Hadoop 常用命令
hadoop命令及使用方法

hadoop命令及使用方法Hadoop是一个分布式计算框架,用于存储和处理大规模数据集。
下面是一些常用的Hadoop命令及其使用方法:1. hdfs命令:- hdfs dfs -ls <路径>:列出指定路径下的文件和目录。
- hdfs dfs -mkdir <路径>:创建一个新的目录。
- hdfs dfs -copyFromLocal <本地路径> <HDFS路径>:将本地文件复制到HDFS 上。
- hdfs dfs -copyToLocal <HDFS路径> <本地路径>:将HDFS上的文件复制到本地。
- hdfs dfs -cat <文件路径>:显示HDFS上的文件内容。
2. mapred命令:- mapred job -list:列出当前正在运行的MapReduce作业。
- mapred job -kill <job_id>:终止指定的MapReduce作业。
3. yarn命令:- yarn application -list:列出当前正在运行的应用程序。
- yarn application -kill <application_id>:终止指定的应用程序。
4. hadoop fs命令(与hdfs dfs命令功能相似):- hadoop fs -ls <路径>:列出指定路径下的文件和目录。
- hadoop fs -cat <文件路径>:显示HDFS上的文件内容。
- hadoop fs -mkdir <路径>:创建一个新的目录。
- hadoop fs -put <本地文件路径> <HDFS路径>:将本地文件复制到HDFS上。
- hadoop fs -get <HDFS路径> <本地文件路径>:将HDFS上的文件复制到本地。
hdfs 常用命令

hdfs 常用命令HDFS(Hadoop分布式文件系统)是ApacheHadoop项目的一部分,是一种分布式文件系统,它为应用程序提供高可用性,稳定性和可扩展性。
HDFS中的文件可以以分布式方式存储在不同的节点服务器上,从而允许存储容量更大的文件,因此可以更有效地处理海量数据。
HDFS也支持由命令行控制的文件和数据操作。
本文将介绍HDFS 的常用命令,以便在HDFS系统中更有效地管理文件和数据。
一、管理文件1. hadoop fslshadoop fsls命令用于查看HDFS文件,可以获得文件的元数据信息,包括文件名,权限,访问时间,文件大小等。
例如:hadoop fsls /user/hadoop/word.txt,可以查看用户hadoop下word.txt文件的基本信息。
2. hadoop fsmkdirhadoop fsmkdir命令用于创建HDFS目录,一次只能创建一级子目录,例如:hadoop fsmkdir /user/hadoop/test,可以创建用户hadoop下test目录。
3. hadoop fsputhadoop fsput命令用于将本地文件上传到HDFS上,例如:hadoop fsput /home/user/Desktop/word.txt /user/hadoop/word.txt,可以将本地的word.txt文件上传到用户hadoop的根目录下。
4. hadoop fsgethadoop fsget命令用于从HDFS上下载文件到本地,例如:hadoop fsget /user/hadoop/test/test.txt /home/user/Desktop/test.txt,可以将用户hadoop下test目录下的test.txt文件下载到本地桌面。
5. hadoop fsrmhadoop fsrm命令用于删除HDFS中的文件,例如:hadoop fsrm /user/hadoop/word.txt,可以删除用户hadoop下的word.txt文件。
hdfs常用命令操作笔记

hdfs常用命令操作笔记HDFS(Hadoop Distributed File System)是Hadoop生态系统中的核心组件,用于存储大规模数据。
以下是HDFS的一些常用命令操作:1. 查看目录信息:```bashhdfs dfs -ls <path>```2. 创建目录:```bashhdfs dfs -mkdir <path>```3. 从本地剪切到HDFS目录:```bash```4. 追加文件到已存在的文件末尾:```bashhdfs dfs -appendToFile <local_path> <hdfs_path>```5. 显示文件内容:```bashhdfs dfs -cat <path>```6. 修改文件所属权限(`-chgrp`、`-chmod`、`-chown`):这些命令类似于Linux文件系统中的用法,用于修改文件所属的组、权限和所有者。
7. 从本地路径复制文件到HDFS:```bash```8. 从HDFS复制文件到本地:```bashhdfs dfs -copyToLocal <hdfs_path> <local_path> ```9. 在HDFS中复制文件到另一个路径:```bashhdfs dfs -cp <src_path> <dest_path>```10. 在HDFS中移动文件:```bashhdfs dfs -mv <src_path> <dest_path>```11. 删除文件或文件夹:注意:删除操作是不可逆的,请谨慎操作。
如果要删除文件夹及其内容,需要添加`-r`选项。
```bashhdfs dfs -rm <path>```12. 查看文件的末尾内容:这个命令类似于Unix的`tail`命令,可以查看文件的最后几行。
hadoop基本命令_建表-删除-导数据
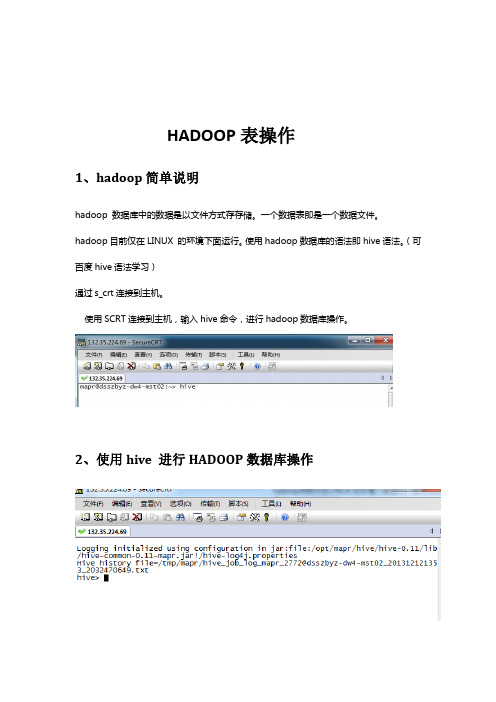
HADOOP表操作1、hadoop简单说明hadoop 数据库中的数据是以文件方式存存储。
一个数据表即是一个数据文件。
hadoop目前仅在LINUX 的环境下面运行。
