Test Analysis
sensitivity analysis学术语言-概述说明以及解释

sensitivity analysis学术语言-概述说明以及解释1.引言1.1 概述在学术研究和实践中,sensitivity analysis(敏感性分析)是一种重要的方法,用于评估模型输出结果对输入参数变化的敏感程度。
通过分析模型输入参数的变化对输出结果的影响,可以帮助研究人员更好地理解模型的稳定性和可靠性。
敏感性分析不仅可以帮助我们识别哪些参数对模型的结果影响最大,还可以帮助我们优化模型,提高模型的预测能力和可靠性。
本文将深入探讨sensitivity analysis的概念、在学术研究中的重要性以及方法及应用。
通过对这些内容的综合讨论,读者将能够了解敏感性分析在科研领域中的广泛应用和意义。
1.2 文章结构文章结构部分的内容可以按照以下内容进行编写:文章结构部分旨在介绍整篇文章的组织结构,为读者提供一个整体的概览。
本文共分为三大部分:引言、正文和结论。
在引言部分,我们将首先对sensitivity analysis的概念进行概述,说明其在学术研究中的重要性,并阐述本文的目的。
接着,正文部分将对sensitivity analysis的概念进行详细解释,阐述其在学术研究中的重要性,并介绍其方法及应用。
最后,在结论部分,我们将总结文章的主要内容,展望sensitivity analysis未来的发展方向,以及得出结论。
通过这样明确的结构安排,读者可以更清晰地了解本文的主要内容和逻辑顺序,有助于他们更好地理解和消化文章内容。
1.3 目的本文的主要目的在于探讨sensitivity analysis在学术研究中的重要性和应用。
通过对sensitivity analysis概念、方法及其在学术研究中的具体应用进行深入分析,希望能够进一步加深对该分析方法的理解,为研究人员提供更好的参考和指导。
同时,也旨在探讨sensitivity analysis在未来的发展方向和应用前景,为学术界提供启示和启发。
Analysis+of+Common+Errors+in+College+English+Test

汇报人:
202X-12-30
• Common errors in the writing section
• Common errors in reading comprehension section
Example
Candidates may not have an accurate understanding of the meaning of a key word, resulting in a deviation in their understanding of the entire article.
Candidates may not be able to infer the author's intention or make accurate judgments about the main idea of the article based on the information in the article, resulting in incorrect answer selection.
Position usage
Correct or inappropriate positions can lead to fusion about the intended meaning of a sentence
03
Article usage
The use of "a," "an," and "the" is essential in English grammar,
• Common errors in the listening section
《现代试井分析》试井解释方法

well K1
Homogeneous 均质油藏
well K1
K2
Double porosity
双孔介质:只有 一种介质可以产 出流体
现代试井分析 Modern Well Test Analysis
Pwf
(r,t)
Pi
qB 345.6Kh
ln
8.085t
r2w
Ps
qB
8.085t
Pi 345.6Kh (ln r 2w 2S)
Pi
qB 345.6Kh
(ln
8.085t
r2w
ln
e2S
)
Pi
qB 345.6Kh
ln
8.085t
(rwes )2
它对测试的数据产生了干扰,是试井中的不利因素。有条件的话进行井底关井。
现代试井分析 Modern Well Test Analysis
Slide 1
Modern well test
三. 表皮系数
现象描述:由于钻井液 的侵入、射开不完善、酸 化、压裂等原因,在井筒 周围有一个很小的环状区 域,这个区域的渗透率与 油层不同。 因此,当原油从油层流入 井筒时,产生一个附加压 力降,这种效应 叫做表皮效应。
现代试井分析 Modern Well Test Analysis
Slide 10
Modern well test
四、流动阶段即从每一个阶段可以获得的信息
第一阶段:刚刚开井的 一段短时间。可以得到 井筒储集系数C.
要进行第一和第二阶段 的压力分析,必须使用 高精度的压力计,测得 早期的压力变化数据。
Perforation Inflow Test Analysis (PITA)

