AIX 5.3主机性能评估-CPU性能评估
AIX主机安全风险评估测评实施指导书
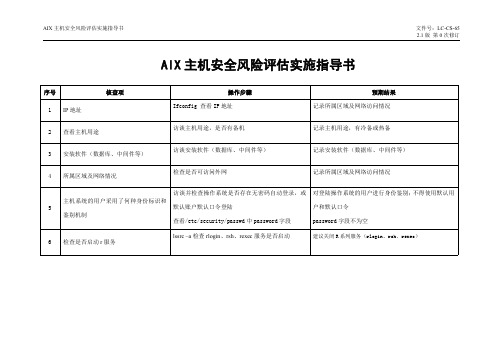
AIX主机安全风险评估实施指导书序号核查项操作步骤预期结果1IP地址Ifconfig查看IP地址记录所属区域及网络访问情况2查看主机用途访谈主机用途,是否有备机记录主机用途,有冷备或热备3安装软件(数据库、中间件等)访谈安装软件(数据库、中间件等)记录安装软件(数据库、中间件等)4所属区域及网络情况检查是否可访问外网记录所属区域及网络访问情况5主机系统的用户采用了何种身份标识和鉴别机制访谈并检查操作系统是否存在无密码自动登录,或默认账户默认口令登陆查看/etc/security/passwd中password字段对登陆操作系统的用户进行身份鉴别;不得使用默认用户和默认口令password字段不为空6检查是否启动r服务lssrc–a检查rlogin、rsh、rexec服务是否启动建议关闭R系列服务(rlogin、rsh、rexec)7受信主机配置如果启动R服务,检查各个用户主目录下的.rhosts文件,查看/etc/hosts.equiv文件应删除.rhosts及/etc/hosts.equiv文件中的用户或主机;.rhosts文件中不包含++/etc/hosts.equiv文件中不包含+8操作系统的系统补丁安装情况oslevel–r或instfix–I|grep.ML查看系统补丁是否是最新询问是否有专人负责更新补丁应及时进行补丁装载,并对服务器先进性兼容性测试有专人负责更新补丁9是否有专人负责更新补丁询问是否有专人负责更新补丁有专人负责更新补丁10关键主机系统是否具有冗余备份的措施访谈是否有备机,热备还是冷备服务器有冷备或热备11获得主机DNS地址在命令提示符下输入ifconfig-a/etc/resolv.conf文件查看nameserver记录主机的DNS地址12服务器是否安装多系统访谈服务器是否安装了多系统服务器应只安装一个系统13查看主机路由信息netstat-rn,可查看当前路由表信息路由表的flags字段显示路由状态:U向上。
AIX CPU负载评估方式及使用方法
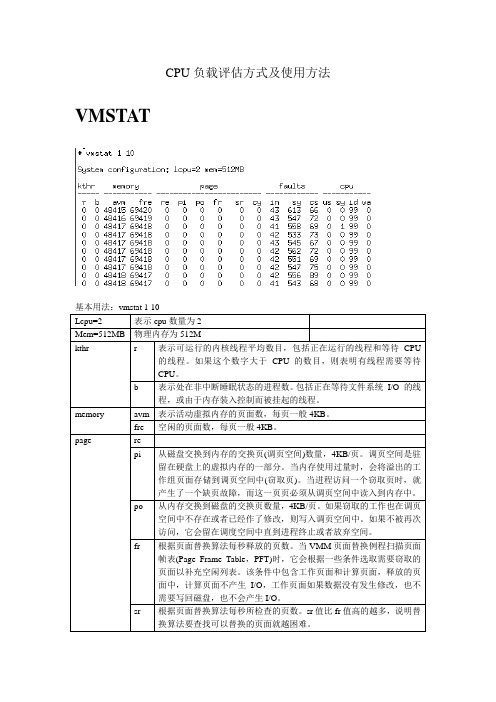
观测到的每秒系统调用次数。
cs
观测到的每秒钟上下文切换次数。
Cpu
us
用户模式所消耗的CPU时间。
sy
系统模式所消耗的CPU时间。
id
没有未决本地磁盘I/O时CPU空闲或等待时间的百分比。
wa
有未决本地磁盘I/O时CPU空闲的时间百分比。wa的值如果超过25%,就表明磁盘子系统可能没有被正确平衡,或者这也可能是磁盘工作负荷很重的结果。
msg/s
报告IPC消息原语的数量。
sema/s
报告IPC信号量原语的数量。
sar –c 1 30
报告系统调用。
scall/s
报告系统调用的总数。
exec/s
报告exec系统调用的总数。
fork/s
报告fork系统调用的总数。
sread/s
报告读系统调用的总数。
swrit/s
报告写系统调用的总数。
rchar/s
free值比较大,pi,po为0,表明内存非常富裕。空闲较多。
如果r不大于b,通常是CPU问题的症状,这可能是由于I/O或者内存瓶颈造成的。
SAR
基本用法:sar 1 10
sar 110
sar命令输出的是一个整体的cpu使用情况的一个统计。
第一行统计信息包含了sar命令本身启动的cpu消耗,所以往往是偏高的。
tprof -x sleep 30
在当前目录下生成sleep.prof文件。报告每个进程占用CPU的情况。
Total
表示该进程被占用CPU的次数。次数高则表示该进程占用CPU时间多。
PS
基本用法:ps aux |head -20
ps aux |head -20
AIX 5.3主机性能评估-磁盘的IO性能评估

AIX 5.3主机性能评估-磁盘的I/O性能评估磁盘的I/O性能评估对磁盘IO的性能考虑:1)将频繁访问的文件系统和裸设备应尽可能放置在不同的磁盘上。
2)在建立逻辑卷时尽可能使用mklv的命令开关给不同的文件系统和裸设备赋予不同的内策略。
3)使用磁盘设备驱动适配器的功能属性构建合适的RAID方式,以获得更高的数据安全性和存取性能。
一般考虑采用RAID5或者RAID10方式,对于写要求比较高的系统,一般建议采用RAID10方式;关于RAID10 与RAID 5的比较,可以见piner的文章,作为补充我会在后面贴出。
