第4章 参数估计
教育与心理统计学 第四章 抽样理论与参数估计考研笔记-精品

第四章抽样理论与参数估计第一节抽样理论的基本知识分层抽样,又叫分层随机抽样,这种抽样方法是按照总体已有的某些特征,承认总体中已有的差异,按差异将总体分为几个不同的部分,每一部分称为一个层,在每一个层中实行简单随机抽样。
它充分利用了总体的已知信息,因而是一种非常适用的抽样方法,其样本代表性及推论的精确性一般优于简单随机抽样。
分层的原则是层与层之间的变异越大越好,各层内的变异要小。
试述分层抽样的原则和方法?分层抽样是按照总体上已有的某些特征,将总体分成几个不同部分,在分别在每一部分中随机抽样。
分层的总的原则是:各层内的变异要小,而层与层之间的变异越大越好。
在具体操作中,没有一成不变的标准,研究人员可根据研究需要依照多个分层标准,视具体情况而定。
⑷两阶段随机抽样两阶段随机抽样首先将总体分成M个部分,每一部分叫做一个"集团"(或"群"),第一步从M个集团中随机抽取m个"集团”作为第一阶段样本,第二步是分别从所选取的m个"集团”中抽取个体(g构成第二阶段样本。
一般而言,两阶段抽样相对于简单随机抽样,标准误要大些,但是,两阶段抽样简便易行,节省经草贼,因而它是大规模调查研究中常被使用的抽样方法。
例如,如果我们要了解全国城市初中二年级学生的身高,第一步我们可以从全国几百个城市中随机抽取几十个城市作为第一阶段的样本。
第二步,在第一阶段随机抽取出来的城市中再随机抽取初中二年级的学生。
(二)非旃抽样非概率抽样不是完全按随机原则选取样本,有方便抽样、判断抽样。
方便抽样是由调查人员自由、方便地选择被调查者的非随机选样。
判断抽样是通过某些条件过滤,然后选择某些被调查者参与调查的抽样法。
当采取非概率抽样的方法选取样本时,研究者要说明采用此种方取样的原因以及对研究结果可能造成的影响。
第二节抽样分布[统计量分布、基本随机变量函数的分布]总体:又称母全体、全域,指具有某种特征的一类事物的全体。
第四章中心极限定理与参数估计

当 n 很大时,近似地服从正态分布.
第四章 中心极限定理与参数估计
例 1、对敌人的防御工事进行 80 次轰炸,每次轰炸命中目标炸弹 数目的数学期望为 2,方差为 0.8,且各次轰炸相互独立,求在 80 次轰炸中有 150 颗~170 颗炸弹命中目标的概率。 解:第 i 次轰炸命中目标炸弹的数目 X i (i 1,2,,80) 都是离散型随机
根据随机变量数学期望的性质,计算数学期望
80
80
80
E( X ) E( X i ) E( X i ) 2 160
i 1
i 1
i 1
第四章 中心极限定理与参数估计
由于离散型随机变量变量 X 1 , X 2 ,, X 80 相互独立,根据随机
变量方差的性质,计算方差
80
80
80
D( X ) D( X i ) D( X i ) 0.8 64 82
分大时,离散型随机变量 X 近似服从参数为 np, npq ( p q 1)
的正态分布,即近似有离散型随机变量 X ~ N(np, npq) 定理4.22表明:
正态分布是二项分布的极限分布, 当n充分大时, 可 以利用该定理来计算二项分布的概率.
随机变量 X 的取值在数学期望 E(X ) 附近的密集程度越低。
第四章 中心极限定理与参数估计
(3)在使用切贝谢夫不等式时,要求随机变量 X 的数学期望 E( X ) 与方差 D( X ) 一定存在,这时无论随机变量 X 的概率分布已知或未
知,都可以对事件 X E(X ) 发生的概率进行估计。 2、切贝谢夫不等式的应用举例 例1、 已知电站供电网有电灯 10000 盏,夜间每一盏灯开灯的概率 皆为 0.8,且它们开关与否相互独立,试利用切贝谢夫不等式估计夜 晚同时开灯的灯数在 7800 盏~8200 盏之间的概率。
参数估计的一般步骤

参数估计的一般步骤引言:参数估计是统计学中一项重要的任务,它用于根据样本数据来推断总体参数的值。
参数估计的一般步骤包括确定估计方法、选择样本、计算估计值和进行推断。
本文将详细介绍参数估计的一般步骤,并以人类的视角进行描述,使读者更好地理解和应用这些步骤。
一、确定估计方法在参数估计中,首先需要确定合适的估计方法。
估计方法可以分为点估计和区间估计两种。
点估计方法通过单个数值来估计参数的值,例如最大似然估计和矩估计。
区间估计方法则通过一个区间来估计参数的范围,例如置信区间估计。
选择合适的估计方法是参数估计的第一步。
二、选择样本在确定了估计方法后,接下来需要选择合适的样本进行参数估计。
样本应当具有代表性,能够反映总体的特征。
为了保证样本的代表性,可以使用随机抽样方法来选择样本。
通过合理选择样本,可以减小估计误差,提高参数估计的准确性。
三、计算估计值在选择好样本后,需要计算参数的估计值。
对于点估计方法,可以使用最大似然估计或矩估计等方法来计算参数的估计值。
对于区间估计方法,可以使用置信区间估计来计算参数的范围。
计算估计值时,需要根据样本数据和估计方法进行相应的计算,确保估计结果的准确性。
四、进行推断在计算得到估计值后,需要进行推断,即根据估计值对总体参数进行推断。
对于点估计方法,可以直接使用估计值作为总体参数的估计值。
对于区间估计方法,可以使用置信区间来表示总体参数的范围。
通过推断可以了解总体参数的可能取值范围,帮助做出正确的决策和预测。
总结:参数估计的一般步骤包括确定估计方法、选择样本、计算估计值和进行推断。
在进行参数估计时,需要选择合适的估计方法和样本,计算出估计值,并进行相应的推断。
参数估计在统计学中扮演着重要的角色,它帮助我们根据样本数据来推断总体参数的值,从而更好地了解和应用统计学。
通过本文的介绍,希望读者能够更好地理解和应用参数估计的一般步骤。
第四章 参数估计

