多元统计分析经典案例
多元统计分析案例分析

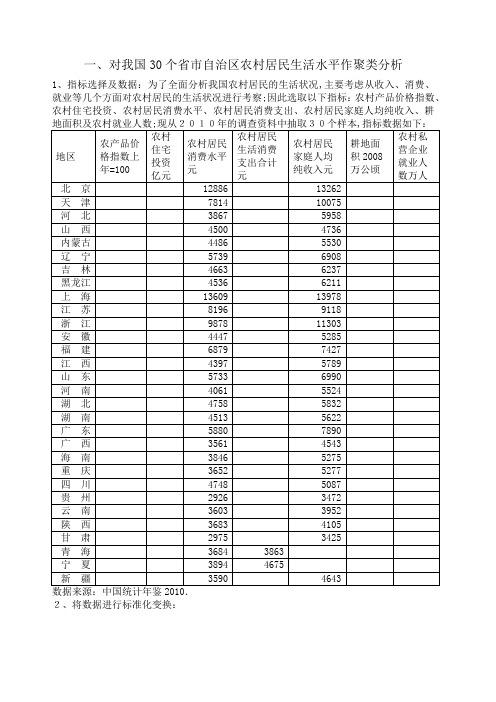
一、对我国30个省市自治区农村居民生活水平作聚类分析1、指标选择及数据:为了全面分析我国农村居民的生活状况,主要考虑从收入、消费、就业等几个方面对农村居民的生活状况进行考察。
因此选取以下指标:农村产品价格指数、农村住宅投资、农村居民消费水平、农村居民消费支出、农村居民家庭人均纯收入、耕地面积及农村就业人数。
现从2010年的调查资料中2、将数据进行标准化变换:3、用K-均值聚类法对样本进行分类如下:分四类的情况下,最终分类结果如下:第一类:北京、上海、浙江。
第二类:天津、、辽宁、、福建、甘肃、江苏、广东。
第三类:浙江、河北、内蒙古、吉林、黑龙江、安徽、山东、河南、湖北、四川、云南。
第四类:山西、青海、宁夏、新疆、重庆、贵州、陕西、湖南、广西、江西、。
从分类结果上看,根据2010年的调查数据,第一类地区的农民生活水平较高,第二类属于中等水平,第三类、第四类属于较低水平。
二、判别分析针对以上分类结果进行判别分析。
其中将新疆作作为待判样本。
判别结果如下:从上可知,只有一个地区判别组和原组不同,回代率为96%。
下面对新疆进行判别:已知判别函数系数和组质心处函数如下:判别函数分别为:Y1=0.18x1 +0.493x2 + 0.087x3 + 1.004x4 + 0.381x5 -0.041x6 -0.631x7 Y2=0.398x1+0.687x2 + 0.362x3 + 0.094x4 -0.282x5 + 1.019x6 -0.742x7 Y3=0.394x1-0.197x2 + 0.243x3-0.817x4 + 0.565x5-0.235x6 + 0.802x7 将西藏的指标数据代入函数得:Y1=-1.08671Y2=-0.62213Y3=-0.84188计算Y值与不同类别均值之间的距离分别为:D1=138.5182756D2=12.11433124D3=7.027544292D4=2.869979346经过判别,D4最小,所以新疆应归于第四类,这与实际情况也比较相符。
完整版本多元统计分析实例汇总

多元统计剖析实例院系 : 商学院学号 :姓名 :多元统计剖析实例本文采集了 2012 年 31 个省市自治区的农林牧渔和有关农业数据 , 经过对对采集的数据进行比较剖析对 31 个省市自治区进行分类 . 选用了 6个指标农业产值 , 林业产值 . 牧业总产值 , 渔业总产值 , 乡村居民家庭拥有生产性固定财产原值 , 乡村居民家庭经营耕地面积 .数据以下表 :一. 聚类法设定 4 个群聚 , 采纳了系统聚类法 . 下表为 spss 剖析以后的结果 .聚类表群集组合初次出现阶群集阶群集 1 群集 2 系数群集 1 群集 2 下一阶1 5 7 226.381 0 0 132 2 9 1715.218 0 0 53 22 24 1974.098 0 0 74 1 29 5392.690 0 0 65 2 30 6079.755 2 0 66 1 2 11120.902 4 5 87 4 22 21528.719 0 3 118 1 26 23185.444 6 0 149 12 20 26914.251 0 0 1910 27 31 35203.443 0 0 2011 4 28 50321.121 7 0 2212 11 13 65624.068 0 0 2413 5 25 114687.756 1 0 1714 1 21 169600.075 8 0 2215 8 18 188500.814 0 0 2116 17 19 204825.463 0 0 2117 5 14 268125.103 13 0 2018 3 23 387465.457 0 0 2619 6 12 425667.984 0 9 2320 5 27 459235.019 17 10 2321 8 17 499195.430 15 16 2522 1 4 559258.810 14 11 2823 5 6 708176.881 20 19 2424 5 11 854998.386 23 12 2825 8 10 1042394.608 21 0 2626 3 8 1222229.597 18 25 2927 15 16 1396048.280 0 0 2928 1 5 1915098.014 22 24 3029 3 15 3086204.552 26 27 3030 1 3 6791755.637 28 29 0Rescaled Distance Cluster CombineCASE 0 5 1015 20 25 Label Num +--------- +--------- +--------- +--------- +---------+内蒙 5 -+吉林7 -+云南25 -+-+江西14 -+ +-+陕西27 -+-+ |新疆31 -+ +-+安徽12 -+-+ | |广西20 -+ +-+ +------- +辽宁 6 ---+ | |浙江11 -+----- + |福建13 -+ |重庆22 -+ +--------------------------------- +贵州24 -+ | |山西 4 -+--- + | |甘肃28 -+ | | |北京 1 -+ | | |青海29 -+ +--------- + |天津 2 -+ | |上海9 -+ | |宁夏30 -+--- + |西藏26 -+ |海南21 -+ |河北 3 ---+----- + |四川23 ---+ | |黑龙江8 -+-+ +------------- + |湖南18 -+ +--- + | | |湖北17 -+-+ +-+ +------------------------- + 广东19 -+ | |江苏10 ------- + |山东15 ----------- +----------- +河南16 ----------- +群集成员事例 4 群集1: 北京 12: 天津 13: 河北 14: 山西 15: 内蒙 26: 辽宁 17: 