机器学习期末试题
机器学习基础期末考试试题

机器学习基础期末考试试题一、选择题(每题2分,共20分)1. 在机器学习中,下列哪个算法属于监督学习算法?A. 决策树B. K-meansC. 遗传算法D. 随机森林2. 以下哪个是线性回归的假设条件?A. 特征之间相互独立B. 特征与目标变量之间存在非线性关系C. 目标变量的误差项服从正态分布D. 所有特征都是类别型变量3. 支持向量机(SVM)的主要目标是什么?A. 找到数据点之间的最大间隔B. 减少模型的复杂度C. 增加模型的泛化能力D. 所有选项都正确4. 在深度学习中,卷积神经网络(CNN)通常用于处理哪种类型的数据?A. 音频数据B. 图像数据C. 文本数据D. 时间序列数据5. 交叉验证的主要目的是:A. 减少模型的过拟合B. 增加模型的复杂度C. 减少训练集的大小D. 增加模型的运行时间二、简答题(每题10分,共30分)6. 解释什么是过拟合,并给出一个避免过拟合的策略。
7. 描述随机森林算法的基本原理,并简述其相对于决策树的优势。
8. 解释梯度下降算法的工作原理,并说明为什么它在优化问题中如此重要。
三、计算题(每题25分,共50分)9. 假设你有一个线性回归模型,其目标函数为 \( J(\theta) =\frac{1}{2m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)})^2 \),其中 \( h_\theta(x) = \theta_0 + \theta_1 x_1 + \theta_2x_2 \)。
给定以下数据点:\[\begin{align*}x_1 & : [1, 2, 3] \\x_2 & : [1, 3, 4] \\y & : [2, 4, 5]\end{align*}\]请计算该模型的损失函数 \( J(\theta) \)。
10. 给定一个二分类问题的数据集,使用逻辑回归模型进行分类。
如果模型的决策边界是 \( w_1 x_1 + w_2 x_2 - \theta = 0 \),其中\( w_1 = 0.5 \),\( w_2 = -1 \),\( \theta = 0.5 \)。
机器学习期末试题

机器学习期末试题Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】中国科学院大学 课程编号:712008Z? 试 题 专 用 纸课程名称:机器学习任课教师:卿来云——————————————————————————————————————————————— 姓名学号成绩一、基础题(共36分)1、请描述极大似然估计MLE 和最大后验估计MAP 之间的区别。
请解释为什么MLE 比MAP 更容易过拟合。
(10分)2、在年度百花奖评奖揭晓之前,一位教授问80个电影系的学生,谁将分别获得8个奖项(如最佳导演、最佳男女主角等)。
评奖结果揭晓后,该教授计算每个学生的猜中率,同时也计算了所有80个学生投票的结果。
他发现所有人投票结果几乎比任何一个学生的结果正确率都高。
这种提高是偶然的吗请解释原因。
(10分)3、假设给定如右数据集,其中A 、B 、C 为二值随机变量,y 为待预测的二值变量。
(a) 对一个新的输入A =0,B =0,C =1,朴素贝叶斯分类器将会怎样预测y(10分)(b) 假设你知道在给定类别的情况下A 、B 、C 是独立的随机变量,那么其他分类器(如Logstic 回归、SVM 分类器等)会比朴素贝叶斯分类器表现更好吗为什么(注意:与上面给的数据集没有关系。
)(6分) 二、回归问题。
(共24分) 现有N 个训练样本的数据集(){}1,Ni i i x y ==,其中,i i x y 为实数。
1. 我们首先用线性回归拟合数据。
为了测试我们的线性回归模型,我们随机选择一些样本作为训练样本,剩余样本作为测试样本。
现在我们慢慢增加训练样本的数目,那么随着训练样本数目的增加,平均训练误差和平均测试误差将会如何变化为什么(6分)平均训练误差:A、增加 B、减小平均测试误差:A、增加 B、减小2.给定如下图(a)所示数据。
粗略看来这些数据不适合用线性回归模型表示。
《机器学习》期末考试-A卷

XXXXXXXX 学院2020 至 2021 学年第 一 学期《机器学习》期末考试试题(A 卷)一、选择题。
(本题共 25 小题,每小题2分,共50分)1.贝叶斯公式正确的说法是( ) A. P(B|A)=P (A| B)*P(A)/P(B) B. P(B|A)=P (A| B)*P(A)/P(AB) C. P(B|A)=P (A| B)*P(B)/P(AB) D. P(B|A)=P (A| B)*P(B)/P(A)2.a=np.arange(2,15)print(a[1:7:3])输出结果:( ) A. [2 5] B. [2 5 8] C. [1 7 3] D. [3 6]3.Python 语言语句块的标记是( ) A. 分号 B. 逗号 C. 缩进 D. /4.Python 内置函数( )函数可以返回列表、元组、字典、集合、字符串以及range 对象中所有元素的个数。
A. len B. count C. size D. shape5.以下程序的输出结果是( )lcat =[“狮子”,“猎豹”,“虎猫”,“花豹”,“孟加拉虎”,“美洲豹”,“雪豹”] for s in lcat:if “豹” in s:print(s,end=" ") continueA. 雪豹B. 猎豹 花豹 美洲豹 雪豹C. 猎豹D. 猎豹花豹 美洲豹 雪豹6.在图灵测试中,如果有超过( )的测试者不能分清屏幕后的对话者是人还是机器,就可以说这台计算机通过了测试并具备人工智能。
A. 30% B. 40% C. 50% D. 60%7.关于k-NN 算法,以下哪个选项是正确的?( ) A. 可用于分类 B. 可用于回归 C. 可用于分类和回归8.以下两个距离(欧几里得距离和曼哈顿距离)已经给出,我们通常在K-NN 算法中使用这两个距离。
这些距离在点A (x1,y1)和点B (x2,Y2)之间。
你的任务是通过查看以下两个图形来标记两个距离。
机器学习期末试题及答案

