Mixed depth representations for dialog processing
基于属性增强的神经传感融合网络的人脸识别算法论文
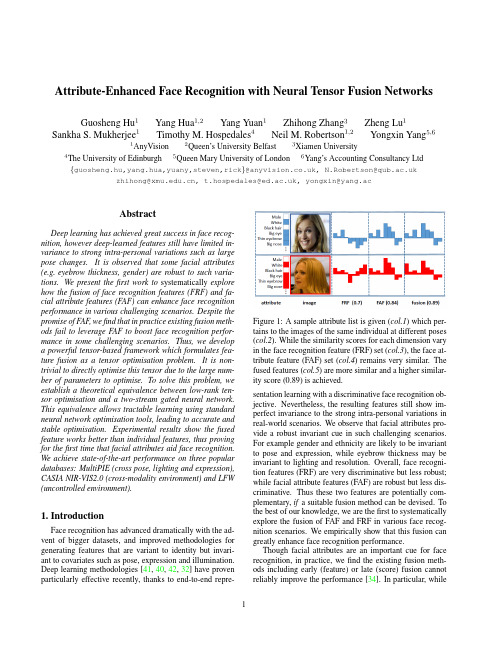
Attribute-Enhanced Face Recognition with Neural Tensor Fusion Networks Guosheng Hu1Yang Hua1,2Yang Yuan1Zhihong Zhang3Zheng Lu1 Sankha S.Mukherjee1Timothy M.Hospedales4Neil M.Robertson1,2Yongxin Yang5,61AnyVision2Queen’s University Belfast3Xiamen University 4The University of Edinburgh5Queen Mary University of London6Yang’s Accounting Consultancy Ltd {guosheng.hu,yang.hua,yuany,steven,rick}@,N.Robertson@ zhihong@,t.hospedales@,yongxin@yang.acAbstractDeep learning has achieved great success in face recog-nition,however deep-learned features still have limited in-variance to strong intra-personal variations such as large pose changes.It is observed that some facial attributes (e.g.eyebrow thickness,gender)are robust to such varia-tions.We present thefirst work to systematically explore how the fusion of face recognition features(FRF)and fa-cial attribute features(FAF)can enhance face recognition performance in various challenging scenarios.Despite the promise of FAF,wefind that in practice existing fusion meth-ods fail to leverage FAF to boost face recognition perfor-mance in some challenging scenarios.Thus,we develop a powerful tensor-based framework which formulates fea-ture fusion as a tensor optimisation problem.It is non-trivial to directly optimise this tensor due to the large num-ber of parameters to optimise.To solve this problem,we establish a theoretical equivalence between low-rank ten-sor optimisation and a two-stream gated neural network. This equivalence allows tractable learning using standard neural network optimisation tools,leading to accurate and stable optimisation.Experimental results show the fused feature works better than individual features,thus proving for thefirst time that facial attributes aid face recognition. We achieve state-of-the-art performance on three popular databases:MultiPIE(cross pose,lighting and expression), CASIA NIR-VIS2.0(cross-modality environment)and LFW (uncontrolled environment).1.IntroductionFace recognition has advanced dramatically with the ad-vent of bigger datasets,and improved methodologies for generating features that are variant to identity but invari-ant to covariates such as pose,expression and illumination. Deep learning methodologies[41,40,42,32]have proven particularly effective recently,thanks to end-to-endrepre-Figure1:A sample attribute list is given(col.1)which per-tains to the images of the same individual at different poses (col.2).While the similarity scores for each dimension vary in the face recognition feature(FRF)set(col.3),the face at-tribute feature(FAF)set(col.4)remains very similar.The fused features(col.5)are more similar and a higher similar-ity score(0.89)is achieved.sentation learning with a discriminative face recognition ob-jective.Nevertheless,the resulting features still show im-perfect invariance to the strong intra-personal variations in real-world scenarios.We observe that facial attributes pro-vide a robust invariant cue in such challenging scenarios.For example gender and ethnicity are likely to be invariant to pose and expression,while eyebrow thickness may be invariant to lighting and resolution.Overall,face recogni-tion features(FRF)are very discriminative but less robust;while facial attribute features(FAF)are robust but less dis-criminative.Thus these two features are potentially com-plementary,if a suitable fusion method can be devised.To the best of our knowledge,we are thefirst to systematically explore the fusion of FAF and FRF in various face recog-nition scenarios.We empirically show that this fusion can greatly enhance face recognition performance.Though facial attributes are an important cue for face recognition,in practice,wefind the existing fusion meth-ods including early(feature)or late(score)fusion cannot reliably improve the performance[34].In particular,while 1offering some robustness,FAF is generally less discrimina-tive than FRF.Existing methods cannot synergistically fuse such asymmetric features,and usually lead to worse perfor-mance than achieved by the stronger feature(FRF)only.In this work,we propose a novel tensor-based fusion frame-work that is uniquely capable of fusing the very asymmet-ric FAF and FRF.Our framework provides a more powerful and robust fusion approach than existing strategies by learn-ing from all interactions between the two feature views.To train the tensor in a tractable way given the large number of required parameters,we formulate the optimisation with an identity-supervised objective by constraining the tensor to have a low-rank form.We establish an equivalence be-tween this low-rank tensor and a two-stream gated neural network.Given this equivalence,the proposed tensor is eas-ily optimised with standard deep neural network toolboxes. Our technical contributions are:•It is thefirst work to systematically investigate and ver-ify that facial attributes are an important cue in various face recognition scenarios.In particular,we investi-gate face recognition with extreme pose variations,i.e.±90◦from frontal,showing that attributes are impor-tant for performance enhancement.•A rich tensor-based fusion framework is proposed.We show the low-rank Tucker-decomposition of this tensor-based fusion has an equivalent Gated Two-stream Neural Network(GTNN),allowing easy yet effective optimisation by neural network learning.In addition,we bring insights from neural networks into thefield of tensor optimisation.The code is available:https:///yanghuadr/ Neural-Tensor-Fusion-Network•We achieve state-of-the-art face recognition perfor-mance using the fusion of face(newly designed‘Lean-Face’deep learning feature)and attribute-based fea-tures on three popular databases:MultiPIE(controlled environment),CASIA NIR-VIS2.0(cross-modality environment)and LFW(uncontrolled environment).2.Related WorkFace Recognition.The face representation(feature)is the most important component in contemporary face recog-nition system.There are two types:hand-crafted and deep learning features.Widely used hand-crafted face descriptors include Local Binary Pattern(LBP)[26],Gaborfilters[23],-pared to pixel values,these features are variant to identity and relatively invariant to intra-personal variations,and thus they achieve promising performance in controlled environ-ments.However,they perform less well on face recognition in uncontrolled environments(FRUE).There are two main routes to improve FRUE performance with hand-crafted features,one is to use very high dimensional features(dense sampling features)[5]and the other is to enhance the fea-tures with downstream metric learning.Unlike hand-crafted features where(in)variances are en-gineered,deep learning features learn the(in)variances from data.Recently,convolutional neural networks(CNNs) achieved impressive results on FRUE.DeepFace[44],a carefully designed8-layer CNN,is an early landmark method.Another well-known line of work is DeepID[41] and its variants DeepID2[40],DeepID2+[42].The DeepID family uses an ensemble of many small CNNs trained in-dependently using different facial patches to improve the performance.In addition,some CNNs originally designed for object recognition,such as VGGNet[38]and Incep-tion[43],were also used for face recognition[29,32].Most recently,a center loss[47]is introduced to learn more dis-criminative features.Facial Attribute Recognition.Facial attribute recog-nition(FAR)is also well studied.A notable early study[21] extracted carefully designed hand-crafted features includ-ing aggregations of colour spaces and image gradients,be-fore training an independent SVM to detect each attribute. As for face recognition,deep learning features now outper-form hand-crafted features for FAR.In[24],face detection and attribute recognition CNNs are carefully designed,and the output of the face detection network is fed into the at-tribute network.An alternative to purpose designing CNNs for FAR is tofine-tune networks intended for object recog-nition[56,57].From a representation learning perspective, the features supporting different attribute detections may be shared,leading some studies to investigate multi-task learn-ing facial attributes[55,30].Since different facial attributes have different prevalence,the multi-label/multi-task learn-ing suffers from label-imbalance,which[30]addresses us-ing a mixed objective optimization network(MOON). Face Recognition using Facial Attributes.Detected facial attributes can be applied directly to authentication. Facial attributes have been applied to enhance face verifica-tion,primarily in the case of cross-modal matching,byfil-tering[19,54](requiring potential FRF matches to have the correct gender,for example),model switching[18],or ag-gregation with conventional features[27,17].[21]defines 65facial attributes and proposes binary attribute classifiers to predict their presence or absence.The vector of attribute classifier scores can be used for face recognition.There has been little work on attribute-enhanced face recognition in the context of deep learning.One of the few exploits CNN-based attribute features for authentication on mobile devices [31].Local facial patches are fed into carefully designed CNNs to predict different attributes.After CNN training, SVMs are trained for attribute recognition,and the vector of SVM scores provide the new feature for face verification.Fusion Methods.Existing fusion approaches can be classified into feature-level(early fusion)and score-level (late fusion).Score-level fusion is to fuse the similarity scores after computation based on each view either by sim-ple averaging[37]or stacking another classifier[48,37]. Feature-level fusion can be achieved by either simple fea-ture aggregation or subspace learning.For aggregation ap-proaches,fusion is usually performed by simply element wise averaging or product(the dimension of features have to be the same)or concatenation[28].For subspace learn-ing approaches,the features arefirst concatenated,then the concatenated feature is projected to a subspace,in which the features should better complement each other.These sub-space approaches can be unsupervised or supervised.Un-supervised fusion does not use the identity(label)informa-tion to learn the subspace,such as Canonical Correlational Analysis(CCA)[35]and Bilinear Models(BLM)[45].In comparison,supervised fusion uses the identity information such as Linear Discriminant Analysis(LDA)[3]and Local-ity Preserving Projections(LPP)[9].Neural Tensor Methods.Learning tensor-based compu-tations within neural networks has been studied for full[39] and decomposed[16,52,51]tensors.However,aside from differing applications and objectives,the key difference is that we establish a novel equivalence between a rich Tucker [46]decomposed low-rank fusion tensor,and a gated two-stream neural network.This allows us achieve expressive fusion,while maintaining tractable computation and a small number of parameters;and crucially permits easy optimisa-tion of the fusion tensor through standard toolboxes. Motivation.Facial attribute features(FAF)and face recognition features(FRF)are complementary.However in practice,wefind that existing fusion methods often can-not effectively combine these asymmetric features so as to improve performance.This motivates us to design a more powerful fusion method,as detailed in Section3.Based on our neural tensor fusion method,in Section5we system-atically explore the fusion of FAF and FRF in various face recognition environments,showing that FAF can greatly en-hance recognition performance.3.Fusing attribute and recognition featuresIn this section we present our strategy for fusing FAF and FRF.Our goal is to input FAF and FRF and output the fused discriminative feature.The proposed fusion method we present here performs significantly better than the exist-ing ones introduced in Section2.In this section,we detail our tensor-based fusion strategy.3.1.ModellingSingle Feature.We start from a standard multi-class clas-sification problem setting:assume we have M instances, and for each we extract a D-dimensional feature vector(the FRF)as{x(i)}M i=1.The label space contains C unique classes(person identities),so each instance is associated with a corresponding C-dimensional one-hot encoding la-bel vector{y(i)}M i=1.Assuming a linear model W the pre-dictionˆy(i)is produced by the dot-product of input x(i)and the model W,ˆy(i)=x(i)T W.(1) Multiple Feature.Suppose that apart from the D-dimensional FRF vector,we can also obtain an instance-wise B-dimensional facial attribute feature z(i).Then the input for the i th instance is a pair:{x(i),z(i)}.A simple ap-proach is to redefine x(i):=[x(i),z(i)],and directly apply Eq.(1),thus modelling weights for both FRF and FAF fea-tures.Here we propose instead a non-linear fusion method via the following formulationˆy(i)=W×1x(i)×3z(i)(2) where W is the fusion model parameters in the form of a third-order tensor of size D×C×B.Notation×is the tensor dot product(also known as tensor contraction)and the left-subscript of x and z indicates at which axis the ten-sor dot product operates.With Eq.(2),the optimisation problem is formulated as:minW1MMi=1W×1x(i)×3z(i),y(i)(3)where (·,·)is a loss function.This trains tensor W to fuse FRF and FAF features so that identity is correctly predicted.3.2.OptimisationThe proposed tensor W provides a rich fusion model. However,compared with W,W is B times larger(D×C vs D×C×B)because of the introduction of B-dimensional attribute vector.It is also almost B times larger than train-ing a matrix W on the concatenation[x(i),z(i)].It is there-fore problematic to directly optimise Eq.