x
n
总体标准差,若 未知,可用样本
标准差代替
36
总体均值的置信区间引例
(2 未知)
例:某商场从一批袋装食品中随机抽取10袋,测得 每袋重量(单位:克)分别为789,780,794, 762,802,813,770,785,810,806,要 求以95%的把握程度,估计这批食品的平均每袋 重量的区间范围。假定食品重量服从正态分布。
0.95,Z/2=1.96
x Z 2
n
,
x
Z
2
n
26 1.96 6 ,26 1.96 6
100
100
24.824,27.176
我们可以95%的概率保证平均每天 参加锻炼的时间在24.824~ 27.176 分钟之间。
一般置信水平
一般使用的置信水平是:90%, 95%, 99%
Confidence Level
▪ 总体服从正态分布,且总体方差(2)已知 ▪ 如果不是正态分布,可以由正态分布来近似 (n 30)
2. 使用正态分布统计量Z
Z
x s
m ~ N (0,1)
n
3. 总体均值 在1-置信水平下的置信区间为
s
s
x
Za 2
,x n
Za 2 n
总体均值的置信区间
(2 已知)
抽样极限误差:
s x Za 2 n
❖ 定理1
当总体 X ~ N ( m , s 2 ) 时,抽自该总体
的简单随机样本 x1 , x 2 , , x n 的样本平均数
服从数学期望为 ,方差为 s2的正态分布,
n
即 x ~ N (m, s2 ) 。
n
Z x ~ N (0,1) n
参数估计

(2)再用样本k阶矩代替相应的总体k阶矩
上一页
下一页
返回
设 总 体X ~ N ( , 2 ), , 2 未 知 , 设 例1: ( X 1 , X 2 ,..., X n )为 来 自 总 体 的 样 本 , 求 X 与 2的 矩 估 计 量 。
解:先建立待估参数与总体矩的关系
维随机变量,样本的联合概率密度为:
f ( x1 , x2 ,, xn ) f X 1 ( x1 ) f X 2 ( x2 ) f X n ( xn )
f ( x1 , ) f ( x2 , ) f ( xn , ) f ( xi , )
i 1
n
显然上式也为θ的函数,记作 L( ),即
L( ) f ( xi , )
i 1 n
我们称 L( ) 为似然函数。
小结:
似然函数
n p( x i ; ) i 1 L( ) n f ( x i ; ) i 1
由上可知,求极大似然估计值就是求使 L( ) 取最大的θ值。 下面我们用例子来说明求解极大似然估计值的步骤。
6
3
[ x dx x dx]
2 3 0 0
2
用样本k阶矩代替相应的总体k阶矩,得θ的矩估计量:
ˆ 2X
2)将数据代入,得θ的矩估计值为:
ˆ 2x 2 1 xi 8.9 8 i 1
8
计 算 器 的 使 用
例3:设总体X在区间[a,b]上服从均匀分布, a , b
实为 发生的概率。
根据极大似然原理,
概率大的事件在一次观测中更容易发生。
现在只做一次抽样, 事件 { X 1 x1 , X 2 x2 ,, X n xn } 故 认为其概率较大。 认为其概率较大。 也即我们应选择 使 L( ) 取最大值。 我们把使 L( ) 取最大值的 值称为 的极大 竟然发生了,
(04)第4章 参数估计

(2)99%的置信区间是多少?
(3)若样本容量为40,而观测的数据不变,则 95%的置信区间又是多少?
5 - 31
统计学
STATISTICS
总体均值的区间估计
(例题分析)
12, s 4.1
解:(1)已知n=15, 1- = 95%, =0.05 ,x
统计学
STATISTICS
总体均值的区间估计
统计学
STATISTICS
大样本的估计方法
不论总体是不是服从正态分布,在大样本 (n 30)时,样本均值均服从正态分布。 若已知 2 x
x ~ N ( ,
总体均值 在1- 置信水平下的置信区间为
n
)
z
n
~ N (0,1)
z 2
有效性:对同一总体参数的两个无偏点估计量, 有更小标准差的估计量更有效
ˆ P( )
ˆ1 的抽样分布
B A
ˆ2 的抽样分布
ˆ
5 - 11
ˆ ˆ1 是比 2 更有效,是一个更好的估计量
统计学
STATISTICS
有效性
(efficiency)
x1 x2 x3 样本均值 x 3 x1 2 x2 3x3 和 x1 6
统计学
STATISTICS
第 4 章 参数估计
4.1 参数估计的基本原理 4.2 一个总体参数的区间估计 4.4 样本容量的确定
5-1
统计学
STATISTICS
4.1 参数估计的一般问题
4.1.1 估计量与估计值 4.1.2 点估计与区间估计 4.1.3 评价估计量的标准
第四章线性系统参数估计的最小二乘法
测得铜导线在温度Ti (o C) 时的电阻 Ri (Ω ) 如表 6-1,求电阻 R 与温度 T 的近似函数关系。
i
1
2
3
4
5
6
7
Ti (o C) Ri (Ω )
19.1 76.30
25.0 77.80
30.1 79.25
36.0 80.80
40.0 82.35
45.1 83.90
50.0 85.10
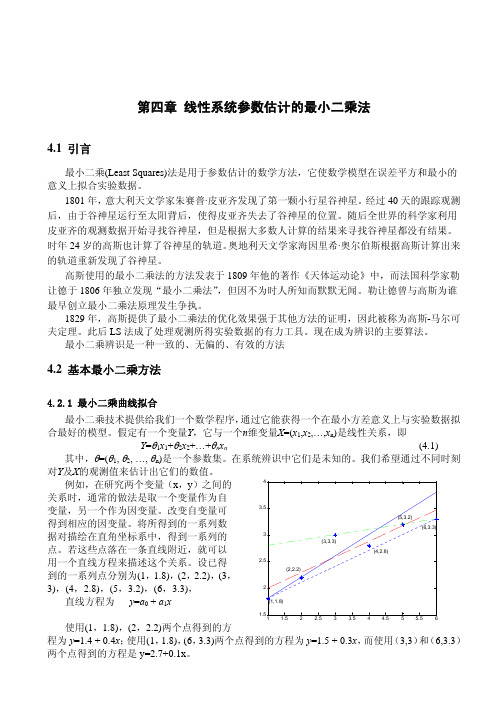
使用(1,1.8),(2,2.2)两个点得到的方
1.5 1 1.5 2 2.5 3 3.5 4 4.5 5 5.5 6
程为 y=1.4 + 0.4x;使用(1,1.8),(6,3.3)两个点得到的方程为 y=1.5 + 0.3x,而使用(3,3)和(6,3.3)
两个点得到的方程是 y=2.7+0.1x。
(4.1)
其中,θ=(θ1, θ2, …, θn)是一个参数集。在系统辨识中它们是未知的。我们希望通过不同时刻
对Y及X的观测值来估计出它们的数值。
例如,在研究两个变量(x,y)之间的
4
关系时,通常的做法是取一个变量作为自
变量,另一个作为因变量。改变自变量可
3.5
得到相应的因变量。将所得到的一系列数
据对描绘在直角坐标系中,得到一系列的
X T XΘˆ = X TY
(4.7)
得
Θˆ=( X T X )−1 X TY
(4.8)
这样求得的Θˆ 就称为Θ的最小二乘估计(LSE),在统计学上,方程(4.7)称为正则方程,称ε
为残差。
在前面讨论的例子中,把 6 个数据对分别代入直线方程y=a0 + a1x中可得到 1 个由 6 个直线
统计学(第三版)课后答案 袁卫等主编

