概率与统计7-6
概率论与数理统计复习7章

( n − 1) S 2 ( n − 1) S 2 = 1 − α 即P 2 <σ2 < 2 χα 2 ( n − 1) χ1−α 2 ( n − 1) ( n − 1) S 2 ( n − 1) S 2 置信区间为: 2 , χα 2 ( n − 1) χ12−α 2 ( n − 1)
则有:E ( X v ) = µv (θ1 , θ 2 ,⋯ , θ k ) 其v阶样本矩是:Av = 1 ∑ X iv n i =1
n
估计的未知参数,假定总体X 的k阶原点矩E ( X k ) 存在,
µ θ , θ ,⋯ , θ = A k 1 1 1 2 µ2 θ1, θ 2 ,⋯ , θ k = A2 用样本矩作为总体矩的估计,即令: ⋮ µ θ , θ ,⋯ , θ = A k k k 1 2 ɵ ɵ ˆ 解此方程即得 (θ1 , θ 2 ,⋯ , θ k )的一个矩估计量 θ 1 , θ 2 ,⋯ , θ k
+∞
−∞
xf ( x ) dx = ∫ θ x θ dx =
1 0
令E ( X ) = X ⇒
θ +1
θ
ˆ = X ⇒θ =
( )
X 1− X
θ +1
2
θ
7.2极大似然估计法
极大似然估计法: 设总体X 的概率密度为f ( x,θ ) (或分布率p( x,θ )),θ = (θ1 ,θ 2 ,⋯ ,θ k ) 为 未知参数,θ ∈ Θ, Θ为参数空间,即θ的取值范围。设 ( x1 , x2 ,⋯ , xn ) 是 样本 ( X 1 , X 2 ,⋯ , X n )的一个观察值:
i =1 n
概率论与数理统计第7章参数估计PPT课件

a1(1, ,k )=v1
1 f1(v1, ,vk )
假定方程组a2(1, ,k ) v2 ,则可求出2 f2(v1, ,vk )
ak (1, ,k ) vk
k fk (v1, ,vk )
则x1 xn为X的样本值时,可用样本值的j阶原点矩Aj估计vj,其中
Aj
1 n
n i1
xij ( j
L(x1, ,xn;ˆ)maxL(x1, ,xn;),则称ˆ(x1, ,xn)为
的一种参数估计方法 .
它首先是由德国数学家
高斯在1821年提出的 ,然而, 这个方法常归功于英国统
Gauss
计学家费歇(Fisher) . 费歇在1922年重新发现了
这一方法,并首先研究了这
种方法的一些性质 .
Fisher
10
极大似然估计是在已知总体分布形式的情形下的 点估计。
极大似然估计的基本思路:根据样本的具体情况
注:估计量为样本的函数,样本不同,估计量不 同。
常用估计量构造法:矩估计法、极大似然估计法。
4
7.1.1 矩估计法
矩估计法是通过参数与总体矩的关系,解出参数, 并用样本矩替代总体矩而得到的参数估计方法。 (由大数定理可知样本矩依概率收敛于总体矩, 且许多分布所含参数都是矩的函数)
下面我们考虑总体为连续型随机变量的情况:
n
它是的函数,记为L(x1, , xn; ) f (xi , ), i 1
并称其为似然函数,记为L( )。
注:似然函数的概念并不仅限于连续随机变量 ,
对于离散型随机变量,用 P {Xx}p(x,)
替代f ( x, )
即可。
14
设总体X的分布形式已知,且只含一个未知参数,
《概率论与数理统计》7

未知参数 , ,, 的函数.分别令
12
k
L(1,,k ) 0,(i 1,2,...,k)
或令
i
ln L(1,,k ) 0,(i 1,2,...,k)
i
由此方程组可解得参数 i 的极大似然估计值 ˆi.
例5 设X~b(1,p), X1, X2 , …,Xn是来自X的一个样本,
求参数 p 的最大似然估计量.
解 E( X ) ,E( X 2 ) D( X ) [E( X )]2 2 2
由矩估计法,
【注】
X
1
n
n i 1
X
2 i
2
2
ˆ X ,
ˆ
2
1 n
n i 1
(Xi
X )2
对任何总体,总体均值与方差的矩估计量都不变.
➢常见分布的参数矩估计量
(1)若总体X~b(1, p), 则未知参数 p 的矩估计量为
7-1
第七章
参数估计
统计 推断
的 基本 问题
7-2
参数估 计问题
(第七章)
点估计 区间估 计
假设检 验问题 (第八章)
什么是参数估计?
参数是刻画总体某方面概率特性的数量.
当此数量未知时,从总体抽出一个样本, 用某种方法对这个未知参数进行估计就 是参数估计.
例如,X ~N ( , 2),
若, 2未知, 通过构造样本的函数, 给出
k = k(A1, A2 , …, A k)
用i 作为i的估计量------矩估计量.
例1 设总体X服从[a,b]上的均匀分布,a,b未知,
X1, X2 , …,Xn为来自总体X的样本,试求a,b的 矩估计量.
解 E(X ) a b , D(X ) (b a)2
《概率论与数理统计》第七章

