模式识别实验一
模式识别上机实验报告

实验一、二维随机数的产生1、实验目的(1) 学习采用Matlab 程序产生正态分布的二维随机数 (2) 掌握估计类均值向量和协方差矩阵的方法(3) 掌握类间离散度矩阵、类内离散度矩阵的计算方法(4) 熟悉matlab 中运用mvnrnd 函数产生二维随机数等matlab 语言2、实验原理多元正态分布概率密度函数:11()()2/21/21()(2)||T X X d p X eμμπ---∑-=∑其中:μ是d 维均值向量:Td E X μμμμ=={}[,,...,]12Σ是d ×d 维协方差矩阵:TE X X μμ∑=--[()()](1)估计类均值向量和协方差矩阵的估计 各类均值向量1ii X im X N ω∈=∑ 各类协方差矩阵1()()iTi iiX iX X N ωμμ∈∑=--∑(2)类间离散度矩阵、类内离散度矩阵的计算类内离散度矩阵:()()iTi iiX S X m X m ω∈=--∑, i=1,2总的类内离散度矩阵:12W S S S =+类间离散度矩阵:1212()()Tb S m m m m =--3、实验内容及要求产生两类均值向量、协方差矩阵如下的样本数据,每类样本各50个。
1[2,2]μ=--,11001⎡⎤∑=⎢⎥⎣⎦,2[2,2]μ=,21004⎡⎤∑=⎢⎥⎣⎦ (1)画出样本的分布图;(2) 编写程序,估计类均值向量和协方差矩阵;(3) 编写程序,计算类间离散度矩阵、类内离散度矩阵; (4)每类样本数增加到500个,重复(1)-(3)4、实验结果(1)、样本的分布图(2)、类均值向量、类协方差矩阵根据matlab 程序得出的类均值向量为:N=50 : m1=[-1.7160 -2.0374] m2=[2.1485 1.7678] N=500: m1=[-2.0379 -2.0352] m2=[2.0428 2.1270] 根据matlab 程序得出的类协方差矩阵为:N=50: ]0628.11354.01354.06428.1[1=∑ ∑--2]5687.40624.00624.08800.0[N=500:∑--1]0344.10162.00162.09187.0[∑2]9038.30211.00211.09939.0[(3)、类间离散度矩阵、类内离散度矩阵根据matlab 程序得出的类间离散度矩阵为:N=50: ]4828.147068.147068.149343.14[=bS N=500: ]3233.179843.169843.166519.16[b =S根据matlab 程序得出的类内离散度矩阵为:N=50:]0703.533088.73088.71052.78[1=S ]7397.2253966.13966.18975.42[2--=S ]8100.2789123.59123.50026.121[=W SN=500: ]5964.5167490.87490.86203.458[1--=S ]8.19438420.78420.70178.496[2=S ]4.24609071.09071.06381.954[--=W S5、结论由mvnrnd 函数产生的结果是一个N*D 的一个矩阵,在本实验中D 是2,N 是50和500.根据实验数据可以看出,当样本容量变多的时候,两个变量的总体误差变小,观测变量各个取值之间的差异程度减小。
模式识别实验报告

模式识别实验报告————————————————————————————————作者:————————————————————————————————日期:实验报告实验课程名称:模式识别姓名:王宇班级: 20110813 学号: 2011081325实验名称规范程度原理叙述实验过程实验结果实验成绩图像的贝叶斯分类K均值聚类算法神经网络模式识别平均成绩折合成绩注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和2、平均成绩取各项实验平均成绩3、折合成绩按照教学大纲要求的百分比进行折合2014年 6月实验一、 图像的贝叶斯分类一、实验目的将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。
二、实验仪器设备及软件 HP D538、MATLAB 三、实验原理 概念:阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。
并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。
最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。
而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。
类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。
上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。
这时如用全局阈值进行分割必然会产生一定的误差。
分割误差包括将目标分为背景和将背景分为目标两大类。
实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。
模式识别 实验报告一

402
132
识别正确率
73.36
84.87
99.71
70.31
82.89
86.84
结果分析:
实验中图像3的识别率最高,图像1和图像2的识别率次之。图像1和图像2的分辨率相对图像3更低,同时图像2有折痕影响而图像1则有大量噪声。通过阈值处理能较好的处理掉图像1的噪声和图像2的折痕,从而使得图像1的识别率有所提升,而图像2的识别率变化不大。从而可以得出结论,图像3和图像2识别率不同的原因主要在于图像分辨率,而图像2和图像1识别率的不同则在于噪声干扰。
实验报告
题目
模式识别系列实验——实验一字符识别实验
内容:
1.利用OCR软件对文字图像进行识别,了解图像处理与模式识别的关系。
2.利用OCR软件对文字图像进行识别,理解正确率的概念。
实验要求:
1.利用photoshop等软件对效果不佳的图像进行预处理,以提高OCR识别的正确率。
2.用OCR软件对未经预处理和经过预处理的简体和繁体中文字符图像进行识别并比较正确率。
图像4内容既有简体又有繁体,从识别结果中可了解到错误基本处在繁体字。
遇到的问题及解决方案:
实验中自动旋转几乎没效果,所以都是采用手动旋转;在对图像4进行识别时若采用系统自己的版面分析,则几乎识别不出什么,所以实验中使用手动画框将诗的内容和标题及作者分开识别。
主要实验方法:
1.使用汉王OCR软件对所给简体和繁体测试文件进行识别;
2.理,再次识别;
实验结果:
不经过图像预处理
经过图像预处理
实验图像
图像1
图像2
图像3
图像4
图像1
图像2
字符总数
458
模式识别实验报告

