广义估计方程PPT课件
GMM广义矩估计

ˆ) 是自相关序列,取法和线性的 • 如果 gt (wt , 类似
26
检验问题
和线性情况类似,我们也可以得到相应的非 线性模型的检验方法
27
Example
28
Stochastic Volatility Models
如果模型被J-统计量拒绝,大的ti 的表示第 i 个 矩条件被错误指定
13
两步最小二乘 如果模型(1.1)的误差项是条件同方差,那么
Ext xt t2 2 xx S
ˆ S 的相合估计可以表示为 S ˆ 2 S xx 典型的取 n 2 1 ˆ ) 2 where ˆ ˆ n ( y z
ˆW ˆ S )1 S W ˆS ˆS (S W ˆ S )1 (1.9) (S W xz xz xz xz xz xz
ˆ(W ˆ )) ( W )1 WSW ( W )1 (1.8 avar( xz xz xz xz xz xz
9
估计的效率
GMM估计效率的定义
序列不相关的矩: (通常 gt (0 ) 为遍历平稳的 MDS),那么 S avar(g ) E[gt (0 )gt (0 ))] 根据White(1982), S 的一个异方差(HC)估计
ˆ)g ( ˆ) S 1/nt 1 g t ( t
n
15
序列相关时的矩:如果总体的矩条件gt (0 ) 是 遍历平稳,但是序列相关的过程,那么
ˆ( S ˆ 1 ) arg min ng S ˆ 1 g n n
S 的一致估计可以由下式给出
n 1 n 1 ˆ) 2 ˆt2 xt xt ( yt zt S xt xt n t 1 n t 1
广义估计方程估计方法

广义估计方程估计方法一、引言在统计学中,估计是一种对未知参数进行估算的方法。
广义估计方程估计方法(Generalized Estimating Equations, GEE)是一种广义线性模型的推广,用于对重复测量数据或相关数据的参数进行估计。
本文将对广义估计方程估计方法进行全面、详细、完整地探讨。
二、广义估计方程广义估计方程是一种基于分布式模型的估计方法,适用于多个观测之间存在相关性的情况。
通常,我们需要通过一个参数向量来描述我们感兴趣的总体特征。
然而,在重复测量或相关数据中,观测之间的相关性可能导致传统估计方法的失效。
GEE的核心思想是通过建立“广义估计方程”来估计参数,而不需要对观测值的相关性做出严格的假设。
通过最大化针对广义估计方程构建的“Q函数”,可以得到参数的估计值。
三、GEE的模型设定在使用GEE进行参数估计之前,我们需要根据实际问题来设定模型。
在GEE中,模型的设定包括以下几个方面:1. 响应变量和预测变量在GEE中,我们需要明确定义响应变量和预测变量。
响应变量是我们希望通过模型来解释和预测的变量,而预测变量是我们用来解释和预测响应变量的变量。
2. 分布族和连接函数在GEE中,我们需要选择一个合适的分布族和连接函数来描述响应变量的分布和均值。
根据实际情况,我们可以选择正态分布、泊松分布、二项分布等不同的分布族,并选择合适的连接函数。
3. 协变量和随机因素GEE中的协变量是指预测变量中的固定效应,可以通过参数估计来确定其与响应变量的关系。
随机因素是指预测变量中的随机效应,可以通过随机效应模型来建模。
4. 相关结构在GEE中,我们需要明确指定观测之间的相关结构。
常见的相关结构包括独立、自回归、交叉设计等。
四、GEE的估计方法GEE的估计方法主要包括以下几个步骤:1. 构建广义估计方程根据模型设定,我们可以构建广义估计方程。
广义估计方程是一个非线性方程组,其中包含了我们感兴趣的参数。
2. 选择合适的工作相关矩阵在构建广义估计方程时,我们需要选择一个合适的工作相关矩阵。
泊松广义估计方程

