exp6_二叉树
数据结构二叉树实验报告
一 、实验目的和要求(1)掌握树的相关概念,包括树、节点的度、树的度、分支节点、叶子节点、孩子节点、双亲节 点、树的深度、森林等定义。
(2)掌握树的表示,包括树形表示法、文氏图表示法、凹入表示法和括号表示法等。
(3)掌握二叉树的概念,包括二叉树、满二叉树和完全二叉树的定义。
(4)掌握二叉树的性质。
(5)重点掌握二叉树的存储结构,包括二叉树顺序存储结构和链式存储结构。
(6)重点掌握二叉树的基本运算和各种遍历算法的实现。
(7)掌握线索二叉树的概念和相关算法的实现。
(8)掌握哈夫曼树的定义、哈夫曼树的构造过程和哈夫曼编码的产生方法。
(9)掌握并查集的相关概念和算法。
(10)灵活运用二叉树这种数据结构解决一些综合应用问题。
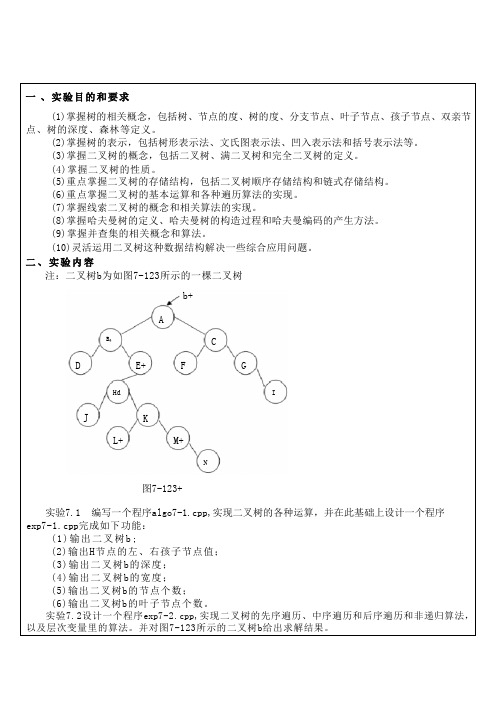
二、实验内容注:二叉树b 为如图7-123所示的一棵二叉树图7-123+实验7.1 编写一个程序algo7-1.cpp,实现二叉树的各种运算,并在此基础上设计一个程序exp7-1.cpp 完成如下功能:(1)输出二叉树b ;(2)输出H 节点的左、右孩子节点值; (3)输出二叉树b 的深度; (4)输出二叉树b 的宽度; (5)输出二叉树b 的节点个数;(6)输出二叉树b 的叶子节点个数。
实验7.2设计一个程序exp7-2.cpp,实现二叉树的先序遍历、中序遍历和后序遍历和非递归算法, 以及层次变量里的算法。
并对图7-123所示的二叉树b 给出求解结果。
b+ACF GIKL+NM+E+HdJD₄B臣1607-1.CPPif(b?-HULL)re3P4+;Qu[rear]-p-b;Qu[rear].1no=1;while(reart=front){Front++;b=Qu[front]-P;lnum-Qu[front].1no;if(b->Ichildt=NULL)rpar+t;Qu[rear]-p=b->1child;Qu[rear].Ino-lnun+1;if(D->rch11d?=NULL)1/根结点指针入队//根结点的层次编号为1 1/队列不为空1/队头出队1/左孩子入队1/右孩子入队redr+t;qu[rear]-p=b->rchild;Qu[rear].1no-lnun*1;}}nax-0;lnun-1;i-1;uhile(i<=rear){n=0;whdle(i<=rear ge Qu[1].1no==1num)n+t;it+;Inun-Qu[i].1n0;if(n>max)nax=n;}return max;田1607-1.CPPreturn max;}elsereturn o;口×int Modes(BTNode *D) //求二叉树D的结点个数int nun1,nun2;if(b==NULL)returng,else if(b->ichild==NULL&D->rchild==NULL)return 1;else{num1-Hodes(b->Ichild);num2=Nodes(b->rchild);return(num1+nun2+1);LeafNodes(BINode *D) //求二叉树p的叶子结点个数int num1,num2;1f(D==NULL)return 0;else if(b->1chi1d==NULLc& b->rch11d==NULL)return 1;else{num1-LeafModes(b->lchild);num2=LeafNodes(b->rchild);return(nun1+nun2);int程序执行结果如下:xCProrn FlslirosfViu l SudiollyPrjecslro7 LJebuglFoj7 ex<1)输出二叉树:A<B<D,E<H<J,K<L,M<,N>>>>),C<F,G<,I>>)<2)'H’结点:左孩子为J石孩子为K(3)二叉树b的深度:7<4)二叉树b的宽度:4(5)二叉树b的结点个数:14(6)二叉树b的叶子结点个数:6<?>释放二叉树bPress any key to continue实验7 . 2程序exp7-2.cpp设计如下:坠eTPT-2.EPP#include<stdio.h》winclude<malloc.h>deFn Masie 00typde chr ElemTyetypede sruct nde{ElemType data;stuc node *lclldstruct node rchild;》BTHode;extern vod reaeBNodeBTNode extrn void DispBTHode(BTNodeuoid ProrderBTNode *b)if(b?-NULL)- 回1 / 数据元素1 / 指向左孩子1 / 指向右孩子*eb car *str)xb1 / 先序遍历的递归算法1 / 访问根结点/ / 递归访问左子树1 7 递归访问右子树/ / 根结点入栈//栈不为空时循环/ / 退栈并访问该结点/ / 右孩子入栈{》v oidprintf(*c“,b->data); Preorder(b->lchild); Pre0rder(b->rchild);Preorder1(BTNode *b)BTNode xSt[Maxsize],*p;int top=-1;if(b!-HULL)top++;St[top]-b;uhle (op>-)p-St[top];top--;printf("%c“,p->data);if(p->rchild?-HULL)A约e程p7-2.CPPprintF(”后序逅历序列:\n");printf(" 递归算法=");Postorder(b);printf("\n");printf(“非递归算法:“);Postorder1(b);printf("\n");序执行结果如下:xCAPrograFleicsoftVisal SudlyrjecsProj 2Debuzlroj72ex"二叉树b:A(B(D,ECH<J,K(L,M<,N)>))),C(F,GC.I>))层次遍历序列:A B C D E F G H I J K L M N先序遍历序列:递归算法:A B D E H J K L M N C F G I非归算法:A B D E H J K L M N C F G I中序遍历序列:递归算法: D B J H L K M N E A F C G I非递归算法:D B J H L K M N E A F C G I后序遍历序列:递归算法: D J L N M K H E B F I G C A非递归算法:D J L N H K H E B F I G C APress any key to continue臼p7-3.CPP15Pp a t h[p a t h l e n]-b->d a t a;//将当前结点放入路径中p a t h l e n t+;/7路任长度培1Al1Path1(b->ichild,patn,pathlen);1/递归扫描左子树Al1Path1(b->rchild,path,pathlen); //递归扫描右子树pathlen-- ; //恢复环境uoid