(3)because the large number of parameters of W makes training slow and leads to overfitting.To address this we propose a tensor de-composition technique and a neural network architecture to solve an equivalent optimisation problem in the following two subsections.3.2.1Tucker Decomposition for Feature FusionTo reduce the number of parameters of W,we place a struc-tural constraint on W.Motivated by the famous Tucker de-composition[46]for tensors,we assume that W is synthe-sised fromW=S×1U(D)×2U(C)×3U(B).(4) Here S is a third order tensor of size K D×K C×K B, U(D)is a matrix of size K D×D,U(C)is a matrix of sizeK C×C,and U(B)is a matrix of size K B×B.By restricting K D D,K C C,and K B B,we can effectively reduce the number of parameters from(D×C×B)to (K D×K C×K B+K D×D+K C×C+K B×B)if we learn{S,U(D),U(C),U(B)}instead of W.When W is needed for making the predictions,we can always synthesise it from those four small factors.In the context of tensor decomposition,(K D,K C,K B)is usually called the tensor’s rank,as an analogous concept to the rank of a matrix in matrix decomposition.Note that,despite of the existence of other tensor de-composition choices,Tucker decomposition offers a greater flexibility in terms of modelling because we have three hyper-parameters K D,K C,K B corresponding to the axes of the tensor.In contrast,the other famous decomposition, CP[10]has one hyper-parameter K for all axes of tensor.By substituting Eq.(4)into Eq.(2),we haveˆy(i)=W×1x(i)×3z(i)=S×1U(D)×2U(C)×3U(B)×1x(i)×3z(i)(5) Through some re-arrangement,Eq.(5)can be simplified as ˆy(i)=S×1(U(D)x(i))×2U(C)×3(U(B)z(i))(6) Furthermore,we can rewrite Eq.(6)as,ˆy(i)=((U(D)x(i))⊗(U(B)z(i)))S T(2)fused featureU(C)(7)where⊗is Kronecker product.Since U(D)x(i)and U(B)B(i)result in K D and K B dimensional vectors re-spectively,(U(D)x(i))⊗(U(B)z(i))produces a K D K B vector.S(2)is the mode-2unfolding of S which is aK C×K D K B matrix,and its transpose S T(2)is a matrix ofsize K D K B×K C.The Fused Feature.From Eq.(7),the explicit fused representation of face recognition(x(i))and facial at-tribute(z(i))features can be achieved.The fused feature ((U(D)x(i))⊗(U(B)z(i)))S T(2),is a vector of the dimen-sionality K C.And matrix U(C)has the role of“clas-sifier”given this fused feature.Given{x(i),z(i),y(i)}, the matrices{U(D),U(B),U(C)}and tensor S are com-puted(learned)during model optimisation(training).Dur-ing testing,the predictionˆy(i)is achieved with the learned {U(D),U(B),U(C),S}and two test features{x(i),z(i)} following Eq.(7).3.2.2Gated Two-stream Neural Network(GTNN)A key advantage of reformulating Eq.(5)into Eq.(7)is that we can nowfind a neural network architecture that does ex-actly the computation of Eq.(7),which would not be obvi-ous if we stopped at Eq.(5).Before presenting thisneural Figure2:Gated two-stream neural network to implement low-rank tensor-based fusion.The architecture computes Eq.(7),with the Tucker decomposition in Eq.(4).The network is identity-supervised at train time,and feature in the fusion layer used as representation for verification. network,we need to introduce a new deterministic layer(i.e. without any learnable parameters).Kronecker Product Layer takes two arbitrary-length in-put vectors{u,v}where u=[u1,u2,···,u P]and v=[v1,v2,···,v Q],then outputs a vector of length P Q as[u1v1,u1v2,···,u1v Q,u2v1,···,u P v Q].Using the introduced Kronecker layer,Fig.2shows the neural network that computes Eq.(7).That is,the neural network that performs recognition using tensor-based fu-sion of two features(such as FAF and FRF),based on the low-rank assumption in Eq.(4).We denote this architecture as a Gated Two-stream Neural Network(GTNN),because it takes two streams of inputs,and it performs gating[36] (multiplicative)operations on them.The GTNN is trained in a supervised fashion to predict identity.In this work,we use a multitask loss:softmax loss and center loss[47]for joint training.The fused feature in the viewpoint of GTNN is the output of penultimate layer, which is of dimensionality K c.So far,the advantage of using GTNN is obvious.Direct use of Eq.(5)or Eq.(7)requires manual derivation and im-plementation of an optimiser which is non-trivial even for decomposed matrices(2d-tensors)[20].In contrast,GTNN is easily implemented with modern deep learning packages where auto-differentiation and gradient-based optimisation is handled robustly and automatically.3.3.DiscussionCompared with the fusion methods introduced in Sec-tion2,we summarise the advantages of our tensor-based fusion method as follows:Figure3:LeanFace.‘C’is a group of convolutional layers.Stage1:64@5×5(64feature maps are sliced to two groups of32ones, which are fed into maxout function.);Stage2:64@3×3,64@3×3,128@3×3,128@3×3;Stage3:196@3×3,196@3×3, 256@3×3,256@3×3,320@3×3,320@3×3;Stage4:512@3×3,512@3×3,512@3×3,512@3×3;Stage5:640@ 5×5,640@5×5.‘P’stands for2×2max pooling.The strides for the convolutional and pooling layers are1and2,respectively.‘FC’is a fully-connected layer of256D.High Order Non-Linearity.Unlike linear methods based on averaging,concatenation,linear subspace learning [8,27],or LDA[3],our fusion method is non-linear,which is more powerful to model complex problems.Further-more,comparing with otherfirst-order non-linear methods based on element-wise combinations only[28],our method is higher order:it accounts for all interactions between each pair of feature channels in both views.Thanks to the low-rank modelling,our method achieves such powerful non-linear fusion with few parameters and thus it is robust to overfitting.Scalability.Big datasets are required for state-of-the-art face representation learning.Because we establish the equivalence between tensor factorisation and gated neural network architecture,our method is scalable to big-data through efficient mini-batch SGD-based learning.In con-trast,kernel-based non-linear methods,such as Kernel LDA [34]and multi-kernel SVM[17],are restricted to small data due to their O(N2)computation cost.At runtime,our method only requires a simple feed-forward pass and hence it is also favourable compared to kernel methods. Supervised method.GTNN isflexibly supervised by any desired neural network loss function.For example,the fusion method can be trained with losses known to be ef-fective for face representation learning:identity-supervised softmax,and centre-loss[47].Alternative methods are ei-ther unsupervised[8,27],constrained in the types of super-vision they can exploit[3,17],or only stack scores rather than improving a learned representation[48,37].There-fore,they are relatively ineffective at learning how to com-bine the two-source information in a task-specific way. Extensibility.Our GTNN naturally can be extended to deeper architectures.For example,the pre-extracted fea-tures,i.e.,x and z in Fig.2,can be replaced by two full-sized CNNs without any modification.Therefore,poten-tially,our methods can be integrated into an end-to-end framework.4.Integration with CNNs:architectureIn this section,we introduce the CNN architectures used for face recognition(LeanFace)designed by ourselves and facial attribute recognition(AttNet)introduced by[50,30]. LeanFace.Unlike general object recognition,face recognition has to capture very subtle difference between people.Motivated by thefine-grain object recognition in [4],we also use a large number of convolutional layers at early stage to capture the subtle low level and mid-level in-formation.Our activation function is maxout,which shows better performance than its competitors[50].Joint supervi-sion of softmax loss and center loss[47]is used for training. The architecture is summarised in Fig.3.AttNet.To detect facial attributes,our AttNet uses the ar-chitecture of Lighten CNN[50]to represent a face.Specifi-cally,AttNet consists of5conv-activation-pooling units fol-lowed by a256D fully connected layer.The number of con-volutional kernels is explained in[50].The activation func-tion is Max-Feature-Map[50]which is a variant of maxout. We use the loss function MOON[30],which is a multi-task loss for(1)attribute classification and(2)domain adaptive data balance.In[24],an ontology of40facial attributes are defined.We remove attributes which do not characterise a specific person,e.g.,‘wear glasses’and‘smiling’,leaving 17attributes in total.Once each network is trained,the features extracted from the penultimate fully-connected layers of LeanFace(256D) and AttNet(256D)are extracted as x and z,and input to GTNN for fusion and then face recognition.5.ExperimentsWefirst introduce the implementation details of our GTNN method.In Section5.1,we conduct experiments on MultiPIE[7]to show that facial attributes by means of our GTNN method can play an important role on improv-Table1:Network training detailsImage size BatchsizeLR1DF2EpochTraintimeLeanFace128x1282560.0010.15491hAttNet0.050.8993h1Learning rate(LR)2Learning rate drop factor(DF).ing face recognition performance in the presence of pose, illumination and expression,respectively.Then,we com-pare our GTNN method with other fusion methods on CA-SIA NIR-VIS2.0database[22]in Section5.2and LFW database[12]in Section5.3,respectively. Implementation Details.In this study,three networks (LeanFace,AttNet and GTNN)are discussed.LeanFace and AttNet are implemented using MXNet[6]and GTNN uses TensorFlow[1].We use around6M training face thumbnails covering62K different identities to train Lean-Face,which has no overlapping with all the test databases. AttNet is trained using CelebA[24]database.The input of GTNN is two256D features from bottleneck layers(i.e., fully connected layers before prediction layers)of LeanFace and AttNet.The setting of main parameters are shown in Table1.Note that the learning rates drop when the loss stops decreasing.Specifically,the learning rates change4 and2times for LeanFace and AttNet respectively.Dur-ing test,LeanFace and AttNet take around2.9ms and3.2ms to extract feature from one input image and GTNN takes around2.1ms to fuse one pair of LeanFace and AttNet fea-ture using a GTX1080Graphics Card.5.1.Multi-PIE DatabaseMulti-PIE database[7]contains more than750,000im-ages of337people recorded in4sessions under diverse pose,illumination and expression variations.It is an ideal testbed to investigate if facial attribute features(FAF) complement face recognition features(FRF)including tra-ditional hand-crafted(LBP)and deeply learned features (LeanFace)to improve the face recognition performance–particularly across extreme pose variation.Settings.We conduct three experiments to investigate pose-,illumination-and expression-invariant face recogni-tion.Pose:Uses images across4sessions with pose vari-ations only(i.e.,neutral lighting and expression).It covers pose with yaw ranging from left90◦to right90◦.In com-parison,most of the existing works only evaluate perfor-mance on poses with yaw range(-45◦,+45◦).Illumination: Uses images with20different illumination conditions(i.e., frontal pose and neutral expression).Expression:Uses im-ages with7different expression variations(i.e.,frontal pose and neutral illumination).The training sets of all settings consist of the images from thefirst200subjects and the re-maining137subjects for testing.Following[59,14],in the test set,frontal images with neural illumination and expres-sion from the earliest session work as gallery,and the others are probes.Pose.Table2shows the pose-robust face recognition (PRFR)performance.Clearly,the fusion of FRF and FAF, namely GTNN(LBP,AttNet)and GTNN(LeanFace,At-tNet),works much better than using FRF only,showing the complementary power of facial features to face recognition features.Not surprisingly,the performance of both LBP and LeanFace features drop greatly under extreme poses,as pose variation is a major factor challenging face recognition performance.In contrast,with GTNN-based fusion,FAF can be used to improve both classic(LBP)and deep(Lean-Face)FRF features effectively under this circumstance,for example,LBP(1.3%)vs GTNN(LBP,AttNet)(16.3%), LeanFace(72.0%)vs GTNN(LeanFace,AttNet)(78.3%) under yaw angel−90◦.It is noteworthy that despite their highly asymmetric strength,GTNN is able to effectively fuse FAF and FRF.This is elaborately studied in more detail in Sections5.2-5.3.Compared with state-of-the-art methods[14,59,11,58, 15]in terms of(-45◦,+45◦),LeanFace achieves better per-formance due to its big training data and the strong gener-alisation capacity of deep learning.In Table2,2D meth-ods[14,59,15]trained models using the MultiPIE images, therefore,they are difficult to generalise to images under poses which do not appear in MultiPIE database.3D meth-ods[11,58]highly depend on accurate2D landmarks for 3D-2D modellingfitting.However,it is hard to accurately detect such landmarks under larger poses,limiting the ap-plications of3D methods.Illumination and expression.Illumination-and expression-robust face recognition(IRFR and ERFR)are also challenging research topics.LBP is the most widely used handcrafted features for IRFR[2]and ERFR[33].To investigate the helpfulness of facial attributes,experiments of IRFR and ERFR are conducted using LBP and Lean-Face features.In Table3,GTNN(LBP,AttNet)signifi-cantly outperforms LBP,80.3%vs57.5%(IRFR),77.5% vs71.7%(ERFR),showing the great value of combining fa-cial attributes with hand-crafted features.Attributes such as the shape of eyebrows are illumination invariant and others, e.g.,gender,are expression invariant.In contrast,LeanFace feature is already very discriminative,saturating the perfor-mance on the test set.So there is little room for fusion of AttrNet to provide benefit.5.2.CASIA NIR-VIS2.0DatabaseThe CASIA NIR-VIS2.0face database[22]is the largest public face database across near-infrared(NIR)images and visible RGB(VIS)images.It is a typical cross-modality or heterogeneous face recognition problem because the gallery and probe images are from two different spectra.The。
纹理物体缺陷的视觉检测算法研究--优秀毕业论文

