SVM-及SMO算法实现报告
svm实验报告总结

svm实验报告总结SVM实验报告总结支持向量机(SVM)是一种常用的机器学习算法,它在模式识别、分类、回归等领域有着广泛的应用。
本文将对SVM算法进行实验,旨在探究SVM算法的原理、应用和优缺点。
一、实验原理SVM的基本思想是将低维度的数据映射到高维度的空间中,从而使数据在高维空间中更容易被线性分隔。
SVM算法的核心是支持向量,这些支持向量是距离分类决策边界最近的数据点。
SVM通过找到这些支持向量来建立分类器,从而实现数据分类。
二、实验步骤1. 数据预处理本实验使用的数据集是Iris花卉数据集,该数据集包含了三种不同种类的花朵,每种花朵有四个属性:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
首先需要将数据集划分为训练集和测试集,以便在训练模型时进行验证。
2. 模型训练本实验使用Python中的sklearn库来构建SVM分类器。
首先需要选择SVM的核函数,有线性核函数、多项式核函数、径向基核函数等。
在本实验中,我们选择径向基核函数作为SVM的核函数。
接着需要设置SVM的参数,包括C值和gamma值。
C值是惩罚系数,用于平衡模型的分类精度和泛化能力;gamma值是径向基函数的系数,用于控制支持向量的影响范围。
3. 模型评估本实验使用准确率和混淆矩阵来评估模型的性能。
准确率是指模型在测试集上的分类精度,而混淆矩阵则可以用来分析模型在不同类别上的分类情况。
三、实验结果本实验使用径向基核函数的SVM分类器在Iris数据集上进行了实验。
实验结果表明,SVM分类器的准确率达到了97.78%,同时在混淆矩阵中也可以看出模型在不同花朵种类上的分类情况。
实验结果表明,SVM分类器在分类问题上有着较好的表现。
四、实验总结SVM算法是一种常用的机器学习算法,它在模式识别、分类、回归等领域有着广泛的应用。
本实验通过对Iris数据集的实验,探究了SVM算法的原理、应用和优缺点。
实验结果表明,在SVM算法中,径向基核函数是一种比较适用的核函数,在设置SVM参数时需要平衡模型的分类精度和泛化能力。
机器学习SVM(支持向量机)实验报告

实验报告实验名称:机器学习:线性支持向量机算法实现学员: 张麻子学号: *********** 培养类型:硕士年级:专业:所属学院:计算机学院指导教员:****** 职称:副教授实验室:实验日期:ﻬ一、实验目得与要求实验目得:验证SVM(支持向量机)机器学习算法学习情况要求:自主完成。
二、实验内容与原理支持向量机(Support Vector Machine,SVM)得基本模型就是在特征空间上找到最佳得分离超平面使得训练集上正负样本间隔最大。
SVM就是用来解决二分类问题得有监督学习算法。
通过引入了核方法之后SVM也可以用来解决非线性问题。
但本次实验只针对线性二分类问题。
SVM算法分割原则:最小间距最大化,即找距离分割超平面最近得有效点距离超平面距离与最大。
对于线性问题:假设存在超平面可最优分割样本集为两类,则样本集到超平面距离为:需压求取:由于该问题为对偶问题,可变换为:可用拉格朗日乘数法求解。
但由于本实验中得数据集不可以完美得分为两类,即存在躁点。
可引入正则化参数C,用来调节模型得复杂度与训练误差。
作出对应得拉格朗日乘式:对应得KKT条件为:故得出需求解得对偶问题:本次实验使用python编译器,编写程序,数据集共有270个案例,挑选其中70%作为训练数据,剩下30%作为测试数据。
进行了两个实验,一个就是取C值为1,直接进行SVM训练;另外一个就是利用交叉验证方法,求取在前面情况下得最优C值.三、实验器材实验环境:windows7操作系统+python编译器。
四、实验数据(关键源码附后)实验数据:来自UCI机器学习数据库,以Heart Disease数据集为例。
五、操作方法与实验步骤1、选取C=1,训练比例7:3,利用python库sklearn下得SVM()函数进行训练,后对测试集进行测试;2、选取训练比例7:3,C=np、linspace(0、0001,1,30)}。
