MIME(BASE64-QP) 编码-解码程序代码
base64解析

base64解析
base64编码是一种用64个字符来表示任意二进制数据的方法。
它是一种简单
的文本编码方式,可以将任何类型的文本或二进制数据编码为文本文件,例如电子邮件附件,图像文件或其他二进制数据文件。
Base64编码的性质非常强,使用
base64编码可以将任何字符、数字和控制字符统一转换为64个字符组成的字符串,比其他任何字符串编码都要有效得多,以节省空间,保护数据完整性,防止数据泄漏。
Base64编码的优点很多,首先,它有效地解决了字符编码的繁琐问题,编码
规则简洁易懂,能够有效缩短图片信息在文件传输过程中的传输时间和存储空间。
它还支持大多数常用浏览器,并且极其方便,可以简单方便地对图片文件和文本文件进行编解码,从而能够轻松地实现图片保护,确保数据的真实性,避免图片被破解和失真。
总之,base64编码是一种强大,有效,安全的编码方式,在文件传输、信息加密和从字符串或二进制数据文件提取信息等方面都有重要作用,今后传输文件和安全传输信息将会更加容易,更安全。
Base64编码与解码原理

Base64编码与解码原理Base64编码是使⽤64个可打印ASCII字符(A-Z、a-z、0-9、+、/)将任意字节序列数据编码成ASCII字符串,另有“=”符号⽤作后缀⽤途。
base64索引表base64编码与解码的基础索引表如下base64编码原理(1)base64编码过程Base64将输⼊字符串按字节切分,取得每个字节对应的⼆进制值(若不⾜8⽐特则⾼位补0),然后将这些⼆进制数值串联起来,再按照6⽐特⼀组进⾏切分(因为2^6=64),最后⼀组若不⾜6⽐特则末尾补0。
将每组⼆进制值转换成⼗进制,然后在上述表格中找到对应的符号并串联起来就是Base64编码结果。
由于⼆进制数据是按照8⽐特⼀组进⾏传输,因此Base64按照6⽐特⼀组切分的⼆进制数据必须是24⽐特的倍数(6和8的最⼩公倍数)。
24⽐特就是3个字节,若原字节序列数据长度不是3的倍数时且剩下1个输⼊数据,则在编码结果后加2个=;若剩下2个输⼊数据,则在编码结果后加1个=。
完整的Base64定义可见RFC1421和RFC2045。
因为Base64算法是将3个字节原数据编码为4个字节新数据,所以Base64编码后的数据⽐原始数据略长,为原来的4/3。
(2)简单编码流程下⾯举例对字符串“ABCD”进⾏base64编码:对于不⾜6位的补零(图中浅红⾊的4位),索引为“A”;对于最后不⾜3字节,进⾏补零处理(图中红⾊部分),以“=”替代,因此,“ABCD”的base64编码为:“QUJDRA==”。
base64解码原理(1)base64解码过程base64解码,即是base64编码的逆过程,如果理解了编码过程,解码过程也就容易理解。
将base64编码数据根据编码表分别索引到编码值,然后每4个编码值⼀组组成⼀个24位的数据流,解码为3个字符。
对于末尾位“=”的base64数据,最终取得的4字节数据,需要去掉“=”再进⾏转换。
解码过程可以参考上图,逆向理解:“QUJDRA==” ——>“ABCD”1)将所有字符转化为ASCII 码;2)将ASCII 码转化为8位⼆进制;3)将8位⼆进制3个归成⼀组(不⾜3个在后边补0)共24位,再拆分成4组,每组6位;4)将每组6位的⼆进制转为⼗进制;5)从Base64编码表获取⼗进制对应的Base64编码;(2)base64解码特点base64编码中只包含64个可打印字符,⽽PHP在解码base64时,遇到不在其中的字符时,将会跳过这些字符,仅将合法字符组成⼀个新的字符串进⾏解码。
Base64编解码

Base64编解码一、编码原理Base64是一种基于64个可打印字符来表示二进制数据的表示方法。
由于2的6次方等于64,所以每6个比特为一个单元,对应某个可打印字符。
三个字节有24个比特,对应于4个Base64单元,即3个字节需要用4个可打印字符来表示。
编码后的数据比原来的数据略长,是原来的4/3倍。
它可用来作为电子邮件的传输编码。
在Base64中的可打印字符包括字母A-Z、a-z、数字0-9 ,这样共有62个字符,此外两个可打印符号在不同的系统中而不同(Base64de 编码表如下所示)。
Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据。
包括MIME的email,email via MIME, 在XML中存储复杂数据.Base64编码表二、编码流程步骤1:将要编码的所有字符都转化成对应的ASCII码。
步骤2:将所有的ASCII码转换成对应的8位长的二进制数。
步骤3:将所得的二进制数从高位到低位开始分成6位一组,最后一组不足六的则补充0步骤4:将每组二进制数转换成十进制数,然后对照base64的编码表查找得到相应的编码。
注意:1、要求被编码字符是8bit的,所以须在ASCII编码范围内,\u0000-\u00ff,中文就不行。
2、如果被编码的字符串中字符的个数为3的倍数,按照上面的步骤即可得到正确的base64编码。
但是如果不是3的倍数则要分情况讨论。
如果是3的倍数余1,则要在编好的码字后面加上两个“=”,如果是3的倍数余2,这要在编好的码字后面加上一个“=”。
(例如w的base64编码为dw==,w1的base64编码为dzE=)下面我们来对具体的字符串进行编码举例,以便更好的理解编码流程:编码「Man」在此例中,Base64算法将三个字符编码为4个字符特殊情况A的编码为QQ= =BC的编码为QkM=三、核心算法程序算法的基本原理如下:由于每次转换都需要6个bit,而这6个bit可能都来自一个字节,也可以来自前后相临的两个字节。
Base64编码解码(源代码)

