数字IC后端流程 PPT
《芯片后端验证》PPT课件
28 精选ppt
28
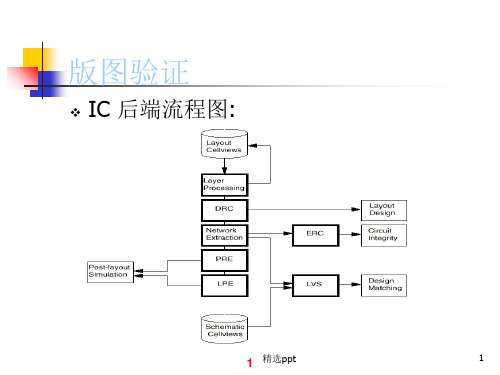
版图验证工具-Dracula
❖ 版图->GDSII 格式转换 WHY:Dracula 处理对象是GDSII文件
操作步骤:
执行:CIW->File->Export->Stream… 弹出如下窗口:
29 精选ppt
29
版图验证工具-Dracula
运行目录
输出文件名
30 精选ppt
Hierarchical VS Flatten
Online VS offline
25 精选ppt
25
版图验证工具-Dracula
❖ Dracula 主要功能: 1.设计规则检查-DRC * 2.电气规则检查-ERC 3.版图&原理图一致性检查-LVS * 4.版图参数提取-LPE 5.寄生电阻提取-PRE
2 精选ppt
2
版图验证工具-DIVA
❖ Diva -Design Interactive Verification Automation
DIVA 是 Cadence软件中的验证工具集, 用它可以找出并纠正设计中的错误.它除了可 以处理物理版图和准备好的电气数据,从而进 行版图和线路图的对查(LVS)外。还可以在 设计的初期就进行版图检查,尽早发现错误并 互动地把错误显示出来,有利于及时发现错误 所在,易于纠正。
BJT、二极管的面积,周长,结点寄生电容 等)并以Hspice 网表方式表示电路。
7 精选ppt
7
版图验证工具-DIVA
❖ DIVA工具流程
8 精选ppt
8
版图验证工具-DIVA
❖ Design Rule Checking
9 精选ppt
9
数字后端简要流程教材

• set_max_delay: 1、对于仅包含组合逻辑的模块,用此命令约束所有输入到输出 的总延时。 例如: set_max_delay 5 -from all_inputs() -to all_outputs 2、对于含有多个时钟的模块,可用通常的方法定义一个时钟, 用此命令进行约束定义时钟和其他时钟之间的关系。 例如:set_max_delay 0 –from CLK2 –to all_register(clock_pin) • set_min_delay: 1、对于仅包含组合逻辑的模块,定义指定路径的最小延时。 例如:set_min_delay 3 -from all_inputs() 2、和set_fix_hold一起使用,只是DC添加一定的延迟,满足最 小延迟需求。
set_operating_conditions set_drive on Clock set_driving_cell on inputs
Clock Divider Logic Block B Block A
set_load on outputs set_max_capacitance set_max_transition &set_max_fanout on input &output ports or current_design;
数字后端简要流程
HDL代码
逻辑综合
布局布线
形式验证
综合的定义
• 逻辑综合:决定设计电路逻辑门之间的相互连接。 • 逻辑综合的目的:决定电路门级结构,寻求时序、面积和功耗的平衡, 增强电路的测试性。 • 逻辑综合的过程(constraint_driven) : Synthesis = Translation + Logic Optimization + Mapping
IC设计流程课件

综合(Synthesis)
门级验证(Gate-level Verification)
后端设计(Back-end Design)
电路参数提取(Circuit Extraction)
版图后仿真(Post-layout Simulation)
物理
生产(Manufacture) 测试(Test)
数据形式与工具
目前DC可称作ASIC业界最流行的综合工具和 实际标准
09/11/08
6
西安邮电学院ASIC中心
静态时序分析工具
CMOS集成电路版图
静态时序分析技术是一种穷尽分析方法,可以 提取整个电路的所有时序路径,且不依赖于激 励,运行速度很快,占用内存很少,适合进行 超大规模的片上系统电路的验证,可以节省多 达20%的设计时间,但是静态时序分析存在的 问题在于不了解电路的动态行为。
09/11/08
11
西安邮电学院ASIC中心
版本管理工具
CMOS集成电路版图
在芯片开发流程中,文档、代码、网表 、工具配置脚本、工艺库甚至EDA工具本 身都在不断变更,版本控制的重要性日益 凸显。
常用的版本管理工具有CVS、Subvision 等,都包括windows和linux等版本。
09/11/08
IC设计流程课件
09/11/08
1
数字IC设计的流程
CMOS集成电路版图
逻辑
流程
需求分析(Requirement)
算法设计(Algorithm Optimization)
结构设计(Architecture Exploration)
RTL设计(RTL Design)
RTL验证(RTL Verification)
数字IC后端流程

2020/10/16
7
西安邮电大学微电子学系
Data Setup
CMOS集成电路版图
逻辑单元库:一个完整的单元库由不同的功能电路所组 成,种类和数量很多,根据其应用可分为三类:
标准单元(standard cells)
组合逻辑
时序逻辑
模块宏单元(macro block)
ROM
RAM
专用模块(如ASSP、DSP等)
Black box商业IP(如ARM、标准单元等)
模拟模块(如PLL、振荡器等)
输入输出单元(I/O pad cell)
输入
输出
三态
考虑ESD
双向
2020/10/16
8
西安邮电大学微电子学系
Data Setup
CMOS集成电路版图
Physical Reference Libraries
2020/10/16
2020/10/16
5
西安邮电大学微电子学系
Data Setup
CMOS集成电路版图
后端设计数据准备
设计网表
gate-level netlist
设计约束文件 SDC file
物理库文件 sc.lef/io.lef/macro.lef
时序库文件 sc.lib/io.lib/macrand name designations for each layer/via Physical and electrical characteristics of each layer/via Design rules for each layer/Via (Minimum wire widths and wire-to-wire spacing, etc.) Units and precision for electrical units Colors and patterns of layers for display …
SoC设计方法与实现 第12章 后端设计 课件PPT

信号完整性
信号完整性随着深亚微米制程在不断进步而成为SoC 设计首要考虑的问题之一
互连线上的耦合电容、电阻增大 电流密度更高、电压更低
信号完整性是指一个信号能对电路产生正确的响应
信号具有特定电压下所要求水平
信号完整性问题主要表现为串扰、压降和电迁移
串扰
串扰:Crosstalk 信号线之间存在耦合电容
存在于同一层间及不同层间
信号线与衬底之间存在耦合电容 串扰
延迟:两条信号线同时翻转会导致信号比预先的变快或变慢 噪声:一条信号线的翻转会给相邻的线路中注入电压针刺型干扰
串扰引起的延迟和噪声主导信号完整性
对电路的时序和功能有极为重要的影响
压降
压降:IR drop 电源网络上瞬间的电流的抽取造成基本单元上的电压下降
短路或开路
信号完整性的检查和修正
芯片制造厂与EDA公司合作开发检查规则
对串扰的消除的方法
定义高速信号、模拟信号 通常是增加两条金属线的距离(Spacing) 加隔离线(Shielding) 综合阶段,减少非关键路径上的驱动尺寸
对于压降和电迁移消除的方法
