SPSS第八课:征服一般线性模型GeneralLinearModel菜单详解(上)
Spss软件常用菜单含义与功能介绍
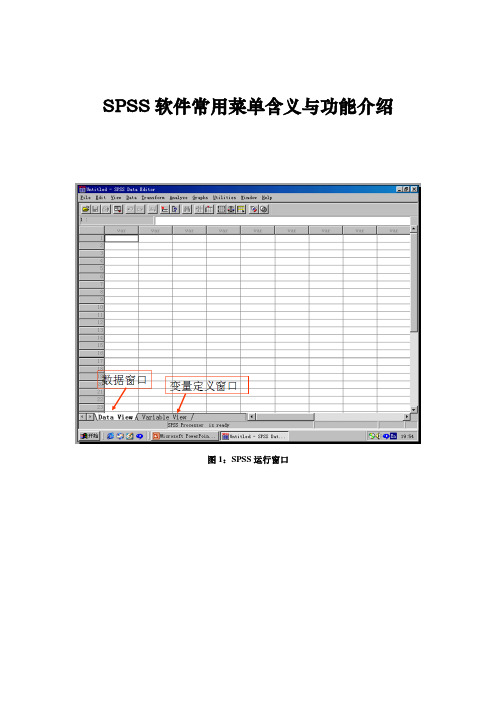
SPSS软件常用菜单含义与功能介绍图1:SPSS运行窗口1、计算产生变量根据已经存在的变量,经过函数计算后,建立新变量或替换员原量的值。
图2:计算产生变量图3:分类汇总1、描述性统计(1)频数分布分析:通过频数分布表、直方图,以及集中趋势和离散趋势的各种统计量,描述数据的分布特征。
(2)描述性统计分析:计算描述数据的集中趋势和离散趋势的各种统计量,还可以做标准化变换(变成均值为0,方差为1的数据)。
(3)探索性分析:判断数据有无离群点(outliers),极端值(extreme values);进行正态分布检验和方差齐性检验;了解数据指标之间差异的特征。
(1)双变量相关分析:分析两个变量之间是否存在相关关系。
(2)偏相关分析:剔除其他变量的影响的情况下,计算两变量之间的相关系数。
3、聚类分析与判别分析(1)系统聚类:最常用的聚类方法。
(2)判别分析:判别所研究的对象属于哪一类的统计方法。
(1)线性回归:一个因变量(dependent )与多个自变量(independents )之间存在线性数量关系。
(2)曲线拟合:可以完成11种曲线的自动拟合(根据需要进行选择),并进行参数估计与检验,绘制拟合图形等。
自变量(independent )只能选一个或者使用时间作为自变量(time: 即使用1,2,3,…,),即只能做一元函数的曲线拟合。
因变量(dependent )可以选多个,将分别做多个一元函数的拟合。
模型Models 模型名称 模型表达式Linear 线性模型 01*y b b x =+ Logarithmic对数模型01*ln y b b x =+Inverse 逆模型 01/y b b x =+ Quadratic 二次模型 2012**y b b x b x =++ Cubic 三次模型 230123***y b b x b x b x =+++Compound 复合模型 01*x y b b =Power 幂模型 10*b y b x = S S 型模型 01/b b x y e +=Growth 生长模型 01*b b x y e += Exponential 指数模型 1*0*b x y b e =LogisticLogistic 模型011/(1)b b x y e --=+一般可以先选择所有的11种模型,再根据结果选择最佳模型。
spss各模块菜单含义

spss各模块菜单含义spss各模块菜单含义◆Reports报表……OLAP在线分析处理……case Summaries案例摘要……Report Summaries in Rows行摘要……Report Summaries in Columns列摘要◆descriptives Statistics描述统计……Frequencies频数分析……Descriptives描述分析……Explore数据探索……Crosstabs交叉分析……Ratio连续变量的对比分析◆Custom Tables定制表格……basic Tables基本表格……General Tables多功能综合表格……Multiple Response Table多选题制表……Tables of Frequencies 多变量频数表◆Compare Mean均值比较分析过程……Means单变量的综合描述统计……Independent Sample T test独立样本的T检验……Paired Sample T test配对样本的T检验……One-Way ANOVA 单变量方差分析◆General Linear Model一般线性模型……Univariate单一因变量线性模型……Multivar iate 多个因变量线性模型……Repeated Measures重测数据的方差分析……Variance Components方差成分模型◆Mixed Models混合线性模型……linear线性模型◆Correlate 相关分析……Bivariate Pearson/ Kendall/Spearman非参数相关分析……Partial双变量相关分析……Distance相似性、非相似性分析◆Regression 回归分析……Liner线性回归分析……Curve Estimation曲线估计……Binary Logistic二分变量回归分析……Multinomial Logistic 多项类别变量回归分析……Ordinal序数的回归分析……Probit 概率分析……Nonlinear 非线性回归分析……Weight Estimation 不同权数的线性回归分析……2-stage Least Squares 二阶最小平方回归分析……Optimal Scaling最优尺度分析◆Loglinear 对数线性回归分析……General 一般对数线性回归分析……Logit单因变量多自变量回归分析……Model Selection分层对数线性模型◆Classify聚类和判别分析……K-means Cluster 快速聚类分析(指定分类数聚类分析)……Hierarchical Cluster系统聚类分析(未知分类数聚类分析)……Discriminent 判别分析◆Data Reduction 数据浓缩(降维)处理……Factor因子分析……Correspondence对应分析……Optimal Scaling最优尺度分析◆Scale项目分析……Reliability Ananlysis可靠性分析……Multidimensional Scaling多维等级分析……Multidimensional Scaling(POXSCAL)◆Nonparametric T ests 非参数统计……Chi-Square 相对比例假设检验……Binomial特定时间发生概率检验……Run随即序列检验……1-Sample Kolmogorov Smirnov 样本分布检验……2-Independent Samples 双不相关组分布分析……K Independent Samples多不相关组分布分析……2 Related Samples双相关变量分布分析……K Related Samples相关变量分布分析◆Time Series时间序列……Exponential Smoothing 平衡序列的随机分量……Autoregression一阶自回归误差线性方差检验……ARIMA综合自回归移动平均分析……Seasonal Decomposition对时间序列增倍和加性季节因子分析◆Survival生存分析……Life Tables 生命表分析……Kaplan-Meier 双事件分布检验……Cox Regression事件与时间变量相互分析……Cox w/Time Dep cov时间函数Cox分析◆Multiple Response多选题处理……Define sets多选题变量定义……Frequencies多选题频数分析……Crosstabs多选题交叉分析◆Missing value Analysis 缺失值分析。
SPSS菜单说明

