R学习笔记
R语言中分类算法-决策树算法(学习笔记)

R语⾔中分类算法-决策树算法(学习笔记)决策树算法⼀、信息增益信息增益(Kullback–Leibler divergence)⼜叫做information divergence,relative entropy或者KLIC。
在概率论和信息论中,信息增益是⾮对称的,⽤以度量两种概率分布P和Q的差异。
信息增益描述了当使⽤Q进⾏编码时,再使⽤P进⾏编码的差异。
通常P代表样本或观察值的分布,也有可能是精确计算的理论分布。
Q代表⼀种理论,模型,描述或者对P的近似。
P到Q的信息增益(注意,信息增益是要讲⽅向的,以下公式的计算是从P到Q的信息增益),公式定义为:在信息增益中,衡量标准是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。
对⼀个特征⽽⾔,系统有它和没它时信息量将发⽣变化,⽽前后信息量的差值就是这个特征给系统带来的信息量。
所谓信息量,就是熵。
假如有变量X,其可能的取值有n种,每⼀种取到的概率为Pi,那么X的熵就定义为⼆、信息熵信息熵的概念来描述信源的不确定度。
⼀个信源发送出什么符号是不确定的,衡量它可信息熵的概念来描述信源的不确定度。
⼀以根据其出现的概率来度量。
概率⼤,出现机会多,不确定性⼩;反之就⼤。
的单调递降函数;两个独⽴符号所产⽣的不确定性应等于各⾃不不确定性函数f是概率P的单调递降函数;确定性之和,即f(P1,P2)=f(P1)+f(P2),这称为可加性。
同时满⾜这两个条件的函数f 。
是对数函数,即。
在信源中,考虑的不是某⼀单个符号发⽣的不确定性,⽽是要考虑这个信源所有可能发⽣情况的平均不确定性。
若信源符号有n种取值:U1…Ui…Un,对应概率为:P1…Pi…Pn,且各种符号的出现彼此独⽴。
这时,信源的平均不确定性应当为单个符号不确定性-logPi的统计平均值(E),可称为信息熵,即,式中对数⼀般取2为底,单位为⽐特。
但是,也可以取其它对数底,采⽤其它相应的单位,它们间可⽤换底公式换算。
拉丁语发音学习笔记

拉丁语(意式)发音
注:
1.J(名称jott)不是拉丁字母,据说是德国人后来加入的。
W是两个V的连体,很有可能也是德国人加入的。
2.K、X、Y也不是拉丁语本土字母,都来自于希腊字母,仅用于拼写希腊语借词。
二.元音
在拉丁语中,字母a、e、i、o、u为元音字母,其中e和o有长短之分。
Y可能发[y]音,但多半可能发音同i。
三.双元音
拉丁语双元音有ae[ai]、oe[oi]、au[au]、eu[eu]四个。
四.辅音
b[b]
c在后元音前[k];在前元音前[t∫]
ch[k]
d[d]
f[f]
g在后元音前[g];在前元音前[dg]
gh[g]
gn[gn]
h不发音
k[k]发音同c,只是k仅用于拼写希腊语词,c用于拼写拉丁语词。
l[l]
m[m]
n在c、g、k、x前[ŋ];其它情况[n]
p[p]
ph[f]
q只出现在qu中,发音[kw],qu被认为是一个辅音。
r[r],单独一个r是闪音,rr和rh是颤音。
s[s]在浊音之间浊化成[z]
sc在后元音前[sk];在前元音前[∫]
ss[s]
t[t]
th[t]
ti出现在元音前[tsi],但ti前有s,x时又为[ti]
v[v],仿古式为[w]
x[ks];在元音前浊化为[gz]
z[ts]或[dz]。
【R语言学习笔记】7.将数据划分为训练集、验证集和测试集

【R语⾔学习笔记】7.将数据划分为训练集、验证集和测试集1. ⽬的:介绍将数据集划分为训练集、验证集和测试集的⽅法。
2. 数据来源:github3. 此博客主要介绍划分数据的⽅法,因此不对变量做过多介绍。
4. 划分⽅法4.1 将变量划分为训练集、验证集和测试集Method 1:## partitioning into training (50%), validation (30%), and test (20%) sets# randomly sample 50% of the row IDs for trainingtrain.rows <- sample(rownames(housing.df), dim(housing.df)[1]*0.5)# sample 30% of the row IDs into the validation set, drawing only from records not already in the training set# use setdiff() to find records not already in the training setvalid.rows <- sample(setdiff(rownames(housing.df), train.rows), dim(housing.df)[1]*0.3)# assign the remaining 20% row IDs serve as testtest.rows <- setdiff(rownames(housing.df), union(train.rows, valid.rows))# create the 3 data frames by collecting all columns from the appropriate rowshousing.train <- housing.df[train.rows, ]housing.valid <- housing.df[valid.rows, ]housing.test <- housing.df[test.rows, ]Method 2:## alternativetrain.rows <- sample(1:nrow(housing.df), dim(housing.df)[1]*0.5)housing.train <- housing.df[train.rows,]remain <- housing.df[-train.rows,]valid.rows <- sample(1:nrow(remain), dim(housing.df)[1]*0.3) #dim(housing.df)[1]*0.3 -> be careful!housing.valid <- remain[valid.rows,]housing.test <- remain[-valid.rows,]4.2 将数据划分为训练集和测试集Method 1:## partitioning into training (60%) and validation (40%)set.seed(1) ## to get the same sequence of numbers# randomly sample 60% of the row IDs for training; the remaining 40% serve as validation train.rows <- sample(rownames(housing.df), dim(housing.df)[1]*0.6)# collect all the columns with training row ID into training set:housing.train <- housing.df[train.rows, ]# assign row IDs that are not already in the training set, into validationvalid.rows <- setdiff(rownames(housing.df), train.rows)housing.valid <- housing.df[valid.rows, ]Method 2:## alternative 1# collect all the columns without training row ID into validation settrain.rows <- sample(1:nrow(housing.df), dim(housing.df)[1]*0.6)housing.train <- housing.df[train.rows, ]housing.valid <- housing.df[-train.rows, ]Method 3:## alternative 2: generate random numbersgp <- runif(nrow(housing.df)) # generate uniform random numbershousing.train <- housing.df[gp < 0.6,]housing.test <- housing.df[gp >=0.6,]Method 4:## alternative 3n_obs <- nrow(housing.df) # get the number of observationspermuted_rows <- sample(n_obs) # shuffle row indices: permuted_rowshousing_shuffled <- housing.df[permuted_rows,] # randomly order data: Sonarsplit <- round(n_obs * 0.6) # identify row to split on: splithousing.train <- housing_shuffled[1: split,] # create trainhousing.test <- housing_shuffled[(split+1):nrow(housing_shuffled),] # create test。
R语言学习笔记内附实例及代码

