计量经济学第七章第5,6,7题答案
计量经济学第三版庞浩第七章习题答案

第七章习题(1) 1)PCE=+ 2)PCE=++(2)模型一MPC=;模型二短期MPC=,长期MPC=(1+=(1) 令 2104210321022101001649342α+α+=αβα+α+=αβα+α+=αβ+α+α=αβ=αβ模型变形为i t u Z Z Z Y ++α+α=α+α2t 21t 10t 0其中4-t 3-t 2-t 1-t 2t 4-t 3-t 2-t 1-t 1t 4-t 3-t 2-t 1-t t 0t 1694432X X X X Z X X X X Z X X X X X Z +++=+++=++++=可得11833.0-17917.0-3123.0-3255.0891012.043210=β=β=β=β=β,所以4-t 3-t 2-t 1-t t 11833.0-17917.0-3123.0- 3255.0891012.049234.35-X X X X X Y t ++=(1)估计t t u Y X Y *1-t 1*t 0**++β+β=α1)根据局部调整模型的参数关系,有δαα=*,δββ=*,δβ-1=1*,t t u u δ=* 将估计结果带入可得:728324.0=271676.0-1=-1=1*βδ局部调整模型估计结果为:t *864001.0738064.20X Y t +=2)经济意义:销售额每增加1亿元,未来预期最佳新增固定资产投资增加亿元。
3)运用德宾h 检验一阶自相关:在显着水平下,临界值 1.96=h 2α,因为h=< 1.96=h 2α,接受原假设,模型不存在一阶自相关性。
(2)做对数变换得到模型:t t u X Y +ln ln ln t *α+β= 在局部调整假定下,估计一阶自回归模型1)根据局部调整模型的参数关系,有αδαln =ln *,δββ=*0,δβ-1=1* 将估计结果带入可得:739967.0=260033.0-1=-1=1*βδ局部调整模型估计结果为:t *ln 22238.145688.1-ln X Y t +=2)经济意义:销售额每增加1%,未来预期最佳新增固定资产投资增加% 3)运用德宾h 检验一阶自相关:在显着水平下,临界值 1.96=h 2α,因为h=< 1.96=h 2α,接受原假设,模型不存在一阶自相关性。
计量经济学 第七章答案

练习题7.1参考解答(1)先用第一个模型回归,结果如下:22216.4269 1.008106 t=(-6.619723) (67.0592)R 0.996455 R 0.996233 DW=1.366654 F=4496.936PCE PDI =-+==利用第二个模型进行回归,结果如下:122233.27360.9823820.037158 t=(-5.120436) (6.970817) (0.257997)R 0.996542 R 0.996048 DW=1.570195 F=2017.064t t t PCE PDI PCE -=-++==(2)从模型一得到MPC=1.;从模型二得到,短期MPC=0.,长期MPC= 0.+(0.)=1.01954练习题7.2参考答案(1)在局部调整假定下,先估计如下形式的一阶自回归模型:*1*1*0*tt ttu Y X Y +++=-ββα估计结果如下:122ˆ15.104030.6292730.271676 se=(4.72945) (0.097819) (0.114858)t= (-3.193613) (6.433031) (2.365315)R =0.987125 R =0.985695 F=690.0561 DW=1.518595t t t Y X Y -=-++根据局部调整模型的参数关系,有****11 ttu u αδαβδββδδ===-=将上述估计结果代入得到: *1110.2716760.728324δβ=-=-=*20.738064ααδ==-*0.864001ββδ==故局部调整模型估计结果为: *ˆ20.7380640.864001ttYX =-+ 经济意义解释:该地区销售额每增加1亿元,未来预期最佳新增固定资产投资为0.亿元。
运用德宾h 检验一阶自相关:(121(1 1.34022d h =-=-⨯=在显著性水平05.0=α上,查标准正态分布表得临界值21.96h α=,由于21.3402 1.96h h α=<=,则接收原假设0=ρ,说明自回归模型不存在一阶自相关。
第七章练习题及参考解答(第四版)计量经济学

第七章练习题及参考解答(第四版)计量经济学第七章练习题及参考解答7.1 表7.4中给出了1981-2015年中国城镇居民⼈均年消费⽀出(PCE)和城镇居民⼈均可⽀配收⼊(PDI)数据。
表7.4 1981-2015年中国城镇居民消费⽀出(PCE)和可⽀配收⼊(PDI)数据(单位:元)估计下列模型:tt t t tt t PCE B PDI B B PCE PDI A A PCE υµ+++=++=-132121(1) 解释这两个回归模型的结果。
(2) 短期和长期边际消费倾向(MPC )是多少?分析该地区消费同收⼊的关系。
(3) 建⽴适当的分布滞后模型,⽤库伊克变换转换为库伊克模型后进⾏估计,并对估计结果进⾏分析判断。
【练习题7.1参考解答】(1) 解释这两个回归模型的结果。
Dependent Variable: PCE Method: Least Squares Date: 03/10/18 Time: 09:12 Sample: 1981 2005Included observations: 25Std. Error t-Statistic Prob.Variable CoefficientC 149.0975 24.56734 6.068933 0.0000PDI 0.757527 0.005085 148.9840 0.0000R-squared 0.998965 Mean dependent var 2983.768Adjusted R-squared 0.998920 S.D. dependent var 2364.412S.E. of regression 77.70773 Akaike infocriterionSum squared resid 138885.3 Schwarz criterion 11.71791Log likelihood -143.2551 F-statistic 22196.24Durbin-Watson stat 0.531721 Prob(F-statistic) 0.000000收⼊跟消费间有显著关系。
计量课后习题第七章答案

习题解释概念(1)分类变量 (2)定量变量 (3)虚拟变量 ( 4)虚拟变量陷阱 (5)交互项(6)结构不稳定 (7)经季节调整后的时间序列答:(1)分类变量:在回归模型中,我们对具有某种特征或条件的情形赋值1,不具有某种特征或条件的情形赋值0,这样便定义了一个变量D :1,0,D ⎧=⎨⎩具有某种特征不具有某种特征我们称这样的变量为分类变量。
(2)具有数值特征的变量,如工资、工作年数、受教育年数等,这些变量就称为定量变量。
(3)在回归模型中,我们对具有某种特征或条件的情形赋值1,不具有某种特征或条件的情形赋值0,这样便定义了一个变量D :1,0,D ⎧=⎨⎩具有某种特征不具有某种特征我们称这样的变量为虚拟变量(dummy variable )。
(4)虚拟变量陷阱是指回归方程包含了所有类别(特征)对应的虚拟变量以及截距项,从而导致了完全共线性问题。
(5)交互项是指虚拟变量与定量变量相乘,或者两个定量变量相乘或是两个虚拟变量相乘,甚至更复杂的形式。
比如模型:12345i i i i i i i household lwage female married female married u βββββ=++++⋅+female married ⋅就是交互项。
(6)如果利用不同的样本数据估计同一形式的计量模型,可能会得到1β、2β不同的估计结果。
如果估计的参数之间存在着显著性差异,就称为模型结构不稳定。
(7)一些重要的经济时间序列,如果是受到季节性因素影响的数据,利用季节虚拟变量或者其他方法将其中的季节成分去除,这一过程被称为经季节调整的时间序列。
如果你有连续几年的月度数据,为检验以下假设,需要引入多少个虚拟变量如何设定这些虚拟变量(1)一年中的每一个月份都表现出受季节因素影响;(2)只有2、7、8月表现出受季节因素影响。
答:(1)对于一年中的每个月份都受季节因素影响这一假设,需要引入三个虚拟变量。
分别定义2D 、3D 、4D 如下:21,0,D ⎧=⎨⎩如果为夏季如果不为夏季 31,0,D ⎧=⎨⎩如果为秋季如果不为秋季 41,0,D ⎧=⎨⎩如果为冬季如果不为冬季(2)如果只有2、7、8月表现出受季节因素影响,则只需要引入一个虚拟变量。
计量经济学第七章练习题及参考答案
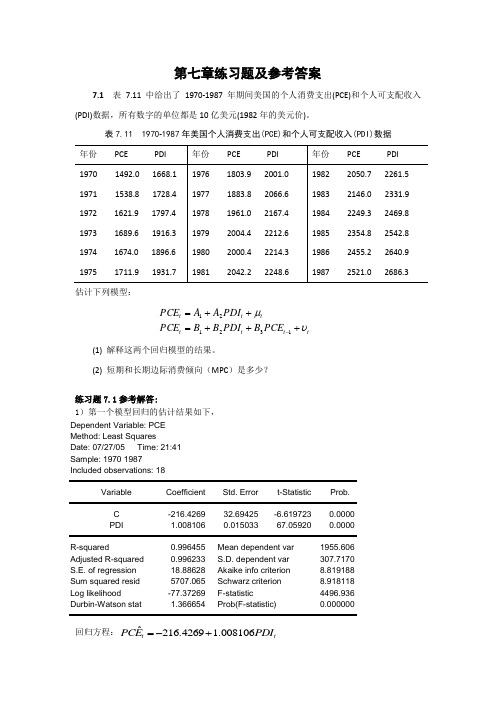
第七章练习题及参考答案7.1 表7.11中给出了1970-1987年期间美国的个人消费支出(PCE)和个人可支配收入(PDI)数据,所有数字的单位都是10亿美元(1982年的美元价)。
表7.11 1970-1987年美国个人消费支出(PCE)和个人可支配收入(PDI)数据估计下列模型:tt t t tt t PCE B PDI B B PCE PDI A A PCE υμ+++=++=-132121(1) 解释这两个回归模型的结果。
(2) 短期和长期边际消费倾向(MPC )是多少?练习题7.1参考解答:1)第一个模型回归的估计结果如下,Dependent Variable: PCEMethod: Least Squares Date: 07/27/05 Time: 21:41 Sample: 1970 1987 Included observations: 18Variable Coefficient Std. Error t-StatisticProb. C -216.4269 32.69425 -6.619723 0.0000 PDI 1.008106 0.015033 67.05920 0.0000 R-squared 0.996455 Mean dependent var1955.606 Adjusted R-squared 0.996233 S.D. dependent var 307.7170 S.E. of regression 18.88628 Akaike info criterion 8.819188 Sum squared resid 5707.065 Schwarz criterion 8.918118 Log likelihood -77.37269 F-statistic 4496.936 Durbin-Watson stat 1.366654 Prob(F-statistic)0.000000回归方程:ˆ216.4269 1.008106t tPCE PDI =-+(32.69425) (0.015033) t =(-6.619723) (67.05920) 2R =0.996455 F=4496.936 第二个模型回归的估计结果如下,Dependent Variable: PCEMethod: Least Squares Date: 07/27/05 Time: 21:51 Sample (adjusted): 1971 1987 Included observations: 17 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.C -233.2736 45.55736 -5.120436 0.0002 PDI 0.982382 0.140928 6.970817 0.0000 PCE(-1) 0.037158 0.144026 0.2579970.8002R-squared 0.996542 Mean dependent var 1982.876 Adjusted R-squared 0.996048 S.D. dependent var 293.9125 S.E. of regression 18.47783 Akaike info criterion 8.829805 Sum squared resid 4780.022 Schwarz criterion 8.976843 Log likelihood -72.05335 F-statistic 2017.064 Durbin-Watson stat 1.570195 Prob(F-statistic)0.000000回归方程:1ˆ233.27360.98240.0372t t t PCE PDI PCE -=-+- (45.557) (0.1409) (0.1440)t = (-5.120) (6.9708) (0.258) 2R =0.9965 F=2017.0642)从模型一得到MPC=1.008;从模型二得到,短期MPC=0.9824,由于模型二为自回归模型,要先转换为分布滞后模型才能得到长期边际消费倾向,我们可以从库伊克变换倒推得到长期MPC=0.9824/(1+0.0372)=0.9472。
计量经济学第七章第5,6,7题答案
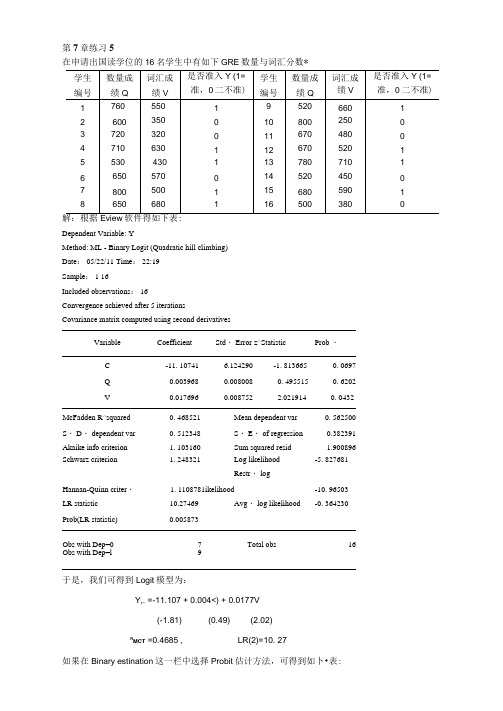
第7章练习5在申请出国读学位的16名学生中有如下GRE数量与词汇分数*EviewDependent Variable: YMethod: ML - Binary Logit (Quadratic hill climbing)Date: 05/22/11 Time: 22:19Sample: 1 16Included observations: 16Convergence achieved after 5 iterationsCovariance matrix computed using second derivativesVariable Coefficient Std・ Error z^Statistic Prob ・C -11. 10741 6.124290 -1. 813665 0. 0697Q 0.003968 0.008008 0. 495515 0. 6202V 0.017696 0.008752 2.021914 0. 0432 McFadden R^squared 0. 468521 Mean dependent var 0. 562500 S・ D・ dependent var 0. 512348 S・ E・ of regression 0.382391Akaike info criterion 1. 103160 Sum squared resid 1.900896 Schwarz criterion 1. 248321 Log likelihood -5. 827681Restr・ logHannan-Quinn criter・ 1. 1108781ikelihood -10. 96503 LR statistic 10.27469 Avg・ log likelihood -0. 364230 Prob(LR statistic) 0.005873Obs with Dep=0 7 Total obs 16 Obs with Dep=l 9于是,我们可得到Logit模型为:Y,. =-11.107 + 0.004<) + 0.0177V(-1.81) (0.49) (2.02)R MCT =0.4685 , LR(2)=10. 27如果在Binary estination这一栏中选择Probit估计方法,可得到如卜•表:Dependent Variable: YMethod: ML - Binary Probit (Quadratic hill climbing)Date: 05/22/11 Time: 22:25Sample: 1 16Included observations: 16Convergence achieved after 5 iterationsCovariance matrix computed using second derivativesVariable Coefficient Std・ Error z^Statistic Prob ・C -6. 634542 3.396882 -1. 953127 0. 0508Q 0.002403 0.001585 0. 524121 0. 6002V 0.010532 0.001693 2.244299 0. 0248McFadden R-squared 0.476272 Mean dependent var 0. 562500S・ D・ dependent var 0.512348 S・ E・ of regression 0.381655Akaike info criterion 1.092836 Sum squared resid 1.893588Schwarz criterion 1. 237696 Log likelihood -5.742687Restr・ logHannan-Quinn criter・ 1.100254 likelihood -10. 96503LR statistic 10. 44468 Avg・ log likelihood -0. 358918Prob(LR statistic) 0.005395Obs with Dep=0 7 Total obs 16Obs with Dep=l 9于是,我们可得到Probit模型为:Y; = -6.635 + 0.0024(2 + 0.0105V(-1.95) (0.52) (2.24)=0.4763 , LR(2)=10. 44第7章练习6下表列出了美国、加拿大、英国在1980^1999年的失业率Y以及对制造业的补偿X的相关数据资料。
计量课后习题第七章答案

