N-Gram的数据结构
n-gram评价标准

n-gram评价标准
n-gram是一种用于文本分析和自然语言处理的技术,它可以用
来分析文本中连续的n个项(通常是单词或字符)。
在评价n-gram
模型时,可以从几个方面进行考量。
首先,可以从模型的覆盖范围来评价n-gram模型。
n-gram模
型的覆盖范围越广,能够捕捉到更多的语言特征,从而提高模型的
预测准确性。
其次,可以从模型的准确性和精确度来评价。
一个好
的n-gram模型应该能够准确地预测下一个词或字符的可能性,这可
以通过perplexity(困惑度)等指标来评价。
另外,还可以从模型
的实用性和应用效果来评价,即在实际应用中,n-gram模型是否能
够有效地提高文本分析和处理的效率和准确性。
此外,还可以考虑n-gram模型的平滑技术和参数调优对模型性
能的影响。
平滑技术可以帮助解决数据稀疏和未登录词等问题,而
参数调优可以进一步提高模型的性能。
总的来说,评价n-gram模型可以从覆盖范围、准确性、实用性、平滑技术和参数调优等多个方面来进行综合考量,以期得出对模型
性能全面准确的评价。
N-Gram及其平滑技术

式中对空的等价类没有估计概率,因为空等价类并没 有对应任何有效事件。
Turing-Good估计的优缺点 和适用范围
缺点:( 1 )无法保证概率估计的“有序 性”,即出现次数多的事件的概率大于 出现次数少的事件的概率。(2)pr与r/N不 能很好地近似,好的估计应当保证 pr<=r/N。 优点:其它平滑技术的基础。 适用范围:对0<r<6的小计数事件进行估 计。
r =0
对pr求偏导,得到交叉检验估计:
1 Cr pr = , 其中 µ = µ nr
∑ Cr
r
= 保留部分语料的大小
如果测试部分也作为保留部分的话,就是典型的 极大似然估计:
C r = r ⋅ nr ⇒ p r = r / N
留一估计
留一方法是交叉检验方法的扩展,基本思想是 将给定N个样本分为N-1个样本作为训练部分, 另外一个样本作为保留部分。这个过程持续N 次,使每个样本都被用作过保留样本。 优点:充分利用了给定样本,对于N中的每个 优点: 观察,留一法都模拟了一遍没有被观察到的情 形。 对于留一方法,pr的极大似然估计为:
R R r =1 r r =0 r r
∑
R
r =1
r ⋅ nr = N 或
∑
R
r=0
pr ⋅ nr = 1
交叉检验(1)
交叉检验就是把训练样本分为m份,其中一份
作为保留部分,其余m-1份作为训练部分。训 练部分作为训练集估计概率pr,保留部分作为 测试集进行测试。 我们使用Cr表示保留部分中计数为r的计数等价 类的观察个数。对于保留部分使用最大似然法 对进行概率pr进行估计,即使对数似然函数最 大化:
留一估计可以利用计数r=1的事件来模拟未现 事件,对于未现事件有如下估计:
多关键词模糊匹配算法名词解释

编辑距离:是指两个字串之间,由一个转成另一个所需的最少编辑操作次数;俄罗斯科学家Vladimir Levenshtein在1965年提出这个概念;编辑距离越小的两个字符串越相似,当编辑距离为0时,两字符串相等。
距离:两个子串之间的“差异”叫做距离。
海明距离:相同位相同值的个数。
Hash函数:就是把任意长度的输入(又叫做预映射,pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。
这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。
简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
Simhash算法:分为5个步骤:分词(带权重w)、hash(得hash值)、加权(hash值*w)、合并(多关键词)、降维(海明距离)。
算法伪代码:1,将一个f维的向量V初始化为0;f位的二进制数S初始化为0;2,对每一个特征:用传统的hash算法对该特征产生一个f位的签名b。
对i=1到f:如果b的第i位为1,则V的第i个元素加上该特征的权重;否则,V的第i个元素减去该特征的权重。
3,如果V的第i个元素大于0,则S的第i位为1,否则为0;4,输出S作为签名。
通配符:一种特殊语句,主要有星号(*)和问号(?),用来模糊搜索文件。
当查找文件夹时,可以使用它来代替一个或多个真正字符;当不知道真正字符或者懒得输入完整名字时,常常使用通配符代替一个或多个真正的字符。
TF词频(Term Frequency):是指某一个给定的词语在该文件中出现的次数。
一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
这个数字通常会被正规化,以防止它偏向长的文件。
(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。
n-gram计算例子