使用hadoop数据库的语法即hive语法。
(可百度hive语法学习)通过s_crt连接到主机。
使用SCRT连接到主机,输入hive命令,进行hadoop数据库操作。
2、使用hive 进行HADOOP数据库操作3、hadoop数据库几个基本命令show datebases; 查看数据库内容; 注意:hadoop用的hive语法用“;”结束,代表一个命令输入完成。
usezb_dim;show tables;4、在hadoop数据库上面建表;a1: 了解hadoop的数据类型int 整型; bigint 整型,与int 的区别是长度在于int;int,bigint 相当于oralce的number型,但是不带小数点。
doubble 相当于oracle的numbe型,可带小数点;string 相当于oralce的varchar2(),但是不用带长度;a2: 建表,由于hadoop的数据是以文件有形式存放,所以需要指定分隔符。
create table zb_dim.dim_bi_test_yu3(id bigint,test1 string,test2 string)row format delimited fields terminated by '\t' stored as textfile; --这里指定'\t'为分隔符a2.1 查看建表结构: describeA2.2 往表里面插入数据。
由于hadoop的数据是以文件存在,所以插入数据要先生成一个数据文件,然后使用SFTP将数据文件导入表中。
数据文件的生成,第一步,在EXECLE中按表的顺序依次放入要需要的数据,然后复制到UE编码器中生成文件,保存格式为TXT。
hdfs操作常用的shell命令实验总结

hdfs操作常用的shell命令实验总结在Hadoop分布式文件系统(HDFS)中,有一些常用的Shell命令可帮助用户管理和操作文件。
本文将总结几个常用的HDFS Shell命令及其功能。
1. ls命令ls命令用于列出指定目录中的文件和子目录。
通过使用ls命令,可以快速查看HDFS中的文件结构,并确定文件和目录的权限、大小和修改日期。
2. mkdir命令mkdir命令用于创建一个新的HDFS目录。
可以使用该命令在指定路径下创建一个新的目录,以便于组织和存储文件。
3. put命令put命令用于将本地文件上传到HDFS中的指定位置。
可以使用put命令将本地系统中的文件复制到HDFS,以便于后续的处理和分析。
4. get命令get命令用于将HDFS中的文件下载到本地系统。
使用get命令可以将HDFS上的文件复制到本地,方便离线查看和处理。
5. rm命令rm命令用于删除HDFS中的文件或目录。
可以使用rm命令删除不再需要的文件或目录,释放存储空间。
6. mv命令mv命令用于移动HDFS中的文件或目录,并可更改名称。
通过使用mv命令,可以重新组织HDFS中的文件结构,或更改文件的命名。
7. cat命令cat命令用于打印HDFS中文件的内容到标准输出。
可以使用cat命令快速查看文件的内容,对文件进行简单的检查。
8. chmod命令chmod命令用于更改HDFS中文件或目录的权限。
通过使用chmod命令,可以为文件或目录设置适当的权限,以确保数据的安全性和可访问性。
总之,以上提到的命令是HDFS操作中常用的一些Shell命令。
它们能够帮助用户管理和操作HDFS中的文件和目录,方便数据的存储、上传、下载、删除、移动和查看。
这些命令是Hadoop生态系统中不可或缺的一部分,对于大规模数据处理和分析具有重要的作用。
hadoop的distcp命令

hadoop的distcp命令
distcp是Hadoop的一个工具,用于在Hadoop集群之间复制数据。
它的命令格式如下:
hadoop distcp [options] <源路径> <目标路径>
其中,[options]是可选项,用于指定一些额外的配置参数。
常用的选项包括:
- -i:忽略校验和,即不使用CRC校验
- -p:保持文件属性,包括权限、修改时间等信息
- -update:只复制源路径中修改时间较新的文件
- -delete:删除目标路径中存在但源路径中不存在的文件
- -overwrite:覆盖目标路径中已存在的文件
- -bandwidth <带宽限制>:限制网络带宽
示例:
1. 将本地目录/tmp/data1拷贝到Hadoop集群的
/user/hadoop/data1目录下:
hadoop distcp /tmp/data1
hdfs://namenode:8020/user/hadoop/data1
2. 保持文件属性,并限制带宽为100MB/s:
hadoop distcp -p -bandwidth 100 /tmp/data1
hdfs://namenode:8020/user/hadoop/data1。
熟悉常用的linux操作和hadoop操作实验报告

熟悉常用的linux操作和hadoop操作实验报告本实验主要涉及两个方面,即Linux操作和Hadoop操作。
在实验过程中,我深入学习了Linux和Hadoop的基本概念和常用操作,并在实际操作中掌握了相关技能。
以下是我的实验报告:一、Linux操作1.基本概念Linux是一种开放源代码的操作系统,它允许用户自由地使用、复制、分发和修改系统。
Linux具有更好的性能、更高的安全性和更好的可定制性。
2.常用命令在Linux操作中,一些常用的命令包括:mkdir:创建目录cd:更改当前目录ls:显示当前目录中的文件cp:复制文件mv:移动文件rm:删除文件pwd:显示当前所在目录chmod:更改文件权限chown:更改文件所有者3.实验操作在实验中,我对Linux的文件系统、文件权限、用户与组等进行了学习和操作。
另外,我还使用Linux命令实现了目录创建、文件复制、删除等操作。
二、Hadoop操作1.基本概念Hadoop是一种开源框架,用于处理大规模数据和分布式计算。