Analyze统计
General Linear Model——Univariable 单因变量方差分析
Correlate相关——Bivariate 双变量相关 Regression回归分析——Linear 线性回归
Curve Estimation曲线预测模型 Scale——Reliability Analysis可靠性分析
File 文件
New新建——Data 数据库 Open打开 Save 保存 Save as 另存 Print 打印
Edit 编辑
Undo撤消 Cut 剪切 Copy复制 Paste粘贴 Clear清除
Data数据
Define variable定义变量 Insert variable插入变量 Insert case插入案例 Go to case查找 Sort cases排序 Transpose 转置 Select cases选择案例
Transform转化
Compute 生成新变量 Recode转化成新变量
Analyze统计
Summarize概括数据——Frequencies频率 Descriptives描述 Explore探索 Crosstabs交叉表格
Analyze统计
Tables表格组——Basic tables基本表 General tables总表
Multiple response tables多重反应表 Tables of frequencies频率表
Analyze统计
Compare means比较平均值—Means平均值 One-Sample T Test一维样本T检验
Independent-Samples T Test 独立样本T检验 Paired-Samples T Test配对样本T检验 Nhomakorabea(信度分析)
[课件]第八章SPSS的相关分析和线性相关分析PPT
![[课件]第八章SPSS的相关分析和线性相关分析PPT](https://img.taocdn.com/s3/m/76ebd16e2b160b4e767fcfdd.png)
SPSS
通过该表得到模型系数的概率值可以发现,常数项系 数差异不显著,而身高的系数差异显著,因此可以 留在模型中,即该模型为:
y0 .7 1 9x
SPSS
SPSS
SPSS
SPSS
练习
• 现有1978~2003年城镇居民消费额和人均 国内生产总值的相关数据保存在居民生 活.sav中,现要求建立城镇居民消费额y与 人均国内生产总值之间的线性模型。
为 了 用 矩 阵 表 示 上 式 , 令
y1 1 x11 ... 1 x 21 Y ,X ... ... ... y 1 x n1 n x12 x 22 ... xn2 ... x1k 0 1 ... x 2 k , 1 , 2 ... ... ... ... ... x nk k n
SPSS
第八章SPSS 的相关分析 和线性相关 分析
SPSS
第一节相关分析和 线性回归分析概述
函数关系
事物之间关系 统计关系
SPSS
• 函数关系指的是两事物之间的一种一一对 应关系。即当一个变量x取一定值时,另一 变量y可以依确定的函数取唯一确定的值。 • 统计关系指两事物之间的一种非一一对应 关系,即当一个变量x取一定值时,另一变 量y无法依确定的函数取唯一确定的值。
SPSS
回归分析的一般步骤
1.确定回归方程中的解释变量x和被解释变量 y 2.确定回归模型 3.建立回归方程 4.对回归方程进行各种检验 5.利用回归方程进行预测
回归分析方法 SPSS
一元线性回归 多元线性回归
数 学 模 型 及 定 义
模 型 参 数 估 计
spss中一般线性模型

03:31
3
Univariate(单因变量方差分析)基本过程
03:31
4
1 主对话框
Dependent Variable:因变量
Fixed Facter: 固定因子,所有可能的水 平都出现在样本中,如分组等
Random Facter: 随机因子,所有可能 的取值并不都在样本中出现,如观察个 体
Device*Target。
模型中包括所有3维效应,
定义效应类型为All3-way, 单击变量Llight、 Device、 Target。 单击箭头按钮, Model框中出现3维交互效应项:Ligh*Device*Target。
03:31
12
Ⅲ、选择平方和分解的方法
Sum of squares:
03:31
9
B、选择模型中的主效应 (Model)
首先定义效应类型为Main effects
鼠标键单击某一个因素,该变量名 背景将改变颜色(一般变为蓝色), 单击Build Term(s)栏中下面的 箭头,该变量出现在Mode1中。一 个变量名占一行称为主效应项。欲 在模型中包括几个主效应项,就进 行几次如上的操作。
Residuals plot:绘制残差图。
Lack of fit:检查因素和因变量间的关系是否被充分描述。
General estimable function:可以根据一般估计函数自定义假设
检验。对比系数矩阵的行与一般估计函数是线性组合的。
03:31
22
二、完全随机设计资料的方差分析
例1 为研究多酚保健饮料对急性缺氧的影响,将60 只Wistar小白鼠随机分为低、中、高三个剂量组和 一个对照组,每组15只小白鼠。对照组给予蒸馏水 0.25ml灌胃,低、中、高剂量组分别给予2.0、4.0、 8.0g/kg的饮料溶于0.2~0.3ml蒸馏水后灌胃,每天一 次。40天后,对小白鼠进行耐缺氧存活时间实验, 结果如表1。试比较不同剂量的茶多酚保健饮料对 延长小白鼠的平均耐缺氧存活时间有无差别。
一般线性模型

Tests of Between-Subjects Effects Dependent Variable: 重 量 Source Corrected Model Intercept group food Error Total Corrected Total Type III Sum of Squares 2521.294a 74359.534 2376.376 144.918 340.543 77221.370 2861.836 df 9 1 7 2 14 24 23 Mean Square 280.144 74359.534 339.482 72.459 24.324 F 11.517 3056.985 13.956 2.979 Sig . .000 .000 .000 .084
(F)固定因素 (R)随机因素 (C)协变量
是否在模型中包括截距 方差分析模型类别
19
20
【Contrast钮】 弹出Contrast对话框,用于对精细趋势检验和精确两两 比较的选项进行定义,使用频率少; 【Plots钮】 用于指定用模型的某些参数作图,比如用food和group 来作图,用的也比较少(指国内,因为它主要是用来做 模型诊断用的)。 【Post Hoc钮】 该按钮弹出的两两比较对话框。本题对food作两两比较, 方法为SNK法。 【Save钮】 将模型拟合时产生的中间结果或参数保存为新变量供继 续分析时用,如预测值、残差、诊断用指标等。 【Options钮】 定义选项,可以定义输出哪些指标的估计均数、并做所 选择的两两比较,还有其他一些输出,如常用描述指标、 方差齐性检验等。 21
5
一般线性模型
-General Linear Model菜单
generalized linear model结果解释-概述说明以及解释

