第9章 假设检验
商务统计学Ch09假设检验

总体比例
例: 一个城市成年人拥有手机的比例 π = 0.68
Basic Business Statistics, 11e © 2009 Prentice-Hall, Inc..
Chap 9-3
零假设,H0
检验声称或断言
例:在美国每个家庭平均有3台电视机 ( H0 : μ 3 )
是总体参数,不是样本统计量
Basic Business Statistics, 11e © 2009 Prentice-Hall, Inc..
Chap 9-18
均值的Z假设检验 (σ 已知)
把样本统计量 ( X ) 转换为 ZSTAT 检验统计量
的假设检验
σKnown 已知 (Z 检验) 检验统计量是:
σ Unknown 未知 (t 检验)
如何避免假设检验中存在的陷阱
假设检验中的伦理道德问题
Basic Business Statistics, 11e © 2009 Prentice-Hall, Inc..
Chap 9-2
假设是什么?
假设是关于总体 参数的声称(断言):
总体均值
例: 一个城市的每月电话账单均值 μ = $42
统计决策 不拒绝H0 拒绝H0 H0为真 正确决策 概率1 - α 第一类错误 概率α H0为假 第二类错误 概率β 正确决策 概率1 - β
(续)
Basic Business Statistics, 11e © 2009 Prentice-Hall, Inc..
Chap 9-13
假设检验决策中可能的错误
因为ZSTAT = -2.0 < -1.96,拒绝零假设并有足够的证据得 出在美国每个家庭中电视机台数不是3
假设检验

Z <Zα/2
所以接受原假设,即该医院病 所以接受原假设 即该医院病 人候诊的时间无显著变化.。 人候诊的时间无显著变化 。
0.025
1- α
接受区域
0.025(α/2) ( )
-1.96
若
Z > Zα
2
则否定H 则否定 0
或总体分布未知、 或总体分布未知、大样本
0.025 0.025(2/α) ( )
检验统计量: 检验统计量
-1.96
1- α
x − µ0 t= ~ n − 1) ( s 1.96( Z ) ( n
2/α
t > t α (n − 1)
2
则否定H 则否定 0
t ≤ t α (n − 1)
2
则接受H 则接受 0
0.025 -1.96 1.96( Z 2/α ) ( 0.025(2/α) ( )
属于:总体正态,已知方差, 属于:总体正态,已知方差,双侧检验 ( H0: µ= µ0 )
(一)总体正态,已知方差,双侧检验 ( H0: µ= µ0 ) 总体正态,已知方差, 解:该批瓷砖进货的抗断强度X ~N( µ , 1.12 ) 该批瓷砖进货的抗断强度 ( S1 作假设 H0: µ= µ0 = 32.50 作假设:
x H 0 : µ = 300;H1 : µ ≠ 300 总体分布正态 但σ2未知, x =297, 总体分布正态,但 未知, n=10 =
x − µ0 t= ~ t(n − 1) s n 0.025 x − µ 0 297 − 3001- α t= = = −2.35 s 4.028 -1.96 1.96( Z ( n 10
医学统计学-第9章 关联性分析
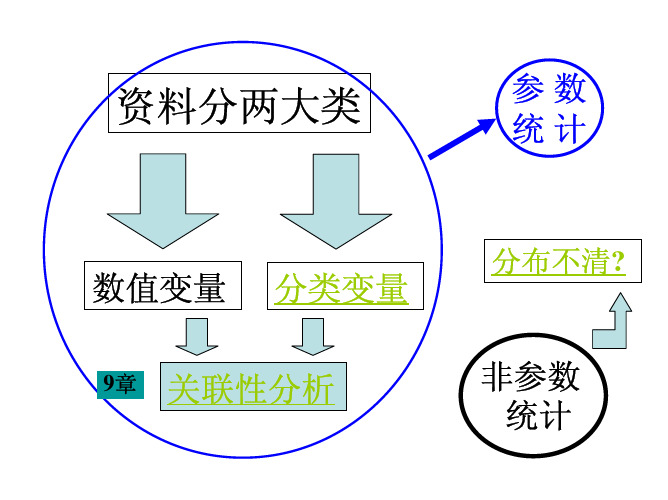
关于两种属性的关联程度,我们用pearson
列联系数表达:
对于2×2列联表
关联系数r介于
(9-10)(110-1~2) 0.5 = 0.71 之 间, 该值越大,关
联程度越高。
理论上我们还要作总体为列联系数为0的假设 检验,但这个假设等价于以上的χ2检验。
例9-3 为观察行为类型与冠心病的关系,某研究
r的取值范围在±1之间,为正值时,正相关。 为负值时,负相关。 r=0时为零相关。 ρ是总 体相关系数,r是ρ的估计值。 假设是建立ρ的基础上。。。
相关系数的计算
利用例题的资料试计算凝血酶浓度X与凝 血时间Y之间的样本相关系数。
4.相关分析条件
用于双变量正态分布资料, X、Y都是正态分布。
9.2 两个连续随机变量间的相关分析
例 某地研究2-7岁急性白血病患儿的血小
板数与出血症状程度之间的相关性,结果见下 表:试用秩相关进行分析。
首先先将实测原始数据由小到大排序 编秩,以pi表示Xi秩次;qi表示Yi的
次,见上表所示。
观察值相同的取平均秩次;将pi、qi直接 替换(9-1)中的X和Y的均数,直接得 到如下算式:
计算结果如下:
九
(9-11)
关联系数为:
关联系数的范围:
其中,R是列联表的行数,C是列联表列数。
双向有序分类资料的关联性检验
市场营销调研第9章