吉林 28: 黑龙江 29: 上海 110: 江苏 111: 浙江 112: 安徽 113: 福建 114: 江西 115: 山东 316: 河南 117: 湖北 118: 湖南 119: 广东 120: 广西 121: 海南 122: 重庆 123: 四川 124: 贵州 125: 云南 126: 西藏 427: 陕西 128: 甘肃 129: 青海 130: 宁夏 131: 新疆 2从 SPSS剖析结果能够获得 , 内蒙 , 吉林 , 黑龙江 , 新疆为第 2族群 , 这一族群的特色是农业收入可能不高 , 可是农民的固定财产 , 和耕地面积特别高 , 农民的充裕程度或许机械化程度较高; 山东是第 3族群 , 这一族群中六个指标都处于较高水平,农林牧渔四项收入都处于较高水平并且农民充裕; 西藏处于第 4族群 , 这是因为 , 西藏人员较少 , 自然条件恶劣 , 可使用耕地少 , 可是 , 因为国家的扶助 , 农民的固定 财产许多 , 农民相对而言比较富裕 ; 大部分省份属于第 1族群 , 这一族群的特色在 于六项指标都没有较为突出的一项, 或许农林牧渔收入的原来就少, 或许是农民 的固然比较辛苦 , 整体的农业收入较高 , 可是农民的收入水平比较低, 固定财产较 少 .三. 鉴别法X 1,X 2,X 3,X 4,X 5,X 6分别代表农业产值 , 林业产值 . 牧业总产值 , 渔业总产值 , 乡村居民家庭拥有生产性固定财产原值, 乡村居民家庭经营耕地面积 .剖析事例办理纲要未加权事例N百分比有效31 100.0清除的缺失或越界组代码 0 .0 起码一个缺失鉴别变量 0 .0 缺失或越界组代码还有起码一 0.0个缺失鉴别变量共计 0 .0 共计31 100.0实验结果剖析 :组统计量有效的 N (列表状态)Average Linkage (Between Groups) 均值 标准差 未加权的已加权的1农业总产值 1463.8900 1062.0348625 25.000 林业总产值 118.5768 87.02052 25 25.000 牧业总产值 830.3664 671.10440 25 25.000渔业总产值291.4128346.719022525.000乡村居民家庭拥有生产性固定14432.3400 5287.92950 25 25.000 财产原值乡村居民家庭经营耕地面积 1.5496 .88484 25 25.000 2 农业总产值1582.2975 543.92851 4 4.000林业总产值93.3500 37.71131 4 4.000 牧业总产值1021.3175 372.88255 4 4.000 渔业总产值38.3500 27.49067 4 4.000 乡村居民家庭拥有生产性固定30226.4175 4233.77839 4 4.000 财产原值乡村居民家庭经营耕地面积9.4975 3.30626 4 4.000 3 农业总产值3960.6200 . a 1 1.000林业总产值107.0100a1 1.000 .牧业总产值2285.9200 . a 1 1.000 渔业总产值1267.0700 . a 1 1.000 乡村居民家庭拥有生产性固定19168.1400 . a 1 1.000 财产原值乡村居民家庭经营耕地面积 1.6400 . a 1 1.000 4 农业总产值53.3900 . a 1 1.000林业总产值 2.5600 . a 1 1.000牧业总产值59.0200a1 1.000 .渔业总产值.2200 . a 1 1.000乡村居民家庭拥有生产性固定52935.0700 . a 1 1.000财产原值乡村居民家庭经营耕地面积 1.8900 . a 1 1.000 从表上能够看出 , 组均值之间差值很大 . 各个分组 , 在 6 项指标上均值有较明显的差别 .组均值的均等性的查验Wilks 的 Lambda F df1 df2 Sig.农业总产值.773 2.640 3 27 .070林业总产值.928 .699 3 27 .561牧业总产值.801 2.238 3 27 .107渔业总产值.691 4.019 3 27 .017乡村居民家庭拥有生产性固定.253 26.538 3 27 .000财产原值组均值的均等性的查验Wilks 的 Lambda F df1 df2 Sig.农业总产值.773 2.640 3 27 .070林业总产值.928 .699 3 27 .561牧业总产值.801 2.238 3 27 .107渔业总产值.691 4.019 3 27 .017乡村居民家庭拥有生产性固定.253 26.538 3 27 .000财产原值乡村居民家庭经营耕地面积.190 38.263 3 27 .000 由表中能够知道 ,13456 指标之间的 sig 值较小 ,2 指标 sig 值有 0.561 较大 ,可是仍说明接受原假定 , 各指标族群间差别较大 .汇聚的组内矩阵农业总产值林业总产值牧业总产值渔业总产值有关性农业总产值 1.000 .449 .895 .400 林业总产值.449 1.000 .489 .481牧业总产值.895 .489 1.000 .294渔业总产值.400 .481 .294 1.000乡村居民家庭拥有生产性固定-.093 -.262 -.052 -.040财产原值乡村居民家庭经营耕地面积.056 -.033 .181 -.104汇聚的组内矩阵乡村居民家庭拥有生产性固定资乡村居民家庭经产原值营耕地面积有关性农业总产值-.093 .056林业总产值-.262 -.033牧业总产值-.052 .181渔业总产值-.040 -.104乡村居民家庭拥有生产性固定 1.000 .326财产原值乡村居民家庭经营耕地面积.326 1.000从表中能够知道 , 查验结果 p 值>0.05, 此时 , 说明协方差矩阵相等,能够进行 bayes 查验 .Fisher剖析法协方差矩阵的均等性的箱式查验对数队列式AverageLinkage(BetweenGroups) 秩对数队列式1 6 61.1252 . a . b3 . c . b4 . c . b汇聚的组内 6 62.351打印的队列式的秩和自然对数是组协方差矩阵的秩和自然对数。
