田间试验与统计分析课后习题解答及复习资料.
试验设计与分析课后习题解答及复习资料

试验设计与分析课后习题解答及复习资料田间试验与统计分析-习题集及解答1.在种田间试验设计方法中,属于顺序排列的试验设计方法为:对比法设计、间比法2.若要控制来自两个方面的系统误差,在试验处理少的情况下,可采用:拉丁方设计3.如果处理内数据的标准差或全距与其平均数大体成比例,或者效应为相乘性,则在进行方差分析之前,须作数据转换。
其数据转换的方法宜采用:对数转换。
4.对于百分数资料,如果资料的百分数有小于30%或大于70%的,则在进行方差分析之前,须作数据转换。
其数据转换的方法宜采用:反正弦转换(角度转换)。
5.样本平均数显著性测验接受或否定假设的根据是:小概率事件实际不可能性原理。
6.对于同一资料来说,线性回归的显著性和线性相关的显著性:一定等价。
7.为了由样本推论总体,样本应该是:从总体中随机地抽取的一部分8.测验回归和相关显著性的最简便的方法为:直接按自由度查相关系数显著表。
9.选择多重比较的方法时,如果试验是几个处理都只与一个对照相比较,则应选择:LSD法。
10.如要更精细地测定土壤差异程度,并为试验设计提供参考资料,则宜采用:空白试验11.当总体方差为末知,且样本容量小于30,但可假设==(两样本所属的总体方差同质)时,作平均数的假设测验宜用的方法为:t 测验12.因素内不同水平使得试验指标如作物性状、特性发生的变化,称为:效应13.若算出简单相差系数大于1时,说明:计算中出现了差错。
14.田间试验要求各处理小区作随机排列的主要作用是:获得无偏的误差估计值15.正态分布曲线与轴之间的总面积为:等于1。
16.描述总体的特征数叫:参数,用希腊字母表示;描述样本的特征数叫:统计数,用拉丁字母表示。
17.确定分布偏斜度的参数为:自由度18.用最小显著差数法作多重比较时,当两处理平均数的差数大于LSD0.01时,推断两处理间差异为:极显著19.要比较不同单位,或者单位相同但平均数大小相差较大的两个样本资料的变异度宜采用:变异系数20.选择多重比较方法时,对于试验结论事关重大或有严格要求的试验,宜用:q测验。
试验设计与分析课后习题解答及复习资料

试验设计与分析课后习题解答及复习资料田间试验与统计分析-习题集及解答1.在种田间试验设计方法中,属于顺序排列的试验设计方法为:对比法设计、间比法2.若要控制来自两个方面的系统误差,在试验处理少的情况下,可采用:拉丁方设计3.如果处理内数据的标准差或全距与其平均数大体成比例,或者效应为相乘性,则在进行方差分析之前,须作数据转换。
其数据转换的方法宜采用:对数转换。
4.对于百分数资料,如果资料的百分数有小于30%或大于70%的,则在进行方差分析之前,须作数据转换。
其数据转换的方法宜采用:反正弦转换(角度转换)。
5.样本平均数显著性测验接受或否定假设的根据是:小概率事件实际不可能性原理。
6.对于同一资料来说,线性回归的显著性和线性相关的显著性:一定等价。
7.为了由样本推论总体,样本应该是:从总体中随机地抽取的一部分8.测验回归和相关显著性的最简便的方法为:直接按自由度查相关系数显著表。
9.选择多重比较的方法时,如果试验是几个处理都只与一个对照相比较,则应选择:LSD法。
10.如要更精细地测定土壤差异程度,并为试验设计提供参考资料,则宜采用:空白试验11.当总体方差为末知,且样本容量小于30,但可假设==(两样本所属的总体方差同质)时,作平均数的假设测验宜用的方法为:t 测验12.因素内不同水平使得试验指标如作物性状、特性发生的变化,称为:效应13.若算出简单相差系数大于1时,说明:计算中出现了差错。
14.田间试验要求各处理小区作随机排列的主要作用是:获得无偏的误差估计值15.正态分布曲线与轴之间的总面积为:等于1。
16.描述总体的特征数叫:参数,用希腊字母表示;描述样本的特征数叫:统计数,用拉丁字母表示。
17.确定分布偏斜度的参数为:自由度18.用最小显著差数法作多重比较时,当两处理平均数的差数大于LSD0.01时,推断两处理间差异为:极显著19.要比较不同单位,或者单位相同但平均数大小相差较大的两个样本资料的变异度宜采用:变异系数20.选择多重比较方法时,对于试验结论事关重大或有严格要求的试验,宜用:q测验。
尔雅网课田间试验与统计分析课后及考试习题答案

1【多选题】田间试验任务的主要来源有()。
A、农业生产实践中发现或提出了新的问题,需要通过田间试验进行解决。
B、农业科学工作者经常需要通过田间试验开展有关作物生长发育和遗传规律以及作物与环境之间相互关系等研究。
C、不同地区和不同单位之间经常有相同或类似的项目需要进行研究,受其它地区或单位的委托进行研究也是田间试验任务的一个重要来源。
D、根据农业生产发展的需要,各级农业行政部门或科研主管部门经常会下达一些田间试验项目。
我的答案:ABCD2【判断题】田间试验的任务就是在大田条件下评价农业生产新技术、新产品和新品种的实际效果,解决农业生产中需要解决的问题。
我的答案:√1【单选题】试验目的要明确就是()。
A、要求田间试验的各项试验条件要接近试验结果欲推广地区的自然条件和生产条件B、对试验要解决的问题有充分的了解,对预期结果做到心中有数C、必须坚持唯一差异原则D、在相同或类似的条件下进行同样的试验或生产实践,能获得类似的结果我的答案:B2【单选题】试验条件要有代表性就是要求田间试验的各项试验条件要接近试验结果欲推广地区的(),只有这样才能使试验结果在欲推广地区的生产上发挥增产增效作用。
A、自然条件、生产条件B、天气条件C、土壤条件D、市场条件我的答案:A3【单选题】为了保证试验结果的准确可靠,进行田间试验时,必须坚持(),随时随地注意试验的准确性,力求避免造成不应有的试验误差。
