Java中如何实现Tree的数据结构算法
数据结构(Java版)图2(最小生成树)

最小生成树举例
A
50 60 52 65 50
C
45 42 30 50
A
C
45
B
40
D
G
B
40 50
D
42 30
G
E
70
F
E
F
(a) 无向带权连通图G
(b) 无向带权图G 的最小生成树T
从最小生成树的定义可知,构造n个顶点的无向带权连 通图的最小生成树,必须满足如下三个条件: ① 必须包含n个顶点。 ② 有且仅有n-1条边。 ③ 没有回路。
)
将ej边加入到tree中;
}
实践项目
设计一个程序实现Prim和Kruskal算法.
表5-1 lowcost[ ]数组数据变化情况 表5-2 closest[ ]数组数据变化情况
扫描次数
closest[0]
closest[1]
closest[2]
closest[3]
closest[4]
closest[5]
求最小生成树算法
普里姆算法(Prim) (从点着手)
适合于求边稠密的最小生成树 适合于求边稀疏的最小生成树
克鲁斯卡尔算法(Kruskal)(从边着手)
普里姆算法(Prim)思想
1.
2.
3.
4.
令集合U={u0}(即从顶点u0开始构造最小生 成树),集合T={}。 从所有顶点u∈U和顶点v∈V-U的边权中选择最 小权值的边(u,v),将顶点v加入到集合U中,边 (u,v)加入到集合T中。 如此重复下去,直到U=V时则最小生成树构造完 毕。 此时集合U就是最小生成树的顶点集合,集合T 就是最小生成树的边集。
java treemap实现原理

java treemap实现原理Java TreeMap是Java中非常常用的一种数据结构,使用红黑树作为其底层实现。
它提供了一种将键映射到值的方式,键是唯一的,并且按照升序进行排序。
Java TreeMap的实现原理是非常有趣的,它主要涉及到红黑树、迭代器、比较器等知识点。
在本文中,我们将深入了解Java TreeMap的实现原理,并理解如何在代码中使用它。
1. 红黑树红黑树是一种自平衡的二叉搜索树。
它通过保持一些简单规则来保证树的平衡,以确保左右子树的高度之差不超过1,并且保证每个节点的颜色都为红色或黑色。
这些规则允许红黑树保持在O(log n)的时间复杂度下进行插入、搜索和删除操作。
在Java TreeMap中,红黑树被用作底层存储结构。
当添加一个新的键值对时,它会首先检查根节点是否为空。
如果是,则创建一个新的节点并将其设置为根节点。
否则,它会沿着树的路径查找适当的叶子节点,并将其插入为其左侧或右侧的子节点。
为了保持树的平衡,通过旋转和重新着色来调整节点的颜色和位置。
每个节点都有一个颜色标记,标记为红色或黑色,红色表示该节点是一个违反规则的节点,黑色表示该节点是一个符合规则的节点。
2. TreeMap的比较器Java TreeMap还有另一个重要的组件,即比较器。
所有元素的排序都是通过比较器来定义的。
比较器定义了如何将元素按照升序排列,应该提供一个实现了 Comparator 接口的类。
在Java TreeMap的实现中,比较器用来将元素按照顺序排列。
它允许 TreeMap 将元素按照自定义顺序排序而不是按照它们的自然顺序排序。
也就是说,比较器的作用是自定义元素排序的规则并将其存储在TreeMap中。
3. TreeMap的迭代器Java TreeMap还提供了迭代器,用于遍历TreeMap中的元素。
什么是迭代器?迭代器是用于遍历集合或列表中元素的指针。
在Java中,每个集合或列表都可以通过iterator() 方法返回它的迭代器。
springboot构造树形结构数据并查询的方法

springboot构造树形结构数据并查询的方法Spring Boot是一个用于开发和构建独立的、基于Spring框架的Java应用程序的工具。
构建树形结构数据的方法通常包括两个步骤:创建树形结构数据并进行查询。
一、创建树形结构数据1.定义树节点类在Java中,我们首先需要定义一个树节点类,包含节点的属性和子节点列表。
一个基本的树节点类定义如下:```javapublic class TreeNodeprivate Object data; // 节点数据private List<TreeNode> children; // 子节点列表//构造函数public TreeNode(Object data)this.data = data;this.children = new ArrayList<>(;}//添加子节点public void addChild(TreeNode child)children.add(child);}//获取子节点列表public List<TreeNode> getChildrereturn children;}// 其他属性的getter和setter方法```2.构建树形结构数据构建树形结构数据的方法通常是通过遍历原始数据集合,根据节点关系来构建树结构。
以下是一个示例方法:```javapublic TreeNode buildTree(List<Object> dataList)//构建根节点TreeNode root = new TreeNode(null);//按照节点关系构建树for (Object data : dataList)//获取节点属性,例如父节点ID和节点ID等Object parentId = getParentId(data);Object nodeId = getNodeId(data);//创建当前节点TreeNode node = new TreeNode(data);//查找父节点TreeNode parent = findNode(root, parentId);//将当前节点添加到父节点的子节点列表中if (parent != null)parent.addChild(node);} elseroot.addChild(node);}}return root;```在这个示例方法中,我们通过遍历原始数据集合,根据节点关系创建树节点对象,并构建树结构。
java tree用法

java tree用法
Java中的Tree是一种数据结构,它可以用来表示层次关系的数据,比如文件系统、组织结构等。
在Java中,Tree的常见实现包括Binary Tree、Binary Search Tree、AVL Tree、Red-Black Tree等。
这些Tree结构在Java中都有对应的类库实现,可以直接使用。
在Java中,可以使用TreeMap和TreeSet来实现Tree结构。
TreeMap是基于红黑树实现的,它可以用来存储键值对,并且能够根据键进行排序。
TreeSet是基于TreeMap实现的,它是一个有序的集合,能够自动对元素进行排序。
在使用TreeMap和TreeSet时,需要注意以下几点:
1. 添加的元素必须实现Comparable接口或者在构造TreeMap 和TreeSet时传入Comparator对象,以便进行元素的比较和排序。
2. TreeMap和TreeSet是基于红黑树实现的,因此插入、删除和查找操作的时间复杂度都是O(logN),其中N为元素个数。
3. TreeMap和TreeSet是有序的,它们会根据元素的大小进行排序,因此在遍历时可以得到有序的结果。
除了TreeMap和TreeSet,Java中还有一些第三方库实现了更复杂的Tree结构,比如Apache Commons Collections中的TreeBag、TreeList等。
总之,Java中的Tree结构可以通过TreeMap和TreeSet来实现,它们能够提供高效的插入、删除和查找操作,并且能够自动对元素进行排序。
在实际开发中,可以根据具体的需求选择合适的Tree实现来处理层次关系的数据。
java实现tree树形结构

