卷积码举例
通信原理-CH12-卷积码

14
12.2 卷积码的图解表示
状态图和状态转移图
取出已达到稳定状态的一节网格,可得到状态图 再把目前状态与下一行状态重叠起来,可得到反映状态 转移的状态转移图 b
00=a 01=b 10=c 11=d 00 11 11 01 01 10 (a) 2 1 3 d=11 c (b)
15
a=00 11 00 10 b=01 00 a c=10 11 01 00 10 d 01
对应于每组k个输入比特,编码后产生n个输出比特 树状图中每个节点引出2k条支路 网格图和状态图(状态转移图)都有2k(N-1)种可能的状态。 每个状态引出2k条支路,同时也有2k条支路从其它状态 或本状态引入
17
12.3 卷积码的解析表示
主要内容
延时算子多项式表示 半无限矩阵表示
18
12.3 卷积码的解析表示
M mj
00 00 00 a 11 a 10 11 b 01
00 a 11 10 b 01 11 c 00 01 d 10 00 a 11 10 b 01 11 c 00 01 d 10 10
a b c d a b c d a b c d a b c d
m1m2
Mj
Mj-1
Mj-2
a 11 10 c 00 11 b 01 01 d 10
12.2 卷积码的图解表示
树状图(续) :(2, 1, 3)卷积编码器
00 00 00 a 11 a 10 11 b 01 a 11 10 11 c 00 b 01 01 d 10 00 a 11 10 b 01 11 c 00 01 d 10 00 a 11 10 b 01 11 c 00 01 d 10 a b c d a b c d a b c d a b c d
第五章 卷积码码1

给定一卷积码的子生成元为: g(1,1)=10011,g(1,2)=11101 判断该码的参数,写出生成矩阵,给出编码电路; 假设信息序列m=110110000…,试求出编码序列C∞
10/13/2018
信道编码
23
5.2 卷积码的矩阵描述与编码
10/13/2018 信道编码 14
5.2 卷积码的矩阵描述与编码 D
(n0,1,m)卷积码的生成矩阵
为便于理解,仍以(2,1,2)卷积码为例 设:m=(m0,m1,m2,…)
m
D
C
C=(C0,C1,C2,…),其中Ci=(ci(1),ci(2)) 若输入信息序列分别为 m=m’+m’’+m’’’ =(100…)+(0100..)+(0010...)=(1110…) 编码器相应输出的码序列为: C=mG∞=(1110…) 11 01 11… 00 11 01 11… 00 00 11 01 11… 信道编码 10/13/2018 ………
G∞=
10/13/2018
信道编码
25
5.2 卷积码的矩阵描述与编码
(n0,1,m)卷积码的生成矩阵 根据子生成元可画出(2,1,4)码的编码电路:
m
D
D
D
D
C
g(1,1)=10011,g(1,2)=11101
信道编码
10/13/2018
26
5.2 卷积码的矩阵描述与编码
(n0,1,m)卷积码的生成矩阵
卷积码的生成矩阵与编码 系统卷积码的校验矩阵 初始截短码 卷积码的距离特性
10/13/2018
信道编码
卷积码

