差异显著性检验模板
P、F、t值的意义【范本模板】

P值的意义:有显著性差异统计学意义(P值)结果的统计学意义是结果真实程度(能够代表总体)的一种估计方法.专业上,P值为结果可信程度的一个递减指标,P值越大,我们越不能认为样本中变量的关联是总体中各变量关联的可靠指标。
P值是将观察结果认为有效即具有总体代表性的犯错概率.如P=0。
05提示样本中变量关联有5%的可能是由于偶然性造成的。
即假设总体中任意变量间均无关联,我们重复类似实验,会发现约20个实验中有一个实验,我们所研究的变量关联将等于或强于我们的实验结果.(这并不是说如果变量间存在关联,我们可得到5%或95%次数的相同结果,当总体中的变量存在关联,重复研究和发现关联的可能性与设计的统计学效力有关。
)在许多研究领域,0.05的P值通常被认为是可接受错误的边界水平。
如何判定结果具有真实的显著性在最后结论中判断什么样的显著性水平具有统计学意义,不可避免地带有武断性。
换句话说,认为结果无效而被拒绝接受的水平的选择具有武断性。
实践中,最后的决定通常依赖于数据集比较和分析过程中结果是先验性还是仅仅为均数之间的两两〉比较,依赖于总体数据集里结论一致的支持性证据的数量,依赖于以往该研究领域的惯例。
通常,许多的科学领域中产生P值的结果≤0。
05被认为是统计学意义的边界线,但是这显著性水平还包含了相当高的犯错可能性。
结果0。
05≥P>0.01被认为是具有统计学意义,而0。
01≥P≥0.001被认为具有高度统计学意义。
但要注意这种分类仅仅是研究基础上非正规的判断常规。
所有的检验统计都是正态分布的吗?并不完全如此,但大多数检验都直接或间接与之有关,可以从正态分布中推导出来,如t 检验、f检验或卡方检验。
这些检验一般都要求:所分析变量在总体中呈正态分布,即满足所谓的正态假设。
许多观察变量的确是呈正态分布的,这也是正态分布是现实世界的基本特征的原因.当人们用在正态分布基础上建立的检验分析非正态分布变量的数据时问题就产生了,(参阅非参数和方差分析的正态性检验)。
差异显著性检验课件

该方法通过比较两组数据的秩次(相 对大小)来检验差异显著性,特别适 用于处理小样本数据或数据不符合正 态分布的情况。它能够提供更准确的 差异显著性判断。
秩次检验
总结词
秩次检验是一种非参数统计方法,通过 比较数据的秩次来分析差异显著性。
VS
详细描述
秩次检验适用于处理不服从正态分布的数 据,尤其在处理小样本数据或数据分布不 明确时具有优势。它能够提供更全面的差 异显著性分析结果,包括差异的方向和显 著性水平。
,或者比较多个分类变量之间的
关联程度。
适用场景
实验研究
当需要比较实验组和对照组之 间的差异时,可以使用差异显
著性检验。
调查数据
在社会科学调查中,当需要比 较不同群体或地区的差异时, 可以使用差异显著性检验。
医学研究
在医学研究中,差异显著性检 验常用于比较不同治疗方案或 药物的效果。
质量控制
在生产过程中,差异显著性检 验可用于检测产品质量或过程 参数的波动是否在可接受范围
流行病学调查
分析不同人群的生理指标 差异,研究疾病的流行病 学特征。
心理学研究中的应用
人格特质研究
通过比较不同人格特质人群的心理指标, 探究人格特质与心理指标的关系。
认知能力评估
评估不同认知能力人群的心理指标差异, 了解认知能力的发展规律。
情绪状态分析
分析不同情绪状态下心理指标的变化,探 究情绪状态对心理指标的影响。
常用方法
t检验
用于比较两组均值的差异,包括 独立样本t检验和配对样本t检验。
01
方差分析
02 用于比较两组或多组数据的方差 是否存在显著差异,包括单因素 方差分析和多因素方差分析。
均数差异显著性检验EXCEL

随机事件(random event) 随机事件 不确定事件(indefinite event) 不确定事件 为了研究随机现象,需要进行大量重复的调查、实验、 为了研究随机现象,需要进行大量重复的调查、实验、 测试等,这些统称为试验。 测试等,这些统称为试验。
二、频率(frequency) 频率( )
