9.2-随机变量的模拟
随机现象的数学模拟

主题一、Matlab中的统计学图形化工具为便于初学者快速认识各种分布的特征,窥探matlab统计学工具箱的性能,首先我们来试用Matlab统计学工具箱中提供的三个图形化工具:disttool,randtool,dfittool一、概率分布绘制工具在Matlab命令行中输入>> disttool图中各项:Distribution:分布类型Function:函数类型(概率密度函数/累积分布函数)Probability:当前数据点的概率值X:当前数据点坐标值(概率分布的统计变量)Mu:期望Sigma:方差Upper/Lower bound:期望和方差的可调范围例:二项分布对泊松分布的逼近1. 打开disttool,选择Distribution=Binomial; FunctionType=PDF;Trials=10;Probability=0.5。
选择菜单Edit-> Axis Properties,将X limits设为0到20,Y limits设为0到0.42.在命令行再次输入disttool,打开新的窗口,同样选择Binomial, PDF, Trials=20;Probability=0.25。
同样将X limits设为0到20,Y limits设为0到0.43.打开第三个disttool,选择Binomial,PDF,Trials=100,Probability=0.05。
同样将X limits设为0到20,Y limits设为0到0.44.打开第四个disttool,选择Distribution=Poisson;FunctionType=PDF;Lambda=5;同样将X limits设为0到20,Y limits设为0到0.4此时前面所打开的四个窗口应该已经嵌入为一个窗口中的四个标签页(见下图底部)。
如果没有,请选择菜单Desktop->Dock Figures将他们叠嵌在一起。
数学建模之随机性模型与模拟方法

三、随机数的生成
我们知道对于丢硬币的随机结果可以用以下的离散 随机变量的改里函数来描述
X P(x) 0 0.5 1 0.5
如果我们需要模拟随机变量的以个值或一个集合, 可以用丢硬币然后记录其其结果的方法来得到,然 而这具又相当的局限性,这里我们用数学程序来产 生拟随机变量。即看上去是随机出现的,但并非真 正的随家便朗,它们产生于一个梯推公式。不过这 些拟随机数并没有明显的规律,当给于适当的伸缩 之后,它们非常接近于在 0,1 区间的均匀分布。
600
1030 3408 2520
382.5
489 1808 859
3.137
3.1595 3.141592 3.1795
由此可以看出蒙特卡罗方法的基本步骤:首先,建立 一个概率模型,使它的某个参数等于问题的解。然后按 照假设的分布,对随机变量选出具体的值(这一过程又 叫着抽样),从而构造出一个确定性的模型,计算出结 果。再通过几次抽样实验的结果,的到参数的统计特性, 最终算出解的近似值。 蒙特卡罗方法主要用再难以定量分析的概率模型,这 种模型一般的不到解析的结果,或虽然又解析结果,但 计算代价太大以至不可用。也可以用在算不出解析结果 的定性模型中。 用蒙特卡罗方法解题,需要根据随机变量遵循的分布 规律选出具体的至,即抽样。随机变量的抽样方法很多, 不同的分布采用的方法不尽相同。在计算机上的各种分 布的随机数事实上都是按照一定的确定性方法产生的伪 随机数。
X 1 [2 ln( RND1 )]1/ 2 cos(2 RND2 )
和
X 2 [2 ln( RND1 )]1/ 2 cos(2 RND2 )
来给出 X 的两个值,令X X 2 或 X X1 可以生成 ( , ) 型的正态分布。
微观经济学 数学基础 第9章 随机过程I

有了前面的准备工作,我们现在就可以着手学习,研究现代金融理论所必须也是最重要 的数学工具——随机过程理论了。为什么金融理论研究中一定要使用随机过程理论呢?这是 因为在金融现象中一些主要价格指标例如利率、汇率、股票指数、价格等等都表现出一定的 随机性(randomness)。股票价格明天会是多少,一直吸引和困惑了最富有头脑的理论家和实 践者,早期金融思考就是试图对这个问题作出令人信服的回答1,越来越多的证据显示:人 们倾向认识到,试图超越市场去预测价格走势,总体上是徒劳的,只有通过使用随机过程理
这三种形式的效率构造出整个可获得信息的嵌套结构。但是很不幸,迄今为止它还不 能被经验检验所证实。这是因为市场效率必须和一个市场均衡模型同时被联合检验,研 究者无法分辨究竟哪一个因素对结论更有说服力或者反面作用。在经验研究产生任何有 决定性的结论之前,市场效率与其说是作为一种理论,还不如说是作为一个信念而存在。
6 也可以称之为一次实现(realization)或者轨迹(trajectory)。它实际上是随机过程的一个历史记录,是现代模 拟(simulation)技术的基础。
7 这时的时间参数集为 T = {tk : k = 0,1,2......},有时就直接简化为 T = {k : k = 0,1,2......} 。
微观金融学中使用上述随机微积分技术来研究诸如衍生金融产品定价、动态消费/投资 决策等问题。以随机过程为基础的最优化方法归属于动态随机规划方法之下,以 Samuelson、 Merton、Black、Scholes 等人的研究成果为最杰出的代表。本章中就提供它们的最重要两种 应用——为欧式看涨期权定价和求解动态消费/投资问题。
9.1.1 定义 假设 Ω = {ω} 是随机试验的样本空间, T 是一个参数集(往往是时间),如果对于每一个 t ∈T ,都有随机变量 X (ω, t) 与之对应,则称依赖于 t 的一族随机变量 X (ω,t) 为随机过程, 也可以称为随机函数。 我们可以把一个随机过程看成两个自变量,即状态和时间的函数。ω 的定义域是整个样 本空间, t 的定义域是整个时间轴 [0, ∞) 或者其中的一个时间段 [0,T ] ,即:
高中数学必修二课件:随机模拟