generalized linear model结果解释-概述说明以及解释1.引言1.1 概述概述部分的内容可以包括对广义线性模型的简要介绍以及结果解释的重要性。
以下是一种可能的编写方式:在统计学和机器学习领域,广义线性模型(Generalized Linear Model,简称GLM)是一种常用的统计模型,用于建立因变量与自变量之间的关系。
与传统的线性回归模型不同,广义线性模型允许因变量(也称为响应变量)的分布不服从正态分布,从而更适用于处理非正态分布的数据。
广义线性模型的理论基础是广义线性方程(Generalized Linear Equation),它通过引入连接函数(Link Function)和系统误差分布(Error Distribution)的概念,从而使模型能够适应不同类型的数据。
结果解释是广义线性模型分析中的一项重要任务。
通过解释模型的结果,我们可以深入理解自变量与因变量之间的关系,并从中获取有关影响因素的信息。
结果解释能够帮助我们了解自变量的重要性、方向性及其对因变量的影响程度。
通过对结果进行解释,我们可以推断出哪些因素对于观察结果至关重要,从而对问题的本质有更深入的认识。
本文将重点讨论如何解释广义线性模型的结果。
我们将介绍广义线性模型的基本概念和原理,并指出结果解释中需要注意的要点。
此外,我们将提供实际案例和实例分析,以帮助读者更好地理解结果解释的方法和过程。
通过本文的阅读,读者将能够更全面地了解广义线性模型的结果解释,并掌握解释结果的相关技巧和方法。
本文的目的是帮助读者更好地理解和运用广义线性模型,从而提高统计分析和机器学习的能力。
在接下来的章节中,我们将详细介绍广义线性模型及其结果解释的要点,希望读者能够从中受益。
1.2文章结构文章结构部分的内容应该是对整篇文章的结构进行简要介绍和概述。
这个部分通常包括以下内容:文章结构部分的内容:本文共分为引言、正文和结论三个部分。
其中,引言部分主要概述了广义线性模型的背景和重要性,并介绍了文章的目的。
SPSS数据分析教程-8-线性回归分析

结果及其解释
“t”列记录了各回归系数t检验的t统计量,而 Sig.列记录了相应的显著性值。这里,只有X1 和X3的显著性值小于0.1,注意到回归方程的 常数项也不显著。然而,大部分情况下不显著 的预测变量都要从回归方程中移除,而回归常 数代表了响应变量的基本水平,不管显著与否, 大部分情况都保留在回归方程中。因此,我们 可以仅仅考虑Y和X1、X3之间的关系而忽略其 他预测变量。
回归分析的分类
根据回归函数的形式,回归分析可以分为线性 回归和非线性回归:
线性回归: Y= ¯0 +¯1 X1+¯2 X2 + +¯p Xp +²
(y)
非线性回归 如果预测变量和响应变量之间有上页(¤ )所示 的关系,但是不能表示为(y)所示的线性方程 的形式,我们称该回归关系为非线性回归。
回归术语
对于有一个响应变量的线性回归,当p=1时, 我们称为简单线性回归(Simple Linear Regression,或称为一元线性回归),当 p>2 时我们称为多元线性回归(Multiple Linear Regression)。
回归和相关分析
回归分析是在相关分析的基础上,确定了变量 之间的相互影响关系之后,准确的超出这种关 系的数量方法。因此,一般情况下,相关分析 要先于回归分析进行,确定出变量间的关系是 线性还是非线性,然后应用相关的回归分析方 法。在应用回归分析之前,散点图分析是常用 的探索变量之间相关性的方法。
简约回归模型
简约回归模型结果及解释
动手练习
数据文件world95.sav记录了1995年统计的各个国家的生育率 (fertility)和妇女的平均预期寿命(lifeexpf)等数据。 1)探索性分析这两个变量,探察两个变量中是否存在异常点。 2)做出这两个变量的散点图,建立两个变量的线性回归模型,判断 得到的模型的合理性。 3)利用生育率来预测妇女的预期寿命。并设置相关选项,以进一步 检验关于线性回归的假定条件。判断该数据是否满足线性回归的 假定条件。 4)并进行回归诊断,对模型的系数进行解释。从输出结果,判断妇 女多要一个小孩对她的寿命的影响情况。。
第八章 一般线性模型――General Linear Model菜单详解

第八章一般线性模型――General Linear Model菜单详解请注意,本章的标题用了一些修辞手法,一般线性模型可不是用一章就可以说清楚的,因为它包括的内容实在太多了。
那么,究竟我们用到的哪些分析会包含在其中呢?简而言之:凡是和方差分析粘边的都可以用他来做。
比如成组设计的方差分析(即单因素方差分析)、配伍设计的方差分析(即两因素方差分析)、交叉设计的方差分析、析因设计的方差分析、重复测量的方差分析、协方差分析等等。
因此,能真正掌握GLM菜单的用法,会使大家的统计分析能力有极大地提高。
实际上一般线性模型包括的统计模型还不止这些,我这里举出来的只是从用SPSS作统计分析的角度而言的一些。
好了,既然一般线性模型的能力如此强大,那么下属的四个子菜单各自的功能是什么呢?请看:∙Univariate子菜单:四个菜单中的大哥大,绝大部分的方法分析都在这里面进行。
∙Multivariate子菜单:当结果变量(应变量)不止一个时,当然要用他来分析啦!∙Repeted Measures子菜单:顾名思义,重复测量的数据就要用他来分析,这一点我可能要强调一下,用前两个菜单似乎都可以分析出来结果,但在许多情况下该结果是不正确的,应该用重复测量的分析方法才对(不能再讲了,再讲下去就会扯到多水平模型去了)。
∙Variance Components子菜单:用于作方差成份模型的,这个模型实在太深,不是一时半会说的请的,所以我在这里就干脆不讲了。
出于模型复杂性、篇幅、应用范围及乱七八糟一系列的理由,当然主要是我懒得一一解释,我决定本章采用举例讲解的方式,及讲解一些常见的分析实例,通过这种方法来熟悉那些最为常用的分析方法。
对统计分析的数据格式不太熟悉的朋友,请一定先去看看统计软件第一课:论统计软件中的数据录入格式,会大有帮助的。
§8.1两因素方差分析下面的这个例子来自《卫生统计学》第四版,书还没有出来,大家先尝尝鲜。
spss中一般线性模型解析

Simple:对预测变量或因素变量的每一水平都与参照水平进行比 较。选择Last或First作为参照水平;
Difference:对预测变量或因素每一水平的效应,除第一水平以 外,都与其前面各水平的平均效应进行比较。与Helmert对照方 法相反;
注: 只有Deviation和Simple 需要选择参考水平,Last(系统 默认)和First。
08:44
8
A、选择效应类型
Interactin:交互效应 Main effects:主效应 All2-way: 所有2维交互效应 All3-way:所有3维交互效应
All4-Way:所有4维交互效应
All5-Way:所有5维交互效应
08:44
9
B、选择模型中的主效应 (Model)
模型中包括所有3维效应,
定义效应类型为All3-way,
单击变量Llight、 Device、 Target。 单击箭头按钮, Model框中出现3维交互效应项:Ligh*Device*Target。
08:44 12
Ⅲ、选择平方和分解的方法
Sum of squares:
TYPEⅠ(嵌套设计)、 TYPEⅡ(平衡设计、仅主 效应)、 TYPE Ⅲ(系统默认、最常 用) TYPEIV(不完整数据)。
08:44
11
C. 建立模型中的交互项
模型中包括三个变量的所有2维交互效应项,
定义效应类型为All2-way, 单击light、Device、Target三个变量名, 单击箭头按钮。 Model中出现三个 2维交互效应项: Light*Device、 Light*Target、 Device*Target。
SPSS第8章