统计学第一章1.什么是统计学?怎样理解统计学与统计数据的关系?答:统计学是一门收集、整理、显示和分析统计数据的科学。
统计学与统计数据存在密切关系,统计学阐述的统计方法来源于对统计数据的研究,目的也在于对统计数据的研究,离开了统计数据,统计方法以致于统计学就失去了其存在意义。
2.简要说明统计数据的来源答:统计数据来源于两个方面:直接的数据:源于直接组织的调查、观察和科学实验,在社会经济管理领域,主要通过统计调查方式来获得,如普查和抽样调查。
间接的数据:从报纸、图书杂志、统计年鉴、网络等渠道获得。
3.简要说明抽样误差和非抽样误差答:统计调查误差可分为非抽样误差和抽样误差。
非抽样误差是由于调查过程中各环节工作失误造成的,从理论上看,这类误差是可以避免的。
抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以控制的。
4.答:(1)有两个总体:A品牌所有产品、B品牌所有产品(2)变量:口味(如可用10分制表示)(3)匹配样本:从两品牌产品中各抽取1000瓶,由1000名消费者分别打分,形成匹配样本。
(4)从匹配样本的观察值中推断两品牌口味的相对好坏。
第二章、统计数据的描述思考题1描述次数分配表的编制过程答:分二个步骤:(1)按照统计研究的目的,将数据按分组标志进行分组。
按品质标志进行分组时,可将其每个具体的表现作为一个组,或者几个表现合并成一个组,这取决于分组的粗细。
按数量标志进行分组,可分为单项式分组与组距式分组单项式分组将每个变量值作为一个组;组距式分组将变量的取值范围(区间)作为一个组。
统计分组应遵循“不重不漏”原则(2)将数据分配到各个组,统计各组的次数,编制次数分配表。
2.解释洛伦兹曲线及其用途答:洛伦兹曲线是20世纪初美国经济学家、统计学家洛伦兹根据意大利经济学家帕累托提出的收入分配公式绘制成的描述收入和财富分配性质的曲线。
洛伦兹曲线可以观察、分析国家和地区收入分配的平均程度。
3. 一组数据的分布特征可以从哪几个方面进行测度?答:数据分布特征一般可从集中趋势、离散程度、偏态和峰度几方面来测度。
参数估计的一般步骤

参数估计的一般步骤
参数估计是统计学中的一种方法,用于根据样本数据估计总体参数的值。
它是一个重要的统计推断技术,可以帮助我们了解和描述总体的特征。
参数估计的一般步骤如下:
1. 确定研究对象和目标参数:首先,我们需要明确研究对象是什么,需要估计的是哪个参数。
例如,我们可能希望估计某个产品的平均寿命,那么研究对象是产品,目标参数是平均寿命。
2. 收集样本数据:为了进行参数估计,我们需要收集一定数量的样本数据。
样本应该能够代表总体,并且必须是随机选择的,以避免抽样偏差。
3. 选择合适的估计方法:根据研究对象和目标参数的不同,我们可以选择不同的估计方法。
常见的估计方法包括点估计和区间估计。
点估计给出一个单一的数值作为参数的估计值,而区间估计给出一个范围,以表明参数估计值的不确定性。
4. 计算估计值:根据选择的估计方法,我们可以使用样本数据计算出参数的估计值。
例如,对于平均寿命的估计,我们可以计算样本的平均值作为总体平均寿命的估计值。
5. 评估估计的准确性:估计值的准确性可以通过计算估计的标准误
差或置信区间来评估。
标准误差反映了估计值与真实参数值之间的差异,而置信区间提供了参数估计值的不确定性范围。
6. 解释和应用估计结果:最后,我们需要解释估计结果并应用于实际问题中。
根据估计结果,我们可以得出结论,做出决策或提出建议。
参数估计是一种重要的统计推断方法,可以帮助我们了解总体特征并做出准确的推断。
通过正确的步骤和方法,我们可以获得可靠的参数估计结果,并将其应用于实际问题中。
第4章参数估计和假设检验