模式识别实验报告实验一、最近邻规则的聚类算法一、实验要求编写采用最近邻规则的聚类算法,距离采用欧式距离,阈值可设定。
采用二维特征空间中的10个样本对程序进行验证。
x1 = (0,0) ,x2 = (3,8) ,x3 = (2,2) ,x4 = (1,1) ,x5 = (5,3),x6 = (4,8) ,x7 = (6,3) ,x8 = (5,4) ,x9 = (6,4) ,x10 = (7,5)。
二、实验步骤○1、选取距离阈值T,并且任取一个样本作为第一个聚合中心Z1,如:Z1=x1;○2、计算样本x2到Z1的距离D21;若D21≤T,则x2∈Z1,否则令x2为第二个聚合中心,Z2=x2。
设Z2=x2,计算x3到Z1和Z2的距离D31和D32 。
若D31>T和D32>T,则建立第三个聚合中心Z3 ;否则把x3归于最近邻的聚合中心。
依此类推,直到把所有的n个样本都进行分类。
○3、按照某种聚类准则考察聚类结果,若不满意,则重新选取距离阈值T、第一个聚合中心Z1,返回第二步②处,直到满意,算法结束。
三、程序设计详见附件1:test1.m。
四、仿真结果最近邻聚类算法:阈值T=1,第一个聚类中心(5,4)最近邻聚类算法:阈值T=3,第一个聚类中心(5,4)最近邻聚类算法:阈值T=6,第一个聚类中心(5,4)最近邻聚类算法:阈值T=10,第一个聚类中心(5,4)五、结果分析1、考虑阈值对聚类的影响:由上述仿真结果可知,阈值大小对于分类的影响非常大。
当阈值小于1的时候,样本(10个)共分为10类;而当阈值大于10的时候,样本全分为1类;当阈值在其中时,随着阈值的变化分类页多样化。
所以选取合适的阈值是正确分类的前提标准!2、考虑初始聚类中心对聚类的影响:在合适的阈值下,第一个聚类中心的选取对分类结果几乎没有什么影响;而相对的,阈值不合适的情况下,第一个聚类中心的选取对分类结果还是有一些影响,仿真结果会出现一些偏差。
《模式识别》实验报告K-L变换特征提取

《模式识别》实验报告K-L变换特征提取基于K-L 变换的iris 数据分类⼀、实验原理K-L 变换是⼀种基于⽬标统计特性的最佳正交变换。
它具有⼀些优良的性质:即变换后产⽣的新的分量正交或者不相关;以部分新的分量表⽰原⽮量均⽅误差最⼩;变换后的⽮量更趋确定,能量更集中。
这⼀⽅法的⽬的是寻找任意统计分布的数据集合之主要分量的⼦集。
设n 维⽮量12,,,Tn x x x =x ,其均值⽮量E=µx ,协⽅差阵()T x E=--C x u)(x u ,此协⽅差阵为对称正定阵,则经过正交分解克表⽰为x =TC U ΛU ,其中12,,,[]n diag λλλ=Λ,12,,,n u u u =U 为对应特征值的特征向量组成的变换阵,且满⾜1T-=UU。
变换阵TU 为旋转矩阵,再此变换阵下x 变换为()T -=x u y U ,在新的正交基空间中,相应的协⽅差阵12[,,,]xn diag λλλ==x U C U C。
通过略去对应于若⼲较⼩特征值的特征向量来给y 降维然后进⾏处理。
通常情况下特征值幅度差别很⼤,忽略⼀些较⼩的值并不会引起⼤的误差。
对经过K-L 变换后的特征向量按最⼩错误率bayes 决策和BP 神经⽹络⽅法进⾏分类。
⼆、实验步骤(1)计算样本向量的均值E =µx 和协⽅差阵()T xE ??=--C x u)(x u5.8433 3.0573 3.7580 1.1993??=µ,0.68570.0424 1.27430.51630.04240.189980.32970.12161.27430.3297 3.1163 1.29560.51630.12161.29560.5810x----=--C (2)计算协⽅差阵xC 的特征值和特征向量,则4.2282 , 0.24267 , 0.07821 , 0.023835[]diag =Λ-0.3614 -0.6566 0.5820 0.3155 0.0845 -0.7302 -0.5979 -0.3197 -0.8567 0.1734 -0.0762 -0.4798 -0.3583 0.0755 -0.5458 0.7537??=U从上⾯的计算可以看到协⽅差阵特征值0.023835和0.07821相对于0.24267和4.2282很⼩,并经计算个特征值对误差影响所占⽐重分别为92.462%、5.3066%、1.7103%和0.52122%,因此可以去掉k=1~2个最⼩的特征值,得到新的变换阵12,,,newn k u u u -=U。
模式识别教学改进项目阶段实验计划