对版图进行动态功耗、静态功耗分析 修改版图的布局,改进电源及高速信号线宽度
时钟树综合流程
使用EDA工具自动生成时钟树
缓冲器的插入
根据寄存器的位置和数量,决定插入缓冲器的 层数、驱动力的大小和位置
时钟线的布线
时钟线的优先级高于一般信号线,所以先布时钟线
From placement Set clock constraints
Perform clock tree synthesis
通过在布局密度较低的区域插入一些冗余金属块, 使其表面平坦,提高芯片良率。
数字集成电路 数字集成电路设计流程和设计方法PPT课件

pmos p2 (i2, il, b); pmos p3 (i3, i2, c); pmosp4 (il, vdd, b); pmos p5 (i2, il, c); pmos p6 (i3, i2, a); pmos p7 (co, vdd, i3); end module
第16页/共58页
第17页/共58页
pmos p4 (i4, vdd, b); pmos p5 (i4, vdd, a); pmos p6 (co, vdd, en); pmos n6 (co, vss, en); end module
第18页/共58页
2.2 设计描述
• 四、物理描述
•
电路的物理描述是用来定义在硅表面的物理实现,并由物理实现
数字集成电路设计总体上可分为
1.电路设计(前端设计)
电路设计是指根据对ASIC的要求或规范,从电路系统的行为描述开 始,直到设计出相应的电路图,对于数字系统来说就是设计出它的 逻辑图或逻辑网表
2.版图设计(后端设计)
版图设计就是根据逻辑网表进一步设计集成电路的物理版图,也就 是制造工艺所需的掩膜版的版图。
Verilog-HDL 描述进位算法描述
module carry (co,a,b,c); output co; input a,b,c;
wire #10 co=(a&b)|(a&c)|(b&c) end module
第11页/共58页
2.2 设计描述
• 三、结构描述
•
结构描述规定了电路系统的结构,规定了元件之间的连接关系,
第4页/共58页
2.1 设计流程
• 二、Top-Down设计
•
从电路行为到逻辑结构的转换是由逻辑综合这一步骤自动进行的。逻辑综合
IC后端流程(初学必看)

校中IC后端考查报告之阳早格格创做本教程通过对付synopsys公司给的lab举止训练,从verilog代码到版图的所有过程(天然不过基础过程,果为真真一个庞大的安排不是那么简朴便完毕的),此教程的脚段便是为了让大家尽量相识数字IC安排的大概过程,为以去教习建坐一个前提.此教程不过自己探索真验的截止,本去不代表真质皆是精确的,不过为了证明大概的过程,内里一定另有很多已完备而且有过失的场合,尔正在以后的教习核心会对付其逐一完备战建正.以后端过程大概包罗一下真质:1.逻辑概括(工具DC 逻辑概括是搞吗的便不必阐明了把?)2.安排的形式考证(工具formality)形式考证便是功能考证,主要考证过程中的各个阶段的代码功能是可普遍,包罗概括前RTL代码战概括后网表的考证,果为此刻IC安排的规模越去越大,如果对付门级网表举止径背仿果然话,会耗费较少的时间(规模大的话以至要数星期),那对付于一个对付时间央供庄重(安排周期短)的asic安排去道是不可容忍的,而形式考证只用几小时即可完毕一个庞大的考证.其余,果为版图后搞了时钟树概括,时钟树的拔出表示着加进布图工具的本去的网表已经被建改了,所以有需要考证与本去的网表是逻辑等价的.3.固态时序分解(STA),某种程度上去道,STA是ASIC安排中最要害的步调,使用primetime对付所有安排布图前的固态时序分解,不时序违规,则加进下一步,可则沉新举止概括.(PR后也需做signoff 的时序分解)4.使用cadence公司的SOCencounter对付概括后的网表举止自动筹备布线(APR)5.自动筹备以去得到简曲的延时疑息(sdf文献,由寄死RC战互联RC 所组成)反标注到网表,再搞固态时序分解,与概括类似,固态时序分解是一个迭代的历程,它与芯片筹备布线的通联非常稀切,那个支配常常是需要真止许多次才搞谦足时序需要,如果出违规,则加进下一步.6.APR后的门级功能仿真(如果需要)7.举止DRC战LVS,如果通过,则加进下一步.8.用abstract对付此lab真验举止抽与,爆收一个lef文献,相称于一个hard macro.9.将此macro动做一个模块正在其余一个top安排中举止调用.10.安排一个新的ASIC,第二次安排,咱们需要增加PAD,果为不PAD,便不是一个完备的芯片,简曲支配底下会道.11.沉复第4到7步1.逻辑概括1)安排的verilog代码2)概括之前,咱们要采用库,写佳拘束条件,建改dc的开用文献,目标库采用TSMC(此安排皆是用TSMC18的库)的typical.db.(采用max库会比较佳)Dc的下令稠稀,然而是最基础的下令好已几,此安排的拘束文献下令如下:create_clock -period 10 [get_ports clk] //用于时钟的创造set_clock_latency -source -max 0.2 [get_ports clk] //中部时钟到core的clk 连线延时set_clock_latency -max 0.1 [get_ports clk] //core的clk到寄存器clk端的net连线延时set_clock_uncertainty -setup 2[get_ports clk] //时钟延时的不决定性,供setup违规时会被估计进去set_clock_uncertainty –hold 1 【all_clocks】set_input_delay -max 0.5 -clock clk[get_ports [list [remove_from_coll [all_inputs] clk] ] //输进延时,中部旗号到input端的连线延时set_output_delay -max 0.5 -clock clk [all_outputs] //输出延时set_driving_cell -lib_cell INVX4 [all_inputs] //输进端的启动强度set_load -pin_load 0.0659726 [all_outputs] //输出端的驱能源set_wire_load_model -name tsmc18_wl10 -library typical //内里net的连线模型set_wire_load_mode enclosed //定义建模连线背载相闭模式set_max_area 0compilereport_timingreport_constraintchange_names -rule verilog –hierset_fix_multiple_ports_net –all//输出网表,自动筹备布线需要//输出ddc//输出延时文献,固态时序分解时需要//输出拘束疑息,自动筹备布线需要3)逻辑概括开用design_vision.R输进拘束文献.F4)时序分解概括以去咱们需要分解一下时序,瞅时序是可切合咱们的央供,概括本质上是一个setup时间的谦足历程,然而是咱们概括的时间,连线的背载不过库提供的(即上头的wire_load),本去不是本质的延时,所以普遍搞完概括以去,时间余量(slack)该当为时钟的30%(体味值),以便为后里本质筹备布线留住富足的延时空间.果为如果slack太小,以至交近于0,虽然咱们瞅起去是不时序违规的,然而是本质筹备以去,时序肯定无法谦足.