A、重复原则B随机排列C、唯一差异原则D、一致原则我的答案:C4【多选题】田间试验的基本要求包括()。
A、试验目的要明确B、试验条件要有代表性C、试验结果要准确可靠D、试验结果要有重演性我的答案:ABCD5【多选题】为了满足重演性的要求,有哪些要注意的环节( )A完全掌握试验所处的自然条件和生产条件B、有及时、准确、完整的田间观察记载,以便分析产生各种试验结果的原因,找出规律性的东西C、每一项试验最好在本地重复进行2~3年,以便弄清作物对不同年份气候条件的反应D、如果将试验结果推广到其他地区,还应进行多点试验。
《田间试验与统计分析》复习资料

0≠β《田间试验与统计分析》复习题目1一、判断题:判断结果填入括弧,以√表示正确,以×表示错误。
(每小题2分,共14分) 1 多数的系统误差是特定原因引起的,所以较难控制。
( ) 2 否定正确无效假设的错误为统计假设测验的第一类错误。
( )3 A 群体标准差为5,B 群体的标准差为12, B 群体的变异一定大于A 群体。
( )4 “唯一差异”是指仅允许处理不同,其它非处理因素都应保持不变。
( )5 某班30位学生中有男生16位、女生14位,可推断该班男女生比例符合1∶1(已知84.321,05.0=χ)。
( ) 6 在简单线性回归中,若回归系数,则所拟合的回归方程可以用于由自变数X可靠地预测依变数Y 。
( )7 由固定模型中所得的结论仅在于推断关于特定的处理,而随机模型中试验结论则将用于推断处理的总体。
( )二、填空题:根据题意,在下列各题的横线处,填上正确的文字、符号或数值。
(每个空1分,共16分 )1 对不满足方差分析基本假定的资料可以作适当尺度的转换后再分析,常用方法有、 、 、 等。
2 拉丁方设计在 设置区组,所以精确度高,但要求 等于 ,所以应用受到限制。
3 完全随机设计由于没有采用局部控制,所以为保证较低的试验误差,应尽可能使 试验的环境因素相当均匀 。
4 在对单个方差的假设测验中:对于C H =20σ:,其否定区间为2,212ναχχ-<或2,22ναχχ>;对于C H ≥20σ:,其否定区间为2,12ναχχ-<;而对于C H ≤20σ:,其否定区间为2,2ναχχ>。
5 方差分析的基本假定是 、 、 。
6 一批玉米种子的发芽率为80%,若每穴播两粒种子,则每穴至少出一棵苗的概率为 。
7 当多个处理与共用对照进行显著性比较时,常用 方法进行多重比较。
三、选择题:将正确选择项的代码填入题目中的括弧中。
(每小题2分,共10分 ) 1 田间试验的顺序排列设计包括 ( )。
田间试验与统计分析(第三版)答案

第四章1、什么是假设检验?假设检验的步骤是什么?假设检验有什么注意事项?答:假设检验是根据样本的统计数对样本所属的总体参数提出的假设是否被否定所进行的检验。
假设检验的步骤是1、提出假设;2、计算概率;3、统计推断;4、得出结论假设检验的注意事项有:注意两类错误:(1)要有合理的实验设计和准确的实验操作,避免系统误差,降低误差,提高实验的准确性和精确性。
(2)选用的假设检验方法要符合其应用条件。
(3)选用合理的统计假设。
(4)正确理解假设检验结论的统计意义。
(5)统计分析结论的而应用,还要与经济效益相结合起来综合考虑。
2、什么是一尾检验和两尾检验?各自在什么条件下应用?他们的无效假设与备选假设是怎样确定的?答:一尾假设:利用一尾概率进行假设检验称为一尾检验两尾检验:利用一尾概率进行假设检验称为一尾检验一般在不能通过已知条件或专业知识排除一种情况的话,是要做双尾检验的;但如果可以排除一种情况(例如已知统计量不会偏大),则可以做上单尾或下单尾检验,这样做可以提高检验的精度,因为知道了更多的信息。
值得提一句,方差分析都是做上单尾检验.3、什么是显著性水平?它与假设检验结果有什么关系?怎样选择显著性水平?答:显著水平用来推断无效假设否定与否的概率标准称为显著水平。
是指当原假设为正确时人们却把它拒绝了的概率或风险。
它是公认的小概率事件的概率值,必须在每一次统计检验之前确定,通常取α=0.05或α=0.01。
这表明,当作出接受原假设的决定时,其正确的可能性(概率)为95%或99%。
选你用哪种显著水平,应根据实验要求或者实验结论的重要性而定。
如果实验过程中难以控制的因素较多,实验误差较大,则显著水平可选取低一点,反之则选择高一点。
4、假设检验的两类错误是什么?如何降低犯这两类错误的概率?答:Ⅰ型错误(α错误)--把非真实差异当做真实差异;Ⅱ型错误(β错误)--把真实差异当做非真实差异;为了降低反两类错误的概率,一般选取适当的显著水平和增加实验的重复次数5、什么是参数的点估计和区间估计?答:点估计是利用样本数据对未知参数进行估计得到的是一个具体的数据;区间估计是通过样本数据估计未知参数在置信度下的最可能的存在区间得到的结果是一个区间6、已知普通的水稻单株产量服从正态分布,平均单株产量μ0=250gg ,标准差σ0=2.78gg 。
田间试验与统计分析课后习题解答及复习资料

名师精编优秀资料田间试验与统计分析-习题集及解答1. 2. 3. 在种田间试验设计方法中,属于顺序排列的试验设计方法为:对比法设计、 间比法 若要控制来自两个方面的系统误差,在试验处理少的情况下,可采用:拉丁 方设计 如果处理内数据的标准差或全距与其平均数大体成比例,或者效应为相 乘性, 则在进行方差分析之前, 须作数据转换。
其数据转换的方法宜采用: 对数转换。
对于百分数资料,如果资料的百分数有小于 30%或大于 70%的,则在进 行方差分析之前,须作数据转换。
其数据转换的方法宜采用:反正弦转换 (角度转换)。
样本平均数显著性测验接受或否定假设的根据是: 小概率事件实际不可能性 原理。
