CPFSK与Viterbi译码的实现和分析
基于FPGA的删除卷积码Viterbi软判决译码器的研究

基于FPGA的删除卷积码Viterbi软判决译码器的研究熊磊;姚冬苹;谈振辉;牟丹【期刊名称】《北京交通大学学报》【年(卷),期】2004(028)005【摘要】采用FPGA实现删除卷积码Viterbi软判决译码,与传统方式相比,提高了译码器的工作速度和可靠性,降低了功耗.在译码器的设计中,提出了"ACS全复用结构"和采用路径的相对量度取代绝对量度的方法,并得出了相对量度的上边界,从而有效地降低译码器的复杂度,使得利用单片FPGA芯片实现删除卷积码Viterbi软判决译码成为现实.对各种软判决的距离度量的计算方法进行了分析比较,得出了采用"1范数"和相关值取代欧氏距离最为合适.仿真结果表明,所设计的译码器具有良好的性能,与理论边界值只有0.2~0.4 dB的差距.【总页数】4页(P36-39)【作者】熊磊;姚冬苹;谈振辉;牟丹【作者单位】北京交通大学,电子信息工程学院,北京,100044;北京交通大学,电子信息工程学院,北京,100044;北京交通大学,电子信息工程学院,北京,100044;北京交通大学,电子信息工程学院,北京,100044【正文语种】中文【中图分类】TN911.22【相关文献】1.具有信道估计功能的Viterbi软判决译码器的FPGA实现 [J], 王培;倪天龙;王群生2.基于FPGA的卷积码Viterbi译码器性能研究 [J], 陈新永;杨瑞娟;肖玉芬;曾浩3.(2,1,7)卷积码Viterbi译码器FPGA实现方案 [J], 韩可;邓中亮;施乐宁4.基于FPGA的卷积码Viterbi编码/译码器的设计与实现 [J], 张成;杨健5.基于FPGA的卷积码Viterbi译码器实现方法 [J], 李明阳;柏鹏;屈鹏;张毓桐因版权原因,仅展示原文概要,查看原文内容请购买。
viterbi译码算法详解

viterbi译码算法详解Viterbi译码算法是一种常用的序列解码算法,广泛应用于语音识别、自然语言处理、通信等领域。
本文将详细介绍Viterbi译码算法的原理和步骤,以及它的应用。
Viterbi译码算法是一种动态规划算法,用于在给定观测序列的情况下,求解最可能的隐藏状态序列。
在这个过程中,算法会基于概率模型和观测数据,通过计算每个可能的状态路径的概率,选择概率最大的路径作为输出。
Viterbi译码算法的基本原理是利用动态规划的思想,将问题分解为一系列子问题,并利用子问题的最优解来求解整体问题的最优解。
在Viterbi译码算法中,我们假设隐藏状态的转移概率和观测数据的发射概率已知,然后通过计算每个时刻的最优路径来递推地求解整个序列的最优路径。
具体而言,Viterbi译码算法包括以下步骤:1. 初始化:对于初始时刻t=0,计算每个隐藏状态的初始概率,即P(x0=s)。
2. 递推计算:对于时刻t>0,计算每个隐藏状态的最大概率路径。
假设在时刻t-1,每个隐藏状态的最大概率路径已知,则在时刻t,可以通过以下公式计算:P(xt=s) = max(P(xt-1=i) * P(xi=s) * P(ot=s|xi=s))其中,P(xt=s)表示在时刻t,隐藏状态为s的最大概率路径;P(xt-1=i)表示在时刻t-1,隐藏状态为i的最大概率路径;P(xi=s)表示从隐藏状态i转移到隐藏状态s的转移概率;P(ot=s|xi=s)表示在隐藏状态s的情况下,观测到观测值为s的发射概率。
3. 回溯路径:在最后一个时刻T,选择概率最大的隐藏状态作为最终的输出,并通过回溯的方式找到整个序列的最优路径。
通过上述步骤,Viterbi译码算法可以求解出给定观测序列下的最可能的隐藏状态序列。
这个算法的时间复杂度为O(N^2T),其中N 是隐藏状态的个数,T是观测序列的长度。
Viterbi译码算法在实际应用中有着广泛的应用。
FEC前向纠错,卷积编码之维特比译码

