使用SEM?∙第三部分: SEM 假设o合理的样本量o连续和正态内生变量o模型识别(识别方程)o完整数据或缺失数据的适当处理o模型规范和因果关系的理论基础∙第四部分: 使用AG建立和检验模型o结构方程——多重回归关系的说明o使用AG绘制模型o将数据读入到AMOS中o选择AMOS分析选项和运行模型∙第五部分: AMOS 输出解释o评估整体模型拟合o绝对拟合检验o相对拟合检验o修改模型获得较好的拟合优度o浏览路径图o独立参数的显著性检验∙第六部分:摘要:结论的实质性解释第一部分:介绍关于文档本课程使用AMOS(距结构分析)软件对结构方程进行简单的介绍和概述。
结构方程模型(SEM) 包括多种统计技术,如路径分析,验证性因子分析,带潜变量的因果关系模型,甚至方差分析和多重线性回归。
课程介绍SEM的逻辑,SEM的假设和输入需求,怎样使用AMOS执行SEM分析。
到课程结束,能够使用AMOS拟合SEM。
也能给出SEM适合研究问题的评价和SEM方法基本假设的概述。
应该已经知道使用SAS,SPSS或类似统计软件怎样产生多重线性回归分析。
也应该理解怎样解释多重线性回归分析的输出。
最后,应该理解基本微软视窗导航操作:打开文件和文件夹,保存文件,重新调用先前保存过的文件,等等。
访问AMOS可以用下列三种方法访问AMOS:1.个人计算机用户须从SPSS公司(SPSS 许可版本)或者Smallwaters 公司(独立版本)获得许可密码2.德克萨斯大学的教师,学生和职员经由STATS 视窗终端服务器访问AMOS。
要使用终端服务器,必须获得ITS计算机账号(或分类账号),然后在NT服务器上验证账号。
接下来下载和配置客户端软件使个人计算机,Macintosh,或UNIX 工作站能连接终端服务器。
张伟豪元分析培训视频笔记-L5-0120-出版偏误

出版偏误就是我们没有找到的文章对我们结果的影响,因为没有找到的文章都被作为缺失值,而出版偏误属于非随机缺失,因此会对结果产生影响检验出版偏误由以上几种方法运行数据后,点击红框选项,进行出版偏误分析首先出现漏斗图,发现漏斗图两侧的点并不均衡,左边很多,右边没有,说明可能有出版偏误但是还要看具体统计数据,选择view下面的选项,可以看不同的出版偏误解释方式,先看第一个以上数字的意思是还需要找多少篇不显著的文章,才能没有出版偏误,也就是将Alpha值设为0.05,也就是大于0.05(不显著),而Z值到达了1.95995,也就是小于1.96(不显著),才能达到研究不显著。
那就需要424篇,才能达到不显著。
而我们只有13篇文章,差距太大了,显然不太可能,因此说明我们没有出版偏误。
但是差距多大算差的多?如果现在不是424篇而是42篇呢?这个差距大还是小?现在还没有学者给出标准,因此只能看P值的显著性,P小于0.05就说明没有出版偏误。
下边的分析是指,不一定非要找不到的文章都是不显著的,可以有一点或一小部分是显著的也不会有大的影响,因此可以自己主观设定标准,红框中和下边的1都是不显著,可以自己设定一下,有一点显著的标准,比如0.95,0.98等我们先设定为0.9,下边的均值比率先保持1,然后计算结果显示,还需要41篇文章,才能达到我们设定的标准如果我们把均值比率也设定为0.95,那么结果显示还需要80篇文章才能达到我们设定的标准。
但是问题和上面方法一样,没有标准告诉我们究竟差多少篇才算够大,没有出版偏误。
因此我们一般用上面的经典方法,看P值就可以了。
我们再看其他几个结果,点红框中的next table红框中的上面是没有修正的结果,下边是修正后的结果,如果这个P值大于0.05,说明没有出版偏误,以上两个结果都大于0.05,说明没有出版偏误再看下一个报表,也看红框中的P值,也大于0.05,说明没有出版偏误。
