古文字的字形整理 及其编码的原则
汉语言文学古代汉语期末重点整理

通论——字典辞书一、文史工具书的编排方式(一)部首编排法:根据汉字的形体结构,把具有相同偏旁的归为一部,这个共同的偏旁就是部首。
部首按笔画的多少为先后次序。
同部首的字也按字的笔画多少的先后次序排列。
(二)音序排列法:音序排列法是按汉字的读音来编排所收的字词的。
古代字典辞的音序排列法主要有两种:一种是按传统36字母的顺序编排。
一种是按《广韵》韵部或平水韵韵部韵的顺序编排。
(三)号码查字法把汉字按照一定的原则分别编出号码,通行的是四角号码检字法。
四角号码检字法由王云五发明,1925年5月出版《号码检字法》。
二、主要工具书(一)《说文解字》简称《说文》,东汉许慎撰。
正文十四篇书末“叙”和目录为一篇,共十五篇。
收字以小篆为主,兼收古文、籀文、重文。
据《叙》载,全书共收字9353个,重文1163个,合计10516个。
体例:一是按小篆的形体,把9353字分成540部;二是于每一篆下先释义,再分析字形结构。
(二)《康熙字典》用十二地支分成十二集,每集又分为上、中、下三卷,加上书前凡例、等韵、总目、检字及书后的补遗、备考等六卷,凡四十二卷。
全书正文共收字47035个。
按《字汇》《正字通》体例立部首214个。
体例:于单字下先注音释义,注音:依次列举《唐韵》、《广韵》等前代韵书的反切,并标注直音;释义:解说字的本义、别音别义,并于每一义项下面列举书证。
有所考辨就在释文末用“按”字表示。
主要特点:一是收字多,超出了以前的任何一部字书;二是注重解形和注音;三是义项收录完备;四是引例十分丰富,例句出处明确。
五是确定了后世字典辞书的部首数量与基本编排方式。
(三)《汉语大字典》按部首排列,设200个部首,共收汉字56000个,是目前我国收字最多的字典之一。
先列楷书字形,然后收列能够反映形体流变、源流演变关系的有代表性的甲骨文、金文、小篆和隶书的形体。
释义:古今兼备以古为主,义项排列一般按照本义、引申义、通假义的顺序,义项下面尽可能征引文献为证。
字形历史演变的规律

这种简化方式在独体字和合体字中都有发 现。
截除性简化使字形发生了突变,从截余的 部分是难以推测未截之前的字形原貌的。
但是,当未截形体和已截形体均已发现的 情况下,知道有这种简化方式,就可以很 快的发现它们之间的联系。如果不知道有 这种简化方式,往往会误以为它们是毫不 相干的两个字。
过去古文字研究者在比较字形时总结的填 实与虚框无别,方圆无别等原则,都是总 体性简化的一方面局部现象。而最主要的 趋势是把各部宽窄不一的图形变为粗细均 匀的单线条,以达到方便书写的目的。
同类图形在简化中往往有相似的演变过程 。因此,在利用简化的规律来判定不同的 形体是否为同一独体字或同一基本偏旁时 ,最好能有已知的同类实例作为旁证。
字形历史演变的规律
汉字字形的历史演变呈现着错综复杂的现 象。当我们用历史比较法从字形上去判断 一个未识的古文字应该是哪个已识字的前 身时,自然会产生这样的问题:究竟什么 样的形体差异可以视为同一字或同一偏旁 历史演变的结果,而什么样的形体差异就 是不同字和不同偏旁相区别的标志呢?
从我们已知的古文字资料分析总结,在汉字脱胎于 图像而成为记录语言的符号体系,逐步发展到小篆 的过程中,持续作用于字形演变的主要原因有三个 :1,为了便于掌握和使用,符号要求越简单越好 。其结果是字形的简化。2,为了保证记录语言的 精确性并不断提高这种精确性,一方面在简化的过 程中力图保持不同符号的区别,另一方面使原来承 担不止一音一义的同一符号在形体上增加新的区别 标志,使之分别承担原有音义的一部分。其结果是 字形的分化。3,由于简化和分化都是群众性的行 为,其结果必然导致同一个字存在多种异体。为了 保证文字在社会上的统一使用,必须把异体字限制 到最低数量,其结果就是字形的规范化。
甲骨文字源研究务必贯彻“三通原则”