多元统计分析数据

多元统计分析数据一、聚类分析例1、为深入了解我国人口的文化程度状况,现利用1990年全国人口普查数据对全国30个省市自治区进行聚类分析。
分析选用了三个指标:(1)大学以上文化程度的人口占全部人口的比例(DXBZ);(2)初中文化程度的人口占全部人口的比例(CZBZ);(3)文盲半文盲人口占全部人口的比例(WMBZ),分别用来反映例2、根据信息基础设施的发展状况,对世界20个国家和地区进行分类。
这里选取了发达国家、新兴工业化国家、拉美国家、亚洲发展中国家、转型国家等不同类型的20个国家作聚类分析。
描述信息基础设施的变量主要的有六个:call——千人拥有电话号码,movecall——每千户居民蜂窝移动电话,fee——高峰时期每三分钟国际电话成本,computer——每千人拥有的计算机数,mips——每千例3、为了研究1982年全国各地区农民家庭收支的分布规律,根据抽样调查资料进行分类处理,共抽取28个省、市、自治区的样本,每个样本有六个指标,这六个指标反映了平均每人生活消费的支出情况,其原始数据见表3。
例4为了研究世界各国森林、草原资源的分布规律,共抽取了21个国家的数据,每个国家4项指标,原始例5 若要从沪市的蒲发银行、齐鲁石化、东北高速、武钢股份、东风汽车等53家上市公司中优选适合开放式基金组合投资的10只股票,我们以总股本和流通股本为分类标志,根据这53家公司的总股本和A股流通股本数据(见表5.3),用聚类分析法将它们分成若干类,再从各类公司中选出比较活跃的股票建立股票池。
例6沪市上市公司2001年末总股本在10000—12000万股、流通股本在3600—5050万股之间共有23家(对于股本结构在其它范围内的上市公司,用雷同的方法,可以建立相应的每股收益预测模型),各公司2000年及2001年有关的财务数据见表。
二、判别分析例1、人文发展指数是联合国开发计划署于1990年5月发表的第一份《人类发展报告》中公布的。
多元统计分析案例分析
一、对我国30个省市自治区农村居民生活水平作聚类分析1、指标选择及数据:为了全面分析我国农村居民的生活状况,主要考虑从收入、消费、就业等几个方面对农村居民的生活状况进行考察;因此选取以下指标:农村产品价格指数、农村住宅投资、农村居民消费水平、农村居民消费支出、农村居民家庭人均纯收入、耕2、将数据进行标准化变换:第一类:北京、上海、浙江;第二类:天津、、辽宁、、福建、甘肃、江苏、广东;第三类:浙江、河北、内蒙古、吉林、黑龙江、安徽、山东、河南、湖北、四川、云南;第四类:山西、青海、宁夏、新疆、重庆、贵州、陕西、湖南、广西、江西、;从分类结果上看,根据2010年的调查数据,第一类地区的农民生活水平较高,第二类属于中等水平,第三类、第四类属于较低水平;二、判别分析从上可知,只有一个地区判别组和原组不同,回代率为96%; 下面对新疆进行判别:判别函数分别为:Y1= + + + +Y2=+ + + +Y3= + + +将西藏的指标数据代入函数得:Y1=Y2=Y3=计算Y值与不同类别均值之间的距离分别为:D1=D2=D3=D4=经过判别,D4最小,所以新疆应归于第四类,这与实际情况也比较相符;三,因子分析:分析数据在上表的基础上去掉两个耕地面积和农村固定资产投资两个指标;经spss软件分析结果如下:1各指标的相关系数阵:从中可以看出,大部分指标的相关系数都比较高,各变量之间的线性关系较明确,能够从中提取公共因子,适合因子分子;2检验:由上表可知:巴特利特球度检验统计量的观测值为.相应的概率p接近为0.如果显着性水平a为,由于显着性水平小于,拒绝零假设,认为相关系数矩阵与单位阵有显着差异,同时,KOM值为,根据Kaiser给出的度量标准可知原有变量适合进行因子分析3各指标的贡献率如下表:从中可以看出,各个指标的贡献率都在百分之五十之上比较高;从上表中可以看出,第一个因子的特征根为.解释原有五个变量总方差的68%,累积方差贡献率为%;第二个因子的特征根为,解释原有变量总方差%,累计方差贡献率为%;4碎石图:5因子载荷阵如下:由上表可知,各指标在第一个因子上的载荷比较高,说明第一个因子很重要;第二个因子与原有变量的相关性较小,它对原有变量的解释作用不显着;为便于对各因子进行命名,对因子载荷阵实施正交旋转;旋转之后的因子载荷阵:6从上表可见,每个因子只有几个指标的因子载荷较大,因此可根据上表进行分类;将五个指标按高载荷分成两类:四,主成分分析:1各指标间的相关系数矩阵如下表所示:可以看到有些指标之间的相关性较强,如果直接进行综合分析会造成信息重叠,所以用主成分分析将多个指标化成几个不相关的综合指标;2求相关矩阵的特征值和特征向量:从上表可知,前两个特征值累计贡献率已达%;说明前两个主成分基本包含了全部指标具有的信息;因此,取前两个特征值,并计算相应的特征向量:3由上述因子分子的因子载荷阵计算主成分的特征向量阵为:所以,前两个主成分为:第一个主成分:F1= X1++ ++第二个主成分:F2=在第一主成分中第二、三、四个指标的系数较大,这三个指标起主要作用,刻划了农居民的收入支出状况的综合指标;在第二主成分中,第一个指标系数较大,是农产品价格水平指标;4因子得分:根据上表写出以下因子得分函数:F1=农产品价格指数+农村居民消费+消费支出+家庭人均纯收入+就业人数F2=农产品价格指数+农村居民消费消费支出+家庭人均纯收入就业人数5综合评价:以两个因子的方差贡献率为权数,综合评价模型为:Z=+旋转之后的方差贡献率F1= X1++ ++F2=将各地区指标值代入上式得到各地区农村生活水平的综合值及排名:6对结果进行分析:从中可以看出,各地区的农村居民生活水平存在差异;其中,北京、上海、浙江、江苏地区的综合评价值排名前列,说明这几个城市农村居民的生活水平比较高;主要表现在农民收入水平和消费水平两个方面;这几个城市属于沿海地区,经济比较发达,工农业发展遥遥领先于其他地区;其次,天津、山东、福建、辽宁、广东综合评价值相对较低;不过也处于全国前十的地位;青海、贵州、广西、重庆、新疆、甘肃、陕西、云南等几个地区农村居民生活水平发展比较落后;原因是这些地区大多位于中国中西部,地理位置不佳,交通不便,经济发展水平不高,进而影响到农村经济的发展;农村居民收入水平和消费水平均比较低;因此,要提高这些地区农民的生活水平,政府应该加大这些地区的基础设施建设,提高这些地区农村居民的收入水平;。