PAPER 2005-031Perforation Inflow Test Analysis (PITA)N.M.A. RAHMANFekete Associates Inc.M. POOLADI-DARVISHUniversity of CalgaryL. MATTARFekete Associates Inc.This paper is to be presented at the Petroleum Society’s 6th Canadian International Petroleum Conference (56th Annual Technical Meeting), Calgary, Alberta, Canada, June 7 – 9, 2005. Discussion of this paper is invited and may be presented at the meeting if filed in writing with the technical program chairman prior to the conclusion of the meeting. This paper and any discussion filed will be considered for publication in Petroleum Society journals. Publication rights are reserved. This is a pre-print and subject to correction.AbstractDue to economics or time constraints, well-testing is sometimes reduced to perforating a well under-balanced, and analyzing the inflow characteristics. The objective of a Perforation Inflow Test Analysis (PITA) is to estimate the initial reservoir pressure, permeability and skin, immediately after perforating the well. This information can be used for evaluating future development strategy. However, special analytical procedures are required for analyzing the data, because these perforation inflow tests are shorter than conventional well tests and the influx rates are not measured.In this study, the working equations for analyzing these short tests are presented, and the procedure required for calculating meaningful estimates of the reservoir parameters is presented. Analyses of early-time and late-time data are the two major components of this approach. The early-time analysis is used for estimating the skin, and the late-time analysis is used for estimating the initial pressure and permeability. A distinctive feature of the PITA is that it does not require calculation of the influx rates, which are generally not available during a perforation test. A special derivative, called the impulse derivative, can be used to determine if the data collected is sufficient to yield meaningful results from a PITA. It is particularly important that the reservoir-dominated flow regime be reached, if the estimates of initial reservoir pressure, permeability and skin are to be acceptable. Good estimates of these parameters from a PITA will minimize the uncertainty associated with non-uniqueness in inverse problems, when modeling the test data.IntroductionConventional well tests have served the petroleum industry faithfully for decades as the primary and most reliable means of:•quantifying deliverability,•characterizing the reservoir,•collecting reservoir fluid samples, and•evaluating the condition of the well.However, for the last few years, oil and gas producers have been searching for alternatives that could yield the desiredPETROLEUM SOCIETYCANADIAN INSTITUTE OF MINING, METALLURGY & PETROLEUM1information in less time, in a more environmentally-friendly manner, and at a cheaper cost than from conventional well tests. The trend has inevitably been towards tests of shorter duration. Although it is accepted that results from short tests with small radii of investigation may not be as reliable as those from conventional well tests, it is reasonable to accept that they could be of value in assisting with strategic decisions about field development, when an increased margin of error can be tolerated.In offshore wells, in addition to the potentially exorbitant cost of testing (several millions of dollars), the drive towards green (shorter) tests is fuelled by environmental considerations, such as requirements for restricted flaring of hydrocarbons. In Alberta and elsewhere in North America, the driving force towards inexpensive tests is the marginal economics of low deliverability wells. Either way, there is an increasing trend towards these green tests to replace conventional well tests. One such green test consists of simply allowing the well to flow into the closed wellbore after perforating (closed chamber test). As the fluid from the reservoir enters the wellbore (with a fixed volume), the wellbore pressure builds up. The pressure data is collected usually at the wellhead for a period of hours or days, depending on the reservoir’s flow potential. These tests have been variously called: Slug test, Surge Test, Perforation Inflow Diagnostic (PID), or Closed Chamber Test. Interests in analyzing the data from this kind of tests have been documented in Reference 1.Although, some efforts are reported in the literature to analyze the data from a perforation inflow test, none of these provides a complete set of reservoir information. In this study, we present a complete and systematic analysis procedure that yields estimates of initial reservoir pressure, permeability and skin. We have called this procedure “Perforation Inflow Test Analysis” (PITA). When the captured data is sufficient to see at least some portion of the reservoir-dominated flow, the resulting permeability and skin values can be determined uniquely. This means that in the case of small influx of fluid into the wellbore, one can determine if this is due to low permeability or high skin.Mathematical BackgroundThe basis of PITA is the slug-test model originally proposed by Ramey and co-workers2, 3 in the seventies. A few years ago, Kuchuk4 proposed a late-time approximation of the solution. Although the estimation of reservoir pressure with this approximate solution appears to be reasonable, the permeability estimation may not be. This can be appreciated by comparing the late-time solution of Kuchuk with the one for liquid to be presented later in this section (Equation 2).As mentioned above, the solutions of PITA to be used in this study have been derived from the slug test formulation, as outlined by Ramey and co-workers in References 2 and 3. The following steps are involved in developing the working equations for analysis of data:•Set up the diffusivity equation in pressure and time for liquid influx, and in pseudo-pressure and pseudo-time for gas influx, with appropriate initial andboundary conditions,•Take Laplace transforms with respect to the temporal variable (time or pseudo-time) of the diffusivityequation and the boundary condition,•Develop solution in the Laplace domain for pressure in liquid flow, or for pseudo-pressure in gas flow,•Find the early- and late-time approximations of the solution in the Laplace domain,•Invert analytically the early- and late-time approximations of the solution to the real time orpseudo-time domain. These early- and late-timeapproximations are indeed the straight-line solutionswith appropriate plotting functions, which form thebasis of PITA.Details of the mathematical development are being presented in Reference 5. The early-time data is used to estimate skin, and the late-time data to estimate initial pressure and permeability. In gas wells, the pressure data is usually measured at the wellhead, and are converted to the bottom-hole condition. This conversion is primarily due to hydrostatic head, because the influx rate into the wellbore diminishes very rapidly, and frictional losses are not significant. Moreover, the analysis of gas well data requires the conversion of data –pressure to pseudo-pressure, and time to pseudo-time. The definitions and computational procedure of these pseudo-variables can be found in Reference 6. The fluid influx rate into the well is not measured, nor is it necessary for the analysis.Nevertheless, it can be estimated using closed chamber calculations, provided the assumption of single-phase flow can be justified. Figure 1 shows the typical profiles of measured pressure and calculated influx rate for a perforation test of a water well. As shown here, the influx rate declines very rapidly.The working equations in practical metric units for liquid (single-phase oil or water) and gas cases are presented below:Case I: Liquid InfluxAnalysis of Early-Time DatasCtppkhpp wiwwµ)10842.1)(24()(00×∆−+= (1)Analysis of Late-Time DatatkhppCpp wiiw−×+=2)()10842.1)(24(03µ (2)Case II: Gas InfluxAnalysis of Early-Time DatasVtkhwawiww)10842.1)(24()(30×∆−+=ψψψψ (3)23Analysis of Late-Time Data aw i w i w t kh V ∆−×+=2)()10842.1)(24(03ψψψψ (4)Influx Rate CalculationsAlthough calculations of influx rates are not required for analyzing the data for estimating reservoir properties, the influx rates can be calculated for any other diagnostic purposes by using the material balance principles as shown below:Liquid Rate)()000,1)(24(td dp g V q wu l ∆=ρ (5)Gas Rate)()000,1()24(td dp B c V q wg g w g ∆= (6)Flow RegimesIt is very obvious that the data for PITA is significantly influenced by wellbore storage. It is also very evident that the data is also directly influenced by the flow capacity (kh ) and the skin. Therefore, one needs to distinguish the part of the data dominated by wellbore storage (afterflow effects) from the part of data that is dominated by reservoir characteristics (reservoir pressure and permeability). As shown in Equations 1 and 3, the early-time data contains information about the skin, because of significant fluid influx rates (see Figure 1). Also, Equations 2and 4 show that the late-time data can be exploited to estimate reservoir pressure and permeability. Thus, proper identification of these flow regimes is important in order to choose appropriate data ranges from a perforation inflow test for appropriate analyses. Details of the analysis procedure are discussed in the next section.From the authors’ experience, it has been observed that the measured pressure in a set of data must contain at least some portion of the reservoir-dominated flow in order for the estimated reservoir pressure, permeability and skin to be representative of the reservoir. Alternatively speaking, the test period must be long enough to see the reservoir-dominated flow at late times. A special kind of derivative is used to confirm if the data has seen the reservoir-dominated flow. Cinco-Ley et al .7 originally introduced this derivative, and later Kuchuk 4called this “impulse derivative” (IDER ), which can be defined as:Liquid Influxtd dp t IDER w∆=2)(……………………………...……….(7)Gas Influxawa t d d t IDER ∆∆=ψ2)(…………….……………...……….(8)This approach is similar to the traditional well-testinterpretation, where a derivative plot is used to differentiate the wellbore flow regime from the infinite-acting radial flow regime. However, the derivative for PITA is different from the traditional derivative of well testing. Figure 2 shows the computed values of impulse derivative. Here, one can appreciate the advantage of using the impulse derivative, which behaves in a slightly different way from the traditional well-test derivative. As shown, the early-time data (wellbore storage) has a slope of 2 (well-test derivative has a slope of 1), and the late-time data (reservoir flow) has a slope of 0 (flat line – the same as the well-test derivative). This particular example shows that the test period should last for at least 160 hours for the estimated reservoir parameters to be representative.Thus, once the impulse derivative has been plotted with time (or pseudo-time) in log-log scales, it is easy to recognize whether or not the reservoir-dominated flow exists. If it does,reasonable values of reservoir pressure, permeability and skin can be determined. At least some of the late-time data should fall on the flat part of the derivative as shown in Figure 2, in order to get a reliable analysis. If this data exists, then skin can be calculated from the early-time data. If there is no reservoir flow, then a unique interpretation of the given data is not possible.Analysis of DataIn traditional well test interpretation, we start analyzing the data from early-time to late-time. In PITA, we start with the late-time data first, to obtain reservoir pressure and permeability. After this, we analyze the early-time data (where the derivative slope is 2) to obtain skin. Even though a complete analysis can be obtained from the derivative plot alone, it is useful to generate specialized plots to confirm the analysis. As presented earlier, the working equations for liquid and gas influxes are slightly different. For liquid influx, the data is analyzed in terms of pressure and time. For gas influx, the data is analyzed in terms of pseudo-pressure and pseudo-time. Table 1 summarizes the procedures for analyzing data for liquid and gas influxes, which involve specialized plots of derivative and bottom-hole pressures with different time scales. In liquid influx, we need to specify the wellbore storage constant (C ) due to rising liquid level in the wellbore, which is a function of wellbore capacity (V u ) and liquid density. In gas influx, we need to specify the wellbore or chamber volume (V w ).Now, we present two examples with synthetic data for water wells to illustrate the analysis technique discussed above. The analysis of data presented in Figures 1 and 2 are presented first as Example 1. The input parameters of Example 1 are shown in Table 2. As mentioned earlier, one needs to have data for at least 160 hours in order of estimate representative reservoir parameters. In the analysis, we are using this minimum amount of data. Figure 3 presents the analysis of the late portion of the data (for 160 hours). A straight line is drawn through the few last data points. The intercept of this straight line at 1/t = 0yields the reservoir pressure of 6,001 kPa (cf. model reservoir pressure of 6,000 kPa), and the slope yields a permeability of0.8 mD (cf. model permeability of 1 mD). However, the permeability estimate can be improved to 0.98 mD if the data for 500 hours are available for this specific case. Figure 4 presents the analysis of the early-time portion of the same data set. A straight line is drawn anchoring at 4,000 kPa, which is the initial cushion pressure. Using the estimated reservoir pressure and permeability from the analysis of the late portion of the data, the slope of the line yields a skin of +5.86 (cf. model skin of +6). Example 1 indeed shows that the reasonable estimates of the reservoir parameters can be obtained with PITA.The second synthetic set of data [Example 2] for a high-permeability reservoir is generated by using the parameters in Table 3. Figure 5 shows that one needs data for at least 20 hours for the analysis to be representative. Here, we are analyzing data for 20 hours to obtain the reservoir parameters. The late-time portion of the data is analyzed in Figure 6. The intercept of the straight line yields the reservoir pressure as 9,704 kPa (cf. model reservoir pressure of 9,700 kPa), and the slope yields the permeability as 95.8 mD (cf. model permeability of 110 mD). Figure 7 presents the analysis of the early portion of the data, anchoring at 6,200 kPa (the initial cushion pressure). Using the estimated initial reservoir pressure and permeability from the analysis of late-time data, the slope of the line yields a skin of +13.2 (cf. model skin of +12). Example 2 also shows that PITA is capable of yielding reasonable estimates of reservoir parameters.An important question one may face, when observing a slow rate of pressure buildup in the wellbore, is whether the poor performance is because of high skin or low permeability. While the latter cause may lead to an abandonment of the well, the former may be resolved by stimulation. The two synthetic examples given above, show that PITA can differentiate between a case with high permeability and skin and another case with low permeability and skin. Moreover, the procedure to estimate the reservoir parameters with PITA is simple. DiscussionIt has been shown that PITA can yield reasonable estimates of the reservoir parameters, if the data contain some portion of the reservoir-dominated flow. This can be ascertained by computing the impulse derivative and plotting this with time (or pseudo-time) in log-log scales. If a given set of data contains some portion of reservoir-dominated flow, as demonstrated by a flat portion (zero slope) of the impulse derivative plot, the possibility of estimating a non-unique set of values of permeability and skin is reduced. This is because when the reservoir-dominated flow is not established, the reservoir pressure and permeability estimates will not be reasonable. Such poor estimates of reservoir pressure and permeability will adversely affect the estimate of skin (see Equation 1 and 3). Thus, when estimated properly, the reservoir parameters will reduce the chance of yielding a set of non-unique parameters significantly, when modeling the reservoir.One significant advantage of PITA is that the analyst does not have to calculate the influx rates as part of the analysis of the data. Often, with a set of noisy pressure data, the calculated rate becomes noisier.As shown earlier, wellbore volume or wellbore capacity needs to be known a priori for estimating the reservoir parameters. There can be occasions when these values may not be known with a reasonable accuracy. In such situations, an over-estimated wellbore volume or wellbore capacity will lead to an over-estimation of permeability (see Equations 2 and 4).However, the estimates of reservoir pressure and skin appear to be unaffected (see Equations 1 and 3), as a result of a poor estimate of the wellbore volume or wellbore capacity.The development of the analysis procedure is well grounded in acceptable theory. As a result, we now have a much better sense of the interpretation and the validity of these very short tests, because we now have a clear understanding of the flow regimes. In practice, we know that the longer the flow, the better the test. Nonetheless, it is important to validate the results of PITA by comparing these with those from other tests – for example, permeability obtained from a traditional flow-buildup test, or reservoir pressure obtained from a static-gradient survey. Because of well cleanup and other such considerations, the value of skin could be different between various tests. Until we have enough experience to determine to what extent PITA can be relied on, we recommend that these comparisons be done as often as possible, and we encourage analysts to publish their results.Conclusions1. We have developed a systematic and comprehensiveanalysis of data obtained from perforation inflow tests.2. Reasonable estimates of reservoir properties can beobtained, if the data sees at least some portion of the reservoir-dominated flow.3. Impulse derivative should be used to confirm whether ornot the pressure data contains any reservoir-dominated flow.4. The late-time portion of data yields reservoir pressure andpermeability, and the early-time portion yields the skin.AcknowledgementThe authors wish to thank the management of Fekete Associate Inc. for permission to publish this paper. Helpful assistance from Mr. Garth Stotts is gratefully appreciated.NOMENCLATUREB g=Gas formation volume factor, m3/m3c g=Gas compressibility, kPa-1C=Wellbore storage constant for rising liquidlevel (oil or water), 1,000V u / (ρg), m3/kPa g=Acceleration due to gravity, 9.80665 m/s2h=Net pay thickness, mk=Permeability, mDIDER=Impulse derivative, defined in Equation 7,kPa-hr (liquid), and in Equation 8,(kPa)3-hr/(µPa.s)2 (gas)p i=Initial reservoir pressure, kPap w=Pressure at wellbore, kPap w0=Initial cushion pressure or wellbore pressureat time ∆t = 0, kPaq g=Rate of gas influx into wellbore, 103m3/d4q l=Rate of liquid influx into wellbore, m3/ds=Skin factor∆t=Time since beginning of fluid influx, hr∆t a=Pseudo-time since beginning of fluid influx,hr-kPa/µPa.sV u=Wellbore volume per unit length (wellborecapacity), m3/mV w=Wellbore (chamber) volume, m3ψw=Pseudo-pressure at wellbore, (kPa)2/µPa.s ψw0=Initial cushion pseudo-pressure or wellborepseudo - pressure at time ∆t a = 0,(kPa)2/µPa.sψi=Initial reservoir pseudo - pressure,kPa2/µPa.sφ=Porosity, fractionµ=Liquid viscosity, mPa.sρ=Liquid density, kg/m3 REFERENCES1.HAWKWES, R.V., and DAKHLIA, H., FieldObservations of Perforation Inflow Diagnostic (PID)Testing of Shallow Low-Permeability Gas Wells; Paper2004-282 presented at CIPC, Calgary, A B, June 8-10,2004.2.RAMEY, H.J., JR., and AGARWAL, R.G., AnnulusUnloading Rates as Influenced by Wellbore Storage andSkin Effect; SPEJ, pp. 453-462, October 1972.3.RAMEY, H.J., JR., AGARWAL, R.G., and MARTIN,I., Analysis of ‘Slug Test’ or DST Flow Period Data;Journal of Canadian Petroleum Technology, pp. 37-47,July-September 1975.4.KUCHUK, F.J., A New Method for Determination ofReservoir Pressure; Paper SPE 56418 presented at SPEATCE, Houston, TX, October 5-8, 1999.5.RAHMAN, N.M.A., POOLADI-DARVISH, M., andMATTAR, L., Development of Equations andProcedure for Perforation Inflow Test Analysis; PaperSPE 95510 to be presented at SPE ATCE, Dallas, TX,October 9-12, 2005.6.RAHMAN, N.M.A., MATTAR, L., and ZAORAL, K.,A New Method for Computing Pseudo-Time for RealGas Flow Using the Material Balance Equation; Paper2004-182 presented at CIPC, Calgary, A B, June 8-10,2004.7.CINCO-LEY, H., KUCHUK, F.J., AYOUB, J.A.,SAMANIEGO-V., F. and AYESTARAN, L., Analysisof Pressure Tests through the Use of InstantaneousSource Response Concepts; Paper SPE 15476 presentedat SPE ATCE, New Orleans, LA, October 5-8, 1986.5Type of FluidInfluxDerivative Analysis Late-Time Data Analysis Early-Time Data AnalysisWater/Oil•Basis: Equation 7•Plot log [impulsederivative] versus log[time] for the entiredata•Data on the zero-slopeline represents thereservoir-dominatedflow – use this tocalculate p i and k [Late-Time Data Analysis]•Data on the early-timeline with slope 2represents theafterflow-dominatedflow – use this tocalculate s [Early-TimeData Analysis]•Basis: Equation 2•Select an appropriaterange of data fromthe DerivativeAnalysis• Plot p w versus 1/∆t asa straight line• Estimate p i from theintercept at 1/∆t = 0•Use slope of the lineto estimate k•Basis: Equation 1•Select an appropriaterange of data fromthe DerivativeAnalysis• Plot p w versus∆t as astraight line with p w0as an anchor point• Estimate s from theslope of the line,using the alreadyestimated values of p iand k.Gas•Basis: Equation 8•Convert the raw data topseudo-variables•Plot in log-log scales ofthe impulse derivativeversus pseudo-time forthe entire data•Data on the zero-slopeline represents thereservoir-dominatedflow – use this tocalculate p i (from ψi)and k [Late-Time DataAnalysis]•Data on the early-timeline with slope 2represents theafterflow-dominatedflow – use this tocalculate s [Early-TimeData Analysis]•Basis: Equation 4•Select an appropriaterange of data fromthe DerivativeAnalysis• Plot ψw versus 1/∆t aas a straight line• Estimate ψi from theintercept at 1/∆t a = 0• Convert ψi to p i•Use slope of the lineto estimate k•Basis: Equation 3•Select an appropriaterange of data fromthe DerivativeAnalysis• Plotψw versus∆t a asa straight line withψw0 as an anchorpoint• Estimate s from theslope of the line,using the alreadyestimated values of ψiand k.TABLE 1: Summary of data-analysis procedures for liquid and gas influxes.6Permeability, k, mD1Initial reservoir pressure, p i, kPa6,000Initial cushion pressure, p w0, kPa4,000Total system compressibility, c t, kPa-1 4.5e-7Viscosity, µ, mPa.s0.553Net pay thickness, h, m10Porosity, φ, fraction0.2Wellbore capacity, V u, m3/m0.002Skin, s+6TABLE 2: Input parameters to generate the synthetic data for Example 1.Permeability, k, mD110Initial reservoir pressure, p i, kPa9,700Initial cushion pressure, p w0, kPa6,200Total system compressibility, c t, kPa-18.0e-7Viscosity, µ, mPa.s0.553Net pay thickness, h, m18Porosity, φ, fraction0.2Wellbore capacity, V u, m3/m0.026Skin, s+12TABLE 3: Input parameters to generate the synthetic data for Example 2.Figure 1: Typical pressure and calculated rate profiles in a per foration test.7Figure 2: Impulse derivative contrasting the wellbore-and reservoir-dominated flow.8Figure 4: Early-time data analysis for estimating skin.9Figure 6: Late-time data analysis for estimating reservoir pressure and permeab i lity.Figure 7: Early-time analysis for estimating skin.10。
如何使用TestStand进行测试结果分析与报告生成

