solrcloud创建solr5.4.0+tomcat_7+zookeeper
Solr安装使用教程

Solr安装使⽤教程⼀、安装1.1 安装jdksolr是基于lucene⽽lucene是java写的,所以solr需要jdk----当前安装的solr-7.5需要jdk-1.8及以上版本,下载安装jdk并设置JAVA_HOME即可。
jdk下载地址:1.2 安装solr下载solr,然后解压即可,windows和linux都可以下.tgz(.tgz本质是.tar.gz)和.zip解压出来都⼀样的。
solr下载地址:要注意图中的链接是下载页⾯的链接并不是solr⽂件的链接,直接wget链接就报gzip: solr-7.5.0.tgz: not in gzip format或End-of-central-directory signature not found.了。
1.3 设置系统资源限制设置最⼤进程数t和打开⽂件数为65000(可能其他⼀些资源也要修改但我安装时没见有其他问题,⽂档也没看到专门说明)ulimit -u 65000ulimit -n 65000⼆、solr基本⽤法对于没⽤过的新⼿⽽⾔,⾸先最关⼼的是怎么运⾏起来看这东西长什么样其他什么⾼级⽤法后⽽再说,这⾥我们就来做这件事。
2.1 启停进⼊解压后⽂件的bin⽬录,执⾏:# 启动./solr start# 停⽌./solr stopsolr默认拒绝以root⾝份启动,root加-force选项可以启动,但后续进⾏操作(如创建核⼼等)还是会有问题,推荐使⽤普通⽤户动。
启动完成后默认监听8983端⼝,访问可见界⾯如下2.2 solr核⼼(core)创建与删除在上⾯启动起来的页⾯可以看到solr就是就是这么⼀个界⾯简陋的东西----页⾯简单(没⼏个页⾯)加布局丑陋。
solr中⼀个核⼼(core)相当于⼀个搜索引擎,然后上传⽂件时也是上传到指定核⼼;solr可以建⽴多个solr。
solr默认没有core,我们先来创建⼀个core。
通过命令创建和删除core:# 创建core,-c指定创建的core名./solr create -c test_core1# 删除core,-c指定删除的core名./solr delete -c test_core1完成后回刷新solr界⾯,点击下拉“Core Selector”即可看到刚才建⽴的core,选择core即可进⼊core的管理界⾯,如下图。
SolrCloud安装手册基于solr

solrCloud集群安装手册—基于solrS. 2. 1、SolrCloud 集群架构概览1.1 SolrCloud 索引架构SolKloud 的索引存储中,三台服务器都要存索引。
1.2 ZooKeeper 架构ZooKeeper 集群,同时在三台服务器中配置ZooKeepero Shardl SolrCloudshardsShard2其中每一个分片有两份数据,一个是leader^ 同机器上,可以保证在某一台服务器down 掉后, 另一个是备份。
分别存储在不 仍可提供完整的数据服务。
c a har d25 hards —♦114.212-83.2430114.212.86.102O1I4.212.82.189 • 114,212.83.243 0114.212-82489—•114.212.86402/3.1JDK配置(1)解压JDK的压缩包至/usr/local/ U录下tar -zxvf JDK 压缩包位置-C /usr/local/(2)修改配置文件vi /etc/profile在下面添加如下内容export JAVA_HOME=/usr/local/jdkl.8.0_45exp ort CLASSPATH二•:${JAVA_HOME}/lib:${JAVA_HOME}/lib/tools・jarexport PATH=S{JAVA_HOME}/bin:$PATH然后在命令行中输入source /etc/profile输入命令java -version査看是否安装正确3.2Tomcat 配置(1)解压tomcat的压缩包至/home/dell/sofhvare tl录下tar -zx\・f ap aclie-tonicat-8.0.14.tar.gz(2)运行tomcat 中的staitiip.sh 运行tomcat(3)由于防火墙的原因无法访问8080端口,以下步骤为开放8080端口:/sbin/iptables -I INPUT -p tcp -dport 8080 寸ACCEPTservice iptables saveservice iptables restart或者直接禁用防火墙:停止/启动防火墙/sbin/service ip tables restart "重启/sbin/service ip tables stop —停止/sbi n/service ip tables start -启动1)重启后生效开启: chkconfig ip tables on 关闭:chkconfig iptables off2)即时生效,重启后失效开启:service ip tables start 关闭:service ip tablesstop然后访问服务器的8080端口査看tomcat是否安装正确。
solr使用流程