泊松广义估计方程泊松广义估计方程是一种统计推断方法,用于估计泊松分布中未知参数的值。
泊松分布是一种离散概率分布,常用于描述单位时间内某事件发生的次数。
泊松广义估计方程是通过最大似然估计的方法,求解泊松分布的参数估计值。
在介绍泊松广义估计方程之前,我们先了解一下泊松分布。
泊松分布是一种概率分布模型,用于描述在一定时间或空间范围内,某事件发生的次数。
泊松分布的概率质量函数为:P(X=k) = (λ^k * e^(-λ)) / k!其中,λ表示单位时间或空间内事件的平均发生率,k表示事件发生的次数。
泊松广义估计方程是通过最大似然估计的方法,求解泊松分布的参数估计值。
最大似然估计是一种常用的参数估计方法,通过寻找最大化观测数据出现的可能性来确定参数的值。
在泊松广义估计方程中,我们希望找到使得观测数据出现的概率最大的参数值。
假设我们有n个观测数据,分别为x1, x2, ..., xn。
根据泊松分布的概率质量函数,我们可以得到n个数据同时出现的概率为:L(λ) = ∏(i=1 to n) [P(X=xi)] = ∏(i=1 to n) [(λ^xi * e^(-λ)) / xi!]为了方便计算,我们取对数得到对数似然函数:ln(L(λ)) = ∑(i=1 to n) [xi * ln(λ) - λ - ln(xi!)]为了求解参数λ的估计值,我们需要对对数似然函数进行最大化。
为了方便计算,我们对对数似然函数求导,并令导数等于零:d[ln(L(λ))/dλ] = ∑(i=1 to n) [xi/λ - 1] = 0通过求解上述方程,我们可以得到泊松广义估计方程的解,即参数λ的估计值。
除了求解参数估计值,我们还可以通过泊松广义估计方程进行假设检验。
假设我们有一个假设H0,我们希望通过观测数据来判断该假设的真实性。
我们可以构建一个统计量,然后根据该统计量的值来判断是否拒绝假设H0。
泊松广义估计方程在实际应用中具有广泛的应用。
单因素重复测量广义估计方程

单因素重复测量广义估计方程
在单因素重复测量设计中,我们通常使用广义估计方程来建立
模型,以便对重复测量数据进行分析。
广义估计方程的一般形式为:g(μ) = Xβ。
其中,g()是连接函数,μ是均值,X是自变量的设计矩阵,β是待估参数。
通过对广义估计方程进行估计,可以得到参数的估计值,进而进行假设检验和参数推断。
在实际应用中,我们需要考虑到重复测量数据的相关性,因此
在建立广义估计方程模型时,需要选择合适的相关结构,比如自相
关结构或者交互作用结构,以更好地描述数据之间的相关关系。
此外,还需要考虑到可能存在的缺失数据、异方差性等问题,对模型
进行适当的修正和调整。
总之,单因素重复测量广义估计方程是一种强大的统计分析工具,能够有效地处理重复测量设计实验数据,提供对参数的一致估
计和推断,为实验结果的解释和应用提供了有力的支持。
在实际应
用中,需要结合具体的研究问题和数据特点,合理选择模型结构和参数估计方法,以获得准确可靠的分析结果。
多组随时间变化的广义估计方程

随时间变化的广义估计方程是指在时间序列数据中,通过对数据进行建模和估计的过程中,考虑时间变化对参数估计的影响。
在统计学中,广义估计方程(GEE)是一种常用的参数估计方法,用于处理相关性数据和长期追踪观察数据。
广义估计方程通常用于分析长期追踪数据或者重复测量数据,在这些数据中观测值之间可能存在相关性。
传统的参数估计方法,如普通最小二乘法(OLS),通常假设观测值之间是独立同分布的,而忽略了观测值之间的相关性。
而在长期追踪数据或者重复测量数据中,观测值之间往往存在一定的相关性,因此传统的参数估计方法可能会产生偏差较大的估计结果。
随时间变化的广义估计方程则是对传统的广义估计方程进行了拓展,考虑了时间变化对参数估计的影响。
