多元线性回归模型实验报告
多元线性回归SPSS实验报告
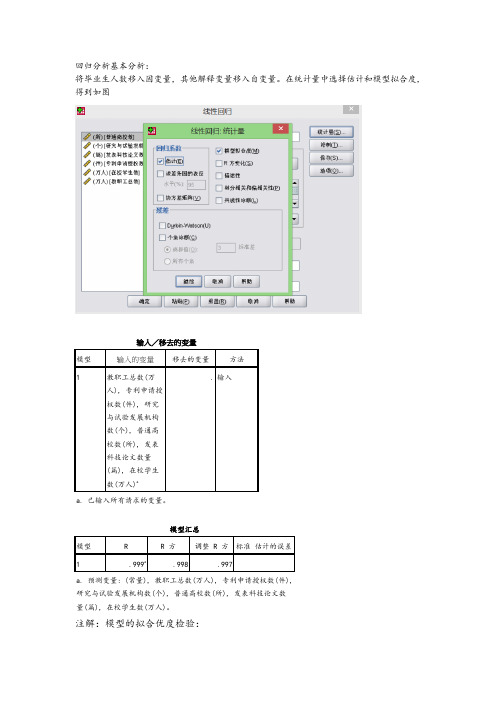
49%;可以认为:这些变量存在多重共线性。需要建立回归方程。
2.重建回归方程
模型
输入/移去的变量b
输入的变量
移去的变量
方法
1
教职工总数(万
人), 专利申请授
权数(件), 研究
b. 预测变量: (常量), 教职工总数(万人), 专利申请授权数(件), 研究与试验发展机构数(个), 普通高校数(所), 发表 科技论文数量(篇)。 c. 预测变量: (常量), 教职工总数(万人), 专利申请授权数(件), 研究与试验发展机构数(个), 发表科技论文数量(篇)。 d. 预测变量: (常量), 教职工总数(万人), 专利申请授权数(件), 发表科技论文数量(篇)。 e. 预测变量: (常量), 教职工总数(万人), 发表科技论文数量(篇)。 f. 因变量: 毕业生数(万人)
. 输入
a. 已输入所有请求的变量。
模型汇总
模型
R
R 方 调整 R 方 标准 估计的误差
1
.999a
.998
.997
a. 预测变量: (常量), 教职工总数(万人), 专利申请授权数(件), 研究与试验发展机构数(个), 普通高校数(所), 发表科技论文数 量(篇), 在校学生数(万人)。
注解:模型的拟合优度检验:
第五列:回归方程的估计标准误差=
Anovab
模型
平方和
df
均方
F
Sig.
1
回归
6
.000a
残差
7
总计
13
a. 预测变量: (常量), 教职工总数(万人), 专利申请授权数(件), 研究与试验发展机构 数(个), 普通高校数(所), 发表科技论文数量(篇), 在校学生数(万人)。 b. 因变量: 毕业生数(万人)
计量经济实验报告多元(3篇)

第1篇一、实验目的本次实验旨在通过多元线性回归模型,分析多个自变量与因变量之间的关系,掌握多元线性回归模型的基本原理、建模方法、参数估计以及模型检验等技能,提高运用计量经济学方法解决实际问题的能力。
二、实验背景随着经济的发展和社会的进步,影响一个变量的因素越来越多。
在经济学、管理学等领域,多元线性回归模型被广泛应用于分析多个变量之间的关系。
本实验以某地区居民消费支出为例,探讨影响居民消费支出的因素。
三、实验数据本实验数据来源于某地区统计局,包括以下变量:1. 消费支出(Y):表示居民年消费支出,单位为元;2. 家庭收入(X1):表示居民家庭年收入,单位为元;3. 房产价值(X2):表示居民家庭房产价值,单位为万元;4. 教育水平(X3):表示居民受教育程度,分为小学、初中、高中、大专及以上四个等级;5. 通货膨胀率(X4):表示居民消费价格指数,单位为百分比。
四、实验步骤1. 数据预处理:对数据进行清洗、缺失值处理和异常值处理,确保数据质量。
2. 模型设定:根据理论知识和实际情况,建立多元线性回归模型:Y = β0 + β1X1 + β2X2 + β3X3 + β4X4 + ε其中,Y为因变量,X1、X2、X3、X4为自变量,β0为截距项,β1、β2、β3、β4为回归系数,ε为误差项。
3. 模型估计:利用统计软件(如SPSS、R等)对模型进行参数估计,得到回归系数的估计值。
4. 模型检验:对估计得到的模型进行检验,包括以下内容:(1)拟合优度检验:通过计算R²、F统计量等指标,判断模型的整体拟合效果;(2)t检验:对回归系数进行显著性检验,判断各变量对因变量的影响是否显著;(3)方差膨胀因子(VIF)检验:检验模型是否存在多重共线性问题。
5. 结果分析:根据模型检验结果,分析各变量对因变量的影响程度和显著性,得出结论。
五、实验结果与分析1. 拟合优度检验:根据计算结果,R²为0.812,F统计量为30.456,P值为0.000,说明模型整体拟合效果较好。
实验二 多元线性回归模型 瑜

《计量经济学》实验报告多元线性回归模型四、实验结果及分析(附上必要的回归分析报告,并作以分析)1、设定问题国家税收总收入与工商税收、农业税收之间的关系2、查找数据日期国家税收总收入(亿元)工商税收(亿元)X1 农业税收(亿元)X2 1990 2821.86 1858.99 87.861991 2990.17 1981.11 90.651992 3296.91 2244.21 119.171993 4255.30 3194.49 125.741994 5126.88 3914.22 231.491995 6038.04 4589.68 278.091996 6909.82 5270.04 369.461997 8234.04 6553.89 397.481998 9262.80 7625.42 398.803.阐述理论由经济理论知,工商税收和农业税收是影响或决定国家税收总收入的主要因素。
一般而言,当工商税收和农业税收增加时,国家税收总收入随着增加,它们之间具有正向的变动趋势,反之,国家税收总收入减少。
在这里,将国家税收总收入作为被解释变量(Y),工商税收作为解释变量(X1t ) 农业税收作为解释变量(X2t),其他变量及随机因素的影响均归并到随机变量u t中,建立工商税收X1t 、农业税收X2t和国家税收总收入Y之间的多元线性回归模型。
4、画散点图X1与Y的散点图X2与Y的散点图根据上图散点分布情况可以看出,在2000~2008年期间,国家税收总收入和工商税收和农业税收之间存在较为明显的线性关系。
5、建立模型设多元线性回归模型:Yt = β+ β1X1t+β2X2t+ ut其中,Yt——表示国家税收总收入(亿元)β0、β 1 、β2——待定系数X1t——表示工商税收(亿元)注:实验报告在下次上机时间交(打印版、电子版),任缺其一本次试验无效。
