(完整word版)普里姆算法求最小生成树
求出下图的最小生成树

求出下图的最小生成树解:MATLAB程序:% 求图的最小生成树的prim算法。
% result的第一、二、三行分别表示生成树边的起点、终点、权集合% p——记录生成树的的顶点,tb=V\pclc;clear;% a(1,2)=50; a(1,3)=60;% a(2,4)=65; a(2,5)=40;% a(3,4)=52;a(3,7)=45;% a(4,5)=50; a(4,6)=30;a(4,7)=42;% a(5,6)=70;% a=[a;zeros(2,7)];e=[1 2 20;1 4 7;2 3 18;2 13 8;3 5 14;3 14 14;4 7 10;5 6 30;5 9 25;5 10 9;6 10 30;6 11 30;7 8 2;7 13 5;8 9 4;8 14 2;9 10 6;9 14 3;10 11 11;11 12 30];n=max([e(:,1);e(:,2)]); % 顶点数m=size(e,1); % 边数M=sum(e(:,3)); % 代表无穷大a=zeros(n,n);for k=1:ma(e(k,1),e(k,2))=e(k,3);enda=a+a';a(find(a==0))=M; % 形成图的邻接矩阵result=[];p=1; % 设置生成树的起始顶点tb=2:length(a); % 设置生成树以外顶点while length(result)~=length(a)-1 % 边数不足顶点数-1temp=a(p,tb);temp=temp(:); % 取出与p关联的所有边d=min(temp); % 取上述边中的最小边[jb,kb]=find(a(p,tb)==d); % 寻找最小边的两个端点(可能不止一个)j=p(jb(1));k=tb(kb(1)); % 确定最小边的两个端点result=[result,[j;k;d]]; % 记录最小生成树的新边p=[p,k]; % 扩展生成树的顶点tb(find(tb==k))=[]; % 缩减生成树以外顶点endresult % 显示生成树(点、点、边长)weight=sum(result(3,:)) % 计算生成树的权程序结果:result =1 4 7 8 14 7 9 13 10 10 14 10 11 4 7 8 14 9 13 102 5 113 6 12 7 10 2 2 3 5 6 8 9 11 14 30 30 weight =137附图最小生成树的权是137。
图最小生成树

是按逐个将顶点连通的方式来构造最
小生成树的。
10
从连通网络 N = { V, E }中的某一顶点 u0 出 发,选择与它关联的具有最小权值的边( u0, v), 将其顶点加入到生成树的顶点集合U中。 以后每一步从一个顶点在 U 中,而另一个顶点不 在U中的各条边中选择权值最小的边(u, v),把该 边加入到生成树的边集TE中,把它的顶点加入到 集合 U 中。如此重复执行,直到网络中的所有顶 点都加入到生成树顶点集合U中为止。
for (i=0; i<G.vexnum; ++i)
// 建零入度顶点栈S
if (!indegree[i]) Push(S, i); // 入度为0者进栈 count = 0; // 对输出顶点计数
while (!StackEmpty(S)) { Pop(S, i); printf(i, G.vertices[i].data); ++count; // 输出i号顶点并计数 for (p=G.vertices[i].firstarc; p; p=p->nextarc) { k = p->adjvex; // 对i号顶点的每个邻接点的入度减1
23
由于AOV网中有些活动之间没有次序要求,它们在拓扑序列的 位置可以是任意的,因此拓扑排序的结果不唯一。
C1 C3 C4
对右图进行拓扑排序,可得一个拓扑序列: C1,C3,C2,C4,C7,C6,C5 也可得到另一个拓扑序列: C2,C7,C1,C3,C4,C5,C6
C7 C2
C6 C5
还可以得到其它的拓扑序列。学生按照任何一个拓扑序列都可 以完成所要求的全部课程学习。 在AOV网中不应该出现有向环。因为环的存在意味着某项活动 将以自己为先决条件,显然无法形成拓扑序列。 判定网中是否存在环的方法:对有向图构造其顶点的拓扑有序 序列,若网中所有顶点都出现在它的拓扑有序序列中,则该 AOV网中一定不存在环。
(完整word版)数据结构试题试卷四含答案

模拟试题四模拟试题四一、选择题(20分)1。
由两个栈共享一个存储空间的好处是()。
A)减少存取时间,降低下溢发生的几率B)节省存储空间,降低上溢发生的几率C)减少存取时间,降低上溢发生的几率D)节省存储空间,降低下溢发生的几率2。
设有两个串p和q,求q在p中首次出现位置的运算称做()。
A)连接B)模式匹配 C)求子串D)求串长3。
n个顶点的连通图中边的条数至少为()。
A)0 B)l C)n—l D)n4.对一个具有n个元素的线性表,建立其有序单链表的时间复杂度为( )。
A)O(n)B)O(1)C)O(n2) D) O(log2n)5.在双向循环链表中,在p所指的结点之后插入s指针所指的结点,其操作是( )。
A) p—>next=s; s—〉prior=n;p->next—>prior=s;s-〉next:p->next。
B) s—〉priOFp;s->next—p->next;p—>next=s; p—〉next->priOFS.C) p-〉next=s;p-〉next—〉priOFS; s->prior=p; s-〉next=p—〉next.D) s—>prior=p; s-〉next=p—〉next; p-〉next—〉priOFS;p-〉next=S.6,串的长度是( ).A)串中不同字符的个数 B)串中不同字母的个数C)串中所含字符的个数n(n>0) D)串中所含字符的个数n(n≥0)7.若有一个钱的输入序列是l,2,…,n,输出序列的第一个元素是n,则第i个输出元素是()。
A) n—i B) n—i—l C)n—i+l D)不确定8.设有一个栈,元素的进栈次序为A,B,C,D,E,下列( )是不可能的出栈序列。
A) A,B,C,D,E B)B,C, D,E,AC)E,A, B,C,D D)E,D, C,B,A9。
在一棵度为3的树中,度为3的结点数有2个,度为2的结点数有1个,度为l的结点数有2个,那么度为0的结点数有()个。
PRIM算法求最小生成树

xx学院《数据结构与算法》课程设计报告书课程设计题目 PRIM算法求最小生成树院系名称计算机科学与技术系专业(班级)姓名(学号)指导教师完成时间一、问题分析和任务定义在该部分中主要包括两个方面:问题分析和任务定义;1 问题分析本次课程设计是通过PRIM(普里姆)算法,实现通过任意给定网和起点,将该网所对应的所有生成树求解出来。
在实现该本设计功能之前,必须弄清以下三个问题:1.1 关于图、网的一些基本概念1.1.1 图图G由两个集合V和E组成,记为G=(V,E),其中V是顶点的有穷非空集合,E是V中顶点偶对的有穷集,这些顶点偶对称为边。
通常,V(G)和E(G)分别表示图G的顶点集合和边集合。
E(G)也可以为空集。
则图G只有顶点而没有边。
1.1.2 无向图对于一个图G,若边集E(G)为无向边的集合,则称该图为无向图。
1.1.3 子图设有两个图G=(V,E)G’=(V’,),若V’是V的子集,即V’⊆V ,且E’是E的子集,即E’⊆E,称G’是G的子图。
1.1.4 连通图若图G中任意两个顶点都连通,则称G为连通图。
1.1.5 权和网在一个图中,每条边可以标上具有某种含义的数值,该数值称为该边的权。
把边上带权的图称为网。
如图1所示。
1.2 理解生成树和最小生成树之间的区别和联系1.2.1 生成树在一个连通图G中,如果取它的全部顶点和一部分边构成一个子图G’,即:V(G’)= V(G)和E(G’)⊆E(G),若边集E(G’)中的边既将图中的所有顶点连通又不形成回路,则称子图G’是原图G的一棵生成树。
1.2.2 最小生成树图的生成树不是唯一的,把具有权最小的生成树称为图G的最小生成树,即生成树中每条边上的权值之和达到最小。
如图1所示。
图1.网转化为最小生成树1.3 理解PRIM(普里姆)算法的基本思想1.3.1 PRIM算法(普里姆算法)的基本思想假设G =(V,E)是一个具有n个顶点的连通网,T=(U,TE)是G的最小生成树,其中U是T的顶点集,TE是T的边集,U和TE的初值均为空集。
最小生成树---普里姆算法(Prim算法)和克鲁斯卡尔算法(Kruskal算法)