多元统计分析案例

一.搜集的必要性消费是实现国民经济良性循环的关键,而消费结构是否合理,又是消费的关键问题。
考察消费结构是研究和衡量居民消费水平,生活质量的一条重要的途径,可以从侧面反映一国宏观经济发展的基本状况,是联合国划分一国经济发展阶段的重要手段之一。
改革开放以来,我国的经济政治体制改革直接影响了农村居民生活水平及消费结构。
二提出使用的多元消费结构是一种客观存在,消费结构的分类则是人们主观的产物,可以根据实际需要对消费结构进行不同的分类,消费结构首先可以分为宏观消费结构与微观消费结构两个类型。
宏观消费结构是指我国考察的消费资料最终实现的分布,如个人消费与公共消费各自所占的比重,个人消费与社会集团以及社会集团各自的比重,各地区和城乡居民消费各自的比重。
微观消费结构是从单个家庭和个人着眼考察的消费结构,是指居民生活消费内容的组成方式,是宏观消费的基础。
三.进行选定多元统计方法的研究设计和实现的步骤因子分析的基本思想是通过对变量的相关系数矩阵的内部结构进行分析,从中找出少数几个能够控制员是变量的因子,建立因子分析模型,利用公共因子再现原始变量之间的相关关系,达到简化变量,降低变两位数和对原始变量在解释及命名的目的。
设有m个原始变量,表示为x1,x2,…,xm,根据因子分析的要求,假设这些变量已经标准化(均值为0,标准差为1),假设m个变量可以由n个因子f1,f2,…,fn表示为线性组合,即:x1=a11f1+a12f2+…+a1nfn+ε1x2=a21f1+a22f2+…+a2nfn+ε2…xm=am1f1+am2f2+…+amnfn+εm上式为因子分析的数学模型,如果利用矩阵形量向量,它的每一个分量表示一个指标或变量;F称为因子向量,每一个分量表示一个因子,由于它们出现在每个原始变量的线性表达式中,所以又称为公共因子;矩阵A为因子载荷矩阵,其元素aij称为因子载荷;ε称为特殊因子,表示原始变量中不能由因子解释的部分,均值为0。
多元统计分析实例

多元统计分析实例院系: 商学院学号: 姓名:多兀统计分析实例本文收集了 2012年31个省市自治区的农林牧渔和相关农业数据,通过对对 收集的数据进行比较分析对31个省市自治区进行分类•选取了 6个指标农业产值 林业产值.牧业总产值,渔业总产值,农村居民家庭拥有生产性固定资产原值,农 村居民家庭经营耕地面积. 数据如下表: 江 区 京津北H 蒙宁林龙海苏江徽建西东南北南东西南庆川州南藏西肃海夏牘地北天河山内辽吉黒上江浙安福江山河湖湖广广海重四贵77西陕甘青宁新农业总产值 林业驰产{牧业总产懾业总产侬村居民家庭拥有生产性[5166.2954.83 154.16 12 98 12767. 09 0・5195.^9 £ 79 105. 01 61, 66 17508. 57 1. 58 3095.29 77.88 1747. 66 1?7. 74 17904. S3 1789847-41 79, 07 298. 83 8. 42 ^808. 38 2.51171.-57 97. 7G U1S. 86 26. 08 293曲.旳 10. 4 1539.65128. 68 16ZL 23 618. 74 249^7. 92 3. 781166.ES90. 1 1130. 36 34. 14 24937. SB S. 272315. 64 134. 51350. 63 77. 92 31507. 91 13. 56171.48 9.5572. 59 57. 45 4146. 13 0. 262966.72 99. 75 1226,18 1235.4 14541. 03 L251229.36 142.14 549. 01 687. 05 22747. 33 6 541867.64 209. 5 1119.73 334. 43 15134. 35 1. 391263.71 256. 45 48L 28 p03. 36 11821. 38 731003.21 228. 91 752. 63 333. 06 gggg. 31 L 57 39&0.储 107.01 22S5. 92 1267. 07 19168.14 L &4 3958.^5 140. 85 2255. 61 SS.4 12980. 72 1. &2 2488. 06 100.05 1334, X 626, 23 10813. 13 1. 71 2651.69 259. 97 1488. 58 279. 94 3904. 32 1. 22 2229. 27222.74 1134.14 914. 05 8516. 72 0.53 1724 245. 56 1072. 77 331. 74 11851. 56 L 37 4S0. 72 137.85 214. 14 236.27 11387. 06 0. 83 341.51 43.48 453. 9 44. 99 122S5. 74 L 29 2764- 9 151. 52269. 86 163. 77 13759.17 1.14364. 54.19421. 55 28. 21 11957. 31 L 181398.17225. S3 912. 97 63.1 19020. 92 1.. 6 53.39 2” 56 59. 02 0. 22 52935. 07 L 891526.23 58. 44 598. 72 14. 61 12273. 06 L 52984,24 20. 07 231. 72 1,8 1$486. 44 2. 72 117-09 4.57 137. 08 0. 56 21919.甜 L 33 240, 4&9・77 105, 72 13. 36 24266.19 3・69 1675収04485. 37 15* 26 35Q70. 315 76.聚类法设定4个群聚,采用了系统聚类法.