solr使用流程Solr使用流程一、概述Solr是一个开源的企业级搜索平台,基于Apache Lucene构建。
它提供了强大的全文搜索、分布式搜索、面向文档的搜索和高级搜索功能。
Solr的使用流程可以分为以下几个步骤:准备环境、创建索引、搜索数据。
二、准备环境在开始使用Solr之前,首先需要准备好运行环境。
Solr可以运行在各种操作系统上,包括Windows、Linux和Mac OS。
在安装Solr 之前,确保已经安装了Java Development Kit(JDK),并配置好了JAVA_HOME环境变量。
然后,从Solr官网下载最新版本的Solr,并解压到本地目录中。
三、创建索引1. 定义Schema在开始创建索引之前,需要定义Schema。
Schema是Solr中的模式文件,用于定义索引字段的类型、分析器和其他属性。
可以使用任何文本编辑器打开schema.xml文件,并根据需求进行修改。
常见的字段类型包括文本类型、日期类型、布尔类型等。
2. 导入数据在定义好Schema之后,需要将数据导入到Solr中。
Solr支持多种数据导入方式,包括手动导入和自动导入。
手动导入可通过提交XML或JSON格式的数据来实现,而自动导入则可以通过配置数据源和定时任务来实现。
3. 创建索引数据导入完成后,即可创建索引。
在Solr中,索引是由一系列的文档组成,每个文档都包含多个字段。
可以使用Solr提供的API来创建索引,也可以使用Solr的客户端工具来操作。
创建索引的过程包括向Solr提交文档、更新索引和删除索引等操作。
四、搜索数据创建索引完成后,即可开始搜索数据。
Solr提供了丰富的搜索功能,可以通过关键字、范围、过滤条件等进行高级搜索。
可以使用Solr 提供的查询语法来构建查询语句,并通过HTTP请求将查询发送给Solr服务器。
Solr会返回与查询条件匹配的文档列表。
1. 构建查询语句在构建查询语句时,需要考虑搜索的字段、搜索的关键字和搜索的条件。
solr配置及数据库及文档解析

一、准备数据1.去官网下载最新的solr。
当前最新为4.5版本。
2.准备tomcat7.(下载tomcat7)二、配置solr。
1.将下载的solr4.5解压得到:2.将example\solr-webapp 下的solr.war 放到tomcat的webapp下。
3.启动tomcat 此时报错,solr.war 解压关闭tomcat 删除solr.war4.得到solr 项目5.配置solr_home :将下载的solr包中解压的example/solr 文件夹copy到d:/solr/solr_home(路径可以任意修改)。
6.打开tomcat下的webapp\solr\WEB-INF 下的web.xml,修改添加如下代码:<env-entry><env-entry-name>solr/home</env-entry-name><env-entry-value>D:/solr/solr_home</env-entry-value><env-entry-type>ng.String</env-entry-type></env-entry>7.其中<env-entry-value> 中的值即为第5步中配置的路径。
8.copy 下载包中的example\lib\ext 下的jar包全部放到tomcat 的lib 目录下。
9设置solr/collection/conf/中的solrconfig.xml 中jar包路径,将路径该对就可以了。
10.将C:\app\solr-4.5.0\solr-4.5.0\example\resources下的log4j.properties拷贝到C:\Program Files\Apache Software Foundation\Tomcat 7.0\webapps\solr\WEB-INF\classes下。
Tomcat、TongWeb5.0、TongWeb6.0部署solr

Tomcat、TongWeb5.0、TongWeb6.0部署solr将solr,solr-4.7.2复制到某⼀路径下,⽐如F盘根⽬录。
1、tomcat中进⾏配置,配置如下:<Context docBase="F:/solr" reloadable="true" ><Environment name="solr/home" type="ng.String" value="F:/solr-4.7.2/example/solr" override="true" /></Context>将tomcat启动,启动solr服务器,就可以进⾏索引创建及查询了。
2、东⽅通TongWeb5.0中进⾏配置。
配置如下:a、东⽅通安装⽬录下 **\TongWeb5.0\config\twns.xml 的<deployments></deployments>标签中间添加<web-app context-root="solr" name="solr" source-path="F:\solr" />b、solr主⽬录配置: F:\solr\WEB-INF\web.xml 中加⼊<env-entry><env-entry-name>solr/home</env-entry-name><env-entry-value>F:\solr-4.7.2\example\solr</env-entry-value><env-entry-type>ng.String</env-entry-type></env-entry>3、东⽅通TongWeb6.0中进⾏配置,配置如下:a、把solr1\solr-4.7.2\dist\solr-4.7.2.war包复制到TongWeb6.0\autodeploy⽬录下b、在TongWeb6.0\bin\tongweb.xml⽂件⾥添加:<web-app name="solr-4.7.2" original-location="D:\TongWeb6.0\autodeploy\solr-4.7.2.war"location="${tongweb.app}\solr-4.7.2" context-root="/solr-4.7.2" vs-names="server" is-directory="false" enabled="true" description="autodeploy---solr-4.7.2.war" deploy-order="100" object-type="user" jsp- compile="false" dtd-validate="false" is-autodeploy="true" version="" retire-state="none" retire-strategy="nature" retire-timeout="0" version-serial-number="1"/>指定war位置和系统访问路径。
solr配置

9. 将example/lib/ext/下的所有jar包复制到tomcat/webapps/solr/WEB-INF的lib目录中,一共5个,是solr的独立日志处理模块;可以修改core名称,不过修改时需要将对应文件夹下面的core.properties里面的name名称一并换掉
10. 在tomcat/webapps/solr/WEB-INF/下新建一个classes目录,将example/resources下的log4j.properties文件复制到该classes目录中,否则日志模块无法正常工作;
solr 配置
1. 下载solr压缩包(下面均已solr-4.7.0解说)
ห้องสมุดไป่ตู้
2. 解压solr-4.7.0.tgz
3. 新建一个Solr文件夹(名称与位置随意),我建在了D盘下
4. 然后在Solr下面创建solr1文件夹(做集群使用,后续会讲到),
5. 最后在solr1下创建两个文件夹,分别为tomcat(存放tomcat,自己放入,下面我就不提到了,假设端口为8080)和home(存放core和索引信息)
<env-entry-value>D:\Solr\solr1\home</env-entry-value>
<env-entry-type>ng.String</env-entry-type>
</env-entry>
12. 重启tomcat
13. 浏览器输入:http://localhost:8080/solr就能看到solr的管理界面了
6. 将example/webapps目录下的solr.war复制到tomcat的webapps目录中
solr完整快速搭建版(学习笔记)