它使用Hadoop分布式文件系统(HDFS)来存储数据,使用MapReduce来处理大规模数据集。
2.常用命令在Hadoop操作中,一些常用的命令包括:hdfs dfs:操作HDFS文件系统hadoop fs:操作Hadoop分布式文件系统hadoop jar:运行Hadoop任务hadoop namenode -format:格式化文件系统start-all.sh:启动所有Hadoop服务3.实验操作在实验中,我熟悉了Hadoop的安装过程、配置过程和基本概念。
我使用Hadoop的命令对文件系统进行操作,如创建、删除、移动文件等。
此外,我还学会了使用MapReduce处理大规模数据集。
总结通过本次实验,我巩固了Linux和Hadoop操作的基本知识和技能。
我深入了解了Linux和Hadoop的基本概念和常用操作,并学会了使用相关命令进行实际操作。
hadoop中put用法

hadoop中put用法Hadoop是一个开源的分布式存储和计算框架,旨在解决大规模数据处理的问题。
在Hadoop中,Put是一个常用的命令,用于将数据加载到Hadoop分布式文件系统(HDFS)中。
本文将详细介绍Hadoop中Put命令的用法和相关注意事项。
一、Put命令简介在Hadoop中,Put命令用于将本地文件或文件夹上传到HDFS中的指定位置。
该命令的语法如下:```hadoop fs -put <localsrc> ... <dst>```其中,`<localsrc>`表示本地文件或文件夹的路径,`<dst>`表示目标位置在HDFS中的路径。
二、Put命令的用法1. 将单个文件上传到HDFS如果需要将单个文件上传到HDFS中,可以使用以下命令:```hadoop fs -put /path/to/localfile /path/to/hdfs```其中,`/path/to/localfile`是本地文件的路径,`/path/to/hdfs`是HDFS 中目标位置的路径。
例如,要将本地的文件`/home/user/data.txt`上传到HDFS中的`/user/hadoop`目录下,可以使用以下命令:```hadoop fs -put /home/user/data.txt /user/hadoop```2. 将文件夹上传到HDFS如果需要将整个文件夹上传到HDFS中,可以使用以下命令:```hadoop fs -put /path/to/localdir /path/to/hdfs```其中,`/path/to/localdir`是本地文件夹的路径,`/path/to/hdfs`是HDFS中目标位置的路径。
例如,要将本地的文件夹`/home/user/data`上传到HDFS中的`/user/hadoop`目录下,可以使用以下命令:```hadoop fs -put /home/user/data /user/hadoop```该命令将递归地将整个`/home/user/data`文件夹上传到HDFS中,并保持相同的目录结构。
Hadoop创建用户及HDFS权限,HDFS操作等常用Shell命令

Hadoop创建⽤户及HDFS权限,HDFS操作等常⽤Shell命令sudo addgroup #添加⼀个hadoop组sudo usermod -a -G hadoop larry#将当前⽤户加⼊到hadoop组sudo gedit etc/sudoers#将hadoop组加⼊到sudoer在root ALL=(ALL) ALL后 hadoop ALL=(ALL) ALL修改hadoop⽬录的权限sudo chown -R larry:hadoop /home/larry/hadoop<所有者:组⽂件>sudo chmod -R 755 /home/larry/hadoop修改hdfs的权限sudo bin/hadoop dfs -chmod -R 755 /sudo bin/hadoop dfs -ls /修改hdfs⽂件的所有者sudo bin/hadoop fs -chown -R larry /sudo bin/hadoop dfsadmin -safemode leave #解除hadoop的安全模式hadoop fs -copyFromLocal <localsrc> URI#拷贝本地⽂件到hdfshadoop fs -cat file:///file3 /user/hadoop/file4#将路径指定⽂件的内容输出到stdouthadoop fs -chgrp [-R] GROUP URI#改变⽂件的所属组hadoop fs -chmod [-R] 755 URI#改变⽤户访问权限hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]#修改⽂件的所有者hadoop fs -copyToLocal URI localdst#拷贝hdfs⽂件到本地hadoop fs -cp URI [URI …] <dest>#拷贝hdfs⽂件到其它⽬录hadoop fs -du URI [URI …]#显⽰⽬录中所有⽂件的⼤⼩hadoop fs -getmerge <src> <localdst> [addnl]#合并⽂件到本地⽬录在IDEA中使⽤Java API 或者 Scala API 操作HDFS的时候,有时候会报这个错误:Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=Apache_Jerry, access=其实就是你的⽤户,对所操作的⽂件没有相应的权限,这⾥报错就很明显,没有写的权限,我们在测试的时候可以使⽤⼀个简单粗暴地⽅法,就是将所有⽂件的所有权限都开放,这样你跑代码就不会出现这种错误了切换到你的虚拟机界⾯命令如下:hadoop fs -chmod -R 777 ///这⾥是所有的⽂件均授予777权限也可以指定某个⽂件夹进⾏赋权之后在web端可以看到⽂章素材来源,仅做学习整理:。
