AMCM1992B层次分析题目
层次分析法例题详解语言学概论

层次分析法例题详解,层次分析法题目层次分析法(AHP法)。
层次分析法是美国匹兹堡大学T.LSaaby 教授在20世纪70年代初提出的一种多目标决策分析方法。
这一方法的核心是对决策行为、决策方案及决策对象进行评价与选择,并对其进行优劣排序,从而为决策者提供定量形式的决策信息。
一致性检验,最后获取各评价指标重要性大小的排序系数,即评价指标的权重系数。
层次分析法确定权数的步骤如下。
①构造判断矩阵。
层次分析法运用层次分析法确定各评价指标的权数,首先是构造判断矩阵B,表示同一层次各个指标的相对重要性的判断值。
1.问题重述本文要求分析Y,Q两个旅游城市旅游业发展水平,并且给出了两个城市各方面因素的对比,如城市规模与密度,经济条件,交通条件,生态环境条件,宣传与监督,旅游规格,空气质量,城市规模,人口密度,人均GDP,人均住房面积,第三产业增加值占GDP比重,税收GDP,外贸依存度,市内外交通,人均拥有绿地面积,污水集中处理率,环境噪音,国内外旅游人数,理赔金额,立案数量,A级景点数量,旅行社数量,星级饭店数量。
建立数学模型进行求解。
2.问题分析本文要求分析y,Q两个旅游城市旅游业发展水平,在对y,Q两个城市的分析中,发现需要考虑因素较多。
第一、城市规模与度,包括城市规模与人口密度第二、经济条件,包括外贸依存度,人均GDP,人均住房面积,第二产业增加值占GDP比重,税收GDP.第三、交通条件,包括市内外交通。
第四,生态环境条件包括空气质量,人均绿地面积,污水处理能力,环境噪音。
第五、宣传与监督,包括国内外旅游人数,游客投诉立案件数。
第六、旅游规格,包括A级景点个数,旅行社个数,星级饭店个数,这就涉及到层次分析法来估算各个指标的权重,评出最优方案。
具体内容如下:(1)本文选择了对y,Q两个旅游城市旅游业发展水平有影响的19个指标作为评价要素,指标规定如下:城市规模:城市的人口数量人口密度:单位面积土地上居住的人口数。
层次分析法练习参考答案

层次分析法练习练习一、市政工程项目建设决策问题提出市政部门管理人员需要对修建一项市政工程项目进行决策,可选择的方案是修建通往旅游区的高速路(简称建高速路)或修建城区地铁(简称建地铁)。
除了考虑经济效益外,还要考虑社会效益、环境效益等因素,即是多准则决策问题,试运用层次分析法建模解决。
1、建立递阶层次结构在市政工程项目决策问题中,市政管理人员希望通过选择不同的市政工程项目,使综合效益最高,即决策目标是“合理建设市政工程,使综合效益最高”。
为了实现这一目标,需要考虑的主要准则有三个,即经济效益、社会效益和环境效益。
但问题绝不这么简单。
通过深入思考,决策人员认为还必须考虑直接经济效益、间接经济效益、方便日常出行、方便假日出行、减少环境污染、改善城市面貌等因素(准则),从相互关系上分析,这些因素隶属于主要准则,因此放在下一层次考虑,并且分属于不同准则。
假设本问题只考虑这些准则,接下来需要明确为了实现决策目标、在上述准则下可以有哪些方案。
根据题中所述,本问题有两个解决方案,即建高速路或建地铁,这两个因素作为措施层元素放在递阶层次结构的最下层。
很明显,这两个方案于所有准则都相关。
将各个层次的因素按其上下关系摆放好位置,并将它们之间的关系用连线连接起来。
同时,为了方便后面的定量表示,一般从上到下用A 、B 、C 、D 。
代表不同层次,同一层次从左到右用1、2、3、4。
代表不同因素。
这样构成的递阶层次结构如下图。
目标层A准则层B准则层C措施层D图1 递阶层次结构示意图2、构造判断矩阵并请专家填写征求专家意见,填写后的判断矩阵如下:表2 判断矩阵表3、计算权向量及检验计算所得的权向量及检验结果见下:表4 层次计算权向量及检验结果表4、层次总排序及检验层次总排序及检验结果见下:表5 C层次总排序(CR = 0.0000)表D层次总排序(CR = 0.0000)5、结果分析从方案层总排序的结果看,建地铁(D2)的权重(0.6592)远远大于建高速路(D1)的权重(0.3408),因此,最终的决策方案是建地铁。
层次分析法案例

层次分析法案例层次分析法(Analytic Hierarchy Process, AHP)是一种常用的决策分析方法,由美国运筹学家托马斯·L·萨蒂(Thomas L. Saaty)在20世纪70年代提出。
该方法通过将决策问题分解为更小的部分,并通过比较这些部分的重要性来帮助决策者做出最终选择。
下面是一个层次分析法的案例分析。
首先,决策者需要明确决策目标,然后将其分解为多个层次,包括目标层、准则层和方案层。
目标层是决策的最终目的,准则层是影响决策的因素,方案层是可供选择的具体方案。
在本案例中,假设一个公司需要决定投资哪个研发项目。
目标层即为“选择最佳研发项目”。
准则层可能包括“技术可行性”、“市场潜力”、“成本效益”和“风险评估”。
方案层则是公司正在考虑的四个研发项目:A、B、C和D。
接下来,决策者需要对准则层的各个因素进行两两比较,并根据其相对重要性给出评分。
评分通常采用1-9的标度,其中1表示两个因素同等重要,9表示一个因素比另一个因素重要得多。
例如,如果认为“市场潜力”比“技术可行性”更重要,可以给出一个大于1的分数,如3或5。
完成准则层的两两比较后,决策者需要对方案层的每个方案根据每个准则进行评估。
这一步骤同样采用1-9的标度进行评分。
然后,利用层次分析法的计算方法,对准则层和方案层的评分矩阵进行一致性检验。
如果一致性比率在可接受范围内(通常小于0.1),则认为评分矩阵具有一致性,可以继续进行下一步计算;否则,需要重新评估评分。
一致性检验通过后,计算准则层和方案层的权重。
这通常是通过计算每个因素或方案在所有比较中的相对重要性来实现的。
最后,将方案层的权重与准则层的权重相乘,得到每个方案的综合得分。
根据综合得分,决策者可以选择得分最高的方案作为最终决策。
在这个案例中,如果项目C的综合得分最高,那么公司应该选择投资项目C。
层次分析法的优势在于它能够系统地处理复杂的决策问题,并通过量化的方式帮助决策者理解各个因素和方案的相对重要性。
层次分析法例题

