Collection [FH92]. command [FH83]. Compiler [Slo95, WG92].
vba collection用法

vba collection用法VBA Collection用法VBA(Visual Basic for Applications)是一种在Microsoft Office中广泛使用的编程语言。
在VBA中,Collection是一种用于存储和管理数据的重要对象。
它类似于数组,但是与数组不同的是,Collection对象可以动态地增加和删除元素,使其成为处理灵活数据结构的理想选择。
在本文中,我们将一步一步回答有关VBA Collection的常见问题,并详细介绍其用法和一些示例。
第一部分:Collection对象的基本介绍1. 什么是Collection?Collection是一个VBA对象,可以存储任意类型的元素。
它是一种非常灵活和方便的数据结构,可以根据需要动态调整大小,添加或删除元素。
与数组不同,Collection是一种线性结构,可以根据索引访问元素,但是它不需要预先声明大小。
2. 如何声明和创建Collection对象?在VBA中,可以使用关键字Dim声明并创建一个Collection对象。
例如:Dim myCollection As Collection3. 如何向Collection对象添加元素?使用Collection对象的Add方法可以向其中添加元素。
例如:myCollection.Add "apple",表示向myCollection中添加一个名为"apple"的元素。
4. 如何从Collection对象中删除元素?Collection对象提供了Remove和RemoveAll两种方法来删除元素。
Remove用于删除指定索引的元素,而RemoveAll用于删除Collection 中的所有元素。
5. 如何访问Collection对象中的元素?Collection对象通过索引访问其中的元素。
可以使用索引或key来引用元素。
索引是一个基于1的整数,表示元素在Collection中的位置,而key是一个唯一的字符串,用于引用元素。
python中collections的用法

python中collections的用法Python中collections模块是一个高效且便捷的工具,提供了多种数据类型的实现,用于解决一些常见的问题。
本文将介绍collections模块的几个主要数据类型及其用法,希望能为读者提供一些实用的工具和思路。
一、Counter(计数器)Counter是collections模块中一个常用的数据类型,它可以用来统计可哈希对象(如列表、元组、字符串等)中各元素的出现次数。
下面是一个简单的例子:```pythonfrom collections import Counterlst = ['apple', 'banana', 'apple', 'orange', 'orange', 'banana', 'apple']counter = Counter(lst)print(counter)```输出结果如下:```Counter({'apple': 3, 'banana': 2, 'orange': 2})```Counter对象本质上是一个字典,以元素作为键,出现次数作为值。
Counter对象的常用方法包括:1. most_common(n):返回出现次数最多的n个元素,以及它们的出现次数。
```pythonprint(counter.most_common(2))```输出结果如下:```[('apple', 3), ('banana', 2)]```2. elements():返回一个迭代器,按照计数重复每个元素。
```pythonprint(list(counter.elements()))```输出结果如下:```['apple', 'apple', 'apple', 'banana', 'banana', 'orange', 'orange']```二、deque(双端队列)deque是一个双端队列,它可以快速地从两端进行增删操作,相比列表,在队列的两端插入和删除元素的时间复杂度都是O(1)。
collection接口定义的方法

collection接口定义的方法Collection接口是Java集合框架中的根接口之一,它定义了一组通用的操作方法,用于对集合中的元素进行管理和操作。
下面是Collection接口定义的一些重要方法:1. boolean add(E element):将指定的元素添加到集合中。
如果集合由于容量限制无法添加元素,则抛出异常。
2. boolean addAll(Collection<? extends E> collection):将指定集合中的所有元素添加到当前集合中。
如果集合由于容量限制无法添加元素,则抛出异常。
3. void clear(:清空集合中的所有元素。
4. boolean contains(Object object):判断集合中是否包含指定的元素。
5. boolean containsAll(Collection<?> collection):判断集合是否包含指定集合的所有元素。
6. boolean isEmpty(:判断集合是否为空。
7. Iterator<E> iterator(:返回一个迭代器,用于遍历集合中的元素。
8. boolean remove(Object object):从集合中删除指定的元素。
9. boolean removeAll(Collection<?> collection):从集合中删除包含在指定集合中的所有元素。
10. boolean retainAll(Collection<?> collection):从集合中仅保留包含在指定集合中的元素,删除其他元素。
11. int size(:返回集合中存储的元素数量。
12. Object[] toArray(:将集合中的元素转换为数组。
13. <T> T[] toArray(T[] array):将集合中的元素转换为指定类型的数组。
上述方法提供了对集合中元素的增删改查操作,以及对集合之间的比较、合并等操作。
Python中collections模块的详细用法介绍

Python中collections模块的详细⽤法介绍1. 介绍collections是Python内建的⼀个集合模块,提供了许多有⽤的集合类和⽅法。
可以把它理解为⼀个容器,⾥⾯提供Python标准内建容器 dict , list , set , 和 tuple 的替代选择。
import collectionsprint(dir(collections))# ['ChainMap', 'Counter', 'Mapping', 'MutableMapping', 'OrderedDict', 'UserDict', 'UserList', 'UserString', '_Link', '_OrderedDictItemsView', '_OrderedDictKeysView', '_OrderedDictValuesView', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__getattr__', '__⾥⾯有许多⽅法,我们只介绍常⽤的⽅法。
2.常⽤⽅法namedtuple() :创建⼀个命名元组⼦类的⼯⼚函数deque : ⾼效增删改双向列表,类似列表(list)的容器,实现了在两端快速添加(append)和弹出(pop)defaultdict :当字典查询时,为key不存在提供⼀个默认值。
OrderedDict :有序词典,就是记住了插⼊顺序Counter :计数功能1. namedtuple() 命名元组参数dtuple(typename, field_names, *, rename=False, defaults=None, module=None)typename : 命名的名字,返回⼀个新的元组⼦类,名为 typenamefield_names :可以是⼀个['x', 'y']这样的序列,也可以是'x, y'或者'x y'rename : python3.1添加,如果 rename 为真,⽆效域名会⾃动转换成位置名。
collection用法及搭配

Collection用法及搭配1.引言在程序开发中,集合(c ol le ct io n)是一种重要的数据结构,用于存储和操作一组相关对象。
使用集合可以简化代码逻辑,提高代码的可读性和可维护性。
本文将介绍集合的基本概念、常用操作和一些常见的集合搭配用法。
2.集合的基本概念2.1集合的定义与特点集合是一种无序、不重复的数据结构。
在P yt ho n中,常用的集合类型包括列表、元组、字典和集合。
列表(l i st)是有序的集合,元素可重复;元组(tu pl e)是有序的集合,元素不可变;字典(d ic ti on ar y)是无序的集合,由键值对组成;集合(se t)是无序的、不重复的集合。
2.2集合的创建和初始化集合可以通过字面值或构造函数来创建和初始化。
例如,使用方括号[]创建列表,使用小括号()创建元组,使用大括号{}创建字典和集合。
2.3集合的基本操作集合支持多种基本操作,包括增加元素、删除元素、修改元素和查询元素。
通过使用集合的内置方法,我们可以轻松地进行这些操作。
3. Li st(列表)3.1L i s t的特点与用途列表是P yt ho n中最常见的集合类型之一,它可以容纳任意类型的元素,包括数字、字符串、布尔值等。
列表是有序的,并且允许元素重复。
列表常用于存储一组有序的数据。
3.2L i s t的基本操作列表支持多种基本操作,如添加元素、删除元素、修改元素、查询元素等。
我们将详细介绍这些操作,并给出相应的示例代码。
4. Tu ple(元组)4.1T u p l e的特点与用途元组是P yt ho n中的另一种集合类型,它与列表类似,但元组的元素不可变。
元组常用于存储不可变的数据,例如坐标值、日期时间等。
4.2T u p l e的基本操作元组支持多种基本操作,但与列表不同,元组的元素不可变,因此涉及到修改元素的操作往往会引发错误。
我们将介绍元组的创建、访问、删除等操作,并给出相应的示例。
python中collections的用法