摘 要
在竞争激烈的工业自动化生产过程中,机器视觉对产品质量的把关起着举足 轻重的作用,机器视觉在缺陷检测技术方面的应用也逐渐普遍起来。与常规的检 测技术相比,自动化的视觉检测系统更加经济、快捷、高效与 安全。纹理物体在 工业生产中广泛存在,像用于半导体装配和封装底板和发光二极管,现代 化电子 系统中的印制电路板,以及纺织行业中的布匹和织物等都可认为是含有纹理特征 的物体。本论文主要致力于纹理物体的缺陷检测技术研究,为纹理物体的自动化 检测提供高效而可靠的检测算法。 纹理是描述图像内容的重要特征,纹理分析也已经被成功的应用与纹理分割 和纹理分类当中。本研究提出了一种基于纹理分析技术和参考比较方式的缺陷检 测算法。这种算法能容忍物体变形引起的图像配准误差,对纹理的影响也具有鲁 棒性。本算法旨在为检测出的缺陷区域提供丰富而重要的物理意义,如缺陷区域 的大小、形状、亮度对比度及空间分布等。同时,在参考图像可行的情况下,本 算法可用于同质纹理物体和非同质纹理物体的检测,对非纹理物体 的检测也可取 得不错的效果。 在整个检测过程中,我们采用了可调控金字塔的纹理分析和重构技术。与传 统的小波纹理分析技术不同,我们在小波域中加入处理物体变形和纹理影响的容 忍度控制算法,来实现容忍物体变形和对纹理影响鲁棒的目的。最后可调控金字 塔的重构保证了缺陷区域物理意义恢复的准确性。实验阶段,我们检测了一系列 具有实际应用价值的图像。实验结果表明 本文提出的纹理物体缺陷检测算法具有 高效性和易于实现性。 关键字: 缺陷检测;纹理;物体变形;可调控金字塔;重构
Keywords: defect detection, texture, object distortion, steerable pyramid, reconstruction
II
马兰士 SR8200说明书