对于同一资料来说,线性回归的显著性和线性相关的显著性:一定等价。
为了由样本推论总体,样本应该是:从总体中随机地抽取的一部分 测验回归和相关显著性的最简便的方法为:直接按自由度查相关系数显著 表。
选择多重比较的方法时,如果试验是几个处理都只与一个对照相比较,则应 选择:LSD 法。
如要更精细地测定土壤差异程度,并为试验设计提供参考资料,则宜采用: 空白试验 = = (两样本 所属的总体方差同质)时,作平均数的假设测验宜用的方法为:t 测验 因素内不同水平使得试验指标如作物性状、特性发生的变化,称为:效应 若算出简单相差系数 大于 1 时,说明:计算中出现了差错。
田间试验要求各处理小区作随机排列的主要作用是: 获得无偏的误差估计值 正态分布曲线与 轴之间的总面积为:等于 1。
描述总体的特征数叫:参数,用希腊字母表示;描述样本的特征数叫:统计 数,用拉丁字母表示。
确定 分布偏斜度的参数为:自由度4.5. 6. 7. 8. 9. 10.11. 当总体方差为末知,且样本容量小于 30,但可假设 12. 13. 14. 15. 16. 17.18. 用最小显著差数法作多重比较时,当两处理平均数的差数大于 LSD0.01 时, 推断两处理间差异为:极显著 19. 要比较不同单位, 或者单位相同但平均数大小相差较大的两个样本资料的变 异度宜采用:变异系数 20. 选择多重比较方法时,对于试验结论事关重大或有严格要求的试验,宜用: q 测验。
田间试验与统计分析复习名词解释及问答

复习思考题第一章绪论1.田间试验的两个主要特点是什么?2.田间试验的四点基本要求是什么?3.统计分析方法有哪些基本功用?4.田间试验从开始到获得试验结论一般要经过哪些过程?第Ⅰ部分田间试验部分第二章田间试验设计1.解释名词:因素,水平,处理2.制订试验方案时需考虑哪些要点?3.举例说明简单效应、平均效应和互作效应的概念和计算方法?4.田间试验主要有哪三方面的误差来源?如何控制?5.环境设计的三原则是什么?分别有什么作用?6.对比法、间比法、完全随机、随机区组、拉丁方、裂区、条区等7种环境设计方法分别应用了环境设计三原则(重复,随机和局部控制)中的哪些原则?这些设计方法各有什么特点?各适合于什么情况下使用?7.控制土壤差异的小区技术有哪些方面?第三章田间试验实施1.田间试验的布置与管理有哪些主要环节?2.常用的抽样方法有哪些?第Ⅱ部分统计分析部分第四章基本统计概念1.解释名词:总体,样本,观测值、变数、参数、统计数,抽样分布2.各举1-2个例子说明田间试验资料有哪些主要类型?3.举例说明如何计算一个样本的算术平均数、方差、标准差和变异系数?4.常见的统计分布有哪些?其中哪些是抽样分布?第五章统计假设测验1.解释名词:无效假设,备择假设,两尾测验,一尾测验,α错误,β错误肯定区间,否定区间,显著水平2.统计假设测验的基本原理和过程是什么?3.各举1个例子说明如何进行以下类型的假设测验:总体方差未知时单个样本平均数的t测验,总体方差未知时两个成组样本平均数的假设测验,两个成对样本平均数的假设测验,单个二项样本百分数的假设测验,两个二项样本百分数的假设测验,单个样本方差的假设测验,两个样本方差的假设测验,适合性测验,独立性测验第六章总体参数的区间估计1.解释名词:置信区间,置信度2.举例说明如何根据一个样本的平均数和方差估计总体的平均数和方差?第七章方差分析及其应用1.方差分析的基本过程有哪些?2.多重比较时如何进行字母标记?3.方差分析对数据有哪些基本假定?在不符合这些假定时通常进行数据转换的方法有哪些?4.各举1个例子说明如何进行以下试验资料的方差分析:单因素完全随机试验,单因素随机区组试验,二因素随机区组试验,裂区试验,多年多点试验,组内又分亚组的单向分组资料第八章直线回归和相关1.以一数据实例说明如何进行相关分析和回归分析?2.直线回归和相关在应用时需注意哪些要点?。
田间试验与统计分析习题.doc

四川农业大学植物生产类专业生物统计考试复习题第一章田间试验一、名词解释试验指标、试验因素、因素水平、试验处理、试验小区、总体、样本、样本容量、隋机样本总体准确性精确性二、简答题1、田间试验有哪些特点?保证田间试验质量的基本要求有哪些?2、什么是试验误差?随机误差与系统误差有何区别?田间试验误差有哪些主要来源及相应的控制途径?3、控制土壤差异的小区技术包括哪些内容?各措施有何作用?4、田间试验设计的基本原则及其作用为何?5、什么是试验方案?如何制订一个完善的试验方案?6、简述完全随机设计、随机区组设计、拉丁方设计和裂区设计各自的特点及其应用条件。
三、应用题1、有5个油菜品种A、B、C、D、E(其中E为对照)进行品种比较试验,重复3次,随机区组设计,试绘制田间排列图。
2、拟对4个水稻品种(副区因素)进行3种密度(主区因素)的栽培试验,重复3次,裂区设计,试绘制田间排列图。
第二章资料的整理与描述一、名词解释数量性状资料质量性状资料次数资料计量资料算术平均数几何平均数中位数众数调和平均数标准差变异系数二、简答题1、试验资料分为那几类?各有何特点?2、简述计量资料整理的步骤。
3、常用的统计表和统计图有哪些?4、算术平均数有哪些基本性质?三、应用题计算下面两个玉米品种的10个果穗长度(cm)的平均数、标准差和变异系数,解释所得结果。
BS24: 19 21 20 20 18 19 22 21 21 19金皇后: 16 21 24 15 26 18 20 19 22 19第三章常用概率分布一、名词解释随机事件概率的统计定义小概率事件实际不可能性原理正态分布标准正态分布两尾概率一尾概率二项分布标准误t分布分布 F分布二、简答题1、事件的概率具有那些基本性质?2、正态分布的密度曲线有何特点?3、标准误与标准差有何联系与区别?4、样本平均数抽样总体与原始总体的两个参数间有何联系?三、应用题1、已知随机变量~(100, 0.1),求的总体平均数和标准差。