n-gram计算例子English Answer:N-grams.N-grams are sequences of n words from a text or speech. They are used in natural language processing (NLP) for various tasks such as language modeling, machine translation, and text classification.Examples of N-grams.1-grams (unigrams): Single words, such as "the", "dog", and "runs".2-grams (bigrams): Pairs of words, such as "the dog", "dog runs", and "runs fast".3-grams (trigrams): Triples of words, such as "the dog runs", "runs fast", and "fast and".N-gram Calculation Example.Given the sentence "The dog runs fast and barks loudly", we can calculate the n-grams as follows:1-grams: the, dog, runs, fast, and, barks, loudly.2-grams: the dog, dog runs, runs fast, fast and, and barks, barks loudly.3-grams: the dog runs, dog runs fast, runs fast and, fast and barks, and barks loudly.Applications of N-grams.N-grams are widely used in NLP tasks:Language modeling: N-grams can be used to predict the next word in a sequence, which is essential for text generation and machine translation.Machine translation: N-grams can capture word and phrase-level dependencies, improving translation accuracy.Text classification: N-grams can be used to identify patterns and extract features for text classification tasks.Additional Notes.The order of words in n-grams is important.N-grams with higher values of n (e.g., 4-grams, 5-grams) can capture longer-range dependencies but may also suffer from data sparsity.N-grams are typically smoothed using techniques suchas Witten-Bell smoothing or Good-Turing smoothing to handle unseen n-grams.中文回答:N-Gram.N-Gram 是从文本或语音中提取的 n 个单词序列。
n-gram 分词 原理

n-gram 分词原理一、什么是n-gram分词n-gram分词是一种基于统计的文本处理方法,它将文本按照一定的规则进行切割,形成不同长度的词组。
其中n代表词组的长度,可以是1、2、3等。
二、n-gram分词的原理1. 数据预处理在进行n-gram分词之前,需要对原始文本进行预处理。
这包括去除特殊字符、停用词等。
预处理后的文本更加干净,有助于提高分词的准确性。
2. 构建n-gram模型n-gram模型是基于马尔可夫链的一种文本生成模型。
它将文本看作是一个由词组组成的序列,通过统计词组出现的频率来预测下一个词组的概率。
3. 分词在n-gram模型中,分词的过程就是根据给定的n值,将文本切割成一定长度的词组。
例如,当n=1时,就是将文本切割成单个词语;当n=2时,就是将文本切割成两个词语的组合,依此类推。
4. 评估分词结果对于分词结果,我们可以通过一些指标来评估其准确性。
常见的指标包括精确率、召回率和F1值等。
通过这些指标,我们可以了解到n-gram分词的效果如何,并对其进行优化。
三、n-gram分词的应用1. 机器翻译n-gram分词在机器翻译中有着广泛的应用。
通过将源语言和目标语言的文本切割成一定长度的词组,可以更好地进行翻译。
2. 文本分类在文本分类任务中,n-gram分词可以将文本切割成词组,并将每个词组表示为特征向量。
这样可以更好地表示文本的语义信息,提高分类的准确性。
3. 信息检索n-gram分词可以用于信息检索中的查询扩展。
通过将查询文本切割成词组,并扩展查询词,可以提高检索的准确性和召回率。
四、n-gram分词的优缺点1. 优点n-gram分词简单易懂,容易实现。
同时,它能够捕捉到词组的上下文信息,提高分词的准确性。
2. 缺点n-gram分词忽略了词与词之间的顺序关系,可能会导致分词结果的歧义。
另外,n-gram模型对于未出现的词组无法进行处理。
五、总结n-gram分词是一种基于统计的文本处理方法,通过将文本切割成一定长度的词组,可以捕捉到词组的上下文信息,提高分词的准确性。
算法:N-gram语法

算法:N-gram语法⼀、N-gram介绍 n元语法(英语:N-gram)指⽂本中连续出现的n个语词。
n元语法模型是基于(n - 1)阶马尔可夫链的⼀种概率语⾔模型,通过n个语词出现的概率来推断语句的结构。
这⼀模型被⼴泛应⽤于概率论、通信理论、计算语⾔学(如基于统计的⾃然语⾔处理NLP)、计算⽣物学(如序列分析)、数据压缩等领域。
N-gram⽂本⼴泛⽤于⽂本挖掘和⾃然语⾔处理任务。
它们基本上是给定窗⼝内的⼀组同时出现的单词,在计算n元语法时,通常会将⼀个单词向前移动(尽管在更⾼级的场景中可以使X个单词向前移动)。
例如,对于句⼦"The cow jumps over the moon" ,N = 2(称为⼆元组),则 ngram 为:the cowcow jumpsjumps overover thethe moon 因此,在这种情况下,有 5 个 n-gram。
再来看看 N = 3,ngram 将为:the cow jumpscow jumps overjumps over theover the moon 因此,在这种情况下,有 4 个 n-gram。
所以,在⼀个句⼦中 N-grams 的数量有: Ngrams(K) = X - (N - 1) 其中,X 为给定句⼦K中的单词数,N 为 N-gram 的N,指的是连续出现的 N 个单词。
N-gram⽤于各种不同的任务。
例如,在开发语⾔模型时,N-grams不仅⽤于开发unigram模型,⽽且还⽤于开发bigram和trigram模型。
⾕歌和微软已经开发了⽹络规模的 n-gram模型,可⽤于多种任务,例如拼写校正、分词和⽂本摘要。
N-gram的另⼀个⽤途是为受监督的机器学习模型(例如SVM,MaxEnt模型,朴素贝叶斯等)开发功能。
其想法是在特征空间中使⽤标记(例如双字母组),⽽不是仅使⽤字母组合。
下⾯简单介绍⼀下如何⽤ Java ⽣成 n-gram。
ngram语义编码