甲骨文字源研究务必贯彻“三通原则”甲骨文的研究工作,整体上分为两大块。
一是对甲骨文的释读,二是对甲骨文的字源研究,即确定其字形的来源和意义,这是完全不同的两件事。
东汉许慎的《说文解字》(简称《说文》)把整个汉字史一分为二,许慎之前的汉字不仅是不成熟的,而且其字形演变过程在文献上不可考,只有靠后来考古资料补充。
《说文解字》标志着汉字系统的成熟,同时,此后的汉字字形的演变过程都被清晰记载。
所谓的甲骨文的释读,实际就是建立甲骨文与现代汉字的对应,确认某个字就是现代的某个字。
这个对应就是建立从甲骨文到现代汉字字形演变的完整链条。
这个链条又分为上下两截。
上一截是从甲骨文到《说文》,下一截是从《说文》到现代汉字。
由于下一截是清晰的,因此关键就在上一截,即确认从甲骨文到《说文》的字形演变链条,确认甲骨文某个字的字形就是《说文》某个字的字形。
完成确认,就是完成释读。
当然对《说文》所无的极少数字形,上、下两截的分界点可以定位晚至宋朝的韵书。
甲骨文的释读只需关注甲骨文已经产生之后,由甲骨文字形到《说文》字形之间的的演变史,而无需关注字形本身的起源和意义,无需关注甲骨文字形的字源究竟是什么,其内涵何在。
而要确认甲骨文字形本身的来源,确定甲骨文字形的内涵,就需要研究和追溯甲骨文之前的历史,而非甲骨文之后的历史。
目前的甲骨文研究,主要集中在甲骨文的释读上,所关注的仅仅是甲骨文产生之后,从甲骨文字形到《说文》之间的字形演变史。
而没有关注甲骨文之前,甲骨文字形要素本身的漫长形成史。
目前甲骨学的成果也仅仅体现在甲骨文的释读上,在甲骨文字源的确认和内涵解读上,几乎为零,甚至为负。
为零是没有研究,不去研究,而为负则是进行错误的、臆断的、误导性的研究。
现在学界对甲骨文字源和确认和解释99.9%都是错误的、臆断的。
在对甲骨文字形内涵、字源的研究上,我摸索出了一个“三通”原则,也是基本的方法论。
必须做到这“三通”,才可以认为靠谱,真的通了。
试从字的结体、组合中找规律

试从字的结体、组合中找规律中国文字是由不同点画组合排列的。
点画的形态由简单到复杂,由曲直到多变,组成了篆、隶、楷、行、草等形体,由不同角不同面逐渐组合为方块字。
结体由不规整变为规整,形成了对称、匀称、平稳等组字基本原则,从而构成了和谐完整的组字关系。
在这种组字的形态中,古人们从字中发现了美的元素和美的表现,自觉不自觉地在文字运用过程中形成了书法艺术。
这种艺术在晋魏时代,趋于成熟并达到高潮同时古人也积累了不少经验和论述,开创了中国灿烂的书法文化。
在书法艺术发展过程中,也表现出以实用为主的方块宇对书法艺术的某些关系,并逐渐成为原理原则。
随着时代的需要,人们又从方块字中寻找新的组字关系,以满足审美的需求,:改革开放以来,随着各种“书展”和“书法热”的到来,这种组字关系,正向多元、多向、多维发展。
现在我就以王羲之《兰亭序》行书为代表,试探这种关系。
在王羲之及其前后的时代,书法艺术仍然沿用方块字的形式,不过逐步解构了上下方整,前后齐平,状如算子的呆板状态,创造了绚丽多姿、奇异变化的新关系。
这种关系,所以有昧、有意、有韵、有神采,书者认为:虽有解构,但是和谐;虽有变化,但是统一;虽然欹侧,但是稳实;虽有错落,但是适度。
组合合理,对比有致,违而不犯,和而不同,“无形”之线皆有度,“中和”之美贯始终。
在王羲之的行书结构中,提出了解构和变化的八条审美原则和方法。
现就其中变化、尽态、错落、欹侧几条原则和方法进行分解,举例说明:,一、变化线。
变化,是艺术的生命,也是行书结构最基本的要求。
笔笔不同,字字相异,就是相同的字也千姿百态;通过用笔、结体产生藏露、轻重、曲直、疏密、大小、长短等形态,以致数画并施,其形各异,众点齐列,为体互乖。
如“悲”(同形异化),“经”(同旁异变),“双”(同画异态),“国”(同字异体),从上述字例看出,通过形态变、角度变、位置变,使其千变万化,但也不是随意而变,变化要自然适度,以人们心理适怀为准,不宜超过心理承受能力的极限。
汉字的编码规则