如何使用TestStand进行测试结果分析与报告生成使用TestStand进行测试结果分析与报告生成TestStand是由National Instruments(NI)开发的一款用于自动化测试的软件平台。
它提供了一个集成环境,能够帮助工程师进行自动化测试流程的管理、执行、结果分析和报告生成。
本文将介绍如何使用TestStand进行测试结果分析与报告生成的步骤。
一、测试结果分析在测试完成后,通过TestStand可以方便地对测试结果进行分析。
以下是使用TestStand进行测试结果分析的步骤:1. 打开TestStand软件并加载测试序列。
2. 选择要分析的测试结果,并将其导入到TestStand的结果查看器中。
3. 在结果查看器中,可以对测试结果进行筛选、排序、过滤、标记等操作,以便更好地分析测试数据。
通过TestStand的结果查看器,用户可以方便地查看每个测试步骤的执行结果、记录错误信息、分析测试结果的趋势等。
此外,还可以根据需要自定义结果查看器的显示格式,以满足特定的分析需求。
二、报告生成生成测试报告是测试工程师工作的重要部分。
TestStand提供了丰富的报告生成功能,以下是使用TestStand生成测试报告的步骤:1. 在TestStand中选择要生成报告的测试序列。
2. 配置报告生成的格式和样式,包括报告的封面、页眉、页脚、表格格式、图表样式等。
3. 导入需要包含在报告中的测试结果和数据。
4. 运行报告生成器,即可生成测试报告。
TestStand的报告生成器支持多种输出格式,包括HTML、PDF、Word、Excel等。
用户可以根据需要选择合适的输出格式,并通过自定义模板来定制报告的外观和布局。
三、自定义分析和报告功能除了基本的结果分析和报告生成功能外,TestStand还提供了一系列的扩展功能,可以帮助用户进行更深入的数据分析和报告定制。
以下是几个示例:1. 脚本和插件:TestStand支持用户编写自定义的脚本和插件,以实现特定的数据分析和处理功能。
统计学术语中英对照