在应用随时间变化的广义估计方程进行参数估计时,需要考虑时间变化的趋势以及时间点对参数估计的影响,从而更准确地描述数据的变化规律。
在实际应用中,随时间变化的广义估计方程常常用于医学、生态学、社会科学等领域的研究中。
在医学领域,对于长期追踪的临床研究数据,研究人员往往需要考虑患者的观测数据之间的相关性,并且需要分析时间变化对治疗效果或者疾病进展的影响,这时随时间变化的广义估计方程就可以提供更为准确的参数估计和模型拟合结果。
随时间变化的广义估计方程的核心思想是通过建立包含时间变化的模型来描述数据的变化规律,从而更准确地进行参数估计和统计推断。
在建立随时间变化的广义估计方程模型时,研究人员需要考虑以下几个关键因素:1. 时间变化的趋势:对于时间序列数据,需要分析时间变化的趋势,判断观测数据是增加、减少还是保持稳定的趋势。
这可以通过绘制趋势图、计算趋势指标等方式进行分析。
2. 时间点的影响:在随时间变化的广义估计方程中,不同的时间点可能对参数估计产生不同的影响,研究人员需要分析不同时间点的数据分布和变化规律,从而更准确地描述数据的变化情况。
3. 模型拟合和参数估计:在建立随时间变化的广义估计方程模型后,研究人员需要对模型进行拟合,并进行参数估计和系数检验等统计推断,从而得到符合实际情况的参数估计结果。
gee模型 广义估计方程

gee模型广义估计方程广义估计方程(Generalized Estimating Equations,简称GEE)是一种统计方法,用于处理重复测量数据或相关数据的分析。
在许多研究领域,如医学、社会科学和环境科学中,我们经常会遇到重复测量的数据,即同一被试在不同时间点或不同条件下的多次测量结果。
GEE方法可以有效地利用这些相关数据,提供一种有效的参数估计和推断方法。
GEE方法的提出是为了解决传统估计方法在处理相关数据时的一些限制。
传统的估计方法,如广义线性模型(Generalized Linear Model,简称GLM),通常基于独立观测数据的假设,而忽视了重复测量数据的相关性。
然而,在重复测量数据中,观测值之间往往存在相关性,这种相关性的存在可能导致参数估计的偏差和推断的不准确性。
GEE方法通过引入一个广义估计方程来解决这个问题。
广义估计方程通过建立观测值的均值和方差之间的关系,将相关数据的相关结构纳入估计过程中。
具体而言,广义估计方程通过使用一组工作相关矩阵,将观测值的均值和方差进行联合建模。
这样,就可以在估计过程中考虑到观测值之间的相关性,从而得到更准确的参数估计和推断结果。
GEE方法的核心思想是通过最大化广义估计方程来估计参数。
在实际应用中,一般使用迭代算法来求解广义估计方程中的参数。
常用的迭代算法有牛顿-拉夫逊算法、广义牛顿方法等。
这些算法通过迭代的方式,不断调整参数的估计值,直到收敛为止。
最终得到的参数估计值具有一致性和渐近正态性,可以用于推断和假设检验。
GEE方法在实践中具有广泛的应用。
例如,在医学研究中,研究者常常需要比较不同治疗方法对疾病进展的影响。
如果采用传统的GLM方法,将忽视患者间的相关性,可能导致参数估计的偏差和推断的不准确性。
而采用GEE方法,可以充分利用患者间的相关性,提供更准确的参数估计和推断结果。
GEE方法还可以用于处理其他类型的数据,如二项数据、计数数据和时间序列数据等。
广义估计方程

广义估计方程广义估计方程(GEE)是用来描述数据之间线性关系的一种统计方法,具有十分广泛的应用领域。
在其应用之前,我们首先要了解其基本原理以及相关知识。
一、本原理广义估计方程是一种回归模型,它通过观察估计和解释数据之间的线性关系,最小化对不同数据的误差和偏差。
与一般的线性回归模型(OLS)不同,这种模型可以处理连续变量和类别变量,以及持续变量和非持续变量。