Longpath(BTNode *b,Elemtype path[1,int pathlen,Elemtype longpath[],int elongpatnien) int i;1f(b==NULL){if(pathlen>longpatnlen) //若当前路径更长,将路径保存在1ongpatn中for(i-pathlen-1;i>-8;i--)longpath[i]=path[1];longpathlen-pathlen;elsepath[pathlen]=b->data; pathlen4; //将当前结点放入路径中//路径长度增1iongPath(b->lchild,path₇pathlen,langpath,longpathien);//递归扫描左子树LongPath(b->rchiid,path,pathien,longpath,longpathien);//递归扫描石子树pathlen--; /7饮其环境oid DispLeaf(BTNode xb)- 口凶uoid DispLeaf(BTNode xb)iE(D!=NULL){ if(b->1child--HULL B& b->rchild--HULL)printf("3c“,b->data);elsepispLeaf(b->ichild);DispLeaf(b->rchild);oid nain()8TNodexb;ElenType patn[Maxsize],longpath[Maxsize];int i.longpathien-U;CreateBTNode(b,"A(B(D,E(H(J,K(L,H(,N))))),C(F,G(,I)))");printf("\n二灾树b:");DispBTNode(b);printf("\n\n*);printf(”b的叶子结点:");DispLeaf(b);printf("\n\n");printf("A11Path:");A11Path(b);printf("m");printf("AiiPath1:n");AliPath1(b.path.);printf("");LongPath(b,path,8,longpath,longpathlen);printf(”第一条量长路径长度=d\n”,longpathlen);printf(”"第一茶最长路径:");for(i=longpathlen;i>=0;i--)printf("c",longpatn[1]);printf("\n\n");。
二叉树知识点总结

二叉树知识点总结1. 二叉树的性质1.1 二叉树的性质一:二叉树的深度二叉树的深度是指从根节点到叶子节点的最长路径长度。
对于一个空树而言,它的深度为0;对于只有一个根节点的树而言,它的深度为1。
根据定义可知,深度为k的二叉树中,叶子节点的深度值为k。
由此可知,二叉树的深度为所有叶子节点深度的最大值。
1.2 二叉树的性质二:二叉树的高度二叉树的高度是指从根节点到叶子节点的最短路径长度。
对于一个空树而言,它的高度为0;对于只有一个根节点的树而言,它的高度为1。
由此可知,二叉树的高度总是比深度大一。
1.3 二叉树的性质三:二叉树的节点数量对于一个深度为k的二叉树而言,它最多包含2^k - 1个节点。
而对于一个拥有n个节点的二叉树而言,它的深度最多为log2(n+1)。
1.4 二叉树的性质四:满二叉树满二叉树是一种特殊类型的二叉树,它的每个节点要么是叶子节点,要么拥有两个子节点。
满二叉树的性质是:对于深度为k的满二叉树而言,它的节点数量一定是2^k - 1。
1.5 二叉树的性质五:完全二叉树完全二叉树是一种特殊类型的二叉树,它的所有叶子节点都集中在树的最低两层,并且最后一层的叶子节点从左到右依次排列。
对于一个深度为k的完全二叉树而言,它的节点数量一定在2^(k-1)和2^k之间。
2. 二叉树的遍历二叉树的遍历是指按照一定的顺序访问二叉树的所有节点。
二叉树的遍历主要包括前序遍历、中序遍历和后序遍历三种。
2.1 前序遍历(Pre-order traversal)前序遍历的顺序是:根节点 -> 左子树 -> 右子树。
对于一个二叉树而言,前序遍历的结果就是按照“根-左-右”的顺序访问所有节点。
2.2 中序遍历(In-order traversal)中序遍历的顺序是:左子树 -> 根节点 -> 右子树。
对于一个二叉树而言,中序遍历的结果就是按照“左-根-右”的顺序访问所有节点。
2.3 后序遍历(Post-order traversal)后序遍历的顺序是:左子树 -> 右子树 -> 根节点。
6节点二叉树形态数

6节点二叉树形态数二叉树是一种常见且重要的数据结构,在计算机科学和算法设计中被广泛应用。
它由一个根节点和分别连接到根节点的左子树和右子树组成,每个子树也是二叉树。
不同的二叉树形态可以带来不同的特性和应用。
在这篇文章中,我们将着重探讨六节点二叉树的形态数,并讨论它的生动场景和实际用途,以及对于算法设计和数据结构的指导意义。
六节点二叉树形态数指的是具有六个节点的所有不同形态的二叉树数量。
在六节点二叉树中,根节点有两个选择,它可以连接到两棵不同的子树上。
而这两棵子树的形态又可以由它们各自的节点数量确定。
例如,如果根节点连接到一棵有三个节点的子树,那么剩下两个节点将连接到另一棵有两个节点的子树。
因此,我们可以通过递归的方式计算出六节点二叉树的形态数。
对于六节点二叉树,形态数为132种。
这意味着有132种不同的六节点二叉树形态。
其中一些形态可能是对称的,而其他形态可能是非对称的。
这些形态数与具体的二叉树设计和应用有关。
二叉树在日常生活中有许多应用。
举例来说,我们可以将六节点二叉树看作一个家庭谱系图,其中根节点代表祖辈,子树代表各个家庭分支。
通过观察六节点二叉树的不同形态,我们可以了解到不同家庭的结构和关系。
此外,二叉树还可以用于实现搜索算法和排序算法。
比如二叉搜索树是一种特殊的二叉树结构,它可以在O(log n)的时间内进行搜索和插入操作。
对于六节点二叉树,我们可以通过选择不同的节点顺序构建不同的二叉搜索树,并比较它们在搜索和排序方面的性能。
对于算法设计和数据结构的指导意义,我们可以通过研究六节点二叉树的形态数,深入理解递归和二叉树结构的性质。
同时,对于更大规模的二叉树,我们可以借鉴六节点二叉树的思想,将问题分解为更小规模的子问题,并通过组合和迭代得到最终的解。
总之,六节点二叉树的形态数是一个有趣而具有挑战性的问题。
通过研究六节点二叉树,我们不仅可以深入理解二叉树结构和递归思想,还可以应用于实际生活和算法设计中。
10.3二叉树看跌期权定价与平价原理

第10章二叉树法期权定价及其Python应用本章精粹蒙特卡罗模拟法便于处理报酬函数复杂、标的变量多等问题,但是在处理提前行权问题时却表现出明显的不足。
本章将要介绍的二叉树法可以弥补蒙特卡罗模拟法的这种不足。
二叉树的基本原理是:假设变量运动只有向上和向下两个方向,且假设在整个考察期内,标的变量每次向上或向下的概率和幅度不变。