• 【主对话框】
– Variance Components过程的主对话框和 Univariate过程没有什么区别,这里不再详细介 绍,只是有一点需要指出:由于需要估计方差 大小,模型中必须要指定至少一个随机因素变 量方可运算。
义。此处我们单击Add钮,则变量trial被加入右侧大框中, 括号里的“4”表示被重复测量了四次。可以在大框中加入 多个重复测量变量的定义。 • 4. Measure>>:如果所进行的重复测量有嵌套现象,如 对每个病人共重复测量四周的血压,但每次测量均重复三 次,此时每次测量的三次重复就嵌套在四周的重复测量中, 需要单击该钮扩展预定义框,在新出现的下部部分定义所 嵌套的重复测量变量。
• 除了大家都能想到的多元正态、方差齐以外,多元方差分 析还有其他的些适用条件:
– 首先,它要求各应变量间的确存在一定的关系,这可以从专业或 分析目的上来判断,如测量全身多处的骨骼指标都是为了反映骨 龄的大小;
– 其次,它在样本规模上有一定的要求,不仅总样本量要较大,各 单元格中样本数量也应较大,否则所进行的多元分析检验效能太 低,不容易得出阳性结论。
– Maximum likelihood:用最大似然法对方差做 估计,对固定效应做估计时不考虑自由度。
– Restricted maximum likelihood:采用限制最 大似然法(REML)对方差做无偏估计,前面的三 种估计方法实际上都是单水平模型的传统估计 方法,REML是真正按照多水平模型的情况开 发的算法,大多数情况下都更精确。在SAS的 Mixed过程中,默认的拟合方法也是REML。我 推荐大家尽量使用此法。
spss中一般线性模型解读

09:39
14
可供选择的对照方法
None:不进行均数比较;
Deviation:比较预测变量或因素的每个水平的效应。选择Last或 First作为参照的水平;
Simple:对预测变量或因素变量的每一水平都与参照水平进行比 较。选择Last或First作为参照水平;
Difference:对预测变量或因素每一水平的效应,除第一水平以 外,都与其前面各水平的平均效应进行比较。与Helmert对照方 法相反;
09:39
16
2.4 Post Hoc按钮
均数多重比较(事后检验)
09:39
17
2.5 Save按钮(选择保存运算值)
通过在对话框中的选择, 可以将所计算的预测值、 残差和诊断值(回归分析 时)作为新的变量保存在 编辑数据文件中。以便在 其他统计分析中使用这些 值。
09:39
18
2.5 Save按钮(选择保存运算值)
一般线性模型(一)
09:39
1
一般线性模型
一般线性模型单变量分析的基本过程 完全随机设计资料的方差分析 随机区组(单位组)设计资料的方差分析
09:39
2
一、一般线性模型单变量分析的基本过程
General Linear Model(GLM,一般线性模型)
包括:
Univariate(单因变量多因素方差分析), Multivariate(多因变量方差分析), Repeated Measures(重复测量方差分析), Variance(方差分量分析)
Device*Target。
模型中包括所有3维效应,
定义效应类型为All3-way, 单击变量Llight、 Device、 Target。 单击箭头按钮, Model框中出现3维交互效应项:Ligh*Device*Target。
Spss菜单解释