n
n
ln xi
(4)的极大似然估计量为:ˆ
n
n2 i1
lnX
i
2
i1
第七章 参数估计 ‹#›
例 9 设X~b(1,p), X1,X2,…,Xn是来自X的一个样本, 试求参数p的最大似然估计量
解: 设x1, x2,, xn,是相应于样本X1,X2,…,Xn 的一个样本值,X
的分布律为:
(3)以样本各阶矩A1, ,Ak代替总体各阶矩1,
得各参数的矩估计
ˆi gi(A1, ,Ak ), i 1, , k
, k,
第七章 参数估计 ‹#›
注意:
在实际应用时,为求解方便,也可以用
中心矩 i 代替原点矩i,相应地以样本中心矩Bi 估计 i.
(二)最大似然估计法
最(极)大似然估计的原理介绍
第七章
参数估计
目录/Contents
第1章 随机事件与 2 概率
§ 1 点估计
§3
估计量的评选标准
第七章 参数估计 ‹#›
问题的提出:
在实际进行统计时,有不少总体的(我们关心的某 确定指标)概率分布是已知的。比如
例 1 产品寿命服从的分布
X~
f
(
x)
1
x
e
x0
0
其他
但其中有参数是未知的: θ
n
似然函数 L f xi , 。 i 1
, xn ,
极大似然原理:L(ˆ( x1 ,
,
xn
))
max
L(
).
计算简化方法:
在求L 的最大值时,通常转换为求:lnL 的最大值,
lnL 称为对数似然函数.
利用
概率与统计

概率与统计是一门重要的数学学科,在各个领域都有广泛的应用。
概率与统计不仅帮助我们理解随机事件的规律,还可以通过收集和分析数据来进行预测和决策。
首先,让我们来探讨一下概率的概念。
概率是描述事件发生可能性的度量,用一个介于0到1之间的数值表示。
0表示事件不可能发生,1表示事件一定会发生。
而在0到1之间的数值则表示事件发生的可能性大小。
概率可以通过实验、统计或推理等方法进行计算。
在生活中,我们经常会用到概率,例如天气预报中的降雨概率,投资市场中的回报概率等等。
然后是统计学,在概率的基础上,统计学通过收集、整理和分析数据来了解现象的规律。
统计学有两个主要的分支,描述统计和推断统计。
描述统计是对现有数据进行总结和分析,例如平均数、方差、标准差等。
推断统计则是通过已有数据对总体进行推断,例如对人口比例、产品质量等进行估计。
概率与统计常常相互结合,互为补充。
概率可以帮助我们预测未来事件的可能性,而统计则可以通过收集数据来加强概率推测的准确性。
例如,我们可以通过收集大量的数据,计算出某种疾病的患病率,进而预测未来某人患病的概率。
又或者,我们可以通过统计数据来评估某种药物的疗效,进而推测该药物适用于什么类型的病人。
除此之外,概率与统计还可以帮助我们做出决策。
在不确定的情况下,我们可以通过计算概率来评估不同决策的可能结果,并选择可能性最高的决策。
例如,在投资市场中,我们可以通过统计数据来评估不同投资项目的风险和收益,进而做出最明智的投资决策。
最后,概率与统计也具有广泛的应用领域。
在自然科学中,概率与统计可以帮助我们解释现象的规律,例如天气模型、物理实验等。
在社会科学中,概率与统计可以帮助我们研究人类行为和社会现象,例如经济统计、人口普查等。
在工程领域中,概率与统计可以帮助我们评估产品质量、优化生产过程等,进而提高生产效率。
综上所述,概率与统计是一门重要的数学学科,它不仅帮助我们理解随机事件的规律,还可以通过收集和分析数据来进行预测和决策。
《概率论与数理统计》第7章作业题

第七章
(2)
1 x x 0
1
1
dx
2
1
0
1 由此得 1 , 在上式中以 X 1
x dx , 1
代替1 ,
得到 的矩估计量和矩估计值分别为:
X x ˆ ˆ . 1 X , 1 x
解 由题设可得 1-2 的一个置信水平为1- 的置信区间为
第七章
1 1 ( X Y ) t 2 ( n1 n2 2) S w n1 n2
由题设1- = 0.95, /2 = 0.025, n1 = 4, n2 = 5, n1+ n2-2 = 7,查表和计算得
x1 0.14125,
3s12 0.00002475,
x2 0.1392,
2 2 3 s 4 s 2 2 1 2 4s2 0.0000208, s 2 ( 0 . 00255 ) w 7 t 2 (n1 n2 2) t 0.025 (7) 2.3646, x1 x2 0.00205,
1 0.95,n A n B 10 F (n A - 1, n B - 1) F0.025(9,9) 4.03,
2
1 F (n A - 1, n B - 1) F0.975(9,9) 14.03 2
第七章
2 2 / 故方差比 A B
得 1-2 的一个置信水平为0.95的置信区间为
1 1 ( x1 x2 ) t 2 ( n1 n2 2) s w n1 n2 1 1 0 . 00205 2 . 3646 0 . 00255 4 5 (0.002 0.004) (0.002,0.006).
概率论与数理统计第七章