田间试验与统计分析课后答案

田间试验与统计分析课后答案田间试验与统计分析课后答案【篇一:田间试验与统计方法作业题参考答案】=txt>作业题(一)参考答案一、名词解释(10分)1 边际效应2 唯一差异性原则3 小概率实际不可能性原理4 统计假设 5 连续性矫正1 边际效应:指种植在小区或试验地边上的植株因其光照、通风和根系吸收范围等生长条件与中间的植株不同而产生的差异。
2 唯一差异性原则:指在试验中进行比较的各个处理,其间的差别仅在于不同的试验因素或不同的水平,其余所有的条件都应完全一致。
3 小概率实际不可能性原理:概率很小的事件,在一次试验中几乎不可能发生或可以认为不可能发生。
4 统计假设:就是试验工作者提出有关某一总体参数的假设。
5 连续性矫正:连续性矫正:?2分布是连续性变数的分布,而次数资料属间断性变数资料。
研究表明,当测验资料的自由度等于1时,算得的?2值将有所偏大,因此应予以矫正,统计上称为连续性矫正。
二、填空(22分)1、试验观察值与理论真值的接近程度称为(准确度)。
5、用一定的概率保证来给出总体参数所在区间的分析方法称为(区间估计),保证概率称为(置信度)。
6、试验设计中遵循(重复)和(随机排列)原则可以无偏地估计试验误差。
7、样本标准差s s=(?(x?)n?12),样本均数标准差sx=x2s1.72440.5453。
n1012(?e?)iikk(o?e)222228、次数资料的?测验中,??=(),当自由度为(1),?c= ?)。
(?ci?11eei9、在a、b二因素随机区组试验的结果分析中已知总自由度为26,区组自由度为2,处理自由度为8,a因素自由度为2,则b因素的自由度为(2),a、b二因素互作的自由度为(4),误差的自由度为(16)。
10、统计假设测验中直接测验的是(无效)假设,它于与(备择)假设成对立关系。
211、相关系数的平方称为(决定系数),它反映了(由x不同而引起的y的平方和u??(?y?)占y总平方和ssy??(y??y))的比例。
田间试验与统计分析课后答案

田间试验与统计分析课后答案1. 田间试验的概念和意义田间试验是一种农业科学研究方法,旨在通过对农作物在实际田间环境中的种植和管理,对其生长发育、产量和品质等因素进行观察和分析,以便得出科学合理的农业管理建议和决策。
田间试验的意义在于:•评估新的农作物品种和栽培技术的效果和适应性。
•研究不同环境因素对农作物生长和产量的影响,为合理选择适应性更强的品种和种植技术提供依据。
•评估农药、肥料和其他农业生产输入品质及其使用方法对农作物产量和品质的影响,为农业生产提供技术指导。
•收集和处理试验数据,进行统计分析,提供科学的试验结果,为农业科学研究提供数据支持。
2. 田间试验的步骤田间试验一般包括以下几个步骤:2.1. 试验目标确定试验目标的确定是田间试验的第一步。
根据研究的目的和问题,确定试验的主要内容和指标,并制定相应的试验方案。
2.2. 试验设计与样本选择试验设计的选择是田间试验的关键环节。
常见的试验设计包括随机区组设计、区组设计、蛇形区组设计等。
根据试验要求和资源条件,选择适当的试验设计,并确定样本数量和选择方法。
2.3. 试验布置与操作根据试验设计和样本选择的结果,制定试验布局和操作流程。
包括土壤处理、播种、施肥、灌溉、农药处理等。
在试验过程中,要注意保持试验田地的统一性和稳定性,尽量减少误差。
2.4. 数据采集与处理根据试验目标和指标,采集相关的数据。
数据采集要确保准确性和完整性,可以采用现场测量、采样和实验室分析等方法。
采集到的数据要经过预处理和整理,以便进行后续的分析和推断。
2.5. 数据分析与结果阐释对采集到的数据进行统计分析,包括描述统计和推断统计。
描述统计主要包括数据的集中趋势、离散程度和相关性等指标的计算和分析。
推断统计主要包括参数估计、假设检验和方差分析等。
分析结果应该结合试验目标和指标,对试验结果进行解释和阐述。
3. 统计分析在田间试验中的应用统计分析在田间试验中起到了至关重要的作用,主要包括以下几个方面:3.1. 试验设计和样本选择统计分析方法可以帮助确定适当的试验设计和样本选择,以保证试验结果的可靠性和有效性。
田间试验统计复习题答案

田间试验统计复习题答案一、选择题1. 田间试验中常用的一种设计方法是()。
A. 随机区组设计B. 完全随机设计C. 因子设计D. 拉丁方设计答案:A2. 下列哪项不是田间试验的误差来源?()A. 土壤肥力不均B. 种子质量差异C. 施肥量不均D. 试验设计答案:D3. 田间试验中,如果处理效应显著,但误差较小,说明()。
A. 试验设计不合理B. 试验结果可靠C. 试验结果不可靠D. 试验误差过大答案:B二、填空题1. 田间试验中,____是指在相同条件下进行的试验,以确保试验结果的可比性。
答案:重复性2. 田间试验的统计分析中,____是用来衡量试验误差大小的指标。
答案:方差3. 田间试验中,____是指试验结果的可靠性,通常通过显著性检验来确定。
答案:有效性三、简答题1. 简述田间试验设计中的随机化原则及其重要性。
答案:随机化原则是指在田间试验设计中,将处理随机分配给试验单元,以减少试验误差和偏差,提高试验结果的可靠性。
其重要性在于能够确保试验结果的客观性和代表性,避免由于人为因素或环境差异带来的影响。
2. 描述田间试验中重复试验的作用及其对结果的影响。
答案:重复试验是指在田间试验中对同一处理进行多次试验,其作用是减少随机误差,提高试验结果的稳定性和可靠性。
重复试验可以增加样本量,从而减少试验误差,使得试验结果更加接近真实情况。