统计学术语中英对照部门: xxx时间: xxx整理范文,仅供参考,可下载自行编辑population 母体sample 样本census 普查sampling 抽样quantitative 量的qualitative/categorical 质的discrete 离散的continuous 连续的population parameters 母体参数sample statistics 样本统计量descriptive statistics 叙述统计学inferential/inductive statistics 推论 ...抽样调查<sampliing survey单纯随机抽样<simple random sampling系统抽样<systematic sampling分层抽样<stratified sampling整群抽样<cluster sampling多级抽样<multistage sampling常态分配(Parametric Statistics>无母数统计学(Nonparametric Statistics>实验设计(Design of Experiment>参数(Parameter>Data analysis 资料分析Statistical table 统计表Statistical chart 统计图Pie chart 圆饼图Stem-and-leaf display 茎叶图Box plot 盒须图Histogram 直方图Bar Chart 长条图Polygon 次数多边图Ogive 肩形图Descriptive statistics 叙述统计学Expectation 期望值Mode 众数Mean 平均数Variance 变异数Standard deviation 标准差Standard error 标准误Covariance matrix 共变异数矩阵Inferential statistics 推论统计学Point estimation 点估计Interval estimation 区间估计Confidence interval 信赖区间Confidence coefficient 信赖系数Testing statistical hypothesis 统计假设检定Regression analysis 回归分析Analysis of variance 变异数分析Correlation coefficient 相关系数Sampling survey 抽样调查Census 普查Sampling 抽样Reliability 信度Validity 效度Sampling error 抽样误差Non-sampling error 非抽样误差Random sampling 随机抽样Simple random sampling 简单随机抽样法Stratified sampling 分层抽样法Cluster sampling 群集抽样法Systematic sampling 系统抽样法Two-stage random sampling 两段随机抽样法Convenience sampling 便利抽样Quota sampling 配额抽样Snowball sampling 雪球抽样Nonparametric statistics 无母数统计The sign test 等级检定Wilcoxon signed rank tests 魏克森讯号等级检定Wilcoxon rank sum tests 魏克森等级和检定Run test 连检定法Discrete uniform densities 离散的均匀密度Binomial densities 二项密度Hypergeometric densities 超几何密度Poisson densities 卜松密度Geometric densities 几何密度Negative binomial densities 负二项密度Continuous uniform densities 连续均匀密度Normal densities 常态密度Exponential densities 指数密度Gamma densities 伽玛密度Beta densities 贝他密度Multivariate analysis 多变量分析Principal components 主因子分析Discrimination analysis 区别分析Cluster analysis 群集分析Factor analysis 因素分析Survival analysis 存活分析Time series analysis 时间序列分析Linear models 线性模式Quality engineering 品质工程Probability theory 机率论Statistical computing 统计计算Statistical inference 统计推论Stochastic processes 随机过程Decision theory 决策理论Discrete analysis 离散分析Mathematical statistics 数理统计统计学 : Statistics母体 : Population样本 : Sample资料分析 : Data analysis统计表 : Statistical table统计图 : Statistical chart圆饼图 : Pie chart茎叶图 : Stem-and-leaf display盒须图 : Box plot直方图 : Histogram长条图 : Bar Chart次数多边图 : Polygon肩形图 : Ogive叙述统计学 : Descriptive statistics期望值 : Expectation众数 : Mode平均数 : Mean变异数 : Variance标准差 : Standard deviation标准误 : Standard error共变异数矩阵 : Covariance matrix推论统计学 : Inferential statistics点估计 : Point estimation区间估计 : Interval estimation信赖区间 : Confidence interval信赖系数 : Confidence coefficient统计假设检定 : Testing statistical hypothesis回归分析 : Regression analysis变异数分析 : Analysis of variance相关系数 : Correlation coefficient抽样调查 : Sampling survey普查 : Census抽样 : Sampling信度 : Reliability效度 : Validity抽样误差 : Sampling error非抽样误差 : Non-sampling error随机抽样 : Random sampling简单随机抽样法 : Simple random sampling分层抽样法 : Stratified sampling群集抽样法 : Cluster sampling系统抽样法 : Systematic sampling两段随机抽样法 : Two-stage random sampling便利抽样 : Convenience sampling配额抽样 : Quota sampling雪球抽样 : Snowball sampling无母数统计 : Nonparametric statistics等级检定 : The sign test魏克森讯号等级检定 : Wilcoxon signed rank tests魏克森等级和检定 : Wilcoxon rank sum tests连检定法 : Run test离散的均匀密度 : Discrete uniform densities二项密度 : Binomial densities超几何密度 : Hypergeometric densities卜松密度 : Poisson densities几何密度 : Geometric densities负二项密度 : Negative binomial densities连续均匀密度 : Continuous uniform densities常态密度 : Normal densities指数密度 : Exponential densities伽玛密度 : Gamma densities贝他密度 : Beta densities多变量分析 : Multivariate analysis主因子分析 : Principal components区别分析 : Discrimination analysis群集分析 : Cluster analysis因素分析 : Factor analysis存活分析 : Survival analysis时间序列分析 : Time series analysis线性模式 : Linear models品质工程 : Quality engineering机率论 : Probability theory统计计算 : Statistical computing统计推论 : Statistical inference随机过程 : Stochastic processes决策理论 : Decision theory离散分析 : Discrete analysis数理统计 : Mathematical statistics统计名词市调辞典众数(Mode> 普查(census>指数(Index> 问卷(Questionnaire>中位数(Median> 信度(Reliability>百分比(Percentage> 母群体(Population> 信赖水准(Confidence level> 观察法(Observational Survey> 假设检定(Hypothesis Testing> 综合法(Integrated Survey> 卡方检定(Chi-square Test> 雪球抽样(Snowball Sampling> 差距量表(Interval Scale> 序列偏差(Series Bias> 类别量表(Nominal Scale> 次级资料(Secondary Data> 顺序量表(Ordinal Scale> 抽样架构(Sampling frame> 比率量表(Ratio Scale> 集群抽样(Cluster Sampling>连检定法(Run Test> 便利抽样(Convenience Sampling> 符号检定(Sign Test> 抽样调查(Sampling Sur>算术平均数(Arithmetic Mean> 非抽样误差(non-sampling error> 展示会法(Display Survey> 调查名词准确效度(Criterion-Related Validity> 元素(Element> 邮寄问卷法(Mail Interview> 样本(Sample> 信抽样误差(Sampling error> 效度(Validity> 封闭式问题(Close Question>精确度(Precision> 电话访问法(Telephone Interview> 准确度(Validity> 随机抽样法(Random Sampling> 实验法(Experiment Survey>抽样单位(Sampling unit> 资讯名词市场调查(Marketing Research> 决策树(Decision Trees>容忍误差(Tolerated erro> 资料采矿(Data Mining>初级资料(Primary Data> 时间序列(Time-Series Forecasting>目标母体(Target Population> 回归分析(Regression>抽样偏差(Sampling Bias> 趋势分析(Trend Analysis>抽样误差(sampling error> 罗吉斯回归(Logistic Regression>架构效度(Construct Validity> 类神经网络(Neural Network>配额抽样(Quota Sampling> 无母数统计检定方法(Non-Parametric Test>人员访问法(Interview> 判别分析法(Discriminant Analysis>集群分析法(cluster analysis> 规则归纳法(Rules Induction>内容效度(Content Validity> 判断抽样(Judgment Sampling>开放式问题(Open Question> OLAP(Online Analytical Process>分层随机抽样(Stratified Random sampling> 资料仓储(Data Warehouse>非随机抽样法(Nonrandom Sampling> 知识发现(Knowledge DiscoveryAbsolute deviation, 绝对离差Absolute number, 绝对数Absolute residuals, 绝对残差Acceleration array, 加速度立体阵Acceleration in an arbitrary direction, 任意方向上的加速度Acceleration normal, 法向加速度Acceleration space dimension, 加速度空间的维数Acceleration tangential, 切向加速度Acceleration vector, 加速度向量Acceptable hypothesis, 可接受假设Accumulation, 累积Accuracy, 准确度Actual frequency, 实际频数Adaptive estimator, 自适应估计量Addition, 相加Addition theorem, 加法定理Additive Noise, 加性噪声Additivity, 可加性Adjusted rate, 调整率Adjusted value, 校正值Admissible error, 容许误差Aggregation, 聚集性Alpha factoring,α因子法Alternative hypothesis, 备择假设Among groups, 组间Amounts, 总量Analysis of correlation, 相关分析Analysis of covariance, 协方差分析Analysis Of Effects, 效应分析Analysis Of Variance, 方差分析Analysis of regression, 回归分析Analysis of time series, 时间序列分析Analysis of variance, 方差分析Angular transformation, 角转换ANOVA <analysis of variance), 方差分析ANOVA Models, 方差分析模型ANOVA table and eta, 分组计算方差分析Arcing, 弧/弧旋Arcsine transformation, 反正弦变换Area 区域图Area under the curve, 曲线面积AREG , 评估从一个时间点到下一个时间点回归相关时的误差ARIMA, 季节和非季节性单变量模型的极大似然估计Arithmetic grid paper, 算术格纸Arithmetic mean, 算术平均数Arrhenius relation, 艾恩尼斯关系Assessing fit, 拟合的评估Associative laws, 结合律Asymmetric distribution, 非对称分布Asymptotic bias, 渐近偏倚Asymptotic efficiency, 渐近效率Asymptotic variance, 渐近方差Attributable risk, 归因危险度Attribute data, 属性资料Attribution, 属性Autocorrelation, 自相关Autocorrelation of residuals, 残差的自相关Average, 平均数Average confidence interval length, 平均置信区间长度Average growth rate, 平均增长率Bar chart, 条形图Bar graph, 条形图Base period, 基期Bayes' theorem , Bayes定理Bell-shaped curve, 钟形曲线Bernoulli distribution, 伯努力分布Best-trim estimator, 最好切尾估计量Bias, 偏性Binary logistic regression, 二元逻辑斯蒂回归Binomial distribution, 二项分布Bisquare, 双平方Bivariate Correlate, 二变量相关Bivariate normal distribution, 双变量正态分布Bivariate normal population, 双变量正态总体Biweight interval, 双权区间Biweight M-estimator, 双权M估计量Block, 区组/配伍组BMDP(Biomedical computer programs>, BMDP统计软件包Boxplots, 箱线图/箱尾图Breakdown bound, 崩溃界/崩溃点Canonical correlation, 典型相关Caption, 纵标目Case-control study, 病例对照研究Categoricalvariable, 分类变量Catenary, 悬链线Cauchy distribution, 柯西分布Cause-and-effect relationship, 因果关系Cell, 单元Censoring, 终检Center of symmetry, 对称中心Centering and scaling, 中心化和定标Centraltendency, 集中趋势Central value, 中心值CHAID -χ2 Automatic Interaction Detector, 卡方自动交互检测Chance, 机遇Chance error, 随机误差Chance variable, 随机变量Characteristic equation, 特征方程Characteristic root, 特征根Characteristic vector, 特征向量Chebshev criterion of fit, 拟合的切比雪夫准则Chernoff faces, 切尔诺夫脸谱图Chi-square test, 卡方检验/χ2检验Choleskey decomposition, 乔洛斯基分解Circle chart, 圆图Class interval, 组距Class mid-value, 组中值Class upper limit, 组上限Classified variable, 分类变量Cluster analysis, 聚类分析Cluster sampling, 整群抽样Code, 代码Coded data, 编码数据Coding, 编码Coefficient of contingency, 列联系数Coefficient of determination, 决定系数Coefficient of multiple correlation, 多重相关系数Coefficient of partial correlation, 偏相关系数Coefficient of production-moment correlation, 积差相关系数b5E2RGbCAP Coefficient of rank correlation, 等级相关系数Coefficient of regression, 回归系数Coefficient of skewness, 偏度系数Coefficient of variation, 变异系数Cohort study, 队列研究Collinearity, 共线性Column, 列Column effect, 列效应Column factor, 列因素Combination pool, 合并Combinative table, 组合表Common factor, 共性因子Common regression coefficient, 公共回归系数Common value, 共同值Common variance, 公共方差Common variation, 公共变异Communality variance, 共性方差Comparability, 可比性Comparison of bathes, 批比较Comparison value, 比较值Compartment model, 分部模型Compassion, 伸缩Complement of an event, 补事件Complete association, 完全正相关Complete dissociation, 完全不相关Complete statistics, 