统计学第四版答案(贾俊平)
统计学第四版贾俊平课后试探题答案

统计课后试探题答案第一章试探题什么是统计学统计学是关于数据的一门学科,它搜集,处置,分析,说明来自各个领域的数据并从中得出结论。
说明描述统计和推断统计描述统计;它研究的是数据搜集,处置,汇总,图表描述,归纳与分析等统计方式。
推断统计;它是研究如何利用样本数据来推断整体特点的统计方式。
统计学的类型和不同类型的特点统计数据;按所采纳的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观看值,其结果表现为具体的数值。
统计数据;按统计数据都搜集方式分;观测数据:是通过调查或观测而搜集到的数据,这种数据是在没有对事物人为操纵的条件下取得的。
实验数据:在实验中操纵实验对象而搜集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时刻点搜集到的数据,也叫静态数据。
时刻序列数据:按时刻顺序搜集到的,用于描述现象随时刻转变的情形,也叫动态数据。
说明分类数据,顺序数据和数值型数据答案同举例说明整体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡确实是整体,从中抽取一百个进行检测,这一百个灯泡的集合确实是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特点的数值确实是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特点的数值确实是统计量,变量确实是说明现象某种特点的概念,比如说灯泡的寿命。
变量的分类变量能够分为分类变量,顺序变量,数值型变量。
变量也能够分为随机变量和非随机变量。
体会变量和理论变量。
举例说明离散型变量和持续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”持续型变量,取之持续不断,不能一一列举,比如“温度”。
第二章试探题什么是二手资料?利用二手资料应注意什么问题与研究内容有关,由他人调查和实验而来已经存在,并会被咱们利用的资料为“二手资料”。
统计学第四版答案(贾俊平)知识分享

统计学第四版答案(贾俊平)请举出统计应用的几个例子:1、用统计识别作者:对于存在争议的论文,通过统计量推出作者2、用统计量得到一个重要发现:在不同海域鳗鱼脊椎骨数量变化不大,推断所有各个不同海域内的鳗鱼是由海洋中某公共场所繁殖的3、挑战者航天飞机失事预测请举出应用统计的几个领域:1、在企业发展战略中的应用2、在产品质量管理中的应用3、在市场研究中的应用④在财务分析中的应用⑤在经济预测中的应用你怎么理解统计的研究内容:1、统计学研究的基本内容包括统计对象、统计方法和统计规律。
2、统计对象就是统计研究的课题,称谓统计总体。
3、统计研究方法主要有大量观察法、数量分析法、抽样推断法、实验法等。
④统计规律就是通过大量观察和综合分析所揭示的用数量指标反映的客观现象的本质特征和发展规律。
举例说明分类变量、顺序变量和数值变量:分类变量:表现为不同类别的变量称为分类变量,如“性别”表现为“男”或“女”,“企业所属的行业”表现为“制造业”、“零售业”、“旅游业”等,“学生所在的学院”可能是“商学院”、“法学院”等顺序变量:如果类别有一定的顺序,这样的分类变量称为顺序变量,如考试成绩按等级分为优、良、中、及格、不及格,一个人对事物的态度分为赞成、中立、反对。
这里的“考试成绩等级”、“态度”等就是顺序变量。
数值变量:可以用数字记录其观察结果,这样的变量称为数值变量,如“企业销售额”、“生活费支出”、“掷一枚骰子出现的点数”。
定性数据和定量数据的图示方法各有哪些:1、定性数据的图示:条形图、帕累托图、饼图、环形图2、定量数据的图示:a、分组数据看分布:直方图b、未分组数据看分布:茎叶图、箱线图、垂线图、误差图c、两个变量间的关系:散点图d、比较多个样本的相似性:雷达图和轮廓图直方图与条形图有何区别:1、条形图中的每一个矩形表示一个类别,其宽度没有意义,而直方图的宽度则表示各组的组距。
2、由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
统计学贾俊平第四版课后习题答案
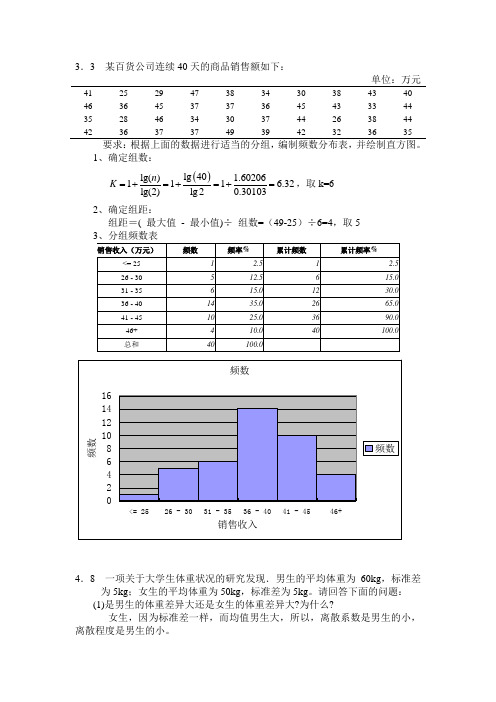
3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1、确定组数: ()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取54.8 一项关于大学生体重状况的研究发现.男生的平均体重为60kg ,标准差为5kg ;女生的平均体重为50kg ,标准差为5kg 。
请回答下面的问题: (1)是男生的体重差异大还是女生的体重差异大?为什么?女生,因为标准差一样,而均值男生大,所以,离散系数是男生的小,离散程度是男生的小。
(2)以磅为单位(1ks=2.2lb),求体重的平均数和标准差。