那么这几个计算结果都一样,如果出现有的有偏误有的没有该怎么办呢?这就要用到最后一种方法trim and fill上图为运行结果这种方法的原理是,先把左边偏离比较多的,影响比较小的文章移除,每移除一个就计算一次,看看是否平均分布,如果没有再继续移除,直到平均分布为止,最后会算出一个校正后的效果量,trim就是剪的意思。
张伟豪元分析培训视频笔记-L5-0117-CMA分析与报表解读

以上是元分析的步骤以上为森林图点击红框中,放大图形放大后可以再调整尺寸,如红框中放大后图形,方框的大小代表权重,越大代表权重越大。
方框是点估计值,也就是左边中的ODDS ratio,两边线段是置信区间,如果不包含1,(因为是ODDS ratio,所以是1,要是RR 就是0),那么就是显著,如果包含了就是不显著,Z值小于1.96,P值大于0.05,说明就是不显著上图红框代表权重,一般文章里不会报告权重如果放大显示,权重就显示为数字,而不是图形了上图为分析的固定效应和随机效应,随机效应的置信区间明显比较宽,是因为随机效应加入了组间方差,因此会比较宽,而且点估计值也不一样。
需要报告哪个就写哪个下一步要看有没有同质性或异质性,如果没有异质性就用固定效应,有异质性就用随机效应。
从森林图中看,每个研究的估计值和区间都差很多,因此直觉判断为有异质性,然后就要看计算结果点next table看结果结果中卡方值Q为163.165,主要看P值,小于0.1,说明有异质性,I值为92.645,一般I 小于25为没有异质性,25到50之间为一般异质性,大于75为高度异质性。
T值为组间方差,I值为组间方差T除以总方差,也就是说组间方差所占比例高达92.645,每组和每组间的差异很大。
I值为标准化值,范围从0到1.另外,I值的缺点是如果样本比较少,比如只有十几篇文章,那么I值就会不太精确。
点击红框可以更改图表颜色,用以复制到word中去一般P值小于0.1就可以,说明就有异质性,如果看森林图里有明显的的偏离中心而且权重比较大的值,可以把这篇文章删掉,那么P值就可能大于0.1了,这样就说明没有异质性,直接报告固定效应的值就可以了另外一个判断异质性的标准就是I值,上图为I值的特性异质性的处理,一种是有异质性就不进行元分析,第二种是探讨原因,忽略后直接进行随机效果分析(后边会讲到这两种方法,分别是上图中的次群体分析和元回归分析),第三种是找出极端值,删除后直接用固定效果报告。
张伟豪AMOS培训视频3笔记

视频3关于自由度的解释在SEM中,自由度DF=p*(p+1)/2在这个公式中,p可以理解为模型中测量题目的数量,由此去算自由度。
T为参数,自由度要大于等于参数。
什么是自由度?如下图所示:图中打对勾的都是一个参数,也就是说,每个残差都是有一个参数,除1以外的估计值各是一个参数,(没有被影响,没有箭头刺的)潜变量本身也是一个参数,因此上图共有10个参数。
实际上模型自由度为49,怎么得来的呢?78是上图中算出的总自由度。
29由下面几张图构成SEM在操作上的要求如下4.指最好引用别人经验证信效度的问卷,不要自创问卷6.问卷题目不要过多,构面也不要过多检验每个构面时要注意的问题当拟合度指标都是0时,说明这个构面的题目只有三个,因为三个题目的自由度为0,那么它的解就是唯一值,而不是最优值,就不需要拟合度了,因此就都是0,这也是为什么每个构面要求最少3个题目的原因。
估计值小于0.6的题目要删除,上图中CS7估计值为0.48,要删除。
但如果删除的题目正好是第一题,那么,估计值1就会被删掉,因为系统默认第一个题目的估计值是1,这时候就需要手动添加第二个题目的估计值为1,操作如下图:双击第二个题目的箭头,在Regreesion Weight框里填入1.如果构面的估计值都达到了标准,但是拟合度有问题,如上图,卡方值为6.134,大于3,其他拟合度指标也不理想,这时就需要打开output查看。
主要查看上图中的Modification Indices这一项(在检查每个构面时需要勾选output的这一项,如下图),只需要看最上面的表格项。