x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16 x17 x18 x19 x20 x21 x22 x23 x24 x25
可以看出交织可能会造成独立错误变成突发错误的特殊情况
级联码
级联码的最初想法是为了进一步降低残余误码率,但事实上它同 级联码的最初想法是为了进一步降低残余误码率, 样可以提高较低信噪比下的性能。 样可以提高较低信噪比下的性能。这是由较好构造的短码进一步 构造性能更好的长码的一种途径
纠正突发错误的码
分组码、循环码均可以检测、纠正突发错误 分组码、循环码均可以检测、 对于一个能纠正l个错误的( 对于一个能纠正l个错误的(n, k)分组码,要求: 分组码,要求: r = n – k ≥ 2l 2l 即一个( 即一个(n, k)分组码最多能纠正(n – k)/2个突发错误 分组码最多能纠正( )/2个突发错误 若再要求该( 若再要求该(n, k)分组码能够检测d个突发错误,则要求: 分组码能够检测d个突发错误,则要求: r=n–k≥l+d
下面是未进行交织处理的序列
x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16 x17 x18 x19 x20 x21 x22 x23 x24 x25
假设在信道上发送时,产生了2个突发错误,如下红色部分所示: 假设在信道上发送时,产生了2个突发错误,如下红色部分所示:
10 11(1) 00 11(0) c 01 00(1)
b 01(1)
10(0)
a
11 d 01(0)
10(1)
卷积码的图解表示— 卷积码的图解表示—树状图
观察卷积码的状态迁移图,可知根据输入值的不同,编码器只向两种状态迁移, 观察卷积码的状态迁移图,可知根据输入值的不同,编码器只向两种状态迁移, 因此也可以用二叉树来描述卷积码 树状图绘制方法: 树状图绘制方法: 1)先假设其从某一状态开始; 先假设其从某一状态开始; 2)输入为0时,树状图向上延伸;输入为1时,向下延伸; 输入为0 树状图向上延伸;输入为1 向下延伸; 3)按照状态图在时间上的迁移顺序依次绘制,分支上的数字为编码器的输出 按照状态图在时间上的迁移顺序依次绘制, 编码方法: 编码方法: 1)从树根开始编码,每一节点为码元输入点; 从树根开始编码,每一节点为码元输入点; 2)到达每一节点时按照下一输入的码元向上(0)或向下(1)走; 到达每一节点时按照下一输入的码元向上( 或向下( 3)编码完毕后,将行走路径上的依次进行排列,即可得到卷积码序列 编码完毕后,将行走路径上的依次进行排列,
卷积码及维特比译码 notes
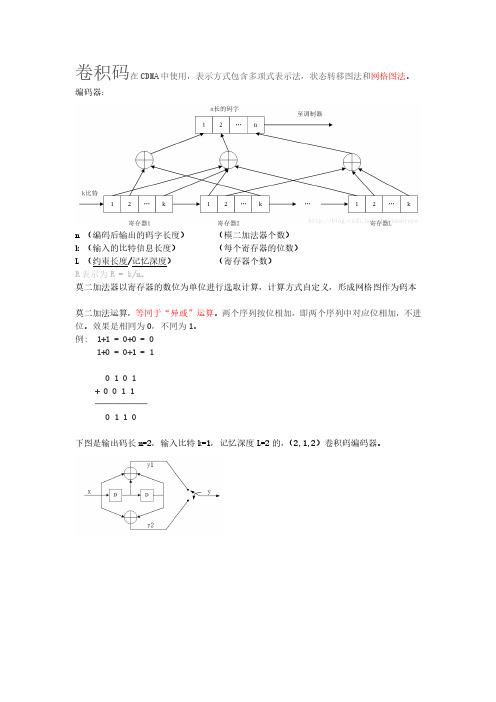
卷积码在CDMA中使用,表示方式包含多项式表示法,状态转移图法和网格图法。
编码器:n (编码后输出的码字长度)(模二加法器个数)k (输入的比特信息长度)(每个寄存器的位数)L (约束长度/记忆深度)(寄存器个数)R表示为R = k/n。
莫二加法器以寄存器的数位为单位进行选取计算,计算方式自定义,形成网格图作为码本莫二加法运算,等同于“异或”运算。
两个序列按位相加,即两个序列中对应位相加,不进位。
效果是相同为0,不同为1。
例: 1+1 = 0+0 = 01+0 = 0+1 = 10 1 0 1+ 0 0 1 1──────0 1 1 0下图是输出码长n=2,输入比特k=1,记忆深度L=2的,(2,1,2)卷积码编码器。
如编码序列“0 1 1 0 0”在图中的序列如下:汉明距离两个二进制数之间进行逐位对比,得到不同的个数如1000,与1100为1,与1110为2,与1111为3维特比算法综合状态之间的转移概率和前一层各状态的概率情况计算出概率最大的状态转换路径,从而推断出隐含状态的序列的情况。
的分支度量(汉明距离)。
其中有两条路径的分支量度为0。
3.寻找最大似然路径 - 译码过程维特比算法的关键点在于,接收机可以使用分支度量和先前计算的路径度量递推地计算当前状态的路径度量。
初始时,状态00代价为0,其它状态代价为正无穷(∞)。
算法的主循环由两个主要步骤组成:首先计算下一时刻监督比特序列的分支度量,然后计算该时刻各状态的路径度量。
路径度量的计算可以认为是一个“加-比-选”的过程1)将分支度量与上一时刻状态的路径度量相加。
2)每一状态比较来自前一时刻状态可达到的所有路径(只有两条这样的路径进行比较)3)每一状态删除其余到达路径,选择最小度量的路径保留(称为幸存路径/存活路径)若进入某个状态的部分路径中,有两条路径的度量值相等,则可以任选其一作为幸存路径。
下图显示了维特比译码的过程。
此例接收到的位序列为11 10 11 00 01 10(偷偷告诉你:这是有误码的信息)此时,产生了具有相同路径度量的四个不同路径,通向这四个状态的任一路径都是可能发送的比特序列(它们都具有度量为2的汉明距离)。
卷积码