R语言入门R是开源的统计绘图软件,也是一种脚本语言,有大量的程序包可以利用。
R中的向量、列表、数组、函数等都是对象,可以方便的查询和引用,并进行条件筛选。
R具有精确控制的绘图功能,生成的图可以另存为多种格式。
R编写函数无需声明变量的类型,能利用循环、条件语句,控制程序的流程。
R网络资源:R主页:R资源列表NCEASR Graphical Manual统计之都:QuikR丁国徽的R文档:R语言中文论坛一、用函数install.packages(),[直接输入就可以联网,第一次的话之后选择镜像,然后选择包下载即可]如果已经连接到互联网,在括号中输入要安装的程序包名称,选择镜像后,程序将自动下载并安装程序包。
例如:要安装picante包,在控制台中输入install.packages("picante")已经安装了?二. 安装本地zip包路径:Packages>install packages from local files选择本地磁盘上存储zip包的文件夹。
(文件,运行R的脚本,选择所在文档)三.调用程序包在控制台中输入如下命令library(“picnate”)程序包内的函数的用法与R内置的基本函数用法一样。
四.程序包内部都有哪些函数?分别有什么功能?查询程序包内容最常用的方法:1 菜单帮助>Html帮助;2 查看pdf帮助文档五.查看函数的帮助文件函数的默认值是什么?怎么使用?使用时需要注意什么问题?需要查询函数的帮助。
1 ?t.test 直接打开相关函数的说明和使用模板。
2 RGui>Help>Html help 同样的效果,同上3 apropos("t.test")合理使用T 检验,五种模式的T 检验4 help("t.test")帮助同1-25 help.search("t.test")有关T 检验的一切东西都可以查出来。
landmark r 学习笔记

学习笔记目录1 三工区建立 (1)1.1 井工区建立 (1)1.2 井工区管理 (2)1.3 手工删除井工区 (3)1.4 PreR5000 (4)2 地震数据加载(R5000) (5)2.1 三维数据加载 (5)2.2 二维数据加载 (5)3 井数据加载 (6)3.1 文本数据加载 (6)3.2 曲线加载(all) (7)3.3 删除无用的分层数据 (8)4 测井解释(PETROWORKS) (10)4.1 曲线编辑(LogEdit) (10)4.2 测井数据分析 (10)4.3 测井曲线预处理 (11)5 地质解释(STRATWORKS) (15)5.1 模版编辑 (15)5.2 定义断层 (16)5.3 拾取正断层 (16)5.4 逆断层 (17)5.5 制作泡泡图 (17)5.6 岩性统计 (18)6 合成记录制作 (20)6.2 子波提取 (20)6.3 相关曲线 (20)7 地震解释 (21)7.1 数据加载 (21)7.2 合成记录制作 (22)7.3 资料解释 (22)8 迭后处理(POSTSTACK) (30)8.1 相关处理 (30)8.2 属性提取 (30)8.3 波形分类 (35)9 RAVE (36)9.1 二维交汇(2D Crossplot) (36)9.2 三维交汇(3D Crossplot) (36)9.3 二维骨架(二维矩阵2D Matrix) (36)9.4 随机相关(Rank Correlation) (36)9.5 统计参数概况(Summary Statistics) (36)9.6 聚类分析(Cluster Analysis) (36)10 时深转换 (39)10.1 TDQ (39)10.2 Depthteam Express (40)11 POWERVIEW(综合解释) (42)11.1 启动PowerView (42)11.2 设置解释员优先权 (43)11.3 检查数据 (43)11.4 数据转换显示 (48)11.6 断层相关组合 (52)11.7 层位解释 (52)11.8 解释正确性确认(ezviladator)??? (54)11.9 断层多边形解释 (55)11.10 网格等值线制作 (57)12 POWERCALCULATOR (58)12.1 建立计算公式 (58)12.2运行计算 (58)12.3查看工区数据 (59)12.4两层叠合并移动 (60)12.5振幅提取 (60)13 GEOPROBE(地质探测) (61)13.1 GeoProbe项目管理 (61)13.2 存储说明 (62)13.3 功能键说明 (63)13.4 层位解释 (65)13.5 河道追综 (67)13.6 断层解释 (68)13.7 显示钻井 (69)13.8 任意线显示 (69)13.9 层拉平 (69)13.10 层位反拉平 (70)13.11 谱分解(Spectral Decomposition) (70)13.12 数据处理 (70)13.13 井位设计 (71)13.14 地质体(Geobody) (72)14 频谱分析 (74)14.1 调谐体(Tuning Cube) (74)14.2 体搜索(Volume Recon) (76)14.3 调谐图(Tuning Mapper) (76)15 R5000 (77)15.1 功能介绍 (77)15.2 ¥工区恢复 (78)15.3 问题讲解 (81)1三工区建立工区建立包括井工区的建立和地震工区的建立,工区的建立必须首先建立井工区,然后才能建立地震工区。
一元线性回归

一元线性回归简介回归分析是研究存在相关关系而且存在因果关系的变量之间的依存关系的一种理论分析与方法。
只含有一个解释变量的线性回归模型称为一元线性回归模型,含有多个解释变量的线性回归模型称为多元线性回归模型。
一元线性模型是最基本的线性回归模型。
在R语言中实现线性回归最重要的函数是lm()函数。
接下来我们以一个例子详细说明如何在R语言中实现一元线性回归模型的参数估计和检验,并用得到的模型进行预测。
本例选取“城镇居民家庭人均消费支出”为被解释变量Y,选取“城镇居民家庭人均可支配收入”为解释变量X。
与变量的选择相对应,从1981—2005年各年的《中国统计年鉴》中选取了1980—2004年我国城镇居民家庭的人均消费支出与人均可支配收入数据,为剔除价格水平的影响,又进一步以1978年为基期,利用城镇居民消费价格指数,将所有名义数据调整为实际数据。
我们将数据复制到Excel中,然后另存为CSV文件,保存文件为consume.csv。
操作指南在R语言中,要完成一个一元线性回归模型分析,大致有5个步骤:读入数据、作散点图、估计参数、检验和预测。
下面我们将写出实现这些步骤的代码。
‘>’表示命令提示符,后面是我们要输入的命令,注释以#开头。
#读入数据,并保存在变量consume中>consume<-read.csv('consume.csv')#作散点图,如图1-1>plot(Y~X,data=consume,main='城镇居民人均消费支出和人均可支配收入散点图',ylab='人均消费支出',xlab='人均可支配收入')>fit<-lm(Y~X,data=consume)#用lm()函数建立线性回归模型>summary(fit)#查看回归结果,包括参数估计和检验Call:lm(formula=Y~X,data=consume)Residuals:Min1Q Median3Q Max-29.932-7.298-2.6308.90042.619Coefficients:(Intercept)93.2408277.08040213.17 3.38e-12***X0.7184320.007009102.51<2e-16***---Signif.codes:0‘***’0.001‘**’0.01‘*’0.05‘.’0.1‘’1Multiple R-squared:0.9977F-statistic: 1.051e+04on 1and 23DF,p-value:< 2.2e-16#根据以上结果,在5%的显著性水平下,模型的参数通过了t 检验和F 检验。
也能做精算actuar 包学习笔记一