ngram语义编码通常指的是基于ngram模型的语义编码方法,主要用于自然语言处理领域。
在这种方法中,文本被分割成不同长度的N个连续项(通常是单词或字符),然后使用这些ngram来表示文本,并进行语义分析和编码。
具体来说,ngram语义编码可以分为以下几个步骤:
1. N-gram提取:将文本按照N个连续项进行切分,得到不同的N-gram序列。
例如,对于句子我爱自然语言处理,当N取2时,可以得到我爱、爱自然、自然语言、语言处理等2-gram 序列。
2. 特征表示:对于提取得到的N-gram序列,可以将其转换成向量表示,通常可以使用词袋模型(Bag of Words)或者TF-IDF等方法进行向量化表示。
3. 语义编码:使用机器学习或深度学习模型对得到的N-gram特征进行语义编码,以捕捉文本的语义信息。
这可能涉及到词嵌入(Word Embedding)或者更高级的语义模型。
4. 应用:进行文本分类、情感分析、信息检索等自然语言处理任务,利用N-gram语义编码来表征文本并进行相应的语义分析。
总的来说,N-gram语义编码是一种基于N-gram模型的文本表示和语义分析方法,可以用于从文本数据中提取语义信息并进行各种NLP任务。
大规模汉语语料库中任意n的n-gram统计算法及知识获取方法

大规模汉语语料库中任意n 的n -gram 统计算法及知识获取方法1)张 民 李 生 赵铁军(哈尔滨工业大学计算机科学与工程系,哈尔滨150001) 收稿日期:1996年1月21日 作者简介:张民,男,1970年生,博士生,已发表多篇论文,研究方向为计算语言学和机器翻译。
李生,男,1943年生,教授,已发表多篇论文,研究方向为人工智能、计算语言学和机器翻译。
赵铁军,男,1962年生,副教授,已发表多篇论文,研究方向为人工智能、计算语言学和机器翻译。
1)本项研究得到国家863基金(863230620320623)的资助。
摘要 本文提出并实现了一种大规模汉语语料库中字、词级任意n 的n 2gram 统计算法,本算法可以一次性统计出所有不大于任意n (本文n 取为256)的字、词级n 2gram ,可将传统n 2gram 统计时的指数空间开销变为线性的,且与所统计的元数无关。
基于这种n 2gram 的统计,本文还进行了汉语信息熵的计算及字、词级知识获取的研究。
本算法及本文的研究结果已应用于我们研制的机译系统中。
关键词 n 元语法 统计 信息熵 知识获取A lgor ith m of n -gram Sta tistics for Arb itrary n andKnowledge Acqu isition Ba sed on Sta tisticsZhang M in ,L i Sheng and Zhao T iejun(D ep art m ent of Co mp u ter S cience and E ng ineering ,H arbin Institu te of T echnology ,H arbin 150001)Abstract A new algo rithm of n 2gram statistics fo r arb itrary n at w o rd o r ph rase level is p ro 2po sed and realized in th is paper ,w ith w h ich the n 2gram fo r all n at w o rd o r ph rase level can be cal 2cu lated at the sam e ti m e .Based on the n 2gram ,the Ch inese info rm ati on en tropy and know ledge ac 2qu isiti on at w o rd o r ph rase level have also been studied .T he algo rithm and its resu lt have been in 2tegrated w ith a M T system .Keyword n 2gram ,statistics ,info rm ati on en tropy ,know ledge acqu isiti on1 引 言随着经验主义方法的重新崛起,基于统计的NL P 技术越来越被众多的各国学者所接受。
自然语言处理中常见的文本生成模型(十)