译码主要确定译码规则,使其差错率最小
1 2 – 译码器根据接收序列来产生信息序列M的一个估值M’,如果两者不同,
则表示译码出错 – 如信道传输的码字是X,当且只有当接收序列Y不等于X时,出现译码错 误
最大似然译码
译码主要确定译码规则,使其差错率最小
– 译码器必须根据接受序列y来产生信息序列M的一个估计
§12.1.1 卷积码的图解表示
树状图- tree
– 一个(2,1,3)卷积码编码器。 假设初始状态为全0 第一个比特输入为 0->00 ,1->11 第二个比特输入时,第一个比特右移一位,这时输出比特同时受前输入比 特和前一位比特决定 ...... 第四个比特输入时,第一个比特移出移位寄存器而消失
编码后序列。由于卷积码的线性性质,所有码序列之间的最 小汉明距应等于非零码序列的最小汉明重量,即非零码序列 中1码的个数。由此可见,要求最小距或自由距,只要考虑码 树中下半部的码序列就可以了 – 例: abca abcb abdc abdd 5 3 4 4 因而:dmin = 3
§12.2 卷积码的距离特性
维特比译码
进入第四级网格时,4条幸存支路又延伸为8条, 经计算路径量度并比较后又丢弃其中4条。在 比较是如果出现量度相同的情况,可以任意选 取其中一条。继续下去,到第10步时,会发现, 所有幸存路径已经合并称为一条全0路径,纠 错完毕。 译码结束的判断:可以在网格图的终结出加上 (N-1)*K个已知信息(即N-1条支路),发送固定 码,如全零,作为结束信息。
– 应用最多也是性能最接近最佳的是维特比译码,但
是硬件复杂。门限译码性能最差,但硬件简单。维 特比译码和序列译码都是建立在最大似然译码的基 础之上的
汉明码卷积码交织码原理实例