java实现tree树形结构树节点遍历⼯具类:1 @UtilityClass2public class TreeUtil {3/**4 * 两层循环实现建树5 *6 * @param treeNodes 传⼊的树节点列表7 * @return8*/9public <T extends TreeNode> List<T> bulid(List<T> treeNodes, Object root) {1011 List<T> trees = new ArrayList<>();1213for (T treeNode : treeNodes) {1415if (root.equals(treeNode.getParentId())) {16 trees.add(treeNode);17 }1819for (T it : treeNodes) {20if (it.getParentId() == treeNode.getId()) {21if (treeNode.getChildren() == null) {22 treeNode.setChildren(new ArrayList<>());23 }24 treeNode.add(it);25 }26 }27 }28return trees;29 }3031/**32 * 使⽤递归⽅法建树33 *34 * @param treeNodes35 * @return36*/37public <T extends TreeNode> List<T> buildByRecursive(List<T> treeNodes, Object root) {38 List<T> trees = new ArrayList<T>();39for (T treeNode : treeNodes) {40if (root.equals(treeNode.getParentId())) {41 trees.add(findChildren(treeNode, treeNodes));42 }43 }44return trees;45 }4647/**48 * 递归查找⼦节点49 *50 * @param treeNodes51 * @return52*/53public <T extends TreeNode> T findChildren(T treeNode, List<T> treeNodes) {54for (T it : treeNodes) {55if (treeNode.getId() == it.getParentId()) {56if (treeNode.getChildren() == null) {57 treeNode.setChildren(new ArrayList<>());58 }59 treeNode.add(findChildren(it, treeNodes));60 }61 }62return treeNode;63 }64 }TreeUtil树模型:1 @Data2public class TreeNode {3protected int id;4protected int parentId;5protected String name;6protected List<TreeNode> children = new ArrayList<TreeNode>();78public void add(TreeNode node) {9 children.add(node);10 }11 }TreeNode 部门树:1 @Data2 @EqualsAndHashCode(callSuper = true)3public class DeptTree extends TreeNode {4private String name;5 }DeptTree构建部门树⽅法:1public List<DeptTree> getDeptTree(List<SysDept> depts) {2 List<DeptTree> treeList = depts.stream()3 .filter(dept -> !dept.getDeptId().equals(dept.getParentId()))4 .map(dept -> {5 DeptTree node = new DeptTree();6 node.setId(dept.getDeptId());7 node.setParentId(dept.getParentId());8 node.setName(dept.getName());9return node;10 }).collect(Collectors.toList());11return TreeUtil.bulid(treeList, 0);12 }getDeptTree。
java解析四则运算为树形的方法_概述及解释说明

java解析四则运算为树形的方法概述及解释说明1. 引言1.1 概述:本文将讨论Java解析四则运算为树形结构的方法。
四则运算是数学中最基础的运算,包括加法、减法、乘法和除法。
通过对四则运算表达式进行解析,可以将其转化为树形结构,以提供更方便的处理和计算方式。
在本文中,我们将介绍四则运算及其解析方式的简介,并重点关注树形结构在这种解析中的应用。
1.2 文章结构:本文共分为5个部分:引言、正文、解释说明、结论和后记。
在引言部分,我们将给出文章的概述,简述整篇文章的内容与目标。
在正文部分,我们将详细介绍四则运算及其解析方式的简介,并探究树形结构在这种解析中的作用。
在解释说明部分,我们会阐述将四则运算表达式转化为树形结构的基本概念和原理,并讨论Java中实现这一过程的方法。
接着,我们还会探讨树形结构在四则运算解析中的优势和应用场景。
在结论部分,我们将总结文章要点和重点论述内容,并对Java解析四则运算为树形的方法进行评价并展望未来的发展方向。
最后,在后记部分,我们将留下一些附加信息和感想。
1.3 目的:本文的目的是提供一个全面且易懂的解析四则运算为树形结构的方法,并探讨这种方法在Java中的应用。
通过深入了解四则运算的解析和树形结构的应用,读者可以更好地理解并使用这些技术,进一步提高程序设计和算法实现能力。
本文还旨在为Java开发者提供一个可靠而有效的工具,以便于他们处理复杂的四则运算表达式。
跟随本文学习并实践这种方法可以增强编码技巧和培养抽象思维能力,在日常开发中收获不少益处。
2. 正文:2.1 四则运算及其解析方式简介:在数学中,四则运算指的是加法、减法、乘法和除法这四种基本运算。
它们是最常见和基础的数学运算,广泛应用于各个领域。
在计算机科学中,我们通常需要将四则运算表达式进行解析,以便计算机能够理解和执行。
2.2 树形结构在四则运算解析中的应用:树形结构是一种非常适合表示嵌套层次关系的数据结构。
节点树的数据库表设计及java实现

节点树的数据库表设计及java实现节点树的数据库表设计及Java实现节点树是一种常见的数据结构,它由多个节点组成,每个节点可以有多个子节点,但只有一个父节点。
在数据库中,节点树通常用于表示层级关系,例如组织结构、分类目录等。
在设计节点树的数据库表时,需要考虑以下几个方面:1. 节点表的结构节点表应该包含以下字段:- id:节点的唯一标识符,通常为自增长的整数。
- name:节点的名称,可以是任意字符串。
- parent_id:父节点的id,如果该节点是根节点,则parent_id为null。
- sort_order:节点在同级节点中的排序顺序,通常为整数。
2. 数据库索引的设计为了提高查询效率,应该在节点表上创建以下索引:- parent_id:用于查询某个节点的所有子节点。
- sort_order:用于查询某个节点的兄弟节点,并按照排序顺序排序。
3. Java实现在Java中,可以使用递归算法来遍历节点树。
以下是一个简单的示例代码:```public class Node {private int id;private String name;private List<Node> children;// getters and setterspublic void addChild(Node child) {if (children == null) {children = new ArrayList<>();}children.add(child);}public List<Node> getChildren() {return children;}public static Node buildTree(List<Node> nodes, int parentId) {Node parent = null;for (Node node : nodes) {if (node.getParentId() == parentId) {if (parent == null) {parent = node;} else {parent.addChild(node);}buildTree(nodes, node.getId());}}return parent;}}```在上面的代码中,Node类表示节点,包含id、name和children 三个字段。
java拼接树形结构名称

java拼接树形结构名称
在Java中拼接树形结构名称通常涉及到树的遍历和字符串拼接操作。
首先,我们需要有一个树形结构的数据模型,通常是通过节点和指向子节点的引用来表示。
然后,我们可以使用深度优先搜索(DFS)或广度优先搜索(BFS)等算法来遍历树的节点,并在遍历的过程中将节点的名称拼接成所需的形式。
下面我将从以下几个方面来讨论如何在Java中拼接树形结构名称:
1. 数据模型,首先我们需要定义树形结构的数据模型,通常是通过节点类和树类来表示。
节点类包含节点名称和子节点引用,树类包含根节点和遍历等方法。
2. 深度优先搜索(DFS),DFS是一种用于遍历或搜索树或图的算法。
我们可以使用递归或栈来实现DFS,在遍历的过程中将节点的名称拼接成所需的形式。
3. 广度优先搜索(BFS),BFS是另一种用于遍历或搜索树或图的算法。
我们可以使用队列来实现BFS,在遍历的过程中将节点
的名称拼接成所需的形式。
4. 字符串拼接,在遍历树的过程中,我们可以使用StringBuilder或StringBuffer等工具类来进行字符串的拼接操作,以提高性能和避免频繁的字符串对象创建。
5. 递归与迭代,在实现DFS或BFS时,可以选择使用递归或迭
代的方式来遍历树的节点,不同的方式可能会影响到拼接名称的顺
序和方式。
总之,在Java中拼接树形结构名称涉及到树的遍历和字符串拼
接操作,我们可以根据具体的需求选择合适的算法和数据结构来实现。
希望以上的回答能够满足你的要求。
路径枚举法创建树形结构数据java