利用交叉验证方法求出C值得最优解。
支持向量机SMO算法实现(注释详细)
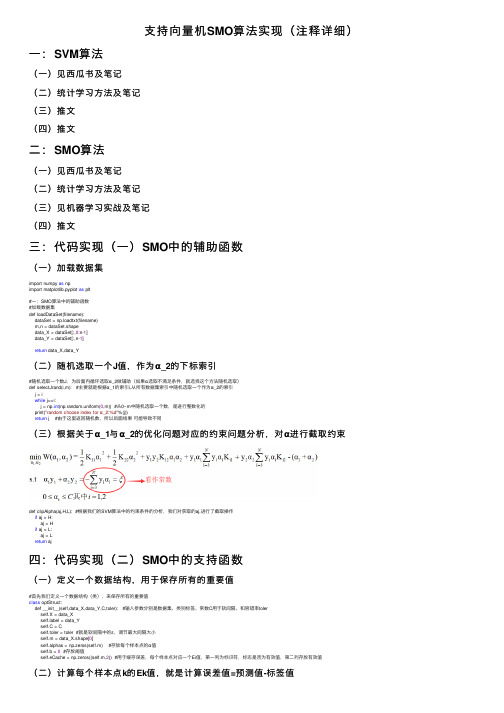
⽀持向量机SMO算法实现(注释详细)⼀:SVM算法(⼀)见西⽠书及笔记(⼆)统计学习⽅法及笔记(三)推⽂(四)推⽂⼆:SMO算法(⼀)见西⽠书及笔记(⼆)统计学习⽅法及笔记(三)见机器学习实战及笔记(四)推⽂三:代码实现(⼀)SMO中的辅助函数(⼀)加载数据集import numpy as npimport matplotlib.pyplot as plt#⼀:SMO算法中的辅助函数#加载数据集def loadDataSet(filename):dataSet = np.loadtxt(filename)m,n = dataSet.shapedata_X = dataSet[:,0:n-1]data_Y = dataSet[:,n-1]return data_X,data_Y(⼆)随机选取⼀个J值,作为α_2的下标索引#随机选取⼀个数J,为后⾯内循环选取α_2做辅助(如果α选取不满⾜条件,就选择这个⽅法随机选取)def selectJrand(i,m): #主要就是根据α_1的索引i,从所有数据集索引中随机选取⼀个作为α_2的索引j = iwhile j==i:j = np.int(np.random.uniform(0,m)) #从0~m中随机选取⼀个数,是进⾏整数化的print("random choose index for α_2:%d"%(j))return j #由于这⾥返回随机数,所以后⾯结果可能导致不同(三)根据关于α_1与α_2的优化问题对应的约束问题分析,对α进⾏截取约束def clipAlpha(aj,H,L): #根据我们的SVM算法中的约束条件的分析,我们对获取的aj,进⾏了截取操作if aj > H:aj = Hif aj < L:aj = Lreturn aj四:代码实现(⼆)SMO中的⽀持函数(⼀)定义⼀个数据结构,⽤于保存所有的重要值#⾸先我们定义⼀个数据结构(类),来保存所有的重要值class optStruct:def __init__(self,data_X,data_Y,C,toler): #输⼊参数分别是数据集、类别标签、常数C⽤于软间隔、和容错率tolerself.X = data_Xbel = data_Yself.C = Cself.toler = toler #就是软间隔中的ε,调节最⼤间隔⼤⼩self.m = data_X.shape[0]self.alphas = np.zeros(self.m) #存放每个样本点的α值self.b = 0 #存放阈值self.eCache = np.zeros((self.m,2)) #⽤于缓存误差,每个样本点对应⼀个Ei值,第⼀列为标识符,标志是否为有效值,第⼆列存放有效值(⼆)计算每个样本点k的Ek值,就是计算误差值=预测值-标签值#计算每个样本点k的Ek值,就是计算误差值=预测值-标签值def calcEk(oS,k):# 根据西⽠书6.24,我们可以知道预测值如何使⽤α值进⾏求解fxk = np.multiply(oS.alphas,bel).T@(oS.X@oS.X[k,:])+oS.b #np.multiply之后还是(m,1),(oS.X@oS.X[k,:])之后是(m,1),通过转置(1,m)@(m,1)-->实数后+b即可得到预测值fx#获取误差值EkEk = fxk - bel[k]return Ek(三)重点:内循环的启发式⽅法,获取最⼤差值|Ei-Ej|对应的Ej的索引J#内循环的启发式⽅法,获取最⼤差值|Ei-Ej|对应的Ej的索引Jdef selectJ(i,oS,Ei): #注意我们要传⼊第⼀个α对应的索引i和误差值Ei,后⾯会⽤到maxK = -1 #⽤于保存临时最⼤索引maxDeltaE = 0 #⽤于保存临时最⼤差值--->|Ei-Ej|Ej = 0 #保存我们需要的Ej误差值#重点:这⾥我们是把SMO最后⼀步(根据最新阈值b,来更新Ei)提到第⼀步来进⾏了,所以这⼀步是⾮常重要的oS.eCache[i] = [1,Ei]#开始获取各个Ek值,⽐较|Ei-Ej|获取Ej的所有#获取所有有效的Ek值对应的索引validECacheList = np.where(oS.eCache[:,0]!