SVM-及SMO算法实现
SVM-及SMO算法实现报告

最大距离Maximum Marginal
选择使得间隙最大的函数作为分割平面是由很多道理的,比如说从概
率的角度上来说,就是使得置信度最小的点置信度最大(听起来很拗 口),从实践的角度来说,这样的效果非常好,等等。
最大距离
(x,y) M
M
wx+b=1 f(x)=wx+b=0 wx+b=-1
例如,当训练点数目超过4000时,存储核函数矩阵需要多达128兆。
求解方法:坐标上升法
min
a l 1 l l y i y j i j K ( x i , x j ) i 2 i 1 j 1 i 1
固定除 i 之外的所有参数,这时W可看作只是关于 i 的函数,那么直接对 i
问题提出
线性可分的分类问题:(令黑色的点 = -1, 白色的点 =
+1)
f ( x) wr x b
+1 -1
所以当有一个新的点x需要预测属于哪个分类的时候,我们用sgn(f(x)),
就可以预测了,sgn表示符号函数,当f(x) > 0的时候,sgn(f(x)) = +1, 当f(x) < 0的时候sgn(f(x)) = –1。
w ,b a
f ( x) max min
a w ,b
f ( x)
求解
将两式带回L(w,b,a)得到对偶问题的表达式
1 2 L(w, b, a) w ai ( yi (w xi b) 1) 2 1 L(w, b, a) ai yi xi a j y j x j ai yi w xi ai yi b ai 2 i, j
l
支持向量机SMO算法实现(注释详细)
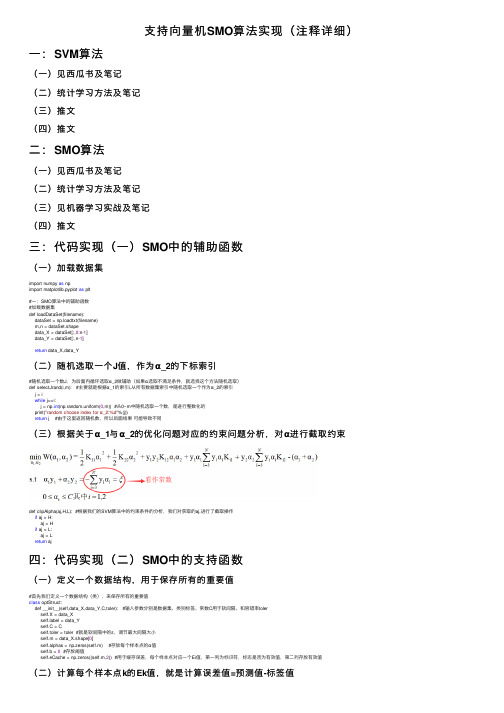
⽀持向量机SMO算法实现(注释详细)⼀:SVM算法(⼀)见西⽠书及笔记(⼆)统计学习⽅法及笔记(三)推⽂(四)推⽂⼆:SMO算法(⼀)见西⽠书及笔记(⼆)统计学习⽅法及笔记(三)见机器学习实战及笔记(四)推⽂三:代码实现(⼀)SMO中的辅助函数(⼀)加载数据集import numpy as npimport matplotlib.pyplot as plt#⼀:SMO算法中的辅助函数#加载数据集def loadDataSet(filename):dataSet = np.loadtxt(filename)m,n = dataSet.shapedata_X = dataSet[:,0:n-1]data_Y = dataSet[:,n-1]return data_X,data_Y(⼆)随机选取⼀个J值,作为α_2的下标索引#随机选取⼀个数J,为后⾯内循环选取α_2做辅助(如果α选取不满⾜条件,就选择这个⽅法随机选取)def selectJrand(i,m): #主要就是根据α_1的索引i,从所有数据集索引中随机选取⼀个作为α_2的索引j = iwhile j==i:j = np.int(np.random.uniform(0,m)) #从0~m中随机选取⼀个数,是进⾏整数化的print("random choose index for α_2:%d"%(j))return j #由于这⾥返回随机数,所以后⾯结果可能导致不同(三)根据关于α_1与α_2的优化问题对应的约束问题分析,对α进⾏截取约束def clipAlpha(aj,H,L): #根据我们的SVM算法中的约束条件的分析,我们对获取的aj,进⾏了截取操作if aj > H:aj = Hif aj < L:aj = Lreturn aj四:代码实现(⼆)SMO中的⽀持函数(⼀)定义⼀个数据结构,⽤于保存所有的重要值#⾸先我们定义⼀个数据结构(类),来保存所有的重要值class optStruct:def __init__(self,data_X,data_Y,C,toler): #输⼊参数分别是数据集、类别标签、常数C⽤于软间隔、和容错率tolerself.X = data_Xbel = data_Yself.C = Cself.toler = toler #就是软间隔中的ε,调节最⼤间隔⼤⼩self.m = data_X.shape[0]self.alphas = np.zeros(self.m) #存放每个样本点的α值self.b = 0 #存放阈值self.eCache = np.zeros((self.m,2)) #⽤于缓存误差,每个样本点对应⼀个Ei值,第⼀列为标识符,标志是否为有效值,第⼆列存放有效值(⼆)计算每个样本点k的Ek值,就是计算误差值=预测值-标签值#计算每个样本点k的Ek值,就是计算误差值=预测值-标签值def