用R也能做精算—actuar包学习笔记(一)李皞(中国人民大学统计学院风险管理与精算)本文是对R中精算学专用包actuar使用的一个简单教程。
actuar项目开始于2005年,在2006年2月首次提供公开下载,其目的就是将一些常用的精算功能引入R系统。
actuar是一个集成化的精算函数系统,虽然其他R包中的很多函数可以供精算师使用,但是为了达到某个目的而寻找某个包的某个函数是一个费时费力的过程,因此,actuar将精算建模中常用的函数汇集到一个包中,方便了人们的使用。
目前,该包提供的函数主要涉及风险理论,损失分布和信度理论,特别是为非寿险研究提供了很多方便的工具。
如题所示,本文是我在学习actuar包过程中的学习笔记,主要涉及这个包中一些函数的使用方法和细节,对一些方法的结论也有稍许探讨,因此能简略的地方简略,而讨论的地方可能讲的会比较详细。
文章主要是针对R语言的初学者,因此每种函数或数据的结构进行了尽可能直白的描述,以便于理解,如有描述不清或者错漏之处,敬请各位指正。
闲话少提,下面就正式开始咯!1 数据描述本节介绍描述数据的基本方法,数据类型主要分为分组数据和非分组数据。
对于非分组数据的描述方法大家会比较熟悉,无论是数量上,还是图形上的,比如均值、方差、直方图、柱形图还有核密度估计等。
因此下文的某些部分只介绍如何处理分组数据。
1.1 构造分组数据对象分组数据是精算研究中经常见到的数据类型,虽然原始的损失数据比分组数据包含有更多的信息,但是某些情况下受条件所限,只能获得某个损失所在的范围。
与此同时,将数据分组也是处理原始数据的基本方法,通过将数据分到不同的组中,我们可以看到各组中数据的相对频数,有助于对数据形成直观的印象(比如我们对连续变量绘制直方图);而且在生存函数的估计中,数据量经常成千上万,一种处理方法是选定合适的时间或损失额度间隔,对数据进行分组,然后再使用分组数据进行生存函数的估计,这样可以有效减小计算量。
统计R学习笔记
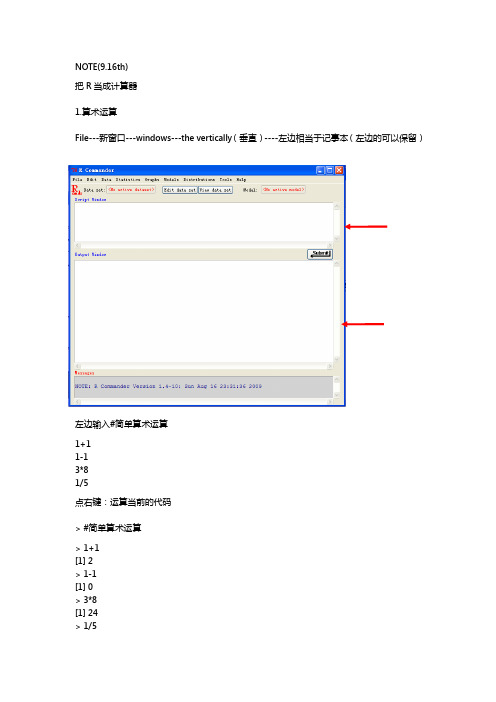
NOTE(9.16th)把R当成计算器1.算术运算File---新窗口---windows---the vertically(垂直)----左边相当于记事本(左边的可以保留)左边输入#简单算术运算1+11-13*81/5点右键:运算当前的代码> #简单算术运算> 1+1[1] 2> 1-1[1] 0> 3*8[1] 24> 1/5[1] 0.2(R中#是提示作用)平方根:sqrt(?)1+sqrt(1+sqrt(1+sqrt(2))) 立方:4^(1/3)(多少次幂)二.#建立简单的对象1.先赋值(学习赋值语句)<-表示等于x<-2Y=35->zobjects() #查看现有对象[1] "x" "Y" "z"rm(x)----移除电脑建立所有对象rm(list=ls())#慎用,移除所有对象再运算x+Y+z(x/Y)^(1/3)w<-x+2*Y+10*z^2(赋予新的值)注意:一定要区别大小写三#建立向量matrixv<-c(1,2,3)C---把1,2,3连成向量h<-c(x,y,z,w)-----把x,y,z,w变成向量k<-c(v,h)-----可以不断运算#向量的算术运算v*2向量的乘法(对应的元素相乘)h<-c(4,5,6)v*h再另h1<-c(3,5)> h1[1] 3 5> v[1] 1 2 3> v*h1[1] 3 10 9警告信息:In v * h1 : 长的对象长度不是短的对象长度的整倍数因为v的3没有对应的数,所以再把v中的3和h1中的第一个3乘一次四.#向量元素的索引只取向量元素中的一部分向量h[3]----取第三个元素h[2]---取第二个元素h[1:2]---取第一个到第二个元素h[c(1,3)]---取第一个,第三个五.#rep(),seq()函数Rep---repeatRep(2,8)---把2重复8次rep(c(2,3),c(3,4))----向量重复Seq----序列seq(from=0,to=1,length=10)----0-1产生10个数,9个间隔产生等差序列KEY OF R----HELP在后边输入> help("seq")或?seqstarting httpd help server ... Done产生向量2,4,6,8,10seq(from=0,to=1,length=11)2*(1:5)----:表示从1到5的数Attention:一定要注意是用英文的符号!!2013.10.14th画图----直方图x<-rnorm(100)----从标准正态分布里产生随机数数> x<-rnorm(100)> x[1] 0.341019718 0.232379800 -1.156626786 -0.013856883 -0.079887867[6] 0.105013772 -1.122563463 0.141311078 -1.203527506 1.617024288[11] 1.882750286 1.787700346 -0.094190399 0.344903331 -0.703671085[16] -0.450606133 0.242303165 1.238181966 1.066555721 0.494756905[21] 0.685797591 -2.736760356 -0.089690631 -1.666324609 0.223574925[26] -1.525330731 1.405092774 1.259759907 1.304417029 0.043141531[31] 0.388122525 -0.043076269 -0.160404380 -0.271311951 1.119678989[36] -0.090459611 -1.046401794 -0.221043437 0.098923434 -0.542525595[41] -0.032062588 -0.720217246 0.339581709 1.007299430 -0.021627639[46] 1.214776541 -0.424784206 -1.249418227 0.791781085 -0.770785046[51] 0.374259448 -0.522112542 -1.002355477 1.473828173 -1.163678070[56] 0.051130757 -0.006516286 1.215113429 0.285956584 -0.238135538[61] 0.914600607 0.291277244 2.540533053 1.526002529 0.792335698[66] -0.310752916 0.499751815 -0.698590551 -0.204159783 1.079188693[71] 0.836828566 0.722438863 0.088398640 -0.912404063 3.105980352[76] 0.370655484 -1.545378507 2.260279793 0.261019588 0.169971020[81] -1.017774240 2.689896807 0.874411838 -0.894351550 -0.551249948[86] 1.378679481 -0.068646910 0.551432663 1.172866188 -2.035676088[91] 0.656948321 0.445607324 -1.642623913 0.550977676 -0.028277642[96] -1.937337915 1.577919383 -0.190344210 -1.225727248 -0.340590751X是向量,列向量查询第一个数----x【1】sum(x>0)---大于0的数有多少次(在50中间徘徊)Sum----求和,true---1 false---0X>0----逻辑判断> x>0[1] TRUE TRUE FALSE FALSE FALSE TRUE FALSE TRUE FALSE TRUE TRUE TRUE[13] FALSE TRUE FALSE FALSE TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE[25] TRUE FALSE TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE TRUE FALSE[37] FALSE FALSE TRUE FALSE FALSE FALSE TRUE TRUE FALSE TRUE FALSE FALSE[49] TRUE FALSE TRUE FALSE FALSE TRUE FALSE TRUE FALSE TRUETRUE FALSE[61] TRUE TRUE TRUE TRUE TRUE FALSE TRUE FALSE FALSE TRUE TRUE TRUE[73] TRUE FALSE TRUE TRUE FALSE TRUE TRUE TRUE FALSE TRUE TRUE FALSE[85] FALSE TRUE FALSE TRUE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE[97] TRUE FALSE FALSE FALSE>下面把我的数值做成直方图hist(x)#histogramHistogram of xx F r e q u e n c y-3-2-1012340510*******求帮助----在右边方框里输入?Hist 回车怎么把数据导入R 里面新建需要的数据的excel 保存csv 格式Csv---标点符号分割的格式数据read.csv("D:\\x.csv")读取 #导入数据population<-read.csv("D:\\population.csv")最好存在D 盘,而且路径不要有中文的,不好读出来而且excel 要标准,第一列是英文名称---如population ,并且只有一列。
R语言学习笔记(数据的读取与保存)