=0)[0] #根据误差缓存中第⼀列⾮0,获取对应的有效误差值if len(validECacheList) > 1: #如果有效误差缓存长度⼤于1(因为包括Ei),则正常进⾏获取j值,否则使⽤selectJradn⽅法选取⼀个随机J值for k in validECacheList:if k == i: #相同则不处理continue#开始计算Ek值,进⾏对⽐,获取最⼤差值Ek = calcEk(oS,k)deltaE = abs(Ei - Ek)if deltaE > maxDeltaE: #更新Ej及其索引位置maxK = kmaxDeltaE = deltaEEj = Ekreturn maxK,Ej #返回我们找到的第⼆个变量α_2的位置else: #没有有效误差缓存,则随机选取⼀个索引,进⾏返回j = selectJrand(i,oS.m)Ej = calcEk(oS,j)return j,Ej(四)实现更新Ek操作#实现更新Ek操作,因为除了最后我们需要更新Ei之外,我们在内循环中计算α_1与α_2时还是需要⽤到E1与E2,#因为每次的E1与E2由于上⼀次循环中更新了α值,所以这⼀次也是需要更新E1与E2值,所以单独实现⼀个更新Ek值的⽅法还是有必要的def updateEk(oS,k):Ek = calcEk(oS,k)oS.eCache[k] = [1,Ek] #第⼀列1,表⽰为有效标识五:代码实现(三)SMO中的内循环函数外循环是要找违背KKT条件最严重的样本点(每个样本点对应⼀个α),这⾥我们将外循环的该判别条件放⼊内循环中考虑。
svm实验报告总结

SVM实验报告1. 背景支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,广泛应用于分类问题,特别是二分类问题。
SVM的基本思想是通过找到一个最优超平面,将不同类别的样本分开。
该算法在模式识别、图像分割、文本分类等领域都有较好的性能。
2. 分析2.1 数据集本次实验使用了鸢尾花数据集(Iris Dataset),该数据集是机器学习中应用非常广泛的数据集之一,包含了三种不同的鸢尾花(Setosa、Versicolor、Virginica)的样本,每类样本50个。
2.2 SVM算法SVM算法的核心在于寻找一个最优的超平面,使得不同类别的样本点到超平面的距离最大化。
其决策函数可以表示为:f(x)=sign(w T x+b)其中,w是超平面的法向量,b是超平面的截距。
SVM算法通过构建拉格朗日函数并求解对偶问题,可以得到超平面的参数。
2.3 实验步骤本次实验的具体步骤如下:1.加载数据集:使用机器学习库中的函数加载鸢尾花数据集。
2.数据预处理:对数据进行标准化处理,以便提高模型的训练效果。
3.划分训练集和测试集:将数据集划分为训练集和测试集,用于模型的训练和评估。
4.训练模型:使用训练集对SVM模型进行训练。
5.模型评估:使用测试集对训练好的模型进行评估。
6.结果分析:根据评估结果对模型进行分析,并提出相应的建议。
3. 结果经过实验,得到了以下结果:1.样本标准化前的准确率为82%,样本标准化后的准确率提升到96%。
2.在训练集上的准确率高于测试集,表明模型存在轻微的过拟合。
3.SVM模型在鸢尾花数据集上表现良好,能够对三种鸢尾花进行有效分类。
4. 建议根据实验结果,可以针对模型的性能提出以下建议:1.考虑增加更多的训练样本,以减小模型的过拟合现象。
2.尝试调整超参数,如正则化参数C和核函数参数等,以提高模型的泛化能力。
3.可以尝试使用其他优化算法,如随机梯度下降法等,以加快模型的训练速度。
SVM的SMO算法实现

SVM的SMO算法实现SVM(Support Vector Machine)是一种常用的分类算法,其原理是将数据集映射到一个高维空间中,使得不同类别的样本能够被一个超平面正确分割。