模式识别教学改进项目阶段实验计划1. 背景介绍模式识别是计算机科学和人工智能领域的重要研究方向,涉及到机器研究、数据挖掘和模型建立等技术。
为了提高模式识别课程的教学效果,我们计划进行一项教学改进项目。
2. 目标该项目的目标是通过引入实验环节,帮助学生更好地理解和应用模式识别的理论知识。
具体目标包括:- 提供实践机会,让学生能够亲自动手构建和训练模式识别模型;- 培养学生的问题解决能力和创新思维;- 加强学生对模式识别算法的理解和运用能力。
3. 实验内容和步骤3.1 实验一:数据预处理3.1.1 实验目的通过实际操作,使学生掌握数据预处理的基本步骤和技术。
3.1.2 实验步骤- 收集适当的模式识别数据集;- 进行数据清洗,处理数据中的噪声和缺失值;- 对数据进行特征选择和降维。
3.2 实验二:分类器构建与训练3.2.1 实验目的让学生了解常用的分类器算法,并能够构建和训练分类器模型。
3.2.2 实验步骤- 介绍常见的分类器算法,如K近邻、支持向量机、决策树等;- 学生根据实验要求,选择合适的分类器算法;- 使用已处理好的数据集,构建和训练分类器模型。
3.3 实验三:模型评估与优化3.3.1 实验目的教导学生如何评估和优化模式识别模型的性能。
3.3.2 实验步骤- 介绍模型评估指标,如准确率、召回率、F1值等;- 学生根据实验要求,评估已构建的模型的性能;- 针对模型的性能问题,进行优化措施的尝试和调整。
4. 评估和改进为了评估实验计划的有效性和改进之处,我们将进行以下评估和改进措施:- 定期收集学生的反馈意见和建议;- 对实验过程和结果进行分析和总结;- 根据评估结果,对实验计划进行适当调整和改进。
5. 时间安排本实验计划将在课程教学周期内进行,具体时间安排如下:- 实验一:第3周- 实验二:第5周- 实验三:第8周6. 预期成果通过本项目的实施,我们预期能够达到以下成果:- 学生对模式识别的理解更加深入;- 学生的实践操作能力和问题解决能力得到提升;- 学生对模式识别技术的应用能力有所提高。
《模式识别》线性分类器设计实验报告
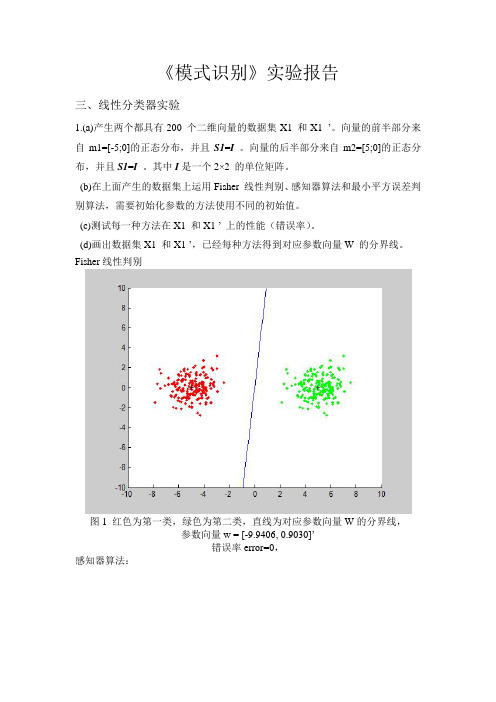
《模式识别》实验报告三、线性分类器实验1.(a)产生两个都具有200 个二维向量的数据集X1 和X1 ’。
向量的前半部分来自m1=[-5;0]的正态分布,并且S1=I 。
向量的后半部分来自m2=[5;0]的正态分布,并且S1=I。
其中I是一个2×2 的单位矩阵。
(b)在上面产生的数据集上运用Fisher 线性判别、感知器算法和最小平方误差判别算法,需要初始化参数的方法使用不同的初始值。
(c)测试每一种方法在X1 和X1 ’ 上的性能(错误率)。
(d)画出数据集X1 和X1 ’,已经每种方法得到对应参数向量W 的分界线。
Fisher线性判别图1 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数向量w = [-9.9406, 0.9030]’错误率error=0,感知器算法:图2 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1;0.1];迭代次数iter=2参数向量w = [-4.8925, 0.0920]’错误率error=0图3 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];迭代次数iter=2参数向量w = [-3.9925, 0.9920]’错误率error=0图4 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[10; 10];迭代次数iter=122参数向量w = [-5.6569, 7.8096]’错误率error=0图5 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 50];迭代次数iter=600参数向量w = [-27.0945, 37.4194]’错误率error=0图6 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 100];迭代次数iter=1190参数向量w = [-54.0048, 74.5875]’错误率error=0最小平方误差判别算法:图7 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1; 0.1];参数向量w = [-0.1908, -0.0001]’错误率error=0图8 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.5; 0.5];参数向量w = [-0.1924, 0.1492]’错误率error=0图9 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 0.5];参数向量w = [-0.1914, 0.0564]’错误率error=0图10 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];参数向量w = [-0.1943, 0.3359]’错误率error= 0.00502.重复1.中的实验内容,数据集为X2 和X2 ’。
模式识别实验报告