完备统计量Completely randomized design, 完全随机化设计Composite event, 联合事件Composite events, 复合事件Concavity, 凹性Conditional expectation, 条件期望Conditional likelihood, 条件似然Conditional probability, 条件概率Conditionally linear, 依条件线性Confidence interval, 置信区间Confidence limit, 置信限Confidence lower limit, 置信下限Confidence upper limit, 置信上限Confirmatory Factor Analysis , 验证性因子分析Confirmatory research, 证实性实验研究Confounding factor, 混杂因素Conjoint, 联合分析Consistency, 相合性Consistency check, 一致性检验Consistent asymptotically normal estimate, 相合渐近正态估计p1EanqFDPw Consistent estimate, 相合估计Constrained nonlinear regression, 受约束非线性回归Constraint, 约束Contaminated distribution, 污染分布Contaminated Gausssian, 污染高斯分布Contaminated normal distribution, 污染正态分布Contamination, 污染Contamination model, 污染模型Contingency table, 列联表Contour, 边界线Contribution rate, 贡献率Control, 对照, 质量控制图Controlled experiments, 对照实验Conventional depth, 常规深度Convolution, 卷积Corrected factor, 校正因子Corrected mean, 校正均值Correction coefficient, 校正系数Correctness, 正确性Correlation coefficient, 相关系数Correlation, 相关性Correlation index, 相关指数Correspondence, 对应Counting, 计数Counts, 计数/频数Covariance, 协方差Covariant, 共变Cox Regression, Cox回归Criteria for fitting, 拟合准则Criteria of least squares, 最小二乘准则Critical ratio, 临界比Critical region, 拒绝域Critical value, 临界值Cross-over design, 交叉设计Cross-section analysis, 横断面分析Cross-section survey, 横断面调查Crosstabs , 交叉表Crosstabs 列联表分析Cross-tabulation table, 复合表Cube root, 立方根Cumulative distribution function, 分布函数Cumulative probability, 累计概率Curvature, 曲率/弯曲Curvature, 曲率Curve Estimation, 曲线拟合Curve fit , 曲线拟和Curve fitting, 曲线拟合Curvilinear regression, 曲线回归Curvilinear relation, 曲线关系Cut-and-try method, 尝试法Cycle, 周期Cyclist, 周期性D test, D检验Data acquisition, 资料收集Data bank, 数据库Data capacity, 数据容量Data deficiencies, 数据缺乏Data handling, 数据处理Data manipulation, 数据处理Data processing, 数据处理Data reduction, 数据缩减Data set, 数据集Data sources, 数据来源Data transformation, 数据变换Data validity, 数据有效性Data-in, 数据输入Data-out, 数据输出Dead time, 停滞期Degree of freedom, 自由度Degree of precision, 精密度Degree of reliability, 可靠性程度Degression, 递减Density function, 密度函数Density of data points, 数据点的密度Dependent variable, 应变量/依变量/因变量Dependent variable, 因变量Depth, 深度Derivative matrix, 导数矩阵Derivative-free methods, 无导数方法Design, 设计Determinacy, 确定性Determinant, 行列式Determinant, 决定因素Deviation, 离差Deviation from average, 离均差Diagnostic plot, 诊断图Dichotomous variable, 二分变量Differential equation, 微分方程Direct standardization, 直接标准化法Direct Oblimin, 斜交旋转Discrete variable, 离散型变量DISCRIMINANT, 判断Discriminant analysis, 判别分析Discriminant coefficient, 判别系数Discriminant function, 判别值Dispersion, 散布/分散度Disproportional, 不成比例的Disproportionate sub-class numbers, 不成比例次级组含量Distribution free, 分布无关性/免分布Distribution shape, 分布形状Distribution-free method, 任意分布法Distributive laws, 分配律Disturbance, 随机扰动项Dose response curve, 剂量反应曲线Double blind method, 双盲法Double blind trial, 双盲实验Double exponential distribution, 双指数分布Double logarithmic, 双对数Downward rank, 降秩Dual-space plot, 对偶空间图DUD, 无导数方法Duncan's new multiple range method, 新复极差法/Duncan新法Error Bar, 均值相关区间图Effect, 实验效应Eigenvalue, 特征值Eigenvector, 特征向量Ellipse, 椭圆Empirical distribution, 经验分布Empirical probability, 经验概率单位Enumeration data, 计数资料Equal sun-class number, 相等次级组含量Equally likely, 等可能Equivariance, 同变性Error, 误差/错误Error of estimate, 估计误差Error type I, 第一类错误Error type II, 第二类错误Estimand, 被估量Estimated error mean squares, 估计误差均方Estimated error sum of squares, 估计误差平方和Euclidean distance, 欧式距离Event, 事件Event, 事件Exceptional data point, 异常数据点Expectation plane, 期望平面Expectation surface, 期望曲面Expected values, 期望值Experiment, 实验Experimental sampling, 实验抽样Experimental unit, 实验单位Explained variance <已说明方差)Explanatory variable, 说明变量Exploratory data analysis, 探索性数据分析Explore Summarize, 探索-摘要Exponential curve, 指数曲线Exponential growth, 指数式增长EXSMOOTH, 指数平滑方法Extended fit, 扩充拟合Extra parameter, 附加参数Extrapolation, 外推法Extreme observation, 末端观测值Extremes, 极端值/极值F distribution, F分布F test, F检验Factor, 因素/因子Factor analysis, 因子分析Factor Analysis, 因子分析Factor score, 因子得分Factorial, 阶乘Factorial design, 析因实验设计False negative, 假阴性False negative error, 假阴性错误Family of distributions, 分布族Family of estimators, 估计量族Fanning, 扇面Fatality rate, 病死率Field investigation, 现场调查Field survey, 现场调查Finitepopulation, 有限总体Finite-sample, 有限样本First derivative, 一阶导数First principal component, 第一主成分First quartile, 第一四分位数Fisher information, 费雪信息量Fitted value, 拟合值Fitting a curve, 曲线拟合Fixed base, 定基Fluctuation, 随机起伏Forecast, 预测Four fold table, 四格表Fourth, 四分点Fraction blow, 左侧比率Fractional error, 相对误差Frequency, 频率Frequency polygon, 频数多边图Frontier point, 界限点Function relationship, 泛函关系Gamma distribution, 伽玛分布Gauss increment, 高斯增量Gaussian distribution, 高斯分布/正态分布Gauss-Newton increment, 高斯-牛顿增量General census, 全面普查Generalized least squares, 综合最小平方法GENLOG (Generalized liner models>, 广义线性模型Geometric mean, 几何平均数Gini's mean difference, 基尼均差GLM (General liner models>, 通用线性模型Goodness of fit, 拟和优度/配合度Gradient of determinant, 行列式的梯度Graeco-Latin square, 希腊拉丁方Grand mean, 总均值Gross errors, 重大错误Gross-error sensitivity, 大错敏感度Group averages, 分组平均Grouped data, 分组资料Guessed mean, 假定平均数Half-life, 半衰期Hampel M-estimators, 汉佩尔M估计量Happenstance, 偶然事件Harmonic mean, 调和均数Hazard function, 风险均数Hazard rate, 风险率Heading, 标目Heavy-tailed distribution, 重尾分布Hessian array, 海森立体阵Heterogeneity, 不同质Heterogeneity of variance, 方差不齐Hierarchical classification, 组内分组Hierarchical clustering method, 系统聚类法High-leverage point, 高杠杆率点High-Low, 低区域图Higher Order Interaction Effects,高阶交互作用HILOGLINEAR, 多维列联表的层次对数线性模型Hinge, 折叶点Histogram, 直方图Historical cohort study, 历史性队列研究Holes, 空洞HOMALS, 多重响应分析Homogeneity of variance, 方差齐性Homogeneity test, 齐性检验Huber M-estimators, 休伯M估计量Hyperbola, 双曲线Hypothesis testing, 假设检验Hypothetical universe, 假设总体Image factoring,, 多元回归法Impossible event, 不可能事件Independence, 独立性Independent variable, 自变量Index, 指标/指数Indirect standardization, 间接标准化法Individual, 个体Inference band, 推断带Infinitepopulation, 无限总体Infinitely great, 无穷大Infinitely small, 无穷小Influence curve, 影响曲线Information capacity, 信息容量Initial condition, 初始条件Initial estimate, 初始估计值Initial level, 最初水平Interaction, 交互作用Interaction terms, 交互作用项Intercept, 截距Interpolation, 内插法Interquartile range, 四分位距Interval estimation, 区间估计Intervals of equal probability, 等概率区间Intrinsic curvature, 固有曲率Invariance, 不变性Inverse matrix, 逆矩阵Inverse probability, 逆概率Inverse sine transformation, 反正弦变换Iteration, 迭代Jacobian determinant, 雅可比行列式Joint distribution function, 分布函数Joint probability, 联合概率Joint probability distribution, 联合概率分布K-Means Cluster逐步聚类分析K means method, 逐步聚类法Kaplan-Meier, 评估事件的时间长度Kaplan-Merier chart, Kaplan-Merier图Kendall's rank correlation, Kendall等级相关Kinetic, 动力学Kolmogorov-Smirnove test, 柯尔莫哥洛夫-斯M尔诺夫检验Kruskal and Wallis test, Kruskal及Wallis检验/多样本的秩和检验/H检验DXDiTa9E3dKurtosis, 峰度Lack of fit, 失拟Ladder of powers, 幂阶梯Lag, 滞后Large sample, 大样本Large sample test, 大样本检验Latin square, 拉丁方Latin square design, 拉丁方设计Leakage, 泄漏Least favorable configuration, 最不利构形Least favorable distribution, 最不利分布Least significant difference, 最小显著差法Least square method, 最小二乘法Least Squared Criterion,最小二乘方准则Least-absolute-residuals estimates, 最小绝对残差估计Least-absolute-residuals fit, 最小绝对残差拟合Least-absolute-residuals line, 最小绝对残差线Legend, 图例L-estimator, L估计量L-estimator of location, 位置L估计量L-estimator of scale, 尺度L估计量Level, 水平Leveage Correction,杠杆率校正Life expectance, 预期期望寿命Life table, 寿命表Life table method, 生命表法Light-tailed distribution, 轻尾分布Likelihood function, 似然函数Likelihood ratio, 似然比line graph, 线图Linear correlation, 直线相关Linear equation, 线性方程Linear programming, 线性规划Linear regression, 直线回归Linear Regression, 线性回归Linear trend, 线性趋势Loading, 载荷Location and scale equivariance, 位置尺度同变性Location equivariance, 位置同变性Location invariance, 位置不变性Location scale family, 位置尺度族Log rank test, 时序检验Logarithmic curve, 对数曲线Logarithmic normal distribution, 对数正态分布Logarithmic scale, 对数尺度Logarithmic transformation, 对数变换Logic check, 逻辑检查Logistic distribution, 逻辑斯特分布Logit transformation, Logit转换LOGLINEAR, 多维列联表通用模型Lognormal distribution, 对数正态分布Lost function, 损失函数Low correlation, 低度相关Lower limit, 下限Lowest-attained variance, 最小可达方差LSD, 最小显著差法的简称Lurking variable, 潜在变量Main effect, 主效应Major heading, 主辞标目Marginal density function, 边缘密度函数。
统计学常用表格
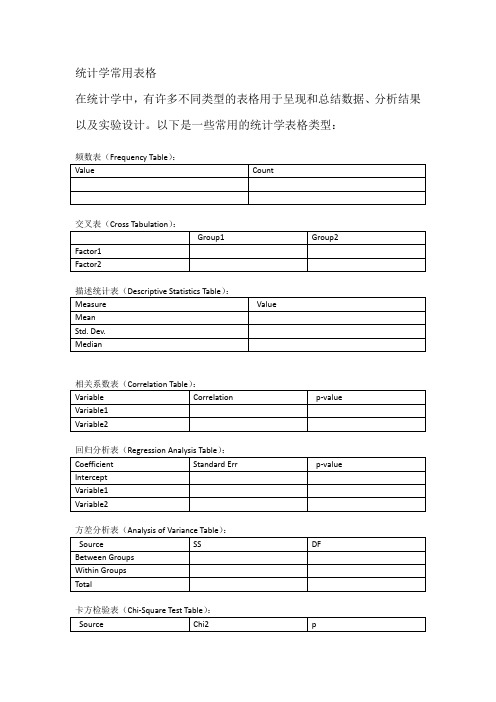
统计学常用表格在统计学中,有许多不同类型的表格用于呈现和总结数据、分析结果以及实验设计。
以下是一些常用的统计学表格类型:交叉表(Cross Tabulation):实验设计表(Experimental Design Table):说明:统计学表格类型:1.频数表(Frequency Table):描述变量各个取值的出现频率。
2.交叉表(Cross Tabulation):将两个或多个变量的频数列在一个表格中,用于观察它们之间的关系。
3.描述统计表(Descriptive Statistics Table):包括均值、中位数、标准差等描述性统计指标,用于概括数据分布的特征。
4.相关系数表(Correlation Table):展示变量之间的相关关系,通常包括皮尔逊相关系数或斯皮尔曼等级相关系数。
5.回归分析表(Regression Analysis Table):呈现回归模型的系数、标准误差、t统计量等信息。
6.方差分析表(Analysis of Variance Table):用于展示方差分析的结果,包括组间方差、组内方差、F统计量等。
7.卡方检验表(Chi-Square Test Table):展示卡方检验的结果,通常用于分析分类变量之间的关联。
8.生存分析表(Survival Analysis Table):包括生存曲线、中位生存时间等,用于描述时间至事件发生的分布。
9.混淆矩阵(Confusion Matrix):用于评估分类模型的性能,特别是在分类问题中。
10.ANOVA表(ANOVA Table):用于分析方差,通常与方差分析一起使用,包括平方和、自由度、均方等。
11.正态性检验表(Normality Test Table):用于检验数据是否符合正态分布。
12.实验设计表(Experimental Design Table):描述实验设计中的因子水平、处理组合以及实验结果。
全国英语等级考试三级考试真题及解析