汉字的编码规则一、概述汉字的编码规则是涉及计算机处理和传输汉字的重要技术。
为了使计算机能够准确、快速地处理和传输汉字,制定了各种编码规则,包括汉字的输入编码、存储编码、输出编码和通信编码。
二、汉字的输入编码规则汉字的输入编码规则是将汉字输入计算机的一种方式。
常用的汉字输入方式有:拼音输入法、五笔输入法、手写输入法等。
每种输入方式都有其独特的编码规则。
1. 拼音输入法:根据汉字的拼音进行输入,输入的编码长度较短,但同音字较多,需要用户进行选择。
2. 五笔输入法:根据汉字的字形进行输入,输入的编码长度较长,但能够较准确地输入汉字,不需要用户进行选择。
3. 手写输入法:根据用户的手写输入进行识别,能够快速地输入汉字,但需要用户进行手写,并需要一定的手写技巧。
三、汉字的存储编码规则汉字的存储编码规则是将汉字在计算机内存中进行存储和管理的规则。
常用的存储编码方式有:UTF-8编码、UTF-16编码等。
1. UTF-8编码:是一种可变长度的编码方式,每个汉字的编码长度可以是1到4个字节,具有较好的兼容性和可读性,是目前使用最广泛的编码方式。
2. UTF-16编码:是一种定长编码方式,每个汉字的编码长度为2个字节,适用于处理大量的汉字数据。
四、汉字的输出编码规则汉字的输出编码规则是将汉字在计算机屏幕上或打印机上输出的规则。
常用的输出编码方式有:GB2312编码、GBK编码等。
1. GB2312编码:是一种国家标准的汉字编码方式,包含了6763个汉字,适用于一般的文本输出。
2. GBK编码:是一种扩展的汉字编码方式,包含了20902个汉字,适用于处理大量的汉字文本。
五、汉字的通信编码规则汉字的通信编码规则是用于在计算机网络中传输汉字的数据格式。
为了保证传输的准确性和效率,需要使用统一的通信编码规则。
常用的通信编码方式有:MIME编码、HZ编码等。
1. MIME编码:是一种通用的数据编码方式,可以将汉字转换为二进制数据或ASCII码进行传输。
论汉字形体演变所体现的文字二重律

论汉字形体演变所体现的文字二重律[内容提要] 汉字在使用与发展中,一直受到两条规律的约制,一是简易律,即形体的简单易写,由图绘变为线条、由象形变为不象形、由较繁复的符号变为较为简单的符号。
小篆是对甲骨金文的简化;隶书是对小篆的简化;楷书是对隶书的简化,草书和行书是对楷书的简化。
另一个是区别律。
为使汉字的形体明确,音义明确,彼此之间要有区别,以达表达功能的目的。
在某些程度上具有汉字繁化的功能。
同时,在区别律繁化后,简易律又起作用了。
汉字就是在这两律的作用下达到相对的平衡。
一、汉字形体演变的内部机制形体演变体现了汉字体系的发展变化,不同时代的文字资料中,同一个字都发生了变化,有的变得面目全非。
字形有两种不同性质的状态,一种是被社会认可的相对长久的字形变化,一种是个人书写的变化,字形演变是汉字通过自我调节,不断从无序走向有序,汉字的演变是一个个字进行但并非是孤立的,而要受整个汉字体系的制约,这是因为:(一)字与字之间既相互区别又相互联系的整体关系,决定字形变与不变。
这种变化往往是汉字与其他字的聚合关系导致的。
如:两个字的形体相似,便会引发甲字和乙字,或是丙字的形体变化。
(二)字形演变是从属于文字体系的整体调整,如某一独体字发生变化,其它的作为偏旁的字也就要发生变化,单字字形的变化,必须着眼于整体字序的优化,文字字体不允许某个字的优化,破坏整个汉字体系的有序度。
(三)汉字字形的总体特征决定汉字形体。
古文字阶段字形演变不能背离又结合体被假借后的字,就加上形符加以区别,使其向表意方向回归。
(四)字形的演变还受其他因素的制约。
其中人们的主观意愿的介入成为推动汉字简化的一股区大力量的不同时代对字义的理解不同或观念不同等,也会导致汉字字形演变。
(五)源远流长的书法艺术对字形变化产生重大影响,汉字具有实用性,又具有审美价值(表现汉字形体美)。
书法是着重表现汉字形体总的艺术,那些一味求简单而缺乏美感汉字是受排斥的字形演变是汉字字序发展的需要。
甲骨文构形规律及文化