Base64编码解码(源代码)Base64 Content-Transfer-Encoding ( RFC2045 ) 可对任何⽂件进⾏base64 编解码,主要⽤于MIME邮件内容编解码// 11111100 0xFC // 11000000 0x3 // 11110000 0xF0 // 00001111 0xF // 11000000 0xC0 // 00111111 0x3Fbyte *lmMimeEncodeBase64(const byte *octetSource, int size) { byte *m_Base64_Table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";int base64size = (((((size) + 2) / 3) * 4) + 1) / 76 * 78 + 78; //add "/r/n" for each line'byte *strEncode = (byte *)MALLOC(base64size); byte cTemp[4];//By RFC2045 --The encoded output stream must be represented in lines of no more than 76 characters each int LineLength=0; int i, len, j=0;MEMSET(strEncode, 0, base64size);for(i=0; i<size; i+=3) { MEMSET(cTemp,0,4);//cTemp[0]=octetSource[i]; //cTemp[1]=octetSource[i+1]; //cTemp[2]=octetSource[i+2];//len=strlen((char *)cTemp);if(i<size-3){ len = 3; cTemp[0]=octetSource[i]; cTemp[1]=octetSource[i+1]; cTemp[2]=octetSource[i+2]; } else{ len = 0; if(i<size){ cTemp[0]=octetSource[i]; ++len; } if(i<size-1){cTemp[1]=octetSource[i+1]; ++len; } if(i<size-2){ cTemp[2]=octetSource[i+2]; ++len; } //DBGPRINTF("temp[0] = %d", cTemp[0]); //DBGPRINTF("temp[1] = %d", cTemp[1]); //DBGPRINTF("temp[2] = %d",cTemp[2]); //DBGPRINTF("strEncode[0] = %d", ((int)cTemp[0] & 0xFC)>>2); //DBGPRINTF("strEncode[1] = %d",((int)cTemp[0] & 0x3)<<4 | ((int)cTemp[1] & 0xF0)>>4); //DBGPRINTF("strEncode[2] = %d", ((int)cTemp[1] & 0xF)<<2 | ((int)cTemp[2] & 0xC0)>>6); //DBGPRINTF("strEncode[3] = %d", (int)cTemp[2] & 0x3F); //DBGPRINTF("strEncode[0] = %c",m_Base64_Table[((int)cTemp[0] & 0xFC)>>2]); //DBGPRINTF("strEncode[1] = %c", m_Base64_Table[((int)cTemp[0] & 0x3)<<4 | ((int)cTemp[1] & 0xF0)>>4]); //DBGPRINTF("strEncode[2] = %c", m_Base64_Table[((int)cTemp[1] & 0xF)<<2 | ((int)cTemp[2] &0xC0)>>6]); //DBGPRINTF("strEncode[3] = %c", m_Base64_Table[(int)cTemp[2] & 0x3F]); }if(len==3) { strEncode[j++] = m_Base64_Table[((int)cTemp[0] & 0xFC)>>2]; strEncode[j++] =m_Base64_Table[((int)cTemp[0] & 0x3)<<4 | ((int)cTemp[1] & 0xF0)>>4]; strEncode[j++] = m_Base64_Table[((int)cTemp[1] & 0xF) <<2 | ((int)cTemp[2] & 0xC0)>>6]; strEncode[j++] = m_Base64_Table[(int)cTemp[2] & 0x3F]; LineLength+=4;if(LineLength>=76) {strEncode[j++]='/r'; strEncode[j++]='/n'; LineLength=0;} } else if(len==2) { strEncode[j++] =m_Base64_Table[((int)cTemp[0] & 0xFC)>>2]; strEncode[j++] = m_Base64_Table[((int)cTemp[0] & 0x3 )<<4 | ((int)cTemp[1] & 0xF0 )>>4]; strEncode[j++] = m_Base64_Table[((int)cTemp[1] & 0x0F)<<2]; strEncode[j++] = '='; LineLength+=4;if(LineLength>=76) {strEncode[j++]='/r'; strEncode[j++]='/n'; LineLength=0;} } else if(len==1) { strEncode[j++] =m_Base64_Table[((int)cTemp[0] & 0xFC)>>2]; strEncode[j++] = m_Base64_Table[((int)cTemp[0] & 0x3 )<<4]; strEncode[j++] = '='; strEncode[j++] = '='; LineLength+=4; if(LineLength>=76) {strEncode[j++]='/r'; strEncode[j++]='/n'; LineLength=0;} } memset(cTemp,0,4); } //strEncode[j] = '/0'; //DBGPRINTF("--finished encode base64size = %d, j = %d", base64size, j); //for(i=j; i<base64size; i++){ // DBGPRINTF("--rest char is: %c", strEncode[i]); //} return strEncode; }byte GetBase64Value(char ch) { if ((ch >= 'A') && (ch <= 'Z')) return ch - 'A'; if ((ch >= 'a') && (ch <= 'z')) return ch - 'a' + 26; if ((ch >= '0') && (ch <= '9')) return ch - '0' + 52; switch (ch) { case '+': return 62; case '/': return 63; case '=': /* base64 padding */ return 0; default: return 0; } } byte *lmMimeDecodeBase64(const byte *strSource, int *psize) { byte *m_Base64_Table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; int i, j, k, size = STRLEN((char *)strSource); int n = 0; //return value byte *octetDecode = (byte *)MALLOC( (((size) - 1) / 4) *3 ); byte cTemp[5]; int Length=0; int asc[4];for(i=0;i<size;i+=4) { MEMSET(cTemp,0,5);cTemp[0]=strSource[i]; cTemp[1]=strSource[i+1]; cTemp[2]=strSource[i+2]; cTemp[3]=strSource[i+3];Length+=4; if(Length==76) { i+=2; Length=0; }for(j=0;j<4;j++) { //if(cTemp[j]=='='){ // asc[j]=0; //}else{ for(k=0;k<(int)STRLEN((char*)m_Base64_Table);k++) { if(cTemp[j]==m_Base64_Table[k]) asc[j]=k; } //} } if('='==cTemp[2] && '='==cTemp[3]) { octetDecode[n++] = (byte)(int)(asc[0] << 2 | asc[1] << 2 >> 6); } else if('='==cTemp[3]) { octetDecode[n++] = (byte)(int)(asc[0] << 2 | asc[1] << 2 >> 6); octetDecode[n++] = (byte)(int)(asc[1] << 4 | asc[2] << 2 >> 4); } else { octetDecode[n++] = (byte)(int)(asc[0] << 2 | asc[1] << 2 >> 6); octetDecode[n++] = (byte)(int)(asc[1] << 4 | asc[2] << 2 >> 4); octetDecode[n++] = (byte)(int)(asc[2] << 6 | asc[3] << 2 >> 2); }//cTemp[0] = GetBase64Value((char)strSource[i]); //cTemp[1] = GetBase64Value((char)strSource[i+1]); //cTemp[2] = GetBase64Value((char)strSource[i+2]); //cTemp[3] = GetBase64Value((char)strSource[i+3]);//Length+=4; //if(Length==76) //{ // i+=2; // Length=0; //}//octetDecode[n++] = (cTemp[0] << 2) | (cTemp[1] >> 4); //octetDecode[n++] = (cTemp[1] << 4) | (cTemp[2] >> 2); //octetDecode[n++] = (cTemp[2] << 6) | (cTemp[3]);} *psize = n; return octetDecode; }。
windows2003 电脑操作系统乱码处理