第4章参数估计和假设检验第四章参数估计与假设检验掌握参数估计和假设检验的基本思想是正确理解和应⽤其他统计推断⽅法的基础,后⾯将要学习的⽅差分析、⾮参数检验、回归分析、时间序列等统计推断⽅法都是在此基础上展开的。
需要特别指出的是,所有的统计推断都要以随机样本为基础。
如果样本是⾮随机的,统计推断⽅法就不适⽤了。
由于相关知识在先修课程中已经学习过,本章主要在回顾相关知识的基础上,补充讲解必要样本容量的计算、p值、参数估计和假设检验⽅法的软件操作和结果分析等内容。
本章的主要内容包括:(1)参数估计的基本思想和软件实现。
(2)简单随机抽样情况下样本容量的计算。
(3)假设检验的基本原理。
(4)假设检验中的p值。
(5)⼏种常⽤假设检验的软件实现。
第⼀节参数估计⼀、参数估计的基本概念参数估计是指利⽤样本信息对总体数字特征作出的估计。
例如,我们可以通过估计⼀部分产品的合格率对整批产品的合格率作出估计,通过调查⼀个样本的⼈⼝数来对全国的⼈⼝数作出估计,等等。
参数估计可以分为点估计和区间估计。
点估计是指根据样本数据给出的总体未知参数的⼀个估计值。
对总体参数进⾏估计的⽅法可以有多种,例如矩估计法、极⼤似然估计法等,得到的估计量(样本统计量)并不是唯⼀的。
例如我们可以使⽤样本均值对总体均值作出估计,也可以使⽤样本中位数对总体均值进⾏估计。
因此,在参数估计中我们需要对估计量的好坏作出评价,这就涉及到估计量的评价准则问题。
常⽤的估计量评价准则包括⽆偏性、有效性、⼀致性等。
⽆偏性是指估计量的数学期望与总体参数的真实值相等;有效性的含义是,在两个⽆偏估计量中⽅差较⼩的估计量较为有效,⽅差越⼩越有效;⼀致性是指随着样本容量的增⼤,估计量的取值应该越来越接近总体参数。
样本的随机性决定了估计结果的随机性。
由于每⼀个点估计值都来⾃于⼀个随机样本,所以总体参数真值刚好等于⼀个具体估计值的可能性极⼩。
区间估计的⽅法则以概率论为基础,在点估计的基础上给出了⼀个置信区间,并给出了这⼀区间包含总体真值的概率,⽐点估计提供了更多的信息。
统计学 第4章 假设检验

【解】研究者想收集证据予以支持的假设是该 城市中家庭拥有汽车的比率超过30%。 因此,建立的原假设和备择假设为 H0 :μ≤30% H1 :μ>30%
结论与建议
◆原假设和备择假设是一个完备事件组, 而且相互对立。在一项假设检验中,原假设和 备择假设必有一个成立,而且只有一个成立; ◆先确定备择假设,再确定原假设。因为 备择假设大多是人们关心并想予以支持和证实 的,一般比较清楚和容易确定; ◆等号“=”总是放在原假设上; ◆因研究目的不同,对同一问题可能提出 不同的假设,也可能得出不同的结论。 ◆假设检验主要是搜集证据来推翻和拒绝 原假设。
◆理想地,只有增加样本容量,能同时减小 犯两类错误的概率,但增加样本容量又受到很多 因素的限制; ◆通常,只能在两类错误的发生概率之间进 行平衡,发生哪一类错误的后果更为严重,就首 要控制哪类错误发生的概率; ◆在假设检验中,一般先控制第Ⅰ类错误的 发生概率。因为犯第Ⅰ类错误的概率是可以由研 究者控制的。
假设检验的过程
提出假设 作出决策
拒绝假设 别无选择!
总体
我认为人口的平 均年龄是50岁
抽取随机样本
均值 x = 20
二、原假设与备择假设
什么是假设?
对总体参数的具体数
值所作的陈述
我认为这种新药的疗效 比原有的药物更有效!
总体参数包括总体均值、 总体比率、总体方差等 分析之前必须陈述
备择假设。
500g
【解】研究者抽检的意图是倾向于证实这种洗 涤剂的平均净含量并不符合说明书中的陈述。 因此,建立的原假设和备择假设为 H0:μ≥500 H1:μ< 500
提出假设例3
一家研究机构估计,某城市中家庭拥有 汽车的比率超过 30% 。为验证这一估计是否 正确,该研究机构随机抽取了一个样本进行 检验。试陈述用于检验的原假设与备择假设
参数估计的一般步骤