Hadoop基本命令(记一次Hadoop课后实验)

Hadoop基本命令(记⼀次Hadoop课后实验)实验平台:操作系统:Centos7Hadoop 版本:2.10.0JDK 版本:8实验⽬的理解 HDFS 在 Hadoop 体系结构中的⾓⾊熟练使⽤ HDFS 操作常⽤的 Shell 命令;熟悉 HDFS 操作常⽤的 Java API实验内容⼀:编程实现以下功能,并利⽤Hadoop提供的Shell命令完成相同任务:1.向HDFS中上传任意⽂本⽂件,如果指定的⽂件在HDFS中已经存在,由⽤户指定是追加到原有⽂件末尾还是覆盖原有的⽂件Shell命令:1. 检查⽂件是否存在hadoop fs -test -e text.txt2. 上传本地⽂件到HDFS系统的/workspace⽬录hadoop fs -put text.txt3. 追加到⽂件末尾的指令hadoop fs -appendToFile local.txt text.txt4. 查看和对⽐hadoop fs -cat text.txt5. 覆盖原来⽂件,第⼀种命令形式hadoop fs -copyFromLocal -f local.txt test.txt6. 覆盖原来⽂件,第⼆种命令形式hadoop fs -cp -f file:///home/godfrey/workspace/local.txt text.txt2.从HDFS中下载指定⽂件,如果本地⽂件与要下载的⽂件名称相同,则⾃动对下载的⽂件重命名if $(hadoop fs -test -e /home/godfrey/workspace/text.txt);then $(hadoop fs -copyToLocal text.txt ./text.txt);else $(hadoop fs -copyToLocal text.txt ./text2.txt);fi3.将 HDFS 中指定⽂件的内容输出到终端中hadoop fs -cat text.txt4.显⽰ HDFS 中指定的⽂件的读写权限、⼤⼩、创建时间、路径等信息5.给定HDFS中某⼀个⽬录,输出该⽬录下的所有⽂件的读写权限、⼤⼩、创建时间、路径等信息,如果该⽂件是⽬录,则递归输出该⽬录下所有⽂件相关信息hadoop fs -ls -R -h /6.提供⼀个HDFS内的⽂件的路径,对该⽂件进⾏创建和删除操作。
hadoop的基本操作命令

hadoop的基本操作命令Hadoop是目前最流行的分布式计算框架之一,其强大的数据处理能力和可扩展性使其成为企业级应用的首选。
在使用Hadoop时,熟悉一些基本操作命令是必不可少的。
以下是Hadoop的基本操作命令:1. 文件系统命令Hadoop的文件系统命令与Linux系统类似,可以用于管理Hadoop的文件系统。
以下是一些常用的文件系统命令:- hdfs dfs -ls:列出文件系统中的文件和目录。
- hdfs dfs -mkdir:创建一个新目录。
- hdfs dfs -put:将本地文件上传到Hadoop文件系统中。
- hdfs dfs -get:将Hadoop文件系统中的文件下载到本地。
- hdfs dfs -rm:删除文件系统中的文件或目录。
- hdfs dfs -du:显示文件或目录的大小。
- hdfs dfs -chmod:更改文件或目录的权限。
2. MapReduce命令MapReduce是Hadoop的核心计算框架,用于处理大规模数据集。
以下是一些常用的MapReduce命令:- hadoop jar:运行MapReduce作业。
- hadoop job -list:列出所有正在运行的作业。
- hadoop job -kill:终止正在运行的作业。
- hadoop fs -copyFromLocal:将本地文件复制到Hadoop文件系统中。
- hadoop fs -copyToLocal:将Hadoop文件系统中的文件复制到本地。
- hadoop fs -rmr:删除指定目录及其所有子目录和文件。
3. YARN命令YARN是Hadoop的资源管理器,用于管理Hadoop集群中的资源。
以下是一些常用的YARN命令:- yarn node -list:列出所有节点的状态。
- yarn application -list:列出所有正在运行的应用程序。
- yarn application -kill:终止正在运行的应用程序。
hadoop常用命令详细解释

hadoop常⽤命令详细解释hadoop命令分为2级,在linux命令⾏中输⼊hadoop,会提⽰输⼊规则Usage: hadoop [--config confdir] COMMANDwhere COMMAND is one of:namenode -format format the DFS filesystem#这个命令⽤于格式化DFS系统:hadoop namenode -formatesecondarynamenode run the DFS secondary namenode#运⾏第⼆个namenodenamenode run the DFS namenode#运⾏DFS的namenodedatanode run a DFS datanode#运⾏DFS的datanodedfsadmin run a DFS admin client#运⾏⼀个DFS的admin客户端mradmin run a Map-Reduce admin client#运⾏⼀个map-reduce⽂件系统的检查⼯具fsck run a DFS filesystem checking utility#运⾏⼀个DFS⽂件系统的检查⼯具fs run a generic filesystem user client#这个是daoop⽂件的系统的⼀级命令,这个⾮常常见稍后详细讲解这个命令:例如hadoop fs -ls /balancer run a cluster balancing