4)尽可能利用内存读写带宽远比直接磁盘I/O操作性能优越的特点,使频繁访问的文件或数据置于内存中进行操作处理;社区论坛在这里,顺带提一下裸设备以及文件系统的对比。
裸设备的优点:1)由于旁路了文件系统缓冲器而进行直接读写,从而具有更好的性能。
对硬盘的直接读写就意味着取消了硬盘与文件系统的同步需求。
这一点对于纯OLTP系统非常有用,因为在这种系统中,读写的随机性非常大以至于一旦数据被读写之后,它们在今后较长的一段时间内不会得到再次使用。
除了OLTP,raw设备还能够从以下几个方面改善DSS应用程序的性能:排序:对于DSS环境中大量存在的排序需求,raw设备所提供的直接写功能也非常有用,因为对临时表空间的写动作速度更快。
序列化访问:raw设备非常适合于序列化I/O动作。
同样地,DSS中常见的序列化I/O(表/索引的完全扫描)使得raw设备更加适用于这种应用程序。
2)直接读写,不需要经过OS级的缓存。
节约了内存资源,在一定程度上避免了内存的争用。
3)避免了操作系统的cache预读功能,减少了I/O。
4)采用裸设备避免了文件系统的开销。
比如维护I-node,空闲块等。
裸设备的缺点:1、裸设备的空间大小管理不灵活。
在放置裸设备的时候,需要预先规划好裸设备上的空间使用。
还应当保留一部分裸设备以应付突发情况。
AIX 5.3主机性能评估-Memory性能评估参考模板

Memory性能评估1、VMM的管理简介首先,还是简单讲解一下内存以及的VMM的一点工作原理。
内存和交换空间一般都是用页面来进行分配和管理的。
在内存中存在两种类型的页面:计算页面(一般为可执行文件段中的页面)和文件页面(存储的数据文件的页面)。
当我们执行程序或者读入数据的时候,内存中的页面就逐渐被占用。
当空闲的内存只剩maxfree的时候,vmm 的调页就被唤醒,通过调页算法,将内存中的页面转移到交换空间中。
一直到空闲内存达到maxfree,才停止调页。
在这里,我们涉及到两个参数:1)Minfree:最小空闲页链表尺寸。
一旦低于该值,系统偷页以填充页链表,保证有足够的内存页面。
偷页就是将不常用的页面替换出去。
2)Maxfree:最大空闲页链表尺寸。
一旦高于该值,系统停止偷页。
如果发现空闲列表不足,可以用下面的方法增加minfree参数#vmo -o minfree=1000 -o maxfree=1008Setting maxfree to 1008Setting minfree to 1000#vmo –o minfree=1000 –o maxfree=1008 –P # -P参数使修改永久生效一般情况下,minfree和maxfree通过下面的公式得到:maxfree=minmum(memory/128,128) ,minfree=maxfree-8注意:在AIX 5.2之前的版本请使用/usr/samples/kernel/vmtune命令。
#/usr/samples/kernel/vmtune –f 1000 –F 1008另外,关于内存的使用,我们还有两个经常碰到的参数需要关注:Minperm:用户I/O文件访问的最小缓冲区页数Maxperm:用户I/O文件访问的最大缓冲区页数Minperm和maxperm这两个参数的默认值分别为20%和80%。
在这里主要与性能相关的是maxperm参数。
《Aix + Oracle 系统性能管理及实战》60页,约10万字,WORD

Aix + Oracle 系统性能管理及实战更多资料下载,请收藏2010-12-2目录AIX 5.3主机性能评估 (3)一、CPU性能评估 (3)1、vmstat (3)2、sar (4)3、iostat (7)4、tprof (7)5、ps (9)6、解决CPU占用的惩罚机制nice和renice (10)7、小结 (12)二、Memory性能评估 (12)1、VMM的管理简介 (12)2、使用vmstat确定内存的使用情况 (16)3、svmon命令 (16)4、内存的调整 (17)三、磁盘的I/O性能评估 (18)1、iostat查看 (19)2、sar –d查看 (22)3、使用lslv –l lvname来评估逻辑卷的碎片情况 (24)4、lslv –p 评估物理布局 (25)5、使用vmstat 命令评估调页空间的I/O (25)6、使用filemon命令监控系统I/O (26)7、监视磁盘I/O 的小结 (28)8、案例 (29)9、RAID10和RAID5的比较 (30)四、NETWORK性能评估 (33)1、ping命令查看网络的连通性 (34)2、netstat –i检查网络的接口 (34)3、netstat –r检查主机的路由情况 (35)4、netpmon (37)5、其他一些常用的命令 (39)五、补充:关于topas的使用说明 (39)六、主机日常检查脚本 (42)AIX 5.3主机性能评估对于AIX主机的性能评估,我们从下面的4个方面来逐一介绍:CPU、MEMORY、I/O 系统和网络这4个方面来描述。
一、CPU性能评估首先,我们还是先来看一下CPU的性能评估。
下面先主要介绍几个看CPU性能的命令。
1、vmstat使用vmstat来进行性能评估,该命令可获得关于系统各种资源之间的相关性能的简要信息。
当然我们也主要用它来看CPU的一个负载情况。
下面是我们调用vmstat命令的一个输出结果:$vmstat 1 2System configuration: lcpu=16 mem=23552MBkthr memory page faults cpu----- ----------- ------------------------ ----------------- -----------r b avm fre re pi po fr sr cy in sy cs us sy id wa0 0 3091988 2741152 0 0 0 0 0 0 1849 26129 4907 8 1 88 30 0 3091989 2741151 0 0 0 0 0 0 2527 32013 6561 15 2 77 6对上面的命令解释如下:Kthr段显示内容♦r列表示可运行的内核线程平均数目,包括正在运行的线程和等待CPU 的线程。
AIX操作系统性能分析报告

AIX操作系统性能分析报告1)CPU$ vmstat 5 5System configuration: lcpu=8 mem=7744MBkthr memory page faults cpu----- ----------- ------------------------ ------------ ----------- r b avm fre re pi po fr sr cy in sy cs us sy id wa1 5 1943309 1817 0 341 109 2018 6836 0 1246 3524 5000 34 3 32 311 8 1943312 861 0 23 812 1975 2909 0 1227 776 4348 13 3 45 392 6 1945483 1855 0 78 737 1189 1880 0 639 1287 2119 30 1 39 302 5 1949024 1921 0 307 73 1002 2973 0 511 3190 1719 57 1 20 224 9 1959284 2146 0 400 35 2745 21198 0 824 21885 30 45 62 2 12 24从上面结果看出,CPU的idle在12-45之间,wait在22-39之间,表示目前处于空闲状态的CPU基本属于正常;但是处于等待状态的CPU较多,即有较多的进程在等待获取资源后才能进入CPU运行。
2)内存$ vmstat 5 5System configuration: lcpu=8 mem=7744MBkthr memory page faults cpu----- ----------- ------------------------ ------------ ----------- r b avm fre re pi po fr sr cy in sy cs us sy id wa1 5 1943309 1817 0 341 109 2018 6836 0 1246 3524 5000 34 3 32 311 8 1943312 861 0 23 812 1975 2909 0 1227 776 4348 13 3 45 392 6 1945483 1855 0 78 737 1189 1880 0 639 1287 2119 30 1 39 302 5 1949024 1921 0 307 73 1002 2973 0 511 3190 1719 57 1 20 224 9 1959284 2146 0 400 35 2745 21198 0 824 21885 30 45 62 2 12 24从上面看出,avm(激活虚拟内存页)为1.95M*4K=7.8G;fre(物理内存中的空闲页)为1.9k*4k=7.6M,而物理内存有8G,表示物理内存已经被充分利用。