自然语言处理(NLP)是人工智能领域的一个重要分支,它致力于使计算机能够理解、解释、操作和回应人类语言。
文本生成模型是NLP中的一个重要部分,它可以通过学习大量的语言数据来生成符合语法和语义规则的文本。
本文将介绍几种常见的文本生成模型,包括N-gram模型、循环神经网络(RNN)、长短期记忆网络(LSTM)和生成对抗网络(GAN)等。
N-gram模型是一种基于统计的文本生成模型,它利用N-gram语法模型来预测下一个词的概率。
N-gram是指文本中连续的N个词或字符,通过统计语料库中不同N-gram出现的频率,可以得出下一个词出现的概率。
N-gram模型简单直观,但是在处理长文本和复杂语法时效果不佳。
循环神经网络(RNN)是一种能够处理序列数据的神经网络,它的内部结构包含循环连接,可以在处理序列数据时保留之前的信息。
RNN可以用于文本生成,通过学习语料库中的语言规律,可以生成符合语法和语义规则的文本。
然而,传统的RNN模型存在梯度消失和梯度爆炸的问题,导致长序列数据的依赖关系学习困难。
为了解决RNN模型的问题,长短期记忆网络(LSTM)被提出。
LSTM通过增加门控机制来控制信息的流动,有效地解决了梯度消失和梯度爆炸的问题,使得模型能够更好地处理长序列数据。
LSTM在文本生成任务中表现出色,可以生成更加连贯和合理的文本。
除了传统的生成模型之外,生成对抗网络(GAN)也被应用于文本生成任务。
GAN由生成器和判别器两部分组成,生成器负责生成文本,判别器负责判断生成的文本是否真实。
通过不断的对抗训练,生成器可以生成更加接近真实文本的结果。
GAN在文本生成任务中表现出色,可以生成更加真实和多样的文本。
总的来说,文本生成模型在NLP领域起到了至关重要的作用。
N-gram模型、RNN、LSTM和GAN等不同的模型在处理文本生成任务中都有各自的优势和局限性。
未来,随着NLP技术的不断发展,相信会有更多更先进的文本生成模型涌现出来,为人们的生活带来更多便利。
skipgram原理

skipgram原理Skip-gram模型是自然语言处理中一种经典的词向量表示方法,通过词的上下文来学习词的分布式表示。
该模型的原理可以分为以下几个部分:数据预处理、神经网络架构、目标函数和优化算法。
在数据预处理阶段,需要将原始文本转换为模型所需的输入形式。
通常,需要将文本划分为单词序列,并根据设定的窗口大小,提取出每个单词的上下文。
例如,对于句子"The quick brown fox jumps over thelazy dog.",如果窗口大小为2,则可以得到以下的上下文单词对:("quick", "The"), ("quick", "brown"), ("brown", "quick"), ("brown", "fox"), ("fox", "brown"), ("fox", "jumps"), ("jumps", "fox"), ("jumps", "over"), ("over", "jumps"), ("over", "the"), ("the", "over"), ("the", "lazy"), ("lazy", "the"), ("lazy", "dog"), ("dog", "lazy")。
ngram算法原理

ngram算法原理ngram算法是一种基于统计的自然语言处理方法,用于分析文本中的语言模式。
它通过将文本分割成连续的n个字母或单词序列,并计算它们在文本中的出现频率,从而揭示出文本中的潜在规律和关联性。
ngram算法的基本思想是,通过统计文本中连续出现的n个字母或单词的频率,来推断文本的特征和结构。
其中,n被称为ngram的大小,可以是1、2、3等任意正整数。
当n为1时,即为unigram;当n为2时,即为bigram;当n为3时,即为trigram,以此类推。
ngram算法的应用非常广泛,常见的应用包括文本分类、机器翻译、语音识别、信息检索等领域。
在文本分类中,ngram算法可以用于提取文本特征,将文本转化为向量表示,从而实现文本分类任务。
在机器翻译中,ngram算法可以用于建模源语言和目标语言之间的语言模式,从而提高翻译质量。
在语音识别中,ngram算法可以用于建模语音信号的概率分布,从而提高识别准确率。
在信息检索中,ngram算法可以用于计算查询词和文档之间的相似度,从而实现精准的信息检索。
ngram算法的实现步骤主要包括以下几个部分:1. 数据预处理:将文本进行分词或分字处理,得到一系列的单词或字母序列。
2. 统计ngram频率:对于每个ngram(n个连续的字母或单词),统计其在文本中的出现频率。
可以使用哈希表等数据结构来实现高效的频率统计。
3. 特征提取:根据ngram的频率,将文本转化为向量表示。
可以用每个ngram在文本中的频率作为特征值,构成一个特征向量。
4. 模型训练和预测:使用训练数据来训练一个分类器或回归模型,然后使用该模型来预测新的文本。
5. 模型评估:使用测试数据来评估模型的性能,常用的评估指标包括准确率、召回率、F1值等。
ngram算法的优点在于简单易用,能够捕捉文本中的局部信息和上下文关系,适用于各种自然语言处理任务。
然而,ngram算法也存在一些问题,比如数据稀疏性和维度灾难等。
ngram函数用法

ngram函数用法一、什么是ngram函数ngram函数是一种用于文本分析和自然语言处理的工具,用于将文本分割成连续的n个元素的序列。
在ngram中,n表示元素的数量,可以是单个字符、单词或其他更大的单位。
ngram函数可以帮助我们理解文本的结构和语义,从而进行文本分类、情感分析、语言模型等任务。
二、ngram函数的基本用法ngram函数的基本用法是将文本分割成连续的n个元素的序列。
在Python中,可以使用nltk库中的ngrams函数来实现。
下面是一个简单的例子:import nltktext = "This is an example sentence."tokens = nltk.word_tokenize(text)ngrams = list(nltk.ngrams(tokens, 2))print(ngrams)输出结果为:[('This', 'is'), ('is', 'an'), ('an', 'example'), ('example', 'sentence'), ('s entence', '.')]在上面的例子中,我们将文本分割成了两个单词的序列。
可以看到,ngrams函数返回了一个包含元组的列表,每个元组表示一个ngram序列。
三、ngram函数的参数说明ngram函数有几个常用的参数,下面是对这些参数的说明:1.sequence:要分割的文本序列,可以是字符串、列表等可迭代对象。
2.n:要分割的元素个数。
3.pad_left:是否在序列的左侧填充空白元素,默认为False。
4.pad_right:是否在序列的右侧填充空白元素,默认为False。
5.pad_symbol:填充空白元素的符号,默认为None。
N-gram基本原理