模式识别实验报告关键信息项:1、实验目的2、实验方法3、实验数据4、实验结果5、结果分析6、误差分析7、改进措施8、结论1、实验目的11 阐述进行模式识别实验的总体目标和期望达成的结果。
111 明确实验旨在解决的具体问题或挑战。
112 说明实验对于相关领域研究或实际应用的意义。
2、实验方法21 描述所采用的模式识别算法和技术。
211 解释选择这些方法的原因和依据。
212 详细说明实验的设计和流程,包括数据采集、预处理、特征提取、模型训练和测试等环节。
3、实验数据31 介绍实验所使用的数据来源和类型。
311 说明数据的规模和特征。
312 阐述对数据进行的预处理操作,如清洗、归一化等。
4、实验结果41 呈现实验得到的主要结果,包括准确率、召回率、F1 值等性能指标。
411 展示模型在不同数据集或测试条件下的表现。
412 提供可视化的结果,如图表、图像等,以便更直观地理解实验效果。
5、结果分析51 对实验结果进行深入分析和讨论。
511 比较不同实验条件下的结果差异,并解释其原因。
512 分析模型的优点和局限性,探讨可能的改进方向。
6、误差分析61 研究实验中出现的误差和错误分类情况。
611 分析误差产生的原因,如数据噪声、特征不充分、模型复杂度不足等。
612 提出减少误差的方法和建议。
7、改进措施71 根据实验结果和分析,提出针对模型和实验方法的改进措施。
711 描述如何优化特征提取、调整模型参数、增加训练数据等。
712 预测改进后的可能效果和潜在影响。
8、结论81 总结实验的主要发现和成果。
811 强调实验对于模式识别领域的贡献和价值。
812 对未来的研究方向和进一步工作提出展望。
在整个实验报告协议中,应确保各项内容的准确性、完整性和逻辑性,以便为模式识别研究提供有价值的参考和借鉴。
《模式识别》课程实验 线性分类器设计实验

《模式识别》课程实验线性分类器设计实验一、实验目的:1、掌握Fisher 线性分类器设计方法;2、掌握感知准则函数分类器设计方法。
二、实验内容:1、对下列两种情况,求采用Fisher 判决准则时的投影向量和分类界面,并做图。
12{(2,0),(2,2),(2,4),(3,3)}{(0,3),(2,2),(1,1),(1,2),(3,1)}T T T T T T T T T ωω⎧=⎪⎨=-----⎪⎩ 12{(1,1),(2,0),(2,1),(0,2),(1,3)}{(1,2),(0,0),(1,0),(1,1),(0,2)}T T T T T T T T T T ωω⎧=⎪⎨=-----⎪⎩ 2、对下面的两类分类问题,采用感知准则函数,利用迭代修正求权向量的方法求两类的线性判决函数及线性识别界面,并画出识别界面将训练样本区分的结果图。
12{(1,1),(2,0),(2,1),(0,2),(1,3)}{(1,2),(0,0),(1,0),(1,1),(0,2)}T T T T T T T T T T ωω⎧=⎪⎨=-----⎪⎩ 三、实验原理:(1)Fisher 判决准则投影方向:*112()w w S μμ-=-(2)感知准则函数:()()kT p z Z J v v z ==-∑当k Z为空时,即()0J v ,*v即为所求p四、解题思路:1、fisher线性判决器:A.用mean函数求两类样本的均值B.求两类样本的均值的类内离散矩阵SiC.利用类内离散矩阵求总类内离散矩阵SwD.求最佳投影方向WoE.定义阈值,并求得分界面2、感知准则函数分类器:A.获得增广样本向量和初始增广权向量B.对样本进行规范化处理C.获得解区,并用权向量迭代修正错分样本集,得到最终解区五、实验结果:1、fisher线性判决分类器:条件:取pw1=pw2=0.5,阈值系数为0.5A.第一种情况B.第二种情况2、感知准则函数判决:条件:取步长row为1判决结果:六、结果分析:1、fisher线性判决器中,调整阈值系数时,分界面会随之平行上下移动,通过调整阈值系数的大小,就能比较合理的得到分界面。
模式识别基础实验报告资料

2015年12月实验一 Bayes 分类器的设计一、 实验目的:1. 对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识;2. 理解二类分类器的设计原理。
二、 实验条件:1. PC 微机一台和MATLAB 软件。
三、 实验原理:最小风险贝叶斯决策可按下列步骤进行:1. 在已知)(i P ω,)|(i X P ω,c i ,,1 =及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率:∑==c j jj i i i P X P P X P X P 1)()|()()|()|(ωωωωω c j ,,1 =2. 利用计算出的后验概率及决策表,按下式计算出采取i α决策的条件风险: ∑==c j j j i i X P X R 1)|(),()|(ωωαλα a i ,,1 =3. 对2中得到的a 个条件风险值)|(X R i α(a i ,,1 =)进行比较,找出使条件风险最小的决策k α,即:)|(min )|(,,1X R X R k c i k αα ==, 则k α就是最小风险贝叶斯决策。
四、 实验内容:假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为: 正常状态:)(1ωP =0.9;异常状态:)(2ωP =0.1。
现有一系列待观察的细胞,其观察值为x :-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531-2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752-3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682-1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532)|(1ωx P )|(2ωx P 类条件概率分布正态分布分别为(-2,0.25)(2,4)。
决策表为011=λ(11λ表示),(j i ωαλ的简写),12λ=6, 21λ=1,22λ=0。
模式识别实验【范本模板】