calcEk(oS,k):# 根据西⽠书6.24,我们可以知道预测值如何使⽤α值进⾏求解fxk = np.multiply(oS.alphas,bel).T@(oS.X@oS.X[k,:])+oS.b #np.multiply之后还是(m,1),(oS.X@oS.X[k,:])之后是(m,1),通过转置(1,m)@(m,1)-->实数后+b即可得到预测值fx#获取误差值EkEk = fxk - bel[k]return Ek(三)重点:内循环的启发式⽅法,获取最⼤差值|Ei-Ej|对应的Ej的索引J#内循环的启发式⽅法,获取最⼤差值|Ei-Ej|对应的Ej的索引Jdef selectJ(i,oS,Ei): #注意我们要传⼊第⼀个α对应的索引i和误差值Ei,后⾯会⽤到maxK = -1 #⽤于保存临时最⼤索引maxDeltaE = 0 #⽤于保存临时最⼤差值--->|Ei-Ej|Ej = 0 #保存我们需要的Ej误差值#重点:这⾥我们是把SMO最后⼀步(根据最新阈值b,来更新Ei)提到第⼀步来进⾏了,所以这⼀步是⾮常重要的oS.eCache[i] = [1,Ei]#开始获取各个Ek值,⽐较|Ei-Ej|获取Ej的所有#获取所有有效的Ek值对应的索引validECacheList = np.where(oS.eCache[:,0]!=0)[0] #根据误差缓存中第⼀列⾮0,获取对应的有效误差值if len(validECacheList) > 1: #如果有效误差缓存长度⼤于1(因为包括Ei),则正常进⾏获取j值,否则使⽤selectJradn⽅法选取⼀个随机J值for k in validECacheList:if k == i: #相同则不处理continue#开始计算Ek值,进⾏对⽐,获取最⼤差值Ek = calcEk(oS,k)deltaE = abs(Ei - Ek)if deltaE > maxDeltaE: #更新Ej及其索引位置maxK = kmaxDeltaE = deltaEEj = Ekreturn maxK,Ej #返回我们找到的第⼆个变量α_2的位置else: #没有有效误差缓存,则随机选取⼀个索引,进⾏返回j = selectJrand(i,oS.m)Ej = calcEk(oS,j)return j,Ej(四)实现更新Ek操作#实现更新Ek操作,因为除了最后我们需要更新Ei之外,我们在内循环中计算α_1与α_2时还是需要⽤到E1与E2,#因为每次的E1与E2由于上⼀次循环中更新了α值,所以这⼀次也是需要更新E1与E2值,所以单独实现⼀个更新Ek值的⽅法还是有必要的def updateEk(oS,k):Ek = calcEk(oS,k)oS.eCache[k] = [1,Ek] #第⼀列1,表⽰为有效标识五:代码实现(三)SMO中的内循环函数外循环是要找违背KKT条件最严重的样本点(每个样本点对应⼀个α),这⾥我们将外循环的该判别条件放⼊内循环中考虑。
SMO方法的实现及证明

SMO 方法的实现及证明1.问题的阐述SVM 是从线性可分情形下的最优分类面发展而来。
基本思想可以用图(2-16)的二维情况说明。
图2-16 线性可分情况下的最优分类线图中实心点和空心点代表两类样本,H 为分类线H1,H2分别为过各类中离分界线最近的样本且平行于分类线的直线,它们之间的距离叫做分类间隔(margin)。
所谓最优分类线就是要求分类线不仅能将两类正确分开(训练错误率为0),而且使分类间隔最大。
推广到一般线性可分情形,假设分类方程为0,=+><b ωx 1,1{,−+∈∈y R d x ,对其进行归一化,样本集,满足},,,2,1),,(=n i y i i x K 01),(≥−+><b y i ωx i(1)构造损失函数作为目标函数及约束条件,即:()∑+=ii C w W ξ2:minimize 2α(2-a) ()i b x w y i i T i ∀−≥+,1 subject to ξ(2-b)i i ∀≥,0ξ(2-c)经过拉格朗日变换以及KKT 定理推导,式子变为:0 subject to 21)(:minimize ,=≤≤−=∑∑∑iii i ij i ji j i j i i yCx x y y W αααααα(3)引入核函数,最后的目标函数变为:()iC y K y y W i ni i i n i nj j i j i ni i ∀≤≤=−=∑∑∑∑====,00 subject to 21)(: maximize 1111ααααααj i x ,x (4)改写为矩阵相乘的格式,得到:l i C f i T ,....,1,00 subject to 21)(minT =≤≤=−=ααy αe Q αααT(5)其中e 为全1向量,为所有变量的上界,为C Q l l ×的半正定矩阵。