都是各乘以2.21,男生的平均体重为60kg×2.21=132.6磅,标准差为5kg ×2.21=11.05磅;女生的平均体重为50kg×2.21=110.5磅,标准差为5kg×2.21=11.05磅。
(3)粗略地估计一下,男生中有百分之几的人体重在55kg一65kg之间?计算标准分数:Z1=x xs-=55605-=-1;Z2=x xs-=65605-=1,根据经验规则,男生大约有68%的人体重在55kg一65kg之间。
(4)粗略地估计一下,女生中有百分之几的人体重在40kg~60kg之间?计算标准分数:Z1=x xs-=40505-=-2;Z2=x xs-=60505-=2,根据经验规则,女生大约有95%的人体重在40kg一60kg之间。
最新统计学第四版答案(贾俊平)

请举出统计应用的几个例子:1、用统计识别作者:对于存在争议的论文,通过统计量推出作者2、用统计量得到一个重要发现:在不同海域鳗鱼脊椎骨数量变化不大,推断所有各个不同海域内的鳗鱼是由海洋中某公共场所繁殖的3、挑战者航天飞机失事预测请举出应用统计的几个领域:1、在企业发展战略中的应用2、在产品质量管理中的应用3、在市场研究中的应用④在财务分析中的应用⑤在经济预测中的应用你怎么理解统计的研究内容:1、统计学研究的基本内容包括统计对象、统计方法和统计规律。
2、统计对象就是统计研究的课题,称谓统计总体。
3、统计研究方法主要有大量观察法、数量分析法、抽样推断法、实验法等。
④统计规律就是通过大量观察和综合分析所揭示的用数量指标反映的客观现象的本质特征和发展规律。
举例说明分类变量、顺序变量和数值变量:分类变量:表现为不同类别的变量称为分类变量,如“性别”表现为“男”或“女”,“企业所属的行业”表现为“制造业”、“零售业”、“旅游业”等,“学生所在的学院”可能是“商学院”、“法学院”等顺序变量:如果类别有一定的顺序,这样的分类变量称为顺序变量,如考试成绩按等级分为优、良、中、及格、不及格,一个人对事物的态度分为赞成、中立、反对。
这里的“考试成绩等级”、“态度”等就是顺序变量。
数值变量:可以用数字记录其观察结果,这样的变量称为数值变量,如“企业销售额”、“生活费支出”、“掷一枚骰子出现的点数”。
定性数据和定量数据的图示方法各有哪些:1、定性数据的图示:条形图、帕累托图、饼图、环形图2、定量数据的图示:a、分组数据看分布:直方图b、未分组数据看分布:茎叶图、箱线图、垂线图、误差图c、两个变量间的关系:散点图d、比较多个样本的相似性:雷达图和轮廓图直方图与条形图有何区别:1、条形图中的每一个矩形表示一个类别,其宽度没有意义,而直方图的宽度则表示各组的组距。
2、由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
统计学课后习题答案(第四版)贾俊平(第4、5、7、10章)

《统计学》第四版 第四章练习题答案众数:M o =1O;中位数:中位数位置=n+1/2=5.5 , M e =10 ;平均数:(2) Q L 位置=n/4=2.5, Q L =4+7/2=5.5 ; Q u 位置=3n/4=7.5 , Q u =12(4) 4.2 和 M O =23。
将原始数据排序后,计算中位数的位置为:中位数位置=n+1/2=13,第13个位置上的数值为23,所以中位数为 M e =23(2)Q L 位置=n/4=6.25, Q L ==19 ; Q u 位置=3n/4=18.75,Q u =26.5茎 叶 频数 5 5 1 6 6 7 8 3 71 3 4 8 85(3)第一种排队方式: 离散程度大于第二种排队方式。
(4 )选方法二,因为第二种排队方式的平均等待时间较短,且离散程度小于第一种排队方 式。
_ Z X i4.4 ( 1)X8223/30=274.14.1 ( 1 ) 二X i X =n96.9,6 102' (X i-X ) _156.4 42n -1, 9由于平均数小于中位数和众数,所以汽车销售量为左偏分布。
(1)从表中数据可以看出,年龄出现频数最多的是 19和23,故有个众数,即 M O =19(3)⑶平均数-A =600/25=24,标准差—(XLX)\ n —1210626.6525-1n(4) 偏态系数SK=1.08,峰态系数K=0.77(5) 分析:从众数、中位数和平均数来看,网民年龄在 23-24岁的人数占多数。
由于标准差较大,说明网民年龄之间有较大差异。
从偏态系数来看,年龄分布为右偏,由于偏态系数 1,所以,偏斜程度很大。
由于峰态系数为正值,所以为尖峰分布。
(1)茎叶图如下: 大于 4.3 —2'(X 一 X ) 4.080.714nn -1■ 8由于两种排队方式的平均数不同,所以用离散系数进行比较。
