统计学4
统计学第4章学习指导
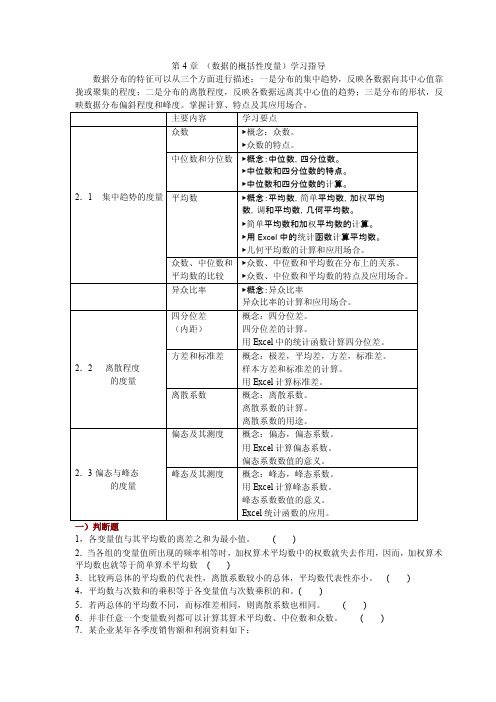
第4章(数据的概括性度量)学习指导数据分布的特征可以从三个方面进行描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布偏斜程度和峰度。
掌握计算、特点及其应用场合。
主要内容学习要点2.1 集中趋势的度量众数▶概念:众数。
▶众数的特点。
中位数和分位数▶概念:中位数,四分位数。
▶中位数和四分位数的特点。
▶中位数和四分位数的计算。
平均数▶概念:平均数,简单平均数,加权平均数,调和平均数,几何平均数。
▶简单平均数和加权平均数的计算。
▶用Excel中的统计函数计算平均数。
▶几何平均数的计算和应用场合。
众数、中位数和平均数的比较▶众数、中位数和平均数在分布上的关系。
▶众数、中位数和平均数的特点及应用场合。
异众比率▶概念:异众比率异众比率的计算和应用场合。
2.2离散程度的度量四分位差(内距)概念:四分位差。
四分位差的计算。
用Excel中的统计函数计算四分位差。
方差和标准差概念:极差,平均差,方差,标准差。
样本方差和标准差的计算。
用Excel计算标准差。
离散系数概念:离散系数。
离散系数的计算。
离散系数的用途。
2.3偏态与峰态的度量偏态及其测度概念:偏态,偏态系数。
用Excel计算偏态系数。
偏态系数数值的意义。
峰态及其测度概念:峰态,峰态系数。
用Excel计算峰态系数。
峰态系数数值的意义。
Excel统计函数的应用。
一)判断题1,各变量值与其平均数的离差之和为最小值。
( )2.当各组的变量值所出现的频率相等时,加权算术平均数中的权数就失去作用,因而,加权算术平均数也就等于简单算术平均数( )3.比较两总体的平均数的代表性,离散系数较小的总体,平均数代表性亦小。
( )4,平均数与次数和的乘积等于各变量值与次数乘积的和。
( )5.若两总体的平均数不同,而标准差相同,则离散系数也相同。
( )6.并非任意一个变量数列都可以计算其算术平均数、中位数和众数。
统计学第四章课后习题答案

第四章一.思考题1、一组数据的分布特征可以从哪几个方面进行测度?答:可以从三个方面进行测度和描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布的偏态和峰态。
2、怎样理解平均数在统计学中的地位?答:平均数在统计学中具有重要的地位,它是进行统计分析和统计推断的基础。
从统计学思想上看,平均数是一组数据的重心所在,是数据误差相互抵消后的必然结果。
3、简述四分位数的计算方法。
答:四分位数是一组数据排序后处于25%和75%位子上的值。
四分位数是通过3个点将全部数据等分成4分,其中每部分包含25%的数据。
中间的四分位数就是中位数,因此通常所说的四分位数是指处在25%位置上的数值和处在75%位置上的数值。
它是根据为分组数据计算四分位数时,首先对数据进行排序,然后确定四分位数所在的位置,该位置上的数据就是四分位数。
4、对于比率数据的平均数为什么采用几何平均?答:几何平均数是适用于特殊数据的一种平均数,主要适用于计算平均比率。
当所掌握的变量值本身是比率的形式时,采用几何平均法计算平均比率更为合理。
5、简述众数、中位数、平均数的特点和应用场合。
答:众数是数据中出现次数次数最多的变量值。
主要应用于分类数据。
中位数是一组数据排序后处于中间位置的变量值,其适用于顺序数据。
平均数也称均值,它是一组数据相加后除以数据个数的结果,是集中去世的主要测量值,它适用于数值型数据。
6、简述异众比率、四分位差、方差、标准差的使用场合。
答:异众比率主要适合测度分类数据的离散程度,对于顺序数据以及数值型数据也可以计算异众比率。
四分位差主要用于测度顺序数据的离散程度。
方差和标准差适用于测度数值型数据的离散程度。
7、标准分数有哪些用途?答:首先是比较不同单位和不同质数据的位置。
其次是和正态分布结合起来,求得概率和标准分值之间的对应关系。
还有就是在假设检验和估计中应用。
统计学第四章课后题及答案解析