训练向量通过i x φ函数被映射到更高维的空间(可能为无穷维), ,其中为核函数。
svm求解 序列最小优化算法

svm求解序列最小优化算法摘要:1.SMO 算法概述2.SMO 算法的关键步骤3.SMO 算法的代码实践4.SMO 算法在支持向量机中的应用5.总结正文:一、SMO 算法概述序列最小优化算法(Sequential Minimal Optimization,简称SMO)是一种求解支持向量机(Support Vector Machine,简称SVM)模型参数的迭代算法。
它通过每次优化一个变量,直至找到最优解,从而提高模型的预测性能。
二、SMO 算法的关键步骤1.初始化参数:初始化拉格朗日乘子α和阈值b。
2.预测误差:计算当前参数下的预测误差。
3.确定最小化目标:根据预测误差,确定需要最小化的目标函数。
4.优化拉格朗日乘子:通过最小化目标函数,更新拉格朗日乘子。
5.检查停止条件:当满足停止条件(如达到迭代次数限制或预测误差足够小)时,结束迭代。
6.输出结果:输出当前最优参数。
三、SMO 算法的代码实践以下是使用Python 实现SMO 算法的简单示例:```pythonimport numpy as npdef predict_error(X, y, alpha, b, X_test):# 计算预测误差passdef minimize_alpha(alpha, X, y, b, X_test):# 优化拉格朗日乘子passdef smo(X, y, max_iter, tol):# 初始化参数alpha = np.zeros(len(X[0]))b = 0# 迭代for _ in range(max_iter):# 计算预测误差error = predict_error(X, y, alpha, b, X_test)# 确定最小化目标if error > tol:# 优化拉格朗日乘子alpha = minimize_alpha(alpha, X, y, b, X_test)else:# 检查停止条件breakreturn alpha, b# 示例:使用SMO 算法构建半监督式支持向量机模型#...# 示例:使用SMO 算法求解序列最小优化问题#...```四、SMO 算法在支持向量机中的应用SMO 算法在支持向量机中应用广泛,可以用于求解分类问题和回归问题。
机器学习——支持向量机(SVM)之拉格朗日乘子法,KKT条件以及简化版SMO算法分析

机器学习——⽀持向量机(SVM)之拉格朗⽇乘⼦法,KKT条件以及简化版SMO算法分析SVM有很多实现,现在只关注其中最流⾏的⼀种实现,即序列最⼩优化(Sequential Minimal Optimization,SMO)算法,然后介绍如何使⽤⼀种核函数(kernel)的⽅式将SVM扩展到更多的数据集上。
1.基于最⼤间隔分隔数据⼏个概念:1.线性可分(linearly separable):对于图6-1中的圆形点和⽅形点,如果很容易就可以在图中画出⼀条直线将两组数据点分开,就称这组数据为线性可分数据2.分隔超平⾯(separating hyperplane):将数据集分隔开来的直线称为分隔超平⾯3.如果数据集是1024维的,那么就需要⼀个1023维的超平⾯来对数据进⾏分隔4.间隔(margin):数据点到分隔⾯的距离称为间隔5.⽀持向量(support vector):离分隔超平⾯最近的那些点⽀持向量机的优点:泛化错误率低,计算开销不⼤,结果易解释⽀持向量机的缺点:对参数调节和核函数的选择敏感,原始分类器不加修改仅适⽤于处理⼆类问题适⽤数据类型:数值型和标称型数据2.寻找最⼤间隔如何求解数据集的最佳分隔直线?