(2) X 二一^ =63/9=7, S = ■■n中位数位置=n+1/2=15.5 , M e=272+273/2=272.5(2) Q L位置=n/4=7.5, Q L==(258+261)/2=259.5 ; Q u 位置=3n/4=22.5 , Q u=(284+291)/2=287.5' (^-X ^ /3002-7 = 21.17 I n —1 \ 30—12100 +3000 +15004.5 (1)甲企业的平均成本=总成本/总产量=-2100 3000---- + ----- 15 20乙企业的平均成本=总成本/总产量=3255150015006255=18.293255 1500 1500 342____ + _____ + _____152030原因:尽管两个企业的单位成本相同, 但单位成本较低的产品在乙企业的产量中所占比重较 大,因此拉低了总平均成本。
统计学课后习题答案_(第四版)_贾俊平

《统计学》第四版 第四章练习题答案4.1 (1)众数:M 0=10; 中位数:中位数位置=n+1/2=5.5,M e =10;平均数:6.91096===∑nxx i(2)Q L 位置=n/4=2.5, Q L =4+7/2=5.5;Q U 位置=3n/4=7.5,Q U =12 (3)2.494.1561)(2==-=∑-n i s x x (4)由于平均数小于中位数和众数,所以汽车销售量为左偏分布。
4.2 (1)从表中数据可以看出,年龄出现频数最多的是19和23,故有个众数,即M 0=19和M 0=23。
将原始数据排序后,计算中位数的位置为:中位数位置= n+1/2=13,第13个位置上的数值为23,所以中位数为M e =23(2)Q L 位置=n/4=6.25, Q L ==19;Q U 位置=3n/4=18.75,Q U =26.5(3)平均数==∑nx x i600/25=24,标准差65.612510621)(2=-=-=∑-n i s x x(4)偏态系数SK=1.08,峰态系数K=0.77(5)分析:从众数、中位数和平均数来看,网民年龄在23-24岁的人数占多数。
由于标准差较大,说明网民年龄之间有较大差异。
从偏态系数来看,年龄分布为右偏,由于偏态系数大于1,所以,偏斜程度很大。
由于峰态系数为正值,所以为尖峰分布。
4.3 (1(2)==∑nxx i63/9=7,714.0808.41)(2==-=∑-n i s x x (3)由于两种排队方式的平均数不同,所以用离散系数进行比较。
第一种排队方式:v 1=1.97/7.2=0.274;v 2=0.714/7=0.102.由于v 1>v 2,表明第一种排队方式的离散程度大于第二种排队方式。
(4)选方法二,因为第二种排队方式的平均等待时间较短,且离散程度小于第一种排队方式。
4.4 (1)==∑nx x i8223/30=274.1中位数位置=n+1/2=15.5,M e =272+273/2=272.5(2)Q L 位置=n/4=7.5, Q L ==(258+261)/2=259.5;Q U 位置=3n/4=22.5,Q U =(284+291)/2=287.5(3) 17.211307.130021)(2=-=-=∑-n i s x x4.5 (1)甲企业的平均成本=总成本/总产量=41.193406600301500203000152100150030002100==++++乙企业的平均成本=总成本/总产量=29.183426255301500201500153255150015003255==++++原因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。
最新统计学第四版答案(贾俊平)资料

请举出统计应用的几个例子:1、用统计识别作者:对于存在争议的论文,通过统计量推出作者2、用统计量得到一个重要发现:在不同海域鳗鱼脊椎骨数量变化不大,推断所有各个不同海域内的鳗鱼是由海洋中某公共场所繁殖的3、挑战者航天飞机失事预测请举出应用统计的几个领域:1、在企业发展战略中的应用2、在产品质量管理中的应用3、在市场研究中的应用④在财务分析中的应用⑤在经济预测中的应用你怎么理解统计的研究内容:1、统计学研究的基本内容包括统计对象、统计方法和统计规律。
2、统计对象就是统计研究的课题,称谓统计总体。
3、统计研究方法主要有大量观察法、数量分析法、抽样推断法、实验法等。
④统计规律就是通过大量观察和综合分析所揭示的用数量指标反映的客观现象的本质特征和发展规律。
举例说明分类变量、顺序变量和数值变量:分类变量:表现为不同类别的变量称为分类变量,如“性别”表现为“男”或“女”,“企业所属的行业”表现为“制造业”、“零售业”、“旅游业”等,“学生所在的学院”可能是“商学院”、“法学院”等顺序变量:如果类别有一定的顺序,这样的分类变量称为顺序变量,如考试成绩按等级分为优、良、中、及格、不及格,一个人对事物的态度分为赞成、中立、反对。
这里的“考试成绩等级”、“态度”等就是顺序变量。
数值变量:可以用数字记录其观察结果,这样的变量称为数值变量,如“企业销售额”、“生活费支出”、“掷一枚骰子出现的点数”。
定性数据和定量数据的图示方法各有哪些:1、定性数据的图示:条形图、帕累托图、饼图、环形图2、定量数据的图示:a、分组数据看分布:直方图b、未分组数据看分布:茎叶图、箱线图、垂线图、误差图c、两个变量间的关系:散点图d、比较多个样本的相似性:雷达图和轮廓图直方图与条形图有何区别:1、条形图中的每一个矩形表示一个类别,其宽度没有意义,而直方图的宽度则表示各组的组距。