参数估计的一般步骤参数估计是统计学中的一种方法,用于根据样本数据估计总体参数的取值。
它在各个领域都有广泛的应用,例如经济学、医学、社会学等。
本文将介绍参数估计的一般步骤,帮助读者了解如何进行参数估计。
一、确定参数类型在进行参数估计之前,首先需要确定要估计的参数类型。
参数可以是总体均值、总体比例、总体方差等,根据具体问题来确定。
二、选择抽样方法接下来,需要选择合适的抽样方法来获取样本数据。
常用的抽样方法有简单随机抽样、系统抽样、分层抽样等。
选择合适的抽样方法可以保证样本的代表性,从而提高参数估计的准确性。
三、收集样本数据在进行参数估计之前,需要收集样本数据。
收集样本数据时要注意数据的准确性和完整性,避免数据采集过程中的偏差。
四、计算点估计量得到样本数据后,可以计算点估计量来估计总体参数的取值。
点估计量是根据样本数据计算得出的一个具体数值,用来估计总体参数的未知值。
常见的点估计量有样本均值、样本比例等。
五、构建置信区间除了点估计量,还可以构建置信区间来估计总体参数的取值范围。
置信区间是一个区间估计,表示总体参数的真值有一定的概率落在该区间内。
置信区间的计算方法与具体的参数类型有关,可以利用统计学中的分布理论或抽样分布来计算。
六、进行假设检验除了估计总体参数的取值,参数估计还可以用于假设检验。
假设检验是根据样本数据来判断总体参数是否符合某个特定的假设。
在假设检验中,需要先提出原假设和备择假设,然后计算检验统计量,最后根据统计显著性水平来判断是否拒绝原假设。
七、解释结果需要对参数估计的结果进行解释和说明。
解释结果时要清楚、简洁,避免使用过于专业的术语,以便读者能够理解和接受。
参数估计是统计学中重要的内容之一,它可以帮助我们从有限的样本数据中推断总体的特征。
通过合理选择抽样方法、收集准确的样本数据,并运用适当的统计方法,我们可以得到准确可靠的参数估计结果,为实际问题的决策提供科学依据。
第4章参数估计案例辨析及参考答案[整理]
![第4章参数估计案例辨析及参考答案[整理]](https://img.taocdn.com/s3/m/63d0ecec760bf78a6529647d27284b73f342365d.png)
第4章 参数估计案例辨析及参考答案案例4-1 某研究者测得某地120名正常成人尿铅含量(mg ·L -1)如下:尿铅含量 0~ 4~ 8~ 12~ 16~ 20~ 24~ 28~ 32~ 36~ 合计 例数1422291815106321120试据此资料估计正常成人平均尿铅含量的置信区间及正常成人尿铅含量的参考值范围。
由表中数据得到该例的120n =,10038.S =,67300.S X =,某作者将这些数据代入公式(4-20),即采用X X Z S α+计算得到正常成人平均尿铅含量100(1)α-%置信区间为(-∞,14.068 4);采用公式X Z S α+计算得到正常成人尿铅含量100(1)α-%参考值范围为(-∞,26.030 6)。
请问这样做是否合适?为什么?应当怎么做?案例辨析 该定量资料呈偏峰分布,不适合用正态分布法计算100(1)%α-参考值范围。
正确做法 可以用百分位数法求正常成人尿铅含量100(1)α-%参考值范围的单侧上限。
例如,当α=0.05时,可直接求95P 分位数,(0,95P )就是所求的正常成人尿铅含量的95%正常值范围。
欲求正常成人尿铅含量总体均数的置信区间,当样本含量n 较大(比如说,n 大于30或50)时,样本均数就较好地接近正态分布(根据数理统计上的中心极限定理)。
本例, 因为120n =较大,不必对原始数据作对数变换就可以用X X Z S α+估计总体均数的置信区间。
案例4-2 在BiPAP 呼吸机治疗慢性阻塞性肺病的疗效研究中,某论文作者为了描述试验前的某些因素是否均衡,在教材表4-5中列出了试验前患者血气分析结果。
由于作者觉得自己数据的标准差较大,几乎和均数一样大,将标准差放在文中显得不雅观,于是他采用“均数±标准误”(X X S ±),而不是“均数±标准差”(X S ±)来对数据进行描述。
问在研究论文中以教材表4-5方式报告结果正确吗?为什么?教材表4-5 试验组和对照组治疗前血气分析结果(X X S ±)组别 例数 年龄/岁pHp a (CO 2)/kPap a (O 2)/kPa S a (O 2)/% 试验组 12 63.00±4.33 7.36±0.05 63.00±4.33 9.25±0.5585.12±1.73 对照组1062.50±3.95 7.38±0.06 63.00±4.339.16±0.6286.45±2.25案例辨析 描述数据的基本特征不能采用X X S ±,因为X S 为反映抽样误差大小的指标,只表示样本均数的可靠性,而不能反映个体的离散程度。
计量经济学第二版第四章课后习题答案

4.31)建立经济模型:i t t t CPI GDP Y μβββ+++=ln ln ln 321其中 Y 表示为商品进口额,GDP 表示为国内生产总值,CPI 表示为居民消费价格指数。
模型参数估计结果:t t t CPI GDP Y ln 057053.1ln 656674.1060149.3ln -+-=(0.337427)(0.092206) (0.214647)t= (-9.069059) (17.96703) (-4.924618)992218.02=R 991440.02=RF=1275.093(2)居民消费价格指数的回归系数的符号不能进行合理的经济意义解释,且CPI 与进口之间的简单相关系数呈现正向变动。
可能数据中有多重共线性。
计算相关系数:从上图可知, GDP 与CPI 之间存在较高的线性相关。
3)已知:i t t GDP A A Y 121ln ln μ++= i t t CPI B B Y 221ln ln μ++= i t t CPI C C GDP 321ln ln μ++=对以上三个模型分别进行回归,结果如下:t t GDP Y ln 218573.1090667.4ln +-=(0.384252) (0.035196)t= (-10.64579) (34.62222)982783.02=R 981963.02=R F=1198.698t t CPI Y ln 253662.1442420.5ln +-=(1.253662) (0.228046)t= (-4.341218) (11.68091)866619.02=R 860268.02=R F=136.4437t t CPI GDP 245971.2437984.1ln +-=(0.734328) (0.133577)t= (-1.958231) (16.81400)930855.02=R 927563.02=R F=282.7107单方程拟合效果都很好,回归系数显著,可决系数较高,GDP 和CPI 对进口分别有显著的单一影响,在这两个变量同时引入模型时影响方向发生了改变,这只有通过相关系数的分析才能发现。
袁卫《统计学》配套题库【课后习题】第4章~第6章【圣才出品】

