遗传算法中的染色体基础知识
遗传算法中的染色体长度

遗传算法中的染色体长度遗传算法是一种模拟自然界进化过程进行优化求解的方法。
其中,染色体是遗传信息的载体,也是遗传算法中的一个重要概念。
在遗传算法中,染色体长度的设置对算法的效率和精度有着重要的影响。
一、什么是染色体长度?在遗传算法中,染色体是由基因组成的。
每个基因代表某种特征或属性,如旅行商问题中,基因可以表示旅行的城市编号。
而染色体长度是指由多少个基因组成的,即染色体上基因的数量。
二、如何设置染色体长度?染色体长度的设置需要结合具体的问题进行分析。
对于求解特定问题,染色体长度的设置不合理会导致遗传算法的效率和精度下降。
通常情况下,我们可以从以下几个方面考虑染色体长度的设置:1.基因数目在遗传算法中,基因的数目与染色体长度有直接关系。
基因数目越多,染色体越长。
基因数目的多少需要结合问题特点来确定。
一般来说,问题的解空间越大,需要的基因数目越多。
例如,对于TSP问题求解,需要代表每个城市,因此基因数目与城市数目一致。
2. 编码方式基因的编码方式也会影响染色体长度的设置。
在二进制编码方式下,每个基因可用一个二进制位表示,因此基因数目等于染色体长度。
而在其他编码方式下,如十进制编码和浮点数编码,基因数目和染色体长度并不相等。
3.算法性能染色体长度的设置对算法性能有着直接的影响。
如果染色体长度过短,那么基因表达的信息就会不足,导致算法搜索空间过窄,难以找到更多的优秀解。
如果染色体长度过长,那么算法的搜索空间将变得非常庞大,难以在有限的时间内搜索到优秀解。
因此,在实际应用中,需要不断调整染色体长度,以达到最优解的要求。
三、总结染色体长度是遗传算法中一个非常重要的参数,直接影响了算法的性能。
染色体长度的设置需要结合具体问题进行分析,同时需要综合考虑基因数目、编码方式和算法性能等因素。
只有在合理和科学的设置下,算法才能够更好地求解问题,发挥出其应有的性能和效果。
遗传算法关键术语

遗传算法是一种模拟自然选择和遗传机制的优化算法,用于解决复杂的优化问题。
以下是一些遗传算法中的关键术语:
个体(Individual):表示问题解空间中的一个潜在解,通常由一组参数或染色体表示。
染色体(Chromosome):由基因串联而成的结构,用于表示一个个体的特征或解。
基因(Gene):染色体中的一个元素,代表个体的一个特定特征或属性。
种群(Population):包含多个个体的集合,用于代表问题解空间的一个子集。
适应度(Fitness):用于度量个体的优劣程度,通常是通过目标函数或评价指标来计算的。
选择(Selection):根据个体适应度,从种群中选择个体用于产生后代。
交叉(Crossover):将两个个体的染色体部分交换,产生新的个体。
变异(Mutation):随机改变个体染色体中的基因,以增加种群的多样性。
迭代(Generation):遗传算法的每一轮进化称为一代,种群中的个体经过选择、交叉和变异产生下一代。
终止条件(Termination Criterion):用于决定何时终止遗传算法的运行,通常根据达到一定的迭代次数或满足特定的适应度要求。
遗传算法通过模拟生物进化的过程,不断优化种群中的个体,从而找到问题的最优解或接近最优解的解。
这些关键术语在遗传算法的理解和应用中起着重要的作用。
遗传算法的基本结构

遗传算法的基本结构一、引言遗传算法是一种模拟自然进化过程的优化算法,被广泛应用于求解复杂问题。
本文将介绍遗传算法的基本结构。
二、遗传算法的基本概念1.个体:表示问题的一个解,也称为染色体。
2.种群:由多个个体组成的集合。
3.适应度函数:用于评价个体的优劣程度。
4.选择操作:根据适应度函数选择优秀的个体。
5.交叉操作:将两个个体进行配对,并通过交叉操作产生新的个体。
6.变异操作:对某些个体进行随机变异,以增加种群的多样性。
三、遗传算法流程1.初始化种群:随机生成一定数量的初始解作为种群。
2.计算适应度函数:对每一个个体计算其适应度值。
3.选择操作:根据适应度函数选择优秀的个体作为下一代种群。
4.交叉操作:对选出来的优秀个体进行配对,并通过交叉操作产生新的个体加入下一代种群。
5.变异操作:对某些选出来的优秀个体进行随机变异,以增加下一代种群的多样性。
6.重复步骤2-5,直到满足终止条件(如达到最大迭代次数或找到最优解)。
四、遗传算法的优点1.能够在大规模搜索空间中寻找全局最优解。
2.对于复杂问题,遗传算法比其他优化算法更具有鲁棒性。
3.易于实现和理解,不需要对问题进行过多的数学建模。
五、遗传算法的应用1.组合优化问题:如旅行商问题、背包问题等。
2.函数优化问题:如函数极值求解等。
3.机器学习中的特征选择和参数调整等。
六、总结遗传算法是一种基于自然进化过程的优化算法,具有广泛的应用前景。
本文介绍了遗传算法的基本概念、流程、优点和应用,并希望能够为读者提供一些参考和启示。
遗传算法的五个基本要素