一、介绍Python中collections库Python是一种高级编程语言,被广泛应用于数据分析、人工智能、网络编程等领域。
在Python中,collections是一个非常重要的库,它提供了许多用于管理集合数据(如列表、字典、元组等)的工具和数据结构。
collections库中的各种数据结构能够帮助开发者高效地进行数据处理和管理,并且在实际开发中有着广泛的应用。
二、使用collections库的常见数据结构1. namedtuple:namedtuple是collections库中的一个数据结构,它为元组添加了字段名,并且可以像类一样使用点语法来访问元组的元素。
这在某些场景下能够提高代码的可读性和可维护性,让开发者可以更加方便地处理数据。
2. deque:deque是双向队列的缩写,它是一种具有队列和栈的特性的数据结构。
在Python中,使用deque可以快速地实现线程安全的队列操作,而且它的添加和弹出操作是线性时间复杂度的,比列表的操作效率更高。
3. Counter:Counter是collections库中的另一个数据结构,它可以帮助开发者快速统计可迭代对象中各个元素的个数,并且以字典的形式返回统计结果。
这在对一组数据进行分析时非常有用,可以帮助开发者快速得到数据的分布情况。
4. defaultdict:defaultdict是一个带有默认值的字典。
它在字典的基础上进行了扩展,如果访问的键不存在,则会返回一个默认值,这样就避免了因为键不存在而引发的错误。
5. OrderedDict:有序字典是collections库中提供的另一个数据结构,它可以保持字典元素的插入顺序,这在需要按顺序遍历字典元素的场景下非常有用。
在Python 3.7及以后版本中,字典本身也保持了元素的插入顺序,因此使用OrderedDict的场景相对较少。
6. ChainMap:ChainMap是一种将多个字典或映射映射到一个视图上的方法。
collection接口方法

collection接口方法Collection接口方法详解概述Collection是Java集合框架中的一个接口,它继承了Iterable 接口,并且是List、Set等集合类的父接口。
本文将详细介绍Collection接口的各种方法以及它们的作用。
方法列表1. boolean add(E element)•参数:要添加的元素(element)•返回值:添加成功返回true,否则返回false•作用:将指定的元素添加到集合中2. boolean remove(Object element)•参数:要移除的元素(element)•返回值:移除成功返回true,否则返回false•作用:从集合中移除指定的元素3. boolean contains(Object element)•参数:待查找的元素(element)•返回值:如果集合包含指定的元素,返回true,否则返回false •作用:判断集合中是否包含指定元素4. boolean isEmpty()•返回值:如果集合为空,返回true,否则返回false•作用:判断集合是否为空5. int size()•返回值:返回集合中元素的个数•作用:获取集合的大小6. boolean addAll(Collection<? extends E> collection)•参数:要添加的集合(collection)•返回值:如果集合发生变化,返回true,否则返回false•作用:将指定集合中的所有元素添加到当前集合7. boolean removeAll(Collection<?> collection)•参数:要移除的集合(collection)•返回值:如果集合发生变化,返回true,否则返回false•作用:从当前集合中移除包含在指定集合中的所有元素8. void clear()•作用:清空集合中的所有元素9. boolean containsAll(Collection<?> collection)•参数:待查找的集合(collection)•返回值:如果当前集合包含指定集合中的所有元素,返回true,否则返回false•作用:判断当前集合是否包含指定集合中的所有元素10. boolean retainAll(Collection<?> collection)•参数:要保留的集合(collection)•返回值:如果当前集合发生变化,返回true,否则返回false •作用:保留当前集合中在指定集合中也存在的元素,移除其他元素11. Object[] toArray()•返回值:返回一个包含集合中所有元素的数组•作用:将集合转换为数组12. T[] toArray(T[] array)•参数:要转换的数组(array)•返回值:返回包含集合中所有元素的数组•作用:将集合转换为指定类型的数组总结通过上述详细介绍,我们了解了Collection接口中的常用方法及其作用。
postman中collection作用

postman中collection作用Postman是一款非常受欢迎的API测试工具,它提供了各种不同功能来帮助用户测试和模拟API调用。
其中,Postman中的Collection是一种非常重要的功能,它在API测试和调试中起着重要的作用。
在本文中,我们将深入了解Collection的作用及其用法。
一、Collection的定义Collection在Postman中是一组API请求的集合,可以将它们组织在一起以便于管理和运行。
它可以包括多个请求,例如Get、Post、Put、Delete等,这些请求通常是在测试同一个API的不同方面。
Collection还可以具有多个延迟执行、变量、预处理脚本等,有助于在测试API时保持一致性。
二、Collection的作用1. 提高测试效率使用Collection可以简化API测试的流程,节省用户大量的时间和精力。
一次性运行一组请求意味着节省了打开和关闭请求的时间,用户可以在单个集合中管理和运行一组API,使测试流程高效而快速。
2. 提高测试准确性集合中的每个请求可以进行配置、验证和优化,从而可以在测试时获得更准确的结果。
集合中的变量和其他测试环境可以帮助我们准确地模拟API的真实使用情况,避免了因为错误的参数或环境导致的测试失败。
3. 改善测试管理集合可以帮助用户更好地整理用户的API请求,将其分组别名,方便用户使用。
这种组织结构可以帮助用户更好地管理其测试请求,从而使测试工作变得更加容易和高效。
4. 更好的协作效率集合可以被共享给整个团队,团队成员可以轻松访问和使用,从而提高了协作效率,也可以提高团队整体的效率。
三、Collection的使用1. 创建一个Collection在创建一个Collection之前,用户需要确保已安装了Postman。
打开Postman,然后选中Collections选项卡,然后点击New Collection按钮。
2. 添加请求在创建Collection之后,可以添加请求。
Adobe Acrobat SDK 开发者指南说明书

This guide is governed by the Adobe Acrobat SDK License Agreement and may be used or copied only in accordance with the terms of this agreement. Except as permitted by any such agreement, no part of this guide may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, recording, or otherwise, without the prior written permission of Adobe. Please note that the content in this guide is protected under copyright law.
collection 用法

collection 用法Collection在英语中的意思是“收集”,在计算机科学中是一个非常常见的术语。
它是Java语言中的一个接口,用来表示一组对象,这些对象被称作元素。
Collection接口为许多常见的数据结构定义了通用操作,如添加、删除和遍历元素,提供了一种方便和统一的方式来操作这些数据结构。
Collection接口有两个子接口:List和Set。
List接口定义了一个序列,我们可以通过指定的索引访问其中的元素。
Set接口定义了一组不重复的元素,而且没有涉及到索引的概念。
除此之外,Collection还有自己的一些完整实现,如ArrayList、LinkedList、HashSet和TreeSet 等。
使用Collection可以来完成很多任务,如查找重复元素、获取元素个数、找出最大/最小元素等。
下面列举了一些Collection接口的使用示例:1. 创建一个ListList<String> list = new ArrayList<>();list.add("apple");list.add("banana");list.add("orange");2. 遍历一个Listfor (String fruit : list) {System.out.println(fruit);}3. 创建一个SetSet<Integer> set = new HashSet<>(); set.add(1);set.add(2);set.add(3);4. 判断Set是否包含某个元素if (set.contains(3)) {System.out.println("Set contains 3"); }5. 获取List中的元素个数int size = list.size();System.out.println("List contains " + size + " elements");6. 获取Set中的最大/最小值int max = Collections.max(set);int min = Collections.min(set);System.out.println("Max value: " + max);System.out.println("Min value: " + min);总之,Collection接口是Java集合框架中的一个重要组成部分。
collections模块简介

