决策树分类算法的时间和性能测试(DOC)
决策树算法介绍(DOC)
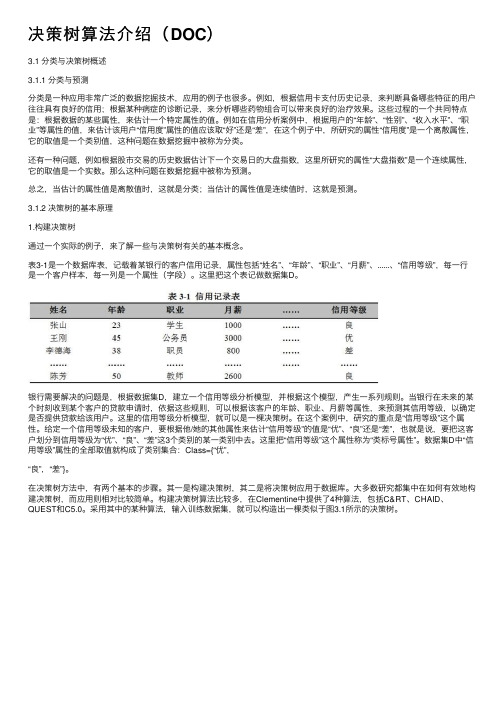
决策树算法介绍(DOC)3.1 分类与决策树概述3.1.1 分类与预测分类是⼀种应⽤⾮常⼴泛的数据挖掘技术,应⽤的例⼦也很多。
例如,根据信⽤卡⽀付历史记录,来判断具备哪些特征的⽤户往往具有良好的信⽤;根据某种病症的诊断记录,来分析哪些药物组合可以带来良好的治疗效果。
这些过程的⼀个共同特点是:根据数据的某些属性,来估计⼀个特定属性的值。
例如在信⽤分析案例中,根据⽤户的“年龄”、“性别”、“收⼊⽔平”、“职业”等属性的值,来估计该⽤户“信⽤度”属性的值应该取“好”还是“差”,在这个例⼦中,所研究的属性“信⽤度”是⼀个离散属性,它的取值是⼀个类别值,这种问题在数据挖掘中被称为分类。
还有⼀种问题,例如根据股市交易的历史数据估计下⼀个交易⽇的⼤盘指数,这⾥所研究的属性“⼤盘指数”是⼀个连续属性,它的取值是⼀个实数。
那么这种问题在数据挖掘中被称为预测。
总之,当估计的属性值是离散值时,这就是分类;当估计的属性值是连续值时,这就是预测。
3.1.2 决策树的基本原理1.构建决策树通过⼀个实际的例⼦,来了解⼀些与决策树有关的基本概念。
表3-1是⼀个数据库表,记载着某银⾏的客户信⽤记录,属性包括“姓名”、“年龄”、“职业”、“⽉薪”、......、“信⽤等级”,每⼀⾏是⼀个客户样本,每⼀列是⼀个属性(字段)。
这⾥把这个表记做数据集D。
银⾏需要解决的问题是,根据数据集D,建⽴⼀个信⽤等级分析模型,并根据这个模型,产⽣⼀系列规则。
当银⾏在未来的某个时刻收到某个客户的贷款申请时,依据这些规则,可以根据该客户的年龄、职业、⽉薪等属性,来预测其信⽤等级,以确定是否提供贷款给该⽤户。
这⾥的信⽤等级分析模型,就可以是⼀棵决策树。
在这个案例中,研究的重点是“信⽤等级”这个属性。
给定⼀个信⽤等级未知的客户,要根据他/她的其他属性来估计“信⽤等级”的值是“优”、“良”还是“差”,也就是说,要把这客户划分到信⽤等级为“优”、“良”、“差”这3个类别的某⼀类别中去。
决策树算法

3
第一节 决策树算法原理
优点: 使用者不需要了解很多背景知识,只要训练事例能用属性 →结论的方式表达出来,就能用该算法学习; 决策树模型效率高,对训练集数据量较大的情况较为适合; 分类模型是树状结构,简单直观,可将到达每个叶结点的 路径转换为IF→THEN形式的规则,易于理解; 决策树方法具有较高的分类精确度。
14
第一节 决策树算法原理
决策树算法的大体框架都是一样的,都采用了贪心(非回 溯的)方法来以自顶向下递归的方式构造决策树。 它首先根据所使用的分裂方法来对训练集递归地划分递归 地建立树的节点,直至满足下面两个条件之一,算法才停 止运行:( 1)训练数据集中每个子集的记录项全部属于 一类或某一个类占压倒性的多数;(2)生成的树节点通 过某个终止的分裂准则;最后,建立起决策树分类模型。
4
第一节 决策树算法原理
缺点: 不易处理连续数据。数据的属性必须被划分为不同的类别 才能处理,但是并非所有的分类问题都能明确划分成这个 区域类型; 对缺失数据难以处理,这是由于不能对缺失数据产生正确 的分支进而影响了整个决策树的生成; 决策树的过程忽略了数据库属性之间的相关性。
5
第一节 决策树算法原理
21
2.1 ID3算法
属性选择度量 在树的每个节点上使用信息增益(information gain)度量选 择测试属性。这种度量称作属性选择度量或分裂的优良性度 量。 选择具有最高信息增益(或最大信息熵压缩)的属性作为当 前节点的测试属性。该属性使得对结果划分中的样本分类所 需的信息量最小,并反映划分的最小随机性或“不纯性”。 这种信息理论方法使得对一个对象分类所需的期望测试数目 达到最小,并确保找到一棵简单的(但不必是最简单的)树。
第10章 决策树

的算法,其剪枝的方法也不尽相同。常用的剪枝方法有预剪枝和后剪枝两种。例如CHILD和C5.0采用预剪枝,CART则采用后
剪枝。
(1)预剪枝:是指在构建决策树之前,先指定好生长停止准则(例如指定某个评估参数的阈值),此做法适合应用于大规模
和CART几乎同时被提出,但都采用类似的方法从训练样本中学习决策树。
决策树算法