R语⾔学习笔记(数据的读取与保存)library(MASS)#载⼊package MASSdata(package="MASS") #查看MASS中的数据集data(SP500,package="MASS") #载⼊MASS中的SP500数据集data(SP500) #简化写法getwd() #返回当前⼯作⽬录setwd("d:/r/r-data") #将当前⼯作路径修改为data=read.table("d:/r/r-data/salary.txt",header=T)data #没有设置⼯作⽬录setwd("d:/r/r-data")data1=read.table("salary.txt",header=T)data1 #设定⼯作⽬录data2=read.csv("salary.csv",header=T)data2 #读⼊CSV⽂件data3=scan("salary.txt",skip=1,what=list(City="",Work=0,Price=0,Salary=0))data3 #不存在header参数,skip=1说明读取时跳过表⽰名称的第⼀⾏mode(data) #显⽰对象的类型names(data) #显⽰对象中的标签dim(data) #显⽰对象的维度data$Salary #通过$符号来选择字段attach(data)Salarydetach(data) #attach()可以直接通过变量名称来获取变量信息,detach()⽤来撤销data.fwf=read.fwf("d:/r/r-data/fwf.txt",widths=c(2,4,4,3),=c("w","x","y","z"))data.fwf #widths⽤来指定4个变量的宽度,s指定4个变量的名称data.excel=read.delim("clipboard") #clipboard即剪贴板data.excel #通过剪贴板的⽅式来读取excel中的内容install.packages("RODBC")library(RODBC)channel=odbcConnectExcel2007("Salary.xlsx") #通过RODBC包来连接EXCEL⽂件sqlTables(channel) #列出Excel中的表格data.excel12=sqlFetch(channel,"Sheet1") #读取sheet1data.excel12=sqlQuery(channel,"select * from[Sheet1$]") #在channel中使⽤sqlclose(channel) #关闭channel的连接mode(data.excel12);dim(data.excel12)library(RMySQL)con=dbConnect(MySQL(),user="root",password="xjs123",dbname="mysql")#打开⼀个MySQL的连接s=dbListTables(con) #将数据库中的表名存⼊ss=dbListField(con,"event")dbReadTable(con,"event") #获取全表query=dbSendQuery(con,"select *from event")fetch(query) #显⽰SQL的结果dbRemoveTable(con,"event") #删除表dbDisconnect(con) #关闭连接load("d:/r/r-data/Salary.Rdata") #读⼊R格式⽂件head(data,5) #显⽰数据集前五⾏cat(c("AB","C"),c("E","F"),"n",sep="")#cat()可以连接字符串、数字向量等i=1:5cat("i=",i,"n",sep=",") #sep=“,”是以逗号为分隔符cat(c("AB","C"),c("E","F"),file="d:/r/r-data/cat.txt",sep=".")readLines("d:/r/r-data/cat.txt") #以⾏的形式读取⽂本cat(i,file="d:/r/r-data/cat.txt",append=TRUE)readLines("d:/r/r-data/cat.txt") #append=TRUE表⽰追加内容,不覆盖之前内容a=file("d:/r/r-data/cat.txt") #通过file先打开⼀个连接cat("1 2 3 4 ","2 3 5 7","11 13 15 17", file=a, sep="\n") #\n表⽰换⾏read.table(a)data1=read.table("d:/r/r-data/salary.txt",header=T)write.table(data1,file="d:/r/r-data/salary1.txt",s=T,quote=F)#写⼊数据write.csv(data1,file="d:/r/r-data/salary1.csv",s=F,quote=F)data.csv=read.csv("d:/r/r-data/salary1.csv")dim(data.csv)#写⼊CSV⽂件save(data,file="d:/r/r-data/salary1.Rdata") #保存R⽂件load("d:/r/r-data/salary1.Rdata") #读⼊R⽂件head(data,5)。
【RNotebook】R学习笔记

【RNotebook】R学习笔记IntroR为数据分析提供了⽅便的统计功能,可⽤于创建⾼级数据可视化。
查看这些资源以了解有关 R 的更多信息::下载 R、⽂档和帮助的⽹站:R 核⼼团队⼿册的链接,包括介绍、管理和帮助:R 的编码教程集合:帮助您在 R 中处理数据、图形和统计数据Python是⼀种通⽤语⾔,可⽤于创建数据分析所需的内容。
以下是开始学习 Python 的⼀些资源::⼀个⽹站,提供帮助您⼊门的指南:来⾃ PSF 站点的 Python 3 教程:Python 的编码教程合集RStudio: This web page explains some of the reasons why RStudio is many analysts’ preferred choice for interfacing with R. You’ll learn about the advantages of using RStudio for data analysis, from ease of use to accessibility of graphics and more.: This online introduction to data analysis and R programming is a good starting point for R and RStudio users. It also includes a list of detailed explanations about the advantages of using R and RStudio. You’ll also find a helpful guide for getting set up with RStudio. Online communitiesOnline communities allow you to connect with other R users no matter where you live. This list includes forums and discussion channels where you can join the conversation. It also includes social media tags you can use on your existing social media platforms to connect with other data analysts.The RStudio Community forum is a great place to get help and find solutions to challenges you have with R–and maybe helpsomeone else out, too!: The R language subreddit is an active online community on the social media platform Reddit, where R users go to discuss R, ask questions, and share tips.: rOpenSci has a community forum where R users can ask questions and search for solutions. It also includes links to their Best Practices guide and support pages.This is a community with another Slack channel where R learners and mentors can gather and connect. This is a great place to chat about using R for data science.: If you use Twitter, you can connect with other R users using the hashtag #rstats; a lot of R developers and analysts are active on Twitter.Use Kaggle to ask a questionCheck out websites like R for Data Science Online Learning Community and RStudio Community.let's talk about some specific situations when you might use it for data analysis. Here's three scenarios: reproducing your analysis, processing lots of data, and creating data visualizations.Basic计算Addition: +Subtraction: -Multiplication: *Division: /Exponentiation: ^Modulo: %%Notice from the last expression that R is case sensitive: "R" is not equal to "r".数据类型Decimal values like 4.5 are called numerics.Whole numbers like 4 are called integers. Integers are also numerics.To create a vector of integers using the c() function, you must place an L directly after each number. c(1L, 5L, 15L)Boolean values (TRUE or FALSE) are called logical.Text (or string) values are called characters.The most common data structures in the R programming language include:VectorsData framesMatricesArraysYou can determine what type of vector you are working with by using the typeof() function.typeof(c(“a” , “b”))#> [1] "character"R语⾔中=和<-功能基本相同,有时候=会出错,所以⽤<-。
R语言学习笔记——C#中如何使用R语言setwd()函数