MATLAB第六次预习报告研五队李振坤S201301104线性分组码1. 基本概念●系统码:编码后,信息码元本身不变,只在信息码元后加入监督码元。
●线性码:监督码元和信息码元成线性关系的码型。
●分组码:将信息码分组,并为每组信息码附加若干监督码的编码。
分组码一般用表示,为实际传送的码长,是信息码长,是监督码长。
●线性分组码:分组码的信息码元和监督码元,由一些线性代数方程联系起来。
分组是指编、译码过程是按分组进行的,而线性是指分组码中的监督码元按线性方程生成的。
【注】线性分组码的编码问题,就是要建立一组线性方程组,已知k个系数(即信息码),要求n-k个未知数(即监督码)。
2. 线性分组码的主要性质(1)封闭性封闭性是指码中任意两许用码组之和(逐位模2和)仍为一许用码组,这就是说,若A1和A2为码中的两个许用码组,则A1+A2仍为其中的一个许用码组。
(2)码的最小距离等于非零码的最小重量因为线性分组码具有封闭性,因而两个码组之间的距离(模2减)必是另一码组的重量。
为此,码的最小距离也就是码的最小重量,当然,除全“0”码组外。
3. 汉明码汉明码是用于纠正单个错误的线性分组码,其特点为:(1)最小码距(2)纠错能力【注】(3)监督码长(4)总码长()(5)信息码长()(6)编码效率(当r很大时,R趋向于1,效率高)因此,当r=3,4,5,6……时,分别有(7,4)、(15,11),(31,26),(63,57)等汉明码。
4. (7,4)汉明码在(7,4)汉明码中,码组为,其中为4个信息元,为3个监督码元。
监督码元与信息元之间的关系为:(9-4)生成矩阵G:编码时使用,用于产生整个码组,包括信息码和监督码。
改写为其中称为生成矩阵,它的各行是线性无关的。
为阶单位矩阵;为阶矩阵。
由生成矩阵可以产生整个码组,码组C是系统码(即信息码保持不变,监督码附加其后)。
【注】(1)上述生成矩阵为典型形式,保证能产生系统码。
213卷积码编码和译码

No.15 (2,1,3)卷积码的编码及译码摘要:本报告对于(2,1,3)卷积码原理部分的论述主要参照啜刚教材和课件,编程仿真部分绝对原创,所有的程序都是在Codeblocks 8.02环境下用C语言编写的,编译运行都正常。
完成了卷积码的编码程序,译码程序,因为对于短于3组的卷积码,即2 bit或4 bit纠错是没有意义的,所以对正确的短序列直接译码,对长序列纠错后译码,都能得到正确的译码结果。
含仿真结果和程序源代码。
如果您不使用Codeblocks运行程序,则可能不支持中文输出显示,但是所有的数码输出都是正确的。
一、 卷积码编码原理卷积码编码器对输入的数据流每次1bit 或k bit 进行编码,输出n bit 编码符号。
但是输出的分支码字的每个码元不仅于此时可输入的k 个嘻嘻有关,业余前m 个连续式可输入的信息有关,因此编码器应包含m 级寄存器以记录这些信息。
通常卷积码表示为 (n,k,m). 编码率 k r n=当k=1时,卷积码编码器的结构包括一个由m 个串接的寄存器构成的移位寄存器(成为m 级移位寄存器、n 个连接到指定寄存器的模二加法器以及把模二加法器的输出转化为穿行的转换开关。
本报告所讲的(2,1,3)卷积码是最简单的卷积码。
就是2n =,1k =,3m =的卷积码。
每次输入1 bit 输入信息,经过3级移位寄存器,2个连接到指定寄存器的模二加法器,并把加法器输出转化为串行输出。
编码器如题所示。
二、卷积码编码器程序仿真 C 语言编写的仿真程序。
为了简单起见,这里仅仅提供数组长度30 bit 的仿真程序,当然如果需要可以修改数组大小。
为了更精练的实现算法,程序输入模块没有提供非法字符处理过程,如果需要也可以增加相应的功能。
进入程序后,先提示输入数据的长度,请用户输入int (整型数)程序默认用户输入的数据小于30,然后提示输入01数码,读入数码存储与input 数组中,然后运算输出卷积码。
现代通信技术-卷积码