Solr学习笔记由于公司一个网站需要实现搜索功能的更新换代,在和编辑和领导沟通了一段时间之后,我们决定不再使用之前的通过JDBC发送sql语句进行搜索的方法。
一番比较,我们决定选用Lucene来搭建我们全文搜索的框架。
后来由于开发时间有限,Solr对lucene的集成非常好,我们决定使用Struts+Spring+Solr+IKAnalyzer的一个开发模式来快速搭建一个企业级搜索平台。
自己之前没有接触过这方面的东西,从不断看网上的帮助文档,逛论坛,逛wiki,终于一点一点的开发出一个有自己风格并又适合公司搜索要求的这么一个全文搜索功能。
网上对于lucene,solr的资料并不是那么多,而且大多是拷贝再拷贝,开发起来难度是有的,项目缺陷也是有的,但是毕竟自己积累了这么一个搭建小型搜索引擎的经验,很有收获,所以准备写个笔记记录下来,方便自己以后回忆,而且可以帮助一下其他学者快速搭建一个企业级搜索。
主要思想:此企业级搜索分2块,一块是Solr项目:仅关于Solr一系列配置,索引,建立/更新索引配置。
另一块是网站项目:Action中通过httpclient通信,类似webService一个交互实现,访问配置完善并运行中的Solr,发送查询请求,得到返回的结果hits(solrJ查询,下面详解),传递给jsp页面。
1.下载包Lucene3.5Solr3.5IKAnalyzer3.2.8中文分词器(本文也仅在此分词器配置的基础上)开发时段:2011.12中旬至1月中旬(请自己下载…)都是最新版,个人偏好新东西,稳定不稳定暂不做评论。
2.搭建Solr项目:1.apache-solr-3.5.0\dist下得apache-solr-3.5.0.war复制到tomcat下webapps目录,并更改名字为solr.war,运行生成目录.2.将IKAnalyzer的jar包导入刚生成的项目中lib目录下。
3.Solr项目配置中文分词:在solr/conf/schema.xml中<types>节点下添加个<fieldType>类型(可直接拷贝下段代码)<!--hu add IKAnalyzer configuration--><fieldType name="textik" class="solr.TextField" ><analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/><analyzer type="index"><tokenizer class="org.wltea.analyzer.solr.IKT okenizerFactory"isMaxWordLength="false"/><filter class="solr.StopFilterFactory"ignoreCase="true" words="stopwords.txt"/><filter class="solr.WordDelimiterFilterFactory"generateWordParts="1"generateNumberParts="1"catenateWords="1"catenateNumbers="1"catenateAll="0"splitOnCaseChange="1"/><filter class="solr.LowerCaseFilterFactory"/><filter class="solr.EnglishPorterFilterFactory"protected="protwords.txt"/><filter class="solr.RemoveDuplicatesT okenFilterFactory"/></analyzer><analyzer type="query"><tokenizer class="org.wltea.analyzer.solr.IKT okenizerFactory" isMaxWordLength="false"/><filter class="solr.StopFilterFactory"ignoreCase="true" words="stopwords.txt"/><filter class="solr.WordDelimiterFilterFactory"generateWordParts="1"generateNumberParts="1"catenateWords="1"catenateNumbers="1"catenateAll="0"splitOnCaseChange="1"/><filter class="solr.LowerCaseFilterFactory"/><filter class="solr.EnglishPorterFilterFactory"protected="protwords.txt"/><filter class="solr.RemoveDuplicatesT okenFilterFactory"/></analyzer></fieldType>此配置不过多解释:<analyzer type="query">此处配置type并分成index和query 代表着在索引和查询时候的分词实现,isMaxWordLength表示是以何种分词实现,true,false各代表一种,具体请看IKAnalyzer说明文档。
Solrj操作Solr4