R语⾔学习笔记——C#中如何使⽤R语⾔setwd()函数在R语⾔编译器中,设置当前⼯作⽂件夹可以⽤setwd()函数。
> setwd("e://桌⾯//")> setwd("e:\桌⾯\")> setwd("e:/桌⾯/")这三种结构都是可以编译通过的,但是在VS C#中却不⾏,只有⼀种能运⾏成功。
(PS:R语⾔在VS中运⾏要先配置环境,还没配置的童鞋先要配置好,才可运⾏,如有问题可看我前⾯的随笔。
)就是这种结构,engine.Evaluate("setwd('e:/桌⾯/')");我调试了很多次,确实只有这样写才能设置它的⼯作⽂件夹,但是必须保证⽂件夹存在。
下⾯贴上完整代码,我是在winform中调试的,然后⽤PictuerBox显⽰图⽚。
//配置R语⾔环境private void LoadRPath(string RVersion = "R-3.4.1")//默认R-3.4.1{string dlldir = @"C:\Program Files\R\" + RVersion + @"\bin\x64";//默认64位bool r_located = false;var rPath = System.Environment.Is64BitProcess ?string.Format(@"C:\Program Files\R\" + RVersion + @"\bin\x64") :string.Format(@"C:\Program Files\R\" + RVersion + @"\bin\i386");dlldir = rPath;while (r_located == false){try{REngine.SetEnvironmentVariables(dlldir);r_located = true;}catch{if (System.Environment.Is64BitProcess){MessageBox.Show(@"找不到R运⾏环境:\R\" + RVersion + @"\bin\x64 " + " \n请⼿动添加⽂件夹⽬录");}else{MessageBox.Show(@"找不到R运⾏环境:\R\" + RVersion + @"\bin\i386" + " \n请⼿动添加⽂件夹⽬录");}FolderBrowserDialog folderBrowserDialog1 = new FolderBrowserDialog();if (folderBrowserDialog1.ShowDialog() == DialogResult.OK){dlldir = @folderBrowserDialog1.SelectedPath;}}}}private void CalculateHist(){//避免产⽣相同名称⽂件string rnd = System.Guid.NewGuid().ToString().Replace("-", "");string fileName = "i" + rnd + "_Hist.png";//拿到程序运⾏⽬录string sysPath = Application.StartupPath;string dir = sysPath + "\\RImage\\Hist\\";string fullDir = dir + fileName;//创建⽂件夹Directory.CreateDirectory(Path.GetDirectoryName(dir));//替换dir = dir.Replace("\\", "/");//设置⼯作⽂件夹engine.Evaluate("setwd('" + dir + "')");engine.Evaluate(string.Format("png(file='{0}',bg ='transparent',width={1},height={2})", fileName, this.ptbHist.Width, this.ptbHist.Height)); // string Rcode = @"library('scatterplot3d')// z <- seq(-10, 10, 0.01)// x <- cos(z)// y <- sin(z)// scatterplot3d(x, y, z, highlight.3d=TRUE, col.axis='blue', col.grid='lightblue',main='3d绘图',pch=20)// ";engine.Evaluate(@"x <- (0:12) * pi / 12y <- cos(x)plot(x,y);");//engine.Evaluate(Rcode);engine.Evaluate("dev.off()");//var x = engine.Evaluate("x <- rnorm(100, mean=50, sd=10)").AsNumeric();//engine.Evaluate("hist(x)");//var x = engine.Evaluate("x <- 1:100").AsNumeric();//var y = engine.Evaluate("y <- 5:105").AsNumeric();//engine.Evaluate("model = function (a, b){23.86+5.525*b-2.5725*a-6.6413*b^2-5.1862*a^2}"); //evaluate function//engine.Evaluate("z = outer(x, y ,model)");//engine.Evaluate("contour(x,y,z, nlevels = 10)");//string path = System.IO.Path.GetFullPath(fileName);Bitmap image = new Bitmap(fullDir);ptbHist.Image = image;} 欢迎⼤家交流学习~~~~~~~~。
也能做精算actuar

用R也能做精算—actuar包学习笔记(三)李皞(中国人民大学统计学院风险管理与精算)3 风险理论本部分主要介绍风险理论中的聚合风险模型。
在机动车保险中,对于一辆或一批机动车,其每年发生的事故次数服从一个离散分布,每次事故的损失金额服从一个离连续分布。
那么,这一年总的损失额可以表示为:(1)可以看出是一个随机和,我们把事故次数的分布称作索赔频率分布(frequencydistribution),每次损失额的分布称作索赔强度分布(severity distribution),的分布称为复合分布(compound distribution)。
上一小节讲如何估计分布的参数,假设我们已经将频率分布和强度分布的参数估计出来了,那么现在的问题就是如何得到总损失额的分布,事实上,就保险公司的整体运营来讲,精算师可能更关心这个分布。
对于的分布,我们有:(2)其中,是频率分布,是强度分布,是强度分布的n重卷积。
如果随机变量仅在0,1,2…取值,那么n重卷积的计算方法如下:(3)3.1 连续分布的离散化为什么要对连续分布进行离散化?通常我们假设索赔强度分布是连续分布,虽然理论上可以这么讲,但是实际操作中通常会采用一些数值计算方法来计算复合分布,这些方法要求索赔强度具有离散的分布,因此需要对现有的连续分布进行离散化处理。
在某种程度上,离散化更加接近实际,比如损失额通常是整数倍的货币单位。
所谓离散化就是将连续分布的支集区域划分为若干小区域,然后以这个区域中的某一个点代替原来连续分布在这片区域的取值概率。
这个“代表点”可以是这个区域的左右端点,也可以是区域中点。
此外,通常只对分布的“主体”进行离散化,什么叫做分布的“主体”?以正态分布为例,其分布的支集为,显然不可能对其所有取值范围进行离散化,由于正态分布在两侧的取值概率很小,可以忽略不计,我们于是可以以均值为中心,以若干倍标准差为半径划定一个区域,在这个区域上进行离散化,这个区域上的分布函数就是该分布的“主体”,区域的大小则依赖于研究的精确程度。
R语言学习笔记之lm函数详解

R语⾔学习笔记之lm函数详解
在使⽤lm函数做⼀元线性回归时,发现lm(y~x+1)和lm(y~x)的结果是⼀致的,⼀直没找到两者之间的区别,经过⼤神们的讨论和测试,才发现其中的差别,测试如下:
-------------------------------------------------------------
-------------------------------------------------------------
结果可以发现,两者的结果是⼀样的,并⽆区别,但是若改为lm(y~x-1)就能看出+1和-1的差别在哪了,测试结果如下:
说明:coefficients()函数是输出模型的参数估计值,
Intercept是指的截距,x对应的便是系数,对于⼀元线性回归⽅程y=ax+b来说,2.251599便是b的值,1.980810便是a的值。
此时再看lm(y~x)、lm(y~x+1)、lm(y~-1)三者的区别便可发现:
+1表⽰有截距项与-1相对应,
-1指没有截距项,
⽽x表⽰默认有截距项。
到此这篇关于R语⾔学习笔记之lm函数详解的⽂章就介绍到这了,更多相关R语⾔lm函数内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
R与VaR计算的学习笔记