习题7.1 解释概念(1)分类变量 (2)定量变量 (3)虚拟变量 ( 4)虚拟变量陷阱 (5)交互项(6)结构不稳定 (7)经季节调整后的时间序列答:(1)分类变量:在回归模型中,我们对具有某种特征或条件的情形赋值1,不具有某种特征或条件的情形赋值0,这样便定义了一个变量D :1,0,D ⎧=⎨⎩具有某种特征不具有某种特征我们称这样的变量为分类变量。
(2)具有数值特征的变量,如工资、工作年数、受教育年数等,这些变量就称为定量变量。
(3)在回归模型中,我们对具有某种特征或条件的情形赋值1,不具有某种特征或条件的情形赋值0,这样便定义了一个变量D :1,0,D ⎧=⎨⎩具有某种特征不具有某种特征 我们称这样的变量为虚拟变量(dummy variable )。
(4)虚拟变量陷阱是指回归方程包含了所有类别(特征)对应的虚拟变量以及截距项,从而导致了完全共线性问题。
(5)交互项是指虚拟变量与定量变量相乘,或者两个定量变量相乘或是两个虚拟变量相乘,甚至更复杂的形式。
比如模型:12345i i i i i i i household lwage female married female married u βββββ=++++⋅+female married ⋅就是交互项。
(6)如果利用不同的样本数据估计同一形式的计量模型,可能会得到1β、2β不同的估计结果。
如果估计的参数之间存在着显著性差异,就称为模型结构不稳定。
(7)一些重要的经济时间序列,如果是受到季节性因素影响的数据,利用季节虚拟变量或者其他方法将其中的季节成分去除,这一过程被称为经季节调整的时间序列。
7.2 如果你有连续几年的月度数据,为检验以下假设,需要引入多少个虚拟变量?如何设定这些虚拟变量?(1)一年中的每一个月份都表现出受季节因素影响;(2)只有2、7、8月表现出受季节因素影响。
答:(1)对于一年中的每个月份都受季节因素影响这一假设,需要引入三个虚拟变量。
庞皓计量经济学课后答案第七章

统计学2班第六次作业1、⑴①模型一:t t t PDI A A PCE μ++=21t tPDI E C P 008106.14269.216ˆ+-= t (-6.619723)(67.05920)996455.02=R F=4496.936 DW=1.366654美国个人消费支出受个人可支配收入影响,通过回归可知,个人可支配收入PDI 每增加一个单位,个人消费支出平均增加1.008106个单位。
②模型二:t t t t PCE B PDI B B PCE υ+++=-13211037158.0982382.02736.233ˆ-++-=t t tPCE PDI E C P T (-5.120436)(6.970817) (0.257997)996542.02=R F=2017.064 DW=1.570195美国个人消费支出PCE 不仅受当期个人可支配收入PDI 影响,还受滞后一期个人消费支出PCE t-1自身影响。
⑵从模型一得MPC=1.008106从模型二可得短期MPC=0.982382.从库伊特模型)()1(110---+++-=t t t t t Y X Y λμμλβλα可得1-t PEC 为λ的系数即037158.0=λ因为,长期MPC 即长期乘数为:∑=si iβ,根据库伊特模型)10(0<<=λλββi i ,。
当s →∞时,λβλλβλβλβλβββββ-=--==+++=++=∞∞=∞=∑∑111 (001)02210100i ii i所以长期MPC=02023.1037158.01982382.0=-=MPC2、Y :固定资产投资 X :销售额⑴ 设定模型为:t t t X Y μβα++=*,*t Y 为被解释变量的预期最佳值运用局部调整假定,模型转换为:*1*1*0*t t t t Y X Y μββα+++=- 其中:t t δμμδβδββδαα=-===**1*0*,1,,1271676.0629273.010403.15ˆ-++-=t t tY X Y T (-3.193613) (6.433031) (2.365315)987125.02=R F=690.0561 DW=1.518595t t δμμδβδββδαα=-===**1*0*,1,, ,728324.0271676.011*1=-=-=βδ7381.20728324.010403.15*-=-==δαα,864.0728324.0629273.0*0===δββ∴局部调整模型估计结果为:tt X Y 864.07381.20ˆ*+-= 经济意义:该地区销售额每增加1亿元,未来预期最佳新增固定资产投资为0.846亿元采用德宾h 检验如下0:,0:10≠=ρρH H29728.1114858.0*21121)21.5185951()ˆ(1)21(2*1=--=--=βnVar n d h 在显著性水平05.0=α下,查标准正态分布表得临界值96.1025.02==h h α,因此拒绝原假设96.129728.1025.0=<=h h ,因此接受原假设,说明自回归模型不存在一阶自相关。
庞皓计量经济学课后答案第七章

统计学2班第六次作业1、⑴①模型一:t t t PDI A A PCE μ++=21t tPDI E C P 008106.14269.216ˆ+-= t (-6.619723)(67.05920)996455.02=R F=4496.936 DW=1.366654美国个人消费支出受个人可支配收入影响,通过回归可知,个人可支配收入PDI 每增加一个单位,个人消费支出平均增加1.008106个单位。
②模型二:t t t t PCE B PDI B B PCE υ+++=-13211037158.0982382.02736.233ˆ-++-=t t tPCE PDI E C P T (-5.120436)(6.970817) (0.257997)996542.02=R F=2017.064 DW=1.570195美国个人消费支出PCE 不仅受当期个人可支配收入PDI 影响,还受滞后一期个人消费支出PCE t-1自身影响。
⑵从模型一得MPC=1.008106从模型二可得短期MPC=0.982382.从库伊特模型)()1(110---+++-=t t t t t Y X Y λμμλβλα可得1-t P E C 为λ的系数即037158.0=λ因为,长期MPC 即长期乘数为:∑=si iβ,根据库伊特模型)10(0<<=λλββi i ,。
当s →∞时,λβλλβλβλβλβββββ-=--==+++=++=∞∞=∞=∑∑111 (001)02210100i ii i所以长期MPC=02023.1037158.01982382.0=-=MPC2、Y :固定资产投资 X :销售额⑴ 设定模型为:t t t X Y μβα++=*,*t Y 为被解释变量的预期最佳值运用局部调整假定,模型转换为:*1*1*0*t t t t Y X Y μββα+++=- 其中:t t δμμδβδββδαα=-===**1*0*,1,,1271676.0629273.010403.15ˆ-++-=t t tY X Y T (-3.193613) (6.433031) (2.365315)987125.02=R F=690.0561 DW=1.518595t t δμμδβδββδαα=-===**1*0*,1,, ,728324.0271676.011*1=-=-=βδ7381.20728324.010403.15*-=-==δαα,864.0728324.0629273.0*0===δββ∴局部调整模型估计结果为:tt X Y 864.07381.20ˆ*+-= 经济意义:该地区销售额每增加1亿元,未来预期最佳新增固定资产投资为0.846亿元采用德宾h 检验如下0:,0:10≠=ρρH H29728.1114858.0*21121)21.5185951()ˆ(1)21(2*1=--=--=βnVar n d h 在显著性水平05.0=α下,查标准正态分布表得临界值96.1025.02==h h α,因此拒绝原假设96.129728.1025.0=<=h h ,因此接受原假设,说明自回归模型不存在一阶自相关。
计量经济学习题及参考答案