统计学第四章课后题及答案解析统计学第四章课后题及答案解析以下是为大家整理的统计学第四章课后题及答案解析的相关范文,本文关键词为统计学,第四章,课后,答案,解析,第四章,练习题,单项选择,,您可以从右上方搜索框检索更多相关文章,如果您觉得有用,请继续关注我们并推荐给您的好友,您可以在综合文库中查看更多范文。
第四章练习题一、单项选择题1.由反映总体单位某一数量特征的标志值汇总得到的指标是()A.总体单位总量b.质量指标c.总体标志总量D.相对指标2.各部分所占比重之和等于1或100%的相对数()A.比例相对数b.比较相对数c.结构相对数D.动态相对数3.某企业工人劳动生产率计划提高5%,实际提高了10%,则提高劳动生产率的计划完成程度为()A.104.76%b.95.45%c.200%D.4.76%4.某企业计划规定产品成本比上年度降低10%实际产品成本比上年降低了14.5%,则产品成本计划完成程度()A.14.5%b.95%c.5%D.114.5%5.在一个特定总体内,下列说法正确的是()A.只存在一个单位总量,但可以同时存在多个标志总量b.可以存在多个单位总量,但必须只有一个标志总量c.只能存在一个单位总量和一个标志总量D.可以存在多个单位总量和多个标志总量6.计算平均指标的基本要求是所要计算的平均指标的总体单位应是()A.大量的b.同质的c.有差异的D.不同总体的7.几何平均数的计算适用于求()A.平均速度和平均比率b.平均增长水平c.平均发展水平D.序时平均数8.一组样本数据为3、3、1、5、13、12、11、9、7这组数据的中位数是()A.3b.13c.7.1D.79.某班学生的统计学平均成绩是70分,最高分是96分,最低分是62分,根据这些信息,可以计算的测度离散程度的统计量是()A.方差b.极差c.标准差D.变异系数10.用标准差比较分析两个同类总体平均指标的代表性大小时,其基本的前提条件是()A.两个总体的标准差应相等b.两个总体的平均数应相等c.两个总体的单位数应相等D.两个总体的离差之和应相等11.已知4个水果商店苹果的单价和销售额,要求计算4个商店苹果的平均单价,应采用()A.简单算术平均数b.加权算术平均数c.加权调和平均数D.几何平均数12.算术平均数、众数和中位数之间的数量关系决定于总体次数的分布状况。
统计学 4 综合指标

特征的一种概括。
件下的具体表现。
统计指标
重要特点:数量性;具体性; 综合性
数量指标
质量指标
分类 绝对数指标 相对数指标 平均数指标
总规模、总水平 工作总量的指标 相对水平或工 作质量的指标
指标体系 具有内在联系的一系列指标所
构成的整体,即称为指标体系。
第四章 总量指标和相对指标
第一节 总量指标
概念
总量指标是指用来表明社会经济现象在一定时间、地 点、条件下的总规模、总水平或工作总量的指标。
作用
(1)是对社会经济现象认识的起点; (2)是国民经济宏观管理和企业经济核算的基
础性指标,是实行目标管理的工具; (3)是计算相对指标和平均指标的基础。
分类
按反映总体的内容分 按反映的时间状态分 按计量单位分
x1 f1 x2 f 2 xn f n xf x f1 f 2 f n f
f1 fn f x x1 xn x f f f
•
• •
•
2、影响因素 (1)各组变量值x的大小 (2)各组次数f
当变量值x比较大的次数f也多时,平均 数就靠近变量值大的一方;当变量值x较小而 次数f较多时,平均数就靠近变量值小的一方, 变量值的次数f的多少对平均数的大小起着权 衡轻重的作用,故称f为权数。权数除用次数 f表示外,还可用频率(权重)f/∑f表示。
1.孟加拉国--人口--14737万--面积---14.40万Km2--人口密度---1023人/Km2 2.日本--人口--12762万--面积---37.78万Km2--人口密度—338人/Km2 3.印度--人口-109535万--面积--328.76万Km2--人口密度---333人/Km2 4.菲律宾--人口---8947万--面积---30.00万Km2--人口密度—298人/Km2 5.越南--人口---8440万--面积---32.96万Km2--人口密度---256人/Km2 6.英国--人口---6060万--面积---24.48万Km2--人口密度--248人/Km2 7.德国--人口---8245万--面积---35.70万Km2--人口密度--231人/Km2 8.巴基斯坦--人口--16580万--面积---80.39万Km2--人口密度---206人/Km2 9.意大利--人口---5813万--面积---30.12万Km2--人口密度--193人/Km2 10.尼日利亚--人口--13186万---面积92.38万Km2--人口密度---143人/Km2 11.中国--人口-132256万--面积--959.70万Km2—人口密度—138人/Km2 12.印度尼西亚--人口--24545万--面积--191.94万Km2--人口密度—128人/Km2
统计学第4章综合指标