P(A) = p
统计概率
抛掷一枚硬币发生正面朝上的试验记录 实验者 蒲丰 投掷次数 4040 发生正面朝上的次数 频率(m/n) 频率 2048 6019 12012 0.5069 0.5016 0.5005
K 皮尔逊 12000 K 皮尔逊 24000
随着实验次数的增多, 随着实验次数的增多,正面朝上这个事件发生的频率稳定 接近0.5,我们称0.5作为这个事件的概率 作为这个事件的概率。 接近 ,我们称 作为这个事件的概率。
第四章 均数差异显著性检验 — t检验
河南农业职业学院 孙攀峰
目的要求
显著性检验的目的、 显著性检验的目的、 方法以及步骤 Excel进行 Excel进行t检验的步 进行t 骤、方法
第一节 概率及分布概述
一、事件
定义:在一定条件下, 定义:在一定条件下,某种事物出现与否 就称为是事件。 就称为是事件。 自然界和社会生活上发生的现象是各 种各样的,常见的有两类。 种各样的,常见的有两类。
若在相同的条件下,进行了n次试验,在这n 若在相同的条件下,进行了 次试验,在这 次试验 次试验中,事件 出现的次数 称为事件A出现的 出现的次数m称为事件 次试验中,事件A出现的次数 称为事件 出现的 频数,比值 称为事件A出现的频率 频数,比值m/n称为事件 出现的频率 称为事件 出现的频率(frequency), , 记为W(A)=m/n。 。 记为
第五章_差异显著性检验

学习目标
1. 了解假设检验的基本思想 2. 掌握假设检验的步骤 3. 能对实际问题作假设检验 4. 利用置信区间进行假设检验 5. 利用P - 值进行假设检验
第一节 假设检验的一般问题
一. 假设检验的概念 二. 假设检验的步骤 三. 假设检验中的小概率原理 四. 假设检验中的两类错误 五. 双侧检验和单侧检验
✓ 所以观测值 x可i 以看作由两部分组成,即
xi i
表示误差
为总体平均数,反映了总体特征
第二节 显著性检验的基本原理
x ✓ 若样本含量为n,则可得到 n 个观测,x 1 ,x 2 ,…, n
样本平均数
x x in ( i ) /n
说明样本平均数并非等于总体平均数, 它还包含试验误差的成分
第一节 统计推断的意义和原理
统计假设检验又称显著性检验(significance test), 它是根据某种实际需要,对未知的或不完全知道的总体 参数提出一些假设,然后根据样本的实际结果和统计量 的分布规律,通过一定的计算,作出在一定概率意义下 应当接受哪种假设的方法。统计假设检验的假设是对总 体提出的,由于最后检验的结论只有两种,即与要比较 的总体参数间存在显著差异和不存在显著差异两种。
误差(12)所造成。
第二节 显著性检验的基本原理
虽然处理效应 (12)未知,但试验的表面效应
(x1x2)是可以计算的,借助数理统计方法可以对试
验误差 (1作2)出估计。所以,可从试验的表
面效应与试验误差的权衡比较中间接地推断处 理效应是否存在,这就是显著性检验的基本思 想。
第二节 显著性检验的基本原理
➢ 提出无效假设的同时,相应地提出一对应相反 假设,称为备择假设,简记 H A
➢ 备择假设是在无效假设被否定时准备接受的假 设
差异显著性检验t检验课件

目录
• 差异显著性检验t检验概述 • t检验的数学模型 • t检验的实施步骤 • t检验的案例分析 • t检验的局限性及解决方法 • t检验的软件实现与结论
01
差异显著性检验t检验概述
定义与概念
差异显著性检验t检验是一种常用的统计分析方法,用 于比较两组数据的均值是否存在显著差异。它利用t分 布理论来评估数据的可靠性。
配对样本t检验案例
总结词
配对样本t检验用于比较两个相关样本的平均值之间是否存在显著差异。
详细描述
配对样本t检验(也称为两相关样本t检验)是一种常用的差异显著性检验方法,用于比较两个相关样 本的平均值之间是否存在显著差异。例如,假设我们有两个由同一组研究对象在不同时间点上收集的 样本,我们要检验这两个样本的平均血压值是否存在显著差异。
01 如果p值小于0.05,那么我们可以认为这两个样本
的均值存在显著差异。