将考察期分为若干阶段,根据标的变量的历史波动率模拟标的变量在整个考察期内所有可能的发展路径,并由后向前以倒推的形式走过所有结点,同时用贴现法得到在0时刻的价格。
如果存在提前行权的问题,必须在二叉树的每个结点处检查在这一点行权是否比下一个结点上更有利,然后重复上述过程。
10.1 二叉树法的单期欧式看涨期权定价假设:(1) 市场为无摩擦的完美市场,即市场投资没有交易成本。
这意味着不支付税负,没有买卖价差(Bid-Ask Spread)、没有经纪商佣金(Brokerage Commission)、信息对称等。
(2) 投资者是价格的接受者,投资者的交易行为不能显著地影响价格。
(3) 允许以无风险利率借入和贷出资金。
(4) 允许完全使用卖空所得款项。
(5) 未来股票的价格将是两种可能值中的一种。
为了建立好二叉树期权定价模型,我们先假定存在一个时期,在此期间股票价格能够从现行价格上升或下降。
下面用实例来说明二叉树期权定价模型的定价方法。
1. 单一时期内的买权定价假设股票今天(t =0)的价格是100美元,一年后(t =1)将分别以120美元或90美元出售,就是1年后股价上升20%或下降10%。
期权的执行价格为110美元。
年无风险利率为8%,投资者可以这个利率放款(购买这些利率8%的债券)或借款(卖空这些债券)。
如图10-1所示。
今天 1年后t =0 t =1u S 0=120 上升20% 1000=Sd S 0=90 下降10%u 0max(u ,0)max(120110,0)10C S X =-=-=?0=Cd 0max(d ,0)max(90110,0)0C S X =-=-=图10-1 买权价格图10-1表示股票买权的二叉树期权定价模型。
正则二叉树

正则二叉树正则二叉树是一个数学名词。
在根树中,若每个分支点的出度小于或等于m,则称该树为m叉树。
如果每个分支点的出度恰好等于m,则称该树为m叉正则树。
m=2时,该根树称为二叉正则树。
若其所有树叶层次相同,称为二叉完全正则树要理解什么是二叉树正则,必须了解树、有向树、根树、叉树等概念。
一个连通且无回路的无向图,称为树。
如果有向图在不考虑边的方向时,是一棵树,那么这个有向图称为有向树。
若一棵有向树,恰有一个结点入度为0,其余所有结点的入度均为1,则称该有向树为根树。
扩展资料树的概念下图我们日常生活中所见到的树,可以看到,从主树干出发,向上衍生出很多枝干,而每一根枝干,又衍生出一些枝丫,就这样组成了我们在地面上可以看到的树的结构,但对于每一个小枝丫来讲,归根结底,还是来自于主树干的层层衍生形成的。
我们往往需要在计算机中解决这样一些实际问题例如:•用于保存和处理树状的数据,例如家谱,组织机构图•进行查找,以及一些大规模的数据索引方面•高效的对数据排序先不提一些复杂的功能,就例如对于一些有树状层级结构的数据进行建模,解决实际问题,我们就可以利用“树” 这种结构来进行表示,为了更符合我们的习惯,我们一般把“树” 倒过来看,我们就可以将其归纳为下面这样的结构,这也就是我们数据结构中的“ 树”树中的常见术语•结点:包含数据项以及指向其他结点的分支,例如上图中圆A 中,既包含数据项A 又指向 B 和 C 两个分支•特别的,因为A 没有前驱,且有且只有一个,所以称其为根结点•子树:由根结点以及根结点的所有后代导出的子图称为树的子树•例如下面两个图均为上面树中的子树•结点的度:结点拥有子树的数目,简单的就是直接看有多少个分支,例如上图A 的度为2,B的度为1•叶结点:也叫作终端结点,即没有后继的结点,例如E F G H I•分支结点:也叫作非终端结点,除叶结点之外的都可以这么叫•孩子结点:也叫作儿子结点,即一个结点的直接后继结点,例如B 和C 都是A 的孩子结点•双亲结点:也叫作父结点,一个结点的直接前驱,例如A 是B 和C 的双亲结点•兄弟结点:同一双亲的孩子结点互称为兄弟结点例如B 和C 互为兄弟•堂兄弟:双亲互为兄弟结点的结点,例如D 和E 互为堂兄弟•祖先结点:从根结点到达一个结点的路径上的所有结点,A B D 结点均为H 结点的祖先结点•子孙结点:以某个结点为根的子树中的任意一个结点都称为该结点的子孙结点,例如C 的子孙结点有 E F I•结点的层次:设根结点层次为1,其余结点为其双亲结点层次加1,例如,A 层次为1,BC 层次为2•树的高度:也叫作树的深度,即树中结点的最大层次•有序/无序树:树中结点子树是否从左到右为有序,有序则为有序树,无序则为无序树可能大家也看到了,上面我举的例子,分支全部都在两个以内,这就是我们今天所重点介绍的一种树——“二叉树”二叉树在计算机科学中,二叉树(英语:Binary tree)是每个结点最多只有两个分支(即不存在分支度大于2的结点)的树结构。
第七章二叉树和三叉树的期权定价方法

7.1.1 二叉树格的校对 二叉树格方法应该是风险中性过程一个良好的相似。
dS rSdt SdW
因此,我们应以这样的方式参数设置晶格,即保持着连续时间模型的 一些基本属性,这一过程就叫做校准。从 St 开始,经过一个小的时间 步 t ,从 2.5 节我们可以看到新价格是一个随机变量 St t ,且
0.4 ,存续期为 5 个月,利用 B-S 模型,我们知道结果是:
>> call blsprice(50,50,0.1,5 / 12,0.4)
6
>> call 6.1165 如果我们想用二叉树格方法逼近结果的话, 我们首先就要定义格 参数,假定每个时间步为一个月,然后
t 1 / 12 0.0833
最后我们得到这样的等式
e 2 rt 2t (u d )e tt 1
其中,利用 u 1 / d ,可以转化为二次方程:
u 2 e rt u(1 e 2rt ) ett 0
2t
方程的一个跟为
u (1 e 2 rt t ) (1 e 2 rt t ) 2 4e 2 rt
欧式看涨期权接收到通常我们所定义的参数和在此情况下的时 间步 N,通过增加最后一个参数,我们得到了更为精确的价格(同一 计算时间的增加) 。
call(50,50,0.1,5 / 12,0.4,5) >> call latticeEur
>> call
6.3595
call(50,50,0.1,5 / 12,0.4,500) >> call latticeEur
f 0 e rt [ pfu (1 p) f d ]
二叉树的复杂度计算公式

二叉树的复杂度计算公式二叉树是一种常见的数据结构,它在计算机科学中扮演着非常重要的角色。
在实际应用中,我们经常需要对二叉树的复杂度进行计算。
二叉树的复杂度计算涉及到许多方面,如平均时间复杂度、最坏时间复杂度、空间复杂度等。
在接下来的内容中,我们将介绍二叉树的复杂度计算公式,详细说明各种复杂度的计算方法。
二叉树的基本概念二叉树是一种树形结构,它由节点和边组成,每个节点最多有两个子节点。
在二叉树中,每个节点都有一个值,用来存储数据。
节点之间通过边相连,形成一个层次结构。
二叉树的一个特点是,每个节点最多有两个子节点,一个称为左子节点,另一个称为右子节点。