第七讲古文字构形及文化(一)汉字的三类符号:(1)图画体,包括甲骨文、金文、大篆、小篆;(2)笔划体,包括隶书、楷书;(3)流线体,包括草书、行书。
金文多数晚于甲骨文,但是图形性强于甲骨文,因为金属刻铸不怕字形圆曲,甲骨的刀刻更适于平直笔划。
大篆、小篆(简帛文字,便于书写)逐渐失去图形性。
隶书、楷书成为毫无图形性的“方块字”。
流线体是快速急就的便写字体,跟正规字体并用。
草字写起来快读起来难,行书写读都比较方便。
隶变和草化都是应用频繁的结果。
草书、行书是关于汉字书写的一种流线体符号古文字的走向草化(草篆、草隶、章草、今草)草书的源起至迟自春秋战国即已出现孙呈衍《急就章考异》已提出“草从篆生”。
当代学者陆锡兴《论汉代草书》对草书起源进行了深入的阐述,他“不同意草书从隶书中产生的传统说法”,指出“小篆之前早已有古草书了”,“汉代草书体制上随篆书,就其草法来说,古文字草字是它的直接源头,汉代草书沿用了古文草法”。
裘先生提出章草源于古隶的俗体,是以大量文字数据为依据的。
秦代古隶中已出现一些草率写法,如“”(堤)、“”(正)等,为后世的草书所继承,正说明了秦隶俗体中已孕育出草书萌芽。
陆锡兴先生在《论汉代草书》中也列举了部分古文字草书字例,如春秋时期齐侯镈上的“”()字,字的下部件用一种交叉笔划来取代文字中复杂部件的草法,增加了书写的便捷性。
汉草的字形“”(齿)的下部、“”(兴)的上部皆沿用了此草法。
因此可以肯定,春秋战国时期已经有少量古草书字存在,并对汉代章草书的形成产生影响。
“对于章草书的来源,从总体上来说汉代章草书在秦汉古隶俗体的基础上发展而来,但也有一小部分字形直接出自战国时代的古文字草书”。
比如战国秦墓青川木牍中出现的“堤”()、“九”()、“陷”()、“有”()等字;云梦睡虎地秦简中出现的“作”()、“筝”()、“必”()等字形;《老子甲本》中出现的“是”()、“亲”()、“徒”()等字。
清代高二适在其《新定急就章及考证》中亦指出章草的字形,有少数草承篆籀之字,必须上溯到篆籀字形,推究其由隶、篆变草的轨迹。
篆书造字原则

篆书造字原则
篆书是中国古代的一种传统书法形式,其字体优美、雄奇、秀丽,被誉为“书中之王”。
在篆书中,造字原则十分重要,它是规范篆书
字形和美感的基础。
首先,篆书造字要注意字形的规范性和准确性。
字形规范是指字的长宽比例、笔画粗细、结构等要符合一定的标准。
准确性则是指字形的每个笔画都要按照一定的顺序和方向书写,不能出现错误或歪曲。
其次,篆书造字要注重美感。
篆书是一种艺术形式,其字形应该注重美感和艺术性。
在造字时,需要注意字形的整体美感、内部比例和平衡、笔画的速度和力度等因素。
最后,篆书造字还要考虑字的意义和表现形式。
篆书是一种表现力很强的书法形式,字形可以通过笔画的形状、长度、粗细等形式表现出字的含义和象征意义。
总之,篆书造字原则是规范篆书字形和美感的基础,需要注意字形的规范性、准确性和美感,同时注重字的含义和表现形式。
通过不断的练习和学习,才能掌握篆书造字的方法和技巧,创造出更加优美的篆书字体。
- 1 -。
说文解字体例整理