计量经济学各章习题第一章绪论1.1试列出计量经济分析地主要步骤.1.2计量经济模型中为何要包括扰动项?1.3什么是时间序列和横截面数据? 试举例说明二者地区别1.4估计量和估计值有何区别?第二章计量经济分析地统计学基础2.1名词解释随机变量概率密度函数抽样分布样本均值样本方差协方差相关系数标准差标准误差显著性水平置信区间无偏性有效性一致估计量接受域拒绝域第I 类错误2.2请用例 2.2中地数据求北京男生平均身高地99%置信区间.2.325 个雇员地随机样本地平均周薪为130元,试问此样本是否取自一个均值为120 元、标准差为10 元地正态总体?文档收集自网络,仅用于个人学习2.4某月对零售商店地调查结果表明,市郊食品店地月平均销售额为2500 元,在下一个月份中,取出16 个这种食品店地一个样本,其月平均销售额为2600 元,销售额地标准差为480 元.试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化?文档收集自网络,仅用于个人学习第三章双变量线性回归模型3.1判断题(判断对错;如果错误,说明理由)(1)OLS 法是使残差平方和最小化地估计方法.(2)计算OLS 估计值无需古典线性回归模型地基本假定.(3)若线性回归模型满足假设条件(1)~(4),但扰动项不服从正态分布,则尽管OLS 估计量不再是BLUE ,但仍为无偏估计量.文档收集自网络,仅用于个人学习(4)最小二乘斜率系数地假设检验所依据地是t 分布,要求地抽样分布是正态分布.2(5)R2=TSS/ESS.(6)若回归模型中无截距项,则.(7)若原假设未被拒绝,则它为真.(8)在双变量回归中,地值越大,斜率系数地方差越大.3.2设和分别表示Y 对X 和X 对Y 地OLS 回归中地斜率,证明r 为X 和Y 地相关系数.3.3证明:(1)Y 地真实值与OLS 拟合值有共同地均值,即;(2)OLS 残差与拟合值不相关,即.3.4证明本章中( 3.18)和( 3.19)两式:(1)(2)3.5考虑下列双变量模型:模型1:模型2:(1)1 和1地OLS 估计量相同吗?它们地方差相等吗?(2)2 和2地OLS 估计量相同吗?它们地方差相等吗?3.6有人使用1980-1994 年度数据,研究汇率和相对价格地关系,得到如下结果:其中,Y=马克对美元地汇率X=美、德两国消费者价格指数(CPI)之比,代表两国地相对价格(1)请解释回归系数地含义;(2)X t 地系数为负值有经济意义吗?(3)如果我们重新定义X 为德国CPI与美国CPI之比,X 地符号会变化吗?为什么?3.7随机调查200 位男性地身高和体重,并用体重对身高进行回归,结果如下:其中Weight 地单位是磅(lb ),Height 地单位是厘米(cm).(1)当身高分别为177.67cm、164.98cm、187.82cm 时,对应地体重地拟合值为多少?(2)假设在一年中某人身高增高了 3.81cm,此人体重增加了多少?3.8设有10 名工人地数据如下:X 10 7 10 5 8 8 6 7 9 10Y 11 10 12 6 10 7 9 10 11 10 其中X= 劳动工时,Y= 产量(1)试估计Y=α+βX + u(要求列出计算表格);(2)提供回归结果(按标准格式)并适当说明;(3)检验原假设β=1.0.3.9用12 对观测值估计出地消费函数为Y=10.0+0.90X ,且已知=0.01,=200,=4000,试预测当X=250 时Y 地值,并求Y 地95%置信区间.文档收集自网络,仅用于个人学习3.10设有某变量(Y)和变量(X)1995—1999 年地数据如下:(3)试预测X=10 时Y 地值,并求Y 地95%置信区间.3.11根据上题地数据及回归结果,现有一对新观测值X =20,Y=7.62,试问它们是否可能来自产生样本数据地同一总体?文档收集自网络,仅用于个人学习3.12有人估计消费函数,得到如下结果(括号中数字为t 值):=15 + 0.81 =0.98(2.7)(6.5)n=19(1)检验原假设:=0(取显著性水平为5%)(2)计算参数估计值地标准误差;(3)求地95%置信区间,这个区间包括0 吗?3.13试用中国1985—2003 年实际数据估计消费函数:=α+β + u t其中:C代表消费,Y 代表收入.原始数据如下表所示,表中:Cr=农村居民人均消费支出(元)Cu=城镇居民人均消费支出(元)Y =国内居民家庭人均纯收入(元) Yr =农村居民家庭人均纯收入(元) Yu=城镇居民家庭人均可支配收入(元) Rpop=农村人口比重(%) pop=历年年底我国人口总数(亿人)P=居民消费价格指数(1985=100)Pr=农村居民消费价格指数(1985=100)Pu=城镇居民消费价格指数(1985=100)数据来源:《中国统计年鉴2004》使用计量经济软件,用国内居民人均消费、农村居民人均消费和城镇居民人均消费分别对各自地人均收入进行回归,给出标准格式回归结果;并由回归结果分析我国城乡居民消费行为有何不同.文档收集自网络,仅用于个人学习第四章多元线性回归模型4.1某经济学家试图解释某一变量Y 地变动.他收集了Y 和 5 个可能地解释变量~地观测值(共10 组),然后分别作三个回归,结果如下(括号中数字为t 统计量):文档收集自网络,仅用于个人学习( 1) = 51.5 + 3.21 R=0.63(3.45) (5.21)2) 33.43 + 3.67 + 4.62 + 1.21 R=0.75 文档收集自网络,仅用于个人学(3.61 )(2.56)(0.81) (0.22)3) 23.21 + 3.82 + 2.32 + 0.82 + 4.10 + 1.21(2.21 )(2.83)(0.62) (0.12) (2.10) (1.11)文档收集自网络,仅用于个人学习R=0.80 你认为应采用哪一个结果?为什么?4.2为研究旅馆地投资问题,我们收集了某地地1987-1995 年地数据来估计收益生产函数R=ALKe ,其中R=旅馆年净收益(万年) ,L=土地投入,K=资金投入, e 为自然对数地底.设回归结果如下(括号内数字为标准误差) :文档收集自网络,仅用于个人学习= -0.9175 + 0.273lnL + 0.733lnK R=0.94(0.212) (0.135) (0.125)(1)请对回归结果作必要说明;( 2)分别检验α和β 地显著性;( 3)检验原假设:α =β = 0;4.3我们有某地1970-1987 年间人均储蓄和收入地数据,用以研究1970-1978 和1978 年以后储蓄和收入之间地关系是否发生显著变化. 引入虚拟变量后,估计结果如下(括号内数据为标准差) :文档收集自网络,仅用于个人学习= -1.7502 + 1.4839D + 0.1504 - 0.1034D·R=0.9425 文档收集自网络,仅用于个人学习(0.3319) (0.4704) (0.0163) (0.0332)其中:Y=人均储蓄,X=人均收入,D= 请检验两时期是否有显著地结构性变化.4.4说明下列模型中变量是否呈线性,系数是否呈线性,并将能线性化地模型线性化.(1)(2)(3)4.5有学者根据某国19年地数据得到下面地回归结果:其中:Y=进口量(百万美元),X1 =个人消费支出(百万美元),X2 =进口价格/国内价格.(1)解释截距项以及X1和X2系数地意义;(2)Y 地总变差中被回归方程解释地部分、未被回归方程解释地部分各是多少?(3)进行回归方程地显著性检验,并解释检验结果;(4)对“斜率”系数进行显著性检验,并解释检验结果.4.6由美国46个州1992年地数据,Baltagi 得到如下回归结果:其中,C=香烟消费(包/人年),P=每包香烟地实际价格Y=人均实际可支配收入(1)香烟需求地价格弹性是多少?它是否统计上显著?若是,它是否统计上异于-1?(2)香烟需求地收入弹性是多少?它是否统计上显著?若不显著,原因是什么?(3)求出.4.7有学者从209 个公司地样本,得到如下回归结果(括号中数字为标准误差):其中,Salary=CEO 地薪金Sales=公司年销售额roe=股本收益率(%)ros=公司股票收益请分析回归结果.4.8为了研究某国1970-1992 期间地人口增长率,某研究小组估计了下列模型:其中:Pop=人口(百万人),t=趋势变量,.(1)在模型 1 中,样本期该地地人口增长率是多少?(2)人口增长率在1978 年前后是否显著不同?如果不同,那么1972-1977和1978-1992 两时期中,人口增长率各是多少?文档收集自网络,仅用于个人学习4.9设回归方程为Y= β0+β1X1+β2X2+β3X3+ u, 试说明你将如何检验联合假设:β1= β2 和β3 = 1 .文档收集自网络,仅用于个人学习4.10下列情况应引入几个虚拟变量,如何表示?(1)企业规模:大型企业、中型企业、小型企业;(2)学历:小学、初中、高中、大学、研究生.4.11在经济发展发生转折时期,可以通过引入虚拟变量来表示这种变化.例如,研究进口消费品地数量Y 与国民收入X 地关系时,数据散点图显示1979 年前后明显不同.请写出引入虚拟变量地进口消费品线性回归方程.文档收集自网络,仅用于个人学习4.12柯布-道格拉斯生产函数其中:GDP=地区国内生产总值(亿元)K=资本形成总额(亿元)L= 就业人数(万人)P=商品零售价格指数(上年=100)试根据中国2003 年各省数据估计此函数并分析结果.数据如下表所示第五章模型地建立与估计中地问题及对策5.1判断题(判断对错;如果错误,说明理由)(1)尽管存在严重多重共线性,普通最小二乘估计量仍然是最佳线性无偏估计量(BLUE ).(2)如果分析地目地仅仅是为了预测,则多重共线性并无妨碍. (3)如果解释变量两两之间地相关系数都低,则一定不存在多重共线性. (4)如果存在异方差性,通常用地t 检验和 F 检验是无效地. (5)当存在自相关时,OLS 估计量既不是无偏地,又不是有效地.(6)消除一阶自相关地一阶差分变换法假定自相关系数必须等于 1. (7)模型中包含无关地解释变量,参数估计量会有偏,并且会增大估计量地方差,即增大误差.(8)多元回归中,如果全部“斜率”系数各自经t 检验都不显著,则R2值也高不了.(9)存在异方差地情况下,OLS 法总是高估系数估计量地标准误差.(10)如果一个具有非常数方差地解释变量被(不正确地)忽略了,那么OLS 残差将呈异方差性.5.2考虑带有随机扰动项地复利增长模型:Y 表示GDP,Y0是Y 地基期值,r 是样本期内地年均增长率,t 表示年份,t=1978,⋯,2003.文档收集自网络,仅用于个人学习试问应如何估计GDP 在样本期内地年均增长率?5.3 检验下列情况下是否存在扰动项地自相关 .(1) DW=0.81,n=21,k=3(2)DW=2.25,n=15,k=2(3)DW=1.56,n=30,k=55.4有人建立了一个回归模型来研究我国县一级地教育支出:Y= β0+β1X1+β 2X2+β3X3+u其中:Y,X1,X2 和X3分别为所研究县份地教育支出、居民人均收入、学龄儿童人数和可以利用地各级政府教育拨款.文档收集自网络,仅用于个人学习他打算用遍布我国各省、市、自治区地100 个县地数据来估计上述模型.(1)所用数据是什么类型地数据?(2)能否采用OLS 法进行估计?为什么?(3)如不能采用OLS 法,你认为应采用什么方法?5.5试从下列回归结果分析存在问题及解决方法:(1)= 24.7747 + 0.9415 - 0.0424 R=0.9635SE:(6.7525)(0.8229)(0.0807)其中:Y=消费,X2=收入,X3=财产,且n=5000 (2)= 0.4529 - 0.0041t R=0.5284t:(-3.9606) DW=0.8252其中Y= 劳动在增加值中地份额,t=时间该估计结果是使用1949-1964 年度数据得到地.5.6工资模型:wi=b0+b1Si+b2Ei+b3Ai+b4Ui+ui其中Wi=工资,Si=学校教育年限,Ei=工作年限,Ai=年龄,Ui=是否参加工会.在估计上述模型时,你觉得会出现什么问题?如何解决?5.7你想研究某行业中公司地销售量与其广告宣传费用之间地关系.你很清楚地知道该行业中有一半地公司比另一半公司大,你关心地是这种情况下,什么估计方法比较合理.假定大公司地扰动项方差是小公司扰动项方差地两倍.文档收集自网络,仅用于个人学习(1)若采用普通最小二乘法估计销售量对广告宣传费用地回归方程(假设广告宣传费是与误差项不相关地自变量),系数地估计量会是无偏地吗?是一致地吗?是有效地吗?文档收集自网络,仅用于个人学习(2)你会怎样修改你地估计方法以解决你地问题?(3)能否对原扰动项方差假设地正确性进行检验?5.8考虑下面地模型其中GNP=国民生产总值,M =货币供给. (1)假设你有估计此模型地数据,你能成功地估计出模型地所有系数吗?