分隔超平⾯的形式可以写成其中 w = (w1,w2,w3...wd)为法向量,决定了超平⾯的⽅向,其中d等于数据的维度,这很好理解,假设⼆维的(x1,x2)点可以被 ax+b=0 分隔,这⾥⾯直线 ax+b=0 是⼀维的,但是这⾥⾯a和x都是⼆维的b为位移项,决定了超平⾯与原点之间的距离对于图6-3中A点到分隔直线的距离为表⽰向量的模,,w与w共轭的内积再开⽅假设超平⾯(w,b)能将训练样本正确分类,即对于 ,有则两个异类⽀持向量到超平⾯的距离之和为欲找到具有“最⼤间隔(maximum margin)”的划分超平⾯,也就是要找到能满⾜中约束的参数w和b,使得最⼤,即 ,其中约束条件为 s.t. ,其实这个约束条件就是把两个不等式合并成了⼀个显然,为了最⼤化间隔,仅需最⼤化,这等价于最⼩化,于是上式可重写为 ,其中约束条件为 s.t.这就是⽀持向量机(Support Vector Machine,简称SVM)的基本型对于这类带有不等式约束的最优化问题,可以使⽤拉格朗⽇乘⼦法(Lagrange Multiplier)对其进⾏求解。
SVM算法说明和优化算法介绍

SVM算法说明和优化算法介绍SVM(Support Vector Machine,支持向量机)是一种常用的机器学习算法,用于分类和回归分析。
SVM的基本思想是通过在特征空间中构造一个最优超平面,将不同类别的样本分开。
本文将为您介绍SVM的基本原理、分类和回归问题的实现方法以及一些常见的优化算法。
SVM的基本原理是寻找一个能够最大化类别间间隔(margin)的超平面,从而达到更好的分类效果。
在特征空间中,样本点可以用向量表示,所以SVM也可以看作是在特征空间中寻找一个能够最优分割两类样本的超平面。
为了找到这个最优超平面,SVM使用了支持向量(Support Vector),即离超平面最近的样本点。
支持向量到超平面的距离被称为间隔,而最优超平面使得间隔最大化。
对于线性可分的情况,SVM的目标是最小化一个损失函数,同时满足约束条件。
损失函数由间隔和误分类样本数量组成,约束条件则包括对超平面的限制条件。
通过求解优化问题,可以得到最优超平面的参数值。
对于非线性可分的情况,SVM使用核函数进行转换,将低维特征空间中的样本映射到高维特征空间中,从而使得样本在高维空间中线性可分。
SVM在分类问题中的应用广泛,但也可以用于回归问题。
在回归问题中,SVM的目标是找到一个超平面,使得点到该平面的距离尽可能小,并且小于一个给定的阈值。
SVM回归的思想是通过引入一些松弛变量,允许样本点在一定程度上偏离超平面来处理异常数据,从而得到更好的回归结果。
在实际应用中,SVM的性能和效果受到许多因素的影响,如数据集的分布、样本的数量和特征的选择等。
为了进一步优化SVM的性能,许多改进算法被提出。
下面我们介绍几种常见的SVM优化算法。
1.序列最小优化算法(SMO):SMO是一种简单、高效的SVM优化算法。
它通过将大优化问题分解为多个小优化子问题,并使用启发式方法进行求解。
每次选择两个变量进行更新,并通过迭代优化这些变量来寻找最优解。
SVM的SMO算法实现

SVM的SMO算法实现SVM(Support Vector Machine)是一种常用的分类算法,其原理是将数据集映射到一个高维空间中,使得不同类别的样本能够被一个超平面正确分割。
SMO(Sequential Minimal Optimization)算法是一种用于求解SVM问题的优化算法,其核心思想是将大问题分解为一系列的小问题,通过迭代求解这些小问题来得到最优解。
SMO算法允许一次只优化两个变量,即选择两个变量α_i和α_j进行优化。
具体的优化步骤如下:1. 选择一对需要优化的变量α_i和α_j,使用启发式方法选取这两个变量。
一般选择两个变量时,先遍历整个α向量,找到违反KKT条件最严重的点,KKT(Karush-Kuhn-Tucker)条件是SVM问题的最优性条件,通过判断α向量是否满足该条件来选择需要优化的变量。
2.固定其他变量,通过求解子问题的方式更新选择的两个变量。
通过求解两个变量的二次规划问题,得到更新后的α_i和α_j。
3.更新阈值b。
每次更新α_i和α_j之后,都需要计算新的阈值b。
根据KKT条件,选择满足条件的α_i或α_j来更新阈值b。
4.判断终止条件。
迭代过程中,根据一定的终止条件来决定是否终止算法,一般可以设置最大迭代次数或目标误差。
SMO算法的具体实现如下:1.初始化α向量、阈值b和错误率向量E。
2.选择需要优化的两个变量α_i和α_j。
3.计算变量α_i和α_j的边界。
4.根据变量α_i和α_j是否满足边界来选择优化方法。
5.在选择的两个变量上进行优化。
求解两个变量的二次规划子问题,得到更新后的α_i和α_j。