二、AHP 求解层次分析法(Analytic Hierarchy Process )是一种定量与定性相结合的多目标决策分析法,将决策者的经验给予量化,这在对目标(因素)结构复杂且缺乏必要数据的情况下较为实用。
(一)、建立递阶层次结构目标层:最优生鲜农产品流通模式。
准则层:方案的影响因素有:1c 自然属性、2c 经济价值、3c 基础设施、5c 政府政策。
方案层:设三个方案分别为:1A 农产品产地一产地批发市场一销地批发市场一消费者、2A 农产品产地一产地批发市场一销地批发市场一农贸市场一消费者、3A 农业合作社一第三方物流企业一超市一消费者(本文假设农产品的生产地和销地不在同一个地区)。
。
图3—1 递阶层次结构(二)、构造判断(成对比较)矩阵所谓判断矩阵昰以矩阵的形式来表述每一层次中各要素相对其上层要素的相对重要程度。
为了使各因素之间进行两两比较得到量化的判断矩阵,引入1~9的标度,见表3—1.目标层:准则层:方案层:表3—1 标度值为了构造判断矩阵,作者对6个专家进行了咨询,根据专家和作者的经验,四个准则下的两两比较矩阵分别为:(三)、层次单排序及其一致性检验层次单排序就是把本层所有要素针对上一层某一要素,排出评比的次序,这种次序以相对的数值大小来表示。
对应于判断矩阵最大特征根λmax的特征向量,经归一化(使向量中各元素之和等于1)后记为W。
W的元素为同一层次因素对于上一层次因素某因素相对重要性的排序权值,这一过程称为层次单排序。
能否确认层次单排序,需要进行一致性检验,所谓一致性检验是指对A确定不一致的允许范围。
a,则λ比n 大的越多,A 的不一致性越严重。
用最大特征值对由于λ连续的依赖于ij应的特征向量作为被比较因素对上层某因素影响程度的权向量,其不一致程度越大,引起的判断误差越大。
因而可以用λ―n数值的大小来衡量 A 的不一致程度。
用一致性指标进行检验:max 1nCI n λ-=-。
其中max λ是比较矩阵的最大特征值,n 是比较矩阵的阶数。
层次分析法例题.docx

某物流企业需要采购一台设备,在采购设备时需要从功能、价格与可维护性三个角度进行评价,考虑应用层次分析法对 3 个不同品牌的设备进行综合分析评价和排序,从中选出能实现物流规划总目标的最优设备,其层次结构如下图所示。
以 A 表示系统的总目标,判断层中B1表示功能,B2表示价格, B3表示可维护性。
C1,C2,C3表示备选的3种品牌的设备。
目A判断功能 B1价格B2性B3方案品1品 C品3C2C采次构解题步骤:1、标度及描述人们定性区分事物的能力习惯用 5个属性来表示,即同样重要、稍微重要、较强重要、强烈重要、绝对重要,当需要较高精度时,可以取两个相邻属性之间的值,这样就得到 9个数值,即 9个标度。
为了便于将比较判断定量化,引入1~9比率标度方法,规定用1、3、5、7、9分别表示根据经验判断,要素 i 与要素 j 相比:同样重要、稍微重要、较强重要、强烈重要、绝对重要,而 2、4、6、8表示上述两判断级之间的折衷值。
度定(比因素 i 与 j )1因素 i 与 j 同重要3因素 i 与 j 稍微重要5因素 i 与 j 重要7因素 i 与 j 烈重要9因素 i 与 j 重要2、 4、 6、 8两个相判断因素的中倒数因素 i 与 j 比得判断矩 a ij,因素 j 与 i 相比的判断 a ji =1/ a ij注: a ij表示要素 i 与要素 j 相重要度之比,且有下述关系:a ij =1/a ji;a ii =1; i , j=1 ,2,⋯, n 然,比越大,要素 i 的重要度就越高。
2、构建判断矩阵A判断矩阵是层次分析法的基本信息,也是进行权重计算的重要依据。
根据结构模型,将图中各因素两两进行判断与比较,构造判断矩阵:●判断矩阵 A B( 即相对于物流系统总目标,判断层各因素相对重要性比较 ) 如表 1所示;●判断矩阵 B 1 C ( 相对功能,各方案的相对重要性比较 ) 如表 2 所示;●判断矩阵 B 2 C( 相对价格,各方案的相对重要性比较 ) 如表 3 所示;●判断矩阵 B 3 C( 相对可维护性, 各方案的相对重要性比较 ) 如表 4 所示。
数学建模基础(入门必备)

一、数学模型的定义现在数学模型还没有一个统一的准确的定义,因为站在不同的角度可以有不同的定义。
不过我们可以给出如下定义:“数学模型是关于部分现实世界和为一种特殊目的而作的一个抽象的、简化的结构。
”具体来说,数学模型就是为了某种目的,用字母、数学及其它数学符号建立起来的等式或不等式以及图表、图象、框图等描述客观事物的特征及其内在联系的数学结构表达式。
一般来说数学建模过程可用如下框图来表明:数学是在实际应用的需求中产生的,要解决实际问题就必需建立数学模型,从此意义上讲数学建模和数学一样有古老历史。
例如,欧几里德几何就是一个古老的数学模型,牛顿万有引力定律也是数学建模的一个光辉典范。
今天,数学以空前的广度和深度向其它科学技术领域渗透,过去很少应用数学的领域现在迅速走向定量化,数量化,需建立大量的数学模型。
特别是新技术、新工艺蓬勃兴起,计算机的普及和广泛应用,数学在许多高新技术上起着十分关键的作用。
因此数学建模被时代赋予更为重要的意义。
二、建立数学模型的方法和步骤1. 模型准备要了解问题的实际背景,明确建模目的,搜集必需的各种信息,尽量弄清对象的特征。
2. 模型假设根据对象的特征和建模目的,对问题进行必要的、合理的简化,用精确的语言作出假设,是建模至关重要的一步。
如果对问题的所有因素一概考虑,无疑是一种有勇气但方法欠佳的行为,所以高超的建模者能充分发挥想象力、洞察力和判断力,善于辨别主次,而且为了使处理方法简单,应尽量使问题线性化、均匀化。
3. 模型构成根据所作的假设分析对象的因果关系,利用对象的内在规律和适当的数学工具,构造各个量间的等式关系或其它数学结构。
这时,我们便会进入一个广阔的应用数学天地,这里在高数、概率老人的膝下,有许多可爱的孩子们,他们是图论、排队论、线性规划、对策论等许多许多,真是泱泱大国,别有洞天。
不过我们应当牢记,建立数学模型是为了让更多的人明了并能加以应用,因此工具愈简单愈有价值。
层次分析法案例

层次分析法案例层次分析法(Analytic Hierarchy Process,AHP)是一种多目标决策方法,它通过构建层次结构、建立判断矩阵、计算权重和一致性检验等步骤,帮助决策者进行系统化的决策分析。
下面我们通过一个案例来详细介绍层次分析法的具体应用。
案例背景:某公司准备引进一款新的生产设备,但在选择适合的设备时面临多个因素的考量,比如设备的性能、价格、维护成本等。
为了做出最合理的决策,公司决定采用层次分析法来进行决策分析。
步骤一,构建层次结构。
首先,公司将引进新设备的决策问题分解为三个层次,目标层、准则层和方案层。
目标层是引进新设备,准则层包括设备性能、价格和维护成本,方案层则是具体的设备选项。
在这个案例中,我们假设有A、B、C三种设备可供选择。
步骤二,建立判断矩阵。
接下来,公司需要对准则层和方案层进行两两比较,以确定它们之间的相对重要程度。
通过专家意见调查或者问卷调查,公司得到了比较矩阵,比如设备性能对价格的重要程度、设备性能对维护成本的重要程度等。
步骤三,计算权重。
利用AHP的计算方法,公司可以根据比较矩阵计算出每个准则和方案的权重。
这些权重可以帮助公司确定对于引进新设备而言,性能、价格和维护成本的重要程度,以及A、B、C三种设备的优劣。
步骤四,一致性检验。
在计算权重之后,公司需要进行一致性检验,以确保比较矩阵的合理性和可靠性。
如果比较矩阵通过一致性检验,则可以继续进行下一步决策分析。
步骤五,综合分析。
最后,公司可以利用计算出的权重,对三种设备进行综合分析,以确定最佳的选择。
在这个案例中,公司可以根据性能、价格和维护成本的权重,对A、B、C 三种设备进行打分和排名,从而做出最合理的决策。
通过以上案例,我们可以看到层次分析法在多目标决策问题中的应用。
它通过构建层次结构、建立判断矩阵、计算权重和一致性检验等步骤,帮助决策者进行系统化的决策分析,提高决策的科学性和准确性。
总之,层次分析法是一种强大的决策分析工具,它不仅可以用于企业的决策问题,也可以应用于个人生活中的选择问题。
1992年美赛题(AB)