下表为spss分析之后的结果.C A S E 0 5 10 15 20 25 内蒙 5 -+吉林7 -+云南25 - + -+江西14 -+ +-+陕西27 - + -+ |新疆31 -+ +- +安徽12 -+-+ 11广西20 —+ + — + +——————— +辽宁 6 ---+ | |浙江11 -+—+ 1福建13 -+ 1重庆22 -+ + ............... ....... + 贵州24 -+ 1|山西 4 -+ -+ | |甘肃28 -+ | | |北京 1 -+ | | |青海29 + + + | 1天津 2 -+ 1|上海9 -+ 1|宁夏30 -+ - +|西藏26 -+ |海南21 -+ |河北 3 | 1四川23 - + | |黑龙江8 -+-+ + .......... + |湖南18 -+ + + | | |湖北17 - + -+ +-+ + -------------- ■...... + 广东19 -+ | |江苏10 --——+ |山东15 ...... + ....... +河南16 ...... +从SPSS分析结果可以得到,内蒙,吉林,黑龙江,新疆为第2族群,这一族群的特点是农业收入可能不高,但是农民的固定资产,和耕地面积非常高,农民的富余程度或者机械化程度较高;山东是第3族群,这一族群中六个指标都处于较高水平农林牧渔四项收入都处于较高水平而且农民富余;西藏处于第4族群,这是因为,西藏人员较少,自然条件恶劣,可使用耕地少,但是,由于国家的扶持,农民的固定资产较多,农民相对而言比较富足;大多数省份属于第1族群,这一族群的特点在于六项指标都没有较为突出的一项,或者农林牧渔收入的本来就少,或者是农民的虽然比较辛苦,总体的农业收入较高,但是农民的收入水平比较低,固定资产较少•三.判别法X1,X2,X3,X4,X5,X6分别代表农业产值,林业产值.牧业总产值,渔业总产值,农村居民家庭拥有生产性固定资产原值,农村居民家庭经营耕地面积实验结果分析:从表上可以看出,组均值之间差值很大.各个分组,在6项指标上均值有较明显的差异.由表中可以知道,13456指标之间的sig 值较小,2指标sig 值有0.561较大, 不过仍说明接受原假设,各指标族群间差异较大.从表中可以知道,检验结果p值>0.05,此时,说明协方差矩阵相等,可以进行bayes检验.Fisher 分析法协方差矩阵的均等性的箱式检验典型判别式函数摘要由表中看出,函数1,2的特征值达到0.911,0.822比较大,对判别的贡献大由表中可知,3个Fishe判别函数分别为y i 2.928 0.003X20.626X6y2 2.269 0.002X2 0.489X6y3 0.975 0.009X2 0.01X3 0.03X4 0.037X6农村居民家庭拥有生产性固定资产原值对判别数据所属群体无用该表是原始变量与典型变量(标准化的典型判别函数)的相关系数,相关系数的绝对值越大,说明原始变量与这个判别函数的相关性越强.从表中可以看出相关性较强.符合较好.由上表可知各类别重心的位置,通过计算观测值与各重心的距离,距离最小的即为该观测值的分类.贝叶斯分析法该表为贝叶斯函数判别函数的取值,从图中可以知道三类贝叶斯函数y1 0.03X1 0.029X2 0.03X3 0.002X4 0.001X5 0.153X1 8.418第一类:第二y2 0.06X10.42X2 0.009X3 0.004X40.004X5 4.286X6 38.18类;第三y3 0.02X-I0.010X20.002X30.010X40.001X5 1.X620.732类;第四类:『4 0.OO3X-I 0.051X20.004x30.006x40.002x5 1.675x661.646将各样品的自变量值代入上述4个BayeS判别函数,得到函数值。
多元统计分析经典案例

29
Copyright CAE
当你看一张map时 .. 问你自己
• 它意味着什么? • 它对理解数据有什么附加的作用? • 它对我们所知道的市场/顾客的思考方式是否适 合?
– 如果不是 - 错在什么地方?
• 它是否帮助我更好地了解市场?
30
Copyright CAE
当你看一张map时 .. 问你自己
Bird
Dog
40% 40% 20% 20% 50%
Cat
10%
16
Copyright CAE
现在我们用颜色和动物名称两个变量 来做2-维的图表
努力来显示..
- 那些动物在颜色方面最相似,那些区别最大? - 那些颜色更倾向那类动物 - 那些动物和那些颜色有更强的相关性,那些相关性很弱
17
Copyright CAE
Copyright CAE
相关性分析 Correspondence Analysis
9
Copyright CAE
结构
• • • • • • 什么是相关性分析? 尝试通过练习了解它 输入的类型 设计录入的格式 执行分析 解释和表述分析的结果
10
Copyright CAE
什么是相关性分析?
• 经常也称作 Brand Mapping 或 CORAN Mapping
6
Copyright CAE
我们通常使用的多元分析技术…...
• • • • • • • • 相关性分析(Brand Mapping ) 主成分分析 因子分析 多元回归 聚类分析/市场细分 联合性分析/ 平衡(Trade off) 分析 判别分析 etc. etc. etc.
7
Copyright CAE
多元统计分析实例

4.从Model Summary(b)可知:复相关系数 R Square为0.860
5. 将x1=600,x2=2.5带入y关于x1、x2的二元线性回归方程: y=0.32x1-84.361x2+184.613
中即可求得E(y)的点估计为165,也可以用SPSS求出。置信水平为0.95的置信区 为(105,225)
第三次 多元统计作业
1. 设已有六个样品,每个样品对某项指标进行了测试,分别等于1,2,5,7,9,10.它们 先各自成一类,供六类,使用类与类之间的最大距离进行聚类分析。 利用SPSS,进行最大距离法聚类,输出结果如下:
B
Std. Error
184.613
72.304
Beta
t
Sig.