华中科技大学管理学院工商管理系
高收入家庭样本 样本百分数 p1=16%
低收入家庭样本 p2=3.5%
样本量
n1=300
n2=200
H 0: p1 p2 , H1: p1 p2
采用z检验,
华中科技大学管理学院工商管理系
z
p1 p 2 p1 (1 p1 ) p 2 (1 p 2 ) n1 n2 0.1 6 0.1 3 5
0.1 6(1 0.1 6) 0.1 3 5 (1 0.1 3 5 ) 300 200 0.7 8
查表得到z*=1.96。由于z<z*,故接受H0,拒 绝H1,认为家庭收入水平对人们购买该新产品 的意向没有显著影响
华中科技大学管理学院工商管理系
显著性水平与否定域 显著性水平是指样本分布中,否定域概率的 大小,用a表示,它通常是事先确定的 显著性水平越小,否定域范围越小,越不容 易否定H0 在市场研究中,一般选取a=0.010.05
华中科技大学管理学院工商管理系
假设检验的方法
在市场研究中得到的数据有下面几类:类别 数据、顺序数据、等量数据以及比率数据 对等量数据的检验称为参数检验
华中科技大学管理学院工商管理系
对百分数的检验
对百分数的检验包括对总体百分数的检验和对 不同样本百分数之间差别的检验 对总体百分数假设的检验 例: 某公司进行一次新产品研究,其中一个方面 是调查新产品将来可能的占有率。
华中科技大学管理学院工商管理系
对500名潜在用户调查后发现有15%的 潜在用户回答很可能或绝对可能购买 该新产品。公司的其它研究表明,在新产
第九章 研究假设的检验
九章节假设检验续

E1 ( ( x)) E2 ( ( x)) .
二、一致最优功能无偏检验
对另外两类双边假设检验问题
H 0:
,
0
H1: 0
(13)
和 H0:1 2; H1: 1 or 2 (14)
虽然样本旳联合密度函数(或分布率)(单参数)具
有定理9.1和定理9.2中旳常见体现式,有关这两
类检验问题旳UMPT也不存在。实际上例9.2早 已阐明了这一事实。
既然对上述两类检验问题不存在UMPT,哪 怎样处理呢?象估计问题一样,自然是对检验提 出某种合适旳要求,然后在满足这种特定要求旳 较小旳检验类中寻找最优旳检验,其中一种简朴 旳要求就是所谓旳无偏性。
定义9.2 设 ( x) 是假设检验问题 H0: 0; H1: 1
旳检验函数, 若其功能函数 g( ) E ( ( x)) 满
注意: (1) 有关r和c 旳拟定方法可参看N-P引理旳注。
(2) 假如定理中旳 c( )是 旳严格单减函数,则
定理旳结论一样成立, 只需要将(10)中旳不 等号变化方向。
(3) 对假设检验问题
H 0:
,
0
H1: 0
则定理8.1旳结论全部成立。
(4) 对假设检验问题
H 0:
,
0
H1: 0
和假设检验问题
0
H
:1
0
1
0
,
H
:1
1
1
0
.
现抽取 n个此类设备进行试验直到设备不能正
常工作为止,并统计其寿命分别为 x1, x2 ,, xn ,
试求这个检验问题的水 平为的UMPT。
解 样本旳联合密度函数为
n
p( x, ) n I{min{ xi }0}( x)exp{ xi }
第九章 假设检验的基本原理

表9-1 假设检验中的两类错误
拒绝H0 接受H0
H0为真 α错误 正确
H0为假 正确 β错误
为了将两种错误同时控制在相对最小的 程度,研究者往往通过选择适当的显著性水 平而对α错误进行控制,如α=0.05或α= 0.01。
对β错误,则一方面使样本容量增大, 另一方面采用合理的检验形式(即单侧检验 或双侧检验)来使β误差得到控制。
或称研究假设、对立假设;是与零假设相对立的假 设,即存在差异的假设。
进行假设检验时,一般是从零假设出 发,以样本与总体无差异的条件计算统计 量的值,并分析计算结果在抽样分布上的 概率,根据相应的概率判断应接受零假设、 拒绝研究假设还是拒绝零假设、接受研究 假设。
2.小概率事件
样本统计量的值在其抽样分布上出 现的概率小于或等于事先规定的水平, 这时就认为小概率事件发生了。把出现 概率很小的随机事件称为小概率事件。
6.假设检验的基本步骤
一个完整的假设检验过程,一般经过四 个主要步骤:
⑴.提出假设 ⑵.选择检验统计量并计算统计量的值 ⑶.确定显著性水平 ⑷.做出统计结论
第九章
假设检验的基本原理
利用样本信息,根据一定 概率,对总体参数或分布的某 一假设作出拒绝或保留的决断, 称为假设检验。
1.假设
假设检验一般有两互相对立的假设。
H0:零假设,或称原假设、虚无假设(null hypothesis)、解消假设;是要检验的对象之间没
有差异的假设。
H1:备择假设(alternative hypothesis),
α=0.05 和 α=0.01。
4.假设检验的形式 在抽样分布曲线上,显著性水平既可以 放在曲线的一端(单侧检验),也可以分在 曲线的两端(双侧检验)。
第9章假设检验习题解答

