第2章 数据分析
第二章 误差及分析数据的统计处理

第二章误差及分析数据的统计处理§2-1 定量分析中的误差定量分析的任务是准确测定试样中组分的含量。
但是,即使是技术很熟练的分析工作者,用最完善的分析方法和最精密的仪器,对同一样品进行多次测定,其结果也不会完全一样。
这说明客观上存在着难以避免的误差。
因此,我们在进行定量测量时,不仅要得到被测组分的含量,而且还应对分析结果作出评价,判断其准确性(可靠程度),找出产生误差的原因,并采取有效的措施,减少误差。
一、误差的表示:从理论上说,样品中某一组分的含量必有一个客观存在的真实数据,称之为“真值”。
测定值(x)与真实值(T)之差称为误差(绝对误差)。
误差 E = X - T误差的大小反映了测定值与真实值之间的符合程度,也即测定结果的准确度。
测定值> 真实值误差为正测定值< 真实值误差为负分析结果的准确度也常用相对误差表示。
相对误差E r = E / T×100%= (X-T) / T×100%用相对误差表示测定结果的准确度更为确切。
二、误差的分类根据误差的性质与产生原因,可将误差分为:系统误差、随机误差和过失误差三类。
(一)系统误差系统误差也称可定误差、可测误差或恒定误差。
系统误差是由某种固定原因引起的误差。
1、产生的原因(1)方法误差:是由于某一分析方法本身不够完善而造成的。
如滴定分析中所选用的指示剂的变色点与化学计量点不相符;又如分析中干扰离子的影响未消除等,都系统的影响测定结果偏高或偏低。
(2)仪器误差:是由于所用仪器本身不准确而造成的。
如滴定管刻度不准(1ml刻度内只有9个分度值),天平两臂不等长等。
(3)试剂误差:是由于实验时所使用的试剂或蒸馏水不纯造成的。
例如配制标准溶液所用试剂的纯度要求在99.9%;再如:测定水的硬度时,若所用的蒸馏水含Ca2+、Mg2+等离子,将使测定结果系统偏高。
(4)操作误差:是由于操作人员一些主观上的原因而造成的。
比如,某些指示剂的颜色由黄色变到橙色即应停止滴定,而有的人由于视觉原因总是滴到偏红色才停止,从而造成误差。
MATLAB数据分析方法第2章数据描述性分析

MATLAB数据分析⽅法第2章数据描述性分析2.1 基本统计量与数据可视化1.均值、中位数、分位数、三均值均值、中位数:mean(A)、media(A)分位数:prctile(A,P),P∈[0,100]prctile(A,[25,50,75]) %求A的下、中、上分位数三均值:w=[0.25,0.5,0.75];SM=w*prctile(A,[25,50,75])%例:计算安徽16省市森林资源统计量A=xlsread('senlin.xls','sheet1')M=mean(A); %均值,MD=median(A); %中位数SM=[0.25,0.5,0.25]*prctile(A,[25,50,75]); %三均值[M;MD;SM]2.⽅差、标准误、变异系数⽅差:var(A,flag),flag默认0表⽰修正的⽅差,取1为未修正标准差:std(A,flag),同上变异系数:v=std(A)./abs(mean(A))k阶原点矩、中⼼距:ak=mean(A.^k)bk=mean((A-mean(A)).^k)%中⼼距系统命令bk=moment(A,k)3.极差、四分位极差(上、下分位数之差)R=rangr(A)R1=iqr(A)4.异常点判别(截断点)XJ=parctile(A,[25])-1.5*R1SJ=parctile(A,[75])+1.5*R15.偏度、峰度偏度:sk=skewness(A,flag),默认1,取0为样本数据修正的偏度峰度:ku=kurtosis(A,flg)-3,同上2.1.2 多维样本数据协⽅差:cov(A)相关系数:corr(A)标准化:zscore(A)2.1.3 样本数据可视化1.条形图bar(x)%样本数据x的条形图,横坐标为1:length(x)bar(x,y)%先把x和y⼀⼀对应,然后将x从⼩到⼤排序画图2.直⽅图hist(x,n)%数据x的直⽅图,n为组数,确省时n=10[h,stats]=cdfplot(x)%x的经验分布函数图,stats给出数据最⼤最⼩值、中位数、均值、标准差直⽅图基础上附加正态密度曲线histfit(x)histfit(x,nbins)%nbins指定bar个数,缺省时为x中数据个数的平⽅根3.盒图,五个数值点组成:最⼩值、下四分位数、中位数、上四分位数、最⼤值。
第二章方差分析与相关分析