SMO(Sequential Minimal Optimization)算法是一种用于求解SVM问题的优化算法,其核心思想是将大问题分解为一系列的小问题,通过迭代求解这些小问题来得到最优解。
SMO算法允许一次只优化两个变量,即选择两个变量α_i和α_j进行优化。
具体的优化步骤如下:1. 选择一对需要优化的变量α_i和α_j,使用启发式方法选取这两个变量。
一般选择两个变量时,先遍历整个α向量,找到违反KKT条件最严重的点,KKT(Karush-Kuhn-Tucker)条件是SVM问题的最优性条件,通过判断α向量是否满足该条件来选择需要优化的变量。
2.固定其他变量,通过求解子问题的方式更新选择的两个变量。
通过求解两个变量的二次规划问题,得到更新后的α_i和α_j。
3.更新阈值b。
每次更新α_i和α_j之后,都需要计算新的阈值b。
根据KKT条件,选择满足条件的α_i或α_j来更新阈值b。
4.判断终止条件。
迭代过程中,根据一定的终止条件来决定是否终止算法,一般可以设置最大迭代次数或目标误差。
SMO算法的具体实现如下:1.初始化α向量、阈值b和错误率向量E。
2.选择需要优化的两个变量α_i和α_j。
3.计算变量α_i和α_j的边界。
4.根据变量α_i和α_j是否满足边界来选择优化方法。
5.在选择的两个变量上进行优化。
求解两个变量的二次规划子问题,得到更新后的α_i和α_j。
6.更新阈值b。
7.更新错误率向量E。
8.判断终止条件。
如果满足终止条件则停止迭代,否则返回第2步继续迭代。
完整的SMO算法实现如下:```pythondef smo(X, y, C, tol, max_iter):m, n = X.shapealpha = np.zeros(m)b=0iters = 0while iters < max_iter:alpha_changed = 0for i in range(m):E_i = np.sum(alpha * y * kernel(X, X[i, :])) + b - y[i]if (y[i] * E_i < -tol and alpha[i] < C) or (y[i] * E_i > tol and alpha[i] > 0):j = select_second_alpha(i, m)E_j = np.sum(alpha * y * kernel(X, X[j, :])) + b - y[j]alpha_i_old = alpha[i]alpha_j_old = alpha[j]if y[i] != y[j]:L = max(0, alpha[j] - alpha[i])H = min(C, C + alpha[j] - alpha[i])else:L = max(0, alpha[i] + alpha[j] - C)H = min(C, alpha[i] + alpha[j])if L == H:continueeta = 2 * kernel(X[i, :], X[j, :]) - kernel(X[i, :], X[i, :]) - kernel(X[j, :], X[j, :])if eta >= 0:continuealpha[j] = alpha[j] - y[j] * (E_i - E_j) / etaalpha[j] = clip_alpha(alpha[j], H, L)continuealpha[i] = alpha[i] + y[i] * y[j] * (alpha_j_old - alpha[j]) b1 = b - E_i - y[i] * (alpha[i] - alpha_i_old) *kernel(X[i, :], X[i, :]) - y[j] * (alpha[j] - alpha_j_old) * kernel(X[i, :], X[j, :])b2 = b - E_j - y[i] * (alpha[i] - alpha_i_old) *kernel(X[i, :], X[j, :]) - y[j] * (alpha[j] - alpha_j_old) * kernel(X[j, :], X[j, :])if 0 < alpha[i] < C:b=b1elif 0 < alpha[j] < C:b=b2else:b=(b1+b2)/2alpha_changed += 1if alpha_changed == 0:iters += 1else:iters = 0return alpha, b```以上是SMO算法的简单实现,其中使用了一些辅助函数(如选择第二个变量、计算核函数等),这些函数需要根据具体的问题进行实现。