直接观察数据中出现次数最多的数。
平均指标在统计分析中应用
描述统计
用平均指标描述数据的集中 趋势和一般水平,如用算术 平均数描述班级学生的平均 成绩。
比较分析
通过比较不同组数据的平均 指标,揭示它们之间的差异 和联系,如比较不同班级的 平均成绩以评估教学效果。
推断统计
在总体分布未知的情况下, 利用样本平均指标对总体进 行推断,如通过样本均值推 断总体均值。
总量指标的作用
作为计算相对指标和平均指标的基础
描述社会经济现象的总规模和总水平
总量指标种类与计算方法
总量指标的种类
01
时点指标:反映现象在某一时刻上的总量 ,如年末人口数、股票价格等。
03
02
时期指标:反映现象在一段时期内的总量, 如国内生产总值、人口数等。
04
总量指标的计算方法
直接计数法:对总体单位进行逐一计数, 然后汇总得到总量指标。
相对指标种类与计算方法
结构相对指标
部分与总体之比,反映总
总体中不同部分数量之比,反映各部分之间的 比例关系。
比较相对指标
同一现象在不同空间条件下的数量对比,反映现象在不同地区的差异程度。
相对指标种类与计算方法
强度相对指标
两个性质不同但有一定联系的总量指标之比,反映现象的强度、密度和普遍程度。
平均指标种类与计算方法
算术平均数
$bar{x} = frac{sum x}{n}$,其中$sum x$为所有数值之和,$n$为 数值个数。
几何平均数
$G = sqrt[n]{prod x_i}$,其中$prod x_i$为所有数值之积,$n$为 数值个数。
中位数
将数据从小到大排列,若数据量为奇数则取中间数,若数据量为偶数 则取中间两数的平均值。
统计4:显著性检验

统计4:显著性检验在统计学中,显著性检验是“假设检验”中最常⽤的⼀种,显著性检验是⽤于检测科学实验中实验组与对照组之间是否有差异以及差异是否显著的办法。
⼀,假设检验显著性检验是假设检验的⼀种,那什么是假设检验?假设检验就是事先对总体(随机变量)的参数或总体分布形式做出⼀个假设,然后利⽤样本信息来判断这个假设是否合理。
在验证假设的过程中,总是提出两个相互对⽴的假设,把要检验的假设称作原假设,记作H0,把与H0对⽴的假设称作备择假设,记作H1。
假设检验需要解决的问题是:指定⼀个合理的检验法则,利⽤已知样本的数据作出决策,是接受假设H0,还是拒绝假设H0。
1,假设检验的基本思想假设检验的基本思想是⼩概率反证法思想。
⼩概率思想是指⼩概率事件(P<0.01或P<0.05)在⼀次试验中基本上不会发⽣。
反证法思想是先提出原假设(记作假设H0),再⽤适当的统计⽅法确定原假设成⽴的可能性⼤⼩:若可能性⼩,则认为原假设不成⽴;若可能性⼤,则认为原假设是成⽴的。
2,假设检验的思路假设检验思路是:先假设,后检验,通俗地来说就是要先对数据做⼀个假设,然后⽤检验来检查假设对不对。
⼀般⽽⾔,把要检验的假设称之为原假设,记为H0;把与H0相对对⽴(相反)的假设称之为备择假设,记为H1。
如果原假设为真,⽽检验的结论却劝你拒绝原假设,把这种错误称之为第⼀类错误(弃真),通常把第⼀类错误出现的概率记为α;就是说,拒绝真假设的概率是α。
如果原假设不真,⽽检验的结论却劝你接受原假设,把这种错误称之为第⼆类错误(取伪),通常把第⼆类错误出现的概率记为β;就是说,接受假假设的概率是β。
因此,在确定检验法则时,应尽可能使犯这两类错误的概率都较⼩。
⼀般来说,当样本容量固定时,如果减少犯⼀类错误的概率,则犯另⼀类错误的概率往往增⼤。
如果要使犯两类错误的概率都减少,除⾮增加样本容量。
⼆,显著性检验什么是显著性检验?在给定样本容量的情况下,我们总是控制犯第⼀类错误的概率α,这种只对犯第⼀类错误的概率加以控制,⽽不考虑犯第⼆类错误的概率β的检验,称作显著性检验。
统计学第四章重点知识点