路径枚举法创建树形结构数据java(原创实用版)目录1.路径枚举法简介2.创建树形结构数据的步骤3.Java 实现树形结构数据的示例正文1.路径枚举法简介路径枚举法是一种在计算机科学中用于创建树形结构的方法。
树形结构是一种层次化的数据结构,它由一个根节点和许多子节点组成。
路径枚举法的基本思想是以一种递归的方式遍历树形结构,同时记录每个节点的路径。
通过这种方法,我们可以创建具有特定属性的树形结构数据。
2.创建树形结构数据的步骤创建树形结构数据的步骤可以概括为以下几个:(1) 定义树形结构的节点类:首先,我们需要定义一个表示树形结构节点的类,该类应包含节点的基本信息(如名称、值等)以及指向其子节点的引用。
(2) 创建节点:根据预先设定的规则,创建树形结构的根节点以及各级子节点。
(3) 添加节点属性:为每个节点分配特定的属性,如颜色、大小等。
(4) 建立节点间的关系:将每个节点与其相应的子节点连接起来,形成树形结构。
(5) 存储树形结构数据:将创建好的树形结构数据存储到计算机内存中,以便后续使用。
3.Java 实现树形结构数据的示例以下是一个使用 Java 语言实现的简单树形结构数据示例:```javaclass TreeNode {String name;int value;List<TreeNode> children;public TreeNode(String name, int value) { = name;this.value = value;this.children = new ArrayList<>();}}public class TreeFormation {public static void main(String[] args) {// 创建树形结构数据的步骤TreeNode root = new TreeNode("root", 1);TreeNode child1 = new TreeNode("child1", 2); TreeNode child2 = new TreeNode("child2", 3); TreeNode child3 = new TreeNode("child3", 4);root.children.add(child1);root.children.add(child2);child1.children.add(child3);// 存储树形结构数据printTree(root, 0);}public static void printTree(TreeNode node, int level) { for (int i = 0; i < level; i++) {System.out.print(" ");}System.out.println( + ": " + node.value); for (TreeNode child : node.children) {printTree(child, level + 1);}}}```运行上述代码,输出结果如下:```root: 1child1: 2child3: 4child2: 3```通过这个示例,我们可以看到如何使用 Java 语言创建一个简单的树形结构数据。
FP-Tree算法详细过程(Java实现)
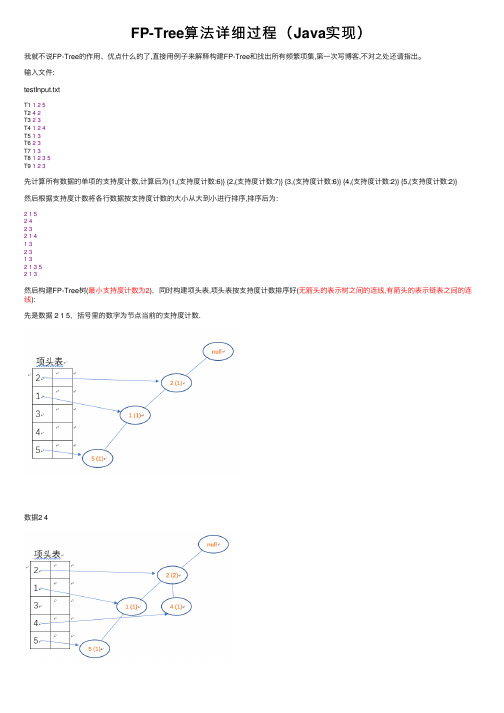
FP-Tree算法详细过程(Java实现)我就不说FP-Tree的作⽤、优点什么的了,直接⽤例⼦来解释构建FP-Tree和找出所有频繁项集,第⼀次写博客,不对之处还请指出。
输⼊⽂件:testInput.txtT1 125T2 42T3 23T4 124T5 13T6 23T7 13T8 1235T9 123先计算所有数据的单项的⽀持度计数,计算后为{1,(⽀持度计数:6)} {2,(⽀持度计数:7)} {3,(⽀持度计数:6)} {4,(⽀持度计数:2)} {5,(⽀持度计数:2)}然后根据⽀持度计数将各⾏数据按⽀持度计数的⼤⼩从⼤到⼩进⾏排序,排序后为:21524232141323132135213然后构建FP-Tree树(最⼩⽀持度计数为2),同时构建项头表,项头表按⽀持度计数排序好(⽆箭头的表⽰树之间的连线,有箭头的表⽰链表之间的连线):先是数据 2 1 5,括号⾥的数字为节点当前的⽀持度计数.数据2 4数据2 3数据 2 1 4数据 1 3数据 2 3数据 1 3数据 2 1 3 5数据 2 1 3构建完成后,从项透表的最后⼀个项5开始,从树周为5的节点向上遍历,找出条件模式基有{2 (1),1 (1)}和{2 (1),1 (1),3 (1)}两个条件模式基,由于3的⽀持度计数⼩于最⼩⽀持度计数,在构建的时候不能加⼊树中,所以构建后的项头表和条件FP-Tree树为:因为其条件FP-Tree为单路径,所以只要找出{2 (2),1 (2)}的所有⼦项集加上后缀{5 (2)}即可,得出3个频繁项集{2(2),1(2),5(2)}、{2(2),5(2)}、{1(2),5(2)}.然后是4,条件模式基为{2(1)}和{2(1),1(1)},1⼩于最⼩⽀持度计数,不参与树的构造,遍历得出频繁项集{2(2),4(2)}然后是3,条件模式基为{2(2),1(2)}、{2(2)}、{1(2)}由于该条件FP-Tree不是单路径,所以应该遍历该项头表,即从1开始,此时后缀为3遍历时,⾸先将项头表的1与其前⼀次后缀连接,得到⼀个频繁项集{1(4),3(4)},⽀持度计数为1在树中出现的总次数,1-频繁项集也是如此得到,因为那时前⼀次后缀为空;然后得到1的条件模式基为{2(2)},因为只有⼀个,所以可以直接遍历其所有⼦项加上此时的后缀13构成⼀个频繁项集{2(2),1(2),3(2)},⽀持度计数为条件模式基的⽀持度计数如果有两个条件模式基,则继续构建树,直到条件模式基为1个或树只有⼀条路径然后是1,条件模式基为{2(4)},遍历后得到{2(4),1(4)}最后是2,⽆条件模式基总结我在写代码的时候难点主要在构建条件FP-Tree然后找频繁项这⾥,我⼀开始并没有⽤构建条件FP-Tree来找频繁项,⽽是通过第⼀次的条件模式基,然后找出各项的所有条件模式基的⼦项,将满⾜⽀持度计数的并不重复的加⼊挑选出来,⽀持度计数需要与某项的所有条件模式基进⾏⽐较,若包含在该条件模式基中,则加上该条件模式基的⽀持度计数.最后贴出我的Java代码(注意:我的代码是针对单项为"1 2 4"、"a v c d"这种单个字符的,若处理的数据为"啤酒开瓶器抹布"需要修改代码):MyFrequentItem.javapublic class MyFrequentItem {//每项中含有的元素private String array;//该项的⽀持度计数private int support;//该项的长度,即第⼏项集private int arrayLength;public MyFrequentItem(String array,int support) {this.array=array;this.support=support;arrayLength=array.length();}public String getArray() {return array;}public void setArray(String array) {this.array = array;}public int getSupport() {return support;}public void setSupport(int support) {this.support = support;}public int getArrayLength() {return arrayLength;}public void setArrayLength(int arrayLength) {this.arrayLength = arrayLength;}}View CodeFP_tree.javaimport java.io.BufferedReader;import java.io.File;import java.io.FileReader;import java.util.ArrayList;import java.util.Arrays;import java.util.Collections;import parator;import java.util.HashMap;/**** @author⽯献衡**/class FP_Node{//树String item;int supportCount;ArrayList<FP_Node> childNode;FP_Node parent;public FP_Node(String item,int supportCount,FP_Node parent) {this.item=item;this.supportCount=supportCount;this.parent = parent;childNode = new ArrayList<FP_Node>();}}class LinkedListNode{//链表,同⼀条链表存储的TP_Node节点的item相同FP_Node node;LinkedListNode next;public LinkedListNode(FP_Node node) {this.node=node;next=null;}}public class FP_tree {//⽂件位置private String filePath;//存储从⽂件中读取的数据private String[][] datas;//Integer代表频繁项集的项数,String表⽰频繁项集各项组成的字符串private HashMap<Integer, HashMap<String,MyFrequentItem>> myFrequentItems;//单项出现的次数,⽤来排序HashMap<String, Integer> signalCount;//最⼩⽀持度计数private int minSupportCount;//最⼩置信度private double minConf;//记录的总条数private int allDataCount;//强规则ArrayList<String> strongRules;//弱规则ArrayList<String> weakRules;private MyFrequentItem frequentItem;;public FP_tree(String filePath,int minSupportCount) {this.minSupportCount = minSupportCount;this.filePath = filePath;strongRules = new ArrayList<String>();weakRules = new ArrayList<String>();myFrequentItems = new HashMap<Integer, HashMap<String,MyFrequentItem>>();//读取数据readFile();}/*** .读取⽂件中的数据储存到datas*/private void readFile() {ArrayList<String[]> list = new ArrayList<String[]>();try {String string;FileReader in = new FileReader(new File(filePath));BufferedReader reader = new BufferedReader(in);while((string=reader.readLine())!=null) {list.add(string.substring(3).split(" "));}allDataCount = list.size();datas = new String[allDataCount][];list.toArray(datas);reader.close();in.close();list.clear();} catch (Exception e) {// TODO: handle exception}}public void startTool(double minConf){this.minConf = minConf;//扫描并且排序scanAndSort();//初始化myFrequentItemsfor(int i=1;i<=signalCount.size();i++) {myFrequentItems.put(i, new HashMap<String, MyFrequentItem>());}HashMap<String, Integer> originList = new HashMap<String, Integer>();//将datas的每条记录转换成⼀条排序好的字符串和它的⽀持度的形式//如记录{2,1,5}转换成215和1,就如条件模式基以及其⽀持度计数String s;for(String[] strs : datas) {s = "";for (String string : strs) {s+=string;}if(originList.containsKey(s))originList.put(s,originList.get(s)+1);elseoriginList.put(s,1);}//构造TP树,同时构造链表以及找出所有频繁项fp_Growth(originList, signalCount, "",Integer.MAX_VALUE);int n = signalCount.size();HashMap<String, MyFrequentItem> map = new HashMap<String, MyFrequentItem>(); String string;//输出各频繁项集的频繁项,包括它们的⽀持度计数for(int i=1;i<=n;i++) {map = myFrequentItems.get(i);System.out.println(i+"-项频繁项集为:");for (MyFrequentItem myFrequentItem : map.values()) {System.out.print("{");string = myFrequentItem.getArray();for(int j=0;j<myFrequentItem.getArrayLength();j++) {System.out.print(string.charAt(j)+",");}System.out.print("(⽀持度计数:"+myFrequentItem.getSupport()+")} ");}System.out.println();}//计算k-频繁项集中各频繁项的置信度int k=3;if(myFrequentItems.get(k).size()!=0) {for (MyFrequentItem frequentItem : myFrequentItems.get(k).values()) {relevance(frequentItem);}}}/*** .计算该最⼤频繁项集与其⼦项集的关联性* @param index 频繁集中的第index个* @param k 项频繁集*/private void relevance(MyFrequentItem myFrequentItem2) {//该项的⽀持度int support = myFrequentItem2.getSupport();//该频繁项的元素拼接成的字符串String nowFrequentString = myFrequentItem2.getArray();//找出所有⼦项集childRelevance(nowFrequentString.toCharArray(), 0, "", "", support);System.out.println();for(String weakRule : weakRules) {System.out.println(weakRule);}for(String strongRule : strongRules) {System.out.println(strongRule);}//输出之后清空weakRules.clear();strongRules.clear();}/*** .找出所有⼦项集* @param child* @param k* @param childString 为⼦项集拼接的字符串* @param otherString除⼦项集以外的拼接的字符串* @param support*/private void childRelevance(char[] child,int k,String childString,String otherString,int support) { if(child.length==k) {//空串和其本⾝不计算if(childString.length()==k||childString.length()==0) return;//计算置信度calculateRelevance(childString, otherString, support);}else {childRelevance(child, k+1, childString, otherString+child[k], support);//该字符不要childRelevance(child, k+1, childString+child[k], otherString, support);//该字符要}}/*** .计算置信度* @param childString* @param otherString* @param support*/private void calculateRelevance(String childString,String otherString,int support) {String rule="";//获取⼦频繁项childString的⽀持度计数int childSupport = myFrequentItems.get(childString.length()).get(childString).getSupport();double conf = (double)support/(double)childSupport;rule+="{";for(int m=0;m<childString.length();m++)rule+=(childString.charAt(m)+",");rule+="}-->{";for(int m=0;m<otherString.length();m++) {rule+=(otherString.charAt(m)+",");}rule+=("},confindence(置信度):"+support+"/"+childSupport+"="+conf);if(conf<minConf) {rule+=("由于此规则置信度未达到最⼩置信度的要求,不是强规则");weakRules.add(rule);}else {rule+=("为强规则");strongRules.add(rule);}}/*** .构建树并找出所有频繁项* @param originList 每条路径和该路径的⽀持度计数* @param originCount originList中每个字符的⽀持度计数* @param suffix 后缀*/private void fp_Growth(HashMap<String, Integer> originList,HashMap<String, Integer>originCount,String suffix,int suffixSupport) {FP_Node root = new FP_Node(null, 0, null);//条件FP-Tree的根节点//表头项ArrayList<LinkedListNode> headListNode = new ArrayList<LinkedListNode>();//构建树,并检查是否为单路径树if(treeGrowth(suffix,root, originList, originCount, headListNode)) {//如果是单路径树,直接进⾏递归出所有⼦频繁项String string = "";while(root.childNode.size()!=0) {root = root.childNode.get(0);string+=root.item;}//递归找出所有频繁项findFrequentItem(0, "", string.toCharArray(), suffixSupport, suffix,originCount);}else {//不是单路径树,从最后⼀个表头项的最后⼀个往上找条件模式基findConditional(headListNode, originCount, suffix);}}private boolean treeGrowth(String suffix,FP_Node root,HashMap<String, Integer> originList,HashMap<String, Integer>originCount,ArrayList<LinkedListNode> headListNode) { //链表的当前节点HashMap<String, LinkedListNode> nowNode = new HashMap<String, LinkedListNode>();//表⽰是否找到该字符所在的节点,有则true,否则false并创⼀个新的节点boolean flag;//⽤来记录树是否为单路径boolean isSingle = true;FP_Node treeHead;LinkedListNode listNode;String[] strings;int support;for (String originString : originList.keySet()) {//获取该条件模式基的⽀持度计数support = originList.get(originString);strings = originString.split("");treeHead = root;for(int i=0;i<strings.length; i++) {//⼩于最⼩⽀持度计数的不加⼊树中if(originCount.get(strings[i])<minSupportCount)continue;flag = false;for(FP_Node node : treeHead.childNode) {if(strings[i].equals(node.item)) {flag = true;node.supportCount+=support;treeHead = node;break;}}if(!flag) {//创建新的树节点,同时创建新的链表节点for(int j=i;j<strings.length;j++) {//⼩于最⼩⽀持度计数的不加⼊树中if(originCount.get(strings[j])<minSupportCount)continue;//创建新的树节点FP_Node node = new FP_Node(strings[j], support,treeHead);if(nowNode.containsKey(strings[j])) {//构建链表listNode = new LinkedListNode(node);nowNode.get(strings[j]).next = listNode;nowNode.put(strings[j], listNode);}else {//构建链表listNode = new LinkedListNode(node);headListNode.add(listNode);nowNode.put(strings[j], listNode);}//构建树treeHead.childNode.add(node);treeHead = node;}break;}}}while(root.childNode.size()!=0) {//判断是否为单路径if(root.childNode.size()==1) {root = root.childNode.get(0);}else {isSingle = false;break;}}if(isSingle) return true;Collections.sort(headListNode,new Comparator<LinkedListNode>() {//将链表的头节点按出现的总次数的降序排列@Overridepublic int compare(LinkedListNode o1, LinkedListNode o2) {int p = originCount.get(o2.node.item)-originCount.get(o1.node.item);if(p==0)//如果⽀持度计数相等,按字典序排序return pareTo(o2.node.item);elsereturn p;}});return isSingle;}/*** .找出各项的条件模式基,从headNode后⾯遍历链表的每个节点,* .从每个节点中node开始向树的上⽅遍历,直到根节点停⽌*/private void findConditional(ArrayList<LinkedListNode> hNode,HashMap<String, Integer> originSupport,String suffix) {//当前链表节点LinkedListNode nowListNode;//当前树节点FP_Node nowTreeNode;//条件模式基HashMap<String, Integer> originList;//所有条件模式基中各个事务出现的次数,⽅便条件FP-Tree在构造的时候剪枝HashMap<String, Integer> originCount;String ori;String item;String suf;for(int i=hNode.size()-1;i>=0;i--) {//获取链表头节点nowListNode = hNode.get(i);item = nowListNode.node.item;suf = item+suffix;//树中的单项⽀持度计数必定⼤于或等于最⼩⽀持度计数(构建树的完成的剪枝),所以将该项加其后缀加⼊频繁项集myFrequentItems.get(suf.length()).put(suf, new MyFrequentItem(suf, originSupport.get(item)));originList = new HashMap<String, Integer>();originCount = new HashMap<String, Integer>();int min;while(nowListNode!=null) {//从链表保存的树节点的⽗节点开始向上遍历nowTreeNode = nowListNode.node.parent;//获取该节点的⽀持度计数min = nowListNode.node.supportCount;//⽤来保存该条件模式基ori = "";while(nowTreeNode!=null&&nowTreeNode.item!=null) {if(originCount.containsKey(nowTreeNode.item)) {//如果条件模式基有如21和2这样两条及以上的有共同元素的,⽀持度计数叠加originCount.put(nowTreeNode.item, originCount.get(nowTreeNode.item)+min);}else {originCount.put(nowTreeNode.item, min);}//保存条件模式基,按树的上⾯向下的顺序保存ori=nowTreeNode.item+ori;nowTreeNode = nowTreeNode.parent;}if(ori!="")originList.put(ori, min);nowListNode = nowListNode.next;}if(originList.size()!=0) {//条件模式基不为空if(originList.size()==1) {//只有⼀条,直接递归其所有⼦项集for (String modeBasis : originList.keySet()) {findFrequentItem(0, "", modeBasis.toCharArray(), originList.get(modeBasis), suf,null);}}else {//构建条件FP-Treefp_Growth(originList, originCount,suf,originSupport.get(item));}}}}/**** @param j 当前指向的modeBasis中的位置* @param child 当前⼦项* @param modeBasis 条件模式基中各个字符或单路径树各个节点组成的字符串* @param support 该⼦项的所有单项中最⼩的⽀持度计数* @param suffix 后缀,⼦项加上后缀即为新的频繁项* @param originCount 单路径树各个节点的⽀持度计数*/private void findFrequentItem(int j,String child,char[] modeBasis,int support,String suffix,HashMap<String, Integer> originCount) { if(j==modeBasis.length) {if(child.length()!=0) {//⼦项不为空child=child+suffix;frequentItem = new MyFrequentItem(child, support);myFrequentItems.get(child.length()).put(child, frequentItem);}}else {int p = support;//originCount为null时,代表为条件模式基,条件模式基中各项⽀持度计数相等if(originCount!=null)p =originCount.get(String.valueOf(modeBasis[j]));findFrequentItem(j+1, child+modeBasis[j], modeBasis,support<p?support:p,suffix,originCount);//要该字符findFrequentItem(j+1, child, modeBasis,support,suffix,originCount);//不要该字符}}/*** .扫描两遍数据,第⼀遍得出各个事物出现的总次数* .第⼆遍将每条记录中的事务根据出现的总次数进⾏排序*/private void scanAndSort() {//储存单项的总次数signalCount = new HashMap<String, Integer>();String c;for (String[] string : datas) {//第⼀遍扫描,储存每个字符出现的次数for(int i=0;i<string.length;i++) {c = string[i];if(signalCount.containsKey(c)) {signalCount.put(c, signalCount.get(c)+1);}else {signalCount.put(c, 1);}}}for (String[] string : datas) {//第⼆遍扫描,按每个字符出现的总次数的降序进⾏排序Arrays.sort(string,new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {int p = signalCount.get(o2)-signalCount.get(o1);if(p==0)//如果出现的次数相等,按字典序排序return pareTo(o2);elsereturn p;}});}}}View CodeMyClient.javapublic class MyClient {public static void main(String[] args) {String filePath = "src/apriori/testInput.txt";FP_tree tp_tree = new FP_tree(filePath, 2);tp_tree.startTool(0.7);}}View Code输出:1-项频繁项集为:{1,(⽀持度计数:6)} {2,(⽀持度计数:7)} {3,(⽀持度计数:6)} {4,(⽀持度计数:2)} {5,(⽀持度计数:2)}2-项频繁项集为:{2,3,(⽀持度计数:4)} {2,4,(⽀持度计数:2)} {1,3,(⽀持度计数:4)} {2,5,(⽀持度计数:2)} {1,5,(⽀持度计数:2)} {2,1,(⽀持度计数:4)} 3-项频繁项集为:{2,1,3,(⽀持度计数:2)} {2,1,5,(⽀持度计数:2)}4-项频繁项集为:5-项频繁项集为:{3,}-->{2,1,},confindence(置信度):2/6=0.3333333333333333由于此规则置信度未达到最⼩置信度的要求,不是强规则{1,}-->{2,3,},confindence(置信度):2/6=0.3333333333333333由于此规则置信度未达到最⼩置信度的要求,不是强规则{1,3,}-->{2,},confindence(置信度):2/4=0.5由于此规则置信度未达到最⼩置信度的要求,不是强规则{2,}-->{1,3,},confindence(置信度):2/7=0.2857142857142857由于此规则置信度未达到最⼩置信度的要求,不是强规则{2,3,}-->{1,},confindence(置信度):2/4=0.5由于此规则置信度未达到最⼩置信度的要求,不是强规则{2,1,}-->{3,},confindence(置信度):2/4=0.5由于此规则置信度未达到最⼩置信度的要求,不是强规则{1,}-->{2,5,},confindence(置信度):2/6=0.3333333333333333由于此规则置信度未达到最⼩置信度的要求,不是强规则{2,}-->{1,5,},confindence(置信度):2/7=0.2857142857142857由于此规则置信度未达到最⼩置信度的要求,不是强规则{2,1,}-->{5,},confindence(置信度):2/4=0.5由于此规则置信度未达到最⼩置信度的要求,不是强规则{5,}-->{2,1,},confindence(置信度):2/2=1.0为强规则{1,5,}-->{2,},confindence(置信度):2/2=1.0为强规则{2,5,}-->{1,},confindence(置信度):2/2=1.0为强规则若有不⾜之处,还请指出.。
java实现二叉树的基本操作