2.553 .027
95% Confidence Interval for B
Lower Bound
Upper Bound
25.473 343.754
x1
.320
.097
.389 3.301
.007 .106
.533
x2
-8、设河流的一个断面的年径流量为y,该断面上的上游流域的年平均降水量为x1,年平均
饱和差为x2,现共有14年的观测记录:
时间(a) x1
x2
y
时间(a) x1
x2
y
1
720
1.80
290
8
579
2.22
151
2
553
2.67
多元统计分析因子分析案例

y3
0.372 -0.017 -0.500 0.575 -0.295 -0.182 0.361 -0.245 0.099 -0.100 -0.256 -0.134 -0.078 0.560 0.103
y4
-0.119 0.289 0.710 0.361 -0.178 -0.070 0.448 -0.230 0.070 -0.165 -0.206 0.092 0.213 -0.234 -0.028
X5
精明
X6
诚实
X7
推销
X8
经验
X9
积极性
X10
抱负
X11
理解
X12
潜力
X13
交际能力 X14
适应性
X15
0.162 0.213 0.040 0.221 0.292 0.316 0.158 0.322 0.133 0.315 0.319 0.332 0.333 0.259 0.236
0.431 -0.033 0.237 -0.125 -0.249 -0.131 -0.400 -0.039 0.553 0.046 -0.068 -0.022 0.024 -0.079 0.421
Y2 0.538 0.500 0.492 -0.270 -0.212 -0.31表达式
y 1 0 . 2 x 1 7 0 . 3 x 6 2 1 0 . 2 x 3 3 0 0 . 5 x 2 4 1 0 . 5 x 8 5 3 0 . 4 x 8 6 7 y 2 0 . 5 x 1 3 0 . 5 x 2 8 0 0 . 4 x 0 3 9 0 . 2 x 2 4 7 0 . 2 x 0 5 1 0 . 3 x 6 2 1
X3:第三产业占GDP比重 X7:每万人拥有卫生技术人员数 X8:每万人高等学校在校生数 X9:教育经费投入占GDP比重 X16:每万人科研机构数 X17:科研经费占GDP比重
多元统计分析课程案例教学探析

多元统计分析课程案例教学探析随着大数据时代的到来,人们对数据的深入探索和分析变得越来越重要,多元统计分析便应运而生。
多元统计分析是指通过对多个变量之间的关系进行统计分析,从而深入探索数据间的内在关系。
多元统计分析包含了多种方法和技术,如主成分分析、聚类分析、判别分析等。
本文将通过案例教学的方式,探析多元统计分析的核心思想和方法。
一、主成分分析案例主成分分析是多元统计分析中最为常见的方法之一,通过对数据进行降维处理,将原始数据转化为新的主成分,从而探索数据之间的内在关系。
下面以一组汽车销售数据为例,演示主成分分析的过程。
数据集包含了10个变量,包括汽车品牌、价格、尺寸、燃油效率等信息。
首先需要进行数据清洗和预处理,如缺失值补充、标准化等。
然后,进行主成分分析,得到了一组新的主成分,其中第一主成分占原始数据总方差的70.8%。
可以发现,第一主成分与汽车的价格、尺寸和燃油效率密切相关,可以将其解释为“高档大型节能车”。
第二主成分与品牌和颜色相关,可以解释为“品牌特征”。
通过主成分分析可以深入探索各个变量之间的关系,发现数据的内在结构和规律,为进一步的分析和决策提供了依据。
二、聚类分析案例聚类分析是一种无监督学习方法,通过将数据分成若干个类别,发现数据间的相似性和差异性。
下面以一组消费者偏好数据为例,演示聚类分析的过程。
数据集包含了20个消费者的购物偏好信息,包括购物种类、消费水平等。
首先需要进行数据清洗和预处理,如缺失值补充、标准化等。
然后,进行聚类分析,确定聚类数量和相似性度量方式。
本案例使用了层次聚类分析方法,通过计算每个点之间的欧氏距离,得到了一棵完全连接聚类树。
可以将数据分为三类:高消费、中消费和低消费。
通过聚类分析可以发现不同消费者群体间的购物行为和消费水平存在显著差异,为制定营销策略和定位目标消费群体提供了依据。
三、判别分析案例判别分析是一种有监督学习方法,用于对事先分配到已知类别的数据进行分类。
多元统计分析及实例讨论

添加标题
百米跑成绩
添加标题
跳远成绩
添加标题
百米跨栏
添加标题
1500米跑成绩
添加标题
铅球成绩
添加标题
例3 奥运会十项全能 运动项目
添加标题
跳高成绩
添加标题
得分数据的因子分 析
添加标题
400米跑成绩
添加标题
铁饼成绩
添加标题
撑杆跳远成绩
添加标题
标枪成绩
1
0.59
1
0.35 0.42 1
0.34
0.51
0.38
1
0.63 0.49 0.19 0.29 1
0.40
0.52
0.36
0.46 0.34
1
0.28 0.31 0.73 0.27 0.17 0.32 1
0.20
0.36
0.24
0.39 0.23 0.33
0.24
1
0.11 0.21 0.44 0.17 0.13 0.18 0.34 0.24 1
1. 因子分析基本思想简介
单击此处 添加大标 题内容
多元统计分析是以p个变量的n次观测数所组成的数据为依据。 简化数据结构(降维) 将某些较复杂的数据结构通过变量变换等方法使相互依赖的变量变成互不相关的;将
高维空间数据投影成到低维空间数据; 分类与判别(归类) 对所考察观测点(或变量)按相似程度进行分类或归类; 变量间的相互联系 相互依赖关系:分析一个或几个变量的变化是否依赖于另一 些变量的变化;变量间相关关系:分析两组变量相互关系; 多元数据的统计推断 多元正态分布的均值向量与协方差阵的估计及其假设检验; 多元统计分析的理论基础 多维随机变量及其分布,抽样分布
(完整版)多元统计分析实例汇总

多元统计分析实例院系: 商学院学号: 姓名:多兀统计分析实例本文收集了 2012年31个省市自治区的农林牧渔和相关农业数据,通过对对 收集的数据进行比较分析对31个省市自治区进行分类•选取了 6个指标农业产值 林业产值.牧业总产值,渔业总产值,农村居民家庭拥有生产性固定资产原值,农 村居民家庭经营耕地面积. 数据如下表:江 区 京津北H 蒙宁林龙海苏江徽建西东南北南东西南庆川州南藏西肃海夏牘地北天河山内辽吉黒上江浙安福江山河湖湖广广海重四贵77西陕甘青宁新农业总产值 林业驰产{牧业总产懾业总产侬村居民家庭拥有生产性[5166.2954.83 154.16 12 98 12767. 090・5 195.^9 £ 79 105. 01 61, 66 17508. 57 1. 58 3095.29 77.88 1747. 66 1?7. 74 17904. S3 1789847-41 79, 07 298. 83 8. 42 ^808. 38 2.51171.-57 97. 7G U1S. 86 26. 08 293曲.旳 10. 4 1539.65128. 68 16ZL 23 618. 74 249^7. 92 3. 781166.ES90. 1 1130. 36 34. 14 24937.SB S. 272315. 64 134. 51350. 63 77. 92 31507. 9113. 56171.48 9.5572. 59 57. 45 4146. 13 0. 262966.72 99. 