2、由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
统计学第四版答案(贾俊平)

请举出统计应用的几个例子:1、用统计识别作者:对于存在争议的论文,通过统计量推出作者2、用统计量得到一个重要发现:在不同海域鳗鱼脊椎骨数量变化不大,推断所有各个不同海域内的鳗鱼是由海洋中某公共场所繁殖的3、挑战者航天飞机失事预测请举出应用统计的几个领域:1、在企业发展战略中的应用2、在产品质量管理中的应用3、在市场研究中的应用④在财务分析中的应用⑤在经济预测中的应用你怎么理解统计的研究内容:1、统计学研究的基本内容包括统计对象、统计方法和统计规律。
2、统计对象就是统计研究的课题,称谓统计总体。
3、统计研究方法主要有大量观察法、数量分析法、抽样推断法、实验法等。
④统计规律就是通过大量观察和综合分析所揭示的用数量指标反映的客观现象的本质特征和发展规律。
举例说明分类变量、顺序变量和数值变量:分类变量:表现为不同类别的变量称为分类变量,如“性别”表现为“男”或“女”,“企业所属的行业”表现为“制造业”、“零售业”、“旅游业”等,“学生所在的学院”可能是“商学院”、“法学院”等顺序变量:如果类别有一定的顺序,这样的分类变量称为顺序变量,如考试成绩按等级分为优、良、中、及格、不及格,一个人对事物的态度分为赞成、中立、反对。
这里的“考试成绩等级”、“态度”等就是顺序变量。
数值变量:可以用数字记录其观察结果,这样的变量称为数值变量,如“企业销售额”、“生活费支出”、“掷一枚骰子出现的点数”。
定性数据和定量数据的图示方法各有哪些:1、定性数据的图示:条形图、帕累托图、饼图、环形图2、定量数据的图示:a、分组数据看分布:直方图b、未分组数据看分布:茎叶图、箱线图、垂线图、误差图c、两个变量间的关系:散点图d、比较多个样本的相似性:雷达图和轮廓图直方图与条形图有何区别:1、条形图中的每一个矩形表示一个类别,其宽度没有意义,而直方图的宽度则表示各组的组距。
2、由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
统计学第四版答案(贾俊平)

第1章统计和统计数据1.1 指出下面的变量类型。
(1)年龄。
(2)性别。
(3)汽车产量。
(4)员工对企业某项改革措施的态度(赞成、中立、反对)。
(5)购买商品时的支付方式(现金、信用卡、支票)。
详细答案:(1)数值变量。
(2)分类变量。
(3)数值变量。
(4)顺序变量。
(5)分类变量。
1.2 一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。
(1)这一研究的总体是什么?样本是什么?样本量是多少?(2)“月收入”是分类变量、顺序变量还是数值变量?(3)“消费支付方式”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。
(2)数值变量。
(3)分类变量。
1.3 一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。
(1)这一研究的总体是什么?(2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有的网上购物者”。
(2)分类变量。
1.4 某大学的商学院为了解毕业生的就业倾向,分别在会计专业抽取50人、市场营销专业抽取30、企业管理20人进行调查。
(1)这种抽样方式是分层抽样、系统抽样还是整群抽样?(2)样本量是多少?详细答案:(1)分层抽样。
(2)100。
第3章用统计量描述数据为7.2分钟,标准差为1.97分钟,第二种排队方式的等待时间(单位:分钟)如下:5.56.6 6.7 6.87.1 7.3 7.4 7.8 7.8(1)计算第二种排队时间的平均数和标准差。
(2)比两种排队方式等待时间的离散程度。
(3)如果让你选择一种排队方式,你会选择哪一种?试说明理由。
详细答案:(1)(岁);(岁)。
(2);。
第一中排队方式的离散程度大。
(3)选方法二,因为平均等待时间短,且离散程度小。
统计学贾俊平第四版课后习题测验答案

3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1、确定组数:()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取5(1) 对这个年龄分布作直方图;(2) 从直方图分析成人自学考试人员年龄分布的特点。
解:(1)制作直方图:将上表复制到Excel 表中,点击:图表向导→柱形图→选择子图表类型→完成。
即得到如下的直方图:(见Excel 练习题2.6)(2)年龄分布的特点:自学考试人员年龄的分布为右偏。
解:(1)根据上面的数据,画出两个班考试成绩的对比条形图和环形图。
3.14 已知1995—2004年我国的国内生产总值数据如下(按当年价格计算):要求:(2)绘制第一、二、三产业国内生产总值的线图。