1992 MCM A: Air-Traffic-Control Radar PowerYou are to determine the power to be radiated by an air-traffic-control radar at a major metropolitan airport. The airport authority wants to minimize the power of the radar consistent with safety and cost. The authority is constrained to operate with its existing antennae and receiver circuitry. The only option that they are considering is upgrading the transmitter circuits to make the radar more powerful. The question that you are to answer is what power (in watts) must be released by the radar to ensure detection of standard passenger aircraft at a distance of 100 kilometers.1992 MCM B: Emergency Power RestorationPower companies serving coastal regions must have emergency response systems for power outages due to storms. Such systems require the input of data that allow the time and cost required for restoration to be estimated and the “value” of the outage judged by objective criteria. In the past, Hypothetical Electric Company (HECO) has been criticized in the media for its lack of a prioritization scheme.You are a consultant to HECO power company. HECO possesses a computerized database with real time access to service calls that currently require the following information:•time of report,•type of requestor,•estimated number of people affected, and•location (x,y).Cre sites are located at coordinates (0,0) and (40,40), where x and y are in miles. The region serviced by HECO is within -65 < x < 60 and -50 < y < 50. The region is largely metropolitan with an excellent road network. Crews must return to their dispatch site only at the beginning and end of shift. Company policy requires that no work be initiated until the storm leaves the area, unless the facility is a commuter railroad or hospital, which may be processed immediately if crews are available.HECO has hired you to develop the objective criteria and schedule the work for the storm restoration requirements listed in Table 1 using their work force described in Table 2. Note that the first call was received at 4:20 A.M. and that the storm left the area at 6:00 A.M. Also note that many outages were not reported until much later in the day.HECO has asked for a technical report for their purposes and an “executive summary” in laymen's terms that can be presented to the media. Further, they would like recommendations for the future. To determine your prioritized scheduling system, you will have to make additional assumptions. Detail those assumptions. In the future, you may desire additional data. If so, detail the information desired.Table 1. Storm restoration requirements. (table incomplete)。
层次认知测试题及答案

层次认知测试题及答案1. 题目:请识别下列句子中使用的主要修辞手法。
A. 他像一只受伤的鹿一样蹒跚而行。
B. 那座山高得直插云霄。
C. 她的歌声甜美得如同天籁。
答案:A项使用了比喻,B项使用了夸张,C项使用了拟人。
2. 题目:在以下选项中,哪一个不是由三个相同的字母组成的单词?A. bookB. momC. dad答案:A项不是由三个相同的字母组成的单词。
3. 题目:下列哪个选项是正确的成语使用?A. 他做事总是半途而废,真是虎头蛇尾。
B. 她总是喜欢在人群中出风头,真是鹤立鸡群。
C. 他总是喜欢独来独往,真是凤毛麟角。
答案:B项是正确的成语使用。
4. 题目:根据所给的逻辑关系,选择正确的答案。
如果今天是星期三,那么明天是星期几?A. 星期二B. 星期四C. 星期五答案:B项是正确的答案。
5. 题目:在以下句子中,哪一个使用了倒装句?A. 他不仅学习好,而且体育也好。
B. 只有努力学习,才能取得好成绩。
C. 虽然他很聪明,但是他不勤奋。
答案:B项使用了倒装句。
6. 题目:根据所给的数学公式,计算下列表达式的值。
如果 \( x = 2 \),\( y = 3 \),计算 \( x^2 + y^2 \)。
答案:\( x^2 + y^2 = 2^2 + 3^2 = 4 + 9 = 13 \)。
7. 题目:在以下选项中,哪一个是正确的语法结构?A. 他去图书馆看书。
B. 他去图书馆看书去了。
C. 他去图书馆看书了。
答案:A项是正确的语法结构。
8. 题目:根据所给的物理定律,下列哪个选项描述了正确的运动状态?A. 一个物体在没有外力作用下,将保持静止或匀速直线运动。
B. 一个物体在受到外力作用下,将改变其速度。
C. 一个物体在受到外力作用下,将保持其速度不变。
答案:A项描述了正确的运动状态。
结束语:以上是层次认知测试题及答案,希望能够帮助您更好地理解和掌握相关知识点。
数学建模之层次分析法

层次分析法层次分析法是一种解决多目标的复杂问题的定性与定量相结合的决策分析方法。
该方法将定量分析与定性分析结合起来,用决策者的经验判断各衡量目标能否实现的标准之间的相对重要程度,并合理地给出每个决策方案的每个标准的权数,利用权数求出各方案的优劣次序,比较有效地应用于那些难以用定量方法解决的课题。
缺点:(1)层次分析法的主观性太强,模型的搭建,判断矩阵的输入都是决策者的主观判断,往往会因为决策者的考虑不周、顾此失彼而造成失误。
(2)层次分析法模型的内部结构太过理想化,完全分离、彼此独立的层次结构在实践中很难做到.(5)层次分析法只能从给定的决策方案中去选择,而不能给出新的、更优的策略。
1.模型的应用用于解决多目标的复杂问题的定性与定量相结合的决策分析。
(1)公司选拔人员,(2)旅游地点的选取,(3)产品的购买等,(4)船舶投资决策问题(下载文档),(5)煤矿安全研究,(6)城市灾害应急能力,(7)油库安全性评价,(8)交通安全评价等.2.步骤①建立层次结构模型首先明确决策目标,再将各个因素按不同的属性从上至下搭建出一个有层次的结构模型,模型如下图所示。
准则层目标层方案层目标层:表示解决问题的目的,即层次分析要达到的总目标。
通常只有一个总目标。
准则层:表示采取某种措施、政策、方案等实现预定总目标所涉及的中间环节。
方案层:表示将选用的解决问题的各种措施、政策、方案等。
通常有几个方案可选。
注意:(1)任一元素属于且仅属于一个层次;任一元素仅受相邻的上层元素的支配,并不是任一元素与下层元素都有联系; (2)虽然对准则层中每层元素数目没有明确限制,但通常情况下每层元素数最好不要超过 9 个.这是因为,心理学研究表明,只有一组事物在 9 个以内,普通人对其属性进行判别时才较为清楚。
当同一层次元素数多于 9 个时,决策者对两两重要性判断可能会出现逻辑错误的概率加大,此时可以通过增加层数,来减少同一层的元素数.②构造判断(成对比较)矩阵以任意一个上一层的元素为准则,对其支配的下层各因素之间进行两两比较。
层次分析法作业答案

你已经去过几家主要的摩托车商店,基本确定将从三种车型中选购一种。
你选择的标准主要有:价格,耗油量大小,舒适程度和外表美观情况。
经反复思考比较,构造了它们的成对比较矩阵为⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡1315518731315181517131 三种车型(记为a,b,c)关于价格,耗油量,舒适程度及你对他们外观喜欢程度的成对比较矩阵为(价格)⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡121321213121 (耗油量)⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡127151712151 (舒适程度)⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡141531415131 (外观)⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡171531713151 (1)根据上述矩阵可以看出这四项标准在你的心目中的比重是不同的,请按由大到小的顺序排出。
(2)哪辆车最便宜,哪辆车最省油,哪辆车最舒适,你认为哪辆车最漂亮?用层次分析法确定你对这三种车型的喜欢程度(用百分比表示)。
比建模过程如下:先构建成对比较矩阵1378111552311133751114853x x x x ⎡⎤⎢⎥⎢⎥ ⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥1⎢⎥⎣⎦A =列向量归一化,得到矩阵B=0.62450.68180.52500.47060.20820.22730.37500.29410.08920.04550.07500.17650.07810.04550.02500.0588⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦,然后按行求和得到矩阵C =2.30191.10460.38620.2074⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦,再对矩阵C = 2.30191.10460.38620.2074⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦归一化得到w =0.57530.27610.09650.0518⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦,2.49401.20970.38940.2111*?A w ⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦=1/4 2.4940/0.5753 1.2097/0.27610.3894/0.09650.2111/0.0518 1.2068µ=⨯+++=()同理,可求得下面四个比较矩阵权向量和最大特征根。
层次分析法例题(20210228092920)