上图中MI指修正指数,指数越高,越需要修正,上图中e1到e2最大,为23.598,表示如果使e1和e2相关,那么模型卡方值会至少降低23.598。
Par Change指如果e1和e2相关,参数会变为0.3。
总的意思来说,就表示这两个题目有点多余,需要删除一个。
那么删除哪个呢?首先考虑如下,如果删除e1,那么e1和e2,e1和e5都会删掉,也就是会降低23.598+6.410=大约30的卡方值;如果删除e2,那么e1和e2,e2和e4,e2和e6都会删掉,也就是会降低23.598+10.357+5.833=大约39的卡方值;相比来说,删除e2降低的卡方值更多,因此考虑删除e2。
张伟豪SPSS培训视频4笔记(个案选择、相关分析、卡方检验、信效度分析)

张伟豪SPSS培训视频4笔记(个案选择、相关分析、卡⽅检验、信效度分析)关于问卷问题的设计,如上图,我们分为反映型指标和形成型指标。
上图指向外边的红⾊箭头是反映型指标,如果要衡量旅馆满意度,可以通过这四个指标,⽽这四个指标都代表着如果我们对旅馆满意,我们会有什么想法和反映,⽽且反映型指标中的任何⼀个发⽣变动,其他⼏个都会跟着发⽣变动,⽐如我很欣赏这家旅馆指数下降了,那么其他⼏个指标也会跟着下降。
这就是反映型指标的特点,也就是通常所说的内部⼀致性,⼀般常⽤的软件如SPSS,AMOS等,都是使⽤反映型指标。
上图中是形成型指标,这些指标的任何⼀个发⽣变动,其他指标是不会变动的,⼀般只有很少的软件可以使⽤这种指标。
如果在做描述性统计分析时通过偏度和峰度发现某些值不是正态分布,需要找出这些影响正态分布的异常值,可以通过箱图找出来。
操作如下图形——旧对话框——箱图,如果只是查看以分类变量来区分的变量情况,就选择个案组摘要,如果查看CS1的分布,以性别作为区分,分别选⼊,确定可以看到⼥性有⼏个异常值,数字代表的是最左边列⾃带的列数字,⽽不是我们⾃⼰设定的序号,所以要删除异常值,要从⼤往⼩依次删,因为如果先删⼩的⽐如170,那么删完后282会变为281,就会删错。
如果要查看多个变量的箱图,就选择各个变量的摘要,然后选择多个变量进去,确定就会同时出现多个变量的箱图和异常值。
⼀般删除⼀两个异常值就会变回正态分布,不需要全部删除异常值。
箱图中的三条线,从上到下依次是75分位数,50分位数(平均数),25分位数。
另外⼀种查看异常值的⽅法在描述性统计对话框中,将左下⾓打上对勾,确定后,最后⼏列就会出现新值只需要查看这些值(Z值)有没有⼤于3的就可以,⼤于3的为异常值,进⾏降序排列,马上就可以看出。
如果要分析两个分类变量是否有相互影响的关系,就需要⽤交叉表(卡⽅检验)选择分析——描述性统计——交叉表格,如果选⼊的两个分类变量有因果关系,那么因变量要放到⾏⾥,⾃变量放到列⾥。
张伟豪元分析培训视频笔记-L5-0107-固定效果与随机效果Fix and Random effect model
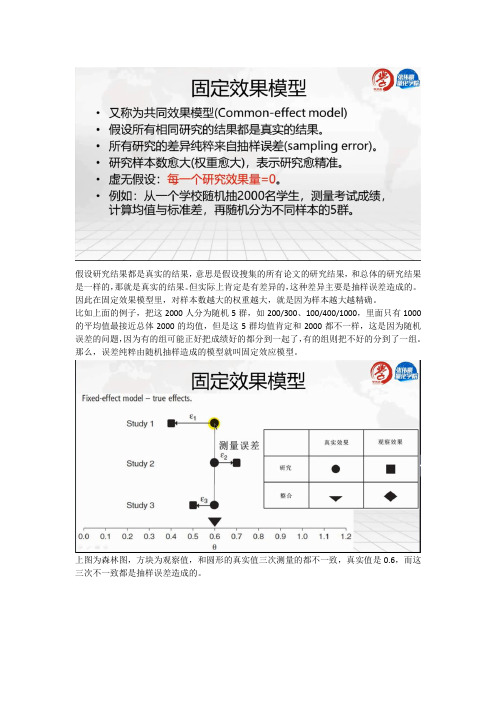
假设研究结果都是真实的结果,意思是假设搜集的所有论文的研究结果,和总体的研究结果是一样的,那就是真实的结果。
但实际上肯定是有差异的,这种差异主要是抽样误差造成的。
因此在固定效果模型里,对样本数越大的权重越大,就是因为样本越大越精确。
比如上面的例子,把这2000人分为随机5群,如200/300、100/400/1000,里面只有1000的平均值最接近总体2000的均值,但是这5群均值肯定和2000都不一样,这是因为随机误差的问题,因为有的组可能正好把成绩好的都分到一起了,有的组则把不好的分到了一组。
那么,误差纯粹由随机抽样造成的模型就叫固定效应模型。
上图为森林图,方块为观察值,和圆形的真实值三次测量的都不一致,真实值是0.6,而这三次不一致都是抽样误差造成的。