最⼩⽣成树---普⾥姆算法(Prim算法)和克鲁斯卡尔算法(Kruskal算法)最⼩⽣成树的性质:MST性质(假设N=(V,{E})是⼀个连通⽹,U是顶点集V的⼀个⾮空⼦集,如果(u,v)是⼀条具有最⼩权值的边,其中u属于U,v属于V-U,则必定存在⼀颗包含边(u,v)的最⼩⽣成树)普⾥姆算法(Prim算法)思路:以点为⽬标构建最⼩⽣成树1.将初始点顶点u加⼊U中,初始化集合V-U中各顶点到初始顶点u的权值;2.根据最⼩⽣成树的定义:从n个顶点中,找出 n - 1条连线,使得各边权值最⼩。
循环n-1次如下操作:(1)从数组lowcost[k]中找到vk到集合U的最⼩权值边,并从数组arjvex[k] = j中找到该边在集合U中的顶点下标(2)打印此边,并将vk加⼊U中。
(3)通过查找邻接矩阵Vk⾏的各个权值,即vk点到V-U中各顶点的权值,与lowcost的对应值进⾏⽐较,若更⼩则更新lowcost,并将k存⼊arjvex数组中以下图为例#include<bits/stdc++.h>using namespace std;#define MAXVEX 100#define INF 65535typedef char VertexType;typedef int EdgeType;typedef struct {VertexType vexs[MAXVEX];EdgeType arc[MAXVEX][MAXVEX];int numVertexes, numEdges;}MGraph;void CreateMGraph(MGraph *G) {int m, n, w; //vm-vn的权重wscanf("%d %d", &G->numVertexes, &G->numEdges);for(int i = 0; i < G->numVertexes; i++) {getchar();scanf("%c", &G->vexs[i]);}for(int i = 0; i < G->numVertexes; i++) {for(int j = 0; j < G->numVertexes; j++) {if(i == j) G->arc[i][j] = 0;else G->arc[i][j] = INF;}}for(int k = 0; k < G->numEdges; k++) {scanf("%d %d %d", &m, &n, &w);G->arc[m][n] = w;G->arc[n][m] = G->arc[m][n];}}void MiniSpanTree_Prim(MGraph G) {int min, j, k;int arjvex[MAXVEX]; //最⼩边在 U集合中的那个顶点的下标int lowcost[MAXVEX]; // 最⼩边上的权值//初始化,从点 V0开始找最⼩⽣成树Tarjvex[0] = 0; //arjvex[i] = j表⽰ V-U中集合中的 Vi点的最⼩边在U集合中的点为 Vjlowcost[0] = 0; //lowcost[i] = 0表⽰将点Vi纳⼊集合 U ,lowcost[i] = w表⽰ V-U中 Vi点到 U的最⼩权值for(int i = 1; i < G.numVertexes; i++) {lowcost[i] = G.arc[0][i];arjvex[i] = 0;}//根据最⼩⽣成树的定义:从n个顶点中,找出 n - 1条连线,使得各边权值最⼩for(int i = 1; i < G.numVertexes; i++) {min = INF, j = 1, k = 0;//寻找 V-U到 U的最⼩权值minfor(j; j < G.numVertexes; j++) {// lowcost[j] != 0保证顶点在 V-U中,⽤k记录此时的最⼩权值边在 V-U中顶点的下标if(lowcost[j] != 0 && lowcost[j] < min) {min = lowcost[j];k = j;}}}printf("V[%d]-V[%d] weight = %d\n", arjvex[k], k, min);lowcost[k] = 0; //表⽰将Vk纳⼊ U//查找邻接矩阵Vk⾏的各个权值,与lowcost的对应值进⾏⽐较,若更⼩则更新lowcost,并将k存⼊arjvex数组中for(int i = 1; i < G.numVertexes; i++) {if(lowcost[i] != 0 && G.arc[k][i] < lowcost[i]) {lowcost[i] = G.arc[k][i];arjvex[i] = k;}}}int main() {MGraph *G = (MGraph *)malloc(sizeof(MGraph));CreateMGraph(G);MiniSpanTree_Prim(*G);}/*input:4 5abcd0 1 20 2 20 3 71 2 42 3 8output:V[0]-V[1] weight = 2V[0]-V[2] weight = 2V[0]-V[3] weight = 7最⼩总权值: 11*/时间复杂度O(n^2)克鲁斯卡尔算法(Kruskal算法)思路:以边为⽬标进⾏构建最⼩⽣成树在边集中依次寻找最⼩权值边,若构建是不形成环路(利⽤parent数组记录各点的连通分量),则将其添加到最⼩⽣成树中。
最小生成树问题课程设计