遗传算法的五个基本要素遗传算法是一种模拟生物进化过程的搜索算法,它通过不断地迭代和选择最优解来解决问题。
遗传算法的五个基本要素是遗传、变异、选择、交叉和编码,这些要素共同构成了遗传算法的核心。
一、遗传遗传算法的第一个基本要素是遗传。
遗传是指通过复制种群中的个体来创建新的种群。
在遗传算法中,我们通常使用一种称为染色体或基因组的表示法来代表问题空间中的解决方案。
染色体通常被表示为一组二进制位,这些位代表了解决方案的特征或属性。
二、变异变异是指染色体中的某些位发生随机变化,以引入新的解决方案。
变异有助于打破种群的平衡,增加搜索空间的多样性,从而促进算法找到更好的解决方案。
变异通常是通过随机改变染色体中的某些位来实现的,这种变化可以是替换、添加或删除位。
三、选择选择是指根据个体的适应度或质量来选择哪些个体将被复制到下一代。
在遗传算法中,我们通常使用适应度函数来评估每个解决方案的质量。
适应度函数通常与问题的目标函数相对应,因此可以根据问题的具体需求来定义。
选择过程通常采用轮盘赌机制,根据个体的适应度来决定其在下一代中的比例。
四、交叉交叉是指两个个体之间进行随机配对,以创建新的个体。
交叉有助于在搜索过程中产生新的解决方案,从而扩大搜索空间。
在遗传算法中,我们通常使用一些特定的交叉策略,如单点交叉、多点交叉等。
这些策略可以根据问题的具体需求和搜索空间的大小来选择。
五、编码编码是指将问题空间中的解决方案转换为一种可以用于遗传操作的形式。
编码过程通常采用二进制编码、浮点数编码等不同的方式,这取决于问题的具体需求和搜索空间的大小。
良好的编码方式可以提高算法的效率和鲁棒性,并帮助算法更快地找到最优解。
综上所述,遗传算法的五个基本要素——遗传、变异、选择、交叉和编码,共同构成了遗传算法的核心。
这些要素相互作用,相互影响,共同推动搜索过程,以找到问题的最优解。
在实际应用中,我们应根据问题的具体需求和搜索空间的大小来选择合适的参数和操作,以获得最佳的搜索效果。
基因遗传算法的组成部分包

基因遗传算法(Genetic Algorithms,GA)是一种启发式搜索算法,常用于优化和搜索问题。
它模拟自然选择和遗传机制来找到问题的解。
基因遗传算法的主要组成部分包括:1. 个体(Individuals):- 个体是基因遗传算法中的潜在解决方案。
在优化问题中,每个个体通常代表一个候选解。
2. 染色体(Chromosomes):- 染色体是个体的编码,它包含了解决方案的基因。
基因可以是二进制、整数、浮点数等形式。
3. 基因(Genes):- 基因是染色体的基本单元,它是编码问题解决方案的一部分。
基因的形式取决于问题的性质。
4. 适应度函数(Fitness Function):- 适应度函数用于评估每个个体的质量。
它根据问题的特定目标为每个个体分配一个适应度值,该值越高表示个体越优秀。
5. 选择(Selection):- 选择操作模拟自然选择的过程,优秀的个体有更大的概率被选择为父代,从而传递其优秀的特征。
6. 交叉(Crossover):- 交叉操作模拟基因的交换。
它将两个父代染色体的一部分基因互换,产生新的个体。
7. 变异(Mutation):- 变异操作引入随机性,通过随机改变染色体中的一些基因值,以便引入新的特征。
8. 种群(Population):- 种群是所有个体的集合。
每一代,新的个体通过选择、交叉和变异产生,并替代上一代。
9. 终止条件(Termination Condition):- 终止条件是算法停止迭代的条件,可以是达到特定的适应度阈值、达到最大迭代次数等。
10. 遗传算法参数(GA Parameters):- 这包括种群大小、交叉率、变异率等,这些参数对算法的性能和效率产生重要影响。
基因遗传算法的性能取决于这些组成部分的合理配置和调整。
根据不同问题的性质,可以对这些组成部分进行适当的定制。
遗传算法基础

比例选择法(轮盘赌)
• 基本思想
各个个体被选中的概率与其适应度大小成正比。 设群体大小为 M,个体 i 的适应度大小为F ( xi ) ,则 个体 i 被选中的概率为
Pi =
F ( xi )
∑ F (x )
i =1 i
M
比例选择法(轮盘赌)
• 具体步骤 1)计算各基因适应度值和选择概率 Pi 2)累计所有基因选择概率值,记录中间累 加值S - mid 和最后累加值 sum = ∑ Pi 3)产生一个随机数 N,0〈 N 〈 1 4)选择对应中间累加值S - mid 的基因进 入交换集 5)重复(3)和(4),直到获得足够的基 因。
t i
t i i
n
模式定理
• 选择算子的作用
f (H , t) m( H , t + 1) = m( H , t ) f (t )
若 若
f (H , t) >1,m(H,t)增加 f (t ) f ( H , t ) <1,m(H,t)减少 f (t )
在选择算子的作用下,对于平均适用度高于群体平 在选择算子的作用下, 均适应度的模式,其样本数将增长, 均适应度的模式,其样本数将增长,对于平均适用 度低于群体平均适应度的模式, 度低于群体平均适应度的模式,其样本数将减少
f ( x) f ( x) f ( x) f ( x) f ( x) f ( x)
F(x)
F(x)
F(x)
F(x)=f(x)+C
遗传算法基本要素与实现技术
• 选择算子 • 适应度较高的个体被遗传到下一代群体中 的概率较大,适应度较低的个体被遗传到 下一代群体中的概率较小。 • 选择方法 比例选择法(轮盘赌) 锦标赛选择法
遗传算法基本原理