说文解字体例整理
《说文解字》是中国古代经典著作之一,它是中国汉字史上重要的一部字典。
其体例按照“始一终亥,部内字的体例是同牵条属”和“据形系联”的原则进行编排。
具体来说,它有以下几个特点:
1. 检字部首:许慎在《说文解字》中列举了 540 个部首,这些部首是按照小篆的形体结构分析而来的。
这些部首对于汉字的检字法和后世的字典编纂产生了深远的影响。
2. 检字正文:在检字部首之后,许慎添加了一些检字正文,这些正文是按照汉字的书写顺序进行编排的。
不过,这一部分被认为是后人添加的,因为在许慎原著中,汉字的书写顺序并不是重要的。
3. 检字别体字:在《说文解字》中,许慎对于一些汉字的别体字也进行了收录和解释。
这些别体字为后人徐铉所注,不可能出现在许慎原著中。
4. 部首与字义的关系:许慎在《说文解字》中按照部首对汉字进行了分类,并且每个部首都有特定的意义。
每个汉字都与其所属的部首存在一定的联系,这种联系被称为“部首与字义的关系”。
《说文解字》的体例是按照“始一终亥,部内字的体例是同牵条属”和“据形系联”的原则进行编排的。
它的检字部首和检字正文被认为是后人添加的,但是部首与字义的关系却是许慎原著中就有的。
古代汉语通论知识整理
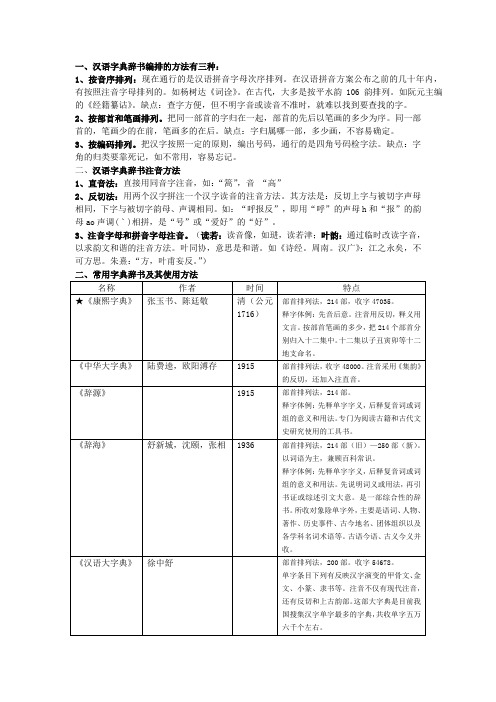
一、汉语字典辞书编排的方法有三种:1、按音序排列:现在通行的是汉语拼音字母次序排列。
在汉语拼音方案公布之前的几十年内,有按照注音字母排列的。
如杨树达《词诠》。
在古代,大多是按平水韵106韵排列。
如阮元主编的《经籍纂诂》。
缺点:查字方便,但不明字音或读音不准时,就难以找到要查找的字。
2、按部首和笔画排列。
把同一部首的字归在一起,部首的先后以笔画的多少为序。
同一部首的,笔画少的在前,笔画多的在后。
缺点:字归属哪一部,多少画,不容易确定。
3、按编码排列。
把汉字按照一定的原则,编出号码,通行的是四角号码检字法。
缺点:字角的归类要靠死记,如不常用,容易忘记。
二、汉语字典辞书注音方法1、直音法:直接用同音字注音,如:“篙”,音“高”2、反切法:用两个汉字拼注一个汉字读音的注音方法。
其方法是:反切上字与被切字声母相同,下字与被切字韵母、声调相同。
如:“呼报反”,即用“呼”的声母h和“报”的韵母ao声调(ˋ)相拼,是“号”或“爱好”的“好”。
3、注音字母和拼音字母注音。
(读若:读音像,如琎,读若津;叶韵:通过临时改读字音,以求韵文和谐的注音方法。
叶同协,意思是和谐。
如《诗经。
周南。
汉广》:江之永矣,不可方思。
朱熹:“方,叶甫妄反。
”)平水韵:唐宋以后人们写诗所用的诗韵。
上平声15韵,下平声15韵,上声29韵,去声30韵,入声17韵,共106韵。
三、《说文解字》的体例、价值和说文四家《说文解字》的体例:简称《说文》,东汉许慎著。
是我国规存最早的字典。
全书分汉字为540部,开创了以部首统率汉字的字典编纂法,收字以小篆为主。
收字9395个,另有重文1163个。
《说文解字》的价值:1、确定了“六书”理论;2、按照“六书”原则,创立了汉字部首,制定了按部首编排字数的体例;3、保留了小篆,便于从字形说明本意,并为释读甲金骨文提供了依据;4、保留了先秦词义和汉代训诂资料;5、保留了古音资料;6、记载了丰富的古代文化资料。
说文四家:清代研究《说文解字》的四大家:段玉裁《说文解字注》,桂馥《说文解字义证》,王筠《说文句读》,朱骏声《说文通训定声》。
汉字第一套编码原理

汉字第一套编码原理
汉字第一套编码原理是指对汉字进行编码的基本原理和方法。
汉字编码是为了实现计算机对汉字的处理和传输,提高信息处理效率和准确性。
汉字第一套编码原理的核心是根据汉字的笔画、结构和音形等特点,将每个汉字赋予一个唯一的编码。
这个编码可以是数字、字母或符号等形式,如GB2312编码、Unicode编码等。
其中GB2312编码是我国第一套汉字编码标准,使用较为广泛。
汉字编码的基本原理是采用“区位码”或“区位数”的方法。
即将汉字按拼音或笔画的顺序排列,将其划分为94个区,每个区内包
含94个位,共计8836个码位。
其中前两位表示区号,后两位表示位号,通过区号和位号的组合可以唯一确定一个汉字的编码。
汉字编码的实现方法包括手工编码和自动编码两种。
手工编码需要人为设置汉字的编码,存在编码重复、冲突等问题;自动编码则是由计算机自动分配编码,避免了手工编码存在的问题,但需要对编码方案进行优化和调整。
总之,汉字第一套编码原理是汉字编码的基础和核心,它的应用不仅可以提高信息处理效率,还可以促进中文信息技术的发展和应用。
- 1 -。
古文字的字形整理 及其编码的原则