随机效果模型——每个论文之间由于样本、研究方法等的不一致,造成研究结果不一致,这叫做组间方差。
每个研究本身因为样本等原因,和真实值也会有误差,这叫做组内方差。
总方差就是组内加组间方差,当模型里面是这两个方差相加的时候,就是随机效果模型总方差就是组间方差加上组内方差(固定效果),整个的模型就是随机效果模型。
随机效果模型如上图——虚无假设是所有研究平均效果量为0,固定效果模型是每一个研究平均效果量为0.举例说明,从5个学校抽2000人,这5个学校之间就有差异,比如有的学校好,有的差,那么这个就是组间差异,而从每个学校抽的学生也会有差异,比如有的学生好,有的学生差,那么这就是组内差异。
所以随机效果既包括组间差异,也包括组内差异。
上图中上面的误差(方块到圆圈)是组内方差,是抽样时产生的误差,下面的误差是组间方差。
上面这段文字的意思是——固定效果里,如果选了很多论文,里面有的论文样本很小,有的样本很大,那么就会给小样本赋很小的权重,给大样本赋很大的权重,这样的话即使把那些小样本删掉,对总体也不会有很大影响。
但是随机效果里,就会把小样本赋比较大的权重,大样本赋比较小的权重,从而平衡两种样本。
张伟豪元分析培训视频笔记-L5-0111-多种数据形态输入

因为在输入数据时,很多论文的数据形式不一样,比如有的是发生率和总数、有的是发生的和不发生的,那么在输入数据时就要像上图一样,下面的红框是三种格式,可以任意增加格式形式,选哪个标签就用哪种输入形式。
每增加一种输入形式,就选一次上图中红框的增加输入格式。
不管输入几种形式的数据,右边黄色框都会转为一样形式的效果量。
要注意的是,增加数据形式只能是同一类的,不能跨类别,比如有的选上面红框的,有的选下面红框的,这就是两类数据格式了,差别太大,无法同时输入。
最后,如果搜集的文章数据形态无法找到对应的输入方式,那么就只能放弃这篇文章。
张伟豪AMOS培训视频1和2笔记

CR为Z值,CR=estimate/S.E,该值大于1.96为显著。
SE为标准误,那什么是标准差什么是标准误?简单说标准误就是几组标准差,是重复测量好几次,而标准差只是测量一次。
Estimate为非标准化系数,它表示:如人才需求增加1个单位,人才环境增加0.593个单位。
而标准化系数表示:如人才需求增加1个标准差,人才环境增加0.523个标准差。
论文中如果是问卷数据,推荐直接用标准化系数。
如果是普通的,带单位的,例如想知道投入1万块能打来多少的XX东西的增长,就看非标准化系数。
方框内数字代表因素负荷量(因子载荷量)factor loading,或者测量权重measurement weight,建议值为大于0.6,小于0.95,0.7为理想值,一般低于0.6要删除题目,(一个题构面最少要3个题目),最低不能低于0.5,被删除的题目说明缺乏题目信度。
在报告中显示为:非标准化系数报告只要是显著,一般无需删除题目,而第一个题目一般都为1,一般也不需要删除,但最终还要看标准化系数。
上半部分方框中代表各潜变量之间的关系,也就是路径假设,如果均为显著,则所提出的假设成立,AMOS只显示显著性低于0.001为***,其他均显示数字,只要低于0.05均为显著。
验证性分析即问卷是引用的别人的,此时因子负荷量大于0.6可接受,该题目可不删除;探索性分析即问卷是自己设计的,此时因子负荷量大于0.5就可以接受,该题目可不删除。
该项测量的是题目的信度。
红色方框上边为标准化路径系数,一般情况下只要非标准化是显著的,此数据就不需要看大小,只需要比较下和其他系数的大小就可以,看看谁的影响大。
建议最小要大于0.2,大于0.3为较为理想,以上最小的标准化路径系数为态度影响行为意图,为0.222,符合标准。
SMC该部分框内部分表示题目信度,是上图中标准化因子载荷值的平方,一般大于0.36即为有效,0.5以上为理想,可不删除该题目。