遗传算法基本原理遗传算法是一种模拟自然选择和遗传机制的优化方法,它模拟了生物进化的过程,通过不断迭代和优化来寻找最优解。
遗传算法的基本原理包括编码、选择、交叉和变异等步骤。
首先,编码是将问题的解表示为染色体的过程。
染色体可以是二进制、实数、排列等形式,不同的编码方式会影响算法的性能和收敛速度。
选择是指根据适应度函数的值来选择优秀个体的过程,适应度函数通常是问题的目标函数,它衡量了个体的优劣。
选择的方法有轮盘赌、锦标赛等多种方式,其中轮盘赌是一种常用的选择方法,它模拟了自然界中适者生存的原理。
接下来,交叉是指两个个体之间基因信息的交换过程,它模拟了生物界中的杂交现象。
交叉的方式有单点交叉、多点交叉、均匀交叉等多种方式,不同的交叉方式会影响算法的搜索能力和多样性。
最后,变异是指个体基因信息的随机改变过程,它可以增加种群的多样性,防止陷入局部最优解。
遗传算法的基本原理可以通过一个简单的例子来说明。
假设我们要用遗传算法来解决一个简单的优化问题,比如求解函数f(x)=x^2的最小值。
首先,我们需要对变量x进行编码,假设采用二进制编码。
然后,我们需要初始化一个种群,种群中的个体就是我们编码后的染色体。
接下来,我们需要计算每个个体的适应度,即计算函数f(x)的值。
然后,我们进行选择操作,选择优秀的个体进行交叉和变异操作。
通过不断迭代,我们可以逐渐优化种群,最终找到函数f(x)的最小值对应的x值。
总之,遗传算法是一种强大的优化方法,它通过模拟生物进化的过程来寻找最优解。
遗传算法的基本原理包括编码、选择、交叉和变异等步骤,通过这些步骤的不断迭代和优化,我们可以找到问题的最优解。
遗传算法在实际应用中有着广泛的应用,比如在工程优化、机器学习、数据挖掘等领域都有着重要的作用。
希望本文对遗传算法的基本原理有所帮助,谢谢阅读。
遗传算法基本概念

遗传算法基本概念一、引言遗传算法(Genetic Algorithm,GA)是一种基于生物进化原理的搜索和优化方法,它是模拟自然界生物进化过程的一种计算机算法。
遗传算法最初由美国科学家Holland于1975年提出,自此以来,已经成为了解决复杂问题的一种有效工具。
二、基本原理遗传算法通过模拟自然界生物进化过程来求解最优解。
其基本原理是将问题转换为染色体编码,并通过交叉、变异等操作对染色体进行操作,从而得到更优的解。
1. 染色体编码在遗传算法中,问题需要被转换成染色体编码形式。
常用的编码方式有二进制编码、实数编码和排列编码等。
2. 适应度函数适应度函数是遗传算法中非常重要的一个概念,它用来评价染色体的适应性。
适应度函数越高,则该染色体越有可能被选中作为下一代群体的父代。
3. 选择操作选择操作是指从当前群体中选择出适应度较高的个体作为下一代群体的父代。
常用的选择方法有轮盘赌选择、竞赛选择和随机选择等。
4. 交叉操作交叉操作是指将两个父代染色体的一部分基因进行交换,产生新的子代染色体。
常用的交叉方法有单点交叉、多点交叉和均匀交叉等。
5. 变异操作变异操作是指在染色体中随机改变一个或多个基因的值,以增加种群的多样性。
常用的变异方法有随机变异、非一致性变异和自适应变异等。
三、算法流程遗传算法的流程可以概括为:初始化种群,计算适应度函数,选择父代,进行交叉和变异操作,得到新一代种群,并更新最优解。
具体流程如下:1. 初始化种群首先需要随机生成一组初始解作为种群,并对每个解进行编码。
2. 计算适应度函数对于每个染色体,需要计算其适应度函数值,并将其与其他染色体进行比较。
3. 选择父代根据适应度函数值大小,从当前种群中选择出若干个较优秀的染色体作为下一代群体的父代。
4. 进行交叉和变异操作通过交叉和变异操作,在选出来的父代之间产生新的子代染色体。
5. 更新最优解对于每一代种群,需要记录下最优解,并将其与其他染色体进行比较,以便在下一代中继续优化。
遗传算法中的染色体基础知识
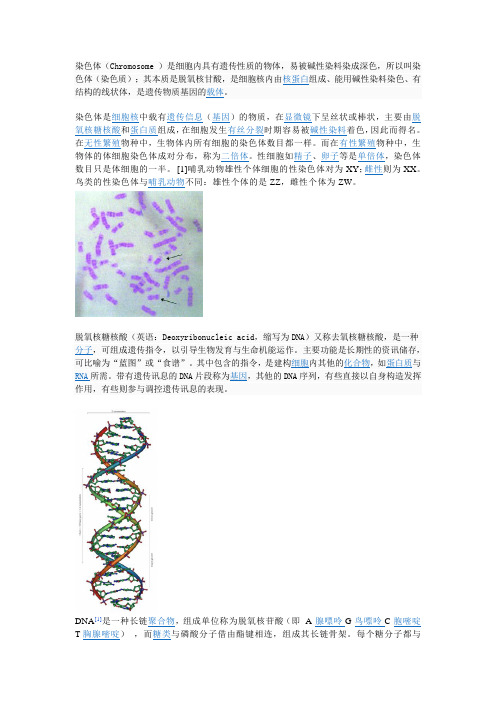
染色体是细胞核中载有遗传信息(基因)的物质,在显微镜下呈丝状或棒状,主要由脱氧核糖核酸和蛋白质组成,在细胞发生有丝分裂时期容易被碱性染料着色,因此而得名。
在无性繁殖物种中,生物体内所有细胞的染色体数目都一样。
而在有性繁殖物种中,生物体的体细胞染色体成对分布,称为二倍体。
性细胞如精子、卵子等是单倍体,染色体数目只是体细胞的一半。
[1]哺乳动物雄性个体细胞的性染色体对为XY;雌性则为XX。
鸟类的性染色体与哺乳动物不同:雄性个体的是ZZ,雌性个体为ZW。
DNA[1]是一种长链聚合物,组成单位称为脱氧核苷酸(即A-腺嘌呤G-鸟嘌呤C-胞嘧啶T-胸腺嘧啶),而糖类与磷酸分子借由酯键相连,组成其长链骨架。
每个糖分子都与四种碱基里的其中一种相接,这些碱基沿着DNA长链所排列而成的序列,可组成遗传密码,是蛋白质氨基酸序列合成的依据。
读取密码的过程称为转录,是以DNA双链中的一条为模板复制出一段称为RNA的核酸分子。
多数RNA带有合成蛋白质的讯息,另有一些本身就拥有特殊功能,例如rRNA、snRNA与siRNA。
在细胞内,DNA能组织成染色体结构,整组染色体则统称为基因组。
染色体在细胞分裂之前会先行复制,此过程称为DNA复制。
对真核生物,如动物、植物及真菌而言,染色体是存放于细胞核内;对于原核生物而言,如细菌,则是存放在细胞质中的类核里。
染色体上的染色质蛋白,如组织蛋白,能够将DNA组织并压缩,以帮助DNA与其他蛋白质进行交互作用,进而调节基因的转录。
在脱氧核糖核酸和核糖核酸中,起配对作用的部分是含氮碱基。
5种碱基都是杂环化合物,氮原子位于环上或取代氨基上,其中一部分(取代氨基,以及嘌呤环的1位氮、嘧啶环的3位氮)直接参与碱基配对。
碱基置换类型及缺失和插入突变示意图碱基共有5种:胞嘧啶(缩写作C)、鸟嘌呤(G)、腺嘌呤(A)、胸腺嘧啶(T,DNA 专有)和尿嘧啶(U,RNA专有)。
顾名思义,5种碱基中,腺嘌呤和鸟嘌呤属于嘌呤族(缩写作R),它们具有双环结构。
遗传算法介绍