java实现二叉树的基本操作一、二叉树的定义树是计算机科学中的一种基本数据结构,表示以分层方式存储的数据集合。
树是由节点和边组成的,每个节点都有一个父节点和零个或多个子节点。
每个节点可以对应于一定数据,因此树也可以被视作提供快速查找的一种方式。
若树中每个节点最多只能有两个子节点,则被称为二叉树(Binary Tree)。
二叉树是一种递归定义的数据结构,它或者为空集,或者由一个根节点以及左右子树组成。
如果左子树非空,则左子树上所有节点的数值均小于或等于根节点的数值;如果右子树非空,则右子树上所有节点的数值均大于或等于根节点的数值;左右子树本身也分别是二叉树。
在计算机中实现二叉树,通常使用指针来表示节点之间的关系。
在Java中,定义一个二叉树节点类的代码如下:```public class BinaryTree {int key;BinaryTree left;BinaryTree right;public BinaryTree(int key) {this.key = key;}}```在这个类中,key字段表示该节点的数值;left和right字段分别表示这个节点的左右子节点。
1. 插入节点若要在二叉树中插入一个节点,首先需要遍历二叉树,找到一个位置使得插入新节点后,依然满足二叉树的定义。
插入节点的代码可以写成下面这个形式:```public void insert(int key) {BinaryTree node = new BinaryTree(key); if (root == null) {root = node;return;}BinaryTree temp = root;while (true) {if (key < temp.key) {if (temp.left == null) {temp.left = node;break;}temp = temp.left;} else {if (temp.right == null) {temp.right = node;break;}temp = temp.right;}}}```上面的代码首先创建了一个新的二叉树节点,然后判断二叉树根是否为空,若为空,则将这个节点作为根节点。
java treeset原理