第二章方差分析与相关分析在统计学中,方差分析和相关分析是两种常用的数据分析方法。
方差分析用于比较两个或多个组之间的差异,而相关分析用于探究变量之间的关系。
本章将详细介绍方差分析和相关分析的概念、原理和应用。
1.方差分析方差分析是一种用于比较不同组之间差异的统计方法。
它基于一种基本假设,即不同组之间的差异是由于随机误差造成的。
方差分析以方差作为度量不同组之间差异的指标,通过计算组内方差和组间方差来评估不同组之间的差异程度。
方差分析通常包括三个步骤:建立假设、计算方差和进行显著性检验。
首先,建立假设,即空假设和备择假设。
空假设认为不同组之间的差异是由于随机误差造成的,而备择假设则认为不同组之间存在显著差异。
接下来,计算组内方差和组间方差,通过比较两者的大小来评估不同组之间的差异程度。
最后,进行显著性检验,判断不同组之间的差异是否显著。
方差分析广泛应用于实验设计和数据分析中。
例如,在医学研究中,可以用方差分析比较不同治疗方法的疗效差异;在市场调研中,可以用方差分析比较不同广告策略的效果差异。
2.相关分析相关分析用于探究两个变量之间的关系。
它通过计算两个变量之间的相关系数来评估它们之间的相关性。
相关系数的取值范围为-1到1,负值表示负相关,正值表示正相关,而0表示无相关。
相关分析通常包括两个步骤:计算相关系数和进行显著性检验。
首先,计算两个变量之间的相关系数。
常用的相关系数包括皮尔逊相关系数和斯皮尔曼相关系数。
皮尔逊相关系数适用于连续变量之间的相关性分析,而斯皮尔曼相关系数适用于有序变量之间的相关性分析。
接下来,进行显著性检验,判断两个变量之间的相关性是否显著。
相关分析广泛应用于各个领域的数据分析中。
例如,在经济学中,可以用相关分析研究两个经济指标之间的相关性;在社会学中,可以用相关分析探究两个社会变量之间的关系。
3.应用案例方差分析和相关分析在实际应用中的案例非常丰富。
以方差分析为例,假设我们研究了三种不同的农药对作物产量的影响。
分析化学:第二章_误差和分析数据处理二

化学分析
第二章 误差和分析数据处理
4
• 对于很小的数字,可用指数形式表示。例如,离 解常数Ka=0.000018,可写成Ka=1.8×10-5;很大的 数字也可采用这种表示方法。例如2500L,若为 三位有效数字,可写成2.50×103L。
• 例如,0.0121×25.64×1.0578=0.328,其中,有 效数字位数最少的0.0121相对误差最大,故计 算结果应修约为三位有效数字。
化学分析
第二章 误差和分析数据处理
11
• 3. 百分数表示 • 高含量组分(>10%),保留四位有效数字; • 中含量组分(1~10%),保留三位有效数字; • 低含量组分(<1%),保留两位有效数字。 • 4. 其他运算 • 乘方或开方,结果的有效数字位数不变,
化学分析
第二章 误差和分析数据处理
19
3.正态分布曲线规律:
• (1) x=μ时,y值最大,体现了测量值的集中趋 势。说明误差为零的测量值出现的概率最大。 大多数测量值集中在算术平均值的附近。
• (2) 曲线以x=μ这一直线为其对称轴,说明绝对 值相等的正、负误差出现的概率相等。
• (3) 当x趋于-∞或+∞时,曲线以x轴为渐近线。 即小误差出现概率大,大误差出现概率小。
化学分析
第二章 误差和分析数据处理
5
• 对pH、pM、lgc、lgK等对数值,其有效数字的
位数仅取决于小数部分数字的位数,整数部分 只说明其真数的方次。如pH=11.02,即[H+]= 9.6×10-12mol/L,其有效数字为两位而非四位。
第二章 误差和分析数据的处理

第二章误差和分析数据的处理第一节误差及其产生的原因定量分析的任务是准确测定试样中各组分的含量,因此必须使分析结果具有一定的准确度。
不准确的分析结果将会导致生产上的损失、资源上的浪费和科学上的错误结论。
在定量分析中,由于受到分析方法、测量仪器、所用试剂和分析人员主观条件等方面的限制,故使测定的结果不可能和真实含量完全一致;即使是分析技术非常熟练的分析人员,用最完善的分析方法、最精密的仪器和最纯的试剂,在同一时间,同样条件下,对同一试样进行多次测定,其结果也不会完全一样。
这说明客观存在着难于避免的误差。
因此,人们在进行定量分析时,不仅要得到被测组分的含量,而且必须对分析结果进行评价,判断分析结果的准确性(可靠程度),检查产生误差的原因,采取减小误差的有效措施,从而不断提高分析结果的准确程度。
分析结果与真实结果之间的差值称为误差。
分析结果大于真实结果,误差为正;分析结果小于真实结果,误差为负。
一、误差的分类根据误差的性质与产生的原因,可将误差区分为系统误差和偶然误差两类。
(一)系统误差系统误差(systematic error)也叫可定误差(determination error),它是由某种确定的原因引起的,一般有固定的方向(正或负)和大小,重复测定可重复出现。
根据系统误差的来源,可区分为方法误差、仪器误差、试剂误差及操作误差等四种。
(1)方法误差:由于分析方法本身的缺陷或不够完善所引起的误差。
例如,在质量分析法中,由于沉淀的溶解或非被测组分的共沉淀;在滴定分析法中,由于滴定反应进行不完全,干扰离子的影响,测定终点和化学计量点不符合等,都会产生这种误差。
(2)仪器误差:由于所用仪器本身不够准确或未经校正所引起的误差。
例如,天平两臂不等长,砝码、滴定管刻度不够准确等,会使测定结果产生误差。
(3)试剂误差:由于试剂不纯和蒸馏水中含有杂质引入的误差。
(4)操作误差:由于操作人员的习惯与偏向而引起的误差。
例如,读取滴定管的读数时偏高或偏低,对某种颜色的变化辨别不够敏锐等所造成的误差。
《数据分析》教案