s1’’ =11100(28), s2’’ = 01001(9) s3’’ =11000(24), s4’’ = 10011(19)
这一轮仍然不会发生变异。
于是,得第三代种群S3:
s1=11100(28), s2=01001(9) s3=11000(24), s4=10011(19)
做交叉运算,让s1’与s4’,s2’与s3’ 分别交换 后两位基因,得
s1’’=11111(31), s2’’=11100(28) s3’’=11000(24), s4’’=10000(16)
这一轮仍然不会发生变异。
于是,得第四代种群S4:
s1=11111(31), s2=11100(28) s3=11000(24), s4=10000(16)
染色体 适应度 选择概率 积累概率 选中次数
s1=01101 169
0.14
0.14
1
s2=11000 576
0.49
0.63
2
69
0
s4=10011 361
0.31
1.00
1
于是,经复制得群体:
s1’ =11000(24), s2’ =01101(13) s3’ =11000(24), s4’ =10011(19)
例如,对于5个城市的TSP,我们用符号A、 B、C、D、E代表相应的城市,用这5个符号的 序列表示可能解即染色体。
然后进行遗传操作。设 s1=(A, C, B, E, D, A),s2=(A, E, D, C, B, A)
实施常规的交叉或变异操作,如交换后三位,得
s1’=(A,C,B,C,B,A), s2’=(A,E,D,E,D,A) 或者将染色体s1第二位的C变为E,得
遗传算法的组成

遗传算法的组成
遗传算法是一种基于生物进化原理的优化算法,它通过模拟遗传、变异、选择等生物进化过程,来寻找最优解。
遗传算法由以下几个组成部分构成:
1. 表示个体的染色体
在遗传算法中,个体通常用染色体来表示,染色体由一系列基因组成。
每个基因可以取多个值,称为基因型。
染色体的长度取决于问题的复杂度和所需的解的精度。
2. 适应度函数
适应度函数用于评估染色体的适应度,即染色体对问题的解决程度。
适应度函数是一个映射函数,将染色体映射到一个实数值,这个值越大代表染色体的适应度越高。
3. 选择算子
选择算子用于选择优秀的个体,将其保留下来作为后代的父母。
常用的选择算子有轮盘赌选择、锦标赛选择等。
4. 交叉算子
交叉算子用于将两个父亲的染色体进行交叉,产生新的子代染色体。
交叉算子的作用是将两个染色体的优良特征进行组合,产生更优秀
的后代染色体。
5. 变异算子
变异算子用于对子代染色体进行变异,引入新的基因型,增加染色体的多样性。
变异算子的作用是防止算法陷入局部最优解,增加算法搜索空间。
遗传算法通常包含以上几个组成部分,这些组成部分相互作用,形成一个遗传算法的完整流程。
通过不断进行选择、交叉、变异等操作,遗传算法可以快速地找到问题的最优解。
遗传算法广泛应用于优化、机器学习、数据挖掘等领域,具有很高的应用价值。
遗传算法介绍(内含实例)