第4章参数估计思考题1.简述评价估计量好坏的标准。
答:(1)无偏性,指估计量抽样分布的数学期望等于被估计的总体参数。
设总体参数为θ,所选择的估计量为∧θ,如果E (∧θ)=θ,则称∧θ为θ的无偏估计量。
(2)有效性,指对同一总体参数的两个无偏估计量,有更小标准差的估计量更有效。
(3)一致性,指随着样本量的增大,点估计量的值越来越接近被估总体的参数。
即一个大样本给出的估计量要比一个小样本给出的估计量更接近总体的参数。
2./2a z n的含义是什么?答:z α/2是标准正态分布上侧面积为α/2时的z 值;/2a z n 是估计总体均值时的边际误差,也称为估计误差或误差范围。
3.说明区间估计的基本原理。
答:在点估计的基础上,给出总体参数估计的一个区间范围,该区间通常由样本统计量加减抽样误差得到。
4.解释置信水平的含义。
答:如果将构造置信区间的步骤重复多次,置信区间中包含总体参数真值的次数所占的比率称为置信水平,或称为置信系数。
5.解释置信水平为95%的置信区间。
答:抽取100个样本,根据每一个样本构造一个置信区间,这样,由100个样本构造的总体参数的100个置信区间中,有95%的区间包含了总体参数的真值,而5%则没包含。
6.简述样本量与置信水平、总体方差、允许误差的关系。
答:(1)样本量与置信水平成正比,在其他条件不变的情况下,置信水平越大,所需的样本量也就越大;(2)样本量与总体方差成正比,总体的差异越大,所要求的样本量也越大;(3)样本量与允许误差的平方成反比,即允许误差越大,所需的样本量就越小。
练习题1.从一个标准差为5的总体中抽出一个容量为40的样本,样本均值为25。
(1)样本均值的抽样标准差x σ等于多少?(2)在95%的置信水平下,允许误差是多少?解:(1)已知:σ=5,n =40,_x=25,α=0.05,z 0.05/2=1.96。
则样本均值的抽样标准差为:0.7940x n σσ===(2)允许误差为:/2 1.96 1.5540E z n α==⨯=2.某快餐店想要估计每位顾客午餐的平均花费金额,在为期3周的时间里选取49名顾客组成了一个简单随机样本。
《统计学》第4章 参数估计

与总体参数之间的偏差。然而,由于可靠性由抽样标准误差决定,一个
具体的点估计值无法给出可靠性的度量。此外,总体参数的真值未知,
我们也无法得到点估计值与总体参数之间的偏差大小。这个问题可以通
过区间估计来解决。
第四章 参数估计
《统计学》
17
4.2 区间估计
求得的መ 1 , 2 , … , 称为的极大似然估计值,相应的估计量
መ 1 , 2 , … , 称为的极大似然估计量。
第七章 参数估计
《统计学》
14
4.2 点估计与区间估计
极大似然估计(MLE) 的一般步骤如下:
(1) 由总体分布导出样本的联合概率函数(或联合密度函数);
平表示所有区间中有95% 的区间包含总体参数真值,因此A 队的估计结果
中有5% 的区间(1 个) 未包含总体平均身高的真值。同理,90% 的置信水
平表示所有区间中有90% 的区间包含总体参数真值,因此B 队的估计结果
中有10% 的区间(2 个) 未包含总体平均身高的真值。由该例也可以看到,
尽管总体参数的真值是固定的,但基于样本构造的置信区间会随着样本的
计方法,其实质是根据样本观测值发生的可能性达到最大这一原则来选
取未知参数的估计量,理论依据就是概率最大的事件最可能出现。
设X1, X2 , … , Xn是从总体X中抽取的一个样本,样本的联合密度函数(连续
型) 或联合概率函数(离散型) 为
ෑ ( , ) 。
=1
第七章 参数估计
《统计学》
13
区间估计(Interval estimate) 指在点估计的基础上,给出总体参数
统计学第4章 参数估计

无偏性
(unbiasedness)
无偏性:估计量抽样分布的数学期望等于被
估计的总体参数
抽样分布
中,样本 P(ˆ)
均值、比 率、方差
无偏
有偏
分别是总
A
B
体均值、
比率、方
差的无偏
估4计- 2量3
ˆ
统计学
STATISTICS
有效性
(efficiency)
有效性:对同一总体参数的两个无偏点估计
置信水平(1-α)表达了区间估计的可靠性。 它是区间估计的可靠概率。
显著性水平α表达了区间估计的不可靠的概 率。
4 - 20
统计学§4.2 点估计的评价标准
STATISTICS
对于同一个未知参数,不同的方法得到的估 计量可能不同,于是提出问题
应该选用哪一种估计量? 用何标准来评价一个估计量的好坏?
常用 标准
4 - 21
(1) 无偏性 (2) 有效性 (3) 一致性
统计学 定义 STATISTICS
无偏性
(unbiasedness)
若 E(ˆ)
则称 ˆ是 的无偏估计量.
定义的合理性
我们不可能要求每一次由样本得到的
估计值与真值都相等,但可以要求这些估 计值的期望与真值相等.
4 - 22
统计学
量,有更小标准差的估计量更有效
P(ˆ)
ˆ1 的抽样分布
B
无偏估计量还 必须与总体参 数的离散程度
比较小
4 - 24
A
ˆ2 的抽样分布
ˆ
统计学
有效性
STATISTICS
定义 设 ˆ1 1(X1, X 2, , X n )
最新第4章-参数估计思考与练习参考答案