上面为三个变量(有用性、态度、行为意图)的有用性,大于0.19为small,大于0.33为中等,0.67为理想。
张伟豪AMOS培训视频5笔记

一般探讨中介变量有以下三种情况比如恐龙能变成鸟,觉得不可思议,但是如果知道有始祖鸟,就会明白恐龙先变成始祖鸟,再变成鸟类。
始祖鸟就是中介变量。
比如乔丹赢球会促使股市大涨,经研究发现,原来是只有有钱人才能去看球,乔丹赢球会增强这些人的信心,从而投入更多钱到股市中,使股市大涨。
最后得出结论,对政府有信心会使股市大涨,因此除了乔丹赢球,还有很多可以增强民众对政府信心的方法,比如发动战争。
这样就是知道了中介变量是什么,可以用很多自变量去解释。
比如很多人压力大会患忧郁症,经研究发现想得多的人容易患忧郁症,想的多就是中介变量,那么就想办法操控这个中介变量,不让人去想那么多,就会影响最终的因变量,也就是患抑郁症。
检验中介变量有以下三种方法:常见的中介变量有以下几种:如果上图中张老师和林志玲约会,原因是他找了经纪公司,那么经纪公司就是中介变量。
张老师肯定认识经纪公司,这就是显著影响a。
经纪公司也肯定认识林志玲,这是显著影响b。
如果张老师只是通过经纪公司约会林志玲,也就是a和b显著,但是他不认识林志玲,也就是c不显著,那么这就是完全中介效应。
如果张老师本来就认识林志玲,也就是c显著,同时又通过经纪公司约会林志玲,也就是a和b显著,那就是部分中介效应。
中介效应的检验:第一种方法,因果法将有中介关系的三个构面之间的线命名为a、b、cplus,然后代入数据,运行结果是a、b、cplus都显著,说明是部分中介效应。
如果cplus不显著,那就是完全中介效应。
其中a*b称之为间接效果,cplus称之为直接效果。
总效果c=a*b+cplus,操作如下首先将路径图中a和b改为0,意思是没有相关,然后运行,结果就会显示cplus 的估计值变为了0.838,这就是a*b+cplus的结果。
可以举例说明如下如果X到Y要流过150升水,如果只通过c途径,那么c就流150升,如果即通过cplus又通过a和b,a和b一共流了100升,那么cplus就只会流50升。
张伟豪AMOS培训视频8笔记

控制变量和调节变量其实都是自变量,区别在于控制变量本来就在模型中,而调节变量是后来才进入模型中;还有区别就是控制变量没有假设,调节变量是有假设的。
上图中的论文模型,右边蓝框里是控制变量,没有假设。
红框里的是自变量和调节变量,有假设。
在上边这个调节效应假设中,要出现三个变量,这是正确的写法。
论文数据分析后,第一步先检测控制变量,红框中的控制变量size显著。
控制变量监测的结果必须显著,否则就不能叫控制变量,不能出现在模型中。
然后检测主效应,红框中的两个主效应CC和KD都显著,假设H1和H2成立,但是上面的MT调节效应不显著,没关系,这时候不用管它,因为调节效应应该是交互作用,这时的单一MT还不叫调节效应,虽然他现在在模型中。
上图中第三步是调节效应,可以看到检验的是交互作用,都显著,这时候的才是真正的调节效应。
这时候就不需要再报告主效应的CC和KD了。
自变量和因变量是潜变量,调节变量是观察变量的检测方法和都是观察变量检测的方法是一样的,如下下面做一次调节变量有三档的检验,比如不是性别男和女,而是收入高中低,需要建立三个组group在左边点击增加新的group,但是要把all groups的对勾画上,因为如果不画,新增组里就没有图形。
把左边的group名改为low/med/high,把每一组的路径名称也相应的改了。
改路径名的时候记得这次把all group的对勾去掉。
然后在下边新增模型处点击新增然后选择new新增,每新增一个就命名一个,然后每个模型一次检验low=high,low=med,med=high,最后可以再新增一个overall,就是high=low=med。
然后代入数据结果显示都不显著。
做调节效应的4个以及更高的档也是一样的做法。