专题:层次分析法一般情况下,物流系统的评价属于多目标、多判据的系统综合评价。
如 果仅仅依靠评价者的定性分析和逻辑判断,缺乏定量分析依据来评价系统 方案的优劣,显然是十分困难的。
尤其是物流系统的社会经济评价很难作 出精确的定量分析。
层次分析法(Analytical Hierarchy Process )由美国著名运筹学家萨蒂(T . L . Saaty )于1982年提出,它综合了人们主观判断,是一种简明、实 用的定性分析与定量分析相结合的系统分析与评价的方法。
目前,该方法 在国内已得到广泛的推广应用,广泛应用于能源问题分析、科技成果评比、 地区经济发展方案比较,尤其是投入产出分析、资源分配、方案选择及评 比等方面。
它既是一种系统分析的好方法,也是一种新的、简洁的、实用 的决策方法。
♦层次分析法的基本原理人们在日常生活中经常要从一堆同样大小的物品中挑选出最重的物品。
这时,一般是利用两两比较的方法来达到目的。
假设有 n 个物品,其真实重 量用w 1 , w 2,…W n 表示。
要想知道w 1 , w 2,…w n 的值,最简单的就是用秤称 出它们的重量,但如果没有秤,可以将几个物品两两比较,得到它们的重 量比矩阵A 。
由上式可知,n 是A 的特征值,W 是A 的特征向量。
根据矩阵理论,n 是 矩阵A 的唯一非零解,也是最大的特征值。
这就提示我们,可以利用求物品 重量比判断矩阵的特征向量的方法来求得物品真实的重量向量 W 。
从而确 定最重的物品。
将上述n 个物品代表n 个指标(要素),物品的重量向量就表示各指标(要/ivs ...爲严/如果用物品重量向量 W=[w 1,W J W2 …W J W n_w 2,…w n ]T 右乘矩阵A ,则有:AW^/ W]W 2 / W]A ■ ■叫/W] / 叫nw l叫/ %1 H—叫/W] / w 2 / w 2素)的相对重要性向量,即权重向量;可以通过两两因素的比较,建立判断矩阵,再求出其特征向量就可确定哪个因素最重要。
关于层次分析法的例题与解