1.平均时间复杂度平均时间复杂度是指对于具有相同大小输入的所有可能输入实例,算法的期望运行时间。
在计算平均时间复杂度时,我们通常采用平均情况分析的方法。
平均时间复杂度的计算公式如下所示:T(n)=Σ(Ti)/N其中,T(n)表示算法的平均运行时间,Ti表示第i个输入实例的运行时间,N表示所有可能输入实例的个数。
2.最坏时间复杂度最坏时间复杂度是指在最坏情况下,算法的运行时间。
在计算最坏时间复杂度时,我们通常采用最坏情况分析的方法。
最坏时间复杂度的计算公式如下所示:T(n) = max{Ti}其中,T(n)表示算法的最坏运行时间,Ti表示第i个输入实例的运行时间,max{}表示所有输入实例中的最大值。
3.空间复杂度空间复杂度是指在运行算法时所需的内存空间大小。
空间复杂度的计算公式如下所示:S(n)=Σ(Si)/N其中,S(n)表示算法的空间复杂度,Si表示第i个输入实例的内存空间大小,N表示所有可能输入实例的个数。
总结二叉树作为一种常见的数据结构,在计算机科学中应用广泛。
对于二叉树的复杂度计算,我们可以通过平均时间复杂度、最坏时间复杂度和空间复杂度等指标来评估算法的性能。
掌握二叉树复杂度计算的方法,有助于我们更好地分析和优化算法,在实际应用中取得更好的性能表现。
二叉树的广义表表示法__概述及解释说明

二叉树的广义表表示法概述及解释说明1. 引言1.1 概述二叉树是一种常见的数据结构,在计算机科学中广泛应用。
为了有效地表示和操作二叉树,人们提出了各种表示方法。
其中,二叉树的广义表表示法是一种常用且灵活的方式。
1.2 文章结构本文将首先介绍二叉树的广义表表示法的定义和特点。
然后,我们将详细讨论广义表的表示方法,并解释广义表与二叉树之间的关系。
接下来,我们将介绍如何使用广义表表示方法构建二叉树,并讨论相应的转换方法。
最后,我们将探讨在广义表表示法下如何进行遍历和操作二叉树,并提供相应的实现方法和示例场景。
1.3 目的本文的目标是全面而清晰地介绍二叉树的广义表表示法,使读者对该方法有深入理解。
通过学习本文,读者将能够掌握如何使用广义表表示法构建和操作二叉树,并能够在实际问题中应用相关技巧。
同时,本文还旨在帮助读者提高对数据结构和算法相关知识的理解水平,并培养解决实际问题时分析和抽象的能力。
这样,我们完成了“1. 引言”部分的详细撰写。
2. 二叉树的广义表表示法2.1 定义和特点二叉树是一种常用的数据结构,每个节点最多有两个子节点,分别称为左子节点和右子节点。
二叉树的广义表表示法是一种将二叉树以字符串形式进行表示的方法。
在广义表中,以括号形式将二叉树的节点和子树进行包裹,并使用逗号分隔各个元素。
2.2 广义表的表示方法广义表由以下部分组成:- 括号:用来包裹二叉树的节点和子树。
- 节点值:表示该节点存储的数据值。
- 逗号:用于分隔各个元素。
- 空格:可选,用于提高可读性。
例如,假设有一个二叉树如下所示:```A/ \B C/ \D E```它可以表示为广义表形式为:`(A, (B, (), ()), (C, (D, (), ()), (E, (), ())))`解释上述广义表:- `(A`代表当前节点的值为A。
- `(B, (), ())`代表当前节点的左子节点为空并且右子节点为空。
- `(C, (D, (), ()), (E, (), ()))`代表当前节点的左子节点为D、右子节点为E。
二叉树
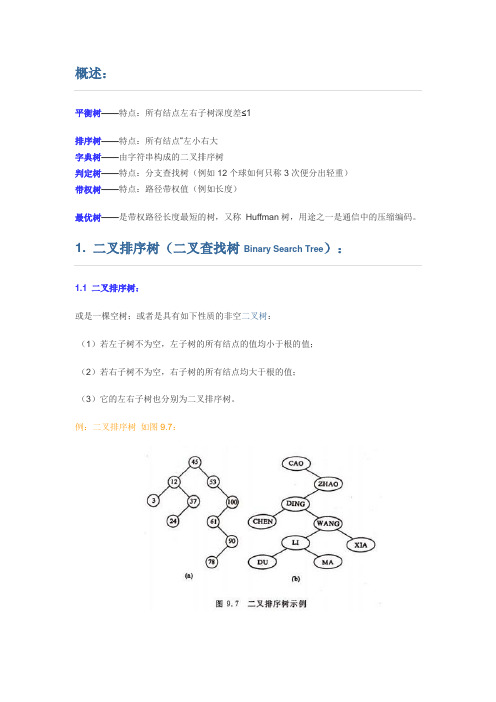
平衡树——特点:所有结点左右子树深度差≤1排序树——特点:所有结点―左小右大字典树——由字符串构成的二叉排序树判定树——特点:分支查找树(例如12个球如何只称3次便分出轻重)带权树——特点:路径带权值(例如长度)最优树——是带权路径长度最短的树,又称Huffman树,用途之一是通信中的压缩编码。
1.1 二叉排序树:或是一棵空树;或者是具有如下性质的非空二叉树:(1)若左子树不为空,左子树的所有结点的值均小于根的值;(2)若右子树不为空,右子树的所有结点均大于根的值;(3)它的左右子树也分别为二叉排序树。
例:二叉排序树如图9.7:二叉排序树的查找过程和次优二叉树类似,通常采取二叉链表作为二叉排序树的存储结构。
中序遍历二叉排序树可得到一个关键字的有序序列,一个无序序列可以通过构造一棵二叉排序树变成一个有序序列,构造树的过程即为对无序序列进行排序的过程。
每次插入的新的结点都是二叉排序树上新的叶子结点,在进行插入操作时,不必移动其它结点,只需改动某个结点的指针,由空变为非空即可。
搜索,插入,删除的复杂度等于树高,期望O(logn),最坏O(n)(数列有序,树退化成线性表).虽然二叉排序树的最坏效率是O(n),但它支持动态查询,且有很多改进版的二叉排序树可以使树高为O(logn),如SBT,AVL,红黑树等.故不失为一种好的动态排序方法.2.2 二叉排序树b中查找在二叉排序树b中查找x的过程为:1. 若b是空树,则搜索失败,否则:2. 若x等于b的根节点的数据域之值,则查找成功;否则:3. 若x小于b的根节点的数据域之值,则搜索左子树;否则:4. 查找右子树。
[cpp]view plaincopyprint?1.Status SearchBST(BiTree T, KeyType key, BiTree f, BiTree &p){2. //在根指针T所指二叉排序樹中递归地查找其关键字等于key的数据元素,若查找成功,3. //则指针p指向该数据元素节点,并返回TRUE,否则指针P指向查找路径上访问的4. //最好一个节点并返回FALSE,指针f指向T的双亲,其初始调用值为NULL5. if(!T){ p=f; return FALSE;} //查找不成功6. else if EQ(key, T->data.key) {P=T; return TRUE;} //查找成功7. else if LT(key,T->data.key)8. return SearchBST(T->lchild, key, T, p); //在左子树继续查找9. else return SearchBST(T->rchild, key, T, p); //在右子树继续查找10.}2.3 在二叉排序树插入结点的算法向一个二叉排序树b中插入一个结点s的算法,过程为:1. 若b是空树,则将s所指结点作为根结点插入,否则:2. 若s->data等于b的根结点的数据域之值,则返回,否则:3. 若s->data小于b的根结点的数据域之值,则把s所指结点插入到左子树中,否则:4. 把s所指结点插入到右子树中。
二叉树知识点总结

二叉树知识点总结二叉树是一种常见的数据结构,它由节点和边组成,每个节点最多有两个子节点。
以下是关于二叉树的知识点总结。
1. 二叉树的基本概念二叉树是一种树形结构,它由节点和边组成。
每个节点最多有两个子节点,分别称为左子节点和右子节点。
如果一个节点没有子节点,则称其为叶子节点。
二叉树可以为空。
2. 二叉树的遍历方式遍历是指按照一定顺序访问二叉树中的所有节点。
常见的遍历方式有前序遍历、中序遍历和后序遍历。