第四章 差异量教学目的:1.理解全距、四分位距、百分位距、平均差、方差、标准差和差异系数等概念;2.掌握各种差异量指标的计算方法。
数据的分布特征不仅有集中趋势,还有离中趋势。
以动态的眼光,从不同的角度看,数据是向中间变动的,也是向两端变动的。
两组数据可能平均水平相同,但两组数据的分布特征并不完全相同。
【如】:比较以下两组数据 A 组:88、82、73、76、81 B 组:92、86、70、72、80两组平均数,80==B A X X 但R A =88-73=15,R B=92-70=22。
即A 组较集中,B 组较分散。
因此,我们描述一组数据的分布特征,既要描述其集中趋势,也要描述其离中趋势。
差异量:表示一组数据的离中趋势或变异程度的量称为差异量。
常用的差异量指标有全距、四分位距、百分位距、平均差、方差、标准差和差异系数。
第一节全距、四分位距、百分位距一、全距全距:是一组数距中最大值与最小值之差。
优点:意义明确,计算方便。
缺点:反响不灵敏,易受极端值影响。
二、四分位距〔一〕四分位距的的概念四分位距:是指一组按大小顺序排列的数据中间部位50%个频数距离的一半。
QD :表示四分位距; Q 3:表示第三四分位数; Q 1:表示第一四分位数。
所以:四分位距的公式又为: 〔二〕四分位数的计算方法 1、原始数据计算法〔1〕将数据由小到大进行排列;〔2〕分别求出三位四分位数〔点〕;〔3〕代入公式计算。
【例如】:有以下16个数据25、22、29、12、40、15、14、39、37、31、33、19、17、20、35、30,其中四分位距的计算方法如下:〔1〕先将原始数据从小到大排列好;12、14、15、17、*19、20、22、25、*29、30、31、33、*35、37、39、40Q1=18 Md=27 Q3=34〔2〕求出Q1、Md、Q3;〔3〕将Q1、Md、Q3的得数代入公式〔4.1〕。
2、频数分布表计算法利用频数分布表计算公式为:关键是分别计算P75和P25,百分位数计算方法掌握了,这里的计算就不会有什么问题。
统计学(第4章)

连续变动结果的总量指标,时期指标是
一个流量。
时间维度上
时期指标的三个特点 具有可加性
时期指标可以累计
时期指标数值大小与时期长短有直接关系
时期指标的数值一般为连续登记
2019/6/15
第四章 描述统计
5
统计学
2、时点指标
时点指标又叫存量指标,是指反映社 会经济现象在某一时点上的总量指标,
四 季度
1 500
计划完成百分数=
1400+1420+1470+1500 5000
=115.8%
注:2010年第一季度前的四个季度的累计量已达5000,说明五年计 划提前三个季度完成。
2019/6/15
第四章 描述统计
33
统计学
(2)累计法
如何确定提前 完成时间?
计算公式:
计划完成相对指标 长期计划期间实际累计完成数 长期计划规定的累计数
时点指标是一个存量。
时间维度上
时点指标的三个特点
不具可加性
不同时点指标数值是不能累加
时点指标数值大小与时点间隔长短无直 接关系
时点指标一般为间断统计
2019/6/15
第四章 描述统计
6
统计学
三、总量指标的计量单位
1、实物量单位(包括度量衡单位) 2、价值量单位 3、劳动量单位(工时和工日)
5 000 1 250 1 340 1 280
102.4
52.4
4 000 1 000 1 030 1 215
121.5
56.1
2 000 500 600 400
80.0
50.0
11 000 2 750 2 970 2 895 105.33
统计学(4)

.
第一节 数据的收集
统计报表
按实施 范围分
按调查 范围分
按主管 系统分
按填报 单位分
按报送 方式分
国部地 全 非 基 专 基 综 电 书 家门方 面 全本 业 层 合 讯 面 统统统 统 面统 统 报 报 报 报 计计计 计 统计 计 表 表 表 表 报报报 报 计 报 表 表表表 表 报表 报
明确规定调查资料的起止时间; 调查资料登记时间:是指对调查单位进行调查并取得调
查资料的时间; 调查工作期限:是指从调查工作开始到调查工作结束所
经历的全部时间。 2.调查空间: 调查单位应在什么地点接受调查。
.
第一节 数据的收集
(五)制定调查的组织实施计划 调查的组织计划,是指为确保实施调查的具体工作计划。 调查的组织实施计划应包括以下内容: ➢ 建立调查工作的组织领导机构,做好人员的配备与分工; ➢ 做好调查前的准备工作。如宣传教育、人员培训、文件
重点单位:是指这些单位的标志总量在总体标志总量中占 有绝大比重的单位。
选取重点单位的原则:根据调查任务和调查对象的基本情 况确定选取的重点单位及数量;也要注意选取管理比较健全、 业务能力强、统计工作基础好的单位为重点单位。
特点:调查单位少;调查对象的标志值比较集中于某些单 位的场合。
注意:重点单位的选择是客观的。只适用于客观存在着重 点单位的情况。
注:1.资料来源于《世界概况》,由美国中央情报局(CIA出版)最权威报道; 2.中国2010年人均GDP为4283美元,居世界182个国家的95位。
.
第一节 数据的收集
1.定类尺度(类别尺度、列名尺度) 是对统计客体类别差异所作的反映,是最粗略、计量层次 最低的测量尺度。
统计学4章练习题+答案