《模式识别》实验报告班级:电子信息科学与技术13级02 班姓名:学号:指导老师:成绩:通信与信息工程学院二〇一六年实验一 最大最小距离算法一、实验内容1. 熟悉最大最小距离算法,并能够用程序写出。
2. 利用最大最小距离算法寻找到聚类中心,并将模式样本划分到各聚类中心对应的类别中.二、实验原理N 个待分类的模式样本{}N X X X , 21,,分别分类到聚类中心{}N Z Z Z , 21,对应的类别之中.最大最小距离算法描述:(1)任选一个模式样本作为第一聚类中心1Z 。
(2)选择离1Z 距离最远的模式样本作为第二聚类中心2Z 。
(3)逐个计算每个模式样本与已确定的所有聚类中心之间的距离,并选出其中的最小距离.(4)在所有最小距离中选出一个最大的距离,如果该最大值达到了21Z Z -的一定分数比值以上,则将产生最大距离的那个模式样本定义为新增的聚类中心,并返回上一步.否则,聚类中心的计算步骤结束。
这里的21Z Z -的一定分数比值就是阈值T ,即有:1021<<-=θθZ Z T(5)重复步骤(3)和步骤(4),直到没有新的聚类中心出现为止。
在这个过程中,当有k 个聚类中心{}N Z Z Z , 21,时,分别计算每个模式样本与所有聚类中心距离中的最小距离值,寻找到N 个最小距离中的最大距离并进行判别,结果大于阈值T 是,1+k Z 存在,并取为产生最大值的相应模式向量;否则,停止寻找聚类中心。
(6)寻找聚类中心的运算结束后,将模式样本{}N i X i ,2,1, =按最近距离划分到相应的聚类中心所代表的类别之中。
三、实验结果及分析该实验的问题是书上课后习题2。
1,以下利用的matlab 中的元胞存储10个二维模式样本X {1}=[0;0];X{2}=[1;1];X {3}=[2;2];X{4}=[3;7];X{5}=[3;6]; X{6}=[4;6];X{7}=[5;7];X{8}=[6;3];X{9}=[7;3];X{10}=[7;4];利用最大最小距离算法,matlab 运行可以求得从matlab 运行结果可以看出,聚类中心为971,,X X X ,以1X 为聚类中心的点有321,,X X X ,以7X 为聚类中心的点有7654,,,X X X X ,以9X 为聚类中心的有1098,,X X X 。
模式识别实验指导书2014版

cpmean(i,:)=mean(meas(strmatch(char(sta(i,1)),species,'exact'),:));
4 5
⎟⎟⎠⎞,
⎜⎜⎝⎛
− −
5 6
⎟⎟⎠⎞, ⎜⎜⎝⎛
− −
6 5
⎟⎟⎠⎞,
⎜⎜⎝⎛
5 5
⎟⎟⎠⎞,
⎜⎜⎝⎛
5 4
⎟⎟⎠⎞,
⎜⎜⎝⎛
4 5
⎟⎟⎠⎞,
⎜⎜⎝⎛
5 6
⎟⎟⎠⎞,
⎜⎜⎝⎛
6 5
⎟⎟⎠⎞⎭⎬⎫
,计算样本协方
差矩阵,求解数据第一主成分,并重建原始数据。
(2)使用 Matlab 中进行主成分分析的相关函数,实现上述要求。
有 c 个不同的水平,表示 c 个不同的类。
表 1-1 fit 方法支持的参数名与参数值列表
参数名
参数值
说明
'normal'
正态分布(默认)
核密度估计(通过‘KSWidth’参数设置核密度估计的窗宽
'kernel'
(默认情况下自动选取窗宽;通过‘KSSupport’参数设置
‘Distribution’ 'mvmn'
信息与电气工程学院专业实验中心 二〇一四年八月
《模式识别》实验一 贝叶斯分类器设计
一、实验意义及目的
掌握贝叶斯判别原理,能够利用 Matlab 编制程序实现贝叶斯分类器设计,熟悉基于 Matlab 的 算法处理函数,并能够利用算法解决简单问题。
模式识别实验课程设计

模式识别实验课程设计一、课程目标知识目标:1. 学生能理解模式识别的基本概念,掌握其应用领域及重要性。
2. 学生能够运用课本知识,对给定的数据集进行预处理,包括数据清洗、特征提取等。
3. 学生能够掌握并运用基本的模式识别算法,如K-近邻、决策树、支持向量机等,对数据集进行分类和识别。
4. 学生能够理解并解释模式识别算法的原理及其优缺点。
技能目标:1. 学生能够运用编程工具(如Python等)实现模式识别算法,对实际问题进行求解。
2. 学生能够通过实验,学会分析数据,选择合适的模式识别方法,并调整参数以优化模型。
3. 学生能够通过小组合作,培养团队协作和沟通能力,提高解决问题的效率。
情感态度价值观目标:1. 学生通过学习模式识别,培养对人工智能和数据分析的兴趣和热情。
2. 学生在实验过程中,学会面对困难和挑战,培养坚持不懈、勇于探索的精神。
3. 学生能够认识到模式识别在生活中的广泛应用,意识到科技对生活的影响,增强社会责任感和使命感。
本课程针对高年级学生,结合学科特点和教学要求,旨在提高学生的理论知识和实践技能。
课程以实验为主,注重培养学生的动手能力和实际问题解决能力。
通过本课程的学习,使学生能够更好地理解和掌握模式识别的理论和方法,为未来进一步学习和应用奠定基础。
二、教学内容本课程教学内容主要包括以下几部分:1. 模式识别概述:介绍模式识别的基本概念、应用领域及其重要性。
关联课本第一章内容。
2. 数据预处理:讲解数据清洗、特征提取和特征选择等数据预处理方法。
关联课本第二章内容。
3. 模式识别算法:- K-近邻算法:原理、实现和应用。
- 决策树算法:原理、实现和应用。
- 支持向量机算法:原理、实现和应用。
关联课本第三章内容。
4. 模式识别模型的评估与优化:介绍模型评估指标,如准确率、召回率等,以及模型优化方法。
关联课本第四章内容。
5. 实际案例分析与实验:- 结合实际案例,运用所学算法进行模式识别。
模式识别实验报告