02
如果p值大于0.05,那么我们不能认为这两个样本 的均值存在显著差异。
t检验的实际应用建议
t检验主要用于比较两个独立样 本的均值是否存在显著差异,或 者一个样本与一个已知值之间是
否存在显著差异。
在进行t检验之前,需要先对数 据进行正态性检验,因为t检验 的前提假设是数据符合正态分布
在科学、工程、医学等领域,差异显著性检验t检验被 广泛应用于验证实验结果、比较实验组与对照组之间的 差异等。
t检验的应用范围
确定两组数据的均值是否存在显著差异,如研究 01 对象的身高、体重、年龄等。
检验一个样本的均值与已知的参照值是否存在显 02 著差异,如检测产品的质量、评估治疗效果等。
比较两个或多个独立样本的均值是否存在显著差 03 异,如不同地区、不同时间的数据比较。
均数差异显著性考验EXCEL

方差分析
用于比较两个或多个独立样本的平均值是否 存在显著差异。
假设检验的逻辑
提出假设
假设两组数据的平均值无显著差异(H0),或存在显著差异(H1)。
确定显著性水平
选择一个合适的显著性水平(如0.05或0.01),用于判断假设是否成立。
计算检验统计量
根据样本数据计算检验统计量,如t值、Z值或F值。
做出决策
总结词
用于检验两组数据是否具有相似的方差。
详细描述
FTEST函数用于进行方差齐性检验,判断两 组数据的方差是否相似。它需要输入两组数 据的标准差和样本数量,并返回F统计量和 p值。
CHITEST函数:卡方检验
总结词
用于检验两个分类变量是否独立。
详细描述
CHITEST函数用于进行卡方检验,判断两个 分类变量之间是否存在关联或独立关系。它 需要输入观察频数和期望频数,并返回卡方
人工智能的介入
自动化和智能化
人工智能技术将应用于均数差异显著性 检验,实现自动化和智能化的数据处理 和分析,提高分析效率和准确性。
VS
数据挖掘与预测
人工智能将通过数据挖掘和机器学习技术 ,发现隐藏在数据中的规律和趋势,为均 数差异显著性检验提供新的思路和方法。
THANKS
感谢观看
03
Excel中常用的均数差异 显著性检验函数
TTEST函数:双样本t检验
总结词
用于比较两组数据的均值是否存在显著差异。
详细描述
TTEST函数可以对两个独立样本或配对样本进行t检验,以判断两组数据的均值是否存 在显著差异。它需要输入样本数据和自由度,并返回t统计量和p值。
FTEST函数:方差齐性检验
均数差异显著性检验 (Excel实现
差异显著性检验t检验

17.平均数
• 调和平均数
资料中各观测值倒数的算术平均数 的倒数, 称为调和平均数,记为H
H ( 1 1 n x1
x112 x1n)1 n
1
1 x
17.平均数
• 对于同一资料:
算术平均数>几何平均数>调和平均数
• 上述五种平均数,最常用的是算术平均数。
17.平均数
• 中位数
将资料内所有观测值从小到大依次排列,位于中 间的那个观测值,称为中位数,记为Md。 当观测值的个数是偶数时,则以中间两个观测值 的平均数作为中位数。当所获得的数据资料呈偏态分 布时,中位数的代表性优于算术平均数。
17.平均数
众数
资料中出现次数最多的那个观测值或次数最多一 组的组中值,称为众数
实例1 小麦的施肥量试验(N) 实例2 小麦的施肥量试验(N、P)
单因素试验
水平
N1
P1
500
P2
900
多因素试验
N2 800 1200
N1P2、 Байду номын сангаас2P2
综合试验
实例2 小麦的施肥量试验(N、P)
水平
N1
P1
500
P2
900
N2 800 1200
{(500-900)+(800-1200)} /2=- 400
本叫大样本。
一、几个相关概念
总体与样本关系:
➢假想总体 ➢统计分析的特点 ➢随机抽取 ➢样本含量与代表性: ➢统计推断或者分析的不确定性
一、几个相关概念
2. 参数与统计量
参数: 由总体计算的特征数叫参数(parameter); 常用希腊字 母表示参数,例如用μ表示总体平均数,用σ表示总体标准差;
显著性差异分析演示文稿

第1页,共14页。