9. 在统计假设的显著性检验中,取小的显著性水平α 的目的在于( B ).
A. 不轻易拒绝备选假设.
B. 不轻易拒绝原假设.
C. 不轻易接受原假设.
D. 不考虑备选假设.
10. 在统计假设的显著性检验中,实际上是( B ).
A. 只控制第一类错误,即控制"拒真"错误.
B. 在控制第一类错误的前提下,尽量减小第二类错误(即受伪)的概率.
C. 同时控制第一类错误和第二类错误.
D. 只控制第二类错误,即控制"受伪"错误.
11. 在统计假设的显著性检验中,下列结论错误的是( C ).
A. 显著性检验的基本思想是“小概率原理”,即小概率事件在一次试验中是几乎不可能 发生.
B. 显著性水平α 是该检验犯第一类错误的概率,即"拒真"概率. C. 记显著性水平为α ,则 1 α 是该检验犯第二类错误的概率,即"受伪"概率.
第 9 章假设检验习题解答
一.选择题
1.假设检验中,显著性水平α 的意义是( A ).
A. H0 为真,经检验拒绝 H0 的概率. B. H0 为真,经检验接受 H0 的概率.
C. H0 不真,经检验拒绝 H0 的概率. D. H0 不真,经检验接受 H0 的概率.
2. 假设检验中的显著性水平α 的意义是( A ).
25.设总体 X ~ N (µ,σ 2 ), 其中µ,σ 2都未知 . X1, X 2 , , X n 为来自该总体的一个样
∑ ∑ 本.记
X
=
1 n
n i =1
Xi,S2
=
1 n −1
n i =1
(Xi
−
X )2
医学统计学-第9章 关联性分析
线性?程度如何?是正相关还是负相关? ⑵统计推断:两者的关系是否有统计学意
义?根据专业知识下结论。
9.2.2 相关系数的统计推断
r是样本相关系数,是总体相关系数ρ的估计
值,要想判断X、Y间是否有相关关系,就要检
验r是否来自总体相关系数ρ为零的总体。方法
本例 ν=n对-2=15-2=13,r0.05,13=0.514, 得到: p<0.05,即相关系数有统计学意义。
tr =
− 0.926 = −8.874,
1 − (0.926)2
ν = 15 − 2 = 13
15 − 2
可按公式(9-2) 计算
查附表C2(教材560),t 0.05,13=2.160;t> t 0.05,13,按α=0.05水准,拒绝H0,接受H1,故 可以认为凝血酶浓度与凝血时间呈负相关关系。
9.2.3 Spearman 秩相关
一、秩相关的概念及其统计描述 前面指出:Pearson积矩相关的假设检验要求
X和Y均服从正态分布。对那些不服从正态 分布或等级资料、总体分布未知的资料,因 难以进行分析,所以就不宜用积矩相关系数 来描述相关性。
此时,可采用等级相关(rank correlation), 或称秩相关来描述两个变量间相关的程度与方 向。该法是利用两变量的秩次大小作线性相关 分析,对原变量的分布不作要求,属非参数统 计方法。
例 某地研究2-7岁急性白血病患儿的血小
板数与出血症状程度之间的相关性,结果见下 表:试用秩相关进行分析。
首先先将实测原始数据由小到大排序 编秩,以pi表示Xi秩次;qi表示Yi的
次,见上表所示。
观察值相同的取平均秩次;将pi、qi直接 替换(9-1)中的X和Y的均数,直接得 到如下算式:
第9章t检验

第9章t 检验t检验(t—tests)又称Student t检验(学生氏t检验),它用以检验单样本均数与总体均数间的差异性,两独立样本均数的差异性(独立样本t检验,又称成组t检验,团体t检验)和两样本配对样本t检验(自身对照)。
它以t分布为其理论基础,具体假设依各种问题的不同而异。
9.1 单样本均数t检验单样本均数t检验(one—Sample t-test for a Mean)可以对单样本均数与已知总体均数(一般为理论值、标准值或经过大量观察所得的稳定值等)进行比较,目的是推断样本所代表的未知总体均数与已知的总体均数有无差别(即样本均数与总体均数的比较)。
[例9—1] 已知某水样中含CaC03的真值(均数)为20.7mg/L,现用某方法重复测定该水样11次,CaC03的含量(mg/L)如下:20.99,20.41,20.10,20.00,20.91,22.60,20q99,20.41,20,00,23.00,22.00问该方法测得的均数是否偏高?(杨树勤。
中国医学百科全书/医学统计学。
上海:上海科学技术出版社,1985.10.3)(1)进入SAS/Win(v8)系统,单击Solutions-Analysis-Analyst,显示分析家窗口。
建立如图9—1所示的SAS数据集文件Sasuser.CaCO3。
A为变量CaCO3;,并保存为Sasuser.CaCO3。
(2)单击Statistics-Hypothesis(假设检验) -one—Samplet-test for a Mean (单样本均数t检验),得到图9.2所示对话框。
图9.1数据文件(部分) 图9—2 one—Sample t-test for a Mean:Cac03(单样本均数t检验)对话框在图9—2所示对话框中可进行如下设置。
、V ariable,待选变量为A(CaCO3)(单击A—Variable)。
Hypotheses,假设检验。
09 第九章 假设检验