因此,它可以让我们分析和探究不同类型的变量之间的关系,从而发现数据中心情及其内在规律。
二、设广义估计方程的假设:(1)独立性假设:假定每个观察者的每个样本值都是独立的。
(2)均值假设:假定每个观察者的均值满足特定的分布。
(3)持续变量假设:假定持续变量的参数呈线性关系。
(4)类别变量假设:假定类别变量的参数呈相同的分布(即假设各类别的参数等于观察值的均值)。
三、型内容模型的总体形式为:Y = Xβ +,中Y为标准化的响应变量,X为解释变量或因变量,β为参数向量,ε为噪声或误差项。
模型的统计量可由最小二乘估计值估计,也可以通过极大似然估计来估计。
四、估计方法广义估计方程的估计方法有:(1)最小二乘估计法:这是最简单、高效的统计方法,它对估计和解释数据之间的线性关系具有很好的效果。
(2)最小平方根估计法:这是一种类似于最小二乘估计法的方法,它的优点是可以消除离群点的影响,并减少噪声的影响。
(3)极大似然估计法:这是一种旨在最大化数据观察到的似然函数的统计方法,可以用来评估线性回归模型中的参数。
(4)贝叶斯估计法:这是一种基于Bayes公式的模型,可以利用先验知识来估计参数的最佳值。
五、用广义估计方程的应用领域非常广泛,可以用来分析不同类型的变量之间的关系,如:病毒感染率与住院时间的关系、抗生素的有效性和疗效的关系、企业投资策略和未来收益的关系等。
它还可以用于诊断模型分析,如:测试一种新药在治疗某病时的效果,或评估一种新技术在改善某段生产过程时的效率。
gee模型 广义估计方程

gee模型广义估计方程1. 介绍广义估计方程(Generalized Estimating Equations,简称GEE)是一种用于处理重复测量数据的统计方法。
重复测量数据是指在同一个研究对象上进行了多次观测的数据,例如长期随访数据、纵向研究数据等。
GEE方法通过建立广义线性模型,利用广义估计方程来估计参数,从而得到关于不同时间点或不同测量条件下的总体平均效应估计。
2. GEE模型的基本原理GEE模型是一种半参数模型,它假设数据的均值和协方差结构之间的关系可以用一个未知的参数向量来描述,而不需要对具体的分布进行假设。
GEE模型的基本原理是通过最大化广义估计方程来估计参数。
GEE模型的广义估计方程可以写成如下形式:其中,是参数向量,是第个观测的均值,是第个观测的协方差矩阵,是第个观测的响应变量。
3. GEE模型的优点GEE模型具有以下几个优点:3.1. 非参数估计GEE模型不需要对数据的分布进行具体的假设,因此适用于各种类型的数据。
3.2. 有效性GEE模型可以通过广义估计方程来估计参数的有效性,得到的估计量具有较小的方差。
3.3. 一致性GEE模型在样本量趋于无穷大时可以得到一致的估计结果。
3.4. 模型灵活性GEE模型可以灵活地处理不同的协方差结构,例如独立、自相关等。
4. GEE模型的应用GEE模型广泛应用于各个领域的研究中,特别适用于处理重复测量数据。
以下是几个常见的应用领域:4.1. 流行病学研究在流行病学研究中,常常需要对同一组人群进行多次观测,例如长期随访研究。
GEE模型可以用于分析不同时间点的数据,从而探索因素对健康状况的影响。
4.2. 医学研究在临床医学研究中,常常需要对同一患者进行多次观测,例如药物治疗的效果评估。
GEE模型可以用于分析不同时间点的治疗效果,从而评估药物的长期疗效。
4.3. 教育研究在教育研究中,常常需要对同一组学生进行多次测量,例如教育干预的效果评估。
GEE模型可以用于分析不同时间点的学习成绩,从而评估教育干预的效果。
广义估计方程瓦尔德卡方值

广义估计方程瓦尔德卡方值(原创实用版)目录1.广义估计方程的概述2.瓦尔德卡方值的定义和性质3.广义估计方程与瓦尔德卡方值的关系4.应用实例与结论正文1.广义估计方程的概述广义估计方程(Generalized Estimating Equations,简称 GEE)是一种用于解决多元回归模型中数据之间相关性问题的统计方法。