电子版由各班长学委汇总以打包形式一并交齐。
多元线性回归模型实验报告
多元线性回归模型一、实验目的通过上机实验,使学生能够使用Eviews 软件估计可化为线性回归模型的非线性模型,并对线性回归模型的参数线性约束条件进行检验。
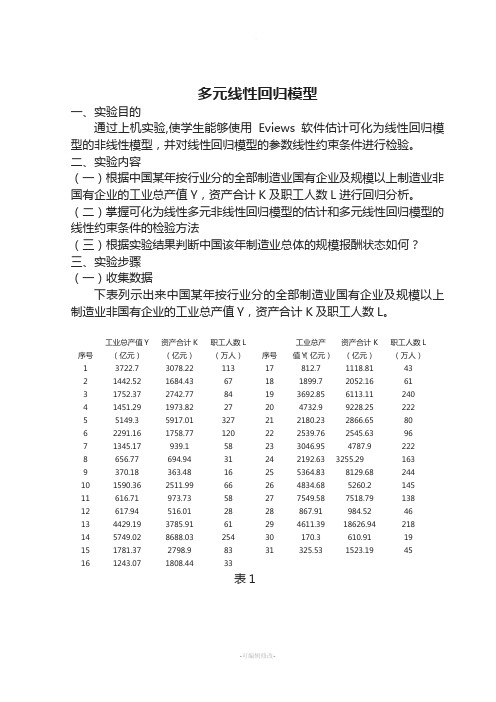
二、实验内容(一)根据中国某年按行业分的全部制造业国有企业及规模以上制造业非国有企业的工业总产值Y,资产合计K及职工人数L进行回归分析。
(二)掌握可化为线性多元非线性回归模型的估计和多元线性回归模型的线性约束条件的检验方法(三)根据实验结果判断中国该年制造业总体的规模报酬状态如何?三、实验步骤(一)收集数据下表列示出来中国某年按行业分的全部制造业国有企业及规模以上制造业非国有企业的工业总产值Y,资产合计K及职工人数L。
序号工业总产值Y(亿元)资产合计K(亿元)职工人数L(万人)序号工业总产值Y(亿元)资产合计K(亿元)职工人数L(万人)1 3722.7 3078.22 113 17 812.7 1118.81 432 1442.52 1684.43 67 18 1899.7 2052.16 613 1752.37 2742.77 84 19 3692.85 6113.11 2404 1451.29 1973.82 27 20 4732.9 9228.25 2225 5149.3 5917.01 327 21 2180.23 2866.65 806 2291.16 1758.77 120 22 2539.76 2545.63 967 1345.17 939.1 58 23 3046.95 4787.9 2228 656.77 694.94 31 24 2192.63 3255.29 1639 370.18 363.48 16 25 5364.83 8129.68 24410 1590.36 2511.99 66 26 4834.68 5260.2 14511 616.71 973.73 58 27 7549.58 7518.79 13812 617.94 516.01 28 28 867.91 984.52 4613 4429.19 3785.91 61 29 4611.39 18626.94 21814 5749.02 8688.03 254 30 170.3 610.91 1915 1781.37 2798.9 83 31 325.53 1523.19 4516 1243.07 1808.44 33表1(二)创建工作文件(Workfile)。
计量经济学实验报告---多元回归模型实验

2011-2012学年第1学期计量经济学实验报告实验(二):多元回归模型实验(1)估计参数利用EViews6估计模型的参数,方法是:1、建立工作文件:首先,双击EViews6图标,进入EViews6主页。
在菜单一次点击File\New\Workfile,出现对话框“Workfile Create”。
在“Workfile structure type ”中选择数据频率:Datad-regular frequency.在“Data specification”中Start data输入“1980”,在End data中输入“2002”点击“ok”出现“Workfile UNTITLED”工作框。
其中已有变量:“c”—截距项“resid”—剩余项。
2、Eviews命令:data y x p1 p2 p3 回车,输入数据,得到如图:图2-1 数据的输入3.对数据进行回归分析,eviews命令:LS Y C X P1 P2 P3图2-2根据上图,模型的估计的结果为:lnY=3.616+0.001lnX-0.506lnP1+0.119lnP2+0.048lnP3(0.450) (0) (0.162) (0.086) 0.051)t=(0.805) (4.652) (-3.115) (1.388) (0.942)R2=0.940 2 r=0.926 F=70.105(2)作对家庭人均鸡肉年消费量Y与猪肉价格P2、牛肉价格P3的散点图,图2-3和图2-4图2-3 图2-4图2-3 家庭人均鸡肉年消费量Y与猪肉价格P2的散点图图2-4 家庭人均鸡肉年消费量Y与牛肉价格P3的散点图由上面两张图可知都呈现线性关系,建立线性回归方程:i i i u X X Y +++=22110i βββi=1,2, .....,23 输入LS Y C P2 P3,用eviews6进行估计的输出结果如图:模型的估计结果为: Y=2.111+0.168P2+0.031P3(0.371)(0.060)(0.077) t=(5.689) (2.813) (0.402)R 2=0.834 2-r =0.817 F=50.150模型检验:①经济意义检验该地区家庭人均鸡肉消费量与鸡肉价格和牛肉价格成正相关,当牛肉价格不变时,猪肉价格上涨1单位,该地区家庭人均鸡肉消费量增加0.168单位;当猪肉价格不变时,牛肉价格上涨1单位,该地区家庭人均鸡肉消费量增加0.031单位,与猪肉价格成更大正相关关系符合一般情况。
实习报告三(多元线性回归分析)

实习报告三(多元线性回归分析)一、问题:为研究糖尿病人血糖的与血清总胆固醇、甘油三脂、空腹胰岛素、糖化血红蛋白的关系,随机抽选27名糖尿病人的血清总胆固醇、甘油三脂、空腹胰岛素、糖化血红蛋白、空腹血糖的测量值如下表,试根据结果考察糖尿病人血糖的与血清总胆固醇、甘油三脂、空腹胰岛素、糖化血红蛋白有无相关关系?试建立血糖与其它几项指标关系的多元线性回归方程。