最小生成树问题课程设计一、课程目标知识目标:1. 理解最小生成树的概念,掌握其定义及性质;2. 学会运用普里姆(Prim)算法和克鲁斯卡尔(Kruskal)算法求解最小生成树问题;3. 了解最小生成树在实际问题中的应用,如网络设计、电路设计等。
技能目标:1. 能够运用普里姆和克鲁斯卡尔算法解决最小生成树问题,并进行算法分析;2. 能够运用所学知识解决实际问题,具备一定的算法设计能力;3. 能够通过合作与交流,提高问题分析和解决问题的能力。
情感态度价值观目标:1. 培养学生对数据结构与算法的兴趣,激发学习热情;2. 培养学生的团队合作意识,学会倾听、尊重他人意见;3. 培养学生面对问题勇于挑战、积极进取的精神。
课程性质:本课程为计算机科学与技术专业的高年级课程,旨在帮助学生掌握图论中的最小生成树问题及其求解方法。
学生特点:学生具备一定的编程基础和图论知识,对算法有一定的了解,但可能对最小生成树问题尚不熟悉。
教学要求:结合学生特点,采用案例教学、任务驱动等方法,注重理论与实践相结合,培养学生的实际操作能力和创新思维。
通过本课程的学习,使学生能够将所学知识应用于实际问题中,提高解决复杂问题的能力。
二、教学内容1. 最小生成树概念与性质- 定义、性质及定理- 最小生成树的构建方法2. 普里姆算法- 算法原理与步骤- 算法实现与复杂度分析- 举例应用3. 克鲁斯卡尔算法- 算法原理与步骤- 算法实现与复杂度分析- 举例应用4. 最小生成树在实际问题中的应用- 网络设计- 电路设计- 其他领域应用案例5. 算法比较与优化- 普里姆与克鲁斯卡尔算法的比较- 算法优化方法及其适用场景6. 实践环节- 编程实现普里姆和克鲁斯卡尔算法- 分析并解决实际问题- 小组讨论与成果展示教学内容依据课程目标进行选择和组织,注重科学性和系统性。
参考教材相关章节,制定以下教学安排:第1周:最小生成树概念与性质第2周:普里姆算法第3周:克鲁斯卡尔算法第4周:最小生成树在实际问题中的应用第5周:算法比较与优化第6周:实践环节与总结三、教学方法本课程将采用以下多样化的教学方法,以激发学生的学习兴趣和主动性:1. 讲授法:教师通过生动的语言和形象的比喻,对最小生成树的概念、性质、算法原理等基础知识进行讲解,使学生快速掌握课程内容。
(完整word版)数据结构应用题练习
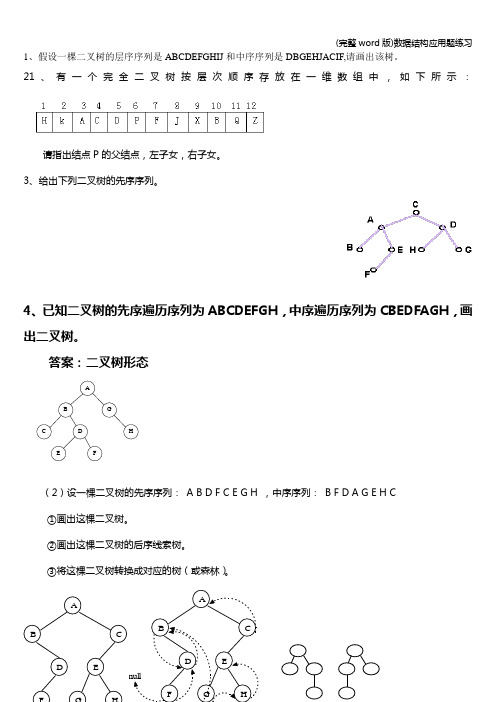
1、假设一棵二叉树的层序序列是ABCDEFGHIJ 和中序序列是DBGEHJACIF,请画出该树。
21、有一个完全二叉树按层次顺序存放在一维数组中,如下所示:请指出结点P 的父结点,左子女,右子女。
3、给出下列二叉树的先序序列。
4、已知二叉树的先序遍历序列为ABCDEFGH ,中序遍历序列为CBEDFAGH ,画出二叉树。
答案:二叉树形态AFHGDECB(2)设一棵二叉树的先序序列: A B D F C E G H ,中序序列: B F D A G E H C ①画出这棵二叉树。
②画出这棵二叉树的后序线索树。
③将这棵二叉树转换成对应的树(或森林)。
ABFD CE HG(1) (2)1、已知一棵二叉树的前序序列为:A,B,D,G,J,E,H,C,F,I,K,L中序序列:D,J,G,B,E,H, A,C,K,I,L,F。
i.写出该二叉树的后序序列;ii.画出该二叉树;iii.求该二叉树的高度(假定空树的高度为-1)和度为2、度为1、及度为0的结点个数。
该二叉树的后序序列为:J,G,D,H,E,B,K,L,I,F,C,A。
该二叉树的形式如图所示:该二叉树高度为:5。
度为2的结点的个数为:3。
度为1的结点的个数为:5。
度为0的结点个数为:4。
5、试用权集合{12,4,5,6,1,2}构造哈夫曼树,并计算哈夫曼树的带权路径长度。
答案:215611187341230WPL=12*1+(4+5+6)*3+(1+2)*4=12+45+12=696、已知权值集合为{5,7,2,3,6,9},要求给出哈夫曼树,并计算带权路径长度WPL 。
答案:(1)树形态:325510199761332(2)带权路径长度:WPL=(6+7+9)*2+5*3+(2+3)*4=44+15+20=79(3) 假设用于通信的电文仅由8个字母组成,字母在电文中出现的频率分别为0.07,0.19,0.02,0.06,0.32,0.03,0.21,0.10。
普里姆算法

使用不同的遍历图的方法,可以得到不同 的生成树;从不同的顶点出发,也可能得 到不同的生成树。
按照生成树的定义,n 个顶点的连通网络 的生成树有 n 个顶点、n-1 条边。
构造最小生成树的准则 必须使用且仅使用该网络中的n-1 条边 来联结网络中的 n 个顶点; 不能使用产生回路的边; 各边上的权值的总和达到最小。
采用邻接矩阵作为图的存储表示。
28
01
01
01
10 14 16 10
10
5 6 25 6 25 6 2
25 24 18 12
25
4 22 3
43
43
原图
(a)
(b)
01
01
01
10
10
10 14 16
5 6 25 6 25 6 2
25
4 22 3
(c)
25
12 25
12
4 22 3
4 22 3
(d)
普里姆(Pபைடு நூலகம்im)算法
普里姆算法的基本思想: 从连通网络 N = { V, E }中的某一顶点 u0 出 发, 选择与它关联的具有最小权值的边 ( u0, v ), 将其顶点加入到生成树顶点集合U中。 以后每一步从一个顶点在 U 中,而另一个 顶点不在 U 中的各条边中选择权值最小的 边(u, v), 把它的顶点加入到集合 U 中。如 此继续下去, 直到网络中的所有顶点都加入 到生成树顶点集合 U 中为止。
(e) (f)
《数据结构》课程设计 普里姆算法 最小生成树

[i].stop_vex,lge[i].weight); /*输出N-1条最小边的信息*/
for(i=0;i<12;i++)
{
line(vex[lge[i].start_vex][0],vex[lge[i].start_vex][1],vex[lge
lge[min]=lge[i];
lge[i]=edge;
vx=lge[i].stop_vex;
for(j=i+1; j<pgraph->n-1; j++)
{
vy=lge[j].stop_vex;
weight=pgraph->arcs[vx][vy];
if(weight<lge[j].weight)
{
{550,250},{520,330},{430,400},{350,450},{270,400},{200,330}};
/*初始化个顶点的坐标*/
int info[12][12];
char *text;
void initalGraph(int vec[][2]) /*画出顶点函数*/
{
int gd=DETECT,gm;
[i].stop_vex][0],vex[lge[i].stop_vex][1]);
}
/*根据生成的最小边数组连线*/
printf("---It is done!---");
getch();
exit(1);
}
此程序再TURBOC2.0环境中编译通过运行.TURBOC2.0下载的地址
最小生成树

对于图G=(V,E)的每一条e∈E, 赋予相应的权数 f(e),得到一个网络图,记为N=(V,E,F),
设T=(为T的权,N中权数最小的 生成树称为N的最小生成树。 许多实际问题,如在若干个城市之间建造铁路网、 输电网或通信网等,都可归纳为寻求连通赋权图 的最小生成树问题。 下面介绍两种求最小生成树的方法:
例1 求下图所示的最小生成树。
v2 e1 v1 e2 e6 v4 e 7 v3
v5
解:按各边的权的不减次序为:
e1 e 2 e3 e7 e6 e 4 e5 e8
所以,首先取 e1 , e2 ,尔后再取 e7 和 e6 , 则构成最小生成树 .
二、破圈法 破圈法就是在图中任取一个圈,从圈中去 掉权最大的边,将这个圈破掉。重复这个 过程,直到图中没有圈为止,保留下的边 组成的图即为最小生成树。 例2 同例1。 解:在圈v2v2v3中,去掉权最大的边e2或e3; 在圈v2v3v4中,去掉权最大的边e4; 在圈v3v4v5中,去掉权最大的边e5; 在圈中v2v3v5,去掉权最大的边e8;
在剩下的图中,已没有圈,于是得到最小生成树, 如下图:
v2 e1 v1 e2 e6 v4 v3 e7
v5
例3 求下图的最小生成树。
C1 1 B1 3 5 A 4 B2 6 5 8 7 6 C4 C3 3 3 4 D3 8 3 C2 8 D2 4 E A
4 3 B2 C4 4 D3 C3 3
B 2 A 3 5 J 2 2 H 5 G 1 F 2 1 S 3 1 4 C 3 4 1 4 E
5
D 2
A 2
B
1
C D 1 2 E
1 S 2 H
最小生成树