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量N Valid 10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075 12.50种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。
统计学第四版(贾俊平)课后所有题答案很全期末考试必备

统计课后思考题答案第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别姆鞘中褪荩嵌允挛锝蟹掷嗟慕峁荼硐治啾穑梦淖掷幢硎觯唬ǘㄐ允荩┧承蚴荩褐荒芄橛谀骋挥行蚶啾鸬姆鞘中褪荨K彩怯欣啾鸬模庑├啾鹗怯行虻摹#渴荩┦敌褪荩喊词殖叨炔饬康墓鄄熘担浣峁硐治咛宓氖怠?统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同 1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
1.8 统计应用实例人口普查,商场的名意调查等。
统计学(人大第四版)课后习题答案___贾俊平、何晓

统计学(人大第四版)3~13章答案3.1 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。
调查结果如下:B EC C AD C B AE D A C B C D E C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E B B E C C A D C B A E B A C E E A B D D C A D B C C A E D C B C B C E D B C C B C要求:(1)指出上面的数据属于什么类型。
顺序数据(2)用Excel制作一张频数分布表。
用数据分析——直方图制作:接收频率E16D17C32B21A14(3)绘制一张条形图,反映评价等级的分布。
用数据分析——直方图制作:(4)绘制评价等级的帕累托图。
逆序排序后,制作累计频数分布表:接收频数频率(%)累计频率(%)C 32 32 32B 21 21 53D 17 17 70E 16 16 86A14 14 1005101520253035CDBAE204060801001203.2 某行业管理局所属40个企业2002年的产品销售收入数据如下: 152 124 129 116 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 108 97 88 123 115 119 138 112 146 113 126 要求:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。
1、确定组数:()l g 40l g () 1.60206111 6.32l g (2)l g 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(152-87)÷6=10.83,取10 3(2)按规定,销售收入在125万元以上为先进企业,115~125万元为良好企业,105~115 万元为一般企业,105万元以下为落后企业,按先进企业、良好3.3 单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42 36 37 37 49 39 42 32 36 35 要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
统计学(贾俊平 第四版)课后习题答案
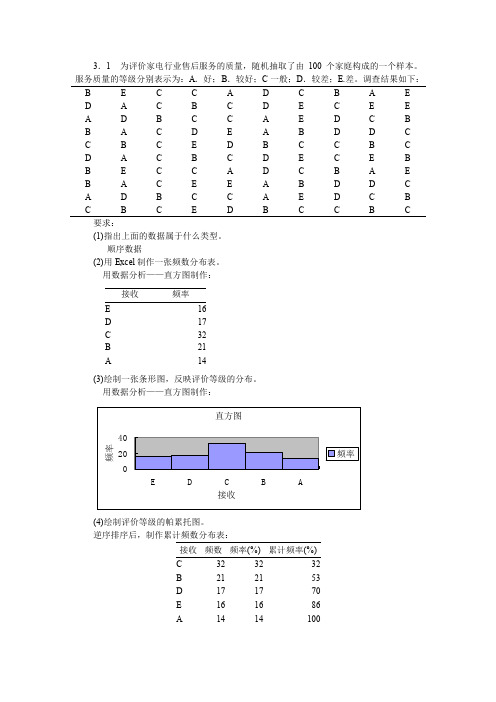
频数
2 3 9 12 7 4 2 1 40
频率%
5.0 7.5 22.5 30.0 17.5 10.0 5.0 2.5 100.0
要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
K 1
l g 4 0 l gn ( ) 1.60206 ,取 1 1 6.3 2 k=6 lg(2) lg 2 0.30103
2、确定组距: 组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取 5 3、分组频数表
要求: (1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。 1、确定组数:
K 1
l g 4 0 l gn ( ) 1.60206 ,取 1 1 6.3 2 k=6 lg(2) lg 2 0.30103
2、确定组距: 组距=( 最大值 - 最小值)÷ 组数=(152-87)÷6=10.83,取 10 3、分组频数表 销售收入
直方图:
组距4,小于等于
40
30
Frequency
20
10