?二、数据:编号总胆固醇甘油三酯空腹胰岛素糖化血红蛋白血糖2 3.79 1.64 7.32 6.9 8.83 6.02 3.56 6.95 10.8 12.34 4.85 1.07 5.88 8.3 11.65 4.6 2.32 4.05 7.5 13.46 6.05 0.64 1.42 13.6 18.37 4.9 8.5 12.6 8.5 11.18 7.08 3 6.75 11.5 12.19 3.85 2.11 16.28 7.9 9.610 4.65 0.63 6.59 7.1 8.411 4.59 1.97 3.61 8.7 9.312 4.29 1.97 6.61 7.8 10.613 7.97 1.93 7.57 9.9 8.414 6.19 1.18 1.42 6.9 9.615 6.13 2.06 10.35 10.5 10.916 5.71 1.78 8.53 8 10.117 6.4 2.4 4.53 10.3 14.818 6.06 3.67 12.79 7.1 9.119 5.09 1.03 2.53 8.9 10.820 6.13 1.71 5.28 9.9 10.221 5.78 3.36 2.96 8 13.622 5.43 1.13 4.31 11.3 14.923 6.5 6.21 3.47 12.3 1624 7.98 7.92 3.37 9.8 13.225 11.54 10.89 1.2 10.5 2026 5.84 0.92 8.61 6.4 13.3三、统计处理:该实际问题涉及五个连续型随机变量:血清总胆固醇()、甘油三脂()、空腹胰岛素()、糖化血红蛋白()、血糖(Y)。
多元线性回归模型实验报告

多元线性回归模型实验报告实验报告:多元线性回归模型1.实验目的多元线性回归模型是统计学中一种常用的分析方法,通过建立多个自变量和一个因变量之间的模型,来预测和解释因变量的变化。
本实验的目的是利用多元线性回归模型,分析多个自变量对于因变量的影响,并评估模型的准确性和可靠性。
2.实验原理多元线性回归模型的基本假设是自变量与因变量之间存在线性关系,误差项为服从正态分布的随机变量。
多元线性回归模型的表达形式为:Y=b0+b1X1+b2X2+...+bnXn+ε,其中Y表示因变量,X1、X2、..、Xn表示自变量,b0、b1、b2、..、bn表示回归系数,ε表示误差项。
3.实验步骤(1)数据收集:选择一组与研究对象相关的自变量和一个因变量,并收集相应的数据。
(2)数据预处理:对数据进行清洗和转换,排除异常值、缺失值和重复值等。
(3)模型建立:根据收集到的数据,建立多元线性回归模型,选择适当的自变量和回归系数。
(4)模型评估:通过计算回归方程的拟合优度、残差分析和回归系数的显著性等指标,评估模型的准确性和可靠性。
4.实验结果通过实验,我们建立了一个包含多个自变量的多元线性回归模型,并对该模型进行了评估。
通过计算回归方程的拟合优度,我们得到了一个较高的R方值,说明模型能够很好地拟合观测数据。
同时,通过残差分析,我们检查了模型的合理性,验证了模型中误差项的正态分布假设。
此外,我们还对回归系数进行了显著性检验,确保它们是对因变量有显著影响的。
5.实验结论多元线性回归模型可以通过引入多个自变量,来更全面地解释因变量的变化。
在实验中,我们建立了一个多元线性回归模型,并评估了模型的准确性和可靠性。
通过实验结果,我们得出结论:多元线性回归模型能够很好地解释因变量的变化,并且模型的拟合优度较高,可以用于预测和解释因变量的变异情况。
同时,我们还需注意到,多元线性回归模型的准确性和可靠性受到多个因素的影响,如样本大小、自变量的选择等,需要在实际应用中进行进一步的验证和调整。
多元线性回归模型之数学建模实验报告

%y= 45.3636+0.3604*x1+3.0906*x2+11.8246*x3
rcoplot(r,rint)
x1=x(a,:)
y1=y(a)
[b1,bint1,r1,rint1,s1]=regress(y1',x1)
b1,bint1,s1
%y= 58.5101+0.4303*x1+2.3449*x2+10.3065*x3
30.0184 59.4982
-19.6030 32.7499
-28.9960 22.3987
-24.1742 26.8599
-23.8105 28.7839
-27.9825 22.9747
-22.6411 27.8754
-32.8481 18.0569
9.3635 48.2532
-30.5838 21.0099
-20.9189 30.3583
-35.7261 13.7317
x3=[0 1 0 1 1 0 1 0 1 0 1 0 0 0 0 1 0 0 0 0 01 0 0 1 1 0 1 0 1];
plot(x1,y,’>’)
plot(x2,y,’*’)
x=[ones(30,1), x1',x2',x3']
[b,bint,r,rint,s]=regress(y',x)
1.0000 53.0000 28.6000 1.0000
1.0000 63.0000 28.3000 0
1.0000 29.0000 22.0000 1.0000
1.0000 25.0000 25.3000 0
1.0000 69.0000 27.4000 1.0000
多元线性回归实验报告

实验题目:多元线性回归、异方差、多重共线性实验目的:掌握多元线性回归的最小二乘法,熟练运用Eviews软件的多元线性回归、异方差、多重共线性的操作,并能够对结果进行相应的分析。
实验内容:习题3.2,分析1994-2011年中国的出口货物总额(Y)、工业增加值(X2)、人民币汇率(X3),之间的相关性和差异性,并修正。