参数估计
湖南商学院信息系 数学教研室
第七章
第一节
第二节
参数估计
矩估计
极大似然估计
第三节
第四节
估计量的优良性准则
正态总体的区间估计(一)
第五节
正态总体的区间估计(二)
总体是由总体分布来刻画的.
总体分布类型的判断──在实际问题中, 我们根据问题本身的专业知识或以往的经验 或适当的统计方法,有时可以判断总体分布 的类型.
本章讨论:
参数估计的常用方法.
估计的优良性准则. 若干重要总体的参数估计问题.
参数估计问题的一般提法 设有一个统计总体,总体的分布函数 为 F(x, ),其中 为未知参数 ( 可以是 向量) . 现从该总体抽样,得样本 X1, X2 , … , Xn
要依据该样本对参数 作出估计,或估计
(m=1,2, ,k)
步骤二、 算出m阶样本原点矩:
1 n m Am X i m 1,2, , k n i 1 步骤三、令 am (1,2,,k) = Am
(m=1,2, ,k)得关于 1,2,,k的 方程组 步骤四、解这个方程组,其解记为
ˆ ( X , X ,, X ) i 1 2 n ,i 1,2, , k
n
1 2 ˆ : ˆ 其中 (X i X ) n i 1
矩法的优点是简单易行,并不需要 事先知道总体是什么分布 . 缺点是,当总体类型已知时,没有 充分利用分布提供的信息 . 一般场合下, 矩估计量不具有唯一性 .
其主要原因在于建立矩法方程时, 选取那些总体矩用相应样本矩代替带 有一定的随意性 .
数和2的矩估计为
例如 求正态总体 N(,2)两个未知参
概率论与数理统计教程第七章答案

.第七章假设检验7.1设总体J〜N(4Q2),其中参数4, /为未知,试指出下面统计假设中哪些是简洁假设,哪些是复合假设:(1) W o: // = 0, σ = 1 ;(2) W o√∕ = O, σ>l5(3) ∕70:// <3, σ = 1 ;(4) % :0< 〃 <3 ;(5)W o :// = 0.解:(1)是简洁假设,其余位复合假设7.2设配么,…,25取自正态总体息(19),其中参数〃未知,无是子样均值,如对检验问题“0 :〃 = 〃o, M :4工从)取检验的拒绝域:c = {(x1,x2,∙∙∙,x25)r∣x-χ∕0∖≥c},试打算常数c ,使检验的显著性水平为0. 05_ Q解:由于J〜N(〃,9),故J~N(",二)在打。
成立的条件下,一/3 5cP o(∖ξ-^∖≥c) = P(∖ξ-μJ^∖≥-)=2 1-Φ(y) =0.05Φ(-) = 0.975,-= 1.96,所以c=L176°3 37. 3 设子样。
,乙,…,25取自正态总体,cr:已知,对假设检验%邛=μ0, H2> /J。
,取临界域c = {(X[,w,…,4):片>9)},(1)求此检验犯第一类错误概率为α时,犯其次类错误的概率夕,并争论它们之间的关系;(2)设〃o=0∙05, σ~=0. 004, a =0.05, n=9,求"=0.65 时不犯其次类错误的概率。
解:(1)在儿成立的条件下,F~N(∕o,军),此时a = P^ξ≥c^ = P0< σo σo )所以,包二为册=4_,,由此式解出c°=窄4f+为% ∖∣n在H∣成立的条件下,W ~ N",啊 ,此时nS = %<c°) = AI。
气L =①(^^~品)二①匹%=①(2δξ^历σoA∣-σ+A)-A-------------- y∕n)。
高中二年级数学概率与统计初步