解:根据题意可建立假设如下: H0:μ ≥20 kg H1:μ <20 kg 这是一个左侧检验问题,拒绝域应在抽样分布的左端。查标准正态 分布表可知,在显著性水平α =0.05下,临界值为-Zα =-1.65,即拒 绝域为(-∞,-1.65)。 由于样本均值 x 19.5 kg,总体方差σ 2=(1.5 kg)2,故检验统计 量的值为 x μ 0 19.5 20 Z 1.826 1.65 σ 1.5 n 50 即检验统计量落入了拒绝域,所以要拒绝原假设H0:μ =20 kg,转 而接受备择假设H1:μ <20 kg,即检验结果充分说明这些食品的平均净 重减少了。
例1:ProCare Industries,Ltd.曾经提供了一种称为“性别选择”的产 品,根据广告上的说法,这种产品可以使夫妇“将生一个男孩的概率增加 到85%,生一个女孩的概率增加到80%。”对于想要男孩的夫妇,“性别 选择”就装在一个蓝色的包装里,对于想要女孩的夫妇,“性别选择”就 装在一个粉色的包装里。假设我们对100对想要女孩的夫妇进行了一项实验, 他们都遵照了在“性别选择”粉色包装上描述的“户内方便使用说明”。 使用常识和非正规统计学方法来判断,如果100个婴儿中包含以下数量的女 孩,我们应该对“性别选择”的有效性得出什么结论?
前面双侧检验例子的Excel操作过程:
P值=2×0.01991631≈0.0398小于显著性水平0.05,故拒 绝原假设而选择备择假设。
(二)总体满足正态分布N(μ ,σ 2),且方差σ 2未知, 小样本(n<30)时,统计量
x μ t ~ t n 1 S n
其中,S为样本标准差 S
实际情况
决策结果
未拒绝H0 拒绝H0
原假设H0真 正确决策 第一类错误α
计量资料统计推断(第9章)

(1)H0:μd= 0 H1:μd≠ 0 α= 0.05
② 120名5岁女孩身高的平均值与全国平均水平有 没有差别?
2
第三节 数值变量资料的统计推断
一.均数的抽样误差与标准误
1. 均数的抽样误差: 由于抽样引起的样本均数与总体均数之差 (X )
3
,
n
X1
n X2
n
XK
, X
样本均数的标准差 ---- 标准误
2.均数的标准误: X (1)意义:
配对号 1 2 3 4 5 6 7 8 9 10 新药组 4.4 5.0 5.8 4.6 4.9 4.8 6.0 5.9 4.3 5.1 安慰剂组 6.2 5.2 5.5 5.0 4.4 5.4 5.0 6.4 5.8 6.2 差值d -1.8 -0.2 0.3 -0.4 0.5 -0.6 1.0 -0.5 -1.5 -1.1
例 某年某市抽样调查了120名5岁女孩身高(cm)资料
105.5 118.6 110.5 104.2 110.9 107.9 108.1 99.1 104.8 116.5 110.4 105.7 118.2 117.0 112.3 116.5 113.2 107.9 104.8 109.6 109.1 108.1 109.4 118.2 103.9 116.0 110.1 99.6 109.3 107.5 108.6 100.6 108.8 103.8 95.3 104.4 102.7 101.0 112.1 118.7 100.2 102.1 114.5 110.4 115.0 120.5 115.5 112.7 103.5 114.4 100.7 116.3 105.1 112.8 118.5 113.3 107.9 114.6 121.4 110.7 108.8 114.7 110.6 110.7 116.6 106.9 105.5 107.4 118.4 115.3 119.7 113.9 116.5 112.9 112.9 110.0 99.5 112.7 106.7 119.1 109.6 110.7 102.8 111.3 105.2 117.0 114.9 120.0 103.4 109.3 108.8 105.7 109.0 108.8 108.1 116.4 108.3 111.0 113.0 101.4 108.7 119.1 106.2 115.2 124.0 98.7 106.0 114.7 111.9 107.3 104.1 109.1 108.8 111.0 106.8 120.2 105.8 103.1 105.0 115.0
计量经济学第九章虚拟变量