由此估计“3例心脏手术全部成功”的概率为( A )
A.0.2
B.0.3
C.0.4
D.0.5
【解析】 由10组随机数知,3个随机数都在4~9中的有569,989两组,故 所求的概率为P=120=0.2.
课后巩固
1.用随机模拟方法估计概率时,其准确程度取决于( B ) A.产生的随机数的大小 B.产生的随机数的个数 C.随机数对应的结果 D.产生随机数的方法
探究1 (1)产生随机数的方法有抽签法、利用计算机或计算器产生随机数的 随机模拟方法等.抽签法产生的随机数能保证机会均等,而计算器或计算机产 生的随机数是伪随机数,不能保证等可能性,但是后者较前者速度快,操作简 单,省时省力.
(2)用产生随机数的方法抽取样本要注意以下两点:①进行正确的编号,并 且编号要连续;②正确把握抽取的范围和容量.
题型三 利用随机模拟估计事件的概率
例3 (1)袋子中有四个小球,分别写有“春、夏、秋、冬”四个字,从中任 取一个小球,取到“冬”就停止,用随机模拟的方法估计直到第二次停止的概 率:先由计算器产生1到4之间取整数值的随机数,且用1,2,3,4表示取出的 小球上分别写有“春、夏、秋、冬”四个字,每两个随机数为一组,代表两次 的结果,经随机模拟产生了20组随机数:
3.袋中有2个黑球,3个白球,除颜色外小球完全相同,从中有放回地取出
一球,连取三次,观察球的颜色.用计算机产生0到9的数字进行模拟试验,用
0,1,2,3代表黑球,4,5,6,7,8,9代表白球,产生下列随机数:
160 288 905 467 589 239 079 146 351 其中表示结果为二白一黑的组数为( B )
第三章(9)随机模拟-仿真模型、蒙特卡洛模拟

Matlab程序: function y=paidui(T) L=zeros(1,T+1);% 等待的顾客人数, T1=zeros(1,T+1); %等待时间的累加, T2=zeros(1,T+1); %服务时间的累加, L1=zeros(1,T+1);%到达顾客人数累加。 t=1; x=0:T; r=rand(1,T); for t=1:T if 0<=r(i) & r(i)<0.4 n=0; elseif 0.4<=r(i) & r(i)<0.7 n=1; else n=2; end;
蒙特卡罗模拟 (Monte Carlo Simulation)
第三章 常用数学模型及建模方法
当所求问题的解可以视为某个随机变量X的概率或期 望的函数时 通过随机抽样 即模拟随机变量X产生 望的函数时,通过随机抽样,即模拟随机变量 的“实验”;然后计算频率或平均值,以估计概率 或期望 或期望;从而得到所求问题的解。 得到 求 的解
p ( k ) : pi ,
i 1 kpຫໍສະໝຸດ (0) 0p ( k ) p ( k 1) ,
p (n) 1
取服从[0, 1]区间上均匀分布的随机数 R[0, 1],则容易证明: P( “ p(k-1) < R < p(k) ” ) = pk = P ( “ = ak” ) 即随机事件 “ p((k-1)) < R < p((k)) ” 与 “ =ak” 有相同的概率分布。 因此,当p(k-1) < R < p(k)时, 则认为事件 =ak发生。 发生 每隔一分钟记录一次系统状态,模拟10分钟的 Matlab程序如下:
>>r=rand(1,10); >>r=rand(1 10); >>for i=1:10; if r(i)<0.4 () ; n(i)=0; elseif 0.4<=r(i) & r(i)<0.7 n(i)=1; else n(i)=2; end; end
第九章 概率与统计-9.2 成对数据的统计分析