collections模块简介除python提供的内置数据类型(int、float、str、list、tuple、dict)外,collections模块还提供了其他数据类型,使⽤如下功能需先导⼊collections模块(import collections):计数器(counter)有序字典(orderedDict)默认字典(defaultdict)可命名元组(namedtuple)双向队列(deque)⼀、计数器(Counter):统计元素的个数,并以字典形式返回{元素:元素个数}class Counter(dict):# class Counter(dict) 表⽰Counter类继承dict类,既⼦类继承⽗类所有功能'''Dict subclass for counting hashable items. Sometimes called a bagor multiset. Elements are stored as dictionary keys and their countsare stored as dictionary values.>>> c = Counter('abcdeabcdabcaba') # count elements from a string>>> c.most_common(3) # three most common elements[('a', 5), ('b', 4), ('c', 3)]>>> sorted(c) # list all unique elements['a', 'b', 'c', 'd', 'e']>>> ''.join(sorted(c.elements())) # list elements with repetitions'aaaaabbbbcccdde'>>> sum(c.values()) # total of all counts15>>> c['a'] # count of letter 'a'5>>> for elem in 'shazam': # update counts from an iterable... c[elem] += 1 # by adding 1 to each element's count>>> c['a'] # now there are seven 'a'7>>> del c['b'] # remove all 'b'>>> c['b'] # now there are zero 'b'>>> d = Counter('simsalabim') # make another counter>>> c.update(d) # add in the second counter>>> c['a'] # now there are nine 'a'9>>> c.clear() # empty the counter>>> cCounter()Note: If a count is set to zero or reduced to zero, it will remainin the counter until the entry is deleted or the counter is cleared:>>> c = Counter('aaabbc')>>> c['b'] -= 2 # reduce the count of 'b' by two>>> c.most_common() # 'b' is still in, but its count is zero[('a', 3), ('c', 1), ('b', 0)]'''# References:# /wiki/Multiset# /software/smalltalk/manual-base/html_node/Bag.html# /Tutorial/Cpp/0380__set-multiset/Catalog0380__set-multiset.htm# /recipes/259174/# Knuth, TAOCP Vol. II section 4.6.3def__init__(*args, **kwds):'''Create a new, empty Counter object. And if given, count elementsfrom an input iterable. Or, initialize the count from another mappingof elements to their counts.>>> c = Counter() # a new, empty counter>>> c = Counter('gallahad') # a new counter from an iterable>>> c = Counter({'a': 4, 'b': 2}) # a new counter from a mapping>>> c = Counter(a=4, b=2) # a new counter from keyword args'''if not args:raise TypeError("descriptor '__init__' of 'Counter' object ""needs an argument")self, *args = argsif len(args) > 1:raise TypeError('expected at most 1 arguments, got %d' % len(args))super(Counter, self).__init__()self.update(*args, **kwds)def__missing__(self, key):'The count of elements not in the Counter is zero.'# Needed so that self[missing_item] does not raise KeyErrorreturn 0def most_common(self, n=None):'''List the n most common elements and their counts from the mostcommon to the least. If n is None, then list all element counts.>>> Counter('abcdeabcdabcaba').most_common(3)[('a', 5), ('b', 4), ('c', 3)]'''# Emulate Bag.sortedByCount from Smalltalkif n is None:return sorted(self.items(), key=_itemgetter(1), reverse=True)return _heapq.nlargest(n, self.items(), key=_itemgetter(1))def elements(self):'''Iterator over elements repeating each as many times as its count.>>> c = Counter('ABCABC')>>> sorted(c.elements())['A', 'A', 'B', 'B', 'C', 'C']# Knuth's example for prime factors of 1836: 2**2 * 3**3 * 17**1>>> prime_factors = Counter({2: 2, 3: 3, 17: 1})>>> product = 1>>> for factor in prime_factors.elements(): # loop over factors... product *= factor # and multiply them>>> product1836Note, if an element's count has been set to zero or is a negativenumber, elements() will ignore it.'''# Emulate Bag.do from Smalltalk and Multiset.begin from C++.return _chain.from_iterable(_starmap(_repeat, self.items()))# Override dict methods where necessary@classmethoddef fromkeys(cls, iterable, v=None):# There is no equivalent method for counters because setting v=1# means that no element can have a count greater than one.raise NotImplementedError('Counter.fromkeys() is undefined. Use Counter(iterable) instead.')def update(*args, **kwds):'''Like dict.update() but add counts instead of replacing them.Source can be an iterable, a dictionary, or another Counter instance.>>> c = Counter('which')>>> c.update('witch') # add elements from another iterable>>> d = Counter('watch')>>> c.update(d) # add elements from another counter>>> c['h'] # four 'h' in which, witch, and watch4'''# The regular dict.update() operation makes no sense here because the# replace behavior results in the some of original untouched counts# being mixed-in with all of the other counts for a mismash that# doesn't have a straight-forward interpretation in most counting# contexts. Instead, we implement straight-addition. Both the inputs# and outputs are allowed to contain zero and negative counts.if not args:raise TypeError("descriptor 'update' of 'Counter' object ""needs an argument")self, *args = argsif len(args) > 1:raise TypeError('expected at most 1 arguments, got %d' % len(args))iterable = args[0] if args else Noneif iterable is not None:if isinstance(iterable, Mapping):if self:self_get = self.getfor elem, count in iterable.items():self[elem] = count + self_get(elem, 0)else:super(Counter, self).update(iterable) # fast path when counter is empty else:_count_elements(self, iterable)if kwds:self.update(kwds)def subtract(*args, **kwds):'''Like dict.update() but subtracts counts instead of replacing them.Counts can be reduced below zero. Both the inputs and outputs areallowed to contain zero and negative counts.Source can be an iterable, a dictionary, or another Counter instance.>>> c = Counter('which')>>> c.subtract('witch') # subtract elements from another iterable>>> c.subtract(Counter('watch')) # subtract elements from another counter >>> c['h'] # 2 in which, minus 1 in witch, minus 1 in watch>>> c['w'] # 1 in which, minus 1 in witch, minus 1 in watch-1'''if not args:raise TypeError("descriptor 'subtract' of 'Counter' object ""needs an argument")self, *args = argsif len(args) > 1:raise TypeError('expected at most 1 arguments, got %d' % len(args)) iterable = args[0] if args else Noneif iterable is not None:self_get = self.getif isinstance(iterable, Mapping):for elem, count in iterable.items():self[elem] = self_get(elem, 0) - countelse:for elem in iterable:self[elem] = self_get(elem, 0) - 1if kwds:self.subtract(kwds)def copy(self):'Return a shallow copy.'return self.__class__(self)def__reduce__(self):return self.__class__, (dict(self),)def__delitem__(self, elem):'Like dict.__delitem__() but does not raise KeyError for missing values.' if elem in self:super().__delitem__(elem)def__repr__(self):if not self:return'%s()' % self.__class__.__name__try:items = ', '.join(map('%r: %r'.__mod__, self.most_common())) return'%s({%s})' % (self.__class__.__name__, items)except TypeError:# handle case where values are not orderablereturn'{0}({1!r})'.format(self.__class__.__name__, dict(self))# Multiset-style mathematical operations discussed in:# Knuth TAOCP Volume II section 4.6.3 exercise 19# and at /wiki/Multiset## Outputs guaranteed to only include positive counts.## To strip negative and zero counts, add-in an empty counter:# c += Counter()def__add__(self, other):'''Add counts from two counters.>>> Counter('abbb') + Counter('bcc')Counter({'b': 4, 'c': 2, 'a': 1})'''if not isinstance(other, Counter):return NotImplementedresult = Counter()for elem, count in self.items():newcount = count + other[elem]if newcount > 0:result[elem] = newcountfor elem, count in other.items():if elem not in self and count > 0:result[elem] = countreturn resultdef__sub__(self, other):''' Subtract count, but keep only results with positive counts.>>> Counter('abbbc') - Counter('bccd')Counter({'b': 2, 'a': 1})'''if not isinstance(other, Counter):return NotImplementedresult = Counter()for elem, count in self.items():newcount = count - other[elem]if newcount > 0:result[elem] = newcountfor elem, count in other.items():if elem not in self and count < 0:result[elem] = 0 - countreturn resultdef__or__(self, other):'''Union is the maximum of value in either of the input counters.>>> Counter('abbb') | Counter('bcc')Counter({'b': 3, 'c': 2, 'a': 1})'''if not isinstance(other, Counter):return NotImplementedresult = Counter()for elem, count in self.items():other_count = other[elem]newcount = other_count if count < other_count else countif newcount > 0:result[elem] = newcountfor elem, count in other.items():if elem not in self and count > 0:result[elem] = countreturn resultdef__and__(self, other):''' Intersection is the minimum of corresponding counts.>>> Counter('abbb') & Counter('bcc')Counter({'b': 1})'''if not isinstance(other, Counter):return NotImplementedresult = Counter()for elem, count in self.items():other_count = other[elem]newcount = count if count < other_count else other_count if newcount > 0:result[elem] = newcountreturn resultdef__pos__(self):'Adds an empty counter, effectively stripping negative and zero counts' result = Counter()for elem, count in self.items():if count > 0:result[elem] = countreturn resultdef__neg__(self):'''Subtracts from an empty counter. Strips positive and zero counts, and flips the sign on negative counts.'''result = Counter()for elem, count in self.items():if count < 0:result[elem] = 0 - countreturn resultdef _keep_positive(self):'''Internal method to strip elements with a negative or zero count'''nonpositive = [elem for elem, count in self.items() if not count > 0] for elem in nonpositive:del self[elem]return selfdef__iadd__(self, other):'''Inplace add from another counter, keeping only positive counts.>>> c = Counter('abbb')>>> c += Counter('bcc')>>> cCounter({'b': 4, 'c': 2, 'a': 1})'''for elem, count in other.items():self[elem] += countreturn self._keep_positive()def__isub__(self, other):'''Inplace subtract counter, but keep only results with positive counts. >>> c = Counter('abbbc')>>> c -= Counter('bccd')>>> cCounter({'b': 2, 'a': 1})'''for elem, count in other.items():self[elem] -= countreturn self._keep_positive()def__ior__(self, other):'''Inplace union is the maximum of value from either counter.>>> c = Counter('abbb')>>> c |= Counter('bcc')>>> cCounter({'b': 3, 'c': 2, 'a': 1})'''for elem, other_count in other.items():count = self[elem]if other_count > count:self[elem] = other_countreturn self._keep_positive()def__iand__(self, other):'''Inplace intersection is the minimum of corresponding counts.>>> c = Counter('abbb')>>> c &= Counter('bcc')>>> cCounter({'b': 1})'''for elem, count in self.items():other_count = other[elem]if other_count < count:self[elem] = other_countreturn self._keep_positive()View CodeCounter类包含⽅法如下:1. most_common:将元素出现的次数按照从⾼到低进⾏排序,并返回前N个元素,若多个元素统计数相同,按照字母顺序排列,N若未指定,则返回所有元素def most_common(self, n=None):'''List the n most common elements and their counts from the mostcommon to the least. If n is None, then list all element counts.>>> Counter('abcdeabcdabcaba').most_common(3)[('a', 5), ('b', 4), ('c', 3)]'''# Emulate Bag.sortedByCount from Smalltalkif n is None:return sorted(self.items(), key=_itemgetter(1), reverse=True)return _heapq.nlargest(n, self.items(), key=_itemgetter(1))2. elements:返回⼀个迭代器,元素被重复多少次,在迭代器中就包含多少个此元素,所有元素按字母序排列,个数<1的不罗列def elements(self):'''Iterator over elements repeating each as many times as its count.>>> c = Counter('ABCABC')>>> sorted(c.elements())['A', 'A', 'B', 'B', 'C', 'C']# Knuth's example for prime factors of 1836: 2**2 * 3**3 * 17**1>>> prime_factors = Counter({2: 2, 3: 3, 17: 1})>>> product = 1>>> for factor in prime_factors.elements(): # loop over factors... product *= factor # and multiply them>>> product1836Note, if an element's count has been set to zero or is a negativenumber, elements() will ignore it.'''# Emulate Bag.do from Smalltalk and Multiset.begin from C++.return _chain.from_iterable(_starmap(_repeat, self.items()))3. update:增加元素的重复次数def update(*args, **kwds):'''Like dict.update() but add counts instead of replacing them.Source can be an iterable, a dictionary, or another Counter instance.>>> c = Counter('which')>>> c.update('witch') # add elements from another iterable>>> d = Counter('watch')>>> c.update(d) # add elements from another counter>>> c['h'] # four 'h' in which, witch, and watch4'''# The regular dict.update() operation makes no sense here because the# replace behavior results in the some of original untouched counts# being mixed-in with all of the other counts for a mismash that# doesn't have a straight-forward interpretation in most counting# contexts. Instead, we implement straight-addition. Both the inputs# and outputs are allowed to contain zero and negative counts.if not args:raise TypeError("descriptor 'update' of 'Counter' object ""needs an argument")self, *args = argsif len(args) > 1:raise TypeError('expected at most 1 arguments, got %d' % len(args))iterable = args[0] if args else Noneif iterable is not None:if isinstance(iterable, Mapping):if self:self_get = self.getfor elem, count in iterable.items():self[elem] = count + self_get(elem, 0)else:super(Counter, self).update(iterable) # fast path when counter is emptyelse:_count_elements(self, iterable)if kwds:self.update(kwds)View Code4. subtract:减少元素重复次数def subtract(*args, **kwds):'''Like dict.update() but subtracts counts instead of replacing them.Counts can be reduced below zero. Both the inputs and outputs areallowed to contain zero and negative counts.Source can be an iterable, a dictionary, or another Counter instance.