17
D
应用举例——最小生成树
Prim算法 34 A 46 19 F B 12 26 25 E 38 cost'={(A, B)34, (C, D)17, (F, E)26}
17
U={A, F, C, D}
V-U={B, E}
cost={(A, B)34, (F, E)26}
25
C
17
D
应用举例——最小生成树
{B, C, D, E, F} (A F)19
{B, C, D, E} {B, D, E} {B, E} {B} {}
(F C)25
(C D)17
(F E)26
adjvex lowcost
adjvex lowcost
4 12
{A, F, C, D, E}
{A,F,C,D,E,B}
(E B)12
21
应用举例——最小生成树
Prim算法——伪代码
1. 将顶点0加入集合U中; 2. 初始化辅助数组shortEdge,分别为lowcost和adjvex赋值; 3. 重复执行下列操作n-1次 3.1 在shortEdge中选取最短边,取其对应的下标k; 3.2 输出边(k, shortEdge[k].adjvex)和对应的权值; 3.3 将顶点k加入集合U中; 3.4 调整数组shortEdge;
U
V-U
输出
adjvex lowcost adjvex lowcost adjvex lowcost adjvex lowcost
0 34 0 34 0 34 0 34
0 46 5 25
0 ∞ 5 25 2 17
0 ∞ 5 26 5 26 5 26
0 19
数据结构之最小生成树Prim算法

数据结构之最⼩⽣成树Prim算法普⾥姆算法介绍 普⾥姆(Prim)算法,是⽤来求加权连通图的最⼩⽣成树算法 基本思想:对于图G⽽⾔,V是所有顶点的集合;现在,设置两个新的集合U和T,其中U⽤于存放G的最⼩⽣成树中的顶点,T存放G的最⼩⽣成树中的边。
从所有uЄU,vЄ(V-U) (V-U表⽰出去U的所有顶点)的边中选取权值最⼩的边(u, v),将顶点v加⼊集合U中,将边(u, v)加⼊集合T中,如此不断重复,直到U=V为⽌,最⼩⽣成树构造完毕,这时集合T中包含了最⼩⽣成树中的所有边。
代码实现1. 思想逻辑 (1)以⽆向图的某个顶点(A)出发,计算所有点到该点的权重值,若⽆连接取最⼤权重值#define INF (~(0x1<<31)) (2)找到与该顶点最⼩权重值的顶点(B),再以B为顶点计算所有点到改点的权重值,依次更新之前的权重值,注意权重值为0或⼩于当前权重值的不更新,因为1是⼀当找到最⼩权重值的顶点时,将权重值设为了0,2是会出现⽆连接的情况。
(3)将上述过程⼀次循环,并得到最⼩⽣成树。
2. Prim算法// Prim最⼩⽣成树void Prim(int nStart){int i = 0;int nIndex=0; // prim最⼩树的索引,即prims数组的索引char cPrims[MAX]; // prim最⼩树的结果数组int weights[MAX]; // 顶点间边的权值cPrims[nIndex++] = m_mVexs[nStart].data;// 初始化"顶点的权值数组",// 将每个顶点的权值初始化为"第start个顶点"到"该顶点"的权值。
for (i = 0; i < m_nVexNum; i++){weights[i] = GetWeight(nStart, i);}for (i = 0; i < m_nVexNum; i ++){if (nStart == i){continue;}int min = INF;int nMinWeightIndex = 0;for (int k = 0; k < m_nVexNum; k ++){if (weights[k]!= 0 && weights[k] < min){min = weights[k];nMinWeightIndex = k;}}// 找到下⼀个最⼩权重值索引cPrims[nIndex++] = m_mVexs[nMinWeightIndex].data;// 以找到的顶点更新其他点到该点的权重值weights[nMinWeightIndex]=0;int nNewWeight = 0;for (int ii = 0; ii < m_nVexNum; ii++){nNewWeight = GetWeight(nMinWeightIndex, ii);// 该位置需要特别注意if (0 != weights[ii] && weights[ii] > nNewWeight){weights[ii] = nNewWeight;}}for (i = 1; i < nIndex; i ++){int min = INF;int nVexsIndex = GetVIndex(cPrims[i]);for (int kk = 0; kk < i; kk ++){int nNextVexsIndex = GetVIndex(cPrims[kk]);int nWeight = GetWeight(nVexsIndex, nNextVexsIndex);if (nWeight < min){min = nWeight;}}nSum += min;}// 打印最⼩⽣成树cout << "PRIM(" << m_mVexs[nStart].data <<")=" << nSum << ": ";for (i = 0; i < nIndex; i++)cout << cPrims[i] << "";cout << endl;}3. 全部实现#include "stdio.h"#include <iostream>using namespace std;#define MAX 100#define INF (~(0x1<<31)) // 最⼤值(即0X7FFFFFFF)class EData{public:EData(char start, char end, int weight) : nStart(start), nEnd(end), nWeight(weight){} char nStart;char nEnd;int nWeight;};// 边struct ENode{int nVindex; // 该边所指的顶点的位置int nWeight; // 边的权重ENode *pNext; // 指向下⼀个边的指针};struct VNode{char data; // 顶点信息ENode *pFirstEdge; // 指向第⼀条依附该顶点的边};// ⽆向邻接表class listUDG{public:listUDG(){};listUDG(char *vexs, int vlen, EData **pEData, int elen){m_nVexNum = vlen;m_nEdgNum = elen;// 初始化"邻接表"的顶点for (int i = 0; i < vlen; i ++){m_mVexs[i].data = vexs[i];m_mVexs[i].pFirstEdge = NULL;}char c1,c2;int p1,p2;ENode *node1, *node2;// 初始化"邻接表"的边for (int j = 0; j < elen; j ++){// 读取边的起始顶点和结束顶点p1 = GetVIndex(c1);p2 = GetVIndex(c2);node1 = new ENode();node1->nVindex = p2;node1->nWeight = pEData[j]->nWeight;if (m_mVexs[p1].pFirstEdge == NULL){m_mVexs[p1].pFirstEdge = node1;}else{LinkLast(m_mVexs[p1].pFirstEdge, node1);}node2 = new ENode();node2->nVindex = p1;node2->nWeight = pEData[j]->nWeight;if (m_mVexs[p2].pFirstEdge == NULL){m_mVexs[p2].pFirstEdge = node2;}else{LinkLast(m_mVexs[p2].pFirstEdge, node2);}}}~listUDG(){ENode *pENode = NULL;ENode *pTemp = NULL;for (int i = 0; i < m_nVexNum; i ++){pENode = m_mVexs[i].pFirstEdge;if (pENode != NULL){pTemp = pENode;pENode = pENode->pNext;delete pTemp;}delete pENode;}}void PrintUDG(){ENode *pTempNode = NULL;cout << "邻接⽆向表:" << endl;for (int i = 0; i < m_nVexNum; i ++){cout << "顶点:" << GetVIndex(m_mVexs[i].data)<< "-" << m_mVexs[i].data<< "->"; pTempNode = m_mVexs[i].pFirstEdge;while (pTempNode){cout <<pTempNode->nVindex << "->";pTempNode = pTempNode->pNext;}cout << endl;}}// Prim最⼩⽣成树void Prim(int nStart){int i = 0;int nIndex=0; // prim最⼩树的索引,即prims数组的索引char cPrims[MAX]; // prim最⼩树的结果数组int weights[MAX]; // 顶点间边的权值cPrims[nIndex++] = m_mVexs[nStart].data;// 初始化"顶点的权值数组",// 将每个顶点的权值初始化为"第start个顶点"到"该顶点"的权值。
03 最小生成树
所选的边都是一端 一端在 1. 所选的边都是一端在V-U中,另一端在U中; 中 另一端在 中 2. 从一个顶点开始逐步增加 中的顶点,Prim算法可称为“加点 从一个顶点开始逐步增加U中的顶点 中的顶点, 算法可称为“ 算法可称为 法”。
普里姆(Prim)算法过程示例 普里姆(Prim)算法过程示例 (Prim)
28 1 10 6 25 25 5 22 4 14 7 18 2 16 3 12
普里姆(Prim)算法过程示例 普里姆(Prim)算法过程示例 (Prim)
28 1 10 6 25 25 5 22 4 14 7 18 2 16 3 12
A B C D E B C
A D E B C
A D E
F 图G
G
F
G
F
G
图G的生成树 的生成树
图G的又一生成树 的又一生成树
1. 如果在一棵生成树上添加一条边,必定构成一个环; 如果在一棵生成树上添加一条边 必定构成一个环 添加一条边 必定构成一个 因为这条边使得它依附的那两个顶点之间有了第二 条路径。 条路径。 2. 一棵有 个顶点的生成树 连通无回路图)有且仅有 一棵有n个顶点的生成树 连通无回路 有且仅有 个顶点的生成树(连通无回路图 有且仅有(n条边,则是 1)条边 如果一个图有 个顶点和小于 条边,如果一个图有 个顶点和小于 条边 条边 如果一个图有n个顶点和小于(n-1)条边 则是 非连通图。如果它多于 连通图。如果它多于(n-1)条边 则一定有回路。 条边,则一定有回路。 多于 条边 则一定有回路 3. 有(n-1)条边的图不一定都是生成树。 条边的图不一定都是生成树。 条边的图不一定都是生成树
最小生成树算法(克鲁斯卡尔算法和普里姆算法)