cidiei
000 111 001 110 011 100 010 101
移存器下一状 态 M3 M2
a (00) b (01) c (10) d (11)
0 1 0 1 0 1 0 1
a (00) b (01) c (10) d (11) a (00) b (01) c (10) d (11)
2.卷积码的几何表述
1.卷积码的基本原理
例: (n, k, N) = (3, 1, 3)卷积码编码器
输入bi M1 bi
M2 bi-1
M3 bi-2
ei di ci
编码输出
输入信息比特序列是bi-2 bi-1 bi bi+1,则当输入bi时,此编码器输 出3比特ci di ei,输入和输出的关系如下:
ci bi d i bi bi 2 ei bi bi `1 bi 2
a
↓1 ↑0 111
001
c
100
010
状态 M3M2 a 00 b 01 c 10 d 11
信息位
b
↓1
110
d
0
101
a b c d a b c d a b c d a b c d
上 半 部
下 半 部
1
1
2.卷积码的几何表述
(2)状态图 码树图还可以改进为状态图:
移存器前一状 当前输入信息 态 位 M3 M2 bi 输出码元
b
000
a
111
110
101 d
100 011
c
001
010
在此图中,虚线表示输入信息位为“0”时状态转变的路线; 实线表示输入信息位为“1”时状态转变的路线。 线条旁的3位数字是编码输出比特。
关于卷积码编码结果的位数

关于卷积码编码结果的位数一、问题描述卷积码的编码是我们经常遇到的,在讲解卷积码的输出时,我们都是如下所示的这个典型的(2,1,3)卷积码为例的,其中1111g =,2101g =。
在这个例子的条件下,我们总是可以迅速地求得正确的编码结果,无论使用离散卷积,还是多项式,还是生成矩阵。
但是,实际中可不都是这样的,生成多项式可能出现左侧或者右侧为零的情况,比如1100g =,2001g =之类的,这样就出现了离散卷积或者多项式相乘后位数不正常的情况,使得输出结果存在前后补零的问题。
另外,输入也不见得都是10111u =这样的,也可能出现1011100u =,此时结果又会出现位数上的疑问。
下面就从根源开始,详细说说这个位数的问题。
二、生成多项式含零考虑生成多项式含零的问题,就用最极端的例子,1100g =,2001g =,前者是右侧含零,后者是左侧含零。
为了更有针对性,暂不考虑输入两侧含零的情况,假设输入10111u =。
1、完整输出的位数首先我们需要对正常完整输出的位数有个理解,在输入为5位,1g 长度为3的情况下,上支路输出位数应该是7位,具体计算是5+3-1。
实际上,对于输入n 位,1g 长度为m 的情况,上支路输出位数应该是n +m -1位,其中m -1是寄存器的个数。
也即输入为n 位时,输出完n 位之后寄存器中还存在输入的数据,只有当寄存器的内容跟输入都无关了,才算输出结束,所以输出除了输入的n 位,还会输出跟寄存器数量相等的m -1位。
当然,这里只讨论了一个支路,总的输出位数应该是n +m -1乘以输出路数。
所以,抛开输入是否为零,生成多项式是否为零的因素不看,正常的完整的输出就应该是n +m -1位,这是后续分析的基础。
2、离散卷积法对于一个一般的111g =,进行离散卷积显然如下图(a )所示,离散卷积的结果长度为7。
但是对于1100g =和2001g =,很多同学就觉得困惑了,因为结果长度不够,不知道该如何合并。
卷积码

9
解: 由 g000 = 1, g001 = 0, g002 = 0, 得: G 0 g 0 g010 = 1, g011 = 1, g012 = 0, G1 g 1 g02
0=
2016/6/28
00
g 0 01 g 1 01 g 2 01
1, g02
1=
1, g02
2=
1。
G 2 g 2 00
i i-1
m0
i-2
c1i
c0i
输出C i
c2i
16
2016/6/28
卷积码的状态流图表示
信号入 m
m0 m0
i
i-1
m0
i-2
c0i
输出C i
c1i
c2i
例13:图示, 试分别用编码矩阵和状态流图来描述该码. 假设输入信息序列是101101011100…,求输出码字.
17
解:n=3,k=1,L=2,记忆阵列为1行3列。
对于图示的(3,1,3)卷积码编码器,假设移位寄存器的初始状态为 (000)
。 如果第 1 位输入为 0 ,编码输出码字为 (000) ,如果输入为 1 ,输出为
(111);第2位输入也有两种可能性,考虑到第1位输入的两种可能,共有 4种可能,对应输出分别为 (00)→(000) (10)→(001) (01)→(111) (11)→(110)
S2 S2 S3 S3
18
2016/6/28
S0
S1
S2
S3
S0 S C 1 S2 S3
000 . 111 . 001 . 110 . . 011 . 100 . 010 . 101
第十二章 卷积码.