utility#作⽤于让各个datanode之间的数据平衡,例如:sh $HADOOP_HOME/bin/start-balancer.sh –t 15%oiv apply the offline fsimage viewer to an fsimage#将fsimage⽂件的内容转储到指定⽂件中以便于阅读,oiv⽀持三种输出处理器,分别为Ls、XML和FileDistribution,通过选项-p指定 fetchdt fetch a delegation token from the NameNode#运⾏⼀个代理的namenodejobtracker run the MapReduce job Tracker node#运⾏⼀个MapReduce的taskTracker节点pipes run a Pipes job#运⾏⼀个pipes作业tasktracker run a MapReduce task Tracker node#运⾏⼀个MapReduce的taskTracker节点historyserver run job history servers as a standalone daemon#运⾏历史服务作为⼀个单独的线程job manipulate MapReduce jobs#处理mapReduce作业,这个命令可以查看提交的mapreduce状态,杀掉不需要的jobqueue get information regarding JobQueues#队列管理,在后续版本中这个命名取消了version print the version#打印haoop版本jar <jar> run a jar file#运⾏⼀个jar包,⽐如mapreduce可以通过hadoop-streaming-1.2.1.jar进⾏开发distcp <srcurl> <desturl> copy file or directories recursively#distcp⼀般⽤于在两个HDFS集群中传输数据。
cdh集群常用命令

cdh集群常用命令以下是CDH集群中常用的命令:1. hdfs dfs -ls: 列出HDFS文件系统中的文件和目录。
2. hdfs dfs -mkdir: 在HDFS中创建新目录。
3. hdfs dfs -put: 将文件从本地文件系统上传到HDFS。
4. hdfs dfs -get: 将文件从HDFS下载到本地文件系统。
5. hdfs dfs -rm: 从HDFS中删除文件或目录。
6. hdfs dfs -chown: 更改文件或目录的所有者。
7. hdfs dfs -chmod: 更改文件或目录的权限。
8. hdfs dfs -cat: 查看文件的内容。
9. hdfs dfs -tail: 查看文件的末尾内容。
10. hdfs dfs -du: 估算文件或目录的大小。
11. hdfs dfs -mv: 移动文件或目录。
12. hdfs dfsadmin -report: 获取HDFS的报告,包括集群的容量、使用情况等信息。
13. yarn node -list: 列出YARN集群中的节点。
14. yarn application -list: 列出YARN集群中正在运行的应用程序。
15. yarn application -kill: 终止指定的YARN应用程序。
16. hadoop fsck: 检查HDFS中的文件完整性和一致性。
17. hadoop job -list: 列出运行中的Hadoop作业。
18. hadoop job -kill: 终止指定的Hadoop作业。
这些是CDH集群中常用的命令,可以帮助您管理和操作HDFS和YARN。
根据您的需求,可以使用这些命令进行文件操作、权限管理、作业管理等任务。
实验4HDFS常用操作

实验4HDFS常用操作Hadoop分布式文件系统(HDFS)是一个高度可靠、可扩展的分布式文件系统,为Hadoop集群提供了存储和处理大量数据的能力。
在Hadoop中,用户可以使用各种HDFS常用操作来管理和操作存储在HDFS上的数据。
本文将介绍HDFS中的一些常用操作方法。
1. 上传文件:使用命令`hadoop fs -put <local_file_path><hdfs_path>`将本地文件上传到HDFS。
例如,`hadoop fs -put/home/user/file.txt /user/hadoop/`将本地文件`file.txt`上传到HDFS的`/user/hadoop/`目录下。
3. 创建目录:使用命令`hadoop fs -mkdir <hdfs_path>`在HDFS上创建目录。
例如,`hadoop fs -mkdir /user/hadoop/data`将在HDFS的根目录下创建一个名为`data`的目录。
4. 删除文件或目录:使用命令`hadoop fs -rmr <hdfs_path>`删除HDFS上的文件或目录。
例如,`hadoop fs -rmr/user/hadoop/file.txt`将删除HDFS上的`/user/hadoop/file.txt`文件。
5. 列出目录内容:使用命令`hadoop fs -ls <hdfs_path>`列出指定目录下的文件和子目录。
例如,`hadoop fs -ls /user/hadoop/`将列出`/user/hadoop/`目录下的文件和子目录。
6. 查看文件内容:使用命令`hadoop fs -cat <hdfs_path>`将HDFS上的文件内容输出到控制台。
例如,`hadoop fs -cat/user/hadoop/file.txt`将显示`/user/hadoop/file.txt`文件的内容。
hadoop数据副本数量相关命令;

Hadoop是一种开源的分布式文件存储和计算系统,被广泛应用于大数据领域。
在Hadoop中,数据的可靠性和容错性是至关重要的,因此Hadoop引入了数据副本机制来保障数据的可靠性。