FEC前向纠错,卷积编码之维特⽐译码因为要学习做WCDMA的流程解析,需要先提取卷积数据,⾸先就要做FEC卷积译码。
于是⽹上翻了好⼤⼀圈,特地学习了下viterbi译码算法,费很⼤⼒⽓才凑齐能够正确跑起来的代码,特记录⼀下。
说点题外话:viterbi是个⼈,全名Andrew J. Viterbi,⼀枚数学家,美国⾼通公司的创始⼈之⼀(没错,就是现在⼿机上那个⾼通芯⽚的⾼通),现代⽆线数字通讯⼯程的奠基⼈。
此外,viterbi算法不但可⽤来做卷积译码,另外⼀个⼴泛的应⽤是做股票证券量化预测计算(隐马模型预测)。
没错,就是⾼频量化交易炒股的算法基础。
美国量化对冲基⾦的传奇,⼤奖章基⾦背后的⽼板James Simons,⾸创将隐马模型预测⽤于炒股,也是⼀枚数学家。
两枚玩数学算法的巨富,谁说学数学算法没⽤的?FEC前向纠错译码⽤的viterbi算法代码摘抄⾃libfec,⾥⾯的实现很全⾯,还有mmx,sse加速版。
测试是做WCDMA,所以解交织和译码⽤的3GPP WCDMA的卷积编码参数(⼀帧编码长度262bits,卷积编码多项式是 r=1/2 k=9),我就只摘取了需要的viterbi29部分,有需要全部实现的同学可以⾃⾏去下载libfec。
下⾯是写来⽤于测试验证算法正确性的线程代码。
从IQ⽂件中⼀次读取2个float数,读取262+8(⼀帧viterbi译码长度)个数据后进⾏译码,若译码成功程序停在对应的测试断点上。
UINT CALLBACK ProcessIQDataThread(void *p_param){Convolution2Viterbi_t *p_sys = (Convolution2Viterbi_t *)p_param;vector<double> *p_data = NULL;int framebits = 262;struct v29 *vp;vector<float> uninter1;vector<float> uninter2;vector<float> radioFrame;vector<float> frameL;vector<float> frameR;vector<uint8_t> viterbi_in;uint8_t viterbi_out[33];uninter2.resize((framebits + 8));uninter1.resize((framebits + 8) * 2);viterbi_in.resize((framebits + 8) * 2);if ((vp = (struct v29 *)create_viterbi29_port(framebits)) == NULL) {return -1;}while (!p_sys->exit_thread){if (!p_data){WaitForSingleObject(p_sys->iq_data_event, 200);p_sys->iq_data_list.Lock();p_data = p_sys->iq_data_list.GetUse();p_sys->iq_data_list.UnLock();}if (!p_data)continue;// 读取2个浮点数for (int i = 0; i < p_data->size() / 2; i++){frameL.push_back(p_data->at(0));frameR.push_back(p_data->at(1));}// ⼀帧译码长度if (frameL.size() >= (framebits + 8)){// 解交织inter2deInterleavingNP(30, inter2Perm, frameL, uninter2);radioFrame.insert(radioFrame.end(), uninter2.begin(), uninter2.end());deInterleavingNP(30, inter2Perm, frameR, uninter2);radioFrame.insert(radioFrame.end(), uninter2.begin(), uninter2.end());if (radioFrame.size() >= (framebits + 8) * 2){// 解交织inter1deInterleavingNP(inter1Columns[1], inter1Perm[1], radioFrame, uninter1);radioFrame.clear();// 使⽤Viterbi算法做FEC译码for (int i = 0; i < (framebits + 8) * 2; i++){viterbi_in.push_back( ((int)uninter1[i] >> 24) );}init_viterbi29_port(vp, 0);update_viterbi29_blk_port(vp, viterbi_in.data(), framebits + 8);chainback_viterbi29_port(vp, viterbi_out, framebits, 0);#ifdef _DEBUG// 数据验证for (int i = 0; i < 33 - 4; i++) {if (viterbi_out[i] == 0x98 && viterbi_out[i + 1] == 0x54 && viterbi_out[i + 2] == 0xA0 && viterbi_out[i + 3] == 0x00) int bbb = 0;if (viterbi_out[i] == 0x05 && viterbi_out[i + 1] == 0x33 && viterbi_out[i + 2] == 0x00 && viterbi_out[i + 3] == 0x0c) int bbb = 0;if (viterbi_out[i] == 0x00 && viterbi_out[i + 1] == 0x03 && viterbi_out[i + 2] == 0xf4 && viterbi_out[i + 3] == 0x40) int bbb = 0;if (viterbi_out[i] == 0xc5 && viterbi_out[i + 1] == 0x80 && viterbi_out[i + 2] == 0x05 && viterbi_out[i + 3] == 0x5a) int bbb = 0;if (viterbi_out[i] == 0xe4 && viterbi_out[i + 1] == 0x00 && viterbi_out[i + 2] == 0x33 && viterbi_out[i + 3] == 0xe6) int bbb = 0;if (viterbi_out[i] == 0x72 && viterbi_out[i + 1] == 0x08 && viterbi_out[i + 2] == 0x38)int bbb = 0;if (viterbi_out[i] == 0xe2 && viterbi_out[i + 1] == 0x00 && viterbi_out[i + 2] == 0x38)int bbb = 0;}#endif}frameL.clear();frameR.clear();}p_sys->iq_data_list.Lock();p_sys->iq_data_list.PushEmpty(p_data);p_data = p_sys->iq_data_list.GetUse();p_sys->iq_data_list.UnLock();}return 0;}解交织 Interleaving.h#pragma once#include <vector>#include <assert.h>const int inter1Columns[4] = {1, // TTI = 10ms2, // TTI = 20ms4, // TTI = 40ms8 // TTI = 80ms};// 25.212 4.2.5.2 table 4: Inter-Column permutation pattern for 1st interleaving:const char inter1Perm[4][8] = {{0}, // TTI = 10ms{0, 1}, // TTI = 20ms{0, 2, 1, 3}, // TTI = 40ms{0, 4, 2, 6, 1, 5, 3, 7} // TTI = 80ms};// 25.212 4.2.11 table 7: Inter-Column permutation pattern for 2nd interleaving:const char inter2Perm[30] = { 0,20,10,5,15,25,3,13,23,8,18,28,1,11,21,6,16,26,4,14,24,19,9,29,12,2,7,22,27,17 };/* FIRST steps two pointers through a mapping, one pointer into the interleaved* data and the other through the uninterleaved data. The fifth argument, COPY,* determines whether the copy is from interleaved to uninterleaved, or back.* FIRST assumes no padding is necessary.* The reason for the define is to minimize the cost of parameterization and* function calls, as this is meant for L1 code, while also minimizing the* duplication of code.*/#define FIRST(UNINTERLEAVED,UNINTERLEAVEDP,INTERLEAVED,INTERLEAVEDP,COPY) \assert(UNINTERLEAVED.size() == INTERLEAVED.size()); \unsigned int rows = UNINTERLEAVED.size() / columns; \assert(rows * columns == UNINTERLEAVED.size()); \const char *colp = permutation; \float *INTERLEAVEDP = &INTERLEAVED[0]; \for (unsigned i = 0; i < columns; i++) { \float *UNINTERLEAVEDP = &UNINTERLEAVED[*colp++]; \for (unsigned int j = 0; j < rows; j++) { \COPY; \UNINTERLEAVEDP += columns; \} \}/** interleaving with No Padding */void interleavingNP(const unsigned int columns, const char *permutation, vector<float> &in, vector<float> &out) {FIRST(in, inp, out, outp, *outp++ = *inp)}/** de-interleaving with No Padding */void deInterleavingNP(const unsigned int columns, const char *permutation, vector<float> &in, vector<float> &out) {FIRST(out, outp, in, inp, *outp = *inp++)}/* SECOND steps two pointers through a mapping, one pointer into the interleaved* data and the other through the uninterleaved data. The fifth argument, COPY,* determines whether the copy is from interleaved to uninterleaved, or back.* SECOND pads if necessary.* The reason for the define is to minimize the cost of parameterization and* function calls, as this is meant for L1 code, while also minimizing the* duplication of code.*/#define SECOND(UNINTERLEAVED,UNINTERLEAVEDP,INTERLEAVED,INTERLEAVEDP,COPY) \assert(UNINTERLEAVED.size() == INTERLEAVED.size()); \int R2 = (UNINTERLEAVED.size() + columns - 1) / columns; \int padding = columns * R2 - UNINTERLEAVED.size(); \int rows = R2; \int firstPaddedColumn = columns - padding; \const char *colp = permutation; \float *UNINTERLEAVEDP = &UNINTERLEAVED[0]; \for (int i = 0; i < columns; i++) { \int trows = rows - (*colp >= firstPaddedColumn); \float *INTERLEAVEDP = &INTERLEAVED[*colp++]; \for (int j = 0; j < trows; j++) { \COPY; \INTERLEAVEDP += columns; \} \}/** interleaving With Padding */void interleavingWP(const int columns, const char *permutation, vector<float> &in, vector<float> &out){SECOND(in, inp, out, outp, *outp = *inp++)}/** de-interleaving With Padding */void deInterleavingWP(const int columns, const char *permutation, vector<float> &in, vector<float> &out){SECOND(out, outp, in, inp, *outp++ = *inp)}/*Determining the constants.From the standard we know:* All frame sizes for the BCH.* transport block is 246 bits* there are two radio frames, 270 bits each* TTI is 20 ms* SF is 256* parity word Li is 16 bits* For all downlink TrCH except BCH, the radio frame size is 2*38400/SF = 76800/SF.* For SF=256 that's 300.* For SF=4 that's 19200.* The maximum code block size for convulutional coding is 540 bits (25.212 4.2.2.2).* That corresponds to a radio frame size of 1080 bits, or a spreading factor of 71,meaning that the smallest spreading factor that can be used is 128.* 76800/128 = 600 coded bits -> roughly 300 data bits.* That corresponds to an input rate of roughly 30 kb/s at.* The maximum code block size for turbo coding is 5114 bits (25.212 4.2.2.2).* That corresponds to a radio frame size of 15342 bits, or a spreading factor of 5,meaning that the smallest spreading factor that can be used is 8.* 76800/8 = 9600 coded bits -> roughly 3200 data bits.* That corresponds to an input rate of roughly 320 kb/s.OK - SO HOW DO YOU GET HIGHER RATES?? HOW CAN YOU USE SF=4??A: Use the full 5114-but code block and then expand it with rate-matching.You still can't get the full ~640 kb/s implied by SF=4, but you get to ~500 kb/s.(pat) A: They considered this problem. See 25.212 4.2.2.2 Code block segmentation.In Layer1, after transport block concatenation, you then simply chop the result upinto the largest pieces that can go through the encoder, then put them back together after. From "higher layers" we are given:* SF: 4, 8, 16, 32, 64, 128, 256.* P: 24, 16, 8, 0 bits* TTI: 10, 20, 40 ms.To simplify things, we set:* TTI 10 ms always on DCH and FACH, 20 ms on PCH and BCH* BCH and PCH are always rate-1/2 convolutional code* DCH and FACH are always rate-1/3 turbo code* no rate-matching, no puncturing* parity word is always 16 bits* So the only parameter than changes is spreading factor.* We will only support 15-slot (non-compressed) slot formats.From our simplifications we also know:* For non-BCH/PCH TrCH there is one radio frame,76800/SF channel (coded) bits, per transport block.* DCH and FACH always use rate-1/3 turbo code,which has 12 terminating bits in the output.* For DCH and FACH, the transport block size is((76800/SF - 12)/3) - P = (25600/SF) - 4 - P data bits,where P is the parity word size.