如果调节变量也是潜变量而不是观察变量怎么办呢?比如上图,如果自变量有三个观察变量,调节变量也有三个观察变量,那么就需要3*3=9次计算,得出他们的交互项,尤其是需要平均中心化的时候,就会操作很多步,很麻烦。
AMOS课堂笔记

结构方程模型——AMOS的操作结构方程模型(structural equation modeling;简称SEM),是经济统计、社会统计和心理统计的合成物,有学者也把它称为潜在变量模型(latent variable models;简称LVM),它整合了因素分析(factor analysis)与路径分析(path analysis)两种统计方法,同时检验模型中包含的显性变量、潜在变量、干扰或误差变量间的关系,进而获得自变量对因变量影响的直接效果、间接效果或总效果。
基本概念1.观察变量(observed varibale),是量表或问卷等测量工具所得的数据,也称外显变量、指标变量。
通常用长方形图标。
2.潜在变量(latent variable),是观察变量间所形成的特质或抽象概念,此特质或抽象概念无法直接测量,而要由观察变量测得的数据资料来反映。
也称构念。
通常用椭园形图标。
(暂且当做因子分析中的因子)3.SEM模型基本上是一种验证性的方法,通常必须有理论或经验法则支持,由理论来引导,在理论导引的前提下才能建构假设模型图。
即使是模型的修正,也必须依据相关理论而来,它特别强调理论的合理性。
此外,SEM模型估计方法中最常用的方法为极大似然法,而此法要求样本数据必须符合多变量正态性假定,样本数也不能太少,一般最少不能低于100,通常样本数与观察变量的比例至少为10:1至15比1间。
(3000-5000的样本量比较适合做结构方程)将原始数据生成协方差或相关关系矩阵,可减少干扰n210.000210.000210.000210.000210.000corr社会参与 1.000corr家庭幸福.449 1.000corr薪资所得.538.643 1.000corr身体健康.576.489.438 1.000corr生活满意.649.746.774.620 1.000stddev15.1409.46016.23013.75020.150mean45.24024.26036.61038.02033.230在绘图中,变量类型所对应的图形是固定的。
张伟豪元分析培训视频笔记-L5-0119-敏感度分析

敏感度分析就是检验某些变量对整体的影响,第一种方法是每次移除一个研究,最后看哪个研究是偏离值
将数据分析后,点最下边的选项卡one-study remove
结果发现,红框中偏离了总体值,总体值是最下边红框的值,说明这个变量对总体影响较大
第二种是累计分析法,就是按照一定的顺序,将研究一个一个加进去,从而发现按照这种顺序整体研究的发展趋势
比如上面数据按照latitude维度进行排序,看看研究结果随着维度的变化会有什么趋势
分析后点击下边红框中
会发现随着维度增高,点估计值越来越大(越来越会发生,因为1是没有效果,越远离1效果越大)
现在我们增加一个年代变量,看看研究随着年代变化会有怎样的变化。
在变量类型可以不选择,红框中的意思是数据类型为整数
输入年代后进行排序
分析后发现年代越现代,效果量越低,也就是越不明显(因为越接近1)
要注意的是,累计分析只是效果量的展示,不是一种分析。
张伟豪AMOS培训视频10笔记