《数据分析》教案数据分析是当今社会中非常重要的一项技能,它不仅可以匡助人们更好地理解数据,还可以为决策提供重要的支持。
为了更好地教授数据分析知识,制定一份完善的教案是非常必要的。
本文将从教案的制定、内容安排、教学方法、评价方式和课程实践五个方面进行详细介绍。
一、教案的制定1.1 确定教学目标:明确教学目标,包括学生应该掌握的知识、技能和能力。
1.2 设计教学内容:根据教学目标设计教学内容,包括数据分析的基本概念、常用工具和技术等。
1.3 制定教学计划:根据教学内容制定教学计划,包括每节课的内容安排、教学方法和评价方式等。
二、内容安排2.1 数据分析基础知识:介绍数据分析的基本概念、数据类型、数据清洗和数据可视化等。
2.2 数据分析工具和技术:介绍常用的数据分析工具,如Python、R等,以及数据分析常用技术,如统计分析、机器学习等。
2.3 数据分析实践案例:通过实际案例演练,让学生了解数据分析在实际问题中的应用。
三、教学方法3.1 理论教学结合实践:结合理论知识和实际案例,让学生更好地理解数据分析的原理和方法。
3.2 互动教学:采用互动式教学方法,如讨论、小组合作等,激发学生的学习兴趣。
3.3 多媒体辅助教学:利用多媒体技术辅助教学,如PPT、视频等,提高教学效果。
四、评价方式4.1 考试评价:定期进行考试,测试学生对数据分析知识的掌握程度。
4.2 作业评价:布置数据分析作业,评价学生对数据分析工具和技术的掌握情况。
4.3 项目评价:组织数据分析项目,评价学生在实际问题中运用数据分析的能力。
五、课程实践5.1 实践课程设计:设计数据分析实践课程,让学生在实际问题中应用数据分析技术。
5.2 实践案例分析:分析实际数据案例,让学生掌握数据分析方法和技术。
5.3 实践成果展示:组织学生展示实践成果,让学生展示他们在数据分析领域的成就。
综上所述,一份完善的数据分析教案应该包括教案的制定、内容安排、教学方法、评价方式和课程实践五个方面。
第二章+误差和分析数据的+处理

总体标准偏差():当测量为无限次测量时,各 测量值对总体平均值的偏离。
公式:
n
(xi ) 2
i 1
n
—总体平均值
只能在总体平均值已知的情况下才使用
• (样本)标准偏差(standard deviation, S):有限次测
量(n20)的各测量值对平均值的偏离。
(2)若分析结果R是测量值X、Y、Z三个测量值相 乘除的结果,例如:R=XY/Z 则:
R X Y Z
RXY Z
• P12 例3
2.1.3.2 偶然误差的传递
1.极值误差法
考虑在最不利的情况下,各步测量带来的误差的 相互累加,这种误差称为极值误差。 用这种简便的方法可以粗略估计可能出现的最大 偶然误差。 一般情况下,当确定了使用的测量仪器和测定步 骤后,各测量值的最大误差就是已知的。 例如:称量;滴定
滴定管读数的极值误差为: ΔV=|±0.01 mL| + |±0.01 mL |=0.02 mL
故滴定剂体积为: (22.10-0.05)mL± 0.02 mL =(22.05±0.02)mL
2. 标准偏差法 (1)和、差的结果的标准偏差的平方是各测量值
标准偏差的平方之和。
(2)积、商的结果的相对标准偏差的平方是各测 量值相对标准偏差的平方之和。
被测组分含量不同时,对分析结果准确度的要求 就不一样。常量组分的分析一般要求相对误差在 0.2%,微量组分在1%到5%。
2.1.4.2 减小测量误差
根据误差的传递规律,分析过程中每一步的测
量误差都会影响最后的分析结果,所以尽量减 小各步的测量误差。 如何减小?
各测量步骤的准确度应与分析方法的准确度相
第二章 交通调查与数据分析

(1)数据整理
(2)计算统计特征值
地点车速平均值 中位车速 常见车速 极差 样本标准差
通常用于掌握道路交通现状,作为评价道路服务水 平的主要指标,也是衡量道路上车辆运营经济特性 的重要参数。
◦ (1)牌照法 ◦ (2)跟车法 ◦ (3)浮动车法
乘观测车从 A点出发到B点, 经过两个交叉口(C、D) 和三个停靠站(E、F和G) ,单方向行驶5次,用秒表 计时,经过整理得到表所示 调查结果,试计算平均区间 车速。
(3)停车延误,车辆由于某种原因而处于静止状态产生 的延误。 (4)行程时间延误,实际行驶的总时间-完全排除干扰后 以畅行速度通过调查路段的行驶时间。 (5)排队延误,车辆排队通过路段的时间-车辆按自由行 驶车速通过的时间。 (6)匝道延误,匝道实际耗时-引道自由行驶时间之差。 调查:确定产生延误的地点、延误类型和大小,评价道 路上交通流的运行效率,分析找出产生延误的原因。 (7)行程时间指数TTI(Travel Time Index),高峰时行程 时间/自由流时的行程时间。
站点调查法:在各站点上设若干名调查员,记录各公交车辆在此站 点的上下乘客数。 公交随车调查法:在公交车辆内设若干名调查员,一般一个车门设 一名,记录在各站点上、下车的乘客数。
公交意向调查、出租车运营调查等
某道路全长2.0km,用浮动车法测量交通量和车速 。试验车在路线上往返6次,测量后数据整理结果 如表所示,试计算该路段交通量、平均行程时间、 平均行程车速。
居民出行(trip) 汽车出行 方式出行 目的出行 货运总流动
居民出行调查 交通流特性调查 机动车、自行车及行人调查 公共交通调查 停车调查 其他交通调查
第二章 误差和分析数据处理-分析化学