显著性检验的意义
• 利用统计学的方法,检验被处理 的问题 是否存在 统计上的显著 性差异。
第2页,共14页。
显著性检验的作用
• 分析工作者常常用标准方法与自己所用的分析方 法进行对照试验,然后用统计学方法检验两种结 果是否存在显著性差异。若存在显著性差异而又 肯定测定过程中没有错误,可以认定自己所用的 方法有不完善之处,即存在较大的系统误差。
• 把计算的F值与查表得到的F值比较,若F 计 < F表 ,则两组数据的精密度不 存在显著性差异;若F计 > F表 则存
在显著性差异。
第14页,共14页。
值,分析工作中则多取0.05的显著性水准,即置信 度为95%。 3. 统计量计算和作出判断。 • 下面介绍 t 检验法和 F检验法。
第5页,共14页。
t检验法
(1)平均值与标准值()的比较
a. 计算t 值
t计算
X
S
n
b. 根据要求的置信度和测定次数查表,得:t表值 c. 比较: t计和t表
• 若t计 > t表,表示有显著性差异,存在系统误差,被 检验方法需要改进。
-如果分析结果之间存在“显著性差异”,就可认为它们之间 有明显的系统误差,
-否则就可以认为没有系统误差,仅为偶然误差引起的正常 情况。
第4页,共14页。
显著性检验的步骤
显著性检验的一般步骤是: 1. 做一个假设,即假设不存在显著性差异,或所有
样本来源于同一体。 2. 确定一个显著性水准,通常等于0.1,0.05,0.01等
所以 X 与μ之间不存在显著性差异
即采用新方法没有引起系统误差。
第8页,共14页。
(2)两组数据的平均值比较(同一试样)
均数差异显著性检验.PPT文档56页

36、“不可能”这个字(法语是一个字 ),只 在愚人 的字典 中找得 到。--拿 破仑。 37、不要生气要争气,不要看破要突 破,不 要嫉妒 要欣赏 ,不要 托延要 积极, 不要心 动要行 动。 38、勤奋,机会,乐观是成功的三要 素。(注 意:传 统观念 认为勤 奋和机 会是成 功的要 素,但 是经过 统计学 和成功 人士的 分析得 出,乐 观是成 功的第 三要素 。
▪
27、只有把抱怨环境的心情,化为上进的力量,才是成功的保证。——罗曼·罗兰
▪
28、知之者不如好之者,好之者不如乐之者。——孔子
▪
29、勇猛、大胆和坚定的决心能够抵得上武器的精良。——达·芬奇
▪
30、意志是一个强壮的盲人,倚靠在明眼的跛子肩上。——叔本华
谢谢!
56
39、没有不老的誓言,没有不变的承 诺,踏 上旅途 ,义无 反顾。 40、对时间的价值没有没有深切认识 的人使整个人生都过得舒适、愉快,这是不可能的,因为人类必须具备一种能应付逆境的态度。——卢梭
显著性差异分析演示文稿

.
1
显著性检验的意义
• 利用统计学的方法,检验被处 理的问题 是否存在 统计上的 显著性差异。
.
2
显著性检验的作用
• 分析工作者常常用标准方法与自己所用的分析 方法进行对照试验,然后用统计学方法检验两 种结果是否存在显著性差异。若存在显著性差 异而又肯定测定过程中没有错误,可以认定自 己所用的方法有不完善之处,即存在较大的系 统误差。
3 10.1 9.55 9.28 9.12 9.01 8.94 8.89 8.85
4 7.71 6.94 6.59 6.39 6.26 6.16 6.09 6.04
5 6.61 5.79 5.41 5.19 5.05 4.95 4.88 4.82
6 5.99 5.14 4.76 4.53 4.39 4.28 4.21 4.15
• 先求合并的标准偏差S合和合并的t值
.
9
S合与t合
偏差平方和
s合 总自由度 =
(X1i X1)2 (X2i X2)2 (n11)(n21)
或
S合
(n11)S12(n21)S2 2 n1n22
再计算
t合|
X1X2 S合
|
n1n2 n1n2
.
10
判断
• 在一定置信度时,查出t表值(总自由度 为 f = n1 + n2 - 2)。
• 若:t计 > t表 则 两组平均值存在显著性 差异。
• 若: t计 < t表 则 两组平均值不存在显著 性差异。
.