虚拟变量的类型
季节虚拟变量
用于反映季节变动对经济活动的影响。
政策虚拟变量
用于反映某项政策实施前后对经济活 动的不同影响。
地区虚拟变量
用于反映不同地区之间经济活动的差 异。
行业虚拟变量
用于反映不同行业之间经济活动的差 异。
虚拟变量的引入原因
解决遗漏变量问题
01
当某些重要变量无法直接观测或获取时,可以通过引入虚拟变
在模型中引入虚拟变量与解释变量的交互项,通过 改变斜率的值来反映不同组别之间的差异。
斜率变动模型的应用
适用于研究不同组别之间在某一解释变量上 的边际效应差异,如不同教育水平对收入的 影响等。
含有多个虚拟变量的模型
含有多个虚拟变量的模型的定义
当模型中引入多个虚拟变量时,称为含有多个虚拟变量的模型。
含有多个虚拟变量的模型的设定
VS
使用计算变量功能
可以使用SPSS的计算变量功能手动创建虚 拟变量。在数据视图中,点击“转换”菜 单下的“计算变量”选项。在弹出的对话 框中,输入虚拟变量的名称和标签,并在 计算表达式中输入相应的逻辑表达式。例 如,对于分类变量`industry`,可以使用如 下表达式生成虚拟变量
SPSS中实现虚拟变量的方法
截距变动模型的设
定
在模型中引入虚拟变量,通过改 变截距项的值来反映不同组别之 间的差异。
截距变动模型的应
用
适用于研究不同组别之间在某一 解释变量上的平均差异,如不同 性别、不同地区等。
斜率变动模型
斜率变动模型的定义
当虚拟变量不仅影响模型的截距项,还影响 解释变量的斜率时,称为斜率变动模型。
斜率变动模型的设定
通过比较政策虚拟变量的系数,可以分析 出政策变动对市场需求的影响程度。
第9章 课外练习

H0,没有充分证据表明该大学英语六级考试的及格率仍然保持在原有水平。
5.解: H 0
:
2 国产
1.75
;
H 1
:
2 国产
1.75
计算 2 统计量的实际值:
2
n
1 s 2
2 0
30 1 2
1.75
33.14
对给定的显著性水平 0.05 ,以及自由度 n-1=29,查 2 分布表,得到检验临界值:
,所以拒
绝 H0,说明该栏目设置的目标观众没有针对性。
3.解: H 0
:
2;H 1
:
2
t x 0 1.88 2 3.16 s n 0.12 10
在显著性水平 0.01下,t
n 1
t 0.01
9
2.82 。因为t t0.01 ,所以拒绝 H0
说明该厂汽车轮胎平均行驶里程与标准不相符。
(1)该批节能灯管采用新技术改造后的使用寿命与原 先相比,是否有显著性差异?
(2)该批节能灯管采用新技术改造后的使用寿命与原先相比,是否有显著性提高?
2.某电视台某栏目是针对平均年龄 65 岁的老年人,现随机抽取收看该栏目的 25 名观众进行了 调查,其平均年龄为 68 岁,样本标准差为 3 岁。假定收看该栏目观众的年龄服从正态分布,试 在显著性水平 0.05 的条件下检验该栏目设置的目标观众是否具有针对性? 3.某汽车轮胎厂生产的轮胎合格标准为平均行驶里程至少 2 万公里,现从该厂生产的一批汽车 轮胎中随机抽取 10 个,测得平均行驶里程为 1.88 万公里,标准差为 0.12 万公里。假定该汽车 轮胎行驶里程近似服从正态分布,试在显著性水平 0.01的条件下,检验该厂汽车轮胎平均 行驶里程与标准是否相符合?
假设检验

一般来说,样本容量一定时,若减少犯第一类错误 的概率,则犯第二类错误的概率则会增加,反之亦然 . 若要使两类错误都减小,除非增加样本容量。
三、 单边假设检验 双边假设检验
H 0 : 0 H1 : 0
单边假设检验 右边检验 H 0 : 0
H1 : 0 H1 : 0
X 0 k 0 P 0 n n
( x)
X k 0 P 0 n n
n
0 z
x
k 0 z / n
拒绝域为
k 0
n z
z
x 0
x 0 即 z z n
第三章
§3.1
假设检验
假设检验
假设检验的思想
假设检验的两类错误 单边假设检验
在总体的分布函数完全未知或只知其形式,但不知其 参数的情况下,为了推断总体的某些性质,提出某些 关于总体的论断或猜测,这就是假设。 假设检验就是根据样本对所提出的假设作出判断: 接受,还是拒绝。 假设检验 总体分布已知, 检验关于未知参数 的某个假设 总体分布未知时的 假设检验问题
2
则接受H0。
前例中,取 0.05 , 则有 k
z 2 z0.025 1.96 ,
x 0.511 ,
x 0 0 . 511 0 . 5 2.2 1.96 n 0.015 9
于是拒绝H0,认为这天包装机工作不正常。
基本概念:
原假设(零假设) H 0 : 0 备择假设(双边备择假设) H1 : 0 检验统计量 Z 拒绝域
X 0 当假设H0为真时, ~ N (0, 1) n
第九章 假设检验