R与VaR计算Date: Jan 12, 2010; 09:47pmAuthor:邓一硕R&数据艺术:()现代金融领域的计量工作大致分为两大块,即资产定价和风险度量。
资产准确定价的目的最终也是为了避免投资过程中可能产生的风险。
由此可见,风险度量工作实际上是现代金融计量领域的核心。
目前,被公认的风险度量方法中VaR方法,因为原理简单、数理基础扎实而成为了一时翘楚。
本文主要结合目前正在风靡的R()软件来介绍一下VaR的原理和实现途径,文章结构树如下:●VaR的定义●VaR的算法及其在R中的实现●历史模拟法(PerformanceAnalytics包)●蒙特卡洛模拟法(PerformanceAnalytics包)●方差-协方差法●指数加权平均法●混合正态模型方法●风险矩阵方法●ARCH类方法(rgarch包)●极值理论方法(fExtremes包)●VaR的检验●VaR的补充方法简介1 VaR的定义VaR是Value at Risk的简称,中文译作“在险价值”。
它是指在市场正常波动情况下,某一金融资产组合,在未来一定时期内,在一定置信水平下所可能产生的最大损失。
假设你拥有一个证券组合,该组合的初始价值为,为特定期内的收益率,假设该组合的期末价值为,则若在某一置信水平下,该组合的最低价值为,则那么,根据VaR的定义得由此可见,计算VaR值等价于计算一定置信水平下的资产组合的最低价值或最低收益率,而计算最低价值或收益率则需依赖于价值序列或收益率序列的分布或概率密度函数。
换句话说,计算金融资产序列的分布函数或概率密度函数正是计算VaR值的核心之处。
2 VaR的算法清楚了VaR的定义,计算VaR的方法也就知道的差不多了。
下面按照难以顺序依次介绍五种主要的VaR算法。
2.1 历史模拟法历史模拟法是最简单的计算VaR的方法。
历史模拟法的原理极其简单:收集一定量的数据,根据事先确定的置信水平,取相应的下分位数就可以了。
R语言学习笔记—K近邻算法

R语⾔学习笔记—K近邻算法K近邻算法(KNN)是指⼀个样本如果在特征空间中的K个最相邻的样本中的⼤多数属于某⼀个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
即每个样本都可以⽤它最接近的k个邻居来代表。
KNN算法适合分类,也适合回归。
KNN算法⼴泛应⽤在推荐系统、语义搜索、异常检测。
KNN算法分类原理图:图中绿⾊的圆点是归属在红⾊三⾓还是蓝⾊⽅块⼀类?如果K=5(离绿⾊圆点最近的5个邻居,虚线圈内),则有3个蓝⾊⽅块是绿⾊圆点的“最近邻居”,⽐例为3/5,因此绿⾊圆点应当划归到蓝⾊⽅块⼀类;如果K=3(离绿⾊圆点最近的3个邻居,实线圈内),则有两个红⾊三⾓是绿⾊圆点的“最近邻居”,⽐例为2/3,那么绿⾊圆点应当划归到红⾊三⾓⼀类。
由上看出,该⽅法在定类决策上只依据最邻近的⼀个或者⼏个样本的类别来决定待分样本所属的类别。
KNN算法实现步骤:1. 数据预处理2. 构建训练集与测试集数据3. 设定参数,如K值(K⼀般选取样本数据量的平⽅根即可,3~10)4. 维护⼀个⼤⼩为K的的按距离(欧⽒距离)由⼤到⼩的优先级队列,⽤于存储最近邻训练元组。
随机从训练元组中选取K个元组作为初始的最近邻元组,分别计算测试元组到这K个元组的距离将训练元组标号和距离存⼊优先级队列5. 遍历训练元组集,计算当前训练元组与测试元组的距离L,将所得距离L与优先级队列中的最⼤距离Lmax6. 进⾏⽐较。
若L>=Lmax,则舍弃该元组,遍历下⼀个元组。
若L < Lmax,删除优先级队列中最⼤距离的元组,将当前训练元组存⼊优先级队列7. 遍历完毕,计算优先级队列中K个元组的多数类,并将其作为测试元组的类别8. 测试元组集测试完毕后计算误差率,继续设定不同的K值重新进⾏训练,最后取误差率最⼩的K值。
R语⾔实现过程:R语⾔中进⾏K近邻算法分析的函数包有class包中的knn函数、caret包中的train函数和kknn包中的kknn函数knn(train, test, cl, k = 1, l = 0, prob = FALSE, use.all = TRUE)参数含义:train:含有训练集的矩阵或数据框test:含有测试集的矩阵或数据框cl:对训练集进⾏分类的因⼦变量k:邻居个数l:有限决策的最⼩投票数prob:是否计算预测组别的概率use.all:控制节点的处理办法,即如果有多个第K近的点与待判样本点的距离相等,默认情况下将这些点都作为判别样本点;当该参数设置为FALSE时,则随机选择⼀个点作为第K近的判别点。
R与VaR计算的学习笔记
R与VaR计算Date: Jan 12, 2010; 09:47pmAuthor:邓一硕R&数据艺术:()现代金融领域的计量工作大致分为两大块,即资产定价和风险度量。
资产准确定价的目的最终也是为了避免投资过程中可能产生的风险。
由此可见,风险度量工作实际上是现代金融计量领域的核心。
目前,被公认的风险度量方法中VaR方法,因为原理简单、数理基础扎实而成为了一时翘楚。
本文主要结合目前正在风靡的R()软件来介绍一下VaR的原理和实现途径,文章结构树如下:●VaR的定义●VaR的算法及其在R中的实现●历史模拟法(PerformanceAnalytics包)●蒙特卡洛模拟法(PerformanceAnalytics包)●方差-协方差法●指数加权平均法●混合正态模型方法●风险矩阵方法●ARCH类方法(rgarch包)●极值理论方法(fExtremes包)●VaR的检验●VaR的补充方法简介1 VaR的定义VaR是Value at Risk的简称,中文译作“在险价值”。
它是指在市场正常波动情况下,某一金融资产组合,在未来一定时期内,在一定置信水平下所可能产生的最大损失。
假设你拥有一个证券组合,该组合的初始价值为,为特定期内的收益率,假设该组合的期末价值为,则若在某一置信水平下,该组合的最低价值为,则那么,根据VaR的定义得由此可见,计算VaR值等价于计算一定置信水平下的资产组合的最低价值或最低收益率,而计算最低价值或收益率则需依赖于价值序列或收益率序列的分布或概率密度函数。
换句话说,计算金融资产序列的分布函数或概率密度函数正是计算VaR值的核心之处。
2 VaR的算法清楚了VaR的定义,计算VaR的方法也就知道的差不多了。
下面按照难以顺序依次介绍五种主要的VaR算法。
2.1 历史模拟法历史模拟法是最简单的计算VaR的方法。
历史模拟法的原理极其简单:收集一定量的数据,根据事先确定的置信水平,取相应的下分位数就可以了。
rCore-Tutorial-Book-v3学习笔记(一)