卫星通信中: (2,1,7)码: g1(133)8 =>( 001011011) g2(171)8 =>( 001111001)
++
++
输入 1 234 567
+++
+
延时算子多项式表示法
总结:对于(n,k,N)卷积码
– 对应于每组k个比特输入,产生n个比特输出 – 网格图和状态图都有2^k(N-1)种可能状态 – 每个节点(和状态)引出2^k条支路,同时也有
简介
§12.1卷积码的结构和描述
– 卷积码的图解表示 – 卷积码的解析表示
§12.2 卷积码的距离特性
– 最小距 – 自由距
§12.3 卷积码的维特比译码
– 最大似然译码 – 维特比译码
§12.1卷积码的结构和描述
卷积码一般形式
– N 为约束长度(constraint length) – (n,k,N) 码, Rc= k/n – 图解表示,解析表示
§12.2 卷积码的距离特性
求解最小距的方法
– 在求最小距或自由距时,我们并不需要列出所有可能出现的 编码后序列。由于卷积码的线性性质,所有码序列之间的最 小汉明距应等于非零码序列的最小汉明重量,即非零码序列 中1码的个数。由此可见,要求最小距或自由距,只要考虑码 树中下半部的码序列就可以了
– 例:
§12.1.1 卷积码的图解表示
树状图- tree
– 一个(2,1,3)卷积码编码器。
假设初始状态为全0
第一个比特输入为 0->00 ,1->11
第二个比特输入时,第一个比特右移一位,这时输出比特同时受前输入比 特和前一位比特决定
卷积码

实线表示信息位0 虚线表示信息位1 节点表示状态 线旁数字为输出码元来自 (2,1,2)卷积码格状图(二)
假定发送序列为11010,为了使全部 信息位通过编码器,在发送序列后面 加上3个零,从而使输入编码器的信 息序列便成11010000。 移位寄存器的状态转移路线为: abdcbcaa; 假定接收序列有错,变成 0101011010010001;
在码的约束长度较小时,这种解码比序列解码 算法效率更高、速度更快,解码器也比较简单, 因而被广泛应用在各种数字通信系统,特别是 卫星通信系统; 最大似然法:把接收序列与所有可能的发送序 列比较,选择一种码距最小的序列作为发送序 列。 维特比对最大似然法作了简化,使之实用化。
(2,1,2)卷积码篱笆图(一)
门限解码
门限解码是一种二进制的择多逻辑解码法 它利用一组正交校验方程进行计算 “正交”的特殊含义
它是指所解的信息位,作为校验方程的一个元素, 出现在这一方程组的每一个方程中,而其他的信息 位至多出现在一个方程中。这样,就可以根据被错 码破坏了的方程数目在方程组中是否占多数来判断 所待解的信息位是否错了。当错码个数小于方程组 中方程数时,用此方法就能对错码进行纠正。
(2,1,2)卷积码篱笆图
实线表示信息位0
虚线表示信息位1
节点表示状态 线旁数字为输出码元
网格图中的状态,通常有2N-1种状态,从N个节点开始, 图形开始重复,且完全相同。
当网格图达到稳定状态后,取两个节点间的一段网格图, 即得到状态转移图。
状态图
卷积码最简的状态转移图
概率解码——维特比解码
卷积码
卷积码实例1——编码器
纠错码卷积码演示文稿