第二章 误差和分析数据处理
第一节 概述
xie 分 析 化 学
产生测定误差的原因:
抽样的代表性; 测定方法的可靠性; 仪器的准确性; 测定方法的复杂性;
测定者的主观性;
操作者的熟练性
xie 分 析 化 学 一、绝对误差和相对误差
第二节 测量误差
绝对误差(absolute error)
减小测量误差
取样量大于0.2g;
滴定液消耗的体积大于20ml;
紫外吸收度在0.2~0.7之间。
xie 分 析 化 学
相对误差=δw/W<1‰
W>δw/1‰=0.0002/1‰=0.2g 相对误差=δv/V<1‰ V>δv/1‰=0.02/1‰=20 ml
增加平行测定次数
xie 分 析 化 学
2 i
n
相对标准偏差(relative standarddeviation;RSD) 或称变异系数(coefficient of variation;CV)
2 ( x x ) i n i 1
S RSD 100% x
n 1 x
100%
例题 :四次标定某溶液的浓度,结果为0.2041、
标准偏差法:
R=x+y-z
R=xy/z
2 2 2 2 SR Sx Sy Sz
Sy 2 Sx 2 SR 2 Sz 2 ( ) ( ) ( ) ( ) R x y z
五、提高分析准确度的方法
xie 分 析 化 学
选择恰当的分析方法
被测组分的含量; 被测组分共存的其它物质的干扰。
0.00022 0.00062 0.00042 0.00002 标准偏差 S 0.0004 (mol/ L) 4 1
第二章 误差和分析数据处理

2位
2位
2位
(6) 数据的第一位数大于等于 8, 有效数字可多算一 位: 9.55 4位 ; 8.2 3位
37
1.0008 0.1000 0.0382
43181 10.98%
五 位有效数字 四 位有效数字 二 位有效数字 一 位有效数字 位数模糊
1.98×10-10 三 位有效数字
54
0.05
0.0040
度)是精密度常见的别名。
一般例行分析精密度用相对平均偏差表示就
够了,但在科研中要用标准偏差或相对标准偏差
来表示。
18
3、准确度和精密度的关系
x1
x2
x3
x4
19
一般情况下,精密度高,准确度不 一定高。 精密度不高,准确度不可靠。 在消除系统误差的前提下,精密度 好,准确度就高。 精密度高是保证准确度好的前提 精密度好不一定准确度高
答:不可以。 3、系统误差和偶然误差在起因及出现规律方面,有什 么不同? 答:系统误差是由确定原因引起的,可重复出现,偶然 误差是由不确定原因引起的,遵循一定的统计规律。
7
4、分析测定中系统误差的特点是: A、由一些原因引起的 B、重复测定会重复出现 C、增加测定次数可减小系统误差 D、系统误差无法消除
☆移液管:25.00mL(4);
☆量筒(量至1mL或0.1mL):25mL(2), 4.0mL(2)
34
有效数字的位数与计算相对误差有关
0.5180g
相对误差=± 0.0001/ 0.5180 ×100%=±0.02%
0.518g
相对误差=± 0.001/0.518 ×100%=±0.2%
35
判断有效数字的位数:
第二章
《网店美工案例教程》 教学课件 第二章 新媒体数据分析指标

2.1 新媒体数据指标体系
AARRR 是运营行业普遍认可的一个业 务分析模型,可以简单理解为:用户怎么 来,来了以后怎么活跃,活跃以后怎么留 下来,留下来以后怎么为产品付费,付费 以后怎么进行口碑传播,如图 2-1 所示。
图 2-1 AARRR 模型
5
2.1 新媒体数据指标体系
1.拉新指标
在拉新环节,潜在用户体验产品后如果觉得不错,才会注册为正式用户。在评估拉新效果时,常 用的指标如下。
账号名称 月推送次数 月推送条数 月推送原创数
表 2-1 某运营类公众号竞品运营数据
运营研究社 360 1500 1860
脑洞运营 450 1400 1850
运营小卖部 590 1300 1890
15
2.2 数据运营四大维度 4.行业数据
行业数据能帮助新媒体运营者了解市场格局和行业变化,制订适宜的运营策略。例如, QuestMobile、易观千帆、极光、TalkingData 等平台,以及清博大数据、新榜、西 瓜数据等新媒体数据榜单平台,都会发布一些行业数据报告。
12
2.2 数据运营四大维度
1.用户数据
用户数据包括用户增长数据、用户属性数据和用户互动数据。其中,用户增长数据是指每天粉丝人 数的变化情况,用户属性数据是指当前新媒体平台的粉丝画像,用户互动数据是指用户对内容的点 赞、留言等互动的情况。
2.图书数据
我们通常将新媒体平台自带的图文数据称为基础图文指标,这是新媒体运营必看的数据。通过它们 运营人员可以知道每篇公众号图文送达人数、阅读人数、转发人数。以微信公众号为例,公众号基 础图文指标主要包含单篇图文阅读数据、单篇图文传播数据以及多篇图文阅读数据。
获取新用户很多时候需要成本,常 见的成本计算方式包括千次曝光成 本(Cost Per Mille,CPM)、单次 点击成本(Cost Per Click,CPC)、 单次获客成本(Cost Per Acquisition, CPA)。
第二章误差和数据处理

第二节 有效数字及其运算法则
一、有效数字 二、数字的修约规则 三、有效数字的运算规则
一、有效数字 (significant figure)
定义:是指在分析工作中实际上能测量到的数字, 有效数字位数包括所有准确数字和一位欠准数字。
解:R= 4.10 0.0050 / 1.97 =0.0104 R/R=-0.02/4.10+0.0001/0.00500–(-0.04)/1.97
=0.035 = 3.5% R =R 0.035 = 0.035 0.0104 = 0.00036 = R - R = 0.0104 - 0.00036 =0.01004
系统误差的来源
•方法误差:方法不恰当或不完善 •仪器误差:仪器不准或未校正 •试剂误差:试剂不纯 •操作误差:个人操作问题
(主观误差)
系统误差的表现方式
•恒量误差:多次测定中系统误差的 绝对值保持不变 •比例误差:系统误差的绝对值随样 品量的增大而成比例增大,相对值不 变。
偶然误差
又称随机误差或不可定误差,是由某些偶 然因素引起的误差。
偶然误差特点
a.方向不确定(误差时正时负) b.大小不确定(误差时大时小) c.符合统计规律
绝对值相等的正负误差出现概率基本相等 小误差出现的概率大,大误差出现的概率小
d.可增加平行测定次数消除
过失误差
在正常情况下不会发生过失误差,是仪器失灵、 试剂被污染、试样的意外损失等原因造成的。 一旦察觉到过失误差的发生,应停止正在进行 的步骤,重新开始实验。
•平均偏差:各个偏差绝对值的平均值。
数据分析基础课程 第2章 数据的收集