旅游业发展水平评价问题摘要为了研究比较两个旅游城市Q、Y的旅游业发展水平,建立层次分析法]3[数学模型,对两个旅游城市Q、Y的旅游业发展水平进行了评价.首先,通过对题目中的图1、表1进行了分析与讨论,根据层次分析法,建立了目标层A、准则层B和子准则层C、方案层D四个层次,通过同一层目标之间的重要性的两两比较,得出判断矩阵,利用]1[MATLAB编程对每个判断矩阵进行求解.其次,用MATLAB软件算出决策组合向量,再比较决策组合向量的大小,由“决策组合向量最大”为目标,得出城市Y的决策组合向量为0.4325,城市Q组合向量为0.5675.最后,通过城市Q旅游业发展水平与旅游城市Y旅游业发展水平的决策组合向量比较,得出城市Q的旅游业发展水平较高.关键词层次分析法MATLAB旅游业发展水平决策组合向量1.问题重述本文要求分析QY,两个旅游城市旅游业发展水平,并且给出了两个城市各方面因素的对比,如城市规模与密度,经济条件,交通条件,生态环境条件,宣传与监督,旅游规格,空气质量,城市规模,人口密度,人均GDP,人均住房面积,第三产业增加值占GDP比重,税收GDP,外贸依存度,市内外交通,人均拥有绿地面积,污水集中处理率,环境噪音,国内外旅游人数,理赔金额,立案数量,A级景点数量,旅行社数量,星级饭店数量.建立数学模型进行求解.2.问题分析本文要求分析QY,两个城市的分析Y,两个旅游城市旅游业发展水平,在对Q中,发现需要考虑因素较多,第一、城市规模与密度,包括城市规模与人口密度.第二、经济条件,包括外贸依存度,人均GDP,人均住房面积,第三产业增加值占GDP比重,税收GDP.第三、交通条件,包括市内外交通.第四,生态环境条件包括空气质量,人均绿地面积,污水处理能力,环境噪音.第五、宣传与监督,包括国内外旅游人数,游客投诉立案件数.第六、旅游规格,包括A级景点个数,旅行社个数,星级饭店个数,这就涉及到层次分析法来估算各个指标的权重,评出最优方案.具体内容如下:(1)本文选择了对QY,两个旅游城市旅游业发展水平有影响的19个指标作为评价要素,指标规定如下:城市规模:城市的人口数量.人口密度:单位面积土地上居住的人口数.是反映某一地区范围内人口疏密程度的指标.人口影响城市规模.人口密度越大城市规模也就越大.人均GDP:即人均国内生产总值.人均城建资金:即用于城市建设的资金总投入.第三产业增加值:增加值率指在一定时期内单位产值的增加值.即第三产业增加值越高越能带动城市经济的发展.税收GDP:税收是国家为实现其职能,凭借政治权力,按照法律规定,通过税收工具强制地、无偿地征收参与国民收入和社会产品的分配和再分配取得财政收入的一种形式.外贸依存度:即城市对于外贸交易的依赖程度.市内交通:即城市市区交通情况.市外交通:即城市郊区交通情况.市内交通与市外交通对于城市交通条件具有同等的重要性.空气质量:即城市总体空气质量情况.空气质量越好对于城市生态环境就越好.人均绿地面积:即反应城市绿化面积以及人口密度的比值关系.污水处理能力:城市污水处理水平.环境噪音:城市环境噪音情况.国内外旅客人数:国内外来旅客一年总人数.人数越多说明宣传与监督就越好.理赔金额:即立案后需要赔付的资金数.立案件数:即在旅游时发生违法事件后公安部立案的件数.A 级景点数量:即A 级景点的个数.A 级景点越多,越能带动旅行社数量以及星级饭店数量,则旅游规格越大.旅行社数量:即旅行社的个数.星级饭店数量:即星级饭店在旅游景点的个数.(2)用层次分析法建立模型,根据判断矩阵,利用MATLAB 软件,算出每个判断矩阵的特征向量W 、最大特征根c 、一次性指标CI ,再结合随机一次性指标,得出每个指标的特征向量.(3)用(2)得出的数据,运用MATLAB 软件算出两个城市的决策组合向量,做比较.3.模型假设1.假设两个城市Q 、Y 的人口流动不大.2.假设两个城市Q 、Y 的各项指标短期内不会发生太大的改变.4.符号说明A : 表示目标层;j B : 表示准则层第j 个指标的名称)6,,2,1( =j ;i C : 表示子准则层第i 个指标的名称()19,,2,1 =i ; q D : 表示方案层第q 个指标的名称()2,1=q ;1w : 表示准则层对目标层的特征向量组成的矩阵; 2w : 表示子准则层对准则层的特征向量组成的矩阵; 3w : 表示方案层对子准则层的特征向量组成的矩阵;CI : 表示一次性指标;CR : 表示随机一次性指标; Z : 表示决策组合向量.5.模型建立与求解5.1 根据层次分析法分析以及题目中的图1可以建立如下表5-1的层次分析结构,并构造两两比较判断矩阵在递阶层次结构中,设上一层元素B 为准则层,所支配的下一层元素为1C ……19C ,要确定元素1C ……n C 对于准则层B 相对的重要性即权重,可分为两种情况:(1)如果1C 2C ……n C 对B 的重要性可定量,其权重可直接确定; (2)如果问题复杂,1C 2C ……n C 对B 的重要性无法直接定量,而是一些定性的,确定权重用两两比较方法.(3)其方法是,对于准则层C ,元素i C 和j C 哪一个更重要,重要多少,按1-9比例标度对重要性程度赋值.表5-2中列出了1-9标度的含义.对于准则B ,n 个元素之间相对重要性的比较得到一个两两比较判断矩阵P =()mxn ij P ,表示其中ij P 表示i P 和j P 对B 的影响之比,显然ij P >0,ij P =ijP 1,ij P =1,由ij P 的特点,P 称为正互反矩阵.通过两两判断矩阵用方根法求出他们的最大特征根和特征向量,求法如下: 1. 判断矩阵每一行元素的乘积,其中ij n1j 1p m =∏=,i =1,2…,n .2. 计算i m 的n 次方根_i w ,_i w =n i m .3. 对向量Tn w w w ⎪⎭⎫ ⎝⎛=__1,...,归一化,即∑==n j ji w 1__i w w ,则Tn w w w ⎪⎭⎫⎝⎛=__1,.为所求的特征向量.4. 计算判断矩阵的最大特征跟max λ,()∑==n1max i iinw pw λ,式中()i pw 表示pw 的第i 个元素.5. 定义⎪⎭⎫ ⎝⎛--=1max n n CI CI λ为矩阵A 的一致性指标,为了确定A 的不一致性程度的容许范围,需要找出衡量A 的一致性指标CI 的标准.引入随机一致性指标RI .平均随机一致性指标RI 是这样得到的;对于固定的n ,随机构造正互反矩阵A ,其中ij a 是从1,2,……9,91......31,21中随机抽取的,这样的A 是最不一致的,取充分大的样子(500个样本)得到A 的最大特征跟的平均值max λ,定义⎪⎭⎫ ⎝⎛--=1max n n RI λ,对于不同的n 得出随机一致性指标RI 的数值如下表5-3表中n =1,2时RI =0,是因为1,2阶的正互反矩阵总是一致阵.令RICICR =,称CR 为一致性比率,当CR <0.1时,本文认为判断矩阵具有满意的一致性,否则就需要调整判断矩阵,使之具有满意的一致性.最后通过计算得出下表5-4(其中n B 表示准则层的特征向量中的第n 个数值,in C 表示指标层的特征向量第n 个准则对第j 个指标的数值)层次总排序一致性检验的方法j n1CI c CI j j ∑==j n 1c RI RI j j ∑==RICI CR =若1.0CR时,所以认为判断矩阵具有满意的一致性,否则就需要调整判断.矩阵,使之具有满意的一致性.5.2根据层次分析法求出各个指标的权重依据题目中的表1分析,对本题做出其中一种假设:(1)经济条件和交通条件重要性相当,生态环境条件最重要,旅游规格、宣传与监督、城市规模与密度依次次之.(2)在城市规模与密度中,城市人口比人口密度重要一点.(3)在经济条件中,第三产业增加值GDP第一重要,其次是人均GDP,税收GDP、外贸依存度、人均城建资金依次次之.(4)在交通条件中,市内交通和市外交通的重要性相当.(5)在生态环境条件中,空气质量第一重要,其次是人均绿地面积,污水处理能力、环境噪音依次次之.(6)在宣传与监督中,国内外旅游人数第一重要,理赔金额、游客投诉立案件数重要性相当.(7)在旅游规格中,A级景点个数第一重要,星级饭店个数、旅行社个数依次次之.(8)对于城市规模,城市Q比城市Y的重要性小一些;对于人口密度,城市Y比城市Q的重要性明显重要;对于人均GDP,城市Q比城市Y的重要性稍重要;对于人均城建资金,城市Q比城市Y的重要性稍微重要;对于第三产业增加值GDP,城市Q比城市Y的重要性小一些;对于税收GDP,城市Q比城市Y的重要性稍小一点;对于外贸依存度,城市Q比城市Y的重要性稍重要;对于市内交通,城市Y比城市Q的重要性稍重要一点;对于市外交通,城市Y比城市Q的重要性比稍重要小一点;归于空气质量,城市Q比城市Y的重要性相当;对于人均绿地面积,城市Y比城市Q的重要性稍重要;对于污水处理能力,城市Y比城市Q的重要性稍重要一些;对于环境噪音,城市Q比城市Y的重要性相当;对于国内外旅游人数,城市Q比城市Y的重要性稍重要;对于理赔金额,城市Q比城市Y的重要性稍重要一些;对于游客投诉立案件数,城市Q比城市Y的重要性稍重要;对于A级景点个数,城市Y比城市Q的重要性稍重要小一些;对于旅行社个数,城市Y比城市Q的重要性稍重要小一些;对于星级饭店个数,城市Q比城市Y的重要性相当.根据上述分析,按1-9比例标度对准则层对目标层、子准层对准则层、目标层对子准则层的重要程度进行赋值,构造准则层对目标层的判断矩阵、子准则层对准则层的判断矩阵、方案层对子准则层的判断矩阵.准则层()6,,2,1 =j B j 对目标层A 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=12312121321141313123412252321114232111431215141411A 利用MATLAB 软件(附录1)求得 最大特征值0719.6m ax =λ特征向量⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=1219.00753.03422.02057.02057.00492.01w一致性检验比率1.00116.0<=CR所以矩阵满足一致性检验.子准则层21,C C 对准则层1B 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=131311B利用MATLAB 软件(附录2)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 子准则层76543,,,,C C C C C 对准则层2B 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=121412312131321431522131511413221412B 利用MATLAB 软件(附录3)求得 最大特征值0681.5m ax =λ特征向量⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=0973.01599.04185.00618.02625.0w一致性检验比率1.00152.0<=CR所以矩阵满足一致性检验.子准则层98,C C 对准则层3B 的判断矩阵⎥⎦⎤⎢⎣⎡=11113B 利用MATLAB 软件(附录4)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 子准则层13121110,,,C C C C 对准则层4B 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎣⎡=1121311121312212133214B 利用MATLAB 软件(附录5)求得最大特征值0104.4m ax =λ特征向量⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=1409.01409.02628.04554.0w 一致性检验比率1.00038.0<=CR所以矩阵满足一致性检验.子准则层161514,,C C C 对准则层5B 的判断矩阵⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=1221211212215B 利用MATLAB 软件(附录6)求得最大特征值0536.3m ax =λ特征向量⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=3108.01958.04934.0w 一致性检验比率1.00462.0<=CR所以矩阵满足一致性检验.子准则层191817,,C C C 对准则层6B 的判断矩阵⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=1221211312316B 利用MATLAB 软件(附录7)求得最大特征值0092.3m ax =λ特征向量⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=2970.01634.05396.0w 一致性检验比率1.00079.0<=CR所以矩阵满足一致性检验.方案层对子准则层的判断矩阵 方案层21,D D 对子准则层1C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=122111C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层2C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=155112C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎢⎣=1667.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层3C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=133113C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层4C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=144114C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层5C 的判断矩阵:⎥⎥⎦⎤⎢⎢⎣⎡=122115C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎢⎣=3333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层6C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=133116C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层7C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=141417C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层8C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=155118C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎢⎣=8333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层9C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=122119C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层10C 的判断矩阵⎥⎦⎤⎢⎣⎡=111110C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层11C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1313111C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=7500.02500.0w因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层12C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1414112C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2000.08000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层13C 