* Fix P=16 for simplicity and transport block size is (25600/SF) - 20.* for SF=256, that's 80 bits.* for SF=16, that's 1580 bits.* for SF=8, that's 3180 bits.* For PCH there is one radio frame,76800/SF channel (coded) bits, per transport block.* SF=64, for that's 1200 channel bits.* It's a rate-1/2 conv code, so that's 1200/2 - 8 - P data bits.* P=16 so that's 1200/2 - 24 = 576 transport bits. Really?*/#if 0const int inter1Columns[] = { 1, 2, 4, 8 };const char inter1Perm[4][8] = {{0},{0, 1},{0, 2, 1, 3},{0, 4, 2, 6, 1, 5, 3, 7}};const char inter2Perm[] = {0, 20, 10, 5, 15, 25, 3, 13, 23, 8, 18, 28, 1, 11, 21,6, 16, 26, 4, 14, 24, 19, 9, 29, 12, 2, 7, 22, 27, 17};vector<char> randomBitVector(int n){vector<char> t(n);for (int i = 0; i < n; i++) t[i] = random() % 2;return t;}void testInterleavings(){int lth1 = 48;int C2 = 30;for (int i = 0; i < 4; i++) {vector<char> v1 = randomBitVector(lth1);vector<char> v2(lth1);vector<char> v3(lth1);v1.interleavingNP(inter1Columns[i], inter1Perm[i], v2);v2.deInterleavingNP(inter1Columns[i], inter1Perm[i], v3);cout << "first " << i << " " << (veq(v1, v3) ? "ok" : "fail") << endl;}for (int lth2 = 90; lth2 < 120; lth2++) {vector<char> v1 = randomBitVector(lth2);vector<char> v2(lth2);vector<char> v3(lth2);v1.interleavingWP(C2, inter2Perm, v2);v2.deInterleavingWP(C2, inter2Perm, v3);cout << "second " << lth2 << " " << (veq(v1, v3) ? "ok" : "fail") << endl;}for (int lth = 48; lth <= 4800; lth *= 10) {TurboInterleaver er(lth);cout << "Turbo Interleaver permutation(" << lth << ") " << (permutationCheck(er.permutation()) ? "ok" : "fail") << endl; vector<char> er1 = randomBitVector(lth);vector<char> er2(lth);er.interleave(er1, er2);vector<char> er3(lth);er.unInterleave(er2, er3);cout << "Turbo Interleaver(" << lth << ") " << (veq(er1.sliced(), er3) ? "ok" : "fail") << endl;}}#endifviterbi译码partab实现 partab.c/* Utility routines for FEC support* Copyright 2004, Phil Karn, KA9Q*/#include <stdio.h>#include "fec.h"unsigned char Partab[256] = {0};int P_init = 0;/* Create 256-entry odd-parity lookup table* Needed only on non-ia32 machines*/void partab_init(void) {int i, cnt, ti;/* Initialize parity lookup table */for (i = 0; i < 256; i++) {cnt = 0;ti = i;while (ti) {if (ti & 1)cnt++;ti >>= 1;}Partab[i] = cnt & 1;}P_init = 1;}/* Lookup table giving count of 1 bits for integers 0-255 */int Bitcnt[] = {0, 1, 1, 2, 1, 2, 2, 3,1, 2, 2, 3, 2, 3, 3, 4,1, 2, 2, 3, 2, 3, 3, 4,2, 3, 3, 4, 3, 4, 4, 5,1, 2, 2, 3, 2, 3, 3, 4,2, 3, 3, 4, 3, 4, 4, 5,2, 3, 3, 4, 3, 4, 4, 5,3, 4, 4, 5, 4, 5, 5, 6,1, 2, 2, 3, 2, 3, 3, 4,2, 3, 3, 4, 3, 4, 4, 5,2, 3, 3, 4, 3, 4, 4, 5,3, 4, 4, 5, 4, 5, 5, 6,2, 3, 3, 4, 3, 4, 4, 5,3, 4, 4, 5, 4, 5, 5, 6,3, 4, 4, 5, 4, 5, 5, 6,4, 5, 5, 6, 5, 6, 6, 7,1, 2, 2, 3, 2, 3, 3, 4,2, 3, 3, 4, 3, 4, 4, 5,2, 3, 3, 4, 3, 4, 4, 5,3, 4, 4, 5, 4, 5, 5, 6,2, 3, 3, 4, 3, 4, 4, 5,3, 4, 4, 5, 4, 5, 5, 6,3, 4, 4, 5, 4, 5, 5, 6,4, 5, 5, 6, 5, 6, 6, 7,2, 3, 3, 4, 3, 4, 4, 5,3, 4, 4, 5, 4, 5, 5, 6,3, 4, 4, 5, 4, 5, 5, 6,4, 5, 5, 6, 5, 6, 6, 7,3, 4, 4, 5, 4, 5, 5, 6,4, 5, 5, 6, 5, 6, 6, 7,4, 5, 5, 6, 5, 6, 6, 7,5, 6, 6, 7, 6, 7, 7, 8,};fec.h/* User include file for libfec* Copyright 2004, Phil Karn, KA9Q* May be used under the terms of the GNU Lesser General Public License (LGPL)*/#ifndef _FEC_H_#define _FEC_H_#ifdef __cplusplusextern "C" {#endif/* r=1/2 k=9 convolutional encoder polynomials */#define V29POLYA 0x1af#define V29POLYB 0x11dvoid *create_viterbi29_port(int len);void set_viterbi29_polynomial_port(int polys[2]);int init_viterbi29_port(void *p, int starting_state);int chainback_viterbi29_port(void *p, unsigned char *data, unsigned int nbits, unsigned int endstate); void delete_viterbi29_port(void *p);int update_viterbi29_blk_port(void *p, unsigned char *syms, int nbits);void partab_init();static inline int parityb(unsigned char x) {extern unsigned char Partab[256];extern int P_init;if (!P_init) {partab_init();}return Partab[x];}static inline int parity(int x) {/* Fold down to one byte */x ^= (x >> 16);x ^= (x >> 8);return parityb(x);}#ifdef __cplusplus}#endif#endif /* _FEC_H_ */viterbi29_port.c/* K=9 r=1/2 Viterbi decoder in portable C* Copyright Feb 2004, Phil Karn, KA9Q* May be used under the terms of the GNU Lesser General Public License (LGPL)*/#include <stdio.h>#include <stdlib.h>#include <memory.h>#include "fec.h"typedef union { unsigned int w[256]; } metric_t;typedef union { unsigned long w[8]; } decision_t;static union { unsigned char c[128]; } Branchtab29[2];static int Init = 0;/* State info for instance of Viterbi decoder */struct v29 {metric_t metrics1; /* path metric buffer 1 */metric_t metrics2; /* path metric buffer 2 */decision_t* dp; /* Pointer to current decision */metric_t* old_metrics, * new_metrics; /* Pointers to path metrics, swapped on every bit */decision_t* decisions; /* Beginning of decisions for block */};/* Initialize Viterbi decoder for start of new frame */int init_viterbi29_port(void* p, int starting_state) {struct v29* vp = p;int i;if (p == NULL)return -1;for (i = 0; i < 256; i++)vp->metrics1.w[i] = 63;vp->old_metrics = &vp->metrics1;vp->new_metrics = &vp->metrics2;vp->dp = vp->decisions;vp->old_metrics->w[starting_state & 255] = 0; /* Bias known start state */return 0;}void set_viterbi29_polynomial_port(int polys[2]) {int state;for (state = 0; state < 128; state++) {Branchtab29[0].c[state] = (polys[0] < 0) ^ parity((2 * state) & abs(polys[0])) ? 255 : 0; Branchtab29[1].c[state] = (polys[1] < 0) ^ parity((2 * state) & abs(polys[1])) ? 255 : 0; }Init++;}/* Create a new instance of a Viterbi decoder */void* create_viterbi29_port(int len) {struct v29* vp;if (!Init) {int polys[2] = { V29POLYA,V29POLYB };set_viterbi29_polynomial_port(polys);}if ((vp = (struct v29*)malloc(sizeof(struct v29))) == NULL)return NULL;if ((vp->decisions = (decision_t*)malloc((len + 8) * sizeof(decision_t))) == NULL) {free(vp);return NULL;}init_viterbi29_port(vp, 0);return vp;}/* Viterbi chainback */int chainback_viterbi29_port(void* p,unsigned char* data, /* Decoded output data */unsigned int nbits, /* Number of data bits */unsigned int endstate) /* Terminal encoder state */{struct v29* vp = p;decision_t* d;if (p == NULL)return -1;d = vp->decisions;/* Make room beyond the end of the encoder register so we can* accumulate a full byte of decoded data*/endstate %= 256;/* The store into data[] only needs to be done every 8 bits.* But this avoids a conditional branch, and the writes will* combine in the cache anyway*/d += 8; /* Look past tail */while (nbits-- != 0) {int k;k = (d[nbits].w[(endstate) / 32] >> (endstate % 32)) & 1;data[nbits >> 3] = endstate = (endstate >> 1) | (k << 7);}return 0;}/* Delete instance of a Viterbi decoder */void delete_viterbi29_port(void* p) {struct v29* vp = p;if (vp != NULL) {free(vp->decisions);free(vp);}}/* C-language butterfly */#define BFLY(i) {\unsigned int metric,m0,m1,decision;\metric = (Branchtab29[0].c[i] ^ sym0) + (Branchtab29[1].c[i] ^ sym1);\ m0 = vp->old_metrics->w[i] + metric;\m1 = vp->old_metrics->w[i+128] + (510 - metric);\decision = (signed int)(m0-m1) > 0;\vp->new_metrics->w[2*i] = decision ? m1 : m0;\d->w[i/16] |= decision << ((2*i)&31);\m0 -= (metric+metric-510);\m1 += (metric+metric-510);\decision = (signed int)(m0-m1) > 0;\vp->new_metrics->w[2*i+1] = decision ? m1 : m0;\d->w[i/16] |= decision << ((2*i+1)&31);\}/* Update decoder with a block of demodulated symbols* Note that nbits is the number of decoded data bits, not the number* of symbols!*/int update_viterbi29_blk_port(void* p, unsigned char* syms, int nbits) { struct v29* vp = p;decision_t* d;if (p == NULL)return -1;d = (decision_t*)vp->dp;while (nbits--) {void* tmp;unsigned char sym0, sym1;int i;for (i = 0; i < 8; i++)d->w[i] = 0;sym0 = *syms++;sym1 = *syms++;for (i = 0; i < 128; i++)BFLY(i);d++;tmp = vp->old_metrics;vp->old_metrics = vp->new_metrics;vp->new_metrics = tmp;}vp->dp = d;return 0;}。
关于基于Xilinx FPGA 的高速Viterbi回溯译码器的性能分析和应用介绍
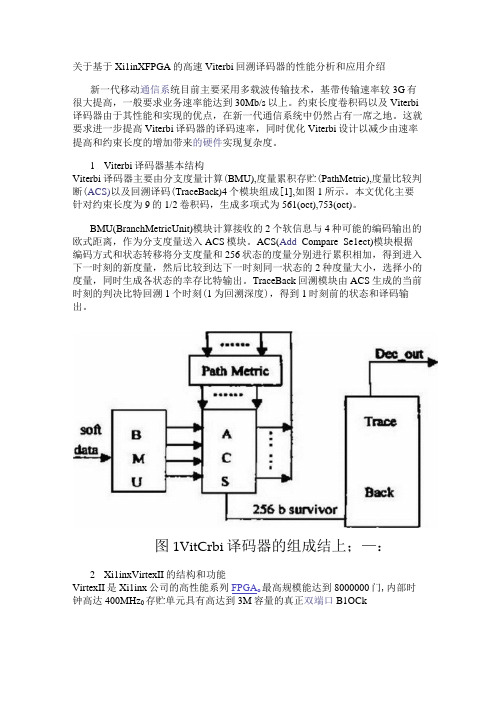
关于基于Xi1inXFPGA的高速Viterbi回溯译码器的性能分析和应用介绍新一代移动通信系统目前主要采用多载波传输技术,基带传输速率较3G有很大提高,一般要求业务速率能达到30Mb/s以上。
约束长度卷积码以及Viterbi 译码器由于其性能和实现的优点,在新一代通信系统中仍然占有一席之地。
这就要求进一步提高Viterbi译码器的译码速率,同时优化Viterbi设计以减少由速率提高和约束长度的增加带来的硬件实现复杂度。
1Viterbi译码器基本结构Viterbi译码器主要由分支度量计算(BMU),度量累积存贮(PathMetric),度量比较判断(ACS)以及回溯译码(TraceBack)4个模块组成[1],如图1所示。
本文优化主要针对约束长度为9的1/2卷积码,生成多项式为561(oct),753(oct)。
BMU(BranchMetricUnit)模块计算接收的2个软信息与4种可能的编码输出的欧式距离,作为分支度量送入ACS模块。
ACS(Add_Compare_Se1ect)模块根据编码方式和状态转移将分支度量和256状态的度量分别进行累积相加,得到进入下一时刻的新度量,然后比较到达下一时刻同一状态的2种度量大小,选择小的度量,同时生成各状态的幸存比特输出。
TraceBack回溯模块由ACS生成的当前时刻的判决比特回溯1个时刻(1为回溯深度),得到1时刻前的状态和译码输出。
图1VitCrbi译码器的组成结上;—:2Xi1inxVirtexII的结构和功能VirtexII是Xi1inx公司的高性能系列FPGA o最高规模能达到8000000门,内部时钟高达400MHz0存贮单元具有高达到3M容量的真正双端口B1OCkRamo 运算单元中包括最多168b 的专用乘法器。
VirtexII 中的可配置单元为C1B(Configurab1e1og ic B1occks)。
C1B 中的资源可以灵活配置成多种结构。
viterbi译码算法详解