2.2.2 二手数据 二手数据也称为次级数据,是指那些从同行或一些媒体上获得的、经过加工整理的数据,比如国家统计 局定期发布的各种数据,从报纸、电视上获取的各种数据。 1.导入Access数据 (1)在Excel中单击“数据”|“自Access”按钮,如图2-5所示。
图2-5 导入Access数据
义的语言或概念。
(5)简明性原则,即表述问题的语言应该尽可能简单明确,不要冗长和啰唆。
(6)客观性原则,即表述问题的语言要客观,不要有诱导性或倾向性语言。
(7)非否定性原则,即要避免使用否定句形式表述问题。 (8)可能性原则,即必须符合被调查者回答问题的能力。凡是超越被调查者理解能力、记 忆能力、计算能力、回答能力的问题,都不应该提出。 (9)自愿性原则,即必须考虑被调查者是否自愿真实回答问题。凡被调查者不可能自愿真 实回答的问题,都不应该正面提出。
6.报告法
报告法是通过报告单位根据一定的原始记录和台账,根据统计表的格式和要求,按照隶属关 系,逐级向有关部门提供统计资料的一种调查方法。
7.自动生成
在大数据时代,数据的产生方式呈现多样化,如从传
感器、摄像头自动收集的数据,电子商务在线交易日志数 据、应用服务器日志数据等自动保存的数据都是自动生成 的数据。
图2-8 选择显示方式和放置位置
(5)单击“确定”按钮,导入的结果如图2-9所示。
图2-9 导入的结果
2.导入网站表格数据
(1)在Excel中单击“数据”|“自网站”按钮,如
图2-10所示。 (2)输入或复制并粘贴网址。
图2-10 导入网站数据
图2-11 选择导入的表格
导入的结果如图2-12所示。
目录/Contents
第二章 数据的收集
数据分析教程

数据分析教程
数据分析是一种重要的技能,可以帮助人们发现并解决问题。
无论是在商业领域,科学研究,还是政府政策制定,数据分析都起着关键作用。
数据分析的第一步是收集数据。
数据可以来自各种渠道,如调查问卷、实验控制组、社交媒体等。
数据的质量和数量很重要,因为它们将决定分析的可靠性和准确性。
一旦数据收集完毕,下一步是对数据进行清洗和整理。
这包括去除重复数据、处理缺失值、转换数据类型等。
只有在数据整洁和有组织的基础上,才能进行进一步的分析。
接下来,就是数据探索和可视化。
通过绘制图表和统计指标,我们可以更好地理解数据的特征和分布。
这有助于提取规律和发现趋势。
在数据探索的基础上,我们可以应用各种统计方法和机器学习算法进行数据分析。
这些方法可以帮助我们从数据中提取有用的信息,发现关联性和模式,并进行预测和决策。
最后,数据分析的结果需要被有效地传达和呈现。
这可以通过撰写报告、制作演示文稿和数据可视化等方式实现。
清晰而直观的呈现可以帮助他人更好地理解分析结果和推断。
总结起来,数据分析是一个系统的过程,涉及数据收集、数据清洗、数据探索、数据分析和结果呈现等多个步骤。
通过掌握
相关的技能和工具,我们可以更好地利用数据解决问题,并做出明智的决策。
数据分析

数据分析数据分析是一门广泛应用于各个领域的重要技术。
通过对大量数据进行收集、整理、分析和解释,我们可以发现隐藏在数据背后的有价值的信息和趋势。
本文将从数据分析的定义、应用领域、数据处理过程以及使用数据分析的好处等方面展开论述。
首先,我们来看看数据分析的定义。
数据分析是指通过收集和处理数据以提取有关问题的信息或者从中发现模式和知识的过程。
数据分析主要通过使用统计学、机器学习和模型推导等技术来处理数据,并从中找出有关问题的答案或者预测未来的趋势。
数据分析在各个领域都有着广泛的应用。
在商业领域中,数据分析可以帮助企业了解市场趋势、消费者行为以及产品销售情况。
企业可以通过数据分析来优化营销策略、改进产品设计以及预测销售量等。
在金融领域中,数据分析可以帮助银行和保险公司识别风险、预测市场波动以及优化投资组合。
在医疗领域中,数据分析可以帮助医生和研究人员发现疾病模式、预测流行病扩散以及辅助临床决策。
在政府领域中,数据分析可以帮助政府机构进行社会经济调查、制定政策以及优化资源分配。
数据分析的过程可以分为几个步骤。
首先是数据收集,这个过程涉及到获取数据的来源。
数据可以来自不同的渠道,例如传感器、调查问卷、数据库等。
接下来是数据整理,这个过程是对数据进行清洗、转换和组织,以便后续的分析。
数据整理包括去除重复数据、缺失数据的处理以及数据格式的转换等。
然后是数据分析,这个过程是应用统计学和机器学习等技术对数据进行处理和解释。
数据分析可以使用多种方法,例如描述性统计、回归分析、聚类分析等。
最后是数据解释,这个过程是根据分析结果对数据进行解释和推断,并提供有关问题的解决方案或者预测。
数据分析的好处不言而喻。
首先,数据分析可以帮助我们更好地了解问题的本质。
通过对大量数据进行分析,我们可以发现问题的根本原因和关键因素。
其次,数据分析可以帮助我们预测未来的趋势。
通过对历史数据和现有数据的分析,我们可以发现一些隐藏的趋势和规律,从而对未来进行预测和规划。
第二章 误差和分析数据处理