SVM——详细讲解SMO算法优化两个变量以及变量的选择

SVM——详细讲解SMO算法优化两个变量以及变量的选择支持向量机(SVM)是一种二分类模型,它在分类超平面的构建过程中,通过优化二次规划问题求解得到最优的超平面。
而序列最小最优化(Sequential Minimal Optimization,SMO)算法则是一种用于求解SVM 二次规划问题的简化算法。
在SVM中,分类超平面可以表示为w*x+b=0,其中w为法向量,b为截距,x为输入样本。
SVM的目标是找到具有最大边界的超平面,使得训练样本与超平面的距离最大化。
优化SVM的问题可以转化为求解以下二次规划问题:\begin{align*}\min\limits_{\alpha} & \quad \frac{1}{2}\sum_{i=1}^{N}{\sum_{j=1}^{N}{\alpha_i \alpha_j y_i y_j K(x_i, x_j)}} - \sum_{i=1}^{N}{\alpha_i}\\s.t. & \quad \sum_{i=1}^{N}{\alpha_i y_i} = 0 \\& \quad 0 \leq \alpha_i \leq C, \quad i = 1, 2, ..., N\end{align*}\]其中,N是训练样本数量,C是惩罚参数,K(x_i,x_j)是核函数。
SMO算法通过迭代优化变量alpha_i和alpha_j,来逐渐优化整个二次规划问题。
SMO算法的核心步骤有两个:选择变量和优化变量。
1.变量的选择:在每次迭代中,SMO算法通过两个嵌套循环选择优化变量alpha_i和alpha_j。
首先,外层循环选择第一个变量alpha_i,通过遍历所有训练样本点,选择违反KKT条件的样本点。
KKT条件是SVM最优解必须满足的条件,对于正样本来说,条件是alpha_i=0,对于负样本来说,条件是alpha_i=C。
如果选择到了违反KKT条件的alpha_i,就进入内层循环。
SVM算法原理及SMO算法概述

SVM算法原理及SMO算法概述SVM (Support Vector Machine) 是一种广泛应用于分类和回归问题的机器学习算法。
它基于统计学习理论中的VC理论,使用间隔最大化的方法进行分类。
在SVM中,我们将训练数据集视为一个在高维空间中的点集。
SVM的目标是找到一个超平面,能够将不同类别的点分开,并且使其离超平面的距离最大化。
这个超平面被称为最优分隔超平面。
具体来说,SVM算法的原理如下:1.数据预处理:将训练样本映射到高维特征空间,使得样本点能够被线性分隔。
2.寻找最优超平面:在高维特征空间中,寻找能够将不同类别的点分开的超平面。
通常情况下,有多个超平面可以进行分类,而SVM的目标是找到使得间隔最大化的那个超平面。
3.使用支持向量进行分类:SVM找到了最优超平面后,它会选择离该超平面最近的一些点,这些点被称为支持向量。
分类时,SVM根据测试点和支持向量的关系进行判断。
SMO (Sequential Minimal Optimization) 是一种用来训练SVM的优化算法。
传统的SVM算法需要同时优化所有的模型参数,计算量较大。
而SMO算法则是一种序列化的简化方法,每次只优化两个模型参数。
SMO算法的主要思想如下:1.初始化模型参数:选择两个待优化的参数α1和α22.选择两个参数:基于一定的策略,选择两个不同的参数α进行优化。
3.通过求解两个参数的约束最优化问题,更新模型参数。
4.更新阈值和偏置:根据更新后的模型参数,计算出新的阈值和偏置。
5.判断终止条件:检查是否满足终止条件,如果满足则停止优化,否则返回第2步。