11
F检验法
• F检验法的意义:
• 标准偏差反映测定结果精密度,是衡量 分析操作条件是否稳定的一个重要标志。 例如,有两个分析人员同时采用同种方 法对同一试样进行分析测定,但得列两 组数据的精密度S1≠S2。要研究其差异是 偶然误差引起的,还是其中一人的工作 有异常情况或是过失。
差异显著性检验模板

同时减少犯这两类错误的概率的唯一的方法是增大样本容 弃真错误和取伪错误的概率存在此消彼长的关系: 量,但这又是不现实的 当弃真错误的概率降低时,取伪错误的概率就会增加 因此,通常都是首先控制弃真错误的概率,即确定显著性 当取伪错误的概率降低时,弃真错误的概率就会增加 水平α
3.双侧检验和单侧检验
假设检验的两种形式 双侧检验 原假设H0 备择假设H1 µ= µ0 µ≠ µ0 单侧检验 µ≥ µ0 µ< µ0 µ≤µ0 µ> µ0
(1) 双侧检验 有两个临界值,两个拒 绝域,每个拒绝域的面积为 α ,原假设µ= µ0,只要 2 µ> µ0或µ<µ0有一侧出现, 就要拒绝原假设。 双侧检验按 α 查表求临界值。
2
(2) 单侧检验
有一个临界值,一个拒绝域, 拒绝域的面积为α 。 当所考察的数值越大越好时, 用单侧检验。 如考察灯泡的寿命 当所考察的数值越小越好时, 用单侧检验。 如考察产品的废品率 单侧检验按α 查表求临界值。
一、假设检验 二、独立样本T检验 三、单因素方差分析
不同性别、不同年龄、不同教育背景、不同收入、 不同客源地的游客群体在旅游购物、游憩动机、 游憩满意度、乃至旅游影响感知等方面肯定存在 差异,但如果只探讨他们之间的微小差异是没有 意义的,我们需要了解的是他们在这些方面是否 存在显著差异。
差异显著性检验属于假设检验的范畴,因而必须 首先了解什么是假设检验(Hypothesis Testing)。
2)选择进行“独立样本T检验”的变量 本例欲进行住宿条件满意度的差异性检验,所以从对话框 左侧的变量列表中选“住宿的环境卫生”、 “住宿的舒 适性”、 “住宿的价格”3个变量,使之进入右侧的“检 验变量(T)”框。
3)设置分组变量 从对话框左侧的变量列表中选“性别”变量,使之进入右 侧的“分组变量(G)”框,继之点击“定义组(D)”, 在弹出的“定义组”对话框中,在“使用指定值(U)” 单选框的“组1(1)”栏输入1,在“组2(2)”输入2, 点击“继续”键,回到“独立样本T检验”窗口。割点 (C)单选框适合连续变量的情况,因而可以不用填写。 接着点击“继续”键,返回“独立样本T检验”对话框。
第九讲-2 非参数检验-差异显著性检验

T界值表(配对比较的符号秩和检验用)
N
单侧:0.05 双侧:0.10
单侧:0.025 单侧:0.01 单侧:0.005 双侧:0.05 双侧:0.02 双侧:0.010
5 0--15
6 2--19
0--21
7 3--25
2--26
0--28
8 5--31
3--33
1--35
0-36
9 8--37
5--40
怎样选用不同设计的秩和检验方法
1)首先要区分试验设计和资料的类型: 2)若是一个样本资料或者配对设计的资料, 来自
非正态总体或总体分布无法确定,可选用 wilcoxon符号秩和检验方法; 3)若是两组独立样本资料,来自非正态分布的定 量资料或有序二分类变量资料(等级资料)宜用 wilcoxon秩和检验;
4. 检验统计量R取较小一个秩号和,R=1.5,有效差值个数
n=11(差值0无效)根据R值查两配对样本T界值表,得
单侧P<0.005,按0.05水平拒绝H0,差异有统计学意义。 注意:查表时,在左侧找到对子数n,将检验统计量R 值与n右侧相邻栏内的界限值相比。
R在界限值内,则其P值大于表上端纵标目之概率水 平; R等于界限值,则其P值等于相应概率水平; R在界限值外,则P值小于相应概率水平,向右移动 一栏,再与界限值比较。
2--26
0--28
3--33
1--35
0-36
5--40
3--42
1-44
8--47
5--50
3-52
10--56
7--59
5-61
13--65
9--69
7-71
注意:本例:n=11,R=1.5,P<0.005
两个样本的差异显著性检验

n1 n2
20
⑤建立 H0 的拒绝域:因 HA: µ1> µ2,故为上尾单侧 检验。当 u > u0.05 时拒绝 H0,由附表查出 u0.05 = 1.645.