Mean =4.06 Std. Dev. =1.221 N =100 0 0 2 4 6 8
组距4,小于等于
组距 5,上限为小于等于 频数 有效 <= 45.00 46.00 - 50.00 51.00 - 55.00 56.00 - 60.00 61.00+ 合计 12 37 34 16 1 100 百分比 12.0 37.0 34.0 16.0 1.0 100.0 累计频数 12.0 49.0 83.0 99.0 100.0 累积百分比 12.0 49.0 83.0 99.0 100.0
统计学第四版问题详解(贾俊平)
第1章统计和统计数据1.1 指出下面的变量类型。
(1)年龄。
(2)性别。
(3)汽车产量。
(4)员工对企业某项改革措施的态度(赞成、中立、反对)。
(5)购买商品时的支付方式(现金、信用卡、支票)。
详细答案:(1)数值变量。
(2)分类变量。
(3)数值变量。
(4)顺序变量。
(5)分类变量。
1.2 一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。
(1)这一研究的总体是什么?样本是什么?样本量是多少?(2)“月收入”是分类变量、顺序变量还是数值变量?(3)“消费支付方式”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。
(2)数值变量。
(3)分类变量。
1.3 一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。
(1)这一研究的总体是什么?(2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有的网上购物者”。
(2)分类变量。
1.4 某大学的商学院为了解毕业生的就业倾向,分别在会计专业抽取50人、市场营销专业抽取30、企业管理20人进行调查。
(1)这种抽样方式是分层抽样、系统抽样还是整群抽样?(2)样本量是多少?详细答案:(1)分层抽样。
(2)100。
第3章用统计量描述数据););=426.67;,,第五章1.23.4.5.6.7.5.8 (1)(3.02%,16.98%)。
(2)(1.68%,18.32%)。
5.9 详细答案:(4.06,24.35)。
5.10详细答案: 139。
5.11 详细答案: 57。
5.12 769。
第6章假设检验平看电,绝平,,绝,,绝在,,=100 =50=14.8 =10.4=0.8 =0.6对,,绝。
对设,。
贾俊平统计学第四版课后答案
第三章节:数据的图表展示…………………………………………………1 第四章节:数据的概括性度量……………………………………………….15 第六章节:统计量及其抽样分布……………………………………………26 第七章节:参数估计………………………………………………. …………28 第八章节:假设检验……………………………………………….. …………38 第九章节:列联分析……………………………………………….. …………41 第十章节:方差分析……………………………………………….. …………43 3. 要求:(1)指出上面的数据属于什么类型。
顺序数据 3.31、确定组数: ()l g 40l g () 1.60206111 6.32l g (2)l g 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取53、分组频数表销售收入(万元)频数频率%累计频数累计频率%<= 25 1 2.5 1 2.5 26 - 30 5 12.5 6 15.0 31 - 35 6 15.0 12 30.0 36 - 40 14 35.0 26 65.0 41 - 45 10 25.0 36 90.0 46+ 4 10.0 40100.0总和40100.0频数246810121416<= 2526 - 3031 - 3536 - 4041 - 4546+销售收入频数频数3.4data605040302010data Stem-and-Leaf PlotFrequency Stem & Leaf3.00 1 . 889 5.00 2 . 01133 7.00 2 . 6888999 2.00 3 . 13 3.00 3 . 569 3.00 4 . 123 3.00 4 . 667 3.00 5 . 012 1.00 5 . 7Stem width: 10 Each leaf: 1 case(s)3.6解:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
请举出统计应用的几个例子:1、用统计识别作者:对于存在争议的论文,通过统计量推出作者2、用统计量得到一个重要发现:在不同海域鳗鱼脊椎骨数量变化不大,推断所有各个不同海域内的鳗鱼是由海洋中某公共场所繁殖的3、挑战者航天飞机失事预测请举出应用统计的几个领域:1、在企业发展战略中的应用2、在产品质量管理中的应用3、在市场研究中的应用④在财务分析中的应用⑤在经济预测中的应用你怎么理解统计的研究内容:1、统计学研究的基本内容包括统计对象、统计方法和统计规律。