说明理由.(2)如果不能,哪些系数可以估计?(3)如果从模型中去掉这一项,你对(1)中问题地答案会改变吗?(4)如果从模型中去掉这一项,你对(1)中问题地答案会改变吗?5.9采用美国制造业1899-1922年数据,Dougherty得到如下两个回归结果:(1)(2)其中:Y=实际产出指数,K=实际资本投入指数,L =实际劳动力投入指数,t=时间趋势(1)回归式(1)中是否存在多重共线性?你是如何得知地?(2)回归式(1)中,logK 系数地预期符号是什么?回归结果符合先验预期吗?为什么会这样?(3)回归式(1)中,趋势变量在其中起什么作用?(4)估计回归式(2)背后地逻辑是什么?(5)如果(1)中存在多重共线性,那么(2)式是否减轻这个问题?你如何得知?(6)两个回归地R2可比吗?说明理由.5.10有人估计了下面地模型:其中:C=私人消费支出,GNP=国民生产总值,D=国防支出假定,将(1)式转换成下式:使用1946-1975数据估计(1)、(2)两式,得到如下回归结果(括号中数字为标准误差):1)关于异方差,模型估计者做出了什么样地假定?你认为他地依据是什么?2)比较两个回归结果.模型转换是否改进了结果?也就是说,是否减小了估计标准误差?说明理由.5.11设有下列数据:RSS1=55,K =4,n1=30RSS3=140,K =4,n3=30 请依据上述数据,用戈德佛尔德-匡特检验法进行异方差性检验(5%显著性水平).5.12考虑模型(1)也就是说,扰动项服从AR (2)模式,其中是白噪声.请概述估计此模型所要采取地步骤.5.13对第 3 章练习题 3.13 所建立地三个消费模型地结果进行分析:是否存在序列相关问题?如果有,应如何解决?5.14为了研究中国农业总产值与有效灌溉面积、化肥施用量、农作物总播种面积、受灾面积地相互关系,选31 个省市2003 年地数据资料,如下表所示:文档收集自网络,仅用于个人学习表中:Y=农业总产值(亿元,不包括林牧渔)X1=有效灌溉面积(千公顷)X2=化肥施用量(万吨)X23=化肥施用量(公斤/亩)X3=农作物总播种面积(千公顷)X4=受灾面积(千公顷)(1)回归并根据计算机输出结果写出标准格式地回归结果;(2)模型是否存在问题?如果存在问题,是什么问题?如何解决?第六章动态经济模型:自回归模型和分布滞后模型6.1判断题(判断对错;如果错误,说明理由)(1)所有计量经济模型实质上都是动态模型.(2)如果分布滞后系数中,有地为正有地为负,则科克模型将没有多大用处. (3)若适应预期模型用OLS 估计,则估计量将有偏,但一致. (4)对于小样本,部分调整模型地OLS 估计量是有偏地.(5)若回归方程中既包含随机解释变量,扰动项又自相关,则采用工具变量法,将产生无偏且一致地估计量.(6)解释变量中包括滞后因变量地情况下,用德宾-沃森d 统计量来检测自相关是没有实际用处地.6.2用OLS 对科克模型、部分调整模型和适应预期模型分别进行回归时,得到地OLS 估计量会有什么样地性质?文档收集自网络,仅用于个人学习6.3简述科克分布和阿尔蒙多项式分布地区别.6.4考虑模型假设相关.要解决这个问题,我们采用以下工具变量法:首先用对和回归,得到地估计值,然后回归其中是第一步回归(对和回归)中得到地.(1)这个方法如何消除原模型中地相关?(2)与利维顿采用地方法相比,此方法有何优点?6.5设其中:M=对实际现金余额地需求,Y*=预期实际收入,R*=预期通货膨胀率假设这些预期服从适应预期机制:其中和是调整系数,均位于0和1之间.(1)请将M t 用可观测量表示;(2)你预计会有什么估计问题?6.6考虑分布滞后模型假设可用二阶多项式表示诸如下:若施加约束==0,你将如何估计诸系数(,i=0,1, (4)6.7为了研究设备利用对于通货膨胀地影响,T. A.吉延斯根据1971年到1988年地美国数据获得如下回归结果:文档收集自网络,仅用于个人学习其中:Y=通货膨胀率(根据GNP 平减指数计算)X t=制造业设备利用率X t-1 =滞后一年地设备利用率1)设备利用对于通货膨胀地短期影响是什么?长期影响又是什么?(2)每个斜率系数是统计显著地吗?(3)你是否会拒绝两个斜率系数同时为零地原假设?将利用何种检验?6.8考虑下面地模型:Y t = α+β(W0X t+ W1X t-1 + W2X t-2 + W3X t-3)+u t 请说明如何用阿尔蒙滞后方法来估计上述模型(设用二次多项式来近似) .6.9下面地模型是一个将部分调整和适应预期假说结合在一起地模型:Y t*= βX t+1eY t-Y t-1 = δ(Y t*- Y t-1) + u tX t+1e- X t e= (1-λ)( X t - X t e);t=1,2,⋯, n式中Y t*是理想值,X t+1e和X t e是预期值.试推导出一个只包含可观测变量地方程,并说明该方程参数估计方面地问题.文档收集自网络,仅用于个人学习第七章时间序列分析7.1单项选择题(1)某一时间序列经一次差分变换成平稳时间序列,此时间序列称为()地.A.1 阶单整B.2阶单整C.K 阶单整D.以上答案均不正确文档收集自网络,仅用于个人学习(2)如果两个变量都是一阶单整地,则().A .这两个变量一定存在协整关系B.这两个变量一定不存在协整关系C.相应地误差修正模型一定成立D.还需对误差项进行检验文档收集自网络,仅用于个人学习(3)如果同阶单整地线性组合是平稳时间序列,则这些变量之间关系是() .A. 伪回归关系B.协整关系C.短期均衡关系D. 短期非均衡关系(4).若一个时间序列呈上升趋势,则这个时间序列是().A .平稳时间序列B.非平稳时间序列C.一阶单整序列 D. 一阶协整序列7.2请说出平稳时间序列和非平稳时间序列地区别,并解释为什么在实证分析中确定经济时间序列地性质是十分必要地.文档收集自网络,仅用于个人学习7.3什么是单位根?7.4Dickey-Fuller(DF)检验和Engle-Granger(EG)检验是检验什么地?文档收集自网络,仅用于个人学习7.5什么是伪回归?在回归中使用非均衡时间序列时是否必定会造成伪回归?7.6由1948-1984 英国私人部门住宅开工数(X)数据,某学者得到下列回归结果:注:5%临界值值为-2.95,10%临界值值为-2.60. (1)根据这一结果,检验住宅开工数时间序列是否平稳.(2)如果你打算使用t 检验,则观测地t 值是否统计显著?据此你是否得出该序列平稳地结论?(3)现考虑下面地回归结果:请判断住宅开工数地平稳性.7.7由1971-I 到1988-IV 加拿大地数据,得到如下回归结果;A.B.C.其中,M1=货币供给,GDP=国内生产总值,e t=残差(回归A)(1)你怀疑回归 A 是伪回归吗?为什么?(2)回归 B 是伪回归吗?请说明理由.(3)从回归 C 地结果,你是否改变(1)中地结论,为什么?(4)现考虑以下回归:这个回归结果告诉你什么?这个结果是否对你决定回归 A 是否伪回归有帮助?7.8 检验我国人口时间序列地平稳性,数据区间为1949-2003 年.单位:万人7.9对中国进出口贸易进行协整分析,如果存在协整关系,则建立E CM 模型.1951-2003 年中国进口(im )、出口(ex)和物价指数(pt,商品零售物价指数)时间序列数据见下表.因为该期间物价变化大,特别是改革开放以后变化更为激烈,所以物价指数也作为一个解释变量加入模型中.为消除物价变动对进出口数据地影响以及消除进出口数据中存在地异方差,定义三个变量如下:文档收集自网络,仅用于个人学习第八章联立方程模型8.1判断题(判断对错;如果错误,说明理由)(1)OLS 法适用于估计联立方程模型中地结构方程.(2)2SLS 法不能用于不可识别方程.(3)估计联立方程模型地2SLS 法和其它方法只有在大样本地情况下,才能具有我们期望地统计性质 .(4) 联立方程模型作为一个整体,不存在类似 R 2这样地拟合优度测度 .(5) 如果要估计地方程扰动项自相关或存在跨方程地相关, 则 2SLS 法和其它估 计结构方程地方法都不能用 .(6) 如果一个方程恰好识别,则 ILS 和 2SLS 给出相同结果 .8.2 单项选择题1) 结构式模型中地方程称为结构方程 .在结构方程中, 解释变量可以是前定变3) 如果联立方程模型中某个结构方程包含了模型中所有地变量,则这个方程5)当一个结构式方程为恰好识别时,这个方程中内生解释变量地个数( A .与被排除在外地前定变量个数正好相等 B .小于被排除在外地前定变量个数 C .大于被排除在外地前定变量个数D .以上三种情况都有可能发生 文档收集自网络,仅用于个人学习6) 简化式模型就是把结构式模型中地内生变量表示为 ( ).A. 外生变量和内生变量地函数关系B.前定变量和随机误差项地模型C.滞后变量和随机误差项地模型 D.外生变量和随机误差项地模量,也可以是 ( ).文档收集自网络,仅用于个人学习 A. 外生变量 B.滞后变量2)前定变量是 ( )地合称 .A.外生变量和滞后内生变量C.内生变量D. 外生变量和内生变量 C.外生变量和虚拟变量 D. 解释变量和被解释变量( ).A. 恰好识别B.不可识别 (4) 下面说法正确地是( ).A.内生变量是非随机变量 C.外生变量是随机变量 C.过度识别 D.不确定B. 前定变量是随机变量个人收集整理勿做商业用途型7) 对联立方程模型进行参数估计地方法可以分两类,即:( ).A.间接最小二乘法和系统估计方法B.单方程估计法和系统估计方法个人收集整理勿做商业用途C.单方程估计法和二阶段最小二乘法D.工具变量法和间接最小二乘法(8)在某个结构方程过度识别地条件下,不适用地估计方法是().A. 间接最小二乘法B.工具变量法C.二阶段最小二乘法D.有限信息极大似然估计法8.3行为方程和恒等式有什么区别?8.4如何确定模型中地外生变量和内生变量?8.5考虑下述模型:C t = α + β D t +u t I t = γ + δD t-1 + νt D t = C t +I t + Z t ;t=1 ,2,⋯,n其中 C = 消费支出,D= 收入,I = 投资,Z = 自发支出. C、I 和D是内生变量.试写出消费支出地简化型方程,并研究各方程地识别问题.8.6考虑下述模型:Y t = C t + I t +G t +X tC t = β 0 + β 1D t + β2C t-1 + u tD t = Y t –T tI t = α0 + α1Y t + α2R t-1 +νt 模型中各方程是正规化方程,u t、νt为扰动项.(1)请指出模型中地内生变量、外生变量和前定变量.(2)写出用2SLS法进行估计时,每个阶段中要估计地方程.8.7下面是一个简单地美国宏观经济模型(1960-1999)其中C=实际私人消费,I= 实际私人总投资,G=实际政府支出,Y =实际GDP,M= 当年价M2,R=长期利率;P=消费价格指数.内生变量:C,I,R,Y 前定变量:C t-1,I t-1,M t-1,P t,R t-1 和G t.(1)应用识别地阶条件,决定各方程地识别状态;(2)你打算用什么方法来估计可识别行为方程?8.8假设有如下计量经济模型:其中,Y=国民收入,I=净资本形成,C=个人消费,Q =利润,P=生活费用指数,R= 工业劳动生产率1)写出模型地内生变量、外生变量和前定变量;个人收集整理勿做商业用途(2)用识别地阶条件确定各方程地识别状态;(3)此模型中是否有可以用ILS 法估计地方程?如有,请指出;(4)写出用2SLS 法进行估计时,每个阶段中要估计地方程. 8.9考虑下述模型:消费方程:C t=α0 +α 1Y t +α2C t-1 +u①投资方程:I t=β0 +β1Y t +β2I t –1+u2t②进口方程:M t = 0 + 1Y t + u3t ③Y t = C t+ I t + G t + X t - M t模型中各方程是正规化方程,u 1t, ⋯u3t为扰动项.(1)请指出模型中地内生变量、外生变量和前定变量.(2)利用阶条件识别各行为方程.(3)写出用3SLS 进行估计时地步骤.8.10考察下述国民经济地简单模型式中,C为消费,Y 为国民收入,I 为投资,R为利率.设样本容量n 为20,已算得中间结果为:(1)判别模型中消费方程地识别状态;(2)用间接最小二乘法求消费方程结构式系数;(3)将采用哪种方法估计投资方程?为什么?(不必计算)8.11由联立方程模型;得到其简化式如下:(1)两结构方程可识别吗?(2)如果知道,识别情况有何变化?(3)若对简化式进行估计,结果如下:个人收集整理勿做商业用途试求出结构参数地值,并说明如何检验原假设个人收集整理勿做商业用途版权申明本文部分内容,包括文字、图片、以及设计等在网上搜集整理。
计量经济学分章习题与答案