9.2 成对数据的统计分析
课程标准
必备知识
自主评价
核心考点
课时作业
1.结合实例,了解样本相关系数的统计含义,了解样本相关系数与标准化数据向量夹
角的关系.
2.结合实例,会通过相关系数比较多组成对数据的相关性.
3.结合具体实例,了解一元线性回归模型的含义,了解模型参数的统计意义,了解最小
= =1
∑ −ҧ 2
=1
= ത − ҧ
时, = ∑ − − 2 达到最小.
=1
经验回归方程
+ 称为关于的______________,也称经验回归函数或经验回归
我们把ො =
ො
最小二乘法
公式,其图形称为经验回归直线.这种求经验回归方程的方法叫做____________,求
返回至目录
(2)样本相关系数.
①样本相关系数的计算公式.
=
∑ − −
=1
∑ − 2
=1
.
∑ − 2
=1
样本相关系数
我们称为变量和变量的______________.
②与标准化数据向量夹角的关系
令′ = ′1 , ′2 , ⋯ , ′ ,′ = ′1 , ′2 , ⋯ , ′ ,
+ 之间的__________.如果______,那么与之间的关系就
可用一元线性函数模型来描述.
返回至目录
(2)一元线性回归模型参数的最小二乘估计.
设满足一元线性回归模型的两个变量的对样本数据为 1 , 1 , 2 , 2 ,⋯ ,
∑ −ҧ −ത
, ,当,的取值为
随机数学模型

天气预报基于大量的气象数据和随机过程模型。
03
随机变量的分布
随机变量的定义与性质
随机变量
在随机试验中,每个样本点被赋予一个实数值,这个 实数值称为随机变量的值。
随机变量的性质
随机变量可以是离散的、连续的、有限的、无限的。
随机变量的分类
根据不同的性质,随机变量可以分为离散型和连续型。
随机变量的分布函数
随机数学模型的重要性
预测不确定性和风
险
随机数学模型能够预测不确定性 和风险,帮助决策者制定更加科 学和合理的决策。
提高决策效率
通过随机数学模型,决策者可以 快速了解系统的动态变化和趋势, 提高决策效率。
优化资源配置
在资源有限的情况下,随机数学 模型可以帮助决策者优化资源配 置,实现资源的最优利用。
随机数学模型的求解方法
解析法
通过数学公式和定理,直接求解模型的解。
数值法
通过数值计算方法,如迭代法、有限差分法等,求解模型的近似 解。
模拟法
通过模拟随机过程,生成样本点,然后对样本点进行分析和统计。
随机数学模型的实例分析
随机游走模型
描述随机行走的数学模型,可以应用于金融市场分析、物理系统模 拟等领域。
仿真优化
随机数学模型用于仿真 优化工程设计,降低实 验成本和风险。
在社会科学领域的应用
01
人口统计学
随机数学模型用于预测人口发展趋势,分析人口结构变化对社会的影响。
02
经济学
随机数学模型在经济学中用于分析市场行为、预测经济趋势和评估政策
效果。
03
社会网络分析
随机数学模型用于分析社会网络的结构和动态,研究人际关系和社会影
实验9 随机模拟

(5)二项分布随机数 1) binornd(n, p):产生一个二项分布随机数 2) binornd(n,p,m,n)产生m行n列的二项分布随机数 例4、产生B(10, 0.8)上的一个随机数,15个随机数, 3行6列的随机数。 命令 (1) y1=binornd(10,0.8) (2) y2=binornd(10,0.8,1,15) (3) y3=binornd(10,0.8,3,6)
生成Y = min{ X 1 , X 2 , , X n }的随机数
(2)离散分布的直接抽样法 设分布律为P(X=xi)= pi , i=1, 2, ... ① 产生均匀随机数u,即u~U(0,1) ②
2,3, xi 若p1 + ... + pi −1 < u ≤ p1 + ... + pi , (i = X = 若u ≤ p1 x1
练习3: 掷一枚骰子两次,比较掷出的点数之和为9 和为10这两个事件何者更容易发生.,
二 中心极限定理 中心极限定理讨论的是充分大的n,互相独立的 随机变量X1,X2,……..,Xn的和的分布问题。即:
∑X
i =1
n
i
近似服从正态分布。
{ X i , i = 1, 2,3}
例7、设{Xi ,i=1,2,3…} 是一些独立同分布的随机变 量且它们都服从泊松分布P(λ),则部分和
(1)均匀分布U(a,b) 1)unifrnd (a,b)产生一个[a,b] 均匀分布的随机数 2)unifrnd (a,b,m, n)产生m行n列的均匀分布随机数矩阵 当只知道一个随机变量取值在(a,b)内,但不 知道(也没理由假设)它在何处取值的概率大,在 何处取值的概率小,就只好用U(a,b)来模拟它。
第七章 虚拟变量和随机解释变量 (2)