N-gram基本原理N-gram模型是⼀种语⾔模型(Language Model,LM),语⾔模型是⼀个基于概率的判别模型,它的输⼊是⼀句话(单词的顺序序列),输出是这句话的概率,即这些单词的联合概率(joint probability)。
N-gram本⾝也指⼀个由N个单词组成的集合,考虑单词的先后顺序,且不要求单词之间互不相同。
常⽤的有 Bi-gram(N=2N=2N=2) 和 Tri-gram (N=3N=3N=3),⼀般已经够⽤了。
例如在上⾯这句话⾥,我可以分解的 Bi-gram 和 Tri-gram :Bi-gram : {I, love}, {love, deep}, {love, deep}, {deep, learning}Tri-gram : {I, love, deep}, {love, deep, learning}N-gram中的概率计算联合概率的简单推导过程:A,B,C三个有顺序的句⼦。
由于P(C/(A,B))=P(A,B,C)/P(A,B)P(B/A) = P(A,B)/P(B)所以P(C/(A,B))=P(A,B,C)/(P(B/A) *P(B))P(A,B,C) = P(C/(A,B))*P(B/A) *P(B)所以我们可以很容易的得到上⾯的多个单词的联合概率,但是由于存在参数空间过⼤等问题,我们可以仅仅考虑之前的⼀个或者⼏个词的前提条件的联合概率,可以降低时间复杂度,减少计算量。
然后通过极⼤似然函数求解上⾯的概率值是从整个数据库中去计算上述的概率值,⽽不是⼀整句话。
1、可以⽤于词性标注,类似成多分类的情况:例如:我爱中国!判断爱的词性可以通过P(词性i/(名词我出现,爱字出现))=P(名词我出现,爱字不同的词性)/P(名词的我出现,爱字所有出现的次数)2、可以⽤于垃圾短信分类:步骤⼀:给短信的每个句⼦断句。
步骤⼆:⽤N-gram判断每个句⼦是否垃圾短信中的敏感句⼦。
MySQL中的全文索引实现及优化

MySQL中的全文索引实现及优化引言:MySQL是一款功能强大的关系型数据库管理系统,广泛应用于各个领域。
在实际开发过程中,对于海量数据的搜索和查询需求越来越常见。
全文索引是一种有效的实现搜索功能的技术手段。
本文将介绍MySQL中的全文索引实现及优化方法,帮助开发者更好地利用这一特性提升查询效率。
一、什么是全文索引全文索引是一种用于对文本进行高效搜索的数据结构,能够实现更复杂的模糊查询、关键词搜索等功能。
与普通索引相比,全文索引可以通过建立倒排索引来提高搜索效率。
MySQL提供了全文索引的功能,使用户能够更方便地进行文本搜索。
二、MySQL中的全文索引MySQL提供了两种类型的全文索引:全文索引和全文索引(N-gram)。
1. 全文索引全文索引(Fulltext Index)是MySQL中最基本的全文搜索功能。
它适用于较短的文本字段,例如文章标题、摘要等。
在创建全文索引之前,需要将表的存储引擎设置为MyISAM。
创建全文索引的方法如下:CREATE FULLTEXT INDEX index_name ON table_name(column_name);在查询时,可以使用MATCH AGAINST语句进行全文搜索,如下所示:SELECT * FROM table_name WHERE MATCH(column_name)AGAINST('keyword');通过使用全文索引,可以实现更快速、更准确的搜索,提高查询效率。
2. 全文索引(N-gram)全文索引(N-gram)是MySQL 5.7版本引入的功能,相对于传统的全文索引更加智能。
它可以实现中文的全文搜索,并支持更复杂的查询操作。
在创建全文索引(N-gram)之前,需要将表的存储引擎设置为InnoDB。
创建全文索引(N-gram)的方法如下:ALTER TABLE table_name ADD FULLTEXT INDEX index_name(column_name) WITH PARSER ngram;在查询时,可以使用MATCH AGAINST语句进行全文搜索,方法与全文索引相同。
ngram 分词个数