使用report_timing下令,不妨查看时序分解报告:****************************************Report : timing-path full-delay max-max_paths 1-sort_by groupDesign : muxDate : Fri Jul 2 12:29:44 2010****************************************Operating Conditions: typical Library: typical(模型库)Wire Load Model Mode: enclosedStartpoint: data2[4] (input port clocked by clk)Endpoint: dataout_reg_15_(rising edge-triggered flip-flop clocked by clk)Path Group: clkPath Type: maxDes/Clust/Port Wire Load Model Library------------------------------------------------mux tsmc18_wl10 typical(线载模型及库)Point Incr Path--------------------------------------------------------------------------input external delay 0.50 0.50 fdata2[4] (in) 0.01 0.51 fmult_14/b[4] (mux_DW_mult_uns_0) 0.00 0.51 fmult_14/U131/Y (INVX1) 0.54 1.05 rmult_14/U161/Y (NOR2X1) 0.14 1.18 fmult_14/U39/S (CMPR42X1) 0.68 1.87 fmult_14/U12/CO (ADDFX2) 0.32 2.19 fmult_14/U11/CO (ADDFX2) 0.23 2.42 fmult_14/U10/CO (ADDFX2) 0.23 2.65 fmult_14/U9/CO (ADDFX2) 0.23 2.88 fmult_14/U8/CO (ADDFX2) 0.23 3.10 fmult_14/U7/CO (ADDFX2) 0.23 3.33 fmult_14/U6/CO (ADDFX2) 0.23 3.56 fmult_14/U5/CO (ADDFX2) 0.23 3.79 fmult_14/U4/CO (ADDFX2) 0.23 4.02 fmult_14/U3/CO (ADDFX2) 0.23 4.25 fmult_14/U2/CO (ADDFX2) 0.22 4.47 fmult_14/product[15] (mux_DW_mult_uns_0) 0.00 4.47 fdataout_reg_15_/RN (DFFTRXL) 0.00 4.47 fdataout_reg_15_/CK (DFFTRXL) 0.00 10.20 r----------------------------------------------------------------------------------------------------------------------------------------------------咱们去瞅以上报告,dc报告的时间会隐现出闭键路径,即延时最大的路径,时序分解包罗二段,前里一段是旗号的延缓时间,即data arrival time 为4.47,底下是估计央供时间,也即相对付于时钟,安排所能忍受的最大延时,由于到达寄存器clk端延时,即clock network delay,所以安排减少了0.30的余量,共样由于时钟的不决定度(大概提前也大概延后0.1),咱们与最坏情况,便是时钟超前0.1,则时间余量减去0.1,末尾一个是门的建坐时间央供,是0.19,末尾得到数据的央供时间.Slack是央供时间减去到达时间的好值,slack越大越佳.越大证明留给筹备布线的时序越宽紧.从报告中咱们瞅出,时序余量为5.55,证明时序达到了央供,足够谦足咱们以去筹备布线的时序央供.天然,咱们有博门的时序分解工具,primetime,底下会轻微介绍.2.形式考证1)怎么包管概括前战概括后的网表逻辑功能是普遍的呢,对付门级网表举止径背仿真,又太浪费时间,于是,一款强盛的考证工具formality,给了咱们很佳的助闲.2)形式考证数据准备:概括前RTL代码,概括后的网表,概括所用到的库.3)考证历程如下:1.最先咱们挨开formality,下令为fm_shell(下令止界里),formality(图形界里).初教者普遍使用图形界里,使用图形界里的时间,工具会自动爆收一个log文献,记录下令,咱们不妨将那个文献真质搞一个fms要领,那样正在下次考证的时间不妨使用下令界里.2.挨开formality如下第一步:最先咱们加进本RTL代码,reference->read_design file->verilog->mux.v,采用佳以去load file第三步:树坐top名 reference->set top design 咱们采用mux为top名共样的要领对付网表举止树坐(第二个菜单栏implementation)而后转到第四栏,面打run matching末尾转到第五栏,verify,如果网表无错,会隐现考证通过.3 固态时序分解固态时序分解主要针对付庞大ASIC安排,4 自动筹备布线1)数据准备第一:需要概括后的网表以即时序拘束第二:需要自动筹备布线的物理库(lef文献,那里用到tsmc18_6lm_cic.lef, tsmc18_6lm_antenna_cic.lef)为了不妨相识lef文档的效率,那里对付lef搞简朴的介绍,lef普遍分为二种:一种是技能物理库,主要包罗工艺疑息,安排准则疑息,金属通孔疑息等.下例是对付金属一层的定义,TYPE指明METAL1是可布线层,WIDTH定义的是METAL1的默认布线宽度,SPACING用于设定METAL1布线间距.DIRECTION HORIZONTAL指明METAL1是用于火仄走线,天然那本去不料味着它不克不迭笔曲走线,正在一些布线资材较少的天区,仍旧不妨采用笔曲布线的.简曲介绍,不妨参照相闭技能文档.LAYER METAL1TYPE ROUTING ;WIDTH 0.230 ;MAXWIDTH 9.9 ;AREA 0.202 ;SPACING 0.230 ;SPACING 0.6 RANGE 10.0 100000.0 ;PITCH 0.560 ;DIRECTION HORIZONTAL ;EDGECAPACITANCE 9.1090e-05 ;END METAL1其余一种便是单元物理库,定义了单元库中各单元的疑息,文献又有二部分一种是SITE语句对付筹备(placement)最小单位的定义,另一部分是采与MACRO语句对付单元属性及几许形状的形貌,下例是对付一个与门为例去瞅瞅lef是怎么样形貌它的.MACRO是单元定义的闭键字,每一个MACRO代表一个单元.CLASS core证明该单元是用于芯片的核心区,SIZE决定了单元的里积大小,比圆5.04是代表该单元的下度,后里咱们搞单元供电route的时间,不妨瞅到它们的宽度便是那个数值.再后里便是定义引足A,B,Y,VDD,VSS等.MACRO AND2X1CLASS CORE ;FOREIGN AND2X1 0.000 0.000 ;ORIGIN 0.000 0.000 ;LEQ AND2XL ;SIZE 2.640 BY 5.040 ;SYMMETRY x y ;SITE tsm3site ;PIN YDIRECTION OUTPUT ;PORTLAYER METAL1 ;RECT 2.355 2.380 2.500 2.660 ;ENDEND YPIN BDIRECTION INPUT ;PORTLAYER METAL1 ;RECT 0.800 2.315 1.215 2.895 ;ENDEND BPIN ADIRECTION INPUT ;PORTLAYER METAL1 ;RECT 0.150 1.820 0.565 2.315 ;ENDEND APIN VSSDIRECTION INOUT ;USE ground ;SHAPE ABUTMENT ;PORTLAYER METAL1 ;RECT 1.790 -0.400 2.640 0.400 ;RECT 1.450 -0.400 1.790 0.575 ;RECT 0.000 -0.400 1.450 0.400 ;ENDEND VSSPIN VDDDIRECTION INOUT ;USE power ;SHAPE ABUTMENT ;PORTLAYER METAL1 ;RECT 1.755 4.640 2.640 5.440ENDEND VDDOBSLAYER METAL1 ;RECT 1.835 1.935 1.885 2.355 ;ENDEND AND2X1第三:时序库文献,typical.lib,也便是时序文献,定义了门的百般时序疑息,某种意思去道,那个战概括使用的db库是等价的.2)筹备布线历程:第一步:挨开encounter 把数据输进,其余正在advanced栏的Power相映位子挖上VDD,战VSS.