⑥结论: 因 u < u 0.05,即 P > 0.05, 所以接受 H0 结论是 第一渔场的马面鲀体长并不比第二号渔场长。
5.标准差(σ i)未知但相等时,两个平均数间差异 显著性检验—成组数据 t 检验
① HA: σ1> σ2 (已知 σ1 不可能小于 σ2) ② HA: σ1< σ2 (已知 σ1 不可能大于 σ2) ③ HA: σ1 ≠ σ2 (包括以上两种情况)
(3)显著水平:常用 α=0.05 或 α=0.01 两个水平
(4)检验统计量:在 H0:σ1= σ2 下可用下式: Fdf1,df2 = s12/s22, df1 = n1-1, df2 = n2-1
6.标准差(σ i)未知且可能不等时,两平均数间差 异显著性检验
1
df k 2 (1 k)2
其中
s12
df1 df2
k
s12
n2 s12 s22 n2 n2
例.5
两组类似的大鼠,一组作对照,另一组做药物处理,然后测 定血糖,结果如下(mg):
=2.160+(2.145-2.160)*0.35
=2.160-0.00525
=2.155
t < t0.05 ( 双侧 ),即 P > 0.05。结论是催产素对大鼠血糖含量的影响 是不显著的
H0:µ1=µ2; HA: µ1 ≠ µ2; α=0.05
tn1n 22
27.92 25.11
2.168
69.384 9.215 ( 1 1 )
差异显著性分析
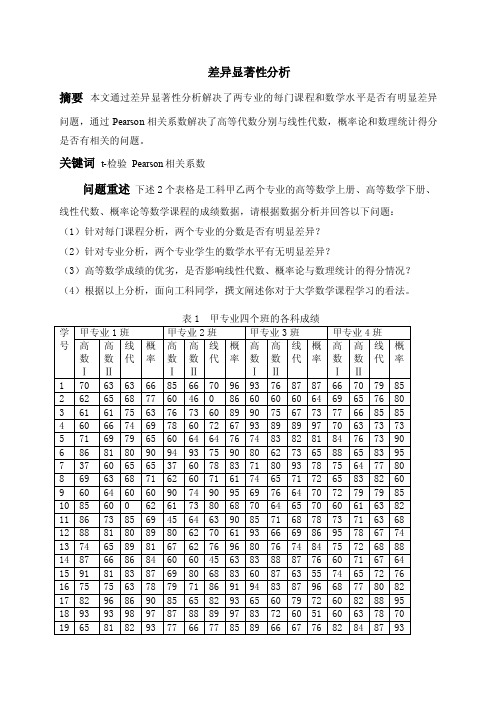
差异显著性分析摘要本文通过差异显著性分析解决了两专业的每门课程和数学水平是否有明显差异问题,通过Pearson相关系数解决了高等代数分别与线性代数,概率论和数理统计得分是否有相关的问题。
关键词t-检验Pearson相关系数问题重述下述2个表格是工科甲乙两个专业的高等数学上册、高等数学下册、线性代数、概率论等数学课程的成绩数据,请根据数据分析并回答以下问题:(1)针对每门课程分析,两个专业的分数是否有明显差异?(2)针对专业分析,两个专业学生的数学水平有无明显差异?(3)高等数学成绩的优劣,是否影响线性代数、概率论与数理统计的得分情况?(4)根据以上分析,面向工科同学,撰文阐述你对于大学数学课程学习的看法。
模型假设1、甲专业中有一个数大于100分,由于是百分制,所以将此数换成0.2、因为每一科的分数总体多数都是处在中间60分左右,不会高分的占多数也不会是低分的占多数,所以样本可以看作是来自正态或近似正态总体。
模型建立1、对问题(1)用T检验来判定两个专业每一科的平均值的差异是否显著,因为T检验就是用于小样本,总体标准差σ未知的正态分布资料,是用于小样本的两个平均值差异程度的检验方法。
它是用T分布理论来推断差异发生的概率,从而判定两个平均数的差异是否显著。
1.建立假设、确定检验水准αH0:μ = μ0 =60(无效假设,)H1:(备择假设)双侧检验,检验水准:α=0.052.计算检验统计量,v=n-13.查相应界值表,确定P值,下结论2、问题(2)也是用T检验来判定两专业的数学水平的均值的差异是否显著,方法与问题(1)一样。
只是针对对象不同3、问题(3)用Pearson相关系数来分别判断线性代数,概率论和数理统计得分是否与高等代数的优劣相关。
Pearson相关系数是用来反映两个变量线性相关程度的统计量。
相关系数用r表示,其中n为样本r描述的是两个变量间线性相关强弱的程度。
r的绝对值越大,表明相关性越强。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
20 娱乐项目安全性
21 服务态度 22 服务效率
07 住宿的价格
08 交通的便捷性
15 商品种类
16 商品特色
23 导向标志与解说
1. 提出假设
本例选择其中的住宿满意度进行独立样本T检验。根据假 设检验的原理,我们提出如下假设:
H1 :不同性别的游客对白水洋景区的住宿满意度存在显 著差异。
H 1a :不同性别的游客对白水洋景区的住宿环境卫生满 意度存在显著差异。 H 1b :不同性别的游客对白水洋景区的住宿的舒适性满 意度存在显著差异。 H 1c :不同性别的游客对白水洋景区的住宿的价格满意 度存在显著差异。
t
X1 X 2
2 (n1 1) S12 (n2 1) S 2 n1 n2 2
1 1 n n 2 1
~ t (n1 n2 2)