viterbi译码算法详解Viterbi译码算法详解Viterbi译码算法是一种在序列估计问题中广泛应用的动态规划算法。
它被用于恢复在一个已知的输出序列中最有可能的输入序列。
该算法最初由Andrew Viterbi在1967年提出,并被广泛应用于各种领域,如语音识别、自然语言处理、无线通信等。
Viterbi译码算法的基本思想是在一个已知的输出序列中寻找最有可能的输入序列。
它通过计算每个可能的输入序列的概率,并选择概率最大的输入序列作为最终的估计结果。
该算法的关键是定义一个状态转移模型和一个观测模型。
状态转移模型描述了输入序列的转移规律,即从一个输入状态转移到另一个输入状态的概率。
观测模型描述了输入序列和输出序列之间的关系,即给定一个输入状态,产生一个输出状态的概率。
在Viterbi译码算法中,首先需要进行初始化。
假设有n个可能的输入状态和m个可能的输出状态,我们需要初始化两个矩阵:状态概率矩阵和路径矩阵。
状态概率矩阵记录了每个时刻每个状态的最大概率,路径矩阵记录了每个时刻每个状态的最大概率对应的前一个状态。
接下来,我们通过递归的方式计算状态概率和路径矩阵。
对于每个时刻t和每个可能的输入状态i,我们计算当前状态的最大概率和对应的前一个状态。
具体的计算方式是通过上一个时刻的状态概率、状态转移概率和观测概率来计算当前时刻的状态概率,并选择其中最大的概率作为当前状态的最大概率。
我们通过回溯的方式找到最有可能的输入序列。
从最后一个时刻开始,选择具有最大概率的状态作为最终的估计结果,并通过路径矩阵一直回溯到第一个时刻,得到整个输入序列的最有可能的估计结果。
Viterbi译码算法的优势在于它能够处理大规模的状态空间和观测空间。
由于使用动态规划的思想,该算法的时间复杂度为O(nmT),其中n和m分别为可能的输入状态和输出状态的数量,T为输出序列的长度。
因此,在实际应用中,Viterbi译码算法能够高效地处理各种序列估计问题。
通过Viterbi译码算法实现译码器优化实现方案