实验步骤:1.建立出口货物总额计量经济模型:(3.1)1.1建立工作文件并录入数据,得到图1图1在“workfile"中按住”ctrl"键,点击“Y、X2、X3”,在双击菜单中点“open group”,出现数据表。
点”view/graph/line/ok”,形成线性图2。
图21.2对(3.1)采用OLS估计参数在主界面命令框栏中输入ls y c x2 x3,然后回车,即可得到参数的估计结果,如图3所示。
图 3根据图3中的数据,得到模型(3.1)的估计结果为(8638.216)(0.012799)(9.776181)t=(-2.110573) (10.58454) (1.928512)F=522.0976从上回归结果可以看出,拟合优度很高,整体效果的F检验通过。
但当=0.05时,= 2.131.有重要变量X3的t检验不显著,可能存在严重的多重共线性。
2.多重共线性模型的识别2.1计算解释变量x2、x3的简单相关系数矩阵。
点击Eviews主画面的顶部的Quick/Group Statistics/Correlatios弹出对话框在对话框中输入解释变量x2、x3,点击OK,即可得出相关系数矩阵(同图4)。
相关系数矩阵图4由图4相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实解释变量之间存在多重共线性。
2.2多重共线性模型的修正将各变量进行对数变换,在对以下模型进行估计。
利用eviews软件,对、X2、X3分别取对数,分别生成lnY、lnX2、lnX3的数据,采用OLS方法估计模型参数,得到回归结果,如图:图5图6模型估计结果为:ln=-20.52+1.5642lnX2+1.7607lnX3(5.4325) (0.0890) (0.6821)t =-3.778 17.578 2.581F=539.736该模型可决系数很高,F检验值,明显显著。
计量经济学实验报告(多元线性回归分析)

计量经济学实验报告(多元线性回归分析)实验2:多元线性回归分析实验目的:学习利用Eviews建立多元线性回归模型,研究64国家婴儿死亡率与妇女文盲率之间的关系。
一、实验内容:1、先验的预期CM和各个变量之间的关系.2、做CM对FLR的回归,得到回归结果。
3、做CM对FLR和PGNP的回归,得到回归结果。
4、做CM对FLR,PGNP和TFR的回归结果,并给出ANOVA。
5、根据各种回归结果,选择哪个模型?为什么?6、如果回归模型(4)是正确的模型,但却估计了(2)或(3),会有什么后果?7、假定做了(2)的回归,如何决定增加变量PGNP和TFR?使用了哪种检验?给出必要的计算结果。
二、实验报告———-多元线性回归分析1、问题提出婴儿死亡率(CM)是指婴儿出生后不满周岁死亡人数同出生人数的比率.一般以年度为计算单位,以千分比表示。
婴儿死亡率是反映一个国家和民族的居民健康水平和社会经济发展水平的重要指标,特别是妇幼保健工作水平的重要指标。
婴儿死亡率(CM)的高低是一个国家或地区社会经济多方面因素协调发展的结果。
由于世界各国婴儿死亡率差别很大,所以就64个国家社会综合发展状况,针对性的研究婴儿死亡率(CM)与女性识字率(FLR)、人均GNP(PGNP)、总生育率(TFR)之间的关系2.指标选择本次实验研究婴儿死亡率与妇女文盲率之间的关系,故应采用婴儿死亡率(CM)和女性识字率(FLR)作为指标。
但影响婴儿死亡率的因素较复杂,尤其是经济发展状况、总生育率等也会对其产生重要影响,考虑到实验的准确性,故引入人均GNP(PGNP)和总生育率(TFR)相关数据。
3。
数据来源数据来源:教师提供4。
数据处理此次实验可直接使用数据,无需进行数据处理。
5。
先验的预期CM 和各个变量之间的关系 【题1】 5-1预期CM 与FLR 存在负相关关系。
一方面,女性受教育程度越高,其知识越丰富,自我保护意识和能力就越强,则更善于保护自己和婴儿;另一方面,女性教育程度越高,其就业机会与收入获得途径就越多,可以更好的保障自己和婴儿的生活.因此,我们预期FLR 的提高会导致CM 降低。
多元线性回归模型线性与非线性估计检验实验报告
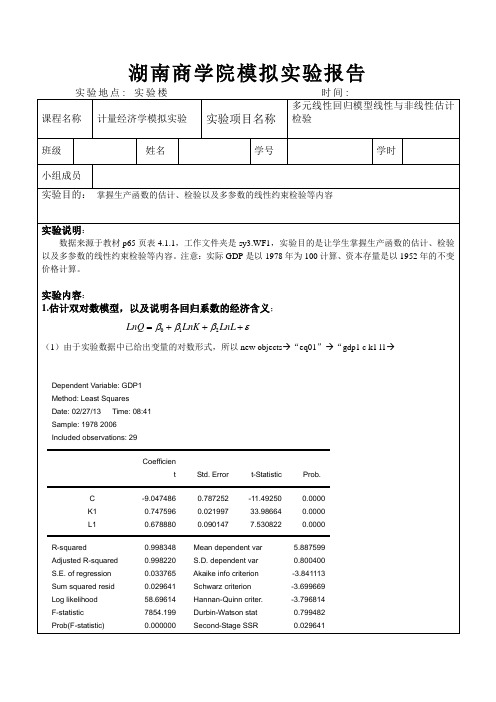
湖南商学院模拟实验报告在回归方程中点view →representations →所以该模型函数形式为Ln GDP= -9.0474855847 + 0.747595717651LnK + 0.678880192961LnL回归系数的经济含义:资本每增加1%,GDP 平均增加0.74759571765%,劳动每增加1%,GDP 平均增加0.67888019296%2.对模型做t 检验和F 检验;T(β0)=-11.49250,T(β1)=33.98664,T(β2)=7.530822,P 值均为0,所以T 检验说明回归模型中系数不为0,在一定显著性水平下这个模型是有意义的,模型中解释变量对于被解释变量有一定解释力度。
F=7854.199,P=0.000000,F 检验说明拒绝原假设,模型总体存在。