高中二年级数学概率与统计初步概率与统计是高中数学中的一门重要课程,它涵盖了概率和统计两个方面。
概率是用来描述事件发生的可能性,而统计则是通过对数据进行收集、分析和解释,来给出结论。
本文将从概率和统计两个角度来介绍高中二年级数学中的初步内容。
一、概率1.1 概率的基本概念概率是描述随机事件发生可能性的数值。
在实际生活中,我们经常会遇到概率的问题,比如投掷一枚硬币正面朝上的概率是多少,抽一张扑克牌时抽到黑桃的概率是多少等等。
1.2 事件与样本空间在概率问题中,事件是指某个具体结果的集合,样本空间是指所有可能结果的集合。
例如,投掷一枚硬币,事件可以是正面朝上,样本空间可以是{正面,反面}。
1.3 概率的计算方法在概率的计算中,有两种主要的方法:频率法和古典概型法。
频率法是通过做大量的实验来计算概率,古典概型法是通过确定每个结果出现的可能性来计算概率。
二、统计2.1 数据的收集与整理统计的第一步是收集数据,并对数据进行整理和分类。
我们可以使用表格、图表等形式来展示数据,以便更好地进行分析。
2.2 数据的描述性统计描述性统计是用来对收集到的数据进行概括和描述的方法。
常用的描述性统计方法包括平均数、中位数、众数、标准差等。
2.3 样本与总体在统计学中,我们通常会采集一部分数据作为样本,用来对整个总体进行推断。
样本的选择要具有代表性,以确保结果的可靠性。
2.4 统计推断统计推断是通过对样本数据进行分析,来推断总体的特征和性质。
常用的统计推断方法包括假设检验、置信区间等。
结论概率与统计是高中数学中的一门重要课程,它们在实际生活和各个领域中都有广泛的应用。
通过学习概率与统计,学生可以培养逻辑思维能力,提高数据分析和决策能力,为将来的学习和工作打下坚实的基础。
希望本文对读者对高中二年级数学概率与统计初步有所帮助。
概率论与数理统计第七章参数估计习题答案

æ çè
x
±
ua
/
2
s n
ö ÷ø
=
(14.95
±
0.1´1.96)
=
(14.754,15.146)
大学数学云课堂
3028709.总体X ~ N (m,s 2 ),s 2已知,问需抽取容量n多大的样本,
才能使m的置信概率为1 -a,且置信区间的长度不大于L?
解:由s
2已知可知m的置信度为1
-
a的置信区间为
64 69 49 92 55 97 41 84 88 99 84 66 100 98 72 74 87 84 48 81 (1)求m的置信概率为0.95的置信区 间.
(2)求s 2的置信概率为0.95的置信区间.
解:x = 76.6, s = 18.14,a = 1- 0.95 = 0.05, n = 20,
大学数学云课堂
3028706.设X1,X 2,L,X n是取自总体X的样本,E(X)= m,D(X)= s 2,
n -1
å sˆ 2 = ( X i+1 - X i )2 ,问k为何值时sˆ 2为s 2的无偏估计. i =1 解:令 Yi = X i+1 - X i , i = 1, 2,¼, n -1, 则E(Yi ) = E( X i+1) - E( X i ) = m - m = 0, D(Yi ) = 2s 2 , n -1 å 于是Esˆ 2 = E[k ( Yi2 )] = k(n -1)EY12 = 2s 2 (n -1)k, i =1 那么当E(sˆ 2 ) = s 2 ,即2s 2 (n -1)k = s 2时, 有k = 1 . 2(n -1)
的密度函数为f
(x,q
概率论与数理统计(第三版)课后答案习题7

第七章 参数估计1. 解 )1()(,)(),,(~p np X D np X E p n B X -==∴⎩⎨⎧=-=⎩⎨⎧==22)1(,)()(B p np X np B X D X X E 即由解之,得n,p 的矩估计量为XB p B X X n 2221,-=⎥⎥⎦⎤⎢⎢⎣⎡-=∧∧注:“[ ]”表示取整。
2. 解 因为:220)(22)(1)1()(1)()(λλθλλθλθλθλ++=⋅=+=⋅==⎰⎰⎰∞+--∞+--∞+∞-dx e x x E dx e x dx x xf x E x x所以,由矩估计法得方程组: ⎪⎩⎪⎨⎧++=+=2221)1(1λλθλθA X 解得λθ,的矩估计量为 ⎪⎩⎪⎨⎧=-=∧∧221B B X λθ3. 解 (1) 由于 222)]([)()(X E X E X D -==σ令 ∑===n i iX n A X E 12221)( 又已知 μ=)(X E故 2σ的矩估计值为 ∑∑==∧-=-=-=n i i n i i X n X n A 12122222)(11μμμσ(2) μ已知时,似然函数为:⎭⎬⎫⎩⎨⎧--⋅=∑=-ni in x L 122222)(21exp )2()(μσπσσ因此∑=---=ni ixn L 12222)(21)2ln(2)(ln μσπσσ令 0)(2112)(ln 124222=-+-=∑=ni ixn L d dμσσσσ解得2σ的极大似然估计为: ∑=∧-=n i i X n 122)(1μσ4. 解 矩估计:λλ=∴=)()(X E X E 令X X E =)(故X =∧λ为所求矩估计量。
注意到 λ=)(X D 若令 2)(B X D =, 可得: 2B =∧λ似然估计:因为λλ-==e k k X P k!)(所以,λ的似然函数为∏=-=ni i xe x L i1!)(λλλ取对数λλλn x x L ni i ni i --=∑∑==11)!ln(ln )(ln令ln 1=-=∑=n xd d ni iλλλ, 解得∑=∧=ni ix n 11λ故,λ极大似然估计量为 X =∧λ5. 解 矩估计:21)1()()(11++=+==⎰⎰+∞+∞-θθθθdx x dx x xf X E令 X X E =)(, 即 X=++21θθ; 解之X X --=∧112θ 似然估计: 似然函数为⎪⎩⎪⎨⎧<<+=⎪⎩⎪⎨⎧<<+=∏∏==其它其它,010,)()1(,010,)1()(11i ni i ni n i i x x x x L θθθθθ 只需求10,)()1()(11<<+=∏=i ni i nx x L θθθ的驻点即可.又∑=++=ni ix n L 11ln )1ln()(ln θθθ令∑=++=ni ix n L d d 11ln 1)(ln θθθ; 解之∑=∧--=ni ixn1ln 1θ6. 解:似然函数为∑===---=-=---∏∏ni i i xn i i n ni x i ex ex L 12222)(l n 21112212)(l n 12)()2(21),(μσσμπσσπσμ取对数得 ∑----===∏n i ini i x x n L 122122)(l n 21)l n ()2l n (2),(ln μσπσσμ由 0)(l n 2112),(ln 0)1()(ln 221),(ln 124222122=∑-+⋅-=∂∂=∑-⋅--=∂∂==n i i n i i x n L x L μσσσμσμσσμμ联立解之,2,σμ的极大似然估计值为 ∑∑-=∑===∧=∧n i n i i in i i x n x n x n 12121)ln 1(ln 1,ln 1σμ7. 解:似然函数为 n i x x e ax L i i n i x a i ai ,,2,1;0,00,)(11 =⎪⎩⎪⎨⎧≤>=∏=--λλλ只需求∑⋅===--==--∏∏ni ai ai x a n i n n ni x a i ex a eax L 111111)()(λλλλλ的最值点。
《概率论与数理统计》课件 第七章 随机变量的数字特征