6.更新阈值b。
7.更新错误率向量E。
8.判断终止条件。
如果满足终止条件则停止迭代,否则返回第2步继续迭代。
完整的SMO算法实现如下:```pythondef smo(X, y, C, tol, max_iter):m, n = X.shapealpha = np.zeros(m)b=0iters = 0while iters < max_iter:alpha_changed = 0for i in range(m):E_i = np.sum(alpha * y * kernel(X, X[i, :])) + b - y[i]if (y[i] * E_i < -tol and alpha[i] < C) or (y[i] * E_i > tol and alpha[i] > 0):j = select_second_alpha(i, m)E_j = np.sum(alpha * y * kernel(X, X[j, :])) + b - y[j]alpha_i_old = alpha[i]alpha_j_old = alpha[j]if y[i] != y[j]:L = max(0, alpha[j] - alpha[i])H = min(C, C + alpha[j] - alpha[i])else:L = max(0, alpha[i] + alpha[j] - C)H = min(C, alpha[i] + alpha[j])if L == H:continueeta = 2 * kernel(X[i, :], X[j, :]) - kernel(X[i, :], X[i, :]) - kernel(X[j, :], X[j, :])if eta >= 0:continuealpha[j] = alpha[j] - y[j] * (E_i - E_j) / etaalpha[j] = clip_alpha(alpha[j], H, L)continuealpha[i] = alpha[i] + y[i] * y[j] * (alpha_j_old - alpha[j]) b1 = b - E_i - y[i] * (alpha[i] - alpha_i_old) *kernel(X[i, :], X[i, :]) - y[j] * (alpha[j] - alpha_j_old) * kernel(X[i, :], X[j, :])b2 = b - E_j - y[i] * (alpha[i] - alpha_i_old) *kernel(X[i, :], X[j, :]) - y[j] * (alpha[j] - alpha_j_old) * kernel(X[j, :], X[j, :])if 0 < alpha[i] < C:b=b1elif 0 < alpha[j] < C:b=b2else:b=(b1+b2)/2alpha_changed += 1if alpha_changed == 0:iters += 1else:iters = 0return alpha, b```以上是SMO算法的简单实现,其中使用了一些辅助函数(如选择第二个变量、计算核函数等),这些函数需要根据具体的问题进行实现。
SVM——详细讲解SMO算法优化两个变量以及变量的选择

SVM——详细讲解SMO算法优化两个变量以及变量的选择支持向量机(SVM)是一种二分类模型,它在分类超平面的构建过程中,通过优化二次规划问题求解得到最优的超平面。
而序列最小最优化(Sequential Minimal Optimization,SMO)算法则是一种用于求解SVM 二次规划问题的简化算法。
在SVM中,分类超平面可以表示为w*x+b=0,其中w为法向量,b为截距,x为输入样本。
SVM的目标是找到具有最大边界的超平面,使得训练样本与超平面的距离最大化。
优化SVM的问题可以转化为求解以下二次规划问题:\begin{align*}\min\limits_{\alpha} & \quad \frac{1}{2}\sum_{i=1}^{N}{\sum_{j=1}^{N}{\alpha_i \alpha_j y_i y_j K(x_i, x_j)}} - \sum_{i=1}^{N}{\alpha_i}\\s.t. & \quad \sum_{i=1}^{N}{\alpha_i y_i} = 0 \\& \quad 0 \leq \alpha_i \leq C, \quad i = 1, 2, ..., N\end{align*}\]其中,N是训练样本数量,C是惩罚参数,K(x_i,x_j)是核函数。