前序遍历:先访问当前节点,然后递归访问左子树和右子树。
中序遍历:先递归访问左子树,然后访问当前节点,最后递归访问右子树。
后序遍历:先递归访问左子树和右子树,最后访问当前节点。
3. 二叉搜索树二叉搜索树(Binary Search Tree)也称为有序二叉树或排序二叉树。
它是一种特殊的二叉树,在满足以下条件的情况下被称为“搜索”:对于任意节点,其左子树中的所有节点的值都小于该节点的值。
对于任意节点,其右子树中的所有节点的值都大于该节点的值。
左右子树也分别为二叉搜索树。
二叉搜索树支持快速查找、插入和删除操作。
它还有一些变种,如平衡二叉搜索树(AVL Tree)和红黑树(Red-Black Tree)等。
4. 二叉堆二叉堆是一种特殊的完全二叉树,它分为最大堆和最小堆两种类型。
最大堆满足父节点的值大于等于其子节点的值,最小堆满足父节点的值小于等于其子节点的值。
在最大堆中,根节点是整个堆中最大的元素;在最小堆中,根节点是整个堆中最小的元素。
二叉堆常用来实现优先队列(Priority Queue),即按照一定优先级顺序处理元素。
5. 二叉树常见问题5.1 判断是否为平衡二叉树平衡二叉树(Balanced Binary Tree)是指任意节点左右子树高度差不超过1的二叉搜索树。
判断一个二叉搜索树是否为平衡二叉树可以通过递归遍历每个节点,计算其左右子树的高度差。
5.2 判断是否为完全二叉树完全二叉树(Complete Binary Tree)是指除了最后一层外,其他层都是满的,并且最后一层的节点都靠左排列的二叉树。
【数据结构】二叉树

【数据结构】⼆叉树【⼆叉树】 ⼆叉树是最为简单的⼀种树形结构。
所谓树形结构,其特征(部分名词的定义就不明确给出了,毕竟不是学术⽂章。
)在于: 1. 如果是⾮空的树形结构,那么拥有⼀个唯⼀的起始节点称之为root(根节点) 2. 除了根节点外,其他节点都有且仅有⼀个“⽗节点”;除此外这些节点还都可以有0到若⼲个“⼦节点” 3. 树中的所有节点都必须可以通过根节点经过若⼲次后继操作到达 4. 节点之间不会形成循环关系,即任意⼀个节点都不可能从⾃⾝出发,经过不重复的径路再回到⾃⾝。
说明了树形结构内部蕴含着⼀种“序”,但是不是线性表那样的“全序” 5. 从树中的任意两个节点出发获取到的两个任意⼦树,要不两者⽆交集,要不其中⼀者是另⼀者的⼦集 限定到⼆叉树,⼆叉树就是任意⼀个节点⾄多只能有两个⼦节点的树形结构。
也就是说,某个节点的⼦节点数可以是0,1或2。
由于可以有两个⼦节点,所以区别两个⼦节点可以将其分别定义为左⼦节点和右⼦节点。
但是需要注意的是,若⼀个节点只有⼀个⼦节点,那么也必须明确这个⼦节点是左⼦节点还是右⼦节点。
不存在“中⼦节点”或者“单⼦节点”这种表述。
由于上述规则对所有节点都⽣效,所以⼆叉树也是⼀个递归的结构。
事实上,递归就是⼆叉树⼀个⾮常重要的特点,后⾯还会提到很多通过递归的思想来建⽴的例⼦。
对于左⼦节点作为根节点的那颗⼆叉树被称为相对本节点的左⼦树,右⼦树是同理。
■ 基本概念 空树 不包含任何节点的⼆叉树,连根节点也没有 单点树 只包含⼀个根节点的⼆叉树是单点树 ⾄于兄弟关系,⽗⼦关系,长辈后辈关系是⼀⾔既明的就不说了。
树中没有⼦节点的节点被称为树叶(节点),其余的则是分⽀节点。
⼀个节点的⼦节点个数被称为“度数”。
正如上所说,⼆叉树任意节点的度数取值可能是0,1或2。
节点与节点之间存在关联关系,这种关联关系的基本长度是1。
通过⼀个节点经过若⼲个关联关系到达另⼀个节点,经过的这些关联关系合起来被称为⼀个路径。
二叉树

6-2-2 二叉树的基本操作与存储实现
1、二叉树的基本操作 Initiate(bt)
Create(x, lbt, rbt)
InsertL(bt, x, parent) InsertR(bt, x, parent) DeleteL(bt,parent) DeleteR(bt,parent)
Search(bt,x)
BiTree DeleteL(BiTree bt, BiTree parent){ BiTree p; if(parent==NULL||parent->lchild==NULL){ cout<<“删除出错”<<endl; return NULL; } p=parent->lchild; parent->lchild =NULL; delete p; return bt ; }
a b c e 0 1 2 3 4 5 a b c d e ^ 6 7 8 9 10 ^ ^ ^ f g
d
f
g
特点:结点间关系蕴含在其存储位置中。浪费空间, 适于存满二叉树和完全二叉树。
二、链式存储结构 1、二叉链表存储法
A
B C E G D B A ^
lchild data rchild
F
^ C ^ typedef struct BiTNode { DataType data; struct BiTNode *lchild, *rchild; }BiTNode, *BiTree; ^ E
二叉树的五种基本形态
A
A
A B
A
B 空二叉树
B
C 左、右子树 均非空
只有根结点 的二叉树
右子树为空
左子树为空
_二叉树期权定价模型

(二)二叉树期权定价模型1.单期二叉树定价模型期权价格=×+×U:上行乘数=1+上升百分比d:下行乘数=1-下降百分比【理解】风险中性原理的应用其中:上行概率=(1+r-d)/(u-d)下行概率=(u-1-r)/(u-d)期权价格=上行概率×C u/(1+r)+下行概率×C d/(1+r)【教材例7-10】假设ABC公司的股票现在的市价为50元。
有1股以该股票为标的资产的看涨期权,执行价格为52.08元,到期时间是6个月。
6个月以后股价有两种可能:上升33.33%,或者降低25%。
无风险利率为每年4%。
【答案】U=1+33.33%=1.3333d=1-25%=0.75=6.62(元)【例题•计算题】假设甲公司的股票现在的市价为20元。
有1份以该股票为标的资产的看涨期权,执行价格为21元,到期时间是1年。
1年以后股价有两种可能:上升40%,或者降低30%。
无风险利率为每年4%。
要求:利用单期二叉树定价模型确定期权的价值。
【答案】期权价格=(1+r-d)/(u-d)×C u/(1+r)=(1+4%-0.7)/(1.4-0.7)×7/(1+4%)=3.27(元)2.两期二叉树模型(1)基本原理:由单期模型向两期模型的扩展,不过是单期模型的两次应用。
【教材例7-11】继续采用[例7-10]中的数据,把6个月的时间分为两期,每期3个月。
变动以后的数据如下:ABC公司的股票现在的市价为50元,看涨期权的执行价格为52.08元,每期股价有两种可能:上升22.56%或下降18.4%;无风险利率为每3个月1%。
【解析】P=(1+1%-0.816)/(1.2256-0.816)=0.47363C U=23.02×0.47363/(1+1%)=10.80C d=0C0=10.80×0.47363/(1+1%)=5.06(2)方法:先利用单期定价模型,根据C uu和C ud计算节点C u的价值,利用C ud和C dd计算C d的价值;然后,再次利用单期定价模型,根据C u和C d计算C0的价值。