3.在5%的显著性水平下对随机干扰项的方差做如下检验:2201:0.01:0.01H H σσ=≠和2201:0.01:0.01H H σσ=<输入scalardeltasqrhat1=0.027/(29-3)→4.利用F 统计量来检验:012112:1:1H H ββββ+=+≠打开eq1→View →Coefficient Tests →WaldCoefficient Restrictions →→输入c(2)+c(3)=1→ok →Wald Test:Equation: EQ1Test Statistic Value df ProbabilityF-statistic 37.38918 (1, 26) 0.0000Chi-square 37.38918 1 0.0000Null Hypothesis Summary:Normalized Restriction (= 0) Value Std. Err.-1 + C(2) + C(3) 0.426476 0.069746Restrictions are linear in coefficients.从输出结果来看P=0.0000,是拒绝原假设的,所以β1+β2≠15*.对模型进行非线性OLS估计:a.设定初始值(双击序列C,在c(1)、c(2)和c(3)所对应的单元格中分别输入0,option中的收敛精度设为0.001,迭代次数100次),保存模型;object→eq2→GDP=C(1)*(K^C(2))*(L^C(3))→option→→ok→→ok→Dependent Variable: GDPMethod: Least SquaresDate: 03/22/15 Time: 17:28Sample: 1978 2006Included observations: 29Convergence achieved after 1 iterationGDP=C(1)*(K^C(2))*(L^C(3))Variable Coefficient Std. Error t-Statistic Prob.C(1) 4.014973 3.34E+17 1.20E-17 1.0000 C(2) 1.942001 1.44E+15 1.35E-15 1.0000C(3) -4.547718 8.71E+15 -5.22E-16 1.0000R-squared -1.858693 Mean dependent var 481.4144Adjusted R-squared -2.078593 S.D. dependent var 359.3645S.E. of regression 630.5381 Akaike info criterion 15.82872Sum squared resid 10337035 Schwarz criterion 15.97017Log likelihood -226.5165 Hannan-Quinn criter. 15.87302Durbin-Watson stat 0.008228。
多元线性回归分析报告

多元线性回归分析报告1. 研究背景在数据科学和统计学领域,多元线性回归是一种常用的分析方法。
它用于探究多个自变量与一个因变量之间的关系,并且可以用于预测和解释因变量的变化。
本文将通过多元线性回归分析来研究一个特定问题,探讨自变量对因变量的影响程度和统计显著性。
2. 数据收集和准备在进行多元线性回归分析之前,需要收集和准备相关的数据。
数据的收集可以通过实验、调查问卷或者从已有的数据集中获得。
在本次分析中,我们使用了一个包含多个自变量和一个因变量的数据集。
首先,我们导入数据集,并进行数据的初步观察和预处理。
这些预处理步骤包括去除缺失值、处理异常值和标准化等。
经过数据准备之后,我们可以开始进行多元线性回归分析。
3. 回归模型建立在多元线性回归分析中,我们建立一个数学模型来描述自变量和因变量之间的关系。
假设我们有p个自变量和一个因变量,可以使用以下公式表示多元线性回归模型:Y = β0 + β1X1 + β2X2 + … + βpXp + ε其中,Y表示因变量,X1, X2, …, Xp分别表示自变量,β0, β1, β2, …, βp表示模型的系数,ε表示模型的误差项。
4. 模型拟合和参数估计接下来,我们使用最小二乘法来估计模型的参数。
最小二乘法通过最小化观测值与模型预测值之间的差异来确定最佳拟合线。
通过估计模型的系数,我们可以得到每个自变量对因变量的影响程度和显著性。
在进行参数估计之前,我们需要检查模型的假设前提,包括线性关系、多重共线性、正态性和异方差性等。
如果模型的假设不成立,我们需要采取相应的方法进行修正。
5. 模型评估和解释在完成模型的参数估计后,我们需要对模型进行评估和解释。
评估模型的好坏可以使用多个指标,如R方值、调整R方值、F统计量和t统计量等。
这些指标可以帮助我们判断模型的拟合程度和自变量的显著性。
解释模型的结果需要注意解释模型系数的大小、符号和显著性。
系数的大小表示自变量对因变量的影响程度,符号表示影响的方向,显著性表示结果是否具有统计意义。
《应用回归分析 》---多元线性回归分析实验报告

《应用回归分析》---多元线性回归分析实验报告
二、实验步骤:
1、计算出增广的样本相关矩阵
2、给出回归方程
Y=-65.074+2.689*腰围+(-0.078*体重)3、对所得回归方程做拟合优度检验
4、对回归方程做显著性检验
5、对回归系数做显著性检验
三、实验结果分析:
1、计算出增广的样本相关矩阵相关矩阵
2、给出回归方程
回归方程:Y=-65.074+2.689*腰围+(-0.078*体重)
3、对所得回归方程做拟合优度检验
由表可知x与y的决定性系数为r2=0.800,说明模型的你和效果一般,x与y 线性相关系数为R=0.894,说明x与y有较显著的线性关系,当F=33.931,显著性Sig.p=0.000,说明回归方程显著
4、对回归方程做显著性检验
5、对回归系数做显著性检验
Beta的t检验统计量t=-6.254,对应p的值接近0,说明体重和体内脂肪比重对腰围数据有显著影响
6、结合回归方程对该问题做一些基本分析