AIX主机性能评估要点

AIX主机性能评估这一篇可以作为我前面发的statspack解读的姊妹篇,再进一步说明如何来观察与数据库紧密联系的主机的性能。
对于AIX主机的性能评估,主要从下面的4个方面来逐一介绍:CPU、MEMORY、IO系统和网络这4个方面来描述。
AIX 5.3主机性能评估 2一、CPU性能评估 21、vmstat 22、sar 33、iostat 54、tprof 65、ps 86、解决CPU占用的惩罚机制nice和renice 97、小结 10二、Memory性能评估 111、VMM的管理简介 112、使用vmstat确定内存的使用情况 143、svmon命令 144、内存的调整 15三、磁盘的IO性能评估 161、iostat查看 172、sar –d查看 203、使用lslv –l lvname来评估逻辑卷的碎片情况 214、lslv –p 评估物理布局 225、使用 vmstat 命令评估调页空间的 IO 236、使用filemon命令监控系统IO 247、监视磁盘 IO 的小结 268、案例 269、RAID10和RAID5的比较 28四、NETWORK性能评估 311、ping命令查看网络的连通性 312、netstat –i检查网络的接口 313、netstat –r检查主机的路由情况 324、netpmon 345、其他一些常用的命令 36五、补充:关于topas的使用说明 36六、主机日常检查脚本 39脚本中包括的内容包括:主机的cpu,memory,io,network检查;ha检查,主机告警日志;数据库表空间,告警日志,job等的检查。
更新:七、结合oracle的一个案例第一部分目录一、CPU性能评估 11、vmstat 12、sar 33、iostat 54、tprof 55、ps 76、解决CPU占用的惩罚机制nice和renice 97、小结 91、vmstat使用vmstat来进行性能评估,该命令可获得关于系统各种资源之间的相关性能的简要信息。
AIX 性能调优-内存、CPU篇

AIX 性能调优-内存、CPU篇sar -P ALL cpu使用情况sar -a 文件访问情况dirblk/s 定位文件时被目录访问守护进程读取的快(512b)的个数iget/s i节点查找系统进程被调用次数lookuppn/s 目录查找进程找到v节点,并获取路径名的次数sar -b buffer的活动情况,包括传输、访问、和命中率bread/s、bwrit/s 块IO操作的数量lread/s、lwrit/s 逻辑 IO请求的个数pread/s、pwrit/s 裸设备IO操作数量%rcache、%rwrit cache命中率,计算共式为:((lreads-breads)/lreads)*100sar -c 系统调用情况exec/s、fork/s 调用和执行系统调用总数sread/s、swrit/s read/writ 系统调用次数rchar/s、wchar/s 被read/writ系统调用的字符数量scall/s 系统调用总数sar -k 内核进程活动情况kexit/s 中断的内核进程数kproc-ov/s 由于进程数的限制无法创建内核进程的次数ksched/s 被作业分派的内核进程数sar -m 消息队列和信号灯活动情况msg/s IPC消息队列活动情况sema/s 信号灯活动情况sar -d 磁盘读写情况sar -q 队列统计信息run-sz 内核线程处于运行队列的平均数%runocc 最近时间段运行队列占用百分比swpq-sz 内核线程等待页面调度的平均数%swpocc 交换队列最近活动情况sar -r 页面调度信息cycle/s 每秒中页面置换次数fault/s 每秒中page fault次数slots 在页空间中空闲页数量odio/s 每秒中不使用页面空间的磁盘io数sar -v 进程、内核线程、i节点、和文件表的状态sar-w 上下文切换次数sar -y tty设备活动情况canch/s tty输入队列中规范的字符数mdmin/s tty modem 中断outch/s 输出队列字符数rawch/s 输入队列字符数revin/s tty接收中断xmtin/s tty传输中断如果CPU的使用率接近100%(usr+system),可以视为是CPU瓶颈。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