1 D 1 0 H (D) 1 D2 0 1
1 0 1 D
G(D)
0
1
1
D2
显然它们是对偶码
H (D) 1 D,1 D2,1
7
大数逻辑译码
由H(D)容易求出(3,1,2)和其对偶码(3,2,2)的校验 矩阵H
110
101
H1
100 000
110 101
000 100 110
100 000 101
13
序列译码
Viterbi译码算法存在的问题
➢ 对m值很大的情况不适用——误码率很难做的很低 ➢ 译每一个分支的计算量不变 ➢ Viterbi译码中路径度量计算方法不适用于比较不同长度的路径,
如 R =(10,10,00,01,11,01,00) C5=(11,10,00,01,10,01) C0=(11) d(R0…R5, C5)=2 d(R0, C0)=1
111
H2 100 111
010 100 111
8
大数逻辑译码
由H1可组成(3,1,2)码的以下4个对e01正交的校验和式:
s01 e01 e02
s02 e01
e03
s11 e01
s22 e01
e11 e12
e21 e23
由H2可得到对e01和e02正交的校验和式:
s0 e01 e02 e03
大数逻辑译码
4. 同时,纠错信号也反馈至伴随式寄存器修正伴随式,以 消除此错误的影响。如果大数判决门没有输出,则说明 第0子组的信息元没有错误,这时从编码器中直接将信息 元输出。 译码器每接收一个码段就对此时前m个时刻输入的码 段译码,故该类译码器的译码约束度等于编码约束度为 m+1。 由于伴随式寄存器中一半以上为1时,大数逻辑门才 有信号输出,所以每次对伴随式修正总能使伴随式重量 减轻,从而不会引起误差传播。
卷积码2019PPT课件

(g0 , g1, g2 , g3, 0,...)
成矩阵 14
14
从卷积码编码器的框图可以看出有3个存储单元,g 完全由 m+1=4段值 g0 , g1, g2 , g3 决定,从m+2=5段起均为0
g(1) (g0 g1 g2 g3) (111 001 010 011)
完全可以决定 g ,从而确定G
27
27
101 000 001
用矩阵表示为
011 001 001
101 000 001
C mG (11 11 11 00 )
011 001 001
101 000 001 011 001 001
101 000
011 001
101 000 001
G
011 001 001 101 000
任一时刻t送至编码器的信息组记为:
mt
m (1) t
,
mt(
2
)
,
mt(
k
0
)
相应的编码输出码段为:
ct
c (1) t
,
ct(
2
)
,
ct(
n0
)
ct 不仅与前面m个时刻的m段输入信息组有关,
还参与此时刻之后m个时刻的输出码段的计 算,其中m为编码器中移位寄存器的个数。
6
6
• 定义:如果在n0位长的子码中,前k0位是原 输入的信息元,则称该卷积码为系统码,
g(1) (g0 g1 g2 g3) (111 001 010 011)
完全可以决定 g ,从而确定G
g(1) 称为该(3, 1, 3)卷积码的生成元。
c (1) l
卷积码原理举例

卷积码原理举例Convolutional codes are a type of error-correcting code used in digital communication systems to detect and correct errors that may occur during transmission. They are widely used in various communication systems, such as wireless communication, satellite communication, and digital television.卷积码是一种在数字通信系统中用于检测和纠正传输过程中可能发生的错误的纠错码。
它们被广泛应用于各种通信系统,如无线通信、卫星通信和数字电视。
The basic principle behind convolutional codes is to introduce redundancy into the transmitted data in such a way that errors can be detected and corrected at the receiver end. This is achieved by encoding the data using a convolutional encoder, which generates a sequence of output symbols based on the input data.卷积码背后的基本原理是在传输的数据中引入冗余,以便在接收端检测和纠正错误。
这是通过使用卷积编码器对数据进行编码来实现的,该编码器根据输入数据生成一系列输出符号。
One way to understand how convolutional codes work is to think of them as a form of forward error correction, where redundant information is added to the original data before transmission. This redundant information allows the receiver to identify and correct errors that may have occurred during transmission, improving the overall reliability of the communication system.理解卷积码如何工作的一种方法是将其视为一种前向纠错码,即在传输之前向原始数据添加冗余信息。
循环码BCH码卷积码