第4章练习题1、一组数据中出现频数最多的变量值称为(A)A.众数B.中位数C.四分位数D.平均数2、下列关于众数的叙述,不正确的是(C)A.一组数据可能存在多个众数B.众数主要适用于分类数据C.一组数据的众数是唯一的D.众数不受极端值的影响3、一组数据排序后处于中间位置上的变量值称为(B)A.众数B.中位数C.四分位数D.平均数4、一组数据排序后处于25%和75%位置上的值称为(C)A.众数B.中位数C.四分位数D.平均数5、非众数组的频数占总频数的比例称为(A)A.异众比率B.离散系数C.平均差D.标准差6、四分位差是(A)A.上四分位数减下四分位数的结果B.下四分位数减上四分位数的结果C.下四分位数加上四分位数D.下四分位数与上四分位数的中间值7、一组数据的最大值与最小值之差称为(C)A.平均差B.标准差C.极差D.四分位差8、各变量值与其平均数离差平方的平均数称为(C)A.极差B.平均差C.方差D.标准差9、变量值与其平均数的离差除以标准差后的值称为(A)A.标准分数B.离散系数C.方差D.标准差10、如果一个数据的标准分数-2,表明该数据(B)A.比平均数高出2个标准差B.比平均数低2个标准差C.等于2倍的平均数D.等于2倍的标准差11、经验法则表明,当一组数据对称分布时,在平均数加减2个标准差的范围之内大约有(B)A.68%的数据B.95%的数据C.99%的数据D.100%的数据12、如果一组数据不是对称分布的,根据切比雪夫不等式,对于k=4,其意义是(C)A.至少有75%的数据落在平均数加减4个标准差的范围之内B. 至少有89%的数据落在平均数加减4个标准差的范围之内C. 至少有94%的数据落在平均数加减4个标准差的范围之内D. 至少有99%的数据落在平均数加减4个标准差的范围之内13、离散系数的主要用途是(C)A.反映一组数据的离散程度B.反映一组数据的平均水平C.比较多组数据的离散程度D.比较多组数据的平均水平14、比较两组数据离散程度最适合的统计量是(D)A.极差B.平均差C.标准差D.离散系数15、偏态系数测度了数据分布的非对称性程度。
统计学 第4章 假设检验

【解】研究者想收集证据予以支持的假设是该 城市中家庭拥有汽车的比率超过30%。 因此,建立的原假设和备择假设为 H0 :μ≤30% H1 :μ>30%
结论与建议
◆原假设和备择假设是一个完备事件组, 而且相互对立。在一项假设检验中,原假设和 备择假设必有一个成立,而且只有一个成立; ◆先确定备择假设,再确定原假设。因为 备择假设大多是人们关心并想予以支持和证实 的,一般比较清楚和容易确定; ◆等号“=”总是放在原假设上; ◆因研究目的不同,对同一问题可能提出 不同的假设,也可能得出不同的结论。 ◆假设检验主要是搜集证据来推翻和拒绝 原假设。
◆理想地,只有增加样本容量,能同时减小 犯两类错误的概率,但增加样本容量又受到很多 因素的限制; ◆通常,只能在两类错误的发生概率之间进 行平衡,发生哪一类错误的后果更为严重,就首 要控制哪类错误发生的概率; ◆在假设检验中,一般先控制第Ⅰ类错误的 发生概率。因为犯第Ⅰ类错误的概率是可以由研 究者控制的。
假设检验的过程
提出假设 作出决策
拒绝假设 别无选择!
总体
我认为人口的平 均年龄是50岁
抽取随机样本
均值 x = 20
二、原假设与备择假设
什么是假设?
对总体参数的具体数
值所作的陈述
我认为这种新药的疗效 比原有的药物更有效!
总体参数包括总体均值、 总体比率、总体方差等 分析之前必须陈述
备择假设。
500g
【解】研究者抽检的意图是倾向于证实这种洗 涤剂的平均净含量并不符合说明书中的陈述。 因此,建立的原假设和备择假设为 H0:μ≥500 H1:μ< 500
提出假设例3
一家研究机构估计,某城市中家庭拥有 汽车的比率超过 30% 。为验证这一估计是否 正确,该研究机构随机抽取了一个样本进行 检验。试陈述用于检验的原假设与备择假设
统计学4