全国英语等级考试三级考试真题及解析全文共3篇示例,供读者参考篇1The National English Proficiency Test (NEPT), also known as the National English Level Examination (NELE), is a standardized test for English language proficiency in China. It is divided into three levels: Level 1 (Elementary), Level 2 (Intermediate), and Level 3 (Advanced). In this document, we will focus on the Level 3 exam, which is considered the most challenging level.The Level 3 exam consists of four sections: Listening, Reading, Writing, and Speaking. Each section assesses different language skills and is designed to test the test taker's ability to understand and communicate effectively in English.Here are some sample questions and explanations for each section of the Level 3 exam:Listening Section:1. What is the main topic of the conversation?A. The weather forecast for tomorrowB. Plans for a weekend tripC. A discussion about a new restaurantD. Problems with public transportationAnswer: B. Plans for a weekend tripExplanation: In this conversation, the speakers are discussing their plans for a weekend trip, so the correct answer is B.Reading Section:2. According to the passage, what is the main cause of air pollution in cities?A. Industrial emissionsB. Vehicle exhaustC. Agricultural activitiesD. DeforestationAnswer: B. Vehicle exhaustExplanation: The passage discusses the main causes of air pollution in cities, with vehicle exhaust being identified as a significant contributor.Writing Section:3. Write a short paragraph about your favorite holiday destination and explain why you enjoy visiting it.Answer: (Sample answer) My favorite holiday destination is the beach because I love the sound of the waves and the feeling of the sand between my toes. I enjoy swimming in the ocean and relaxing under the warm sun. The beach is a place where I can unwind and recharge my batteries.Speaking Section:4. Describe a memorable event from your childhood.Answer: (Sample answer) One memorable event from my childhood was when I won first place in a storytelling competition at school. I was nervous at first, but once I started telling my story, I felt confident and proud of myself. It was a moment of triumph that I will never forget.Overall, the Level 3 exam is a comprehensive test of English proficiency that requires strong listening, reading, writing, and speaking skills. By practicing with sample questions like the ones provided above, test takers can prepare themselves for success on exam day. Good luck!篇2National English Proficiency Test Level Three Exam Questions and AnalysisIntroductionThe National English Proficiency Test (NEPT) is a standardized exam designed to assess individuals' English language skills. The exam is divided into four levels: Level One, Level Two, Level Three, and Level Four. Level Three is targeted towards intermediate learners who have a good understanding of basic grammar, vocabulary, and communication skills. In this article, we will provide a set of sample exam questions for the NEPT Level Three exam, along with detailed explanations and analysis.Exam FormatThe NEPT Level Three exam consists of four sections: Listening, Reading, Writing, and Speaking. Each section is designed to test a different set of language skills, and carries a different weightage in the overall score. The exam is timed, and candidates are required to complete each section within a specified time limit.Sample Questions and AnalysisListening SectionQuestion 1:Listen to the following conversation and answer the questions below:A: What time does the library close?B: It closes at 8 pm on weekdays, and at 5 pm on weekends.Question:What time does the library close on weekdays?Answer: The library closes at 8 pm on weekdays.Analysis:This question tests the candidate's ability to understand and extract information from a spoken conversation. It assesses listening skills, as well as the ability to comprehend and respond to questions based on the information provided.Reading SectionQuestion 2:Read the following passage and answer the questions below:"Climate change is a pressing issue that requires immediate action. Rising global temperatures are causing widespread environmental damage, leading to more frequent naturaldisasters and threatening ecosystems worldwide. It is crucial for governments and individuals to take proactive measures to mitigate the impact of climate change."Questions:1. What is the main topic of the passage?2. Why is it important to address climate change?Answers:1. The main topic of the passage is climate change.2. It is important to address climate change because rising temperatures are causing environmental damage and threatening ecosystems.Analysis:This question tests the candidate's reading comprehension skills, as well as the ability to identify the main idea and key details in a given passage. It also assesses the candidate's ability to draw connections between different pieces of information and synthesize them into a coherent response.Writing SectionQuestion 3:Write an essay of approximately 200 words on the following topic:"Describe a memorable travel experience you have had. Where did you go, and what made the trip special?"Analysis:This question tests the candidate's writing skills, as well as the ability to construct a coherent and well-structured essay. It assesses the candidate's ability to express ideas clearly and accurately, as well as their vocabulary and grammar skills. Candidates are expected to provide detailed descriptions and explanations to support their ideas.Speaking SectionQuestion 4:Describe the picture below and answer the following questions:Picture Description:The picture shows a group of people enjoying a picnic in a park on a sunny day. They are sitting on a picnic blanket, surrounded by trees and flowers. There are food and drinks laidout on the blanket, and everyone seems to be having a good time.Questions:1. What is happening in the picture?2. What do you think the people are doing?Analysis:This question tests the candidate's speaking skills, as well as the ability to describe visual information accurately and coherently. It assesses the candidate's vocabulary, pronunciation, and fluency in speaking. Candidates are expected to provide detailed descriptions and explanations, as well as respond to questions based on the information presented in the picture.ConclusionThe NEPT Level Three exam is designed to assess intermediate learners' English language skills in a variety of areas, including listening, reading, writing, and speaking. The exam questions are structured to test different language skills and abilities, and provide candidates with an opportunity to demonstrate their proficiency in English. By practicing sample exam questions and analyzing their answers, candidates canimprove their performance and achieve success in the NEPT Level Three exam.篇3National English Proficiency Test Level 3 Exam Questions and AnalysisThe National English Proficiency Test (NEPT) Level 3 is an important milestone for English learners in China. It tests the learners' ability in listening, speaking, reading, and writing, and passing this exam demonstrates a certain level of English proficiency. In this article, we will go through some sample questions from the NEPT Level 3 exam and provide detailed analysis and explanations for each question.Listening SectionQuestion 1:What does the speaker say about his trip to Beijing?A. He has never been to Beijing beforeB. He will go to Beijing next weekC. He is in Beijing right nowD. He went to Beijing last monthAnalysis:The correct answer is D. The speaker uses past tense verbs ("went," "visited") to indicate that the trip to Beijing has already happened.Question 2:What is the woman's occupation?A. A doctorB. A teacherC. A lawyerD. A chefAnalysis:The correct answer is A. The woman mentions that she works in a hospital and wears a white coat, which are typical characteristics of a doctor.Speaking SectionQuestion 3:Talk about your favorite movie and explain why you like it.Analysis:This is an open-ended question that requires the test-taker to speak about a personal experience. It is important to provide specific details about the movie and explain the reasons for liking it.Reading SectionQuestion 4:Choose the best title for the passage.A. How to Cook Healthy MealsB. The Benefits of ExerciseC. Tips for Weight LossD. The Importance of SleepAnalysis:The correct answer is A. The passage discusses different ways to prepare healthy meals, including using fresh ingredients, avoiding processed foods, and cooking at home.Writing SectionQuestion 5:Write an essay of at least 200 words on the topic "The Impact of Technology on Society."Analysis:In this essay, it is important to discuss both the positive and negative effects of technology on society. Examples of how technology has changed communication, education, and work can be included to support the arguments.In conclusion, the NEPT Level 3 exam covers a wide range of skills and topics related to the English language. By practicing sample questions and understanding the analysis and explanations, test-takers can improve their performance on the exam and demonstrate their English proficiency. Good luck to all the candidates preparing for the NEPT Level 3 exam!。
英语作文如何写试卷分析