的判断矩阵⎥⎦⎤⎢⎣⎡=111113C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层14C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331114C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验.2115⎥⎥⎦⎤⎢⎢⎣⎡=1441115C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层16C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331116C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层17C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331117C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验.2118⎥⎥⎦⎤⎢⎢⎣⎡=1221118C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子19C 的判断矩阵: ⎥⎦⎤⎢⎣⎡=111119C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 通过准则层()6,,2,1 =j B j 对目标层A 的判断矩阵、子准则层()19,,2,1 =i C i 对准则层()6,,2,1 =j B j 的判断矩阵得出特征向量,建立层次总表5-5层次总排序一致性检验如下:0073.061==∑=j j j CI B CI65274.0j 61j j ==∑=RI B RI0111.065274.00073.0===RI CI CR 由于1.00111.0<=CR ,所以认为层次总排序的结果具有满意的一致性,因此不需要重新调整判断矩阵的元素取值.5.3 利用MATLAB 进行决策组合向量的运算(附录9)⋅⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=⋅⋅=Tw w w Z 2970.0001634.0000005396.00000003108.0000001958.0000004934.00000001409.0000001409.0000002628.0000004554.00000005000.0000005000.00000000973.0000001599.0000004185.0000000618.0000002625.00000002500.0000007500.0132⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡5000.05000.06667.03333.06667.03333.02500.07500.08000.02000.02500.07500.05000.05000.02000.08000.07500.02500.05000.05000.06667.03333.01667.08333.08000.02000.02500.07500.06667.03333.02000.08000.02500.07500.08333.01667.03333.06667.0⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡⋅1219.00753.03422.02057.02057.00492.0 Z ⎥⎦⎤⎢⎣⎡=5675.04325.0 比较Z 值大小可知,12Z Z >,表明城市Q 的旅游发展也水平最高,城市Y 的旅游业发展水平次之,所以城市Q 的旅游发展也水平高.6模型的评价优点:(1) 本文选择了计算比较简单的层次分析法,经过计算得到了相应的综合发展旅游业的估计值,为城市旅游业的发展提供了依据.(2) 使用了MATLAB 软件,减少了计算工作量,大大降低了运算的困难.缺点:判断的结果具有一定的主观性,不能比较切实的结合当地的具体情况,做出科学的决策方案.7参考文献[1] 姜启源等,数学建模(第四版)北京:高等教育出版社.2011年[2] 马莉,数学实验与建模,北京:清华大学出版2010年[3] 王莲芬,层次分析法引论,北京:中国人民大学出版社,1990年附录:附录1x=[1 1/4 1/4 1/5 1/2 1/3;4 1 1 1/2 3 2;4 1 1 1/2 3 2;5 2 2 1 4 3;2 1/3 1/3 1/4 1 1/2;3 1/2 1/2 1/3 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-6)/5 %一致性指标CR=CI/1.24 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =6.0719W =0.04920.20570.20570.34220.07530.1219B =0.04670.21410.21410.29180.08810.1452CI =0.0144CR =0.0116C =0.2146附录2:>> x=[1 3;1/3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250附录3:x=[1 4 1/2 2 3;1/4 1 1/5 1/3 1/2;2 5 1 3 4;1/2 3 1/3 1 2;1/3 2 1/4 1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-5)/4 %一致性指标CR=CI/1.12 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =5.0681W =0.26250.06180.41850.15990.0973B =0.27340.05940.36640.18730.1135CI =0.0170CR =0.0152C =0.2698附录4:x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000附录5:x=[1 2 3 3;1/2 1 2 2;1/3 1/2 1 1;1/3 1/2 1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-4)/3 %一致性指标CR=CI/0.90 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =4.0104W =0.45540.26280.14090.1409B =0.43950.27870.14090.1409CI =0.0035CR =0.0038C =0.3131附录6:x=[1 2 2;1/2 1 1/2;1/2 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-3)/2 %一致性指标CR=CI/0.58 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =3.0536W =0.49340.19580.3108B =0.46060.18790.3515CI =0.0268CR =0.0462C =0.3733附录7:x=[1 3 2;1/3 1 1/2;1/2 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-3)/2 %一致性指标CR=CI/0.58 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =3.0092W =0.53960.16340.2970B =0.51990.16200.3181CI =0.0046CR =0.0079C =0.4015附录8:% 目标层Q,Y对子准则层C1的赋值>> x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C2的赋值x=[1 5;1/5 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.83330.1667B =0.83330.1667CI =CR =NaNC =0.7222End% 目标层Q,Y对子准则层C3的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C4的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.80000.2000B =0.80000.2000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C5的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.66670.3333B =0.66670.3333CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C6的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C7的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.20000.8000B =0.20000.8000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C8的赋值x=[1 5;1/5 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.16670.8333B =0.16670.8333CI =CR =NaNC =0.7222End% 目标层Q,Y对子准则层C9的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C10的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =NaNC =0.5000% 目标层Q,Y对子准则层C11的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.25000.7500B =0.25000.7500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C12的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =W =0.80000.2000B =0.80000.2000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C13的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000% 目标层Q,Y对子准则层C14的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C15的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.20000.8000B =0.20000.8000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C16的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C17的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C18的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C19的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000附录9:% 最终组合权向量:x=[0.75 0 0 0 0 0;0.25 0 0 0 0 0;0 0.2625 0 0 0 0;0 0.0618 0 0 0 0;0 0.4185 0 0 0 0;0 0.1599 0 0 0 0;0 0.0973 0 0 0 0;0 0 0.5 0 0 0;0 0 0.5 0 0 0;0 0 0 0.4554 0 0;0 0 0 0.2628 0 0;0 0 0 0.1409 0 0;0 0 0 0.1409 0 0;0 0 0 0 0.4934 0;0 0 0 0 0.1958 0;0 0 0 0 0.3108 0;0 0 0 0 0 0.5396;0 0 0 0 0 0.1634;0 0 0 0 0 0.2970]x =0.7500 0 0 0 0 00.2500 0 0 0 0 00 0.2625 0 0 0 00 0.0618 0 0 0 00 0.4185 0 0 0 00 0.1599 0 0 0 00 0.0973 0 0 0 00 0 0.5000 0 0 00 0 0.5000 0 0 00 0 0 0.4554 0 00 0 0 0.2628 0 00 0 0 0.1409 0 00 0 0 0.1409 0 00 0 0 0 0.4934 00 0 0 0 0.1958 00 0 0 0 0.3108 00 0 0 0 0 0.53960 0 0 0 0 0.16340 0 0 0 0 0.2970y=[0.0492;0.2057;0.2057;0.3422;0.0753;0.1219]y =0.04920.20570.20570.34220.07530.1219z=x*y运算结果:z =0.03690.01230.05400.01270.08610.03290.02000.10290.10290.15580.08990.04820.04820.03720.01470.02340.06580.01990.0362a=[0.3333 0.8333 0.75 0.2 0.3333 0.75 0.2 0.1667 0.3333 0.5 0.25 0.8 0.5 0.75 0.2 0.75 0.3333 0.3333 0.5;0.6667 0.1667 0.25 0.8 0.6667 0.250.8 0.8333 0.6667 0.5 0.75 0.2 0.5 0.25 0.8 0.25 0.6667 0.6667 0.5]a =Columns 1 through 70.3333 0.8333 0.7500 0.2000 0.3333 0.7500 0.20000.6667 0.1667 0.2500 0.8000 0.6667 0.2500 0.8000Columns 8 through 140.1667 0.3333 0.5000 0.2500 0.8000 0.5000 0.75000.8333 0.6667 0.5000 0.7500 0.2000 0.5000 0.2500Columns 15 through 190.2000 0.7500 0.3333 0.3333 0.50000.8000 0.2500 0.6667 0.6667 0.5000c=a*z运算结果:c =0.43250.5675。
(二)复杂词组层次分析举例
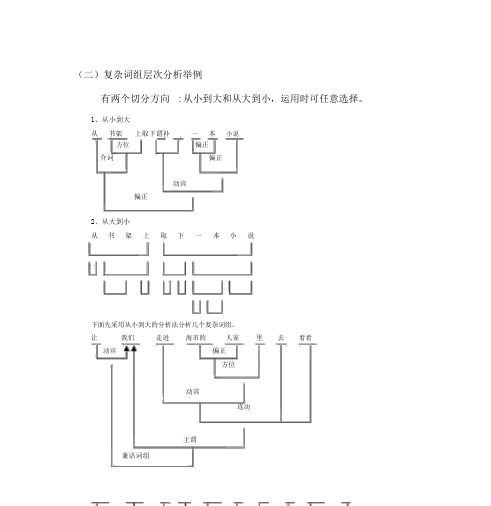
(二)复杂词组层次分析举例有两个切分方向: 从小到大和从大到小,运用时可任意选择。
1、从小到大从书架上取下谓补一本小说方位偏正介词偏正动宾偏正2、从大到小从书架上取下一本小说下面先采用从小到大的分析法分析几个复杂词组。
让我们走进海市的人家里去看看动宾偏正方位动宾连动主谓兼语词组抬到男人家里闹得拜不成天地的偏正偏正方位谓补动宾动宾谓补连动“的”字词组仿佛一只雄鹰展着翼翅浮在天空一样偏正动宾介词偏正谓补连动主谓比况词组动宾留给人们一个灿烂的微笑和一句由衷的感谢动宾偏正偏正偏正偏正偏正偏正联合词组动宾下面用从大到小的方法分析各种类型复杂词组。
A、主谓宾的层次我买了一台电脑主谓动宾偏正偏正B、多项定语忠诚坦白积极正直的共产党员学校那座新教学大楼半径为 R 的圆的圆心的轨迹联合式(修饰语是联合结构)忠诚坦白积极正直的共产党员偏正联合递加式(中心语是偏正结构)学校那座新教学大楼偏正偏正偏正偏正偏正偏正直接式(修饰语式偏正结构)半径为 R 的圆的圆心的轨迹偏正偏正偏正主谓动宾白色和黑色的旗子中间的歪歪斜斜的一条小路雪白的小兔的踪迹C、多项状语保时保质保量地完成任务已经被他猜出来了很感动地点着头联合式保时保质保量地完成任务偏正联合动宾递加式直接式已经被他猜出来了偏正偏正介宾谓补很感动地点着头偏正偏正动宾又仔仔细细地对了一遍D、补语忙得我这一个月都没好好睡过觉V+ 补忙得我这一个月都没好好睡过觉谓补主谓偏正偏正偏正偏偏正正偏正偏正动宾V+O+ 补V+补 +O 趋向补语等他一会儿找过我三次谓补动宾走过来一位老太太看不清黑板上的字动宾谓补偏正拿出一本书拿一本书来拿出来一本书拿一本书出来拿出一本书来拿出一本书来谓补动宾谓补偏正偏正E、双宾语告诉我一个好消息告诉我一个好消息动宾动宾偏正偏正借我一百块钱F、连动出门上街去买菜连动G、兼语请著名的学者做报告动宾主谓偏正动宾H、兼语连动的套用兼语套连动派他去北京请校友来学校参加校庆派他去北京请校友来学校参加校庆动宾主谓连动动宾动宾主谓连动动宾动宾连动套兼语打电话催妹妹赶快离开杭州回家打电话催妹妹赶快离开杭州回家连动动宾动宾主谓偏正连动动宾作业:勤劳勇敢的中国劳动妇女的光辉形象十分不情愿地把手机从书包里掏出来他站起来腾出一把椅子让我坐下。
层次分析法例题