4、使用WPS2000转换内码
WPS2000也能转换内码,支持GB2312、BIG5、GBK等三种主要的汉字编码,并可在输出RTF、TXT、HTM格式文件时对内码进行转换。
四、如何消除网页乱码?
【形成原因】:网页乱码是浏览器(IE等)对HTML网页解释时形成的,如果网页制作时编码为A,浏览器却以编码B显示该网页,就会出现乱码,因此只要你在浏览器中也以编码A显示该网页,就会消除乱码。
1、使用Word2003/XP转换内码
Word2003/XP支持众多的语言,可以正确显示非Unicode类型的文本文件,单击“工具”菜单下的“语言”/设置语言,你可以把默认语言设置成非中文,例如日语,这样Word就可以正确显示日文了。
当然你也可以用它进行简体中文与繁体中文之间的转换工作,如果文件有乱码,你转换一下即可消除。例如要把繁体中文转换为简体中文,方法是:选择要转换内码的文件,在弹出的对话框中,选择“其他编码”中的“繁体中文(BIG5)”一项,打开此文件时就不会出现乱码。
【解决办法】:只能由发件人解决。当发送8位格式的文本文件时,必须事先进行编码,将文件转换为7位ASCII码或更少位数的格式,然后才能保证文件的正确传送。收件人收到7位或更少位格式的邮件后,可以再转换为8位的格式,这样就可避免乱码。
3、收发端用的EMAIL软件和设置不同
一般EMAIL软件的"附件"功能都可以自动对信件先进行编码,然后送出。这样只要收信人使用的EMAIL软件(如Outlook XP等)能区别信件的编码方式,即可自动将信件解码。如果收发件人所用的EMAIL软件默认配置不同、收发件人自己定制的一些选项不同,在收到编码的信件后,系统就未必能识别出信件所用的编码方法,自然也无法自动解码,这样就会出现乱码。
base64 解码 原理

base64 解码原理
Base64是一种编码方式,它将二进制数据转换为可打印字符
的ASCII格式。
其原理如下:
1. 将待编码的数据划分为连续的24位(即3个字节)的分组。
2. 将每个24位的分组划分为4个6位的子分组。
3. 根据Base64编码表,将每个6位的子分组转换为对应的可
打印字符。
4. 如果最后的输入数据长度不足3个字节,会进行填充操作。
一般使用'='字符进行填充。
这样,在Base64编码中,一个3字节的二进制数据通过编码
后会变成4个字符,并且编码后的数据长度总是为4的倍数。
当需要对Base64编码进行解码时,可以按照以下步骤进行:
1. 将待解码的数据划分为连续的4个字符的分组。
2. 根据Base64解码表,将每个字符的编码值转换为对应的6
位二进制数据。
3. 将每个6位的子分组合并为一个24位的分组。
4. 将每个24位的分组划分为3个8位的子分组,并转换为对
应的字节数据。
5. 如果解码后的数据长度大于待解码的数据长度,则剔除填充的字节。
通过以上步骤,就可以将Base64编码的数据解码回原始的二
进制数据。
需要注意的是,Base64编码只是一种编码方式,它并不对数
据进行加密或压缩。
它主要用于在文本协议中传输二进制数据,或者在文本环境中嵌入二进制数据。
base编码解码算法

Base64是一种对字符通过二进制进行编码解码转换的一种编码算法,便于在不同环境间通信,规避了乱码的出现。
具体来说,Base64编码算法将每3个字节24位的数据转化为4个字节32位的数据,从而获得76%的压缩率。
在Python中,可以使用标准库中的base64模块进行Base64的编码和解码。
以下是一个简单的示例:
python
import base64
# 编码
data = b'hello world'
encoded_data = base64.b64encode(data)
print(encoded_data) # 输出:b'aGVsbG8gd29ybGQh'
# 解码
decoded_data = base64.b64decode(encoded_data)
print(decoded_data) # 输出:b'hello world'
在这个例子中,我们首先导入了base64模块,然后定义了一个字符串data,它包含了一些二进制数据。
接着,我们使用base64.b64encode函数对数据进行编码,得到一个字节串encoded_data。
最后,我们使用base64.b64decode函数对字节串进行解码,得到原始的二进制数据。
中文邮件的编码

使用java mail 包收发中文邮件的编码,解码问题以及解决方法JSP教程-邮件相关编码邮件头(参见RFC822,RFC2047)只能包含US-ASCII字符。
邮件头中任何包含非US-ASCII字符的部分必须进行编码,使其只包含US-ASCII字符。
所以使用java mail发送中文邮件必须经过编码,否则别人收到你的邮件只能是乱码一堆。
不过使用java mail 包的解决方法很简单,用它自带的MimeUtility工具中encode 开头的方法(如encodeText)对中文信息进行编码就可以了。
例子:MimeMessagemimeMsg = new MimeMessage(mailSession);//让javamail决定用什么方式来编码,编码内容的字符集是系统字符集mimeMsg.setSubject( MimeUtility.encodeText( Subject) );//使用指定的base64方式编码,并指定编码内容的字符集是gb2312mimeMsg.setSubject( MimeUtility.encodeText( S ubject,”gb2312”,”B”) );通常对邮件头的编码方式有2种,一种是base64方式编码,一种是QP(quoted-printable)方式编码,javamail根据具体情况来选择编码方式。
如“txt测试”编码后内容如下:=?GBK?Q?Txt=B2=E2=CA=D4里面有个=?GBK?Q?,GBK表示的是内容的字符集,?Q?表示的是以QP方式编码的,后面紧跟的才是编码后的中文字符。
所以用MimeUtility工具编码后的信息里包含了编码方式的信息。
邮件的正文也要进行编码,但它不能用MimeUtility里的方法来编码。
邮件正文的编码方式的信息是要放在Content-Transfer-Encoding这个邮件头参数中的,而MimeUtility里面的方法是将编码方式的信息放在编码后的正文内容中。
email三种编码标准