如下图,树坐完以去,记得把树坐的晃设文献搞一个save以便于下次使用第二步:挨开以去,咱们不妨瞅到芯片天区,左边粉白色的便是尺度单元,中间那个便是咱们要安排的天区,64%是指cell里积的占有率,普遍去道统造正在70%安排,布线的时间不会引起拥塞.其余咱们需要对付芯片举止轻微的变动,Floorplan->specify floorplan.,将core to IO那些项皆挖上45,留给电源环的搁置.第三步:增加电源环树坐如下图,NET挖写VDD战VSS,layer采用顶层的二层金属,宽度树坐为20(那个大概,不妨根据本质安排去定),offset采用center in channel,则电源环会被树坐正在IO与core之间.之后电源环便加进去了,天然那是一个小电路,电源筹备比较简朴,对付于一个搀纯的电路,还需要横横增加stripes,落矮IRdrop.第四步:自动筹备以及安插尺度单元,果为此安排较小,并不block,所以不妨曲交举止尺度单元的搁置.Place->standard cells and blocaks->OK而后咱们创造尺度单元已经被加进去了:第五步:安插佳了以去,咱们需要将电源,天,等交心先连交起去,最先咱们正在floorplan中采用global net connection,分别将VDD,VSS 等皆连交起去.而后咱们需要specify route将电源战天线先连交起去,采用route->specify route果为咱们那个安排惟有尺度单元,所以咱们只消采用尺度单元的布线即可:完毕以去,面打OK,会得到底下的图:每止的row皆有线连交到表里的电源环第六步:时钟树概括(CTS),那是一个APR安排中最要害的一环,为什么要举止时钟树概括呢,简朴天道,果为旗号传输的延时,咱们需要让相映路径的时钟路径的也具备共样的延时,通过增加时钟慢冲器的要领,去与消各路径的建坐时间,简曲请参照相闭书籍籍战资料.增加佳时钟树以去的版图如下:加了时钟树以去的版图聚集了很多,果为加了很多buf.时钟树的足本:AutoCTSRootPin clkPeriod 10nsMaxDelay 500ps # set_clock_latencyMinDelay 0ps # set_clock_latencyMaxSkew 100psSinkMaxTran 400psBufMaxTran 400psObstruction NODetailReport YESPadBufAfterGate NORouteClkNet NOPostOpt YESOptAddBuffer YESOptAddBufferLimit 100NoGating NOBuffer CLKBUFX1 CLKBUFXL CLKBUFX2 CLKBUFX3 CLKBUFX4CLKBUFX8 CLKBUFX12 CLKBUFX16 CLKBUFX20 CLKINVXL CLKINVX1 CLKINVX2 CLKINVX3 CLKINVX4 CLKINVX8 CLKINVX12 CLKINVX16 CLKINVX20END而后将足本选中,并举止时钟树概括.第七步:劣化安排,下令optDesign –postCTS,而后report_timing查看时序报告,决定无违规,再举止真足布线.第八步:真足布线,route ->nanoroute->route之后得到的版图如下所示:第九步:保存安排,提与需要的数据.那里特天注意提与gds文献的时间,需要指定库文献中的streamOut.map文献,战merge gds(tsmc18_core.gds)文献,如图所示保存网表,并将此版图提与的网表搞一次formality,与本代码匹配乐成.5 第二次固态时序分解用版图本质提与的延时文献举止6 APR后仿真用modelsim对付版图提与的网表战sdf文献举止仿真.7 用calibre对付版图举止DRC及其LVS考证正在搞那步之前,咱们需要把相闭的文档拷贝到icfb的处事目录下Encounter导出的gds文档:那里是mux8.gds(注意merge库的map文献)技能文档如:,不妨正在厂家提供的库中去找Caliber考证文献:drc,lvs文档第一步:将encounter的版图数据导进virtuoso,挨开icfb&,采用file->import->stream而后将版图疑息战技能文献挖进:导进乐成以去会出现咱们所搞的库,mux便是咱们encounter中所绘的版图.咱们把版图挨开:那便是咱们所绘的版图而后正在此举止drc,战lvs,通过以去再举止底下的处事.第二步:drc查看此处有错,本去不是逻辑有问题,是果为稀度不敷的问题,需要正在encounter阶段加FILLER,FILLER是与逻辑无闭的,果为代工厂的流片加工央供,需要加的,稀度不敷,加工简单引起问题.所以如果DRC 报类似过失,如果是需要流片的版图,除非代工厂共意,可则必须扫除那些过失.第三步:lvs查看1)Lvs查看之前,咱们需要把概括后的verilog文献变换成网表文献,用于lvs,要领如下:末端下真止:v2lvs -v mux.v -l tsmc18_lvs.v -o CHIP.spi -s tsmc18_lvs.spi -c cic_ -ncalibre -lvs -spice layout.spi -hier -auto Calibre-lvs-cur_soce,之后会得到一个的网表文献.()2)用去lvs的网表咱们采用之前导出:而后run lvs,匹配乐成!8 用abstract对付模块举止抽与咱们把8*8乘法器模块用abstract工具导出lef,动做硬核,用于后里自动筹备布线的调用,咱们不妨以后考查中找到模数混同自动版图的安排思维.Abstract Def=>Lef第一步:创造一个新的library,并闭联一个tf文献.注:(1)不需要输进streamOut.map也不必面上(no merge)不需要变动.Top Cell Name 为空第五步:挨开library manager 正在mux库里挨开mux的layout,并采用tools=>layout.第六步:采用 Edit=>Search ,面打 Add Criteria ,如下树坐,采用aplly ,正在采用 WordStr All.第七步:保存退出第八步:挨开abstract,并挨开mux库.而后把mux模块从core导进到block核心,要领:面打mux,而后cell=>move=>block=>OK.第九步:面打GDS图中label,而后面打Q查看Properity.瞅瞅是什么层,而后瞅瞅底下的net的Properity是什么层,以及是什么purpose.层:METAL3,Purpose:pin.简曲含意主要瞅abstract UG.<1> 面打,输进Map text labels to pinsMap text labels to pins 的书籍写要领及含意参照abstract UG.<2>面打<3>面打<4> Export lef之后咱们得到一个该模块的lef文献,底下咱们便用那个模块搞一次调用.9将此macro动做一个模块正在其余一个top安排中举止调用.第一步:最先咱们仍旧回到概括,咱们沉新安排一个top,那个top将包罗新的逻辑功能,之前的mux模块,另有PAD模块.