SpssData菜单Transform菜单Accuracy 精确度,actual frequency 实际频数,adjusted value 校正值,alternative hypothesis 备选假设,analysis of convariance 协方差分析,analysis of variance, ANOV A 方差分析,arithmetic mean 算数均数,asymmetric distribution 非对称分布,autocorrelation 自相关,censored data 截尾数据,censoring 删失失访终检,central limit theorem 中心极限定理,central tendency 集中趋势,chance error 随机误差,class mid-value 组中值,cluster analysis 聚类分析,cluster sampling 整群抽样,coding 编码,coefficient of contingency 列联系数,coefficient of correlation 相关系数,bar chart 条图,bayes theorem 贝叶斯定理,bias 偏性,binomial distribution 二项分布,bivariate normal distribution 双变量正态分布,block 区组,box plot 箱图,canonical correlation 典型相关,case-control study 病例一一对照研究,categorical variable 分类变量,cell 单元,coefficient of determination 决定系数,coefficient ofpartial correlation 偏相关系数,coefficient of product-moment correlation 积差相关系数,coefficient of rank correlation 等级相关系数,coefficient of regression 回归系数,coefficient of variation 变异系数,coefficient of skewness 偏度系数,cohort study 队列研究,communality variance 公共方差,comparability 可比性,complete association 完全相关,complete random design 完全随机设计,degree of freedom 自由度,conditional likelihood 条件似然,conditional probability 条件概率,confidence interval CI 可信(置信)区间,confidence limit CL 可信(置信)限,confirmatory factor analysis 验证性因子分析,confirmatory research 验证性研究,degree of reliability 可靠度,density function 密度函数,dependent variable 因变量,deviation 离差,discrete variable 离散变量,discriminant analysis 判别分析,conjoint analysis 联合分析,consistency test 一致性检验,constraint 约束,contingency table 列联表,contribution rate 贡献率,control 对照控制,controlled experiments 对照实验,correction 校正,correction for continuity 连续性校正,correlation 相关,correlation analysis 相关分析,correlation coefficient 相关系数,distribution 分布,distribution-free method 任意分布方法分布自由方法,dose response curve 剂量反应曲线,dummy variable 哑变量虚拟变量,eigenvalue 特征值特征根,eigenvector 特征向量,equivariance 等方差,error 误差,error of estimate 估计误差,estimated value 估计值,correspondence analysis 对应分析,counts 计数频数,covariance 协方差,Cox regression Cox回归,criteria for fitting 拟合准则,critical value 临界值,cross-over design 交叉设计,cross-section analysis 横断面分析,eigenvalue特征值,特征根eigenvector 特征向量equivariance等方差error误差error of estimate估计误差estimated value估计值euclidean distance欧氏距离event事件expected values期望值design of experiment实验设计exploratory data analysis探索性数据分析exponential curve指数曲线extrapolation外推法extremes极端值,极值,forecast预测fourfold table四格表frequency频数frequency distribution 频数分布general linear model, GLM一般线性模型generalized linear model广义线性模型geometric mean几何均数goodness of fit拟合优度,half-life半衰期harmonic mean调和均数hazard function风险函数,hazard rate风险率heterogeneity异质heterogeneity of variance方差不齐heteroscedasticity 方差不齐hierarchical clustering method分层聚类法histogram直方图homogeneity同质,齐性,homogeneity of variance同方差性homogeneity test齐性检验homoscedasticity方差齐性hypothesis test假设检验,independence独立性independent variable自变量initial mean vectors初始凝聚点interaction交互效应intercept截距interpolation 插值inter-quartile range四分位数间距,interval estimation区间估计inverse matrix逆矩阵iteration迭代,K-means method K-均值聚类法Kaplan-Merier curve Kaplan-Merier 曲线kendall srank correlationKendall等级相关Kolmogorov-Smirnov test K-S检验Kruskal and Wallis test K-W检验,H检验kurtosis峰度L lack offit拟合劣度,失拟Latin square design拉丁方设计least square method最小二乘法legend图例level水平level of significance统计意义水平,life table寿命表likelihood function似然函数likelihood ratio test似然比检验line graph线图linear线性linear correlation直线相关linear equation线性方程linear programming线性规划linear regression线性回归,linear trend线性趋势loading载荷log-rank test时序检验logarithmic scale对数尺度logistic regression logistic回归logit transformation logit转换loglinear model对数线性模型M main effect主效应matched data配对资料matching匹配maximum likelihood method最大似然法maximum likelihood ratio test似然比检验,mean均值mean square,MS均方measurement bias测量性偏倚median中位数median effective dose半数效量median lethal dose半数致死量median survival time中位生存时间median test中位数检验M-estimators M估计量minimumlethal dose最小致死量missing value缺失值multidimensional scaling analysis, MDS多维尺度分析,multinomial distribution多项分布multiple comparison多重比较multiple correlation复相关,多重相关multiple covariance多元协方差multiple linear regression多重线性回归multiple response多重应答,多选题multistage sampling多级抽样multivariate regression多元回归multivariate statistical analysis多变量统计分析,多元统计分析,negative correlation负相关no statistical significance无统计学意义nominal variable名义变量nonlinear regression非线性回归nonparametric statistics非参数统计nonparametric test非参数检验normal distribution正态分布null hypothesis原假设,无效假设numerical variable数值变量O observation unit 观察单位observed value观测值odds ratio,OR优势比,比数比,one-sided test单侧检验one-way ANOV A单因素方差分析optimum allocation最优分配order statistics顺序统计量ordered categories有序分类orthogonal experimental design正交试验设计outlier异常值,离群值overall survey普查P paired design配对设计paired(matched)t-test配对t检验parameter参数,parametric statistics参数统计parametric test参数检验partial correlation 偏相关partial likelihood偏似然函数partial regression coefficient偏回归系数path analysis路径分析percent bar graph百分条图percentage百分比,百分数percentile百分位数,位点periodicity周期性pie graph饼图,圆图,placebo安慰剂point estimation点估计Poisson distribution Poisson分布polynomial curve多项式曲线population总体population mean 总体均值positive correlation正相关posterior distribution后验分布power ofa test检验效能power ofstatistics检验效能precision精度principal component analysis主成分分析prior distribution先验分布product moment乘积矩,协方差,product-limit method乘积极限法proportion构成比prospective study前瞻性研究P-value P值Q qualitative evaluation定性评价qualitative method定性方法quantile-quantile plot Q-Q图quantitative analysis定量分析quantitative evaluation定量评价quartile四分位数questionnaire问卷quick cluster 快速聚类,random event随机事件random sampling随机抽样randomization随机化randomized allocation随机分配randomized block design随机区组设计randomized control trial随机对照试验randomized double blind control trial随机双盲对照试验range极差,全距rank correlation等级(秩)相关rank sum test秩和检验,ranked data等级资料rate率ratio比raw data原始资料regression analysis回归分析regression coefficient 回归系数regression SS回归平方和relative number相对数relative risk,RR相对危险度reliability可靠度,信度replacement level更替水平,residual 残差residual standard deviation 剩余标准差,residual sum of square残差平方和ridge trace岭迹ridit analysis Ridit 分析risk ratio危险比,风险比rotation旋转r×c table r×c表S sample样本sample size 样本量sampling error抽样误差sampling fraction抽样比sampling study抽样研究sampling survey抽样调查,scale测量尺度scatter diagram散点图score test比分检验screening筛检selection bias选择性偏倚semilogarithmic line graph半对数线图sequential design序贯设计sign test符号检验signed rank符号秩significance level显著性水准significance test显著性检验simple correlation简单相关simple regression简单回归,skewness偏度slope斜率spearman rank correlationspearman等级相关spherical distribution球型分布standard deviation,SD标准差,标准离差standard error,SE标准误,标准误差standard normal distribution标准正态分布standardization标准化standardized partial regression coefficient标准化偏回归系数statistic统计量statistical control统计控制,statistical graph统计图statistical inference统计推断statistical significance统计学意义statistical table统计表stem and leaf graph茎叶图step-wise method逐步法strata层(复数)stratification分层stratified cluster sampling分层整群抽样stratified sampling分层抽样structural equation modeling结构方程模型sum ofsquares离差平方和sum ofsquares of deviations from mean 离均差平方和,survey调查survival analysis生存分析survival curve生存曲线survival probability生存概率survival rate生存率survival time生存时间symmetry对称synthetic index综合指数synthetical evaluation综合评价systematic error 系统误差,systematic sampling系统抽样T t-distribution t分布tendency of dispersion 离散趋势test statistic检验统计量testing of hypotheses假设检验theoretical frequency理论频数time series analysis时间序列分析,t-test t检验two-sided test双侧检验two-stage least squares method二阶段最小二乘法two-stage sampling二阶段抽样two-step cluster 两步聚类法two-tailed probability双尾概率two-tailed test双侧检验two-way ANOV A两因素方差分析two-way table双向表type I error I类错误type II error II类错误,unbiased estimate无偏估计uniform distribution均匀分布upper limit上限u-test u检验V variable变量variance方差variance component estimation方差分量估计varimax orthogonal rotation方差最大化正交旋转,weight权重weighted linear regressionmethod 加权直线回归weighting method加权法Z zero correlation零相关z-transformation标准正态(z)变换,各种情形下最常用统计检验方法索引1 单变量连续但样本t检验有序多分类单样本秩和检验无序多分类单样本x2检验二分类二项分布确切概率法2 因变量:连续变量单个自变量:连续相关分析,回归分析有序多分类单因素方差分析,结果解释时利用有序信息无序多分类单因素方差分析二分类两样本 检验多个自变量:连续变量为主线形回归模型分类变量为主方差分析模型,和回归模型实际上等价3 因变量:有序分类变量单个自变量:连续有序分类的Logistic回归有序多分类秩相关分析、CMH x2无序多分类多样本秩和检验(H检验)二分类两样本秩和检验(W检验)多个自变量:连续变量为主有序分类的判别分析,有序分类的Logistic回归分类变量为主有序分类的Logistic回归4 因变量:无序分类变量单个自变量:连续无序分类的Logistic回归有序多分类可将自因变量交换后分析无序多分类x2检验,深入分析可用对数线性模型二分类x2检验多个自变量:连续变量为主判别分析、无序分类的Logistic回归分类变量为主无序分类的Logistic回归5 因变量:二分类变量单个自变量:连续二分类Logistic回归有序多分类可将自/因变量交换后分析无序多分类x2检验,二分类的Logistic回归二分类四格表x2检验,确切概率法多个自变量:连续变量为主判别分析、二分类Logistic回归、两法结果实际等价分类变量为主二分类Logistic回归6 多元分析方法考察的特征需要由多个因素量来表示,同时研究多个自变量对他们的影响:多元方差分析模型、多元回归模型。
SPSS数据分析教程第8章线性回归分析ppt课件