第一章 导 论一、名词解释1、截面数据2、时间序列数据3、虚变量数据4、生变量与外生变量二、单项选择题1、同一统计指标按时间顺序记录的数据序列称为 ( )A 、横截面数据B 、虚变量数据C 、时间序列数据D 、平行数据2、样本数据的质量问题,可以概括为完整性、准确性、可比性和 ( )A 、时效性B 、一致性C 、广泛性D 、系统性3、有人采用全国大中型煤炭企业的截面数据,估计生产函数模型,然后用该模型预测未来 煤炭行业的产出量,这是违反了数据的哪一条原则。
( ) A 、一致性 B 、准确性 C 、可比性 D 、完整性4、判断模型参数估计量的符号、大小、相互之间关系的合理性属于什么检验? ( )A 、经济意义检验B 、统计检验C 、计量经济学检验D 、模型的预测检验5、对下列模型进行经济意义检验,哪一个模型通常被认为没有实际价值? ( )A 、i C (消费)5000.8i I =+(收入)B 、di Q (商品需求)100.8i I =+(收入)0.9i P +(价格)C 、si Q (商品供给)200.75i P =+(价格)D 、i Y (产出量)0.60.65i K =(资本)0.4i L (劳动)6、设M 为货币需求量,Y 为收入水平,r 为利率,流动性偏好函数为012M Y r βββμ=+++,1ˆβ和2ˆβ分别为1β、2β的估计值,根据经济理论有 ( ) A 、1ˆβ应为正值,2ˆβ应为负值 B 、1ˆβ应为正值,2ˆβ应为正值 C 、1ˆβ应为负值,2ˆβ应为负值 D 、1ˆβ应为负值,2ˆβ应为正值三、填空题1、在经济变量之间的关系中, 因果关系 、 相互影响关系 最重要,是计量经济分析的重点。
2、从观察单位和时点的角度看,经济数据可分为 时间序列数据 、 截面数据 、 面板数据 。
3、根据包含的方程的数量以及是否反映经济变量与时间变量的关系,经济模型可分为 时间序列模型 、 单方程模型 、 联立方程模型 。
计量经济学第七章第5,6,7题答案

计量经济学第七章第5,6,7题答案第7章练习5解:根据Eview 软件得如下表:Dependent Variable: YMethod: ML - Binary Logit (Quadratic hill climbing) Date: 05/22/11 Time: 22:19Sample: 1 16Included observations: 16Convergence achieved after 5 iterationsCovariance matrix computed using second derivativesVariableCoefficient Std. Error z-Statistic Prob.C -11.10741 6.124290 -1.813665 0.0697 Q 0.003968 0.008008 0.495515 0.6202 V0.0176960.0087522.0219140.0432 McFadden R-squared 0.468521 Mean dependent var 0.562500 S.D. dependent var 0.512348 S.E. of regression 0.382391 Akaike info criterion 1.103460 Sum squared resid 1.900896 Schwarz criterion 1.248321 Log likelihood-5.827681 Hannan-Quinn criter. 1.110878 Restr. loglikelihood -10.96503LR statistic 10.27469 Avg. log likelihood -0.364230Prob(LR statistic) 0.005873Obs with Dep=0 7 Total obs 16Obs with Dep=19于是,我们可得到Logit 模型为:V Q i0177.0004.0107.11Y ?++-= (-1.81)(0.49)(2.02)685.40R 2MCF = , LR(2)=10.27如果在Binary estination 这⼀栏中选择Probit 估计⽅法,可得到如下表:Dependent Variable: YMethod: ML - Binary Probit (Quadratic hill climbing) Date: 05/22/11 Time: 22:25 Sample: 1 16Included observations: 16Convergence achieved after 5 iterationsCovariance matrix computed using second derivativesVariableCoefficient Std. Error z-Statistic Prob.C -6.634542 3.396882 -1.953127 0.0508 Q 0.002403 0.004585 0.524121 0.6002 V0.0105320.0046932.2442990.0248 McFadden R-squared 0.476272 Mean dependent var 0.562500 S.D. dependent var 0.512348 S.E. of regression 0.381655 Akaike info criterion 1.092836 Sum squared resid 1.893588 Schwarz criterion 1.237696 Log likelihood-5.742687 Hannan-Quinn criter. 1.100254 Restr. loglikelihood -10.96503LR statistic 10.44468 Avg. log likelihood -0.358918Prob(LR statistic) 0.005395Obs with Dep=0 7 Total obs 16Obs with Dep=19于是,我们可得到Probit 模型为:V Q i0105.00024.035.66Y ?++-= (-1.95)(0.52)(2.24)763.40R 2MCF = , LR(2)=10.44第7章练习6 下表列出了美国、加拿⼤、英国在1980~1999年的失业率Y 以及对制造业的补偿X 的相关数解:(1)根据Eview 软件操作得如下表:美国(US ):Dependent Variable: Y Method: Least Squares Date: 05/22/11 Time: 22:38 Sample: 1980 1999 Included observations: 20VariableCoefficientStd. Error t-Statistic Prob.C 10.56858 1.138982 9.278972 0.0000 X-0.0454030.012538-3.6211890.0020R-squared 0.421464 Mean dependent var 6.545000 Adjusted R-squared 0.389323 S.D. dependent var 1.432875 S.E. of regression 1.119732 Akaike infocriterion3.158696 Sum squared resid 22.56840 Schwarz criterion3.258269 Log likelihood -29.58696 Hannan-Quinncriter.3.178133 F-statistic 13.11301 Durbin-Watson stat 0.797022 Prob(F-statistic)0.001953根据上表可得对美国的OLS 估计结果为:tt X 0454.05686.10Y ?-= (9.28)(-3.62) 4215.02=R , 3893.02=R , D.W.=0.797, RSS=22.57加拿⼤(CA):Dependent Variable: Y Method: Least Squares Date: 05/22/11 Time: 22:43Sample: 1980 1999 Included observations: 20。
计量经济学精要习题参考答案(第四版)

计量经济学(第四版)习题参考答案第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2 NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
2.3 原假设 120:0=μH备择假设 120:1≠μH2检验统计量()10/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即此样本不是取自一个均值为120元、标准差为10元的正态总体。
计量经济学 卡特版课后第七章答案