第4章 参数估计 思考与练习参考答案一、最佳选择题1.关于以0为中心的t 分布,错误的是( E )A. t 分布的概率密度图是一簇曲线B. t 分布的概率密度图是单峰分布C. 当ν→∞时,t 分布→Z 分布D. t 分布的概率密度图以0为中心,左右对称E. ν相同时,t 值越大,P 值越大2.某指标的均数为X ,标准差为S ,由公式()1.96, 1.96X S X S -+计算出来的区间常称为( B )。
A. 99%参考值范围B. 95%参考值范围C. 99%置信区间D. 95%置信区间E. 90%置信区间3.样本频率p 与总体概率π均已知时,计算样本频率p 的抽样误差的公式为( C )。
4.在已知均数为μ, 标准差为 σ 的正态总体中随机抽样, X μ->( B )的概率为5%。
A.1.96σB.1.96X σC.0.05/2,t S νD.0.05/2,X t S νE.0.05/2,X t νσ5. ( C )小,表示用样本均数估计总体均数的精确度高。
A. CVB. SC. X σD. RE. 四分位数间距 6. 95%置信区间的含义为( C ):A. 此区间包含总体参数的概率是95%B. 此区间包含总体参数的可能性是95%C. “此区间包含总体参数”这句话可信的程度是95%D. 此区间包含样本统计量的概率是95%E. 此区间包含样本统计量的可能性是95%二、思考题1. 简述标准误与标准差的区别。
答: 区别在于:(1)标准差反映个体值散布的程度,即反映个体值彼此之间的差异;标准误反映精确知道总体参数(如总体均数)的程度。
(2)标准误小于标准差。
(3)样本含量越大,标准误越小,其样本均数更有可能接近于总体均数,但标准差不随样本含量的改变而有明显方向性改变,随着样本含量的增大,标准差有可能增大,也有可能减小。
2. 什么叫抽样分布的中心极限定理?答: 样本含量n越大,样本均数所对应的标准差越小,其分布也逐渐逼近正态分布,这种现象统计学上称为中心极限定理(central limit theorem)。
参数估计的一般步骤

参数估计的一般步骤
参数估计是通过从总体中抽取一个样本,利用样本数据对总体未知参数进行估计的过程。
参数估计的一般步骤如下:
1. 确定总体参数:首先需要明确要估计的总体参数,例如总体均值、总体比例、总体方差等。
2. 选择样本:从总体中抽取一个合适的样本。
样本的选择应该具有代表性,能够反映总体的特征。
3. 收集样本数据:对选择的样本进行观测或测量,收集样本数据。
4. 选择估计方法:根据所收集的样本数据和要估计的总体参数,选择合适的估计方法。
常见的估计方法包括点估计和区间估计。
5. 计算估计量:使用所选择的估计方法,根据样本数据计算出估计量。
估计量是用于估计总体参数的统计量。
6. 评估估计量的性质:评估所计算出的估计量的性质,如无偏性、有效性、一致性等。
这些性质可以帮助判断估计量的优劣。
7. 计算置信区间或置信水平:如果进行的是区间估计,根据估计量和置信水平,计算出总体参数的置信区间。
8. 解释估计结果:根据估计量或置信区间,对总体参数进行推断和解释。
同时,需要考虑估计结果的统计显著性和实际意义。
9. 分析误差和不确定性:考虑样本大小、抽样方法等因素对估计结果的影响,分析可能存在的误差和不确定性。
10. 结论和应用:根据参数估计的结果,得出结论并将其应用于实际问题中,例如进行决策、预测或进一步的研究。
需要注意的是,参数估计的具体步骤和方法会根据不同的统计问题和数据类型而有所差异。
在进行参数估计时,应根据实际情况选择合适的方法,并结合统计学原理和专业知识进行分析和解释。
统计学 第四章 参数估计