从上面的分析过程中可以看出腰围和脂肪比重以及腰围和体重的相关性都是很大的,通过检验可以看出回归方程、回归系数也很显著。
其次可以观察到腰围、脂肪比重、体重的数据都是服从正态分布的。
多元线性回归模型实验报告 计量经济学

多元线性回归模型实验报告计量经济学多元线性回归模型是一种比较常见的经济学建模方法,其可用于对多个自变量和一个因变量之间的关系进行分析和预测。
在本次实验中,我们将使用一个包含多个自变量的数据集,对其进行多元线性回归分析,并对分析结果进行解释。
数据集介绍本次实验使用的数据集来自于UCI Machine Learning Repository,数据集包含有关汽车试验的多个自变量和一个连续因变量。
数据集中包含了204条记录,其中每条记录包含了一辆汽车的14个属性,分别是:MPG(燃油效率),气缸数(Cylinders)、排量(Displacement)、马力(Horsepower)、重量(Weight)、加速度(Acceleration)、模型年(Model Year)、产地(Origin)等。
模型建立在进行多元线性回归分析之前,我们首先需要对数据进行预处理。
为了确保数据的可用性,我们需要先检查数据是否存在缺失值和异常值。
如果有,需要进行相应的处理,以确保因变量和自变量之间的关系受到了正确地分析。
在对数据进行预处理之后,我们可以使用Python中的statsmodels包来对数据进行多元线性回归分析。
具体建模过程如下:```import statsmodels.api as sm# 准备自变量和因变量数据X = data[['Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'Model Year', 'Origin']]y = data['MPG']# 添加常数项X = sm.add_constant(X)# 拟合线性回归模型model = sm.OLS(y, X).fit()# 输出模型摘要print(model.summary())```在上述代码中,我们首先通过data[['Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'Model Year', 'Origin']]选择了所有自变量列,用于进行多元线性回归分析;然后,我们又通过`sm.add_constant(X)`,向自变量数据中添加了一列全为1的常数项,用于对截距进行建模;最后,我们使用`sm.OLS(y, X).fit()`来拟合线性回归模型,并使用`model.summary()`输出模型摘要。
多元线性回归模型实验报告

实验一实验室实验室 机器号机器号 任课教师任课教师实验教师实验教师实验时间实验时间 月 日评语评语一、实验目的和要求多元线性回归模型的变量选择与参数估计 1.1.熟悉多元线性回归模型中的解释变量的引入熟悉多元线性回归模型中的解释变量的引入熟悉多元线性回归模型中的解释变量的引入 2.2.掌握对计算结果的统计分析与经济分析掌握对计算结果的统计分析与经济分析二、实验内容为研究美国人对子鸡的消费量,提供1960——1982年的数据。
年的数据。
其中:其中:Y Y —每人的子鸡消费量,磅—每人的子鸡消费量,磅2X ----每人实际可支配收入,美元每人实际可支配收入,美元每人实际可支配收入,美元 3X ----子鸡每磅实际零售价格,美分子鸡每磅实际零售价格,美分子鸡每磅实际零售价格,美分 4X ----猪肉每磅实际零售价格,猪肉每磅实际零售价格,美分 5X ----牛肉每磅实际零售价格,牛肉每磅实际零售价格,美分美分6X ----子鸡替代品每磅综合实际价格,美分。
子鸡替代品每磅综合实际价格,美分。
6X 是猪肉和牛肉每磅实际零售价格的加权平均,其权数是在猪肉和牛肉的总消费量中两者各占的相对消费量。
者各占的相对消费量。
假定模型为线性回归模型,假定模型为线性回归模型,估计此模型的参数。
对模型进行统计学检验,并估计此模型的参数。
对模型进行统计学检验,并对结果进行经济解释。
对结果进行经济解释。
1、启动Eviews3.12、建立新工作文档,输入时间范围数据19601960——————1982 19823、设模型为Y i =β1+β2X 2+β3X 3+β4X 4+β5X 5+β6X 6+μi4、单击file file→→import 调入数据调入数据5、主页上单击quick quick→→Estimate Equation Estimate Equation,输入,输入y c x2 x3 x4 x5 x6y c x2 x3 x4 x5 x6,单击,单击OK,OK,出现数据回归结果出现数据回归结果出现数据回归结果: :Dependent Variable: Y Method: Least Squares Date: 10/29/10 Time: 22:56 Sample: 1960 1982 Included observations: 23 Variable Coefficient Std. Error t-Statistic Prob. C 38.59691 4.214488 9.158150 0.0000 X2 0.004889 0.004962 0.985370 0.3383 X3 -0.651888 0.174400 -3.737889 0.0016 X4 0.243242 0.089544 2.716443 0.0147 X5 0.104318 0.070644 1.476674 0.1580 X6 -0.071110 0.098381 -0.722805 0.4796 