机器学习期末试题及答案一、选择题1. 机器学习是一种:A. 人工智能子领域B. 数据分析工具C. 算法库D. 编程语言答案:A. 人工智能子领域2. 以下哪种算法是无监督学习算法?A. 决策树B. 支持向量机C. K均值聚类D. 朴素贝叶斯答案:C. K均值聚类3. 在机器学习中,过拟合是指:A. 模型无法适应新数据B. 模型过于简单C. 模型过于复杂D. 模型的精度较低答案:C. 模型过于复杂4. 机器学习任务中的训练集通常包括:A. 特征和标签B. 标签和模型参数C. 特征和模型参数D. 特征、标签和模型参数答案:A. 特征和标签5. 在机器学习中,用于评估模型性能的常见指标是:A. 准确率B. 回归系数C. 损失函数D. 梯度下降答案:A. 准确率二、填空题1. 监督学习中,分类问题的输出是离散值,而回归问题的输出是________________。
答案:连续值/实数值2. 机器学习中的特征工程是指对原始数据进行________________。
答案:预处理3. ________________是一种常见的集成学习算法,通过构建多个弱分类器来提高整体模型的性能。
答案:随机森林4. K折交叉验证是一种常用的评估模型性能和调参的方法,其中K 代表______________。
答案:折数/交叉验证的次数5. 在机器学习中,优化算法的目标是最小化或最大化一个称为______________的函数。
答案:目标函数/损失函数三、简答题1. 请简要解释什么是过拟合,并提出至少三种防止过拟合的方法。
答:过拟合是指在训练数据上表现很好,但在新数据上表现较差的现象。
防止过拟合的方法包括:- 数据集扩充:增加更多的训练样本,从而减少模型对特定数据的过度拟合。
- 正则化:通过在损失函数中引入正则化项,约束模型的复杂度,防止模型过分拟合训练数据。
- 交叉验证:使用交叉验证方法对模型进行评估,通过评估模型在不同数据集上的性能,选择性能较好的模型。
机器学习期末测试练习题4

1、在神经网络模型VggNet中,使用两个级联的卷积核大小为3X3,stride=1的卷积层代替了一个5X5的卷积层,如果将stride设置为2,则此时感受野为A.7X7B.9X9C.5X5D.8X8正确答案:A2、激活函数,训练过程出现了梯度消失问题。
从图中可以判断出四个隐藏层的先后顺序(靠近输入端的为先,靠近输出端的为后)分别为A.DBCAB.ABCDC.ADCB正确答案:D3、在网络训练时,loss在最初几个epoch没有下降,可能原因是B.以下都有可能C.正则参数过高D.陷入局部最小值正确答案:B4、假设有一个三分类问题,某个样本的标签为(1,0,0),模型的预测结果为(0.5,0.4,0.1),则交叉熵损失值(取自然对数结果)约等于A.0.6C.0.8D.0.5正确答案:B5、IoU是物体检测、语义分割领域中的结果评测指标之一,上图中A框是物体的真实标记框,面积为8。
B框是网络的检测结果,面积为7。
两个框的重合区域面积为2。
则IoU的值为A.2/8B.2/13C.2/7D.2/15正确答案:B6、Gram矩阵是深度学习领域常用的一种表示相关性的方法,在风格迁移任务中就使用风格Gram矩阵来表示图像的风格特征,以下关于风格Gram矩阵的论述正确的是A.风格Gram矩阵的大小与输入特征图的通道数、宽、高都不相关B.风格Gram矩阵的大小只与输入特征图的通道数相关C.风格Gram矩阵的大小与输入特征图的通道数、宽、高都相关D.风格Gram矩阵的大小只与输入特征图的宽、咼有关正确答案:B7、现使用YOL0网络进行目标检测,待检测的物体种类为20种,输入图像被划分成7*7个格子,每个格子生成2个候选框,则YOL0网络最终的全连接层输出维度为A.1078B.980C.1470D.1960正确答案:C二、多选题1、池化层在卷积神经网络中扮演了重要的角色,下列关于池化层的论述正确的有A.池化操作具有平移不变性B.池化操作可以实现数据的降维C.池化操作是一种线性变换D.池化操作可以扩大感受野2、以下关于MaxPooling和MeanPooling的论述正确的有A.尺度为(2,2),stride=2的MaxPooling层在梯度后向传播中,后层的梯度值传递给前层对应的最大值位置。
安徽农业大学机器学习期末考试试卷

安徽农业大学机器学习期末考试试卷一、填空题1、工作过程中集中精力工作。
,不要喝酒,不要吃东西,。
如果你必须转移注意力到别的地方,必须停止设备。
2、各类铲刮作业都应低速行驶,角铲土和使用齿耙时必须用。
3、必须高度重视自己在工作中的安全责任。
以的安全意识投入4、如果将平地机放置在露天或不平整的场地上,最好用垫木将平地机架起,以使轮胎减载,然后将轮胎气压降低,并将轮胎遮挡起来,避免阳光直接照射。
5、一旦刮平操作开始后,可使用来改变"坡度跟踪控制器"的提升,这样可以使泥土被带出刮刀外。
6、转向时,或使用轴驱动轮转向时,不得,可使前轮倾斜以减少平地机转向半径,但在高速行驶时不得使用,以防出现急剧的反作用力。
7、做路拱时,先将路料堆放在路中央,使平地机刮刀前倾成角,稍提刀尾,平地机沿堆料中央匀速行驶,使路料沿刮刀向两侧移动。
8、如果用铰接式平地机左(右)倾平地时,使机架向右(左)饺接。
如果驱动轮打滑,则铰接角度,可以切土角度及侧推力。
9、发动机启动后,各仪表读数均应在规定值的范围内。
发动机运转时,不得操作,否则会造成发动机严重损坏。
10、使用平地机清除积雪时,应在轮,并应逐段探明路面的深坑、沟槽情况。
二、判断题1、一旦刮平操作开始后,可使用增减开关来改变"坡度跟踪控制器"的提升,这样可以使泥土被带出刮刀外。
( )2、在陡坡上作业时,不得使用饺接机架,以防止翻车造成严重的人机损伤。
在陡坡上来回进行作业时,刮刀伸出的方向应始终朝向上坡方向。
( )3、开始工作前,仔细检查设备的磨损标记和全部功能。
在接替前一个班时,询问工作条件和设备的功能。
( )4、使用平地机清除积雪时,应在轮胎上安装防滑链,并应逐段探明路面的深坑、沟槽情况。
( )5、严格按照手册规定的螺丝拧紧顺序与拧紧力矩对螺栓和螺母进行拧紧,可以稍微超过给定值。
( )6、在拆卸管路之前释放系统中的压力。
释放蓄能器中的压力。
机器学习期末测试练习题2