算法描述
ID3算法
其核心是在决策树的各级分裂节点上,使用信息增益作为分裂变量的选择标准,来帮助确定生成每个节点时所
应采用的合适自变量
C4.5算法
C4.5决策树算法相对于ID3算法的重要改进是使用信息增益率来选择节点属性。C4.5算法可以克服ID3算法存在
示自变量A的信息熵。
C5.0算法是由计算机科学家J.Ross Quinlan为改进他之前的算法C4.5开发的新版本。该算法增强了对大量数据的处理能力,
并加入了Boosting以提高模型准确率。尽管Quinlan将C5.0算法销售给商业用户,但是该算法的一个单线程版本的源代码
是公开的,因此可以编写成程序,R中就有相应的包实现C5.0算法。
用log函数。可见,发生的概率p越大,其不确定性越低。
考虑到信源的所有可能发生的事件,假设其概率为{1 , 2 , … , },则可以计算其平均值(数学期望),该值被称为信息熵或者经验熵。假设S是s
个数据样本的集合,假定离散变量有m个不同的水平: ( = 1,2, … , ),假设 是类 中的样本数。对一个给定的样本,它总的信息熵为:
CART算法正好适用于连续型特征。CART算法使用二元切分法来处理连续型变量。而使用二元切分法则易于对树构建过程进行调整。
决策树

预修剪技术
预修剪的最直接的方法是事先指定决策树生长的最 大深度, 使决策树不能得到充分生长。 目前, 许多数据挖掘软件中都采用了这种解决方案, 设置了接受相应参数值的接口。但这种方法要求 用户对数据项的取值分布有较为清晰的把握, 并且 需对各种参数值进行反复尝试, 否则便无法给出一 个较为合理的最大树深度值。如果树深度过浅, 则 会过于限制决策树的生长, 使决策树的代表性过于 一般, 同样也无法实现对新数据的准确分类或预测。
决策树的修剪
决策树学习的常见问题(3)
处理缺少属性值的训练样例 处理不同代价的属性
决策树的优点
可以生成可以理解的规则; 计算量相对来说不是很大; 可以处理连续和离散字段; 决策树可以清晰的显示哪些字段比较重要
C4.5 对ID3 的另一大改进就是解决了训练数据中连续属性的处 理问题。而ID3算法能处理的对象属性只能是具有离散值的 数据。 C4.5中对连续属性的处理采用了一种二值离散的方法,具体 来说就是对某个连续属性A,找到一个最佳阈值T,根据A 的取值与阈值的比较结果,建立两个分支A<=T (左枝)和 A>=T (右枝),T为分割点。从而用一个二值离散属性A (只 有两种取值A<=T、A>=T)替代A,将问题又归为离散属性的 处理。这一方法既可以解决连续属性问题,又可以找到最 佳分割点,同时就解决了人工试验寻找最佳阈值的问题。
简介
决策树算法是建立在信息论的基础之上的 是应用最广的归纳推理算法之一 一种逼近离散值目标函数的方法 对噪声数据有很好的健壮性且能学习析取(命题 逻辑公式)表达式
信息系统
决策树把客观世界或对象世界抽象为一个 信息系统(Information System),也称属性--------值系统。 一个信息系统S是一个四元组: S=(U, A, V, f)
《数据挖掘》试题与答案

一、解答题(满分30分,每小题5分)1。
怎样理解数据挖掘和知识发现的关系?请详细阐述之首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。
知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式.流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。
2。
时间序列数据挖掘的方法有哪些,请详细阐述之时间序列数据挖掘的方法有:1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。
例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型.2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。
若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测.3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。