遗传算法介绍(内含实例)现代生物遗传学中描述的生物进化理论:遗传物质的主要载体是染色体(chromsome),染色体主要由DNA和蛋白质组成。
其中DNA为最主要的遗传物质。
基因(gene)是有遗传效应的片断,它存储着遗传信息,可以准确地复制,也能发生突变,并可通过控制蛋白质的合成而控制生物的状态.生物自身通过对基因的复制(reproduction)和交叉(crossover,即基因分离,基因组合和基因连锁互换)的操作时其性状的遗传得到选择和控制。
生物的遗传特性,使生物界的物种能保持相对的稳定;生物的变异特性,使生物个体产生新的性状,以至于形成了新的物种(量变积累为质变),推动了生物的进化和发展。
遗传学算法和遗传学中的基础术语比较染色体又可以叫做基因型个体(individuals),一定数量的个体组成了群体(population),群体中个体的数量叫做群体大小。
各个个体对环境的适应程度叫做适应度(fitness)遗传算法的准备工作:1)数据转换操作,包括表现型到基因型的转换和基因型到表现型的转换。
前者是把求解空间中的参数转化成遗传空间中的染色体或者个体(encoding),后者是它的逆操作(decoding) 2)确定适应度计算函数,可以将个体值经过该函数转换为该个体的适应度,该适应度的高低要能充分反映该个体对于解得优秀程度。
非常重要的过程!遗传算法的基本步骤遗传算法是具有"生成+检测"(generate-and-test)的迭代过程的搜索算法。
基本过程为:1)编码,创建初始集团2)集团中个体适应度计算3)评估适应度4)根据适应度选择个体5)被选择个体进行交叉繁殖,6)在繁殖的过程中引入变异机制7)繁殖出新的集团,回到第二步一个简单的遗传算法的例子:求 [0,31]范围内的y=(x-10)^2的最小值1)编码算法选择为"将x转化为2进制的串",串的长度为5位。
如何高效地编码遗传算法的染色体

如何高效地编码遗传算法的染色体遗传算法是一种模拟生物进化过程的优化算法,它通过模拟自然选择、交叉和变异等操作,对解空间中的个体进行搜索和优化。
在遗传算法中,染色体是个体的基本单位,它承载着问题的解。
如何高效地编码染色体,是遗传算法设计中的重要问题。
一、二进制编码二进制编码是遗传算法中最常用的编码方式。
它将染色体表示为一串二进制位,每个二进制位代表染色体中的一个基因。
二进制编码具有简单、易于操作的特点,适用于大多数问题。
二进制编码的关键在于确定基因的长度。
基因长度的选择应该根据问题的特点和要求来确定。
如果基因长度过短,可能无法表示问题的复杂性;如果基因长度过长,会增加计算复杂度。
因此,需要根据问题的复杂性和可行解的精度来选择合适的基因长度。
二、实数编码实数编码是一种将染色体表示为一串实数的编码方式。
它适用于连续优化问题,如函数优化等。
实数编码的优点在于可以表示问题的连续性,更加精确地描述解空间。
实数编码的关键在于确定染色体中每个基因的取值范围。
取值范围的选择应该根据问题的特点和要求来确定。
如果取值范围过小,可能无法覆盖解空间的全部有效区域;如果取值范围过大,会增加计算复杂度。
因此,需要根据问题的特点和可行解的范围来选择合适的取值范围。
三、排列编码排列编码是一种将染色体表示为一串排列的编码方式。
它适用于排列问题,如旅行商问题等。
排列编码的优点在于可以直接表示问题的排列关系,更加直观地描述解空间。
排列编码的关键在于确定染色体中每个基因的取值范围。
取值范围的选择应该根据问题的特点和要求来确定。
如果取值范围过小,可能无法覆盖解空间的全部有效排列;如果取值范围过大,会增加计算复杂度。
因此,需要根据问题的特点和可行解的范围来选择合适的取值范围。
四、混合编码混合编码是一种将染色体表示为多种编码方式的组合的编码方式。
它适用于复杂问题,如多目标优化等。
混合编码的优点在于可以同时考虑问题的多个方面,更加全面地描述解空间。
遗传算法的基本原理和要点

3
二、遗传算法的工作示意图
4
三、遗传算法的基本构成
遗传算法的基本构成通常包含以下五部分: (1)求解问题或解的遗传编码 (2)产生初始种群的规则 (3)评价个体或染色体优劣的适值或评价函数 (4)产生子代的遗传操作 (5)控制进化过程的各参数设置
5
一、遗传编码 1.二进制编码:不能有效解决许多实际问题,有明显缺陷。 2.实数编码:用实数或浮点数表示个体,对函数优化问题最有效。 3.整数或字母排列编码:用1-n的自然数,A或a-Z或z的字母的排列构成 问题的解的个体。根据是否允许重复分成顺序编码或非顺序编码。常见 于优化组合问题。 4.一般数据结构编码:对于复杂的优化问题,需要用n维数据或更复杂的 结构表示染色体。
遗传算法的基本原理和要点
1
一、遗传算法简介
1.遗传算法 ( GA , Genetic Algorithm ) ,也称进化算法。其基
本思想基于Darwin的进化论和Mendel的遗传学说。
2.由密西根大学Holland教授创建于1975年。
3.特点:不易陷入局部最优,具备很好的全局搜索能力和很快的收
13
7
三、选择操作 是指按某种方法从父代种群中选取一些个体,遗传到下一代种群。通常 以适值大小为依据。适值越大越有可能进化为问题的最优解。适值大小 可以直接以问题目标函数值的大小来表示。
包含三个方面:
1.采样空间 2.采样机理 3.选择概率
8
1.采样空间 由两个因素来确定:大小和成分(父代与子代) 令pop_size为种群大小,off_size为子代大小,规则的采样空间为pop_size ,含有所有的子代与部分父代,扩大的采样空间大小pop_size+off_size, 包含所有的父代与子代。
遗传算法染色体编码