R Model SR8200 User GuideAV Surround ReceiverThe lightning flash with arrowhead symbolwithin an equilateral triangle is intended toalert the user to the presence of uninsulated“dangerous voltage” within the product’senclosure that may be of sufficient magnitudeto constitute a risk of electric shock to persons.The exclamation point within an equilateraltriangle is intended to alert the user to thepresence of important operating andmaintenance (servicing) instructions in theliterature accompanying the product.WARNINGTO REDUCE THE RISK OF FIRE OR ELECTRIC SHOCK,DO NOT EXPOSE THIS PRODUCT TO RAIN OR MOISTURE.CAUTION: TO PREVENT ELECTRIC SHOCK, MATCH WIDEBLADE OF PLUG TO WIDE SLOT, FULLY INSERT.ATTENTION: POUR ÉVITER LES CHOC ÉLECTRIQUES,INTRODUIRE LA LAME LA PLUS LARGE DE LA FICHE DANS LABORNE CORRESPONDANTE DE LA PRISE ET POUSSERJUSQU’AU FOND.NOTE TO CATV SYSTEM INSTALLER:This reminder is provided to call the CATV (Cable-TV) system installer’s attention to Section 820-40 of the NEC which provides guidelines for proper grounding and, in particular, specifies that the cable ground shall be connected to the grounding system of the building, as close to the point of cable entry as practical.NOTE:This equipment has been tested and found to comply withthe limits for a Class B digital device, pursuant to Part 15of the FCC Rules. These limits are designed to providereasonable protection against harmful interference in aresidential installation. This equipment generates, usesand can radiate radio frequency energy and, if notinstalled and used in accordance with the instructions,may cause harmful interference to radio communica-tions. However, there is no guarantee that interferencewill not occur in a particular installation. If this equipmentdoes cause harmful interference to radio or televisionreception, which can be determined by tuning theequipment off and on, the user is encouraged to try tocorrect the interference by one or more of the followingmeasures:-Reorient or relocate the receiving antenna.-Increase the separation between the equipment and receiver.-Connect the equipment into an outlet on a circuit differentfrom that to which the receiver is connected.-Consult the dealer or an experienced radio/TV technician forhelp.NOTE:Changes or modifications not expressly approved by theparty responsible for compliance could void the user’sauthority to operate the equipment.IMPORTANT SAFETY INSTRUCTIONSREAD BEFORE OPERATING EQUIPMENTThis product was designed and manufactured to meet strict quality and safety standards. There are, however, some installation and operation precautions which you should be particularly aware of.1.Read Instructions – All the safety and operating instructionsshould be read before the product is operated.2.Retain Instructions – The safety and operating instructions shouldbe retained for future reference.3.Heed Warnings – All warnings on the product and in the operatinginstructions should be adhered to.4.Follow Instructions – All operating and use instructions should befollowed.5.Cleaning – Unplug this product from the wall outlet beforecleaning. Do not use liquid cleaners or aerosol cleaners. Use a damp cloth for cleaning.6.Attachments – Do not use attachments not recommended by theproduct manufacturer as they may cause hazards.7.Water and Moisture – Do not use this product near water-forexample, near a bath tub, wash bowl, kitchen sink, or laundry tub, in a wet basement, or near a swimming pool, and the like.8.Accessories – Do not place this product on an unstable cart,stand, tripod, bracket, or table. The product may fall, causing serious injury to a child or adult, and serious damage to the product. Use only with a cart, stand, tripod, bracket, or table recommended by the manufacturer, or sold with the product. Any mounting of the product should follow the manufacturer’s instructions, and should use a mounting accessory recommended by the manufacturer.9. A product and cart combination should be moved with care. Quickstops, excessive force, and uneven surfaces may cause theproduct and cart combination to overturn.10.Ventilation – Slots and openings in the cabinet are provided forventilation and to ensure reliable operation of the product and to protect it from overheating, and these openings must not be blocked or covered. The openings should never be blocked by placing the product on a bed, sofa, rug, or other similar surface.This product should not be placed in a built-in installation such asa bookcase or rack unless proper ventilation is provided or themanufacturer’s instructions have been adhered to.11.Power Sources – This product should be operated only from thetype of power source indicated on the marking label. If you are not sure of the type of power supply to your home, consult your product dealer or local power company. For products intended to operate from battery power, or other sources, refer to the operating instructions.12.Grounding or Polarization – This product may be equipped with apolarized alternating-current line plug (a plug having one blade wider than the other). This plug will fit into the power outlet only one way. This is a safety feature. If you are unable to insert the plug fully into the outlet, try reversing the plug. If the plug should still fail to fit, contact your electrician to replace your obsolete outlet. Do not defeat the safety purpose of the polarized plug.AC POLARIZED PLUG13.Power-Cord Protection – Power-supply cords should be routed sothat they are not likely to be walked on or pinched by items placed upon or against them, paying particular attention to cords at plugs, convenience receptacles, and the point where they exit from the product.14.Protective Attachment Plug – The product is equipped with anattachment plug having overload protection. This is a safety feature. See Instruction Manual for replacement or resetting of protective device. If replacement of the plug is required, be sure the service technician has used a replacement plug specified by the manufacturer that has the same overload protection as the original plug.15.Outdoor Antenna Grounding – If an outside antenna or cablesystem is connected to the product, be sure the antenna or cable system is grounded so as to provide some protection against voltage surges and built-up static charges. Article 810 of the National Electrical Code, ANSI/NFPA 70, provides information with regard to proper grounding of the mast and supporting structure, grounding of the lead-in wire to an antenna discharge unit, size of grounding conductors, location of antenna-discharge unit, connection to grounding electrodes, and requirements for the grounding electrode. See Figure 1.16.Lightning – For added protection for this product during a lightningstorm, or when it is left unattended and unused for long periods of time, unplug it from the wall outlet and disconnect the antenna or cable system. This will prevent damage to the product due to lightning and power-line surges.17.Power Lines – An outside antenna system should not be locatedin the vicinity of overhead power lines or other electric light or power circuits, or where it can fall into such power lines or circuits.When installing an outside antenna system, extreme care should be taken to keep from touching such power lines or circuits as contact with them might be fatal.18.Overloading – Do not overload wall outlets, extension cords, orintegral convenience receptacles as this can result in a risk of fire or electric shock.19.Object and Liquid Entry – Never push objects of any kind into thisproduct through openings as they may touch dangerous voltage points or short-out parts that could result in a fire or electric shock.Never spill liquid of any kind on the product.iii20.Servicing – Do not attempt to service this product yourself as opening or removing covers may expose you to dangerous voltage or other hazards. Refer all servicing to qualified service personnel.21.Damage Requiring Service – Unplug this product from the wall outlet and refer servicing to qualified service personnel under the following conditions:a.When the power-supply cord or plug is damaged.b.If liquid has been spilled, or objects have fallen into the product.c.If the product has been exposed to rain or water.d.If the product does not operate normally by following the operating instructions. Adjust only those controls that are covered by the operating instructions as an improper adjustment of other controls may result in damage and will often require extensive work by a qualified technician to restore the product to its normal operation.e.If the product has been dropped or damaged in any way, and f.When the product exhibits a distinct change in performance – this indicates a need for service.22.Replacement Parts – When replacement parts are required, be sure the service technician has used replacement parts specified by the manufacturer or have the same characteristics as the original part. Unauthorized substitutions may result in fire, electric shock, or other hazards.23.Safety Check – Upon completion of any service or repairs to this product, ask the service technician to perform safety checks to determine that the product is in proper operating condition.24.Wall or Ceiling Mounting – The product should be mounted to a wall or ceiling only as recommended by the manufacturer.25.Heat – The product should be situated away from heat sources such as radiators, heat registers, stoves, or other products (including amplifiers) that produce heat.FIGURE 1EXAMPLE OF ANTENNA GROUNDING AS PER NATIONAL ELECTRICAL CODE, ANSI/NFPA 70This Class B digital apparatus complies with Canadian ICES-003.Cet appareil numérique de la Classe B est conforme à la norme NMB-003 du Canada.NEC - NATIONAL ELECTRICAL CODE(NEC ART 250, PART H)FEATURES (2)AMPLIFIER FEATURES (2)AUDIO/VIDEO FEATURES (2)FLEXBILITY FEATURES (2)OTHER FEATURES (2)DESCRIPTION (3)FRONT PANEL (5)FL DISPLAY (7)REAR PANEL (9)REMOTE CONTROL UNIT RC3200A (11)LOADING BATTERIES (11)ACTIVATING THE RC3200A (11)OPERATING DEVICES (12)REMOTE-CONTROLLABLE RANGE (12)OPERATING AMP & TUNER (13)SHOW THE STATUS OF SR8200 ON THE LCD OF RC3200A (15)WORKING WITH MODES (16)ADJUSTING THE SETTINGS (16)LEARNING COMMANDS (18)RECORDING MACROS (18)RC3200 EDIT (20)IMPORTANT NOTICES (21)CLEANING RC3200A (21)HOW TO RESET THE RC3200A (21)CONNECTING (22)CONNECTING THE AUDIO COMPONENTS (22)CONNECTING THE VIDEO COMPONENTS (22)CONNECTING THE VIDEO COMPONENTS WITH S-VIDEO / COMPONENT (23)CONNECTING THE MONITOR AND VIDEO CAMERA (23)CONNECTING THE DIGITAL / 7.1CH INPUT (24)CONNECTING THE SPEAKERS (24)CONNECTING THE SPEAKERS WITH EXTERNAL AMPLIFIER (25)CONNECTING THE ANTENNA AND POWER CORD (25)CONNECTING THE REMOTE CONTROL BUS (RC-5) (26)CONNECTING FOR THE MULTI ROOM (26)SETUP (27)ON SCREEN DISPLAY MENU SYSTEM (27)INPUT SETUP (ASSIGNABLE DIGITAL INPUT) (28)SPEAKER SETUP (28)PREFERENCE (30)SURROUND (31)PL2 (PRO LOGIC II) MUSIC PARAMETER (31)MULTI ROOM (32)7.1 CH INPUT LEVEL (32)DC TRIGGER SETUP.................................................................................32BASIC OPERATION (PLAY BACK) (33)SELECTING AN INPUT SOURCE (33)SELECTING THE SURROUND MODE (33)ADJUSTING THE MAIN VOLUME (33)ADJUSTING THE TONE(BASS & TREBLE) CONTROL (33)TEMPORARILY TURNING OFF THE SOUND (34)USING THE SLEEP TIMER (34)NIGHT MODE (34)DIALOGUE NORMALIZATION MESSAGE (34)SURROUND MODE (35)OTHER FUNCTION (39)TV AUTO ON/OFF FUNCTION (39)ATTENUATION TO ANALOG INPUT SIGNAL (39)LISTENING OVER HEADPHONES (39)VIDEO ON/OFF (39)DISPLAY MODE (39)SELECTING ANALOG AUDIO INPUT OR DIGITAL AUDIO INPUT (39)RECORDING AN ANALOG SOURCE (40)RECORDING A DIGITAL SOURCE (40)7.1 CH INPUT (41)AUX2 INPUT (41)BASIC OPERATION (TUNER) (42)LISTENING TO THE TUNER (42)PRESET MEMORY (42)MULTI ROOM SYSTEM (45)MULTI ROOM PLAYBACK USING THE MULTI ROOM OUT TERMINALS (45)MULTI ROOM PLAYBACK USING THE MULTI SPEAKER TERMINALS (45)OPERATION TO MULTI ROOM OUTPUTS WITH THE REMOTE CONTROLLER FROM SECOND ROOM (45)TROUBLESHOOTING (46)1AMPLIFIER FEATURES• THX Select certified6ch amplifiers have enough power for even the most difficult conditions found in large rooms.Enormous power reserves endow the system with substantial dynamic ability at high sound levels.130 watts to each of the six main channels the power amp section features an advanced, premium high- storage power supply capacitors, and fully discrete output stages housed in cast aluminum heat sinks .• Current feedback 6ch AmplifierCurrent feedback topology combines total operation stability with excellent frequency response,while requiring only minimal amounts of negative feedback.It makes excellent transient response and superb sonic transparency. AUDIO/VIDEO FEATURES•THX SURROUND EX built in to decode the additional two surround buck channels from THX Surround EX-encoded DVDs and laserdiscs.•DTS-ES decoder built in to decode the impeccable 6.1-channel discrete digital audio from DTS-ES encoded DVD-Video discs, DVD-Audio discs, CDs and laserdiscs.•DOLBY DIGITAL decoder built in to decode the 5.1-channel digital audio of DVDs, Digital TV, HDTV, satellite broadcasts and other sources.•DOLBY PRO LOGIC II decoder provides better spatiality and directionality on Dolby Surround program material; provides a convincing three-dimensional sound field on conventional stereo music recordings.•CIRCLE SURROUND decoder built in to decode surround sound from any stereo or passive matrix-encoded material.•Multi-channel (7.1ch)direct inputs accommodate future multi-channel sound formats or an external digital decoder.•192kHz/24-bit D/A CONVERTERS for all channels.•ADDC (Advanced Double Differential Converter) output for STEREO playback.•Source Direct mode bypasses, tone controls and bass management for purest audio quality.•Two sets of Y/Cr/Cb component video inputs and component video outputs provide unsurpassed video quality and switching flexibility from component video sources.•Easy to use on-screen menu system in all video monitor output.FLEXBILITY FEATURESFUTURE-PROOF INTERFACE ARCHITECTUREa versatile RS232 port allows the SR8200’s internal Flash Memory to be directly computer accessed for installing such future upgrades as new DSP algorithms, new surround formats/parameters, and other types of processing updates.MULTIROOM CAPABILITYa full set of line outs for audio, composite video, allows for set-up of an additional system in another room, and complete second-room control can be achieved with such A/V distribution control systems as Xantech, Niles, to name but a few.Digital I/OAssignable six Digital inputs, for connection to other sources, such as DVD,DSS or CD.A optical Digital input on front AUX1 terminals, for connection to portable player or game.Two Digital outputs for connection to digital recorder as CD-R or MD. OTHER FEATURES• High-quality AM/FM tuner with 50 station presets.• 2way programmable learning remote control RC3200A.23E N G L ITHX ® is an exclusive set of standards and technologies established by the world-renowned film production company, Lucasfilm Ltd. THX resulted from George Lucas’ desire to reproduce the movie soundtrack as faithfully as possible both in the movie theater and in the home theater.THX engineers developed patented technologies to accurately translate the sound from a movie theater environment into the home,correcting the tonal and spatial errors that occur.When the THX mode of the SR8200 is on, three distinct THX technologies are automatically added:Re-Equalization-restores the correct tonal balance for watching a movie in a home environment.These sounds are otherwise mixed to be brighter for a large movie theater. Re-EQ compensates for this and prevents the soundtracks from being overly bright and harsh when played in a home theater.Timbre Matching-filters the information going to the surround speakers so they more closely match the tonal characteristics of the sound coming from the front speakers.This ensures seamless panning between the front and surround speakers.Adaptive Decorrelation-slightly changes one surround channel’s time and phase relationship with respect to the other surround channel.This expands the listening position and creates with only two surround speakers the same spacious surround experience as in a movie theater with multiple surround speakers.The Marantz SR8200 was required to pass a rigorous series of quality and performance tests, in addition to incorporating the technologies explained above, in order to be THX Ultra certified by Lucasfilm Ltd.THX Ultra requirements cover every aspect of performance including pre-amplifier and power amplifier performance and operation, and hundreds of other parameters in both the digital and analog domain.Movies which have been encoded in Dolby Digital, DTS, Dolby Pro Logic,stereo and Mono will all benefit from the THX mode when being viewed.The THX mode should only be activated when watching movies which were originally produced for a movie theater environment.THX need not be activated for music, movies made especially for TV,or shows such as sports programming, talk shows, etc.This is because they were originally mixed for a small room environment.“Lucasfilm ®” and “THX ®” are registered trademarks of Lucasfilm Ltd.Lucasfilm and THX are trademarks or registered trademarks of Lucasfilm Ltd. ©Lucasfilm Ltd. & TM. Surround EX is a jointly developed technology of THX and Dolby Laboratories, Inc. and is a trademark of Dolby Laboratories, Inc. All rights reserved. Used under authorization.THX Surround EX - Dolby Digital Surround EX is a joint development of Dolby Laboratories and the THX division of Lucasfilm Ltd.In a movie theater, film soundtracks that have been encoded with Dolby Digital Surround EX technology are able to reproduce an extra channel which has been added during the mixing of the program.This channel, called Surround Back, places sounds behind the listener in addition to the currently available front left, front center,front right, surround right, surround left and subwoofer channels.This additional channel provides the opportunity for more detailed imaging behind the listener and brings more depth, spacious ambience and sound localization than ever before.Movies that were created using the Dolby Digital Surround EX technology when released into the home consumer market may exhibit a Dolby Digital Surround EX logo on the packaging.A list of movies created using this technology can be found on the Dolby web site athttp ://.“SURROUND EX ™” is a trademark of Dolby Laboratories. Used under authorization.DTS was introduced in 1994 to provide 5.1 channels of discrete digital audio into home theater systems.DTS brings you premium quality discrete multi-channel digital sound to both movies and music.DTS is a multi-channel sound system designed to create full range digital sound reproduction.The no compromise DTS digital process sets the standard of quality for cinema sound by delivering an exact copyof the studio master recordings to neighborhood and home theaters.Now, every moviegoer can hear the sound exactly as the moviemaker intended.DTS can be enjoyed in the home for either movies or music on of DVD’s, LD’s, and CD’s.“DTS” and “DTS Digital Surround” are trademarks of Digital Theater Systems, Inc.DTS-ES Extended Surround is a new multi-channel digital signal format developed by Digital Theater Systems Inc. While offering high compatibility with the conventional DTS Digital Surround format, DTS-ES Extended Surround greatly improves the 360-degree surround impression and space expression thanks to further expanded surround signals. This format has been used professionally in movie theaters since 1999.In addition to the 5.1 surround channels (FL, FR, C, SL, SR and LFE),DTS-ES Extended Surround also offers the SB (Surround Back)channel for surround playback with a total of 6.1 channels. DTS-ES Extended Surround includes two signal formats with different surround signal recording methods, as DTS-ES Discrete 6.1 and DTS-ES Matrix 6.1.]Dolby Digital identifies the use of Dolby Digital (AC-3) audio coding for such consumer formats as DVD and DTV. As with film sound, Dolby Digital can provide up to five full-range channels for left, center, and right screen channels, independent left and right surround channels,and a sixth ( ".1") channel for low-frequency effects.Dolby Surround Pro Logic II is an improved matrix decoding technology that provides better spatiality and directionality on Dolby Surround program material; provides a convincing three-dimensional soundfield on conventional stereo music recordings; and is ideally suited to bring the surround experience to automotive sound. While conventional surround programming is fully compatible with Dolby Surround Pro Logic II decoders, soundtracks will be able to be encoded specifically to take full advantage of Pro Logic II playback,including separate left and right surround channels. (Such material is also compatible with conventional Pro Logic decoders.)Circle Surround is backward compatible, such that surround playback is possible from any stereo or passive matrix-encoded material.Five full-bandwidth, discrete channels of information can be extracted from an enormous library of material not multi-channel encoded.These sources include many of today’s DVDs and laser discs, as well as most all video tape, VCD, Compact Disc, radio and television broadcast material.Circle Surround and the symbol are trademarks of SRS Labs, Inc.Circle Surround technology is incorporated under license from SRS Labs, Inc.45E N u MEMO (memory) buttonPress this button to enter the tuner preset memory numbers or station names.i TUNING UP / DOWN buttonsPress thses buttons to change the frequency or the preset number.o F/P (FREQUENCY / PRESET) buttonDuring reception of AM (MW/LW) or FM, you can change the function of the UP/DOWN buttons for scanning frequencies or selecting preset stations by pressing these buttons.!0T-MODE buttonPress this button to select the auto stereo mode or mono mode when the FM band is selected.The “AUTO ” indicator lights in the auto stereo mode.!1P.SCAN (preset scan) buttonThis button is used to scan preset stations automatically.When pressed, the tuner starts scanning the all preset stations. Press again to cancel the P-SCAN.!2VOLUME control knobAdjusts the overall sound level. Turning the control clockwise increases the sound level.!3ATT (Attenuate) buttonIf the selected analog audio input signal is greater than the capable level of internal processing, PEAK indicator will light. If this happens,you should press the ATT button. “ATT ” is displayed when this function is activated.The signal-input level is reduced by about the half. Attenuation will not work with the output signal of “REC OUT” (TAPE, CD-R/MD, VCR1and VCR2 output). This function is memorized for each input function.q POWER switch and STANDBY indicatorWhen this switch is pressed once, the unit turns ON and display appears on the display panel. When pressed again, the unit turns OFF and the STANDBY indicator lights.When the STANDBY indicator is turned on, the unit is NOT disconnected from the AC power.w SELECT (MULTI FUNCTION MODESELECT) buttonPress this button to change the mode for MULTI FUNCTION control dial.e SURROUND MODE Selector & MULTIFUNCTION control dialThis dial changes surround mode sequentially or select contents of OSD menu system.r ENTER (MULTI FUNCTION ENTER)buttonPress this button to enter the setup by MULTI FUNCTION dial.t DISPLAY mode buttonWhen this button is pressed, the FL display mode is changed as NORMAL → Auto Off → Off and the display off indicator(DISP ) lights up in condition of DISPLAY OFF.y CLEAR buttonPress this button to cancel the station-memory setting mode or preset scan tuning.!4MUTE buttonPress this button to mute the output to the speakers. Press it again to return to the previous volume level.!5INPUT FUNCTION SELECTOR buttons (AUDIO/ VIDEO)These buttons are used to select the input sources.The video function selector, such as TV, DVD, DSS, VCR1 and VCR2, selects video and audio simultaneously.Audio function sources such as CD, TAPE, CDR/MD, TUNER, and 7.1CH-IN may be selected in conjunction with a Video source.This feature (Sound Injection) combines a sound from one source with a picture from another.Choose the video source first, and then choose a different audio source to activate this function.Press TUNER button to switch the between FM or AM.!6AUX1 input jacksThese auxiliary video/audio and optical digital input jacks accept the connection of a camcorder, portable DVD, game etc.!7AUX1 buttonThis button is used to select the AUX1 input source.!8AUX2 buttonThis button is used to select the AUX2 (L/R input of 7.1 CH. IN).!9S. (Source) DIRECT buttonWhen this button is pressed, the tone control circuitry is bypassed as well as Bass Management.Notes:•The surround mode is automatically switched to AUTO when the source direct function is turned on.•Additionally, Speaker Configurations are fixed automatically as follow.•Front SPKR = Large, Center SPKR = Large, Surround SPKR = Large, Sub woofer = On@0NIGHT buttonThis button is used to set night mode. This feature reduces the input level of dolby digital sources by 1/3 to 1/4 at their loudest thresholds, preventing the dynamic range or loud sounds without restricting the dynamic range or volume of other sounds or at less than maximum levels.@1SLEEP buttonSet the sleep timer function with this button.@2A/D (Analog/Digital) SELECTOR button This is used to select between the analog and digital inputs.Note:•This button is not used for an input source that is not set to a digital input in the system setup menu.@3M-SPKR (Multi Room Speaker) button Press this button to activate the Multiroom Speaker system . “M-SPKR” indicator will light in the display.@4MULTI (Multi Room) buttonPress this button to activate the Multiroom system . “MULTI ” indicator will light in the display.@5PHONES jack for stereo headphones This jack may be used to listen to the SR8200’s output through a pair of headphones. Be certain that the headphones have a standard 1 / 4" stereo phone plug. Note that the main room speakers will automatically be turned off when the headphone jack is in use. Notes:•When using headphones, the surround mode will automatically change to STEREO.• The surround mode returns to the previous setting as soon as the plug is removed from the jack.@6INFRARED transmitting sensor window This window transmits infrared signals for the remote control unit.@7INFRARED receiving sensor windowThis window receives infrared signals for the remote control unit.6。
EmguCV入门指南-中文翻译版