∆R ∆x ∆y ∆z = + + R x y z
例如 用容量分析法测定药物有效成分的含量,其百 分含量(w%)计算公式:
TVF w% = ×100% m
则w的极值相对误差是:
∆ w ∆V ∆m ∆F = + + w V F m
2. 标准偏差法 定义:利用偶然误差的统计学传递规律估计测量结果的 偶然误差。 规律2:乘、除结果的相 规律1:和、差结果的标准 对标准偏差的平方,等 偏差的平方,等于各测量 于各测量值的相对标准 值的标准偏差的平方和。 偏差的平方和。 公式:R = x + y - z 公式:R = x·y/z
用分析天平称量两个样品,一个是0.0021g,另 一个是0.5432g。两个测量值的绝对误差都是 0.0001g,但相对误差呢
注意: (1)测高含量组分,Er可小;测低含量组分,Er可大 (2)仪器分析法——测低含量组分,Er大 化学分析法——测高含量组分,Er小
常用相对误差表示测定结果的准确度。
测量点
准确度与精密度的关系
精密度高是保证准确度高的前提。 精密度高,不一定准确度就高。
二、系统误差和偶然误差——误差的分类
(一)系统误差(systematic error)
由某种确定原因 确定原因造成的。 确定原因
特 点
单向性 重现性 可测性
对结果的影响比较固定。 重复测定重复出现。 原因可查,可以消除。
(三)准确度与精密度的关系
例:A、B、C、D 四个分析工作者对同一铁标样 (wFe=37.40%)中的铁含量进行测量,结果如图示。
D C B A
36.00 36.50 37.00 平均值 37.50 38.00 真值 表观准确度高, 表观准确度高,精密度低 不可靠) (不可靠)
定性数据分析第二章课后答案
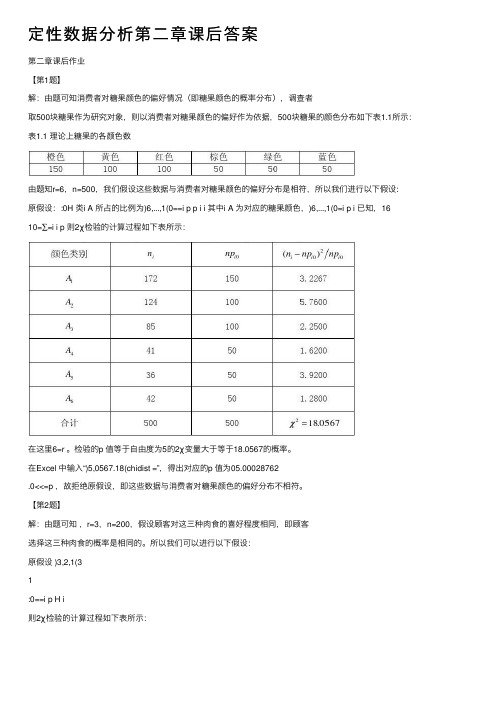
定性数据分析第⼆章课后答案第⼆章课后作业【第1题】解:由题可知消费者对糖果颜⾊的偏好情况(即糖果颜⾊的概率分布),调查者取500块糖果作为研究对象,则以消费者对糖果颜⾊的偏好作为依据,500块糖果的颜⾊分布如下表1.1所⽰:表1.1 理论上糖果的各颜⾊数由题知r=6,n=500,我们假设这些数据与消费者对糖果颜⾊的偏好分布是相符,所以我们进⾏以下假设:原假设::0H 类i A 所占的⽐例为)6,...,1(0==i p p i i 其中i A 为对应的糖果颜⾊,)6,...,1(0=i p i 已知,1610=∑=i i p 则2χ检验的计算过程如下表所⽰:在这⾥6=r 。
检验的p 值等于⾃由度为5的2χ变量⼤于等于18.0567的概率。
在Excel 中输⼊“)5,0567.18(chidist =”,得出对应的p 值为05.00028762.0<<=p ,故拒绝原假设,即这些数据与消费者对糖果颜⾊的偏好分布不相符。
【第2题】解:由题可知,r=3,n=200,假设顾客对这三种⾁⾷的喜好程度相同,即顾客选择这三种⾁⾷的概率是相同的。
所以我们可以进⾏以下假设:原假设 )3,2,1(31:0==i p H i则2χ检验的计算过程如下表所⽰:在这⾥3=r 。
检验的p 值等于⾃由度为2的2χ变量⼤于等于15.72921的概率。
在Excel 中输⼊“)2,72921.15(chidist =”,得出对应的p 值为05.00003841.0<<=p ,故拒绝原假设,即认为顾客对这三种⾁⾷的喜好程度是不相同的。
【第3题】解:由题可知,r=10,n=800,假设学⽣对这些课程的选择没有倾向性,即选各门课的⼈数的⽐例相同,则⼗门课程每门课程被选择的概率都相等。
所以我们可以进⾏以下假设:原假设)10,...,2,1(1.0:0==i p H i 则2χ检验的计算过程如下表所⽰:在这⾥10=r 。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
交易及服务数据 行业数据
关键字搜索、店铺排名、销售、会员等数据查询
电商中重要的数据
数据 平均收入 UV独立访客数 客户获取成本 利润率 转化率 客单价 重复购买率 运营成本 活跃用户数 活跃客户率 参与指数
解释 网站在一定时间内的收入 平均每天的独立访问人数 获得一个新客户所付出的成本 访问的客户中成功完成购买的人数占比 每一个顾客平均购买商品的交易金额 消费者对该品牌产品或者服务的有重复购买 次数的比例 电子商务企业销售客服和数据运营的成本 在一定时间内活跃的用户数字 活跃用户占整体用户的比例 用户的平均会话次数
电商网站评分数据集 ——请计算C对商品4评分
用户 A B C D E 商品1 3 ? 5 2 3 商品2 ? 5 4 4 4 商品3 3 4 2 ? 5 商品4 5 ? ? 3 ?