在Hadoop集裙中,数据会被分成多个块,并将这些块保存在不同的计算机上,以防止单点故障和数据丢失。
在本文中,我们将介绍Hadoop中与数据副本数量相关的一些命令和操作。
1. 查看数据块的副本情况在Hadoop中,可以使用以下命令来查看数据块的副本情况:hdfs fsck / -files -blocks -locations该命令会列出Hadoop集裙中所有块的副本情况,包括块的ID、复本数量、所在的数据节点等信息。
通过这些信息,可以清楚地了解每个数据块的副本情况,从而评估数据的可靠性和容错性。
2. 修改数据块的副本数量在Hadoop中,可以通过以下命令来修改数据块的副本数量:hdfs dfs -setrep -w 3 /user/hadoop/data.txt该命令会将指定文件的副本数量修改为3,这样可以增加数据的容错性和可靠性。
在某些情况下,可能需要根据实际情况来调整数据块的副本数量,以满足系统的要求。
3. 查看集裙的副本数量配置在Hadoop集裙中,可以通过以下命令来查看副本数量的相关配置信息:hadoop fs -getconf dfs.replication该命令会显示Hadoop集裙当前的副本数量配置,可以了解到集裙中数据块的默认副本数量是多少。
在实际应用中,可以根据业务需求和系统性能来调整副本数量的配置。
4. 修改集裙的副本数量配置如果需要修改集裙的副本数量配置,可以通过以下方式来实现:a. 打开Hadoop的配置文件hdfs-site.xml。
b. 修改配置项dfs.replication的值,将其设置为新的副本数量。
c. 保存文件并重启Hadoop集裙。
通过以上步骤,就可以修改Hadoop集裙的副本数量配置,从而影响整个集裙的数据副本情况。
Hadoop命令大全

Hadoop命令大全本节比较全面的向大家介绍一下Hadoop命令,欢迎大家一起来学习,希望通过本节的介绍大家能够掌握一些常见Hadoop命令的使用方法。
下面是Hadoop命令的详细介绍。
Hadoop命令大全1、列出所有HadoopShell支持的命令$bin/hadoopfs-help2、显示关于某个命令的详细信息$bin/hadoopfs-helpcommand-name3、用户可使用以下命令在指定路径下查看历史日志汇总$bin/hadoopjob-historyoutput-dir这条命令会显示作业的细节信息,失败和终止的任务细节。
4、关于作业的更多细节,比如成功的任务,以及对每个任务的所做的尝试次数等可以用下面的命令查看$bin/hadoopjob-historyalloutput-dir5、格式化一个新的分布式文件系统:$bin/hadoopnamenode-format6、在分配的NameNode上,运行下面的Hadoop命令启动HDFS:$bin/start-dfs.shbin/start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。
7、在分配的JobTracker上,运行下面的命令启动Map/Reduce:$bin/start-mapred.shbin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/sla ves文件的内容,在所有列出的slave上启动TaskTracker守护进程。
8、在分配的NameNode上,执行下面的Hadoop命令停止HDFS:$bin/stop-dfs.shbin/stop-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止DataNode守护进程。
Hadoop命令手册使用指南

Hadoop命令手册使用指南2010-06-03 17:27 王亚妮 我要评论(0)字号:T | THadoop命令你是否熟悉,这里就向大家简单介绍一下Hadoop命令使用问题,希望通过本文的介绍大家对Hadoop命令有一定的了解。
AD:在学习Hadoop的过程中,你可能经常遇到Hadoop命令方面的问题,本节就向大家介绍一些常用的Hadoop 命令,欢迎大家一起来学习。
Hadoop命令手册所有的hadoop命令均由bin/hadoop脚本引发。
不指定参数运行hadoop脚本会打印所有命令的描述。
用法:hadoop[--configconfdir][COMMAND][GENERIC_OPTIONS][COMMAND_OPTIONS]Hadoop有一个选项解析框架用于解析一般的选项和运行类。
命令选项描述--configconfdir覆盖缺省配置目录。
缺省是${HADOOP_HOME}/conf。
GENERIC_OPTIONS多个命令都支持的通用选项。
COMMAND命令选项S各种各样的命令和它们的选项会在下面提到。
这些命令被分为用户命令管理命令两组。
Hadoop命令常规选项下面的选项被dfsadmin,fs,fsck和job支持。
应用程序要实现Tool来支持常规选项。
GENERIC_OPTION描述-conf<configurationfile>指定应用程序的配置文件。
-D<property=value>为指定property指定值value。
-fs<local|namenode:port>指定namenode。
-jt<local|jobtracker:port>指定jobtracker。
只适用于job。
-files<逗号分隔的文件列表>指定要拷贝到mapreduce集群的文件的逗号分隔的列表。
只适用于job。
-libjars<逗号分隔的jar列表>指定要包含到classpath中的jar文件的逗号分隔的列表。
hdfs的常用命令