Solrj操作Solr4.0 中CloudSolrServer的一般过程一、准备工作:创建eclipse工程1. 下载solr4.0_src的源码包,解压后,进入目录中,在命令行执行:ant eclipse 则可以生成一个eclipse工程,会在目录中多了关于eclipse工程的文件:.classpath 和 .project;在eclipse导入该生成的工程(lucene-solr),工程名为lucene-solr,可以看到其全部源码;编写自己的代码,就能测试了!注意:需要安装ant 工具,以及ivy包,搜一下,去appache下来,配置好,才能编译通过。
Ant编译时间有点长。
关于ant(another neat tool)不再过多介绍,网上有很多教程。
只要明白ant相当于一个make的工具,其解析biuld.xml文件的相关指令。
2. 下载solr4.0 zip 包,将其中的所有jar包都添加你的eclipse工程中。
(之所以是所有,以防万一编译不过,省的猜缺少那个包,找呀找的!)3. 结合网上关于solr的搭建教程,进行搭建solr,可以用tomcat,也可以用jetty。
我用的jetty+zookeeper,(由于对tomcat的集群配置不了解),zookeeper是独立的zookeeper,而不是jetty内嵌的zookeeper;可以从appache上直接下载!4. 进行相关集群的配置,配置集群,用在工程中用solrj操纵solrCloud二、用solrj操纵CloudSolrServer的一般步骤1. 创建CloudSolrServer的实例:2种方式:(a) CloudSolrServer cloudSolrServer= new CloudSolrServer(zkHostURL);(b) CloudSolrserver.cloudSolrServer = newCloudSolrServer(zkHostURL,lbHttpSolrServer);2. 对CloudSolrServer实例进行设置(a) cloudSolrServer.setDefaultCollection(defaultCollectionName);(b) cloudSolrServer.setzkClientTimeout(zkClientTimeout);(c) cloudSolrServer.setzkConnectTimeout(zkConnectionTimeout);3. 将cloudSolrServer实例连接到zookeeper(a) cloudSolrServer.connect();4. CloudSolrServer 的实例cloudSolrServer 实例化、连接完成,进而可以对其进行add、query、delete操作。
solr使用方法

solr使用方法Solr是一种开源的搜索平台,基于Apache Lucene构建而成。
它提供了强大的全文检索功能和高性能的分布式搜索能力,广泛应用于各种大型网站和企业应用中。
本文将介绍Solr的使用方法,包括安装配置、数据导入、搜索查询等方面。
一、安装配置1. 下载Solr:访问官方网站,下载最新版本的Solr压缩包。
2. 解压缩:将下载的压缩包解压到指定目录。
3. 启动Solr:进入解压后的目录,执行启动命令,等待Solr启动成功。
4. 访问Solr管理界面:打开浏览器,输入Solr的地址和端口号,进入Solr的管理界面。
二、数据导入1. 创建Core:在Solr管理界面中,创建一个Core,用于存储和管理数据。
2. 定义Schema:在Core中定义Schema,指定数据的字段类型、索引配置等。
3. 导入数据:将数据准备好,使用Solr提供的数据导入工具,将数据导入到Core中。
三、搜索查询1. 构建查询请求:使用Solr提供的查询语法,构建查询请求。
2. 发送查询请求:将查询请求发送给Solr服务器,等待返回结果。
3. 解析查询结果:解析返回的结果,获取需要的信息。
四、高级功能1. 分页查询:通过设置start和rows参数,实现分页查询功能。
2. 排序:通过设置sort参数,实现结果的排序。
3. 过滤查询:通过设置fq参数,实现对结果的过滤。
4. 高亮显示:通过设置hl参数,实现搜索关键词的高亮显示。
5. 聚合统计:通过设置facet参数,实现对搜索结果的聚合统计。
五、性能优化1. 索引优化:通过优化索引结构、字段配置等,提升索引的性能。
2. 查询优化:通过合理使用缓存、调整查询参数等,提升查询的性能。
3. 集群部署:将Solr部署到多台服务器上,实现分布式搜索,提升系统的吞吐量和可用性。
六、常见问题解决1. 乱码问题:通过设置字符集、使用适当的分词器等,解决乱码问题。
2. 性能问题:通过调整配置参数、优化查询语句等,解决性能问题。
solrcloud搭建全面总结

solrcloud集群搭建1什么是SolrCloud1.1什么是SolrCloudSolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用SolrCloud。
当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
1.2SolrCloud结构SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。
实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。
SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud 需要由多台服务器组成,由zookeeper来进行协调管理。
下图是一个SolrCloud应用的例子:对上图进行图解,如下:注:1、一个分片有且只有一个主服务节点。
2、collection 是完整体,内容分别存放在各个shard中3、一个shard中的每个core的数据是一致的。
4、从上图可以看出,core才是存放数据的物理结构1.2.1物理结构三个Solr实例(每个实例包括两个Core),组成一个SolrCloud。
1.2.2逻辑结构索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard 上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
注:zk会自动把一个shard上的core创建在不同solr服务上,如下,两个服务器各起了一个solr服务。
Solr4+SolrCloud安装使用手册和详细说明,参考官方文档整理