ngram 分词个数
N-gram 分词是一种文本处理技术,其中 N 代表分词的大小。
N-gram 将文本切分成长度为 N 的连续子序列。
常见的有 unigram(1-gram)、bigram(2-gram)、trigram(3-gram)等。
• Unigram(1-gram):
•将文本切分成单个词语。
例如,"Hello World" 变成 ["Hello", "World"]。
• Bigram(2-gram):
•将文本切分成两个词语的序列。
例如,"Hello World" 变成["Hello", "World"]。
• Trigram(3-gram):
•将文本切分成三个词语的序列。
例如,"Hello World" 变成["Hello", "World"]。
在实际应用中,根据任务的不同,可以选择不同大小的 N。
较小的 N 可能更关注局部上下文,而较大的 N 则可能更关注整体结构。
选择适当的 N 取决于具体的文本分析任务和文本的性质。
例如,在语言建模中,一般使用 bigram 或 trigram 进行建模,以考虑到相邻词语之间的关系。
在文本分类任务中,unigram 通常被用于构建特征,表示文本中单个词语的出现情况。
在实践中,可以通过调整 N 的大小来平衡对上下文信息的关注度。
更大的 N 可能提供更多的上下文信息,但也可能导致数据稀疏问题,特别是当训练数据有限时。
人工智能自然语言技术练习(习题卷12)

人工智能自然语言技术练习(习题卷12)说明:答案和解析在试卷最后第1部分:单项选择题,共45题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]能通过对过去和现在已知状况的分析,推断未来可能发生的情况的专家系统是()A)修理专家系统B)预测专家系统C)调试专家系统D)规划专家系统2.[单选题]RNN可以将()的时间步进行关联处理A)先前B)之后C)丢失D)LSTM3.[单选题]激活函数有很多种,也有很多异同点,以下Relu和Tanh两个激活函数,有什么不同点A)输出的值域不同B)Relu可以做非线性变换而Tanh不可以C)Relu是激活函数但是Tanh不是激活函数D)都不可以做线性变换4.[单选题]不属于面向对象的是A)A: 封装B)B: 继承C)C: 多态D)D: 消息5.[单选题]通常使用到的交叉熵函数是作为什么作用?A)损失函数B)激活函数C)sigmoid函数D)relu函数6.[单选题]下列正确的是A)句法是指描述词语排列的方法B)句法结构一般用树状数据结构表示C)句法分析,是指对输入的单词序列判断其构成是否合乎给定的语法,分析出合乎语法的句子的句法结构。
D)其它3项都对7.[单选题]AUC的值不会大于几?A)1B)2C)3D)48.[单选题]NLP研究的内容中,基础研究不包括( )。
A)隐马尔科夫模型B)字符集的编码体系C)语言计算模型D)资源建设9.[单选题]以下哪种模型是自然语言处理后Bert时代的预训练模型A)Word2VecB)RNNC)XLNetD)LSTM10.[单选题]构建神经网络模型,经常会发生过拟合现象,下列选项中关于拟合说法正确的是?A)过拟合只发生在理论阶段,实际不会发生这种情况B)欠拟合是数据量过多,造成无法全部计算的现象C)过拟合是指数据量大,计算复杂的情况D)训练准确率高,测试准确率低的情况,数据过拟合11.[单选题]哪个算法可以做机器翻译A)LSAB)seq2seqC)TextFastD)LSTM12.[单选题]以下哪个与支持向量机无关A)使用核函数B)将低维向量向高维向量转换C)使低维线性不可分的数据在高维线性可分D)使用向量的都叫支持向量机13.[单选题]以下哪种情况会导致SVM算法性能下降?A)数据线性可分B)数据干净、格式整齐C)数据有噪声,有重复值D)不确定14.[单选题]基于商品评论数据来评估客户对商品的态度运用了到以哪项数据分析工具?( )A)文本挖掘B)情感分析C)自然语言处理D)以上三种都有15.[单选题]以下机器学习算法中,属于聚类算法的是A)K均值算法B)逻辑回归C)线性回归D)支持向量机16.[单选题]在决策树的可视化中可以用以下哪个获取决策树叶子节点的个数A)plotTreeB)plotNodeC)getTreeDepthD)getNumLeafs17.[单选题]以下几个机器学习算法中,哪个算法是比较常用的无监督学习算法A)聚类B)K-近邻算法C)回归算法D)决策树18.[单选题]基于机器学习的情感分类,关键在于特征选择、( )分类模型。
arpa格式ngram语言模型