1、在混淆矩阵中,识别率可以表示为()。
A.(TP)/(TP+TN+FP+FN)B.(TP+FN)/(TP+TN+FP+FN)C.(TP+TN)/(TP+TN+FP+FN)D.(FP+TN)/(TP+TN+FP+FN)正确答案:C2、若我们用一类对另一类的方法来解决多分类问题,当有K类时,我们需要训练()个支持向量机。
A.K(K-1)/2B.K-1C.KD.K(K+1)/2正确答案:A3、如果一个样本空间线性可分,那么,我们能找到()个平面来划分样本。
A.1B.无数C.KD.不确定正确答案:B4、w*是原问题f(w)的解,a* 和 b* 是其对偶问题 h(a,b)的解,则对偶距离定义为()。
A.h(a*,b*)-f(w*)B.f(w*)-h(a*,b*)C.||f(w*)-h(a*,b*)||D.|f(w*)-h(a*,b*)|正确答案:B5、在混淆矩阵中,系统召回率定义为()。
A.TP/(TP+FN)B.TN/(FP+TN)C.TP/(FP+TP)D.TN/(TP+TN)正确答案:A二、多选题1、当我们利用二分类支持向量机来解决多分类问题是,我们有哪两种策略?()A.一类对另一类B.一类对K-1类C.一类对K类D.2类对K-2类正确答案:A、B2、在利用二分类支持向量机来解决多分类的问题中,为了减少支持向量机的个数,我们可以用()来构建树状结构的多分类模型。
A.强化学习B.聚类C.人工神经网络D.决策树正确答案:B、D3、下列对混淆矩阵说法正确的是()。
A.FP:将负样本识别为正样本的数目(概率)B.FN:将正样本识别为负样本的数目(概率)C.TP:将正样本识别为正样本的数目(概率)D.TN:将负样本识别为正样本的数目(概率)正确答案:A、B、C4、在二维空间且样本类别只有两类的情况下,训练样本线性可分,满足最优分类直线的三个条件是()。
A.该直线最大化间隔B.该直线距离支持向量最近C.该直线分开了两类D.该直线位于间隔中间,到所有有支持向量相等正确答案:A、C、D5、二次规划的定义包括()。
《机器学习》期末考试试卷附答案

《机器学习》期末考试试卷附答案一、选择题(每题5分,共25分)1. 机器学习的主要目的是让计算机从数据中____,以实现某些任务或预测未知数据。
A. 抽取特征B. 生成模型C. 进行推理D. 分类标签答案:B. 生成模型2. K-近邻算法(K-NN)是一种____算法。
A. 监督学习B. 无监督学习C. 半监督学习D. 强化学习答案:A. 监督学习3. 在决策树算法中,节点的分裂是基于____进行的。
A. 信息增益B. 基尼不纯度C. 均方误差D. 交叉验证答案:A. 信息增益4. 支持向量机(SVM)的主要目的是找到一个超平面,将不同类别的数据点____。
A. 完全分开B. 尽量分开C. 部分分开D. 不分开答案:B. 尽量分开5. 哪种优化算法通常用于训练深度学习模型?A. 梯度下降B. 牛顿法C. 拟牛顿法D. 以上都对答案:D. 以上都对二、填空题(每题5分,共25分)1. 机器学习可以分为监督学习、无监督学习和____学习。
A. 半监督B. 强化C. 主动学习D. 深度答案:A. 半监督2. 线性回归模型是一种____模型。
A. 线性B. 非线性C. 混合型D. 不确定型答案:A. 线性3. 在进行特征选择时,常用的评估指标有____、____和____。
A. 准确率B. 召回率C. F1 分数D. AUC 值答案:B. 召回率C. F1 分数D. AUC 值4. 神经网络中的激活函数通常用于引入____。
A. 非线性B. 线性C. 噪声D. 约束答案:A. 非线性5. 当我们说一个模型具有很好的泛化能力时,意味着该模型在____上表现良好。
A. 训练集B. 验证集C. 测试集D. 所有集答案:C. 测试集三、简答题(每题10分,共30分)1. 请简要解释什么是过拟合和欠拟合,并给出解决方法。
2. 请解释什么是交叉验证,并说明它的作用。
答案:交叉验证是一种评估模型泛化能力的方法,通过将数据集分成若干个互斥的子集,轮流用其中若干个子集作为训练集,其余子集作为验证集,对模型进行评估。
机器学习(强化学习)期末测试练习题