那个安排的大概框图如下:PDIDGZ为数字输进IO心PDO04CDG为数字输出IO心PVDD1DGZ 为供电PAD下电端PVSS1DGZ 为供电PAD的天电端Multiple为之前搞的宏模块Mux为新加逻辑第二步,代码的改写:咱们沉新编写过verilog代码(戴PAD),戴PAD搞概括有个佳处,不妨不必树坐输进输出端心的启动,果为PAD的启动已经很大了,那样概括出的截止更交近本质.新的verilog代码如下:module mux_1 (clk,clr,a,b,y);//(那里咱们引用了新的逻辑,注意那个mux_1战之前的出半面闭系,不过为了体现调用闭系随便加的一个而已)input clk,clr;input [7:0] a,b;output [15:0] y;reg [15:0] y;always @(posedge clk)beginif(!clr)beginy<=0;endelsebeginy<=a*b;endendendmodulemodulePAD(clk_pcb,clk_core,clr_pcb,clr_core,data1_pcb,data1_core,data2_pcb,dat a2_core,dataout_core,dataout_pcb);(那是PAD模块,注意分离前里的框图是念念是怎么样加的)input clk_pcb,clr_pcb;output clk_core ,clr_core;input [7:0] data1_pcb,data2_pcb;output [7:0] data1_core,data2_core;input [15:0] dataout_core;output [15:0] dataout_pcb;PDIDGZ PAD_CLK (.PAD(clk_pcb),.C(clk_core));PDIDGZ PAD_CLR (.PAD(clr_pcb),.C(clr_core));PDIDGZ PAD_DATA1_0 (.PAD(data1_pcb[0]),.C(data1_core[0])); PDIDGZ PAD_DATA1_1 (.PAD(data1_pcb[1]),.C(data1_core[1])); PDIDGZ PAD_DATA1_2 (.PAD(data1_pcb[2]),.C(data1_core[2])); PDIDGZ PAD_DATA1_3 (.PAD(data1_pcb[3]),.C(data1_core[3])); PDIDGZ PAD_DATA1_4 (.PAD(data1_pcb[4]),.C(data1_core[4])); PDIDGZ PAD_DATA1_5 (.PAD(data1_pcb[5]),.C(data1_core[5])); PDIDGZ PAD_DATA1_6 (.PAD(data1_pcb[6]),.C(data1_core[6])); PDIDGZ PAD_DATA1_7 (.PAD(data1_pcb[7]),.C(data1_core[7])); PDIDGZ PAD_DATA2_0 (.PAD(data2_pcb[0]),.C(data2_core[0])); PDIDGZ PAD_DATA2_1 (.PAD(data2_pcb[1]),.C(data2_core[1])); PDIDGZ PAD_DATA2_2 (.PAD(data2_pcb[2]),.C(data2_core[2])); PDIDGZ PAD_DATA2_3 (.PAD(data2_pcb[3]),.C(data2_core[3])); PDIDGZ PAD_DATA2_4 (.PAD(data2_pcb[4]),.C(data2_core[4])); PDIDGZ PAD_DATA2_5 (.PAD(data2_pcb[5]),.C(data2_core[5])); PDIDGZ PAD_DATA2_6 (.PAD(data2_pcb[6]),.C(data2_core[6])); PDIDGZ PAD_DATA2_7 (.PAD(data2_pcb[7]),.C(data2_core[7]));PDO04CDG PAD_DATAOUT_0 (.I(dataout_core[0]),.PAD(dataout_pcb[0]));PDO04CDG PAD_DATAOUT_1 (.I(dataout_core[1]),.PAD(dataout_pcb[1]));PDO04CDG PAD_DATAOUT_2 (.I(dataout_core[2]),.PAD(dataout_pcb[2]));PDO04CDG PAD_DATAOUT_3 (.I(dataout_core[3]),.PAD(dataout_pcb[3]));PDO04CDG PAD_DATAOUT_4 (.I(dataout_core[4]),.PAD(dataout_pcb[4]));PDO04CDG PAD_DATAOUT_5 (.I(dataout_core[5]),.PAD(dataout_pcb[5]));PDO04CDG PAD_DATAOUT_6(.I(dataout_core[6]),.PAD(dataout_pcb[6]));PDO04CDG PAD_DATAOUT_7 (.I(dataout_core[7]),.PAD(dataout_pcb[7]));PDO04CDG PAD_DATAOUT_8 (.I(dataout_core[8]),.PAD(dataout_pcb[8]));PDO04CDG PAD_DATAOUT_9 (.I(dataout_core[9]),.PAD(dataout_pcb[9]));PDO04CDG PAD_DATAOUT_10 (.I(dataout_core[10]),.PAD(dataout_pcb[10]));PDO04CDG PAD_DATAOUT_11 (.I(dataout_core[11]),.PAD(dataout_pcb[11]));PDO04CDG PAD_DATAOUT_12 (.I(dataout_core[12]),.PAD(dataout_pcb[12]));PDO04CDG PAD_DATAOUT_13 (.I(dataout_core[13]),.PAD(dataout_pcb[13]));PDO04CDG PAD_DATAOUT_14 (.I(dataout_core[14]),.PAD(dataout_pcb[14]));PDO04CDG PAD_DATAOUT_15 (.I(dataout_core[15]),.PAD(dataout_pcb[15]));PVDD1DGZ vdd1 (); (当前不必加的)PVDD1DGZ vdd2 ();PVDD1DGZ vdd3 ();PVDD1DGZ vdd4 ();PVSS1DGZ vss1 ();PVSS1DGZ vss2 ();PVSS1DGZ vss3 ();PVSS1DGZ vss4 ();PCORNERDG c1 ();PCORNERDG c2 ();PCORNERDG c3 ();PCORNERDG c4 ();endmodule#############################顶层模块#########################module top(clock,clear,da1,da2,dataout_out);input clock,clear;input [7:0] da1,da2;output [15:0] dataout_out;wire clk_core,clr_core;wire [7:0] data1_core,data2_core;wire [15:0] dataout_core;wire [15:0] y;PADPAD_TOP(.clk_pcb(clock),.clk_core(clk_core),.clr_pcb(clear),.clr_core(clr_ core),.data1_pcb(da1),.data1_core(data1_core),.data2_pcb(da2),.data2_core( data2_core),.dataout_core(dataout_core),.dataout_pcb(dataout_out));mux_1 mux_1 (.clk(clk_core),.clr(clr_core),.a(data1_core),.b(data2_core),.y(y));mux mutiple (.clk(clk_core),.clr(clr_core),.data1(y[15:8]),.data2(y[7:0]),.dataout(dataout_ core));(那里是对付硬核的调用)endmodule第三步:逻辑概括注意的是,咱们正在逻辑概括之前,需要加如mux的db库文献,此文献由encounter筹备布线以去爆收的延时文献再通过pt固态时序分解以去爆收.