arpa格式ngram语言模型一、什么是arpa格式ngram语言模型arpa格式ngram语言模型是一种用于自然语言处理的统计模型。
它使用ngram的概念,即连续的n个词组成的序列,来对语言进行建模。
arpa格式是一种用来存储ngram语言模型的标准格式,它包含了ngram的概率以及对应的条件概率,可以用来计算句子的概率或生成文本。
二、arpa格式ngram语言模型的优点1. 稀疏性处理能力强:由于ngram语言模型对每个ngram的出现概率进行统计,很多ngram序列在实际文本中并不会出现,这就导致了模型的稀疏性。
而arpa格式可以有效地对稀疏性进行处理,通过一些技巧如平滑算法等,来提高模型的准确性和泛化能力。
2. 高效存储和计算:arpa格式可以高效地存储ngram语言模型的参数,避免了存储冗余信息。
在计算句子概率或生成文本时,arpa格式的模型也可以利用动态规划等算法来减少计算量,提高计算效率。
3. 支持多种应用:arpa格式的ngram语言模型可以应用于诸如语音识别、机器翻译、自然语言生成等多个领域,对于处理长文本、大语料库有着非常好的适应性。
三、arpa格式ngram语言模型的应用1. 语音识别:arpa格式ngram语言模型可以用来提高语音识别系统的准确性,通过统计句子的概率来挑选出最可能的识别结果,提高系统的识别性能。
2. 机器翻译:在机器翻译中,arpa格式ngram语言模型可以用来评估翻译结果的流畅度和准确性,帮助系统选择最合适的翻译候选。
3. 自然语言生成:在自然语言生成任务中,arpa格式ngram语言模型可以用来生成流畅自然的文本,提供更加准确和自然的文本输出。
四、arpa格式ngram语言模型的发展和未来arpa格式ngram语言模型自提出以来,经历了多年的发展。
随着计算机硬件的发展和大规模语料库的建立,深度学习等新技术的应用,arpa格式ngram语言模型仍然在不断发展和完善。
gram矩阵判据证明对偶原理

gram矩阵判据证明对偶原理引言:对偶原理是数学中常见的一个原理,其在线性代数、优化理论等领域中具有重要的应用。
本文将通过介绍gram矩阵的概念和性质,以及使用gram矩阵判据证明对偶原理的方法,来展示对偶原理的实际应用和证明过程。
一、gram矩阵的定义和性质1. gram矩阵的定义:gram矩阵是指由向量集合的内积构成的矩阵,通常用G表示。
假设有n个d维向量组成的集合X={x1,x2,...,xn},则gram矩阵G 的定义为G=[gij],其中gij=xi·xj,即第i行第j列元素为xi和xj的内积。
2. gram矩阵的性质:- gram矩阵是对称矩阵,即对于任意的i和j,都有gij=gji。
- gram矩阵的特征值非负,即G的所有特征值都大于等于0。
- gram矩阵的秩等于向量集合X的秩。
二、使用gram矩阵判据证明对偶原理的方法对偶原理是线性代数中的一个重要原理,它在矩阵论、优化理论等领域都具有广泛的应用。
下面将通过使用gram矩阵判据来证明对偶原理。
1. 假设有一个最小化问题:min f(x),s.t. g(x)≥0,h(x)=02. 定义拉格朗日函数:L(x,λ,μ)=f(x)+λ⋅g(x)+μ⋅h(x)3. 使用gram矩阵判据,我们可以得到以下结论:- 若存在一组λ*和μ*,使得L(x,λ*,μ*)能够取得最小值,则该最小值也是原问题的最小值。
- 若存在一组λ*和μ*,使得L(x,λ*,μ*)能够取得最小值,并且满足KKT条件(即KKT条件是满足约束条件的最优解必须满足的一组条件),则该最小值也是原问题的最优解。
4. 根据gram矩阵的性质,我们可以得到gram矩阵的一个重要性质: - 对于任意的矩阵A和B,都有tr(AB)=tr(BA),其中tr(·)表示矩阵的迹。
5. 基于上述性质,我们可以推导出gram矩阵判据:- 若存在一组λ*和μ*,使得L(x,λ*,μ*)能够取得最小值,并且满足KKT条件,那么一定存在一组α*和β*,使得f(x*)=L(x*,λ*,μ*)=tr(GX*)+α*⋅g(X*)+β*⋅h(X*),其中X*表示向量集合{xi},α*和β*是对应的拉格朗日乘子。
N-Gram的数据结构.
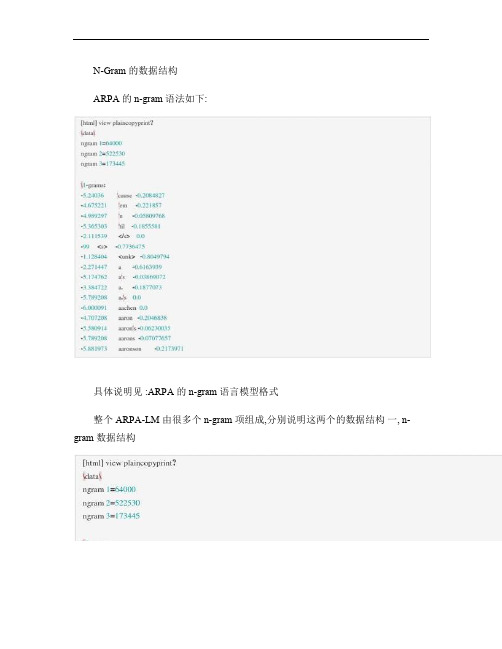
N-Gram 的数据结构ARPA 的 n-gram 语法如下:具体说明见 :ARPA 的 n-gram 语言模型格式整个 ARPA-LM 由很多个 n-gram 项组成,分别说明这两个的数据结构一, n-gram 数据结构words ,表示当前的 n-gram 所涉及的单词,如果是 1-gram ,那就只有一个,如果是2-gram ,那么 words 就包括这两个单词的序号。
log_bo,表示 ngram 的回退概率。
log_prob,表示 ngram 的组合概率。
二, ARPA-LM 数据结构多个项组成的整个 n-gram 语言模型的数据结构如下: [cpp] view plaincopyprint?vocab ,用于构建语言模型的词典指针。
词典定义见:词典内存存储模型 entries,语言模型的所有 ngram 项,是 ARPALMEntry 类型的一个二维数组。
entries[0]存储1-gram , entries[1]存储 2-gram ,依此类推。
n_ngrams,整型数组,依次包含 1-gram,2-gram,3-gram,.... 所包含的 ngram 项个数。
unk_wrd,词典中可以不在语言模型中的词。
unk_id,词典中可以不在语言模型中的词的 ID ,这个 ID 指定为词典的最后一个词序号。
n_unk_words,在读语言模型之后,统计在词典中,但没有用来建立语言模型的词个数,如果没有指定 unk_wrd的话,是不允许的,就表示所有的词典中的词都应该用来建语言模型。
unk_words,存储 6中统计的词序号。
words_in_lm,这个标识词典中的词是否在语言模型中出现。
基于N-gram特征的网络恶意代码分析方法