1、Q-learning算法中,Q函数是
A.状态-动作值函数
B.状态函数
C.估值函数
D.奖励函数
正确答案:A
2、Q(s,a)是指在给定状态s的情况下,采取行动a之后,后续的各个状态所能得到的
回报()
A.总和
B.最大值
C.最小值
D.期望值
正确答案:D
3、在强化学习过程中,学习率越大,表示采用新的尝试得到的结果比例越(),保持旧的结果的比例越()
A.大,小
B.大,大
C.小,大
D.小,小
正确答案:A
4、在强化学习的过程中,()能够在稍微偏离目前最好策略的基础上,尝试更多策略,()能够运用目前最好的策略,获取更高的奖励
A.利用,探索
B.探索,利用
C.利用,输出
D.探索,输出
正确答案:B
5、在epsilon-greedy算法中,epsilon的值越大,采取随机动作的概率越(),采用
当前Q函数最大动作的概率越()
A.小,小
B.大,小
C.大,大
D.小,大
正确答案:B
二、多选题
1、强化学习包含哪些元素
A.Reward
B.Agent
C.State
D.Action
正确答案:A、B、C、D
三、判断题
1、在DQN中,求解Q(s,a)时采用的策略是有限采样s,a,并通过采样值来估计Q值。
(√)
2、可以采用policy gradient算法来设计一款围棋游戏。
(√)
3、在Actor-Critic算法中,Q函数和V函数同时被优化。
(√)
4、TD算法使用完整的采样来计算长期奖励值。
(√)。
《机器学习》期末考试-A卷-参考答案
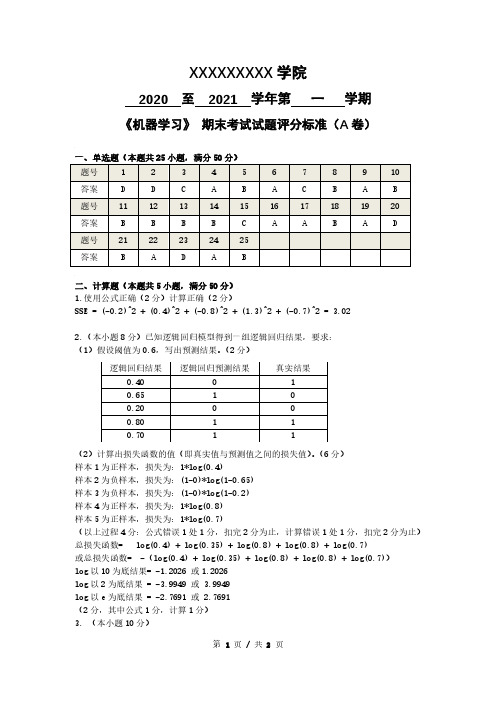
XXXXXXXXX学院2020 至2021 学年第一学期《机器学习》期末考试试题评分标准(A卷)二、计算题(本题共5小题,满分50分)1.使用公式正确(2分)计算正确(2分)SSE = (-0.2)^2 + (0.4)^2 + (-0.8)^2 + (1.3)^2 + (-0.7)^2 = 3.022.(本小题8分)已知逻辑回归模型得到一组逻辑回归结果,要求:(1)假设阈值为0.6,写出预测结果。
(2分)(2)计算出损失函数的值(即真实值与预测值之间的损失值)。
(6分)样本1为正样本,损失为:1*log(0.4)样本2为负样本,损失为:(1-0)*log(1-0.65)样本3为负样本,损失为:(1-0)*log(1-0.2)样本4为正样本,损失为:1*log(0.8)样本5为正样本,损失为:1*log(0.7)(以上过程4分:公式错误1处1分,扣完2分为止,计算错误1处1分,扣完2分为止)总损失函数= log(0.4) + log(0.35) + log(0.8) + log(0.8) + log(0.7)或总损失函数= -(log(0.4) + log(0.35) + log(0.8) + log(0.8) + log(0.7))log以10为底结果= -1.2026 或1.2026log以2为底结果 = -3.9949 或 3.9949log以e为底结果 = -2.7691 或 2.7691(2分,其中公式1分,计算1分)3. (本小题10分)(表格内每空1分,共4分)P = 14/(14+2) = 7/8 = 0.875(2分)(公式和计算各1分)R = 14/(14+1) = 14/15 = 0.933(2分)(公式和计算各1分)F1 = 2*P*R/(P+R) = 28/31 = 0.903(2分)(公式和计算各1分)4.(1)(2分)(2)def standRegres(xArr,yArr):xMat = np.mat(xArr) (1分)yMat = np.mat(yArr).T (1分)xTx = xMat.T * xMat (1分)if np.linalg.det(xTx) == 0.0: (1分)print("矩阵为奇异矩阵,不能求逆")return (1分)ws = xTx.I * (xMat.T*yMat) (1分)return ws (1分)此外:格式3分,错一处扣一分,扣完为止5.我们需要最大化P(X|Ci)P(Ci),i=1,2。
机器学习期末复习题

机器学习期末复习题机器学习期末复习题机器学习是一门研究如何使计算机具备学习能力的学科。
它通过分析和理解数据,从中提取出模式和知识,并利用这些知识来进行预测和决策。
在机器学习的学习过程中,我们需要掌握各种算法和技术。
下面是一些机器学习的期末复习题,帮助大家回顾和巩固相关知识。
1. 什么是监督学习和无监督学习?请举例说明。
监督学习是一种通过已知输入和输出的样本来训练模型的学习方法。
例如,我们可以通过给计算机展示一组图片,并告诉它这些图片中的物体是什么,来训练一个图像分类器。
无监督学习则是一种没有标签的学习方法,它通过分析数据的内在结构和模式来进行学习。
例如,我们可以通过对一组顾客购买记录的分析,来发现隐藏在数据中的潜在市场细分。
2. 请简要介绍一下决策树算法。
决策树算法是一种基于树结构的监督学习算法。
它通过对数据集进行递归分割,构建一棵树来进行分类或回归。
在构建决策树的过程中,算法会选择最佳的特征进行分割,并根据特征的取值将数据集划分为不同的子集。
决策树的优点是易于理解和解释,但容易过拟合。
3. 请简要介绍一下支持向量机算法。
支持向量机(Support Vector Machine,SVM)是一种常用的监督学习算法。
它通过在特征空间中构建一个最优分割超平面,将不同类别的样本分开。
SVM的目标是找到一个最大间隔的超平面,使得样本点到该超平面的距离最大化。
SVM可以通过核函数来处理非线性分类问题。
4. 请简要介绍一下聚类算法。
聚类算法是一种无监督学习算法,它通过对数据进行分组,将相似的样本归为一类。
常用的聚类算法有K均值聚类和层次聚类。
K均值聚类是一种迭代算法,它将数据集分为K个簇,每个簇的中心是该簇中所有样本的均值。
层次聚类则是一种基于树结构的聚类方法,它通过不断合并最相似的簇来构建聚类层次。
5. 请简要介绍一下神经网络算法。
神经网络是一种模仿人脑神经元网络的计算模型。
它由多个节点(神经元)和连接它们的权重组成。
机器学习期末复习题及答案