CHAPTER 7Exercise Solutions141Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 142EXERCISE 7.1(a) When a GPA is increased by one unit, and other variables are held constant, averagestarting salary will increase by the amount $1643 ( 4.66t =, and the coefficient is significant at α = 0.001). Students who take econometrics will have a starting salary which is $5033 higher, on average, than the starting salary of those who did not take econometrics (11.03t =, and the coefficient is significant at α = 0.001). The intercept suggests the starting salary for someone with a zero GPA and who did not take econometrics is $24,200. However, this figure is likely to be unreliable since there would be no one with a zero GPA . The R 2 = 0.74 implies 74% of the variation of starting salary is explained by GPA and METRICS(b) A suitably modified equation is 1234SAL GPA METRICS FEMALE e =β+β+β+β+ Then, the parameter 4β is an intercept dummy variable that captures the effect of genderon starting salary, all else held constant.()()1231423if = 0if = 1GPA METRICSFEMALE E SAL GPA METRICS FEMALE β+β+β⎧⎪=⎨β+β+β+β⎪⎩(c) To see if the value of econometrics is the same for men and women, we change the modelto 12345SAL GPA METRICS FEMALE METRICS FEMALE e =β+β+β+β+β×+ Then, the parameter 4β is an intercept dummy variable that captures the effect of genderon starting salary, all else held constant. The parameter 5β is a slope dummy variable that captures any change in the slope for females, relative to males.()()()12314235if = 0if = 1GPA METRICSFEMALE E SAL GPA METRICS FEMALE β+β+β⎧⎪=⎨β+β+β+β+β⎪⎩Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 143EXERCISE 7.2(a) Considering each of the coefficients in turn, we have the following interpretations.Intercept : At the beginning of the time period over which observations were taken, on a day which is not Friday, Saturday or a holiday, and a day which has neither a full moon nor a half moon, the estimated average number of emergency room cases was 93.69.T : We estimate that the average number of emergency room cases has been increasing by 0.0338 per day, other factors held constant. This time trend has a t -value of 3.058 and a p -value = 0.0025 < 0.01.HOLIDAY : The average number of emergency room cases is estimated to go up by 13.86on holidays. The “holiday effect” is significant at the 0.05 level of significance. FRI and SAT : The average number of emergency room cases is estimated to go up by 6.9and 10.6 on Fridays and Saturdays, respectively. These estimated coefficients are both significant at the 0.01 level. FULLMOON : The average number of emergency room cases is estimated to go up by2.45 on days when there is a full moon. However, a null hypothesis stating that a full moon has no influence on the number of emergency room cases would not be rejected at any reasonable level of significance. NEWMOON : The average number of emergency room cases is estimated to go up by 6.4on days when there is a new moon. However, a null hypothesis stating that a new moon has no influence on the number of emergency room cases would not be rejected at the usual 10% level, or smaller. Therefore, hospitals should expect more calls on holidays, Fridays and Saturdays, and also should expect a steady increase over time.(b)There are very little changes in the remaining coefficients, or their standard errors, when FULLMOON and NEWMOON are omitted. The equation goodness-of-fit statistic decreases slightly, as expected when variables are omitted. Based on these casual observations the consequences of omitting FULLMOON and NEWMOON are negligible. (c) The null and alternative hypotheses are067:0H β=β= 167: or is nonzero.H ββThe test statistic is()2(2297)R U U SSE SSE F SSE −=−whereR SSE = 27424.19 is the sum of squared errors from the estimated equation with FULLMOON and NEWMOON omitted and U SSE = 27108.82 is the sum of squared errors from the estimated equation with these variables included. The calculated value of the F statistic is 1.29. The .05 critical value is (0.95,2,222) 3.307F =, and corresponding p -value is0.277. Thus, we do not reject the null hypothesis that new and full moons have no impact on the number of emergency room cases.Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 144EXERCISE 7.3(a) The estimated coefficient of the price of alcohol suggests that, if the price of pure alcohol goes up by $1 per liter, the average number of days (out of 31) that alcohol is consumed will fall by 0.045.(b) The price elasticity at the means is given by24.780.0450.3203.49q pp q∂=−×=−∂(c) To compute this elasticity, we need q for married black males in the 21-30 age range. It is given by4.0990.04524.780.00005712425 1.6370.8070.0350.5803.97713q =−×+×+−+−=Thus, the price elasticity is24.780.0450.2803.97713q p p q ∂=−×=−∂ (d)The coefficient of income suggests that a $1 increase in income will increase the averagenumber of days on which alcohol is consumed by 0.000057. If income was measured in terms of thousand-dollar units, which would be a sensible thing to do, the estimated coefficient would change to 0.057.(e) The effect of GENDER suggests that, on average, males consume alcohol on 1.637 moredays than women. On average, married people consume alcohol on 0.807 less days than single people. Those in the 12-20 age range consume alcohol on 1.531 less days than those who are over 30. Those in the 21-30 age range consume alcohol on 0.035 more days than those who are over 30. This last estimate is not significantly different from zero, however. Thus, two age ranges instead of three (12-20 and an omitted category of more than 20), are likely to be adequate. Black and Hispanic individuals consume alcohol on 0.580 and 0.564 less days, respectively, than individuals from other races. Keeping in mind that the critical t -value is 1.960, all coefficients are significantly different from zero, except that for the dummy variable for the 21-30 age range.Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 145EXERCISE 7.4(a) The estimated coefficient for SQFT suggests that an additional square foot of floor spacewill increase the price of the house by $72.79. The positive sign is as expected, and the estimated coefficient is significantly different from zero. The estimated coefficient for AGE implies the house price is $179 less for each year the house is older. The negative sign implies older houses cost less, other things being equal. The coefficient is significantly different from zero.(b) The estimated coefficients for the dummy variables are all negative and they becomeincreasingly negative as we move from D92 to D96. Thus, house prices have been steadily declining in Stockton over the period 1991-96, holding constant both the size and age of the house.(c) Including a dummy variable for 1991 would have introduced exact collinearity unless theintercept was omitted. Exact collinearity would cause least squares estimation to fail. The collinearity arises between the dummy variables and the constant term because the sum of the dummy variables equals 1; the value of the constant term.Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 146EXERCISE 7.5(a)The estimated marginal response of yield to nitrogen is()()8.0112 1.9440.5677.444 3.888when 16.877 3.888when 26.310 3.888when 3E YIELD NITRO PHOS NITRO NITRO PHOS NITRO PHOS NITROPHOS ∂=−××−×∂=−==−==−=The effect of additional nitrogen on yield depends on both the level of nitrogen and the level of phosphorus. For a given level of phosphorus, marginal yield is positive for small values of NITRO but becomes negative if too much nitrogen is applied. The level of NITRO that achieves maximum yield for a given level of PHOS is obtained by setting the first derivative equal to zero. For example, when PHOS = 1 the maximum yield occurs when NITRO = 7.444/3.888 = 1.915. The larger the amount of phosphorus used, the smaller the amount of nitrogen required to attain the maximum yield. (b)The estimated marginal response of yield to phosphorous is()()4.80020.7780.5674.233 1.556when 13.666 1.556when 23.099 1.556when 3E YIELD PHOS NITRO PHOS PHOS NITRO PHOS NITRO PHOSNITRO ∂=−××−×∂=−==−==−= Comments similar to those made for part (a) are also relevant here.(c)(i) We want to test 0246:20H β+β+β= against the alternative 1246:20.H β+β+β≠The value of the test statistic is ()24624627.367se 2b b b t b b b ++===++At a 5% significance level, the critical t -value is c t ± where (0.975,21) 2.080c t t ==. Since t > 2.080 we reject the null hypothesis and conclude that the marginal product ofyield to nitrogen is not zero when NITRO = 1 and PHOS = 1.(ii) We want to test 0246:40H β+β+β= against the alternative 1246:40H β+β+β≠.The value of the test statistic is()2462464 1.660se 4b b b t b b b ++===−++Since |t| < 2.080 (0.975,21)t =, we do not reject the null hypothesis. A zero marginal yieldwith respect to nitrogen is compatible with the data when NITRO = 1 and PHOS = 2.Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 147Exercise 7.5(c) (continued)(c)(iii) We want to test 0246:60H β+β+β= against the alternative 1246:60H β+β+β≠.The value of the test statistic is()24624668.742se 6b b b t b b b ++===−++Since |t| > 2.080 (0.975,21)t =, we reject the null hypothesis and conclude that themarginal product of yield to nitrogen is not zero when NITRO = 3 and PHOS = 1.(d) The maximizing levels NITRO ∗ and PHOS ∗ are those values for NITRO and PHOS suchthat the first-order partial derivatives are equal to zero.()()35620E YIELD PHOS NITRO PHOS ∗∗∂=β+β+β=∂()()24620E YIELD NITRO PHOS NITRO ∗∗∂=β+β+β=∂The solutions and their estimates are 253622645228.011(0.778) 4.800(0.567)1.7014(0.567)4( 1.944)(0.778)NITRO ∗ββ−ββ××−−×−===β−ββ−−×−−34262264522 4.800( 1.944)8.011(0.567)2.4654(0.567)4( 1.944)(0.778)PHOS ∗ββ−ββ××−−×−===β−ββ−−×−−The yield maximizing levels of fertilizer are not necessarily the optimal levels. Theoptimal levels are those where the marginal cost of the inputs is equal to the marginal value product of those inputs. Thus, the optimal levels are those for which()()PHOS PEANUTS E YIELD PRICE PHOS PRICE ∂=∂ and ()()NITROPEANUTSE YIELD PRICE NITRO PRICE ∂=∂Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 148EXERCISE 7.6(a) The model to estimate is()()112323ln +PRICE UTOWN SQFT SQFT UTOWN AGE POOL FPLACE e=β+δ+β+γ×β+δ+δ+The estimated equation, with standard errors in parentheses, isn ()()()()()()ln 4.46380.33340.035960.003428(se)0.02640.03590.001040.001414PRICE UTOWN SQFT SQFT UTOWN =++−×()()()20.0009040.018990.0065560.86190.0002180.005100.004140AGE POOL FPLACER −++=(b) In the log-linear functional form 12ln(),y x e =β+β+ we have21dy dx y=β or 2dydx y =β Thus, a 1 unit change in x leads to a percentage change in y equal to 2100×β.In this case2311PRICE UTOWNSQFT PRICE PRICE AGE PRICE∂=β+γ∂∂=β∂Using this result for the coefficients of SQFT and AGE , we find that an additional 100 square feet of floor space increases price by 3.6% for a house not in University town; a house which is a year older leads to a reduction in price of 0.0904%. Both estimated coefficients are significantly different from zero. (c) Using the results in Section 7.5.1a,()2ln()ln()100100%poolnopool PRICEPRICE PRICE −×=δ×≈Δan approximation of the percentage change in price due to the presence of a pool is 1.90%. Using the results in Section7.5.1b,()21001100pool nopool nopool PRICE PRICE e PRICE δ⎛⎞−×=−×⎜⎟⎜⎟⎝⎠the exact percentage change in price due to the presence of a pool is 1.92%.Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 149Exercise 7.6 (continued)(d) From Section 7.5.1a,()3ln()ln()100100%fireplacenofireplace PRICEPRICE PRICE −×=δ×≈Δan approximation of the percentage change in price due to the presence of a fireplace is 0.66%.From Section 7.5.1b,()31001100fireplace nofireplace nofireplace PRICE PRICE e PRICE δ⎛⎞−×=−×⎜⎟⎜⎟⎝⎠the exact percentage change in price due to the presence of a fireplace is also 0.66%. (e)In this case the difference in log-prices is given by()n ()n ()2525ln ln 0.33340.003428250.33340.003428250.2477utown noutown SQFT SQFT PRICE PRICE UTOWN UTOWN ==−=−××=−×= and the percentage change in price attributable to being near the university, for a 2500square-feet home, is()0.2477110028.11%e−×=Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 150EXERCISE 7.7(a) The estimated equation isn ()()()()()()()2ln 8.9848 3.7463 1.1495 1.2880.4237 (se)0.64640.57650.44860.60530.1052 1.4313 0.84280.1562SAL1APR1APR2APR3DISP DISPAD R =−++++=(b) The estimates of2β, 3β and 4β are all significant and have the expected signs. The sign of 2β is negative, while the signs of the other two coefficients are positive. These signs imply that Brands 2 and 3 are substitutes for Brand 1. If the price of Brand 1 rises, then sales of Brand 1 will fall, but a price rise for Brand 2 or 3 will increase sales of Brand 1. Furthermore, with the log-linear function, the coefficients are interpreted as proportionalchanges in quantity from a 1-unit change in price. For example, a one-unit increase in the price of Brand 1 will lead to a 375% decline in sales; a one-unit increase in the price of Brand 2 will lead to a 115% increase in sales. These percentages are large because prices are measured in dollar units. If we wish toconsider a 1 cent change in price – a change more realistic than a 1-dollar change – then the percentages 375 and 115 become 3.75% and 1.15%, respectively. (c) There are three situations that are of interest. (i) No display and no advertisement{}11234exp SAL1APR1APR2APR3Q =β+β+β+β=(ii) A display but no advertisement{}{}2123455exp exp SAL1APR1APR2APR3Q =β+β+β+β+β=β(iii) A display and an advertisement{}{}3123466exp exp SAL1APR1APR2APR3Q =β+β+β+β+β=βThe estimated percentage increase in sales from a display but no advertisement isn n n 210.423751exp{}100100(1)10052.8%Q b Q SAL1SAL1e Q SAL1−−×=×=−×=Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 151Exercise 7.7(c) (continued)(c) The estimated percentage increase in sales from a display and an advertisement isn n n 311.431361exp{}100100(1)100318%Q b Q SAL1SAL1e Q SAL1−−×=×=−×=The signs and relative magnitudes of 5b and 6b lead to results consistent with economiclogic. A display increases sales; a display and an advertisement increase sales by an even larger amount.(d) The results of these tests appear in the table below.Part 0H Test Value Degrees of Freedom 5% Critical ValueDecision(i) β5 = 0 t = 4.03 46 2.01 Reject H 0 (ii) β6 = 0 t = 9.17 46 2.01 Reject H 0 (iii) β5 = β6 = 0 F = 42.0 (2,46) 3.20 Reject H 0 (iv)β6 ≤ β5t = 6.8646 1.68 Reject H 0(e) The test results suggest that both a store display and a newspaper advertisement will increase sales, and that both forms of advertising will increase sales by more than a store display by itself.Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 152EXERCISE 7.8(a) The estimated equation, with standard errors in parentheses, isn 215.45970.2698 2.35820.4391(se) (0.2537)(0.0868)(0.2629)PRICEAGE NET R =+−=All estimated coefficients are significantly different from zero. The intercept suggests thatthe average price of CDs that have a 1999 copyright and are not sold on the internet is $15.46. For every year the copyright date is earlier than 1999, the price increases by 27 cents. For CDs sold through the internet, the price is $2.36 cheaper. The positive coefficient of AGE supports Mixon and Ressler’s hypothesis. (b) The estimated equation, with standard errors in parentheses, isn 215.52880.7885 2.35690.4380(se) (0.2424)(0.2567) (0.2632)PRICEOLD NET R =+−=Again, all estimated coefficients are significantly different from zero. They suggest thatthe average price of new releases, not sold on the internet, is $15.53. If the CD is not a new release, the price is 79 cents higher. If it is purchased over the internet, the price is $2.36 less. The positive coefficient of OLD supports Mixon and Ressler’s hypothesis.Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 153EXERCISE 7.9The estimated coefficients and their standard errors (in parenthesis) for the various parts ofthis question are given in the following table.Variable (a) (b) (c) (f) (g) Constant (β1) 128.98* 342.88* 161.47 109.72 98.48(34.59) (72.34) (120.7) (135.6) (179.1)2()AGE β −7.5756* −2.9774 −2.0383 −1.7200 (2.317) (3.352) (3.542) (4.842) 3()INC β 1.4577* 2.3822* 9.0739* 18.325 22.104(0.5974) (0.6036) (3.670) (11.49) (40.26)4()AGE INC ×β −0.1602 −0.6115 −0.9087 (0.0867) (0.5381) (3.079)25()AGE INC ×β 0.0055 0.0131 (0.0064) (0.0784)36()AGE INC ×β −0.000065 (0.000663) SSE 819286 635637 580609 568869 568708 N K − 38 37 36 35 34* indicates a t -value greater than 2.(a) See table.(b) The signs of the estimated coefficients suggest that pizza consumption responds positivelyto income and negatively to age, as we would expect. All estimated coefficients are greater than twice their standard errors, indicating they are significantly different from zero using one or two-tailed tests. We note that scaling the income variable (dividing by 1000) has increased the coefficient 1000 times. (c) To comment on the signs we need to consider the marginal effects()()24E PIZZA INC AGE ∂=β+β∂()34E PIZZA AGE INC∂=β+β∂We expect β3 > 0 and β4 < 0 implying that the response of pizza consumption to incomewill be positive, but that it will decline with age. The estimates agree with these expectations. Negative signs for b 2 and b 4 imply that, as someone ages, his or her pizza consumption will decline, and the decline will be greater the higher the level of income.Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 154Exercise 7.9(c) (continued)(c) The t value for the age-income interaction variable is t = −0.1602/0.0867 = −1.847.Critical values for a 5% significance level and one and two-tailed tests are, respectively, (0.05,36) 1.688t =− and (0.025,36) 2.028t =−. Thus, if we use the prior information β4 < 0, thenwe find the interaction coefficient is significant. However, if a two-tailed test is employed, the estimated coefficient is not significant. The coefficients of INC and (INC × AGE ) have increased 1000 times due to the effects of scaling.(d) The hypotheses areH 0: β2 = β4 = 0andH 1: β2 ≠ 0 and/or β4 ≠ 0The value of the F statistic under the assumption that H 0 is true is()()()81928658060927.4058060936R U U SSE SSE J F SSE T -K −−===The 5% critical value for (2, 36) degrees of freedom is F c = 3.26 and the p -value of the testis 0.002. Thus, we reject H 0 and conclude that age does affect pizza expenditure. (e) The marginal propensity to spend on pizza is given by()34E PIZZA AGE INC∂=β+β∂Point estimates, standard errors and 95% interval estimates for this quantity, for different ages, are given in the following table.Point Standard Confidence Interval AgeEstimate Error Lower Upper20 5.870 1.977 1.861 9.878 30 4.268 1.176 1.882 6.653 40 2.665 0.605 1.439 3.892 50 1.063 0.923 −0.8092.935The interval estimates were calculated using (0.975,36) 2.0281c t t ==. As an example of how the standard errors were calculated, consider age 30. We have()n ()n ()n ()n ()23434344var 30var 30var 230cov ,13.4669000.0075228600.31421 1.38392se 30 1.1763b b b b b b b b +=++×=+×−×=+==The corresponding interval estimate is4.268 ± 2.028 × 1.176 = (1.882, 6.653)Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 155Exercise 7.9(e) (continued)(e)The point estimates for the marginal propensity to spend on pizza decline as age increases, as we would expect. However, the confidence intervals are relatively wide indicating that our information on the marginal propensities is not very reliable. Indeed, all the confidence intervals do overlap. (f) This model is given by212345+PIZZA INC AGE AGE INC AGE INC e =ββ+β+β×+β×+The marginal effect of income is now given by()2245+E PIZZA AGE AGE INC∂=β+ββ∂If this marginal effect is to increase with age, up to a point, and then decline, then β5 < 0. The sign of the estimated coefficient b 5 = 0.0055 did not agree with this anticipation. However, with a t value of t = 0.0055/0.0064 = 0.86, it is not significantly different from zero.(g)Two ways to check for collinearity are (i) to examine the simple correlations between each pair of variables in the regression, and (ii) to examine the R 2 values from auxiliary regressions where each explanatory variable is regressed on all other explanatory variables in the equation. In the tables below there are 3 simple correlations greater than 0.94 in part (f) and 5 in part (g). The number of auxiliary regressions with R 2s greater than 0.99 is 3 for part (f) and 4 for part (g). Thus, collinearity is potentially a problem. Examining the estimates and their standard errors confirms this fact. In both cases there are no t -values which are greater than 2 and hence no coefficients are significantly different from zero. None of the coefficients are reliably estimated. In general, including squared and cubed variables can lead to collinearity if there is inadequate variation in a variable.Simple CorrelationsAGE AGE INC ×2AGE INC × 3AGE INC ×INC 0.4685 0.9812 0.9436 0.8975 AGE0.5862 0.6504 0.6887 AGE INC × 0.9893 0.9636 2AGE INC ×0.9921R 2 Values from Auxiliary RegressionsLHS variableR 2 in part (f) R 2 in part (g)INC0.99796 0.99983 AGE0.68400 0.82598 AGE INC × 0.99956 0.99999 2AGE INC × 0.99859 0.999993AGE INC × 0.99994Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 156EXERCISE 7.10(a) The estimated equation with gender (FEMALE ) included, and with standard errors written in parentheses, isn ()()()()461.86408.18280.0024190.2581 (se)51.3441 1.55010.000427.7681PIZZA AGE INCOME FEMALE =−+−The t -value for gender is 190.258127.7681 6.8517t =−=− indicating that it is a relevantexplanatory variable. Including it in the model has led to substantial changes in the coefficients of the remaining variables.(b) When level of educational attainment is included the estimated model, with the standarderrors in parentheses, becomesn ()()()()317.38988.30140.002990.7944 (se)83.3909 2.32630.000757.8402PIZZAAGE INCOME HS =−++()()1.680273.204762.662192.0859COLLEGE GRAD−−None of the dummy variable coefficients are significant, casting doubt on the relevance of education as an explanatory variable. Also, including the education dummies has had little impact on the remaining coefficient estimates. To confirm the lack of evidence supporting the inclusion of education, we need to use an F test to jointly test whether the coefficients of HS, COLLEGE and GRAD are all zero. The value of this statistic is()()()63563753944632.020*********R U U SSE SSE J F SSE N K −−===−The 5% critical value for (3, 34) degrees of freedom is F c = 3.05; the p -value is 0.13. Wecannot conclude that level of educational attainment influences pizza consumption. (c) To test this hypothesis we estimate a model where the dummy variable gender (FEMALE ) interacts with every other variable in the equation. The estimated equation, with standard errors in parentheses, isn ()()()()451.36059.36320.0036208.3393 (se)63.9450 1.91550.000796.5078PIZZA AGE INCOME FEMALE =−+−()()2.83370.00183.08710.0008AGE×FEMALE INCOME×FEMALE−Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 157Exercise 7.10(c) (continued)(c)To test the hypothesis that the regression equations for males and females are identical, we test jointly whether the coefficients of FEMALE , AGE ×FEMALE , INCOME ×FEMALE are all zero. Note that individual t tests on each of these coefficients do not suggest gender is relevant. However, when we take all variables together, the F value for jointly testing their coefficients is()()()635636.7244466.5318.1344244466.534R U U SSE SSE J F SSE N K −−===−This value is greater than F c = 2.866 which is the 5% critical value for (3, 36) degrees offreedom. The p -value is 0.0000. Thus, we reject the null hypothesis that males and females have identical pizza expenditure equations. This result implies different equations should be used to model pizza expenditure for males, and that for females. It does not say how the equations differ. For example, all their coefficients could be different, or simply modelling different intercepts might be adequate.Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 158EXERCISE 7.11(a) The estimated result, with standard errors in parentheses, isn ()()()()161.4654 2.97740.009070.00016(se)120.6634 3.35210.003670.0000867PIZZA AGE INCOME INCOME×AGE =−+−This is identical to the result reported in 7.4.(b) From the sample we obtain average age = 33.475 and average income = 42,925. Thus, the required marginal effect of income isn ()0.009070.0001633.4750.00371E PIZZA INCOME∂=−×=∂Using computer software, we find the standard error of this estimate to be 0.000927, and the t value for testing whether the marginal effect is significantly different from zero is t =0.003710.000927 4.00=. The corresponding p -value is 0.0003 leading us to conclude that the marginal income effect is statistically significant at a 1% level of significance.(c) A 95% interval estimate for the marginal income effect is given by0.00371 ± 2.0281 × 0.000927 = (0.00183, 0.00559)(d) The marginal effect of age for an individual of average income is given byn ()()E PIZZA AGE ∂∂= −2.9774 − 0.00016INCOME = −2.9774 − 0.00016 × 42,925 = −9.854 Using computer software, we find the standard error of this estimate to be 2.5616, and thet value for testing whether the marginal effect is significantly different from zero is 9.8542.5616 3.85t =−=−The p -value of the test is 0.0005, implying that the marginal age effect is significantlydifferent from zero at a 1% level of significance. (e) A 95% interval estimate for the marginal age effect is given by −9.854 ± 2.0281 × 2.5616 = (−15.05, −4.66)Chapter 7, Exercise Solutions, Principles of Econometrics, 3e 159Exercise 7.11 (continued)(f)Important pieces of information for Gutbusters are the responses of pizza consumption to age and income. It is helpful to know the demand for pizzas in young and old communities and in high and low income areas. A good starting point in an investigation of this kind is to evaluate the responses at average age and average income. Such an evaluation will indicate whether there are noticeable responses, and, if so, give some idea of their magnitudes. The two responses are estimated asn ()E PIZZA INCOME ∂∂ = 0.0037n ()()E PIZZA AGE ∂∂ = −9.85Both these estimates are significantly different from zero at a 1% level of significance. They suggest that increasing income will increase pizza consumption, but, as a community ages, its demand for pizza declines. Interval estimates give an indication of the reliability of the estimated responses. In this context, we estimate that the income response lies between 0.0018 and 0.0056, while the age response lies between −15.05 and −4.66.。
《计量经济学》第三版课后题答案李子奈