>>> c = Counter('which')>>> c.subtract('witch') # subtract elements from another iterable>>> c.subtract(Counter('watch')) # subtract elements from another counter>>> c['h'] # 2 in which, minus 1 in witch, minus 1 in watch>>> c['w'] # 1 in which, minus 1 in witch, minus 1 in watch-1'''if not args:raise TypeError("descriptor 'subtract' of 'Counter' object ""needs an argument")self, *args = argsif len(args) > 1:raise TypeError('expected at most 1 arguments, got %d' % len(args))iterable = args[0] if args else Noneif iterable is not None:self_get = self.getif isinstance(iterable, Mapping):for elem, count in iterable.items():self[elem] = self_get(elem, 0) - countelse:for elem in iterable:self[elem] = self_get(elem, 0) - 1if kwds:self.subtract(kwds)View Code⼆、有序字典(orderedDict):继承了dict的所有功能,dict是⽆序的,orderedDict刚好对dict作了补充,记录了键值对插⼊的顺序,是有序字典class OrderedDict(dict):'Dictionary that remembers insertion order'# An inherited dict maps keys to values.# The inherited dict provides __getitem__, __len__, __contains__, and get.# The remaining methods are order-aware.# Big-O running times for all methods are the same as regular dictionaries.# The internal self.__map dict maps keys to links in a doubly linked list.# The circular doubly linked list starts and ends with a sentinel element.# The sentinel element never gets deleted (this simplifies the algorithm).# The sentinel is in self.__hardroot with a weakref proxy in self.__root.# The prev links are weakref proxies (to prevent circular references).# Individual links are kept alive by the hard reference in self.__map.# Those hard references disappear when a key is deleted from an OrderedDict.def __init__(*args, **kwds):'''Initialize an ordered dictionary. The signature is the same asregular dictionaries, but keyword arguments are not recommended becausetheir insertion order is arbitrary.'''if not args:raise TypeError("descriptor '__init__' of 'OrderedDict' object ""needs an argument")self, *args = argsif len(args) > 1:raise TypeError('expected at most 1 arguments, got %d' % len(args))try:self.__rootexcept AttributeError:self.__hardroot = _Link()self.__root = root = _proxy(self.__hardroot)root.prev = root.next = rootself.__map = {}self.__update(*args, **kwds)def __setitem__(self, key, value,dict_setitem=dict.__setitem__, proxy=_proxy, Link=_Link):'od.__setitem__(i, y) <==> od[i]=y'# Setting a new item creates a new link at the end of the linked list,# and the inherited dictionary is updated with the new key/value pair.if key not in self:self.__map[key] = link = Link()root = self.__rootlast = root.prevlink.prev, link.next, link.key = last, root, keylast.next = linkroot.prev = proxy(link)dict_setitem(self, key, value)def __delitem__(self, key, dict_delitem=dict.__delitem__):'od.__delitem__(y) <==> del od[y]'# Deleting an existing item uses self.__map to find the link which gets# removed by updating the links in the predecessor and successor nodes.dict_delitem(self, key)link = self.__map.pop(key)link_prev = link.prevlink_next = link.nextlink_prev.next = link_nextlink_next.prev = link_prevlink.prev = Nonelink.next = Nonedef __iter__(self):'od.__iter__() <==> iter(od)'# Traverse the linked list in order.root = self.__rootcurr = root.nextwhile curr is not root:yield curr.keycurr = curr.nextdef __reversed__(self):'od.__reversed__() <==> reversed(od)'# Traverse the linked list in reverse order.root = self.__rootcurr = root.prevwhile curr is not root:yield curr.keycurr = curr.prevdef clear(self):'od.clear() -> None. Remove all items from od.'root = self.__rootroot.prev = root.next = rootself.__map.clear()dict.clear(self)def popitem(self, last=True):'''od.popitem() -> (k, v), return and remove a (key, value) pair.Pairs are returned in LIFO order if last is true or FIFO order if false.'''if not self:raise KeyError('dictionary is empty')root = self.__rootif last:link = root.prevlink_prev = link.prevlink_prev.next = rootroot.prev = link_prevelse:link = root.nextlink_next = link.nextroot.next = link_nextlink_next.prev = rootkey = link.keydel self.__map[key]value = dict.pop(self, key)return key, valuedef move_to_end(self, key, last=True):'''Move an existing element to the end (or beginning if last==False). Raises KeyError if the element does not exist.When last=True, acts like a fast version of self[key]=self.pop(key).'''link = self.__map[key]link_prev = link.prevlink_next = link.nextsoft_link = link_next.prevlink_prev.next = link_nextlink_next.prev = link_prevroot = self.__rootif last:last = root.prevlink.prev = lastlink.next = rootroot.prev = soft_linklast.next = linkelse:first = root.nextlink.prev = rootlink.next = firstfirst.prev = soft_linkroot.next = linkdef __sizeof__(self):sizeof = _sys.getsizeofn = len(self) + 1 # number of links including rootsize = sizeof(self.__dict__) # instance dictionarysize += sizeof(self.__map) * 2 # internal dict and inherited dict size += sizeof(self.__hardroot) * n # link objectssize += sizeof(self.__root) * n # proxy objectsreturn sizeupdate = __update = MutableMapping.updatedef keys(self):"D.keys() -> a set-like object providing a view on D's keys"return _OrderedDictKeysView(self)def items(self):"D.items() -> a set-like object providing a view on D's items"return _OrderedDictItemsView(self)def values(self):"D.values() -> an object providing a view on D's values"return _OrderedDictValuesView(self)__ne__ = MutableMapping.__ne____marker = object()def pop(self, key, default=__marker):'''od.pop(k[,d]) -> v, remove specified key and return the correspondingvalue. If key is not found, d is returned if given, otherwise KeyErroris raised.'''if key in self:result = self[key]del self[key]return resultif default is self.__marker:raise KeyError(key)return defaultdef setdefault(self, key, default=None):'od.setdefault(k[,d]) -> od.get(k,d), also set od[k]=d if k not in od'if key in self:return self[key]self[key] = defaultreturn default@_recursive_repr()def __repr__(self):'od.__repr__() <==> repr(od)'if not self:return'%s()' % (self.__class__.__name__,)return'%s(%r)' % (self.__class__.__name__, list(self.items()))def __reduce__(self):'Return state information for pickling'inst_dict = vars(self).copy()for k in vars(OrderedDict()):inst_dict.pop(k, None)return self.__class__, (), inst_dict or None, None, iter(self.items())def copy(self):'od.copy() -> a shallow copy of od'return self.__class__(self)@classmethoddef fromkeys(cls, iterable, value=None):'''OD.fromkeys(S[, v]) -> New ordered dictionary with keys from S.If not specified, the value defaults to None.'''self = cls()for key in iterable:self[key] = valuereturn selfdef __eq__(self, other):'''od.__eq__(y) <==> od==y. Comparison to another OD is order-sensitivewhile comparison to a regular mapping is order-insensitive.'''if isinstance(other, OrderedDict):return dict.__eq__(self, other) and all(map(_eq, self, other))return dict.__eq__(self, other)try:from _collections import OrderedDictexcept ImportError:# Leave the pure Python version in place.passView Code说明:python v3.6之前的版本dict是⽆序的,3.6版本之后(含v3.6)dict是有序的,⽬测为了兼容性以及100%有序性考虑,建议实现有序功能时使⽤orderedDictorderedDict类补充⽅法:1. clear:清空字典def clear(self):'od.clear() -> None. Remove all items from od.'root = self.__rootroot.prev = root.next = rootself.__map.clear()dict.clear(self)2. popitem:有序删除,类似于栈,按照后进先出的顺序依次删除def popitem(self, last=True):'''od.popitem() -> (k, v), return and remove a (key, value) pair.Pairs are returned in LIFO order if last is true or FIFO order if false.'''if not self:raise KeyError('dictionary is empty')root = self.__rootif last:link = root.prevlink_prev = link.prevlink_prev.next = rootroot.prev = link_prevelse:link = root.nextlink_next = link.nextroot.next = link_nextlink_next.prev = rootkey = link.keydel self.__map[key]value = dict.pop(self, key)return key, valueView Code3. pop:删除指定键值对def pop(self, key, default=__marker):'''od.pop(k[,d]) -> v, remove specified key and return the correspondingvalue. If key is not found, d is returned if given, otherwise KeyErroris raised.'''if key in self:result = self[key]del self[key]return resultif default is self.__marker:raise KeyError(key)return defaultView Code4. move_to_end:将指定键值对移到最后位置def move_to_end(self, key, last=True):'''Move an existing element to the end (or beginning if last==False).Raises KeyError if the element does not exist.When last=True, acts like a fast version of self[key]=self.pop(key).'''link = self.__map[key]link_prev = link.prevlink_next = link.nextsoft_link = link_next.prevlink_prev.next = link_nextlink_next.prev = link_prevroot = self.__rootif last:last = root.prevlink.prev = lastlink.next = rootroot.prev = soft_linklast.next = linkelse:first = root.nextlink.prev = rootlink.next = firstfirst.prev = soft_linkroot.next = linkView Code5. setdefault:设置默认值,默认为None,也可指定值def setdefault(self, key, default=None):'od.setdefault(k[,d]) -> od.get(k,d), also set od[k]=d if k not in od'if key in self:return self[key]self[key] = defaultreturn defaultView Code6. update:更新字典,有则更新,⽆则添加三、默认字典(defaultdict):设置values默认类型,如list、tuple class defaultdict(dict):"""defaultdict(default_factory[, ...]) --> dict with default factoryThe default factory is called without arguments to producea new value when a key is not present, in __getitem__ only.A defaultdict compares equal to a dict with the same items.All remaining arguments are treated the same as if they werepassed to the dict constructor, including keyword arguments."""def copy(self): # real signature unknown; restored from __doc__""" D.copy() -> a shallow copy of D. """passdef__copy__(self, *args, **kwargs): # real signature unknown""" D.copy() -> a shallow copy of D. """passdef__getattribute__(self, *args, **kwargs): # real signature unknown""" Return getattr(self, name). """passdef__init__(self, default_factory=None, **kwargs): # known case of _collections.defaultdict.__init__ """defaultdict(default_factory[, ...]) --> dict with default factoryThe default factory is called without arguments to producea new value when a key is not present, in __getitem__ only.A defaultdict compares equal to a dict with the same items.All remaining arguments are treated the same as if they werepassed to the dict constructor, including keyword arguments.# (copied from class doc)"""passdef__missing__(self, key): # real signature unknown; restored from __doc__"""__missing__(key) # Called by __getitem__ for missing key; pseudo-code:if self.default_factory is None: raise KeyError((key,))self[key] = value = self.default_factory()return value"""passdef__reduce__(self, *args, **kwargs): # real signature unknown""" Return state information for pickling. """passdef__repr__(self, *args, **kwargs): # real signature unknown""" Return repr(self). """passdefault_factory = property(lambda self: object(), lambda self, v: None, lambda self: None) # default """Factory for default value called by __missing__()."""View Code四、可命名元组(namedtuple): 可通过名称访问元组中的元素,提⾼代码可读性def namedtuple(typename, field_names, *, verbose=False, rename=False, module=None): """Returns a new subclass of tuple with named fields.>>> Point = namedtuple('Point', ['x', 'y'])>>> Point.__doc__ # docstring for the new class'Point(x, y)'>>> p = Point(11, y=22) # instantiate with positional args or keywords>>> p[0] + p[1] # indexable like a plain tuple33>>> x, y = p # unpack like a regular tuple>>> x, y(11, 22)>>> p.x + p.y # fields also accessible by name33>>> d = p._asdict() # convert to a dictionary>>> d['x']11>>> Point(**d) # convert from a dictionaryPoint(x=11, y=22)>>> p._replace(x=100) # _replace() is like str.replace() but targets named fieldsPoint(x=100, y=22)"""# Validate the field names. At the user's option, either generate an error# message or automatically replace the field name with a valid name.if isinstance(field_names, str):field_names = field_names.replace(',', '').split()field_names = list(map(str, field_names))typename = str(typename)if rename:seen = set()for index, name in enumerate(field_names):if (not name.isidentifier()or _iskeyword(name)or name.startswith('_')or name in seen):field_names[index] = '_%d' % index。
collection 用法