R-squared 0.944292 Mean dependent var 39.66957 Adjusted R-squared 0.927908 S.D. dependent var 7.372950 S.E. of regression 1.979635 Akaike info criterion 4.423160 Sum squared resid 66.62224 Schwarz criterion 4.719376 Log likelihood -44.86634 F-statistic 57.63303 Durbin-Watson stat 1.100559 Prob(F-statistic) 0.000000 -4-224606264666870727476788082RESID6、将上述回归结果整理如下:、将上述回归结果整理如下:Y i =38.59691+0.004889X 2-0.651888X 3+0.243242X 4+0.104318X 5-0.071110X 6(9.158150) (0.985370)(-3.737889)(2.716443)(1.476674)(-0.722805) R 2=0.944292 修正后R 2=0.927908 F=57.63303三、实验结果从回归结果看,从估计的结果可以看出,模型的拟合较好。
《计量经济学》eviews实验报告多元线性回归模型

2013
517.11
1316.34
40321
2014
530.83
1333.4
43910
要求:
(1)试建立二元线性回归销售模型。
(2)考虑北京地区有人口万人,人均年收入为元,试北京市汽车拥有量做出预测。
二、实验目的
掌握多元线性回归模型的原理,多元线性回归模型的建立、估计、检验及预测的方法,以及相应的EViews软件操作方法。
x2t(人均收入)
2000
104.12
1113.53
10349.7
2001
114.47
1127.89
11577.8
2002
133.93
1142.83
12463.9
2003
163.07
1154.06
13882.6
2003
182.42
1167.76
15637.8
2005
182.42
1184.14
17653
三、实验步骤(简要写明实验步骤)
(1)建立二元线性回归销售模型
(2)预测
在上方输入ls y c x3 x4回车得到下图
在回归方程中有Forecast,残差立为yfse,点击ok后自动得到下图
在上方空白处输入ls y c x3 x4---之后点击proc中的forcase中se输入yfse点击ok得到2015预测值
《计量经济学》实验报告多元线性回归模型
一、实验内容
建立2000-2014年北京市民用汽车拥有量模型。
调查北京市民用汽车拥有量数据见表1。观测变量分别是民用汽车拥有量yt(万辆),北京市年末人口数x1t(万人)和城镇人均可支配收入x2t(千元)。
2021年多元线性回归模型实验报告计量经济学

试验汇报课程名称金融计量学试验项目名称多元线性回归模型班级与班级代码试验室名称(或课室)专业任课老师xxx学号: xxx姓名: xxx试验日期: 5 月3日广东商学院教务处制姓名xxx 试验汇报成绩评语:指导老师(署名)年月日说明: 指导老师评分后, 试验汇报交院(系)办公室保留多元线性回归模型一、试验目经过上机试验,使学生能够使用 Eviews 软件估量可化为线性回归模型非线性模型, 并对线性回归模型参数线性约束条件进行检验。
二、试验内容(一)依据中国某年按行业分全部制造业国有企业及规模以上制造业非国有企业工业总产值Y, 资产累计K及职员人数L进行回归分析。
(二)掌握可化为线性多元非线性回归模型估量和多元线性回归模型线性约束条件检验方法(三)依据试验结果判定中国该年制造业总体规模酬劳状态怎样?三、试验步骤(一)搜集数据下表列示出来中国某年按行业分全部制造业国有企业及规模以上制造业非国有企业工业总产值Y, 资产累计K及职员人数L。
序号工业总产值Y(亿元)资产累计K(亿元)职员人数L(万人)序号工业总产值Y(亿元)资产累计K(亿元)职员人数L(万人)1 3722.7 3078.22 113 17 812.7 1118.81 432 1442.52 1684.43 67 18 1899.7 2052.16 613 1752.37 2742.77 84 19 3692.85 6113.11 2404 1451.29 1973.82 27 20 4732.9 9228.25 2225 5149.3 5917.01 327 21 2180.23 2866.65 806 2291.16 1758.77 120 22 2539.76 2545.63 967 1345.17 939.1 58 23 3046.95 4787.9 2228 656.77 694.94 31 24 2192.63 3255.29 1639 370.18 363.48 16 25 5364.83 8129.68 24410 1590.36 2511.99 66 26 4834.68 5260.2 14511 616.71 973.73 58 27 7549.58 7518.79 13812 617.94 516.01 28 28 867.91 984.52 4613 4429.19 3785.91 61 29 4611.39 18626.94 21814 5749.02 8688.03 254 30 170.3 610.91 1915 1781.37 2798.9 83 31 325.53 1523.19 4516 1243.07 1808.44 33表1(二)创建工作文件(Workfile)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多元线性回归模型实验报告