rCore-Tutorial-Book-v3学习笔记(⼀)概述最近看到清华的⼀个操作系统教程,和其他实验不同的是,这个教程介绍的是完全从零开始实现⼀个Riscv操作系统。
教程所⽤的编程语⾔是Rust,但是我的Rust⽔平只到勉强能看懂代码的地步,所以打算⽤C语⾔照着实现⼀遍。
虽然说是照着实现,但不同的语⾔还是会带来不少细节的不同,相⽐于同个语⾔照抄代码还是能注意到不少平常没在意的东西。
因此开个坑,记录⼀下遇到的问题,代码放在上了。
由于是练习,代码写得⽐较乱。
第⼀部分是实现⼀个最⼩化内核,即能让qemu-system-riscv跑起来并输出Hello world!然后退出就算成功。
得益于SBI的帮助,我们可以少研究很多东西。
这⾥⼤致介绍⼀下SBI,SBI指的是⼀套辅助操作系统内核编程的⼯具,它包含两部分,⼀部分是boot loader,即在机器态⾥初始化裸机上的⼀些寄存器和硬件设备,把操作系统内核读取到对应的内存区域,然后进⼊内核态(Supervisor态,直译为监管者态,太晦涩,因为是操作系统内核主要运⾏的特权级,后⾯均称内核态),开始执⾏内核的第⼀条指令;另⼀部分是提供内核态的系统调⽤,在内核态设置好存储调⽤号和参数的寄存器,然后执⾏指令ecall,系统就会进⼊机器态,由SBI执⾏⼀些机器态才能做的操作,然后返回内核态。
没有SBI,机器态相关的代码就得⾃⼰写了,xv6就是这样做的,所以xv6除了进程、⽂件、内存管理这些模块,还有⼀些充满晦涩代码的模块,这些就是在处理机器态和硬件相关的操作;riscv-pk的系统引导⽤的是BBL(Berkeley Boot Loader),需要机器态做的任务则转发给spike 模拟器的htif模块,由宿主系统执⾏这些任务。
这⾥我⽤的是,和教程⽤的⼀样,虽然是⽤Rust写的,但是已经打包成⼆进制⽂件了,可以直接使⽤。
原先我打算使⽤qemu⾃带的OpenSBI,但是不知道为什么,在调⽤OpenSBI的退出程序功能时,qemu会报错,没法正常退出,RustSBI则不会。
【数据分析R语言实战】学习笔记第十一章对应分析

【数据分析R语⾔实战】学习笔记第⼗⼀章对应分析11.2对应分析在很多情况下,我们所关⼼的不仅仅是⾏或列变量本⾝,⽽是⾏变量和列变量的相互关系,这就是因⼦分析等⽅法⽆法解释的了。
1970年法国统计学家J.P.Benzenci提出对应分析,也称关联分析、R-Q型因⼦分析,其是⼀种多元相依变量统计分析技术。
它通过分析由定性变量构成的交互汇总表,来揭⽰同⼀变量各类别之间的差异,以及不同变量各类别之间的对应关系,这是⼀种⾮常好的分析调查问卷的⼿段。
对应分析是⼀种视觉化的数据分析⽅法,其基⽊思想是将⼀个联列表的⾏和列中各元素的⽐例结构以点的形式在较低维的空间中表⽰出来,优点在于能够将⼏组看不出任何联系的数据,通过视觉上可以接受的定位图展现出来,使⽤起来直观、简单、⽅便,因此⼴泛应⽤于市场细分、产品定位、地质研究以及计算机⼯程等领域。
11.2.1理论基础对应分析是寻求样⽊(⾏)与指标(列)之间联系的低维图⽰法,其关键是利⽤⼀种数据变换⽅法,使含有n个样本观测值和m个变量的原始数据矩阵x变成另⼀个矩阵z, z是⼀个过渡知阵,在接下来的计算中使⽤。
通过z将样本和变量结合起来。
11.2.2 R语⾔实现R中的程序包MASS提供了两个函数,corresp()⽤于做简单⼀的对应分析,mca()⽤于计算多重对应分析,通常使⽤前者,其调⽤格式为corresp(x,nf=1,……)x是数据矩阵:nf表⽰因⼦分析中计算因⼦的个数,通常取2.【例】> ch=data.frame(A=c(47,22,10),B=c(31,32,11),C=c(2,21,25),D=c(1,10,20))> rownames(ch)=c("Pure-Chinese","Semi-Chinese","Pure-English")> library(MASS)> ch.ca=corresp(ch,nf=2)> options(digits=4)> ch.caFirst canonical correlation(s): 0.5521 0.1409Row scores:[,1] [,2]Pure-Chinese 1.2069 0.6383Semi-Chinese -0.1368 -1.3079Pure-English -1.3051 0.9010Column scores:[,1] [,2]A 0.9325 0.9196B 0.4573 -1.1655C -1.2486 -0.5417D -1.5346 1.2773分析结果给出了两个因⼦对应⾏变量、列变量的载荷系数。
R语言学习笔记缺失数据的Bootstrap与Jackknife方法