SMO算法的核心在于选择两个参数进行优化,并通过解决约束最优化问题来更新参数。
通过反复迭代这个过程,最终得到训练好的SVM模型。
SMO算法的优点是可以有效地处理大规模数据集,并且能够避免陷入局部最优解。
同时,SMO算法还可以引入核函数,使得SVM具有非线性分类和回归能力。
总结来说,SVM是一种基于统计学习理论的分类和回归算法,通过间隔最大化的方法寻找最优分隔超平面。
【精编范文】svm算法实验实验报告-优秀word范文 (13页)

本文部分内容来自网络整理,本司不为其真实性负责,如有异议或侵权请及时联系,本司将立即删除!== 本文为word格式,下载后可方便编辑和修改! ==svm算法实验实验报告篇一:SVM 实验报告SVM分类算法一、数据源说明1、数据源说远和理解:采用的实验数据源为第6组:The Insurance Company Benchmark (COIL 201X) TICDATA201X.txt: 这个数据集用来训练和检验预测模型,并且建立了一个5822个客户的记录的描述。
每个记录由86个属性组成,包含社会人口数据(属性1-43)和产品的所有关系(属性44-86 )。
社会人口数据是由派生邮政编码派生而来的,生活在具有相同邮政编码地区的所有客户都具有相同的社会人口属性。
第86个属性:“大篷车:家庭移动政策” ,是我们的目标变量。
共有5822条记录,根据要求,全部用来训练。
TICEVAL201X.txt: 这个数据集是需要预测( 4000个客户记录)的数据集。
它和TICDATA201X.txt它具有相同的格式,只是没有最后一列的目标记录。
我们只希望返回预测目标的列表集,所有数据集都用制表符进行分隔。
共有4003(自己加了三条数据),根据要求,用来做预测。
TICTGTS201X.txt:最终的目标评估数据。
这是一个实际情况下的目标数据,将与我们预测的结果进行校验。
我们的预测结果将放在result.txt文件中。
数据集理解:本实验任务可以理解为分类问题,即分为2类,也就是数据源的第86列,可以分为0、1两类。
我们首先需要对TICDATA201X.txt进行训练,生成model,再根据model进行预测。
2、数据清理代码中需要对数据集进行缩放的目的在于:A、避免一些特征值范围过大而另一些特征值范围过小;B、避免在训练时为了计算核函数而计算内积的时候引起数值计算的困难。
因此,通常将数据缩放到 [ -1,1] 或者是 [0,1] 之间。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
最大距离Maximum Marginal
选择使得间隙最大的函数作为分割平面是由很多道理的,比如说从概
率的角度上来说,就是使得置信度最小的点置信度最大(听起来很拗 口),从实践的角度来说,这样的效果非常好,等等。
最大距离
(x,y) M
M
wx+b=1 f(x)=wx+b=0 wx+b=-1
例如,当训练点数目超过4000时,存储核函数矩阵需要多达128兆。
求解方法:坐标上升法
min
a l 1 l l y i y j i j K ( x i , x j ) i 2 i 1 j 1 i 1
固定除 i 之外的所有参数,这时W可看作只是关于 i 的函数,那么直接对 i
问题提出
线性可分的分类问题:(令黑色的点 = -1, 白色的点 =
+1)
f ( x) wr x b
+1 -1
所以当有一个新的点x需要预测属于哪个分类的时候,我们用sgn(f(x)),
就可以预测了,sgn表示符号函数,当f(x) > 0的时候,sgn(f(x)) = +1, 当f(x) < 0的时候sgn(f(x)) = –1。
w ,b a
f ( x) max min
a w ,b
f ( x)
求解
将两式带回L(w,b,a)得到对偶问题的表达式
1 2 L(w, b, a) w ai ( yi (w xi b) 1) 2 1 L(w, b, a) ai yi xi a j y j x j ai yi w xi ai yi b ai 2 i, j
l
s.t.