HDFS(Hadoop Distributed File System)的常用命令包括:1. 创建目录:hdfs dfs -mkdir /path/to/dir2. 查看目录下的内容:hdfs dfs -ls /path/to/dir3. 上传文件:hdfs dfs -put local_file /path/to/hdfs_file4. 上传并删除源文件:hdfs dfs -put -delete local_file /path/to/hdfs_file5. 查看文件内容:hdfs dfs -cat /path/to/hdfs_file6. 查看文件开头内容:hdfs dfs -head /path/to/hdfs_file7. 查看文件末尾内容:hdfs dfs -tail /path/to/hdfs_file8. 下载文件:hdfs dfs -get /path/to/hdfs_file local_file9. 合并下载文件:hdfs dfs -getmerge /path/to/hdfs_dir local_dir10. 拷贝文件:hdfs dfs -cp /path/to/hdfs_file /path/to/new_hdfs_file11. 追加数据到文件中:hdfs dfs -appendToFile local_file /path/to/hdfs_file12. 查看磁盘空间:hdfs dfs -df /path/to/dir13. 查看文件使用的空间:hdfs dfs -du -h /path/to/dir14. 移动文件:hdfs dfs -mv /path/to/hdfs_file /path/to/new_hdfs_file15. 修改文件副本个数:hdfs dfs -setrep [-R] [-w] [numReplicas] /path/to/file16. 查看校验码信息:hdfs dfs -checksum /path/to/hdfs_file17. 显示路径下的目录、文件和字节数:hdfs dfs -ls -R /path/to/dir18. 从本地拷贝文件:hdfs dfs -cp local_file /path/to/hdfs_file19. 拷贝文件到本地:hdfs dfs -get local_file /path/to/hdfs_file20. 查找目录文件:hdfs dfs -find /start_point -name pattern21. 删除文件:hdfs dfs -rm [-r] [-skipTrash] /path/to/hdfs_file22. 设置工作空间:hdfs dfsadmin -setSpaceQuota [newQuota] /path/to/dir23. 取消工作空间配额限制:hdfs dfsadmin -clrSpaceQuota /path/to/dir24. 查看HDFS版本信息:hdfs version25. 查看HDFS磁盘使用情况:hdfs dfsadmin -report26. 设置HDFS的block大小:hdfs dfsadmin -setBlockSize [size] /path/to/dir27. 设置HDFS的副本因子:hdfs dfsadmin -setReplication [factor] /path/to/file28. 查看HDFS的block分布情况:hdfs dfsadmin -reportBlockSizes [paths]29. 查看HDFS的datanode信息:hdfs dfsadmin -getDatanodeInfo [paths]30. 查看HDFS的datanode列表:hdfs dfsadmin -getDatanodeList [paths]31. 查看HDFS的文件系统状态信息:hdfs dfsadmin -getFileInfo [paths]32. 查看HDFS的文件系统统计信息:hdfs dfsadmin -getStatistics [paths]33. 查看HDFS的集群信息:hdfs dfsadmin -printClusterInfo34. 查看HDFS的文件系统版本信息:hdfs dfsadmin -version以上是hdfs的常用命令,希望对你有帮助。
Hadoop常用命令及范例

Hadoop常⽤命令及范例 hadoop中的zookeeper,hdfs,以及hive,hbase都是hadoop的组件,要学会熟练掌握相关的命令及其使⽤规则,下⾯就是⼀些常⽤命令及对hbase和hive的操作语句,同时也列出了⼀些范例。
start-dfs.sh NameNode 进程启动:hadoop-daemon.sh start namenode DataNode 进程启动:hadoop-daemon.sh start datanode HA ⾼可⽤环境中需要启动的进程: zookeeper: zkServer.sh start 启动 zkServer.sh stop 停⽌ zkServer.sh status 查看状态 leader follwer journalnode 集群命令 hadoop-daemon.sh start journalnode 启动 hadoop-daemon.sh stop journalnode 停⽌ ZKFC 启动 zkfc 进程: hadoop-daemon.sh start zkfc 停⽌ zkfc 进程: hadoop-daemon.sh stop zkfc 1. shell命令管理和 HDFS 的⽂件管理。