相似性度量
Slope one 算法
Slope one算法
在本例中,项目2和1之间的平均评分差值为 (2+(-1))/2=0.5. 因此,item1的评分平均比item2高 0.5。同样的,项目3和1之间的平均评分差值为3 。因此,如果我们试图根据Lucy 对项目2的评 分来预测她对项目1的评分的时候,我们可以得 到 2+0.5 = 2.5。同样,如果我们想要根据她对 项目3的评分来预测她对项目1的评分的话,我 们得到 5+3=8. 如果一个用户已经评价了一些项目,可以这样 做出预测:简单地把各个项目的预测通过加权 平均值结合起来。当用户两个项目都评价过的 时候,权值就高。在上面的例子中,项目1和项 目2都评价了的用户数为2,项目1和项目3 都评价 了的用户数为1,因此权重分别为2和1. 我们可以 这样预测Lucy对项目1的评价:
网络中凡事皆有可能
Ebay: 1995年建立 拍卖的第一件物品:坏掉的雷射指示器,成交价是14.83美元 /comm/new_entry/index_2.html 7月14日,两名温哥华妇女用一支鱼形笔换了他的红色曲别针。不 久,西雅图的一名女画家用一个画着笑脸的陶瓷门把换了他的鱼 形笔。7月25日,美国麻省的斯帕克斯用一个野营炉换了把手。9 月24日,一名加拿大人用一台旧发电机换取了野营炉。11月16日, 一个纽约年轻人用一个啤酒广告霓虹灯、一桶啤酒换取了他的旧 发电机。12月1日,麦克唐纳用这些东西换取了蒙特利尔市一名电 台主持人的雪地车。不久,一家雪地车杂志社用一个免费度假安 排交换那辆雪地车;免费度假安排又换来一辆旧货车。随后的物 物交换包括录音合同,在美国凤凰城免费租用一年的双层公寓, 与著名摇滚歌星艾丽斯· 库珀一起喝下午茶,电视演员科尔宾· 伯恩 森在新片中提供的一个演员角色。最后,加拿大仅有1140个居民 的基普岭小镇,决定提供该镇的一套房子来换取麦克唐纳得到的 这个电影新片角色。
网页加载速度到底多少合适
网页加载速度对网站到达率有重大的作用。 >3秒,57%客户放弃 >5秒,74%客户放弃
大数据时代
可以分析更多的数据,有时候甚至可以处理与某个 特别现象相关的所有数据,不再依赖采样; 数据多,不再追求精度; 不再追求因果,而是相关关系。 目前,银行可以根据求职网站的岗位数量,推断失 业率
2
2
R平方
R平方,该方法借鉴多元线性回归的分析算法来判断 和选择对目标变量有重要意义及价值的自变量。 R平方表示模型输入的各自变量在多大程度上可以解 释目标变量的可变性。取值在[0,1]之间。
共线性问题
相关系数的方法 主成分分析方法 根据业务经验 对变量进行聚类
关联分析
电商中的核心数据
访客数
转化率
如何提升访客数 增加网站视觉效果: 店铺装修 商品内容的介绍和包装(图片) 商品的选款、设计合适的价格 提升好评率和客户评价 提升老客户回访率 服务质量 服务策略
客单价
促销和限销 关联销售 活动
数据需要对比分析
注:客户获取成本:以新客户总数量去除获取客户而支付的总费用 重复购买率 1. 所有购买过产品的顾客,以每个人为独立单位统计重复购买产品的次数。比如 10 个 客户购买了产品,有四个产生了重复购买,则重复购买率为 40%。 2. 单位时间内,重复购买的总次数占比。比如 10 个客户购买了产品,中间有四个人做 了第二次购买, 而这四个人中又有两个人做了第三次购买, 这两个人中又有一个人做了第四 次购买,则重复购买率为 70%。 参与指数=月(周)总访问数/月(周)独立访问数
熟悉业务背景 确保抽取的用户所对应的当时业务背景,与现在的业 务需求即将对应的业务背景没有明显的重要改变
数据转换
产生衍生变量 改变变量分布特征的转换 区间型变量的分箱转换 针对分箱变量进行的标准化操作
生成衍生变量
通过原始数据进行适当的数学推导,产生更有商业 意义的新变量 如:年龄、用户在特定商品上消费的产品占其总消 费额的比例、消费次数等等
每个用户会有一个10维的数据点,以0或1表示,1为是,0为否 可以计算任意用户之间的距离 如果不是0与1,展示的信息会更多 用户,性别,居住地,收入,购买次数,本月购买次数,最大购买金 额,平均购买金额
2.3 电子商务中的可获取数据
流量数据ቤተ መጻሕፍቲ ባይዱ
营销数据
会员数据
浏览量、访客数、登录时间、在线时长、登录IP等 营销费用、到达用户数、打开或点击用户数 姓名、出生日期、真实性别、网络性别、地址、手机号、微 博号、登录记录、交易记录等 交易金额、交易数量、交易人数、交易商品、交易场所、交 易时间、服务链服务等数据
于是,对“n”个项目,想要实现 Slope One, 只需要计算并存储“n”对评分间的平均差值和 评价数目即可。