AIX 5.3主机性能评估-CPU性能评估来源: 作者: BTxigua 时间:2008-03-10 阅读:270/article/e1/1250.html对于AIX主机的性能评估,我们从下面的4个方面来逐一介绍:CPU、MEMORY、I/O 系统和网络这4个方面来描述。
一、CPU性能评估首先,我们还是先来看一下CPU的性能评估。
下面先主要介绍几个看CPU性能的命令。
1、vmstat使用vm stat来进行性能评估,该命令可获得关于系统各种资源之间的相关性能的简要信息。
当然我们也主要用它来看CPU的一个负载情况。
下面是我们调用vmstat命令的一个输出结果:技术社区$vm stat 1 2System configuration: lcpu=16 m em=23552MBkthr m emory page faults cpu----- ----------- ------------------------ ----------------------------r b avm fre re pi po fr sr cy in sy cs us sy id wa0 0 3091988 2741152 0 0 0 0 0 0 1849 26129 4907 8 1 88 30 0 3091989 2741151 0 0 0 0 0 0 2527 32013 6561 15 2 77 6对上面的命令解释如下:Kthr段显示内容♦r列表示可运行的内核线程平均数目,包括正在运行的线程和等待CPU 的线程。
如果这个数字大于CPU 的数目,则表明有线程需要等待CPU。
♦b列表示处在非中断睡眠状态的进程数。
包括正在等待文件系统I/O 的线程,或由于内存装入控制而被挂起的线程。
Mem ory段显示内容♦av m列表示活动虚拟内存的页面数,每页一般4KB♦fre空闲的页面数,每页一般4KBPage段显示内容♦re –该列无效♦pi 从磁盘交换到内存的交换页(调页空间)数量,4KB/页。
调页空间是驻留在硬盘上的虚拟内存的一部分。
当内存使用过量时,会将溢出的工作组页面存储到调页空间中(窃取页)。
当进程访问一个窃取页时,就产生了一个缺页故障,而这一页页必须从调页空间中读入到内存中。
♦po 从内存交换到磁盘的交换页数量,4KB/页。
如果窃取的工作也在调页空间中不存在或者已经作了修改,则写入调页空间中。
如果不被再次访问,它会留在调度空间中直到进程终止或者放弃空间。
♦fr 根据页面替换算法每秒释放的页数。
当VMM页面替换例程扫描页面帧表(Page Fram e Table,PFT)时,它会根据一些条件选取需要窃取的页面以补充空闲列表。
该条件中包含工作页面和计算页面,释放的页面中,计算页面不产生I/O,工作页面如果数据没有发生修改,也不需要写回磁盘,也不会产生I/O。
♦sr 根据页面替换算法每秒所检查的页数。
sr值比fr值高的越多,说明替换算法要查找可以替换的页面就越困难。
♦cy 每秒页面替换代码扫描了PFT多少次。
因为增加空闲列表达到m axfree值,不一定需要完全扫描PFT表,而所有vmstat输出都为整数,所以通常cy列值为0。
Faults段显示内容(其实这段内容不需太多关注)♦in 在该时间间隔中观测到的每秒设备中断数。
♦sy 在该时间间隔中观测到的每秒系统调用次数。
♦cs 在该时间间隔中观测到的每秒钟上下文切换次数。
Cpu段显示内容♦us 列显示了用户模式所消耗的CPU 时间。
♦sy 列详细显示了CPU 在系统模式所消耗的CPU 时间。
♦id 列显示了没有未决本地磁盘I/O 时CPU 空闲或等待时间的百分比。
♦wa 列详细显示了有未决本地磁盘I/O 时CPU 空闲的时间百分比。
wa 的值如果超过25%,就表明磁盘子系统可能没有被正确平衡,或者这也可能是磁盘工作负荷很重的结果。
如果在一个单用户系统中,us + sy时间不超过90%,我们就不认为系统的CPU是受限制的。