这种方法主要通过引入一个似然函数,来估计带有误差的参数。
广义估计方程不仅适用于正态分布的线性模型,还适用于非正态分布的广义线性模型,例如泊松分布、二项分布等。
2.瓦尔德卡方值的定义和性质瓦尔德卡方值(Wald Chi-Squared Statistic)是一种用于检验多元回归模型中参数的显著性水平的统计量。
它的计算公式为:χ = Σ[(观测值 - 期望值) / 期望值]。
瓦尔德卡方值具有以下性质:- 当参数的值为零时,瓦尔德卡方值达到最小;- 当参数的值偏离零时,瓦尔德卡方值会增加;- 当参数的值为零时,瓦尔德卡方分布的值为零;- 瓦尔德卡方值具有自由度,自由度等于参数的个数减去方程的个数。
3.广义估计方程与瓦尔德卡方值的关系广义估计方程与瓦尔德卡方值之间的关系主要体现在参数估计的过程中。
在广义估计方程中,通过引入一个似然函数,可以得到对数似然函数,然后通过对数似然函数求导,可以得到参数的估计值。
同时,在广义估计方程中,可以通过瓦尔德卡方统计量来检验参数的显著性水平。
4.应用实例与结论假设有一个多元线性回归模型:y = β + βx + βx + ε,其中,y 表示因变量,x和 x表示自变量,β、β、β表示参数,ε表示误差。
在这个模型中,如果 x和 x之间存在相关性,那么传统的最小二乘法就不再适用。
此时,可以使用广义估计方程来解决这个问题。
通过广义估计方程,我们可以得到参数的估计值,然后使用瓦尔德卡方统计量来检验参数的显著性水平。
如果瓦尔德卡方统计量的值越大,说明参数的显著性水平越高。
广义估计方程ppt课件

纵向数据(longitudinal data)是按照时间顺序对 个体进行重复测量得到的资料。
比如儿童的生长监测资料,出生后每月测量 其体重(Y变量)以及影响体重的因素(X变量,如性 别、喂养、疾病等),这样每个儿童的多次测量值 称为纵向数据的一个串(cluster),是由一组Y变量 (各次测定的体重)和一组相对应的X变量组成。
S(;, )n i i V i 1()Y (iui)O p
求解方程Var(Yij)=V(μij)·Ф可得到β的一致性估计。其
中Vi表示作业V 协i 方 差A 矩i1/阵2R (iw(ork)iA ngi1/c2 ovariance matrix),
并有
式中:Ri(α)是Yij的作业相关矩阵(working correlated
matrix);Ai是以V(μij)为第i个元素的t维对角矩阵。
精选课件
20
广义估计方程
二、作业相关矩阵
作业相关矩阵是广义估计方程中的一个重要 概念,表示的是因变量的各次重复测量值两两 之间相关性的大小,常用Ri(a)表示,是t×t维对 角阵,t是总测量次数。其第s行第t列的元素表 示Yis和Yit的相关,尽管个体之间的相关性可能 不尽相同,Ri(a)近似地表示个体之间平均的相关。
精选课件
28
应用举例
表2 某药物抗癫痫的随机对照临床试验对照组每2周的发作次数
ID Base Visit1 Visit2 Visit3 Visit4
1
11
5
3
3
3
2
11
3
5
3
3
3
6
2
4
0
5
26
9
2
27
广义估计方程在纵向资料中的应用52页PPT

56、书不仅是生活,而且是现在、过 去和未 来文化 生活的 源泉。 ——库 法耶夫 57、生命不可能有两次,但许多人连一 次也不 善于度 过。— —吕凯 特 58、问渠哪得清如许,为有源头活水来 。—— 朱熹 59、我的努力求学没有得到别的好处, 只不过 是愈来 愈发觉 自己的 无知。 ——笛 卡儿
广义估计方程在纵向资料中的应用