一、单选题1、在条件随机场(CRF)中,参数的学习通常使用哪种优化算法?()A.K-Means聚类B.梯度提升机(GBM)C.支持向量机(SVM)D.随机梯度下降(SGD)正确答案:D2、在概率无向图模型中,什么是团分解(Cluster Decomposition)?()A.一种通过节点之间的边传播信息,以更新节点的边缘概率的方法B.一种用于计算图的分割的算法C.一种将联合概率分布分解为多个局部概率分布的方法D.一种用于表示联合概率分布的无向树正确答案:C3、在数据不完备时,下列哪一种方法不是贝叶斯网络的参数学习方法()A.拉普拉斯近似B.最大似然估计方法C.蒙特卡洛方法D.高斯逼近正确答案:B4、在有向图模型中,什么是条件独立性?()A.给定父节点的条件下,子节点之间独立B.所有节点之间都独立C.所有节点的状态相互独立D.任意两个节点都是独立的正确答案:A5、在概率有向图模型中,节点表示什么?()A.变量B.参数C.条件概率D.边正确答案:A6、下列哪一项表示簇中样本点的紧密程度?()A.簇个数B.簇大小C.簇描述D.簇密度正确答案:D7、闵可夫斯基距离表示为曼哈顿距离时p为:()A.1B.2C.3D.4正确答案:A8、谱聚类与K均值聚类相比,对于什么样的数据表现更好?()A.低维数据B.高维数据C.线性可分数据D.高密度数据正确答案:B9、SVM适用于什么类型的问题?()A.既可用于线性问题也可用于非线性问题B.仅适用于回归问题C.仅适用于非线性问题D.仅适用于线性问题正确答案:A10、对于在原空间中线性不可分的问题,支持向量机()A.在原空间中寻找非线性函数划分数据B.无法处理C.利用核函数把数据映射到高维空间D.在原空间中寻找线性函数划分数据正确答案:C11、LDA主题模型中的alpha参数控制着什么?()A.单词分布的稀疏性B.文档-主题分布的稀疏性C.模型大小D.模型收敛速度正确答案:B12、LDA的全称是什么?()tent Dirichlet AllocationB.Linear Discriminant Analysistent Data AnalysisD.Lin Latent Dirichlet Allocation ear Data Algorithm正确答案:A13、以下对于梯度下降法中学习率lr的阐述,正确的是()A.lr小,收敛速度较快B.lr大,收敛速度较慢C.lr小,收敛速度较慢且较不易收敛D.lr大,收敛速度较快但可能导致不收敛正确答案:D14、在EM算法中,E代表期望,M代表()A.均值B.最大化C.最小化D.均方误差正确答案:B15、梯度下降中如何有效地捕捉到目标函数的全局最优?()A.调整学习速率B.增加模型复杂度C.使用梯度下降的变种算法D.增加训练样本量正确答案:C二、多选题1、下列机器学习常用算法中哪个属于分类算法?()A.K-meansB.最小距离分类器C.KNN(K近邻)D.逻辑回归正确答案:B、C、D2、下列关于决策树的说法正确的是?()A.CART使用的是二叉树B.其可作为分类算法,也可用于回归模型C.不能处理连续型特征D.它易于理解、可解释性强正确答案:A、B、D3、下列属于k近邻算法中常用的距离度量方法的是?()A.余弦相似度B.欧式距离C.曼哈顿距离D.闵可夫斯基距离正确答案:A、B、C、D4、下列属于深度模型的是?()A.DNNB.LightgbmC.LSTMD.Seq2Seq正确答案:A、C、D5、sklearn中RFECV方法分成哪两个部分?()A.RFEB.CVC.NLPD.MM正确答案:A、B6、以下关于蒙特卡洛方法描述正确的是()A.蒙特卡洛方法计算值函数可以采用First-visit方法B.蒙特卡洛方法方差很大C.蒙特卡洛方法计算值函数可以采用Every-visit方法D.蒙特卡洛方法偏差很大正确答案:A、B、C7、为什么循环神经网络可以用来实现自动问答,比如对一句自然语言问句给出自然语言回答()A.因为自动问答可以看成是一种序列到序列的转换B.因为循环神经网络能够处理变长输入C.因为循环神经网要比卷积神经网更强大D.因为卷积神经网络不能处理字符输入正确答案:A、B8、通常有哪几种训练神经网络的优化方法()A.梯度下降法B.随机梯度下降法C.小批量随机梯度下降法D.集成法正确答案:A、B、C9、隐马尔可夫模型的三个基本问题是()A.估值问题B.寻找状态序列C.学习模型参数D.状态更新正确答案:A、B、C10、在数据不完备时,贝叶斯网络的参数学习方法有()A.高斯逼近B.蒙特卡洛方法C.拉普拉斯近似D.最大似然估计方法正确答案:A、B、C11、基于约束的方法通过统计独立性测试来学习结点间的()A.独立性B.相关性C.依赖性D.完备性正确答案:A、B12、基于搜索评分的方法,关键点在于()A.确定合适的搜索策略B.确定评分函数C.确定搜索优先级D.确定选择策略正确答案:A、B13、条件随机场需要解决的关键问题有()A.特征函数的选择B.参数估计C.模型推断D.约束条件正确答案:A、B、C14、以下关于逻辑斯蒂回归模型的描述正确的是()A.针对分类的可能性进行建模,不仅能预测出类别,还可以得到属于该类别的概率B.直接对分类的可能性进行建模,无需事先假设数据分布,这样就避免了假设分布不准确所带来的问题C.模型本质仍然是一个线性模型,实现相对简单D.逻辑斯蒂回归模型是线性回归模型正确答案:A、B、C、D15、LDA模型在做参数估计时,最常用的方法是()A.Gibbs采样方法B.变分推断C.梯度下降D.Beam search正确答案:A、B三、判断题1、关于EM算法的收敛性,EM算法理论上不能够保证收敛()正确答案:×2、多次运行,随机化初始点是对存在局部最优点的函数求解的一种方案()正确答案:√3、训练算法的目的就是要让模型拟合训练数据()正确答案:×4、循环神经网络按时间展开后就可以通过反向传播算法训练了()正确答案:√5、GIS算法的收敛速度由计算更新值的步长确定。
机器学习期末测试练习题3