四、计算题1. 假设一个田间试验有4个处理,每个处理有5个重复,试验结果显示总产量为2000公斤,平均产量为200公斤,标准差为10公斤。
请计算试验的变异系数。
答案:变异系数 = 标准差 / 平均值 = 10 / 200 = 0.05 或 5%五、论述题1. 论述田间试验中控制误差的重要性及其方法。
答案:控制误差在田间试验中至关重要,因为误差的大小直接影响试验结果的准确性和可靠性。
控制误差的方法包括:选择合适的试验设计,如随机区组设计或拉丁方设计,以减少系统误差;确保试验条件的一致性,如土壤肥力、水分供应等;进行重复试验以减少随机误差;使用适当的统计方法进行数据分析,如方差分析等。
《田统(明书)》(二版)部分习题答案
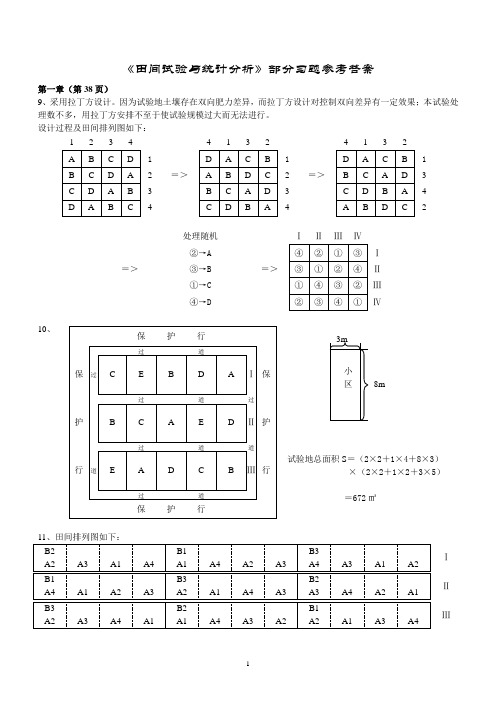
《田间试验与统计分析》部分习题参考答案第一章(第38页)9、采用拉丁方设计。
因为试验地土壤存在双向肥力差异,而拉丁方设计对控制双向差异有一定效果;本试验处理数不多,用拉丁方安排不至于使试验规模过大而无法进行。
设计过程及田间排列图如下:1 2 3 4 =>4 1 3 2 =>4 1 3 2111 2 2 3 3 34 442=>处理随机 =>Ⅰ Ⅱ Ⅲ Ⅳ②→AⅠ ③→B Ⅱ ①→C Ⅲ ④→DⅣ10、试验地总面积S =(2×2+1×4+8×3)×(2×2+1×2+3×5)=672㎡Ⅰ Ⅱ Ⅲ8m6、9、直接法:34.85 3.2236x s == 加权法:34.67 3.3274x s ==10、BS24:201.2472. 6.236%x s c v ===金皇后:203.3993.16.997%x s c v === 结果表明,金皇后资料的变异性比BS24的要大得多。
6、**254.1,46.3692,0.27960.8791,4.6638x x s t u σ======8、12122**2***221301.1632,4.6995, 3.8092.284,4.5324, 3.9490.3444,51e x x xx S S t S F S t k df S --==='''======10、**0.063,0.0437,0.0138, 4.556d d S S t ====12、12*ˆˆ12ˆˆ0.2237,0.2859,0.2577,0.0244,2.549p p ppp u σ-=====-第五章(第142页) 11、123123.148,.117,.102;..367.14.8,.11.7,.10.24489.6333x x x x x x x C ========LSD 法:120.050.010.050.012.052,2.771,1.3089,2.686,3.627x x t t S LSD LSD -=====SSR 法:0.9256x S =两种多重比较方法结果相同。
尔雅网课田间试验与统计分析课后及考试习题答案
1【多选题】田间试验任务的主要来源有()。
A、农业生产实践中发现或提出了新的问题,需要通过田间试验进行解决。
B、农业科学工作者经常需要通过田间试验开展有关作物生长发育和遗传规律以及作物与环境之间相互关系等研究。
C、不同地区和不同单位之间经常有相同或类似的项目需要进行研究,受其它地区或单位的委托进行研究也是田间试验任务的一个重要来源。
D、根据农业生产发展的需要,各级农业行政部门或科研主管部门经常会下达一些田间试验项目。
我的答案:ABCD2【判断题】田间试验的任务就是在大田条件下评价农业生产新技术、新产品和新品种的实际效果,解决农业生产中需要解决的问题。
我的答案:√1【单选题】试验目的要明确就是()。
A、要求田间试验的各项试验条件要接近试验结果欲推广地区的自然条件和生产条件B、对试验要解决的问题有充分的了解,对预期结果做到心中有数C、必须坚持唯一差异原则D、在相同或类似的条件下进行同样的试验或生产实践,能获得类似的结果我的答案:B2【单选题】试验条件要有代表性就是要求田间试验的各项试验条件要接近试验结果欲推广地区的(),只有这样才能使试验结果在欲推广地区的生产上发挥增产增效作用。
A、自然条件、生产条件B、天气条件C、土壤条件D、市场条件我的答案:A3【单选题】为了保证试验结果的准确可靠,进行田间试验时,必须坚持(),随时随地注意试验的准确性,力求避免造成不应有的试验误差。
A、重复原则B随机排列C、唯一差异原则D、一致原则我的答案:C4【多选题】田间试验的基本要求包括()。
A、试验目的要明确B、试验条件要有代表性C、试验结果要准确可靠D、试验结果要有重演性我的答案:ABCD5【多选题】为了满足重演性的要求,有哪些要注意的环节( )A完全掌握试验所处的自然条件和生产条件B、有及时、准确、完整的田间观察记载,以便分析产生各种试验结果的原因,找出规律性的东西C、每一项试验最好在本地重复进行2~3年,以便弄清作物对不同年份气候条件的反应D、如果将试验结果推广到其他地区,还应进行多点试验。
试验设计与分析课后习题解答及复习资料

田间试验与统计分析-习题集及解答1.在种田间试验设计方法中,属于顺序排列的试验设计方法为:对比法设计、间比法2.若要控制来自两个方面的系统误差,在试验处理少的情况下,可采用:拉丁方设计3.如果处理内数据的标准差或全距与其平均数大体成比例,或者效应为相乘性,则在进行方差分析之前,须作数据转换。
其数据转换的方法宜采用:对数转换。
4.对于百分数资料,如果资料的百分数有小于30%或大于70%的,则在进行方差分析之前,须作数据转换。
其数据转换的方法宜采用:反正弦转换(角度转换)。
5.样本平均数显著性测验接受或否定假设的根据是:小概率事件实际不可能性原理。