模式识别实验报告班级:电信08-1班姓名:黄**学号:********课程名称:模式识别导论实验一安装并使用模式识别工具箱一、实验目的:1.掌握安装模式识别工具箱的技巧,能熟练使用工具箱中的各项功能;2.熟练使用最小错误率贝叶斯决策器对样本分类;3.熟练使用感知准则对样本分类;4.熟练使用最小平方误差准则对样本分类;5.了解近邻法的分类过程,了解参数K值对分类性能的影响(选做);6.了解不同的特征提取方法对分类性能的影响(选做)。
二、实验内容与原理:1.安装模式识别工具箱;2.用最小错误率贝叶斯决策器对呈正态分布的两类样本分类;3.用感知准则对两类可分样本进行分类,并观测迭代次数对分类性能的影响;4.用最小平方误差准则对云状样本分类,并与贝叶斯决策器的分类结果比较;5.用近邻法对双螺旋样本分类,并观测不同的K值对分类性能的影响(选做);6.观测不同的特征提取方法对分类性能的影响(选做)。
三、实验器材(设备、元器件、软件工具、平台):1.PC机-系统最低配置512M 内存、P4 CPU;2.Matlab 仿真软件-7.0 / 7.1 / 2006a等版本的Matlab 软件。
四、实验步骤:1.安装模式识别工具箱。
并调出Classifier主界面。
2.调用XOR.mat文件,用最小错误率贝叶斯决策器对呈正态分布的两类样本分类。
3.调用Seperable.mat文件,用感知准则对两类可分样本进行分类。
4.调用Clouds.mat文件,用最小平方误差准则对两类样本进行分类。
5.调用Spiral.mat文件,用近邻法对双螺旋样本进行分类。
6.调用XOR.mat文件,用特征提取方法对分类效果的影响。
五、实验数据及结果分析:(1)Classifier主界面如下(2)最小错误率贝叶斯决策器对呈正态分布的两类样本进行分类结果如下:(3)感知准则对两类可分样本进行分类当Num of iteration=300时的情况:当Num of iteration=1000时的分类如下:(4)最小平方误差准则对两类样本进行分类结果如下:(5)近邻法对双螺旋样本进行分类,结果如下当Num of nearest neighbor=3时的情况为:当Num of nearest neighbor=12时的分类如下:(6)特征提取方法对分类结果如下当New data dimension=2时,其结果如下当New data dimension=1时,其结果如下六、实验结论:本次实验使我掌握安装模式识别工具箱的技巧,能熟练使用工具箱中的各项功能;对模式识别有了初步的了解。
模式识别实验报告 实验一 BAYES分类器设计

P (i X )
P ( X i ) P (i )
P( X ) P( )
j 1 i i
c
j=1,…,x
(2)利用计算出的后验概率及决策表,按下面的公式计算出采取 ai ,i=1,…,a 的条件风 险
R (a i X ) (a i , j ) P ( j X ) ,i=1,2,…,a
1.2 1 0.8 0.6 0.4 0.2 0 -0.2 -5 正常细胞 异常细胞 后验概率分布曲线
后验概率
-4
-3
-2
-1 0 1 细胞的观察值
2
3
4
5
图 1 基于最小错误率的贝叶斯判决
最小风险贝叶斯决策 风险判决曲线如图 2 所示,其中带*的绿色曲线代表异常细胞的条件风险曲线;另一条
光滑的蓝色曲线为判为正常细胞的条件风险曲线。 根据贝叶斯最小风险判决准则, 判决结果 见曲线下方,其中“上三角”代表判决为正常细胞, “圆圈“代表异常细胞。 各细胞分类结果: 1 0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 1 1 0 0 0 1 0 1 其中,0 为判成正常细胞,1 为判成异常细胞
实验一 Bayes 分类器设计
【实验目的】
对模式识别有一个初步的理解, 能够根据自己的设计对贝叶斯决策理论算法有一个深刻 地认识,理解二类分类器的设计原理。
【实验原理】
最小风险贝叶斯决策可按下列步骤进行: (1)在已知 P (i ) , P ( X i ) ,i=1,…,c 及给出待识别的 X 的情况下,根据贝叶斯公 式计算出后验概率:
4 0
请重新设计程序, 完成基于最小风险的贝叶斯分类器, 画出相应的条件风险的分布曲线和分 类结果,并比较两个结果。
模式识别实验一报告

用身高体重数据进行性别分类实验一一.题目要求:1.用dataset1.txt 作为训练样本,用dataset2.txt 作为测试样本,采用身高和体重数据为特征,在正态分布假设下估计概率密度(只用训练样本),建立最小错误率贝叶斯分类器,写出所用的密度估计方法和得到的决策规则,将该分类器分别应用到训练集和测试集,考察训练错误率和测试错误率。
将分类器应用到dataset3 上,考察测试错误率的情况。
(在分类器设计时可以尝试采用不同先验概率,考查对决策和错误率的影响。
)2.自行给出一个决策表,采用最小风险贝叶斯决策重复上面的实验。
二.数据文件:1.dataset1.txt----- 328 个同学的身高、体重、性别数据(78 个女生、250 个男生)(datasetf1:女生、datasetm1:男生)2.dataset2.txt -----124 个同学的数据(40 女、84 男)3.dataset3.txt----- 90 个同学的数据(16 女,74 男)三.题目分析:要估计正态分布下的概率密度函数,假设身高随机变量为X,体重随机变量为Y,二维随机变量(X,Y)的联合概率密度函数是:p x,y=1122{−121−ρ2[x−μ12ς12−2ρx−μ1y−μ2ς1ς2+(y−μ2)2ς22]}其中−∞<x,y<+∞;−∞<μ1,μ2<+∞;ς1,ς2>0;−1≤ρ≤1.并其μ1,μ2分别是X与Y的均值,ς12,ς22,分别是X与Y的方差,ρ是X与Y的相关系数。
运用最大似然估计求取概率密度函数,设样本集中包含N个样本,即X={x1,x2,…x N},其中x k是列向量。
根据教材中公式,令μ=(μ1,μ2)T,则μ=1 Nx kNk=1;协方差矩阵=ς12ρς1ς2ρς1ς2ς22,那么=1N(x kNk=1−μ)(x k−μ)T。
采用最小错误率贝叶斯分类器,设一个身高体重二维向量为x,女生类为ω1,男生类为ω2,决策规则如下:x∈ω1,当Pω1x)>P(ω2|x)ω2,当Pω2x)>P(ω1|x)。
模式识别技术实验报告