统计量t服从自由度为(n1+n2-2)的t分布。 X 1 和 X 2 分别为两组样本的均值,n1和n2分别为两 式中, 2 2 S 组样本的个数,S1 和 2 分别为两组样本的方差。
5)确定设置和输出结果 所有设置确定无误后,点击“确定”按钮,输出分析结 果。
3. SPSS分析结果解读
独立双样本T检验的SPSS输出结果比较简单,仅包含描述 统计和T检验两个输出结果表。 描述性统计量性别
住宿的环境卫 生 住宿的舒适性 住宿的价格 男性 女性 男性 女性 男性 N 204 198 204 198 204 均值 3.4118 3.2626 3.4853 3.2576 3.0098 标准差 .74745 .77507 .71216 .72610 .85955 均值的标准误 .05233 .05508 .04986 .05160 .06018
福建白水洋景区游客满意度评价指标
序号与题项
01 食物的新鲜程度 02 食物的特色 03 食物的卫生程度 09 交通的舒适性 10 交通的安全性 11 自然风光 17 商品质量 18 娱乐项目种类 19 娱乐项目创新性
04 食物的价格
05 住宿的环境卫生 06 住宿的舒适性
12 卫生环境
13 旅游形象 14 门票价格
2)选择进行“独立样本T检验”的变量 本例欲进行住宿条件满意度的差异性检验,所以从对话框 左侧的变量列表中选“住宿的环境卫生”、 “住宿的舒 适性”、 “住宿的价格”3个变量,使之进入右侧的“检 验变量(T)”框。
3)设置分组变量 从对话框左侧的变量列表中选“性别”变量,使之进入右 侧的“分组变量(G)”框,继之点击“定义组(D)”, 在弹出的“定义组”对话框中,在“使用指定值(U)” 单选框的“组1(1)”栏输入1,在“组2(2)”输入2, 点击“继续”键,回到“独立样本T检验”窗口。割点 (C)单选框适合连续变量的情况,因而可以不用填写。 接着点击“继续”键,返回“独立样本T检验”对话框。
(1) 双侧检验 有两个临界值,两个拒 绝域,每个拒绝域的面积为 α ,原假设µ= µ0,只要 2 µ> µ0或µ<µ0有一侧出现, 就要拒绝原假设。 双侧检验按 α 查表求临界值。
2
(2) 单侧检验
有一个临界值,一个拒绝域, 拒绝域的面积为α 。 当所考察的数值越大越好时, 用单侧检验。 如考察灯泡的寿命 当所考察的数值越小越好时, 用单侧检验。 如考察产品的废品率 单侧检验按α 查表求临界值。
一、假设检验
(一)假设检验的基本原理
所谓假设,可以理解为是研究者对于某个有待解决的问题 所提出的暂时性或尝试性的答案。就差异显著性的假设检 验而言,其假设的陈述形式是一种差异式陈述方式。 例如: 不同性别的游客对某一景区提供的住宿条件的满意程度是 否存在显著差异? 不同收入的游客群体对某一景区自然风光的评价是否存在
5. 检验方法的选择
一般而言,差异显著性检验涉及的变量关系可以理解为一 种因果关系。从统计学的观点来看,这种涉及两类变量的 检验属于双变量(bivariate)的统计检验。对于双变量的 假设检验,我们必须指定其中的一个变量为自变量 (independent variable)、另一个为因变量(dependent
1.964
400
.14914
.07594 -.00015
.29842
1.963 398.256
.050
.14914
.07598 -.00023
.29851
方差方程的 Levene检验
均值方程的t检验
差分的95%置信 区间
F 假设 方差 相等 假设 方差 不相 等 .830 .363 3.174 399.030 .002 .22772 .07176 .08665 .36879 Sig. t df Sig. (双 侧) .002 均值 差值 .22772 标准 误差值 .07174 下限 上限
2 2 2. 两总体方差 1 和 2 未知,但它们不相等。
此时属于两样本异方差的T检验,其t统计量的计算式为:
t X1 X 2
2 S12 S 2 n1 n2
其自由度为:
k (1 k ) df n 1 n 1 2 1
2
2
1
其中:
S12 k n1
4.假设检验的步骤
(1) 提出假设。
H 0 : 1 2
H1 : 1 2