6.对于同一资料来说,线性回归的显著性和线性相关的显著性:一定等价。
7.为了由样本推论总体,样本应该是:从总体中随机地抽取的一部分8.测验回归和相关显著性的最简便的方法为:直接按自由度查相关系数显著表。
9.选择多重比较的方法时,如果试验是几个处理都只与一个对照相比较,则应选择:LSD法。
10.如要更精细地测定土壤差异程度,并为试验设计提供参考资料,则宜采用:空白试验11.当总体方差为末知,且样本容量小于30,但可假设==(两样本所属的总体方差同质)时,作平均数的假设测验宜用的方法为:t测验12.因素内不同水平使得试验指标如作物性状、特性发生的变化,称为:效应13.若算出简单相差系数大于1时,说明:计算中出现了差错。
14.田间试验要求各处理小区作随机排列的主要作用是:获得无偏的误差估计值15.正态分布曲线与轴之间的总面积为:等于1。
16.描述总体的特征数叫:参数,用希腊字母表示;描述样本的特征数叫:统计数,用拉丁字母表示。
17.确定分布偏斜度的参数为:自由度18.用最小显著差数法作多重比较时,当两处理平均数的差数大于LSD0.01时,推断两处理间差异为:极显著19.要比较不同单位,或者单位相同但平均数大小相差较大的两个样本资料的变异度宜采用:变异系数20.选择多重比较方法时,对于试验结论事关重大或有严格要求的试验,宜用:q测验。
尔雅网课田间试验与统计分析课后及考试习题答案

1【多选题】田间试验任务的主要来源有()。
A、农业生产实践中发现或提出了新的问题,需要通过田间试验进行解决。
B、农业科学工作者经常需要通过田间试验开展有关作物生长发育和遗传规律以及作物与环境之间相互关系等研究。
C、不同地区和不同单位之间经常有相同或类似的项目需要进行研究,受其它地区或单位的委托进行研究也是田间试验任务的一个重要来源。
D、根据农业生产发展的需要,各级农业行政部门或科研主管部门经常会下达一些田间试验项目。
我的答案:ABCD2【判断题】田间试验的任务就是在大田条件下评价农业生产新技术、新产品和新品种的实际效果,解决农业生产中需要解决的问题。
我的答案:√1【单选题】试验目的要明确就是()。
A、要求田间试验的各项试验条件要接近试验结果欲推广地区的自然条件和生产条件B、对试验要解决的问题有充分的了解,对预期结果做到心中有数C、必须坚持唯一差异原则D、在相同或类似的条件下进行同样的试验或生产实践,能获得类似的结果我的答案:B2【单选题】试验条件要有代表性就是要求田间试验的各项试验条件要接近试验结果欲推广地区的(),只有这样才能使试验结果在欲推广地区的生产上发挥增产增效作用。
A、自然条件、生产条件B、天气条件C、土壤条件D、市场条件我的答案:A3【单选题】为了保证试验结果的准确可靠,进行田间试验时,必须坚持(),随时随地注意试验的准确性,力求避免造成不应有的试验误差。
A、重复原则B随机排列C、唯一差异原则D、一致原则我的答案:C4【多选题】田间试验的基本要求包括()。
A、试验目的要明确B、试验条件要有代表性C、试验结果要准确可靠D、试验结果要有重演性我的答案:ABCD5【多选题】为了满足重演性的要求,有哪些要注意的环节( )A完全掌握试验所处的自然条件和生产条件B、有及时、准确、完整的田间观察记载,以便分析产生各种试验结果的原因,找出规律性的东西C、每一项试验最好在本地重复进行2~3年,以便弄清作物对不同年份气候条件的反应D、如果将试验结果推广到其他地区,还应进行多点试验。
《田间试验与统计分析》复习题

一、简答1.田间试验的意义、特点和要求:指田间土壤、自然气候等环境条件下栽培作物,并进行与作物有关的各种科学研究的试验;特点:①试验研究的对象和材料是农作物,以农作物生长发育的反应作为试验指标研究其生长发育规律、各项栽培技术或条件的效果。
②田间试验具有严格的地区性和季节性。
③田间试验普遍存在误差;要求:(1)试验目的要明确(2)试验要有代表性和先进性:自然条件和农业条件(3)试验结果要正确:正确性包括试验的准确性和精确性(4)试验结果要能够具有重演性2.田间试验常用术语(熟悉概念):试验指标、试验因素、因素水平、试验处理、试验小区、试验单位、总体与个体、有限总体与无限总体、样本、样本容量。
3.样本容量:样本所包含的个体数目称为样本容量,常记为n。
通常将样本容量n >30的样本称为大样本,将样本容量n≤30的样本称为小样本。
观测值:对样本中各个体的某种性状、特性加以考察,如称量、度量、计数或分析化验所得的结果称为观测值。
4.什么是试验误差?试验误差与试验的准确度、精确度有什么关系?试验误差指观察值与其理论值或真值的差异。
系统误差使数据偏离了其理论真值,影响了数据的准确性;偶然误差使数据相互分散,影响了数据的精确性。
//试验误差的来源,如何控制?答:误差包括系统误差和随机误差,①误差的来源(1)试验材料固有的差异(2)试验操作和管理技术的不一致所引起的差异(3)环境条件的差异;②控制方法(1)选择同质一致的试验材料(2)改进操作和管理技术做到标准化(3)控制引起差异的外界主要因素5.田间试验设计的基本原则是什么,其作用是什么?答:田间试验设计的基本原则是重复、随机、局部控制。
其作用是(1)降低试验误差; (2)获得无偏的、最小的试验误差估计; (3)准确地估计试验处理效应; (4)对各处理间的比较能作出可靠的结论。
//试验方案:指根据试验目的与要求而拟定的进行比较的一组试验处理的总称。