基于项目的协同过滤
根据Pearson相关系数来计算相似度。R u,i 是用户u 对商品i的评分,i和j是商品
第2章 数据分析
大数据与乔布斯癌症治疗
苹果公司的传奇总裁史蒂夫· 乔布斯在与癌症斗争的 过程中采用了不同的方式,成为世界上第一个对自 身所有DNA和肿瘤DNA进行排序的人。这使得史蒂 夫· 乔布斯的医生们能够基于乔布斯的特定基因组成, 按所需效果用药。如果癌症病变导致药物失效,医 生可以及时更换另一种药。乔布斯开玩笑说:“我 要么是第一个通过这种方式战胜癌症的人,要么就 是最后一个因为这种方式死于癌症的人。”虽然他 的愿望都没有实现,但是这种获得所有数据而不仅 是样本的方法还是将他的生命延长了好几年。
主要内容
数据的重要性 电子商务中可获得的数据 数据处理和分析
2.1 从数据分析专家林彪说起
1948年辽沈战役开始之后,在东北野战军前线指挥所里面,每天深夜都要 进行例常的“每日军情汇报”:由值班参谋读出下属各个纵队、师、团用 电台报告的当日战况和缴获情况。 司令员林彪的要求很细,俘虏要分清军官和士兵,缴获的枪支,要统计出 机枪、长枪、短枪;击毁和缴获尚能使用的汽车,也要分出大小和类别。 一天深夜,值班参谋正在读着下面某师上报的其下属部队的战报。说他们 下面的部队碰到了一个不大的遭遇战,歼敌部分、其余逃走。与其它之前 所读的战报 看上去并无明显异样,值班参谋就这样读着读着,林彪突然 叫了一声“停!”他的眼里闪出了光芒,问:“刚才念的在胡家窝棚那个 战斗的缴获,你们听到了吗?” 大家带着睡意的脸上出现了茫然,因为如此战斗每天都有几十起,不都是 差不多一模一样的枯燥数字吗?林彪扫视一周,见无人回答,便接连问了 三句: “为什么那里缴获的短枪与长枪的比例比其它战斗略高”? “为什么那里缴获和击毁的小车与大车的比例比其它战斗略高”? “为什么在那里俘虏和击毙的军官与士兵的比例比其它战斗略高”? 结论:赶紧追击,发现并打掉了精悍野战司令部,活抓了廖耀湘
数据的抽取要正确反映业务需求
某业务需求是找出因为使用店铺装修工具而带来显 著销售收入提升的用户群体特征 如何寻找这些人?
有些用户除了使用装修工具,还使用了其他方式 如竞价排名等方式 要保证找出的用户不包含使用了竞价排名等主要 的提升流量和销售收入等手段的用户,尽可能使 得这个用户群仅仅因为店面装修工具而带来的销 售收入的提升。 要求
数据不是万能的
2012年美国大选(结果却一边倒)
数据运营过程中存在的问题
领导的决断性 实际性 真实性 数据相关性 数据的稀疏性 数据的时效性
2.2 电子商务中的数据
卖什么产品利润高 卖什么产品销量大 什么时候卖产品最合适 怎么样搭配地卖 卖给谁最合适 什么样的客户会买 什么样的客户买得最多 到哪里去找这样的客户 如何廉价地找到这样的客户 如何留住这些客户 。。。。
如何面对铺面而来的数据
客单价显著上升,但人均成交件数并没有相应幅度的提高,即该店铺销售的商品 的单价变高。查看该店铺的宝贝销售排行并与T1 天对比,发现该店铺在周一时上 新了一款高价单品,带来了大量销售,另外有一款低价商品,也贡献了很高的转 化率
2.4 常见的数据处理技巧
数据的抽取要正确反映业务需求 数据抽样 分析数据的规模有哪些具体的要求 如何处理缺失值和异常值 数据转换 筛选有效的输入变量 共线性问题
协同过滤算法
基础
和你爱好合得来的人喜好的,你也很有可能喜好; 喜好一件器材 A,而另一件器材 B 与这件十分类似, 就很有可能喜好 B;
收集用户的偏好信息
显性数据 隐形数据
点击、搜索、购买
寻找相似的商品或者用户 产生推荐
基于用户的协同过滤
给定用户评分数据矩阵R 计算用户之间的相似度 根据评分数据和相似矩阵计算推荐结果
让数据说话
王永庆(台塑集团创始人)卖米 Target和怀孕指数预测
美国一名男子闯入他家附近的一家美国零售连锁超市Target 店铺(美国第三大零售商塔吉特)进行抗议:“你们竟然给 我17岁的女儿发婴儿尿片和童车的优惠券。”店铺经理立刻 向来者承认错误,但是其实该经理并不知道这一行为是总公 司运行数据挖掘的结果。一个月后,这位父亲来道歉,因为 这时他才知道他的女儿的确怀孕了。Target比这位父亲知道 他女儿怀孕的时间足足早了一个月。 Target能够通过分析女性客户购买记录,“猜出”哪些是孕妇。 他们从Target的数据仓库中挖掘出25项与怀孕高度相关的商 品,制作“怀孕预测”指数。比如他们发现女性会在怀孕四个 月左右,大量购买无香味乳液。几个月后,她们会买一些养 品,比如镁、钙锌。以此为依据推算出预产期后,就抢先一 步将孕妇装、婴儿床等折扣券寄给客户来吸引客户购买。