遗传算法染色体编码一、引言遗传算法是模拟自然选择和遗传机制的一种优化方法。
在遗传算法中,染色体编码是非常重要的一个环节,它直接影响到算法的性能和效果。
本文将详细介绍遗传算法染色体编码的相关知识。
二、什么是染色体编码染色体编码是指将待优化问题转化为可供计算机处理的二进制串或其他类型的编码形式。
在遗传算法中,染色体即为待优化问题的解,而编码则是将这些解表示成计算机可以处理的形式。
三、常见的染色体编码方式1. 二进制编码二进制编码是最常用的一种染色体编码方式。
它将每个决策变量转换为一个固定长度的二进制串,其中每个位代表该变量在取值域中所对应位置是否被选中。
例如,假设一个决策变量取值范围为[0,5],则可以用3位二进制数来表示该变量的取值:000表示0,001表示1,010表示2,011表示3,100表示4,101表示5。
2. 标准化浮点数编码标准化浮点数编码将每个决策变量转换为一个固定长度的二进制串,其中前一部分表示数值的整数部分,后一部分表示小数部分。
例如,假设一个决策变量取值范围为[0,1],编码长度为10位,则可以将该变量编码为一个10位二进制串,其中前5位表示整数部分,后5位表示小数部分。
3. 标准化整数编码标准化整数编码将每个决策变量转换为一个固定长度的二进制串,其中每个位代表该变量在取值域中所对应位置是否被选中。
例如,假设一个决策变量取值范围为[0,5],则可以用3位二进制数来表示该变量的取值:000表示0,001表示1,010表示2,011表示3,100表示4,101表示5。
四、染色体编码的优缺点1. 优点(1)染色体编码具有较好的可扩展性和灵活性;(2)不同类型的问题可以采用不同的编码方式;(3)染色体编码具有较好的适应性和鲁棒性。
2. 缺点(1)染色体编码需要针对不同类型的问题进行设计和调整;(2)染色体编码过程中可能会出现信息丢失或信息重复等问题。
五、染色体编码的设计原则1. 明确决策变量的取值范围和精度;2. 确定染色体编码长度;3. 选择合适的编码方式;4. 确保编码方式与问题类型相匹配。
遗传算法中的染色体长度

遗传算法中的染色体长度遗传算法是一种模拟自然界遗传和进化过程的优化算法。
在遗传算法中,染色体长度是指染色体上基因的数量或长度。
染色体长度的选择对遗传算法的收敛性和搜索能力有重要影响。
本文将从染色体长度的选择、调整和影响等方面进行阐述。
一、染色体长度的选择染色体长度是遗传算法中一个重要的参数,决定了搜索空间的范围。
染色体长度过短会导致搜索空间不足,降低了算法的搜索能力;染色体长度过长会增加搜索空间的维度,使得算法的计算复杂度增加。
因此,选择合适的染色体长度是提高算法效果的关键。
在选择染色体长度时,需要综合考虑问题的复杂度、目标函数的特性以及计算资源等因素。
对于简单的问题,染色体长度可以选择较短,以减少计算复杂度;对于复杂的问题,染色体长度应选择较长,以增加搜索空间。
二、染色体长度的调整染色体长度的调整是遗传算法中的一个重要步骤。
在算法的迭代过程中,根据问题的特性和算法的收敛情况,可以适时调整染色体长度,以提高算法的搜索能力。
当算法的收敛速度较慢时,可以尝试增加染色体长度,以增加搜索空间,加快算法的收敛速度。
当算法的收敛速度较快时,可以尝试减小染色体长度,以降低计算复杂度,提高算法的运行效率。
三、染色体长度的影响染色体长度对遗传算法的性能有着直接的影响。
合理选择和调整染色体长度可以提高算法的搜索能力和收敛速度,从而得到更优的解。
较短的染色体长度可能导致算法过早陷入局部最优解,搜索能力较弱。
较长的染色体长度可能导致算法的计算复杂度增加,收敛速度较慢。
因此,在实际应用中,需要根据问题的特性和算法的要求,选择合适的染色体长度。
染色体长度的选择还应考虑到问题的约束条件。
若问题存在特定的约束条件,染色体长度应足够长以满足这些约束条件,否则可能无法得到满足约束的解。
染色体长度是遗传算法中的一个重要参数,其选择和调整对算法的性能有着直接的影响。
合理选择和调整染色体长度可以提高算法的搜索能力和收敛速度,从而得到更优的解。
遗传算法中的染色体基础知识
染色体(Chromosome )是细胞内具有遗传性质的物体,易被碱性染料染成深色,所以叫染色体(染色质);其本质是脱氧核甘酸,是细胞核内由组成、能用碱性染料染色、有结构的线状体,是遗传物质基因的。
染色体是中载有()的物质,在下呈丝状或棒状,主要由和组成,在细胞发生时期容易被着色,因此而得名。
在物种中,生物体内所有细胞的染色体数目都一样。
而在物种中,生物体的体细胞染色体成对分布,称为。
性细胞如、等是,染色体数目只是体细胞的一半。
[1]哺乳动物雄性个体细胞的性染色体对为XY;则为XX。
鸟类的性染色体与不同:雄性个体的是ZZ,雌性个体为ZW。
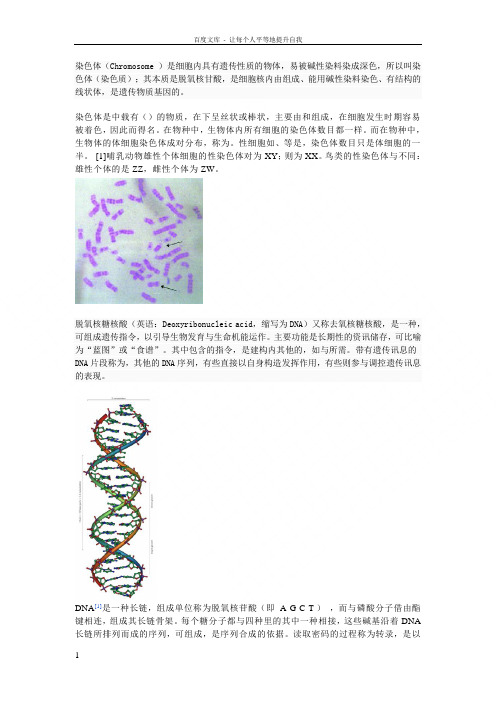
脱氧核糖核酸(英语:Deoxyribonucleic acid,缩写为DNA)又称去氧核糖核酸,是一种,可组成遗传指令,以引导生物发育与生命机能运作。
主要功能是长期性的资讯储存,可比喻为“蓝图”或“食谱”。
其中包含的指令,是建构内其他的,如与所需。
带有遗传讯息的DNA片段称为,其他的DNA序列,有些直接以自身构造发挥作用,有些则参与调控遗传讯息的表现。
DNA[1]是一种长链,组成单位称为脱氧核苷酸(即A-G-C-T-),而与磷酸分子借由酯键相连,组成其长链骨架。
每个糖分子都与四种里的其中一种相接,这些碱基沿着DNA 长链所排列而成的序列,可组成,是序列合成的依据。
读取密码的过程称为转录,是以DNA双链中的一条为模板复制出一段称为RNA的核酸分子。
多数带有合成蛋白质的讯息,另有一些本身就拥有特殊功能,例如rRNA、snRNA与siRNA。
在细胞内,DNA 能组织成结构,整组染色体则统称为。
染色体在细胞分裂之前会先行复制,此过程称为DNA复制。
对真核生物,如动物、植物及真菌而言,染色体是存放于细胞核内;对于而言,如细菌,则是存放在细胞质中的类核里。
染色体上的蛋白,如组织蛋白,能够将DNA组织并压缩,以帮助DNA与其他蛋白质进行交互作用,进而调节基因的转录。
在脱氧核糖核酸和核糖核酸中,起配对作用的部分是含氮碱基。
遗传算法第一章通俗易懂