java treeset原理Java中的TreeSet是一个基于红黑树实现的有序集合,具有自动排序和去重功能。
它是Set接口的实现类之一,继承自AbstractSet 类,实现了NavigableSet接口。
本文将深入介绍Java TreeSet的原理,包括红黑树、TreeSet的实现、遍历方式和常用操作等内容。
1. 红黑树红黑树是一种自平衡二叉查找树,它的每个节点都有一个颜色属性,可以是红色或黑色。
这种树具有以下特性:1. 每个节点要么是黑色,要么是红色。
2. 根节点是黑色。
3. 每个叶子节点(NIL节点,空节点)是黑色。
4. 如果一个节点是红色,那么它的子节点必须是黑色。
5. 从任意一个节点到其每个叶子节点的所有路径都包含相同数目的黑色节点。
这些特性确保了红黑树的平衡性和搜索效率。
插入、删除节点时,需要对树进行旋转和改变颜色等操作,以维持平衡。
2. TreeSet的实现Java TreeSet是基于红黑树实现的有序集合,它的元素按照自然顺序或者指定的比较器顺序进行排序。
TreeSet中的元素必须是可比较的,即实现了Comparable接口或者传入了Comparator比较器。
TreeSet的底层数据结构是红黑树,它的节点类是TreeMap中的Entry类,包含三个属性:key、value和color。
TreeSet的实现主要涉及以下几个方法:1. add(E e):向TreeSet中添加元素e。
首先通过比较器或者自然顺序找到要插入的位置,然后将元素包装成Entry对象,插入红黑树中,最后进行平衡操作。
2. remove(Object o):从TreeSet中删除元素o。
首先通过比较器或者自然顺序找到要删除的节点,然后进行删除操作,最后进行平衡操作。
3. clear():清空TreeSet中的所有元素。
4. iterator():返回一个迭代器,按照自然顺序或者指定的比较器顺序遍历元素。
5. size():返回TreeSet中元素的个数。
treemap排序方法