专题:层次剖析法一般情形下,物流体系的评价属于多目标.多判据的体系分解评价.假如仅仅依附评价者的定性剖析和逻辑断定,缺少定量剖析根据来评价体系计划的好坏,显然是十分艰苦的.尤其是物流体系的社会经济评价很难作出准确的定量剖析.层次剖析法(Analytical Hierarchy Process )由美国有名运筹学家萨蒂(T .L .Saaty )于1982年提出,它分解了人们主不雅断定,是一种简明.适用的定性剖析与定量剖析相联合的体系剖析与评价的办法.今朝,该办法在国内已得到普遍的推广运用,普遍运用于能源问题剖析.科技成果评选.地区经济成长计划比较,尤其是投入产出剖析.资本分派.计划选择及评选等方面.它既是一种体系剖析的好办法,也是一种新的.简练的.适用的决议计划办法.◆ 层次剖析法的基起源基础理人们在日常生涯中经常要从一堆同样大小的物品中遴选出最重的物品.这时,一般是运用两两比较的办法来达到目标.假设有n 个物品,其真实重量用w 1,w 2,…w n 暗示.要想知道w 1,w 2,…w n 的值,最简略的就是用秤称出它们的重量,但假如没有秤,可以将几个物品两两比较,得到它们的重量比矩阵A .假如用物品重量向量W =[w 1,w 2,…w n ]T右乘矩阵A ,则有:由上式可知,n 是A 的特点值,W 是A 的特点向量.根据矩阵理论,n 是矩阵A 的独一非零解,也是最大的特点值.这就提醒我们,可以运用求物品重量比断定矩阵的特点向量的办法来求得物品真实的重量向量W.从而肯定最重的物品.将上述n 个物品代表n 个指标(要素),物品的重量向量就暗示各指标(要素)的相对重要性向量,即权重向量;可以经由过程两两身分的比较,树立断定矩阵,再求出其特点向量就可肯定哪个身分最重要.依此类推,假如n 个物品代表n 个计划,按照这种办法,就可以肯定哪个计划最有价值.◆ 运用层次剖析法进行体系评价的重要步调如下:(1)将庞杂问题所涉及的身分分成若干层次,树立多级递阶的层次构造模子(目标层.断定层.计划层).(2)标度及描写.统一层次随意率性两身分进行重要性比较时,对它们的重要性之比做出断定,赐与量化.(3)对同属一层次的各要素以上一级的要素为准则进行两两比较,根据评价尺度肯定其相对重要度,据此构建断定矩阵A .(4)盘算断定矩阵的特点向量,以此肯定各层要素的相对重要度(权重).(5)最后经由过程分解重要度(权重)的盘算,按照最大权重原则,肯定最优计划.★例题:某物流企业须要倾销一台设备,在倾销设备时须要从功效.价钱与可保护性三个角度进行评价,斟酌运用层次剖析法对3个不合品牌的设备进行分解剖析评价和排序,从中选出能实现物流计划总目标的最优设备,效.解题步调:1.标度及描写人们定性区分事物的才能习习用5个属性来暗示,即同样重要.稍微重要.较强重要.强烈重要.绝对重要,当须要较高精度时,可以取两个相邻属性之间的值,如许就得到9个数值,即9个标度.为了便于将比较判断定量化,引入1~9比率标度办法,划定用1.3.5.7.9分离暗示根据经验断定,要素i与要素j比拟:同样重要.稍微重要.较强重要.强烈重要.绝对重要,而2.4.6.8暗示上述两断定级之间的调和值.标度界说(比较身分i与j)1 身分i与j同样重要3 身分i与j稍微重要5 身分i与j较强重要7 身分i与j强烈重要9 身分i与j绝对重要2.4.6.8 两个相邻断定身分的中央值倒数身分i与j比较得断定矩阵a ij,则身分j与i比拟的断定为a ji=1/a ij 注:aij暗示要素i与要素j相对重要度之比,且有下述关系:aij=1/aji ;aii=1; i,j=1,2,…,n显然,比值越大,则要素i的重要度就越高.2.构建断定矩阵A断定矩阵是层次剖析法的根本信息,也是进行权重盘算的重要根据.目标层断定层计划层图设备倾销层次构造图根据构造模子,将图中各身分两两进行断定与比较,构造断定矩阵:即相对于物流体系总目标,断定层各身分相对重要性比较)如表1所示;相对功效,各计划的相对重要性比较)如表2所示; 相对价钱,各计划的相对重要性比较)如表3所示; 相对可保护性,各计划的相对重要性比较)如表4所 示.一般来讲,在AHP 法中盘算断定矩阵的最大特点值与特点向量,必不须要较高的精度,用乞降法或求根法可以盘算特点值的近似值.●乞降法1)将断定矩阵A 按列归一化(即列元素之和为1):b ij = a ij /Σa ij ; 2)将归一化的矩阵按行乞降:c i =Σb ij (i=1,2,3….n );3)将c i 归一化:得到特点向量W =(w 1,w 2,…w n )T,w i =c i /Σc i , W 即为A 的特点向量的近似值;4)求特点向量W 对应的最大特点值: ●求根法1)盘算断定矩阵A每行元素乘积的n次方根i =1,2, …, n)2,=(w1,w2,…wn)T即为A的特点向量的近似值;3)求特点向量W对应的最大特点值:(1).特点向量与一致性磨练①.各行元素的乘积并求其方根,如,,相似地,②③一致性磨练.现实评价中评价者只能对A进行粗略断定,如许有时会犯不一致的错误.如,已断定C1比C2重要,C2比C3较重要,那么,C1应当比C3更重要.假如又断定C1比C3较重要或一致重要,这就犯了逻辑错误.这就须要进行一致性磨练.根据层次法道理,运用A的理论最大特点值λmax与n之差磨练一致性.查同阶平均随机可以接收,不然从新两两进行比较).表5平均随机一致性指标阶数 3 4 5 6 7 8 9 10 11 1213 14 RI(2).相似于第(1)步的盘算进程,.特点向量相似于第(1)步的盘算进程,可以得到矩阵刀:—C的特点根.特点向相似于第(1)步的盘算进程,.特点向量与获得统一层次各要素之间的相对重要度后,就可以自上而下地盘算各级要素对总体的分解重要度.设二级共有m 个要素c 1, c 2,…,c m ,它们对总值的重要度为w 1, w 2,…, w m ;她的下一层次三级有p 1, p 2,…,p n 共n 个要素,令要素p i 对c j 的重要度(权重)为v ij ,则三级要素p i 的分解重要度为:计划C 1 计划C 2的重要度(权重)=0.230×0.258+0.648×0.333+0.122×0.066=0.283计划C 3的重要度(权重)=0.230×0.637+0.648×0. 075+0.122×0.785=0.291根据各计划分解重要度的大小,可对计划进行排序.决议计划. 层次总排序如表6所示.由表5可以看出,3且品牌1显著优于其他两种品牌的设备.功课:某配送中间的设计中要对某类物流设备进行决议计划,现初步选定三种设备配套计划,运用层次剖析法对优先斟酌的计划进行排序.解:对设备计划的断定重要可以从设备的功效.成本.保护性三方面进行评价.当然,若何评价功效.保护性等,还会用更细一级的指标来权衡.这里为剖析的轻便,省略了更具体的指标.如许,可树立对设备计划进行比较的层次剖析构造图,如图:根据以往经验和相干查询拜访成果显示:相干指标两两比较的成果。
层次分析法例题 (3)