通过Viterbi译码算法实现译码器优化实现方案
1 引言
由于卷积码优良的性能,被广泛应用于深空通信、卫星通信和2G、3G移动通信中。
卷积码有三种译码方法:门限译码、概率译码和Viterbi算法,其中Viterbi算法是一种基于网格图的最大似然译码算法,是卷积码的最佳译码方式,具有效率高、速度快等优点。
从工程应用角度看,对Viterbi译码器的性能*价指标主要有译码速度、处理时延和资源占用等。
本文通过对Viterbi译码算法及卷积码编码网格图特点的分析,提出一种在FPGA设计中,采用全并行结构、判决信息比特与路径信息向量同步存储以及路径度量最小量化的译码器优化实现方案。
测试和试验结果表明,该方案与传统的译码算法相比,具有更高的速度、更低的时延和更简单的结构。
2 卷积编码网格图特点
图1所示为卷积编码网格图结构,图中每一状态有两条输入支路和两条输出支路。
2.1 输入支路的特点
任意一个状态节点Si都有两条输入支路,且这两条输入支路对应的源节点分别为:
此外,i为偶数时,两条输入支路的输入信息都为‘1’;i为奇数时,两条输入支路的输入信息都为‘0’。
2.2 输出支路的特点
任意一个状态节点Si都有两条输出支路,且两条输出支路对应的目的节点分别为:
此外,目的节点是Sj1的输出支路对应的输入信息都为‘0’;目的节点是Sj2的输出支路对应的输入信息都为‘1’。
3 Viterbi译码器的优化算法
3.1 判决信息比特与路径信息向量同步存储算法。
FPGA_ASIC-卷积码的Viterbi高速译码方案

投稿栏目:嵌入式与SOC——PLD CPLD FPGA应用卷积码的Viterbi高速译码方案A High-speed viterbi-decoding Scheme for Convolutional Code(1.南京师范大学分析测试中心,2.南京师范大学物理科学与技术学院)刘国锦1王济生2时斌1朱晓舒1(1. Analysis and Testing Center of Nanjing Normal University, 2. School of Physics and Technology of Nanjing Normal University) LIU Guo-jin1 WANG Ji-sheng2摘要:本文探讨了无线通信中广泛涉及的差错控制问题,介绍了卷积码的编译码原理。
提出了一种卷积码编码,及其高速Viterbi译码的实现方案,对译码的各个组成部分作了分析,并在FPGA中实现了该译码方案。
仿真结果表明,在纠正能力范围内,能够正确纠错并译码,且具有高速译码的优点,达到了预期的效果,该设计方案可以非常容易地应用到很多差错控制的通信系统中。
Abstract: This paper discusses the issue of error-control involved widely in wireless communications, and introduces the coding and endcoding principle of Convolutional Code. A scheme of encoding of Convolutional Code and its high-speed viterbi decoding is proposed, and the components of decoding are analysed, then the scheme is implemented in FPGA. The simulation result indicates that it can correct the error bits exactly within the range of capability error-correcting, and it has the advantage of high-speed decoding. Prospective effect is realized.This design scheme can be applied easily in many communication systems with error-control.关键词:差错控制;卷积码;Viterbi译码;寄存器交换Key words: error-control; Convolutional Code; viterbi decoding; register-exchange中图分类号:TN492 文献标识码:A0 引言在无线通信过程中,由于信道中噪声干扰的存在,会不可避免地造成发送端的码元经过有噪信道到达接收端后,接受的码元中发生了差错,从而影响了无线数据通信的可靠性。
高速VITERBI译码器的优化和实现

摘要:大约束度卷积码作为信道纠错编码在通信中得到了广泛的应用,而其相应的Viterbi 译码器硬件复杂度大,限制了译码速度。
分析了Viterbi译码器的结构,优化了各模块,合理地组织了存储器结构,简化了接口电路。
用FPGA实现Viterbi译码器,提高了译码器速度。
关键词:卷积码Viterbi译码ACS路径度量存储FPGA实现Viterbi算法是一种基于最大后验概率的卷积译码算法,应用广泛。
CDMA的IS-95标准和WCDMA3GPP标准将卷积码作为高速实时数据传输的信道纠错编码,使Viterbi译码器成为移动通信系统的重要组成部分。
为保证纠错性能,卷积码结束度一般选择比较大的,在3GPP中规定约束度K=9。
出于实时性的考虑,移动通信系统中对译码时延的要求比较高,需要高速译码器的支持。
可是Viterbi译码算法的复杂度、所需存储器容量与结束长度成指数增长关系,成为限制译码器速度的瓶颈。
Viterbi译码器每解码一位信息位就需对2k-1个寄存器的状态进行路径度量,并对相应的存储单元进行读写。
这种情况下,可以采用状态路径存储单元分块的方法,以提高其译码性能,缺点是ACS单元与存储器之间的接口电路十分复杂,不易实现。
本文分析和优化了Viterbi译码器的结构,提出了一种FPGA实现方案,简化了接口电路,提高了速度。
用这种结构实现的单片集成译码器译码速率达350kbps、时钟频率30MHz。
以下先分析译碱器总体结构,然后对各模块设计和实现做详细说明。
1算法简述及译码器结构本文采用3GPP标准规定的K=9,码率r=1/2的(753,561)卷积码,卷积编码器送出的码序列C,经过信道传输后送入译码器的序列为R。
译码器根据接受序列R,按最大似然准则力图找出正确的原始码序列。
Viterbi译码过程可用状态图表示,图1表示2个状态的状态转移图。
Sj,t和Sj+N/2,t 表示t时刻的两个状态。
在t+1时刻,这两个状态值根据路径为0或者1,转移到状态S2j+1和S2j+1,t+1。
CPFSK调制解调器设计与实现