二叉树模型
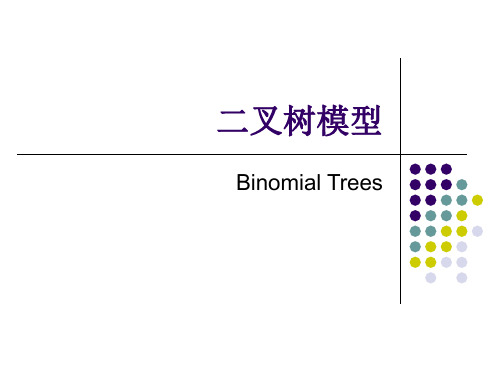
Cd = Max(0,100(.80) - 100) = Max(0,80 - 100) = 0 h = (25 - 0)/(125 - 80) = .556 p = (1.07 - 0.80)/(1.25 - 0.80) = .6
二叉树模型
Binomial Trees
注意: d < exp(r*T) < u 以避免套利 构筑一个无风险的组合,价值为:
V = hS - C
到期时价值为:
Vu = hSu - Cu Vd = hSd – Cd 令 Vu = Vd,可以解得 h (对冲比率, hedge ratio)。
对冲比率
看跌期权的对冲比率公式和看涨期权的一样, 负号表示我们需要同时买入股票和看跌期权:
h 0 13.46 0.299 125 80
因而,我们需要买入299股股票和1000个期权。 成本为 $29,900 (299 x $100) + $5,030 (1,000 x $5.03) = $34,930
Cu
pC u 2
(1 p)Cud 1 r
Cd
pCdu
(1 p)Cd2 1 r
则现在的期权价值为
C pCu (1 p)Cd 1 r
或者:
C
p2Cu2
2p(1
p)Cud
(1
p)
C 2 d2
(1 r)2
•不同状态下的对冲比率是不一样的:
h
Байду номын сангаас
Cu Su
Cd Sd
,
hu
Cu2 Su 2
Cud Sud
二叉树

例.设结点的权集W ={10,12,4,7,5,18,2},建立一棵 哈夫曼树,并求出其带权路径长度。
5.什么是哈夫编码? 在数据通讯中,经常需要将传送的文字转换成由二进制 字符0,1组成的二进制代码,称之为编码。 如果在编码时考虑字符出现的频率,让出现频率高的字 符采用尽可能短的编码,出现频率低的字符采用稍长的编 码,构造一种不等长编码,则电文的代码就可能更短。哈 夫曼编码是一种用于构造使电文的编码总长最短的编码方 案。 6.求哈夫曼编码的方法 (1)构造哈夫曼树 设需要编码的字符集合为{d1,d2,…,dn},它们在电文 中出现的次数集合为{w1,w2,…,wn},以d1,d2,…, dn作为叶结点,w1,w2,…,wn作为它们的权值,构造 一棵哈夫曼树。
6.Insert操作 二叉树的插入操作与查找操作类似,为了将X插入到树 中,实际上就是先对二叉树进行查找操作。如果找到X,则 什么也不做或做一些“更新”。否则,将X插入到遍历路径 的最后一个节点上。 7.Delete操作 删除操作要比插入操作困难,主要是因为其要考虑的 情况比插入多。 如果要删除的节点是一片树叶,那么可以直接删除。 如果节点有一个儿子,则该节点可以在其父节点调整指针 绕过该节点后被删除。复杂的情况是处理有两个儿子的节 点。一般的删除策略是用其右子树的最小数据代替该节点 的数据并递归地删除那个节点。因为有子树中的最小节点 不可能有左儿子,所以第二次Delete要容易。
例.设有A,B,C,D,E,F 6个数据项,其出现的频度分别 为6、5、4、3、2、1,构造一棵哈夫曼树,并确定它们的 哈夫曼编码。
(2)在哈夫曼树上求叶结点的编码。 规定哈夫曼树中的左分支代表0,右分支代表1,则从根 结点到每个叶结点所经过的路径分支组成的0和1的序列便 为该结点对应字符的编码,上图编码为: A=11;B=01;C=00;D=100;E=1011;F=1010。 在哈夫曼编码树中,树的带权路径长度的含义是各个字 符的码长与其出现次数的乘积之和,也就是电文的代码总 长。采用哈夫曼树构造的编码是一种能使电文代码总长为 最短的、不等长编码。 求哈夫曼编码,实质上就是在已建立的哈夫曼树中,从 叶结点开始,沿结点的双亲链域回退到根结点,每回退一 步,就走过了哈夫曼树的一个分支,从而得到一位哈夫曼 码值,由于一个字符的哈夫曼编码是从根结点到相应叶结 点所经过的路径上各分支所组成的0,1序列,因此先得到 的分支代码为所求编码的低位码,后得到的分支代码为所 求编码的高位码。
表达式转表达式二叉树

表达式转表达式⼆叉树表达式树⼆叉树是表达式处理的常⽤⼯具,例如,a+b*(c-d)-e/f可以表⽰成如下所⽰的⼆叉树其中,每个⾮叶⼦节点表⽰⼀个运算符,左⼦树是第⼀个运算数对应的表达式,右⼦树是第⼆个表达式对应的表达式。
每个叶⼦节点都是数。
其在空间利⽤上也⾮常⾼效,节点数等于表达式的长度。
表达式转⼆叉树lrj说⽅法有很多种,下⾯介绍他讲的⼀种:找到“最后计算”的运算符(它是整个表达式树的根),然后递归处理左右两边。
1const int maxn = 1000 + 10;2char str[maxn];3int lch[maxn + 1], rch[maxn + 1]; char op[maxn + 1]; //每个结点的左右⼦结点编号和字符4int nc = 0; //结点数5int build_tree(char* s, int x, int y)6{7int i, c1=-1, c2=-1, p=0;8int u;9if(y-x == 1) //仅⼀个字符,建⽴单独结点10 {11 u = ++nc;12 lch[u] = rch[u] = 0;13 op[u] = s[x];14return u;15 }1617for (i = x; i < y; i++) //寻找根节点的位置18 {19switch (s[i])20 {21case'(': p++; break;22case')': p--; break;23case'+':24case'-': if (!p) c1 = i; break;25case'*':26case'/': if (!p) c2 = i; break;27 }28 }29if (c1 < 0) c1 = c2; //找不到括号外的加减号,就⽤乘除号30if(c1 < 0) return build_tree(s, x+1, y-1); //整个表达式被⼀对括号括起来31 u = ++nc;32 lch[u] = build_tree(s, x, c1);33 rch[u] = build_tree(s, c1+1, y);34 op[u] = s[c1];35return u;36 }前缀式、中缀式、后缀式前缀表达式和后缀表达式分别对应表达式树前序和后序遍历的结果,如果不考虑括号,中缀表达式对应表达式树中序遍历的结果。
二叉树期权定价模型

支付已知红利率资产的期权定价
可通过调整在各个结点上的证券价格,算出期权价格;
如果时刻 it 在除权日之前,则结点处证券价格仍为:
Su j d i j , j 0,1,, i
如果时刻 it 在除权日之后,则结点处证券价格相应调整为:
S (1 )u j d i j
j 0,1, ,i