Collection 用法什么是 collection在计算机编程的领域里,collection(集合)是指把一组元素组织在一起的数据结构。
它可以用来存储和操作多个相关的元素,比如数字、字符串、对象等。
在不同的编程语言中,collection 有不同的实现方式和特点。
Collection 的类型常见的 collection 类型包括列表(list)、元组(tuple)、集合(set)和字典(dictionary)。
下面将对每种类型进行详细介绍。
列表(List)列表是一种有序的集合,可以包含任意类型的元素。
列表中的元素可以根据需要进行增加、删除和修改。
创建列表在大多数编程语言中,可以使用方括号([])来创建一个列表。
例如,在Python 中,可以使用以下代码创建一个包含整数的列表:numbers = [1, 2, 3, 4, 5]访问列表元素要访问列表中的元素,可以使用下标(index)来引用元素的位置。
在大多数编程语言中,列表的下标从0开始。
例如,在上面的列表中,要访问第一个元素(1),可以使用以下代码:first_number = numbers[0]列表的操作列表支持多种操作,包括向列表中添加元素(append())、删除元素(remove())和修改元素值。
例如,在Python中,可以使用以下代码示例来演示这些操作:numbers.append(6) # 向列表末尾添加元素numbers.remove(3) # 删除列表中的某个元素numbers[0] = 10 # 修改列表中的元素值元组(Tuple)元组是一种不可变的有序集合,可以包含任意类型的元素。
元组一经创建,其元素及其顺序不能改变。
创建元组在大多数编程语言中,可以使用圆括号(())来创建一个元组。
例如,在Python 中,可以使用以下代码创建一个包含整数和字符串的元组:person = (1, 'Alice', 25)访问元组元素访问元组中的元素与列表的访问方式相似,同样使用下标来引用元素的位置。
python collection的用法