遗传算法一、解析遗传算法(Genetic Algorithm)是一种启发式搜索算法,它收到生物进化过程的启发,通过模拟自然选择和遗传机制来寻找最优解,遗传算法将问题表示为一个染色体(个体)集合,并通过交叉和变异操作在种群中形成新的染色体。
通过一代代选择和遗传,最终找到具有高适应的解。
遗传算法是是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
遗传算法首先依据某种方式(通常是随机)生成一组候选解,之后,候选解中的个体通过交叉和变异产生新的解群,再在这个解群中选取较优的个体产生新一代的候选解,重复此过程,直到满足某种收敛指标为止。
二、关键词学习遗传算法必须要了解的关键词:种群、个体、基因、交叉、变异、选择;2.1种群就是组候选解的集合,遗传算法正是通过种群的迭代进化,实现了最优解或者近似最优解.2.2个体一个个体对应一个解,也就是构成种群的基本单元。
在遗传算法中,需要把一个解构造成染色体(chromosome)的形式,如同在扇贝例子中,通过染色体来表示扇贝花纹图案,这个过程也被称为编码,而当算法结束时,需要把最优的染色体还原成最优解,这个过程称为解码。
2.3基因染色体是由基因组成的,所以把组成遗传算法染色体(个体)的基本部分称为基因,基因的选择可以多种多样,比如在扇贝例子中,我们用像素作为基因,但实际上扇贝例子的原文是用不同的三角形块作为基因,通过不同三角形块的叠加形成firefox图案。
在实际中遗传算法广泛用到的一种基因是0、1、比特。
0、1、比特基因形成的染色体是一个二进制串。
2.4交叉交叉是将两个父代个体的部分基因进行交换,从而形成两个新的个体。
最简单的交叉如同扇贝例子,在染色体上寻找一个点,然后进行相互交叉,这种交叉称为单点交叉;交叉类型分为:单点交叉(one-point crossover)多点交叉(大于等于2的点进行交叉)(multi-point crossover)均匀交叉(uniform crossover)洗牌交叉(shuffle crossover)2.5变异按照一定的概率将个体中的基因值用其它的基因值来替换,从而形成一个新的个体,如同自然界中生物的变异概率较小,在遗传算法中基因的变异概率也应该设置为较小。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
染色体是细胞核中载有遗传信息(基因)的物质,在显微镜下呈丝状或棒状,主要由脱氧核糖核酸和蛋白质组成,在细胞发生有丝分裂时期容易被碱性染料着色,因此而得名。
在无性繁殖物种中,生物体内所有细胞的染色体数目都一样。
而在有性繁殖物种中,生物体的体细胞染色体成对分布,称为二倍体。
性细胞如精子、卵子等是单倍体,染色体数目只是体细胞的一半。
[1]哺乳动物雄性个体细胞的性染色体对为XY;雌性则为XX。
鸟类的性染色体与哺乳动物不同:雄性个体的是ZZ,雌性个体为ZW。
DNA[1]是一种长链聚合物,组成单位称为脱氧核苷酸(即A-腺嘌呤G-鸟嘌呤C-胞嘧啶T-胸腺嘧啶),而糖类与磷酸分子借由酯键相连,组成其长链骨架。
每个糖分子都与
四种碱基里的其中一种相接,这些碱基沿着DNA长链所排列而成的序列,可组成遗传密码,是蛋白质氨基酸序列合成的依据。
读取密码的过程称为转录,是以DNA双链中的一条为模板复制出一段称为RNA的核酸分子。
多数RNA带有合成蛋白质的讯息,另有一些本身就拥有特殊功能,例如rRNA、snRNA与siRNA。
在细胞内,DNA能组织成染色体结构,整组染色体则统称为基因组。
染色体在细胞分裂之前会先行复制,此过程称为DNA复制。