深度作为泛型参数 .................................................................................................................. 6 矩阵深度 .................................................................................................................................. 6 XML 序列化 .............................................................................................................................. 7
错误异常处理 ............................................................................................................................. 7 代码文档 .................................................................................................................................... 7 XML 文档 ....................................................................................................................................... 7 类函数文档 .................................................................................................................................. 7 VISUAL STUDIO 中的自动补全 ......................................................................................................... 7 例程 ............................................................................................................................................ 7 C# ............................................................................................................................................. 7 C++ .......................................................................................................................................... 8 IronPython ............................................................................................................................... 8 .................................................................................................................................... 8
blendmvs评估指标

blendmvs评估指标BlendMVS是一种基于深度学习的多视图立体重建方法,该方法使用了全局一致性和局部一致性两种评估指标来评估立体重建结果的质量。
全局一致性主要用于评估整体场景的重建质量。
该指标包括两个子指标:稀疏对齐误差和稠密对齐误差。
稀疏对齐误差是指通过匹配稀疏点云的方式计算得到的场景中各个点的3D位置与真实位置之间的距离误差。
稠密对齐误差是指通过匹配稠密点云的方式计算得到的场景中各个点的3D位置与真实位置之间的距离误差。
这两个指标的计算方法都使用了平均重投影误差,即通过将重建结果投影回不同视图上,计算投影像素与对应视图观察到的像素之间的距离。
局部一致性主要用于评估局部细节的重建质量。
该指标包括两个子指标:立体结构误差和立体纹理误差。
立体结构误差是指通过对立体重建结果进行网格化,然后计算网格点之间的距离误差来评估场景结构的重建质量。
立体纹理误差是指通过对立体重建结果进行纹理映射,然后计算纹理像素之间的差异来评估场景纹理的重建质量。
这两个指标的计算方法都使用了平均距离误差,即通过计算对应网格点或纹理像素之间的距离来评估重建质量。
除了全局一致性和局部一致性之外,还可以使用其他一些指标来评估BlendMVS的重建质量。
例如,可以使用视角一致性指标来评估不同视角下观察到的场景的一致性程度。
该指标可以通过计算不同视角下观察到的重建结果之间的距离来评估。
另外,可以使用表面平滑度指标来评估重建结果的平滑程度,该指标可以通过计算网格表面上相邻点之间的平均距离来评估。
在使用BlendMVS进行立体重建时,可以使用以上的评估指标来评估不同步骤的结果质量,并通过对比不同算法或不同参数设置的结果来选择最优的重建结果。
同时,这些评估指标也可以用于指导算法改进和参数优化的过程,以提升立体重建的效果和质量。
总之,BlendMVS使用全局一致性和局部一致性作为主要评估指标来评估立体重建结果的质量,同时还可以使用一些其他指标来进行综合评估。
基于LCS的特征树最大相似性匹配网页去噪算法

【 y w r s C ;caat sct e o erd c o n We ae Ke od 】L S hrc r t r ;ni e ut n i e i e i s i b pgs
0 引言
一
标注并通过神经网络和支持 向量机来对网页块特性到块
重 要性 的映射 函数 进行 学 习 , 最后 得 到通 用 的映射 方 法[ 5 1 。也有基 于规则的 , 通过定义一 些映射规则 , 网页 将 的一些特征转化为权值 , 通过权值 比较来 实现 内容块和 噪声块 的区分 。其 中文献f】 6中提出 了一种利用 文本 块 大小和位置得 到一个 阈值 , 再利用链 接数 和非链 接文 字长度的 比值来 和该 阈值 进行 比较 , 出内容块。文献 得
树 映射 为一个特 征节 点序列 , 用 L S算法 能获 得最长 子序 列全局最 优解 的特 点, 出两棵 特征树 之 间的不 同节点作为候 选 利 C 找 集, 并对候选集进行 聚集评分找 出网页重要 内容块 。给 出 了算法的原 型系统 , 并对每 一个模 块 的实现做 了详尽 的描述 。
2 上海交通 大学 上海市数 字媒体处理与传输重点实验 室, . 上海 2 04 ;.上海文广互动电视有限公司, 0203 上海 2 0 7 ) 00 2
【 摘
要】提 出了一种基 于L S C 的特征 树最大相似 性匹配 网页去噪算法。通过 将 目 网页和相似 网页转化为特征树 , 标 并将特 征
文章编号 :0 2 89 (0 1— 0 4 0 10 — 6 2 2 1) 3 04 — 5 1
基于 L S C 的特征树最大相似性匹配网页去噪算法
宋 鳌 , 支 睁 , 周 军 , 罗传 飞 , 安 然
(.上 海 交通 大 学 电子 工程 系图像 通信 与信 息处 理研 究所 , 海 2 0 4 ; 1 上 0 2 0
堆叠自动编码器的稀疏表示方法(Ⅲ)

堆叠自动编码器的稀疏表示方法自动编码器是一种无监督学习的神经网络模型,它通过学习数据的内部表示来提取特征。
堆叠自动编码器则是由多个自动编码器叠加而成的深层网络模型。
在实际应用中,堆叠自动编码器通过学习更加抽象的特征表示,可以用于特征提取、降维和生成数据等多个领域。
在这篇文章中,我们将探讨堆叠自动编码器的稀疏表示方法,以及其在深度学习中的重要性。
稀疏表示是指在特征提取过程中,只有少数单元才被激活。
在堆叠自动编码器中,通过引入稀疏表示方法,可以让网络学习到更加鲁棒和有意义的特征。
稀疏表示可以有效地降低特征的冗余性,提高网络的泛化能力,使得网络能够更好地适应未见过的数据。
同时,稀疏表示还可以减少模型的计算复杂度,提高模型的训练效率。
因此,稀疏表示在深度学习中具有重要的意义。
在堆叠自动编码器中,稀疏表示的方法有很多种,其中最常用的方法之一是使用稀疏编码器。
稀疏编码器是一种特殊的自动编码器,它通过引入稀疏约束来学习稀疏表示。
在训练过程中,稀疏编码器会对每个隐藏单元引入稀疏性约束,使得只有少数隐藏单元被激活。
这样可以有效地提高特征的鲁棒性和泛化能力。
同时,稀疏编码器还可以使用稀疏性约束来降低特征的冗余性,提高特征的表达能力。
除了稀疏编码器,堆叠自动编码器还可以通过正则化方法来实现稀疏表示。
正则化是一种常用的方法,它可以通过引入额外的惩罚项来控制模型的复杂度。
在堆叠自动编码器中,可以通过引入L1正则化项来推动隐藏单元的稀疏性。
L1正则化项可以使得很多隐藏单元的激活值为0,从而实现稀疏表示。
通过正则化方法实现稀疏表示的堆叠自动编码器具有较好的鲁棒性和泛化能力,同时可以减少模型的计算复杂度,提高模型的训练效率。
另外,堆叠自动编码器还可以通过引入降噪自动编码器来实现稀疏表示。
降噪自动编码器是一种特殊的自动编码器,它可以通过在输入数据上添加噪声来训练模型。
在实际应用中,通过引入随机噪声,可以有效地降低模型对输入数据的敏感度,提高网络的鲁棒性。
视觉问答特征融合的方法

视觉问答特征融合的方法视觉问答(Visual Question Answering,VQA)是计算机视觉与自然语言处理交叉领域的一个重要研究方向。
在VQA任务中,特征融合是提升模型性能的关键技术。
本文将详细介绍几种视觉问答特征融合的方法。
一、基于早期融合的方法早期融合方法主要是在特征提取阶段将视觉特征和文本特征进行融合。
具体来说,可以先将图像通过卷积神经网络(CNN)提取出视觉特征,然后将问题和其对应的文本描述通过循环神经网络(RNN)提取出文本特征。
接下来,将两种特征在早期进行拼接,输入到融合层进行进一步处理。
优点:简单易实现,计算量较小。
缺点:可能无法充分挖掘视觉和文本特征之间的关联。
二、基于注意力机制的方法注意力机制可以使模型关注到输入数据中最重要的部分。
在视觉问答任务中,通过引入注意力机制,可以让模型自动学习到图像和问题中与答案相关的关键信息。
具体方法:将视觉特征和文本特征进行交互,利用注意力机制为每种特征分配权重,然后加权求和得到融合特征。
优点:能够自适应地关注到与问题最相关的图像区域和文本信息。
缺点:计算量相对较大,调参复杂。
三、基于图神经网络的方法图神经网络(Graph Neural Networks,GNNs)可以有效地对结构化数据进行建模。
在视觉问答任务中,可以将图像中的物体和问题中的单词作为图的节点,利用图神经网络学习节点之间的关系。
具体方法:将视觉特征和文本特征编码为图的节点,通过图神经网络学习节点之间的相互作用,最终得到融合特征。
优点:能够捕捉到视觉和文本特征之间的复杂关系。
缺点:计算复杂度较高,对硬件要求较高。
四、基于多模态融合的方法多模态融合方法旨在同时利用多种模态的特征,提高视觉问答的性能。
这类方法通常结合了早期融合、注意力机制和图神经网络等多种融合技术。
具体方法:先对视觉特征和文本特征进行预处理,然后通过多模态融合模块进行特征交互和融合,最后输入到分类器进行答案预测。
《2024年基于多模态注意力机制的视觉问答研究》范文

《基于多模态注意力机制的视觉问答研究》篇一一、引言随着人工智能技术的不断发展,视觉问答(Visual Question Answering,简称VQA)逐渐成为计算机视觉和自然语言处理领域的热门研究课题。
多模态技术能够在理解文本与图像的基础上实现二者间的相互交流与表达,因此在VQA中显得尤为重要。
本文基于多模态注意力机制展开视觉问答研究,旨在解决VQA 领域中的挑战性问题和提升准确率。
二、研究背景及意义视觉问答是一种将图像与自然语言相结合的技术,旨在通过计算机理解图像内容并回答相关问题。
随着互联网和多媒体技术的快速发展,视觉问答在智能教育、智能客服、智能安防等领域具有广泛的应用前景。
多模态注意力机制作为一种融合图像与文本信息的有效方法,可以有效地提升视觉问答系统的准确率和效率。
因此,本文将研究基于多模态注意力机制的视觉问答系统,对于提高人工智能在图像理解与自然语言处理方面的能力具有重要意义。
三、相关工作近年来,多模态技术得到了广泛的研究和应用。
在视觉问答领域,研究者们提出了许多基于深度学习的模型和方法,如基于循环神经网络(RNN)的模型、基于卷积神经网络(CNN)的模型以及基于注意力机制的模型等。
其中,多模态注意力机制通过将图像和文本信息相互关联,提高了模型的表达能力。
然而,现有的多模态注意力机制在处理复杂问题时仍存在一定局限性,如无法准确理解图像上下文信息和回答多层次的问题等。
因此,本文提出了一种新的基于多模态注意力机制的视觉问答模型。
四、研究内容本文提出了一种基于多模态注意力机制的视觉问答模型,该模型包括图像特征提取模块、文本特征提取模块和多模态注意力机制模块。
具体而言:1. 图像特征提取模块:采用卷积神经网络(CNN)对图像进行特征提取,得到图像的多种特征表示。
2. 文本特征提取模块:采用循环神经网络(RNN)或BERT 等预训练模型对问题文本进行特征提取,得到文本的特征表示。
3. 多模态注意力机制模块:该模块利用自注意力机制和交互注意力机制将图像和文本的特征表示相互关联,使得模型能够准确理解图像上下文信息和回答多层次的问题。
深度学习中的正则化方法