SMO算法通过迭代优化变量alpha_i和alpha_j,来逐渐优化整个二次规划问题。
SMO算法的核心步骤有两个:选择变量和优化变量。
1.变量的选择:在每次迭代中,SMO算法通过两个嵌套循环选择优化变量alpha_i和alpha_j。
首先,外层循环选择第一个变量alpha_i,通过遍历所有训练样本点,选择违反KKT条件的样本点。
KKT条件是SVM最优解必须满足的条件,对于正样本来说,条件是alpha_i=0,对于负样本来说,条件是alpha_i=C。
如果选择到了违反KKT条件的alpha_i,就进入内层循环。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
求导优化即可。
可以通过更改优化顺序来使W能够更快地增加并收敛。 如果W在内循环中能够很快地达到最优,那么坐标上升法会是一个很高效的
求极值方法。
问题?
固定以外的所有参数,那么将不再是变量(可以由其他值推出),因
为问题中规定了
=>
因此,我们最少一次需要选取两个参数做优化,比如
i
和 j ,此时
l 1 l 1 1 l l 1 i y1 yi K ( xi , x1 ) 2 i y 2 yi K ( xi , x2 ) i j yi y j K ( xi , x j ) 2 i 3 2 i 3 2 i 3 j 3
目标函数:
其中:
求偏导:
带入w, v: 求得:
SVM 算法与实现
2011 – 11 -18
报告内容
SVM简介
求解算法-SMO优化算法
多分类问题
系统演示
A+
Ax 0w = í à 1 0 Separating Surface: x w = í
w
SVM算法特点
SVM有如下主要几个特点:
(1)非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高
维空间的非线性映射;
(2)对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思
想是SVM方法的核心;
(3)支持向量是SVM的训练结果,在。因此,模型需要存储空间小,算法鲁棒性强;
(4)无序任何前提假设,不涉及概率测度;
(1) SVM算法对大规模训练样本难以实施
第二步,固定除被选取的参数之外的其他参数,确定W极值。
SMO算法
设我们选取了初始值满足了问题中的约束条件。接下来,我们固定,
这样W就是和的函数。并且和满足条件:
由于其余参数都是已知固定,因此为了方便,可将等式右边标记成实
数值。
SMO算法
进而
W (a) i
i 1 l
1 l l i j yi y j K ( xi , x j ) 2 i 1 j 1
l
s.t.
y
i 1 i
l
i
0
x,y为已知数
核函数
线性不可分的情况
我们可以为分错的点加上一点惩罚,对一个分错的点的惩罚函数就是
这个点到其正确位置的距离:
软间隔C-SVM
C是一个由用户去指定的系数,表示对分错的点加入多少的 惩罚,当C很大的时候,分错的点就会更少,但是过拟合的 情况可能会比较严重,当C很小的时候,分错的点可能会很 多,不过可能由此得到的模型也会不太正确
等价于:
b 如果对于: 可以判断: m(a * ) M (a * ) 0 满足: 不满足:
b
b
停止条件2
停止条件3
启发式选择算法
其他求解方法
选块算法
分解算法
分解算法
工作集的选取
相关软件
问题
On the Algorithmic Implementation of Multiclass Kernel-based Vector Machines
例如,当训练点数目超过4000时,存储核函数矩阵需要多达128兆。
求解方法:坐标上升法
min
a l 1 l l y i y j i j K ( x i , x j ) i 2 i 1 j 1 i 1
固定除 i 之外的所有参数,这时W可看作只是关于 i 的函数,那么直接对 i
同理,当
(0,-E)
和
同号时
{
C
a1
参数求解
参数计算:
参数b计算:?
b的求解
设
在界内,则
有
,带入上式得:
两边同乘以
,得
b的求解
在界内,则
在界内,则
、
都在界内,则情况1和情况2的B值相等,任取一个; 取值为情况1和情况2之间的任意值。
都不在界内,则
问题?