基于N-gram特征的网络恶意代码分析方法随着网络技术的飞速发展,网络安全成为了人们越来越关注的话题。
网络恶意代码作为网络安全领域的重要研究对象之一,对网络系统造成了严重的威胁。
为了有效地防范和应对网络恶意代码的威胁,研究人员不断探索各种分析方法来提高网络安全防护能力。
基于N-gram特征的网络恶意代码分析方法,是一种基于统计和机器学习的分析技术,能够有效地识别和分类网络恶意代码,成为了当前网络安全领域的研究热点之一。
一、N-gram特征简介N-gram是一种用于自然语言处理和文本分析的技术,指的是一个N个连续的词组或字符组合。
在网络恶意代码的分析中,采用N-gram技术可以将代码序列化成固定长度的短序列,将代码转化为特征向量进行分析。
通常来说,N-gram特征提取可以基于字符级或者单词级的分析,不同的N值会导致不同级别的特征表示。
在网络恶意代码的分析中,通常选择3-gram或者4-gram作为特征进行分析。
1. 恶意代码分类利用N-gram特征可以对网络恶意代码进行分类,这是一种基于机器学习的分类方法。
通过对已知的恶意代码进行特征提取和训练,可以建立恶意代码的分类模型。
当新的恶意代码样本出现时,可以采用训练好的分类模型进行识别和分类。
这种方法可以提高对未知恶意代码的识别能力,并能够及时响应新的安全威胁。
2. 恶意代码检测除了对已知恶意代码的分类,N-gram特征还可以用于新恶意代码的检测。
在网络安全领域中,恶意代码的变种层出不穷,传统的基于规则或签名的检测方法往往很难及时发现新的恶意代码。
利用N-gram特征进行检测,可以通过比较代码的特征向量来发现模式和相似性,从而及时发现新的恶意代码。
3. 恶意代码行为分析在网络安全的实际场景中,通常会遇到一些变种的恶意代码,这些代码可能会在行为上有所不同,通过对代码的行为进行分析,可以更好地理解其特性。
N-gram特征不仅可以对代码进行静态的分析,还可以以序列的形式将代码的行为表示为特征,从而为对恶意代码的行为分析提供了一种新的思路。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
N-Gram的数据结构
ARPA的n-gram语法如下:
具体说明见:ARPA的n-gram语言模型格式
整个ARPA-LM由很多个n-gram项组成,分别说明这两个的数据结构一,n-gram数据结构
words,表示当前的n-gram所涉及的单词,如果是1-gram,那就只有一个,如果是2-gram,那么words 就包括这两个单词的序号。
log_bo,表示ngram的回退概率。
log_prob,表示ngram的组合概率。
二,ARPA-LM数据结构
多个项组成的整个n-gram语言模型的数据结构如下: [cpp] view plaincopyprint?
vocab,用于构建语言模型的词典指针。
词典定义见:词典内存存储模型 entries,语言模型的所有ngram 项,是ARPALMEntry类型的一个二维数组。
entries[0]存储1-gram,entries[1]存储2-gram,依此类推。
n_ngrams,整型数组,依次包含1-gram,2-gram,3-gram,....所包含的ngram项个数。
unk_wrd,词典中可以不在语言模型中的词。
unk_id,词典中可以不在语言模型中的词的ID,这个ID指定为词典的最后一个词序号。
n_unk_words,在读语言模型之后,统计在词典中,但没有用来建立语言模型的词个数,如果没有指定unk_wrd的话,是不允许的,就表示所有的词典中的词都应该用来建语言模型。
unk_words,存储6中统计的词序号。
words_in_lm,这个标识词典中的词是否在语言模型中出现。