R语⾔学习笔记缺失数据的Bootstrap与Jackknife⽅法⽬录⼀、题⽬⼆、解答a)Bootstrap与Jackknife进⾏估计b)均值与变异系数(⼤样本)的标准差解析式推导与计算c)缺失插补前的Bootstrap与Jackknifed)⽐较各种⽅式的90%置信区间情况(重复100次实验)填补之前进⾏Bootstrap或Jackknife填补之后进⾏Bootstrap或Jackknife⼀、题⽬下⾯再加⼊缺失的情况来继续深⼊探讨,同样还是如习题1.6的构造⽅式来加⼊缺失值,其中a=2, b = 0我们将进⾏如下⼏种操作:⼆、解答a)Bootstrap与Jackknife进⾏估计⾸先构建⽣成数据函数。
# ⽣成数据# ⽣成数据GenerateData <- function(a = 0, b = 0) {y <- matrix(nrow = 3, ncol = 100)z <- matrix(rnorm(300), nrow = 3)y[1, ] <- 1 + z[1, ]y[2, ] <- 5 + 2 * z[1, ] + z[2, ]u <- a * (y[1, ] - 1) + b * (y[2, ] - 5) + z[3, ]# m2 <- 1 * (u < 0)y[3, ] <- y[2, ]y[3, u < 0] <- NAdat_comp <- data.frame(y1 = y[1, ], y2 = y[2, ])dat_incomp <- data.frame(y1 = y[1, ], y2 = y[3, ])# dat_incomp <- na.omit(dat_incomp)return(list(dat_comp = dat_comp, dat_incomp = dat_incomp))}Bootstrap与Jackknife的函数:Bootstrap1 <- function(Y, B = 200, fun) {Y_len <- length(Y)mat_boots <- matrix(sample(Y, Y_len * B, replace = T), nrow = B, ncol = Y_len)statis_boots <- apply(mat_boots, 1, fun)boots_mean <- mean(statis_boots)boots_sd <- sd(statis_boots)return(list(mean = boots_mean, sd = boots_sd))}Jackknife1 <- function(Y, fun) {Y_len <- length(Y)mat_jack <- sapply(1:Y_len, function(i) Y[-i])redu_samp <- apply(mat_jack, 2, fun)jack_mean <- mean(redu_samp)jack_sd <- sqrt(((Y_len - 1) ^ 2 / Y_len) * var(redu_samp))return(list(mean = jack_mean, sd = jack_sd))}进⾏重复试验所需的函数:RepSimulation <- function(seed = 2018, fun) {set.seed(seed)dat <- GenerateData()dat_comp_y2 <- dat$dat_comp$y2boots_sd <- Bootstrap1(dat_comp_y2, B = 200, fun)$sdjack_sd <- Jackknife1(dat_comp_y2, fun)$sdreturn(c(boots_sd = boots_sd, jack_sd = jack_sd))}下⾯重复100次实验进⾏ Y2的均值与变异系数标准差的估计:nrep <- 100## 均值fun = meanmat_boots_jack <- sapply(1:nrep, RepSimulation, fun)apply(mat_boots_jack, 1, function(x) paste(round(mean(x), 3), '±', round(sd(x), 3)))## 变异系数fun = function(x) sd(x) / mean(x)mat_boots_jack <- sapply(1:nrep, RepSimulation, fun)apply(mat_boots_jack, 1, function(x) paste(round(mean(x), 3), '±', round(sd(x), 3)))从上⾯可以发现,Bootstrap与Jackknife两者估计结果较为相近,其中对均值标准差的估计,Jackknife的⽅差更⼩。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
R语言学习笔记(一)说明:前段时间的R语言学习笔记文件坏了,现在记录在博客上,以便于自己学习之用,感兴趣的人还可以看看。
因为刚开始学,记录的东西也不一定正确,请大家指教,里面可能会引用到一些别人的资料等,作为学习之用)读书笔记Basic knowledge for R2011-3-10相关的函数记录与整理1、source("文件名.r"):调取主程序的文件,在程序结构复杂的时候很有用,可以将一部分复杂的运算主程序放入其中。
2、install.packages("fields"):安装程序包3、library(fields):导入程序包4、t(x)转置函数,对于csv中横排的转置很有用5、dev.off():中断函数6、a <- as.character(b):因子型转化为字符型函数7、position <- regexpr('_',a):regexpr()函数对字符的定位很有用,返回值position为特定字符,如字符串a中’_’的位置8、结合定位函数,对字符串如x345_xbt,进行拆分,利用函数substring(要拆分的字符串,开始的字符位置,结束的字符位置)namecol1 <- substring(a, 2, position - 1)namecol2 <- substring(a, position + 1, nchar(a))结合regexpr()函数,这两个命令返回的值为,namecol1<-345;namecol2<-xbt;9、合并向量data.frame(vetor1, vetor2, vetor3)cbind(vetor1, vetor2, vetor3)10、取名字相同的交集unique()函数例如对包含行名的向量R1、R2、R3取名字相同的行,组成新的向量。
nam1 <- rownames(R1)nam2 <- rownames(R2)nam3 <- rownames(R3)tnam <- unique(c(nam1,nam2,nam3))返回结果为只剩下名字相同的行的数值和rownames 或者取一个向量中唯一一个值的数据,合并重复数据。
unique(x, incomparables = FALSE, ...)在R中三个点…,表示可传递参数11、对程序包里面的具体的函数源代码,通过安装包后直接输入函数名回车,可以看到函数;注意找到对应的子函数。
也可以在R镜像网页中的packages中,下载package的数据包,减压后,看文件夹得R函数中,这个包含程序注释,更好。
12、t检验函数t.test(x, ...)## Default S3 method:t.test(x, y = NULL,alternative = c("two.sided", "less", "greater"), mu = 0, paired = FALSE, var.equal = FALSE, conf.level = 0.95, ...)## S3 method for class 'formula't.test(formula, data, subset, na.action, ...)13、对于一个向量x中选择某个符合条件的数值出来(大于某个数或者是某个条件limit),直接利用表达式y<-x[,1][判断语句或者limit函数参数,在外部设定limit值]14、判断两个向量的交集部分选择%in%1:10 %in% c(1,3,5,9)15、帮助已经加载的程序包有哪些函数,可以用主界面的help>html帮助16、regression with damped exponential correlation回归的函数为rdec(),需要的函数包为RDEC17、相关常用的R运算计算log(x)log10(x)exp(x)sin(x)cos(x)tan(x)asin(x)acos(x)min(x)max(x)range(x)length(x)统计检验mean(x)sd(x)var(x)median(x)quantile(x,p)cor(x,y)t.test()lm(y ~ x)wilcox.test()kruskal.test()统计检验lm(y ~ f+x)lm(y ~ x1+x2+x3)bartlett.testbinom.testfisher.testchisq.testglm(y ~ x1+x2+x3, binomial)friedman.test...18、ls() 列出工作空间中的对象;rm() 删除工作空间中的对象19、对象类型转换as.numeric() #转换为数值型as.logical()as.charactor()as.matrix()as.dataframe()R语言学习笔记(二)Introductory statistics whith R -Peter Da(cases form Introductory statistics whith R by Peter Dalgaard)2011.03.21###R镜像官方网站(/mirrors/CRAN/)1、对矩阵的操作,可以利用matrix函数,并且,用rownames()函数给矩阵赋予名字x <- matrix(1:12,nrow=3,byrow=T)rownames(x) <- LETTERS[1:3]x[,1] [,2] [,3] [,4]A 1 2 3 4B 5 6 7 8C 9 10 11 122、对于矩阵的合并,按行合并或者按列合并cbind()\rbind()cbind(A=1:4,B=5:8,C=9:12)A B C[1,] 1 5 9[2,] 2 6 10[3,] 3 7 11[4,] 4 8 12> rbind(A=1:4,B=5:8,C=9:12)[,1] [,2] [,3] [,4]A 1 2 3 4B 5 6 7 8C 9 10 11 123、因子的定义text.pain <- c("none","severe", "medium", "medium", "mild")factor(text.pain)4、利用data.frame()来讲两个向量合并成一个矩阵vetor1 <- rnorm(20)vetor2 <- rnorm(20)d <- data.frame(vetor1,vetor2)5、条件选择,可以利用条件,对别的向量进行操作vetor1 <- rnorm(20)vetor2 <- rnorm(20)a<- vetor1[vetor2>0]##选出向量1中,当向量vetor2中数大于0所对于的数值。
[]号内为选择的条件intake.post[intake.pre > 7000 & intake.pre <= 8000]6、对于缺损值NA,利用is.na(x)来寻找7、d[d$intake.pre>7000,],对于数据库d,在[]中给出d的条件,非常有用intake.pre intake.post8 7515 59759 7515 679010 8230 690011 8770 7335第33页2011.03.221\对数据框中子集的操作###数据框thuesen,包含个向量内容,其中选择,blood.glucose<7的,条件部分和上面的方括号条件设定有点类似。
vetor1 <- rnorm(20)vetor2 <- rnorm(20)d <- data.frame(vetor1,vetor2)thue2 <- subset(d,vetor1<0)> thue22、##对子集中的数值进行转换,结果将会在转换后的矩阵中增加一列转换的那列结果> thue3 <- transform(d,log.gluc=log(vetor1))> thue33、##对一个矩阵进行拆分,函数split()##其中order()函数,是对sort()函数中的原来数据的位置进行罗列<- split(d$vetor1, d$vetor2)4\排序函数sort()data1<- rnorm(20)sort(data1)order(data1)######对于一个矩阵,要利用其中的一个向量来进行排序怎需要用到order()函数其中order(sex,age)代表先以性别进行排序,再用年龄进行排序,order获取的是顺序值5、###apply系列函数的应用apply(a4[,2:6], 1, mean)##代表对于矩阵a4,从2列到第6列开始,取平均值mean,其中参数“1”为按##行计算,如果括号中参数为2,则按列计算,mean可以变为sd,sum、中值median等计算。
case:m <- matrix(rnorm(12),4)apply(m, 2, min)result: [1] -1.1616653 -0.7892404 0.3189893lapply(thuesen, mean, na.rm=T)和sapply(thuesen, mean, na.rm=T)是等效的,其中对于na.rm=T代表的是缺损值不进入计算6\高斯分布随机函数Gaussian(normal):形式为rnorm(n,mean=0,sd=1);随机数runif(n, min=0, max=1)7\排序range(x)其功能等同于才c(min(x),max(x))8\关于协方差的计算var(x,y),如果是矩阵或者数据框,则用cov(x,y)来表示。
####二、关于制图1、基本的制图函数形式x <- runif(50,0,2)##产生两个含50个元素,从0-2的的随机向量x,y。
y <- runif(50,0,2)plot(x, y, main="Main title", sub="subtitle",xlab="x-label", ylab="y-label")###其中main为主标题,sub为副标题,xlab为x轴的名字,ylab=为y轴的名字。