模式识别技术实验报告本实验旨在探讨模式识别技术在计算机视觉领域的应用与效果。
模式识别技术是一种人工智能技术,通过对数据进行分析、学习和推理,识别其中的模式并进行分类、识别或预测。
在本实验中,我们将利用机器学习算法和图像处理技术,对图像数据进行模式识别实验,以验证该技术的准确度和可靠性。
实验一:图像分类首先,我们将使用卷积神经网络(CNN)模型对手写数字数据集进行分类实验。
该数据集包含大量手写数字图片,我们将训练CNN模型来识别并分类这些数字。
通过调整模型的参数和训练次数,我们可以得到不同准确度的模型,并通过混淆矩阵等评估指标来评估模型的性能和效果。
实验二:人脸识别其次,我们将利用人脸数据集进行人脸识别实验。
通过特征提取和比对算法,我们可以识别不同人脸之间的相似性和差异性。
在实验过程中,我们将测试不同算法在人脸识别任务上的表现,比较它们的准确度和速度,探讨模式识别技术在人脸识别领域的应用潜力。
实验三:异常检测最后,我们将进行异常检测实验,使用模式识别技术来识别图像数据中的异常点或异常模式。
通过训练异常检测模型,我们可以发现数据中的异常情况,从而做出相应的处理和调整。
本实验将验证模式识别技术在异常检测领域的有效性和实用性。
结论通过以上实验,我们对模式识别技术在计算机视觉领域的应用进行了初步探索和验证。
模式识别技术在图像分类、人脸识别和异常检测等任务中展现出了良好的性能和准确度,具有广泛的应用前景和发展空间。
未来,我们将进一步深入研究和实践,探索模式识别技术在更多领域的应用,推动人工智能技术的发展和创新。
【字数:414】。
模式识别实验报告哈工程

一、实验背景随着计算机科学和信息技术的飞速发展,模式识别技术在各个领域得到了广泛应用。
模式识别是指通过对数据的分析、处理和分类,从大量数据中提取有用信息,从而实现对未知模式的识别。
本实验旨在通过实践操作,加深对模式识别基本概念、算法和方法的理解,并掌握其应用。
二、实验目的1. 理解模式识别的基本概念、算法和方法;2. 掌握常用的模式识别算法,如K-均值聚类、决策树、支持向量机等;3. 熟悉模式识别在实际问题中的应用,提高解决实际问题的能力。
三、实验内容本次实验共分为三个部分:K-均值聚类算法、决策树和神经网络。
1. K-均值聚类算法(1)实验目的通过实验加深对K-均值聚类算法的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组二维数据,包括100个样本,每个样本包含两个特征值;② 初始化聚类中心:随机选择K个样本作为初始聚类中心;③ 计算每个样本到聚类中心的距离,并将其分配到最近的聚类中心;④ 更新聚类中心:计算每个聚类中所有样本的均值,作为新的聚类中心;⑤ 重复步骤③和④,直到聚类中心不再变化。
(3)实验结果通过实验,可以得到K个聚类中心,每个样本被分配到最近的聚类中心。
通过可视化聚类结果,可以直观地看到数据被分成了K个类别。
2. 决策树(1)实验目的通过实验加深对决策树的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组具有分类标签的二维数据,包括100个样本,每个样本包含两个特征值;② 选择最优分割特征:根据信息增益或基尼指数等指标,选择最优分割特征;③ 划分数据集:根据最优分割特征,将数据集划分为两个子集;④ 递归地执行步骤②和③,直到满足停止条件(如达到最大深度、叶节点中样本数小于阈值等);⑤ 构建决策树:根据递归分割的结果,构建决策树。
(3)实验结果通过实验,可以得到一棵决策树,可以用于对新样本进行分类。
3. 神经网络(1)实验目的通过实验加深对神经网络的理解,掌握其基本原理和实现方法。
模式识别实验报告