75 1226,18 1235.4 14541. 03 L251229.36 142.14 549. 01 687. 05 22747. 33 6 541867.64 209. 5 1119.73 334. 43 15134. 35 1. 391263.71 256. 45 48L 28 p03. 36 11821. 38 731003.21 228. 91 752. 63 333. 06 gggg. 31 L 57 39&0.储 107.01 22S5. 92 1267. 07 19168.14L &4 3958.^5 140. 85 2255. 61 SS.4 12980. 72 1. &2 2488. 06 100.05 1334, X 626, 23 10813. 13 1. 71 2651.69 259. 97 1488. 58 279. 94 3904. 32 1. 22 2229. 27222.74 1134.14 914. 05 8516. 72 0.53 1724 245. 56 1072. 77 331. 74 11851. 56 L 37 4S0. 72 137.85 214. 14 236.27 11387. 06 0. 83 341.51 43.48 453. 9 44. 99 122S5. 74 L 29 2764- 9 151. 5 2269. 86163. 77 13759.17 1.14364. 54.19421. 55 28. 21 11957. 31 L 181398.17225. S3 912. 97 63.1 19020. 92 1.. 6 53.39 2” 56 59. 02 0. 22 52935. 07 L 891526.23 58. 44 598. 72 14. 61 12273. 06 L 52984,24 20. 07 231. 72 1,8 1$486. 44 2. 72 117-09 4.57 137. 08 0. 56 21919.甜 L 33 240, 4& 9・105, 7213. 36 24266.19 3・69 1675収04 485. 37 15* 26 35Q70. 315 76.聚类法设定4个群聚,采用了系统聚类法.下表为spss分析之后的结果.Rescaled Dista nee Cluster Comb ineC A S E 0 5 10 15 20 25 内蒙 5 -+吉林7 -+云南25 - + -+江西14 -+ +-+陕西27 - + -+ |新疆31 -+ +- +安徽12 -+-+ 11广西20 —+ + — + +——————— +辽宁 6 ---+ | |浙江11 -+—+ 1福建13 -+ 1重庆22 -+ + .......................... ............ +贵州24 -+ 1|山西 4 -+ -- + | |甘肃28 -+ | | |北京 1 -+ | | |青海29 + + + |1天津 2 -+ 1| 上海9 -+ 1| 宁夏30 -+ -- + | 西藏26 -+ | 海南21 -+ |河北 3 | 1四川23 - + | |黑龙江8 -+-+ + ................. + |湖南18 -+ + -- + | | |湖北17 - + -+ +-+ + --------------------- ■............ +广东19 -+ | |江苏10 --——+ |山东15 ............ + ............ +河南16 ............ +从SPSS分析结果可以得到,内蒙,吉林,黑龙江,新疆为第2族群,这一族群的特点是农业收入可能不高,但是农民的固定资产,和耕地面积非常高,农民的富余程度或者机械化程度较高;山东是第3族群,这一族群中六个指标都处于较高水平农林牧渔四项收入都处于较高水平而且农民富余;西藏处于第4族群,这是因为,西藏人员较少,自然条件恶劣,可使用耕地少,但是,由于国家的扶持,农民的固定资产较多,农民相对而言比较富足;大多数省份属于第1族群,这一族群的特点在于六项指标都没有较为突出的一项,或者农林牧渔收入的本来就少,或者是农民的虽然比较辛苦,总体的农业收入较高,但是农民的收入水平比较低,固定资产较少•三.判别法X1,X2,X3,X4,X5,X6分别代表农业产值,林业产值.牧业总产值,渔业总产值,农村居民家庭拥有生产性固定资产原值,农村居民家庭经营耕地面积实验结果分析:从表上可以看出,组均值之间差值很大.各个分组,在6项指标上均值有较明显的差异.由表中可以知道,13456指标之间的sig 值较小,2指标sig 值有0.561较大, 不过仍说明接受原假设,各指标族群间差异较大.从表中可以知道,检验结果p值>0.05,此时,说明协方差矩阵相等,可以进行bayes检验.Fisher 分析法协方差矩阵的均等性的箱式检验典型判别式函数摘要由表中看出,函数1,2的特征值达到0.911,0.822比较大,对判别的贡献大由表中可知,3个Fishe判别函数分别为y i 2.928 0.003X20.626X6y2 2.269 0.002X2 0.489X6y3 0.975 0.009X2 0.01X3 0.03X4 0.037X6农村居民家庭拥有生产性固定资产原值对判别数据所属群体无用该表是原始变量与典型变量(标准化的典型判别函数)的相关系数,相关系数的绝对值越大,说明原始变量与这个判别函数的相关性越强.从表中可以看出相关性较强.符合较好.由上表可知各类别重心的位置,通过计算观测值与各重心的距离,距离最小的即为该观测值的分类.贝叶斯分析法该表为贝叶斯函数判别函数的取值,从图中可以知道三类贝叶斯函数第一类:y1 0.03X1 0.029X2 0.03X3 0.002X4 0.001X5 0.153X1 8.418第二类;y2 0.06X10.42X2 0.009X3 0.004X40.004X5 4.286X6 38.18第三类;y3 0.02X-I0.010X20.002X30.010X40.001X5 1.X620.732第四类:『4 0.OO3X-I 0.051X20.004x30.006x40.002x51.675x661.646将各样品的自变量值代入上述4个BayeS判别函数,得到函数值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
– 例如:基本的分析(变量关联表)
• 另外也有复杂性的一面 ....
– 大量附加的分析 – 运用许多的分析技术
• 然而我们需要看到“复杂性问题背后的简单表述 ”
– 使复杂问题简单化
• 为了达到这一目的,你不得不研究复杂问题然后 去提炼出使人容易明白的信息
4
Copyright CAE
• 一张图表总是浓缩数据并使数据变的直观,但是它 也有局限性,大量的数据本身蕴涵的信息将会丢失 (例如仅是重要的信息被保留)。因此,相关性分析 图应当小的心运用和解释(例如我们不能依赖表面 的定位图,因为一些变量可能没有在MAP上表现出 来)
31
Copyright CAE
概念MAP(Perceptual Mapping) 的基本方法
35
Copyright CAE
多元回归 象线性回归一样只不过有更多 的独立变量
Y = c + b1x1 + b2x2 + b3x3 + ... + e
29
Copyright CAE
当你看一张map时 .. 问你自己
• 它意味着什么? • 它对理解数据有什么附加的作用? • 它对我们所知道的市场/顾客的思考方式是否适 合?