UU编码解决了E-mail只能传送ASCII文件的问题。但这种方式其实并不是很方便,因而又发展出一种新的编码标准,其全名是MultipurposeInternetMailExtentions,一般译作“多媒体邮件传送模式”。顾名思义,它可以传送多媒体文件,在一封电子邮件中附加各种格式文件一起送出。
●Binhex编码
Binhex的编码方式常用于Mac机器,在PC上是较少使用的一种编码方式。一般PC上的电子邮件软件,亦多数支持MIME的规格,很少有支持Binhex格式。在常用的电子邮件软件中,唯Eudora具有这种功能,可直接解读Binhex的编码,如果你收到了这种由Binhex所编码的邮件,而且你的mail软件并不是Eudora或其他支持Binhex格式的软件。那也得用一个解读Binhex的程序解码。有一个共享软件Binhex3.exe具有这个功能,它在许多FTP站点都能找到。
由于MIME的方便性,愈来愈多的电子邮件软件采用这种方式。(我们现在最常使用的电子邮件软件Eudora、NetscapeMail、InternetMail等就是采用MIME方式,所以我们才能如此轻松地收发电子邮件。)MIME定义的是一种规格,也可以说是一种统称。
其实能够符合这种规格的编码方式并不是单一的一种,只要符合这种MIME规格便可顺利传送。以货运作为比喻,若货运公司规定送交货运的规格是1立方米大小的箱子便可托运,它并没有限制一定要用木箱或是铁皮箱,只要是1立方米大小,货运公司就帮你送达。至于箱子里你是装食品或是书本或是衣服或是混合着装也没有限定,也就是说,多种格式的文件可以一起寄送。
一、编码的必要性
E-mail只能传送ASCII码(美国国家标准信息交换码)格式的文字信息,ASCII码是7位代码,非ASCII码格式的文件在传送过程中就需要先编成7位的ASCII代码,然后才能通过E-mail进行传送;如果不经过编码,则在传送过程中会因为ASCII码7位的限制而被分解,分解之后只会让收信方看到一堆杂乱的ASCII字符。经过编码后的文件,在传送过程中可顺利传送,不会有“被截掉一位”的危险。但是收信方必须具有相应的解码程序,将这份经过编码的东西还原,才能看到发信人要传送的信息是什么。
Java进行Base64的编码(Encode)与解码(Decode)

Java进⾏Base64的编码(Encode)与解码(Decode)关于base64编码Encode和Decode编码的⼏种⽅式Base64是⼀种能将任意Binary资料⽤64种字元组合成字串的⽅法,⽽这个Binary资料和字串资料彼此之间是可以互相转换的,⼗分⽅便。
在实际应⽤上,Base64除了能将Binary资料可视化之外,也常⽤来表⽰字串加密过后的内容。
如果要使⽤Java 程式语⾔来实作Base64的编码与解码功能,可以参考本篇⽂章的作法。
早期作法早期在Java上做Base64的编码与解码,会使⽤到JDK⾥sun.misc套件下的BASE64Encoder和BASE64Decoder这两个类别,⽤法如下:final BASE64Encoder encoder = new BASE64Encoder();final BASE64Decoder decoder = new BASE64Decoder();final String text = "字串⽂字";final byte[] textByte = text.getBytes("UTF-8");//编码final String encodedText = encoder.encode(textByte);System.out.println(encodedText);//解码System.out.println(new String(decoder.decodeBuffer(encodedText), "UTF-8"));final BASE64Encoder encoder = new BASE64Encoder();final BASE64Decoder decoder = new BASE64Decoder();final String text = "字串⽂字";final byte[] textByte = text.getBytes("UTF-8");//编码final String encodedText = encoder.encode(textByte);System.out.println(encodedText);//解码System.out.println(new String(decoder.decodeBuffer(encodedText), "UTF-8"));从以上程式可以发现,在Java⽤Base64⼀点都不难,不⽤⼏⾏程式码就解决了!只是这个sun.mis c套件所提供的Base64功能,编码和解码的效率并不太好,⽽且在以后的Java版本可能就不被⽀援了,完全不建议使⽤。
base64 解析

base64 解析Base64是网络上常用的一种数据编码方式,用来把任意二进制数据编码为ASCII字符,以便可以在邮件和网页上传输。
以下是Base64编码的具体实现原理和流程:1.二进制数据转换为六位的二进制数。
将二进制数据转换成六位的二进制数,可以利用一种称为位填充的技术。
2. 为转换出来的六位二进制码选择一个标准化字符表。
Base64编码选用了一个标准的64个字符的字符集,包括大小写26个英文字母,0-9的10个数字,和+、/、=等特殊符号。
3.六位二进制码和标准字符表中的字符一一对应。
将每6位二进制码与字符表中的字符一一对应,就可以得到一个对应的字符串,便是Base64编码的最终结果。
4. 使用等号(=)对末尾进行填充因为在转换过程中可能出现6位不够的情况,故而需要填充,Base64采用全部填充字符,使每一组数据都是8个字节,即使最后一组数据不够8个字节,在末尾也要补足等号(=)来实现对8个字节的填充。
从以上可知,Base64是一种十分简单有效的编码方式,它的使用广泛,用于各种位图、文本文件以及其他任意二进制数据文件的传输。
Base64编码的应用由于Base64编码具有简单有效的特点,因此它的应用非常广泛。
1.子邮件电子邮件可以对传输的数据进行Base64编码,由于Base64编码具有简单有效的特点,因此,它可以用来传输文本文件,图片文件等二进制文件。
2.密Base64编码可以用来实现简单的加密,使用Base64编码进行加密,可以实现简单的数据加密,以保护数据安全。
3. HTTP认证Base64编码用于HTTP认证中对密码进行了加密,HTTP认证中要求将用户名和密码使用Base64编码,以保证用户信息的安全性。
4.络协议Base64编码在网络协议中占据重要的地位,因为它可以把二进制数据转换为可传输的ASCII字符,从而实现网络传输。
总结Base64编码简单有效,由于它的简单有效,因此它的使用非常广泛,可以用于电子邮件、加密、HTTP认证以及网络协议。
mime解析流程

mime解析流程
MIME(Multipurpose Internet Mail Extensions)解析流程主要涉及识别和处理网络数据(尤其是电子邮件和HTTP内容)的内容类型和编码。
解析流程如下:
1. 获取Content-Type头信息:首先从邮件消息或HTTP响应头部读取`Content-Type`字段,该字段标识了数据的MIME类型及其参数。
2. 分析类型与子类型:根据`Content-Type`的值(如"text/html"或"application/json")判断数据的基本类型和具体格式。
3. 检查编码参数:查看`charset`等参数确定文本内容的字符编码,或者处理`boundary`用于多部分消息分隔。
4. 内容传输编码解码:若存在`Content-Transfer-Encoding`,则按照指定方式(如base64、quoted-printable)解码数据。
5. 实际内容解析:依据MIME类型执行相应操作,如文本展示、附件存储或二进制流处理等。
总之,MIME解析的核心是识别数据类型并正确解码,确保内容能够被客户端正确理解和使用。
base64的编解码方法【最新】