6、法律的基础有两个,而且只有两个……公平和实用。——伯克 7、有两种和平的暴力,那就是法律和礼节。——歌德
8、法律就是秩序,有好的法律才有好的秩序。——亚里士多德 9、上帝把法律和公平凑合在一起,可是人类却把它拆开。——查·科尔顿 10、一切法律都是无用的,因为好人用不着它们,而坏人又不会因为它们而变得规矩起来。——德谟耶克斯
拉
60、生活的道路一旦选定,就要勇敢地 走到底 ,决不 回头。 ——左
广义估计方程-EmpowerStats
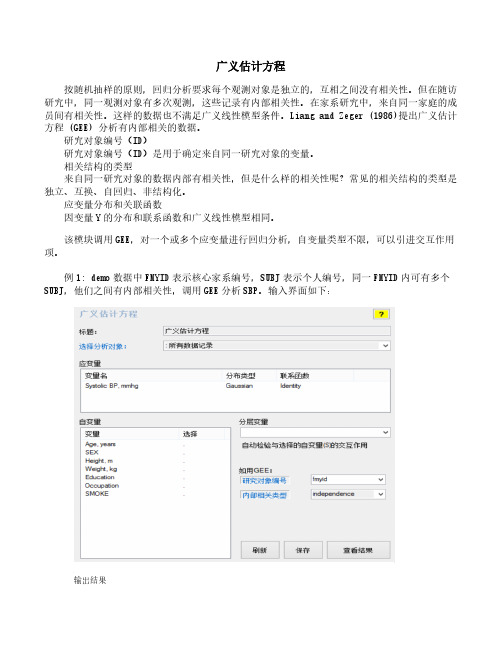
广义估计方程按随机抽样的原则,回归分析要求每个观测对象是独立的,互相之间没有相关性。
但在随访研究中,同一观测对象有多次观测,这些记录有内部相关性。
在家系研究中,来自同一家庭的成员间有相关性。
这样的数据也不满足广义线性模型条件。
Liang and Zeger (1986)提出广义估计方程 (GEE) 分析有内部相关的数据。
研究对象编号(ID)研究对象编号(ID)是用于确定来自同一研究对象的变量。
相关结构的类型来自同一研究对象的数据内部有相关性,但是什么样的相关性呢?常见的相关结构的类型是独立、互换、自回归、非结构化。
应变量分布和关联函数因变量Y的分布和联系函数和广义线性模型相同。
该模块调用GEE,对一个或多个应变量进行回归分析,自变量类型不限,可以引进交互作用项。
例1: demo数据中FMYID表示核心家系编号,SUBJ表示个人编号,同一FMYID内可有多个SUBJ,他们之间有内部相关性,调用GEE分析SBP。
输入界面如下:输出结果广义估计方程结局变量: Systolic BP, mmhg变量分布与联系函数: gaussian模型诊断:自动绘制残差与预测值散点图,以判断残差的方差是否独立于预测值。
例2:如在例1,引进两变量交互作用项于模型中,输入界面如下:注: 在自变量框内右击变量名选“修改选择”,以启动“自动检验分层变量与被选择的自变量的交互作用”功能。
分析结果首先是按分层变量的分层分析,然后是合计的分析及交互作用检验,如下:结局变量: Systolic BP, mmhg变量分布与联系函数: gaussian模型: SBP~AGE+factor(EDU.NEW)+OCCU.NEW+SMOKE+BMI分组因素与选择的自变量交互作用分析: SEX with Age, years Body mass index, kg/m2上表中AGE:factor(SEX)2、BMI:factor(SEX)2分别是AGE、BMI与SEX的交互作用项。
广义估计方程结果解读

广义估计方程结果解读
广义估计方程(GEE)是一种用于处理重复测量数据的统计方法。
它可以通过考虑相关性结构来估计参数,并且可以处理非正态数据和缺失数据。
GEE的结果包括估计的参数值、标准误、置信区间和假设检验结果。
在GEE中,参数估计值表示了变量之间的关系。
例如,如果我们使用GEE 来研究药物对血压的影响,那么药物的系数估计值将告诉我们药物对血压的影响大小。
标准误表示了估计值的精度。
如果标准误很小,那么我们可以相信估计值是准确的。
置信区间告诉我们估计值的可信程度。
如果置信区间很窄,那么我们可以相信估计值是准确的。
假设检验结果告诉我们是否可以拒绝某个假设。
例如,如果我们想知道药物是否对血压有影响,我们可以进行假设检验来确定药物系数是否显著不为零。
总之,GEE的结果可以帮助我们理解变量之间的关系,并且可以确定估计值的精度和可信程度。
这些结果对于研究人员和决策者来说都非常重要,因为它们可以帮助我们做出正确的决策。
批量单因素广义估计方程

批量单因素广义估计方程
批量单因素广义估计方程是一种统计学中常用的方法,用于估计不同因素对某个特定结果的影响程度。