深度学习中的正则化方法深度学习作为人工智能领域的重要分支,已经取得了巨大的突破和应用。
然而,深度学习模型往往具有大量的参数和复杂的结构,容易出现过拟合的问题。
为了解决这个问题,研究者们提出了各种正则化方法,有效地提高了深度学习模型的泛化能力。
本文将介绍几种主要的正则化方法,并探讨其原理和应用。
一、L1正则化(L1 Regularization)L1正则化是一种常用的特征选择方法,它通过在损失函数中引入参数的绝对值之和来限制模型的复杂度。
具体来说,对于深度学习模型中的每个权重参数w,L1正则化的目标是最小化损失函数与λ乘以|w|的和。
其中,λ是一个正则化参数,用来平衡训练误差和正则化项的重要性。
L1正则化的优点是可以产生稀疏的权重模型,使得模型更加简洁和可解释性,但同时也容易产生不可导的点,对于一些复杂的深度学习模型应用有一定的限制。
二、L2正则化(L2 Regularization)与L1正则化不同,L2正则化通过在损失函数中引入参数的平方和来平衡模型的复杂度。
具体来说,对于深度学习模型中的每个权重参数w,L2正则化的目标是最小化损失函数与λ乘以|w|^2的和。
与L1正则化相比,L2正则化不会产生稀疏的权重模型,但能够减小权重的幅度,使得模型更加平滑和鲁棒。
L2正则化也常被称为权重衰减(Weight Decay),通过减小权重的大小来控制模型的复杂度。
三、Dropout正则化Dropout正则化是一种广泛应用于深度学习模型的正则化方法,通过在训练过程中随机将部分神经元的输出置为0来减小模型的复杂度。
具体来说,每个神经元的输出被设置为0的概率为p,而被保留的概率为1-p。
这样做的好处是能够迫使网络学习到多个不同的子网络,从而提高模型的泛化能力。
在测试模型时,通常会将所有神经元的输出乘以p来保持一致性。
四、Batch NormalizationBatch Normalization是一种通过对每一层的输入进行归一化处理来加速训练和提高模型的泛化能力的方法。
opennsfw2 用法 -回复

opennsfw2 用法-回复OpenNSFW2 是一个用于图像分类任务的深度学习模型,其用途是在应用程序中进行图像内容的自动分析和过滤。
OpenNSFW2 旨在识别图像中的不雅内容,以帮助保护用户免受色情或暴力图像的侵害。
本文将一步一步回答关于OpenNSFW2 的用法以及如何集成到应用程序中的问题。
第一步:理解OpenNSFW2 原理和背景OpenNSFW2 是一个基于TensorFlow 的深度学习模型,它是根据现有的色情图像数据集进行训练而来。
该模型使用卷积神经网络(CNN)架构,通过对输入图像进行特征提取和分类,来预测图像的不雅程度。
OpenNSFW2 可以根据图像中的一系列特征,如色调、纹理和形状等,对图像进行分类,并给出一个置信度分数。
第二步:安装和配置OpenNSFW2要使用OpenNSFW2,首先需要在计算机上安装TensorFlow。
可以通过TensorFlow 的官方网站或使用包管理器(如pip)来进行安装。
安装过程可能会因操作系统和计算机配置而有所不同,建议按照TensorFlow 官方文档提供的步骤进行安装。
安装TensorFlow 后,可以从GitHub 上的OpenNSFW2 托管库中下载模型文件。
这些模型文件包含了预先训练好的权重和参数,可供直接使用。
将下载的模型文件放置在项目的合适位置,并将其配置为OpenNSFW2 的默认模型。
第三步:编写代码集成OpenNSFW2现在可以在应用程序中集成OpenNSFW2。
下面以Python 为例,演示如何使用OpenNSFW2 进行图像分类。
1. 导入所需的库和模块:import tensorflow as tfimport numpy as npimport cv22. 加载并配置OpenNSFW2 模型:model_path = 'path/to/open_nsfw-2.0.pb' # 指定下载的模型文件路径graph = tf.Graph()sess = tf.Session(graph=graph)with tf.gfile.GFile(model_path, "rb") as f:graph_def = tf.GraphDef()graph_def.ParseFromString(f.read())with graph.as_default():tf.import_graph_def(graph_def, name='')3. 定义函数以预处理图像:def preprocess_image(image_path):image = cv2.imread(image_path)image = (image - [123.68, 116.779, 103.939]) * 0.017image = cv2.resize(image, (224, 224))image = image.reshape((1, 224, 224, 3))return image4. 定义函数以分类图像:def classify_image(image_path):image = preprocess_image(image_path)input_tensor = graph.get_tensor_by_name('input:0')output_tensor = graph.get_tensor_by_name('predictions:0')predictions = sess.run(output_tensor, {input_tensor: image})nsfw_score = predictions[0][1]return nsfw_score5. 调用分类函数并输出结果:image_path = 'path/to/image.jpg' # 指定待分类的图像路径score = classify_image(image_path)print("NSFW Score:", score)通过以上步骤,就可以在应用程序中使用OpenNSFW2 模型进行图像分类,并获取图像的不雅程度分数。
大规模向量相似度计算(二)——hnswlib的参数含义

大规模向量相似度计算(二)——hnswlib的参数含义摘要:1.引言2.hnswlib库简介3.hnswlib参数详解3.1 相似度计算指标3.2 索引参数3.3 查询参数3.4 其他实用参数4.结论与展望正文:【引言】在本文中,我们将探讨大规模向量相似度计算的一种高效方法——hnswlib库。
hnswlib是一个开源的C++库,专为近似最近邻搜索(ANN)设计,尤其在处理大规模高维数据时表现出优异的性能。
本文将详细解析hnswlib库的参数含义,帮助读者更好地理解和使用这一库。
【hnswlib库简介】hnswlib库基于霍夫曼树(Huffman Tree)构建,利用KD树(k-Dimensional Tree)进行近似最近邻搜索。
与传统的最近邻搜索方法相比,hnswlib在搜索过程中具有更快的收敛速度。
此外,hnswlib还具有较好的并行性能,可以充分利用多核CPU的优势。
【hnswlib参数详解】hnswlib库中的参数分为四大类:相似度计算指标、索引参数、查询参数和其他实用参数。
【3.1 相似度计算指标】hnswlib支持两种相似度计算指标:余弦相似度和欧氏距离。
余弦相似度适用于高维数据的向量表示,尤其在处理文本、图像等高维数据时具有较好的性能。
欧氏距离则适用于一般的几何形状数据。
【3.2 索引参数】索引参数主要包括索引构建方法、索引层级数等。
hnswlib支持LSH (Locality Sensitive Hashing)和HSH(Hashed Simplex)两种索引构建方法。
LSH方法在构建索引时,会根据向量之间的相似度进行分组;HSH方法则利用霍夫曼树对向量进行编码,提高查询效率。
索引层级数影响索引的构建时间和查询性能,需要根据实际需求进行调整。
【3.3 查询参数】查询参数主要包括查询类型、查询结果数量等。
hnswlib支持两种查询类型:单查询和多查询。
单查询用于查询单个向量的最近邻;多查询则用于查询一批向量的最近邻。
vision master 算法例题

Vision Master 算法例题:假设你正在开发一个计算机视觉系统,该系统需要识别图像中的物体。
为了实现这个功能,你可以使用深度学习中的卷积神经网络(CNN)模型。
以下是一个简单的CNN 模型结构:1. 输入层:接收图像数据,通常使用RGB 格式的彩色图像。
2. 卷积层:对输入图像进行卷积操作,提取图像的特征。
3. 激活函数层:如ReLU,用于增加非线性。
4. 池化层:如最大池化,用于降低特征图的空间尺寸。
5. 全连接层:将提取到的特征映射到一个向量空间,用于分类任务。
6. 输出层:输出预测结果,如物体类别的概率分布。
以下是一个使用Python 和TensorFlow 实现的简单CNN 模型:```pythonimport tensorflow as tffrom tensorflow.keras import layers, models# 构建CNN 模型model = models.Sequential()model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.Flatten())model.add(layers.Dense(64, activation='relu'))model.add(layers.Dense(10, activation='softmax'))# 编译模型pile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 训练模型(此处省略数据集加载和预处理部分)# model.fit(x_train, y_train, batch_size=32, epochs=10, validation_data=(x_test, y_test)) ```在这个例子中,我们创建了一个简单的CNN 模型,用于识别具有32x32 像素的彩色图像中的10 个不同类别的物体。
深度学习中的正则化技术

正则化是深度学习中一种重要的技术,主要用于防止过拟合,增强模型的泛化能力。
在深度学习中,正则化通过在损失函数上添加一个惩罚项,来约束模型的复杂度,使得模型在训练过程中更加注重整体的性能,而不是仅仅关注某一层的输出结果。
以下是一些常见深度学习中正则化的方法:1. L1 正则化:L1 正则化是通过在损失函数上添加L1 正则项来约束模型中参数的数量。
这种方法有助于防止过拟合,同时增强模型的泛化能力。
当模型参数较多时,L1 正则化会增加模型的复杂度,使得模型更加鲁棒,不易受到噪声数据的影响。
2. L2 正则化:L2 正则化与L1 正则化类似,也是在损失函数上添加L2 正则项来约束模型中参数的范数。
这种方法有助于防止模型过拟合,同时也能增强模型的泛化能力。
与L1 正则化相比,L2 正则化对模型参数的约束更加宽松,因此更适合于处理大规模数据集。
3. Dropout:Dropout 是一种特殊的正则化技术,它通过在训练过程中有放回地随机丢弃一部分神经元或神经网络层,来防止过拟合。
在每个训练批次中,都随机选择一部分神经元或神经网络层进行训练和测试,这样可以使得模型更加鲁棒,不易受到个别样本或特征的影响。
4. Batch Normalization(批量标准化):Batch Normalization 是另一种正则化技术,它通过对输入数据进行归一化和标准化处理,来增强模型的稳定性。
这种方法可以加快模型的收敛速度,提高模型的性能和泛化能力。
5. Weight decay(权重衰减):权重衰减是一种简单有效的正则化方法,它通过在训练过程中添加权重衰减项来惩罚模型中某些权重较大的参数。
这种方法有助于减少过拟合的风险,同时也能增强模型的泛化能力。
在实际应用中,通常将多种正则化方法结合起来使用,以提高模型的性能和泛化能力。
例如,可以使用L1 和L2 正则化相结合的方法来约束模型中参数的数量和范数;也可以使用Dropout 和Batch Normalization 相结合的方法来增强模型的鲁棒性和稳定性。
深度学习中的特征融合与表示方法(二)

深度学习中的特征融合与表示方法深度学习是一种基于神经网络的机器学习方法,其在各个领域有着广泛的应用。
在深度学习的算法模型中,特征融合与表示方法是非常关键的环节。
在这篇文章中,我们将探讨深度学习中的特征融合与表示方法,并对其进行深入的分析和讨论。
一、特征融合的概念与意义在深度学习过程中,特征融合是指将来自不同源的特征信息进行有效的整合,以提高模型的性能和泛化能力。
特征融合的意义在于,通过融合多个来源的特征,可以综合利用各种信息,使得模型能够更好地理解数据的内在结构和规律。
特征融合的方式多种多样,常见的方法包括加权融合、串联融合和并联融合等。
加权融合是将不同源的特征进行加权求和,使得不同特征的重要性得以体现。
串联融合是将不同特征按照一定的规则进行串联,以增加特征的维度和多样性。
并联融合是将不同特征进行并联,以获得特征的多样性和丰富性。
二、特征融合方法的应用场景特征融合方法广泛应用于计算机视觉、自然语言处理和推荐系统等领域。
在计算机视觉中,特征融合可以将不同尺度和来源的图像特征进行有效的整合,以提高图像处理和识别的准确性。
在自然语言处理中,特征融合可以将不同来源的文本特征进行有效的整合,以提高文本分类和语义分析的性能。
在推荐系统中,特征融合可以将用户行为信息和商品属性信息进行融合,以提高个性化推荐的效果。
三、特征表示方法的选择与优化特征表示方法是用来对原始数据进行高维映射的过程。
合理选择和优化特征表示方法,可以提高深度学习模型的性能和泛化能力。
常见的特征表示方法包括主成分分析(PCA)、线性判别分析(LDA)和稀疏编码等。
主成分分析通过线性变换将原始特征映射到低维度的子空间中,以减少特征的冗余和维度。
线性判别分析通过最大化类间的差异和最小化类内的差异,将原始特征映射到低维度的子空间中,以提高分类的准确性。
稀疏编码是一种基于字典的特征表示方法,通过最小化特征的稀疏性来获得更加紧凑和有表达力的表示。
除了传统的特征表示方法,近年来,深度学习方法也逐渐应用于特征表示的优化。
深度强化学习中的状态空间设计方法(四)