用,掌握统计整理的方法,能够针对具体的调查资料
进行分类、汇总并编制统计表。
教学要求:
了解统计整理的概念和步骤,掌握统计分组、
分配数列及统计表的概念,重点掌握统计分组的
方法 、分配数列的编制,并学回会运用统计表来
表现统计资料。
4、1统计整理概述
检查数据是否真实反映客观实际情况,内 容是否符合实际 检查数据是否有错误,计算是否正确等
数据的审核—原始数据
(RAW DATA)
审核数据准确性的方法
1.
2.
逻辑检查 从定性角度,审核数据是否符合逻辑,内容 是否合理,各项目或数字之间有无相互矛盾 的现象 主要用于对分类和顺序据的审核 计算检查 检查调查表中的各项数据在计算结果和计算 方法上有无错误 主要用于对数值型数据的审核
饮料,就将这一饮料的品牌名字记录一次。
下面的表格是记录的原始数据。
顾客购买饮料的品牌名称
旭日升 露露 旭日升 可口可乐 百事可乐 可口可乐 汇源果汁 可口可乐 露露 可口可乐 可口可乐 旭日升 可口可乐 百事可乐 露露 旭日升 旭日升 百事可乐 可口可乐 旭日升 旭日升 可口可乐 可口可乐 旭日升 露露 旭日升 可口可乐 露露 百事可乐 百事可乐 汇源果汁 露露 百事可乐 可口可乐 百事可乐 汇源果汁 可口可乐 汇源果汁 可口可乐 汇源果汁 露露 可口可乐 旭日升 百事可乐 露露 汇源果汁 可口可乐 百事可乐 露露 旭日升
所以要选择组距式分组
第一步:确定组数。
K 1 lg 50 lg 2 7
第二步:确定各组的组距。 最大值为139,最小值为107,
统计学第四章 综合指标

3、计划完成百分数的计算
A、计划数为绝对数。
绝对数的计划完成百分数 实际绝对水平 100% 计划绝对水平
某工业企业总产值资料如下表:
车 名
间 称
总产值(万元) 计划Hale Waihona Puke 实际数计划完成百分数 (%)
(甲)
甲 乙 丙
(1)
50 110 140
(2)
80 100 140
(3)=(2)/(1)
160.00 90.91 100.00
时期指标与时点指标的联系:
1、二者都属于总量指标。 2、二者通常是相互影响的。
总量指标的计算
总量指标的单位一般有: 实物量单位 价值量单位 劳动量单位
1. 实物单位是根据事物的自然属性和特点采用的计 量单位。 实物单位的分类: ①自然单位:它是按照研究现象的自然状况来计量其 数量的一种计量单位。 ②度量衡单位:它是按照同意的度量衡制度的规定来 计量客观事物数量的一种计量单位。 ③双重单位和复合单位:是指在需要同时采用两个或 两个以上单位来计量事物时采用的单位。 ④标准实物单位:按照统一折算的标准来度量被研究 现象数量的一种计量单位。
相对指标在统计分析中的作用:
• 相对指标为人们深入认识事物发展的质 量与状况提供客观的依据,社会经济现 象总是相互联系、相互制约的关系。 • 计算相对指标可以使不能直接对比的现 象找到可以对比的基础,进行有效的分 析。
二、相对指标的种类及计算方法:
1、结构相对指标: • 定义:是在资料分组的基础上,以总体 总量作为比较标准,求出各组总量占总 体总量的比重,来反映总体内部组成情 况的综合指标。
合
计
300
320
106.67
要求:计算各车间和全厂总产值的计划完成百分数。
统计学第4章 参数估计

无偏性
(unbiasedness)
无偏性:估计量抽样分布的数学期望等于被
估计的总体参数
抽样分布
中,样本 P(ˆ)
均值、比 率、方差
无偏
有偏
分别是总
A
B
体均值、
比率、方
差的无偏
估4计- 2量3
ˆ
统计学
STATISTICS
有效性
(efficiency)
有效性:对同一总体参数的两个无偏点估计
置信水平(1-α)表达了区间估计的可靠性。 它是区间估计的可靠概率。
显著性水平α表达了区间估计的不可靠的概 率。
4 - 20
统计学§4.2 点估计的评价标准
STATISTICS
对于同一个未知参数,不同的方法得到的估 计量可能不同,于是提出问题
应该选用哪一种估计量? 用何标准来评价一个估计量的好坏?
常用 标准
4 - 21
(1) 无偏性 (2) 有效性 (3) 一致性
统计学 定义 STATISTICS
无偏性
(unbiasedness)
若 E(ˆ)
则称 ˆ是 的无偏估计量.
定义的合理性
我们不可能要求每一次由样本得到的
估计值与真值都相等,但可以要求这些估 计值的期望与真值相等.
4 - 22
统计学
量,有更小标准差的估计量更有效
P(ˆ)
ˆ1 的抽样分布
B
无偏估计量还 必须与总体参 数的离散程度
比较小
4 - 24
A
ˆ2 的抽样分布
ˆ
统计学
有效性
STATISTICS
定义 设 ˆ1 1(X1, X 2, , X n )
统计学 第四章 参数估计