一、单选题1、以下关于感知器算法与支持向量机算法说法有误的是A. 由于支持向量机是基于所有训练数据寻找最大化间隔的超平面,而感知器算法却是相对随意的找一个分开两类的超平面,因此大多数时候,支持向量机画出的分类面往往比感知器算法好一些。
B.支持向量机是把所有训练数据都输入进计算机,让计算机解全局优化问题C.感知器算法相比于支持向量机算法消耗的计算资源和内存资源更少 ,但是耗费的计算资源更多D. 以上选项都正确正确答案:C2、假设你在训练一个线性回归模型,有下面两句话:如果数据量较少,容易发生过拟合。
如果假设空间较小,容易发生过拟合。
关于这两句话,下列说法正确的是?A.1正确,2错误B.1和2都错误C.1和2都正确D.1错误,2正确正确答案:A3、下面哪一项不是比较好的学习率衰减方法?t 表示为epoch 数。
A.α=11+2∗tᵯ0 B. α=1√ᵆᵯ0C. α=0.95ᵆᵯ0D.α=e ᵆᵯ0正确答案:D4、你正在构建一个识别足球(y = 1)与篮球(y = 0)的二元分类器。
你会使用哪一种激活函数用于输出层?A.ReLUB. tanhC.sigmoidD. Leaky ReLU正确答案:C5、假设你建立一个神经网络。
你决定将权重和偏差初始化为零。
以下哪项陈述是正确的?A.第一个隐藏层中的每个神经元将在第一次迭代中执行相同的计算。
但经过一次梯度下降迭代后,他们将会计算出不同的结果。
B.第一个隐藏层中的每个神经元节点将执行相同的计算。
所以即使经过多次梯度下降迭代后,层中的每个神经元节点都会计算出与其他神经元节点相同的结果。
C.第一个隐藏层中的每一个神经元都会计算出相同的结果,但是不同层的神经元会计算不同的结果。
D.即使在第一次迭代中,第一个隐藏层的神经元也会执行不同的计算, 他们的参数将以各自方式进行更新。
正确答案:B6、某个神经网络中所有隐藏层神经元使用tanh激活函数。
那么如果使用np.random.randn(…,…)* 1000将权重初始化为相对较大的值。
机器学习(传统机器学习)期末测试练习题

机器学习(传统机器学习)期末测试练习题1、使用K-means算法得到了三个聚类中心,分别是[1,2],[-3,0],[4,2],现输入数据X=[3,1],则X属于第几类A.1B.3C。
2D.不能确定正确答案:B2、对一组无标签的数据X,使用不同的初始化值运行K-means算法50次,如何评测这50次聚类的结果哪个最优A.优化目标函数值最小的一组最优B.需要获取到数据的标签才能评测C.暂无方法D.最后一次运行结果最优正确答案:A3、下图是某个二维高斯混合模型的聚类结果,该GMM 的输出矩阵的形式为A.对角阵且非单位矩阵B.普通方阵C.单位矩阵D.不能确定正确答案:A二、多选题1、以下关于PCA算法的描述正确的有哪些A.即使输入数据X各个维度上的数值相似度较高,依旧需要对其去均值B.使用PCA算法时,数据压缩后的维度M可以设置的偏小一点C.在使用PCA算法时,有可能陷入局部最小值,所以需要使用不同的初始化数值多次计算以获得更好的结果D.已知使用PCA算法压缩后的数据Y以及压缩矩阵A,但是没法大致复原压缩前的数据X正确谜底:A、B2、有L个输入样本,每个样本的特征维度是N。
在设置压缩后的维度M时,以下哪些设置方式是合理的A.M = 0.1*NB.M= 0.1*LC.根据能量百分比准则,保留占据5%能量的M值D.根据能量百分比准则,保留占据95%能量的M值正确答案:A、D3、以下哪些是PCA算法可以解决的问题A.对维度较小的数据进行维度扩充B.对特征相关性较高的数据进行降维C.对维度大于3的数据进行可视化处理D.数据维度压缩正确答案:B、C、D。
山东财经大学《机器学习》2021 -2022学年第一学期期末试卷

山东财经大学《机器学习》2021 -2022学年第一学期期末试卷《机器学习》院/系——年纪——专业——姓名——学号—— 考试范围: 《机器学习》;满分:120 分;考试时间:120 分钟一、选择题(每题 2 分,共 20 分)1. 下列关于机器学习的描述,哪一项是正确的?A.机器学习是一种无需人工干预,机器就能自主产生智能的技术。
B.机器学习是让机器模拟人类的学习行为,以获取新的知识或技能。
C.机器学习仅适用于大规模数据集,不适用于小规模数据集。
D.机器学习是人工智能的一个子集,但两者没有本质区别。
2. 监督学习中的“标签”指的是什么?A.数据集中的特征值B.数据集中的目标变量C.数据集的分布规律D.数据集的噪声3. 下列哪种算法属于无监督学习?A.K-近邻算法B.决策树C.K-均值聚类D.逻辑回归4. 关于正则化技术,下列描述错误的是?A.正则化用于防止过拟合。
B.L1 正则化倾向于产生稀疏的权值。
C.L2 正则化倾向于产生平滑的权值。
D.正则化项越大,模型复杂度越高。
5. 在神经网络中,以下哪项不是常用的激活函数?A.SigmoidB.ReLUC.TanhD.Linear6.在机器学习中,哪项任务通常涉及通过训练数据来预测连续型的目标变量?A.分类B.回归C.聚类D.降维7.下列哪种算法属于集成学习方法?A.决策树B.随机森林C.K-均值聚类D.朴素贝叶斯8.在支持向量机(SVM)中,软间隔 SVM 通过什么方式处理数据中的噪声或异常值?A.增加样本数量B.引入松弛变量C.更改核函数D.调整学习率9.深度学习中,卷积神经网络(CNN)通常用于处理哪种类型的数据?A.文本数据B.图像数据C.序列数据D.表格数据10.当使用神经网络进行训练时,过拟合的一个可能表现是?A.训练集上的损失函数值持续增加B.训练集上的准确率持续增加,但测试集上的准确率停滞不前C.测试集上的损失函数值持续下降D.训练集和测试集上的准确率都持续增加二、填空题(每题 2 分,共 10 分)1.机器学习的三大要素包括______、______和______。
机器学习期末考试试题