由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。
假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测.3. 数据挖掘的分类方法有哪些,请详细阐述之分类方法归结为四种类型:1)、基于距离的分类方法:距离的计算方法有多种,最常用的是通过计算每个类的中心来完成,在实际的计算中往往用距离来表征,距离越近,相似性越大,距离越远,相似性越小。
决策树(完整)

无缺失值样本中在属性 上取值 的样本所占比例
ቤተ መጻሕፍቲ ባይዱ
谢谢大家!
举例:求解划分根结点的最优划分属性
根结点的信息熵:
用“色泽”将根结点划分后获得3个分支结点的信息熵分别为:
属性“色泽”的信息增益为:
若把“编号”也作为一个候选划分属性,则属性“编号”的信息增益为:
根结点的信息熵仍为:
用“编号”将根结点划分后获得17个分支结点的信息熵均为:
则“编号”的信息增益为:
三种度量结点“纯度”的指标:信息增益增益率基尼指数
1. 信息增益
香农提出了“信息熵”的概念,解决了对信息的量化度量问题。香农用“信息熵”的概念来描述信源的不确定性。
信息熵
信息增益
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。决策树算法第8行选择属性
著名的ID3决策树算法
远大于其他候选属性信息增益准则对可取值数目较多的属性有所偏好
2. 增益率
增益率准则对可取值数目较少的属性有所偏好著名的C4.5决策树算法综合了信息增益准则和信息率准则的特点:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
3. 基尼指数
基尼值
基尼指数
著名的CART决策树算法
过拟合:学习器学习能力过于强大,把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,导致泛化性能下降。欠拟合:学习器学习能力低下,对训练样本的一般性质尚未学好。
过拟合无法彻底避免,只能做到“缓解”。
不足:基于“贪心”本质禁止某些分支展开,带来了欠拟合的风险
预剪枝使得决策树的很多分支都没有“展开”优点:降低过拟合的风险减少了训练时间开销和测试时间开销
(三)决策树方法

(三)决策树方法
决策树是一种基于对对象属性进行划分,以构建由多个属性组成的有向无环图的分类算法。
它能够被应用于特征较多的数据集,来预测数据实体的类别,比如判断是否为良性肿瘤或者判断产品的满意度属于高、中、低的哪个类型。
决策树的基本思想是根据实体的对象特征来判断实体的类别,可以把建立决策树的过程想象为一个问答过程,具体步骤如下:
1、生成决策树。
首先根据样本集,计算得出测试属性中信息增益高的属性作为根节点,根据根节点属性值针对所有样本逐一划分,构建二叉子树。
2、根据数据集合进行分类。
对每一个节点都进行分类判断,如果所有样本属于同一类,将节点分配给该类,否则重复第一步。
3、在决策树上添加分支。
每一个分支节点都重复上述过程,只不过是从当前根节点获取一个测试属性来进行划分,直到所有样本均被划分完毕。
4、创建新树结构。
最后,对所有节点总结归纳,建立结构,创建新树结构来替代原来的树,形成一棵完整的决策树。
决策树的优点是它易于实现,易于理解。
且它可以被用于多种应用场景,比如机器学习中的分类问题、关联规则的挖掘以及建模预测等等。
缺点在于它的性能受算法本身的决策过程影响,当测试属性的划分无法明显区分样本时,结果可能会出现错误。
此外,在构建决策树时,需要一定的时间消耗,若样本量较大,处理时间也较长。
决策树C4.5算法总结

数据集准备
数据清洗
去除异常值、缺失值,对数据进行预处理,使其满足算法要 求。
数据分割
将数据集分为训练集和测试集,用于训练和评估决策树模型 。
特征选择与划分
特征重要性评估
计算每个特征对目标变量的影响程度,选择最重要的特征作为划分标准。
特征划分
根据特征的重要性和信息增益率,将数据集划分为不同的子集,形成决策树的 节点。
THANKS
感谢观看
案例二:医疗诊断分类
数据集
医疗诊断数据集包含了1452 条样本,每个样本有11个特 征,目标变量为是否患有某