由样本数量特征得到关于总体的数量特征 统计推断(statistical 的过程就叫做统计推断 的过程就叫做统计推断 inference)。 统计推断主要包括两方面的内容一个是参 统计推断主要包括两方面的内容一个是参 数估计(parameter estimation),另一个 数估计 另一个 假设检验 。 是假设检验(hypothesis testing)。
ˆ P(θ )
无偏 有偏
A
B
θ
ˆ θ
估计量的无偏性直观意义
θ =µ
•
•
•
• •
• • • •
•
2、有效性(efficiency)
有效性:对同一总体参数的两个无偏点估计 有效性: 量,有更小标准差的估计量更有效 。
ˆ P(θ )
ˆ θ1 的抽样分布
B A
ˆ θ2 的抽样分布
θ
ˆ θ
பைடு நூலகம்
3、一致性(consistency)
置信区间与置信度
1. 用一个具体的样本 所构造的区间是一 个特定的区间, 个特定的区间,我 们无法知道这个样 本所产生的区间是 否包含总体参数的 真值 2. 我们只能是希望这 个区间是大量包含 总体参数真值的区 间中的一个, 间中的一个,但它 也可能是少数几个 不包含参数真值的 区间中的一个
均值的抽样分布
总体均值的区间估计(例题分析)
25, 95% 解 : 已 知 X ~N(µ , 102) , n=25, 1-α = 95% , zα/2=1.96。根据样本数据计算得: x =105.36 96。 总体均值µ在1-α置信水平下的置信区间为 σ 10 x ± zα 2 = 105.36 ±1.96× n 25 = 105.36 ± 3.92
统计学第四章的教材