Base64是一种很常用的编码方式,利用它可以将任何二进制的字符编码到可打印的64个字符之中,这样,不管是图片,中文文本等都可以编码成只有ASCII的纯文本。
至于为什么要进行这个转换呢,最初主要使用在EMail领域,早期的一些邮件网关只识别ASCII,如果发现邮件里有其他字符,就会将它们过滤掉,这样中文的邮件,有图片附件的邮件在这些网关上就会发生问题,于是将中文和图片都使用base64编码然后传输,接受后再解码就客服了这个问题了。
Base64除了可以使用在相似场合,还可以用作简单的加密等等。
下面介绍下Base64的方法:首先是Base64中可能出现的所有字符:0 A 17 R 34 i 51 z1 B 18 S 35 j 52 02 C 19 T 36 k 53 13 D 20 U 37 l 54 24 E 21 V 38 m 55 35 F 22 W 39 n 56 46 G 23 X 40 o 57 57 H 24 Y 41 p 58 68 I 25 Z 42 q 59 79 J 26 a 43 r 60 810 K 27 b 44 s 61 911 L 28 c 45 t 62 +12 M 29 d 46 u 63 /13 N 30 e 47 v14 O 31 f 48 w (pad) =15 P 32 g 49 x16 Q 33 h 50 y所有的字符就是'A'~'Z','a'~'z','0'~'9','+','/'共64个,以及末尾的填充字符'='编码的方法是:从输入缓冲中依次取出字符,第一个字符的,从最高位开始取出6个bit,这6个bit的值的范围在0~63,将这个值作为索引,对应上面的表格,找到相应的字符,这便是第一个Base64后的字符,然后将第一个字符的低2位与第二个字符的高4位组成6个bit, 同样查表得到第二个Base64字符,以此类推,从左向右没凑足6个bit就转换成一个Base64字符,由于输入缓冲中每3个字符包含24个bit,这24个bit正好可以转成4个Base64字符,所以没3个字符能组成一个转换循环,如果输入缓冲中字符的个数是3 的整数倍,那么结果就是4的整数倍,两者的长度是3:4的关系,但是如果输入字符不是3的整数倍呢?这就涉及到了末尾填充问题。
Base64编码详解
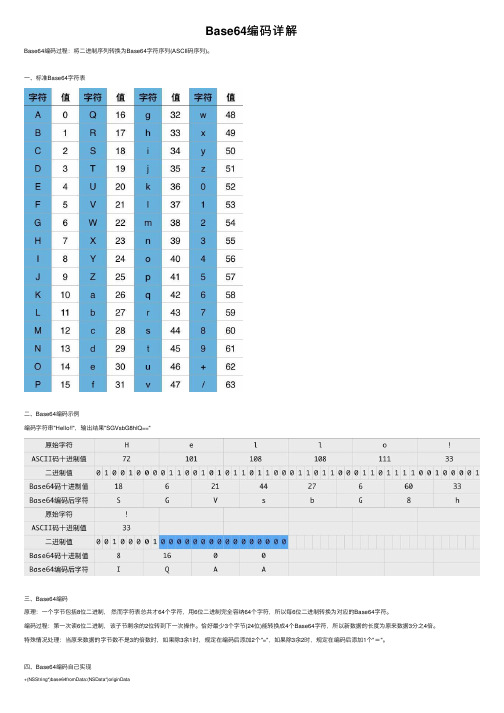
Base64编码详解Base64编码过程:将⼆进制序列转换为Base64字符序列(ASCII码序列)。
⼀、标准Base64字符表⼆、Base64编码⽰例编码字符串"Hello!!",输出结果"SGVsbG8hIQ=="三、Base64编码原理:⼀个字节包括8位⼆进制,然⽽字符表总共才64个字符,⽤6位⼆进制完全容纳64个字符,所以每6位⼆进制转换为对应的Base64字符。
编码过程:第⼀次读6位⼆进制,该⼦节剩余的2位转到下⼀次操作。
恰好最少3个字节(24位)能转换成4个Base64字符,所以新数据的长度为原来数据3分之4倍。
特殊情况处理:当原来数据的字节数不是3的倍数时,如果除3余1时,规定在编码后添加2个"=",如果除3余2时,规定在编码后添加1个"="。
四、Base64编码⾃⼰实现+(NSString*)base64fromData:(NSData*)originData{const uint8_t* input = (const uint8_t*)[originData bytes];NSInteger originLength = [originData length];static char table[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";NSMutableData* encodeData = [NSMutableData dataWithLength:((originLength + 2) / 3) * 4];uint8_t* output = (uint8_t*)encodeData.mutableBytes;NSInteger i;for (i=0; i < originLength; i += 3) {NSInteger value = 0;NSInteger j;for (j = i; j < (i + 3); j++) {value <<= 8;if (j < originLength) {value |= (0xFF & input[j]);}}NSInteger theIndex = (i / 3) * 4;output[theIndex + 0] = table[(value >> 18) & 0x3F];output[theIndex + 1] = table[(value >> 12) & 0x3F];output[theIndex + 2] = (i + 1) < originLength ? table[(value >> 6) & 0x3F] : '=';output[theIndex + 3] = (i + 2) < originLength ? table[(value >> 0) & 0x3F] : '=';}return [[NSString alloc] initWithData:encodeData encoding:NSASCIIStringEncoding];}五、NSData官⽅提供的Base64编码接⼝/* Create an NSData from a Base-64 encoded NSString using the given options. By default, returns nil when the input is not recognized as valid Base-64.*/- (nullable instancetype)initWithBase64EncodedString:(NSString *)base64String options:(NSDataBase64DecodingOptions)options NS_AVAILABLE(10_9, 7_0); /* Create a Base-64 encoded NSString from the receiver's contents using the given options.*/- (NSString *)base64EncodedStringWithOptions:(NSDataBase64EncodingOptions)options NS_AVAILABLE(10_9, 7_0);/* Create an NSData from a Base-64, UTF-8 encoded NSData. By default, returns nil when the input is not recognized as valid Base-64.*/- (nullable instancetype)initWithBase64EncodedData:(NSData *)base64Data options:(NSDataBase64DecodingOptions)options NS_AVAILABLE(10_9, 7_0);/* Create a Base-64, UTF-8 encoded NSData from the receiver's contents using the given options.*/- (NSData *)base64EncodedDataWithOptions:(NSDataBase64EncodingOptions)options NS_AVAILABLE(10_9, 7_0);。
Base64编码与解码详解