这个方程可以帮助我们理解和预测各种现象,从经济学到医学,从环境科学到社会学。
在这个方程中,我们首先需要确定我们要研究的因素。
这些因素可以是任何可能影响结果的变量,比如年龄、性别、收入等。
然后,我们需要收集关于这些因素和结果的数据。
这些数据可以是实验数据,也可以是观察数据。
接下来,我们需要建立一个数学模型来描述这些因素和结果之间的关系。
这个模型通常是一个线性回归模型,可以通过最小二乘法来估计模型参数。
这些参数可以告诉我们每个因素对结果的影响程度。
然后,我们可以使用这个模型来预测未来的结果。
通过将未来的因素值带入模型,我们可以估计未来的结果。
这可以帮助我们做出决策,制定政策或进行预测。
批量单因素广义估计方程在许多领域都有广泛的应用。
例如,在医学研究中,我们可以使用这个方程来研究不同因素对某种疾病的影响。
在经济学研究中,我们可以使用这个方程来研究不同因素对某种经济指标的影响。
在环境科学中,我们可以使用这个方程来研究不同因素对环境污染的影响。
批量单因素广义估计方程是一种强大的工具,可以帮助我们理解和
预测各种现象。
通过合理选择因素和建立适当的模型,我们可以得出有关因素对结果影响的准确估计,并用于决策和预测。
这个方程在不同领域的研究中都有重要的应用,对于推动科学的发展和社会的进步具有重要意义。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
主要内容
一、广义线性模型简介 1)一般线性模型 2)广义线性模型
二、广义估计方程 1)纵向资料 2)广义估计方程 3)应用举例
一、广义线性模型简介
1)一般线性模型
一般线性模型(general linear model),简称线性模型(linear model),是数理 统计学中发展较早、理论丰富而且应用性很强的 一个重要分支。
广义估计方程
(2)
指定Yij边际方差(marginal variance)
是边际期望的已知函数。
Var(Yij)=V(μij)·Ф
式中:V(.)为已知函数;Ф为尺度参 数(scale parameter),表示Y的方差不能被 V(μij)解释的部分。这个参数也是需要模型估 计的,对二项分布和Poisson分布而言,Ф=1。
纵向数据
纵向数据特点 :
同一对象的多次观测之间呈相关倾向 因而,纵向数据与一般的多元应变量的 资料不同,因为它的反应变量之间高度相关。也 有别于时间序列数据,纵向数据是由每个个体的 重复测量数据,按时间顺序组成较短的序列,并 由大量这样的序列组成,而时间序列数据是很多 各数据组成一个长的序列。
纵向数据
广义估计方程
2)广义估计方程
应用:
广义估计方程是在广义线性模型的基础 上发展起来的、专用于处理纵向数据的统计模型。 广义估计方程可以对符合正态分布、二项分布等 多种分布的应变量拟合相应的统计模型,解决了 纵向数据中应变量相关的问题,得到稳健的参数 估计值。
广义估计方程
一、模型的基本构成
假设Yij为第i个个体的第j次测量的 变量(i=1, … k,j=1, … t),Yi=(Yi1,Yi2 … Yij)′,Xij=(Xij1 … Xijp),为对应于Yij的p×1 维解释变量向量。如果解释变量在各个观察时 刻不变(比如性别),则Xi1p=Xi2p … =Xijp。如果j 时刻没有观测值,则Yij和Xij都缺失。
构造如下广义估计方程为:
S(;, )
n i
i
Vi1 ( )(Yi
ui )
Op
求解方程Var(Yij)=V(μij)·Ф可得到β的一致性 估计。其中VVi表i 示作A业i1/ 协2 R方i (差)矩A阵i1/ 2(working covariance matrix),并有
(3)方差齐性,即ei的方差相等
一般线性模型