SOLR使用手册1.SolrCloud安装和使用SolrCloud安装1、首先解压solr-4.4.0压缩文件,复制solr.war到tomcat的webapps下。
2、启动tomcat,用来解压solr.war文件,然后关闭tomcat。
3、拷贝solr-4.4.0\example\lib\ext下的jar到webapps\solr\WEB-INFO\lib下。
webapps\solr\WEB-INFO下新建classes文件夹,将solr-4.4.0\example\resources的log4j.properties拷贝到classes下。
4、在webapps\solr下新建solr_home文件夹,把solr-4.4.0\example\solr下的所有内容拷贝到solr_home下。
为了理解的方便,可以把webapps\solr\solr_home\collection1\conf移到webapps\solr\solr_home下。
5、修改\webapps\solr\WEB-INFO\web.xml文件。
添加如下内容。
<env-entry><env-entry-name>solr/home</env-entry-name><env-entry-value>D:/java/apache-tomcat-6.0.32/webapps/solr/solr_home</env-entry-value><en v-entry-type>ng.String</env-entry-type></env-entry>6、上传solr配置文件java -classpath d:\lib\*;d:\lib\apache-solr-solrj-4.0.0.jar org.apache.solr.cloud.ZkCLI -cmd upconfig -zkhost 127.0.0.1:2181,192.168.1.207:2181,192.168.1.208:2181 -confdir E:\tomcatcluster\collection1\conf -confname testconfclasspath:参数总是报错找不到solrj.jar,干脆把其加入classpath中;lib目录中包含solr.war 中的lib包所有内容zkhost:zookeeper的服务器地址列表;confdir:solr的配置文件目录,包含schema,solrconfig等文件;confname:起个名,下面有用单机例子:java -classpath D:\java\apache-tomcat-6.0.32\webapps\solr\WEB-INF\lib\*;D:\java\apache-tomcat-6.0.32\weba pps\solr\WEB-INF\lib\solr-solrj-4.6.1.jar org.apache.solr.cloud.ZkCLI -cmd upconfig -zkhost 127.0.0.1:2181 -confdir D:\java\apache-tomcat-6.0.32\webapps\solr\solr_home\conf -confname testconfjava -classpath D:\java\apache-tomcat-6.0.32\webapps\solr\WEB-INF\lib\*;D:\java\apache-tomcat-6.0.32\weba pps\solr\WEB-INF\lib\solr-solrj-4.4.0.jar org.apache.solr.cloud.ZkCLI -cmd upconfig -zkhost 127.0.0.1:2181 -confdir D:\java\apache-tomcat-6.0.32\webapps\solr\solr_home\conf -confname testconf7、将上传的配置文件和collection联系起来java -classpath d:\lib\*;d:\lib\apache-solr-solrj-4.0.0.jar org.apache.solr.cloud.ZkCLI -cmd linkconfig -collection europe-collection -confname testconf -zkhost 127.0.0.1:2181,192.168.1.207:2181,192.168.1.208:2181collection:collection的名字,后面有用,要记住单机例子:java -classpath D:\java\apache-tomcat-6.0.32\webapps\solr\WEB-INF\lib\*;D:\java\apache-tomcat-6.0.32\weba pps\solr\WEB-INF\lib\solr-solrj-4.6.1.jar org.apache.solr.cloud.ZkCLI -cmd linkconfig -collection mycollection -confname testconf -zkhost 127.0.0.1:2181java -classpath D:\java\apache-tomcat-6.0.32\webapps\solr\WEB-INF\lib\*;D:\java\apache-tomcat-6.0.32\weba pps\solr\WEB-INF\lib\solr-solrj-4.4.0.jar org.apache.solr.cloud.ZkCLI -cmd linkconfig -collection mycollection -confname testconf -zkhost 127.0.0.1:21818、Solrcloud和zookeeper启动时绑定1、tomcat\bin下新建一个setenv.bat文件,配置启动项第一台服务器:set JAVA_OPTS=-Dbootstrap_confdir=../webapps/solr/solr_home/conf -Dcollection.configName=testconf -Dhost=localhost -Djetty.port=8080 -DzkHost=localhost:2181 -DnumShards=2 -Xms512m -Xmx1024mecho %JAVA_OPTS%后续tomcat服务器:export JAVA_OPTS="-Dhost=107.252.142.195 -Dport=28080 -Dcollection.configName=collection1 -DzkHost=107.252.142.195:2181"添加中文分词。
zrok用法