由样本数量特征得到关于总体的数量特征 统计推断(statistical 的过程就叫做统计推断 的过程就叫做统计推断 inference)。 统计推断主要包括两方面的内容一个是参 统计推断主要包括两方面的内容一个是参 数估计(parameter estimation),另一个 数估计 另一个 假设检验 。 是假设检验(hypothesis testing)。
ˆ P(θ )
无偏 有偏
A
B
θ
ˆ θ
估计量的无偏性直观意义
θ =µ
•
•
•
• •
• • • •
•
2、有效性(efficiency)
有效性:对同一总体参数的两个无偏点估计 有效性: 量,有更小标准差的估计量更有效 。
ˆ P(θ )
ˆ θ1 的抽样分布
B A
ˆ θ2 的抽样分布
θ
ˆ θ
பைடு நூலகம்
3、一致性(consistency)
置信区间与置信度
1. 用一个具体的样本 所构造的区间是一 个特定的区间, 个特定的区间,我 们无法知道这个样 本所产生的区间是 否包含总体参数的 真值 2. 我们只能是希望这 个区间是大量包含 总体参数真值的区 间中的一个, 间中的一个,但它 也可能是少数几个 不包含参数真值的 区间中的一个
均值的抽样分布
总体均值的区间估计(例题分析)
25, 95% 解 : 已 知 X ~N(µ , 102) , n=25, 1-α = 95% , zα/2=1.96。根据样本数据计算得: x =105.36 96。 总体均值µ在1-α置信水平下的置信区间为 σ 10 x ± zα 2 = 105.36 ±1.96× n 25 = 105.36 ± 3.92
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
要求:(1)计算这一比值95%的置 信区间;
(2)得出上述结论时作了什么假 设;
(3)能否以95%的置信水平说明 新酵素的产出率提高了。
已知: x x 1.268, s 0.228 n
1 95%
1求 :
解 :由 95%知Z 1.96
2
: x
第四章
参 数估计
4.1 参数估计的一般问题 4.2 一个总体参数的区间估计 4.3 两个总体参数的区间估计 4.4 样本容量的确定
学习目标
1. 估计量与估计值的概念 2. 点估计与区间估计的区别 3. 评价估计量优良性的标准 4. 一个总体参数的区间估计方法 5. 两个总体参数的区间估计方法 6. 样本容量的确定方法
112.5 102.6 100.0 116.6 136.8
25袋食品的重量
101.0 103.0 102.0
107.5
95.0 108.8
123.5 102.0 101.6
95.4
97.8 108.6
102.8 101.5
98.4
100.5 115.6 102.2 105.0
93.3
解:已知X~N(,102),n=25, 1- = 95%,z/2=1.96。根据
Z
2
S n
1.268
1.96
0.228 36
1.194,1.342
(2)假设36批的样本是随机的。
(3)(1.194,1.342)>1,说明新酵素 的产出率提高了。
P109~5.7
: x
Z
2
s n
450 1.96
已知 : n 400, x 20000, s 6000
1 95%,(大样本) 求:
解 :由1 95%知z 1.96
3. 估计值:估计参数时计算出来的统计量的具 体值
– 如果样本均值 x =80,则80就是的估计值
参数估计的方法
估计方法
点估计
区间估计
点估计
(point estimate)
1. 用样本的估计量直接作为总体参数的估计值
– 例如:用样本均值直接作为总体均值的估计 – 例如:用两个样本均值之差直接作为总体均值
参数估计在统计方法中的地位
统计方法
描述统计
推断统计
参数估计
假设检验
第一节
参数估计的一般问题
一、估计量与估计值
(estimator & estimated value)
1. 估计量:用于估计总体参数的随机变量
– 如样本均值,样本比率、样本方差等
– 例如: 样本均值就是总体均值 的一个估计量
2. 参数用 表示,估计量用 ˆ 表示
n
P
x
n
Z
1
2
Px Z
2
n
x Z
2
1
n
即 : 给定置信度1 就有 : 总体均值的置信区间为:
: x Z
2
n
x
Z
2
n
,x Z
2
n
52 100
439.808,460.192
N : 2199040 ,2300960
习题7: 某汽车轮胎厂欲估计 其轮胎的平均行驶里程,由于轮胎 行驶里程受汽车型号、行驶的路面 以及汽车前后轮位置等影响,因此 使用了大样本 n 400 进行随机配置, 试验结果 x 20000 公里,标准差为 6000公里。要求估计总体均值的置 信区间,置信系数为95%。
P110~5.9
: x
Z
2
n
21.8
1.96
0.3 5
21.55,22.05
(二)大样本 1、方差已知
重复抽样
:
x
Z
2
n
不重复抽样 : x Z
2
n
N N
n 1
2、方差未知
重复抽样 : x Z
2
S n
不重复抽样 : x Z
2
S n
N N
n 1
【例】一家保险公司收集到由36投保个人组成的随 机样本,得到每个投保人的年龄(周岁)数据如下表。 试建立投保人年龄90%的置信区间
36个投保人年龄的数据
23 35 39 27 36 44 36 42 46 43 31 33 42 53 45 54 47 24 34 28 39 36 44 40 39 49 38 34 48 50 34 39 45 48 45 32
已知 : x x 14.8 15.3 15.1 15
n
6
0.05
由1 0.95知Z Z 0.025 1.96
2
求:
解 : : x
Z
2
n
15
1.96
0.05 6
14.96,15.04
2. 表示为 (1 -
为是总体参数未在区间内的比率
3. 常用的置信水平值有 99%, 95%, 90%
相应的 为0.01,0.05,0.10
置信区间
(confidence interval)
1. 由样本统计量所构造的总体参数的估计区间称 为置信区间
2. 统计学家在某种程度上确信这个区间会包含真 正的总体参数,所以给它取名为置信区间
习题6: 某药厂在生产过程中改换了一 种新的酵素,测定了36批的产出率与理论 产出率的比值:
1.28 1.31 1.48 1.10 0.99 1.25 1.22 1.65 1.40 0.95 1.25 1.32 1.23 1.43 1.24 1.73 1.35 1.31 0.92 1.10 1.05 1.39 1.16 1.19 1.41 0.98 0.82 1.22 0.91 1.26 1.32 1.71 1.29 1.17 1.74 1.51
x 35, S 4.5,1 95.45%
求 : 1E 2
解:由1 95.45%知Z 2
2
1E Z
2
S n
N n N 1
2 4.5 1000 100 100 1000 1
0.86件
2 : x E 35 0.86 34.14,35.86
(1 - ) % 区间包含了 % 的区间未包含
影响区间宽度的因素
1.总体数据的离散程度,用 来测度
2. 3.
样本容量, x 置信水平 (1
-
n),影响
z
的大小
评价估计量的标准
无偏性
(unbiasedness)
无偏性:估计量抽样分布的数学期望等于 被估计的总体参数
P(ˆ)
解:已知n=36, 1- = 90%,z/2=1.645。根据样本数
据计算得:
x 39.5 s 7.77
总体均值在1- 置信水平下的置信区间为
x z 2
s 39.5 1.645 7.77
n
36
39.5 2.13
37.37,41.63
投保人平均年龄的置信区间为37.37岁~41.63岁
参数估计(parameter estimation) 就是在抽样及抽样分布的基础上,
根据样本统计量来推断我们所关心 的总体参数。
统计推断的过程
总体
样
样本统计量
本
如:样本均值
、比率、方差
非参数统计是统计学的一个重要分支,它在实践中有着
广泛的应用。所谓统计推断就是由样本观察值去了解总体, 它是统计学的基本任务之一。若根据经验或某种理论我们能 在推断之前就对总体作一些假设,则这些假设无疑有助于提 高统计推断的效率。这种情况下的统计方法称为参数统计。 如果我们所知很少,以致于在推断之前不能对总体作任何假 设,或仅能作一些非常一般性(例如连续分布、对称分布等) 的假设,这时如果仍然使用参数统计方法,其统计推断的结 果显然是不可信的,甚至有可能是错的。在对总体的分布不 作假设或仅作非常一般性假设条件下的统计方法称为非参数 统计。
3. 用一个具体的样本所构造的区间是一个特定的 区间,我们无法知道这个样本所产生的区间是 否包含总体参数的真值
– 我们只能是希望这个区间是大量包含总体参数真值
的区间中的一个,但它也可能是少数几个不包含参 数真值的区间中的一个
置信区间与置信水平
样本均值的抽样分布
x
/2
1–
/2
x
x
为显著性水平 1 则称为置信度。
1. 在点估计的基础上,给出总体参数估计的一个区间 范围,该区间由样本统计量加减抽样误差而得到的
2. 根据样本统计量的抽样分布能够对样本统计量与总 体参数的接近程度给出一个概率度量
– 比如,某班级平均分数在75~85之间,置信水平是95%
置信区间
样本统计量 (点估计)
无偏
有偏
A
B
ˆ
有效性
(efficiency)