最⼩⽣成树算法(克鲁斯卡尔算法和普⾥姆算法)⼀般最⼩⽣成树算法分成两种算法:⼀个是克鲁斯卡尔算法:这个算法的思想是利⽤贪⼼的思想,对每条边的权值先排个序,然后每次选取当前最⼩的边,判断⼀下这条边的点是否已经被选过了,也就是已经在树内了,⼀般是⽤并查集判断两个点是否已经联通了;另⼀个算法是普⾥姆算法:这个算法长的贼像迪杰斯塔拉算法,⾸先选取⼀个点进⼊集合内,然后找这个点连接的点⾥⾯权值最⼩的点,然后每次在选取与集合内任意⼀点连接的点的边的权值最⼩的那个(这个操作可以在松弛那⾥修改⼀下,这也是和迪杰斯塔拉算法最⼤的不同,你每次选取⼀个点后,把这个点能达到的点的那条边的权值修改⼀下,⽽不是像迪杰斯塔拉算法那样,松弛单点权值);克鲁斯卡尔代码:#include<iostream>#include<algorithm>#define maxn 5005using namespace std;struct Node{int x;int y;int w;}node[maxn];int cmp(Node x,Node y){return x.w<y.w;}int fa[maxn];int findfa(int x){if(fa[x]==x)return x;elsereturn findfa(fa[x]);}int join(int u,int v){int t1,t2;t1=findfa(u);t2=findfa(v);if(t1!=t2){fa[t2]=t1;return1;}elsereturn0;}int main(){int i,j;int sum;int ans;int n,m;sum=0;ans=0;cin>>n>>m;for(i=1;i<=m;i++)cin>>node[i].x>>node[i].y>>node[i].w;sort(node+1,node+1+m,cmp);for(i=1;i<=n;i++)fa[i]=i;for(i=1;i<=m;i++){if(join(node[i].x,node[i].y)){sum++;ans+=node[i].w;}if(sum==n-1)break;}cout<<ans<<endl;return0;}普⾥姆算法:#include<iostream>#include<algorithm>#include<cstring>#include<cstdio>#define inf 0x3f3f3fusing namespace std;int Map[1005][1005];int dist[1005];int visit[1005];int n,m;int prime(int x){int temp;int lowcast;int sum=0;memset(visit,0,sizeof(visit)); for(int i=1;i<=n;i++)dist[i]=Map[x][i];visit[x]=1;for(int i=1;i<=n-1;i++){lowcast=inf;for(int j=1;j<=n;j++)if(!visit[j]&&dist[j]<lowcast){lowcast=dist[j];temp=j;}visit[temp]=1;sum+=lowcast;for(int j=1;j<=n;j++){if(!visit[j]&&dist[j]>Map[temp][j]) dist[j]=Map[temp][j];}}return sum;}int main(){int y,x,w,z;scanf("%d%d",&n,&m);for(int i=1;i<=n;i++){for(int j=1;j<=n;j++){if(i==j)Map[i][j]=0;elseMap[i][j]=inf;}}memset(dist,inf,sizeof(dist)); for(int i=1;i<=m;i++){scanf("%d%d%d",&x,&y,&w); Map[x][y]=w;Map[y][x]=w;}z=prime(1);printf("%d\n",z);return0;}。
(完整word版)数据结构(C语言)

《数据结构与算法》复习题应用简答题.1.有下列几种用二元组表示的数据结构,画出它们分别对应的逻辑图形表示,并指出它们分别属于何种结构。
(1)A ={D,R},其中:D={a,b,c,d,e,f,g,h},R ={r},r ={<a,b>,<b,c>,〈c,d〉,〈d,e>,〈e,f〉,<f,g>,<g,h〉}(2)B ={D,R},其中:D={a,b,c,d,e,f,g,h},R ={r},r ={<d,b>,〈d,g〉,<d,a〉,<b,c>,<g,e>,<g,h〉,〈e,f〉}(3)C ={D,R},其中:D={1,2,3,4,5,6},R ={r},r ={(1,2),(2,3),(2,4),(3,4),(3,5),(3,6),(4,5),(4,6)}2.简述顺序表和链表存储方式的特点。
答:顺序表的优点是可以随机访问数据元素,缺点是大小固定,不利于增减结点(增减结点操作需要移动元素)。
链表的优点是采用指针方式增减结点,非常方便(只需改变指针指向,不移动结点)。
其缺点是不能进行随机访问,只能顺序访问。
另外,每个结点上增加指针域,造出额外存储空间增大.3.对链表设置头结点的作用是什么?(至少说出两条好处)答:其好处有:(1)对带头结点的链表,在表的任何结点之前插入结点或删除表中任何结点,所要做的都是修改前一个结点的指针域,因为任何元素结点都有前驱结点(若链表没有头结点,则首元素结点没有前驱结点,在其前插入结点和删除该结点时操作复杂些)。
(2)对带头结点的链表,表头指针是指向头结点的非空指针,因此空表与非空表的处理是一样的。
4.对于一个栈,给出输入项A ,B,C 。
如果输入项序列由A ,B,C 组成,试给出全部可能的输出序列。
5.设有4个元素1、2、3、4依次进栈,而栈的操作可随时进行(进出栈可任意交错进行,但要保证进栈次序不破坏1、2、3、4的相对次序),请写出所有不可能的出栈次序和所有可能的出栈次序.6.现有稀疏矩阵A 如图所示,要求画出三元组表示法和十字链表表示法:⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡--000280000000910000000060000003130150220157.设4维数组的4个下标的范围分别为[-1,0],[1,2],[1,3],[-2,-1],请分别按行序和列序列出各元素。
Prim算法及证明