53.00
66.00
53.00
59.00
精5选5.课00 件ppt 45.00
1.00
1.00
25.00 64
精选课件ppt
z1 61.00 59.00 55.00 56.00 59.00 60.00 52.00 56.00 68.00 60.00 64.00 67.00 56.00 53.00 53.00 60.00 54.00
38
精选课件ppt
表7-1 强度与拉伸倍数的试验数据
序号 1 2 3 4 5 6 7 8 9 10 11 12
拉伸倍数 2.0 2.5 2.7 3.5 4.0 4.5 5.2 6.3 7.1 8.0 9.0 10.0
强度(kg/mm2) 1.6 2.4 2.5 2.7 3.5 4.2 5.0 6.4 6.5 7.3 8.0 8.1
58.00
57.00
62.00
1.00
1.00
23.00
56.00
55.00
57.00
39.00
44.00
46.00
1.69
1.00
15.00
50.00
50.00
68.00
46.00
45.00
56.00
1.08
1.14
25.00
58.00
54.00
60.00
59.00
52.00
51.00
1.00
1.00
5
精选课件ppt
具体地说,回归分析主要解决以下几方面 的问题。
• 通过分析大量的样本数据,确定变量 之间的数学关系式。
• 对所确定的数学关系式的可信程度进 行各种统计检验,并区分出对某一特定变量影 响较为显著的变量和影响不显著的变量。
spss中一般线性模型解析

09:03
16
2.4 Post Hoc按钮
均数多重比较(事后检验)
09:03
17
2.5 Save按钮(选择保存运算值)
通过在对话框中的选择, 可以将所计算的预测值、 残差和诊断值(回归分析 时)作为新的变量保存在 编辑数据文件中。以便在 其他统计分析中使用这些 值ve按钮(选择保存运算值)
09:03
11
C. 建立模型中的交互项
模型中包括三个变量的所有2维交互效应项, 定义效应类型为All2-way,
单击light、Device、Target三个变量名, 单击箭头按钮。 Model中出现三个 2维交互效应项: Light*Device、 Light*Target、
注: 只有Deviation和Simple 需要选择参考水平,Last(系统 默认)和First。
09:03
15
2.3 Plots按钮
Factor:主对话框中所选因素 变量名;
Horizontal:横坐标框
Separate Lines:确定分线变量
Separate Plots:确定分图变量
Predicted Values(预测值)
Unstandardized:非标准化 预测值
Weighted:如果在主对话 框选择了WLS变量,选中 该复选项将保存加权非标准 化预测值
09:03
6
2.1 Model按钮
Ⅰ、在Specify Model栏中指定模型类型
Full Factorial,全模型,系统 默认。包括所有因素的主效应 和所有的交互效应。例如有三 个因素变量,全模型包括三个 因素的主效应、两两的交互效 应和三个因素的高级交互效应。
spss第八课征服一般线性模型generallinearmodel菜单详解(上)

SPSS第八课:征服一般线性模型――General Linear Model菜单详解(上)(兆联投资管理顾问)上次更新日期:2009年06月02日8.1两因素方差分析8.1.1univarate对话框界面说明8.1.2结果解释8.2协方差分析8.2.1分析步骤8.2.2结果解释8.3其他较简单的方差分析问题8.4多元方差分析8.4.1分析步骤8.4.2结果解释8.5重复测量的方差分析8.5.1Repeated measures对话框界面说明8.5.2结果解释请注意,本章的标题用了一些修辞手法,一般线性模型可不是用一章就可以说清楚的,因为它包括的容实在太多了。
那么,究竟我们用到的哪些分析会包含在其中呢?简而言之:凡是和方差分析粘边的都可以用他来做。
比如成组设计的方差分析(即单因素方差分析)、配伍设计的方差分析(即两因素方差分析)、交叉设计的方差分析、析因设计的方差分析、重复测量的方差分析、协方差分析等等。
因此,能真正掌握GLM菜单的用法,会使大家的统计分析能力有极大地提高。
实际上一般线性模型包括的统计模型还不止这些,我这里举出来的只是从用SPSS作统计分析的角度而言的一些。
好了,既然一般线性模型的能力如此强大,那么下属的四个子菜单各自的功能是什么呢?请看:?Univariate子菜单:四个菜单中的大哥大,绝大部分的方法分析都在这里面进行。
?Multivariate子菜单:当结果变量(应变量)不止一个时,当然要用他来分析啦!?Repeted Measures子菜单:顾名思义,重复测量的数据就要用他来分析,这一点我可能要强调一下,用前两个菜单似乎都可以分析出来结果,但在许多情况下该结果是不正确的,应该用重复测量的分析方法才对(不能再讲了,再讲下去就会扯到多水平模型去了)。
?Variance Components子菜单:用于作方差成份模型的,这个模型实在太深,不是一时半会说的请的,所以我在这里就干脆不讲了。
spss中一般线性模型解析