种疾病。
算法应用
使用C4.5算法构建决策树模 型,对数据进行训练和测试 ,评估模型的准确率、召回
率和F1分数等指标。
结果分析
通过决策树模型,可以辅助 医生进行疾病诊断,提高诊 断的准确性和效率。
处理连续属性和缺失值的方法优化
• C4.5算法在处理连续属性和缺失值时采用了一些简单的策略,如将连续属性离散化或忽略缺失值。这些策略可 能导致决策树无法充分利用数据中的信息。因此,一些研究者提出了更复杂的方法来处理连续属性和缺失值, 如使用插值或回归方法来处理连续属性,以及使用特殊标记或填充值来处理缺失值。这些方法可以提高决策树 对连续属性和缺失值的处理能力,从而提高模型的分类准确率。
2
C4.5算法采用了信息增益率、增益率、多变量增 益率等更加复杂的启发式函数,提高了决策树的 构建精度和泛化能力。
3
C4.5算法还引入了剪枝策略,通过去除部分分支 来避免过拟合,提高了决策树的泛化性能。
决策树C4.5算法的应用场景
数据挖掘
C4.5算法广泛应用于数据挖掘 领域,用于分类、回归和聚类
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
决策树分类算法的时间和性能测试姓名:ls学号:目录一、项目要求 (3)二、基本思想 (3)三、样本处理 (4)四、实验及其分析 (9)1.总时间 (9)2.分类准确性. (12)五、结论及不足 (13)附录 (14)一、项目要求(1)设计并实现决策树分类算法(可参考网上很多版本的决策树算法及代码,但算法的基本思想应为以上所给内容)。
(2)使用UCI 的基准测试数据集,测试所实现的决策树分类算法。
评价指标包括:总时间、分类准确性等。
(3) 使用UCI Iris Data Set 进行测试。
二、基本思想决策树是一个类似于流程图的树结构,其中每个内部节点表示在一个属性变量上的测试,每个分支代表一个测试输出,而每个叶子节点代表类或分布,树的最顶层节点是根节点。
当需要预测一个未知样本的分类值时,基于决策树,沿着该树模型向下追溯,在树的每个节点将该样本的变量值和该节点变量的阈值进行比较,然后选取合适的分支,从而完成分类。
决策树能够很容易地转换成分类规则,成为业务规则归纳系统的基础。
决策树算法是非常常用的分类算法,是逼近离散目标函数的方法,学习得到的函数以决策树的形式表示。
其基本思路是不断选取产生信息增益最大的属性来划分样例集和,构造决策树。
信息增益定义为结点与其子结点的信息熵之差。
信息熵是香农提出的,用于描述信息不纯度(不稳定性),其计算公式是Pi为子集合中不同性(而二元分类即正样例和负样例)的样例的比例。
这样信息收益可以定义为样本按照某属性划分时造成熵减少的期望,可以区分训练样本中正负样本的能力,其计算公式是三、样本处理以UCI提供的Iris Plants Database为测试样本,Iris Plants共有sepal-length ,sepal-width ,petal-length ,petal-width四种属性,根据属性的不同分为三种: class:-- Iris Setosa-- Iris Versicolour-- Iris Virginica为方便实现,只取Iris Setosa和Iris Versicolour这两种植物的样例进行测试。
实现该算法的样例集合如下:5.1,3.5,1.4,0.2,Iris-setosa4.9,3.0,1.4,0.2,Iris-setosa4.7,3.2,1.3,0.2,Iris-setosa4.6,3.1,1.5,0.2,Iris-setosa5.0,3.6,1.4,0.2,Iris-setosa5.4,3.9,1.7,0.4,Iris-setosa4.6,3.4,1.4,0.3,Iris-setosa5.0,3.4,1.5,0.2,Iris-setosa4.4,2.9,1.4,0.2,Iris-setosa4.9,3.1,1.5,0.1,Iris-setosa5.4,3.7,1.5,0.2,Iris-setosa4.8,3.4,1.6,0.2,Iris-setosa4.8,3.0,1.4,0.1,Iris-setosa4.3,3.0,1.1,0.1,Iris-setosa5.8,4.0