i 1,2, , 如果 xi pi , 则称 i 1 E( X ) xi pi 为随机变量X的数学期望; i 1
或称为该分布的数学期望,简称期望或均值.
(2)设连续随机变量X的密度函数为p( x),
如果
+
x p( x)dx ,
则称
-
E( X ) xp( x)dx 为随机变量X的数学期望.
5
例2.求二项分布B(n, p)的数学期望.
P(X
k)
n!
k!n
k !
pk
(1
p)nk ,k
1, 2,
, n.
n
解:EX kP{ X k}
k0
n
k
k0
n!
k!n
k !
pk
(1
p)nk
n
np
k 1
k
n 1! 1!n
pk1
k!
(1
p)nk
np[ p (1 p)]n1 np.
特别地,若X服从0 1分布,则EX p.
6
例3. 求泊松分布P( )的数学期望.
注:P( X k) k e , k 1, 2, .
k!
解:EX k k e e
k1
e
k1
k0 k !
k1 k 1 !
k1 k 1 !
ee
e x 1 x 1 x2 1 xn [这里,x ]
当 a 450时,平均收益EY 最大.
28
第二节 方差与标准差
29
引例
比较随机变量X、Y 的期望
X3 4 5 Y1 4 7 P 0.1 0.8 0.1 P 0.4 0.2 0.4
01 2 3 4 5 67
概率论与数理统计第7章参数估计习题及答案

概率论与数理统计第7章参数估计习题及答案第7章参数估计 ----点估计⼀、填空题1、设总体X 服从⼆项分布),(p N B ,10<计量=pXN. 2、设总体)p ,1(B ~X,其中未知参数 01<则 p 的矩估计为_∑=n 1i i X n 1_,样本的似然函数为_ii X 1n1i X )p 1(p -=-∏__。
3、设 12,,,n X X X 是来⾃总体 ),(N ~X 2σµ的样本,则有关于 µ及σ2的似然函数212(,,;,)n L X X X µσ=_2i 2)X (21n1i e21µ-σ-=∏σπ__。
⼆、计算题1、设总体X 具有分布密度(;)(1),01f x x x ααα=+<<,其中1->α是未知参数,n X X X ,,21为⼀个样本,试求参数α的矩估计和极⼤似然估计.解:因?++=+=101α2α1α102++=++=+|a x 令2α1α++==??)(X X EXX --=∴112α为α的矩估计因似然函数1212(,,;)(1)()n n n L x x x x x x ααα=+∑=++=∴ni i X n L 1α1αln )ln(ln ,由∑==++=??ni i X nL 101ααln ln 得,α的极⼤似量估计量为)ln (?∑=+-=ni iXn11α2、设总体X 服从指数分布 ,0()0,x e x f x λλ-?>=??其他,n X X X ,,21是来⾃X 的样本,(1)求未知参数λ的矩估计;(2)求λ的极⼤似然估计.解:(1)由于1()E X λ=,令11X Xλλ=?=i x nn L x x x eλλ=-∑=111ln ln ln 0nii ni ni ii L n x d L n n x d xλλλλλ====-=-=?=∑∑∑故λ的极⼤似然估计仍为1X。
概率论与数理统计(经管类)第七章课后习题答案word