Base64编码与解码详解Base64 是基于 64 个可打印字符 A-Z、a-z、0-9、+、/ 来表⽰⼆进制数据的表⽰⽅法,常⽤于数据在⽹络中的传输。
本篇将分别介绍其编码、解码以及实际运⽤。
Base64 编码Base64 本质是⼀种将⼆进制转为⽂本的⽅案。
基本规则如下:编码时候选⽤ 64 (⼤⼩写英⽂字母,数字,+ /)个字符以及⽤作补位的=来表⽰在编码的时候,将3个字节变为4个字节,4个字节的⾼两位都⽤ 00 来填充,后 6 位来表⽰ 64 个字符。
以⼀个实际的例⼦ "YOU" 为例,其编码过程如下:由上表格可知 "YOU"对应的 Base64 编码为:"WU9V"。
对于要待编码的字符数如果不是 3 的倍数时候,会⽤ 0 去填充,编码出来后⽤ = 号表⽰,如: "ME" 其编码如下:Base64 解码将 4 个字节变为 3 个字节;将 24 bit 左移 16 位,与 255 进⾏与操作,获得第⼀个字符,将 24 bit 左移 8 位,与 255 进⾏与操作,获得第⼆个字符,将 24 bit 与 255 进⾏与操作,获取第三个字符Base64 实现与运⽤场景在 Node 中提供 Buffer 模块,可以进⾏⼆进制或者字符与 Base64 的想换转换,其代码如下:const buf2 = Buffer.alloc(2);buf2.write("M", 0);buf2.write("E", 1);buf2.toString("base64"); //TUU=// base64 解码const decodeBase64 = new Buffer("TUU=", "base64").toString(); //MEBase64 有着⼴泛的使⽤,如:对不⽀持⼆进制传输的场景,将⼆进制数据编码成 Base64 传输给服务器Base64 编码图⽚MIME, 电⼦邮件系统中使⽤ Base64 编码后传输。
C语言实现Base64编码转码

C语⾔实现Base64编码转码关于Base64的介绍有两篇⽂章已经做得⾮常好了:⼀篇是,如果被Q可以看本⽂ ;另⼀篇是阮⼀峰的.说⼀说C语⾔的实现吧,其实维基百科给出了C语⾔的实现了,但是它⽤以处理File,当然原理都是⼀样的,File的处理其实可以放在外⾯做好.另外,根据Base64介绍可以看出来它以6⽐特为⼀个单元,⽽常规1字节为8⽐特,所以Base64编码的核⼼其实是位操作的过程.好了,可以放代码了:static const char *ALPHA_BASE = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";char *encode(const char *buf, const long size, char *base64Char) {int a = 0;int i = 0;while (i < size) {char b0 = buf[i++];char b1 = (i < size) ? buf[i++] : 0;char b2 = (i < size) ? buf[i++] : 0;int int63 = 0x3F; // 00111111int int255 = 0xFF; // 11111111base64Char[a++] = ALPHA_BASE[(b0 >> 2) & int63];base64Char[a++] = ALPHA_BASE[((b0 << 4) | ((b1 & int255) >> 4)) & int63];base64Char[a++] = ALPHA_BASE[((b1 << 2) | ((b2 & int255) >> 6)) & int63];base64Char[a++] = ALPHA_BASE[b2 & int63];}switch (size % 3) {case 1:base64Char[--a] = '=';case 2:base64Char[--a] = '=';}return base64Char;}char *decode(const char *base64Char, const long base64CharSize, char *originChar, long originCharSize) {int toInt[128] = {-1};for (int i = 0; i < 64; i++) {toInt[ALPHA_BASE[i]] = i;}int int255 = 0xFF;int index = 0;for (int i = 0; i < base64CharSize; i += 4) {int c0 = toInt[base64Char[i]];int c1 = toInt[base64Char[i + 1]];originChar[index++] = (((c0 << 2) | (c1 >> 4)) & int255);if (index >= originCharSize) {return originChar;}int c2 = toInt[base64Char[i + 2]];originChar[index++] = (((c1 << 4) | (c2 >> 2)) & int255);if (index >= originCharSize) {return originChar;}int c3 = toInt[base64Char[i + 3]];originChar[index++] = (((c2 << 6) | c3) & int255);}return originChar;}在调⽤的时候⼀定要注意malloc的⼤⼩.这个Base64其实我们经常在⽤,只是没有留意⽽已.⽐如P2P下载⼯具*雷就⽤Base64编码了很多资源,我这⾥找了⼀个电影<独⽴⽇:卷⼟重来.BD1280⾼清国英双语特效中英双字>下载链接是这样的: thu*der://QUFlZDJrOi8vfGZpbGV8JUU3JThCJUFDJUU3JUFCJThCJUU2JTk3JUE1JUVGJUJDJTlBJUU1JThEJUI3JUU1JTlDJTlGJUU5JTg3JThEJUU2JTlEJUE1LkJEMTI4MCVFOSVBQiU5OC 似挺聪明的做法,⾃定义了协议头,后⾯⼀⼤串晕晕乎乎的不知道是什么东西,⼀般的资源都是带⽂件名⾄少能看到后缀名啥的,不过看到最后⼜两个 '=' 字符,这个就很明显是这边⽂章的主题Base64,在看这⾥⾯的字符都在Base64定义的字符内就可以认定这个是Base64编码后的链接.如果你恰好没装*雷,也不想装*雷(这货会偷偷上传⽂件,别问我怎么知道的,亲⼿抓到的),就可以把协议头后⾯的⼀⼤串字符串拷贝出来,decode⼀下可以得到 AAed2k://|file|%E7%8B%AC%E7%AB%8B%E6%97%A5%EF%BC%9A%E5%8D%B7%E5%9C%9F%E9%87%8D%E6%9D%A5.BD1280%E9%AB%98%E6%B8%85%E5%9B%BD%E8%8B%B1掉 AA 剩下 ed2k://|file|%E7%8B%AC%E7%AB%8B%E6%97%A5%EF%BC%9A%E5%8D%B7%E5%9C%9F%E9%87%8D%E6%9D%A5.BD1280%E9%AB%98%E6%B8%85%E5%9B%BD%E8%8B%B1%E 下认得了吧.⽤想⽤的下载⼯具下载吧.当然也可以⽤在线的base64 转码⼯具.以下内容摘⾃维基百科Base64是⼀种基于64个可打印字符来表⽰⼆进制数据的表⽰⽅法。
URL编码和Base64编码(转)