# 弹出队头元素 print(my_queue.popleft()) # 输出:3 ```
这些是collections模块中一些常用的数据结构和用法。通过使用这些数据结构,可以更方 便地处理各种数据集合和数据结构的操作。
2. defaultdict(默认字典):类似于字典,但在访问不存在的键时会返回一个默认值。 ```python from collections import defaultdict
python colຫໍສະໝຸດ ection的用法# 创建一个默认字典,指定默认值为0 my_dict = defaultdict(int)
python collection的用法
# 通过字段名访问元组元素 print() # 输出:'Alice' print(person.age) # 输出:25 ```
4. deque(双端队列):高效地在两端进行插入和删除操作的数据结构。 ```python from collections import deque
python collection的用法
# 创建一个双端队列 my_queue = deque()
# 在队尾插入元素 my_queue.append(1) my_queue.append(2)
# 在队头插入元素 my_queue.appendleft(3)
python collection的用法
# 访问不存在的键,返回默认值 print(my_dict['key']) # 输出:0
# 自定义默认值 my_dict = defaultdict(lambda: 'default') print(my_dict['key']) # 输出:'default' ```
python中collections的用法 -回复

python中collections的用法-回复Python中的collections模块是一个提供了额外数据结构的扩展工具包。
它包含了一些有用的数据结构和容器,用于解决一些常见的编程问题。
在本文中,我们将深入探讨collections模块的用法,并逐步回答中括号内的内容。
1. 为什么要使用collections模块?在Python中,内置的数据结构(如列表、字典等)并不能解决所有的编程问题。
有时我们需要一些更高级的数据结构,以提高代码的效率和可读性。
这就是collections模块派上用场的地方。
2. collections模块中常用的数据结构collections模块提供了许多有用的数据结构,包括:- namedtuple:一个高效的、不可更改的自定义数据类型。
它提供了命名的元组,可以通过属性而不是索引来引用元素。
- deque:一个双向队列,支持高效的添加和删除操作。
- defaultdict:一个带有默认值的字典,当访问不存在的键时,会返回默认值而不是抛出KeyError异常。
- OrderedDict:一个有序字典,按照插入顺序迭代键。
- Counter:一个简单的计数器,用于计算可迭代对象中元素的出现次数。
- ChainMap:一个将多个映射链在一起的数据结构,可以用于在多个字典中查找键。
- defaultdict:一个默认值为0的计数器,用于计算可迭代对象中元素的出现次数。
3. 高级数据结构的具体用法3.1 namedtupleNamedtuple将元组的字段命名,并为其创建一个类。
这使得我们可以通过属性名而不是索引来引用元组的元素,从而提高代码的可读性。
示例代码:pythonfrom collections import namedtuplePerson = namedtuple('Person', ['name', 'age', 'gender'])p1 = Person('John', 25, 'male')print() # 输出:Johnprint(p1.age) # 输出:25print(p1.gender) # 输出:male3.2 dequeDeque是一个双向队列,可以在队列的两端高效地添加和删除元素。
collection.intersection 用法 -回复