,1.2,0.2,Iris-setosa5.7,4.4,1.5,0.4,Iris-setosa5.4,3.9,1.3,0.4,Iris-setosa5.1,3.5,1.4,0.3,Iris-setosa5.7,3.8,1.7,0.3,Iris-setosa5.1,3.8,1.5,0.3,Iris-setosa5.4,3.4,1.7,0.2,Iris-setosa5.1,3.7,1.5,0.4,Iris-setosa4.6,3.6,1.0,0.2,Iris-setosa5.1,3.3,1.7,0.5,Iris-setosa4.8,3.4,1.9,0.2,Iris-setosa5.0,3.0,1.6,0.2,Iris-setosa5.0,3.4,1.6,0.4,Iris-setosa5.2,3.5,1.5,0.2,Iris-setosa5.2,3.4,1.4,0.2,Iris-setosa4.7,3.2,1.6,0.2,Iris-setosa4.8,3.1,1.6,0.2,Iris-setosa5.4,3.4,1.5,0.4,Iris-setosa5.2,4.1,1.5,0.1,Iris-setosa5.5,4.2,1.4,0.2,Iris-setosa4.9,3.1,1.5,0.1,Iris-setosa5.0,3.2,1.2,0.2,Iris-setosa 5.5,3.5,1.3,0.2,Iris-setosa 4.9,3.1,1.5,0.1,Iris-setosa4.4,3.0,1.3,0.2,Iris-setosa5.1,3.4,1.5,0.2,Iris-setosa 5.0,3.5,1.3,0.3,Iris-setosa 4.5,2.3,1.3,0.3,Iris-setosa4.4,3.2,1.3,0.2,Iris-setosa5.0,3.5,1.6,0.6,Iris-setosa 5.1,3.8,1.9,0.4,Iris-setosa4.8,3.0,1.4,0.3,Iris-setosa5.1,3.8,1.6,0.2,Iris-setosa4.6,3.2,1.4,0.2,Iris-setosa5.3,3.7,1.5,0.2,Iris-setosa 5.0,3.3,1.4,0.2,Iris-setosa 7.0,3.2,4.7,1.4,Iris-versicolor6.4,3.2,4.5,1.5,Iris-versicolor 6.9,3.1,4.9,1.5,Iris-versicolor5.5,2.3,4.0,1.3,Iris-versicolor6.5,2.8,4.6,1.5,Iris-versicolor5.7,2.8,4.5,1.3,Iris-versicolor6.3,3.3,4.7,1.6,Iris-versicolor 4.9,2.4,3.3,1.0,Iris-versicolor 6.6,2.9,4.6,1.3,Iris-versicolor 5.2,2.7,3.9,1.4,Iris-versicolor 5.0,2.0,3.5,1.0,Iris-versicolor5.9,3.0,4.2,1.5,Iris-versicolor6.0,2.2,4.0,1.0,Iris-versicolor 6.1,2.9,4.7,1.4,Iris-versicolor5.6,2.9,3.6,1.3,Iris-versicolor6.7,3.1,4.4,1.4,Iris-versicolor 5.6,3.0,4.5,1.5,Iris-versicolor5.8,2.7,4.1,1.0,Iris-versicolor6.2,2.2,4.5,1.5,Iris-versicolor 5.6,2.5,3.9,1.1,Iris-versicolor5.9,3.2,4.8,1.8,Iris-versicolor6.1,2.8,4.0,1.3,Iris-versicolor 6.3,2.5,4.9,1.5,Iris-versicolor 6.1,2.8,4.7,1.2,Iris-versicolor 6.4,2.9,4.3,1.3,Iris-versicolor 6.6,3.0,4.4,1.4,Iris-versicolor 