Prim算法及证明Prim算法及证明(2012-02-21 12:19:12)1、算法概述用于生成连通无向图的最小代价生成树。
2、算法步骤步骤一:树T初始状态为空;步骤二:从图中任意选取一个点加入T;步骤三:从图中找出能与T形成树的所有边,将代价最小的边加入T,形成新的树T;步骤四:检查T中边的条数;步骤五:如果条数小于n-1,返回步骤三,否则程序结束,T为最小代价生成树。
3、算法证明要证明Prim算法生成的是最小生成树,我们分两步来证明:(1)Prim算法一定能得到一个生成树;(2)该生成树具有最小代价。
证明如下:(1)Prim算法每次引入一个新边,都恰好引入一个新节点:如果少于1个,则新加入的边的两个端点已经在树中,引入新边后就会形成回路;如果多于一个,即2个,则这条边的两个端点都不在树中,这条边与原来的树就独立了,不再构成一个新的树。
由于第一步中已直接引入了一个顶点,所以只需再引入n-1条边(即n-1个顶点)即可。
假设Prim算法引入边数小于n-1,就意味着还有剩余的点与已生成的树没有相连(n个节点的连通图最小边数是n-1,少于这个数说明图不连通),且剩余的点中没有任何点可以和树中的点连通,而由于原图是连通的,所以不可能存在这种情况,因此Prim算法不可能在此之前结束。
因此Prim算法必能引入n-1条边,此时得到的树是原图的生成树。
(2)下面我们用循环不变式证明生成的树具有最小代价。
循环不变式如下:假设每次引入新的边后形成的树T包含的点集为X,X中点与点之间的所有边构成一个子图G0,则T是G0的最小代价生成树。
初始化:引入新边之前,先直接引入一个点,由于此时G0中只有一个点,因此该点就是G的最小代价生成树。
保持:令引入新边前的树是T0,点集是X0,构成的子图是G0,引入的边是e,相应的点是y;得到新的树是T1,点集是X1=X0+y,构成的子图是G1。
假设T1不是G1的最小生成树,我们必然可以在G1中其它边中找到一条边d,由于T1本身是树,d加入后形成回路,回路中有代价大于d的边,将其中之一f删掉,从而得到代价更小的树。
数据结构(三十三)最小生成树(Prim、Kruskal)