几个直观的结论
1. 样本均值的均值(数学期望)等于总体均值(式中:M为样本 n 数目); xi 22 23 28 i 1 25 X M 16 2. 抽样误差是随样本不同而不同的随机变量。抽样误差均值 等于0; xX 0
3. 样本均值的方差等于总体方差的1/n。
3
(二)抽样估计的一般步骤 1、设计抽样方案 2、 随机抽取样本(从总体随机抽取部分单位构成样本) 3、搜集样本资料(对样本单位进行调查登记) 4、整理样本资料(审查、分组汇总、计算样本指标的
数值,即计算估计量的具体数值)
5、估计总体指标(即估计总体参数)
总体参数与样本估计量的关系——对于特定的目 的,总体是惟一的,所以参数也是惟一的;而由 于样本是随机的,所以样本估计量是随机变量。
(3)抽样方法。相同条件下,重复抽样的抽样平均误 差大比不重复抽样的抽样平均误差大。
(4)抽样组织方式。由于不同抽样组织方式有不同的 抽样误差,所以,在误差要求相同的情况下,不同抽 样组织方式所必需的抽样数目也不同。
21
不知道总体方差时如何计算
用样本方差代替计算 用过去(总体或样本)方差代替计算 用同类现象(当前 或过去、总体或样本) 方 代替计算 有若干个方差可选择时,选方差最大者 (注意:对比率,即选择最接近0.5的值所 得的方差最大)
进无偏估计量。
29
二、区间估计
(一)区间估计的原理 区间估计就是根据样本估计量以一定 可靠程度推断总体参数所在的区间范围。 特点:考虑了估计量的分布,所以它能 给出估计精度,也能说明估计结果的把握 程度(置信度)。
30
(一)总体均值的置信区间
(1)假定条件
总体服从正态分布,且总体方差(2)已知
统计学第四章统计分析指标
计划完成相对指标
产值计划完成程度若大于100%,说明超额完 成计划;若小于100%,说明没有完成计划, 为正指标。 单位成本计划完成程度若大于100%,说明成 本比计划高,没有完成计划;若小于100%, 说明超额完成计划,为逆指标。 计划完成相对数的分子分母不能互换,在指 标含义、计算范围、核算方法等方面要一致。
计划完成相对指标
长期(通常是五年)计划完成情况—水平法和累计法
总体的一部分单位 总体另一部分单位 比例相对数
人口性别比例 积累与消费比例 农轻重比例
…
…
比例相对指标
人口出生性别比正常值一般在103到107之间。但 我国人口的出生性别比自20世纪80年代中期以来 迅速攀升。 1995年,0岁~4岁人口性别比:118.38 2000年,0岁~4岁人口性别比:120.17 2003年,0岁~4岁人口性6
(1)计划数为绝对数
计划完成相对数=(实际完成数÷同期计划数)×100%
适用于研究分析社会经济现象的规模或水平的计划完成 程度。
计划完成相对指标
〔例〕 某公司2010年计划销售某种产品30万件, 实际销售32万件,则该公司2010年销售计划完成相对 指标是多少?超额完成计划多少?
销售计划完成相对指标 = (32/30)*100% = 106.7% 超额完成计划 = 106.7% - 100% = 6.7%
t1时段
t2时段
t3时段
时期指标的特点: 1. 不同时期的时期指标数值具有可加性; 2. 时期指标的数值大小与时期长短有直接关系; 3. 时期指标数值是连续登记、累计的结果。
时点指标的特点: 1. 不同时期的时点指标数值不具有可加性。 2. 时点指标的数值大小与时间间隔长短无关。 3. 时点指标的数值是间断计数的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第四章例题
•抽样估计中的抽样误差是()
•不可避免要发生的
•抽样估计值与总体参数之差
•可以控制和计算其大小的
•可以通过改进调查方法予以消除的
•一种随机误差
•用于推断总体指标的样本指标有()•样本平均数
•样本成数
•样本容量
•样本方差
•样本标准差
•抽样推断的特点有()
•按随机原则抽取样本
•按随意原则抽取样本
•由样本数据推断总体数据
•缺乏一定的科学性和可靠性
•可以事先计算和控制抽样误差
•影响抽样误差大小的因素有()•样本容量的大小
•被研究总体的标志变异程度
•抽样方法的不同
•抽样总体的标志变异程度
•抽样组织形式的不同
•抽样的组织方式有()
•纯随机抽样
•等距抽样
•重复或不重复抽样
•类型或分类抽样
•整群抽样
•以下说法正确的有()
•所有可能样本指标的平均数等于总体指标
•总体指标与样本指标都是随机变量
•总体指标是确定值,样本指标是随机变量
•样本指标是确定值,总体指标是随机变量
•样本指标的期望值等于总体指标
•一个优良的估计量应满足的标准是()
•一致性
•准确性
•客观性
•无偏性
•有效性
•要提高抽样推断的精确度,可以采用的方法有()•增加样本单位数
•减少样本单位数
•改善抽样方法
•改善抽样组织形式
•缩小总体被研究标志的变异程度
•从总体的1000个单位中,随机抽40个单位进行调查,以下说法正确的有()
•样本单位数为40个
•样本容量为40
•样本个数为40个
•样本单位数为1000个
•一个样本有40个单位
•抽样平均误差是()
•关于抽样指标的平均数
•关于抽样指标的平均差
•关于抽样指标的标准差
•抽样指标与总体指标的平均误差程度
•计算抽样极限误差的衡量尺度
•抽样方案应包括的内容有()
•确定被研究总体的范围
•确定抽样的方法
•确定抽样取多大的样本容量
•确定估计的精确度和可靠程度
•确定调查的经费
•通过区间估计可以掌握()的可能范围
•总体平均数
•抽样平均数
•总体成数
•抽样成数
•抽样误差
•在其他条件不变时,抽样极限误差的大小与概率保证程度的关系是()
•极限误差范围越小,概率保证程度越大
•成反比关系
•极限误差范围越小,概率保证程度越小
•成正比关系
•极限误差范围越大,概率保证程度越小
•先对总体进行分组,再抽取单位的组织形式称为()•多阶段抽样
•分类抽样
•分层抽样
•整群抽样
•类型抽样
判断题
•抽样调查是根据需要和可能凭主观意识抽取部分单位以取得资料的一种非全面调查。
•抽样误差是不可避免的,但人们可以通过调整总体方差的变化来控制抽样误差的大小。
•样本空间的大小实际上就是样本容量的大小。
判断题
•所有可能的样本平均数的期望值等于总体平均数。
•成数就是具有某种属性的单位数在总体单位数中所占的比重。
•样本单位数是影响抽样误差大小的主要因素。
一般地说,样
本单位越多,抽样误差越大;反之,越小。
判断题
•抽样平均误差实际上就是反映抽样指标变异程度的标准差。
•不重复抽样的抽样误差总是小于重复抽样的抽样误差。
•抽样极限误差总是大于抽样平均误差。
•要求的概率保证程度越高,意味着抽样估计的精确度也越高。
计算题
1. 某县收购花生,已知过去几次抽样调查的合格率分别为91%、92%、93%。
今年要求把握程度(即置信度)为0.8664,允许误差不超过3%。
问需要抽多少包发生?
2. 某机械厂采用纯随机不重复抽样方法,从1000箱已入库的某零件中抽取了100箱进行质量检验。
对抽中的箱内零件进行全面检验,结果如下:
废品率(%)箱数
1~2 60
2~3 30
3~4 10
合计100
•要求:
–计算当概率保证为68.27% 时,废品率的可能范围;
–当概率为95.45% 时,若限定废品率不超过0.25 %,应抽检的箱数为多少?
3. 对某生活小区的40户居民家庭进行抽样调查,得平均每户居
民家庭每月的书报费支出为46元,抽样平均误差为4元。
试问整个生活小区的居民家庭平均每月的书报费支出为42~52元之间的可能性有多少?
4. 在重复抽样条件下,若抽样单位数增加了3倍,或减少了50%,其他条件不变,抽样平均误差将发生怎样的变化?
5. 袋装食品的机器,装袋的重量均值可以在200~500克之间
调节,但标准差独立于均值,均为3克。
若每次抽取36袋检查,要求其每袋平均重量至少是250克的概率为95%,机器应调节至平均装多少克?
6. 对某型号电子元件10000支进行耐用性能检查,根据以往抽样测定,耐用性能标准差为89.46小时和91.51小时,合格率为91%和88%
–概率保证程度为86.64%,元件平均耐用时数的误差范围不超过9小时,分别在重复与不重复条件下,计算应抽取的元件数;
–概率保证程度为99.73%,合格率的极限误差不超过5%,分别在重复和不重复条件下,计算应抽取的元件数;
–在不重复抽样条件下,要同时满足(1)和(2)的要求,需抽多少元件?。