如何制定一个完善的试验方案:⑴明确试验目的(2)根据试验目的确定参试因素(3)合理确定参试因素的水平(4)应用唯一差异原则(5)设置对照(6)明确试验因素与试验条件的关系6.控制土壤差异的小区技术主要包括?答:(1)小区形状(小区形状指小区长度与宽度的比例,常有长方形和正方形两种:边际效应明显、土壤差异不清楚时用正方形)(2)小区面积、(3)重复次数(一般2~5次,通常3~4次):增加重复次数、降低小区面积比增大小区面积、降低重复次数效果好(4)设置对照区、(5)设置保护区(作用:防止边际效应;防止人、畜践踏(6)区组和小区的排列7.控制土壤差异通常采取三种措施:(1)选择合适的试验地(2)采用适当的小区技术(3)应用正确的试验设计和相应的统计分析8.田间试验有哪两种设计方法?随机排列设计有哪些方法?随机区组设计的主要优点有哪些?答:(1)顺序排列设计和随机排列设计(2)随机排列设计方法:完全随机设计、随机区组设计、拉丁方设计和裂区设计 (3)简单易用,灵活,符合试验设计三原则,对试验地要求低易于分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
田间试验与统计分析-习题集及解答1. 在种田间试验设计方法中,属于顺序排列的试验设计方法为:对比法设计、 间比法2. 若要控制来自两个方面的系统误差,在试验处理少的情况下,可采用:拉丁 方设计3. 如果处理内数据的标准差或全距与其平均数大体成比例,或者效应为相 乘性,则在进行方差分析之前,须作数据转换。
其数据转换的方法宜采用: 对数转换。
4. 对于百分数资料,如果资料的百分数有小于 30%或大于 70%的,则在进 行方差分析之前,须作数据转换。
其数据转换的方法宜采用:反正弦转换 (角度转换)。
5. 样本平均数显著性测验接受或否定假设的根据是:小概率事件实际不可能性 原理。
6. 对于同一资料来说,线性回归的显著性和线性相关的显著性:一定等价。
7. 为了由样本推论总体,样本应该是:从总体中随机地抽取的一部分 8. 测验回归和相关显著性的最简便的方法为:直接按自由度查相关系数显著表。
9. 选择多重比较的方法时,如果试验是几个处理都只与一个对照相比较,则应选择:LSD 法。
10. 如要更精细地测定土壤差异程度,并为试验设计提供参考资料,则宜采用:空白试验11. 当总体方差为末知,且样本容量小于 30,但可假设 = = (两样本所属的总体方差同质)时,作平均数的假设测验宜用的方法为:t 测验 12. 因素内不同水平使得试验指标如作物性状、特性发生的变化,称为:效应 13. 若算出简单相差系数 大于 1 时,说明:计算中出现了差错。
14. 田间试验要求各处理小区作随机排列的主要作用是:获得无偏的误差估计值 15. 正态分布曲线与 轴之间的总面积为:等于 1。
16. 描述总体的特征数叫:参数,用希腊字母表示;描述样本的特征数叫:统计数,用拉丁字母表示。
17. 确定 分布偏斜度的参数为:自由度 18. 用最小显著差数法作多重比较时,当两处理平均数的差数大于 LSD0.01 时,推断两处理间差异为:极显著 19. 要比较不同单位,或者单位相同但平均数大小相差较大的两个样本资料的变异度宜采用:变异系数 20. 选择多重比较方法时,对于试验结论事关重大或有严格要求的试验,宜用:q 测验。
21. 顺序排列设计的主要缺点是:估计的试验误差有偏性 22. 田间试验贯彻以区组为单位的局部控制原则的主要作用是:更有效地降低试验误差。
23. 拉丁方设计最主要的优点是:精确度高 24. 连续性变数资料制作次数分布表在确定组数和组距时应考虑:(1)极差的大小;(2)观察值个数的多少;(3)便于计算;(4)能反映 出资料的真实面貌。
25. 某蔗糖自动打包机在正常工作状态时的每包蔗糖重量具N(100,2)。
某日 抽查 10 包,得 =101 千克。
问该打包机是否仍处于正常工作状态?此题采 用:(1)两尾测验;(2)u 测验26. 下列田间试验设计方法中,仅能用作多因素试验的设计方法有:(1)裂区 设计;(2)再裂区设计。
27. 对于对比法和间比法设)<∑,(a≠ )。
30. 为了有效地做好试验,使试验结果能在提高农业生产和农业科学的水平上发 挥应有的作用,对田间试验的基本要求是:(1)试验的目的性要明确;(2) 试验的结果要可靠;(3)试验条件要有代表性;(4)试验结果要能够重复。
31. 表示变异度的统计数最常用的有:(1)极差;(2)方差;(3)标准差; (4)变异系数。
32. 试验某生长素对小麦苗发育的效果,调查得未用生长素处理和采用生长素处 理的苗高数据各 10 个。
试测验施用生长素的苗高至少比未用生长素处理的 苗高 2cm 的假设。
此题应为:(1) 测验;(2)一尾测验。
33. 确定试验重复次数的多少应根据:(1)试验地的面积及小区的大小;(2) 试验地土壤差异大小;(3)试验所要求的精确度;(4)试验材料种子的数 量。
34. 对单因素拉丁方试验结果资料方差分析时,变异来源有:(1)总变异;(2)行区组间变异;(3)列区组间变异;(4)处理间变异;(5)试验误差。
35. 在方差分析F测验中,当实得F小于F0.05,应接受Ho(无效假设),认为 处理间差异不显著。
36. 某样本的方差越大,则其观察值之间的变异就越大。
37. 在试验中重复的主要作用是估计试验误差和降低试验误差。
38. 自由度的统计意义是指样本内能自由变动的观察值个数。
39. 数据 3、1、3、1、2、3、4、5 的算术平均数是 2.75,中数是 3。
40. 一般而言,在一定范围内,增加试验小区的面积,试验误差将会降低。
41. 在 =a+bx 方程中,b 的意义是 x 每增加一个单位, 平均地将要增加或减少的单位数。
42. 田间试验可按因素的多少分为单因素试验和多因素试验。
43. 卡平方测验的连续性矫正的前提条件是自由度等于 1。
44. 从总体中抽取的样本要具有代表性,必须是随机抽取的样本。
45. 从一个正态总体中随机抽取的样本平均数,理论上服从正态分布。