2、统计对象就是统计研究的课题,称谓统计总体。
3、统计研究方法主要有大量观察法、数量分析法、抽样推断法、实验法等。
④统计规律就是通过大量观察和综合分析所揭示的用数量指标反映的客观现象的本质特征和发展规律。
举例说明分类变量、顺序变量和数值变量:分类变量:表现为不同类别的变量称为分类变量,如“性别”表现为“男”或“女”,“企业所属的行业”表现为“制造业”、“零售业”、“旅游业”等,“学生所在的学院”可能是“商学院”、“法学院”等顺序变量:如果类别有一定的顺序,这样的分类变量称为顺序变量,如考试成绩按等级分为优、良、中、及格、不及格,一个人对事物的态度分为赞成、中立、反对。
这里的“考试成绩等级”、“态度”等就是顺序变量。
数值变量:可以用数字记录其观察结果,这样的变量称为数值变量,如“企业销售额”、“生活费支出”、“掷一枚骰子出现的点数”。
定性数据和定量数据的图示方法各有哪些:1、定性数据的图示:条形图、帕累托图、饼图、环形图2、定量数据的图示:a、分组数据看分布:直方图b、未分组数据看分布:茎叶图、箱线图、垂线图、误差图c、两个变量间的关系:散点图d、比较多个样本的相似性:雷达图和轮廓图直方图与条形图有何区别:1、条形图中的每一个矩形表示一个类别,其宽度没有意义,而直方图的宽度则表示各组的组距。
2、由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
3、条形图主要用于展示定性数据,而直方图则主要用于展示定量数据。
一组数据的分布特征可以从哪几个方面进行描述:1、数据的水平,反映数据的集中程度2、数据的差异,反映各数据的离散程度3、分布的形状,反映数据分布的偏态和峰态说明平均数、中位数和众数的特点及应用场合:平均数也称为均值,它是一组数据相加后除以数据的个数而得到的结果。
平均数是度量数据水平的常用统计量,在参数估计以及假设检验中经常用到。
中位数是一组在数据排序后处于中间位置上的数值,用Me表示。
中位数是用中间位置上的值代表数据水平,其特点是不受极端值影响,在研究收入分配中很有用。
众数与数据出现的次数有关,着眼于对各数据出现的频率的考察,其大小只与这组数据中的部分数据有关,其特点是不受极端值的影响,具有不惟一性,一组数据中可能会有一个人众数,也可能会有多个或没有。
为什么要计算离散系数:极差、平均差、方差和标准差等都是反映数据分散程度的绝对值,其数值的大小取决于原变量值本身水平高低的影响。
它们与原变量值的计量单位相同,采用不同计量单位计量的变量值,其离散程度的测度值也就不同。
因此,为消除变量值水平高低和数量单位不同对离散程度的测度值的影响,需要计算离散系数。
举例说明离散型随机变量和连续性随机变量:离散型随机变量:设X是一个随机变量,如果它全部可能的取值只有有限个或可数无穷个,则称X为一个离散型随机变量。
包括二项分布、泊松分布、超几何分布,如一定时间内某航空公司接到的订票电话数连续型概率分布:包括正态分布、均匀分布和指数分布。
叙述正态分布曲线的特点:正态曲线的图形是关于x=u对称的钟形曲线,且峰值在x=u处。
正态分布的两个参数u和σ一旦确定,正态分布的具体形式也惟一确定,不同参数取值的正态分布构成一个完整的“正态分布族”。
当X的取值向横轴左右两个方向无限延伸时,正态曲线的左右两个尾端也无限渐近横轴,但理论上永远不会与之相交。
④正态随机变量在特定区间上取值的概率由正态曲线下的面积给出,而且其曲线下的总面积等于1解释中心极限定理的含义:随着样本量n的增大(通常要求n>=30),不论原来的总体是否服从正态分布,样本均值的概率分布都将趋于正态分布,其分布的期望值为总体均值u,方差为总体方差的1/n。
这一定理可表述为:从均值为u、方差为σ^2的总体中,抽取样本量为n的随机样本,当n充分大时(通常要求n>=30),样本均值的分布近似服从均值为u,方差为σ^2/n的正态分布。
说明区间估计的基本原理:区间估计,是在点估计的基础上给出总体参数估计的一个估计区间,该区间通常是由样本统计量加减估计误差得到的。
与点估计不同,进行区间估计时,根据样本统计量的抽样分布,可以对统计量与总体参数的接近程度给出的一个概率度量。
简述评价估计量的标准:无偏性:它是指估计量抽样分布的期望值等于被估计的总体参数;有效性:它是指估计量的方差尽可能小;一致性:它是指随着样本量的增大,点估计量的值越来越接近被估计总体的参数解释置信水平的含义:置信水平,是指总体参数值落在样本统计值某一区内的概率;而置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围。
置信区间越大,置信水平越高。
简述样本量与置信水平、总体方差、估计误差的关系样本量与置信水平成正比,在其他条件不变的情况下,置信水平越大,所需的样本量也就越大;样本量与总体方差成正比,总体的差异越大,所要求的样本量也越大;样本量与估计误差的平方成正比,即允许的估计误差的平方越大,所要求的样本量就越大。
解释原假设和备择假设:原假设:它通常是研究者想收集证据予以推翻的假设,用H0表示,原假设所表达的含义总是指参数没有变化或变量之间没有关系,等号“=”总放在原假设上。