collection.intersection 用法-回复关于Python集合(Collection)的intersection(交集)函数的用法。
Python中的Collection模块提供了许多用于操作集合的函数,这些函数可以对集合进行各种操作,如并集、交集、差集等。
其中,intersection 函数用于计算两个或更多集合的交集。
首先,让我们来看看intersection函数的基本语法:pythonintersection(set1, set2, ...)该函数接受多个参数,每个参数都是一个集合(set)。
它返回一个新的集合,该集合包含了所有参数集合的交集元素。
下面我们来详细讨论一下intersection函数的具体用法。
1. 创建集合首先,我们需要创建几个集合,以便后续使用。
可以使用set()函数或者花括号({})来创建集合。
例如:pythonset1 = set([1, 2, 3, 4, 5])set2 = {4, 5, 6, 7, 8}这样我们就创建了两个集合set1和set2。
2. 使用intersection函数求交集接下来,我们可以使用intersection函数来计算集合的交集。
例如,我们可以计算set1和set2的交集,并将结果保存在一个新的集合中,如下所示:pythonintersection_set = set1.intersection(set2)这样,intersection_set就是set1和set2的交集。
3. 输出结果最后,我们可以输出交集结果,以便进行查看。
可以使用print函数来打印输出。
例如:pythonprint(intersection_set)这样,我们就可以在控制台上看到交集结果。
除了传递两个集合作为参数之外,我们还可以传递多个集合作为参数给intersection函数。
在这种情况下,函数会计算所有集合之间的交集。
例如:pythonset3 = {5, 6, 7, 8, 9}intersection_set = set1.intersection(set2, set3)这样,intersection_set将包含set1、set2和set3之间的交集元素。
collection中的ordereddict和sorted函数 -回复

collection中的ordereddict和sorted函数-回复Collection中的OrderedDict和Sorted函数在Python中,collections模块提供了一种有序的字典类型OrderedDict,它可以保持元素插入的顺序,而不像普通的字典类型是无序的。
此外,Python内建的sorted函数也可以用于对数据进行排序。
本文将详细介绍OrderedDict和sorted函数的使用,并探讨它们的区别和适用场景。
一、OrderedDict的使用OrderedDict是从collections模块中导入的一个类。
它继承了普通字典类型,并在此基础上进行了扩展。
下面通过一些示例来说明OrderedDict的用法:pythonfrom collections import OrderedDict# 创建一个空的OrderedDictod = OrderedDict()# 向OrderedDict中添加元素od['a'] = 1od['b'] = 2od['c'] = 3# 打印OrderedDict的元素和顺序for key, value in od.items():print(key, value)上述代码中,首先通过from关键字导入collections模块,然后从中导入OrderedDict类。
接着创建一个空的OrderedDict实例od,并依次往其中添加了三个键值对。
最后,使用for循环打印出OrderedDict的所有元素和其插入的顺序。
运行上述代码,输出结果如下:a 1b 2c 3可以看出,OrderedDict确实能够按照元素插入的顺序进行迭代和访问。
二、Sorted函数的使用sorted函数是Python内建的排序函数,它可以对列表、元组和字典等可迭代对象进行排序。
下面使用一些示例来说明sorted函数的用法:python# 对一个列表进行排序list1 = [3, 1, 2]sorted_list = sorted(list1)print(sorted_list)# 对一个元组进行排序tuple1 = (3, 1, 2)sorted_tuple = sorted(tuple1)print(sorted_tuple)# 对一个字典进行排序dict1 = {'a': 3, 'c': 1, 'b': 2}sorted_dict = sorted(dict1.items(), key=lambda x: x[0])print(sorted_dict)上述代码中,首先使用sorted函数对一个列表、一个元组和一个字典进行了排序,并分别打印了排序结果。
Java集合源码--Collection框架概述
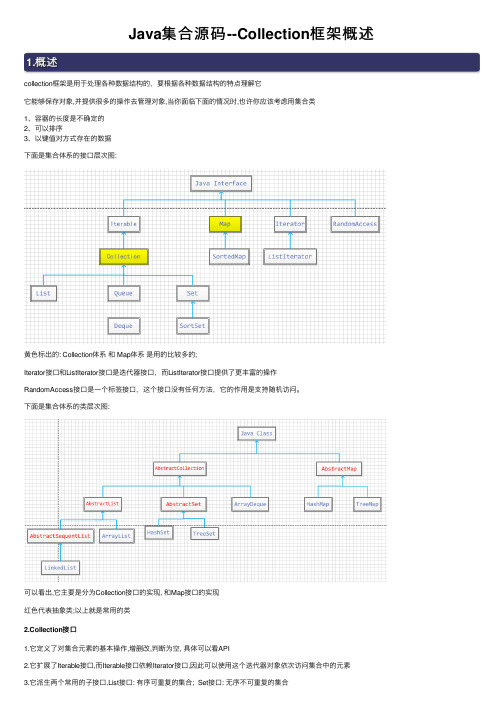
Java集合源码--Collection框架概述1.概述
collection框架是⽤于处理各种数据结构的,要根据各种数据结构的特点理解它
它能够保存对象,并提供很多的操作去管理对象,当你⾯临下⾯的情况时,也许你应该考虑⽤集合类
1、容器的长度是不确定的
2、可以排序
3、以键值对⽅式存在的数据
下⾯是集合体系的接⼝层次图:
黄⾊标出的: Collection体系和 Map体系是⽤的⽐较多的;
Iterator接⼝和ListIterator接⼝是迭代器接⼝,⽽ListIterator接⼝提供了更丰富的操作
RandomAccess接⼝是⼀个标签接⼝,这个接⼝没有任何⽅法,它的作⽤是⽀持随机访问。
下⾯是集合体系的类层次图:
可以看出,它主要是分为Collection接⼝的实现, 和Map接⼝的实现
红⾊代表抽象类;以上就是常⽤的类
2.Collection接⼝
1.它定义了对集合元素的基本操作,增删改,判断为空, 具体可以看API
2.它扩展了Iterable接⼝,⽽Iterable接⼝依赖Iterator接⼝,因此可以使⽤这个迭代器对象依次访问集合中的元素
3.它派⽣两个常⽤的⼦接⼝,List接⼝: 有序可重复的集合; Set接⼝: ⽆序不可重复的集合
3.Map接⼝
映射表, ⽤来存储键值对, 如果提供了键,就可以查找对应的值
4.Iterator接⼝
1.Iterator对象称作迭代器,Iterator接⼝⽅法能以迭代⽅式逐个访问集合中各个元素
2.所有实现了Collection接⼝的容器类都有iterator⽅法,⽤于返回⼀个实现了Iterator接⼝的对象。
mongodb collection字段说明

mongodb collection字段说明MongoDB是一种开源的非关系型数据库,它使用文档来存储数据。
在MongoDB中,数据存储在集合(Collection)中,而每个文档都是一个特定格式的非结构化数据对象。
在MongoDB的集合中,我们可以定义不同的字段来存储数据。
以下是一些常见的字段类型及其说明:1. 字符串类型(String)- 用于存储文本数据。
可以是名字、地址、描述等。
示例:{"name": "John", "address": "123 Main Street"}2. 数值类型(Number)- 用于存储数字数据。
可以是整数、浮点数等。
示例:{"age": 30, "salary": 50000}3. 布尔类型(Boolean)- 用于存储真或假的值。
示例:{"isStudent": true, "hasPets": false}4. 数组类型(Array)- 用于存储多个值的列表。
示例:{"hobbies": ["reading", "coding", "playing"]}5. 对象类型(Object)- 用于存储复杂的数据结构。
示例:{"address": {"street": "123 Main Street", "city": "New York"}}6. 日期类型(Date)- 用于存储日期和时间。
示例:{"createdAt":ISODate("2022-01-01T12:00:00Z")}7. null类型(Null)- 用于表示空值。
Java中的Collection类概述