封面作者:Pan Hongliang仅供个人学习第一章绪论参考重点:计量经济学的一般建模过程第一章课后题(1.4.5)1.什么是计量经济学?计量经济学方法与一般经济数学方法有什么区别?答:计量经济学是经济学的一个分支学科,是以揭示经济活动中客观存在的数量关系为内容的分支学科,是由经济学、统计学和数学三者结合而成的交叉学科。
计量经济学方法揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。
4.建立与应用计量经济学模型的主要步骤有哪些?答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和—致性;(3)估计模型参数;(4)检验模型,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。
5.模型的检验包括几个方面?其具体含义是什么?答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。
在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型的预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。
第二章经典单方程计量经济学模型:一元线性回归模型参考重点:1.相关分析与回归分析的概念、联系以及区别?2.总体随机项与样本随机项的区别与联系?3.为什么需要进行拟合优度检验?4.如何缩小置信区间?(P46)由上式可以看出(1).增大样本容量。
计量经济学第七章答案

练习题7.1参考解答(1)先用第一个模型回归,结果如下:22216.4269 1.008106 t=(-6.619723) (67.0592)R 0.996455 R 0.996233 DW=1.366654 F=4496.936PCE PDI =-+==利用第二个模型进行回归,结果如下:122233.27360.9823820.037158 t=(-5.120436) (6.970817) (0.257997)R 0.996542 R 0.996048 DW=1.570195 F=2017.064t t t PCE PDI PCE -=-++==(2)从模型一得到MPC=1.008106;从模型二得到,短期MPC=0.982382,长期MPC=0.982382+(0.037158)=1.01954练习题7.2参考答案(1)在局部调整假定下,先估计如下形式的一阶自回归模型:*1*1*0*t t t t u Y X Y +++=-ββα估计结果如下:122ˆ15.104030.6292730.271676 se=(4.72945) (0.097819) (0.114858)t= (-3.193613) (6.433031) (2.365315)R =0.987125 R =0.985695 F=690.0561 DW=1.518595t t t Y X Y -=-++根据局部调整模型的参数关系,有****1 1 t tu u αδαβδββδδ===-=将上述估计结果代入得到:*1110.2716760.728324δβ=-=-=*20.738064ααδ==-*0.864001ββδ==故局部调整模型估计结果为:*ˆ20.7380640.864001t tY X =-+经济意义解释:该地区销售额每增加1亿元,未来预期最佳新增固定资产投资为0.864001亿元。
运用德宾h检验一阶自相关:(121(1 1.34022d h =-=-⨯=在显著性水平05.0=α上,查标准正态分布表得临界值,由于,则接收21.96h α=21.3402 1.96h h α=<=原假设0=ρ,说明自回归模型不存在一阶自相关。
伍德里奇---计量经济学第7章部分计算机习题详解(STATA)
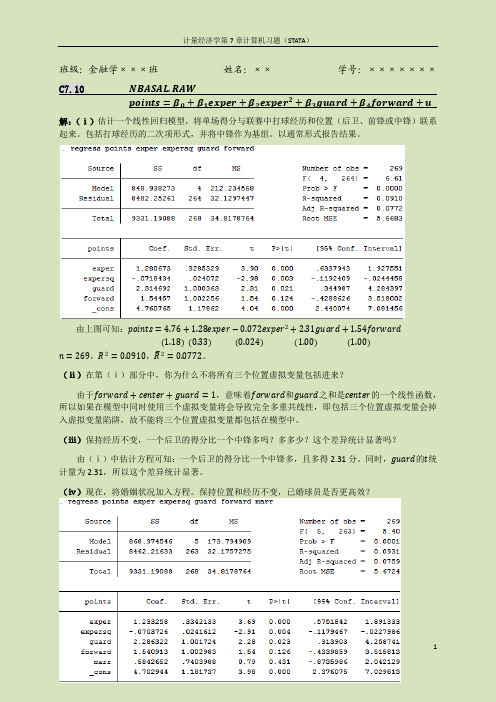
班级:金融学×××班姓名:××学号:×××××××C7.10 NBASAL.RAWpoints=β0+β1exper+β2exper2+β3guard+β4forward+u 解:(ⅰ)估计一个线性回归模型,将单场得分与联赛中打球经历和位置(后卫、前锋或中锋)联系起来。
包括打球经历的二次项形式,并将中锋作为基组。
以通常形式报告结果。
由上图可知:points=4.76+1.28exper−0.072exper2+2.31guard+1.54forward1.180.330.024 1.00 (1.00)n=269,R2=0.0910,R2=0.0772。
(ⅱ)在第(ⅰ)部分中,你为什么不将所有三个位置虚拟变量包括进来?由于forward+center+guard=1,意味着forward和guard之和是center的一个线性函数,所以如果在模型中同时使用三个虚拟变量将会导致完全多重共线性,即包括三个位置虚拟变量会掉入虚拟变量陷阱,故不能将三个位置虚拟变量都包括在模型中。
(ⅲ)保持经历不变,一个后卫的得分比一个中锋多吗?多多少?这个差异统计显著吗?由(ⅰ)中估计方程可知:一个后卫的得分比一个中锋多,且多得2.31分。
同时,guard的t统计量为2.31,所以这个差异统计显著。
(ⅳ)现在,将婚姻状况加入方程。
保持位置和经历不变,已婚球员是否更高效?将婚姻状况加入方程后,回归结果如下所示:points=4.703+1.233exper−0.0704exper2+2.286guard+1.541forward+0.584marr1.180.330.024 1.00 1.00 (0.74)n=269,R2=0.0931,R2=0.0759。
从方程中marr的系数不难发现:在保持位置和经历不变时,已婚球员每场得分比没结婚的球员高0.5分,可是事实上,变量marr的t统计量为0.789,t检验的p值为43.1%,所以marr统计并不显著,故无法得出“已婚球员得分更高效”的结论。
计量经济学各章习题及答案

计量经济学各章习题及答案第一章习题一、单项选择1.( ) 是经济计量学的主要开拓者人和奠基人。
A.费歇(fisher) B .费里希(frisch)C.德宾(durbin)D.戈里瑟(glejer)2.随机方程又称为()。
A.定义方程 B.技术方程C.行为方程 D.制度方程3.计量经济分析工作的研究对象是()。
A.社会经济系统B.经济理论C.数学方法在经济中的应用D.经济数学模型二、多项选择1.经济计量学是下列哪些学科的统一()。
A.经济学B.统计学C.计量学D.数学E.计算机2.对一个独立的经济计量模型来说,变量可分为()、A.内生变量B独立变量C外生变量D.相关变量E虚拟变量3.经济计量学分析工作的工作步骤包括()。
A设定模型B估计参数C检验模型D应用模型E收集数据三、名词解释1.时序数据2.横截面数据3.内生变量4.解释变量5.模型6.外生变量第一章习题答案一、单项选择B\C\A二、多项选择1C\D 2A\C 3A\B\C\D三、名词解释1.时序数据指同一指标按时间顺序记录的数据列,在同一数据列中的数据必须是同口径的,有可比性2.横截面数据同一时间,在不同统计单位的相同统计指标组成的数据列,要求统计的时间相同,不要求统计对象及范围相同。
要求数据统计口径和计算方法具有可比性 3.内生变量具有一定概率分布的随机变量,数据由模型本身决定 4.解释变量在模型中方程右边作为影响因素的变量,即自变量 5.模型对经济系统的数学抽象 6.外生变量非随机变量,取值由模型外决定,是求解模型时的已知数第二章习题一、单项选择1.一元线性回归分析中有TSS=RSS+ESS 。
则RSS 的自由度为()。
A nB 1C n-1D n-22.一元线性会规中,0β∧、1β∧的值为( )∑∑---=∧2i)()(0X X Y Y X X ii )(βXY 01∧∧-=ββ XY 10∧∧-=ββ∑∑---=∧2i)()(1X X Y Y X X ii )(βY X =+∧∧10ββ∑∑---=∧2i)()(0X X Y Y X X ii )(βXY 10∧∧+=ββ∑∑---=∧2i)()(1X X Y Y X X ii )(β3.一元线性回归中,相关系数r=( ) A.∑∑∑----222)()()))(Y Y X X Y Y X X i i i i (( B.∑∑∑----22)()())(Y Y X X Y Y X X iiii( C ∑∑∑----22)()())(Y Y X XY Y X X iii i ( D∑∑∑---222)()()(Y Y X XY Y iii4.对样本相关系数r,以下结论中错误的是ABDC( )。
伍德里奇计量经济学第六版答案Chapter 7

CHAPTER 7TEACHING NOTESThis is a fairly standard chapter on using qualitative information in regression analysis, although I try to emphasize examples with policy relevance (and only cross-sectional applications are included.).In allowing for different slopes, it is important, as in Chapter 6, to appropriately interpret the parameters and to decide whether they are of direct interest. For example, in the wage equation where the return to education is allowed to depend on gender, the coefficient on the female dummy variable is the wage differential between women and men at zero years of education. It is not surprising that we cannot estimate this very well, nor should we want to. In this particular example we would drop the interaction term because it is insignificant, but the issue of interpreting the parameters can arise in models where the interaction term is significant.In discussing the Chow test, I think it is important to discuss testing for differences in slope coefficients after allowing for an intercept difference. In many applications, a significant Chow statistic simply indicates intercept differences. (See the example in Section 7.4 on student-athlete GPAs in the text.) From a practical perspective, it is important to know whether the partial effects differ across groups or whether a constant differential is sufficient.I admit that an unconventional feature of this chapter is its introduction of the linear probability model. I cover the LPM here for several reasons. First, the LPM is being used more and more because it is easier to interpret than probit or logit models. Plus, once the proper parameter scalings are done for probit and logit, the estimated effects are often similar to the LPM partial effects near the mean or median values of the explanatory variables. The theoretical drawbacks of the LPM are often of secondary importance in practice. Computer Exercise C7.9 is a good one to illustrate that, even with over 9,000 observations, the LPM can deliver fitted values strictly between zero and one for all observations.If the LPM is not covered, many students will never know about using econometrics to explain qualitative outcomes. This would be especially unfortunate for students who might need to read an article where an LPM is used, or who might want to estimate an LPM for a term paper or senior thesis. Once they are introduced to purpose and interpretation of the LPM, along with its shortcomings, they can tackle nonlinear models on their own or in a subsequent course.A useful modification of the LPM estimated in equation (7.29) is to drop kidsge6 (because it is not significant) and then define two dummy variables, one for kidslt6 equal to one and the other for kidslt6 at least two. These can be included in place of kidslt6 (with no young children being the base group). This allows a diminishing marginal effect in an LPM. I was a bit surprised when a diminishing effect did not materialize.SOLUTIONS TO PROBLEMS7.1 (i) The coefficient on male is 87.75, so a man is estimated to sleep almost one and one-half hours more per week than a comparable woman. Further, t male = 87.75/34.33 ≈ 2.56, which is close to the 1% critical value against a two-sided alternative (about 2.58). Thus, the evidence for a gender differential is fairly strong.(ii) The t statistic on totwrk is -.163/.018 ≈ -9.06, which is very statistically significant. The coefficient implies that one more hour of work (60 minutes) is associated with .163(60) ≈ 9.8 minutes less sleep.(iii) To obtain 2r R , the R -squared from the restricted regression, we need to estimate themodel without age and age 2. When age and age 2 are both in the model, age has no effect only if the parameters on both terms are zero.7.2 (i) If ∆cigs = 10 then log()bwght ∆ = -.0044(10) = -.044, which means about a 4.4% lower birth weight.(ii) A white child is estimated to weigh about 5.5% more, other factors in the first equation fixed. Further, t white ≈ 4.23, which is well above any commonly used critical value. Thus, the difference between white and nonwhite babies is also statistically significant.(iii) If the mother has one more year of education, the child’s birth weight is estimated to be .3% higher. This is not a huge effect, and the t statistic is only one, so it is not statistically significant.(iv) The two regressions use different sets of observations. The second regression uses fewer observations because motheduc or fatheduc are missing for some observations. We would have to reestimate the first equation (and obtain the R -squared) using the same observations used to estimate the second equation.7.3 (i) The t statistic on hsize 2 is over four in absolute value, so there is very strong evidence that it belongs in the equation. We obtain this by finding the turnaround point; this is the value ofhsize that maximizes ˆsat(other things fixed): 19.3/(2⋅2.19) ≈ 4.41. Because hsize is measured in hundreds, the optimal size of graduating class is about 441.(ii) This is given by the coefficient on female (since black = 0): nonblack females have SAT scores about 45 points lower than nonblack males. The t statistic is about –10.51, so thedifference is very statistically significant. (The very large sample size certainly contributes to the statistical significance.)(iii) Because female = 0, the coefficient on black implies that a black male has an estimated SAT score almost 170 points less than a comparable nonblack male. The t statistic is over 13 in absolute value, so we easily reject the hypothesis that there is no ceteris paribus difference.(iv) We plug in black = 1, female = 1 for black females and black = 0 and female = 1 for nonblack females. The difference is therefore –169.81 + 62.31 = -107.50. Because the estimate depends on two coefficients, we cannot construct a t statistic from the information given. The easiest approach is to define dummy variables for three of the four race/gender categories and choose nonblack females as the base group. We can then obtain the t statistic we want as the coefficient on the black female dummy variable.7.4 (i) The approximate difference is just the coefficient on utility times 100, or –28.3%. The t statistic is -.283/.099 ≈ -2.86, which is very statistically significant.(ii) 100⋅[exp(-.283) – 1) ≈ -24.7%, and so the estimate is somewhat smaller in magnitude.(iii) The proportionate difference is .181 - .158 = .023, or about 2.3%. One equation that can be estimated to obtain the standard error of this difference islog(salary ) = 0β + 1βlog(sales ) + 2βroe + 1δconsprod + 2δutility +3δtrans + u ,where trans is a dummy variable for the transportation industry. Now, the base group is finance , and so the coefficient 1δ directly measures the difference between the consumer products and finance industries, and we can use the t statistic on consprod .7.5 (i) Following the hint, colGPA = 0ˆβ + 0ˆδ(1 – noPC ) + 1ˆβhsGPA + 2ˆβACT = (0ˆβ + 0ˆδ) - 0ˆδnoPC + 1ˆβhsGPA + 2ˆβACT . For the specific estimates in equation (7.6), 0ˆβ = 1.26 and 0ˆδ = .157, so the new intercept is 1.26 + .157 = 1.417. The coefficient on noPC is –.157.(ii) Nothing happens to the R -squared. Using noPC in place of PC is simply a different way of including the same information on PC ownership.(iii) It makes no sense to include both dummy variables in the regression: we cannot hold noPC fixed while changing PC . We have only two groups based on PC ownership so, in addition to the overall intercept, we need only to include one dummy variable. If we try toinclude both along with an intercept we have perfect multicollinearity (the dummy variable trap).7.6 In Section 3.3 – in particular, in the discussion surrounding Table 3.2 – we discussed how to determine the direction of bias in the OLS estimators when an important variable (ability, in this case) has been omitted from the regression. As we discussed there, Table 3.2 only strictly holds with a single explanatory variable included in the regression, but we often ignore the presence of other independent variables and use this table as a rough guide. (Or, we can use the results of Problem 3.10 for a more precise analysis.) If less able workers are more likely to receivetraining, then train and u are negatively correlated. If we ignore the presence of educ and exper , or at least assume that train and u are negatively correlated after netting out educ and exper , then we can use Table 3.2: the OLS estimator of 1β (with ability in the error term) has a downward bias. Because we think 1β ≥ 0, we are less likely to conclude that the training program waseffective. Intuitively, this makes sense: if those chosen for training had not received training, they would have lowers wages, on average, than the control group.7.7 (i) Write the population model underlying (7.29) asinlf = 0β + 1βnwifeinc + 2βeduc + 3βexper +4βexper 2 + 5βage+ 6βkidslt6 + 7βkidsage6 + u ,plug in inlf = 1 – outlf , and rearrange:1 – outlf = 0β + 1βnwifeinc + 2βeduc + 3βexper +4βexper2 + 5βage+ 6βkidslt6 + 7βkidsage6 + u ,oroutlf = (1 - 0β) - 1βnwifeinc - 2βeduc - 3βexper - 4βexper 2 - 5βage - 6βkidslt6 - 7βkidsage6 - u ,The new error term, -u , has the same properties as u . From this we see that if we regress outlf on all of the independent variables in (7.29), the new intercept is 1 - .586 = .414 and each slope coefficient takes on the opposite sign from when inlf is the dependent variable. For example, the new coefficient on educ is -.038 while the new coefficient on kidslt6 is .262.(ii) The standard errors will not change. In the case of the slopes, changing the signs of the estimators does not change their variances, and therefore the standard errors are unchanged (butthe t statistics change sign). Also, Var(1 - 0ˆβ) = Var(0ˆβ), so the standard error of the intercept is the same as before.(iii) We know that changing the units of measurement of independent variables, or entering qualitative information using different sets of dummy variables, does not change the R -squared. But here we are changing the dependent variable. Nevertheless, the R -squareds from the regressions are still the same. To see this, part (i) suggests that the squared residuals will be identical in the two regressions. For each i the error in the equation for outlf i is just the negative of the error in the other equation for inlf i , and the same is true of the residuals. Therefore, the SSRs are the same. Further, in this case, the total sum of squares are the same. For outlf we haveSST = 2211()[(1)(1)]n n i i i i outlf outlf inlf inlf ==-=---∑∑= 2211()()n ni i i i inlf inlf inlf inlf ==-+=-∑∑,which is the SST for inlf . Because R 2 = 1 – SSR/SST, the R -squared is the same in the two regressions.7.8 (i) We want to have a constant semi-elasticity model, so a standard wage equation with marijuana usage included would belog(wage ) = 0β + 1βusage + 2βeduc + 3βexper + 4βexper 2 + 5βfemale + u .Then 100⋅1β is the approximate percentage change in wage when marijuana usage increases byone time per month.(ii) We would add an interaction term in female and usage :log(wage ) = 0β + 1βusage + 2βeduc + 3βexper + 4βexper 2 + 5βfemale+ 6βfemale ⋅usage + u .The null hypothesis that the effect of marijuana usage does not differ by gender is H 0: 6β = 0.(iii) We take the base group to be nonuser. Then we need dummy variables for the other three groups: lghtuser , moduser , and hvyuser . Assuming no interactive effect with gender, the model would belog(wage ) = 0β + 1δlghtuser + 2δmoduser + 3δhvyuser + 2βeduc + 3βexper + 4βexper 2 + 5βfemale + u .(iv) The null hypothesis is H 0: 1δ = 0, 2δ= 0, 3δ = 0, for a total of q = 3 restrictions. If n is the sample size, the df in the unrestricted model – the denominator df in the F distribution – is n – 8. So we would obtain the critical value from the F q ,n -8 distribution.(v) The error term could contain factors, such as family background (including parental history of drug abuse) that could directly affect wages and also be correlated with marijuana usage. We are interested in the effects of a person’s drug usage on his or her wage, so we would like to hold other confounding factors fixed. We could try to collect data on relevant background information.7.9 (i) Plugging in u = 0 and d = 1 gives 10011()()()f z z βδβδ=+++.(ii) Setting **01()()f z f z = gives **010011()()z z βββδβδ+=+++ or *010z δδ=+. Therefore, provided 10δ≠, we have *01/z δδ=-. Clearly, *z is positive if and only if 01/δδ is negative, which means 01 and δδ must have opposite signs.(iii) Using part (ii) we have *.357/.03011.9totcoll == years.(iv) The estimated years of college where women catch up to men is much too high to be practically relevant. While the estimated coefficient on female totcoll ⋅ shows that the gap is reduced at higher levels of college, it is never closed – not even close. In fact, at four years of。
第七章单方程计量经济学应用模型