深度强化学习(Deep Reinforcement Learning,DRL)是一种结合了深度学习和强化学习的新兴技术,近年来在多个领域取得了显著的成果。
其中,状态空间设计是深度强化学习中至关重要的一环,它直接影响着智能体对环境的理解和行为决策过程。
本文将讨论深度强化学习中的状态空间设计方法,以及其在实际应用中的重要性和挑战。
深度强化学习中的状态空间设计方法是指如何将环境的状态信息表示为适合深度神经网络处理的形式。
状态空间的设计对智能体学习和决策的效率和性能有着直接的影响。
一个好的状态空间设计应当能够准确地表达环境的特征,同时又能够尽可能地减少状态空间的维度,以便提高学习的效率和泛化能力。
在深度强化学习中,状态空间的设计方法通常可以分为两类:基于特征提取和基于卷积神经网络。
基于特征提取的方法通常包括手动设计特征和自动特征提取两种方式。
手动设计特征是指根据对环境的理解和经验,人工地提取出对智能体学习和决策有帮助的特征,然后输入到深度神经网络中进行学习。
自动特征提取则是通过深度神经网络自动地学习和提取环境的特征表示。
而基于卷积神经网络的方法则是直接将环境的原始状态信息(如图像)输入到卷积神经网络中进行端到端的学习。
在实际应用中,状态空间的设计方法需要根据具体的环境和任务来选择。
对于一些简单的环境和任务,手动设计特征可能会比较有效,因为通过人工的方式可以更好地理解环境和任务的特点,提取出更加有用的特征。
但是对于一些复杂的环境和任务,自动特征提取和卷积神经网络往往能够取得更好的效果,因为它们可以更好地适应环境和任务的复杂性,自动地学习和提取出更加有效的特征表示。
除了选择合适的状态空间设计方法,状态空间的维度和表示也是深度强化学习中需要考虑的重要问题。
通常来说,状态空间的维度越高,学习和决策的复杂度也就越高,同时学习的效率也会受到影响。
因此,对于高维状态空间的环境和任务,如何合理地降低状态空间的维度成为了一个挑战。
如何使用堆叠自动编码器进行特征融合(四)

特征融合是机器学习中的一个重要问题,它涉及将不同特征融合成一个更具代表性和有用的特征。
堆叠自动编码器是一种常用的特征融合方法,它可以将多个特征进行非线性融合,提取出更高层次的特征表达。
本文将介绍如何使用堆叠自动编码器进行特征融合,并讨论其在实际应用中的一些技巧和注意事项。
一、堆叠自动编码器简介堆叠自动编码器是一种深度学习模型,它由多个自动编码器组成,每个自动编码器都可以学习到数据的不同特征表示。
通过将多个自动编码器进行堆叠,可以构建出一个更加强大的特征提取模型。
在实际应用中,可以使用深度学习框架如TensorFlow或PyTorch来实现堆叠自动编码器。
二、特征融合的意义在机器学习任务中,往往会面对大量的特征数据,这些特征可能来自不同的数据源,具有不同的分布和表达能力。
特征融合的目的是将这些不同的特征进行整合,提取出更加具有代表性和鲁棒性的特征。
这样可以有效地减少特征的维度,降低模型的复杂度,提高模型的泛化能力。
三、堆叠自动编码器的特征融合方法堆叠自动编码器可以通过多层的非线性变换,将输入的特征进行融合,得到更加高层次的特征表达。
在实际应用中,可以将不同类型的特征输入到堆叠自动编码器中,让模型自动学习如何进行特征融合。
在训练过程中,可以使用反向传播算法来优化模型参数,使得模型能够更好地学习到数据的特征表示。
四、堆叠自动编码器的训练技巧在使用堆叠自动编码器进行特征融合时,有一些训练技巧是需要注意的。
首先,需要对输入数据进行预处理,确保数据是归一化的,并且不同特征之间的分布差异不会太大。
其次,需要选择合适的模型结构和超参数,这些参数会直接影响到模型的训练效果。
最后,需要进行合理的训练策略,如使用适当的正则化方法和学习率调度策略,以避免模型的过拟合和训练不稳定。
五、堆叠自动编码器的应用场景堆叠自动编码器在特征融合中有着广泛的应用场景。
例如,在图像识别任务中,可以将图像的不同特征如颜色、纹理和形状等输入到堆叠自动编码器中,进行特征融合和表达学习。
问答对数据集