Java中的Collection类概述Java中的Collection类概述引导语:在使用Java的时候,我们都会遇到使用集合(Collection)的时候,那么Collection是什么呢,以下是店铺分享给大家的Java中的Collection类概述,欢迎阅读!Collection├List│├LinkedList│├ArrayList│└Vector│└Stack└SetMap├Hashtable├HashMap└WeakHashMapCollection接口Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素(Elements)。
一些Collection允许相同的元素而另一些不行。
一些能排序而另一些不行。
Java SDK不提供直接继承自Collection的类,Java SDK提供的类都是继承自Collection 的“子接口”如List和Set。
所有实现Collection接口的类都必须提供两个标准的构造函数:无参数的构造函数用于创建一个空的Collection,有一个Collection 参数的构造函数用于创建一个新的Collection,这个新的Collection 与传入的Collection有相同的元素。
后一个构造函数允许用户复制一个Collection。
如何遍历Collection中的每一个元素?不论Collection的实际类型如何,它都支持一个iterator()的方法,该方法返回一个迭代子,使用该迭代子即可逐一访问Collection中每一个元素。
典型的用法如下:Iterator it = collection.iterator(); // 获得一个迭代子while(it.hasNext()) {Object obj = it.next(); // 得到下一个元素}由Collection接口派生的两个接口是List和Set。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Fernandez:1992:GCA
[FH92] Mary F. Fernandez and David R. Hanson. Garbage collection alternatives for Icon. Software|Practice unbounded [Nil90b]. University [BSK87]. and Experience, 22(8):659{672, AuUNIX [Mit84]. USA [USE94]. use [Gri80]. gust 1992. CODEN SPEXBL. ISSN 0038-0644. values [Nil90b]. Version [Jef94]. Griswold:1983:IPL Very [USE94]. VHLL [USE94].
REFERENCES
SIGPLAN [HOP93, Wex87]. SNOBOL4 [Gri85, Gri83]. SNOBOL4/Icon [Gri85]. Some [Gri94]. St. [Wex87]. Storage [Han80]. stream [Nil90b]. String [Gri90, Gri94]. structure [Gri94]. Structures [Gri89]. Stuttgart [BSK87]. subsystem [Mit84]. supports [Nil90b]. Symposium [USE94, Wex87]. System [Han80]. Tables [GT93]. Techniques [Wex87]. Text [WLL98]. type [Nil90b].
A Bibliography of Publications about the Icon Programming Language
Nelson H. F. Beebe Center for Scienti c Computing University of Utah Department of Mathematics, 322 INSCC 155 S 1400 E RM 233 Salt Lake City, UT 84112-0090 USA Tel: +1 801 581 5254 FAX: +1 801 585 1640, +1 801 581 4148 E-mail: beebe@ (Internet) WWW URL: /~beebe/ 21 September 2000 Version 1.07
References
[GG83] Ralph E. Griswold and Madge T. Griswold. The Icon Programming Language. Prentice-Hall, Englewood Bullinger:1987:HII Cli s, NJ 07632, USA, 1983. ISBN 0-13-449777-5. xviii + 313 pp. LCCN [BSK87] H.-J. Bullinger, B. Shackel, and QA76.73.I19 G74 1983. K. Kornwachs, editors. Humancomputer ACT '87: Interaction | INTERSec-
Abstract
1
2
Execution [JG94]. Expressions [Gri82, WG83a]. extension [Hin87]. Fe [USE94]. Federal [BSK87]. First [Wal89]. First-class [Wal89]. Framework [JG94]. Garbage [FH92]. Generated [Slo95]. Generators [GHK81, Gri88, WG83b]. Germany [BSK87]. Glimpse [JM98]. Goal [Gud92, Nil90a, WG83b, Nil90b, OWG93]. Goal-Directed [Gud92, Nil90a,
WG83b, Nil90b, OWG93]. Graphics [GJT97, Jef94].
GG90, Gri90, Gud92, Han80, JM98, WG92, WLL98, FH83, GHK79, GG93, GG97, Hin87, OG87, OWG93, Shi96, Gri94]. Languages [HOP93, USE94]. Level [USE94, FH83, Nil90a]. Logicon [LC86].
Management [Han80]. Manipulating [GO88]. Manipulation [WLL98]. mappings [Gri80]. Matching [Gri83, Nil90b]. Message [Chr89]. Mexico [USE94]. Minnesota [Wex87]. Monitoring [JG94]. numerical [Gri94]. object [Hin87]. October [USE94]. operational [OWG93]. Operations [GN83]. Optimizing [WG92]. oriented [Hin87]. overview [GHK79]. Pattern [Gri83, Nil90b]. patterns [Wal89]. Paul [Wex87]. Portable [Han80]. Preprints [HOP93]. procedural [OWG93]. Proceedings [USE94, Wex87, BSK87]. Processing [Nil90a, Gri94]. Programmer [GN83]. Programmer-De ned [GN83]. Programming [HOP93, GG83, GG86,
character [Gri80]. Chicon [WLL98]. Chinese [WLL98]. class [Wal89]. This bibliography records books and other Co [WG83a]. Co-expressions [WG83a]. publications about the Icon programming lan- Collection [FH92]. command [FH83]. guage. Compiler [Slo95, WG92]. computation [Gri94]. computer [BSK87]. Computing [Chr89]. Concurrent [Nil90a]. Title word cross-reference Conference [HOP93, BSK87]. Control [GN83]. 2nd [HOP93]. Data [Gri89, Nil90b]. De ned [GN83]. Denotational [Gud92]. Design [GT93]. '87 [BSK87, Wex87]. Directed [Gud92, Nil90a, Nil90b, OWG93, WG83b]. disparate [Hin87]. does [Gri94]. ACM [HOP93]. actors [Chr89]. Driven [Chr89]. Dynamic [GT93]. Alternatives [FH92]. applications [Hin87]. Assembly [Gri94]. Automatically [Slo95]. Emacs [Mit84]. Evaluation [Gri82, Slo95, WG83b]. Based [PTTA99]. brief [Han93].
Gri88, GO88, Gri89, GG90, Gri90, Gri94, GJT97, Han80, Jef94, WG92, FH83, GHK79, GG93, GG97, OG87, Shi96]. Prolog [LC86].
Rebus [Gri85]. recursive [OG87]. relationship [Chr89]. Republic [BSK87]. Required [Gri94]. Rest [JM98]. Result [WG83c]. Santa [USE94]. Scanning [Gri90]. Second [BSK87]. Semantics [Gud92, OWG93]. September [BSK87]. Seque [GO88]. Sequences [GO88, WG83c, Nil90b]. Sets [GT93, Gri80].
Hale Waihona Puke [GG86] Ralph E. Griswold and Madge T. Griswold. The Implementation of the Computer Interaction, held at the Icon Programming Language. PrinceUniversity of Stuttgart, Federal Reton University Press, Princeton, NJ, public of Germany, 1{4 September, USA, 1986. ISBN 0-691-08431-9. x 1987. North-Holland, Amsterdam, + 336 pp. LCCN QA76.73.I19 G76 The Netherlands, 1987. ISBN 01986. US$39.50. 444-70304-7. LCCN QA76.9.S88I325 1987. Griswold:1990:IPL
3
80/pubs/citations/proceedings/ plan/67386/p76-christopher/.