zrok用法
Zookeeper是一个分布式协调服务,主要用于管理大型分布式系统中的数据。
以下是Zookeeper的基本用法:
1. 创建顺序节点:在Zookeeper中,每一个节点都有一个唯一的路径,并且可以存储少量的数据。
Zookeeper会自动为每一个节点添加一个自增的编号,这个编号是用来标识节点的顺序的。
2. 获取和设置数据:Zookeeper允许你存储和获取节点的数据。
你可以使
用`get`命令获取节点的数据,使用`set`命令设置节点的数据。
3. 监控节点:Zookeeper允许你监控节点的变化。
你可以使用`watch`命令监控一个节点,当这个节点发生变化时,Zookeeper会通知你。
4. 获取指定路径下的子节点数:你可以使用`count`命令获取指定路径下的子节点数。
5. 获取指定路径下的子节点:你可以使用`ls`命令获取指定路径下的所有子节点。
6. 获取指定路径下的子节点数:你可以使用`count2`命令获取指定路径下的子节点数。
7. 获取指定路径下的子节点:你可以使用`ls2`命令获取指定路径下的所有子节点。
以上是Zookeeper的一些基本用法,你可以根据实际需要使用其他命令。
更多详细信息建议查询相关论坛或咨询技术人员。
Solr安装部署Tomcat
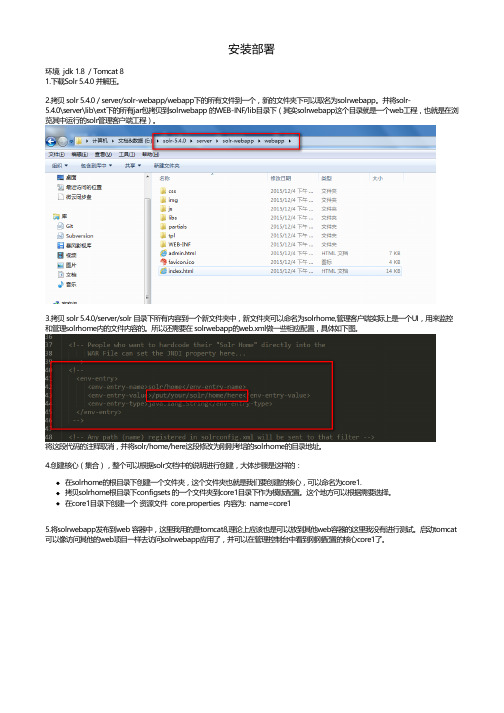
环境 jdk 1.8 / Tomcat 8 1.下载Solr 5.4.0 并解压。 2.拷贝 solr 5.4.0 / server/solr-webapp/webapp下的所有文件到一个,新的文件夹下可以取名为solrwebapp。并将solr5.4.0\server\lib\ext下的所有jar包拷贝到solrwebapp 的WEB-INF/lib目录下(其实solrwebapp这个目录就是一个web工程,也就是在浏 览其中运行的solr管理客户端工程)。
Байду номын сангаас
3.拷贝 solr 5.4.0/server/solr 目录下所有内容到一个新文件夹中,新文件夹可以命名为solrhome,管理客户端实际上是一个UI,用来监控 和管理solrhome内的文件内容的。所以还需要在 solrwebapp的web.xml做一些相应配置,具体如下图。
将这段代码的注释取消,并将solr/home/here这段修改为刚刚考培的solrhome的目录地址。 4.创建核心(集合),整个可以根据solr文档中的说明进行创建,大体步骤是这样的: 在solrhome的根目录下创建一个文件夹,这个文件夹也就是我们要创建的核心,可以命名为core1. 拷贝solrhome根目录下configsets 的一个文件夹到core1目录下作为模版配置。这个地方可以根据需要选择。 在core1目录下创建一个 资源文件 core.properties 内容为: name=core1 5.将solrwebapp发布到web 容器中,这里我用的是tomcat8,理论上应该也是可以放到其他web容器的这里我没有进行测试。启动tomcat 可以像访问其他的web项目一样去访问solrwebapp应用了,并可以在管理控制台中看到刚刚配置的核心core1了。
SolrCloud 5.5集群如何部署

SolrCloud5.5集群如何部署目录SolrCloud5.5 集群如何部署 (1)1. SolrCloud基本概念 (2)1.1 SolrCloud相关概念 (2)1.2 SolrCloud路由 (2)2. Solr5.x和以前版本的区别 (3)3. 部署流程【失败了】 (3)3.1 启动ZK集群 (3)3.2 启动Solr (3)3.3 创建Collection (4)3.4 使用含DIH配置的Collection (5)3.5 验证 (5)4. 使用方法 (7)4.1 向任意一台服务器发送请求 (7)4.2 访问SolrCloud的过程 (8)4.3 发送http请求的方式 (8)4.4 客户端API查询方式 (8)4.5 SolrCloud无法使用DIH和MySQL集成 (8)4.6 SolrCloud提供的URl命令 (10)4.7 SolrCloud提供Client API (11)4.8 SolrJ-5.4.0 客户端库 (11)4.8.1 SolrJ连接SolrCloud进行查询 (12)4.8.2 SolrJ连接SolrCloud创建索引 (14)5. 异常 (15)5.1 This IndexSchema is not mutable (15)5.2 PeerSync: core=example_shard3_replica2 url=http://192.168.232.129:8983/solr ERROR,update log not in ACTIVE or REPLAY state. FSUpdateLog{state=BUFFERING, tlog=null} (16)5.3 配置文件缺失admin-extra.menu-bottom.html、admin-extra.menu-top.html、admin-extra.html (16)5.4 bad request (16)6. 单机SolrCloud部署流程【成功了】 (17)6.1环境 (17)6.2配置文件 (17)6.3 运行命令 (17)6.4 验证 (20)6.5 重启服务 (22)7. 多机SolrCloud部署流程[成功] (22)7.1 环境 (22)7.2 配置文件 (23)7.2 jar包 (23)6.3 启动ZK集群 (23)6.4 运行命令 (23)1.S olrCloud基本概念摘自:/pro/html/201506/45483.html1.1 SolrCloud相关概念SolrCloud中有四个关键名词:core、collection、shard、node。
如何在SpringCloud中实现服务注册与发现