10.6 循环码 10.6.1 循环码的概念: 循环性是指任一码组循环一位后仍然是该编码中的一个码组。 例:一种(7, 3)循环码的全部码组如下 表中第2码组向右移一位即得到第5码组;第5码组向右移一位即得到第7码组。
码组编号
信息位
监督位
码组编号
信息位
*
6.7 RS码 RS码:是q进制BCH码的一个特殊子类,并且具有很强的纠错能力。 RS码的主要优点: 它是多进制纠错编码,所以特别适合用于多进制调制的场合; 它能够纠正t个q位二进制错码,即能够纠正不超过q个连续的二进制错码,所以适合在衰落信道中纠正突发性错码。
10.7 卷积码 卷积码的特点: 监督码元不仅和当前的k比特信息段有关,而且还同前面m = (N – 1)个信息段有关。 将N称为码组的约束度。 将卷积码记作(n, k, m),其码率为k/n。
将 T(x) = h(x)g(x) 和 T (x) = g(x) 代入 化简后,得到 上式表明,生成多项式g(x)应该是(xn + 1)的一个因子。 例:(x7 + 1)可以分解为 为了求出(7, 3)循环码的生成多项式 g(x),需要从上式中找到一个(n – k) = 4次的因子。这样的因子有两个,即 以上两式都可以作为生成多项式。 选用的生成多项式不同,产生出的循环码码组也不同。
码多项式的按模运算 若任意一个多项式F(x)被一个n次多项式N(x)除,得到商式Q(x)和一个次数小于n的余式R(x),即 则在按模N(x)运算下,有 这时,码多项式系数仍按模2运算。 例1:x3被(x3 + 1)除,得到余项1,即 例2: 因为 x x3 + 1 x4 +x2 + 1 x4 + x x2 +x +1 在模2运算中加法和减法一样。
补充:多进制卷积码

§4多进制卷积码● 对于q 进制,例如 q =2 n ,——编码产生一个q 进制的序列由处理二进制的R=k/n 的编码器一个单个q 进制符号如:由R =1/3 的二进制编码器8 进制GF (8)中的符号一一对应● R=k/n 存储级数为m 的q 进制卷积码编码器 的构成① k 个并联的q进制寄存器,时延K i ,i =0,1,…,k –1,m =max K i② n 个GF (q )上的加法器③ 乘法器——(系数)由GF (q )中元素加权,描述每个消息符号对第p 个加法器输出的贡献。
● 例1.GF (2k)上的R =1/2、m =1 的卷积码如下图, (K >1),)2(,,)1()0(kj j j GF x x u ∈],1[],1,1[10α==G G或 D D g D D g α+=+=1)(,1)()1(0)0(0ju )0(j x )1(j x● 例2 2-4进制变换卷积编码器(m = 2)§5.恶性卷积码及译码的错误扩展● 例:考虑下面的卷积码编码器)1(j x )1()0(D g j +=)(2)1(D D g j +=1s 2s )4()0(GF x j ∈1(GF ju由于:当u = (0,0,… ,0)x =(00 00 … 00)状态(00) 当u = (1,1,… , 1)x =(00 00 … 00)状态(11) 导致:假设译码时到了状态(01)收的序列为(11 01 00 00 00 … 00) 译码: 1 1 1 1 1… 1 最大似然(d =0) 但实际发 01 00 00 00 00 … 00 ——(d =2) 信道使得错2-比特导致一大串错甚至无限扩展 这种卷积码——恶性卷积码定义:若卷积编码使得译码具有错误的无限扩展性, 则称此卷积码为恶性卷积码定理:若卷积码的(n ,k ,m )的生成多项式)(,),(),(21D g D g D g n ,都是常数项为1的m 次多项式(m ≥1),则该卷积码为恶性卷积码的 充要条件是:)(D g j (j = 1,2,n )有一个非常数公因式。