13级财务管理 101012013101 蔡珊珊
【摘要】首先做出多元回归模型,对于解释变量作出logx等变换,选择拟合程度最高的模型,然后判断出解释变量之间存在相关性,然后从检验多重线性性入手,由于解释变量之间有的存在严重的线性性,因此采用逐步回归法,将解释变量进行筛选,保留对模型解释能力较强的解释变量,进而得出一个初步的回归模型,最后对模型进行异方差和自相关检验。
【操作步骤】1.输入解释变量与被解释变量的数据
2.作出回归模型
R^2=0.966951 DW=0.626584 F-statictis=241.3763
②我们令y1=log(consumption),x4=log(people),x5=log(price),x6=log(retained),x7= log(gdp),
作出回归模型
②
发现拟合程度很高,也通过了F检验与T检验。
但是我们首先检查模型的共线性
发现x4与x6,x4与x7,x6与x7存在很强的共线性,对模型会造成严重影响。
目前暂用模型y1=10.55028-3.038439x4-0.236518x5+2.647396x6-0.557805x7,我们将陆续进行调整。
3.分别作出各解释变量与被解释变量之间的线性模型
①作出汽车消费量与汽车保有量之间的线性回归模型
R^2=0.956231 DW=0.147867 F-statistic=786.4967
因为prob小于α置信度,则可说明β1不明显为零。
经济意义存在
Y1^=4.142917 + 0.761197x6
(8.283960) (28.04455)
②作出消费量与价格之间的回归模型
R^2=0.644367 DW=0.118214 F-statistic=65.22782 根据经济分析,随着价格的升高,消费量降低,
Y^=18.51057 + 0.455884x5
(353.8845)(8.076374)
不符合经济意义,需要做出调整,且拟合程度不高
③作出消费量与人口之间的回归模型
R^2=0.945427 DW=0.150428 F-statistic=623.6709 Y^=-8.076059 + 2.151258x4
(-7.685368)(24.97340)
符合经济意义,随着人口的增加,对于汽车的需求量也会相应的增加。
④作出消费量与国民生产总值之间的回归模型
R^2=0.935692 DW=0.138340 F-stastistic=523.8036
Y^=12.16450 + 0.783946x7
(46.34009)(22.88678)
符合经济意义,国民生产与消费量同方向变动。
3.排序后发现R1^2>R3^2>R4^2>R2^2
4.对Y关于x6与x4做最小二乘
①加入x4后,R^2=0.956753 adjusted R^2=0.956613均有所增加,但相差不大,
且降低了汽车保有量的效果,x4的prob>0.05的显著性水平,认为显著为零,说明存在多重线性性,因此保留对模型解释能力更强的x6,略去x4。
5.做Y关于x6,x7的最小二乘法
R^2=0.961734 DW=0.286766 F-statistic=439.8306
拟合优度R^2增加不明显,adjusted R^2也增加不显著,由二者的相关系数来看存在严重的共线性,因此舍去
6.做Y关于x6,x5的最小二乘
R^2=0.976233有所增加,且二者之间的相关系数<R^2,可以认为二者之间的多重线性性不存在重大影响,因此保留x5.
7.即目前模型认定为y=0.973261x6-0.174324x5且符合经济意义
8.对模型进行异方差检验
我们采用怀特检验
自由度为g=(1+1)(1+2)/2-1=2
因为x^2(2)=5.991 obs*R-squared=12.969,则obs*R-squared>x^2(2)存在异方差。
10.对模型进行异方差修正
令e=abs(resid),在窗口输入命令ls (y1)/e c (x6)/e (x5)/e
若在置信水平0.05的情况下,可以认为模型不存在异方差。
关键取决于权重的选取。
11.自相关检验
DW=0.4048说明模型存在严重的自相关,我们认为模型存在一阶自相关
LM检验中显示模型存在二阶自相关
检验三阶时又发现模型不存在二阶自相关,因此我们做出自相关图与偏相关图,可以得出模型存在一阶自相关,由于是时间序列,可能存在不稳定性,对结果造成影响。
12.自相关消除
在输入窗输入ls (y1)/e c (x5)/e (x6)/e ar(1)
可以得出ut=0.796179(ut-1)+vt 即p=0.796179 【预测】
得出置信带,通过假设的解释变量的值,我们预测出
【经济意义说明】
模型y/e=-0.178806x5/e+0.978917x6/e+0.796179(ut-1)+vt
,其中y=log(consumption),x6=log(retained),x5=log(price),e=abs(resid)从理论上来说是可行的,意味着汽车消费量随着人口的增加而增加,因此x6的系数为正,但随着价格的增加而减少,因此x5的系数为负。
【模型检验】
JB检验:
JB<X^2 O.O5(2),我们认为误差项是服从正态分布的。
【问题】在检验异方差的时候,若选择的权重都不能很好的消除异方差时候
如何解决?为什么输入ls e c x6与在option中输入权重得出的结果不一致?
没法消除自相关与异方差是什么原因引起的?。