咱们给顶层模块加如拘束:Current_design toplinkcreate_clock -period 10 [get_ports clock]set_clock_latency -source -max 0.2 [get_ports clock]set_clock_latency -max 0.1 [get_ports clock]set_clock_uncertainty -setup 0.01 [get_ports clock]set_input_delay -max 0.5 -clock clock [all_inputs]set_output_delay -max 0.5 -clock clock [all_outputs]#set_driving_cell -lib_cell INVX4 [all_inputs]#set_load -pin_load 0.0659726 [all_outputs]set_wire_load_model -name tsmc18_wl10 -library typicalset_wire_load_mode enclosedset_dont_touch mux(注意此处,便是概括的时间不针对付mux举止概括,概括工具会自动超过鸿沟对付其余逻辑举止概括)set_dont_touch_network [all_clocks]compile -boundarychange_names -rule verilog -hier第四步:筹备布线用概括得到的网表(top.sv)战拘束文献(sdc).并将之前的mux模块的lef文档准备佳.那里遇到了一个问题,正在逻辑概括之前的代码尔已经加如了PAD的VDD ,VSS战corner,然而是概括完以去便不睹了,本果不明,那时正在筹备之前便要脚动增加上去.数据准备:时序文献:对付应于上头的lib文献,typical.lib,block的lib(由PT爆收),PAD的libIo文献:不妨自己定义顶层端心的位子(底下会介怎么样搞io文献)Sdc文献:概括后爆收的拘束文献.Io文献的树坐,主要由四个目标决断,N,W,S,E便战咱们英文里的四个目标的尾字母一般,天然另有NW,WS,SE,NE,四个角,是用与corner 的晃搁,该安排有34个心,中加8个供电PAD,加上四个CORNER 总合有46个PAD,主要的是42个PAD,咱们不妨将那42个PAD搁到自己念树坐的位子,对付于一个真真的安排,要思量以去连线的少度,内里模块晃搁位子等,去合理安插io的位子.如图所示为该安排的PAD筹备图:根据此筹备图,咱们对付此安排的io文献编写如下,io文献对付应本质筹备中的准则是,N是由io文献列表的程序从左到左的搁置,W目标是由下到上的搁置,S共N,E共W.Pad: PAD_TOP/PAD_DATAOUT_12 NPad: PAD_TOP/PAD_DATAOUT_13 NPad: PAD_TOP/PAD_DATAOUT_14 NPad: PAD_TOP/PAD_DATAOUT_15 NPad: PAD_TOP/PAD_CLK NPad: PAD_TOP/vss2 NPad: PAD_TOP/vdd2 NPad: PAD_TOP/PAD_DATA1_0 NPad: PAD_TOP/PAD_DATA1_1 NPad: PAD_TOP/PAD_DATA1_2 NPad: PAD_TOP/PAD_DATA1_3 NPad: PAD_TOP/c1 NEOrient: R0Pad: PAD_TOP/c2 SWPad: PAD_TOP/PAD_DATAOUT_4 WPad: PAD_TOP/PAD_DATAOUT_5 WPad: PAD_TOP/PAD_DATAOUT_6 WPad: PAD_TOP/PAD_DATAOUT_7 WPad: PAD_TOP/vdd1 WPad: PAD_TOP/vss1 WPad: PAD_TOP/PAD_DATAOUT_8 WPad: PAD_TOP/PAD_DATAOUT_9 WPad: PAD_TOP/PAD_DATAOUT_10 WPad: PAD_TOP/PAD_DATAOUT_11 WPad: PAD_TOP/c3 NWPad: PAD_TOP/PAD_DATAOUT_0 SPad: PAD_TOP/PAD_DATAOUT_1 SPad: PAD_TOP/PAD_DATAOUT_2 SPad: PAD_TOP/PAD_DATAOUT_3 WPad: PAD_TOP/PAD_CLR SPad: PAD_TOP/vdd3 SPad: PAD_TOP/vss3 SPad: PAD_TOP/PAD_DATA2_7 SPad: PAD_TOP/PAD_DATA2_6 SPad: PAD_TOP/PAD_DATA2_5 SPad: PAD_TOP/PAD_DATA2_4 SPad: PAD_TOP/PAD_DATA2_3 EPad: PAD_TOP/PAD_DATA2_2 EPad: PAD_TOP/PAD_DATA2_1 EPad: PAD_TOP/PAD_DATA2_0 EPad: PAD_TOP/vdd4 EPad: PAD_TOP/vss4 EPad: PAD_TOP/PAD_DATA1_7 EPad: PAD_TOP/PAD_DATA1_6 EPad: PAD_TOP/PAD_DATA1_5 EPad: PAD_TOP/PAD_DATA1_4 E十足准备佳以去,咱们导进所有的准备数据会瞅到一个有PAD战宏模块的的芯片图果为PAD的里积较大,所以其余单元战模块瞅起去便比较小了.第五步:筹备。
数字IC设计方法学(共52张PPT)

➢比方,RTL综合等后端处理阶段和RTL代码功能仿真阶段可以并行进行;再如, 后端设计过程中的静态时序分析和后仿真可以并行进行。 ➢多阶段之间的并行操作缩短了IC设计周期,但也给设计中数据管理提出了更 高要求,因为多个操作阶段间有数据依赖关系。 ➢设计各阶段间的反复迭代和并行操作要求数字IC设计必须有严格的数据管理机 制才能保证工程正常进行。
➢在指令装载状态下,可重构密码协处理器将密码程序中的指令按顺序装载到指令存 储器中。在指令执行状态下,可重构密码协处理器自动地、不断地从指令存储器中取 出指令、进行译码并加以执行,直至所有指令执行完毕。在空闲状态下,可重构密码 协处理器不进行指令装载操作和指令执行操作,并保持所有的运算结果存放器的值不 变。 ➢主处理器只需对指令执行使能信号ins_exe施加一个脉冲,就可以将可重构密码协处理 器设置为指令执行状态,从而启动指令自动执行过程,然后在整个过程中不再需要主处理 器的干预,这大大减少了主处理器的控制开销和可重构密码协处理器访问外部设备的开销 ,提高了加/解密的处理速度。
clk rst insnumr_en insw_en
指令装载 控制逻辑
i n s w_a d d r< 1 2 : 0 >
d a t a b u<s7 : 0 >
clk
rst
o p c o d<ex : 0 > c o n d a t<ax : 0 >
jump_id halt_id
逻辑
指令译码
ins<207:0> comp_id<4:0>
可重构密码协处理器
IC设计流程简介PPT课件

7. ESD:IO,不同电源,地之间
.