算法如何终止?
对于SMO算法,其中的两个参数如何选择呢?
b * y j , j { j | a j 0} * d ( a ) 左移: j b y j , j { j | 0 a j C} * b y j , j { j | a j C}
分别乘以yi:
b * , j { j | a j 0} - y jd (a j ) b * , j { j | 0 a j C},当y j 1 * b , j { j | a j C} b * , j { j | a j 0} - y jd (a j ) b * , j { j | 0 a j C},当y j 1 * b , j { j | a j C}
问题提出
线性可分的分类问题:(令黑色的点 = -1, 白色的点 =
+1)
f ( x) wr x b
+1 -1
所以当有一个新的点x需要预测属于哪个分类的时候,我们用sgn(f(x)),
就可以预测了,sgn表示符号函数,当f(x) > 0的时候,sgn(f(x)) = +1, 当f(x) < 0的时候sgn(f(x)) = –1。
xi Rn , yi Y {1,1}, i 1,...,l
1 w 2
2
优化目标:
min
s.t.
w xi b 1, yi 1 w xi b 1, yi 1
x,y为已知数
求解
建立拉格朗日公式:
求偏导数:
求解:对偶问题
min max
随机?启发式规则
一个自然的想法是那些违反KKT最严重的点,他们对间距贡献最大, 因此可以通过该启发规则来完成调整参数的选取。(并且此种启发 规则计算量小)
停止条件1
满足KKT条件
KKT条件:
并设 代入得:
0, j { j | a j 0} d (a j ) b * y j 0, j { j | 0 a j C} 0, j { j | a j C}
软支持向量机求解
构造拉格朗日公式:
求偏导数:
求解问题
数据集合:
T {( x1, y1 ),...,( xl , yl )} (Rn y)l
xi Rn , yi Y {1,1}, i 1,...,l
优化目标:
max
a
1 l l i yi y j i j K( xi , x j ) 2 i 1 j 1 i 1
参数的求解
最终参数的解为:
其中: 0 2
new
C 和 0 1
new
C
?
a的取值范围
当a1和a2异号时,也就是一个为1,一个为-1时,他
们可以表示成一条直线,斜率为1。如下图:
a1-a2=E 横轴是
,纵轴是 ,
a2 和 既要在矩形方框内, C
{
(C,C-E)
也要在直线上,因此
统一:
* b , j { j | a j 0, y j 1} { j | 0 a j C} { j | a j C, y j 1} - y jd (a j ) * b , j { j | a j 0, y j 1} { j | 0 a j C} { j | a j C, y j 1}
l
s.t.
y
i 1 i
l
i
0
i 1,...,l
0 i C,
其中C为人为设定,x,y为已知数
问题?
实际上在处理大型问题时,由于存储和计算两方面的要求,这些算法
往往会失效。
这些算法都要存储与训练集相应的核矩阵,然而存储核矩阵所需要的
内存是随着训练集中训练点数L的平凡增长的。
(2) 用SVM解决多分类问题存在困难
经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一
般要解决多类的分类问题。可以通过多个二类支持向量机的组合来解决。主要有一 对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合 来解决。主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的 分类精度。如:与粗集理论结合,形成一种优势互补的多类问题的组合分类器。
w ,b a
f ( x) max min
a w ,b
f ( x)
求解
将两式带回L(w,b,a)得到对偶问题的表达式
1 2 L(w, b, a) w ai ( yi (w xi b) 1) 2 1 L(w, b, a) ai yi xi a j y j x j ai yi w xi ai yi b ai 2 i, j
可以由和其他参数表示出来。
SMO算法
SMO算法由Microsoft Research的John C. Platt在1998年提出,并成为最快
的二次规划优化算法,特别针对线性SVM和数据稀疏时性能更优。
第一步选取一对参数,选取方法使用启发式方法(Maximal violating pair)。
f ( x, y ) w w f ( x, y ) w w 1 w w
M
目标函数: 等价于: 因为 w 单调, : 并且为了计算方便
max 2M
2 w
min
min
w
1 w 2
2
求解问题
数据集合:
T {( x1, y1 ),...,( xl , yl )} (Rn y)l