46. 在一定的概率保证下,估计参数可能出现的范围和区间,称为置信区间(置信距)。
47. 试验误差分为系统误差和随机误差。
48. 在拟定试验方案时,必须在所比较的处理之间应用唯一差异的原则。
49. 在多重比较中,当样本数大于等于 3 时,t 测验,SSR 测验、q 测验的显著尺度 q 测验最高,t 测验最低。
50. 试验资料按所研究的性状、特性可以分为数量性状和质量性状资料。
51. 样本可根据样本容量的多少为:大样本、小样本。
52. 对比法、间比法试验,由于处理是作顺序排列,因而不能够无偏估计出试验的误差。
53. 小区的形状有长方形、正方形。
一般采用长方形小区。
54. 在边际效应受重视的试验中,方形小区是有利的,因为就一定的小区面积来讲,方形小区具有最小的周长,使受到影响的植株最少。
55. 完全随机设计应用了试验设计的重复和随机两个原则。
56. 试验设计的三个基本原则是重复、随机和局部控制。
57. 在田间试验中,设置区组的主要作用是进行局部控制。
58. 两个变数的相关系数为 0.798,对其进行假设测验时,已知 =0.798,那么在 1%水平上这两个变数的相关极显著。
59. 随机区组设计应用了试验设计的重复、随机和局部控制三个原则。
60. 试验方案试验计时,一般要遵循以下原则: 明确的目的性 、 严密的可比性 和 试验的高效性 。
61. 试验误差分为系统误差和随机误差,一般所指的试验误差为随机误差。
62. 试验误差:使观察值偏离试验处理真值的偶然影响称为试验误差或误差。
63. 试验指标:衡量试验处理效果的标准称为试验指标(experimental index),简称指标(index)。
在田间试验中,用作衡量处理效果的具体的作物性状即 为指标,例如产量、植株高等。
64. 准确性(accuracy)与精确性(precision) 统计工作是用样本的统计数来推断 总体参数的。
我们用统计数接近参数真值的程度,来衡量统计数准确性的高 低,用样本中的各个变量间变异程度的大小,来衡量该样本精确性的高低。
因此,准确性不等于精确性。
准确性是说明测定值对真值符合程度的大小, 而精确性则是多次测定值的变异程度。
65. 标准差:统计学上把方差或均方的平方根取正根的值称为标准差(standard deviation)。
标准差,能度量资料的变异程度,反映平均数的代表性优劣。
标准差(方差)大,说明资料变异大,平均数代表性差;反之,说明资料的 变异小,平均数的代表性好。
66. 标准差为方差或均方的平方根,用以表示资料的变异度,其单位与观察 值的度量单位相同。
67. 参数与统计数 参数:由总体的全部观察值计算得的总体特征为参数,它是 该总体真正的值,是固定不变的,总体参数不易获得,通常用统计数来估计 参数。
统计数:由标本观察值计算得到的样本特征数为统计数,它因样本不 同常有变动。
它是估计值,根据样本不同而不同。
68. 试验因素:试验因素(experimental factor)指试验中能够改变,并能引起试 验指标发生变化,而且在试验中需要加以考察的各种条件,简称因素或因子 (factor)。
69. 因素水平(factor level): 对试验因素所设定的量的不同级别或质的不同状态称为因素的水平,简称水平。
70. 试验处理(experimental treatment): 事先设计好的实施在试验单位上的 具体项目叫试验处理,简称处理。
在单因素试验中,实施在试验单位上的具体项目就是试验因素的某一水平,故对单因素试验时,试验因素的一个水平就是一个处理。
在多因素试验中,实施在试验单位上的具体项目是各因素的某一水平组合,所以,在多因素试验时,试验因素的一个水平组合就是一个处理。
71. 试验小区(experimental plot): 安排一个试验处理的小块地段称为试验小 区,简称小区。
72. 试验单位(experimental unit):亦称试验单元,是指施加试验处理的材料 单位。
这个单位可以是一个小区,也可以是一穴、一株、一穗、一个器官等。
73. 试验单位(experimental unit):亦称试验单元,是指施加试验处理的材料 单位。
这个单位可以是一个小区,也可以是一穴、一株、一穗、一个器官等。
74. 总体(population):根据试验研究目的确定的研究对象的全体称为总体(po pulation),其中的一个研究单位称为个体(individual)。
个体是统计研究中的 最基本单位,根据研究目的,它可以是一株植物,一个稻穗,也可以是一种作物,一个作物品种等。
75. 有限总体(finite population)与无限总体(infinite population):包含无穷 多个个体的总体称为无限总体;包含有限个个体的总体称为有限总体。
76. 样本(sample):从总体中抽取的一部分供观察测定的个体组成的集合,称 为样本。
77. 样本容量(sample size):样本所包含的个体数目称为样本容量,常记为 n。
通常将样本容量 n >30 的样本称为大样本,将样本容量 n≤30 的样本称为小 样本。
78. 观测值(observation) 对样本中各个体的某种性状、特性加以考察,如称量、 度量、计数或分析化验所得的结果称为观测值。
79. 处理效应(treatment effect):是处理因素作用于受试对象的反应,是研究 结果的最终体现。
80. 区组:将整个试验环境分成若干个最为一致的小环境,称为区组。
81. 回归: 回归(regression)是指由一个(或多个)变量的变异来估测另一个变量的变异。
82. 相关: 相关(correlation)是指两个变量间有一定的关联,一个性状的变化必 然会引起另一性状的变化。