treemap排序方法Treemap是一种基于键值对的数据结构,它能够以树形结构进行有序存储和快速查询。
在Treemap中,每个键值对被称为一个条目,键可以是任何可比较的数据类型,例如整数、字符串或自定义对象。
Treemap会根据键的自然顺序进行排序,并保持有序状态。
Treemap排序方法是一种高效地对数据集合进行排序的算法。
通过将数据存储在Treemap中,可以轻松地按照键的顺序对数据进行迭代操作,而不需要手动编写排序算法。
以下是Treemap排序方法的详细介绍和使用示例。
1. 概述Treemap是一个基于红黑树实现的有序映射。
在Treemap中,每个节点表示一个条目,节点按照键的自然顺序进行排序。
Treemap提供了一系列的方法来操作和访问存储在树中的数据。
2. 创建Treemap在Java中,可以通过以下代码创建一个Treemap:```TreeMap<KeyType, ValueType> treeMap = new TreeMap<>();```其中,KeyType是键的类型,ValueType是值的类型。
例如,要创建一个按照整数键进行排序的Treemap,可以使用以下代码:```TreeMap<Integer, String> treeMap = new TreeMap<>();```3. 插入和删除条目可以使用put()方法向Treemap中插入新的条目,使用remove()方法删除指定条目。
例如,假设要向Treemap中插入一个整数键值对(1, "A"),可以使用以下代码:```treeMap.put(1, "A");```要删除指定的键值对,可以使用以下代码:```treeMap.remove(1);```4. 遍历TreemapTreemap提供了多种方法来遍历其中的条目。
可以使用keySet()方法获取所有键的集合,然后通过迭代器或for-each循环遍历键值对。
路径枚举法创建树形结构数据java