古文字字形整理和编码的单位
• 字系:同时代、同形制全部的字符群 • 字组:同一字系中记词职能相同(音义相同) 的多个字形的群体 • 字种:记词职能相同、结构(构意)相同的多 个字形的群体。同一字组中不同的字种互为异 构字 • 字样:同一字种中仅仅写法不同的个体。同一 字种中不同的字样互为异写字 指称型古文字字库搜集字种,全原形古 文字字库搜集字样。古文字编码应当以字种为
古文字不能作为某种字体与现代汉字对应
职能与现代汉字不对应 辖——暴爆曝 闲——窒钟—— 蟯——景影
化——(变)化、 (教)化不同形
• 形体与现代汉字不对应 癝 眤 堡 狈 辫 • 字样繁多难以穷尽 “酉”在甲文中的字样约有 24 种 • 未识字只有字形而无音义
古文字字库的两种类型
• 古文字字库可以有两种类型:(1)指称型古 文字字库。这种字库的功用,是在创建某些文 本时,出于讲述或引用的需要,在行文中提到 某个或某几个古文字时,能够把这些个古文字 插到文本里去。(2)全原形古文字字库。这 种字库的最高要求是要在计算机里再现一切现 有的古文字实用文本中的字样。后一种要以前 一种为基础。 • 创建一种指称型历史字体的字库,要求字形准 和全,一般采用从古文字实用文本中选择字形, 即使重新写字模,也要以选择好的字形为依据。 字形选择必须整理文本用字。
“酉”的甲骨文异形字样
一般的甲骨文异形字样
齒:
一般应选择上面列举字形的8作主形
“隹”的甲骨文异形字样
隹:
一般应选择上面列举字形的8作主形
字种的划分
以甲骨文为例,在字组中选择的字种数: 一 1 元 3 天 4 史 2 上 2 帝 6 旁 3 下 2 示 3 福 6 祭 3 祀 4
古文字编码的有利条件
从造字法看按属于

从造字法看按属于造字是中华民族的瑰宝,是中华文明的重要组成部分。
自古以来,我国古人就以创造文字的方式来记录历史,传承文化。
在文字的演化发展中,经历了甲骨文、金文、篆文、隶书等多个阶段。
这些历史遗留下来的文字不仅代表了当时的文化形态和思想观念,也反映了人类文明的进步和发展。
在今天,学习造字法对于中文学习者来说仍然具有重要的指导意义。
首先,对于汉字的排列方式,一般是由左到右,由上到下。
这其中有自然排列和规制排列两种方式。
自然排列是遵从自然形态而出现的排列方式,比如画出一只鸟,它的头部通常在左侧,“孔”字形态更多地由左侧的竖折纵顶部开始,朝右下方水平向右提示;而规制排列则是根据规矩制定的排列方式,如一首诗句应该从上向下排列,从右向左读。
这些排列方式与阅读的顺序密切相关,因此熟练掌握排列方式对于中文阅读非常重要。
其次,造字的构成方式可以分为两部分,分别是形声和义符。
形声是通过声音来组成字的方式,将一部分代表意义的部分和另一部分代表读音的部分组合起来,如“河”字,由“氵”和“可”两个部分组成,而“氵”代表了“水”的意义,而“可”则代表了它的读音。
“义符则是直接由含有自己本身的意义的单歩组成,如“人”字,就是一个代表“人”的单字,也可以用在组合中。
最后,我们需要注意的是造字的原则。
造字需要符合语言本身的规律和特点,同时也要考虑语音和意义的相协调。
由于中文的语言特性,其中很多字由相同的部分组成,这些部分在构建新字时可以重复利用,如“奉”字和“朋”字中的“月”部分。
因此,合理利用现有字和部首的方式来构建新字,不仅可以延续古人遗留下来的文化,还可以丰富中文的表达能力。
总之,学习造字法需要全面深入地了解汉字的演化、排列方式、构成方式和原则。
对于中文阅读和写作,掌握造字法的指导意义非常重要,可以准确理解文字含义、写出规范的中文,同时也能善于创造新的字体,展现汉字的美。
汉文造字法大揭秘

汉文造字法大揭秘
汉字作为世界上最古老、最独特、最复杂的文字之一,一直以来都是中华文化的瑰宝。
汉字在发展演变过程中,经历了许多创新和变革,其中最重要的一次就是汉文造字法的出现。
汉文造字法是指汉字的创造方法,它的出现可以追溯到商朝晚期至西周早期的甲骨文时期。
在这个时期,人们用刻在龟骨和兽骨上的文字来记录日常生活、祭祀、战争等各种活动。
这些文字是由当时的祭司、巫师等专门的记事人员按照一定的构造法则创造出来的。
汉文造字法有三大原则:
一、象形原则
汉字最初是图像化的,每个字都是一个具体的事物或动作的象形表示。
例如,人的形状就象征着人,水的形状就象征着水等等。
二、指事原则
指事原则是指用一个字来代表一个抽象的概念或动作。
这些字与象形字相似,但它们不再是一个具体的事物或动作的象形表示。
例如,日表示天空中的太阳,而日后来就用来表示“天”或“日子”。
三、会意原则
会意原则是指用两个或多个字合并在一起,表示一种更复杂的意思。
这些字的意义不是通过象形或指事的方式表示出来,而是通过组合多个字来表达特定的概念。
例如,“心”和“口”合在一起就表示“忧虑”。
通过这些原则,汉文造字法最终发展成为了一种高度复杂而又精
细的艺术。
汉字成为了中华文化的代表,同时也影响了全世界的文化发展。
千字文编号法