(1)启动 Zookeeper zkServer.sh start (2)启动 HDFS 的命令 start-dfs.sh (3)启动 Yarn 的命令 start-yarn.sh (4)显⽰ HDFS 中/data/test ⽬录信息 hadoop fs -mkdir /data/test hadoop fs -lsr /data/test (5)将本地⽂件/tmp/log.txt ⽂件上传到/data/test ⽬录中 hadoop fs -put /tmp/log.txt /data/test (6)设置⽂件/data/test/log.txt 的副本数为 3 hadoop fs -setrep -w 3 /data/test/log.txt (7)显⽰/data/test/log.txt ⽂件内容 hadoop fs -cat /data/test/log.txt (8)将/data/test/log.txt ⽂件移动到集群/user/hadoop ⽬录下 hadoop fs -mkdir /user/hadoop hadoop fs -mv /data/test/log.txt /user/hadoop (9)将/data/test/log.txt ⽂件下载到/home/hadoop ⽬录下 hadoop fs -copyToLocal /data/test/log.txt /home/hadoop/ (10)关闭 HDFS 命令 stop-dfs.sh (11)停⽌ Zookeeper zkServer.sh stop 2.将学⽣数据存储到 Hive 数据仓库中,信息包括(学号,姓名,性别,年龄,联系⽅式, 邮箱),创建表语法如下: 启动 hive 前切记要先启动 mysql 数据库 create table student(sno string ,name string ,sex string ,age int ,phone string, email string) row format delimited fields terminated by ',' ;(1)将本地数据“/tmp/student.dat”加载到 student 表,写出操作语句 load data local inpath '/tmp/student.dat' overwrite into table student; (2)写 HQL 语句查询全部学⽣信息 select * from student; (3)写 HQL 语句查询各个年龄及对应学⽣数量 (4) select age,count(*) from student group by age; (5)写 HQL 语句查询全部学⽣的姓名和性别 select name,sex from student; (6)写 HQL 语句查询年龄为 18 的学⽣姓名和联系⽅式 select name,phone from student where age=18; (7)写 HQL 语句查看 student 表结构 describe student; (8)写 HQL 语句删除 student 表 drop table student; (9)导出⽣地/home/hadoop/out ⽬录,写出语 from student insert overwrite local directory '/home/hadoop/out' select *; 3.员⼯表 employee 包含两个列族 basic 和 info,使⽤ shell 命令完成以下操作。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop 常用命令:
1、hadoop dfs
查看Hadoop HDFS支持的所有命令
2、hadoop dfs help
显示所有dfs命令的帮助信息
3、hadoop dfs -ls /
列出目录及文件信息
4、hadoop dfs -put 1.txt /user
将本地文件系统的1.txt复制到HDFS文件系统的/user目录下
5、hadoop dfs -copyFromLocal 1.txt /test
将本地文件1.txt 复制到HDFS的文件夹test下,等同于put
6、hadoop dfs -moveFromLocal /home/hadoop/1.txt /test1
将本地文件移动到HDFS文件系统上
7、hadoop dfs -get /test/1.txt /home/hadoop
将HDFS中的test.txt复制到本地文件系统中,与-put命令相反
8、hadoop dfs -copyToLocal /test/1.txt /home/hadoop
将HDFS上的文件复制到本地,等同于get
9、hadoop dfs -moveToLocal /test1/1.txt /home/hadoop
将HDFS的1.txt 文件移动到本地目录
10、hadoop dfs -cat /test/1.txt
查看HDFS文件系统里1.txt的内容
11、hadoop dfs -tail /test/1.txt
查看HDFS文件系统中1.txt最后1KB的内容
12、hadoop dfs -rm /test/1.txt
将1.txt这个文件移动到回收站
13、hadoop dfs -rm -skipTrash /test/1.txt
直接将1.txt这个文件删除
14、hadoop dfs -rmr /test
将test这个文件目录,包括底下的子目录、文件移动到回收站
15、hadoop dfs -rmr -skipTrash /test
直接将test这个文件目录,包括底下的子目录、文件删除
16、hadoop dfs -count /test1
查看test1目录底下的目录树和文件数,输出格式:目录数文件数大小文件名17、hadoop dfs -expunge
清空回收站
18、hadoop dfs -mkdir /test1
创建文件目录
19、hadoop dfs -touchz /1.txt
创建一个0字节的HDFS空文件
20、hadop dfs -chown -R hadoop:hadoop /test1
表示将/test1目录下所有文件的所属用户和所属组改为hadoop 21、hadoop dfs -chown -R hadoop /test1
表示将/test1目录下所有文件的所属组改为hadoop
22、hadoop dfs -chmod -R +r /test1
表示将/test1目录下的所有文件赋予读的权限。