如何在SpringCloud中实现服务注册与发现随着微服务这种新型的服务架构的兴起,越来越多的企业开发人员开始将自己的应用程序拆分成多个小型服务来实现更好的可伸缩性和故障容错能力。
而Spring Cloud正是针对这种微服务架构设计的一组框架。
其中一个核心能力就是服务注册与发现。
服务注册与发现是微服务架构中非常重要的一项能力。
它为微服务应用程序提供了一种机制,用于自动将应用程序中新部署的服务(新实例)注册到注册中心,并将其删除时注销。
在分布式应用程序中,注册中心通常是一个独立的服务。
它可以将服务实例集中保存在一起并提供给其他服务使用。
这种方法就可以让多个微服务之间更好的协作。
利用SpringCloud可以非常方便地实现服务注册与发现的功能。
下面我将从实现服务注册与发现的三种方法(Eureka、Consul、Zookeeper)入手,分别介绍它们的具体实现方式。
1. 使用Eureka实现服务注册与发现通过Eureka可以很好地解决服务之间的注册与发现问题。
其中,Eureka Server是用来管理多个微服务实例的注册中心。
而Eureka Client是用来在应用程序中注册微服务实例并定期向Eureka Server发送心跳的组件。
在Spring Cloud中,可以通过以下配置来实现Eureka Server:```yml# Eureka Server Configurationserver:port: 8761eureka:instance:hostname: localhostclient:register-with-eureka: falsefetch-registry: false```而在Eureka Client中,主要是配置一下要注册到哪个Eureka Server上以及其中一些心跳等信息:```yml# Eureka Client Configurationspring:application:name: eureka-clienteureka:client:service-url:defaultZone: http://localhost:8761/eureka/instance:prefer-ip-address: truelease-renewal-interval-in-seconds: 30lease-expiration-duration-in-seconds: 90```2. 使用Consul实现服务注册与发现除了Eureka,Consul也是一种用于解决服务注册与发现问题的工具。
solr基本配置(1)

solr基本配置(1)Solr基本配置说明版本说明:solr版本solr-5.4.0,中⽂分词库版本:ik-analyzer-solr5-5.xJdk 版本:1.7.x以下⽂档中的“yld”为创建的coreSolr核⼼⽬录结构说明1、解压后的solr⽬录结构如下核⼼要要关注的⽬录结构是图中带红⾊框bin, solr 和solr-webapp.bin:提供启动关闭solr 命令(默认启动端⼝8983); 启动:solr start ;停⽌:solr stop -p 8983solr-webapp:⼀般情况不需要修改。
Solr:⽂件夹⾥存放创建的core2、core的⽬录结构每个新建的core包含(hotword,yld为新建的core) ,conf和data,libconf:主要⽤于存放core的配置⽂件,(1)、schema.xml⽤于定义索引库的字段及分词器等,这个配置⽂件是核⼼⽂件(2)、solrconfig.xml定义了这个core的配置信息data:主要⽤于存放core的数据,即index-索引⽂件和log-⽇志记录lib:主要存放⼀些当前core需要的jar包,如mysql驱动包,中⽂分词库等新建coreSolr⾥⾯的core就像数据库⾥⾯的⼀个表,⽤来管理索引和相关配置1 %solrhome%/server\solr 下新建⽂件夹new_core2 %solrhome%/\example\example-DIH\solr\db 下的conf ,lib ,data 拷贝到new_core3 进⼊http://ip:8983/solr/后点击“core Admin”4 点击“Add Core ”展现如下界⾯5 core创建成功,如下图所⽰6 根据实际情况,修改,new_core 下config ⾥的内容Schema.xml, solrconfig.xml .删除实际中不需要的⽂件。
模式配置Schema.xml属性名称描述Indexed Indexed Field 可以进⾏搜索和排序。
eclipse上springCloud分布式微服务搭建-干货