路径枚举法创建树形结构数据java一、引言二、路径枚举法概述路径枚举法是一种基于路径的方式来创建树形结构数据的方法。
该方法的基本思想是通过遍历数据集合中的每个元素,然后根据元素的路径信息将其插入到树形结构中的适当位置。
三、路径枚举法的实现步骤1.定义树形结构的节点类首先,我们需要定义一个树形结构节点的类。
该类需要包含节点的数据以及子节点的列表。
以下是一个示例代码:p u bl ic cl as sT re eNo d e{p r iv at eO bj ec td ata;p r iv at eL is t<Tr eeN o de>c hi ld re n;//省略构造方法和其他方法}2.创建根节点并初始化在使用路径枚举法创建树形结构数据时,首先需要创建一个根节点,并将其作为最顶层的节点。
以下是一个示例代码:T r ee No de ro ot=n ewT r ee No de();3.枚举数据集合并插入到树中接下来,我们需要遍历数据集合,将每个元素插入到树形结构中的适当位置。
f o r(Ob je ct el em ent:da ta Co ll ec ti on){S t ri ng[]pa th=e lem e nt.g et Pa th();//获取元素的路径信息T r ee No de cu rr en tNo d e=ro ot;//从根节点开始查找f o r(in ti=0;i<p ath.le ng th;i++){S t ri ng no de Na me=pa t h[i];T r ee No de ch il dN ode=cu rr en tN od e.fin d Ch il d(no de Na me);//查找当前路径对应的子节点i f(c hi ld No de==nul l){c h il dN od e=ne wT ree N od e();c h il dN od e.se tD ata(no de Na me);//将子节点的数据设置为路径名称c u rr en tN od e.ad dCh i ld(c hi ld No de);//将子节点添加到当前节点的子节点列表中}c u rr en tN od e=ch ild N od e;//将当前路径对应的子节点设置为当前节点}//将元素添加到最后一个路径对应的子节点T r ee No de le af No de=n ew Tr ee No de();l e af No de.s et Da ta(e le me nt);c u rr en tN od e.ad dCh i ld(l ea fN od e);}4.树形结构数据的使用经过以上步骤,我们已经成功使用路径枚举法创建了树形结构数据。
java 树形结构递归实现

java 树形结构递归实现在编程中,树形结构是一种非常常见的数据结构,它由节点和边组成,可以用于表示层次化的数据关系。
在 Java 中,我们可以通过递归来实现树形结构的数据操作。
接下来,我们将逐步介绍如何使用Java 递归来实现树形结构。
1. 定义树的节点类首先,我们需要定义树形结构的节点类。
一个节点类通常包含一个值以及左右子节点。
它的定义如下:```javapublic class TreeNode {int value;TreeNode left;TreeNode right;public TreeNode(int value) {this.value = value;left = null;right = null;}}```2. 插入节点接下来,我们需要实现向树中插入节点的方法。
算法思路是,从根节点开始比较,如果值比当前节点小,在其左子树中查找,否则在右子树中查找。
直到找到一个空位,将新节点插入进去。
实现代码如下:```javapublic void insert(TreeNode root, int value) {if (value < root.value) {if (root.left == null) {root.left = new TreeNode(value);} else {insert(root.left, value);}} else {if (root.right == null) {root.right = new TreeNode(value);} else {insert(root.right, value);}}}```3. 遍历树我们可以使用三种遍历方法来遍历树的节点:先序遍历(preorder):根节点 -> 左子树 -> 右子树中序遍历(inorder):左子树 -> 根节点 -> 右子树后序遍历(postorder):左子树 -> 右子树 -> 根节点以下是先序遍历代码的实现:```javapublic void preorder(TreeNode root) {if (root != null) {System.out.print(root.value + " ");preorder(root.left);preorder(root.right);}}```中序遍历和后序遍历的代码实现也非常类似,读者可以自行尝试实现。
java树形结构获取某一层级的数据的方法

java树形结构获取某一层级的数据的方法Java是一种面向对象的编程语言,它提供了丰富的数据结构和算法库,可以用来处理各种复杂的数据结构。
其中,树形结构是一种常见的数据结构,它由根节点和若干子节点组成,每个节点可以有任意多个子节点,形成一个层级关系。
本文将介绍如何使用Java来获取树形结构中某一层级的数据。
我们需要定义一个树形结构的数据模型。
在Java中,可以使用类来表示一个节点,节点类包含一个数据成员和一个子节点列表。
以下是一个简单的节点类的示例:```javapublic class TreeNode {private Object data;private List<TreeNode> children;public TreeNode(Object data) {this.data = data;this.children = new ArrayList<>();}public void addChild(TreeNode child) {this.children.add(child);}public List<TreeNode> getChildren() {return this.children;}public Object getData() {return this.data;}}```在这个节点类中,我们使用了一个`Object`类型的`data`成员来存储节点的数据,使用一个`List<TreeNode>`类型的`children`成员来存储子节点列表。
同时,我们还提供了一些方法来添加子节点、获取子节点列表和获取节点的数据。
接下来,我们可以创建一个树形结构,并获取其中某一层级的数据。
假设我们有以下这样一个树形结构:```plaintextA/ | \B C D/ \ / \E F G H/ \ / \ / \I J K L M N```我们可以使用以下代码来创建这个树形结构:```javaTreeNode root = new TreeNode("A"); TreeNode nodeB = new TreeNode("B"); TreeNode nodeC = new TreeNode("C"); TreeNode nodeD = new TreeNode("D"); root.addChild(nodeB);root.addChild(nodeC);root.addChild(nodeD);TreeNode nodeE = new TreeNode("E"); TreeNode nodeF = new TreeNode("F"); nodeB.addChild(nodeE);nodeB.addChild(nodeF);TreeNode nodeG = new TreeNode("G"); TreeNode nodeH = new TreeNode("H"); nodeD.addChild(nodeG);nodeD.addChild(nodeH);TreeNode nodeI = new TreeNode("I");TreeNode nodeJ = new TreeNode("J");nodeE.addChild(nodeI);nodeE.addChild(nodeJ);TreeNode nodeK = new TreeNode("K");TreeNode nodeL = new TreeNode("L");nodeF.addChild(nodeK);nodeF.addChild(nodeL);TreeNode nodeM = new TreeNode("M");TreeNode nodeN = new TreeNode("N");nodeH.addChild(nodeM);nodeH.addChild(nodeN);```现在我们已经创建了这个树形结构,接下来我们可以实现一个方法来获取某一层级的数据。
多叉树数据结构java