交叉效度评估的方法把上图中所有数据平均分成两群打开转换——计算变量在变量名称框输入random,在函数值栏选择全部,在下面函数和特殊变量选入RV Bemoulli双击选入,在()里填入0.5,意思是将所有数据平均分成两群,每群各占50%最后一列就会出现random列然后打开一个模型,添加一个分组group,将两个分组分别命名,代表刚才的随机两个组分别命名为validation确定和calibration校正项然后点击上边红框中这个按键就会自动在左边红框区域新建5个模型,不用再手动添加5个模型分别代表第一个:测量结构全等第二个:结构路径全等第三个:结构残差全等第四个:结构方差及协方差全等第五个:测量残差全等然后选入数据,运行然后打开output,查看最后的model comparison,主要看每一个的的第一行,P 值应该大于0.05(因为我们希望所分开的两个模型差异不显著,所以模型才有交叉效度),如果p值稍微小于0.05,如第一行的为0.038,那就看TLI的值,这个值小于0.05则模型没有显著性差异。
因为p值是统计上的显著性,TLI是实物上的显著性,P值不显著代表可能有很小部分模型不重合,但是只要后边的TLI是0,就没有关系。
这种方式在理论模型的验证中必须用(也就是自己将两个以前学者的模型融合到一起,来看看这种模型的拟合度,也就是这种论文就是证明下新模型可用),其原理就是两个模型凑到一起你怎么知道还是可用的呢?就需要统计数据来验证,理论上需要你再收集另一组同质数据来验证,但是这样太有难度,所以大多数人会用这种方法将自己的数据一分为二,来进行验证,但是也会经常不能通过,因为数据有问题就通不过。
所以一般需要300个以上的样本才能做,如果样本不足200个,就需要再收集另一组同质样本。
二因子成长模型的计算方式和流程(时间序列分析)上图中是一个二因子成长模型,红框中的两个是两个变量,ICEPT是截距,SLOPE 是斜率。
张伟豪元分析培训视频笔记-L5-0105-评估研究质量

并不是每个元分析文章都会做研究质量评估,有的会做可以以这些标准进行计分,分数越高文章质量越好,最后每篇文章得出的分数在0到10分之间协变量就是自变量,用自变量做回归分析累积式分析就是每篇文章得到的分数相加敏感性分析就是不同质量文章对整体的影响,比如文章质量高的对整体有影响,还是质量低的对整体有影响研究设计是否和自己的一样,比如社会科学都是发问卷发表年份就是定义你搜索的文章是哪年到哪年的,就是范围语言——找英文的还是中文的文章从多篇文章中选择——比如从100篇中选20篇样本数——不要找太小的研究的相似性——最好和自己的研究类似按照步骤将文章转化为数据,输入后就该进行数据分析了将转换的数据录入excel里面然后要转换数据为共同标准,OR,RR等后边会讲到然后决定了固定效果或随机效果,还要看看森林图和漏斗图(后边会讲)统计分析里要做异质性检验,Tau-square是组间差异(后面会讲),收集的文章越多,,这个值越大,所以没有固定标准,是作为后面几个值得参考依据的Q检验缺乏统计检验力,因此将标准调高,用0.1而不是0.05.如果I-square程度在中和高,那么就要进行异质性原因探讨敏感度分析一种是one study remove,意思是一次移除一篇文章,看看它的影响力,如果移除后对整体参数影响很大,就说明这篇文章很重要Cumulative是根据文章发表的时间作为影响参数,看看随着时间的变化,整体的变化。
也可以用前面讲到的影响分数等,其实除了时间还有很多可以作为影响参数的。
最后是进行出版偏误检验上图为元分析整个的流程研究问题——是主观的,自己衡量文献搜索数据萃取——2要有两个以上作者总结,如果意见不一致应该剔除掉这个数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
上表中体现了题目信度,构面的组合信度,以及构面的收敛效度。
分别来解释
非标准化系数Unstd除以标准误SE等于Z值Z-value,Z值大于1.96为显著。
标准化系数Std大于0.6即达到标准,该题目可不删除。
SMC代表题目信度,大于0.36即达到标准,该题目可不删除。
(SMC=Std的平方根,因此Std 达到标准SMC也就达到标准)
CR代表构面的组成信度,大于0.7即达到标准。
AVE代表构面的收敛效度,大于0.36为可接受,大于0.5为理想。