URL编码和Base64编码(转)我们经常会遇到所谓的URL编码(也叫百分号编码)和Base64编码。
先说⼀下Bsae64编码。
BASE64编码是⼀种常⽤的将⼆进制数据转换为64个可打印字符的编码,常⽤于在通常处理⽂本数据的场合,表⽰、传输、存储⼀些⼆进制数据。
例如邮件系统的MIME协议等。
这个协议的⽤途,是确保接收⽅在只能识别可见⽂本字符的情况下,能够接受和识别⼆进制数据。
编码后数据长度⼤约为原长的135.1%。
Base64编码是⼀种⼀对⼀的映射编码,其编码长度始终是3的倍数,不⾜3位,⽤=填充。
所以,如果你看到⼀⼤堆乱七⼋糟的数据后⾯是=结尾的,⼤部分时候可以判定是Base64编码。
由于Base64是映射编码,所以如果⼈为改变它的映射表,就可以作为⼀种简单的数据加密⼿段了。
再说⼀下URL编码,这个编码通常⽤在⽹页地址(URL)的传递中,在URL解释中,部分字符例如/ +等,有着特定的意义,因此不能直接使⽤Base64编码来传输地址⽂本。
这个编码也适⽤于统⼀资源标志符(URI)的编码。
URI所允许的字符分作保留与未保留。
保留字符是那些具有特殊含义的字符. 例如, 斜线字符⽤于URL (或者更⼀般的, URI)不同部分的分界符,未保留字符没有这些特殊含义。
URL编码把保留字符表⽰为%开头的特殊字符序列,所以⼜叫做百分号编码。
2005年1⽉发布的RFC 3986,强制所有新的URI必须对未保留字符不加以百分号编码;其它字符要先转换为UTF-8字节序列, 然后对其字节值使⽤百分号编码。
但是在⽬前的实际应⽤中,⼀个URL地址在做百分号编码之前,其未保留的字符序列不⼀定采⽤的是UTF-8编码,也有可能是ANSI编码。
此外,部分早期的系统将空格编码成+,⽽不是标准推荐的%20,这是我们在实际应⽤中应该注意的事项。
邮件出现乱码怎么办啊

邮件出现乱码怎么办啊?一般来说,乱码邮件的原因有下面三种:(1)由于发件人所在的国家或地区的编码和中国大陆不一样,比如我国台湾或香港地区一般的E-mail编码是BIG5码,如果在免费邮箱直接查看可能就会显示为乱码。
(2)发件人使用的邮件软件工具和你使用的邮件软件工具不一致造成的。
(3)由于发件人邮件服务器邮件传输机制和免费邮箱邮件传输机制不一样造成的。
一般说来对于绝大多数乱码的邮件解决方法可以采用下面的方法:首先用Outlook Express将乱码的邮件收取下来,然后打开这封邮件,查一下View(查看)→Encoding(编码),然后调整其下的编码设置试试看,比如可以选择Chinese Simple(简体中文)、Chinese Traditional(繁体中文)、中文HZ或Unicode试试看。
一般来说,绝大多数乱码的邮件都可以修正过来。
如果觉得这样很麻烦,可以将GB2312设置为默认的字体,方法如下(以Outlook Express 5为例):通过“工具→选项→阅读→字体”,在“编码”处选好GB2312,然后选“设为默认值”。
邮件乱码巧破译来源:《新潮电子》相信许多网友都遇到过乱码邮件,一些奇奇怪怪的字符,不知道是什么意思。
产生乱码邮件的最主要原因在于传输机制不同或邮件的编码不同,如果能够识别这些编码,就可以找到破解的办法。
邮件乱码巧破译一、E-mail编码标准由于一个汉字是用两个扩展ASCII码表示,对DOS、Windows及Unix系统来说,所有英文字母及符号都是用ASCII码来代表,ASCII码只用到每个字节的前7位。
而一些电脑系统在通信时不使用8-bit clean传输方式,无法处理8位的数据或硬把8位数据当作7位来处理,数据就会被破坏。
对电子邮件来说,有时候一个邮件在送达收信人的过程中,会经过很多台主机的转接传输服务,这中间的主机假如有一台不具备8-bit clean的传输条件,中文邮件可能就会被破坏。
Python使用base64模块进行二进制数据编码详解