假定µ未知, 双边检验:对于假设 假定µ未知
H 0:σ = σ ;H1:σ ≠ σ
2、非参数假设检验 、
X1, ,X n ~ X , L 总体分布未知, 由观测值x1, …, xn 检验假设H0:F(x)=F0(x;θ); H1: F(x)≠F0(x;θ) θ θ
iid
i .i .d
任何一个有关随机变量未知分布的假设称 为统计假设或简称假设 假设。 假设 一个仅牵涉到随机变量中几个未知参数的 参数假设。 假设称为参数假设 参数假设 这里所说的假设只是一个设想,至于它是否成 立,在建立假设时并不知道,还需要进行考察。
X − µ0 U= σ0 n
(3)对于给定的检验水平α=0.05构造小概率事件 P{|U|>U }=α 确定拒绝区域为|U|>Uα 2
α 2
(4)根据样本观察值计算统计量U的值
解:
(1)提出待检假设H。:µ =800
X − µ0 (2)根据H0选取统计量 U= σ0 n 在H0成立的条件下U~N(0,1) (3)对于给定的检验水平α=0.05构造小概率事件 P{|U|>Uα 2 }=α 确 定 拒 绝 区 域 为 |U |> U α (4)根据样本观察值计算统计量U的值
下面将通过具体例子,给出检验规则
单正态总体的假设检验
iid
1、σ2已知的情形 、 已知的情形—U检验 检验
值 x1, ,xn检验假设H 0:µ = µ0;H1:µ ≠ µ0。 L
设X 1, ,X n ~N ( µ,σ 2 ), 给定检验水平α,由观测 L
根据假设H0:µ=µ0;H1:µ≠µ0, 构造统计量 µ
第九章 假设检验

五、双侧检验与单侧检验
(一)假设的形式
研究的问题
假设 双侧检验
H0 H1
左侧检验
右侧检验
= 0 ≠0
0 < 0
0 > 0
(一)双侧检验 1、原假设与备择假设的确定
例如,某种零件的尺寸,要求其平均长度为10 厘米,大于或小于10厘米均属于不合格 建立的原假设与备择假设应为 H0: 10 H1: 10
(2)提出备择假设: H1: 4
4、显著性水平与拒绝域 抽样分布
拒绝域 /2
置信水平
拒绝域
1-
/2
接受域
H0值 样本统计量
临界值
临界值
抽样分布
拒绝域 /2 1- 接受域 H0值
置信水平 拒绝域
/2
临界值
临界值
样本统计量
抽样分布
拒绝域 /2 1- 接受域 H0值
置信水平
拒绝域 /2
•
当概率足够小时,可以作为从实际可能
性上,把零假设加以否定的理由。因为根据
这个原理认为:在随机抽样的条件下,一次
实验竟然抽到与总体参数值有这么大差异的
样本,可能性是极小的,实际中是罕见的,
几乎是不可能的。
四、假设检验中的两类错误
(一)第一类错误(弃真错误)
1、原假设为真时拒绝原假设 2、第一类错误的概率为
(四)计算检验统计量的值 (五)作出统计决策
1、计算检验的统计量 2、根据给定的显著性水平,查表得出相应 的临界值Z或Z/2 3、将检验统计量的值与 水平的临界值进 行比较 4、得出拒绝或不拒绝原假设的结论
显著性水平与拒绝域 抽样分布
拒绝域 /2
置信水平
拒绝域
统计学课件第9篇章分类数据分析

谢谢聆听
其他回归模型
总结词
除了线性回归分析和Logistic回归分析之外,还有许多其他类型的回归模型可 供选择。
详细描述
这些模型包括岭回归、套索回归、多项式回归、逐步回归等,每种模型都有其 特定的适用场景和假设条件。选择合适的回归模型需要考虑数据的特征、模型 的预测精度和解释性等因素。
06 分类数据分析的实际应用
市场细分分析
市场细分
通过分类数据分析,将市场划分为不 同的细分市场,以便更好地理解客户 需求和行为,从而制定更有效的营销 策略。
消费者行为研究
通过分析消费者的购买行为、偏好和 态度,了解不同细分市场的消费者需 求和趋势,以优化产品设计和市场定 位。
人口统计学研究
人口普查
利用分类数据分析对人口普查数据进行处理和分析,了解人口分布、年龄结构、 性别比例等人口统计学特征。
05 分类数据的回归分析
线性回归分析
总结词
线性回归分析是一种通过建立自变量与因变量之 间的线性关系来预测因变量的方法。
总结词
线性回归分析的假设包括线性关系、误差项独立 同分布、误差项无偏和误差项同方差。
详细描述
线性回归分析基于最小二乘法原理,通过拟合一 条直线来描述自变量和因变量之间的关系。这种 方法适用于因变量是连续变量的数据,并且自变 量和因变量之间存在线性关系。
选择合适的图形类型,将频数分布表 中的数据按照分类变量进行分组并绘 制图形。
相对频率与累积频率
相对频率
01
某一组的频数与总频数之比,用于表示该组在总体中的相对重
要程度。
累积频率
02
某一组的相对频率与前面所有组的相对频率之和,用于表示该
组及之前所有组在总体中的相对重要程度。
医学统计学第9章 关联性分析思考与练习参考答案