那么如何求出区别效度?如下:
首先将所有潜变量拉相关,选择plugins下的draw covariance,会自动所有潜变量相关。
然后选择output里面的all implied moment。
运行后打开output,如下图
查看implied(for all variables)correlation,只选择复制潜变量这一块,
粘贴到excel表中,在第二列插入一个AVE,因为AVE是平方值,而皮尔森相关是开方值,两者没法相互比较,因此需要将AVE开平方(使用excel里的开方公式功能),填入表格中。
最后就会形成区别效度的表格,如下图
如何解释区别效度?如下
将每个构面的AVE值和其他几个构面的皮尔森相关系数相比较,如果大于其他几个值,则该构面的区别效度较高,如服务质量的AVE为0.759,和0.431,0.487,0.737,0.510相比较,均大于这几个值,则服务质量的区别效度较高。
另外,如果构面的AVE略小于其中一个构面的皮尔森相关值,只要差距不大,论文报告中也可以写上“差距不大,在可接受范围”。
进行验证式因子分析时出现的问题汇总:
1、小于0.45直接删掉该题目
2、高于1也直接删掉该题目
3、解释如下
这种属于一半高一半低
就将这个构面分成两个构面,如下
这样,因素负荷量就达到了标准。
出现这种情况的原因在于设计问卷时,同一构面引用了不
同学者的问卷,虽然是同一问题(如忠诚度),但是含义不一样,因此在借用问卷时,一个构面只能引用一个学者设计的问卷,但不同构面可以引用不同学者的。
4、见前文所述。
5、转向就行。
6、这种情况(即构面AVE值小于0.36),只能用皮尔森相关先分析一下,看看有没有相关度接近0或1的题目,删除该题目。
如果要构建二阶模型,那么必要条件就是所包含的一阶模型之间要有中高度相关,一般相关系数要高于0.5。
但大多数情况下不能自己构建二阶模型,都需要引用原来学者已经用过证明过的模型。
但如果构建二阶模型,比一阶模型会有信息的损失。
不要自己随意设计构面,如上图,构面就是错的。
那么如何判断可不可以设计二阶模型呢?如下图
首先看一阶模型的卡方值,此卡方值为423.207。
然后再构建二阶模型,如下图
二阶模型的卡方值为432.695,与一阶模型的卡方值相差不多,(需要二者相除,越接近1表明越好),因此这种情况就意味着构建二阶模型后损失的信息较少,可以构建二阶模型。
这个值被称为目标系数。
协方差矩阵问题。
有时候审稿人会要你的协方差矩阵,他可以推算你的数据有没有造假,因此SEM无法造假。
有时候你也可以要来国外作者的协方差矩阵,因为他的论文很好,你想要做一篇和他一样的论文,来进行跨文化比较。
那要来别人的协方差矩阵应该如何处理呢?如下:
首先选中output里面的sample moment选项,然后运行数据
查看sample moment下的sample covariance,将此表格复制,粘贴到excel里面。
如果别人跟你要协方差矩阵,就可以这样给他。
但是如果你收到别人这样的表格,应该按如下处理:
首先把无用的文字都删掉,只留下上图的数据,然后在最前面插入一列,在最上面命名为ROWTYPE_,在平行行命名为VARNAME_,在ROWTYPE_的这一列下所有的表格里填入COV,如下图
在COV最下边输入N(代表样本数),在后面输入样本数295,如下图所示
然后将表格另存为97—03版本的excel,因为AMOS只能读取2007以下的excel版本。
这时,先查看别人论文中的卡方值,如下图,卡方值为1092.768,然后再带入刚才的excel 协方差矩阵运行,看看两个卡方值相差多少。
再打开刚才另存的excel时,要注意,选择excel8.0,其他的AMOS是读不出来的。
如下图
运行后,发现卡方值为1092.879,与之前相差不多,说明数据没有造假,是一致的,没有问题。
如下图。