Python使⽤base64模块进⾏⼆进制数据编码详解前⾔昨天团队的学妹来问关于POP3协议的问题,所以今天稍稍研究了下POP3协议的格式和Python⾥⾯的poplib。
⽽POP服务器往回传的数据⾥有⼀部分需要⽤到Base64进⾏解码,所以就顺便看了下Python⾥⾯的base64模块。
本篇先讲⼀下base64模块,该模块提供了关于Base16,Base32,Base64,Base85和Ascii85的编码和解码相关的函数。
有关poplib模块的内容,会在后⾯发上来。
嗯,⼜挖了⼀个坑,这辈⼦挖的坑填不完了...由於歷史原因,Internet上有些郵件系統只⽀援7Bit的字元傳輸,⽽漢字的內碼是8Bit的,當在電⼦郵件中發送中⽂時,如果經過這些只⽀援7Bit字元的郵件系統,便會將漢字內碼的第⼋位元的1全部變成0。
以”中⽂”兩字為例,HEX為A4A4A4E5,當最⾼位元被清掉時就會變成24242465,也就是”$$$e”。
telnet也存在這樣⼦的問題。
除了中⽂郵件外,使⽤電⼦郵件傳送圖⽚、程式、壓縮⽂件等也會發⽣這個問題。
所以在電⼦郵件中⼀般採⽤各種郵件編碼⽅式來解決這個問題,將8Bit按照⼀定的規則進⾏編碼,便可以完好地通過只⽀持7Bit字元的郵件系統。
常⾒的郵件編碼有UU與MIME,⽽MIME(Multipurpose Internet Mail Extentions)⼀般翻譯成「多媒體傳送模式」,顧名思義,它標榜的就是可以傳送多媒體型式的檔案,可以在⼀封mail中附加各種型式檔案⼀起送出。
MIME定義兩種編碼⽅法:Base64與QP(Quote-Printable),兩者使⽤時機不同,QP的規則是對於資料中的7bits無須重複encode,僅8bits資料轉成7bits。
QP編碼適⽤於⾮US-ASCII的⽂字內容,例如我們的中⽂檔案,⽽Base64的編碼規則,是將整個檔案重新編碼,編成7bits,它是⽤於傳送binary檔案時使⽤。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
#include #include "mimeb64.h" //--------------------------------------------------------------------------#pragma package(smart_init) //--------------------------------------------------------------------------// 4bit binary to char 0-F char Hex2Chr( unsigned char n ) { n &= 0xF; if ( n < 10 ) return ( char )( n + '0' ); else return ( char )( n - 10 + 'A' ); } //--------------------------------------------------------------------------// char 0-F to 4bit binary unsigned char Chr2Hex( char c ) { if ( c >= 'a' && c <= 'z' ) c = c - 'a' + 'A'; if ( c >= '0' && c <= '9' ) return ( int )( c - '0' ); else if ( c >= 'A' && c <= 'F' ) return ( int )( c - 'A' + 10 ); else return -1; } //--------------------------------------------------------------------------// // char { Base64 code table 0-63 : A-Z(25) a-z(51), 0-9(61), +(62), /(63) Base2Chr( unsigned char n ) n &= 0x3F; if ( n < 26 ) return ( char )( n + 'A' ); else if ( n < 52 ) return ( char )( n - 26 + 'a' ); else if ( n < 62 ) return ( char )( n - 52 + '0' ); else if ( n == 62 ) return '+'; else return '/'; } //--------------------------------------------------------------------------unsigned char Chr2Base( char c ) { if ( c >= 'A' && c <= 'Z' ) return ( unsigned char )( c - 'A' ); else if ( c >= 'a' && c <= 'z' ) return ( unsigned char )( c - 'a' + 26 );
-N- 不对栈溢出作检查 -k- 不使用标准栈框架 -d -3 合并重复的字符串 使用 386 指令
-r- 未知^_^ 为方便使用,在 BCB 中可编写下面这个函数: aOp : 0(QPEncode) 1(QPDecode) 2(Base64Encode) 3(Base64Decode)
AnsiString MimeQPBase64( AnsiString aSrc, int aOp ) { int n; TMemoryStream * buf; AnsiString s = ""; buf = new TMemoryStream( ); try { n = aSrc.Length( ); if ( aOp == 0 ) { // QPEncode buf->Size = n * 3 + 1; QPEncode( ( char * )( buf->Memory ), ( unsigned char * )( aSrc.c_str( ) ), n ); } else if ( aOp == 2 ) { // Base64Encode buf->Size = n * 4 / 3 + 1; Base64Encode( ( char * )( buf->Memory ), ( unsigned char * )( aSrc.c_str( ) ), n );
file:///D|/技术资料/标准及技术/协议/MIME(BASE64-QP) 编码-解码程序代码.htm(第 3/7 页)2006-6-28 20:34:55
MIME(BASE64/QP) 编码/解码程序代码
*/ // // // 之后便可以使用MimeQPBase64这个函数了。注意:编译时要保证 mimeb64.obj 在搜索路径中。 其它语言直接使用这四个函数即可。
Function Base64Encode( aDest : PChar; aSrc : PByte; aLen : Integer ) : Integer; External; Function Base64Decode( aDest : PByte; aSrc : PChar // 因为DELPHI不包含string.h中的函数,所以要写这么个函数 Function _strlen( aStr : PChar ) : Integer; cdecl; Begin Result := Length( aStr ); End; // aOp : 0(MimeEncode) 1(MimeDecode) 2(Base64Encode) 3(Base64Decode)
Function MimeQPBase64( aSrc : String; aOp : Integer ) : String; Var n : Integer; buf : TMemoryStream; Begin Result := ''; buf := TMemoryStream.Create; Try n := Length( aSrc ); If ( aOp = 0 ) Then Begin // QPEncode buf.Size := n * 3 + 1; QPEncode( PChar( buf.Memory ), PByte( PChar( aSrc ) ), n ); End Else If ( aOp = 2 ) Then Begin // Base64Encode buf.Size := n * 4 DIV 3 + 1; Base64Encode( PChar( buf.Memory ), PByte( PChar( aSrc ) ), n ); End Else Begin buf.Size := n + 1; If ( aOp = 1 ) Then // QPDecode n := QPDecode( PByte( buf.Memory ), PChar( aSrc ) ) Else // Base64Decode n := Base64Decode( PByte( buf.Memory ), PChar( aSrc ) ); PByteArray( buf.Memory )[n] := 0; End; Result := PChar( buf.Memory ); Finally buf.Free; End; End;
#ifdef __cplusplus } #endif //--------------------------------------------------------------------------#endif
下面是 C 文件: //--------------------------------------------------------------------------// MIME(QP & Base64) Encode/DecБайду номын сангаасde unit. (C) // Copyright (c) 2000, 01 Mental Studio - // Author : Raptor - raptorz@
file:///D|/技术资料/标准及技术/协议/MIME(BASE64-QP) 编码-解码程序代码.htm(第 2/7 页)2006-6-28 20:34:55
MIME(BASE64/QP) 编码/解码程序代码
// /*
在 Delphi 中则要编写下面这个单元:
Unit Mime; Interface Function MimeQPBase64( aSrc : String; aOp : Integer ) : String; Implementation {$L mimeb64.obj} Function QPEncode( Function QPDecode( aDest : PChar; aSrc : PByte; aLen : Integer ) : Integer; External; aDest : PByte; aSrc : PChar ) : Integer; External; ) : Integer; External;
首先我要在这里向各位纠正我犯在一个错误:Base64 只是 MIME 的一种编码方案, 我原来所说的 MIME 其实是 MIME 的另一种 编码方案 -- Quoted-Printable ,所以我对本文作了一些修正, 并对由此而给大家带来的误导表示歉意。 May.6-01 最近在研究 POP3 时碰到一个问题,即其中的中文都是经过 MIME 编码了的, 如 MS Outlook Express 是用 Base64 ,而 FoxMail 则 用的是 QP , 本来想找几个现成的编码/解码的代码,结果只在 UDDF 中找到一个 Delphi 的 Base64 Decode , 虽然 UDDF 说是 Encode/Decode ,但我是没找到 Encode 的部分,而且写得不好, 只好自已写一个了。 此代码是一个 BCB 的单元,非常简单,提供了四个函数, 要改成 Delphi 或其它 C/C++ 也很容易,有需要的自已改吧。此代码经 过测试,结果正确。 补充:因为不久前有一位用 VC 的朋友在引用此代码时出碰到一些困难, 是由于 BCB 的 AnsiString 的特殊性造成的,所以我将此 代码改写为标准 C 的,本来是应该这样的, 但我习惯了用 AnsiString 所以才写成那样的,不过现在只好改写了。但为了方便 Delphi/BCB 使用,我还是特别加了一些东东,详见程序的注释,目的无非是为了更好用一些,其它语言的请自行参考吧。Mar.3101 再补充:为了使这段程序更加实用,我将其整理为几个单元, 分别用于 Delphi 和 C++Builder 。包括对数据流 TMemoryStream 和 字符串的处理。可以在本站作品中下载。Aug.14-01 下面是头文件: //--------------------------------------------------------------------------// MIME(QP & Base64) Encode/Decode unit. (H) // Copyright (c) 2000, 01 Mental Studio - // Author : Raptor - raptorz@ //--------------------------------------------------------------------------#ifndef mimeb64H #define mimeb64H //--------------------------------------------------------------------------#ifdef __cplusplus extern "C" { #endif int int int int QPEncode( QPDecode( Base64Encode( Base64Decode( char * const aDest, const unsigned unsigned char * const aDest, const char * const aDest, const unsigned unsigned char * const aDest, const char char char char * * * * aSrc, int aLen ); aSrc ); aSrc, int aLen ); aSrc );