数据结构(三⼗三)最⼩⽣成树(Prim、Kruskal) ⼀、最⼩⽣成树的定义 ⼀个连通图的⽣成树是⼀个极⼩的连通⼦图,它含有图中全部的顶点,但只有⾜以构成⼀棵树的n-1条边。
在⼀个⽹的所有⽣成树中,权值总和最⼩的⽣成树称为最⼩代价⽣成树(Minimum Cost Spanning Tree),简称为最⼩⽣成树。
构造最⼩⽣成树的准则有以下3条:只能使⽤该图中的边构造最⼩⽣成树当且仅当使⽤n-1条边来连接图中的n个顶点不能使⽤产⽣回路的边 对⽐两个算法,Kruskal算法主要是针对边来展开,边数少时效率会⾮常⾼,所以对于稀疏图有很⼤的优势;⽽Prim算法对于稠密图,即边数⾮常多的情况会更好⼀些。
⼆、普⾥姆(Prim)算法 1.Prim算法描述 假设N={V,{E}}是连通⽹,TE是N上最⼩⽣成树中边的集合。
算法从U={u0,u0属于V},TE={}开始。
重复执⾏下⾯的操作:在所有u属于U,v 属于V-U的边(u,v)中找⼀条代价最⼩的边(u0,v0)并加⼊集合TE,同时v0加⼊U,直到U=V为⽌。
此时TE中必有n-1条边,则T=(V,{TE})为N的最⼩⽣成树。
2.Prim算法的C语⾔代码实现/* Prim算法⽣成最⼩⽣成树 */void MiniSpanTree_Prim(MGraph G){int min, i, j, k;int adjvex[MAXVEX]; /* 保存相关顶点下标 */int lowcost[MAXVEX]; /* 保存相关顶点间边的权值 */lowcost[0] = 0;/* 初始化第⼀个权值为0,即v0加⼊⽣成树 *//* lowcost的值为0,在这⾥就是此下标的顶点已经加⼊⽣成树 */adjvex[0] = 0; /* 初始化第⼀个顶点下标为0 */for(i = 1; i < G.numVertexes; i++) /* 循环除下标为0外的全部顶点 */{lowcost[i] = G.arc[0][i]; /* 将v0顶点与之有边的权值存⼊数组 */adjvex[i] = 0; /* 初始化都为v0的下标 */}for(i = 1; i < G.numVertexes; i++){min = INFINITY; /* 初始化最⼩权值为∞, *//* 通常设置为不可能的⼤数字如32767、65535等 */j = 1;k = 0;while(j < G.numVertexes) /* 循环全部顶点 */{if(lowcost[j]!=0 && lowcost[j] < min)/* 如果权值不为0且权值⼩于min */{min = lowcost[j]; /* 则让当前权值成为最⼩值 */k = j; /* 将当前最⼩值的下标存⼊k */}j++;}printf("(%d, %d)\n", adjvex[k], k);/* 打印当前顶点边中权值最⼩的边 */lowcost[k] = 0;/* 将当前顶点的权值设置为0,表⽰此顶点已经完成任务 */for(j = 1; j < G.numVertexes; j++) /* 循环所有顶点 */{if(lowcost[j]!=0 && G.arc[k][j] < lowcost[j]){/* 如果下标为k顶点各边权值⼩于此前这些顶点未被加⼊⽣成树权值 */lowcost[j] = G.arc[k][j];/* 将较⼩的权值存⼊lowcost相应位置 */adjvex[j] = k; /* 将下标为k的顶点存⼊adjvex */}}}}Prim算法 3.Prim算法的Java语⾔代码实现package bigjun.iplab.adjacencyMatrix;/*** 最⼩⽣成树之Prim算法*/public class MiniSpanTree_Prim {int lowCost; // 顶点对应的权值public CloseEdge(Object adjVex, int lowCost) {this.adjVex = adjVex;this.lowCost = lowCost;}}private static int getMinMum(CloseEdge[] closeEdges) {int min = Integer.MAX_VALUE; // 初始化最⼩权值为正⽆穷int v = -1; // 顶点数组下标for (int i = 0; i < closeEdges.length; i++) { // 遍历权值数组,找到最⼩的权值以及对应的顶点数组的下标if (closeEdges[i].lowCost != 0 && closeEdges[i].lowCost < min) {min = closeEdges[i].lowCost;v = i;}}return v;}// Prim算法构造图G的以u为起始点的最⼩⽣成树public static void Prim(AdjacencyMatrixGraphINF G, Object u) throws Exception{// 初始化⼀个⼆维最⼩⽣成树数组minSpanTree,由于最⼩⽣成树的边是n-1,所以数组第⼀个参数是G.getVexNum() - 1,第⼆个参数表⽰边的起点和终点符号,所以是2 Object[][] minSpanTree = new Object[G.getVexNum() - 1][2];int count = 0; // 最⼩⽣成树得到的边的序号// 初始化保存相关顶点和相关顶点间边的权值的数组对象CloseEdge[] closeEdges = new CloseEdge[G.getVexNum()];int k = G.locateVex(u);for (int j = 0; j < G.getVexNum(); j++) {if (j!=k) {closeEdges[j] = new CloseEdge(u, G.getArcs()[k][j]);// 将顶点u到其他各个顶点权值写⼊数组中}}closeEdges[k] = new CloseEdge(u, 0); // 加⼊u到⾃⾝的权值0for (int i = 1; i < G.getVexNum(); i++) { // 注意,这⾥从1开始,k = getMinMum(closeEdges); // 获取u到数组下标为k的顶点的权值最短minSpanTree[count][0] = closeEdges[k].adjVex; // 最⼩⽣成树第⼀个值为uminSpanTree[count][1] = G.getVexs()[k]; // 最⼩⽣成树第⼆个值为k对应的顶点count++;closeEdges[k].lowCost = 0; // 下标为k的顶点不参与最⼩权值的查找了for (int j = 0; j < G.getVexNum(); j++) {if (G.getArcs()[k][j] < closeEdges[j].lowCost) {closeEdges[j] = new CloseEdge(G.getVex(k), G.getArcs()[k][j]);}}}System.out.print("通过Prim算法得到的最⼩⽣成树序列为: {");for (Object[] Tree : minSpanTree) {System.out.print("(" + Tree[0].toString() + "-" + Tree[1].toString() + ")");}System.out.println("}");}} 4.举例说明Prim算法实现过程 以下图为例: 测试类:// ⼿动创建⼀个⽤于测试最⼩⽣成树算法的⽆向⽹public static AdjacencyMatrixGraphINF createUDNByYourHand_ForMiniSpanTree() {Object vexs_UDN[] = {"V0", "V1", "V2", "V3", "V4", "V5", "V6", "V7", "V8"};int arcsNum_UDN = 15;int[][] arcs_UDN = new int[vexs_UDN.length][vexs_UDN.length];for (int i = 0; i < vexs_UDN.length; i++) // 构造⽆向图邻接矩阵for (int j = 0; j < vexs_UDN.length; j++)if (i==j) {arcs_UDN[i][j]=0;} else {arcs_UDN[i][j] = arcs_UDN[i][j] = INFINITY;}arcs_UDN[0][5] = 11;arcs_UDN[1][2] = 18;arcs_UDN[1][6] = 16;arcs_UDN[1][8] = 12;arcs_UDN[2][3] = 22;arcs_UDN[2][8] = 8;arcs_UDN[3][4] = 20;arcs_UDN[3][6] = 24;arcs_UDN[3][7] = 16;arcs_UDN[3][8] = 21;arcs_UDN[4][5] = 26;arcs_UDN[4][7] = 7;arcs_UDN[5][6] = 17;arcs_UDN[6][7] = 19;for (int i = 0; i < vexs_UDN.length; i++) // 构造⽆向图邻接矩阵for (int j = i; j < vexs_UDN.length; j++)arcs_UDN[j][i] = arcs_UDN[i][j];return new AdjMatGraph(GraphKind.UDN, vexs_UDN.length, arcsNum_UDN, vexs_UDN, arcs_UDN);}public static void main(String[] args) throws Exception {AdjMatGraph UDN_Graph = (AdjMatGraph) createUDNByYourHand_ForMiniSpanTree();MiniSpanTree_Prim.Prim(UDN_Graph, "V0");} 输出为:通过Prim算法得到的最⼩⽣成树序列为: {(V0-V1)(V0-V5)(V1-V8)(V8-V2)(V1-V6)(V6-V7)(V7-V4)(V7-V3)} 分析算法执⾏过程:从V0开始:-count为0,k为0,closeEdges数组的-lowCost为{0 10 INF INF INF 11 INF INF INF},adjVex数组为{V0,V0,V0,V0,V0,V0,V0,V0,V0}-⽐较lowCost,于是k为1,adjVex[1]为V0,minSpanTree[0]为(V0,V1),lowCost为{0 0 INF INF INF 11 INF INF INF}-k为1,与V1的权值⾏⽐较,得到新的-lowCost为:{0 0 18 INF INF 11 16 INF 12},adjVex数组为{V0,V0,V1,V0,V0,V0,V1,V0,V1}-⽐较lowCost,于是k为5,adjVex[5]为V0,minSpanTree[1]为(V0,V5),lowCost为{0 0 18 INF INF 0 16 INF 12}-k为5,与V5的权值⾏⽐较,得到新的-lowCost为{0 0 18 INF 26 0 16 INF 12},adjVex数组为{V0,V0,V1,V0,V5,V0,V1,V0,V1}-⽐较lowCost,于是k为8,adjVex[8]为V1,minSpanTree[2]为(V1,V8),lowCost为{0 0 18 INF INF 0 16 INF 0}... 三、克鲁斯卡尔(Kruskal)算法 1.Kruskal算法描述 Kruskal算法是根据边的权值递增的⽅式,依次找出权值最⼩的边建⽴的最⼩⽣成树,并且规定每次新增的边,不能造成⽣成树有回路,直到找到n-1条边为⽌。
普里姆算法构造最小生成树的过程