若在期权有效期内有多个已知红利率,则 it 时刻结点的相应的证券价格为:
2、保持不变,仍为 S ;
3、下降到原先的 d 倍,即 Sd
Su3
Su2
Su2
Su
Su
Su
S
S
S
S
Sd
Sd
Sd
Sd2 Sd2
Sd3
一些相关参数:
u e 3t
d1 u
pm
2 3
pd
t 12 2
r
q
2 2
1 6
t
2 1
pu
12 2
r q
2
6
控制方差技术 基本原理:期权A和期权B的性质相似,我们可以得到期权B的解析定价公
的波动率,mˆ i 为 i 在风险中性世界中的期望增长率, ik为 i 和 k 之间的瞬间相关系数)
常数利率和随机利率的蒙特卡罗模拟 利率为常数时:期权价值为(初始时刻设为0):
.
f erT Eˆ fT
其中, Eˆ 表示风险中性世界中的期望。
利率为变量时:期权价值为(初始时刻设为0): f Eˆ erT fT
j 0,1, ,i
注意:由于
u 1 d
,使得许多结点是重合的,从而大大简化了树图。
得到每个结点的资产价格之后,就可以在二叉树模型中采用倒推定价 法,从树型结构图的末端T时刻开始往回倒推,为期权定价。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验六二叉树【实验目的】1、掌握二叉树的基本存储表示。
2、掌握二叉树的遍历操作实现方法(递归和非递归方法)。
3、理解并实现二叉树的其他基本操作。
4、掌握二叉树的重要应用---哈夫曼编码的实现。
【实验学时】4-6学时【实验预习】回答以下问题:1、二叉树的二叉链表存储表示。
2、二叉树的三种基本遍历方式。
3、解释哈夫曼树和带权路径长度WPL。
【实验内容和要求】1、编写程序exp6_1.c,实现二叉树的链式存储及基本操作。
以下图所示的二叉树实现二叉树的二叉链表存储及基本操作,回答下列问题,补充完整程序,并调试运行验证结果。
(1)按照先序序列建立该二叉树。
读入的字符序列为应为:__________________________________(*表示空指针)。
(2)该二叉树的三种遍历序列:先序序列:__________________________;中序序列:__________________________;后序序列:__________________________;(3)按层次遍历该二叉树,得到的序列为:_______________________。
(4)该二叉树的深度为:________。
(5)该二叉树的叶子结点数为:___________。
(6)交换该二叉树所有结点的左右次序得到的新二叉树为:(画出新二叉树的图)(7)新二叉树的三种遍历序列分别为:先序序列:__________________________;中序序列:__________________________;后序序列:__________________________;exp6_1.c参考程序如下:#include<stdio.h>#include<malloc.h>#define MAX 20/*---二叉树的二叉链表存储表示---*/typedef struct BTNode{char data ; /*结点数据*/struct BTNode *lchild; /*左孩子指针*/struct BTNode *rchild ; /*右孩子指针*/}*BiTree;/*---非递归遍历辅助队列---*/typedef struct{BiTree data[MAX];int front,rear;} queue;void createBiTree(BiTree *t); /*先序遍历创建二叉树*/void PreOrder(BiTree p); /*先序遍历二叉树*/void InOrder(BiTree p); /*中序遍历二叉树*/void PostOrder(BiTree p,int *count); /*后序遍历二叉树*/void RPreorder(BiTree p); /*先序遍历的非递归算法*/void RInorder(BiTree p); /*中序遍历的非递归算法*/void RPostorder(BiTree p); /*后序遍历的非递归算法*/int depth(BiTree t); /*求二叉树的深度算法*/BiTree gettreenode(char x,BiTree lptr,BiTree rptr);/*后序复制二叉树-建立结点*/ BiTree copytree(BiTree t); /*以后序遍历的方式复制二叉树*/ BiTree swap(BiTree b); /*交换二叉树的结点的左右孩子*/ void ccOrder(BiTree t); /*利用循环队列实现层次遍历*/int Leaves(BiTree t); /*统计二叉树叶子结点(递归)*/ void release(BiTree t); /*释放二叉树*//*先序遍历创建二叉树*/void createBiTree(BiTree *t){char s;BiTree q;printf("\nplease input data:");s=getchar();getchar(); /*扔掉存在键盘缓冲区的输入结束回车符*/if(s=='*') /*子树为空则返回*/{*t=NULL;return;}q=(BiTree)malloc(sizeof(struct BTNode));if(q==NULL){printf("Memory alloc failure!");exit(0);}q->data=s;*t=q;createBiTree(&q->lchild);/*递归建立左子树*/createBiTree(&q->rchild);/*递归建立右子树*/}/*createBiTree*//*先序遍历二叉树,补充递归算法*/void PreOrder(BiTree p){}/*PreOrder*//*中序遍历二叉树,补充递归算法*/void InOrder(BiTree p){}/*InOrder*//*后序遍历二叉树,补充递归算法*/void PostOrder(BiTree p,int *count){}/*PostOrder*//*先序遍历的非递归算法*/void RPreorder(BiTree p){BiTree stack[MAX],q;int top=0,i;for(i=0; i<MAX; i++) stack[i]=NULL; /*初始化栈*/ q=p;while(q!=NULL){printf("%c",q->data);if(q->rchild!=NULL) _______________________; /*右指针进栈*/if(q->lchild!