第七章 虚拟变量和随机解释变量本章将讨论两种不同的模型:虚拟变量模型和随机解释变量模型,以及模型设定的其它问题。
第一节 虚拟变量模型在我们以前考虑的模型中,解释变量都是定量变量(如成本、价格、收入、产出等),但在经济研究中,因变量经常受到一些定性变量的影响(如性别、种族、季节、不同历史时期等),我们把这类定性变量称为虚拟变量。
习惯上用D表示虚拟变量,虚拟变量的取值通常为0和1。
0表示变量具备某种属性,1表示变量不具备某种属性。
一、包含一个虚拟变量的模型如果我们要研究的问题中解释变量只分为两类。
则需引入一个模拟变量。
例9.1建立模型研究中国妇女在工作中是否受到歧视。
令Y=年薪,X=工作年限⎩⎨⎧=,女性,男性101D 可以建立如下模型:i i i i u D B X B B Y +++=210 )1.9( 与一般的回归模型一样,假定0)(=i u E 男性就业者的平均年薪:i i i i X B B D X Y E 10)0,(+== )2.9(女性就业者的平均年薪:210)1,(B X B B D X Y E i i i i ++== )3.9(如果B 2=0则说明不存在性别歧视,如果02<B ,则说明存在性别歧视。
图9.1表明男女就业者的平均年薪对工龄的函数具有相同斜率B 1,即随着工龄的增长男女工资的增长幅度相同;截距不同,说明男女的初始年薪不同。
我们称这种虚拟变量只影响截距不影响斜率的模型为加法模型。
图9.1不同性别就业者的收入(加法模型,B 2<0)如果随着工龄增加,男性与女性的年薪差距也发生变化,则模型(9.1)就变为i i i i i u X D B X B B Y +++=210 )4.9(图9.2描绘了男性年薪增加较快的情况。
我们称虚拟变量只影响斜率而不影响截距的模型为乘法模型如(9.4)如果男性与女性的初始年薪和年薪增加速度都有差异,我们可以将加法模型和乘法模型结合起来,得到如下模型i i i i i i u D B X D B X B B Y ++++=3210 )5.9(模型(9.5)可以用来表示截距和斜率都发生变化的模型。
数学建模随机模型

• 内部规律复杂数据统计分析 – 常用模型回归模型数学原理软件
• 30个销售周期数据: – 销售量、价格、广告费用、同类产品均价
销售周期 公司价 (元) 它厂价 (元) 广告(百万元)
1
3.85
3.80
5.50
2
3.75
4.00
6.75
…
…
…
…
29
3.80
Pn (t t) Pn1 (t)bn1t Pn1 (t)dn1t Pn (t)(1 bnt dnt) o(t) 10
建模
ห้องสมุดไป่ตู้
微分方程
dPn dt
bn1Pn1 (t) d P n1 n1 (t) (bn
dn )Pn (t)
bn=n,dn=n
dPn dt
(n 1)Pn1(t) (n 1)Pn1(t) ( )nPn (t)
• 价格差 x1=0.1 • 价格差 x1=0.3
yˆ x10.1 30.2267 7.7558x2 0.6712x22 yˆ x10.3 32.4535 8.0513x2 0.6712x22
x1 x2 7.5357 yˆ x10.3 yˆ x10.1
18
销售量预测
yˆ ˆ0 ˆ1x1 ˆ2 x2 ˆ3x22
价差x1=它厂价x3-公司价x4 控制x1 估计x3,调整x4
预测y
控制价格差 x1=0.2元,投入广告费 x2=6.5 百万元
yˆ ˆ0 ˆ1 x1 ˆ2 x2 ˆ3 x22 8.2933(百万支)
销售量预测区间为 [7.8230,8.7636](置信度95%) 上限用作库存管理的目标值 下限用来把握公司的现金流
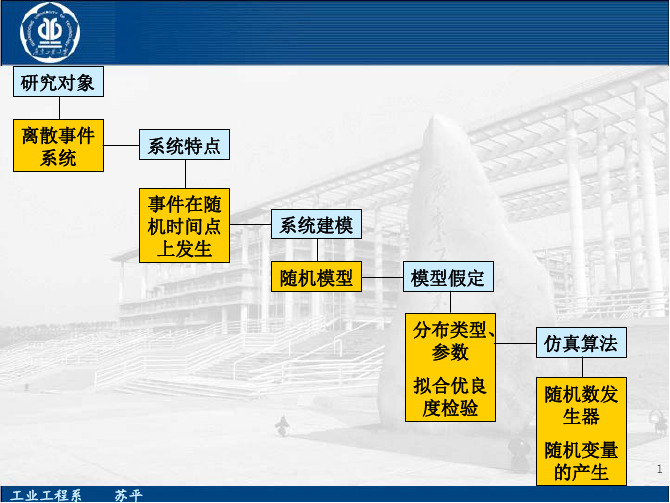
第3章 随机变量模型确定与随机变量生成方法
例如, 均匀分布函数U(a, b), 其密度函数为:
f
(x)
b
1
a
a xb
0
其它
f(x)
1 ba
b a b ' a '
0 a ba b
x
a为位置参数
16
工业工程系 苏平
3.1 随机变量和随机分布概述
常用随机分布类型及其特性
1、随机分布的参数类型
(2) 比例参数(记为β )
决定分布函数在其取值范围内取值的比例尺。β的改变
若存在非负函数f(x),使得随机变量X取值于任意区 间(a, b)的概率为
b
P(a,b) a f (x)dx
X —— 连续型随机变量;f(x) ——X的概率密度函数。
6
工业工程系 苏平
3.1 随机变量和随机分布概述
连续型随机变量
f (x) 0
f (x)dx 1
随机变量X概率分布函数
x
F(x) f (x)dx
极大似然估计法
例: 指数分布,被估计的参数 ( 0),其分布密度函
数为
f
(x)
1
ex
由 L( ) f (x1) f (x2 )... f (xn )
L(
)
1
e x1 /
1
e x2 /
1
e xn /
n
exp
1
n i 1
xi
为求使L(β)取最大值的 ˆ ,先对L(β)取自然对数:
3.1 随机变量和随机分布概述
随机变量的数字特征
2、方差和标准差
方差表示随机变量相对于均值的平均分散和变动程度。 随机变量X的方差定义为
D(X ) E X E(X )2
随机变量与随机过程模拟