机器学习期末考试试题# 机器学习期末考试试题## 一、选择题(每题2分,共20分)1. 机器学习中的监督学习主要解决的问题类型是: - A. 回归问题- B. 分类问题- C. 聚类问题- D. 以上都是2. 下列哪个算法不是用于分类的:- A. 决策树- B. 支持向量机- C. K-means- D. 逻辑回归3. 在神经网络中,激活函数的作用是:- A. 增加计算复杂度- B. 引入非线性- C. 减少训练时间- D. 降低模型的泛化能力4. 交叉验证的主要目的是:- A. 加速模型训练- B. 减少模型过拟合- C. 增加数据量- D. 减少计算资源消耗5. 下列哪个不是深度学习模型:- A. 卷积神经网络(CNN)- B. 循环神经网络(RNN)- C. 随机森林- D. 长短期记忆网络(LSTM)## 二、简答题(每题10分,共30分)1. 请简述机器学习中的过拟合现象及其可能的解决方案。
2. 解释什么是特征工程,并说明其在机器学习中的重要性。
3. 描述一下什么是模型的泛化能力,并举例说明如何评估一个模型的泛化能力。
## 三、计算题(每题15分,共30分)1. 给定一个线性回归模型 \( y = \beta_0 + \beta_1 x_1 +\epsilon \),其中 \( \epsilon \) 服从均值为0的正态分布。
假设我们有以下数据点:- \( x_1 = [1, 2, 3, 4, 5] \)- \( y = [2, 4, 5, 4, 5] \)- 请计算最小二乘法估计的参数 \( \beta_0 \) 和 \( \beta_1 \)。
2. 假设有一个简单的二分类问题,我们使用逻辑回归模型进行分类。
给定以下数据点和对应的标签:- 特征:\( [x_1, x_2] = [[2, 1], [3, 0], [1, 1], [4, 1]] \) - 标签:\( y = [1, 0, 1, 0] \)- 请写出逻辑回归的假设函数 \( h(x) \),并计算使用梯度下降法更新参数的一次迭代过程。
机器学习试卷试题及答案

机器学习试题(一共30题,标有下划线的,如34,3_2,只用选择其中一题)1 .在回归模型中,下列哪一项在权衡欠拟合(under-fitting)和过拟合(C)Ver-fitting)中影响最大?A.多项式阶数B.更新权重W时,使用的是矩阵求逆还是梯度下降C,使用常数项2 .假设你有以下数据:输入和输出都只有一个变量。
使用线性回归模型(y=wx+b)来拟合数据。
那么使用留一法(1eave-OneOut)交叉验证得到的均方误差是多少?A. 10/27B. 39/27C. 49/27D. 55/273_1.下列关于极大似然估计(MaXimUm1ike1ihoodEstimate,M1E),说法正确的是(多选)?A. M1E可能并不存在B. M1E总是存在C.如果M1E存在,那么它的解可能不是唯一的D.如果M1E存在,那么它的解一定是唯一的3_2.下列哪些假设是我们推导线性回归参数时遵循的(多选)?AX与Y有线性关系(多项式关系)B.模型误差在统计学上是独立的C,误差一般服从O均值和固定标准差的正态分布D.X是非随机且测量没有误差的4_1.为了观察测试Y与X之间的线性关系,X是连续变量,使用下列哪种图形比较适合?A.散点图B.柱形图C.直方图D,以上都不对4_2,一般来说,下列哪种方法常用来预测连续独立变量?A.线性回归B.逻辑回顾C,线性回归和逻辑回归都行D.以上说法都不对5.个人健康和年龄的相关系数是-1.09o根据这个你可以告诉医生哪个结论?A.年龄是健康程度很好的预测器B.年龄是健康程度很糟的预测器C.以上说法都不对6.下列哪一种偏移,是我们在最小二乘直线拟合的情况下使用的?图中横坐标是输入X,纵坐标是输出Y overtica1offsetsperpendicu1aroffsetsA,垂直偏移(vertica1offsets)B.垂向偏移(perpendicu1aroffsets)C,两种偏移都可以D.以上说法都不对7 .假如我们利用Y是X的3阶多项式产生一些数据(3阶多项式能很好地拟合数据)。
机器学习期末考试填空题

机器学习期末考试填空题1.Series是⼀种⼀维数组对象,包含⼀个值序列。
Series中的数据通过( )访问。
参考答案: 索引2.理想中的激活函数是阶跃函数,但因其不连续、不光滑,实际常⽤( )作为激活函数。
该函数把可能在较⼤范围内变化的输⼊值挤压到(0,1)输出值范围内,因此有时也被称为“挤压函数”。
参考答案: sigmoid函数(注意⼩写)3.属性shape返回的是( )。
参考答案: 维度4.⾃助法约有( )的样本没有出现在训练集中,可⽤作测试集。
参考答案: 1/35.Numpy中的ndarray的size属性返回的是( )。
参考答案: 数组元素个数6.从数据中学得模型的过程称为“学习”或( ),这个过程通过执⾏某个学习算法来完成。
参考答案: 训练7.SVM的主要⽬标是寻找最佳( ),以便在不同类的数据间进⾏正确分类。
参考答案: 超平⾯8.当学习器把训练样本学得“太好”了的时候,可能已经把训练样本⾃⾝的⼀些特点当作了所有潜在样本都会具有的⼀般性质,这样就会导致泛化性能下降。
这种现象在机器学习中称为( )。
参考答案: 过拟合9.训练过程中使⽤的数据称为“训练数据”,其中每个样本称为⼀个“训练样本”;学得模型后,使⽤其进⾏预测的过程称为( )。
参考答案: 测试10.sklearn模块的( )⼦模块提供了多种⾃带的数据集,可以通过这些数据集进⾏数据的预处理、建模等操作,从⽽练习使⽤sklearn模块实现数据分析的处理流程和建模流程。
参考答案: datasets11.Pandas通过read_json函数读取( )数据。
参考答案: JSON (注意⼤写)12.回归任务中最常⽤的性能度量是( )。
参考答案: 均⽅误差13.Numpy的主要数据类型是( )。
参考答案: ndarray14.若训练过程的⽬标是预测连续值,此类学习任务称为( )。
参考答案: 回归15.聚类试图将数据集中的样本划分为若⼲个通常是不相交的⼦集,每个⼦集称为⼀个( )。
机器学习课程期末考试试题