习题1.设总体X服从指数分布试求的极大似然估计.若某电子元件的使用寿命服从该指数分布,现随机抽取18个电子元件,测得寿命数据如下(单位:小时):16, 19, 50, 68, 100, 130, 140, 270, 280, 340, 410, 450, 520, 620, 190, 210, 800, 1100.求的估计值.解:令得2.设总体X的概率密度为试求(1)解:(1)(2)解得3.设总体X服从参数为(可参考例7-8)解:由矩法,应有解得习题1.证明样本均值证:2.证明样本的k阶矩证:3.设总体(1)(2)(3)都是的无偏估计,并求出每一估计量的方差,问哪个方差最小?证:故的方差最小.4.设总体(1)证明(2)求(1)证:又(2)似然函数因习题1.土木结构实验室对一批建筑材料进行抗断强度试验.已知这批材料的抗断强度.现从中抽取容量为6的样本测得样本观测值并算的解:2.设轮胎的寿命X服从正态分布,为估计某种轮胎的平均寿命,随机地抽取12只轮胎试用,测得它们的寿命(单位:万千米)如下:试求平均寿命(例7-21,)解:平均寿命3.两台车床生产同一种型号的滚珠,已知两车床生产的滚珠直径X,Y分别服从现由甲,乙两车床的产品中分别抽出25个和15个,测得求两总体方差比的置信度的置信区间.解:此处的置信度的置信区间为:4.某工厂生产滚珠,从某日生产的产品中随机抽取9个,测得直径(单位:毫米)如下:设滚珠直径服从正态分布,若(1)已知滚珠直径的标准差毫米;(2)未知标准差求直径均值解: (1)直径均值(2)5.设灯泡厂生产的一大批灯泡的寿命X服从正态分布令随机地抽取16个灯泡进行寿命试验,测得寿命数据如下(单位:小时):1502 1480 1485 1511 1514 1527 1603 1480 1532 1508 1490 1470 1520 1505 1485 1540求该批灯泡平均寿命解:6.求上题灯泡寿命方差解:7.某厂生产一批金属材料,其抗弯强度服从正态分布.现从这批金属材料中随机抽取11个试件,测得它们的抗弯强度为(单位:公斤):注意这里是求的置信求(1)平均抗弯强度(2)抗弯强度标准差解: (1)(2)故8.设两个正态总体中分别取容量为10和12的样本,两样本互相独立.经算得解:9.为了估计磷肥对农作物增产的作用,现选20块条件大致相同的土地.10块不施磷肥,另外10块施磷肥,得亩产量(单位:公斤)如下:不施磷肥的560 590 560 570 580 570 600 550 570 550 施磷肥的620 570 650 600 630 580 570 600 600 580 设不施磷肥亩产和施磷肥亩产均服从正态分布,其方差相同.试对施磷肥平均亩产与不施磷肥平均亩产之差作区间估计().解:10.有两位化验员A,B独立地对某种聚合的含氮量用同样的方法分别进行10次和11次测定,测定的方差分别为.设A,B两位化验员测定值服从正态分布,其总体方差分别为.求方差比的置信度的置信区间.解:的置信度的置信区间为:自测题7一、填空题设总体是未知参数的无偏估计.解:是未知参数的无偏估计则二、一台自动车床加工零件长度X(单位:厘米)服从正态分布.从该车床加工的零件中随机抽取4个,测得长度分别为:12.6,13.4,12.8,13.2.试求: (1)样本方差;(2)总体方差的置信度为95%的置信区间.(附:解: (1)(2)三、设总体(1)已知(2)已知,样本容量n至少应取多大?(附)解: (1)(2)故区间长度为四、某大学从来自A,B两市的新生中分别随机抽取5名与6名新生,测其身高(单位:厘米)后,算的.假设两市新生身高分别服从正态分布:,的置信度为的置信区间.(附:解:。
概率论与数理统计习题及答案-第七章

1 F(x,β)=
x
,
x ,
0,
x .
其中未知参数 β>1,α>0,设 X1,X2,…,Xn 为来自总体 X 的样本 (1) 当 α=1 时,求 β 的矩估计量; (2) 当 α=1 时,求 β 的极大似然估计量; (3) 当 β=2 时,求 α 的极大似然估计量. 【解】
2 0.025
(19)
32.852,
2 0.975
(19)
8.907
(1) μ的置信度为 0.95 的置信区间
s
18.14
x ta/2 (n 1) 76.6
2.093 (68.11,85.089)
n
20
(2) 2 的置信度为 0.95 的置信区间
(2)
D( ˆ1 )
2
2
D( X1 )
1
2
D(X2 )
4
X
2
5
2
,
3
3
9
9
3
2
1
2
3
5 2
D(ˆ2 ) D( X1) D( X 2 ) ,
4
4
8
D(ˆ3
)
1
2
D( X1 )
D(X
2
)
2
(
x),
0 x ,
0,
其他.
X1,X2,…,Xn 为其样本,试求参数θ的矩法估计.
概率与数理统计第7章参数估计习题与答案