6.8,2.8,4.8,1.4,Iris-versicolor6.7,3.0,5.0,1.7,Iris-versicolor6.0,2.9,4.5,1.5,Iris-versicolor5.7,2.6,3.5,1.0,Iris-versicolor5.5,2.4,3.8,1.1,Iris-versicolor5.5,2.4,3.7,1.0,Iris-versicolor5.8,2.7,3.9,1.2,Iris-versicolor6.0,2.7,5.1,1.6,Iris-versicolor5.4,3.0,4.5,1.5,Iris-versicolor6.0,3.4,4.5,1.6,Iris-versicolor6.7,3.1,4.7,1.5,Iris-versicolor6.3,2.3,4.4,1.3,Iris-versicolor5.6,3.0,4.1,1.3,Iris-versicolor5.5,2.5,4.0,1.3,Iris-versicolor5.5,2.6,4.4,1.2,Iris-versicolor6.1,3.0,4.6,1.4,Iris-versicolor5.8,2.6,4.0,1.2,Iris-versicolor5.0,2.3,3.3,1.0,Iris-versicolor5.6,2.7,4.2,1.3,Iris-versicolor5.7,3.0,4.2,1.2,Iris-versicolor5.7,2.9,4.2,1.3,Iris-versicolor6.2,2.9,4.3,1.3,Iris-versicolor5.1,2.5,3.0,1.1,Iris-versicolor5.7,2.8,4.1,1.3,Iris-versicolor根据样本说明中对样本的总统计:对四种属性进行进一步划分:sepal-length 4.3-5.84 a 5.84-7.9 bsepal-width 2.0-3.05 c 3.05-4.4 dpetal-length 1.0-3.76 e 3.76-6.9 fpetal-width 0.1-1.20 g 1.20-2.5 h得到处理后的测试样例集为:test sepal-length sepal-width petal-length petal-width class1 a d e g Iris-setosa2 a c e g Iris-setosa3 a d e g Iris-setosa4 a d e g Iris-setosa6 a d e g Iris-setosa7 a d e g Iris-setosa8 a d e g Iris-setosa9 a c e g Iris-setosa10 a d e g Iris-setosa11 a d e g Iris-setosa12 a d e g Iris-setosa13 a c e g Iris-setosa14 a c e g Iris-setosa15 a d e g Iris-setosa16 a d e g Iris-setosa17 a d e g Iris-setosa18 a d e g Iris-setosa19 a d e g Iris-setosa20 a d e g Iris-setosa21 a d e g Iris-setosa22 a d e g Iris-setosa23 a d e g Iris-setosa24 a d e g Iris-setosa25 a d e g Iris-setosa26 a c e g Iris-setosa27 a d e g Iris-setosa28 a d e g Iris-setosa29 a d e g Iris-setosa30 a d e g Iris-setosa31 a d e g Iris-setosa32 a d e g Iris-setosa33 a d e g Iris-setosa34 a d e g Iris-setosa35 a d e g Iris-setosa36 a d e g Iris-setosa37 a d e g Iris-setosa38 a d e g Iris-setosa39 a c e g Iris-setosa40 a d e g Iris-setosa41 a d e g Iris-setosa42 a c