建立与U(0,1)分布的关系?
二、离散型随机变量的模拟 两点分布随机变量的模拟 若构造模型
1, A发生 X 0, A不发生
给定p 取随机数u N
其中P(A)=p,则易 知P(X=1)=P(A)=p, P(X=0)=P( A )=1-p=q。 利用对事件A的模拟可得 一次实验中之结果信息: 若A发生,则认为X取1, 若A不发生,则认为X取0。
一、统计实验法与伪随机数
•
•
•
目前计算机高级语言大多都具有产生伪随机数 的标准函数,专用仿真语言均设有伪随机数发 生器,适合大多数情况下的仿真需求。 计算机不会产生绝对随机的随机数,计算机只 能产生“伪随机数”。其实绝对随机的随机数 只是一种理想的随机数,即使计算机怎样发展, 它也不会产生一串绝对随机的随机数。计算机 只能生成相对的随机数,即伪随机数。 伪随机数并不是假随机数,这里的“伪”是有 规律的意思,就是计算机产生的伪随机数既是 随机的又是有规律的。怎样理解呢?产生的伪 随机数有时遵守一定的规律,有时不遵守任何 规律;伪随机数有一部分遵守一定的规律;另 一部分不遵守任何规律。
主要内容
一.统计实验法与伪随机数 二.离散型随机变量的模拟 三.连续型随机变量的模拟 四.随机过程模拟
一、统计实验法与伪随机数
如何求解? 随机事件概率的计算 随机变量分布函数的求得 数量化 解 析 法 物理 实验 法 逻辑性
随机事件 随机变量分布函数
计算机模拟方法 状态描述? (统计实验法)
随机现象
u<=p否? Y X=1
X=0
二、离散型随机变量的模拟 几何分布随机变量的模拟 设随机变量X有几何分布,即有分布列 P(X=k)=qk-1p,k=1,2,„。对X进行模拟的目的 是希望得知在一次实验中X究竟取1,2,3„中的 哪一个正整数。 将X视为贝努力实验中事件A首次发生时之 实验序数,则当X=k时说明前k-1次实验A不发 生,而在第k次实验时A发生。利用贝努力实验 的独立重复性,有 P( X k ) P( AA...AA) qk 1 p
9.2 目标出现的概率分布(无水印)

9.2 目标出现的概率分布搜索的目的在于找到目标或确定目标所在的位置。
目标位置对于搜索者来说是未知的。
但搜索者对它的位置可能有某种程度的了解或某些先验知识,这种先验的了解通常用目标出现的概率分布来表示。
我们现在考虑离散型和连续型两种目标概率分布。
9.2.1 目标概率分布的离散型假如我们把搜索的空间区域J 分成很多不相交的离散区域J 1,J 2,…,J n ,若已知目标在上述各区域中出现的概率分别为p 1,p 2,…,p n ,这就构成了目标出现的一种离散型概率分布。
若11=∑=n i i p,则称这个分布是完全的目标分布,若11<∑=ni i p ,则称这个分布是不完全的目标分布。
例1 1963年4月10日,美国海军核潜艇“长尾鲨”在“云雀”舰的伴随下进行试航。
上午9点17分,“长尾鲨”用水下电话向“云雀”报告说:该艇难于保持平衡。
“云雀”随即利用罗兰电子导航系统测定了舰位A (北纬41°45′,西经65°00′)。
“云雀”在完成了与“长尾鲨”最后一次联络的几秒钟后,从水下电话中听到断裂杂声。
试求出“长尾鲨”失事地点的概率分布。
设点A 确是“云雀”在通话时的真实位置,考虑到水下通话的最大距离约为2.5海里,那么“长尾鲨”应在以A 点为中心。
2.5海里为半径的园域里,记为区域Ⅰ。
考虑到罗兰导航系统误差引起的“云雀”舰位的不准确,可将搜索海域扩大为一个以A 为中心,10×10平方海里的海域,在这个海域之内且在区域Ⅰ之外的部分,我们记为区域Ⅱ(如图9-1)。
于是可以根据经验给出“长尾鲨”出现的概率分布:P =⎩⎨⎧“长尾鲨”位于区域Ⅱ“长尾鲨”位于区域Ⅰ,4.0,6.0最后果然在区域Ⅰ中*处找到了失事的“长尾鲨”。
9.2.2 目标概率分布的连续型设目标位于n 维欧氏空间X 内,定义X 上的n 维概率密度,使得对n 维欧氏空间中的区域S ,总有P {目标位于 S 中}= P {x ∈ S }=dx x P s ⎰)( =⎰⋅⋅⋅⋅⋅⋅s n n dx dx dx x x x P 2121),,( (9-1) 则称 P (x )为目标位于 X 点的概率密度。
随机数产生与模拟