英语作文如何写试卷分析Examining the English Test: A Deep Analysis.As an educator, it's crucial to regularly evaluate and analyze student performance to identify strengths, weaknesses, and areas for improvement. This article delves into the intricacies of conducting a thorough analysis of an English test, focusing on various aspects such as the quality of questions, student responses, and areas for further consideration.1. Overview of the Test.The first step in analyzing an English test is to understand its purpose and format. Was it a diagnostic test to assess students' baseline knowledge? Or was it a formative assessment to monitor progress throughout the term? The format, including the types of questions (multiple-choice, essay, cloze test, etc.), also provides valuable insights into the areas being tested.2. Evaluation of Questions.The quality of the questions is crucial in determining the validity and reliability of the test. Are the questions aligned with the course objectives and learning outcomes? Do they cover a range of topics and skills, including reading comprehension, vocabulary, grammar, and writing? Are the questions clear and unambiguous, or do they leave room for interpretation? Evaluating these aspects helps identify any gaps or biases in the test design.3. Analysis of Student Responses.Analyzing student responses provides a window intotheir understanding and application of English concepts. By examining patterns in their answers, teachers can identify common mistakes, misconceptions, and areas where further clarification is needed. For example, if students struggle with a particular grammar rule or vocabulary term, the teacher can adjust their teaching methods to focus on those areas.4. Identification of Strengths and Weaknesses.Analyzing student performance not only reveals areas of weakness but also highlights areas of strength. By identifying students' strengths, teachers can encourage them to build upon their existing knowledge and skills. Weaknesses, on the other hand, provide an opportunity for targeted intervention and additional support.5. Consideration for Future Tests.Finally, analyzing an English test should include consideration for future assessments. Based on the insights gained from the current test, teachers can make informed decisions about improving future tests. This might include adding or removing questions, adjusting the difficulty level, or introducing new types of questions to cover additional topics or skills.In conclusion, analyzing an English test is a crucial process that provides valuable insights into studentperformance and areas for improvement. By carefully evaluating the test's format, questions, and student responses, teachers can gain a deeper understanding oftheir students' needs and adjust their teaching methods accordingly. This iterative process of analysis and improvement is essential for ensuring that students receive the most effective and targeted instruction possible.。
成绩质量分析PPT模板全文

教师层面
Teachers test quality analysis
1 教育观念更新难
教育观念难以更新,在教学改革中,部分人自觉或不自觉地将新课程又引入了过去的老路。虽有些许变化,但变化 不大,不少教师对新课程改革的认识还不到位,影响改革进程。
2 教师能力需加强
第3节
暴露出的问题
考试组织层面
Teachers test quality analysis
个别老师工作责任不强,存在马虎和粗心现象
01
监考未认真组织好学 生。
02
登分过程中错漏现象 不减。
成绩层面
Teachers test quality analysis
成绩不均衡
班级学科成绩不均衡,掉队现象严重。
英语多方面练
倡导读英语,说英语,用英语,让学生在使用对话中掌握对话,不能仅满足于 学生会读,会背。
英语常规工作不足
加强英语读写的练习,多练习,多训练。本次考试反应出教学常规工作缺少实效。 各项常规工作还是不到位,问题还是很多,课堂上重知识的传授,轻能力的培 养,学生学习还是很被动,作业训练形式单调,基础知识联系较多,课外积累 与拓展训练较少,练习册辅导跟不上新课节奏,造成训练不全面,以至学生难 以适应那种注重能力考查的难题。
2. 完善质量分析制度,使分析成果落实到教师、学生的具体行动上。 继续降低工作重心,转变思想、改进工作方法。反思教 学、管理中存在的问题。进而提出解决问题的对策及建议。
3. 强化薄弱学科和年段教学,促进学科均衡发展,切实解决好存在问题。对成绩较差的学生多鼓励,多做思想工作,多进行分 层教学,抓基础为主。
今后教学建议
Teachers test quality analysis
python中analysis的用法

python中analysis的用法
Python中的analysis是一种数据分析工具,它能够帮助我们对数据进行探索和分析。
在Python中,我们可以使用pandas库来处理数据,并使用其内置的analysis功能来分析数据。
具体来说,我们可以使用以下方法:
1. describe()方法:该方法可以输出数据集的统计信息,包括均值、标准差、最小值、最大值等。
2. corr()方法:该方法可以计算数据集中各列之间的相关性系数,用于探索不同变量之间的关系。
3. value_counts()方法:该方法可以统计数据集中每个值的频率,用于分析数据的分布情况。
4. groupby()方法:该方法可以按照指定的列对数据集进行分组,并对每个组进行聚合操作,用于探索不同组之间的差异。
除了以上方法外,Python中还有许多其他的analysis工具,例如numpy库、matplotlib库等,它们能够帮助我们更加深入地理解和分析数据。
- 1 -。
analysis的动词形式

analysis的动词形式【最新版】目录1.分析动词形式的重要性2.analysis 的动词形式的构成3.如何使用 analysis 的动词形式4.使用 analysis 的动词形式的实例正文一、分析动词形式的重要性动词形式是英语语法中的重要组成部分,它能够清晰地表达动作发生的时间、方式以及主语与动词之间的关系。
对于学习英语的人来说,掌握动词形式是提高英语水平的关键。
analysis 作为英语中一个常用的词汇,了解其动词形式对于提高英语表达能力具有重要意义。
二、analysis 的动词形式的构成analysis 是一个名词,表示“分析”。
要将其转换为动词形式,需要在词尾添加后缀“-ze”。
因此,analysis 的动词形式为“analyses”(第三人称单数形式)和“analyzing”(现在分词形式)。
此外,还可以构成过去式(analyzed)和过去分词(analyzed)等形式。
三、如何使用 analysis 的动词形式1.第三人称单数形式:当表示第三人称单数时,使用“analyses”。
例如:He analyzes the data carefully.(他认真地分析数据。
)2.现在分词形式:在使用现在分词形式时,表示动作正在进行。
例如:I am analyzing the results of the experiment.(我正在分析实验结果。
)3.过去式和过去分词形式:表示过去发生的动作时,使用过去式(analyzed);表示被动语态时,使用过去分词(analyzed)。
例如:The data was analyzed by the computer.(数据被计算机分析了。
)四、使用 analysis 的动词形式的实例1.She analyzes complex problems easily.(她轻易地分析复杂问题。
)2.The computer program analyzes the information quickly.(计算机程序快速地分析信息。
学生英语试卷分析及今后计划

学生英语试卷分析及今后计划Students' English Test Paper Analysis and Future Plans。
English language proficiency is a crucial skill for students worldwide, serving as a gateway to academic success and global communication. Therefore, analyzing students' English test papers provides valuable insights into their strengths, weaknesses, and areas for improvement. In this document, we will delve into the analysis of a typical English test paper, highlighting common trends and suggesting future plans to enhance students' language proficiency.Analysis of English Test Paper:。
1. Reading Comprehension:。
Reading comprehension is a fundamental skill assessed in English tests. Analysis of test papers often reveals varying levels of proficiency in understanding written texts. Some students demonstrate strong comprehension skills by accurately identifying main ideas, supporting details, and implied meanings. However, others struggle with comprehension, often due to limited vocabulary or lack of reading practice. 。
试卷指标分析课件PPT模板试卷分析

分析结果的解读
试题实例
选项 难度 区分度
A B C D E
单选1
1.00 0.00 0.0 0.0 100.0* 0..0 0.0
单选2
0.07 0.16 7.5* 1.5 1.5 25.4 64.2
单选3
0.56 0.35 3.2 12.9 56.5* 1.6 25.8
分析结果的解读
题量偏少
题量偏少,试卷覆盖面 小考试不足以反映学生 对知识的掌握情况;试 题太难或者太容易,导 致优生和差生都不能或 者都能正确回答;试题 区分度太差足以区分不 同水平的学生学生作弊 考试评卷给分尺度不一
如结合定量分析数据结果对不同专业考生具体差异,考生在学习中普遍存 在的问题,教学中的薄弱环节等进行分析。另外,对试卷命题质量中比如 题目表述是否科学、文字表述是否正确以及阅卷情况等直接进行定性分析
试卷分析的方法
分析的主体
综合分析是试卷分析的主体,定量分析只能 为综合分析提供辅助的参考依据。脱离定量 分析过程的综合分析是片面的,没有综合分 析的定量分析是教条的。
提高质量的措施
标准差和极值
制定命题双向细目表命题双向细目表是一门课程教学内容和掌握层次两个维度下的一 种考试命题抽样方案,它命题人员着手命题、审题制卷和作效度验证的一个根本依据。
试题中教学大纲 要求的比例关系: 熟悉 :掌握 :了解 50 : 30 : 20
试题与认知分级的比例关系: 年 级 回忆 :解释 :问题解决
项目 分值 评分
语言 表述
5
考点 广度
5
教学 重点
5
题型 题量
5
试题 难度
5
合计 25
提高质量的措施
信息的利用
text analysis tool使用

text analysis tool使用Text Analysis Tool(文本分析工具)是一种能够对文本进行自动分析和处理的软件或在线服务。
它通过使用自然语言处理(NLP)和机器学习技术,能够帮助用户从大量的文本中提取有用的信息,进行情感分析、关键词提取、实体识别、主题分类、文本摘要和机器翻译等任务。
文本分析工具可以进行情感分析。
情感分析是通过分析文本中的情感倾向来判断文本的情感极性,通常分为正面、负面和中性三种情感。
例如,我们可以通过文本分析工具来分析用户在社交媒体上发表的评论,判断用户对某个产品或事件的态度是正面还是负面,从而为企业或机构提供决策参考。
文本分析工具可以进行关键词提取。
关键词提取是从文本中自动识别和提取出具有代表性的词语或短语。
这对于文本的分类、搜索和总结非常有用。
例如,在新闻报道中,我们可以使用文本分析工具自动提取出与某个特定话题相关的关键词,以便更好地理解新闻事件的主要内容。
文本分析工具还可以进行实体识别。
实体识别是指从文本中识别出具有特定意义的实体,如人物、地点、组织机构、时间等。
通过实体识别,我们可以从大量的文本数据中提取出关键的信息,帮助我们更好地理解文本的含义和上下文。
例如,在金融领域,我们可以使用文本分析工具自动识别出公司名称、股票代码和财务数据,以便进行投资分析和决策。
文本分析工具还可以进行主题分类。
主题分类是将文本分为不同的主题或类别,以便更好地组织和管理文本数据。
例如,在社交媒体上对用户的帖子进行主题分类,可以帮助我们快速了解用户的兴趣和需求,从而提供更好的个性化推荐服务。
文本分析工具还可以进行文本摘要。
文本摘要是将文本内容进行压缩和概括,提取出文本的关键信息和要点。
通过文本摘要,我们可以快速了解一篇文档或文章的主要内容,从而节省时间和精力。
例如,在新闻报道中,我们可以使用文本分析工具自动生成新闻摘要,方便读者快速浏览和了解新闻事件的要点。
文本分析工具还可以进行机器翻译。
英语成绩分析范文六篇