局限性:
线性模型只能拟合应变量服从正态分 布的资料,如果应变量是分类变量,或不服从正 态分布的变量,线性模型则不能适用。
广义线性模型
2)广义线性模型
概念:
很多非线性模型,如指数模型、Logistic回归 模型,如对应变量作一定的变量变换可满足或近似满足线 性模型分析的要求,能够借助线性模型的分析思路解决模 型构造、参数估计和模型评价等一系列问题。这就是广义 线性模型(generalized linear model)
传统的统计方法一般都要求应变量 是独立的,因而,由于应变量之间的相关, 纵向数据不能用传统的方法来分析。因为 如果忽略重复测量间的相关性,将损失数 据中的信息,参数估计可能不准确。因此, Liang和Zeger等创立了广义估计方程 (generalized estimating equations) 。
广义线性模型
模型构造:
(1)应变量,相互独立,服从指数分布族,方差能够 表达为均数的函数。应变量的期望值记为: E(Yi)=μi。
(2)线性部分,即自变量的线性组合,β为待求的参 数向量。 ηi=β0+ β1Xi1+ β2Xi2+ … βjXij=X’i β
广义线性模型
(3)联接函数(link function),将应变量的期望值 和线性预测值ηi关联起来。 g(μi )= ηi=β0+ β1Xi1+ β2Xi2+ … βjXij g(. )是联接函数,联接函数的作用就是对应变 量作变换使之符合正态分布,变量变换的类型依 应变量的分布不同而不同。通过指定应变量的分 布和联接函数,就可以拟合各种不同的模型。
广义估计方程
模型构成如下:
(1) 指定Yij的边际期望(marginal expectation) 是协变量Xij线性组合的已知函数。 E(Yij)=μij,g(μij)=β0+β1Xij1+β2Xij2+…βpXijp 式中:g(.)称为联接函数; β=(β1…βp)’为模型需要估计的参数向量。
SUCCESS
THANK YOU
2019/8/9
广义估计方程
(3)
指定Yij协方差是边际均数和参数α的函
数。
μit;α)
Cov(Yis,Yit)=c(μis,
式中:c(.)为已知函数;α又叫相关参
数 (correlation parameter);s和t分别表示
第s次和第t次测量。
广义估计方程
广义线性模型
分布 模型
表1 常见的概率分布和联接函数
联接函数
数学表达式
正态分布
恒等函数
多元线性回归模型
log
1
Βιβλιοθήκη η=μ二项分布
Logit函数
Logistic回归模型
二项分布
Probit函数
η=Φ-1(π)
Probit回归模型
广义线性模型
优点:
广义线性模型不仅可以用于拟合应变 量服从正态分布的模型,还可以拟合应变量服从 二项分布、Poisson分布、负二项分布等指数分布 族的模型,通过指定不同的联接函数,把指数分 布族的众多模型统一到一个模型框架中,具有极 大的灵活性,其应用也日趋广泛。
析 一般线性模型
方差分
一般线性模型
应用:
用于研究某个指标(应变量,记为Yi) 与一组指标(Xi1, Xi2,… ,Xij)之间的线性关 系。
表达式: yi=β0+ β1Xi1+ β2Xi2+ …
βjXij+ei
一般线性模型
一般线性模型对于残差分布的三个重要假设: (1)独立 (2)符合正态分布,且均数为0
纵向数据
概念:
纵向数据(longitudinal data)是按照 时间顺序对个体进行重复测量得到的资料。
比如儿童的生长监测资料,出生后每月 测量其体重(Y变量)以及影响体重的因素(X变量, 如性别、喂养、疾病等),这样每个儿童的多次测 量值称为纵向数据的一个串(cluster),是由一组 Y变量(各次测定的体重)和一组相对应的X变量组 成。