随机数的产生与模拟
1 均匀随机数的产生
组合发生器 :
Maclaren 和 Marsaglia在1965年提出 的著名的组合发生器是组合同余发生 器,该算法的具体步骤如下:
本章目录 13
随机数的产生与模拟
1 均匀随机数的产生
组合发生器
1用第一个LCG产生
:
k 个随机数,一般取
k
128
随机数的产生与模拟
用随机模拟方法解决实际问题时,首先 要解决的是随机数的产生方法,或称随 机变量的抽样方法。
本章目录 1
随机数的产生与模拟
伪随机数: 在计算机上用数学方法产生均匀随机
数是指按照一定的计算方法而产生的数 列,它们具有类似于均匀随机变量的独 立抽样序列的性质,这些数既然是依照 确定算法产生的,便不可能是真正的随 机数,因此常把用数学方法产生的随机 数称为伪随机数。
本章目录 20
随机数的产生与模拟
2非均匀随机数的产生
2 合成法 :
当
g( y)
为离散形式时,即
p(x)
n i1 i
pi (x),其中i
0,
n
i1 i
1
pi (x) 是密度函数,其抽样过程如下:
1 产生一个正的随机整数J ,使得P{J j} p j ,j 1,2,...,n
2 产生分布为 p j (x) 的随机数。
令 rn xn 2L n 1,2,... 则rn 即为FSR方法产生的均匀随机数列。
本章目录 11
随机数的产生与模拟
1 均匀随机数的产生
组合发生器 : 先用一个随机数发生器产生的随机数列为
基础,再用另一个发生器对随机数列进行重新 排列得到的新数列作为实际使用的随机数。这 种把多个独立的发生器以某种方式组合在一起 作为实际使用的随机数,希望能够比任何一个 单独的随机数发生器得到周期长、统计性质更 优的随机数,即组合发生器。
【原创】人教A版(2019)高中数学必修第二册:随机模拟(教案)