二、AHP 求解层次分析法(Analytic Hierarchy Process )是一种定量与定性相结合的多目标决策分析法,将决策者的经验给予量化,这在对目标(因素)结构复杂且缺乏必要数据的情况下较为实用。
(一)、建立递阶层次结构目标层:最优生鲜农产品流通模式。
准则层:方案的影响因素有:1c 自然属性、2c 经济价值、3c 基础设施、5c 政府政策。
方案层:设三个方案分别为:1A 农产品产地一产地批发市场一销地批发市场一消费者、2A 农产品产地一产地批发市场一销地批发市场一农贸市场一消费者、3A 农业合作社一第三方物流企业一超市一消费者(本文假设农产品的生产地和销地不在同一个地区)。
。
图3—1 递阶层次结构(二)、构造判断(成对比较)矩阵所谓判断矩阵昰以矩阵的形式来表述每一层次中各要素相对其上层要素的相对重要程度。
为了使各因素之间进行两两比较得到量化的判断矩阵,引入1~9的标度,见表3—1.目标层:准则层:方案层:表3—1 标度值为了构造判断矩阵,作者对6个专家进行了咨询,根据专家和作者的经验,四个准则下的两两比较矩阵分别为:(三)、层次单排序及其一致性检验层次单排序就是把本层所有要素针对上一层某一要素,排出评比的次序,这种次序以相对的数值大小来表示。
对应于判断矩阵最大特征根λmax的特征向量,经归一化(使向量中各元素之和等于1)后记为W。
W的元素为同一层次因素对于上一层次因素某因素相对重要性的排序权值,这一过程称为层次单排序。
能否确认层次单排序,需要进行一致性检验,所谓一致性检验是指对A确定不一致的允许范围。
a,则λ比n 大的越多,A 的不一致性越严重。
用最大特征值对由于λ连续的依赖于ij应的特征向量作为被比较因素对上层某因素影响程度的权向量,其不一致程度越大,引起的判断误差越大。
因而可以用λ―n数值的大小来衡量 A 的不一致程度。
用一致性指标进行检验:max 1nCI n λ-=-。
其中max λ是比较矩阵的最大特征值,n 是比较矩阵的阶数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
AMCM 92问题-B 应急电力修复系统的修复计划
为沿海地区服务的电力公司必须具备应急系统来处理风暴引起的电力中断。
这样的系统需要由估计的修复时间和费用与由客观准则判定的停电的“价值”构成的数据输入,过去HECO电力公司曾因缺乏优先方案而遭受传播媒介的批评。
设想你是HECO电力公司顾问。
HECO具有一个实时处理的,通常包含下述信息的服务电话的计算机数据库:
报修时间;需求者类型;估计受害人数;地点(X,Y)。
有两个工程队调度所,分别位于(0,0)和(40,40),其中x, y以英里为单位。
HECO的服务区域在-65<x<65和-50<y<50之内。
因为该地区完全都市化了,有极好的道路网络。
工程队只是在上班和下班时必须回调度所。
公司的政策是:若停电的设施是铁
路或医院,只要有工程队可派就立即处理,其他情形都要等暴风雨
离开这一地区后才开始工作。
HECO请你为表92B-1所列的暴风雨修复请求和表92B-2所列的维修能力建立客观准则和安排工作计划。
注意,第一个电话是凌晨4:20接到的,暴风雨在上午6:00离开该地区,还要注意很多停电户是当酬反迟才报修的。
HECO出自自身的目的需要一份技术报告和一份用外行术语写就的“执行简要”来提交新闻媒介。
他们希望有对将来的建议。
为决定你的优先计划安排系统,你还需作一些附加的假设,请详述这些假设。
将来你可能希望有附加的数据,如果有,详述这些需要的信息。