CPFSK调制解调器设计与实现本文主要设计实现了CPFSK调制解调通信系统,系统中包含m序列加密解密电路、RS编译码电路、交织与解交织电路、卷积编译码电路以及CPFSK调制解调电路。
文中首先设计了系统的总体框图,然后对系统中的各个电路的设计与实现作了深入的研究。
在系统的加密部分中,本文基于m序列设计32级m序列加密解密电路,并在FPGA的硬件基础上,采用Verilog语言实现了32级m序列加密解密电路;在系统的纠错码中,采用了RS(255,239)码与(2,1,7)卷积码级联的方式,并在两编码器的级联中间插入了交织器,以提高纠错系统的纠错性能;对于RS(255,239)码的编码电路,本文对其传统的编码算法进行了改进,并在FPGA的硬件基础上,采用Verilog语言实现了RS(255,239)编码电路,并基于Altera的IP核实现了RS(255,239)码的译码电路;在研究RS编译码电路中,还研究了电路工作过程中遇到的码率匹配问题和串并转换问题,并提出了该问题的解决方案,在FPGA的硬件基础上,采用Verilog语言设计实现了码率匹配电路和串并转换电路;交织器本文采用卷积交织的方法来实现,并在FPGA的硬件基础上,采用Verilog语言实现了交织与解交织电路;对于(2,1,7)卷积码的编码电路,本文在FPGA的硬件基础上,采用Verilog语言实现了(2,1,7)卷积编码电路,而(2,1,7)卷积码的译码电路,本文采用Viterbi译码算法来实现,并基于Altera的IP核实现了Viterbi 译码电路;最后,CPFSK调制解调电路采用了其特殊的一种方式MSK调制,采用Verilog语言设计实现了MSK经典的正交调制电路,并在DFT算法的基础上,设计了一种更加简单有效的MSK解调方案,采用Verilog语言实现了该解调电路。
在硬件实现的同时,本文还在Matlab平台上对各个模块进行了仿真验证,确保电路设计的正确性。
Viterbi译码的Matlab实现

2010年12月(上)Viterbi 译码的Matlab 实现张慧(盐城卫生职业技术学院,江苏盐城224006)[摘要]本文主要介绍了Viterbi 译码是一种最大似然译码算法,是卷积编码的最佳译码算法。
本文主要是以(2,1,2)卷积码为例,介绍了Viterbi 译码的原理和过程,并用Matlab 进行仿真。
[关键词]卷积码;Viterbi 译码1卷积码的类型卷积码的译码基本上可划分为两大类型:代数译码和概率译码,其中概率译码是实际中最常采用的卷积码译码方法。
2Viterbi 译码Viterbi 译码是由Viterbi 在1967年提出的一种概率译码,其实质是最大似然译码,是卷积码的最佳译码算法。
它利用编码网格图的特殊结构,降低了计算的复杂性。
该算法考虑的是,去除不可能成为最大似然选择对象的网格图上的路径,即,如果有两条路径到达同一状态,则具有最佳量度的路径被选中,称为幸存路径(surviving path )。
对所有状态都将进行这样的选路操作,译码器不断在网格图上深入,通过去除可能性最小的路径实现判决。
较早地抛弃不可能的路径降低了译码器的复杂性。
为了更具体的理解Viterbi 译码的过程,我们以(2,1,2)卷积码为例,为简化讨论,假设信道为BSC 信道。
译码过程的前几步如下:假定输入数据序列m ,码字U ,接收序列Z ,如图1所示,并假设译码器确知网格图的初始状态。
图1时刻t 1接收到的码元是11,从状态00出发只有两种状态转移方向,00和10,如图a 所示。
状态转换的分支量度是2;状态转换的分支径量度是0。
时刻t 2从每个状态出发都有两种可能的分支,如图b 所示。
这些分支的累积量度标识为状态量度┎a ,┎b ,┎c ,┎d ,与各自的结束状态相对应。
同样地,图c 中时刻t 3从每个状态出发都有两个分支,因此,时刻时到达每个状态的路径都有两条,这两条路径中,累积路径量度较大的将被舍弃。
如果这两条路径的路径量度恰好相等,则任意舍弃其中一条路径。
第9章Viterbi译码及其实现

第9章Viterbi译码及其实现Viterbi译码是一种使用动态规划算法来解码卷积码的方法,它通过寻找最有可能的路径来恢复被编码的数据。
在这篇文章中,我们将介绍Viterbi译码的基本原理以及如何实现它。
1. Viterbi译码原理:Viterbi译码是一种基于有向无环图(DAG)的动态规划算法。
它的基本思想是在每一个时刻,选取最有可能的路径来解码出当前的数据。
具体来说,它会使用一个状态转移图来表示每个时刻的状态以及状态之间的转移。
每个状态表示接收到的一串码元,其中可能包含错误。
在Viterbi译码中,我们需要确定的是在给定的时刻,以及所有之前的时刻,哪个状态是最有可能接收到当前的码元。
为了实现这一点,我们需要每个时刻的状态转移图以及每个状态接收到正确码元的概率。
通过比较不同路径的概率,我们可以选择最有可能的路径。
2. Viterbi译码实现:Viterbi译码可以通过以下步骤实现:1)初始化:在初始时刻,我们首先需要将所有状态的概率初始化为1,并将每个状态的前一个状态设置为初始状态。
这样做是为了确保在选择路径时考虑所有可能的路径。
2)递推计算:从初始时刻开始,我们根据每个状态接收到的码元和切换到下一个状态的概率,更新每个状态的概率以及前一个状态。
具体来说,我们可以使用以下公式进行计算:当前状态概率=当前状态接收到的码元概率*前一个状态概率*切换到当前状态的概率3)路径选择:一旦计算出所有状态的概率,我们可以比较不同路径的概率,选择最有可能的路径。
具体来说,我们可以从最后一个时刻的状态开始,根据每个状态的概率选择前一个状态,直到回到初始状态。
4)结果恢复:一旦选择了最有可能的路径,我们可以根据这条路径中每个状态接收到的码元恢复原始数据。
通过以上步骤,我们可以使用Viterbi译码来解码卷积码并恢复原始数据。
总结:Viterbi译码是一种有效的卷积码译码方法,它使用了动态规划算法来选择最有可能的路径。
维特比译码详解

维特比译码(Viterbi decoding)是一种用于纠正或还原由信道引起的错误的算法,广泛应用于数字通信、无线通信和数字广播等领域。
该算法基于动态规划的原理,常用于解决卷积编码的译码问题。
以下是维特比译码的详细步骤:
1. **初始化:** 对于每个可能的状态,初始化路径度量(metric)为一个大的值,初始状态路径度量为零。
路径度量表示从初始状态到当前状态的路径上的权重。
2. **逐步前向计算:** 从输入序列的第一个符号开始,对于每个时刻和每个状态,计算经过该状态的路径度量。
这是通过考虑前一个时刻的所有状态,并选择路径度量最小的路径来完成的。
路径度量的更新是通过将前一个时刻的路径度量与相应的转移度量和观测度量相加而完成的。
3. **路径存储:** 对于每个状态,在每个时刻保留路径度量最小的路径。
这些路径构成一个以时间为轴的路径树。
4. **回溯:** 在到达输入序列的末尾后,通过回溯路径树,选择路径度量最小的路径。
这条路径即为最有可能的解码路径。
5. **输出:** 从回溯的路径中提取最终的解码结果。
维特比译码的关键点是在整个过程中维护状态度量,选择具有最小度量的路径。
这种选择基于动态规划的原理,通过逐步计算局部最优解来找到全局最优解。
维特比译码特别适用于卷积编码,其中编码器的状态对应于过去的输入符号。
这种算法在无线通信、数字广播和其他数字通信系统中得到广泛应用,以提高通信系统的可靠性。
支持不同约束长度VITERBI译码器的设计实现与重构【控制理论与控制工程..

知识水坝为您整理
知识水坝为您整理
第四章Viterbi译码器重构策略研究
V'lrtex支持的重构方式有两种,一是按列重构,图4一H为其局部动态重构的示意图,它要求设计时必须有严格的模块划分,将电路划分为固定的逻辑块(FixedLogic)和重构的逻辑块口artialReconfiguredLogic),模块之间的数据必须通过磁总线∞usMacro)进行交换。
微总线保证了重构时各个模块之间的数据正常交换。
还有一种是小比特流的重构方式,使用于对设计改动比较小的场合,重构时仅仅比较电路前后的差别,产生相应的bit流,修改设计完成重构。
图4.11VirtexFPGA局部重构示意
对于第一种方法,可重构逻辑的划分有如下一些规则:
①重构模块必须占满FPGA的一整列,即是按列重构;
②重构模块的边界是不可改变的,重构模块所占据的位置和面积在一次划分好后,
再不可随意改变。
③重构模块与其他重构模块及固定模块之间必须通过微总线来实现信号的传递。
4.1.4重构技术的应用和性能
动态重构技术运用于系统设计中是一种对灵活性和速度的一种设计方法,与传统的纯软件设计和硬件设计方法相比较,既有软件的灵活性,又有纯硬件系统的速度,如图4—12所示:
灵活件
软件
可重构件
硬件速度
图4—12可重构技术与软、硬件设计性能对比
可重构系统主要适用于如下系统设计:①最新通信系统:DR-FPGA的动态重构特性正好可以适应不同制式和不同标准的通信要求,满足软件无线电技术的发展和第三代移动通信系统(3G)的需要,本文主要是针对此项应用,设计了不同参数的
45。
可编程Viterbi译码器设计与实现