11
后端设计
验证关键点
1. 制定一个完整的检查列表,逐项确认 2. DRC, LVS参数设置:与实际使用工艺一致 3. ESD, LATCHUP, Antenna分析 4. 关键网络提取,进行电路仿真 5. 关键单元接口提取,进行电路仿真 6. 导出GDS应包含所有掩膜层,可增加LOGO,
IC设计流程简介
2009.10.20
.
1
前端设计 后端设计 流片 封测
主题
.
2
前端设计
设计流程
1. 需求分析
2. 概要设计
3. 详细设计
4. 编码
5. 设计规则检查
6. 功能验证
7. 综合,BSD和扫描链插入,形式验证,时序 分析
8. 时序验证
.
3
前端设计
EDA工具
1. 仿真:VCS, Verilog-XL,NC-Verilog,Modelsim 2. 综合:DC 3. 时序分析:PT 4. 形式验证:Formality 5. 设计规则检查:Nlint,Leda
.
10
后端设计
设计关键点
1. 专人负责维护基本单元,IP及代工厂资料
2. 约束条件合理,无遗漏
• 时钟,输入输出,负载等
3. 单元布局,电源、地网络分布合理
4. 时序驱动的布局布线
5. 结合独立工具进行串扰,天线效应检查,提高分析准 确度
• PT-SI:串扰分析,Hercules:天线效应
6. 静态时序分析和动态时序仿真相结合
4. 填写Customer Database Release Notice表格
5. 填写Layout Design Database Information 表格
数字IC设计流程与工具讲义(PPT 52页)

数字后端设计流程-2
哪些工作要APR工具完成? 芯片布图(RAM,ROM等的摆放、芯片供电网络配置、 I/O PAD摆放) 标准单元的布局 时钟树和复位树综合 布线 DRC LVS DFM(Design For Manufacturing)
时钟树综合的目的: 低skew 低clock latency
数字后端设计流程-6 时钟树和复位树综合
时钟树和复位树综合为什么要放在APR时再做呢? 在DC综合时并不知道各个时序元件的布局信息,时钟 线长度不确定。 DC综合时用到的线载模型并不准确。
数字后端设计流程-7 布线
将分布在芯片核内的模块、标准单元和输入输出接口单 元(I/O pad)按逻辑关系进行互连,其要求是百分之百 地完成他们之间的所有逻辑信号的互连,并为满足各种 约束条件进行优化。 布线工具会自动进行布线拥塞消除、优化时序、减小耦 合效应、消除串扰、降低功耗、保证信号完整性等问题。
原理 把设计划分成无数个逻辑锥
(logic cone)的形式,以逻辑锥为 基本单元进行验证.当所有的逻 辑锥都功能相等,则验证 successful ! 逻辑锥
锥顶作为比较点.它可以由原始 输出,寄存器输入,黑盒输入充当
---- formality自动划分
数字前端设计流程-15 形式验证
什么时候需要做形式验证? Verify RTL designs vs. RTL designs -- the rtl revision is made frequently Verify RTL designs vs. Gate level netlists -- verify synthesis results -- verify manually coded netlists,such as Design Ware verify Gate level netlists vs. Gate level netlists -- test insertion -- layout optimization
数字IC后端流程

11.Tape out。在所有检查和验证都正确无误的情况下把最后的版图GDSⅡ文件传递给Foundry厂进行掩膜制造。
2.布局规划。主要是标准单元、I/O Pad和宏单元的布局。I/O Pad预先给出了位置,而宏单元则根据时序要求进行摆放,标准单元则是给出了一定的区域由工具自动摆放。布局规划后,芯片的大小,Core的面积,Row的形式、电源及地线的Ring和Strip都确定下来了。如果必要 在自动放置标准单元和宏单元之后, 你可以先做一次PNA(power network analysis)--IR drop and EM .
6.ECO(Engineering Change Order)。针对静态时序分析和后仿真中出现的问题,对电路和单元布局进行小范围的改动.
7.Filler的插入(pad fliier, cell filler)。Filler指的是标准单元库和I/O Pad库中定义的与逻辑无关的填充物,用来填充标准单元和标准单元之间,I/O Pad和I/O Pad之间的间隙,它主要是把扩散层连接起来,满足DRC规则和设计需要。
8.布线(Routing)。Global route-- rack assign --Detail routing--Routing optimization 布线是指在满足工艺规则和布线层数限制、线宽、线间距限制和各线网可靠绝缘的电性能约束的条件下,根据电路的连接关系将各单元和I/O Pad用互连线连接起来,这些是在时序驱动(Timing driven ) 的条件下进行的,保证关键时序路径上的连线长度能够最小。--Timing report clear
那你可用write_milkway, read_milkway 传递数据。
4.时钟树生成(CTS Clock tree synthesis) 。芯片中的时钟网络要驱动电路中所有的时序单元,所以时钟源端门单元带载很多,其负载延时很大并且不平衡,需要插入缓冲器减小负载和平衡延时。时钟网络及其上的缓冲器构成了时钟树。一般要反复几次才可以做出一个比较理想的时钟树。---Clock skew.