第7章参数估计----点估计一、填空题1、设总体X服从二项分布B(N,p),0P1,X1,X2X n是其一个样本,那么矩估计量p?XN.2、设总体X~B(1,p),其中未知参数0p1,X1,X2,X n是X的样本,则p的矩估计为_ 1n in1X i _,样本的似然函数为_in1X i(1p)1Xp__。
i3、设X1,X2,,X n是来自总体X~N(,2)的样本,则有关于及2的似然函数2L(X,X,X n;,)_12 in112e12(X) i22__。
二、计算题1、设总体X具有分布密度f(x;)(1)x,0x1,其中1是未知参数,X1,X2,X为一个样本,试求参数的矩估计和极大似然估计.n解:因E(X ) 1x1a()α1(α1)xdx1x dxαα112a2|xααα12令E(X)X?α?α122X1α?为的矩估计1Xn因似然函数L(x1,x2,x;)(1)(x1x2x)nnnlnLnln(α1)lnX,由αii1 l nLαnα 1inlnX0得,i1n ?的极大似量估计量为(1)αnln Xii12、设总体X服从指数分布f(x)xe,x00,其他,X1,X2,X n是来自X的样本,(1)求未知参数的矩估计;(2)求的极大似然估计.56解:(1)由于1 E(X),令11 X X,故的矩估计为? 1 X(2)似然函数nL(x,x,,x )e12ni nx i 1nlnLnlnxii1 ndlnLnnx0 indi1x ii1故的极大似然估计仍为1 X 。
3、设总体 2 X~N0,, X 1,X 2,,X n 为取自X 的一组简单随机样本,求 2 的极大似然估计;[解](1)似然函数n1 Le i122 x i 2 22n 22en 2x i 2 i 12于是n2nnx2i lnLln2ln2222i1 dlnLn1d224 22n i1 2x i,令 d lnL 2d 2 0,得的极大似然估计:n 122X ini1. 4、设总体X 服从泊松分布P(),X 1,X 2,,X n 为取自X 的一组简单随机样本,(1)求 未知参数估计;(2)求大似然估计. 解:(1)令E(X )X?X ,此为估计。
概率论与数理统计第七章课后习题及参考答案

5.设总体 X 的概率密度为
f
(x,
)
(
1) x
,0
x
1,
0, 其他.
其中 1是未知参数, X1 , X 2 ,…, X n 是来自 X 的一个样本.试求参数
2
的矩估计和极大似然估计.现有样本观测值 0.1 ,0.2 ,0.9 ,0.8 ,0.7 及 0.7 ,
求参数 的矩估计值和极大似然估计值.
1 2 2 c 2 2 ( 1 c) 2 ,
n
n
取 c 1 即可. n
14.设总体 X 的均值为 ,方差为 2 ,从总体中抽取样本 X1 , X 2 , X 3 ,证明
(
x,
,
2
)
1
1
1
e 2 2
(ln x )2
,
x
0,
2 x
0,
x 0.
其中 , 0 为未知参数, X1 , X 2 ,…, X n 是取自该总体的一
个样本,求参数 , 2 的极大似然估计.
解: xi 时,似然函数为
L(, 2 )
(
1 2 )n
1 x1x2 xn
exp{
dL
d
n exp{
n i 1
( xi
)}
0,
所以 L( ) 是 的单调增函数,从而对满足条件 xi 的任意 ,有
n
n
L( ) exp{ i1 (xi )} exp{ i1 (xi m1iinn{xi})} ,
即 L( ) 在 m1iinn{xi} 时取最大值, 故 的极大似然估计值为ˆ m1iinn{xi} . 7.(1) 设总体 X 具有分布律
ˆ1 X1 ;
ˆ2
概率论与数理统计第七章习题讲解