问答对数据集1. 介绍问答对数据集是指一个包含大量问题和答案对的数据集。
这些问题和答案对被广泛应用于各种自然语言处理任务,如问答系统、对话系统、知识图谱构建等。
问答对数据集的质量和规模对于训练和评估这些任务中的模型十分关键。
2. 问答对数据集的来源问答对数据集可以通过多种途径获取。
以下是一些常见的数据集来源方式:2.1 人工标注人工标注是获得高质量问答对数据集的一种常见方式。
研究人员或者众包工人可以使用一些预定义的问题集合对某个特定领域或主题中的文本数据进行标注。
这种方式可以保证获得准确的问题和答案对,但需要耗费大量的人力和时间成本。
2.2 在线社区在线社区是另一个常见的问答对数据集来源。
许多社区网站,如Quora、知乎等,拥有用于提问和回答问题的平台。
这些网站上的问题和答案对可以被爬虫程序获取并用于构建问答对数据集。
不过,由于在这些平台上问题和答案的质量参差不齐,需要进行筛选和清洗。
2.3 历史记录一些应用程序或平台可能会记录用户之间的对话历史。
这些历史记录可以包含问题和答案对,可以被用来构建问答对数据集。
但是由于这些历史记录是实际用户对话的结果,可能含有噪声和不规范的语言表达,需要进行预处理和过滤。
2.4 知识图谱知识图谱是一个结构化的知识库,包含了大量的实体、属性和关系。
通过从知识图谱中提取问题和答案对,可以构建高质量的问答对数据集。
这种方式可以保证问题和答案的准确性,但是需要有一个完善的知识图谱作为数据源。
3. 问答对数据集的标注方式问答对数据集的标注一般包括问题和答案的对应关系。
以下是一些常见的问答对数据集标注方式:3.1 手工标注手工标注是最常见的问答对数据集标注方式。
标注人员需要阅读问题,并为每个问题寻找合适的答案。
标注人员可以通过搜索引擎等工具来获取答案,并进行确认和整理。
手工标注需要标注人员具备专业领域的知识和阅读理解能力。
3.2 自动标注自动标注是一种通过模型或算法自动生成问答对的方式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Mixed Depth Representations for Dialog ProcessingSusan W.McRoy(mcroy@) Department of EECSUniversity of Wisconsin–Milwaukee Milwaukee,WI53201Syed S.Ali(syali@)Department of Mathematical SciencesUniversity of Wisconsin–MilwaukeeMilwaukee,WI53201Susan M.Haller(haller@)CS&E DepartmentUniversity of Wisconsin–ParksideKenosha,WI53141AbstractWe describe our work on developing a general purpose tutoring system that will allow students to practice their decision-making skills in a number of domains.The tutoring system,B2,supports mixed-initiative natural language interaction.The natural language processing and knowledge representation components are also gen-eral purpose—which leads to a tradeoffbetween the limitations of superficial processing and syntactic rep-resentations and the difficulty of deeper methods and conceptual representations.Our solution is to use a mixed-depth representation,one that encodes syntactic and conceptual information in the same structure.Asa result,we can use the same representation framework to produce a detailed representation of requests(which tend to be well-specified)and to produce a partial repre-sentation of questions(which tend to require more infer-ence about the context).Moreover,the representations use the same knowledge representation framework thatis used to reason about discourse processing and domain information—so that the system can reason with(and about)the utterances,if necessary.IntroductionBuilding decision support systems involves the collection and representation of a large amount of knowledge.It also involves providing mechanisms for reasoning over this knowledge efficiently.To make the best use of these efforts,our project group,which involves researchers at the University of Wisconsin-Milwaukee,the University of Wisconsin-Parkside,and the Medical College of Wiscon-sin,is working on a system to redeploy our decision sup-port tools to build new systems for educating students. Our aim is to give students an opportunity to practice their decision making skills by considering a number of scenarios that differ from each other in a controlled man-ner.We also wish to give students the opportunity to ask the system to explain what factors most influenced the system.Another important goal of this work is to develop tools that will cover a number of different domains,includ-ing medical diagnosis,life skills such as good nutrition and budgeting,and student success in their degree pro-gram.Thus,the graphical parts of the system interface are fairly generic.Most interaction between the student and the system uses natural language.This approach allows the system to explain fairly sophisticated topics (such as why a positive computed tomography,CT,scan supports the diagnosis of gallstones)and to tailor the interaction to the user’s concerns and apparent level of understanding.This approach also gives the student a great deal offlexibility in how she phrases her questions or requests.Students’utterances may be short and am-biguous,requiring extensive reasoning about the domain or the discourse model to fully resolve.However,full dis-ambiguation is rarely necessary.Our solution is to use a mixed-depth representation.A mixed-depth representation is one that may be shal-low or deep in different places,depending on what was known or needed at the time the representation was cre-ated(Hirst and Ryan,1992).Moreover,“shallow”and “deep”are a matter of degree.Shallow representations can be a surface syntactic structure,or it can be the text itself(as a string of characters).Deep represen-tations might be a conventionalfirst-order(or higher-order)AI knowledge representation,taking into account such aspects of language understanding as lexical disam-biguation,marking case relations,attachment of modi-fiers of uncertain placement,reference resolution,quanti-fier scoping,and distinguishing extensional,intensional, generic,and descriptive noun phrases.Unlike quasi-logical form,which is used primarily for storage of in-formation,mixed-depth representations are well-formed propositions,subject to logical inference.Disambigua-tion,when it occurs,is done by reasoning.Other systems that represent sentence meaning at multiple levels(e.g.,syntactic,semantic,and pragmatic) build separate complete structures for each level.So,for example,when processing an utterance,a parser must either defer all semantic processing or resolve semantic ambiguities without the full knowledge necessary to do so correctly.The mixed-depth approach opportunisti-cally builds semantic constituent structures as soon as enough information is available.(Minimally,this will be information about the syntax of the utterance but it may include some semantic information about proper-ties of discourse objects introduced by the utterance). This allows us to do as much semantic interpretation as possible,as soon as possible.In our work,we use a parser with a linguisticallybased grammar to process the student’s typed inputs and produce a structure that captures syntactic mark-ing and bracketing,along with some conceptual informa-tion.Encoding decisions that require reasoning about the domain or about the discourse context are left to the knowledge representation and discourse processing components,respectively.The primary benefits of this approach are:Generality The representation language and concep-tual structures that are built during the initial parsing phase are not specific to any one domain. Expressiveness The representation language is very expressive;our grammar covers a wide variety of syn-tactic constructions including fragments and sentences with embedded sentences(e.g.relative clauses and clause complements).For example,students can re-quest a diagnostic exercise using a variety of forms including Give me a story problem,I want you to de-scribe a case for me.,Tell me a story.,A story please. or Another case.Uniformity The structures that are built by the parser are all subject to inference;they use the same con-ceptual framework that is used by the other compo-nents,including discourse processing,planning,and plan recognition.For example,students can request a diagnostic exercise by mentioning any step of the tutoring plan including Tell me a story.or Quiz me. or by mentioning the overall tutoring plan with Tutor me.This paper gives an overview of our tutoring system, B2.It describes the natural language and knowledge rep-resentation components of B2,and our approach to the representation of questions and requests.The domain that we have developed most thoroughly helps medical students learn a statistical model for medical diagnosis. Many of the examples will be taken from this domain.The Need for A Discourse ModelThefirst prototype of our current system is Banter(Had-dawy et al.,1996).Banter is a tutoring shell that presents predefined story problems and short-answer questions on the basis of stored information about a par-ticular medical situation,such as a patient who sees her doctor complaining of abdominal pains.This informa-tion comprises statistical relations among known aspects of a patient’s medical history,findings from physical ex-aminations of the patient,results of previous diagnostic tests,and the different candidate diseases.The infor-mation is represented as a Bayesian belief network.The system also includes a facility for explaining the system’s reasoning to the student,The Banter shell has been de-signed to be general enough to be used with any network having nodes of hypotheses,observations,and diagnostic procedures.A preliminary(and informal)user study of the Banter system with students at the Medical College of Wiscon-sin revealed two important facts:First,students like the idea of being able to set up hypothetical cases and witness how different actions might(or might not!)af-fect the statistical likelihood of a candidate diagnosis. Second,students do not like,and will not use,a sys-tem that overwhelms them with irrelevant information or that risks misleading them because it answers questions more narrowly than a teacher would.Students want to ask brief,context-dependent questions,such as“Why CT?”or“What about ultrasound?”and they prefer to give brief,context-dependent responses.Moreover,stu-dents like explanations that are tailored to their needs—sometimes only a single word answer,sometimes the an-swer along with its justification.A discourse model is necessary to deal with this.The B2ArchitectureThe B2system performs three distinct,but interrelated, tasks that rely on a variety of information sources.The tasks are:•Managing the interaction between the user and B2, including the interpretation of context-dependent ut-terances.•Reasoning about the domain,for example,the relation between components of a medical case history and dis-eases that might occur.•Meta-reasoning about the Bayesian reasoner and its conclusions,including an ability to explain the con-clusions by identifying the factors that were most sig-nificant.The B2system consists of seven components(see Fig-ure1).In the diagram,solid,directed arrows indicate the direction of informationflow between components. The system gets the user’s input using a graphical user interface that supports both natural language interac-tion and mouse inputs.The Parser component of the Parser/Generator performs thefirst level of processing on the user input using its grammar and the domain information from the Knowledge Representation Com-ponent.The Parser interprets the user’s inputs to form propositional representations of surface-level utterances for the Discourse Analyzer.The Generator produces natural language outputs from the text messages(propo-sitional descriptions of text)that it receives from the Discourse Planner.The system as a whole is controlled by a module called the Discourse Analyzer.The Discourse Analyzer deter-mines an appropriate response to the user’s actions on the basis of a model of the discourse and a model of theGUICharacter StreamGui ActionsParser/GeneratorDiscourse PlannerDiscourse AnalyzerText Plan ActsDiscourse KR AccessCharacter StreamDiscourse Action KR Updates Text Plan OperatorsDomain Knowledge AccessKnowledge Representation ComponentBayesian NetworkMediatorKR UpdatesBayesian Net ProbabilitiesQueries to Bayesian NetDomain KnowledgeAccessStreamCharacter Information RequestsBayesian NetText MessagesKnowledge Representation (KR)of User Surface ActsFigure 1:The B2architecturedomain,stored in the knowledge representation compo-nent.The Analyzer invokes the Discourse Planner to se-lect the content of the response and to structure it.The Analyzer relies on a component called the Mediator to interact with the Bayesian network processor.This Me-diator processes domain level information,such as rank-ing the effectiveness of alternative diagnostic tests.All phases of this process are recorded in the knowledge rep-resentation component,resulting in a complete history of the discourse.Thus,the knowledge representation component serves as a central “blackboard”for all other components.Together these seven components handle the three tasks mentioned above.They interact by addressing and handling queries to each other.However,the knowledge underlying these queries and the knowledge needed to generate a response can come from a variety of knowl-edge sources.Translating between knowledge sources is not an effective solution.The information sources that B2uses include:•Linguistic knowledge —knowledge about the mean-ings of utterances and plans for expressing meanings as text.•Discourse knowledge —knowledge about the inten-tional,social,and rhetorical relationships that link utterances.•Domain knowledge —factual knowledge of the medi-cal domain and the medical case that is under consid-eration.•Pedagogy —knowledge about the tutoring task.•Decision-support —knowledge about the statistical model and how to interpret the information that is derivable from the model.In B2,the interaction between the tasks is possible be-cause the information for all knowledge sources is rep-resented in a uniform framework.The knowledge rep-resentation component serves as a central “blackboard”for all other components.The Knowledge RepresentationBlackboardB2represents both domain knowledge and discourse knowledge in a uniform framework as a propositional se-mantic network.This allows the system to reason with (and about)utterances if necessary.A propositional semantic network is a framework for representing the concepts of a cognitive agent who is ca-pable of using language (hence the term semantic ).The information is represented as a graph composed of nodes and labeled directed arcs.In a propositional semantic network,the propositions are represented by the nodes,rather than the arcs;arcs represent only non-conceptual binary relations between nodes.The particular sys-tems that are being used for B2are SNePS and ANA-LOG (Ali,1994a;Ali,1994b;Shapiro and Group,1992)which provide facilities for building and finding nodes as well as for reasoning and truth-maintenance.These systems satisfy the following additional constraints:•Each node represents a unique concept;•Each concept represented in the network is represented by a unique node;•The knowledge represented about each concept is rep-resented by the structure of the entire network con-nected to the node that represents that concept.These constraints allow efficient inference when process-ing natural language.For example,such networks can represent complex descriptions (common in the medical domain),and can support the resolution of ellipsis and anaphora,as well as general reasoning tasks such as sub-sumption (Ali,1994a;Ali,1994b;Maida and Shapiro,1982;Shapiro and Rapaport,1987;Shapiro and Rapa-port,1992).! ANTCLASS caseMEMBERv1CASE-NUMBERCASE-INFOCASE-INFOv2v3CQACTOBJECT1ACTIONLEX describePLANOBJECT1OBJECT2ACTIONconjoin LEX LEXM6M8M9M10M12M13FORALLFORALLFORALLP1P2P3Figure2:A rule stating that if V1is the case number ofa case,and V2and V3are two pieces of case information,then a plan for generating a description of the case willpresent the two pieces of information in a coordinatingconjunction.We characterize a knowledge representation as uni-form when it allows the representation of different kindsof knowledge in the same knowledge base using the sameinference processes.The knowledge representation com-ponent of B2is uniform because it provides a representa-tion of the discourse knowledge,domain knowledge,andprobabilistic knowledge(from the Bayesian net).Thissupports intertask communication and cooperation forinteractive processing of tutorial dialogs.The rule in Figure2is a good example of how theuniform representation of information in the semanticnetwork allows us to relate domain information(a med-ical case)to discourse planning information(a plan todescribe it).This network represents a text plan for de-scribing a medical case to the user.Text plans are rep-resented as rules in the knowledge representation.Rulesare general statements about objects in the domain;theyare represented by using case frames1that have FORALLor EXISTS arcs to nodes that represent variables that arebound by these quantifier arcs.In Figure2,node M13is a rule with three universally quantified variables(atthe end of the FORALL arcs),an antecedent(at the endof the ANT arc),and a consequent(at the end of the CQarc).This means that if an instance of the antecedentis believed,then a suitably instantiated instance of theconsequent is believed.Node P1represents the conceptthat something is a member of the class case and P2represents the concept that the case concept has a casenumber and case information.For more details aboutthe knowledge representation,see(McRoy et al.,1997).2HIDA stands for radio-nuclide hepatobilary imaging,adiagonistic test.ATTITUDEFORMUTTERANCEB3M5IMPERactionCONTENTM4AGENTACTB1OBJECTLEX PRONOUN"hearer"ACTION M6M7M8B4MEMBERCLASSM11LEX "tell"M1B2DOBJECT NP DETLEX "a"M2M3MEMBERIOBJECTB5OBJECTPRONOUN"story"LEXCLASSM9M10LEX "me"M12M13Figure 4:Node B3represents an utterance whose formis imperative,and whose content (M4)is the proposition that the hearer (B1)will tell a story (B2)to the speaker (B5).In the semantic network,we represent the sequencing of utterances explicitly,with asserted propositions that use the BEFORE-AFTER case frame.The order in which utterances occurred (system and user)can be de-termined by traversing these structures.This represen-tation is discussed in detail in (McRoy et al.,1997).The Interpretation LevelIn the third level,we represent the system’s inter-pretation of each utterance.Each utterance event (from level 1)will have an associated system interpre-tation,which is represented using the INTERPRETA-TIONLEXM7askACTION!M115exchangeLEXM114MEMBER!M97systemuserOBJECT1LEXOBJECT1LEXM19best-test(HIDA,gallstones,jones-case)LEXanswert . best-test(t, gallstones, jones-case)M106M99EVENT2EVENT1CLASS!M116M113!AGENTACTM112LEXacceptM111OBJECT1ACTION!M14ACTIONM108ACTAGENTACTAGENTM110M107INTERPRETATION-OFINTERPRETATIONFigure 6:Node M115represents the proposition that node M113is an exchange comprised of the events M99and M108.M108is the proposition that The user an-swered “HIDA is the best test to rule in Gallstones”.Additionally,node M116represents the proposition that the interpretation of M113is event M112.M112is the proposition that the user has accepted M96.(M96is the question that the system asked in event M99.)and underlying knowledge representations of domain and discourse information(Shapiro and Group,1992;Shapiro and Rapaport,1992;Ali,1994a;Ali,1994b).An Internet-accessible,graphical front-end to B2has been developed using the JAVA 1.1programming lan-guage.It can be run using a network browser,such as Netscape.The interface that the user sees communicates with a server-side program that initiates a LISP process.SummaryThe goal of the B2project is to give students an oppor-tunity to practice their decision making skills where the primary modality of interaction is English.We give stu-dents the opportunity to ask the system to explain what factors were most influential to its decision and why.The natural language processing and knowledge rep-resentation components of B2are general purpose.It builds a five-level model of the discourse,that repre-sents what was literally said,what was meant,and how each utterance and its interpretation relates to previ-ous ones.This is necessary because students’utterances may be short and ambiguous,requiring extensive rea-soning about the domain or the discourse model to fully resolve.We have shown how our mixed-depth repre-sentations encode syntactic and conceptual information in the same structure.This allows us to defer any ex-tensive reasoning until needed,rather than when pars-ing.We use the same representation framework to pro-duce a detailed representation of requests and to pro-duce a representation of questions.The representations use the same knowledge representation framework that is used to reason about discourse processing and domain information—so that the system can reason with (and about)the utterances.AcknowledgementsThis work was supported by the National Science Foun-dation,under grants IRI-9701617and IRI-9523666and by a gift from the University of Wisconsin Medical School,Department of Medicine.ReferencesAli,S.S.(1994a).A Logical Language for Natural LanguageProcessing.In Proceedings of the 10th Biennial Cana-dian Artificial Intelligence Conference ,pages 187–196,Banff,Alberta,Canada.Ali,S.S.(1994b).A “Natural Logic”for Natural LanguageProcessing and Knowledge Representation .PhD thesis,State University of New York at Buffalo,Computer Sci-ence.Grosz,B.J.and Sidner,C.L.(1986).Attention,intentions,and the structure of putational Linquis-tics ,12.Haddawy,P.,Jacobson,J.,and Jr.,C.E.K.(1996).Aneducational tool for high-level interaction with bayesian networks.Artificial Intelligence and Medicine .(to ap-pear).Haller,S.(1996).Planning text about plans interactively.International Journal of Expert Systems ,pages 85—112.Hirst,G.and Ryan,M.(1992).Mixed-depth representa-tions for natural language text.In Jacobs,P.,editor,Text-Based Intelligent Systems .Lawrence Erlbaum As-sociates.Maida,A.S.and Shapiro,S.C.(1982).Intensional conceptsin propositional semantic networks.Cognitive Science ,6(4):291–330.Reprinted in R.J.Brachman and H.J.Levesque,eds.Readings in Knowledge Representation ,Morgan Kaufmann,Los Altos,CA,1985,170–189.McRoy,S.,Haller,S.,and Ali,S.(1997).Uniform knowl-edge representation for nlp in the b2system.Journal of Natural Language Engineering ,3(2).McRoy,S.W.(1995).Misunderstanding and the negotiationof meaning.Knowledge-based Systems ,8(2–3):126–134.McRoy,S.W.and Hirst,G.(1995).The repair of speechact misunderstandings by abductive pu-tational Linguistics ,21(4):435–478.Shapiro,S.,Rapaport,W.,Cho,S.-H.,Choi,J.,Feit,E.,Haller,S.,Kankiewicz,J.,and Kumar,D.(1994).A dictionary of SNePS case frames.Shapiro,S.C.and Group,T.S.I.(1992).SNePS-2.1User’sManual .Department of Computer Science,SUNY at Buffalo.Shapiro,S.C.and Rapaport,W.J.(1987).SNePS consideredas a fully intensional propositional semantic network.In Cercone,N.and McCalla,G.,editors,The Knowledge Frontier ,pages 263–315.Springer–Verlag,New York.Shapiro,S.C.and Rapaport,W.J.(1992).The SNePSputers &Mathematics with Applications ,23(2–5).。