De s i g n a n d i mp l e me n t a t i o n f o r p r o g r a mma b l e Vi t e r b i d e c o d e r
码 器 整 体 结 构 图如 图 1所 示 。
2 9
基金项目 : 国 家 自然科 学 基 金 重 点 项 目( 6 1 1 3 6 0 0 2)
《 电子 技 术 应 用 》 2 0 1 4 年 第4 0 卷 第3 期
Ap p l i c a t i o n o f I n t eg r a t e d Ci r cu i t s
是 P MU 与 A C S单 元 的接 口部 分 , 它 与 前 者 的作 用 刚 好 相 反 ,它 是 将 P MU 中 取 来 的 4路 路 径 度 量 信 息 转 换 成 4
路 并行 的路径 度量值 , 然 后送人 到 A C S U进行运 算 。
1 . 4 幸 存 路 径 度 量 存 储 管 理 单 元
d e s i g n e d a n d t h e c o d i n g o f( 2, 1 , 7 )f o r m a t i s i m p l e me n t e d b y A S I C .C o m p a r e d t h e p e f r o r ma n c e o f t h e t w o d e s i g n, t h e ma x i mu m
ma d e t h e b e n e i f c i a l a t t e mp t f o r t h e c o mmu n i c a t i o n s y s t e m i n t e r ms o f c h a n n e l t r a n s mi s s i o n.T h e d e d i c a t e d p r o c e s s o r a r c h i t e c t u r e i s
动态规划:卷积码Viterbi译码算法

动态规划:卷积码的Viterbi译码算法学院:网研院姓名:xxx 学号:xxx 一、动态规划原理动态规划(dynamic programming)是运筹学的一个分支,是求解决策过程(decision process)最优化的数学方法。
动态规划算法通常用于求解具有某种最优性质的问题。
在这类问题中,可能会有许多可行解,每一个解都对应于一个值,我们希望找到具有最优值的解。
动态规划算法与分治法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。
与分治法不同的是,适合于用动态规划求解的问题,经分解得到子问题往往不是互相独立的。
若用分治法来解这类问题,则分解得到的子问题数目太多,有些子问题被重复计算了很多次。
如果我们能够保存已解决的子问题的答案,而在需要时再找出已求得的答案,这样就可以避免大量的重复计算,节省时间。
动态规划程序设计是对解最优化问题的一种途径、一种方法,而不是一种特殊算法。
不象搜索或数值计算那样,具有一个标准的数学表达式和明确清晰的解题方法。
动态规划程序设计往往是针对一种最优化问题,由于各种问题的性质不同,确定最优解的条件也互不相同,因而动态规划的设计方法对不同的问题,有各具特色的解题方法,而不存在一种万能的动态规划算法,可以解决各类最优化问题。
二、卷积码的Viterbi译码算法简介在介绍维特比译码算法之前,首先了解一下卷积码编码,它常常与维特比译码结合使用。
(2,1,3)卷积码编码器是最常见的卷积码编码器,在本次实验中也使用了(2,1,3)卷积码编码器,下面介绍它的原理。
(2,1,3)卷积码是把信源输出的信息序列,以1个码元为一段,通过编码器输出长为2的一段码段。
该码段的值不仅与当前输入码元有关,而且也与其之前的2个输入码元有关。
如下图所示,输出out1是输入、第一个编码器存储的值和第二个编码器存储的值逻辑加操作的结果,输出out2是输入和第二个编码器存储的值逻辑加操作的结果。
Viterbi译码的FPGA免回溯实现

Viterbi译码的FPGA免回溯实现
王栋良;秦建存
【期刊名称】《无线电工程》
【年(卷),期】2007(037)004
【摘要】卷积码在多种通信领域中广泛应用,Viterbi译码是对卷积码的一种最大似然译码算法.随着卷积码约束度的增加,并行维特比译码所需的硬件资源呈指数增长,限制其硬件实现.介绍了一种串行译码结构的FPGA实现方案,在保证性能译码的前提下有效地节省资源.同时提出了充分利用FPGA的RAM存储单元的免回溯Viterbi解码实现算法,减少了译码时延,这种算法在串行和并行译码中都可以应用.【总页数】3页(P27-28,60)
【作者】王栋良;秦建存
【作者单位】中国电子科技集团公司第54研究所,河北,石家庄,050081;中国电子科技集团公司第54研究所,河北,石家庄,050081
【正文语种】中文
【中图分类】TN911.22
【相关文献】
1.Viterbi译码器回溯算法实现研究 [J], 王建新;于贵智
2.基于Xilinx FPGA的高速Viterbi回溯译码器 [J], 牟澄磊;张惠萍;赵新胜
3.卷积编码及Viterbi译码的低时延FPGA设计实现 [J], 张健;吴倩文;高泽峰;周志刚
4.软判决Viterbi译码和序列译码在FPGA上的实现 [J], 方锦明
5.MIMO-OFDM系统二相ACS前向回溯基4 Viterbi译码器设计与实现 [J], 薛莲
因版权原因,仅展示原文概要,查看原文内容请购买。
Viterbi译码的FPGA免回溯实现

Viterbi 译码的FPGA 免回溯实现王栋良,秦建存(中国电子科技集团公司第54研究所,河北石家庄050081)摘 要 卷积码在多种通信领域中广泛应用,Viterbi 译码是对卷积码的一种最大似然译码算法。
随着卷积码约束度的增加,并行维特比译码所需的硬件资源呈指数增长,限制其硬件实现。
介绍了一种串行译码结构的FPG A 实现方案,在保证性能译码的前提下有效地节省资源。
同时提出了充分利用FPG A 的RAM 存储单元的免回溯Viterbi 解码实现算法,减少了译码时延,这种算法在串行和并行译码中都可以应用。
关键词 卷积码;Viterbi 译码;免回溯;FPG A中图分类号 T N911.22 文献标识码 A 文章编号 1003-3106(2007)04-0027-02A Implementation of a N on 2backtracking ViterbiDecoding Algorithm in FPGAW ANG D ong 2liang ,QI N Jian 2cun(The 54th Research Institude o f CETC ,Shijiazhuang Hebei 050081,China )Abstract C onv olutional coding has been widely used in many communication fields ,and Viterbi decoding alg orithm is a maximum likelihood alg orithm for the conv olutional code.The hardware res ource required for parallel Viterbi decoding shows an exponential increase with the increase of constraint length of conv olutional code ,which limits its hardware im plementation.In this paper ,a FPG A im plementation of a serial Viterbi decoding architecture is presented ,which saves hardware res ource without per formance deterioration.Meanwhile ,a non 2backtracking s olution of Viterbi decoding alg orithm using the RAM units of FPG A is provided in the paper.The s olution can reduce the delay of decoding ,and can be im plemented in both serial decoding and parallel decoding.K ey w ords converlutional code ;viterbi decoding ;non 2backtracking ;FPG A收稿日期:20062122250 引言卷积码因其良好的纠错能力在多种通信领域中得到了广泛的应用。
第9章 Viterbi译码及其实现

“黑色经典”系列之《DSP嵌入式系统开发典型案例》第9章Viterbi译码及其实现华清远见<ARM开发培训班>培训教材在通信系统中,信息传输的可靠性和有效性是相当重要的。
信息在传输时是经由信道(Channel)传输。
当其在信道传输过程中会受到各种干扰,使得传输信息掺杂各种错误序列在其中。
因此,在通信系统中,良好的纠错码可以有效地应用在信息传输过程中,以降低信息的误码率。
信息在传输时,先由信源发出消息,如语言、图像、文字等,消息进入通信系统后,经由信源编码器编码成信息序列1。
编码过程中,为了使传输有效,还加上一些与传输信息无关的冗余度。
接着信息序列1经过信道编码器编码成信息序列2,序列2是将信息序列1加入了更多的冗余数据(Redundancy Data),以抵抗信道中的各种干扰。
数字信号一般不适合直接在信道上传输,所以调制器是将数字信号转变成模拟信号,使其在信道中传输。
而信道中难免会受到噪声干扰,使信道的输出序列不同于信道的输入序列。
解调器将信道的输出序列由原来的模拟信号转化成数字信号,既是接收序列3,信息序列中因噪声干扰会掺杂一些错误的码元在其中。
信道译码器利用序列中的冗余码元去纠正错误,并且根据信道译码器的结果,产生接近于信息序列1的接收序列1。
整个译码过程是根据信道编码的结果和噪声在信道中的特性所得到的。
理想的结果是所有的错误都被更正回来,即接收序列等同于发送序列。
9.1 Viterbi译码概述在众多的纠错码中,卷积码(Convolutional Code)是一种在实际中得到广泛应用、性能很好的纠错码。
卷积码是不同于分组码的另一种码,它虽然也是把k个信息比特编成n个比特,但k和n都很小,延时小,特别适宜于以串行形式传输信息。
与分组码不同,卷积码中编码后的n个码元不但与当前段的众个信息码元有关,而且与前面(N−1)段的信息有关,编码过程中相互关联的码元为Nn个。
在编码器复杂程度相同的情况下,卷积码的性能优于分组码。
软判决Viterbi译码和序列译码在FPGA上的实现