Group→Fixed Factors
2021/4/8
27
建立数据文件:耐缺氧时间.sav.
定义变量 输入数据 开始分析:analyze →General Linear Model →Univariate
Y→Dependent Variable Group→Fixed Factors Post Hoc : Group → Post Hoc Tests for
Descriptive Statistics, Homogeneity tests
2021/4/8
29
主要结果---描述性统计量
Be tw een-Subje cts Factors
Group 1 2 3 4
Value Label 对照组 低剂量组 中剂量组 高剂量组
N 15 15 15 15
Des cript ive Statist ics
2021/4/8
7
Ⅱ、建立自定义模型
Factors&Covariates 框中 自动列出可以作为因素的 变量名,其后面的括号中 标有字母“F”(固定因 子)、“R”(随机因子) 或者“C”(协变量)。
2021/4/8
8
A、选择效应类型
Interactin:交互效应 Main effects:主效应 All2-way: 所有2维交互效应 All3-way:所有3维交互效应 All4-Way:所有4维交互效应 All5-Way:所有5维交互效应
Total
26.0780
中剂量组 35.07 24.33 28.11 33.97 24.74 21.86 29.79 28.65 22.68 25.13 23.01 34.44 28.32 31.69 29.04
SPSS数据分析教程第8章线性回归分析ppt课件
实现步骤
精选课件ppt
图7-1 在菜单中选择“Linear”命令
40
精选课件ppt
图7-2 “Linear Regression”对话框(一)
41
精选课件ppt
图7-3 “Linear Regression:Statistics”对话框
42
精选课件ppt
图7-4 “Linear Regression:Plots”对话框
36
精选课件ppt
回归参数显著性检验的基本步骤。 ① 提出假设 ② 计算回归系数的t统计量值 ③ 根据给定的显著水平α确定临界值,或者 计算t值所对应的p值 ④ 作出判断
37
精选课件ppt
7.2.2 SPSS中实现过程
研究问题 合成纤维的强度与其拉伸倍数有关,测得 试验数据如表7-1所示。求合成纤维的强度与 拉伸倍数之间是否存在显著的线性相关关系。
精选课件ppt
60
(2)回归方程的显著性检验(F检验) 多元线性回归方程的显著性检验一般采用 F检验,利用方差分析的方法进行。
精选课件ppt
61
(3)回归系数的显著性检验(t检验) 回归系数的显著性检验是检验各自变量x1, x2,…,对因变量y的影响是否显著,从而找出 哪些自变量对y的影响是重要的,哪些是不重 要的。 与一元线性回归一样,要检验解释变量对 因变量y的线性作用是否显著,要使用t检验。
4
精选课件ppt
• 在回归分析中,因变量y是随机变量,自 变量x可以是随机变量,也可以是非随机的确 定变量;而在相关分析中,变量x和变量y都是 随机变量。
• 相关分析是测定变量之间的关系密切程度, 所使用的工具是相关系数;而回归分析则是侧 重于考察变量之间的数量变化规律,并通过一 定的数学表达式来描述变量之间的关系,进而 确定一个或者几个变量的变化对另一个特定变 量的影响程度。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS第八课:征服一般线性模型――General Linear Model菜单详解(上)(武汉兆联投资管理顾问有限公司)上次更新日期:2009年06月02日8.1 两因素方差分析8.1.1 univarate对话框界面说明8.1.2 结果解释8.2 协方差分析8.2.1 分析步骤8.2.2 结果解释8.3 其他较简单的方差分析问题8.4 多元方差分析8.4.1 分析步骤8.4.2 结果解释8.5 重复测量的方差分析8.5.1 Repeated measures对话框界面说明8.5.2 结果解释请注意,本章的标题用了一些修辞手法,一般线性模型可不是用一章就可以说清楚的,因为它包括的内容实在太多了。
那么,究竟我们用到的哪些分析会包含在其中呢?简而言之:凡是和方差分析粘边的都可以用他来做。
比如成组设计的方差分析(即单因素方差分析)、配伍设计的方差分析(即两因素方差分析)、交叉设计的方差分析、析因设计的方差分析、重复测量的方差分析、协方差分析等等。
因此,能真正掌握GLM菜单的用法,会使大家的统计分析能力有极大地提高。
实际上一般线性模型包括的统计模型还不止这些,我这里举出来的只是从用SPSS作统计分析的角度而言的一些。
好了,既然一般线性模型的能力如此强大,那么下属的四个子菜单各自的功能是什么呢?请看:∙Univariate子菜单:四个菜单中的大哥大,绝大部分的方法分析都在这里面进行。
∙Multivariate子菜单:当结果变量(应变量)不止一个时,当然要用他来分析啦!∙Repeted Measures子菜单:顾名思义,重复测量的数据就要用他来分析,这一点我可能要强调一下,用前两个菜单似乎都可以分析出来结果,但在许多情况下该结果是不正确的,应该用重复测量的分析方法才对(不能再讲了,再讲下去就会扯到多水平模型去了)。
Variance Components子菜单:用于作方差成份模型的,这个模型实在太深,不是一时半会说的请的,所以我在这里就干脆不讲了。
出于模型复杂性、篇幅、应用范围及乱七八糟一系列的理由,当然主要是我懒得一一解释,我决定本章采用举例讲解的方式,及讲解一些常见的分析实例,通过这种方法来熟悉那些最为常用的分析方法。
对统计分析的数据格式不太熟悉的朋友,请一定先去看看统计软件第一课:论统计软件中的数据录入格式,会大有帮助的。
§8.1 两因素方差分析下面的这个例子来自《卫生统计学》第四版,书还没有出来,大家先尝尝鲜。
例8.1 对小白鼠喂以A、B、C三种不同的营养素,目的是了解不同营养素增重的效果。
采用随机区组设计方法,以窝别作为划分区组的特征,以消除遗传因素对体重增长的影响。
现将同品系同体重的24只小白鼠分为8个区组,每个区组3只小白鼠。
三周后体重增量结果(克)列于下表,问小白鼠经三种不同营养素喂养后所增体重有无差别?区组号A营养素B营养素C营养素150.1058.2064.50247.8048.5062.40353.1053.8058.60463.5064.2072.50571.2068.4079.30641.4045.7038.40761.9053.0051.20842.2039.8046.20根据统计分析的要求,我们建立了三个变量来包括上述信息,即group表示区组,food代表使用的营养素,weight表示最终的重量,即:group food weight1 1 50.011 2 58.20依此类推。
8.1.1 univarate对话框界面说明这里只有一个结果变量weight,要采用univarate对话框,如下所示:在上面的这些框框钮钮中,最常用的有:Dependent Variable框、Fixed Factors框、Model钮、Post Hoc钮,下面我们来一一解释。