=NULL) q=q->lchild; /*顺着左指针继续向下*/else if(top>0) q=stack[--top]; /*左子树访问完,出栈继续访问右子树结点*/else q=NULL;}}/*RPreorder*//*中序遍历的非递归算法*/void RInorder(BiTree p){}/*RInorder*//*后序遍历的非递归算法*/void RPostorder(BiTree p){BiTree stack[MAX],q;int i,top=0,flag[MAX];for(i=0; i<MAX; i++) /*初始化栈*/{stack[i]=NULL;flag[i]=0;}q=p;while(q!=NULL||top!=0){if(q!=NULL) /*当前结点进栈,先遍历其左子树*/{stack[top]=q;flag[top]=0;top++;q=q->lchild;}else{while(top){if(flag[top-1]==0) /*遍历结点的右子树*/{q=stack[top-1];q=q->rchild;flag[top-1]=1;break;}else{q=stack[--top];printf("%c",q->data); /*遍历结点*/}}}if(top==0) break;}}/*RPostorder*//*求二叉树的深度算法,补充递归算法*/int depth(BiTree t){}/*depth*//*建立结点*/BiTree gettreenode(char x,BiTree lptr,BiTree rptr){BiTree t;t=(BiTree)malloc(sizeof(struct BTNode));t-> data = x;t->lchild = lptr;t->rchild = rptr;return(t);}/*gettreenode*//*以后序遍历的方式递归复制二叉树*/BiTree copytree(BiTree t){BiTree newlptr,newrptr,newnode;if(t==NULL)return NULL;if(t->lchild!=NULL)newlptr = copytree(t->lchild);else newlptr = NULL;if(t->rchild!=NULL)newrptr = copytree(t->rchild);else newrptr = NULL;newnode = gettreenode(t->data, newlptr, newrptr);return(newnode);}/*copytree*//*交换二叉树的结点的左右孩子*/BiTree swap(BiTree b){BiTree t,t1,t2;if(b==NULL)t=NULL;else{t=(BiTree)malloc(sizeof(struct BTNode));t->data=b->data;t1=swap(b->lchild); /*递归交换左子树上的结点*/t2=swap(b->rchild); /*递归交换右子树上的结点*/t->lchild=t2; /*交换根t的左右子树*/t->rchild=t1;}return(t);}/*swap*//*利用循环队列实现层次遍历*/void ccOrder(BiTree t){}/*ccOrder*//*统计二叉树叶子结点,补充递归算法*/ int Leaves(BiTree t){}/*Leaves*//*释放二叉树*/void release(BiTree t){if(t!=NULL){release(t->lchild);release(t->rchild);free(t);}}/*release*/int main(){BiTree t=NULL,copyt=NULL;int c=0,select;do{printf("\n***************MENU******************\n");printf(" 1. 按先序序列建立二叉树\n");printf(" 2. 遍历二叉树(三种递归方法)\n");printf(" 3. 遍历二叉树(三种非递归方法)\n");printf(" 4. 层次遍历二叉树\n");printf(" 5. 输出二叉树的深度\n");printf(" 6. 统计二叉树的叶子结点数(递归)\n");printf(" 7. 后序遍历方式复制一棵二叉树\n");printf(" 8. 交换二叉树所有结点的左右孩子\n");printf(" 0. EXIT");printf("\n***************MENU******************\n");printf("\ninput choice:");scanf("%d",&select);getchar();switch(select){case 1:printf("\n1-按先序序列建立二叉树:\n");printf("请依次输入结点序列:\n");createBiTree(&t);if(t!=NULL)printf("二叉树创建成功!\n");elseprintf("二叉树未创建成功!\n");break;case 2:printf("\n2-遍历二叉树(三种递归方法):\n");printf("\n先序遍历序列:");PreOrder(t);printf("\n中序遍历序列:");InOrder(t);printf("\n后序遍历序列:");PostOrder(t,&c);printf("\n");break;case 3:printf("\n3-遍历二叉树(三种非递归方法):\n");printf("\n先序遍历的非递归:");RPreorder(t);printf("\n中序遍历的非递归:");RInorder(t);printf("\n后序遍历的非递归:");RPostorder(t);printf("\n");break;case 4:printf("\n4-层次遍历二叉树:\n");printf("\n按层次遍历:");ccOrder(t);printf("\n");break;case 5:printf("\n5-输出二叉树的深度:\n");printf("\n二叉树的深度:%d",depth(t));printf("\n");break;case 6:printf("\n6-统计二叉树的叶子结点数(递归):\n");printf("\n叶子结点数为:%d",Leaves(t));printf("\n");break;case 7:printf("\n7-后序遍历方式复制一棵二叉树:\n");copyt=copytree(t);if(copyt!=NULL){printf("\n先序递归遍历复制的二叉树:");PreOrder(copyt);}elseprintf("\n复制失败!");printf("\n");break;case 8:printf("\n8-交换二叉树所有结点的左右孩子:\n");printf("\n先序递归遍历交换后的二叉树:");PreOrder(swap(t));printf("\n");break;case 0:release(t); /*释放二叉树*/break;default:break;}}while(select);return 0;}2、编写程序exp6_2.c,实现哈夫曼树的建立和哈夫曼编码。