1 6
1 3
因此T1,T3是的无偏估计量. (2) X1,X2,X3,X4相互独立
1 1 1 5 2 2 1 D(T1 ) [ D( X1 ) D( X 2 )] [ D( X 3 ) D( X 4 )] 2 ( ) 36 9 36 9 18 1 1 5 D(T3 ) [ D( X1 ) D( X 2 ) D( X 3 ) D( X 4 )] (1 1 1 1) 2 2 16 16 20
故 E(Y)=aE(X1)+bE(X2)=(a+b)=, (a+b=1) 所以,对于任意常数,a,b(a+b=1), Y=aX1+bX2都是的无偏估计. 由于两样本独立,故两样本均值X1和X2独立,所以
2 2 2 2 a ( 1 a ) a b ] 2 D(Y ) a 2 D( X 1 ) b 2 D( X 2 ) [ ] 2 [ n1 n2 n1 n2 dD(Y ) 2a 2(1 a ) 2 由极值必要条件 [ ] 0 da n1 n2
1 E( X )
1 0
xf ( x)dx.
1 1 0
x dx x 1 1 解出 ( )2 1 1
1
将总体一阶矩1换成样本一阶矩A1=X ,
得到参数的矩估计量
矩估计值
X 2 ( ) 1 X
x 2 ( ) 1 x
( x1 x2 t / 2 ( n1 n2 2) sw
1 1 2 (n1 1) S12 (n2 1) S22 2 ) Sw , Sw Sw . n1 n2 n1 n2 2
n1=4,n2=5,1-=0.95, =0.05, t/2(n1+n2-2)=t0.025(7)= 2.3646
概率论与数理统计第七章参数估计
例1. 设总体X的数学期望和方差分别是μ,
σ2 ,求μ , σ2的矩估计量。
E(X )
E( X 2 ) D( X ) [EX ]2 2 2
(3) 写出方程 ln L 0
i1
若方程有解,
求出L(θ)的最大值点 ˆ(x1,x2,..x.n,)
于 是 ˆ ˆ ( X 1 , X 2 , . . . , X n ) 即 为 的 极 大 似 然 估 计 量
例2. 设总体X服从参数λ>0的泊松分布,求 参数λ的极大似然估计量。
例3. 已知某产品的不合格率为p,有简单随机样本 X1 ,X2 ,…, Xn,求p的极大似然估计量。 若抽取100件产品,发现10件次品,试估计p.
ˆ(x1,x2,..x.n,),使得
L (ˆ) m a x L (), (或 L (ˆ) s u p L ())
则 称 ˆ ( x 1 ,x 2 , . . . ,x n ) 为 的 极 大 似 然 估 计 值
称 ˆ ( X 1 ,X 2 ,...,X n ) 为 极 大 似 然 估 计 量
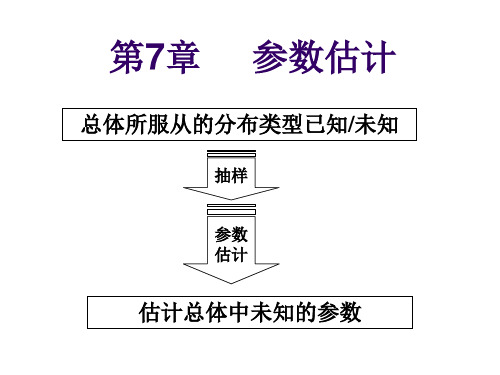
第7章 参数估计
总体所服从的分布类型已知/未知
抽样
参数 估计
估计总体中未知的参数
参数估计 参数估计问题是利用从总体抽样得到的信息
来估计总体的某些参数. 估计新生儿的体重
估计废品率
估计湖中鱼数
§7.1
点估计
设有一个统计总体,总体的分布函数
为 F(x, ),其中为未知参数 (可以是向量) .
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第六节分布参数的区间估计
一、置信区间公式
二、典型例题
)10(
一、置信区间公式
置信区间是的
的置信度为则为未知参数其中的分布律为的总体分布它来自的大样本设有一容量α-=-=->-1,,1,0,)1();( ,)10(,501p p x p p p x f X X n x x ,24,2422⎪⎪⎭
⎫ ⎝⎛-+----a ac b b a ac b b , 22/αz n a +=其中),2(22/αz X n b +-=.2
X n c =
推导过程如下:
因为(0–1)分布的均值和方差分别为
),
1(,2p p p -==σμ , ,,, 21是一个样本设n X X X 因为容量n 较大,由中心极限定理知)1()1(1p np np X n p np np X n i i --=--∑=
, )1,0( 分布近似地服从N ,1)1(2/2/ααα-≈⎭
⎬⎫⎩⎨⎧<--<-z p np np X n z P
2/2/)
1( ααz p np np X n z <--<-不等式,
0)2()( 222/222/<++-+X n p z X n p z n αα等价于,24,242
221a
ac b b p a ac b b p -+-=---=令, 22/αz n a +=其中),2(22/αz X n b +-=.
2X n c =的置信区间是的近似置信水平为则α-1p ).
,(21p p
二、典型例题
设从一大批产品的100个样品中, 得一级品60个, 求这批产品的一级品率p 的置信水平为0.95的置信区间.
解一级品率p 是(0-1)分布的参数,
,
100=n ,6.010060==x ,
95.01=-α,96.1025.02/==z z α,
84.103 22/=+=αz n a 则例1
)2(22/αz X n b +-=)2(2
2/αz x n +-=,84.123-=22x n X n c ==,36=a
ac b b p 242
1---=于是a
ac b b p 2422-+-=,50.0=,69.0=p 的置信水平为0.95的置信区间为).69.0,50.0(
设从一大批产品的120个样品中, 得次品9个, 求这批产品的次品率p 的置信水平为0.90的置信区间.
解,120=n ,09.0100
9==x ,90.01=-α例22
2αz n a +=则,
71.122=)2(22αz X n b +-=)2(22αz x n +-=,31.24-=2X n c -=2
x n -=,972.0=
p 的置信水平为0.90的置信区间为).143.0,056.0(a ac b b p 2421---=于是,056.0=a
ac b b p 2422-+-=,143.0=。