模式识别实验报告实验一、线性分类器的设计与实现1. 实验目的:掌握模式识别的基本概念,理解线性分类器的算法原理。
2. 实验要求:(1)学习和掌握线性分类器的算法原理;(2)在MATLAB 环境下编程实现三种线性分类器并能对提供的数据进行分类;(3)对实现的线性分类器性能进行简单的评估(例如算法适用条件,算法效率及复杂度等)。
注:三种线性分类器为,单样本感知器算法、批处理感知器算法、最小均方差算法批处理感知器算法算法原理:感知器准则函数为J p a=(−a t y)y∈Y,这里的Y(a)是被a错分的样本集,如果没有样本被分错,Y就是空的,这时我们定义J p a为0.因为当a t y≤0时,J p a是非负的,只有当a是解向量时才为0,也即a在判决边界上。
从几何上可知,J p a是与错分样本到判决边界距离之和成正比的。
由于J p梯度上的第j个分量为∂J p/ða j,也即∇J p=(−y)y∈Y。
梯度下降的迭代公式为a k+1=a k+η(k)yy∈Y k,这里Y k为被a k错分的样本集。
算法伪代码如下:begin initialize a,η(∙),准则θ,k=0do k=k+1a=a+η(k)yy∈Y k|<θuntil | ηk yy∈Y kreturn aend因此寻找解向量的批处理感知器算法可以简单地叙述为:下一个权向量等于被前一个权向量错分的样本的和乘以一个系数。
每次修正权值向量时都需要计算成批的样本。
算法源代码:unction [solution iter] = BatchPerceptron(Y,tau)%% solution = BatchPerceptron(Y,tau) 固定增量批处理感知器算法实现%% 输入:规范化样本矩阵Y,裕量tau% 输出:解向量solution,迭代次数iter[y_k d] = size(Y);a = zeros(1,d);k_max = 10000; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% k=0;y_temp=zeros(d,1);while k<k_maxc=0;for i=1:1:y_kif Y(i,:)*a'<=tauy_temp=y_temp+Y(i,:)';c=c+1;endendif c==0break;enda=a+y_temp';k=k+1;end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %k = k_max;solution = a;iter = k-1;运行结果及分析:数据1的分类结果如下由以上运行结果可以知道,迭代17次之后,算法得到收敛,解出的权向量序列将样本很好的划分。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
模式识别实验一
实验人:胡虎跃(S0704335)
实验题目:极大似然估计和Fisher 线形判别分析
p.127 Prob. 1
(a)、编写程序,对实验数据中的W1的三个特征进行计算,求解最大似然估计u 和δ; (b)、处理二维数据,处理W1中的任意两个特征的组合; (c)、处理三维数据,处理W1中的三个特征的组合;
(d)、在这三维高斯模型可分离的条件下,编写程序估计类别w2中的均值和协方差矩阵中的3个参数;
(e)、比较前4种方式计算出来的均值的异同,并加以解释; (f)、比较前4种方式计算出来的方差的异同,并加以解释。
答:(a )程序为solution1_1.m 。
试验结果为:
u =-0.0709 -0.6047 -0.9110
σ1 = 0.9062 σ2 =4.2007 σ3 = 4.5419
(b )、程序为solution1_2.m
处理二维数据,结果见下表:
(c )、程序为solution1_3.m 处理三维数据,结果如下:
;
∑ =
(d )、程序为solution1_4.m 试验结果为:
(-0.1126 0.4299 0.0037)μ=;
0.0539 0 0 0 0.0460 0 0 0 0.0073⎛⎫
⎪∑= ⎪ ⎪⎝⎭
;
(e )、针对1ω这个类别,我们会发现,其实(a )(b )(c )三种计算方法中的对于不同维数的模型所得到的对应列的均值是相等的。
(d )的结果也是同样的。
(f )、结论:
A 、通过观察代码的运行结果,我们可以发现,在一维模型中所得到的方差,与在二维模型和三维模型中所得到的协方差阵的对角线上的各个元素是相等的。
B 、如果说三维的高斯模型是可分离的话,从计算得到的结果中我们可以发现:所得到的协方差矩阵中非对角线元素是都为零的,而对角线上对应的元素与所假设一维模型时计算得到的结果则是一致的。
p.129 Prob. 9
(a)、编写用FISHER线性判别方法,对三维数据求最优方向w的通用程序;
(b)、对表格中的类别W2和W3,计算最优方向w;
(c)、画出表示最优方向w的直线,并且标记出投影后的点在直线上的位置;
(d)、在这个子空间中,对每种分布用一维高斯函数拟合,并且求分类决策面;
(e)、(b)中得到的分类器的训练误差是什么?
(f)、为了比较,使用非最优方向w=(1.0,2.0,-1.5)’重复(d)(e)两个步骤。
在这个非最优子空间中,训练误差是什么。
答:(a)、通用程序的源程序见“3-9”文件夹。
(b)、由程序运行结果可知:类别W2和W3的最优方向为
(c)、表示最优方向w的直线如图所示:
投影后的点在直线上的位置见上图中绿色块和直线上的红块,亮绿色的五角星和深蓝色的五角星。
(d)、在这个子空间中,对每种分布用一维高斯函数拟合,结果如图所示:
可以看到,可得w2和w3的分类决策面为X=0.03997。
(e)、因为W2中的点投影后的值为:
第二类中小于0.03997的有一个数据;
W2中的点投影后的值为:
第三类中大于0.03997的有两个个数据。
所以:(b)中得到的分类器的训练误差为:
=(1/10)*0.5+(2/10)*0.5
=0.15
(f)、使用非最优方向w=(1.0,2.0,-1.5)’重复(d)(e)两个步骤,结果如图所示:
将交点放大,可得W2和W3的分类决策面X=-0.1819。
因为W2中的点投影后的值为:
第二类中大于-0.1819的有2个数据;
因为W3中的点投影后的值为:
第三类中小于-0.1819的有三个数据。
所以在这个非最优子空间中,训练误差为:
35 .0
)2/1(
10
/3
)2/1(
10 /4
)3
(
)3
/2
(
)2
(
)2
/3
(
)
(
=
⨯
+
⨯
=
∈
+
∈
=w
p
w
R
x
p
w
p
w
R
x
p
error
p。