普里姆算法构造最小生成树的过程介绍如下:
1.从任意一个点开始,将该点加入已选点集中。
2.对于已选点集中的每一个点,找到与其相连的所有边中权值最
小的边,并记录该边的另一个端点。
3.在所有记录的点中选择一个与已选点集相连的权值最小的点,
并将该点加入已选点集中,同时将该点与已选点集中的某个点(如与其相连的权值最小的点)之间的边加入最小生成树中。
4.重复步骤2和步骤3,直到已选点集包含所有点为止。
最终得到的最小生成树是所有可能的生成树中权值最小的一棵。
该算法的时间复杂度为O(ElogV),其中E为边数,V为点数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
沈阳航空航天大学课程设计报告课程设计名称:数据结构课程设计课程设计题目:Prim算法求最小生成树院(系):计算机学院专业:计算机科学与技术(物联网方向)班级:学号:姓名:指导教师:学术诚信声明本人声明:所呈交的报告(含电子版及数据文件)是我个人在导师指导下独立进行设计工作及取得的研究结果。
尽我所知,除了文中特别加以标注或致谢中所罗列的内容以外,报告中不包含其他人己经发表或撰写过的研究结果,也不包含其它教育机构使用过的材料。
与我一同工作的同学对本研究所做的任何贡献均己在报告中做了明确的说明并表示了谢意。
报告资料及实验数据若有不实之处,本人愿意接受本教学环节“不及格”和“重修或重做”的评分结论并承担相关一切后果。
本人签名: 日期:2015 年 1 月15 日沈阳航空航天大学课程设计任务书计算机科学与技术课程设计名称数据结构课程设计专业(物联网方向)学生姓名班级学号题目名称Prim算法生成最小生成树起止日期2015 年 1 月 5 日起至2015 年 1 月16 日止课设内容和要求:在n个城市之间建立网络,只需保证连通即可,求最经济的架设方法,利用Prim算法输出n个城市之间网络图,输出n个节点的最小生成树。
其中,n个城市表示n个节点,两个城市间如果有路则用边连接,生成一个n个节点的边权树,要求键盘输入。
参考资料:算法与数据结构,严蔚敏、吴伟民,清华大学出版社,2006C程序设计,谭浩强,清华大学出版社,2010教研室审核意见:教研室主任签字:指导教师(签名)年月日学生(签名)2015 年 1 月15 日目录学术诚信声明 .............................................................................................................. - 1 -一课程设计目的和要求.......................................................................................... - 4 -1.1课程设计目的 .. (4)1.2课程设计的要求 (4)二实验原理分析 ........................................................................................................ - 5 -2.1最小生成树的定义 (5)2.2P RIM算法的基本思想 (5)三概要分析和设计 .................................................................................................... - 8 -3.1概要分析 . (8)3.2概要设计 (9)四测试结果 ............................................................................................................ - 14 -4.1实验一 . (14)4.2实验二 (14)4.3实验三 (15)参考文献 .................................................................................................................... - 16 -附录(关键部分程序清单).............................................................................. - 17 -一课程设计目的和要求1.1 课程设计目的(一)根据算法设计需要,掌握连通网的数据表示方法;(二)掌握最小生成树的Prim算法;(三)学习独立撰写报告文档。
1.2 课程设计的要求在n个城市之间建立网络,只需保证连通即可,求最经济的架设方法,利用Prim算法输出n个城市之间网络图,输出n个节点的最小生成树。
其中,n个城市表示n个节点,两个城市间如果有路则用边连接,生成一个n个节点的边权树,要求键盘输入。
二实验原理分析2.1 最小生成树的定义一个有n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有n 个结点,并且有保持图连通的最少的边。
最小生成树可以用kruskal(克鲁斯卡尔)算法或Prim(普里姆)算法求出。
(1). 最小生成树的概述在一给定的无向图G = (V, E) 中,(u, v) 代表连接顶点 u 与顶点 v 的边(即),而 w(u, v) 代表此边的权重,若存在 T 为 E 的子集(即)且为无循环图,使得 w(T) 最小,则此 T 为 G 的最小生成树。
最小生成树其实是最小权重生成树的简称。
(2). 最小生成树的分析构造最小生成树可以用多种算法。
其中多数算法利用了最小生成树的下面一种简称为MST的性质:假设N=(V,{E})是一个连通网,U 是顶点集V的一个非空子集。
若(u,v)是一条具有最小权值(代价)的边,其中u∈U,v∈V-U,则必存在一棵包含边(u.v)的最小生成树。
2.2 Prim算法的基本思想假设G =(V,E)是一个具有n个顶点的连通网,T=(U,TE)是G的最小生成树,其中U是T的顶点集,TE是T的边集,U和TE的初值均为空集。
算法开始时,首先从V中任取一个顶点(假定取V0),将它并入U中,此时U={V0},然后只要U是V的真子集,就从那些其一个端点已在T中,另一个端点仍在T外的所有边中,找一条最短(即权值最小)边,假定为(i,j),其中Vi∈U,Vj∈(V-U),并把该边(i,j)和顶点j分别并入T的边集TE和顶点集U,如此进行下去,每次往生成树里并入一个顶点和一条边,直到n-1次后就把所有n个顶点都并入到生成树T的顶点集中,此时U=V,TE中含有n-1条边,T就是最后得到的最小生成树。
可以看出,在普利姆算法中,是采用逐步增加U中的顶点,常称为“加点法”。
为了实现这个算法在本设计中需要设置一个辅助数组closedge[ ],以记录从U到V-U具有最小代价的边。
当辅助数组中存在两个或两个以上的最小代价的边时,此时最小生成树的形态就不唯一,此时可以在程序中采用递归的算法思想求出每个最小生成树。
(1). 在prim算法中要解决两个问题1)在无向网中,当从一个顶点到其他顶点时,若其边上的权值相等,则可能从某一起点出发时,会得到不同的生成树,但最小生成树的权值必定相等,此时我们应该如何把所有的最小生成树求解出来;2)每次如何从生成树T中到T外的所有边中,找出一条权值最小的边。
例如,在第k次(1≤k≤n-1)前,生成树T中已有k个顶点和k-1条边,此时T中到T外的所有边数为k(n-k),当然它也包括两顶点间没有直接边相连,其权值被看作常量的边在内,从如此多的边中找出最短的边,其时间复杂度0(k (n-k)),是很费时间的,是否有好的方法能够降低查找最短边的时间复杂度。
(2). 上述问题的解决方法针对1)中出现的问题,可以通过算法来实现,详情请看Prim算法的概述;针对2)中出现的问题,通过对Prim算法的分析,可以使查找最短边的时间复杂度降低到O(n-k)。
具体方法是假定在进行第k次前已经保留着从T中到T外的每一顶点(共n-k个顶点)的各一条最短边,进行第k次时,首先从这n-k条最短边中,找出一条最最短的边,它就是从T中到T外的所有边中的最短边,假设为(i,j),此步需进行n-k次比较;然后把边(i,j)和顶点j分别并入T中的边集TE和顶点集U中,此时T外只有n-(k+1)个顶点,对于其中的每个顶点t,若(j,t)边上的权值小于已保留的从原T中到顶点t的最短边的权值,则用(j,t)修改之,使从T中到T外顶点t的最短边为(j,t),否则原有最短边保持不变,这样,就把第k次后从T中到T外每一顶点t的各一条最短边都保留下来了,为进行第k+1次运算做好了准备,此步需进行n-k-1次比较。
所以,利用此方法求第k次的最短边共需比较2(n-k)-1次,即时间复杂度为O(n-k)。
三概要分析和设计3.1 概要分析通过对上述算法的分析,将从以下三方面来进行分析:(1). 输入数据的类型在本次设计中,是对无向图进行操作,网中的顶点数,边数,顶点的编号及每条边的权值都是通过键盘输入的,他们的数据类型均为整型,其中,权值的范围为0~32768(即“∞”);(2). 输出数据的类型当用户将无向图创建成功以后,就可以通过键盘任意输入一个起点值将其对应的最小生成树的生成路径及其权值显示出来;(3). 测试数据本次设计中是通过用Prim算法求最小生成树,分别用以下三组数据进行测试:(一)假设在创建无向图时,只输入一个顶点,如图1所示,验证运行结果;A图1.单一节点的无向图(二)假设创建的无向图如图2所示,验证运行结果;图2.网中存在权值相等的边(三)假设创建的无向图如图3所示,验证结果;图3,网中的权值各不相等3.2 概要设计在本次设计中,网的定义为G=(V,E),V表示非空顶点集,E表示边集,其存储结构这里采用邻接矩阵的方式来存储。
1 数据类型的定义在本设计中所涉及到的数据类型定义如下:(1). 符号常量的定义算法中涉及到两个符号常量,定义如下:#define MAX 20 功能:用于表示网中最多顶点个数;#define INFINIT 32768 功能:用于表示权的最大值,即∞。
(2). 结构体的定义整个算法中涉及的结构体定义如下:✓定义结构体ArcNode功能:用于存放边的权值typedef struct{int adj;//权值}ArcNode;✓定义结构体AdjMatrix功能:用于表示网的结构及存储方式。
typedef struct{int vexs[MAX];//vexs表示顶点向量int vexnum,arcnum;//分别表示图的顶点数和弧数ArcNode arcs[MAX][MAX];//邻接矩阵}AdjMatrix✓定义结构体Node功能:用于表示求最小生成树时用到的辅助数组。
typedef struct{int adjvex;//存放顶点编号int lowcost;//存放顶点权值}Node;✓外部变量的定义算法中涉及到两个外部变量,定义如下:Node close[MAX]功能:存放每个顶点所连接的边所对应的权值;int flag=0功能:标志变量,当创建网时,输入的顶点个数<=1时,直接输出“不存在最小生成树”程序不在往后执行,否则继续往下执行。