机器学习课程期末考试试题### 机器学习课程期末考试试题一、选择题(每题2分,共20分)1. 在机器学习中,通常所说的“过拟合”是指:- A. 模型在训练集上表现很好,但在测试集上表现较差 - B. 模型在训练集上表现较差- C. 模型在训练集和测试集上表现都很差- D. 模型在训练集上表现一般,但在测试集上表现很好2. 支持向量机(SVM)的核心思想是:- A. 找到最佳拟合线- B. 找到最佳拟合平面- C. 在特征空间中找到最优的决策边界- D. 在数据空间中找到最优的决策边界3. 以下哪个算法是用于聚类分析的?- A. 逻辑回归- B. 决策树- C. K-means- D. 随机森林4. 在神经网络中,激活函数的作用是:- A. 增加模型的复杂度- B. 引入非线性因素- C. 减少模型的复杂度- D. 使模型更容易训练5. 交叉验证的主要目的是什么?- A. 减少模型训练时间- B. 减少模型的过拟合风险- C. 提高模型的泛化能力- D. 增加模型的复杂度二、简答题(每题10分,共30分)1. 描述机器学习中的“训练集”和“测试集”的区别,并解释为什么在机器学习中需要将数据集分为训练集和测试集。
2. 解释什么是“决策树”,并简述如何使用决策树进行分类。
3. 什么是“梯度下降”算法?它在机器学习中如何应用?三、计算题(每题25分,共50分)1. 假设我们有一个简单的线性回归问题,模型的预测函数为 \( f(x) = wx + b \),其中 \( w \) 是权重,\( b \) 是偏置项。
给定数据集 \( \{(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)\),其中\( y_i = wx_i + b + \epsilon_i \),\( \epsilon_i \) 是噪声项。
请推导最小二乘法的权重 \( w \) 和偏置 \( b \) 的更新公式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
中国科学院大学
课程编号:712008Z 试题专用纸
课程名称:机器学习任课教师:卿来云
———————————————————————————————————————————————
姓名
学号成绩
一、基础题(共36分)
1、请描述极大似然估计MLE 和最大后验估计MAP 之间的区别。
请解释为什么MLE 比MAP 更容易过拟合。
(10分)
2、在年度百花奖评奖揭晓之前,一位教授问80个电影系的学生,谁将分别获得8个奖项(如最佳导演、最佳
男女主角等)。
评奖结果揭晓后,该教授计算每个学生的猜中率,同时也计算了所有80个学生投票的结果。
他发现所有人投票结果几乎比任何一个学生的结果正确率都高。
这种提高是偶然的吗?请解释原因。
(10分)
3、假设给定如右数据集,其中A 、B 、C 为二值随机变量,y 为待预测的二值变量。
(a)对一个新的输入A =0,B =0,C =1,朴素贝叶斯分类器将会怎样预测y ?(10分)
(b)假设你知道在给定类别的情况下A 、B 、C 是独立的随机变量,那么其他分类器(如Logstic
回归、SVM 分类器等)会比朴素贝叶斯分类器表现更好吗?为什么?(注意:与上面给的数据集没有关系。
)(6分)二、回归问题。
(共24分)
现有N 个训练样本的数据集(){}1
,N
i i i x y ==D ,其中,i i x y 为实数。
1.我们首先用线性回归拟合数据。
为了测试我们的线性回归模型,我们随机选择一些样本作为训练样本,剩余样本
作为测试样本。
现在我们慢慢增加训练样本的数目,那么随着训练样本数目的增加,平均训练误差和平均测试误差将会如何变化?为什么?(6分)平均训练误差:A 、增加B 、减小平均测试误差:A 、增加
B 、减小
2.给定如下图(a)所示数据。
粗略看来这些数据不适合用线性回归模型表示。
因此我们采用如下模型:
()exp i i i y wx ε=+,其中()~0,1i N ε。
假设我们采用极大似然估计w ,请给出log 似然函数并给出w 的估计。
(8分)
3.给定如下图(b)所示的数据。
从图中我们可以看出该数据集有一些噪声,请设计一个对噪声鲁棒的线性回归模型,
并简要分析该模型为什么能对噪声鲁棒。
(10
分)
(a)(b)
A B C y 0010010011000011111110011
1
1
三、SVM 分类。
(第1~5题各4分,第6题5分,共25分)
下图为采用不同核函数或不同的松弛因子得到的SVM 决策边界。
但粗心的实验者忘记记录每个图形对应的模型和参数了。
请你帮忙给下面每个模型标出正确的图形。
1、2111min , s.t.
22N
i i C ξ=⎛⎫+ ⎪⎝⎭
∑w ()00, 1, 1,....,,
T i i i y w i N ξξ≥+≥-=w x 其中0.1C =。
2、2
111min , s.t.22N i i C ξ=⎛⎫+ ⎪⎝⎭
∑w ()00, 1, 1,....,,
T i i i y w i N ξξ≥+≥-=w x 其中1C =。
3、()
111
1max ,2N N N i i j i j i j i i j y y k ααα===⎛⎫- ⎪
⎝⎭
∑∑∑x x 1
s.t. 0, 1,....,, 0
N
i i i i i N y αα=≥==∑其中()()
2
,T T k '''=+x x x x x x 。
4、()
111
1max ,2N N N i i j i j i j i i j y y k ααα===⎛⎫
- ⎪
⎝⎭
∑∑∑x x 1
s.t. 0, 1,....,, 0
N
i i i i i N y αα=≥==∑其中()21,exp 2k ⎛⎫''=-- ⎪⎝⎭
x x x x 。
5、()
111
1max ,2N N N i i j i j i j i i j y y k ααα===⎛⎫
- ⎪
⎝⎭
∑∑∑x x 1
s.t. 0, 1,....,, 0
N
i i i i i N y αα=≥==∑其中()(
)2
,exp k ''
=--x x x x 。
6、考虑带松弛因子的线性SVM 分类器:2111min , s.t.22N
i i C ξ=⎛⎫+ ⎪⎝⎭
∑w (
)
00, 1, 1,....,, T i i i y w i N ξξ≥+≥-=w x 下面有
一些关于某些变量随参数C 的增大而变化的表述。
如果表述总是成立,标示“是”;如果表述总是不成立,标示“否”;如果表述的正确性取决于C 增大的具体情况,标示“不一定”。
共3页第2
页
(1)
w不会增大
(2)ˆw增大
(3)ˆw不会减小
(4)会有更多的训练样本被分错
(5)间隔(Margin)不会增大
四、一个初学机器学习的朋友对房价进行预测。
他在一个N=1000个房价数据的数据集上匹配了一个有533个参数的模型,该模型能解释数据集上99%的变化。
1、请问该模型能很好地预测来年的房价吗?简单解释原因。
(5分)
2、如果上述模型不能很好预测新的房价,请你设计一个合适的模型,给出模型的参数估计,并解释你的模型为什么是合理的。
(10分)
共3页第3页。