(2) 选取检验统计量,并在原假设H0成立的条件下计算统计 量的值。 ቤተ መጻሕፍቲ ባይዱ3) 对于给定的显著性水平α ,决定临界值。 α的取值范围为α≤0.01,α≤0.05和α≤0.10,一般情况下, 常用α≤0.05。 当α≤0.05时,差异显著,当α≤0.01时,差异极显著。 (4) 对假设做出判断。 通过对计算获得的统计量与临界值的比较,作出接受或 拒绝零假设的决定。
4)指定输出内容及缺失值处理方法 单击“选项(O)”框,开启选项对话框。
1)“置信区间(C)”编辑框:一般设置95%置信区间。 2)“缺失值”单选框:按分析顺序排除个案(A)表示 当分析计算涉及含有缺失值的变量时,才删除该记录;按 列表排除个案(L)表示只要相关变量有缺失值,则在所 有分析中均将该记录删除;本例选择前者。 3)最后单击“继续”框,返回“独立样本T检验”对话框。
独立样本T检验常用于进行两独立样本均值的比较。所谓 独立样本是指两组样本之间没有任何联系,但各自接受相 同的测量。假设两组样本的个数分别为n1和n2,检验这两 组样本的均值是否相等可以分为以下两种情况考虑。
2 1. 两总体方差 12 和 2 未知,但它们相等。 此时属于两样本等方差检验,其统计量t的计算式为:
女性
198
3.0152
.76389
.05429
独立样本T检验
方差方程 的Levene 检验 均值方程的t检验 差分的95%置信 区间 Sig. F Sig. t df (双 侧) .050 均值差 值 标准 误差 值
下限
上限
住 宿 的 环 境 卫 生
假设 方差 相等 假设 方差 不相 等 .219 .640
2 S12 S 2 n n 1 2
也就是说,独立双样本T检验,首先必须先检验双样本的 方差是否相等,这是选择统计量进行双样本T检验的基 础,方差是否相等需要采用F检验,其统计量的计算式为:
S12 F 2 ~ F (n1 1, n2 1) S2
服从自由度为(n1-1, n2-1)的F分布。
一、假设检验 二、独立样本T检验 三、单因素方差分析
不同性别、不同年龄、不同教育背景、不同收入、 不同客源地的游客群体在旅游购物、游憩动机、 游憩满意度、乃至旅游影响感知等方面肯定存在 差异,但如果只探讨他们之间的微小差异是没有 意义的,我们需要了解的是他们在这些方面是否 存在显著差异。
差异显著性检验属于假设检验的范畴,因而必须 首先了解什么是假设检验(Hypothesis Testing)。
零假设是待检验的假设,如果待检验的假设不成立,那么 其对立假设就成立。
2.假设检验的两类错误
第一类错误: 也称为弃真错误,是指零假设H0实际上是真 实的,而检验结果却拒绝了它。出现第一类错误的概率是 显著性水平α ,因此犯第一类错误的概率是可以控制的。 第二类错误:也称为取伪错误,是指零假设H0实际上是不 真实的,而检验结果却接受了它。第二类错误的概率用β 表示。 总体情况 检验结果 零假设H0为真 对立假设H1为真 接受H0 拒绝H0 判断正确 第一类错误 第二类错误 判断正确
同时减少犯这两类错误的概率的唯一的方法是增大样本容 弃真错误和取伪错误的概率存在此消彼长的关系: 量,但这又是不现实的 当弃真错误的概率降低时,取伪错误的概率就会增加 因此,通常都是首先控制弃真错误的概率,即确定显著性 当取伪错误的概率降低时,弃真错误的概率就会增加 水平α
3.双侧检验和单侧检验
假设检验的两种形式 双侧检验 原假设H0 备择假设H1 µ= µ0 µ≠ µ0 单侧检验 µ≥ µ0 µ< µ0 µ≤µ0 µ> µ0
variable)。 如不同性别的游客对某景区提供的住宿条件的满意度存在 显著差异,这里视性别为自变量,满意度为因变量,即认 为这种满意度的差别是因为性别的不同引起的。 因变量 类别变量 连续变量 自变量(类别变量) 卡方检验 t检验、方差分析
二、独立样本T检验
(一)基本原理
当自变量为间断(类别)变量,因变量为连续变量时,常 使用T检验与方差检验进行有关分析。 SPSS软件提供的T检验有3种形式,分别是单样本T检验 (One-Sample T Test),独立样本T检验(Independent -Sample T Test)和成对样本T检验(Paired-Sample T Test)。 在旅游研究中,比较常用的是独立样本T检验,因而本章 仅讨论独立样本T检验。独立样本T检验在一些教科书中 被称为独立双样本T检验,顾名思义,其显然仅适用于自 变量为两组的情况。如考虑不同性别的游客心理感知差异 时,由于性别只有男女两组,此时应该采取独立样本T检 验方法进行有关检验。