如果在一个多用户系统中,us + sy时间超过80%, 我们就认为系统的CPU是受限的。
其中的进程将要花时间在运行队列中等待。
响应时间和吞吐量会受损害。
检查cpu,我们主要关注报告中的4个cpu列和2个kthr(内核线程)列。
在上面的示例中,我们可以观察到以下几个主要的信息:CPU IDLE比较高,比较空闲;r列为0,表明线程不存在等待;WA值不高,说明I/O压力不大;free值比较大,pi,po为0,表明内存非常富裕。
空闲较多。
2、sar第二个常用的是sar命令,但是sar会增加系统的开销。
当然有些情况下,我们使用sar 比较方便。
sar的输出结果与前面的基本类似,这里不再作详细的介绍,关于命令的语法,也不再作详细的介绍,我们常用的命令格式:#sar 1 3AIX jsdxh_db02 3 5 00C2C1EB4C00 10/24/07System configuration: lcpu=1617:52:26 %usr %sys %wio %idle physc17:52:27 19 7 0 75 8.0017:52:28 19 6 0 75 8.0117:52:29 19 7 0 75 8.02Average 19 7 0 75 8.01在这里,sar命令输出的是一个整体的cpu使用情况的一个统计,统计分项目的内容也比较直观,通过名字就可以理解涵义。
这里有一点比较方便的就是,在最后一行有一个汇总的average行,作为上述统计的一个平均。
另外,补充说明一点的就是,一般来说,第一行统计信息包含了sar命令本身启动的cpu消耗,所以往往是偏高的,所以导致average值也往往是偏高一点的。
当然,这不会对结果产生多大影响。
当我们有多个cpu的时候,而程序采用的是单线程,有时候会出现一种情况,我们检查发现,cpu总体的使用率不高,但是程序响应却比较慢。
这里有可能就是单线程只使用了一个cpu,导致这个cpu100%占用,处理不过来,而其他的cpu却闲置。
这时可以对cpu分开查询,统计每个cpu的使用情况。
#sar -P ALL 1 2AIX jsdxh_db02 3 5 00C2C1EB4C00 10/24/07System configuration: lcpu=1618:03:30 cpu %usr %sys %wio %idle physc18:03:31 0 0 69 0 31 0.001 50 50 0 0 1.002 0 0 0 100 0.523 0 0 0 100 0.484 0 1 0 99 0.545 0 0 0 100 0.466 0 0 0 100 0.537 0 0 0 100 0.478 0 0 0 100 0.539 0 0 0 100 0.4710 0 2 0 98 0.5411 0 0 0 100 0.4612 11 58 0 31 0.0013 100 0 0 0 1.0014 0 0 0 100 0.5315 0 0 0 100 0.47- 19 7 0 75 8.0118:03:32 0 0 71 0 29 0.001 50 50 0 0 1.002 0 0 0 100 0.523 0 0 0 100 0.484 0 1 0 99 0.545 0 0 0 100 0.476 0 0 0 100 0.527 0 0 0 100 0.478 0 0 0 100 0.539 0 0 0 100 0.4710 0 2 0 98 0.5411 0 0 0 100 0.4612 39 41 0 20 0.0013 100 0 0 0 1.0014 0 0 0 100 0.5215 0 0 0 100 0.47- 19 7 0 75 7.98Average 0 0 70 0 30 0.001 50 50 0 0 1.002 0 0 0 100 0.523 0 0 0 100 0.484 0 1 0 99 0.545 0 0 0 100 0.466 0 0 0 100 0.537 0 0 0 100 0.478 0 0 0 100 0.539 0 0 0 100 0.4710 0 2 0 98 0.5411 0 0 0 100 0.4612 28 48 0 24 0.0013 100 0 0 0 1.0014 0 0 0 100 0.5215 0 0 0 100 0.47- 19 7 0 75 8.00上面是分cpu统计的情况,结果应该也比较直观吧。