对真核生物,如动物、植物及真菌而言,染色体是存放于细胞核内;对于原核生物而言,如细菌,则是存放在细胞质中的类核里。
染色体上的染色质蛋白,如组织蛋白,能够将DNA组织并压缩,以帮助DNA与其他蛋白质进行交互作用,进而调节基因的转录。
在脱氧核糖核酸和核糖核酸中,起配对作用的部分是含氮碱基。
5种碱基都是杂环化合物,氮原子位于环上或取代氨基上,其中一部分(取代氨基,以及嘌呤环的1位氮、嘧啶环的3位氮)直接参与碱基配对。
碱基置换类型及缺失和插入突变示意图
碱基共有5种:胞嘧啶(缩写作C)、鸟嘌呤(G)、腺嘌呤(A)、胸腺嘧啶(T,DNA 专有)和尿嘧啶(U,RNA专有)。
顾名思义,5种碱基中,腺嘌呤和鸟嘌呤属于嘌呤族(缩写作R),它们具有双环结构。
胞嘧啶、尿嘧啶、胸腺嘧啶属于嘧啶族(Y),它们的环系是一个六元杂环。
RNA中,尿嘧啶取代了胸腺嘧啶的位置。
值得注意的是,胸腺嘧啶比尿嘧啶多一个5位甲基,这个甲基增大了遗传的准确性。
碱基通过共价键与核糖或脱氧核糖的1位碳原子相连而形成的化合物叫核苷。
核苷再与磷酸结合就形成核苷酸,磷酸基接在五碳糖的5位碳原子上。
DNA(脱氧核糖核酸)的结构出奇的简单。
DNA分子由两条很长的糖链结构构成骨架,通过碱基对结合在一起,就像梯子一样。
整个分子环绕自身中轴形成一个双螺旋。
两条链的空间是一定的,为2nm。
碱基
在形成稳定螺旋结构的碱基对中共有4种不同碱基。
根据它们英文名称的首字母分别称之为A(ADENINE 腺嘌呤)、T(THYMINE 胸腺嘧啶)、C(CYTOSINE 胞嘧啶)、G(GUANINE 鸟嘌呤),另有U(URACIL尿嘧啶)。
DNA与RNA共有的碱基是腺嘌呤、胞嘧啶和鸟嘌呤。
胸腺嘧啶存在于DNA中,而尿嘧啶则存在于RNA中。
每种碱基分别与另一种碱基的化学性质完全互补,嘌呤是双环,嘧啶是单环,两个嘧啶之间空间太大,而嘌呤之间空间不够。
这样A总与T配对,G总与C配对。
这四种化学“字母”沿DNA 骨架排列。
“字母”(碱基)的一种独特顺序就构成一个“词”(基因)。
每个基因有几百甚至几万个碱基对。
嘌呤和嘧啶都有酮-烯醇式互变异构现象,一般生理pH条件下呈酮式。
AGCT(U)四种碱基在DNA中的排列遵循碱基互补配对原则
有些核酸中含有修饰碱基(或稀有碱基),这些碱基大多是在上述嘌呤或嘧啶碱的不同部位甲基化或进行其它的化学修饰而形成的衍生物。
例如有些DNA分子中含有5-甲基胞嘧啶(m5C),5-羟甲基胞嘧啶(hm5C)。
某些RNA分子中含有1-甲基腺嘌呤(m1A)、2,2-二甲基鸟嘌呤(m22G)和5,6-二氢尿嘧啶(DHU)等。
在DNA分子结构中,由于碱基之间的氢键具有固定的数目和DNA两条链之间的距离保持不变,使得碱基配对必须遵循一定的规律,这就是Adenine(A,腺嘌呤)一定与Thymine(T,胸腺嘧啶)配对,Guanine(G,鸟嘌呤)一定与Cytosine(C,胞嘧啶)配对,反之亦然。
碱基间的这种一一对应的关系叫做碱基互补配对原则。
腺嘌呤与胸腺嘧啶之间有两个氢键,鸟嘌呤与胞嘧啶之间有三个氢键,即A=T,G≡C。
根据碱基互补配对的原则,一条链上的A一定等于互补链上的T;一条链上的G一定等于互补链上的C,反之如此。
在DNA转录成RNA时,有两种方法根据碱基互补配对原则判断:1)将模板链根据原则得出一条链,再将得出的链中的T改为U(尿嘧啶)即可;2)将非模板链的T 改为U即可。
如:DNA:A TCGAA TCG(将此为非模板链)TAGCTTAGC(将此为模板链)转录出的mRNA:AUCGAAUCG(可看出只是将非模板链的T改为U,所以模板链又叫无义链。
这也是中心法则和碱基互补配对原则的体现。
)。