千字文编号法
(实用版)
目录
1.千字文编号法的概念
2.千字文编号法的历史发展
3.千字文编号法的应用
4.千字文编号法的意义
正文
千字文编号法是一种以《千字文》为基准,对古籍进行编号的方法。
《千字文》是我国南北朝时期的一部著名的启蒙读物,由梁武帝萧衍组织文人编纂,目的是为了让儿童识字,并便于阅读。
它由一千个汉字组成,每个字都不重复,因此具有很高的文化价值和历史地位。
千字文编号法的历史发展可以追溯到隋唐时期。
当时,由于古籍的传抄和流传过程中,书籍的篇幅和内容都有所损耗和丢失,因此,就需要对古籍进行整理和编号。
而《千字文》由于其独特的性质,就被选作了编号的基准。
这样,每一篇古籍都可以对应到一个《千字文》中的字,便于查找和管理。
千字文编号法的应用主要体现在古籍的整理和阅读上。
通过千字文编号法,人们可以方便地找到和阅读古籍,同时也可以方便地对古籍进行管理和保护。
此外,千字文编号法也对古籍的流传和传播起到了重要的作用。
千字文编号法的意义主要体现在两个方面。
一方面,它为古籍的整理和管理提供了一种有效的方法,对于保护和传承古代文化起到了重要的作用。
另一方面,它也反映了我国古代文化的博大精深和独特魅力,是中华文化宝库中的一颗璀璨明珠。
第1页共1页。
汉字编码原理