y
i 1 i
l
i
0
x,y为已知数
核函数
线性不可分的情况
我们可以为分错的点加上一点惩罚,对一个分错的点的惩罚函数就是
这个点到其正确位置的距离:
软间隔C-SVM
C是一个由用户去指定的系数,表示对分错的点加入多少的 惩罚,当C很大的时候,分错的点就会更少,但是过拟合的 情况可能会比较严重,当C很小的时候,分错的点可能会很 多,不过可能由此得到的模型也会不太正确
软支持向量机求解
构造拉格朗日公式:
求偏导数:
求解问题
数据集合:
T {( x1, y1 ),...,( xl , yl )} (Rn y)l
xi Rn , yi Y {1,1}, i 1,...,l
优化目标:
max
a
1 l l i yi y j i j K( xi , x j ) 2 i 1 j 1 i 1
由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算
(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存
和运算时间。针对以上问题的主要改进有有J.Platt的SMO算法、T.Joachims的 SVM、C.J.C.Burges等的PCGC、张学工的CSVM以及O.L.Mangasarian等的SOR 算法
求导优化即可。
可以通过更改优化顺序来使W能够更快地增加并收敛。 如果W在内循环中能够很快地达到最优,那么坐标上升法会是一个很高效的
求极值方法。
求解问题
数据集合:
T {( x1, y1 ),...,( xl , yl )} (Rn y)l
xi Rn , yi Y {1,1}, i 1,...,l
优化目标:
max
a
1 l l i yi y j i j K( xi , x j ) 2 i 1 j 1 i 1
(2) 用SVM解决多分类问题存在困难
经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一
般要解决多类的分类问题。可以通过多个二类支持向量机的组合来解决。主要有一 对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合 来解决。主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的 分类精度。如:与粗集理论结合,形成一种优势互补的多类问题的组合分类器。
维空间的非线性映射;
(2)对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思
想是SVM方法的核心;
(3)支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支
持向量。因此,模型需要存储空间小,算法鲁棒性强;
(4)无序任何前提假设,不涉及概率测度;
(1) SVM算法对大规模训练样本难以实施
xi Rn , yi Y {1,1}, i 1,...,l
1 w 2
2
优化目标:
min
s.t.
w xi b 1, yi 1 w xi b 1, yi 1
x,y为已知数
求解
建立拉格朗日公式:
求偏导数:
求解:对偶问题
min max
f ( x, y ) w w f ( x, y ) w w 1 w w
M
目标函数: 等价于: 因为 w 单调, : 并且为了计算方便
max 2M
2 w
min
min
w
1 w 2
2
求解问题
数据集合:
T {( x1, y1 ),...,( xl , yl )} (Rn y)l
SVM 算法与实现
2011 – 11 -18
报告内容
SVM简介
求解算法-SMO优化算法
多分类问题
系统演示
A+
Ax 0w = í à 1 0 Separating Surface: x w = í
w
SVM算法特点
SVM有如下主要几个特点:
(1)非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高
l
s.t.
y
i 1 i
l
i
0
i 1,...,l
0 i C,
其中C为人为设定,x,y为已知数
问题?
实际上在处理大型问题时,由于存储和计算两方面的要求,这些算法
往往会失效。
这些算法都要存储与训练集相应的核矩阵,然而存储核矩阵所需要的
内存是随着训练集中训练点数L的平凡增长的。