第十章概率10.3.2随机模拟一、教学目标1.掌握随机模拟试验出现的意义.2.会用随机模拟试验求概率.3.通过对随机模拟的学习,培养学生数学抽象、数学运算、数学建模等数学素养。
二、教学重难点1.理解随机模拟试验出现的意义2.利用随机模拟试验求概率.三、教学过程:(1)创设情景阅读课本,思考在什么情况下用随机模拟来估计概率(2)新知探究问题1:若果用频率估计概率,那么需要做大量的重复实验,请大家想一想有没有其他方法可以替代实验呢?学生回答,教师点拨并提出本节课所学内容(3)新知建构随机模拟的定义:利用计算器或计算机软件可以产生随机数.实际上,我们也可以根据不同的随机试验构建相应的随机数模拟实验,这样就可以快速地进行大量重复试验了,这么随机模拟方式叫做.我们称利用随机模拟解决问题地方法为蒙特卡洛(Monte Carlo)方法.随机模拟来估计概率事件的特点:(1)对于满足“有限性”但不满足“等可能性”的概率问题,我们可采取随机模拟方法来估计概率.(2)对于一些基本事件的总数比较大而导致很难把它列举得不重复、不遗漏的概率问题或对于基本事件的等可能性难于验证的概率问题,可用随机模拟方法来估计概率.(4)数学运用例1.从你所在班级任意选出6名同学,调查他们的出生月份,假设出生在一月,二月……十二月是等可能的.设事件A “至少有两人出生月份相同”,设计一种试验方法,模拟20次,估计事件A发生的概率.【答案】见解析【解析】根据假设,每个人的出生月份在12个月中是等可能的,而且相互之间没有影响,所以观察6个人的出生月份可以看成可重复试验.因此,可以构建如下有放回摸球试验进行模拟:在袋子中装入编号为1,2,…,12的12个球,这些球除编号外没有什么差别.有放回地随机从袋中摸6次球,得到6个数代表6个人的出生月份,这就完成了一次模拟试验.如果这6个数中至少有2个相同,表示事件A发生了.重复以上模拟试验20次,就可以统计出事件A发生的频率.变式训练1:盒中有大小、形状相同的5只白球和2只黑球,用随机模拟法求下列事件的概率:(1)任取一球,得到白球;(2)任取三球,都是白球.【答案】(1)答案见解析(2)答案见解析【解析】(1)用1,2,3,4,5表示白球,6,7表示黑球.步骤:①利用计算器或计算机产生1到7的整数值随机数,每一个数为一组,统计组数n;②统计这n组数中小于6的组数m;③任取一球,得到白球的概率估计值是m n.(2)用1,2,3,4,5表示白球,6,7表示黑球.步骤:①利用计算器或计算机产生1到7的整数值随机数,每三个数为一组,统计组数n;②统计这n组数中,每个数字均小于6的组数m;③任取三球,都是白球的概率估计值是m n.变式训练2:天气预报说,在今后的三天中,每一天下雨的概率均为40%,现部门通过设计模拟实验的方法研究三天中恰有两天下雨的概率:先利用计算器产生0到9之间取整数值的随机数,用1,2,3,4表示下雨,其余6个数字表示不下雨:产生了20组随机数:则这三天中恰有两天降雨的概率约为.【答案】1 4【解析】在20组随机数中,表示三天中恰有两天降雨随机数有:191,271,932,812,393,共5个,∴这三天中恰有两天降雨的概率约为51204P==.故答案为:14.例2.袋子中有四个小球,分别写有“中、华、民、族”四个字,有放回地从中任取一个小球,直到“中”“华”两个字都取到才停止.用随机模拟的方法估计恰好抽取三次停止的概率,利用电脑随机产生0到3之间取整数值的随机数,分别用0,1,2,3代表“中、华、民、族”这四个字,以每三个随机数为一组,表示取球三次的结果,经随机模拟产生了以下18组随机数:由此可以估计,恰好抽取三次就停止的概率为()A.19B.318C.29D.518【答案】C【解析】由随机产生的随机数可知恰好抽取三次就停止的有021,001,130,031,共4组随机数,恰好抽取三次就停止的概率约为42189=,故选:C.变式训练:经统计某射击运动员随机命中的概率可视为710,为估计该运动员射击4次恰好命中3次的概率,现采用随机模拟的方法,先由计算机产生0到9之间取整数的随机数,用0,1,2 没有击中,用3,4,5,6,7,8,9 表示击中,以4个随机数为一组,代表射击4次的结果,经随机模拟产生了20组随机数:7525,0293,7140,9857,0347,4373,8638,7815,1417,55500371,6233,2616,8045,6011,3661,9597,7424,7610,4281根据以上数据,则可估计该运动员射击4次恰好命中3次的概率为()A.25B.310C.720D.14【答案】A【解析】由题意,该运动员射击4次恰好命中3次的随机数为:7525,0347,7815,5550,6233,8045,3661,7424,共8组,则该运动员射击4次恰好命中3次的概率为82= 205.故答案为A.例3:(1)掷两枚质地均匀的骰子,计算点数和为7的概率;(2)利用随机模拟的方法,试验120次,计算出现点数和为7的频率;(3)所得频率与概率相差大吗?为什么会有这种差异?【答案】(1)16(2)答案见解析(3)答案见解析【解析】(1)抛掷两枚骰子,向上的点数有(1,1)、(1,2)、(1,3)、(1,4)、(1,5)、(1,6); (2,1)、(2,2)、(2,3)、(2,4)、(2,5)、(2,6); (3,1)、(3,2)、(3,3)、(3,4)、(3,5)、(3,6); (4,1)、(4,2)、(4,3)、(4,4)、(4,5)、(4,6); (5,1)、(5,2)、(5,3)、(5,4)、(5,5)、(5,6); (6,1)、(6,2)、(6,3)、(6,4)、(6,5)、(6,6).共36种情况,其中点数和为7的有6种情况, ∴概率61366 P==.(2)规定每个表格中的第一个数字代表第一个骰子出现的数字, 第二个数字代表第二个骰子出现的数字从表格中可以查出点数和为7等于23个数据∴点数和为7的频率为:231200.19≈(3)由(1)中点数和为7的概率为10.17 6≈由(2)点数和为7的频率为:231200.19≈一般来说频率与概率有一定的差距,因为模拟的次数不多,不一定能反映真实情况.四、小结:1.随机模拟的定义:2.随机模拟来估计概率事件的特点:五、作业:习题10.3.2。
随机变量与随机过程模拟资料

A
A发生 A不发生 数学处理 判断:u<=p 抽样
给定p 取随机数u
构造模型 B=“U<=p”
u<=p否?
u
N
U
Y A发生 A不发生
二、离散型随机变量的模拟 两点分布随机变量的模拟 设随机变量X有两点分布:P(X=1)=p, P(X=0)=q,其中p+q=1。对X进行模拟的目的是 希望得知在一次实验中X究竟取0与1中的哪一 个值。 构造模型?
i
i 1
二、离散型随机变量的模拟
由于P(Ai)=P(Bi),故知Bi保持了Ai的概率特性, 因此在一次实验中若事件Bi发生了,则可以很自然地 认为Ai事件也就发生了。至于要判断是哪个事件Bi发 生,可通过如下数学处理来进行:
(1)将[0,1]区间划分成若干小区间,各小区间 的分界点坐标依次为L0,L1,...,Ln, 使 L p , 于是小区间Ai=(Li-1,Li)之长度即为pi
建立与U(0,1)分布的关系?
二、离散型随机变量的模拟 两点分布随机变量的模拟 若构造模型
1, A发生 X 0, A不发生
给定p 取随机数u N
其中P(A)=p,则易 知P(X=1)=P(A)=p, P(X=0)=P( A )=1-p=q。 利用对事件A的模拟可得 一次实验中之结果信息: 若A发生,则认为X取1, 若A不发生,则认为X取0。
随机变量与随机过程模拟
主要内容
一.统计实验法与伪随机数 二.离散型随机变量的模拟 三.连续型随机变量的模拟 四.随机过程模拟
一、统计实验法与伪随机数
如何求解? 随机事件概率的计算 随机变量分布函数的求得 数量化 解 析 法 物理 实验 法 逻辑性
随机事件 随机变量分布函数
随机模拟方法及习题