第9章 关联性分析 思考与练习参考答案一、最佳选择题1. 对简单相关系数作假设检验,)(v t t ,统计结论为( B )。
A. 两变量不相关B. 两变量有线性关系C. 两变量无线性关系D. 两变量不会是曲线关系,一定是线性关系E. 上述说法都不准确2. 计算积矩相关系数要求( C )。
A. Y 是正态变量,X 可以不满足正态的要求B. X 是正态变量,Y 可以不满足正态的要求C. 两变量都要求满足正态分布规律D. 两变量只要是测量指标就行E. Y 是定量指标,X 可以是任何类型的数据3. 对两个分类变量的频数表资料作关联性分析,可用( C )。
A. 积矩相关B.秩相关C. 关联系数D. 线性相关E.以上均可4. 由样本算得相关系数r ,t 检验结果为P <0.01,说明( D )。
A. 两变量之间有高度相关性B. r 来自高度相关的总体C. r 来自总体相关系数为0的总体D. r 来自总体相关系数不为0的总体E. r 来自总体相关系数大于0的总体二、思考题1. 1988年某地抽查0~7岁儿童营养不良患病情况如教材表9-10,某医师要想了解年龄与营养不良患病率是否有关,你认为应选用什么统计方法?为什么?教材表9-10 1988年某地抽查0~7岁儿童营养不良患病情况 年龄/岁 0~ 1~ 2~ 3~ 4~ 5~ 6~7 患病人数 98 278 86 29 59 82 34 患病率/%15.711.712.97.48.97.35.1解:提示,用秩相关分析年龄与患病率的关系,因患病率资料一般不服从正态分布。
2. 请查找最近三年主题为相关分析或关联分析的已发表国内医学文献,至少认真阅读其中3篇(建议分别选取Pearson 、Spearman 相关分析和关联分析各1篇),找出其中不妥之处。
3. 在讲散点图时,我们曾提到分层应慎重,有可能出现分层分析与总体情况大相径庭的结果。
请举一两个实例说明这种现象。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
/2
/2
临界值
2013-8-13
0
临界值
样本统计量
26
显著性水平和临界值
(左侧检验)
统计学
STATISTICS
抽样分布
拒绝H0 的区域
接受H0 的区域
1-
临界值
2013-8-13
0
样本统计量
27
显著性水平和临界值
(右侧检验 )
统计学
STATISTICS
抽样分布
接受H0 的区域
拒绝H0 的区域 1-
1-
临界值
2013-8-13
0
样本统计量
36
显著性水平和临界值
(右侧检验 )
统计学
STATISTICS
抽样分布
接受H0 的区域
拒绝H0 的区域 1-
0
2013-8-13
临界值
样本统计量
37
显著性水平和临界值
(右侧检验 )
统计学
STATISTICS
抽样分布
接受H0 的区域
拒绝H0 的区域 1-
6
• •
2013-8-13
一、假设检验的一般问题
(一)假设检验的概念与特征 (二)原假设与备择假设 (三)两类错误与显著性水平 (四)检验统计量与拒绝域 (五)假设检验的步骤
2013-8-13 7
(一)假设检验的概念与特征
什么是假设? (hypothesis) • 对总体参数的的数值所
作的一种陈述
•小概率α的区域
•用临界值将其与H0的接受区域相分离
•对于不同形式的假设,原假设的拒绝 区域也有所不同
2013-8-13
31
显著性水平和拒绝域
(双侧检验 )
统计学
STATISTICS
抽样分布
拒绝H0的区域
接受H0 的区域 拒绝H0 的区域 1-
/2
/2
临界值
2013-8-13
0
临界值
样本统计量
– 备择假设的方向为“<”,称为左侧检验
–
2013-8-13
备择假设的方向为“>”,称为右侧检验
15
假设的形式
假设
原假设 备择假设
统计学
STATISTICS
双侧检验
H0 : = 0 H1 : ≠0
单侧检验 左侧检验
H0 : 0 H1 : < 0
右侧检验
H0 : 0 H1 : > 0
4
•
2013-8-13
统计学
STATISTICS
•
反过来,如果要证明这个人骂过人很 容易,只要有一次被抓住就足够了。
•
看来,企图肯定什么事物很难,而否 定却要相对容易得多。这就是假设检 验背后的哲学。
在假设检验中,一般要设立一个原假 设。如上面的“从来没骂过人”就是 一个原假设
5
•
2013-8-13
统计学
STATISTICS
•
设立该假设的动机主要是企图利用人们掌 握的反映现实世界的数据来找出现实与假 设之间的矛盾,从而否定这个假设。 在多数统计教科书中,假设检验都是以否 定原假设为目标。 如果否定不了,说明证据不足,无法否定 原假设。但不能说明原假设正确。就像一 两天没有听过他骂人还远不能证明他从来 没有骂过人。
–
2013-8-13
–
H1: ≠、<或 某一数值 H0:、 或 某一数值
14
统计学
STATISTICS
双侧检验与单侧检验
1.备择假设没有特定的方向性,并含有符 号“”的假设检验,称为双侧检验 或双尾检验 2.备择假设具有特定的方向性,并含有符 号“>”或“<”的假设检验,称为单侧 检验或单尾检验