Sar还有其他一些比较特殊的使用方法,比如:如果希望多个采样和多个报告,可为sar 命令指定一个输出文件,这样就方便多了。
将sar 命令的标准输出数据定向到/dev/null,并将sar 命令作为后台进程运行。
具体的命令格式为:sar -A -o /temp/sar_result.log 5 300 > /dev/null &关于sar其他的一些使用方法,这里不再详述。
3、iostat第三个可以用来使用的命令是iostat.$ iostat -t 2 4tty: tin tout avg-cpu: % user % sys % idle % iowait0.0 0.0 0.0 0.1 99.8 0.10.0 81.0 0.0 0.1 99.9 0.00.0 40.5 0.0 0.0 100.0 0.00.0 40.5 0.0 0.1 99.1 0.8TTY 的两列信息(tin 和tou)显示了由所有TTY 设备读写的字符数CPU 统计信息列(% user、% sys、% idle 和% iowait)提供了CPU 的使用情况。
注意:第一份报告为系统启动以来的一个累积值。
4、tprof使用tprof命令用于统计每个进程的CPU使用情况# tprof -x sleep 30该命令的输出结果可查看__prof.all文件。
此命令运行30秒钟,在当前目录下创建一个名为_prof.all 的文件。
30秒钟内,CPU 被调度次数约为3000次。
__prof.all 文件中的字段Total 为此进程调度到的CPU次数。
如果进程所对应的Total字段的值为1500,即表示该进程在3000次CPU调度中占用了1500次,或理解为使用了一半的CPU时间。
tprof的输出准确地显示出哪个进程在使用CPU 时间。
在我下面的这一份示例中,可以看到,大部分的cpu时间都是被wait所占用的。
这里的wait实际上是idle进程,可以表明这个系统是一个完全空闲的系统。
$ m ore __prof.allProcess PID TID Total Kernel User Shared Other============= ===== ====== ===============wait 40970 40971 2998 2998 0 0 0wait 32776 32777 2994 2994 0 0 0wait 24582 24583 2985 2985 0 0 0wait 16388 16389 2980 2980 0 0 0syncd 221254 155707 31 31 0 0 0caiUxOs 524540 2294015 3 0 0 3 0 netm73746 73747 1 1 0 0 0 hats_nim 1671242 1220665 1 0 0 1 0snm pd64 598258 1245291 1 1 0 0 0rpc.lockd 639212 1728679 1 1 0 0 0 tprof 704622 2277437 1 0 0 1 0 trclogio 360524 2408625 1 1 0 0 0trace 1523820 2523145 1 0 0 1 0clinfo 1958102 2760945 1 1 0 0 0 sh 1572938 2285709 1 1 0 0 0 ============= ===== ====== ===============Total 12000 11994 0 6 0Process FREQ Total Kernel User Shared Other======= ======== ========== ===========wait 4 11957 11957 0 0 0syncd 1 31 31 0 0 0caiUxOs 1 3 0 0 3 0netm 1 1 1 0 0 0hats_nim 1 1 0 0 1 0snm pd64 1 1 1 0 0 0rpc.lockd 1 1 1 0 0 0tprof 1 1 0 0 1 0trclogio 1 1 1 0 0 0trace 1 1 0 0 1 0clinfo 1 1 1 0 0 0sh 1 1 1 0 0 0======= ======== ========== ===========Total 15 12000 11994 0 6 0在这里,对wait进程作一点补充说明。