eclipse上springCloud分布式微服务搭建-⼲货⼀、创建maven⽗⼯程(pom)pom.xml如下:<?xml version="1.0"encoding="UTF-8"?><project xmlns="/POM/4.0.0"xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/POM/4.0.0/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.snowlink</groupId><artifactId>springCloud</artifactId><version>0.0.1-SNAPSHOT</version><packaging>pom</packaging><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>1.5.5.RELEASE</version></parent><modules><module>springCloud-eureka-server</module><module>springCloud-eureka-client</module></modules><dependencyManagement><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>Dalston.SR3</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-config</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-eureka</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><optional>true</optional></dependency></dependencies></project>⼆、创建两个⼦⼯程两个⼦⼯程都是springBoot的项⽬,⼀个是服务端(server),⼀个是客户端(client)三、服务端配置1、由于服务端在启动类上需要加载@EnableEurekaServer注解,所以服务端的pom.xml⽂件中需要添加依赖:<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-eureka-server</artifactId></dependency>2、服务端启动类package org.springCloud.eureka.server;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import flix.eureka.server.EnableEurekaServer;@SpringBootApplication@EnableEurekaServerpublicclass App{publicstaticvoid main( String[] args ){SpringApplication.run(App.class, args);System.out.println( "Hello World!" );}}3、特别注意:1、com.sun.jersey.api.client.ClientHandlerException:.ConnectException: Connection refused: connect或者flix.discovery.shared.transport.TransportException: Cannotexecute request on any known server原因如下:在默认设置下,Eureka服务注册中⼼也会将⾃⼰作为客户端来尝试注册它⾃⼰,所以我们需要禁⽤它的客户端注册⾏为。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、下载
apache-tomcat-7.0.61.tar.gz solr-5.4.0.tgz zookeeper-3.4.6.tar.gz 并解压,zookeeper集群为:10.0.1.51:2181 10.0.1.52:2181 10.0.1.53:2181 solrcloud集群是:10.0.1.51,10.0.1.52,10.0.1.53:
其中,上述三台主机的主机名对应关系如下:
二、解压zookeeper,并完成配置
1)移动到/user/solrcloud下,并解压
#mv zookeeper-3.4.6.tar.gz /user/solrcloud
#cd /user/solrcloud
#tar –xzvf zookeeper-3.4.6.tar.gz
2)修改zoo.cfg文件
#cd zookeeper-3.4.6/conf
#mkdir data
#mkdir logs
内容如下:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/user/solrcloud/zookeeper-3.4.6/data
dataLogDir=/user/solrcloud/zookeeper-3.4.6/logs
clientPort=2181
server.1=s571:2888:3888
server.2=s572:2888:3888
server.3=s573:2888:3888
3)scp到三台机子都有
scp–r zookeeper-3.4.6 s572:/user/solrclouds573:/user/solrcloud
4)建立myid文件
在s571的zookeeper-3.4.6/data下新建myid文件,内容为1,s572的为2,s573的内容为3。
5)启动三台zookeeper
#bin/zkServer.sh start
6)查看三台zookeeper状态
bin/zkServer.sh status(一台是Leader,两台是follower)
三、安装solr到tomcat
1)解压tomcat
#cp -R apache-tomcat-7.0.61 /user/solrcloud/
修改tomcat的URI编码配置:URIEncoding="UTF-8" useBodyEncodingForURI="true"
2)解压solr-5.4.0.tar
复制solr.core就是solr-5.4.0\server\solr-webapp下面的webapp复制到
#cp
solr-5.4.0/server/solr-webapp/webapp/user/solrcloud/apache-tomcat-7.0.61/web apps下面,之后修改名称为solr。
cd //user/solrcloud/apache-tomcat-7.0.61/webapps/
mvwebappsolr
3)复制需要的jar包和log4j配置文件到tomcat相应目录下。
复制solr相关的jar到solr工程下,log4j.properties 到solr工程classes下cdapache-tomcat-7.0.61/webapps
#cpsolr-5.4.0/server/lib/*.jar solr/WEB-INF/lib/
#cpsolr-5.4.0/server/lib/ext/*.jar solr/WEB-INF/lib/
#mkdirsolr/WEB-INF/classes
#cpsolr-5.4.0/server/resources/log4j.properties solr/WEB-INF/classes/
4)创建solrcloud的统一配置存放目录solrbase和solrhome #cd /user/solrcloud
#mkdir -p solrbase/conf
#mkdir -p solrbase/solrhome
复制配置文件和lib 到solrcloud对应目录下
#cp -r solr-5.4.0/server/solr/configsets/basic_configs/conf/* solrbase/conf/
复制solr.xml 和zoo.cfg到solrhome目录下
#cpsolr-5.4.0/server/solr/solr.xml solr-5.4.0/server/solr/zoo.cfgsolrbase/solrhome
5)修改solr.xml 的jetty.port参数值为tomcat的端口
<int name="hostPort">${jetty.port:8080}</int>
6)tomcat 启动项修改
仅仅在s571上编辑tomcat/bin/catalina.sh,在打开这个文件后的最上面添加如下代码:JAVA_OPTS="-Djetty.port=8080
-Dbootstrap_confdir=/user/solrcloud/solrbase/conf
-Dcollection.configName=solrcloud
-DzkHost=s571:2181,s572:2181,s573:2181 -Dsolr.solr.home=/user/solrcloud/solrb ase/solrhome"
注意:另外两台机子的tomcat启动项如下,下面会有介绍。
JAVA_OPTS="-Djetty.port=8080 -Dcollection.configName=solrcloud
-DzkHost=s571:2181,s572:2181,s573:2181 -Dsolr.solr.home=/user/solrcloud/solrb ase/solrhome"
7)压缩后scp到另外两台服务器
把solrbase apache-tomcat-7.0.61zookeeper-3.4.6打包分发到其它机器上解压启动tomcat即可实现集群。
#tar -zcf solrcloud-all.tar.gz solrbaseapache-tomcat-7.0.61zookeeper-3.4.6
#scpsolrcloud-all.tar.gz s572:/user/solrcloud s573:/user/solrcloud
8)修改另外两台的tomcat启动项catalina.sh
要把其它机器上tomcat启动项的 -Dbootstrap_confdir=/opt/web_app/solrcloud/conf 删除
四、启动三台机器的tomcat
#apache-tomcat-7.0.61/bin/Catalina.sh start (或者用startup.sh)三台都启动
五、SolrCloud的集合(SolrCores)管理API
1)查看solrcloud
http://10.0.1.51:8080/solr/admin.html
进入后点击左边导航栏的cloud查看
2)创建集合:
http://10.0.1.51:8080/solr/admin/collections?action=CREATE&name=test&numSh ards=1&replicationFactor=3&collection.configName=solrcloud
3)删除集合
http://10.0.1.51:8080/solr/admin/collections?action=DELETE&name=test
4)重新加载
http://10.0.1.51:8080/solr/admin/collections?action=RELOAD&name=test
5)创建集合test
http://10.0.1.51:8080/solr/admin/collections?action=CREATE&name=test&numSh ards=1&replicationFactor=3&collection.configName=solrcloud
6)创建结果查看。