•使α和β同时减少的方法:增大样本容量。
•一般来说,哪一类错误带来的后果越严重, 就应当把哪一类错误作为首要的控制目标 •但在假设检验中,通常都是首先控制犯α 错误的概率。
2013-8-13
23
显著性水平与临界值
显著性水平
• 是一个概率值
• 原假设为真时,拒绝原假设的概率 –被称为抽样分布的拒绝域 • 表示为 (alpha) – 常用的 值有0.01, 0.05, 0.10 • 由研究者事先确定
/2
/2
临界值
2013-8-13
0
临界值
样本统计量
34
显著性水平和临界值
(左侧检验)
统计学
STATISTICS
抽样分布
拒绝H0 的区域
接受H0 的区域
1-
临界值
2013-8-13
0
样本统计量
35
显著性水平和临界值
(左侧检验)
统计学
STATISTICS
抽样分布
拒绝H0 的区域
接受H0 的区域
32
显著性水平和拒绝域
(双侧检验 )
统计学
STATISTICS
抽样分布
拒绝H0的区域
接受H0 的区域 拒绝H0 的区域 1-
/2
/2
临界值
2013-8-13
0
临界值
样本统计量
33
显著性水平和拒绝域
(双侧检验 )
统计学
STATISTICS
抽样分布
拒绝H0的区域
接受H0 的区域 拒绝H0 的区域 1-
9
•
2013-8-13
假设检验的特征
•逻辑上运用反证法
统计学
STATISTICS
•统计上依据小概率原理
2013-8-13
1.在一次试验中,一个几乎 不可能发生的事件发生的概 率 2.在一次试验中小概率事件 一旦发生,我们就有理由拒 绝原假设 3.小概率由研究者事先确定
10
假设检验的基本思想
抽样分布
H0为真
H0为假
正确 错误
正确决策 第Ⅱ类错 误() (1 – ) 第Ⅰ类错 正确决策 误() (1-)
21
拒绝H0
两类错误的关系
和的关系就像 翘翘板,小就 大, 大就小
统计学
STATISTICS
你不能保证两 类错误都不犯!
2013-8-13 22
统计学
STATISTICS
2013-8-13 0
H : 10cm
H1 : 10cm
17
统计学
STATISTICS
•
【例2】某品牌洗涤剂在它的产品说明书中声称
:平均净含量不少于500克。从消费者的利益出发 ,有关研究人员要通过抽检其中的一批产品来验 证该产品制造商的说明是否属实。试陈述用于检 验的原假设与备择假设
– 总体参数包括总体均值 、比例、方差等
我认为工艺改革后 绳索的拉力强度没 有发生显著变化
– 分析之前必需陈述
2013-8-13
8
假设检验的概念
•
统计学
STATISTICS
先对总体参数或分布形式作出一 个假设,然后利用样本信息来判断原 假设是否合理。即判断样本信息与原 假设是否有显著性差异,从而决定应 接受或否定原假设。假设检验也称为 显著性检验。 有参数检验和非参数检验,本章 只介绍参数检验。
不同条件下的检验统计量
总体分布 样本容量 大样本 正态总体 小样本
统计学
STATISTICS
已知
2
2未知
t 检验统计量
大样本
非正态总体 小样本
2013-8-13
z 检验统计量 当样本容量足 够大时,也可 采用z检验统 计量
— —
30
统计学
STATISTICS
拒绝域
•拒绝原假设H0的区域。
– –
2013-8-13
H0: 、 或 某一数值 H0:、 或 某一数值
13
统计学
STATISTICS
备择假设
1. 与原假设对立的假设,也称“研究假设 ”
2. 通常把期望出现的结论作为备择假设 3. 研究者想收集证据予以支持的假设。通 常是被认为可能比零假设更符合数据所 代表的现实。 4. 表示为 H1
2013-8-13
统计学
STATISTICS
24
统计学
STATISTICS
临界值
给定了显著性水平 , 也就确定了原假设 H 0 的接受区域和拒绝区域。这两个区域的交 界点就是临界值。
2013-8-13
25
显著性水平和临界值
(双侧检验 )
统计学
STATISTICS
抽样分布
拒绝H0的区域
接受H0 的区域 拒绝H0 的区域 1-
2013-8-13 3
统计学
STATISTICS
如果一个人说他从来没有骂过人。他能够证明吗? • 要证明他没有骂过人,他必须出示他从 小到大每一时刻的录音录像,所有书写 的东西等等,还要证明这些物证是完全 的、真实的、没有间断的。这简直是不 可能的。 即使他找到一些证人,比如他的同学、 家人和同事,那也只能够证明在那些证 人在场的某些片刻,他没有被听到骂人
统计学
• 2. 第二类错误(取伪错误)
– 原假设为假时接受原假设
– 第二类错误的概率为
2013-8-13 20
假设检验的决策结果
假设检验就好象一场审判过程
统计学
STATISTICS
统计检验过程
H0: 无罪
陪审团审判 H0 检验 决策 实际情况
实际情况
裁决
无罪
无罪 有罪
2013-8-13
有罪
错误 TATISTICS
•
【例1】一种零件的生产标准是直径应为10cm,