2、确定码元类型和数量
• 码元是用来作为汉字代码的元素。例如, • 电报码的码元就是0-9这十个阿拉伯数字。 • 码元的种类和数量与编码容量、以及码长、重 码数等指标直接相关。 • 比如电报码,采用十个数目字作码元,四位码 长的编码容量至多10000个汉字,从00 00到9999。超过1万字就是出现重码, 否则就必须增加码长。
• 十个数字如果转换为二进制表示,则只 需四位二进制单位。这样,用“嘀 —— 嗒” 两种状态就可以传输汉字了。 • 电报码的特点是“字”-“码”一一对 应,没有重码。 • 缺点是难以记忆,非经过专门训练无法 使用。
三、编码原理
• 1、确定编码对象 • 汉字的总字数有6万多,现代汉语常用的也有 1万左右。《信息交换用汉字编码字符集基本 集》根据各种统计数据确定收入汉字6763 个。这些汉字就是一个编码对象的数量级。 • “大字符集” 包括大陆、台湾、日本、韩国所 使用的全部汉字的集合。有20902字。 • 数量不同,有关参数也不同。
第四节汉字编码类型
1、流水码
• 流水码的特点是: • ①码元只有10个阿拉伯数字; • ②一般多为等长四码,有效数字不足四 位的在前面加零补足四位; • ③字、码一一对应,没有重码; • ④字、码之间没有理据性,就是没经过 专门训练不能做到“见字识码”;
2、拼音码
• 是以汉字的读音属性为编码依据,采用 键盘上的拉丁字母做为码元的编码方法。 又分为 • “全拼音码”、 • “简化拼音码”、 • “双拼音码”三种。 • 一般不加声调。
四、汉字编码的技术参数指标
• 汉字编码是一个理论与实践性都很强的 课题,而最重要的是它的实践性,也即 在实际应用中的效果。 • 因为这是要解决汉字信息处理的第一个 “人机界面”,所以,几乎全部技术指 标都与“人”密切相关。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
古文字字形整理和编码的单位
• 字系:同时代、同形制全部的字符群
• 字组:同一字系中记词职能相同(音义相同) 的多个字形的群体
• 字种:记词职能相同、结构(构意)相同的多 个字形的群体。同一字组中不同的字种互为异 构字
• 字样:同一字种中仅仅写法不同的个体。同一 字种中不同的字样互为异写字
指称型古文字字库搜集字种,全原形古文字 字库搜集字样。古文字编码应当以字种为单位
为编码进行的古文字字形整理
古文字字形整理的主要任务是认同与优选:
• 分别已识字与未识字
• 对已识字的职能认同(类聚字组),在同一 字组的字种在排序时应当邻近,并优选领字 字种,置于前列,作为本组字的信息代称
• 对字种的形体认同(类聚字样),优选主形, 作为本字种的信息代称,同一字样应视为一 个字,坚持同码
• 指称型古文字字库只保留主形字样,全原形 古文字字库字组中的其他字样与主形认同。
“酉”的甲骨文异形字样
一般应选择上面列举字形的6或7作主形
“齿”的甲骨文异形字样
齒:
一般应选择上面列举字形的8作主形
古文字不能作为某种字体与现代汉字对应
职能与现代汉字不对应
辖——暴爆曝
蟯——景影
闲——窒钟—— 化——(变)化、(教)化不同形
• 形体与现代汉字不对应
癝眤堡狈辫
• 字样繁多难以穷尽
“酉”在甲文中的字样约有 24 种
• 未识字只有字形而无音义
古文字字库的两种类型
• 古文字字库可以有两种类型:(1)指称型古 文字字库。这种字库的功用,是在创建某些文 本时,出于讲述或引用的需要,在行文中提到 某个或某几个古文字时,能够把这些个古文字 插到文本里去。(2)全原形古文字字库。这 种字库的最高要求是要在计算机里再现一切现 有的古文字实用文本中的字样。后一种要以前 一种为基础。
• 小篆结构图式共146种,再次归纳为基本图 式12种,可以套用。
• 重码率:甲骨文经过处理可降低到1.9,但每 码带动字样数平均7.4个,最多39个。
古文字字形部件的拆分与归纳
• 已识字的拆分和归纳均采用依理操作 • 未识字的拆分和归纳均采用依形操作 • 甲骨文已识字基础部件拆分归纳为基础构件
后,能覆盖未识字构件的89·43%
现有的GB13000.1字符集不可能与已经出土的古 文字一一对应,即将出台的超大字符集仍然不够与各 种形制和各时代的古文字对应。古文字的调出只有依 靠自己的编码,要想作好编码,字形的整理必须先行。 新出土的古文字加上原有的古文字,有些已经编成字 表形式或加上解释编成诂林形式,但是,它们的字形 整理还不能符合信息处理的需要。更达不到国际化的 要求。
• 他不需要通篇连续采用来创建长篇文本,在 快速性上可以放宽;因而在码长(码元可以 多一些)的设计上可以不必过于拘泥。
• 古文字信息量大、形体的参照系多,为其设 计形码的区别因素多于现代汉字。
古文字编码可使用的区别因素
• 已识字与未识字首先分开。后者无法设置音 码,应考虑基础部件的作用。
• 基础构件中成字构件可以采用读音(一般与 《说文》小篆认同来确定);非字构件只能 利用线条类型。例如:小篆可分:横、竖、 左斜、右斜、弧、曲、折、封八类。
• 新出土的古文字,不仅使汉字史的研究发生了很大的变化,也 不仅对人类学、历史学、文化学、古地理学、历史语言学…… 起了新的推动作用,而且由于这部分文字所具有的十分典型的 表意文字特点,以及所含有的文化内涵,被不断引进文化教育 领域,迅速走向普及,成为世界各国了解中国文化的一个重要 窗口,因此,已经在印刷品和影视传媒中频频出现。我们统计 了2000年国内的8种重要的报纸和在国际上销量排前10位的普 及刊物,其中的文章已经采用或需要采用古文字原形的地方有 561处,涉及334个字形。
谢谢!
古文字的字形整理 及其编码的原则
王宁 北京师范大学民俗典籍文字研究中心
古文字进入计算机的必要性
• 80年代以来中国内地大量出土的文字,一部分已经进入今文字 阶段,另一部分属于古文字。这一部分古4文字由于是考古发掘 的成果,历史时代确定,无需辨伪,充实了从宋代就开始搜集 的金石文字,掀起了世界性的中国古文字热。
• 古文字进入计算机已经势在必行,科学整理字形,解决编码问 题,是古文字信息处理的前提。
古文字字形整理与编码
对信息处理的重要作用
由于造字技术的发展,已经有不少单位创建了某 种字体的古文字原形字库。拥有古文字字库后,遇到 的最大难题是如何将需要的字形及时找到,以便提供 给其他专业领域和普及层面在创建文本时任意调用。
“隹”的甲骨文异形字样
பைடு நூலகம்隹:
一般应选择上面列举字形的8作主形
字种的划分
以甲骨文为例,在字组中选择的字种数: 一1 元3 天4 史2 上2 帝6 旁3 下2 示3 福6 祭3 祀4
古文字编码的有利条件
• 古文字字库的作用有两个层面:第一,给专 业人员研究和贮存文字使用;第二,供普及 领域指称。后者用量不大,可以单独处理。 主要考虑专业人员使用,编码在易学性上可 以放宽。
古文字编码的难点
• 甲骨文包括未识字只有三千多个,字量更大的字 系重码率及带字的字数都会增加,需要再做一定 的技术处理。
• 编码是依字系分层面编制的,各层面各体制的 字系最好进行历时认同,不要各行其是,但是,这 一点做起来难题很多,目前只能采用分别编码。
• 古文字字库的排序一般采用与《说文》小篆一 致,利用《说文》部首,其实削足适屦,需要 考虑新的、科学的、易于操作的排序原则。