e g Iris-setosa43 a d e g Iris-setosa44 a d e g Iris-setosa45 a d e g Iris-setosa46 a c e g Iris-setosa47 a d e g Iris-setosa48 a d e g Iris-setosa50 a d e g Iris-setosa51 b d f h Iris-versicolor52 b d f h Iris-versicolor53 b d f h Iris-versicolor54 a c f h Iris-versicolor55 b c f h Iris-versicolor56 a c f h Iris-versicolor57 b d f h Iris-versicolor58 a c e g Iris-versicolor59 b c f h Iris-versicolor60 a c f h Iris-versicolor61 a c e g Iris-versicolor62 b c f h Iris-versicolor63 b c f g Iris-versicolor64 b c f h Iris-versicolor65 a c e h Iris-versicolor66 b d f h Iris-versicolor67 a c f h Iris-versicolor68 a c f g Iris-versicolor69 b c f h Iris-versicolor70 a c f g Iris-versicolor71 b d f h Iris-versicolor72 b c f h Iris-versicolor73 b c f h Iris-versicolor74 b c f g Iris-versicolor75 b c f h Iris-versicolor76 b c f h Iris-versicolor77 b c f h Iris-versicolor78 b c f h Iris-versicolor79 b c f h Iris-versicolor80 a c e g Iris-versicolor81 a c f g Iris-versicolor82 a c e g Iris-versicolor83 a c f g Iris-versicolor84 b c f h Iris-versicolor85 a c f h Iris-versicolor86 b d f h Iris-versicolor87 b d f h Iris-versicolor88 b c f h Iris-versicolor89 a c f h Iris-versicolor90 a c f h Iris-versicolor91 a c f g Iris-versicolor92 b c f h Iris-versicolor93 a c f g Iris-versicolor94 a c e g Iris-versicolor95 a c f h Iris-versicolor96 a c f g Iris-versicolor97 a c f h Iris-versicolor98 b c f h Iris-versicolor99 a c e g Iris-versicolor100 a c f h Iris-versicolorEnd四、实验及其分析1.总时间(1).抽取不同规模的样例进行测试,比较决策树构造时间随机抽取10组样例进行测试,运行结果如图2.6,总时间为0.05s图1 10组样例构建决策树随机抽取40组样例进行测试,运行结果如图2.6,总时间为0.167s图2 40组样例构建决策树随机抽取70组样例进行测试,运行结果如图2.6,总时间为0.369s图3 70组样例构建决策树选取100组样例进行测试,运行结果如图2.6,总时间为0.646s图4 100组样例构建决策树得到样例数—时间表:样例个数10 40 70 100运行时间(s) 0.05 0.167 0.369 0.646表1. 样例数—时间表画出样例数—时间折线图:图4 样例数—时间折线图由图4可以看出,本文的决策树分类算法的运行时间与样例数成正比关系。