软判决Viterbi译码和序列译码在FPG A上的实现方锦明(义乌工商职业技术学院,浙江义乌 322000)摘 要:介绍了3位软判决Viterbi译码器和序列译码器的FPG A实现,其中选用了同样的码率1/2和约束长度7.在FPG A实现的基础上,对Viterbi译码器和序列译码器的译码性能进行了测试和比较.结果表明,虽然序列译码器出现很小的译码增益损失,但其译码速度与Viterbi译码器不相上下,所消耗的硬件资源大大低于Viterbi译码器,当然这是以增加译码延时为代价的.关键词:通信技术;软判决;译码;FPG A中图分类号:T N911.22 文献标识码:A 文章编号:1001-7119(2003)04-0344-04Soft2Decision Viterbi and Sequential Decoding on FPGAF ANG Jin2ming(Y iwu Industrial&C ommercial C ollege,Y iwu322000,China)Abstract:FPG A im plementations of a Viterbi decoder and a Sequential decoder are presented,in which the same code rate1/2, constraint length7and32bit s oft decision are adopted.Based on FPG A im plementations,decoding per formances of Viterbi decoder and Sequential decoder have been tested and com pared with each other.I t is shown that,with com parable decoding speed per for2 mance and a slight coding gain loss,the sequential decoder consumes much lower res ource usage than Viterbi decoder.H owever, this is at the cost of an increased decoding delay.K ey w ords:communication technology;s oft2decision;decoding;FPG A0 引 言Viterbi译码器[1,2]具有相当高的计算复杂度,已广泛应用于译码卷积码.Viterbi译码器的译码延时是可预测的,其复杂度也固定,而且能实现最优解码,所以该译码器特别适用于实时应用系统.针对Viterbi译码器的硬件实现方法和如何进一步提高其性能等问题,已有文献从译码速度、占用面积和功率消耗等方面进行了讨论[3~6].序列译码[7]能以较小的计算复杂度实现与通道匹配较好的译码性能,但是由于序列译码器的译码延时具有不确定性,所以该译码器的应用被限制在非实时应用领域;此外,从硬件实现的角度而言,也没有一种可行的方案用序列译码器来替代Viterbi译码器.目前还没有文献专门对Viterbi译码器与序列译码器的硬件实现以及译码延时性能在同样的通道条件下作对比分析.随着便携通讯系统需求量的日益增加和集成电路工艺水平的进一步提高,译码器的功率消耗问题越来越成为一个重要的关键性问题,人们不希望在峰值功耗场合应用序列译码,而是希望在优化的平均功耗场合应用序列译码.文献[8]给出了一个低功耗硬判决序列译码器,并在ASIC实现方面将序列译码器与Viterbi译码器进行了比较.本文 V ol.19 N o.4 Jul.2003 科技通报BU LLETI N OF SCIE NCE AND TECH NO LOGY第19卷第4期2003年7月收稿日期:2003-03-05作者简介:方锦明,男,1965年生,浙江义乌人,讲师,工学硕士.设计的硬件实现方案,通过测试一个优化的Viterbi 结构和一个优化的基于FANO 算法的序列译码结构,用量化的方法精确地比较了序列译码和Viterbi 译码的硬件性能及译码性能.这个方案在X ilinx Virtex FPG A 上得到了实现,并且在同样AWG N 通道条件下测得序列译码和Viterbi 译码的位误码率、译码延时、译码速度和硬件资源消耗等结果数据。
viterbi译码算法C++实现
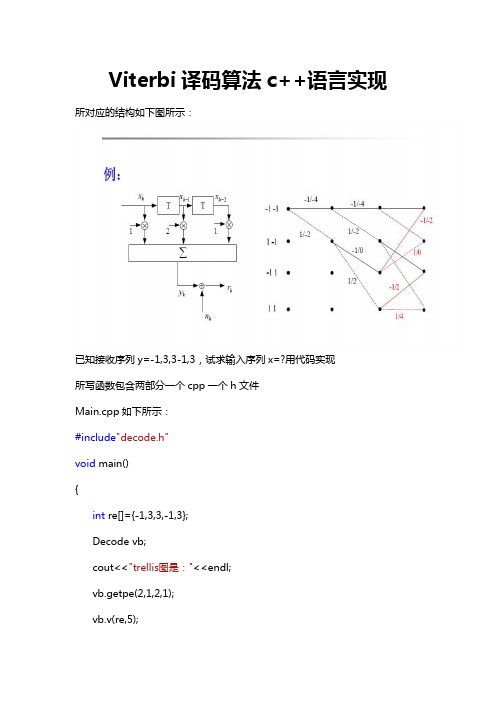
Viterbi译码算法c++语言实现所对应的结构如下图所示:已知接收序列y=-1,3,3-1,3,试求输入序列x=?用代码实现所写函数包含两部分一个cpp一个h文件Main.cpp如下所示:#include"decode.h"void main(){int re[]={-1,3,3,-1,3};Decode vb;cout<<"trellis图是:"<<endl;vb.getpe(2,1,2,1);vb.v(re,5);cout<<"输入的x序列是:"<<endl;for(int i=0;i<5;i++)cout<<re[i]<<" ";getchar();cout<<endl;}Decode.h如下所示:/*对此进行简单的viterbi译码,将viterbi算法具体的细分,最后得到的函数,并且说明详细by:molongXidian University2013年月日23:12:04*/#include<iostream>#include<vector>using namespace std;class Decode{public:void gettrellis();void getpe(int a,int b1,int b2,int b3);void v(int *re,int n);void get_pre(int now,int *pre);int getcurrent(int j,int i,int in);int min_path(int a,int b);int get_out(int pre,int next);private:int trellis[4][4],s_number,multi1,multi2,multi3;struct get_path{int pre;int out;};};/*函数名称:getpe()作用:作为构造类创建对象的时候进行传参,其中第一个参数a 代表的是存储器个数,第二个参数代表的是所看到的从左到右,输入,存储器,存储器所乘的系数,将这三个参数传给类的对象*/void Decode::getpe(int a,int b1,int b2,int b3){s_number=a;multi1=b1;multi2=b2;multi3=b3;}/*函数名称:gettrellis()作用:得到基本的trellis转移图,存储器的个数为,所以有四个状态,定义trellis[4][4];其中trellis[i][j]代表的是原来的状态是i,其中当j=0的时候表示的是输入为的时候所对应的输出,j=1代表的是当输入为时转移到的下一个状态,j=2时代表的是输入为的时候所对应的输出,j=3的时候表示的是当输入为的时候转移到的下一个状态,所得到的trellis图在为类里面定义的私有变量,均可用*/void Decode::gettrellis(){for(int i=0;i<4;i++)for(int j=0;j<4;j++){int l,h;l=i&1;h=(i>>1)&1;if(j%2==0)trellis[i][j]=multi1*(j-1)+multi2*(2*h-1)+multi3*(2*l-1);//输入是或者的时候的输出elsetrellis[i][j]=(j&2)^h;//所转移到的下一状态cout<<trellis[i][j]<<" ";if(j==3)cout<<endl;}}/*函数名称:v(int *re,int n)输入参数:re为接收到的序列,对其进行直接操作,n为序列的个数输出参数:re同样作为输出参数,来表示最后译码所输出来的结果函数作用:对所接收到的序列进行viterbi译码*/void Decode::v(int *re,int n){gettrellis();vector<vector<int>>remb(4);vector<vector<get_path>>path(4);for(int i=0;i<4;i++){remb[i].resize(n);path[i].resize(n);for(int j=0;j<n;j++){remb[i][j]=0;path[i][j].out=100;path[i][j].pre=100;//remb[i][j]=min_path(remb[pre1][j-1]+getcurrent(pre1,i,re[j]),remb[ pre2][j-1]+getcurrent(pre2,i,re[j]));}}/*remb[i][j]的作用是存储当接收第j个序列的时候,到i状态的路径最小值path[i][j].out表示的是i所对应前一个状态pre到状态i时所对应的输出path[i][j].pre表示的是第i个状态所对应的前一个状态是哪一个通过path的存储,最后在remb里面找到路径的最小值,顺着path来输出最后的译码结果*/for(int i=0;i<4;i++){remb[i][0]=getcurrent(0,i,re[0]);path[i][0].pre=0;path[i][0].out=get_out(0,i);}/* 对remb的首列以及path的首列进行初始化操作*/for(int j=1;j<n;j++){for(int i=0;i<4;i++){int pre[2];/*有两个前状态转移到状态i,定义pre[2]*/get_pre(i,pre);/*得到i所对应的前一状态所对应的两个值*/int a=getcurrent(pre[0],i,re[j]);int b=getcurrent(pre[1],i,re[j]);remb[i][j]=min_path(remb[pre[0]][j-1]+getcurrent(pre[0],i,re[j]),remb [pre[1]][j-1]+getcurrent(pre[1],i,re[j]));/*存储到i的最小距离*/if(remb[i][j]==(remb[pre[0]][j-1]+getcurrent(pre[0],i,re[j]))){path[i][j].pre=pre[0];path[i][j].out=get_out(pre[0],i);/*判断前一状态到底是哪一个,删除一条路径,只剩下最小路径*/}else{path[i][j].pre=pre[1];path[i][j].out=get_out(pre[1],i);}}}int minimum;int min=1000;for(int i=0;i<4;i++){if(remb[i][4]<min){min=remb[i][4];minimum=i;}/*通过对最后一列的寻找得到最小距离*/ }for(int j=n-1;j>=0;j--){re[j]=path[minimum][j].out;minimum=path[minimum][j].pre;/*通过path倒序得到译码所对应的输出*/ }}/*函数名称:get(int pre,int now)输入参数:pre表示前一个状态,now表示当前的状态输出参数:从状态pre转移到状态now所对应的输出函数作用:通过前一状态以及当前状态,来确定输出*/int Decode::get_out(int pre,int now){int out,count=0;for(int j=0;j<2;j++)if(trellis[pre][2*j+1]==now){out=2*j-1;count++;}if(count==0)out=1000;return out;}/*函数名称:get_pre(int now,int *pre)输入参数:当前状态now,*pre代表的是now所对应的前一状态的两个值输出参数:得到前一状态的两个值,即得到是哪两个状态可以转移到状态now 函数作用:得到可以转移到当前状态的前一状态的两个值,例如状态->2,0->2那么这就是得到和这两个值*/void Decode::get_pre(int now, int *pre){int count=0;for(int i=0;i<4;i++)for(int k=0;k<2;k++){if(trellis[i][2*k+1]==now&&count==0){pre[0]=i;count++;}if(trellis[i][2*k+1]==now&&count!=0){pre[1]=i;}}}/*函数名称:getcurrent(int j,int i,int in)输入参数:j表示的是前一状态,i表示的是当前状态,in表示的是接收到的数字输出参数:result表示从状态j到状态i所对应的输出和接收参数in的汉明距离函数作用:得到每一个分支的汉明距离,返回的值是绝对值*/int Decode::getcurrent(int j,int i,int in)//j代表前一个,i表示后一个,in表示输入接收到的数字{int result;int count=0;for(int k=0;k<2;k++){if(trellis[j][2*k+1]==i){result=in-trellis[j][2*k];count++;}}if(count==0)result=10000;return abs(result);}//在此处应该返回的是绝对值,不能是单纯的带符号的值/*函数名称:min_path(int a,int b)输入参数:a和b两个数值输出参数:a和b之间的最小值函数作用:取两条转移路径的最小值*/int Decode::min_path(int a,int b){if(a>b)return b;elsereturn a; }。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
C、本文安排
本文安排如下,第 II 部分给出 2CPFSK、 h=0.25 的 4CPFSK 等效基带的产 生和功率谱密度分析;第 III 部分讨论 h=0.25 的 4CPFSK 的 Viterbi 译码实现和 误码率分析。
4 4 44
m
决定相位 ������������ 。同样的,对于所以对于从
State_odd 到 State_even 的 16 条 路 径 , 有 16 个 标 准 状 态 , 为
Standard_odd_to_even(:, m, n) 对于每一个周期的接收符号,判断它是奇数还是偶数编号符号后,将确定它
化为:(π , − 3π , − π)程序运行结果示意图如下:
444
图 3 Viterbi 译码过程举例
随机产生 10000 个点,仿真得到 Viterbi 译码的误码率曲线为:
BER of 4CPFSK h=0.25 using Viterbi Decoding
0
10
-1
10
BER
-2
10
10-3
4
相同。 下面研究相位连续性对信号功率谱的影响。下面是 h=0.5,2CPFSK; h=0.25,
4CPFSK; h=0.25,4CPFSK 的功率谱密度(这些功率谱各自对自己归一化,频率 对符号周期归一化):
0
h=0.5 2CPFSK
h=0.25 2CPFSK
-10
h=0.25 4CPFSK
X: 1.001
,
π 4
,
−
π 4
,
π 4)
相位网格图由这两组状态交替组成。对于编号为奇数的符号,状态由
State_even变 为 State_odd; 对 于 编 号 为 偶 数 的 符 号 , 状 态 由 State_odd变 为
State_even。每一个状态将有四条入路径和四条出路径。
对于每一条路径,都对应一个标准符号。所以对于从State_even 到 State_odd
所对应的状态转换图。和 16 个标准符号之一作对比,求出各自的均方误差。对 于每一个当前状态节点,一共有 4 条如路径,这四条路径的“距离”定义为均方 误差和各条路径出发状态“权重”的和,选择 4 个“距离”中最小的作为本当前 状态的“权重”,并且记录路径来源。这就做完了一级“加比选”。直到最终 4
0
-0.2
-0.4
-0.6
-0.8
-1
-1
-0.5
0
0.5
1
In-Phase
h=0.25 2CPFSK Stellerplot 1
0.8
0.6
0.4
0.2
0
-0.2
-0.4
-0.6
-0.8
-1
-1
-0.5
0
0.5
1
In-Phase
h=0.25 4CPFSK Stellerplot 1
0.8
0.6
0.4
2、试产生 4 进制的 CPFSK,h=0.25,观察其功率谱,并编写维特比检测器, 统计其误码曲线
B、CPFSK 和 Viterbi 译码简介
CPFSK(Continuous-Phase Frequency Shift Keying),即连续相位频移键控, 射频信号相位连续的调制方式。其包络恒定,具有较小功率谱占用率。MSK 是 FSK 信号的相位始终保持连续变化的一种特殊方式。可以看成是调制指数为 0.5 的一种 CPFSK 信号。
= (−3, −1,1,3)
ℎ
=
������ ������
,为有理调制系数
������ −1
������������ = ������ℎ ∑ ������������ ,为累计相位
������ =0
将������0置为 0,可以直接产生调制信号。采用如下电平映射
符号比特
电平值
符号比特 电平值
10
+3
+
������������������)
由当前状态 n 和之前的状态 m 的差值决定������������,也就是频率(注意一旦差值 超过������,则要减去 2������;小于-������,则要加上 2������,来保证本符号相位的变化在集合
(3π , π , − π , π)中);由之前的状态
0.2
0
-0.2
-0.4
-0.6
-0.8
-1
-1
-0.5
0
0.5
1
In-Phase
图 1 CPFSK 星座图(h=0.5,2CPFSK;h=0.25,2CPFSK;h=0.25,4CPFSK)
可以看到,采用了 CPFSK 之后,相位连续变化,星座图上的信号点密集地 在圆上“跑”,不在分立的少数几个点之间跳变。这就是相位连续的表现。同时看
的 16 条路径,有 16 个标准状态,为Standard_even_to_odd(:, m, n), n 代表当前 状态编号,m 代表上一状态编号。由下面式子:
������(������)
=
exp (������������ℎ
������������(������
− ������������
������������������)
-4
10
-12
-10
-8
-6
-4
-2
0
2
4
Eb/n0
图 4 Viterbi 译码误码率曲线
可见,由于 CPFSK 的相位记忆特性,Viterbi 译码后的误码率较低。
5/5
1/5
CPFSK 与 Viterbi 译码的实现和分析
清华大学电子工程系 杨雨潇
2012/6/7
II 2CPFSK 与 4 CPFSK 的等效基带产生和功率谱密度分析
对于 CPFSK,主要特点是本个符号的初始相位是之前所有符号相位变化的累
积和,以此来保证相位连续。其等效基带数学表达式如下:
������(������)
2/5
CPFSK 与 Viterbi 译码的实现和分析
清华大学电子工程系 杨雨潇
2012/6/7
到,在同一进度调制的情况下,h 小,相位越连续。 同时可以看到,对于 h=0.25 的 2、4 进制 CPFSK,它们的星座图一样,这
是由于,对于 h=0.25 的 CPFSK,它们的相位变化都是(± π)的整数倍,所以轨迹
0
-1
00
+1
1
+1
01
-1
11
-3
表 1 二进制与四进制电平映射
随机产生 N=1000 个 0、1 值作为比特流,利用上面的式子可以得到调制信
号。画出三个星座图:
Quadrature Quadrature Quadrature
h=0.5 CPFSK Stellerplot 1
0.8
0.6
0.4
0.2
CPFSK 与 Viterbi 译码的实现和分析
清华大学电子工程系 杨雨潇
2012/6/7
CPFSK 与 Viterbi 译码的实现和分析
清华大学电子工程系 无 99 班 杨雨潇 2009011209 联系方式:yyx09@
I、介绍
A. 题目介绍
1、以等效基带的方式仿真一个过采样率为 10 的 2CPFSK,g(t)为非归零方 波,h 分别为 0.5(即 MSK)和 0.25,观察其功率谱
=
exp (������������ℎ ������������ (������−������������������ )
������������
+
������������������)
其中:
�������� + 1)������
������������为本个符号对应的电平值,对于 2 进制,������������ = (−1,1);对于 4 进制,������������
-20
Y: -22.75
X: 1.001 Y: -30.79
-30
X: 1.001
-40
Y: -33.68
PSD
-50
-60
-3
-2
-1
0
1
2
3
Normalized Frequency(Normalized to bit rate)
图 2 CPFSK 功率谱密度
首先整体上由于是复数基带,三个功率谱的正负频率略有不对称。 接下来,对比 2CPFSK 的 h=0.5 和 0.25 的图,发现 h=0.25 的旁瓣电平更低, 第一旁瓣为-30dB,比 h=0.5 的第一旁瓣-23dB 低约 7dB。所以,CPFSK 中,相 位越连续,带外功率谱越低,带外功率谱下降越快。这也是使用连续相位调制的 初衷之一。 对比 h=0.25 的 2CPFSK 和 4CPFSK 的图,发现对比特率归一化后,4CPFSK 的功率谱带外衰减更快,第一旁瓣为-33dB,约比 2CPFSK 的第一旁瓣-30dB 低约 3dB。这说明多进制 CPFSK 调制的带宽更窄,频谱效率越高。4 进制的频谱利用 率为 2 进制的 2 倍,功率谱下降恰好约为 3dB,这两者之间有无必然联系需要进 一步研究。
3/5
CPFSK 与 Viterbi 译码的实现和分析
清华大学电子工程系 杨雨潇
2012/6/7