第七章单方程计量经济学应用模型一、内容题要本章要紧介绍了假设干种单方程计量经济学模型的应用模型。
包括生产函数模型、需求函数模型、消费函数模型以及投资函数模型、货币需求函数模型等经济学领域常见的函数模型。
本章所列举的内容更多得关注了相关函数模型自身的开展状况,而不是计量模型估量本身。
其目的,是使学习者了解各函数模型是如何开展而来的,即掌握建立与开展计量经济学应用模型的方法论。
生产函数模型,首先介绍生产函数的几个全然咨询题,包括它的定义、特征、开展历程等,并对要素的替代弹性、技术进步的相概念进行了回纳。
然后分不以要素之间替代性质的描述为线索与以技术要素的描述这线索介绍了生产函数模型的开展,前者包括从线性生产函数、C-D生产函数、不变替代弹性〔CES〕生产函数、变替代弹性〔VES〕生产函数、多要素生产函数到超越对数生产函数的介绍;后者包括对技术要素作为一个不变参数的生产函数模型、革新的C-D、CES生产函数模型、含表达型技术进步的生产函数模型、边界生产函数模型的介绍。
最后对各种类型的生产函数的估量以及在技术进步分析中的应用进行了了讨论。
与生产函数模型相仿,需求函数模型仍是从全然概念、全然特性、各种需求函数的类型及其估量方法等方面进行讨论,尤其是对线性支出系统需求函数模型的开展及其估量咨询题进行了较具体的讨论。
消费函数模型局部,要紧介绍了几个重要的消费函数模型及其参数估量咨询题,包括尽对收进假设消费函数模型、相对收进假设消费函数模型、生命周期假设消费函数模型、持久收进假设消费函数模型、合理预期的消费函数模型习惯预期的消费函数模型。
并对消费函数的一般形式进行了讨论。
在其他常用的单方程应用模型中要紧介绍了投资函数模型与货币需求函数模型,前者要紧讨论了加速模型、利润决定的投资函数模型、新古典投资函数模型;后者要紧讨论了古典货币学讲需求函数模型、Keynes货币学讲需求函数模型、现代货币主义的货币需求函数模型、后Keynes货币学讲需求函数模型等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第7章练习5解:根据Eview 软件得如下表:Dependent Variable: YMethod: ML - Binary Logit (Quadratic hill climbing) Date: 05/22/11 Time: 22:19Sample: 1 16Included observations: 16Convergence achieved after 5 iterationsCovariance matrix computed using second derivativesVariable Coefficient Std. Error z-Statistic Prob. C -11.10741 6.124290 -1.813665 0.0697 Q 0.003968 0.008008 0.495515 0.6202 V0.0176960.0087522.0219140.0432 McFadden R-squared 0.468521 Mean dependent var 0.562500 S.D. dependent var 0.512348 S.E. of regression 0.382391 Akaike info criterion 1.103460 Sum squared resid 1.900896 Schwarz criterion 1.248321 Log likelihood -5.827681 Hannan-Quinn criter. 1.110878 Restr. log likelihood -10.96503 LR statistic 10.27469 Avg. log likelihood -0.364230Prob(LR statistic) 0.005873Obs with Dep=0 7 Total obs 16Obs with Dep=19于是,我们可得到Logit 模型为:V Q i0177.0004.0107.11Y ˆ++-= (-1.81) (0.49) (2.02)685.40R 2MCF = , LR(2)=10.27如果在Binary estination 这一栏中选择Probit 估计方法,可得到如下表:Dependent Variable: YMethod: ML - Binary Probit (Quadratic hill climbing) Date: 05/22/11 Time: 22:25 Sample: 1 16Included observations: 16Convergence achieved after 5 iterationsCovariance matrix computed using second derivativesVariable Coefficient Std. Error z-Statistic Prob. C -6.634542 3.396882 -1.953127 0.0508 Q 0.002403 0.004585 0.524121 0.6002 V0.0105320.0046932.2442990.0248 McFadden R-squared 0.476272 Mean dependent var 0.562500 S.D. dependent var 0.512348 S.E. of regression 0.381655 Akaike info criterion 1.092836 Sum squared resid 1.893588 Schwarz criterion 1.237696 Log likelihood -5.742687 Hannan-Quinn criter. 1.100254 Restr. log likelihood -10.96503 LR statistic 10.44468 Avg. log likelihood -0.358918Prob(LR statistic) 0.005395Obs with Dep=0 7 Total obs 16Obs with Dep=19于是,我们可得到Probit 模型为:V Q i0105.00024.035.66Y ˆ++-= (-1.95) (0.52) (2.24)763.40R 2MCF = , LR(2)=10.44第7章练习6下表列出了美国、加拿大、英国在1980~1999年的失业率Y 以及对制造业的补偿X 的相关数据资料。
解:(1)根据Eview 软件操作得如下表: 美国(US ): Dependent Variable: Y Method: Least Squares Date: 05/22/11 Time: 22:38 Sample: 1980 1999 Included observations: 20Variable Coefficient Std. Error t-Statistic Prob. C 10.56858 1.138982 9.278972 0.0000 X-0.0454030.012538-3.6211890.0020R-squared 0.421464 Mean dependent var 6.545000 Adjusted R-squared 0.389323 S.D. dependent var 1.432875 S.E. of regression 1.119732 Akaike info criterion 3.158696 Sum squared resid 22.56840 Schwarz criterion 3.258269 Log likelihood -29.58696 Hannan-Quinn criter. 3.178133 F-statistic 13.11301 Durbin-Watson stat 0.797022Prob(F-statistic)0.001953根据上表可得对美国的OLS 估计结果为:tt X 0454.05686.10Y ˆ-= (9.28) (-3.62) 4215.02=R , 3893.02=R , D.W.=0.797, RSS=22.57加拿大(CA):Dependent Variable: Y Method: Least Squares Date: 05/22/11 Time: 22:43 Sample: 1980 1999 Included observations: 20Variable Coefficient Std. Error t-Statistic Prob. C 9.342452 1.810701 5.159579 0.0001 X-0.0065800.022333-0.2946480.7716R-squared0.004800 Mean dependent var 8.820000 Adjusted R-squared -0.050489 S.D. dependent var 1.600855 S.E. of regression 1.640770 Akaike info criterion 3.922848 Sum squared resid 48.45828 Schwarz criterion 4.022421 Log likelihood -37.22848 Hannan-Quinn criter. 3.942286 F-statistic 0.086817 Durbin-Watson stat 0.578517Prob(F-statistic)0.771634同样,根据上表可得对加拿大(CA )的OLS 估计结果为:tt X 0066.0425.39Y ˆ-= (5.16) (-0.29)0048.02=R , 05.02-=R , D.W.=0.579, RSS=48.46英国(UK ): Dependent Variable: Y Method: Least Squares Date: 05/22/11 Time: 22:48 Sample: 1980 1999 Included observations: 20Variable Coefficient Std. Error t-Statistic Prob. C 12.55426 0.990234 12.67808 0.0000 X-0.0465910.012777-3.6463530.0018R-squared0.424845 Mean dependent var 9.155000 Adjusted R-squared 0.392891 S.D. dependent var 1.916542 S.E. of regression 1.493315 Akaike info criterion 3.734513 Sum squared resid 40.13981 Schwarz criterion 3.834087 Log likelihood -35.34513 Hannan-Quinn criter. 3.753951 F-statistic 13.29589 Durbin-Watson stat 0.698064Prob(F-statistic)0.001847同样,根据上表可得对英国(UK )的OLS 估计结果为:tt X 0466.0543.512Y ˆ-= (12.68) (-3.65)3036.02=R , 29.932=R , D.W.=0.6981, RSS=40.14(2)将三个国家的数据合并成一个样本(共60个样本点),根据Eview 软件得:OLS 估计结果如下:Dependent Variable: Y Method: Least Squares Date: 05/22/11 Time: 22:58 Sample: 1980 2039 Included observations: 60Variable Coefficient Std. Error t-Statistic Prob. C 12.14946 0.820266 14.81161 0.0000 X-0.0495000.009844-5.0287290.0000R-squared 0.303622 Mean dependent var 8.173333 Adjusted R-squared 0.291616 S.D. dependent var 2.009120 S.E. of regression 1.690988 Akaike info criterion 3.921268 Sum squared resid 165.8475 Schwarz criterion 3.991079 Log likelihood -115.6380 Hannan-Quinn criter. 3.948575 F-statistic 25.28811 Durbin-Watson stat 0.492398Prob(F-statistic)0.000005根据上表得估计方程为:tt X 0495.049.112Y ˆ-= (14.81) (-5.03)3036.02=R , 2916.02=R , D.W.=0.49, RSS=165.85(3)在Eviews 软件下,估计变截距固定影响模型得到如下结果:固定影响模型可按最小二乘虚拟变量(LSDV )模型估计,记D 2为加拿大(CA )的虚拟变量;即观测值属于CA 时取值为1,其他取值为0;记D 3为英国的虚拟变量,取值规律同D 2,所以,LSDV 模型的OLS 估计结果如下: X D D it 0383.0011.29221.19348.9Y 32-++= (11.73) (4.12) (4.20) (-4.33)5048.02=R , 4783.02=R , D.W.=0.664, RSS=117.94美国(US )没有设定虚拟变量,成为比较的基准。