备择假设:通常指研究者想收集证据予以支持的假设,用H1或Ha表示。
备择假设所表达的含义是总体参数发生了变化或变量之间有某种关系。
备择假设的形式总是为H1:u≠u0,H1:u<u0或u>u0第一类错误和第二类错误分别是指什么?它们发生的概率大小之间存在怎样的关系:第Ⅰ类错误(弃真错误):原假设为真时拒绝原假设时所犯的错误第Ⅱ类错误(取伪错误):原假设为假时未拒绝原假设当样本容量n确定后,当α变小时,则检验的拒绝域变小,相应的接受域会变大,因此β值也就随之变大;相反,若β变小,则α又会变大.样本量的大小与显著性有怎样的关系:显著性水平与样本的大小密切相关,相关量越大,检验统计量的值也就越大,显著性水平越小,就越有可能拒绝原假设。
相关分析主要解决哪些问题:变量之间是否存在关系如果存在关系,它们之间是什么样的关系变量之间的关系强度如何④样本所反映的变量之间的关系能否代表总体变量之间的关系解释回归模型和估计的回归方程的含义:回归模型是描述因变量y如何依赖于自变量x和误差项的方程。
回归方程是描述因变量y 的期望值如何依赖于自变量x的方程。
估计的回归方程是利用最小二乘法,根据样本数据求出的回归方程的估计。
简述参数最小二乘估计的基本原理:这一公式的x和y的n对观察值,用于描述其关系的直线有多条,用距离观测点最近的一条直线,用它来表示x与y之间的关系与实际数据的误差比其它任何直线都小。
根据这一思想确定直线中未知常数和的方法称为最小二乘法什么是P值?利用P值进行检验和利用统计量进行检验有什么不同?如果能把犯第Ⅰ类错误的真实概率算出来,就可以直接用这个概率做出决策。
而不需要管什么事先给定的显著性水平α,这个犯第Ⅰ类错误的真实概率就是P值。
不同:统计量检验是根据事先确定的显著性水平α围成的拒绝域作出决策,不论检验统计量的值是大是小,只要把它落入拒绝域就拒绝原假设H。
否则就不拒绝H。
这样,无论统计量落在拒绝域的什么位置,你也只能说犯第一错误的概率为α,而用P值检验则能把犯第Ⅰ类错误的真实概率算出来。
获得数据的概率抽样方法有哪些(1)简单随机抽样简单随机抽样又称纯随机抽样,是指在特定总体的所有单位中直接抽取n个组成样本。
它最直观地体现了抽样的基本原理,是最基本的概率抽样。
(2)系统抽样系统抽样也称等距抽样或机械抽样,是按一定的间隔距离抽取样本的方法。
(3)分层抽样分层抽样也叫分类抽样,就是先将总体的所有单位依照一种或几种特征分为若干个子总体,每一个子总体即为一类,然后从每一类中按简单随机抽样或系统随机抽样的办法抽取一个子样本,称为分类样本,它们的集合即为总体样本。
(4)整群抽样整群抽样又称聚类抽样或集体抽样,是将总体按照某种标准划分为一些群体,每一个群体为一个抽样单位,再用随机的方法从这些群体中抽取若干群体,并将所抽出群体中的所有个体集合为总体的样本。
(5)多阶段抽样多阶段抽样又称多级抽样或分段抽样,就是把从总体中抽取样本的过程分成两个或多个阶段进行的抽样方法。
样本量的大小与显著性有怎样的关系通常在做某种统计推断时,显著性水平要求越高,要达到该显著性水平的样本量越大。
样本量越大,检验统计量的值夜就越大,P值就越小,就越有可能拒绝原假设。
反之则相反第1章统计和统计数据1.1 指出下面的变量类型。
(1)年龄。
(2)性别。
(3)汽车产量。
(4)员工对企业某项改革措施的态度(赞成、中立、反对)。
(5)购买商品时的支付方式(现金、信用卡、支票)。
详细答案:(1)数值变量。
(2)分类变量。
(3)数值变量。
(4)顺序变量。
(5)分类变量。
1.2 一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。
(1)这一研究的总体是什么?样本是什么?样本量是多少?(2)“月收入”是分类变量、顺序变量还是数值变量?(3)“消费支付方式”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。
(2)数值变量。
(3)分类变量。
1.3 一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。
(1)这一研究的总体是什么?(2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有的网上购物者”。
(2)分类变量。
1.4 某大学的商学院为了解毕业生的就业倾向,分别在会计专业抽取50人、市场营销专业抽取30、企业管理20人进行调查。
(1)这种抽样方式是分层抽样、系统抽样还是整群抽样?(2)样本量是多少?详细答案:(1)分层抽样。
(2)100。
第3章用统计量描述数据业务窗口处列队3排等待。
为比较哪种排队方式使顾客等待的时间更短,两种排队方式各随机抽取9名顾客,得到第一种排队方式的平均等待时间为7.2分钟,标准差为1.97分钟,第二种排队方式的等待时间(单位:分钟)如下:5.56.6 6.7 6.87.1 7.3 7.4 7.8 7.8(1)计算第二种排队时间的平均数和标准差。