IC封装后道管理分享(课堂PPT)

2.2 每周盘点库存,常用备件低于安全库存时,造出计划
2.3 根据保养文件/计划,对于非易损件提前2个月造成计划
责任人
完成时间
完成进 度
XXX
2012.2.28
进行中
XXX
依据设备情况而定 进行中
XXX
2011.12.31
进行中
XXX
2012.5.1
进行中
XXX
每周
进行中
XXX
每周
进行中
XXX
每月
进行中
XXX
1.5 试运行MES排单系统,方便调度排单、值班长跟踪
XXX
每日
进行中
每周
进行中
2012.1
进行中
2012.2.20 进行中
2012.2.20 进行中
10
2012年品质提升计划
客诉件数: <2件/月; 加工成品率: 99.50%;
-- 管控人为异常,重大异常零缺陷 --良率TOP5项目的改善,设备、工程全员参与良率改善 -- 防呆项目的推广
2
Байду номын сангаас
2012年总体目标
围绕月目标800万展开各项工作 -- 完成公司下达生产指标,生产达成率达95%以上 -- 全面防呆并深入到每个细节, 每个员工 -- 加强值班长队伍的建设,促进值班长的成长 -- 加强执行力建设,人为重大异常零缺陷 -- 5S持续改善与维持 -- 安全事故零缺陷
3
SWOT分析
员工执行力欠佳,品质风险大
4
SWOT分析
机会
威胁
商业产品基本已量产,后续逐步开 展汽车产品计划
学习到国外知名企业的管理模式
重大质量问题隐患 订单的不足与不均衡
数字IC后端流程 PPT

1. Specify the Logical Libraries
2. Define ‘logic0’ and ‘logic1’
3. Create a “Container”: The Design Library
4. Specify TLU+ Parasitic RC Model Files
• 电源条线(power strips)指芯片内部纵 横交错的电源网格(power grid)
Power plan
Write Out Floorplan and DEF Files
设计交换格式DEF(design exchange format)文件是由Cadence公司开发的用于 描述文件物理设计信息的一种文件格式。
基于ICC的数字IC后端设计流程
There is no “golden script” for physical design
Data Setup
布局布线的准备工作,读入网表,跟Foundry提供的STD Cell、 Pad库以及Macro库进行映射。
Data Setup
后端设计数据准备
设计网表
Must be created prior to specifying the pad cell locations
open_mw_cel DESIGN_data_setup create_cell {vss_l vss_r vss_t vss_b} pv0i create_cell {vdd_l vdd_r vdd_t vdd_b} pvdi create_cell {CornerLL CornerLR CornerTR CornerTL} pfrelr
TLU+ is a binary table format that stores the RC coefficients
IC后端流程(初学必看)之欧阳文创编

校外IC后端实践报告本教程通过对synopsys公司给的lab进行培训,从verilog代码到版图的整个流程(当然只是基本流程,因为真正一个大型的设计不是那么简单就完成的),此教程的目的就是为了让大家尽快了解数字IC设计的大概流程,为以后学习建立一个基础。
此教程只是本人探索实验的结果,并不代表内容都是正确的,只是为了说明大概的流程,里面一定还有很多未完善并且有错误的地方,我在今后的学习当中会对其逐一完善和修正。
此后端流程大致包括一下内容:1.逻辑综合(工具DC 逻辑综合是干吗的就不用解释了把?)2.设计的形式验证(工具formality)形式验证就是功能验证,主要验证流程中的各个阶段的代码功能是否一致,包括综合前RTL代码和综合后网表的验证,因为如今IC设计的规模越来越大,如果对门级网表进行动态仿真的话,会花费较长的时间(规模大的话甚至要数星期),这对于一个对时间要求严格(设计周期短)的asic设计来说是不可容忍的,而形式验证只用几小时即可完成一个大型的验证。
另外,因为版图后做了时钟树综合,时钟树的插入意味着进入布图工具的原来的网表已经被修改了,所以有必要验证与原来的网表是逻辑等价的。
3.静态时序分析(STA),某种程度上来说,STA是ASIC设计中最重要的步骤,使用primetime对整个设计布图前的静态时序分析,没有时序违规,则进入下一步,否则重新进行综合。
(PR后也需作signoff的时序分析)4.使用cadence公司的SOCencounter对综合后的网表进行自动布局布线(APR)5.自动布局以后得到具体的延时信息(sdf文件,由寄生RC和互联RC所组成)反标注到网表,再做静态时序分析,与综合类似,静态时序分析是一个迭代的过程,它与芯片布局布线的联系非常紧密,这个操作通常是需要执行许多次才能满足时序需求,如果没违规,则进入下一步。
6.APR后的门级功能仿真(如果需要)7.进行DRC和LVS,如果通过,则进入下一步。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于ICC的数字IC后端设计流程
There is no “golden script” for physical design
Data Setup
布局布线的准备工作,读入网表,跟Foundry提供的STD Cell、 Pad库以及Macro库进行映射。
Data Setup
后端设计数据准备
设计网表Βιβλιοθήκη Data Setup逻辑单元库:一个完整的单元库由不同的功能电路所组 成,种类和数量很多,根据其应用可分为三类:
标准单元(standard cells)
组合逻辑
时序逻辑
模块宏单元(macro block)
ROM
RAM
专用模块(如ASSP、DSP等)
Black box商业IP(如ARM、标准单元等)
Data Setup
The Technology File (.tf file):The technology file is unique to each technology;Contains metal layer technology parameters:
Number and name designations for each layer/via Physical and electrical characteristics of each layer/via Design rules for each layer/Via (Minimum wire widths and wire-to-wire spacing, etc.) Units and precision for electrical units Colors and patterns of layers for display …
Max fanout Max transition Max/Min capacitance
Are usually the same ones used by Design Compiler during synthesis Are specified with variables:
target_library link_library
Data Setup
库文件
时序库:描述单元库中各个单元时序信息的文件。 (.lib库)
单元延时 互连线延时
物理库:是对版图的抽象描述,她使自动布局布线成 为可能且提高了工具效率(.lef库),包含两部分
技术LEF:定义布局布线的设计规则和foundry的工艺信息 单元LEF:定义sc、macro、I/O和各种特殊单元的物理信息, 如对称性、面积大小、布线层、不可布线区域、天线效应参 数等
填充单元(filler/spacer)
I/O spacer用于填充I/O单元之间的空隙以形成power ring 标准单元filler cell与逻辑无关,用于把扩散层连接起来满足DRC规则 和设计需求,并形成power rails
电压钳位单元(tie-high/tie-low) 二极管单元(diode),对违反天线规则的栅输入端加入反偏二极 管,避免天线效应将栅氧击穿 时钟缓冲单元(clock buffer/clock inverter):为最小化时钟偏差 (skew),插入时钟缓冲单元来减小负载和平衡延时 延时缓冲单元(delay buffer):用于调节时序 阱连接单元(well-tap cell):主要用于限制电源或地与衬底之间 的 电阻大小,减小latch-up效应 电压转换单元(level-shifter):多用于低功耗设计
1. Specify the Logical Libraries
2. Define ‘logic0’ and ‘logic1’
3. Create a “Container”: The Design Library
4. Specify TLU+ Parasitic RC Model Files
Data Setup
Logical Libraries
Provide timing and functionality information for all standard cells (and, or, flipflop, …) Provide timing information for hard macros (IP, ROM, RAM, …) Define drive/load design rules:
gate-level netlist
设计约束文件 SDC file
物理库文件 sc.lef/io.lef/macro.lef
时序库文件 sc.lib/io.lib/macro.lib
I/O文件
I/O constraints file(.tdf)
工艺文件
technology file(.tf)
RC模型文件 TLU+
CMOS集成电路版图
--概念、方法与工具
第6IC
数字IC后端流程
Data Setup Design planning Placement CTS Route DFM & Chip Finishing
基于ICC的数字IC后端设计流程
Use IC Compiler to perform placement, DFT, CTS, routing and optimization, achieving timing closure for designs with moderate to high design challenges.
模拟模块(如PLL、振荡器等)
输入输出单元(I/O pad cell)
输入
输出
三态
考虑ESD
双向
Data Setup
Physical Reference Libraries
大家应该也有点累了,稍作休息
CMOS集成电路版图
大家有疑问的,可以询问和交
10
西安邮电大学微电子学系
Data Setup
物理单元库:和逻辑单元库分类相同,但也包括一些特 殊单元,在后端物理实现中的作用有别于其他逻辑电路
TLU+ is a binary table format that stores the RC coefficients
Timing is Based on Cell and Net Delays