随机模拟方法在用传统方法难以解决的问题中,某些问题含有不确定的随机因素,分析起来通常比确定性的问题困难。
有的模型难做定量分析,得不到解析的结果或者是有解析结果,但计算代价太大以至不能使用,在这种情况下,可以考虑随机模拟的方法即Monte Carlo 方法。
该方法是一类以概率统计理论为指导的非常重要的数值计算方法,也是一种用于解决数值问题的基于计算机的统计抽样方法。
目前,随机模拟方法已广泛应用于诸如生物信息学、统计物理学、计算机科学、材料科学、金融学和经济学等领域。
基本知识基本思想为了求解物理、数学、工程技术以及生产管理等方面的问题,首先建立一个概率或者随机过程,使它的参数等于问题的解;然后通过对模型或过程的观察或者抽样实验来计算所求参数的统计特征,最后给出所求解的近似值。
而解的精确度可用估计值的标准误差来表示。
随机模拟方法是一种独具风格的数值计算方法,其优点大致有如下三方面:(A )方法的程序结构简单;(B )算法的概率性和问题的维数无关;(C )方法的适应强。
随机数和伪随机数用Monte Carlo 方法模拟某过程的时候,需要产生各种概率分布的随机变量。
最基本、最简单、最重要的随机变量是在[0,1]上均匀分布的随机变量。
为了方便,通常把[0,1]上均匀分布随机变量的抽样值称为随机数,其他分布随机变量的抽样都可以借助于随机数来实现,因此,随机数是随机抽样的基本工具。
在计算机上用数学的方法产生随机数是目前广泛使用的方法,它的特点是占用内存少、产生速度快、又便于重复产生,比如说平方取中法、移位指令加法、同余法等等。
然而这种随机数是根据确定的递推公式求得的,存在着周期现象,初值确定后所有随机的数便被唯一确定下来,不满足真正随机数的要求,所以通常称数学方法产生的随机数为伪随机数。
在实际应用中,只要这些伪随机数序列通过一系列的统计检验,还是可以把它当称“真正”的随机数来使用。
产生随机数的命令在Matlab 软件中,可以直接产生满足各种分布的随机数,相关命令如下:(1)产生m n 阶[,]a b 均匀分布(,)U a b 的随机数矩阵:unifrnd (a,b,m, n);产生一个[,]a b均匀分布的随机数:unifrnd (a,b);(2)产生m n⨯阶[0,1]均匀分布的随机数矩阵:rand (m, n);产生一个[0,1]均匀分布的随机数:rand;(3) 产生m n⨯阶均值为μ,方差为2σ的正态分布的随机数矩阵:normrnd (,μσ,m, n);(4) 产生m n⨯阶期望值为μ的指数分布的随机数矩阵:exprnd(μ,m,n)若连续型随机变量X的概率密度函数为0 ()00xe xf xxλλ-⎧≥=⎨<⎩,其中0λ>为常数,则称X服从参数为λ的指数分布。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
随机变量模拟
回顾:
高尔顿钉板试验中,小球最终的位置
1n k k X =∑n Y =
其中-1 1
X k p 1/2 1/2
要模拟小球的运动轨迹,首先要模拟随机变量X k ,那么如何模拟随机变量呢?
一、随机数的生成
函数名解释
rand生成(0,1)区间上均匀分布的随机数
unifrnd生成指定区间内均匀分布的随机数
randn生成服从标准正态分布的随机数
normrnd生成指定均值、标准差的正态分布随机数
exprnd生成服从指数分布的随机数
注:rand是采用线性同余法得到的,具有周期性,所以上述命令常被称为伪随机数生成器。
基本语法如下:
rand(m) 生成m*m维的随机数
rand(m,n) 生成m*n维的随机数
rand([m,n,p ...]) 生成排列成m*n*p... 多维向量的随机数问题如何模拟在区间[a, b]内均匀分布随机数?
1. a+(b-a)*rand(m, n)
2. unifrnd(a, b, m, n)
二、离散型随机变量
思考:如何利用rand 生成下列离散型随机变量?
分析:rand 是生成(0,1)上均匀分布随机数,生成数落在(0,0.5)和[0.5,1)上概率均为0.5,故可令
-1 1
X k p 1/2 1/2
⎩⎨⎧≥<=5
.015.01rand ,rand ,-X k
参考程序:N=1000;
X=rand(1,N); for i=1:N
if X(i)<0.5
Y(i)=-1; else
Y(i)=1; end
end
Y 思考:一般的离散随机变量如何模拟?。