多叉树数据结构java多叉树数据结构Java在计算机科学中,多叉树是一种常用的数据结构,它可以用来表示具有层级关系的数据。
在多叉树中,每个节点可以有多个子节点,而不仅仅是两个。
在本文中,我们将探讨多叉树的定义、特性以及如何在Java中实现它。
一、多叉树的定义和特性多叉树是一种树状结构,其中每个节点可以有多个子节点。
与二叉树不同,多叉树的节点个数不受限制,可以有任意多个子节点。
多叉树的节点可以表示不同的实体,例如文件系统中的文件和文件夹,组织结构中的部门和员工等。
多叉树的特性如下:1. 根节点:多叉树的顶层节点称为根节点。
根节点没有父节点,是多叉树的唯一入口。
2. 子节点:每个节点可以有多个子节点。
子节点从属于父节点,与父节点之间存在一对多的关系。
3. 叶子节点:没有子节点的节点称为叶子节点。
叶子节点位于多叉树的最底层,没有子节点可以继续扩展。
4. 路径:从根节点到任意节点的唯一路径称为路径。
路径由一系列的节点连接而成。
5. 深度:节点所在的层级称为深度。
根节点的深度为0,每向下一层深度加1。
6. 子树:以某个节点为根节点的子树称为子树。
子树包含了该节点及其所有子节点。
7. 层次遍历:按层次从上到下、从左到右的顺序遍历多叉树的节点。
二、多叉树的实现在Java中,我们可以使用类来实现多叉树。
一个多叉树节点可以包含以下属性:1. 数据域:用来存储节点的值。
2. 子节点列表:用来存储子节点的引用。
下面是一个简单的多叉树节点的Java实现:```public class MultiTreeNode<T> {private T data;private List<MultiTreeNode<T>> children;public MultiTreeNode(T data) {this.data = data;this.children = new ArrayList<>();}public T getData() {return data;}public void setData(T data) {this.data = data;}public List<MultiTreeNode<T>> getChildren() {return children;}public void addChild(MultiTreeNode<T> child) {children.add(child);}}```上述代码中,MultiTreeNode类有一个泛型参数T,用来表示节点的数据类型。
java生成树形结构的方法

java生成树形结构的方法Java是一种广泛使用的编程语言,在Java中生成树形结构是一项常见的任务。
树形结构是一种层次化的数据结构,由节点和边组成,节点之间的关系呈现出父子关系。
在Java中,可以使用多种方法来生成树形结构,下面将介绍几种常见的方法。
一、使用节点类和边类生成树形结构1. 首先定义一个节点类,节点类包含节点的值和子节点列表。
节点类的定义如下:```javapublic class TreeNode {private int value;private List<TreeNode> children;public TreeNode(int value) {this.value = value;children = new ArrayList<>();}public int getValue() {return value;}public List<TreeNode> getChildren() {return children;}public void addChild(TreeNode child) {children.add(child);}}```2. 然后定义一个边类,边类包含父节点和子节点。
边类的定义如下:```javapublic class TreeEdge {private TreeNode parent;private TreeNode child;public TreeEdge(TreeNode parent, TreeNode child) {this.parent = parent;this.child = child;}public TreeNode getParent() {return parent;}public TreeNode getChild() {return child;}}```3. 最后,使用节点类和边类来生成树形结构。
java递归遍历树形结构

java递归遍历树形结构
Java递归遍历树形结构是指使用递归算法去遍历一个树形结构。
它可以被应用于各种数据结构,如文件夹目录、XML文档、HTML文档等,甚至可以用于神经网络中的前向传播算法。
首先,要理解什么是树形结构,它是一种分层的有向图,具有根节点、子节点和子节点的孩子节点。
树形结构由节点和边组成,每个节点都有一个父节点,除了根节点。
树形结构中可能有多个子节点,每个子节点又可以有多个孩子节点。
Java递归遍历树形结构的步骤如下:
1. 确定根节点:第一步,需要确定树形结构的根节点,即父节点。
2. 遍历子节点:然后,开始遍历根节点的子节点,并检查每个子节点是否有子节点。
3. 如果有子节点:如果子节点有子节点,则递归地遍历该子节点,直到所有节点均被遍历完毕。
4. 返回父节点:最终,当所有子节点都被遍历完毕,返回父节点,继续遍历其他子节点。
5. 遍历完毕:当根节点的所有子节点都被遍历完毕时,表明整个树形结构已经被遍历完毕。
使用递归遍历树形结构的一个重要好处是,它可以很容易地实现树形结构的深度优先遍历。
也就是说,它可以先深入地搜索树形结构的子节点,然后再回溯父节点,最终完成整个树形结构的遍历。
另外,使用Java构建递归遍历树形结构还有另一个好处,就是可以使用函数式编程(Functional Programming)来实现,允许把功能封装在一个函数中,而不必为每个节点编写代码。
总而言之,Java递归遍历树形结构是一种高效的方法,可以有效地搜索和遍历树形结构中的信息,从而更快地完成某些任务。
java树形结构获取某一层级的数据的方法

java树形结构获取某一层级的数据的方法Java树形结构获取某一层级的数据的方法在Java编程中,树形结构是一种非常常见的数据结构。
树形结构由根节点和若干子节点组成,每个节点可以有任意数量的子节点。
树形结构常用于表示层级关系,比如组织结构、文件系统等。
在某些情况下,我们可能需要获取树形结构中的某一层级的数据。
这个需求在很多场景下都非常有用,比如展示组织结构的某一层级的员工信息、展示文件系统的某一层级的文件列表等。
下面将介绍一种通用的方法来获取树形结构中某一层级的数据。
步骤一:定义树形结构我们需要定义一个树形结构的数据类型。
通常情况下,我们可以使用一个节点类来表示树的节点。
节点类可以包含一个值字段和一个子节点列表字段。
节点类的定义如下:```public class TreeNode<T> {private T value;private List<TreeNode<T>> children;// 省略构造方法和其他方法}```在这个节点类中,我们使用泛型T来表示节点的值的类型,这样可以适应不同类型的树。
子节点列表字段使用List来存储子节点,这样可以容纳任意数量的子节点。
步骤二:构建树形结构接下来,我们需要构建一个树形结构。
树形结构通常是由一个根节点开始,然后逐层添加子节点构成的。
我们可以编写一个方法来构建树形结构,方法的输入参数是一个树的深度,输出是构建好的树。
构建树的方法如下:```public TreeNode<String> buildTree(int depth) {if (depth <= 0) {return null;}TreeNode<String> root = new TreeNode<>("Root");for (int i = 0; i < depth; i++) {TreeNode<String> node = new TreeNode<>("Node " + i); root.getChildren().add(node);root = node;}return root;}```在这个方法中,我们首先创建一个根节点,然后循环添加子节点,直到达到指定的深度。