英语成绩分析范文六篇1. Analysis of My English Exam ResultsI recently received my English exam results, and I am pleased to say that I achieved a respectable grade. However, I also know that there is room for improvement, and I would like to take a moment to analyze my results and identify areas that require further attention.Overall, I am happy with my performance in the reading and writing sections of the exam. I received a high score for my comprehension and critical analysis skills, which suggests that I have a strong grasp of the English language and can interact with complex texts effectively. However, the grammar and spelling sections revealed weaknesses in my skills. I made a few careless errors and struggled with some of the more advanced grammar rules. This tells me that I need to focus on developing my attention to detail and honing my grammar knowledge in the future.Furthermore, the speaking and listening components were a mixed bag. While I scored well in some areas, I struggled with others. For example, I need to work on improving my pronunciation and listening skills, as I found it difficult to understand some of the questions posed to me, and my responses were not always clear. On the other hand, I received high marks for my ability to express my opinions and ideas in a clear and coherent manner, which is encouraging.Overall, I believe that my English exam results reflect my progress to date, but they also indicate areas that require more effort andattention. Moving forward, I plan to work on improving my grammar and spelling, as well as my oral communication skills, so that I can continue to develop my English proficiency.2. A Deeper Analysis of My English Test ResultsTaking English tests is always a bit nerve-wracking. You never know exactly what to expect, and sometimes, you can be surprised by the results. This was the case for me when I recently received my English test results. While I was happy to see that I had passed, upon closer inspection, I realized that there was room for improvement.The listening and speaking portions of the test were quite challenging for me. I found it difficult to understand some of the audio recordings, and I also struggled to articulate my thoughts clearly during the speaking portion of the test. This tells me that I need to work on improving my listening and speaking skills. While I have a decent vocabulary and grammatical knowledge, if I cannot communicate my ideas effectively, then my English proficiency is limited.On the other hand, I was pleased to see that I performed well in the reading and writing sections of the test. I demonstrated a strong ability to analyze and interpret texts, and my writing was clear and concise. That being said, there were still some errors that I made in terms of grammar and style, which suggests that I need to continue working on these skills.Overall, while I am content with my performance on the Englishtest, I recognize that there are areas where I need to improve. I plan to focus on my listening and speaking skills, as well as honing my grammar and style, so that I can become a more confident and proficient English speaker.3. An Analysis of My English Language Proficiency Test ResultsI recently took an English Language Proficiency test to assess my ability in the language. My results showed that I am currently at an intermediate level, with a score of 75 out of 100. While I am happy with this result, I know that there is still room for improvement, and I would like to analyze my test results to identify areas that require further attention.My performance in the reading and writing sections of the test was quite good, with a score of 80 out of 100. This indicates that I have a strong grasp of English grammar, vocabulary, and sentence structure. However, I scored lower in the listening and speaking sections of the test, with a score of 70 out of 100. This suggests that I need to work on my listening and speaking skills, including my pronunciation, intonation, and communication skills.To improve my listening skills, I plan to listen to more English audio recordings, podcasts, and television shows. I will also practice speaking with native English speakers to work on my conversational skills. Additionally, I will work on expanding my vocabulary and improving my knowledge of English idioms and expressions.Overall, I am pleased with my English Language Proficiency testresults, but I see it as a starting point for further improvement. With dedication and effort, I am confident that I can continue to develop my English language proficiency and achieve my language goals.4. My TOEFL Test Results AnalysisTaking the TOEFL test was an important step for me in achieving my academic goals. While I was happy to see that I achieved a decent score on the test, I also recognize that there are areas where I need to improve. Here's a deeper analysis of my TOEFL test results:In the reading section of the test, I scored a 22 out of 30. This suggests that I have a strong comprehension of academic texts related to social sciences and natural sciences but need to work on improving my vocabulary and understanding of idiomatic expressions.In the listening section, I scored a 23 out of 30. While this is a decent score, there is still room for improvement. I need to work on my ability to understand conversations and lectures, as well as my note-taking skills.In the speaking section, I scored a 24 out of 30. This result indicates that I have a good command of spoken English and can express my ideas to a certain extent, but I need to improve my intonation, stress, and pronunciation.In the writing section, I scored a 26 out of 30. This result suggeststhat I have excellent writing skills and can express my ideas clearly and effectively. However, I still need to work on my grammar and syntax to improve my writing further.Overall, my TOEFL test results show that I have a good command of the English language, but I need to continue working on improving my skills. By focusing on improving my listening and speaking skills and expanding my vocabulary, I can achieve my academic goals and move forward with confidence.5. An Analysis of My GMAT Exam ResultsTaking the GMAT exam is an important step for anyone who wishes to pursue a career in business or management. As such, I was both nervous and excited to receive my GMAT exam results. While I achieved a decent score overall, there are still areas where I need to improve. Here's an analysis of my GMAT exam results:In the verbal section of the test, I scored a 35 out of 51. This result suggests that I have a good command of the English language, but I need to work on improving my reading comprehension and critical reasoning skills.In the quantitative section, I scored a 47 out of 60. This score indicates that I have a strong grasp of mathematical concepts, but I need to work on my problem-solving skills and time management. Overall, my GMAT exam results suggest that I have the potential to succeed in business and management, but I need to focus on improving my critical thinking and problem-solving skills. Bycontinuing to practice and study, I am confident that I can achieve my academic and career goals.6. A Personal Reflection on My IELTS Exam ResultsTaking the IELTS exam was a major milestone for me in my English language journey. As someone who was not a native English speaker, I was both nervous and excited to receive my exam results. Upon receiving my score, I was delighted to see that I had achieved a score of 8 overall, with a 9 in the reading section and an 8 in the other sections.While I was happy with my results, I also recognized that there were areas where I needed to improve. For example, while I scored highly in the reading section of the test, I struggled more in the speaking section. This tells me that I need to work on my speaking skills, including my pronunciation, intonation, and fluency. Overall, I am proud of my IELTS exam results, but I know that I still have a long way to go in my English language journey. I plan to continue studying and practicing, as well as seeking out opportunities to immerse myself in the language and culture. With effort and dedication, I am confident that I can achieve my language goals and become a more proficient and confident English speaker.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Test AnalysisI. CorrelationCorrelation means the extent to which two sets of results agree with each other. Figure I gives the ranks of 27 students on two tests. This is shown graphically in the scattergram. The students' ranks on Test 1 are shown along the bottom, and those on Test 2 up the side of the graph.Test 1 Test 2(Ranks) (Ranks)Item 1 1 6Item 2 2 4Item 3 3 5Item 4 3 5Item 5 4 5Item 6 5 4Item 7 6 1Item 8 7 6Item 9 8 3Item 10 9 1Item 11 10 4Item 12 11 2Item 13 11 4Item 14 11 4Item 15 12 6Item 16 13 4Item 17 13 5Item 18 14 3Item 19 15 8Item 20 16 5Item 21 16 9Item 22 17 5Item 23 18 7Item 24 19 3Item 25 20 8Item 26 21 6Item 27 22 5Test1T e s t 21 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 221 2 3 4 5 6 7 8 9 10FIG .I CORRELATION = +.29Figure I shows the result of Test 1 and 2. In this case there is some similarity between thetwo sets of results. For example, Student Li Xue came fourth in Test 1, and fifth in the Test 2, and Student Hu came fifth in Test 1 and fourth in Test 2. However, there is not total agreement. The correlation index for this set of results is + .29 which means that there is some agreement between the two sets of results.II. Classical Item Analysis----Reading Comprehension1 2 3 4 5 6 7 8 91011 1213 14 15 16 17 1819 20 F .V . 1 0.14 0.83 0.90.55 0.69 0.79 0.24 0.21 0.62 0.10.55 0.38 0.24 0.310.62 0.90.790.930.55D .I . 0 -0.10.3 0.1 0 0.3 0.2 0.3 0.1 0.50 0.2-0.10 0.3-0.10.1 0.2 0.2 0.1FIG . II2.1 Facility ValueAn item's facility value is the percentage of students to answer it correctly. In this test, the first item is very easy, the F.V. is 100%, that is to say, there are 29 students and 29 of them get the item right. This simple measure immediately gives us some idea of how easy the item is for the trial sample of students. Besides, from the top to the bottom, the F. V.s of the items are the 19th item: 0.93、the 4th : 0.9、the 17th : 0.9、the 3rd : 0.83、the 7th and 18th : 0.79、the 6th :0.69、the 10th and 16th :0.62、as well as the 5th and the last item : 0.55, which means the items are from easy to difficult. On the contrary, the 2nd and the 11th items are too difficult, whose F. V. is only 0.14 and 0.1. The statistics above are showed in FIG. II.2.2 Discrimination IndexIt refers to how difficult an item is , it is important to know how it discriminates, that is how well it distinguishes between students at different levels of ability. Here we rank the students according to their scores in the Test 2. And then divide them into three groups, making sure that the top and bottom groups have equal numbers of students: 9, as follows: TOP BOTTOMScore on Score onstudent Test 2 student Test 21 15 1 112 15 2 113 14 3 114 13 4 115 13 5 106 13 6 97 12 7 78 12 8 79 12 9 6According to this division, we can find the D.I. of this 20 items, they are showed in FIG. II. Generally speaking, the highest D.I. +1.00 is achieved if all the students in the top group get an answer right and none of the students in the bottom group does. But such items are very unusual. Often item writers are content with D.I.s of +0.4 of above, just like the tenth item in our paper. However, an item has a negative D.I., which means that more students in the bottom group were correct than in the top group, like the 2nd、13th and the 16th items. There is obviously something wrong with such items and we should revise or discard them. Meanwhile, there are four items whose D.I.s are 0 in our paper, which means that the correct students in the top and bottom group were same. In a word, except the tenth item, others ' s D.I. were all not working, and should either be altered of dropped from the test because they are not discriminating very well.Here we will take the 10th item as an example, this item has an F.V. of 62%, and still hasa D.I. of +.5, it is discriminating very well for such a difficult item.2.3 ReliabilityHere we estimate it in the method by calculating the split half reliability index. We divide the Test 2 into two halves, with the odd items ( Items 1, 3, 5, 7, etc,) in one test, and the even items ( Items 2, 4, 6, 8, etc.) in the other. Calculate each student ' s scores on the odd and even tests, and then give each student two ranks, one for the odd test and one for the even.. Calculate the rank correlation between the two sets of ranks. We get the correlation between the two halves of the test is .24. Generally speaking, the more strongly the two halves correlates, the higher the reliability will be. So according to the Spearman Brown correlation formula, we get the split half reliability index is .39, which is not a high reliability index.2.4 Descriptive statisticsThe following histogram in FIG. IV show the distribution of scores in the Test 2. We can see from the histogram that the mean, the sum of all the scores that is divided by the number of students, is 11.17. Mode, the most frequently occurring score, is 11. These show how the scores cluster together. The third measure of ' central tendency ' is the median, which is the score obtained by the student who is in the middle of the student rankings. In Test 2, the median is also 11. The range, a very useful measure of ' dispersion ', is the difference between the top score and the bottom score, in Test 2 is 15-9=6. The range and the following standard deviation show how widely the scores are spread out. The former is perhaps an overestimate of the spread of scores while the latter is the measure of dispersion which takes account of every single score. The S.D. is, approximately, the average amount that each student ' s score deviates from the mean. It is the square root of the average squared deviation from the mean of the students ' scores. From the figure III, we can get the S.D. of the Test 2 is 2.2, which means that students ' scores are surrounding around the standard score in Test 2 and accordingly the items have low D.I.s.Number of studentsScore文本文本文本文本文本文本文本文本1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 161 2 3 4 5 6 7 8 9FIG . IVDistribution StatisticsMean 11.17 Mode 11 Median 11Range 15-6=9III. Analysis of the Result in DetailsThe previous two parts mainly focus on the statistics, which make full use of correlation and classical item analysis, and give us a general idea of the exam. However, the analysis is too theoretical to give us a clear account of the test. Then based on these data, detailed analysis will be discussed in this chapter.3.1 The First PassageThe first passage is about domestic animals and some tips to keep them fit. The students are quite familiar with this topic, therefore, most of them have done well in this passage.The first item is set on the first paragraph, asking about the main idea. The first sentence has directly told us the main content, therefore, it is very easy for the students. Actually, all of the students have given a right answer. The F.V . is 100%, and the discrimination index is 0. This item cannot discriminate students belonging to different levels. First of all, as I have mentioned before, it is quite clear at the firstsentence. The following sentences list some of the domesticated animals in detail. Regarding the distracters, alternative B is one of the details given in the second sentence, C and D are irrelevant to the question, so it is very to exclude all of these options. Some modifications should be made regarding both the question and the options.A B C D Blank TotalT 10 - - - - 10 The correct answer is A.M 9 - - - - 9B 10 - - - - 10 F.V. = 100%Total 30 - - - - 29 D.I. =0Compared with the first, the second item is too difficult, or more exactly, too perplexed. There are only four students got the right answer C, while three of the rest chose B, one chose A, and all of the others, totally 21students, chose D. This item is based on the second and third paragraphs. The sentence “Some people feed a pet dog or cat on odds and ends of table scraps, and then wonder why the animal seems listless(倦怠的) and dull.” indicates that without proper food, the animals may seem to be in bad condition, which does not mean they will fall ill, therefore, A is wrong. According to the sentence “domestic animals are not accustomed to roaming(到处走动) in search of food and shelter” , B is wrong. However, if without the context in the passage, maybe it is right. Therefore three students are misled and chose this answer. Totally, there are 21students chose D. Based on this statistics, it is concluded that maybe D is also right. According to the passage, D is right. But C is what implied in the sentence “they are content to do what their masters require”. If the question is changed into “According to the second paragraph, we can imply that when a domestic animal is underfed, it probably ____.”, then C is the only answer. If C is regarded as the right, among the four students who chose C, one is in the lower level, while the others are all in the upper level. Then this item has a good discrimination index. Some adjustment must be made in either C or D to ensure that there is only one correct answer.A B C D Blank TotalT 0 0 3 7 - 10 The correct answer is C. M 1 2 0 6 - 9B 0 1 1 8 - 10 F.V. = 14%Total 1 3 4 22 - 29 D.I. = .5The third item is quite easy. There are 24 students who chose the right answer, A, four students choosing D, and one student choosing C. Since it is quite clear B is opposite to meaning in the passage, therefore, B is wasteful, and so it should be improved to be a useful distracter. C and D are all mentioned in the forth paragraph, but is irrelevant to the question. Generally speaking, it is too easy. The three studentswho chose the wrong answers are mainly in the middle and lower level.A B C D Blank TotalT 9 0 1 3 - 13 The correct answer is A. M 8 0 0 1 - 9B 7 0 0 0 - 7 F.V. = 83%Total 25 0 1 3 - 29 D.I. = .5The fourth item is an easy one. Only three chose the wrong answer, and those students are all of the low and middle level. Thus, this item ahs discriminated students of different levels. But problem is that A is wasteful. This may be because that B is too evident, and should be replaced by a more indirect one.A B C D Blank TotalT 0 10 0 0 - 10 The correct answer is B. M 0 8 1 0 - 9B 0 8 1 1 - 10 F.V. = 90%Total 0 27 2 1 - 29 D.I. = .5The facility value of the fifth item is 0.55, neither too easy nor too difficult. But it does not discriminate the students of different levels. It is too clear that B is not discussed in the passage, so nobody choose it, and it is wasteful. Four students chose C, while nine students chose D, which are good distracters. But the distracter, B, is wasteful.A B C D Blank TotalT 9 0 0 1 - 10 The correct answer is A. M 4 0 2 3 - 9B 3 0 2 5 - 10 F.V. = 55%Total 16 0 4 9 - 29 D.I. = .63.2 The Second ParagraphThis passage is about efficiency and its influence on the modern lives. The opinion discussed in it is quite interesting.The sixth item is a detail question, but the first sentence of the passage have pointed out the main idea of the author, therefore, 20 students chose the right answer, C. A is discussed in the second sentence of the second paragraph, and B is argued in the fifth sentence of the second paragraph. They are right in some aspects according to the passage, but neither are the main points. D is irrelevant to the question, so it is a wasteful distracter. But there is a problem- it does not discriminate the students of different levels. More efforts should be made to improve the option D.A B C D Blank TotalT 2 0 8 0 - 10 The correct answer is C. M 1 1 7 0 - 9B 4 1 5 0 - 10 F.V. = 69%Total 7 2 21 0 - 29 D.I. =.3The seventh item is quite easy, and 23 students got it correctly. But referring to the fact that there is no wasteful option, it is quite good. Moreover, four students in the low level chose the wrong ones, whereas only two in the top level got wrong ones. The problem is that the three distracters seem to be too easy to be excluded, so that these four distracters should be improved.A B C D Blank TotalT 2 0 0 8 - 10 The correct answer is D. M 0 0 0 9 - 9B 1 2 1 6 - 10 F.V. = 79%Total 3 2 1 24 - 29 D.I. =.2The eighth item is too difficult with the facility value being 0.24. The reason why it is so difficult is that the question is too easy, just “The passage tells us ____.”, so lots of the students may become perplexed. There is no wasteful option. What’s more, there are five students in top level got the right answer, much more than those of low level.A B C D Blank TotalT 5 1 4 0 - 10 The correct answer is A. M 2 4 0 3 - 9B 0 5 3 2 - 10 F.V. = 24%Total 7 10 7 5 - 29 D.I. = .5The ninth item is one of the most difficult ones in this test, and just 6 students chose B, the right answer. The question is not directly pointed out in the passage, and must be summarized by students themselves. But it does not discriminate students of different levels. B is wasteful, and although A and D have discussed in the passage, they are not the result of “relaxing the rule of punctuality in factories”A B C D Blank TotalT 3 3 0 4 - 10 The correct answer is B. M 4 1 0 4 - 9B 6 2 0 2 - 10 F.V. = 21%Total 13 6 0 10 - 29 D.I. = .1The tenth is a moderate one, and 18 students did it correctly, who are mainly in the higher level. It is asking about the implication, therefore, it is difficult for some students. It is one of the best items in this test.A B C D Blank TotalT 1 8 0 1 - 10 The correct answer is B. M 0 8 0 1 - 9B 2 3 1 4 - 10 F.V. = 62%Total 3 19 1 6 - 29 D.I. = .53.3 The Third PassageThe third passage is a scientific report, which maybe difficult for some students to understand. It is the most difficult one among the four passages, and most did it poorly. But there is no wasteful item in each item. What’s more, most students who chose the right answers are regarded as top ones.The eleventh item is the most difficult, besides the problematic item 2. But it seems that both B and C are right, but C is regarded as the correct. It is as problematic as the second item. This item must be carefully examined and the options be improved.A B C D Blank TotalT 1 5 2 2 - 10 The correct answer is C.M 0 6 2 1 - 9B 2 6 1 1 - 10 F.V. = 10%Total 3 17 5 4 - 29 D.I. = .1The twelfth item is a moderate one, also one of the best items in this test. The facility value is 0.55, and among those who got C, there are more top students. There is no wasteful option.A B C D Blank TotalT 0 2 8 0 - 10 The correct answer is C.M 2 2 5 0 - 9B 3 3 3 1 - 10 F.V. = 55%Total 5 7 16 1 - 29 D.I. = .5The thirteenth item is a bit difficult. Just 11students chose B, among which seven are top students. There is no wasteful option, too. Generally speaking, it is a good item.A B C D Blank TotalT 1 5 2 2 - 10 The correct answer is B. M 0 2 7 0 - 9B 1 4 4 1 - 10 F.V. = 38%Total 2 11 13 3 - 29 D.I. = .1Although the fourteenth item is quite difficult, its discrimination index is quite positive. It is not directly indicated in the passage, and must be derived and analyzed by students themselves. So is the fifteenth item.A B C D Blank TotalT 3 0 5 2 - 10 The correct answer is A. M 1 1 3 4 - 9B 3 2 3 2 - 10 F.V. = 24%Total 7 3 11 8 - 29 D.I. = 03.4 The Forth PassageThe forth passage is about the value of independence for children in American society, which is quite familiar to students, therefore, most of them did well in the four items.There is no wasteful option in the sixteenth item, and the facility value is quite good. But problem is that the number of those who chose the wrong answers at different levels is the same, so it fails to discriminate students of different levels.A B C D Blank TotalTMBTotalThe seventeenth item is too easy for these freshmen, but there is no wasteful option.A B C D Blank TotalTMBTotalThe eighteenth item is also too easy, and B and D are wasteful distracters. B is just the contrary of what has been discussed in the passage, and D is too definite. These two items should be replaced some other more useful distracters.A B C D Blank TotalTMBTotalThe nineteenth item is the easiest in this test, except the first item. It seems to be no use in this test, and must be improved and modified.A B C D Blank TotalTMBTotalThe twentieth item is a good item, although there is, A, one wasteful distracters. The reason is that, for one thing, it has discriminated the students of different levels, for another thing, it has a positive facility value.A B C D Blank TotalTMBTotalIV. ConclusionIt is regarded that the result of the other test is more truthful, because it is a comprehensive test, testing a series of language abilities, such as reading, writing. This test focuses on the reading and comprehension of English test covering a wide range of subjects.However, this test is not as truthful as the previous one. For one thing, it concentrates on English reading ability. Cases are that some students are very good at reading comprehension, but cannot do well in writing or listening tests. For another thing, this test is not well prepared without pre-testing and careful examination, so that there are a lot of problems, both the questions and the options. Thirdly, the low correlation may also bear on the attitude of students. Since it is not attached to their credits, they may treat it casually. It must be pointed that the first two reasons seem to the main reasons.Generally speaking, the fifth, tenth and fourteenth are best ones, and should be set as models for further improvement. As for further improvement, more consideration should be given to the design of questions and options, as well as the words used.。