【Dependent Variable框】选入需要分析的变量(应变量),只能选入一个。
这里我们的应变量为weight,将他选入即可。
【Fixed Factors框】即固定因素,说的通俗一些,就是--哎呀,我都不知道怎么解释好了,这样,如果你搞不明白,那么绝大多数要分析的因素都应该往里面选。
这里我们要分析的是group和food两个变量,把他们全都给我抓进去!固定因素指的是在样本中它所有可能的取值都出现了,比如例中的food,只可能有1、2、3这三个值,并且都出现了,就被称作固定效应;而相对应的随机效应的因素指的是所有可能的取值在样本中没有都出现,或不可能都出现,如本例中的group,实际上总体中当然不可能只有这8窝,因此要用样本中group的情况来推论总体中group未出现的那些取值的情况时就会存在误差,因此被称为随机因素。
我这里让group 也选入固定框是基于下面的事实:这样做统计分析的结论是完全相同的。
不同的只是推论的那部分。
【Random Factors框】用于选入随机因素,如果你弄不明白,假装没看见他就是了。
【Covariate框】用于选入协方差分析时的协变量,现在还用不到,不过下一个例子我们就要给他送礼了。
【WLS Weight框】即用于选入最小二乘法权重系数。
别理他,根据我的理解,只有统计分析的变态狂才会想起来用他(如有雷同,纯属巧合)!【Model钮】单击后出现一个对话框,用于设置在模型中包含哪些主效应和交互因子,默认情况为Full factorial,即分析所有的主效应和交互作用。
我们这里没有交互作用可分析,所以要改一下,否则将作不出结果来。
将按钮切换到右侧的custum,这时中部的Build Term下拉列表框就变黑可用,该框用于选择进入模型的因素交互作用级别,即是分析主效应、两阶交互、三阶交互、还是全部分析。
这里我们只能分析主效应:选择main,再用黑色箭头将group和food选入右侧的model框中,如果对这段叙述不太清楚,请参考下面的动画。
该对话框中还有两个元素:左下方的Sum of squares框用于选择方差分析模型类别,有1型到4型四种,如果你搞不清他们之间的区别,使用默认的3型即可;中下部有个Include intercept in model复选框,用于选择是否在模型中包括截距,不用改动,默认即可。
【Contrast钮】弹出Contrast对话框,用于对精细趋势检验和精确两两比较的选项进行定义,在这里,该对话框比单因素方差分析的时候还要专业,使用频率也更少,反正我都没用过,就干脆就不介绍了。
【Plots钮】用于指定用模型的某些参数作图,比如用food和group来作图,用的也比较少(指国内,因为它主要是用来做模型诊断用的)。
【Post Hoc钮】该按钮弹出的两两比较对话框和第7章单因素方差分析中的一模一样,不再重复。
本题对food作两两比较,方法为SNK法。
【Save钮】将模型拟合时产生的中间结果或参数保存为新变量供继续分析时用,可保存的东东有预测值、残差、诊断用指标等。
【Options钮】当然是定义选项啦!可以定义输出哪些指标的估计均数、并做所选择的两两比较,还有其他一些输出,如常用描述指标、方差齐性检验等。
好了,都解释完了,再重复以下,我们所作的操作为:1.Analyze==>General Lineal model==>Univariate2.Dependent Variable框:选入weight3.Fixed Factors框:选入group和food4.Model钮:单击5. Custom单选钮:选中6. Model框:选入group和food7.单击OK8.Post Hoc钮:单击9. Post Hoc test for框:选入food10. SNK复选框:选中11.单击OK12.单击OK8.1.2 结果解释按照上题的操作,结果输出如下:Univariate Analysis of Variance这是一个所分析因素的取值情况列表,没有什么不好懂的。
现在大家看到的是一个典型的方差分析表,只不过是两因素的而已,我来解释一下:首先是所用方差分析模型的检验,F值为00.517,P小于0.05,因此所用的模型有统计学意义,可以用它来判断模型中系数有无统计学意义;第二行是截距,它在我们的分析中没有实际意义,忽略即可;第三行是变量GROUP,可见它也有统计学意义,不过我们关心的也不是他;第四行是我们真正要分析的FOOD,非常遗憾,它的P值为0.084,还没有统计学意义。
尽管不太愿意,我们的结论也只能是:尚不能认为三种营养素喂养的小白鼠体重增量有差别。
上表的标题内容翻译如下:Post Hoc TestsFOODHomogeneous Subsets现在是两两比较的结果,方法为SNK法,由于前面总的比较无差异,所以这里三种食物均在一个亚组内,检验无差异,P值为0.121。
前面方差分析FOOD的P值不是0.084吗?这里又是0.121,究竟哪个为准?两两比较只是近似的比较结果,应以前面方差分析的P为准,不过这两个P值不会在检验结果上发生质的冲突,一般只是大小不同而已。
好了,上面是正确的结果,如果model选择是采用Full factor又如何呢?会得出方差分析表如下:看到了吗?由于所谓的交互作用将自由度给全部“吃”掉了,没有误差可用于统计分析,什么结果也做不出来。
§8.2 协方差分析例8.2 某医生欲了解成年人体重正常者与超重者的血清胆固醇是否不同。
而胆固醇含量与年龄有关,资料见下表。
正常组超重组年龄(X1)胆固醇(Y1)年龄(X2)胆固醇(Y2)48 3.5587.333 4.641 4.751 5.8718.443 5.8768.844 4.949 5.1638.733 4.949 3.654 6.742 5.565 6.440 4.939 6.047 5.1527.541 4.145 6.441 4.658 6.856 5.1679.2该题选自《医学统计学》第二版第七章。
考虑到统计分析对数据格式的要求,我们这里建立三个变量:GROUP表示组别,AGE代表年龄,CHOL则表示胆固醇。
8.2.1 分析步骤由于协方差分析涉及到许多较深的统计理论,这里我只好采用照本宣科的方法,告诉大家如何作,而不作过多解释,欲进一步了解原理的朋友请参考《医学统计学》原书。
首先应进行预分析,了解资料是否符合协方差分析的要求,最重要的一点就是看age的影响在两组中是否相同,这可以用age与group是否存在交互作用来表示。
对该问题,粗糙的方法可以是作分组散点图,差不多就可以,也可以进行预分析,看交互作用有无统计学意义,这里用后一种方法中最为精确的步骤来讲解。
预分析步骤:1.Analyze==>General Lineal model==>Univariate2.Dependent Variable框:选入chol3.Fixed Factors框:选入group4.Model钮:单击5. Custom单选钮:选中6. Model框:选入group、age和group*age(后者用interaction方法就可选入)7. Sum of squares列表框:改为Model I8.单击OK9.单击OK该步骤用于判断group和age间是否存在交互作用,如存在,则协方差分析的条件不满足,分析不能继续。