– 如果不是 - 错在什么地方?
• 它是否帮助我更好地了解市场?
30
Copyright CAE
当你看一张map时 .. 问你自己
Mixed/ other Brown Cats White
Dogs Birds 33% Black
24 Copyright CAE
65.4%
相关性分析输入数据的类性
• • • • 百分比或原始数据都可以 品牌的相关联的格子(通常形式) 任何具有缺省/存在的分数类型 切记得分数是以样本的总数而不是以单个样本 为基础的
回归分析是什么?
• 线性回归(Linear Regression)
– 画出因变量(dependent variable)和自变量 (independent variable)之间的关系 – 因变量 = B* 自变量+ 常数项 + 残差
34
Copyright CAE
回归分析是什么?
• 线性回归方程式:
• 帮助客户/市场决策者
– 为实施市场战略而去发现市场的空隙和优化产品的 定位(对于新品牌或新产品的开发/延伸) – 发现市场上决定性的或显著的属性,例如对于选择 不同品牌的重要和有显著区别的属性
12
Copyright CAE
什么是Brand Mapping?
Magic Clean
Cleans well for heavy duty cleaning *
多元统计分析技术
• 一个研究者可能不了解所有的分析技术细节 • 但是他们应该能够正确地选择适当的方法 • 使用多元技术,你不必知道详细的数学公式-但是你应当明白 它的原理 • 多元分析并不是魔术棒,不需要我们开动脑筋就能解决问题 它不会轻易告诉你答案
• 如果问卷设计的很差,多元分析就很难发挥作用
8
26
Copyright CAE
设计输入类型
• 通过系列的类别...
– 请看这个品牌的列表,然后告诉我那一个符合下述的声明 ... – 更便宜,更容易,更快
• 品牌和品牌...
– Now thinking about Mr Muscle, which of these statements describe Mr Muscle – Now thinking about White Cat, which of these statements describe White Cat – Answers can be agree / disagree ratings – Better for smaller brands, when more detailed responses are necessary
Mr. Muscle Is effective in Look removing oil/grease
Blue Moon Leaves a long-lasting shine * Clorox Leaves a shine * Wan Li Cleans and shines in one step * Cleans well for light duty cleaning * GFL
MIXED WHITE
BLACK BROWN
19 Copyright CAE
MIXED WHITE BLACK BROWN
20
Copyright CAE
为了建立这种立体的图表你不得 不...
• 把那些与较多动物相关联的颜色放置在图的中央 位置 • 把那些与较多动物相关联的颜色放置在图的边缘 位置 • 如果一种颜色同时与超过二种以上的动物强相关 ,这些动物将会在图中更接近
什么是多元统计分析?
• 单一问题分析(univariate analysis) 例如频率 分布通常作为数据的第一步的描述分析 • 关联表(bivariate analysis) 总是作为主要的分 析手段而被市场研究者反复 使用
– 把一个问题或变量与另一个关联交叉作表(例如对受 访者背景变量:性别、年龄等)
– Brand Mapping = Correspondence Analysis (usually)
• 相关性分析图
– 一种非常有用的市场研究工具,可以表述一个市场的侧面 (市场细分,品牌定位等) 可以在2维空间内同时表达多维的属性 可以更好的理解品牌和属性之间的关系
11
Copyright CAE
Copyright CAE
相关性分析 Correspondence Analysis
9
Copyright CAE
结构
• • • • • • 什么是相关性分析? 尝试通过练习了解它 输入的类型 设计录入的格式 执行分析 解释和表述分析的结果
10
Copyright CAE
什么是相关性分析?
• 经常也称作 Brand Mapping 或 CORAN Mapping
可能制作的分析图...
Bunnies 5% 80% 15%
Birds
50%
40%
2% 8%
Dogs
40%
40%
10% 10%
Black Brown White Mixed/ other
Cats
20%
10%
20%
50%
15
Copyright CAE
可能制作的分析图...
15% Bunnies 5% 2% 8% 40% 10% 10% 50% Mixed/ other White Brown Black 80%
一个例子- 原始数据
• 以下这张表显示不同家庭宠物的颜色
Cats Black Brown White Mixed/ other
14 Copyright CAE
Dogs 40% 40% 10% 10%
Birds Bunnies 50% 40% 2% 8% 5% 80% 0% 15%
20% 10% 30% 50%
• 通过因子分析程式来运行一组数据
– 减少大量的变量(如产品属性)到小规模的基础变 量。这些变量是高度自相关的变量,例如,受访者 的回答模式都非常相似 – 通过因子提取来解释因子变量。高的得分意味着更 加重要的变量已经被因子所包含
32
Copyright CAE
回归分析 Regression
33
Copyright CAE
– 相关分析(Correspondence analysis) – 回归/多元回归分析(Regression / Multiple regression – 因子分析(Factor analysis) – 聚类分析(Cluster analysis/segmentation)
• 结论
2 Copyright CAE
市场研究中的多元统计分析方法
Multivariate Analysis - an introduction
上海市中消研市场研究有限公司 数据统计部 制作
1 Copyright CAE
讨论议题
• • • • • 我们的研究工作是什么? 什么是多元统计分析(MVA)? 为什么我们需要它? 通常的分析技术 MVA详细介绍及例子:
6
Copyright CAE
我们通常使用的多元分析技术…...
• • • • • • • • 相关性分析(Brand Mapping ) 主成分分析 因子分析 多元回归 聚类分析/市场细分 联合性分析/ 平衡(Trade off) 分析 判别分析 etc. etc. etc.
7
Copyright CAE
– – – – – – Y = C + bx + e Y = 产出(dependent variable /response variable) X = 输入变量(independent variable / regressor) c = 常量 (当x=0时) b = 斜率 e = 误差/残差(error / residual)
25
Copyright CAE
设计输入类型
• 只研究数据并想到进行分析并不是一个好主意 • 分析应该在问卷设计以前的表述/决定研究目标阶 段就开始考虑 • 如果你乡做相关性分析表 - 你通常打算使用(二分 制)不在/在的数据类型 • 这些数据可以通过品牌与品牌或类别系列等形式收 集... i.e.
• 如果同时分析的变量超过二个就被称为多元统 计分析
5
Copyright CAE
为什么要做这种“附加值”的分析?